AI-02a5a5.神经网络-与学习相关的技巧-权重初始值
权重的初始值
在神经网络的学习中,权重的初始值特别重要。实际上,设定什么样的权重初始值,经常关系到神经网络的学习能否成功。
不要将权重初始值设为 0
权值衰减(weight decay):抑制过拟合、提高泛化能力的技巧。
如果想减小权重的值,一开始就将初始值设为较小的值才是正途。
将权重初始值设为0的话,将无法正确进行学习。为什么呢?
在误差反向传播法中,所有的权重值都会进行相同的更新。比如,在2层神经网络中,假设第1层和第2层的权重为0。这样一来,正向传播时,因为输入层的权重为0,所以第2层的神经元全部会被传递相同的值。第2层的神经元中全部输入相同的值,这意味着反向传播时第2层的权重全部都会进行相同的更新。因此,权重被更新为相同的值,并拥有了对称的值(重复的值)。这使得神经网络拥有许多不同的权重的意义丧失了。为了防止“权重均一化”(瓦解权重的对称结构),必须随机生成初始值。
隐藏层的激活值的分布
向一个5层神经网络(激活函数使用sigmoid函数)传入随机生成的输入数据,用直方图绘制各层激活值的数据分布。
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rcParams# 设置中文字体
rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
rcParams['axes.unicode_minus'] = False # 解决负号显示问题def sigmoid(x):return 1 / (1 + np.exp(-x))def ReLU(x):return np.maximum(0, x)def tanh(x):return np.tanh(x)input_data = np.random.randn(1000, 100) # 1000个数据
node_num = 100 # 各隐藏层节点(神经元)数
hidden_layer_size = 5 # 隐藏的层有5层
activations = {} # 激活值的结果保存在这里x = input_datafor i in range(hidden_layer_size):if i != 0:x = activations[i-1]# 改变初始值进行实验!w = np.random.randn(node_num, node_num) * 1# w = np.random.randn(node_num, node_num) * 0.01# w = np.random.randn(node_num, node_num) * np.sqrt(1.0 / node_num) # Xavier初始值,适用 sigmoid、tanh等S型曲线# w = np.random.randn(node_num, node_num) * np.sqrt(2.0 / node_num) # He初始值,适用 ReLUa = np.dot(x, w)# 将激活函数的种类也改变,来进行实验!z = sigmoid(a)# z = ReLU(a)# z = tanh(a)activations[i] = z# 绘制直方图
for i, a in activations.items():plt.subplot(1, len(activations), i+1)plt.title(str(i+1) + "-layer")if i != 0: plt.yticks([], [])# plt.xlim(0.1, 1)# plt.ylim(0, 7000)plt.hist(a.flatten(), 30, range=(0,1))# plt.hist(a.flatten(), 30)if i == 0:plt.xlabel("标准差为1的高斯分布作为权重初始值时的sigmoid的各层激活值的分布", loc='left')
plt.show()

各层的激活值呈偏向0和1的分布。这里使用的sigmoid函数是S型函数,随着输出不断地靠近0(或者靠近1),它的导数的值逐渐接近0。因此,偏向0和1的数据分布会造成反向传播中梯度的值不断变小,最后消失。这个问题称为梯度消失(gradient vanishing)。层次加深的深度学习中,梯度消失的问题可能会更加严重。

集中在0.5附近的分布。没有偏向0和1,所以不会发生梯度消失的问题。但是,激活值的分布有所偏向,不同数量的神经元的输出几乎相同,说明在表现力上会有很大问题。因此,激活值在分布上有所偏向会出现“表现力受限”的问题。
各层的激活值的分布都要求有适当的广度。为什么呢?因为通过在各层间传递多样性的数据,神经网络可以进行高效的学习。反过来,如果传递的是有所偏向的数据,就会出现梯度消失或者“表现力受限”的问题,导致学习可能无法顺利进行。
Xavier初始值
Xavier的论文中,为了使各层的激活值呈现出具有相同广度的分布,推导了合适的权重尺度。推导出的结论是,如果前一层的节点数为 n n n,则初始值使用标准差为的分布 1 n \frac{1}{\sqrt{n}} n1

越是后面的层,图像变得越歪斜,但是呈现了比之前更有广度的分布。因为各层间传递的数据有适当的广度,所以sigmoid函数的表现力不受限制,有望进行高效的学习。

使用tanh函数后,会呈漂亮的吊钟型分布。tanh函数和sigmoid函数同是 S型曲线函数,但tanh函数是关于原点(0, 0)对称的 S型曲线,而sigmoid函数是关于(x, y)=(0, 0.5)对称的S型曲线。
用作激活函数的函数最好具有关于原点对称的性质。
He初始值
Xavier初始值是以激活函数是线性函数为前提而推导出来的。因为sigmoid函数和tanh函数左右对称,且中央附近可以视作线性函数,所以适合使用Xavier初始值。
但当激活函数使用ReLU时,一般推荐使用ReLU专用的初始值,He初始值。
当前一层的节点数为 n n n时,He初始值使用标准差为 2 n \sqrt{\frac{2}{n}} n2 的高斯分布。当Xavier初始值是 1 n \sqrt{\frac{1}{n}} n1时,(直观上)可以解释为,因为ReLU的负值区域的值为0,为了使它更有广度,所以需要2倍的系数。

当“std = 0.01”时,各层的激活值非常小 。神经网络上传递的是非常小的值,说明逆向传播时权重的梯度也同样很小。这是很严重的问题,实际上学习基本上没有进展。

随着层的加深,偏向一点点变大。实际上,层加深后,激活值的偏向变大,学习时会出现梯度消失的问题。

各层中分布的广度相同。由于即便层加深,数据的广度也能保持不变,因此逆向传播时,也会传递合适的值。
当激活函数使用ReLU时,权重初始值使用He初始值,当激活函数为sigmoid或tanh等S型曲线函数时,初始值使用Xavier初始值。这是目前的最佳实践。

神经网络有5层,每层有100个神经元,激活函数使用的是ReLU。
从上图分析可知,std = 0.01时完全无法进行学习。这和刚才观察到的激活值的分布一样,是因为正向传播中传递的值很小(集中在0附近的数据)。因此,逆向传播时求到的梯度也很小,权重几乎不进行更新。相反,当权重初始值为Xavier初始值和He初始值时,学习进行得很顺利。并且,我们发现He初始值时的学习进度更快一些。
# coding: utf-8
import os
import syssys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.util import smooth_curve
from common.multi_layer_net import MultiLayerNet
from common.optimizer import SGD
from matplotlib import rcParams# 设置中文字体
rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 0:读入MNIST数据==========
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
train_size = x_train.shape[0]
batch_size = 128
max_iterations = 2000# 1:进行实验的设置==========
weight_init_types = {'std=0.01': 0.01, 'Xavier': 'sigmoid', 'He': 'relu'}
optimizer = SGD(lr=0.01)networks = {}
train_loss = {}
for key, weight_type in weight_init_types.items():networks[key] = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100],output_size=10, weight_init_std=weight_type)train_loss[key] = []# 2:开始训练==========
for i in range(max_iterations):batch_mask = np.random.choice(train_size, batch_size)x_batch = x_train[batch_mask]t_batch = t_train[batch_mask]for key in weight_init_types.keys():grads = networks[key].gradient(x_batch, t_batch)optimizer.update(networks[key].params, grads)loss = networks[key].loss(x_batch, t_batch)train_loss[key].append(loss)if i % 100 == 0:print("===========" + "iteration:" + str(i) + "===========")for key in weight_init_types.keys():loss = networks[key].loss(x_batch, t_batch)print(key + ":" + str(loss))# 3.绘制图形==========
markers = {'std=0.01': 'o', 'Xavier': 's', 'He': 'D'}
x = np.arange(max_iterations)
for key in weight_init_types.keys():plt.plot(x, smooth_curve(train_loss[key]), marker=markers[key], markevery=100, label=key)plt.xlabel("学习迭代次数")
plt.ylabel("损失函数值")
plt.title("基于MNIST数据集的权重初始值的比较")
plt.ylim(0, 2.5)
plt.legend()
plt.show()
相关文章:
AI-02a5a5.神经网络-与学习相关的技巧-权重初始值
权重的初始值 在神经网络的学习中,权重的初始值特别重要。实际上,设定什么样的权重初始值,经常关系到神经网络的学习能否成功。 不要将权重初始值设为 0 权值衰减(weight decay):抑制过拟合、提高泛化能…...
【springcloud学习(dalston.sr1)】Eureka单个服务端的搭建(含源代码)(三)
该系列项目整体介绍及源代码请参照前面写的一篇文章【springcloud学习(dalston.sr1)】项目整体介绍(含源代码)(一) 这篇文章主要介绍单个eureka服务端的集群环境是如何搭建的。 通过前面的文章【springcloud学习(dalston.sr1)】…...

Node.js数据抓取技术实战示例
Node.js常用的库有哪些呢?比如axios或者node-fetch用来发送HTTP请求,cheerio用来解析HTML,如果是动态网页的话可能需要puppeteer这样的无头浏览器。这些工具的组合应该能满足大部分需求。 然后,可能遇到的难点在哪里?…...
)
[架构之美]Spring Boot集成MyBatis-Plus高效开发(十七)
[架构之美]Spring Boot集成MyBatis-Plus高效开发(十七) 摘要:本文通过图文代码实战,详细讲解Spring Boot整合MyBatis-Plus全流程,涵盖代码生成器、条件构造器、分页插件等核心功能,助你减少90%的SQL编写量…...
windows10 安装 QT
本地环境有个qt文件,这里是5.14.2 打开一个cmd窗口并指定到该文件根目录下 .\qt-opensource-windows-x86-5.14.2.exe --mirror https://mirrors.ustc.edu.cn/qtproject 执行上面命令 记住是文件名,记住不要傻 X的直接复制,是你的文件名 点击…...

WordPress 和 GPL – 您需要了解的一切
如果您使用 WordPress,GPL 对您来说应该很重要,您也应该了解它。查看有关 WordPress 和 GPL 的最全面指南。 您可能听说过 GPL(通常被称为 WordPress 的权利法案),但很可能并不完全了解它。这是有道理的–这是一个复杂…...

计算机网络:什么是计算机网络?它的定义和组成是什么?
计算机网络是指通过通信设备和传输介质,将分布在不同地理位置的计算机、终端设备及其他网络设备连接起来,实现资源共享、数据传输和协同工作的系统。其核心目标是使设备之间能够高效、可靠地交换信息。 关键组成部分 硬件设备 终端设备:如计算…...

C++书本摆放 2024年信息素养大赛复赛 C++小学/初中组 算法创意实践挑战赛 真题详细解析
目录 C++书本摆放 一、题目要求 1、编程实现 2、输入输出 二、算法分析 三、程序编写 四、运行结果 五、考点分析 六、 推荐资料 1、C++资料 2、Scratch资料 3、Python资料 C++书本摆放 2024年信息素养大赛 C++复赛真题 一、题目要求 1、编程实现 中科智慧科技…...

在scala中使用sparkSQL读入csv文件
以下是使用 Spark SQL(Scala)读取 CSV 文件的完整代码示例: scala import org.apache.spark.sql.SparkSession import org.apache.spark.sql.types._object CSVReadExample {def main(args: Array[String]): Unit {// 创建SparkSessionval…...

RabbitMQ 核心概念与消息模型深度解析(一)
一、RabbitMQ 是什么 在当今分布式系统盛行的时代,消息队列作为一种至关重要的中间件技术,扮演着实现系统之间异步通信、解耦和削峰填谷等关键角色 。RabbitMQ 便是消息队列领域中的佼佼者,是一个开源的消息代理和队列服务器,基于…...

论文阅读笔记——双流网络
双流网络论文 视频相比图像包含更多信息:运动信息、时序信息、背景信息等等。 原先处理视频的方法: CNN LSTM:CNN 抽取关键特征,LSTM 做时序逻辑;抽取视频中关键 K 帧输入 CNN 得到图片特征,再输入 LSTM&…...
)
思路解析:第一性原理解 SQL:连接(JOIN)
目录 题目描述 🎯 应用第一性原理来思考这个 SQL 题目 ✅ 第一步:还原每个事件的本质单位 ✅ 第二步:如果一个表只有事件,如何构造事件对? ✅ 第三步:加过滤条件,只保留“同一机器、同一进…...

Java面向对象三大特性深度解析
Java面向对象三大特性封装继承多态深度解析 前言一、封装:数据隐藏与访问控制的艺术1.1 封装的本质与作用1.2 封装的实现方式1.2.1 属性私有化与方法公开化1.2.2 封装的访问修饰符 二、继承:代码复用与类型扩展的核心机制2.1 继承的定义与语法2.2 继承的…...

LabVIEW在电子电工教学中的应用
在电子电工教学领域,传统教学模式面临诸多挑战,如实验设备数量有限、实验过程存在安全隐患、教学内容更新滞后等。LabVIEW 作为一款功能强大的图形化编程软件,为解决这些问题提供了创新思路,在电子电工教学的多个关键环节发挥着重…...

Vue3 怎么在ElMessage消息提示组件中添加自定义icon图标
1、定义icon组件代码: <template><svg :class"svgClass" aria-hidden"true"><use :xlink:href"iconName" :fill"color"/></svg> </template><script> export default defineComponen…...

生活破破烂烂,AI 缝缝补补(附提示词)
写在前面:【Fire 计算器】已上线,快算算财富自由要多少 现实不总温柔,愿你始终自渡。 请永远拯救自己于水火之中。 毛绒风格提示词(供参考): 1. 逼真毛绒风 Transform this image into a hyperrealist…...
张 。。 通过Token实现Loss调优prompt
词编码模型和 API LLM不匹配,采用本地模型 理性中性案例(针对中性调整比较合理) 代码解释:Qwen2模型的文本编码与生成过程 这段代码展示了如何使用Qwen2模型进行文本的编码和解码操作。 模型加载与初始化 from transformers import AutoModelForCausalLM, AutoTokenizer...

Ubuntu 22.04.5 LTS上部署Docker及相关优化
以下是在Ubuntu 22.04.5 LTS上部署Docker及相关优化的步骤: 安装Docker 更新系统:在安装Docker之前,先确保系统是最新的,执行以下命令:sudo apt update sudo apt upgrade -y安装依赖包:安装一些必要的依赖…...
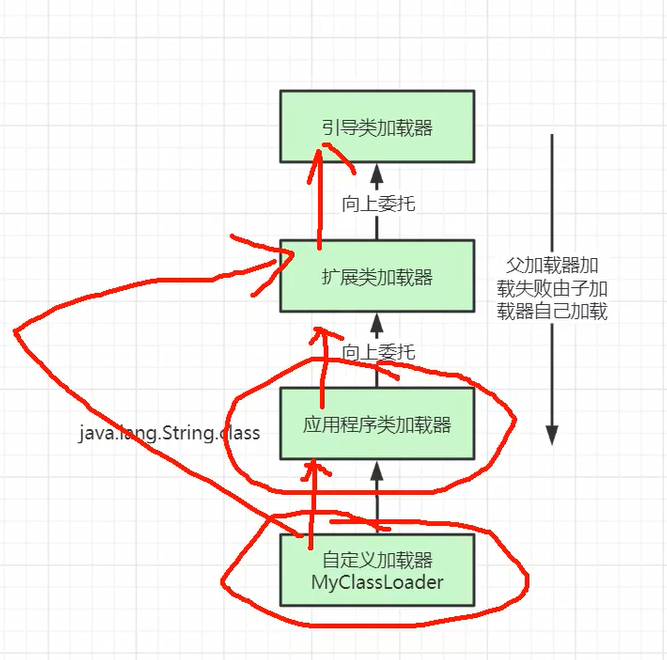
JVM学习专题(一)类加载器与双亲委派
目录 1、JVM加载运行全过程梳理 2、JVM Hotspot底层 3、war包、jar包如何加载 4、类加载器 我们来查看一下getLauncher: 1.我们先查看getExtClassLoader() 2、再来看看getAppClassLoader(extcl) 5、双亲委派机制 1.职责明确,路径隔离ÿ…...
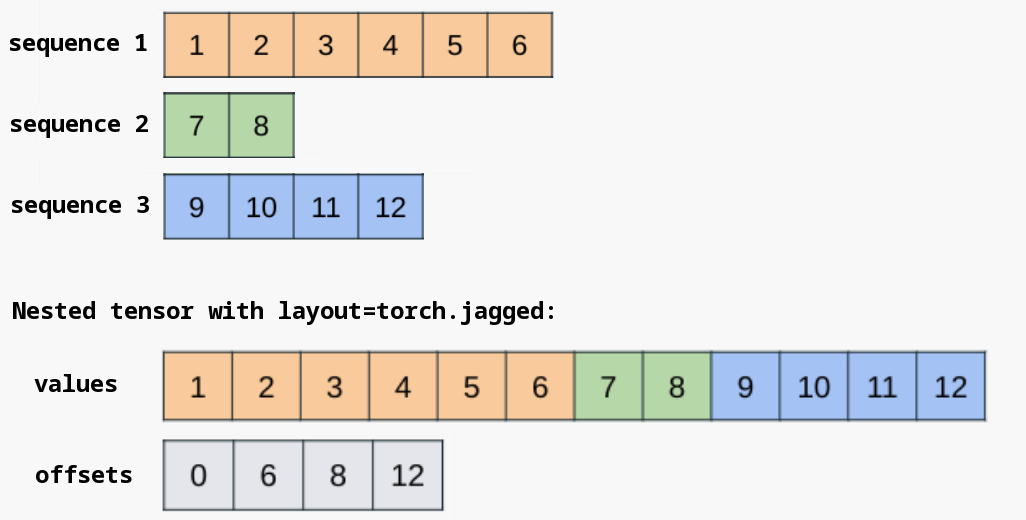
PyTorch API 9 - masked, nested, 稀疏, 存储
文章目录 torch.randomtorch.masked简介动机什么是 MaskedTensor? 支持的运算符一元运算符二元运算符归约操作查看与选择函数 torch.nested简介构造方法数据布局与形状支持的操作查看嵌套张量的组成元素填充张量的相互转换形状操作注意力机制 与 torch.compile 的配…...

进程相关面试题20道
一、基础概念与原理 1.进程的定义及其与程序的本质区别是什么? 答案:进程是操作系统分配资源的基本单位,是程序在数据集合上的一次动态执行过程。核心区别: 动态性:程序是静态文件,进程是动态执行实例…...

微信小程序学习之轮播图swiper
轮播图是小程序的重要组件,我们还是好好学滴。 1、上代码,直接布局一个轮播图组件(index.wxml): <swiper class"swiper" indicator-active-color"#fa2c19" indicator-color"#fff" duration"{{durati…...

【万字逐行详解】深入解析ONNX Runtime图像分类程序main函数
本文将全面、详尽地解析一个使用ONNX Runtime进行图像分类的C++程序,不省略任何一行代码,逐行解释其语法和实现原理。这个程序展示了现代C++在计算机视觉领域的完整应用流程,从模型加载到结果可视化,涵盖了异常处理、性能分析等工程实践。 程序完整解析 1. 主函数框架 i…...
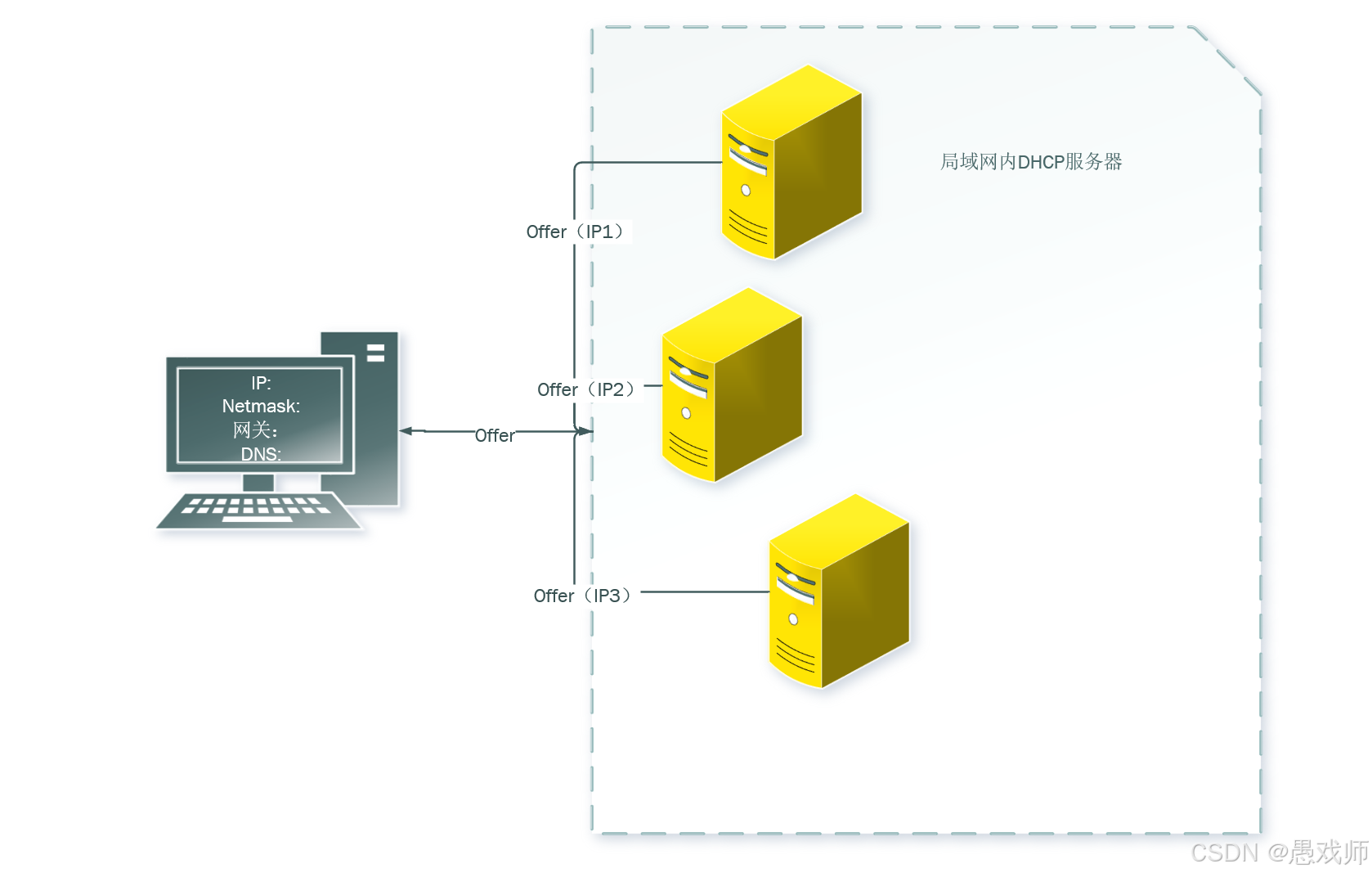
Linux复习笔记(五) 网络服务配置(dhcp)
二、网络服务配置 2.5 dhcp服务配置(不涉及实际操作) 要求:知道原理和常见的参数配置就行 2.5.1 概述DHCP(Dynamic Host Configuration Protocol,动态主机配置协议) DHCP(Dynamic Host Conf…...

智慧工厂管理平台推荐?智慧工厂解决方案提供商有哪些?智慧工厂管理系统哪家好?
随着工业4.0和“双碳”目标的推进,智慧工厂管理平台成为制造企业数字化转型的核心工具。本文基于技术实力、应用场景、安全可靠三大维度,结合最新行业实践与用户需求,精选出十大智慧工厂解决方案提供商,助您快速匹配行业需求&…...

鸿蒙OSUniApp 实现的语音输入与语音识别功能#三方框架 #Uniapp
UniApp 实现的语音输入与语音识别功能 最近在开发跨平台应用时,客户要求添加语音输入功能以提升用户体验。经过一番调研和实践,我成功在UniApp项目中实现了语音输入与识别功能,现将过程和方法分享出来,希望对有类似需求的开发者有…...

windows版redis的使用
redis下载 Releases microsoftarchive/redishttps://github.com/microsoftarchive/redis/releases redis的启动和停止 进入路径的cmd 启动:redis-server.exe redis.windows.conf 停止:ctrlc 连接redis 指定要连接的IP和端口号 -h IP地址 -p 端口…...
Java版OA管理系统源码 手机版OA系统源码
Java版OA管理系统源码 手机版OA系统源码 一:OA系统的主要优势 1. 提升效率 减少纸质流程和重复性工作,自动化处理常规事务,缩短响应时间。 2. 降低成本 节省纸张、打印、通讯及人力成本,优化资源分配。 3. 规范管理 固化企…...
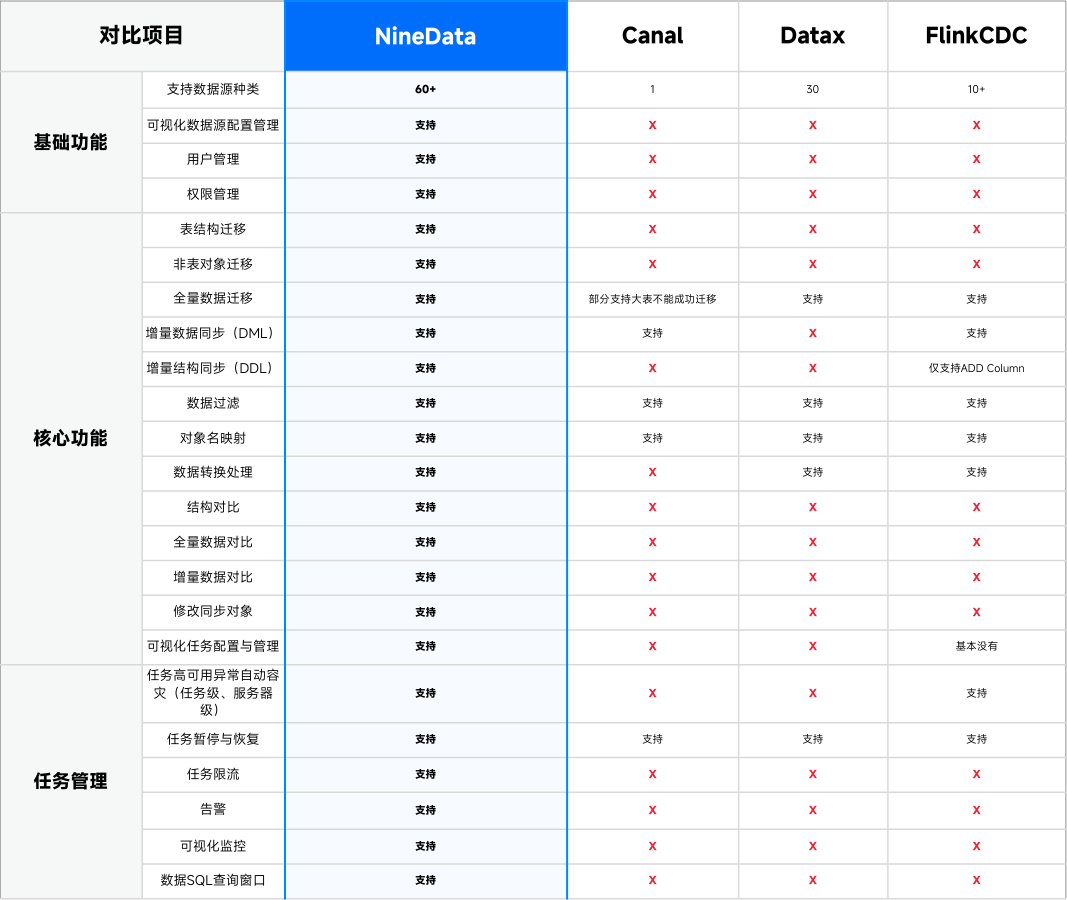
NineData 社区版 V4.1.0 正式发布,新增 4 条迁移链路,本地化数据管理能力再升级
NineData 社区版 V4.1.0 正式更新发布。本次通过新增 4 条迁移链路扩展、国产数据库深度适配、敏感数据保护增强等升级,进一步巩固了其作为高效、安全、易用的数据管理工具的定位。无论是开发测试、数据迁移,还是多环境的数据管理,NineData…...
进阶2_1:QT5多线程与定时器共生死
1、在widget.ui中使用 LCD Number控件 注意:若 LCD 控件不是多线程,LCD控件则会瞬间自增到最大的数值,如上图,说明两者都是多线程处理 2、实现方式 1、创建 LCD 控件并修改为 LCD1 2、创建任务类 mytask. h,对任务类…...