Meta的AIGC视频生成模型——Emu Video
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍Meta的视频生成模型Emu Video,作为Meta发布的第二款视频生成模型,在视频生成领域发挥关键作用。

🌺优质专栏回顾🌺:
- 机器学习笔记
- 深度学习笔记
- 多模态论文笔记
- AIGC—图像
文章目录
- 论文
- 摘要
- 引言
- 相关工作
- 文本到图像(T2I)扩散模型
- 视频生成/预测
- 文本到视频(T2V)生成
- 分解生成
- 方法
- 预备知识
- Emu Video
- 生成步骤
- 图像条件
- 模型结构
- 零终端信噪比 噪声调度
- 插值模型
- 实现简单性
- 稳健的人类评估(JUICE)
- 实现细节
- 架构与初始化
- 高效的多阶段多分辨率训练
- 高质量微调
- 插值模型
- 实验
- 伦理问题
论文
项目:https://emu-video.metademolab.com/assets/emu_video
论文:https://arxiv.org/pdf/2311.10709
摘要
本文提出Emu Video,这是一种文本到视频生成模型,将生成过程分解为两个步骤:
- 先根据文本生成图像;
- 再基于文本
和生成的图像生成视频。
该模型在性能上超越了RunwayML的Gen2和Pika Labs等商业解决方案。
引言
T2I模型在大规模的图像文本对上训练,已经很成功了,可使用视频文本对进一步拓展文本到视频(T2V)生成,但视频生成在质量和多样性方面仍落后于图像生成。原因在于:
- 需要对更高维度的时空输出空间进行建模,且仅以文本提示作为条件;
- 视频文本数据集通常比图像文本数据集小一个数量级。
当前视频生成的主流范式是使用扩散模型一次性生成所有视频帧。而不是NLP中的自回归问题不同,自回归方法在视频生成中具有挑战性,因为从扩散模型生成单个帧就需要多次迭代。
Emu Video通过显式的中间图像生成步骤,将文本到视频生成分解为两个子问题:
- 根据输入文本提示生成图像;
- 基于图像和文本的强条件生成视频。
直观地说,给模型一个起始图像和文本会使视频生成更容易,因为模型只需要预测图像未来的演变。
由于视频文本数据集远小于图像文本数据集,使用预训练的文本到图像(T2I)模型初始化T2V模型,并冻结其权重。在推理时,这种分解方法能显式生成图像,从而保留T2I模型的视觉多样性、风格和质量。
Emu Video证明了将文本到视频(T2V)生成过程分解为:先生成图像,再用生成的图像和文本生成视频。可以大幅提高生成质量。
到此,作者确定了他们的关键设计决策 —— 改变扩散噪声调度和采用多阶段训练,从而能够绕过先前工作中对深度级联模型的需求,高效生成 512 像素高分辨率的视频。该模型也可以根据用户提供的图像和文本提示生成视频。
相关工作
文本到图像(T2I)扩散模型
相比于先前的生成对抗网络(GAN)或自回归方法,扩散模型是文本到图像生成的前沿方法,通过加噪声和预测加入的噪声并去除来学习数据分布,生成输出。
扩散模型去噪可以在像素空间使用,也可以在低维潜在空间使用,本文采用潜在扩散模型进行视频生成。
视频生成/预测
许多先前工作,如掩码预测、LSTMs、GANs 等通常在有限的领域中进行训练和评估。它们适用的场景较为狭窄,可能只在特定类型的视频数据、特定的任务要求或特定的应用场景中表现良好。
本文的研究中,目标是开放集的文本到视频(T2V)生成。开放集意味着处理的数据和任务场景更为广泛和多样,没有预先设定的严格限制,这与之前这些方法所适用的有限领域形成对比。
文本到视频(T2V)生成
多数先前工作通过利用T2I模型来解决T2V生成问题:
- 采用无训练方法,通过在T2I模型中注入运动信息进行零样本T2V生成;
- 通过微调T2I模型实现单样本T2V生成。
这些方法生成的视频质量和多样性有限。
也有许多工作通过向T2I模型引入时间参数,学习从文本条件到生成视频的直接映射,来改进T2V生成。如
- Make-A-Video利用预训练的T2I模型和先验网络,在无配对视频文本数据的情况下训练T2V生成;
- Imagen Video基于Imagen T2I模型构建级联扩散模型。
为解决高维时空空间建模的挑战,部分工作在低维潜在空间训练T2V扩散模型,但这些方法学习从文本到高维视频空间的直接映射具有挑战性。
本文则 采用分解方法来增强条件信号。
分解生成
与Emu Video在分解方面最相似的工作是CogVideo和Make-A-Video:
- CogVideo基于预训练的T2I模型,使用自回归Transformer进行T2V生成,其自回归性质在训练和推理阶段与Emu Video的显式图像条件有根本区别。
- Make-A-Video 利用从共享图像文本空间中学习到的图像嵌入作为条件。,
Emu Video直接利用第一帧作为条件,条件更强。
此外,Make-A-Video从预训练的T2I模型初始化,但对所有参数进行微调,无法像Emu Video那样保留T2I模型的视觉质量和多样性。Stable Video Diffusion是一项与Emu Video同时期的工作,也引入了类似的分解方法进行T2V生成。
Make-A-Video是Meta于2022年发布的模型/论文中:MAKE-A-VIDEO: TEXT-TO-VIDEO GENERATION WITHOUT TEXT-VIDEO DATA
CogVideo是国产的视频生成模型,之前清华大学和智谱AI一起研发了CogView文本生成图像模型,CogVideo由清华大学发布的论文:CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
方法
文本到视频(T2V)生成的目标:构建一个模型,该模型以文本提示 P 作为输入,生成由 T 个 RGB 帧组成的视频 V。
近期的一些模型仅使用文本作为条件,一次性直接生成 T 个视频帧。作者在本论文中认为:通过文本和图像共同提供更强的条件能够提升视频生成效果(验证参见 3.2 节 )。
预备知识
条件扩散模型是一类生成模型,通过迭代对高斯噪声去噪,根据条件输入c生成输出。
在训练时:
- 将时间步 t ∈ [ 0 , N ] t \in[0, N] t∈[0,N]相关的高斯噪声 ϵ t ∼ N ( 0 , 1 ) \epsilon_{t} \sim N(0, 1) ϵt∼N(0,1)添加到原始输入信号X上,得到有噪输入 X t = α t X + 1 − α t ϵ t X_{t}=\alpha_{t} X+\sqrt{1-\alpha_{t}} \epsilon_{t} Xt=αtX+1−αtϵt,其中 α t \alpha_{t} αt定义 “噪声调度”,N是扩散步骤总数。
- 扩散模型通过预测噪声 ϵ t \epsilon_{t} ϵt、 x x x或 v t = α t ϵ t − 1 − α t X v_{t}=\alpha_{t} \epsilon_{t}-\sqrt{1-\alpha_{t}} X vt=αtϵt−1−αtX来对 x t x_{t} xt进行去噪。时间步t的信噪比(SNR)为 ( α t 1 − α t ) 2 (\frac{\alpha_{t}}{1-\alpha_{t}})^{2} (1−αtαt)2,并随着 t → N t \to N t→N而降低。
在推理时:
- 从纯噪声/高斯噪声 X N ∼ N ( 0 , 1 ) X_{N} \sim N(0, 1) XN∼N(0,1)开始去噪生成样本。
对 x t x_{t} xt去噪的三种预测方式:
- 预测 ϵ t \epsilon_{t} ϵt(
常用):- ϵ t \epsilon_{t} ϵt是在时间步 t t t添加到原始输入信号 X X X的高斯噪声 ϵ t ∼ N ( 0 , 1 ) \epsilon_{t}\sim N(0, 1) ϵt∼N(0,1)。如果模型能够准确预测出这个噪声,那么就可以从含噪输入 X t = α t X + 1 − α t ϵ t X_{t}=\alpha_{t}X +\sqrt{1-\alpha_{t}}\epsilon_{t} Xt=αtX+1−αtϵt中减去预测的噪声,从而达到去噪的目的。
- 预测 x x x:
- 这里的 x x x是指原始输入信号 X X X。模型直接预测原始信号本身,在得到预测的原始信号 X ^ \hat{X} X^后,就可以将含噪输入 X t X_{t} Xt中的噪声部分去除。在实际操作中,直接预测原始信号可能会比较复杂,因为模型需要学习从含噪信号中还原出原始信号的复杂映射关系。
- 预测 v t v_{t} vt:
- v t = α t ϵ t − 1 − α t X v_{t}=\alpha_{t}\epsilon_{t}-\sqrt{1 - \alpha_{t}}X vt=αtϵt−1−αtX是一种组合了噪声 ϵ t \epsilon_{t} ϵt和原始信号 X X X的形式。当模型预测出 v t v_{t} vt为 v ^ t \hat{v}_{t} v^t时,可以通过一定的数学变换来去除噪声,恢复原始信号。这种方式综合考虑了噪声和原始信号之间的关系,也是一种有效的去噪策略。
Emu Video

图3描述了分解的文本 - 视频生成过程。
- 首先根据文本 p p p生成图像 I I I;
- 然后使用更强的条件,即生成的图像和文本来生成视频 V V V。
为了使我们的模型 F \mathcal{F} F以图像为条件,我们在时间维度上对图像进行零填充,并将其与一个二进制掩码连接起来,该掩码指示哪些帧是零填充的【类似Trandformer的填充遮蔽(Padding Masking)与未来遮蔽(Future Masking)】,以及含噪输入。
生成步骤
将文本到视频生成分解为两个步骤:
- 首先,根据文本提示 p p p 生成第一帧(图像);
- 然后,利用文本提示 p p p 和图像条件【下面会介绍图像条件怎么来的】生成T帧视频。
这两个步骤均使用潜在扩散模型 F \mathcal{F} F实现,使用预训练的文本到图像模型初始化 F \mathcal{F} F,确保其在初始化时能够生成图像。
只需训练 F \mathcal{F} F解决第二步,即根据文本提示和起始帧/图像推出视频。使用视频文本对训练 F \mathcal{F} F,通过采样起始帧/图像 I I I,让模型根据文本提示 P P P和图像 I I I条件预测 T T T帧( T T T帧会被独立地添加噪声,以生成含噪输入 x t x_{t} xt,而扩散模型的训练目标就是对这个含噪输入进行去噪)。
首先通过逐帧应用图像自动编码器的编码器将视频 v v v转换到潜在空间 X ∈ R T × C × H × W X \in \mathbb{R}^{T×C×H×W} X∈RT×C×H×W,这会降低空间维度。潜在空间中的数据可以通过自动编码器的解码器转换回像素空间。
图像条件
通过将起始帧 I I I与噪声拼接(如上图的concatenate),为模型提供条件。将 I I I表示为单帧视频( T = 1 T=1 T=1),并对其进行零填充,得到 T × C × H × W T ×C ×H ×W T×C×H×W张量,同时使用形状为 T × 1 × H × W T ×1 ×H ×W T×1×H×W的二进制掩码m,在第一时间位置设置为1表示起始帧位置,其他位置为0。将掩码m、起始帧I和有噪视频 x t x_{t} xt按通道连接作为模型输入。
与 Make-a-video等模型中基于语义嵌入设定条件的方法不同,Emu Video 的拼接的方式能让模型利用起始帧 I 的全部信息。基于语义嵌入的方法会在条件设定时丢失部分图像信息,而 Emu Video 的设计避免了这一问题,为生成高质量视频提供了更多有效信息。
掩码 m 用于标记起始帧在序列中的位置,帮助模型识别起始帧,对后续视频生成过程进行更精准的指导。
模型结构
使用预训练的T2I模型Emu初始化潜在扩散模型 F \mathcal{F} F,并添加新的可学习时间参数:
- 在每个空间卷积层之后添加一维时间卷积层;
- 在每个空间注意力层之后添加一维时间注意力层 ;
- 原始的空间卷积层和注意力层保持冻结状态。
在Runway的Gen-1中的时空潜在扩散中也使用了可学习时间参数:
- 在每个残差块中的每个 2D 空间卷积之后引入一个1D 时间卷积。
- 在每个空间 2D 空间注意力块后引入一个时间1D 时间注意力块。
预训练的 T2I 模型以文本作为条件,与上一节的图像条件相结合后,模型 F \mathcal{F} F 同时以文本和图像作为条件。
Emu是Meta发布的一款T2I模型,论文为:Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack
零终端信噪比 噪声调度
作者发现,先前工作(Emu和SD模型)中使用的扩散噪声调度存在训练 - 测试差异,这会阻碍高质量视频的生成。
在训练过程中,该噪声调度会留下一些残留信号,也就是说,即使在扩散的终端时间步N,信噪比(SNR)仍不为零。当我们从不含真实数据信号的随机高斯噪声中采样时,这会导致扩散模型在测试时无法很好地泛化。由于高分辨率视频帧在空间和时间上存在冗余像素,其残留信号更为明显。
作者通过缩放噪声调度并将最终的 α N = 0 \alpha_N = 0 αN=0来解决这个问题,这使得在训练过程中的时间步为N时(扩散过程的最后一个阶段),信噪比也为零。我们发现这个设计决策对于高分辨率视频的生成至关重要。
这个问题和缩放噪声调度方法并非本文首创,在之前的:Common diffusion noise schedules and sample steps are flawed也发现了这个问题。【来源于字节跳动】
插值模型
使用与 F \mathcal{F} F结构相同的插值模型 I I I,将低帧率的 T T T帧视频转换为高帧率的 T p T_{p} Tp帧视频。 输入的 T T T帧通过零交错生成 T p T_{p} Tp帧,并将指示 T T T帧存在的二进制掩码m连接到有噪输入。为提高效率,从 F \mathcal{F} F初始化 I I I,并仅针对插值任务训练 I I I的时间参数。
将低帧率的 T T T帧视频转换为高帧率的 T p T_p Tp帧,能提升视频流畅度与视觉效果,适应多样化应用场景,增强模型竞争力,为用户带来更好体验。
实现简单性
Emu Video在实现方面的简单且高效:
- 训练数据与模型结构简单
- 标准数据集训练:Emu Video采用标准视频文本数据集进行训练,这意味着其训练数据来源广泛且具有通用性,不需要特殊定制的数据集,降低了数据准备的难度和成本。
- 无需深度级联模型:在生成高分辨率视频时,Emu Video不需要像某些其他方法(如Imagen Video中使用7个模型的深度级联结构)那样复杂的模型架构,简化了模型构建和训练流程。
- 推理过程
- 图像与视频生成:推理时,先运行去除时间层的模型F根据文本提示生成图像I,再将I和文本提示作为输入,通过F直接生成高分辨率的T帧视频,这种推理方式简洁高效。
- 帧率提升:借助插值模型I可提高视频帧率,进一步增强视频的视觉效果,且这一操作融入到了整体的推理流程中。
- 模型初始化与风格保留
- 初始化策略:空间层从预训练的T2I模型初始化并保持冻结,这样可以利用T2I模型在大规模图像文本数据集上学习到的概念和风格多样性。
- 风格保留优势:相比Imagen Video需要在图像和视频数据上联合微调以维持风格,Emu Video不需要额外的训练成本就能保留并运用这些风格来生成图像I。许多直接的T2V方法,如Make-a-video,虽然也从预训练T2I模型初始化并冻结空间层,但由于没有采用基于图像的分解方法,无法像Emu Video一样保留T2I模型的质量和多样性 。
稳健的人类评估(JUICE)
由于自动评估指标不能反映质量的提升,主要使用人类评估来衡量T2V生成性能,从视频生成质量(Quality,Q)和生成视频与文本提示的对齐或 “保真度”(Faithfulness,F)两个正交方面进行评估。提出JUICE评估方案,要求评估者在成对比较视频生成结果时说明选择理由,显著提高了标注者之间的一致性。评估者可选择像素清晰度、运动平滑度、可识别对象/场景、帧一致性和运动量等理由来评价视频质量;使用空间文本对齐和时间文本对齐来评价保真度。
实现细节
附录第 1 节提供完整的实现细节,详细内容可以参考附录第 1 节,这里只介绍关键细节。
架构与初始化
采用Emu中的文本到图像 U-Net 架构构建模型,并使用预训练模型初始化所有空间参数。
预训练模型使用一个 8 通道、64×64 的潜在向量,经自动编码器在空间上进行 8 倍下采样,生成 512px 的方形图像。
该模型同时使用一个冻结的 T5-XL 和一个冻结的 CLIP 文本编码器从文本提示中提取特征。
高效的多阶段多分辨率训练
为降低计算复杂度,分两个阶段进行训练。
- 先在低分辨率下,训练更简单的任务,即生成256px、8fps、1s的视频。
- 然后在期望的高分辨率下训练,对4fps、2s的视频进行15K次迭代训练。
a. 使用同SD一样的噪声调度进行256px训练。
b. 在512px训练中使用零终端信噪比噪声调度,扩散训练步数 N = 1000 N = 1000 N=1000
c. 使用DDIM采样器进行采样,采样步数为250步。
SD中的噪声调度是:线性调度。
SD 系列文章参考:Stable Diffusion
高质量微调
通过在一小部分高运动和高质量视频上微调模型,可改善生成视频的运动效果。从训练集中自动识别出1600个具有高运动(根据H.264编码视频中存储的运动信号计算)的视频作为微调子集,并根据美学分数和视频文本与第一帧的CLIP相似度进行筛选。
插值模型
插值模型I从视频模型F初始化,输入8帧,输出 T p = 37 T_{p} = 37 Tp=37帧,帧率为16fps。在训练时使用噪声增强,在推理时对F的样本进行噪声增强。
实验
参照论文原文
伦理问题
参照论文原文
相关文章:
Meta的AIGC视频生成模型——Emu Video
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍Meta的视频生成模型Emu Video,作为Meta发布的第二款视频生成模型,在视频生成领域发挥关键作用。 🌺优质专栏回顾&am…...
Axure难点解决分享:统计分析页面引入Echarts示例动态效果
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢! Axure产品经理精品视频课已登录CSDN可点击学习https://edu.csdn.net/course/detail/40420 课程主题:统计分析页面引入Echarts示例动态效果 主要内容:echart示例引入、大小调整、数据导入 应用场景:统计分析页面…...
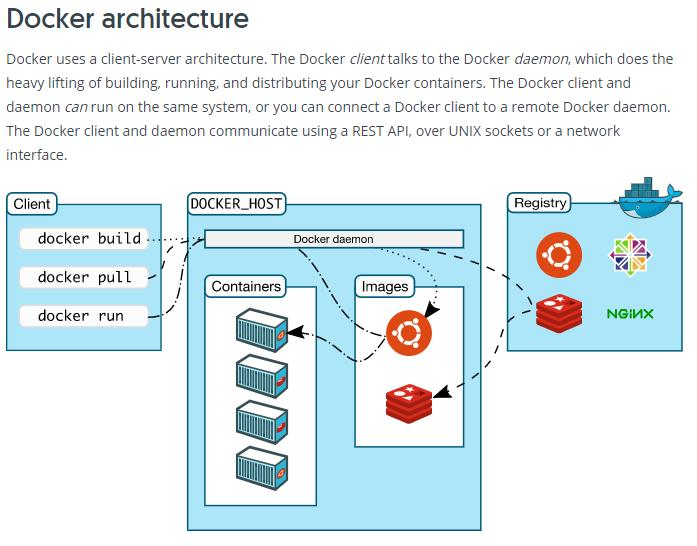
Docker 常见问题及其解决方案
一、安装与启动问题 1.1 安装失败 在不同操作系统上安装 Docker 时,可能会出现安装失败的情况。例如,在 Ubuntu 系统中,执行安装命令后提示依赖缺失。这通常是因为软件源配置不正确或系统缺少必要的依赖包。 解决方案: 确保系统…...

后端开发面试高频50个问题,简单解答
以下是后端开发面试中常见的50个高频问题及其详细解答,涵盖了语言基础、数据库、网络、操作系统、设计模式等多个方面: 编程语言基础 Java 中的 final 关键字有什么作用? final 可以修饰类、方法和变量。修饰类时,类不能被继承&am…...
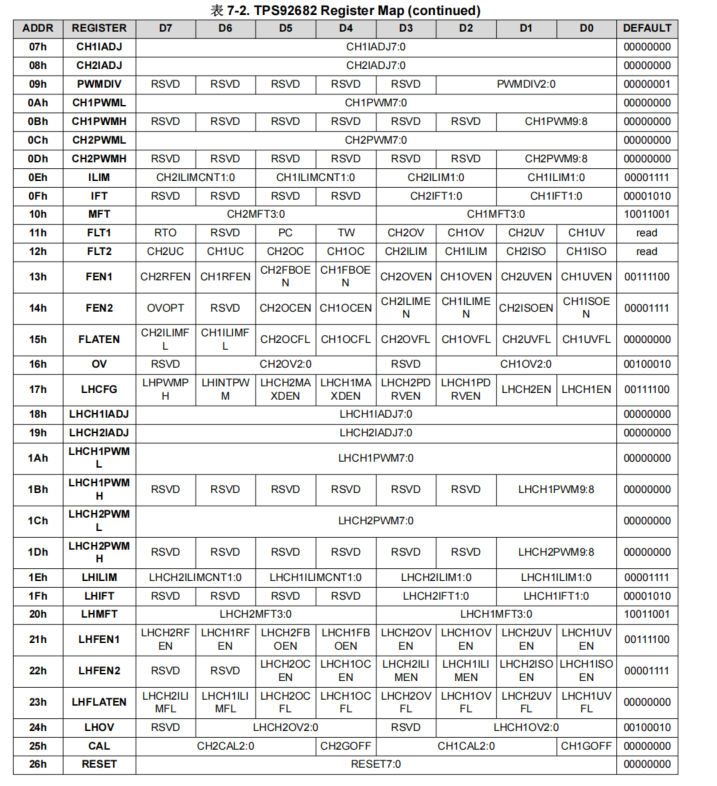
IC解析之TPS92682-Q1(汽车LED灯控制IC)
目录 1 IC特性介绍2 主要参数3 接口定义4 工作原理分析TPS92682-Q1架构工作模式典型应用通讯协议 控制帧应答帧协议5 总结 1 IC特性介绍 TPS92682 - Q1 是德州仪器(TI)推出的一款双通道恒压横流控制器,同时还具有各种电器故障保护,…...

6.01 Python中打开usb相机并进行显示
本案例介绍如何打开USB相机并每隔100ms进行刷新的代码,效果如下: 一、主要思路: 1. 打开视频流、读取帧 self.cam_cap = cv2.VideoCapture(0) #打开 视频流 cam_ret, cam_frame = self.cam_cap.read() //读取帧。 2.使用定时器,每隔100ms读取帧 3.显示到Qt的QLabel…...
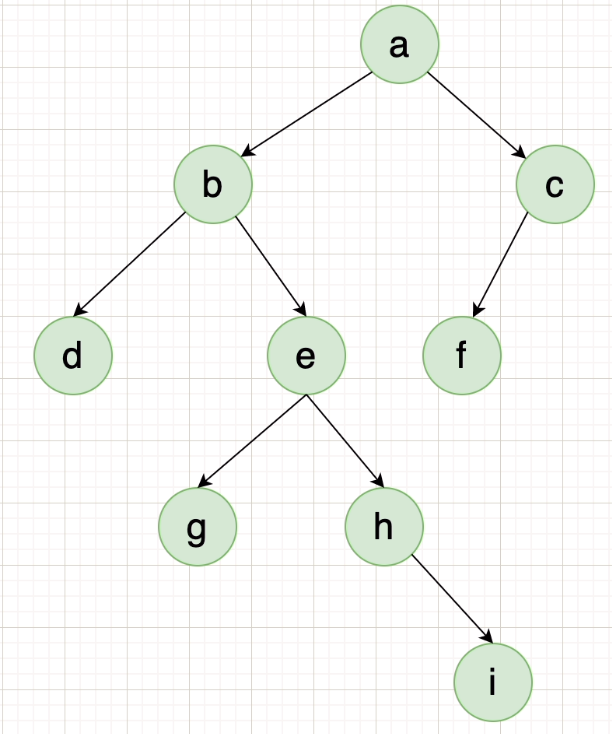
2023华为od统一考试B卷【二叉树中序遍历】
前言 博主刷的华为机考题,代码仅供参考,因为没有后台数据,可能有没考虑到的情况 如果感觉对你有帮助,请点点关注点点赞吧,谢谢你! 题目描述 思路 0.用Character数组存储树,index下标的左右…...

计算机网络:计算机之间的数据传输为什么要以时钟频率同步为基础?
以太网信息同步需要保障时钟同步的主要原因包括以下几点: 1. 确保数据的准确采样与解析 比特级同步:以太网数据传输以连续的比特流形式进行,接收端需在精确的时间点对信号采样。若发送端与接收端时钟不同步,采样时机偏移会导致误…...
在Spark搭建YARN
(一)什么是SparkONYarn模式 Spark on YARN(Yet Another Resource Negotiator)是 Spark 框架在 Hadoop 集群中运行的一种部署模式,它借助 Hadoop YARN 来管理资源和调度任务。 架构组成 ResourceManager:作…...
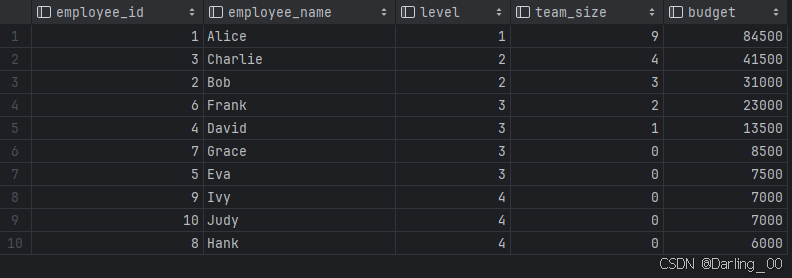
LeetCode_sql刷题(3482.分析组织层级)
题目描述:3482. 分析组织层级 - 力扣(LeetCode) 表:Employees ------------------------- | Column Name | Type | ------------------------- | employee_id | int | | employee_name | varchar | | manager_id …...

Python 之 selenium 打开浏览器指定端口进行接续操作
一般使用 selenium 进行数据爬取时,常用处理流程是让 selenium 从打开浏览器开始,完成全流程的所有操作。但是有时候,我们希望用户先自己打开浏览器进入指定网页,完成登录认证等一系列操作之后(比如用户、密码、短信验…...

MySQL Explain 中 Type 与 Extra 字段详解
引言 在数据库性能调优过程中,理解执行计划(EXPLAIN)的输出信息至关重要。MySQL 的 EXPLAIN 命令能够帮助开发者分析查询的执行路径和效率,其中 Type 和 Extra 字段提供了关键的执行细节。Type 字段表示访问类型,反映…...
不用服务器转码,Web端如何播放RTSP视频流?
在物联网、智慧城市、工业互联网等新兴技术浪潮下,实时视频流(如RTSP协议)作为安防监控、生产巡检、远程协作等场景的核心数据载体,其价值愈发凸显。然而,一个长期困扰行业的痛点始终存在——如何在Web浏览器中直接播…...
如何开发一款 Chrome 浏览器插件
Chrome是由谷歌开发的网页浏览器,基于开源软件(包括WebKit和Mozilla)开发,任何人都可以根据自己需要使用、修改或增强它的功能。Chrome凭借着其优秀的性能、出色的兼容性以及丰富的扩展程序,赢得了广大用户的信任。市场…...
GitHub打开缓慢甚至失败的解决办法
在C:\Windows\System32\drivers\etc的hosts中增加如下内容: 20.205.243.166 github.com 199.59.149.236 github.global.ssl.fastly.net185.199.109.153 http://assets-cdn.github.com 185.199.108.153 http://assets-cdn.github.com 185.199.110.153 http://asset…...

18前端项目----Vue项目收尾优化|重要知识
收尾/知识点汇总 项目收尾二级路由未登录全局路由守卫路由独享守卫图片懒加载路由懒加载打包上线 重要知识点汇总组件通信方式1. props2. 自定义事件3. 全局事件总线4. 订阅与发布pubsub5. Vuex6. 插槽 sync修饰符attrs和listeners属性children和parent属性mixin混入作用域插槽…...
仿RabbitMQ 模拟实现消息队列
文章目录 项目项目介绍开发环境技术选型 开始项目前第三方框架内容介绍muduo搭建服务端,客户端服务端:客户端:makefile muduo库protobuf通信服务端:客户端 sqlitegtest线程池future 认识,async使用promis使用package_t…...
基于Qt的app开发第八天
写在前面 笔者是一个大一下计科生,本学期的课程设计自命题完成一个督促学生自律的打卡软件,目前已经完成了待办和打卡部分功能,本篇要完成规划板块不需要存储就能实现的功能 需求分析 这一板块内容相比前两个板块还有一些特殊,因…...

Springboot之类路径扫描
SpringBoot框架中默认提供的扫描类为:ClassPathBeanDefinitionScanner。 webFlux框架中借助RepositoryComponentProvider扫描符合条件的Repository。 public class ClassPathScanningCandidateComponentProvider{private final List<TypeFilter> includeFilt…...
 - 随笔)
PNG图片转icon图标Python脚本(简易版) - 随笔
摘要 在网站开发或应用程序设计中,常需将高品质PNG图像转换为ICO格式图标。本文提供一份高效Python解决方案,利用Pillow库实现透明背景完美保留的格式转换。 源码示例 from PIL import Imagedef convert_png_to_ico(png_path, ico_path, size):"…...

数据分析-图2-图像对象设置参数与子图
from matplotlib import pyplot as mp mp.figure(A figure,facecolorgray) mp.plot([0,1],[1,2]) mp.figure(B figure,facecolorlightgray) mp.plot([1,2],[2,1]) #如果figure中标题已创建,则不会新建窗口, #而是将旧窗口设置为当前窗口 mp.figure(A fig…...
查询公网IP地址的方法:查看自己是不是公网ip,附内网穿透外网域名访问方案
本地搭建服务并提供互联网连接时,较为传统的方法是使用公网IP地址。因此,如何查询本地自己是不是公网IP,是必须要掌握的一种技巧。当面对确实无公网IP时,则可以通过内网穿透方案,如nat123网络映射工具,将本…...

MVCC:数据库并发控制的利器
在并发环境下,数据库需要处理多个事务同时访问和修改数据的情况。为了保证数据的一致性和隔离性,数据库需要采用一些并发控制机制。MVCC (Multi-Version Concurrency Control,多版本并发控制) 就是一种常用的并发控制技术,它通过维…...
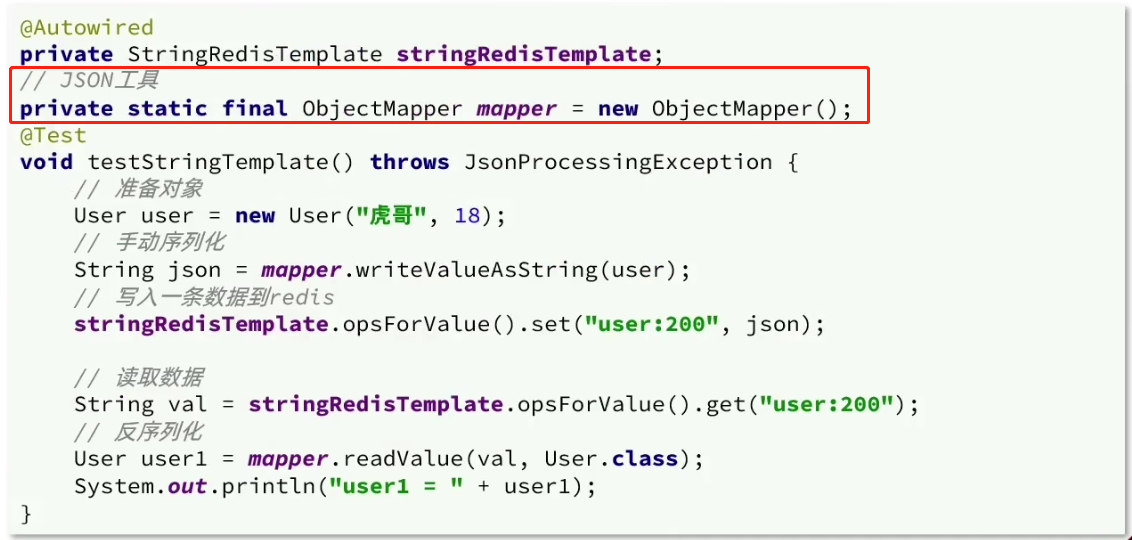
Redis学习打卡-Day1-SpringDataRedis、有状态无状态
Redis的Java客户端 Jedis 以 Redis 命令作为方法名称,学习成本低,简单实用。Jedis 是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此推荐使用 Jedis 连接池代替Jedis的直连方式。 lettuce Lettuce是基于Netty实现的&am…...

【行为型之访问者模式】游戏开发实战——Unity灵活数据操作与跨系统交互的架构秘诀
文章目录 🧳 访问者模式(Visitor Pattern)深度解析一、模式本质与核心价值二、经典UML结构三、Unity实战代码(游戏物品系统)1. 定义元素与访问者接口2. 实现具体元素类3. 实现具体访问者4. 对象结构管理5. 客户端使用 …...
)
Shell脚本实践(修改文件,修改配置文件,执行jar包)
1、前言 需要编写一个shell脚本支持 1、修改.so文件名 2、修改配置文件 3、执行jar包 2、代码解析 2.1、修改.so文件名 so_file_dir="/opt/casb/xxx/lib" # 处理.so文件 cd "$so_file_dir" || { echo "错误: 无法进入目录 $so_file_dir"; exit …...

React Native矢量图标全攻略:从入门到自定义iconfont的高级玩法
“你知道吗?在React Native应用中,仅仅通过一行代码就能召唤出上千个精美矢量图标,甚至还能把设计师精心制作的iconfont完美嵌入——但90%的开发者居然还在用图片方案!” 当我第一次发现同事的APP安装包比我的小了2.3MB,仅仅是因为他正确使用了react-native-vector-icons时…...

x-IMU matlab zupt惯性室内定位算法
基于x-IMU的ZUPT(Zero Velocity Update,零速更新)惯性室内定位算法是一种结合了惯性测量单元(IMU)数据和零速检测技术的室内定位方法。该算法通过检测行人静止状态下的零速区间,对惯性导航系统(…...

hbase shell的常用命令
一、hbase shell的基础命令 # 版本号查看 [rootTest-Hadoop-NN-01 hbase]$ ./bin/hbase version HBase 2.4.0 Source code repository git://apurtell-ltm.internal.salesforce.com/Users/apurtell/src/hbase revision282ab70012ae843af54a6779543ff20acbcbb629# 客户端登录 […...

在企业级项目中高效使用 Maven-mvnd
1、引言 1.1 什么是 Maven-mvnd? Maven-mvnd 是 Apache Maven 的一个实验性扩展工具(也称为 mvnd),基于守护进程(daemon)模型构建,目标是显著提升 Maven 构建的速度和效率。它由 Red Hat 推出,通过复用 JVM 进程来减少每次构建时的启动开销。 1.2 为什么企业在构建过…...