第二十二天打卡
数据预处理
import pandas as pd
from sklearn.model_selection import train_test_splitdef data_preprocessing(file_path):"""泰坦尼克号生存预测数据预处理函数参数:file_path: 原始数据文件路径返回:preprocessed_data: 预处理后的数据集"""# 数据加载与初步查看data = pd.read_csv(file_path)# 缺失值处理age_mean = data['Age'].mean()data['Age'].fillna(age_mean, inplace=True)embarked_mode = data['Embarked'].mode()[0]data['Embarked'].fillna(embarked_mode, inplace=True)data.drop('Cabin', axis=1, inplace=True)# 分类变量编码data = pd.get_dummies(data, columns=['Sex', 'Embarked'], prefix=['Sex', 'Embarked'])# 异常值处理def remove_outliers_IQR(df, column):Q1 = df[column].quantile(0.25)Q3 = df[column].quantile(0.75)IQR = Q3 - Q1lower_bound = Q1 - 1.5 * IQRupper_bound = Q3 + 1.5 * IQRreturn df[(df[column] >= lower_bound) & (df[column] <= upper_bound)]data = remove_outliers_IQR(data, 'Fare')# 删除无用特征useless_columns = ['PassengerId', 'Name', 'Ticket']data.drop(useless_columns, axis=1, inplace=True)return datadef split_dataset(data, test_size=0.2, random_state=42):"""划分预处理后的数据为训练集和测试集参数:data: 预处理后的数据test_size: 测试集占比random_state: 随机种子返回:X_train, X_test, y_train, y_test: 划分后的训练集和测试集"""X = data.drop(['Survived'], axis=1) # 特征,axis=1表示按列删除y = data['Survived'] # 标签X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=random_state) # 划分数据集# 训练集和测试集的形状print(f"训练集形状: {X_train.shape}, 测试集形状: {X_test.shape}") # 打印训练集和测试集的形状return X_train, X_test, y_train, y_test# ====================== 执行预处理和数据集划分 ======================
if __name__ == "__main__":input_file = "train.csv" # 确保文件在当前工作目录preprocessed_data = data_preprocessing(input_file)# 划分数据集X_train, X_test, y_train, y_test = split_dataset(preprocessed_data)# 保存预处理后的数据和划分后的数据集output_file = "train_preprocessed.csv"preprocessed_data.to_csv(output_file, index=False)print(f"\n预处理后数据已保存至:{output_file}")# 保存划分后的数据集(可选)pd.concat([X_train, y_train], axis=1).to_csv("train_split.csv", index=False)pd.concat([X_test, y_test], axis=1).to_csv("test_split.csv", index=False)print(f"训练集已保存至:train_split.csv")print(f"测试集已保存至:test_split.csv")模型
SVM
# SVM
svm_model = SVC(random_state=42)
svm_model.fit(X_train, y_train)
svm_pred = svm_model.predict(X_test)print("\nSVM 分类报告:")
print(classification_report(y_test, svm_pred)) # 打印分类报告
print("SVM 混淆矩阵:")
print(confusion_matrix(y_test, svm_pred)) # 打印混淆矩阵# 计算 SVM 评估指标,这些指标默认计算正类的性能
svm_accuracy = accuracy_score(y_test, svm_pred)
svm_precision = precision_score(y_test, svm_pred)
svm_recall = recall_score(y_test, svm_pred)
svm_f1 = f1_score(y_test, svm_pred)
print("SVM 模型评估指标:")
print(f"准确率: {svm_accuracy:.4f}")
print(f"精确率: {svm_precision:.4f}")
print(f"召回率: {svm_recall:.4f}")
print(f"F1 值: {svm_f1:.4f}")
KNN
# KNN
knn_model = KNeighborsClassifier()
knn_model.fit(X_train, y_train)
knn_pred = knn_model.predict(X_test)print("\nKNN 分类报告:")
print(classification_report(y_test, knn_pred))
print("KNN 混淆矩阵:")
print(confusion_matrix(y_test, knn_pred))knn_accuracy = accuracy_score(y_test, knn_pred)
knn_precision = precision_score(y_test, knn_pred)
knn_recall = recall_score(y_test, knn_pred)
knn_f1 = f1_score(y_test, knn_pred)
print("KNN 模型评估指标:")
print(f"准确率: {knn_accuracy:.4f}")
print(f"精确率: {knn_precision:.4f}")
print(f"召回率: {knn_recall:.4f}")
print(f"F1 值: {knn_f1:.4f}")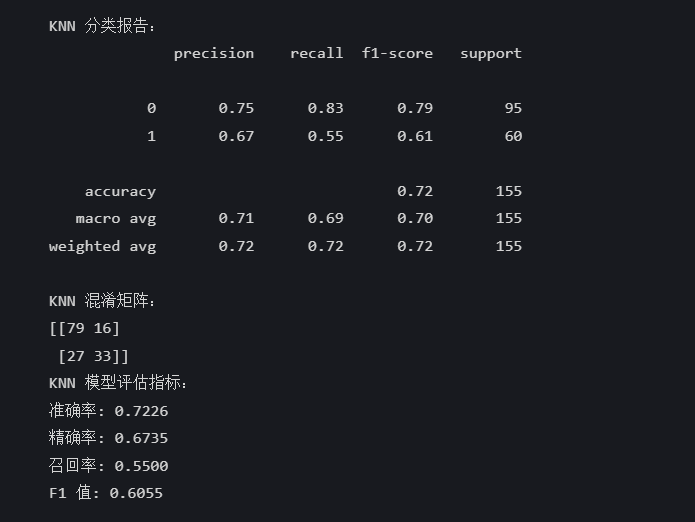
逻辑回归
# 逻辑回归
logreg_model = LogisticRegression(random_state=42)
logreg_model.fit(X_train, y_train)
logreg_pred = logreg_model.predict(X_test)print("\n逻辑回归 分类报告:")
print(classification_report(y_test, logreg_pred))
print("逻辑回归 混淆矩阵:")
print(confusion_matrix(y_test, logreg_pred))logreg_accuracy = accuracy_score(y_test, logreg_pred)
logreg_precision = precision_score(y_test, logreg_pred)
logreg_recall = recall_score(y_test, logreg_pred)
logreg_f1 = f1_score(y_test, logreg_pred)
print("逻辑回归 模型评估指标:")
print(f"准确率: {logreg_accuracy:.4f}")
print(f"精确率: {logreg_precision:.4f}")
print(f"召回率: {logreg_recall:.4f}")
print(f"F1 值: {logreg_f1:.4f}")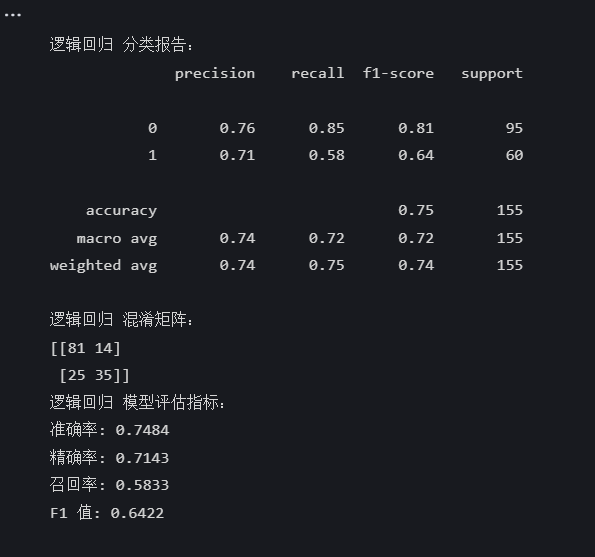
朴素贝叶斯
# 朴素贝叶斯
nb_model = GaussianNB()
nb_model.fit(X_train, y_train)
nb_pred = nb_model.predict(X_test)print("\n朴素贝叶斯 分类报告:")
print(classification_report(y_test, nb_pred))
print("朴素贝叶斯 混淆矩阵:")
print(confusion_matrix(y_test, nb_pred))nb_accuracy = accuracy_score(y_test, nb_pred)
nb_precision = precision_score(y_test, nb_pred)
nb_recall = recall_score(y_test, nb_pred)
nb_f1 = f1_score(y_test, nb_pred)
print("朴素贝叶斯 模型评估指标:")
print(f"准确率: {nb_accuracy:.4f}")
print(f"精确率: {nb_precision:.4f}")
print(f"召回率: {nb_recall:.4f}")
print(f"F1 值: {nb_f1:.4f}")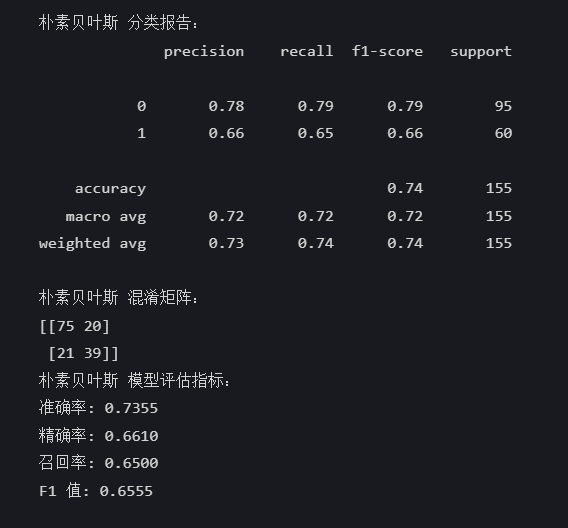
决策树
# 决策树
dt_model = DecisionTreeClassifier(random_state=42)
dt_model.fit(X_train, y_train)
dt_pred = dt_model.predict(X_test)print("\n决策树 分类报告:")
print(classification_report(y_test, dt_pred))
print("决策树 混淆矩阵:")
print(confusion_matrix(y_test, dt_pred))dt_accuracy = accuracy_score(y_test, dt_pred)
dt_precision = precision_score(y_test, dt_pred)
dt_recall = recall_score(y_test, dt_pred)
dt_f1 = f1_score(y_test, dt_pred)
print("决策树 模型评估指标:")
print(f"准确率: {dt_accuracy:.4f}")
print(f"精确率: {dt_precision:.4f}")
print(f"召回率: {dt_recall:.4f}")
print(f"F1 值: {dt_f1:.4f}")随机森林
# 随机森林
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train)
rf_pred = rf_model.predict(X_test)print("\n随机森林 分类报告:")
print(classification_report(y_test, rf_pred))
print("随机森林 混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))rf_accuracy = accuracy_score(y_test, rf_pred)
rf_precision = precision_score(y_test, rf_pred)
rf_recall = recall_score(y_test, rf_pred)
rf_f1 = f1_score(y_test, rf_pred)
print("随机森林 模型评估指标:")
print(f"准确率: {rf_accuracy:.4f}")
print(f"精确率: {rf_precision:.4f}")
print(f"召回率: {rf_recall:.4f}") 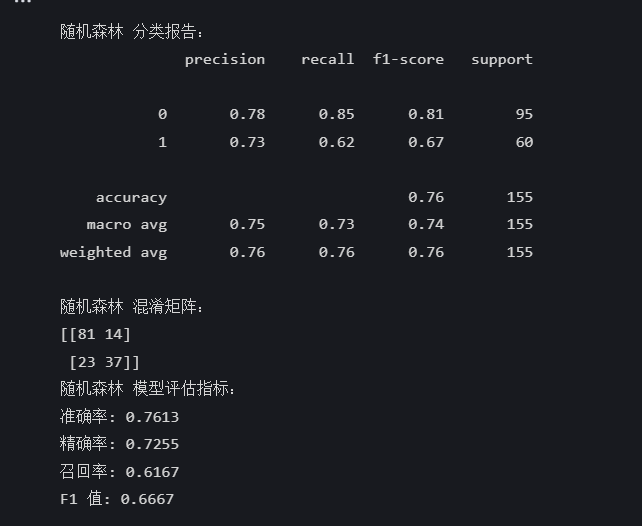
网格搜索优化
# --- 2. 网格搜索优化随机森林 ---
print("\n--- 2. 网格搜索优化随机森林 (训练集 -> 测试集) ---")
from sklearn.model_selection import GridSearchCV
import time
# 定义要搜索的参数网格
param_grid = {'n_estimators': [50, 100, 200],'max_depth': [None, 10, 20, 30],'min_samples_split': [2, 5, 10],'min_samples_leaf': [1, 2, 4]
}# 创建网格搜索对象
grid_search = GridSearchCV(estimator=RandomForestClassifier(random_state=42), # 随机森林分类器param_grid=param_grid, # 参数网格cv=5, # 5折交叉验证n_jobs=-1, # 使用所有可用的CPU核心进行并行计算scoring='accuracy') # 使用准确率作为评分标准start_time = time.time()
# 在训练集上进行网格搜索
grid_search.fit(X_train, y_train) # 在训练集上训练,模型实例化和训练的方法都被封装在这个网格搜索对象里了
end_time = time.time()print(f"网格搜索耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", grid_search.best_params_) #best_params_属性返回最佳参数组合# 使用最佳参数的模型进行预测
best_model = grid_search.best_estimator_ # 获取最佳模型
best_pred = best_model.predict(X_test) # 在测试集上进行预测print("\n网格搜索优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("网格搜索优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))

贝叶斯优化
print("\n--- 2. 贝叶斯优化随机森林 (训练集 -> 测试集) ---")
from skopt import BayesSearchCV
from skopt.space import Integer
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time# 定义要搜索的参数空间
search_space = {'n_estimators': Integer(50, 200),'max_depth': Integer(10, 30),'min_samples_split': Integer(2, 10),'min_samples_leaf': Integer(1, 4)
}# 创建贝叶斯优化搜索对象
bayes_search = BayesSearchCV(estimator=RandomForestClassifier(random_state=42),search_spaces=search_space,n_iter=32, # 迭代次数,可根据需要调整cv=5, # 5折交叉验证,这个参数是必须的,不能设置为1,否则就是在训练集上做预测了n_jobs=-1,scoring='accuracy'
)start_time = time.time()
# 在训练集上进行贝叶斯优化搜索
bayes_search.fit(X_train, y_train)
end_time = time.time()print(f"贝叶斯优化耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", bayes_search.best_params_)# 使用最佳参数的模型进行预测
best_model = bayes_search.best_estimator_
best_pred = best_model.predict(X_test)print("\n贝叶斯优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("贝叶斯优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred)) 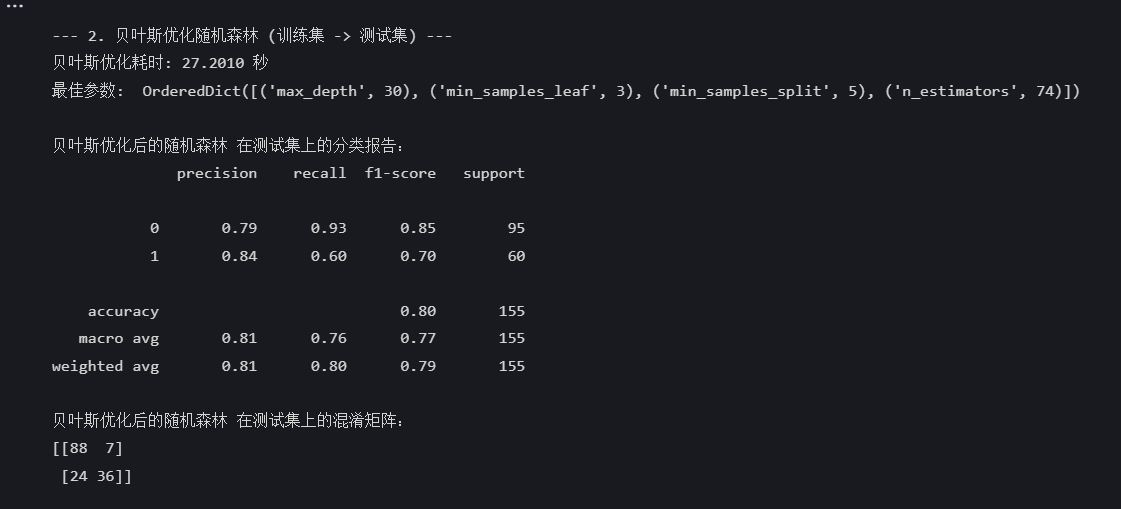
粒子群优化算法
import numpy as np # 导入NumPy库,用于处理数组和矩阵运算
import random # 导入random模块,用于生成随机数
import time # 导入time模块,用于计算优化耗时
from sklearn.ensemble import RandomForestClassifier # 导入随机森林分类器
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix # 导入评估指标
# --- 2. 粒子群优化算法优化随机森林 ---
print("\n--- 2. 粒子群优化算法优化随机森林 (训练集 -> 测试集) ---")# 定义适应度函数,本质就是构建了一个函数实现 参数--> 评估指标的映射
def fitness_function(params): n_estimators, max_depth, min_samples_split, min_samples_leaf = params # 序列解包,允许你将一个可迭代对象(如列表、元组、字符串等)中的元素依次赋值给多个变量。model = RandomForestClassifier(n_estimators=int(n_estimators),max_depth=int(max_depth),min_samples_split=int(min_samples_split),min_samples_leaf=int(min_samples_leaf),random_state=42)model.fit(X_train, y_train)y_pred = model.predict(X_test)accuracy = accuracy_score(y_test, y_pred)return accuracy# 粒子群优化算法实现
def pso(num_particles, num_iterations, c1, c2, w, bounds): # 粒子群优化算法核心函数# num_particles:粒子的数量,即算法中用于搜索最优解的个体数量。# num_iterations:迭代次数,算法运行的最大循环次数。# c1:认知学习因子,用于控制粒子向自身历史最佳位置移动的程度。# c2:社会学习因子,用于控制粒子向全局最佳位置移动的程度。# w:惯性权重,控制粒子的惯性,影响粒子在搜索空间中的移动速度和方向。# bounds:超参数的取值范围,是一个包含多个元组的列表,每个元组表示一个超参数的最小值和最大值。num_params = len(bounds) particles = np.array([[random.uniform(bounds[i][0], bounds[i][1]) for i in range(num_params)] for _ inrange(num_particles)])velocities = np.array([[0] * num_params for _ in range(num_particles)])personal_best = particles.copy()personal_best_fitness = np.array([fitness_function(p) for p in particles])global_best_index = np.argmax(personal_best_fitness)global_best = personal_best[global_best_index]global_best_fitness = personal_best_fitness[global_best_index]for _ in range(num_iterations):r1 = np.array([[random.random() for _ in range(num_params)] for _ in range(num_particles)])r2 = np.array([[random.random() for _ in range(num_params)] for _ in range(num_particles)])velocities = w * velocities + c1 * r1 * (personal_best - particles) + c2 * r2 * (global_best - particles)particles = particles + velocitiesfor i in range(num_particles):for j in range(num_params):if particles[i][j] < bounds[j][0]:particles[i][j] = bounds[j][0]elif particles[i][j] > bounds[j][1]:particles[i][j] = bounds[j][1]fitness_values = np.array([fitness_function(p) for p in particles])improved_indices = fitness_values > personal_best_fitnesspersonal_best[improved_indices] = particles[improved_indices]personal_best_fitness[improved_indices] = fitness_values[improved_indices]current_best_index = np.argmax(personal_best_fitness)if personal_best_fitness[current_best_index] > global_best_fitness:global_best = personal_best[current_best_index]global_best_fitness = personal_best_fitness[current_best_index]return global_best, global_best_fitness# 超参数范围
bounds = [(50, 200), (10, 30), (2, 10), (1, 4)] # n_estimators, max_depth, min_samples_split, min_samples_leaf# 粒子群优化算法参数
num_particles = 20
num_iterations = 10
c1 = 1.5
c2 = 1.5
w = 0.5start_time = time.time()
best_params, best_fitness = pso(num_particles, num_iterations, c1, c2, w, bounds)
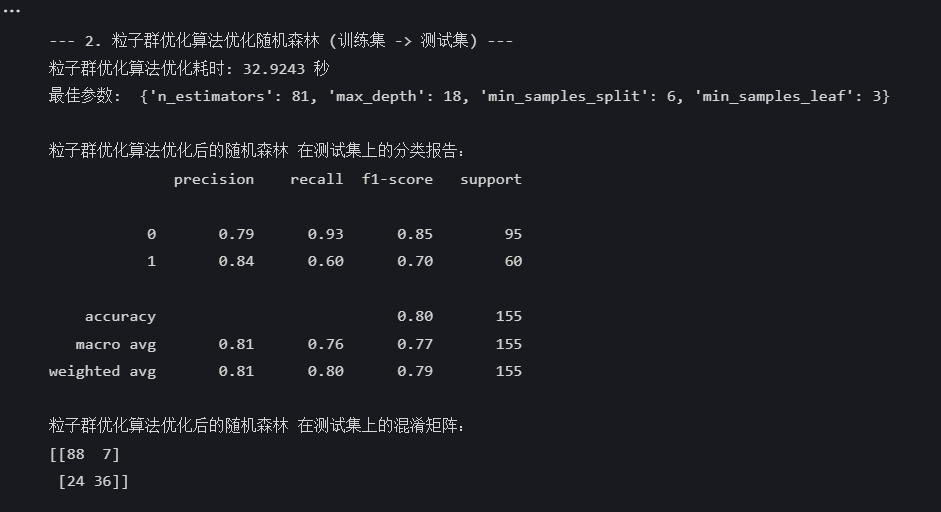
end_time = time.time()print(f"粒子群优化算法优化耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", {'n_estimators': int(best_params[0]),'max_depth': int(best_params[1]),'min_samples_split': int(best_params[2]),'min_samples_leaf': int(best_params[3])
})# 使用最佳参数的模型进行预测
best_model = RandomForestClassifier(n_estimators=int(best_params[0]),max_depth=int(best_params[1]),min_samples_split=int(best_params[2]),min_samples_leaf=int(best_params[3]),random_state=42)
best_model.fit(X_train, y_train)
best_pred = best_model.predict(X_test)print("\n粒子群优化算法优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("粒子群优化算法优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))
XGBOOST
# XGBoost
xgb_model = xgb.XGBClassifier(random_state=42)
xgb_model.fit(X_train, y_train)
xgb_pred = xgb_model.predict(X_test)print("\nXGBoost 分类报告:")
print(classification_report(y_test, xgb_pred))
print("XGBoost 混淆矩阵:")
print(confusion_matrix(y_test, xgb_pred))xgb_accuracy = accuracy_score(y_test, xgb_pred)
xgb_precision = precision_score(y_test, xgb_pred)
xgb_recall = recall_score(y_test, xgb_pred)
xgb_f1 = f1_score(y_test, xgb_pred)
print("XGBoost 模型评估指标:")
print(f"准确率: {xgb_accuracy:.4f}")
print(f"精确率: {xgb_precision:.4f}")
print(f"召回率: {xgb_recall:.4f}")
print(f"F1 值: {xgb_f1:.4f}") 
shape可解释性分析
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import shap
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 设置中文字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题# 加载数据并预处理
def data_preprocessing(file_path):data = pd.read_csv(file_path)# 缺失值处理data['Age'].fillna(data['Age'].mean(), inplace=True)data['Embarked'].fillna(data['Embarked'].mode()[0], inplace=True)data.drop('Cabin', axis=1, inplace=True)# 分类变量编码data = pd.get_dummies(data, columns=['Sex', 'Embarked'], prefix=['Sex', 'Embarked'])# 删除无用特征useless_columns = ['PassengerId', 'Name', 'Ticket']data.drop(useless_columns, axis=1, inplace=True)return data# 加载数据
data = data_preprocessing("train.csv")# 划分特征和目标变量
X = data.drop('Survived', axis=1)
y = data['Survived']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 使用粒子群优化后的最佳参数训练模型
best_params = [180, 28, 2, 1] # 示例参数,实际应使用PSO优化结果
model = RandomForestClassifier(n_estimators=int(best_params[0]),max_depth=int(best_params[1]),min_samples_split=int(best_params[2]),min_samples_leaf=int(best_params[3]),random_state=42
)
model.fit(X_train, y_train)# 预测并评估
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.4f}")# --------------------- SHAP可解释性分析 ---------------------
# 1. 初始化SHAP解释器
explainer = shap.TreeExplainer(model)# 2. 计算训练集样本的SHAP值
shap_values = explainer.shap_values(X_train)# --------------------- 全局解释 ---------------------
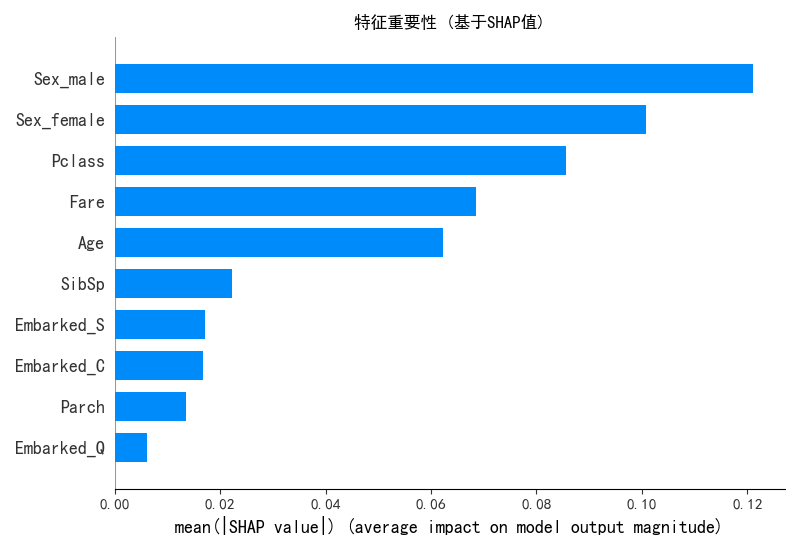
# 3. 特征重要性摘要图
plt.figure(figsize=(10, 6))
shap.summary_plot(shap_values[1], X_train, plot_type="bar", show=False)
plt.title("特征重要性 (基于SHAP值)")
plt.tight_layout()
plt.savefig("shap_feature_importance.png")
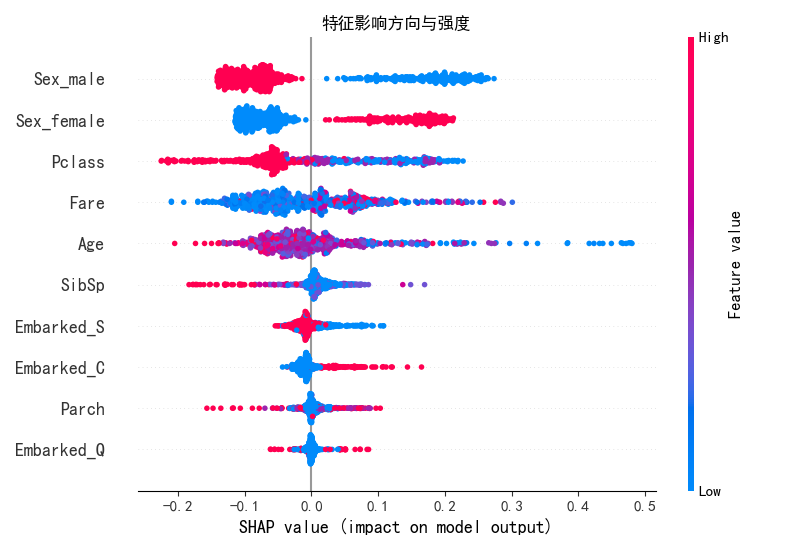
plt.close()# 4. 特征影响方向摘要图
plt.figure(figsize=(10, 6))
shap.summary_plot(shap_values[1], X_train, show=False)
plt.title("特征影响方向与强度")
plt.tight_layout()
plt.savefig("shap_summary_plot.png")
plt.close()# 5. 依赖图 - 选择几个最重要的特征进行分析
for feature in X_train.columns:plt.figure(figsize=(10, 6))shap.dependence_plot(feature, shap_values[1], X_train, show=False)plt.tight_layout()plt.savefig(f"shap_dependence_{feature}.png")plt.close()# --------------------- 局部解释 ---------------------
# 6. 选择几个样本进行详细解释
sample_indices = [0, 1, 2, 3] # 选择前4个样本
for idx in sample_indices:plt.figure(figsize=(10, 6))shap.force_plot(explainer.expected_value[1], shap_values[1][idx], X_train.iloc[idx], matplotlib=True,show=False)plt.title(f"样本 {idx} 的SHAP解释 - 预测存活概率: {model.predict_proba(X_train.iloc[[idx]])[0][1]:.4f}")plt.tight_layout()plt.savefig(f"shap_force_plot_{idx}.png")plt.close()# 7. 决策图 - 展示特征如何影响最终决策
for idx in sample_indices:plt.figure(figsize=(12, 6))shap.decision_plot(explainer.expected_value[1], shap_values[1][idx], X_train.iloc[idx],feature_names=list(X_train.columns),show=False)plt.title(f"样本 {idx} 的决策路径")plt.tight_layout()plt.savefig(f"shap_decision_plot_{idx}.png")plt.close()# 8. 保存SHAP值用于后续分析
shap_data = pd.DataFrame(shap_values[1], columns=X_train.columns)
shap_data.to_csv("shap_values.csv", index=False)print("\nSHAP分析完成! 结果已保存为图片文件。")
聚类
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import seaborn as sns# 标准化数据(聚类前通常需要标准化)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns# 评估不同 k 值下的指标
k_range = range(2, 11) # 测试 k 从 2 到 10
inertia_values = []
silhouette_scores = []
ch_scores = []
db_scores = []for k in k_range:kmeans = KMeans(n_clusters=k, random_state=42)kmeans_labels = kmeans.fit_predict(X_scaled)inertia_values.append(kmeans.inertia_) # 惯性(肘部法则)silhouette = silhouette_score(X_scaled, kmeans_labels) # 轮廓系数silhouette_scores.append(silhouette)ch = calinski_harabasz_score(X_scaled, kmeans_labels) # CH 指数ch_scores.append(ch)db = davies_bouldin_score(X_scaled, kmeans_labels) # DB 指数db_scores.append(db)print(f"k={k}, 惯性: {kmeans.inertia_:.2f}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")# 绘制评估指标图
plt.figure(figsize=(15, 10))# 肘部法则图(Inertia)
plt.subplot(2, 2, 1)
plt.plot(k_range, inertia_values, marker='o')
plt.title('肘部法则确定最优聚类数 k(惯性,越小越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('惯性')
plt.grid(True)# 轮廓系数图
plt.subplot(2, 2, 2)
plt.plot(k_range, silhouette_scores, marker='o', color='orange')
plt.title('轮廓系数确定最优聚类数 k(越大越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('轮廓系数')
plt.grid(True)# CH 指数图
plt.subplot(2, 2, 3)
plt.plot(k_range, ch_scores, marker='o', color='green')
plt.title('Calinski-Harabasz 指数确定最优聚类数 k(越大越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('CH 指数')
plt.grid(True)# DB 指数图
plt.subplot(2, 2, 4)
plt.plot(k_range, db_scores, marker='o', color='red')
plt.title('Davies-Bouldin 指数确定最优聚类数 k(越小越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('DB 指数')
plt.grid(True)plt.tight_layout()
plt.show()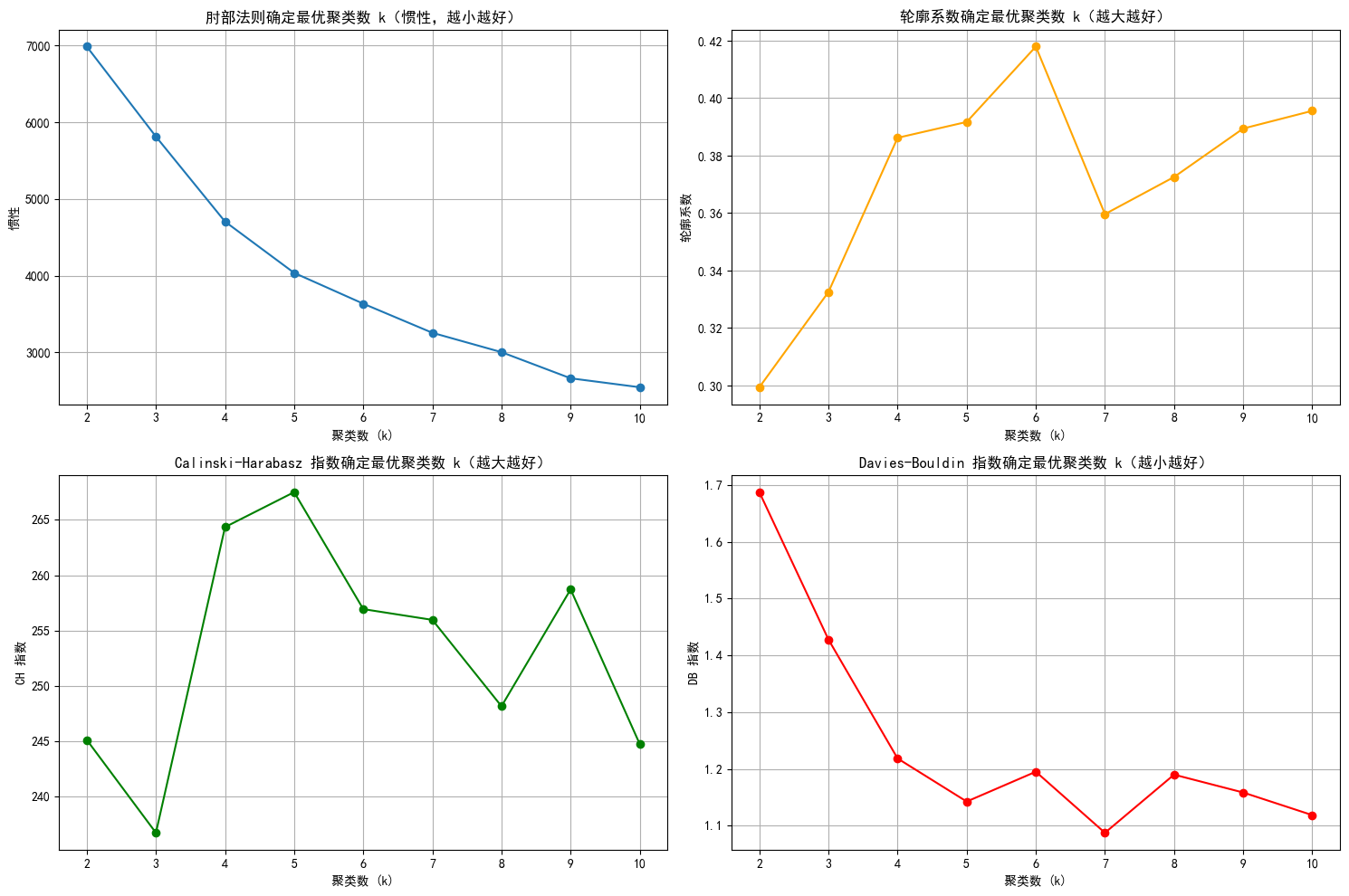
# 提示用户选择 k 值
selected_k = 5# 使用选择的 k 值进行 KMeans 聚类
kmeans = KMeans(n_clusters=selected_k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
X['KMeans_Cluster'] = kmeans_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# KMeans 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=kmeans_labels, palette='viridis')
plt.title(f'KMeans Clustering with k={selected_k} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 KMeans 聚类标签的前几行
print(f"KMeans Cluster labels (k={selected_k}) added to X:")
print(X[['KMeans_Cluster']].value_counts()) 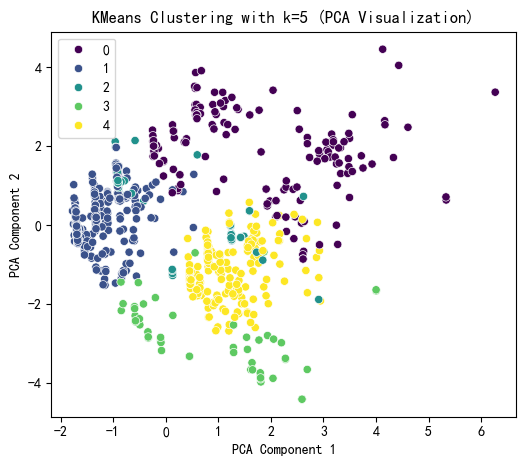
import numpy as np
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns# 评估不同 eps 和 min_samples 下的指标
# eps这个参数表示邻域的半径,min_samples表示一个点被认为是核心点所需的最小样本数。
# min_samples这个参数表示一个核心点所需的最小样本数。eps_range = np.arange(0.3, 0.8, 0.1) # 测试 eps 从 0.3 到 0.7
min_samples_range = range(3, 8) # 测试 min_samples 从 3 到 7
results = []for eps in eps_range:for min_samples in min_samples_range:dbscan = DBSCAN(eps=eps, min_samples=min_samples)dbscan_labels = dbscan.fit_predict(X_scaled)# 计算簇的数量(排除噪声点 -1)n_clusters = len(np.unique(dbscan_labels)) - (1 if -1 in dbscan_labels else 0)# 计算噪声点数量n_noise = list(dbscan_labels).count(-1)# 只有当簇数量大于 1 且有有效簇时才计算评估指标if n_clusters > 1:# 排除噪声点后计算评估指标mask = dbscan_labels != -1if mask.sum() > 0: # 确保有非噪声点silhouette = silhouette_score(X_scaled[mask], dbscan_labels[mask])ch = calinski_harabasz_score(X_scaled[mask], dbscan_labels[mask])db = davies_bouldin_score(X_scaled[mask], dbscan_labels[mask])results.append({'eps': eps,'min_samples': min_samples,'n_clusters': n_clusters,'n_noise': n_noise,'silhouette': silhouette,'ch_score': ch,'db_score': db})print(f"eps={eps:.1f}, min_samples={min_samples}, 簇数: {n_clusters}, 噪声点: {n_noise}, "f"轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")else:print(f"eps={eps:.1f}, min_samples={min_samples}, 簇数: {n_clusters}, 噪声点: {n_noise}, 无法计算评估指标")# 将结果转为 DataFrame 以便可视化和选择参数
results_df = pd.DataFrame(results)# 绘制评估指标图,增加点论文中的工作量
plt.figure(figsize=(15, 10))
# 轮廓系数图
plt.subplot(2, 2, 1)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples] # plt.plot(subset['eps'], subset['silhouette'], marker='o', label=f'min_samples={min_samples}')
plt.title('轮廓系数确定最优参数(越大越好)')
plt.xlabel('eps')
plt.ylabel('轮廓系数')
plt.legend()
plt.grid(True)# CH 指数图
plt.subplot(2, 2, 2)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['ch_score'], marker='o', label=f'min_samples={min_samples}')
plt.title('Calinski-Harabasz 指数确定最优参数(越大越好)')
plt.xlabel('eps')
plt.ylabel('CH 指数')
plt.legend()
plt.grid(True)# DB 指数图
plt.subplot(2, 2, 3)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['db_score'], marker='o', label=f'min_samples={min_samples}')
plt.title('Davies-Bouldin 指数确定最优参数(越小越好)')
plt.xlabel('eps')
plt.ylabel('DB 指数')
plt.legend()
plt.grid(True)# 簇数量图
plt.subplot(2, 2, 4)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['n_clusters'], marker='o', label=f'min_samples={min_samples}')
plt.title('簇数量变化')
plt.xlabel('eps')
plt.ylabel('簇数量')
plt.legend()
plt.grid(True)plt.tight_layout()
plt.show()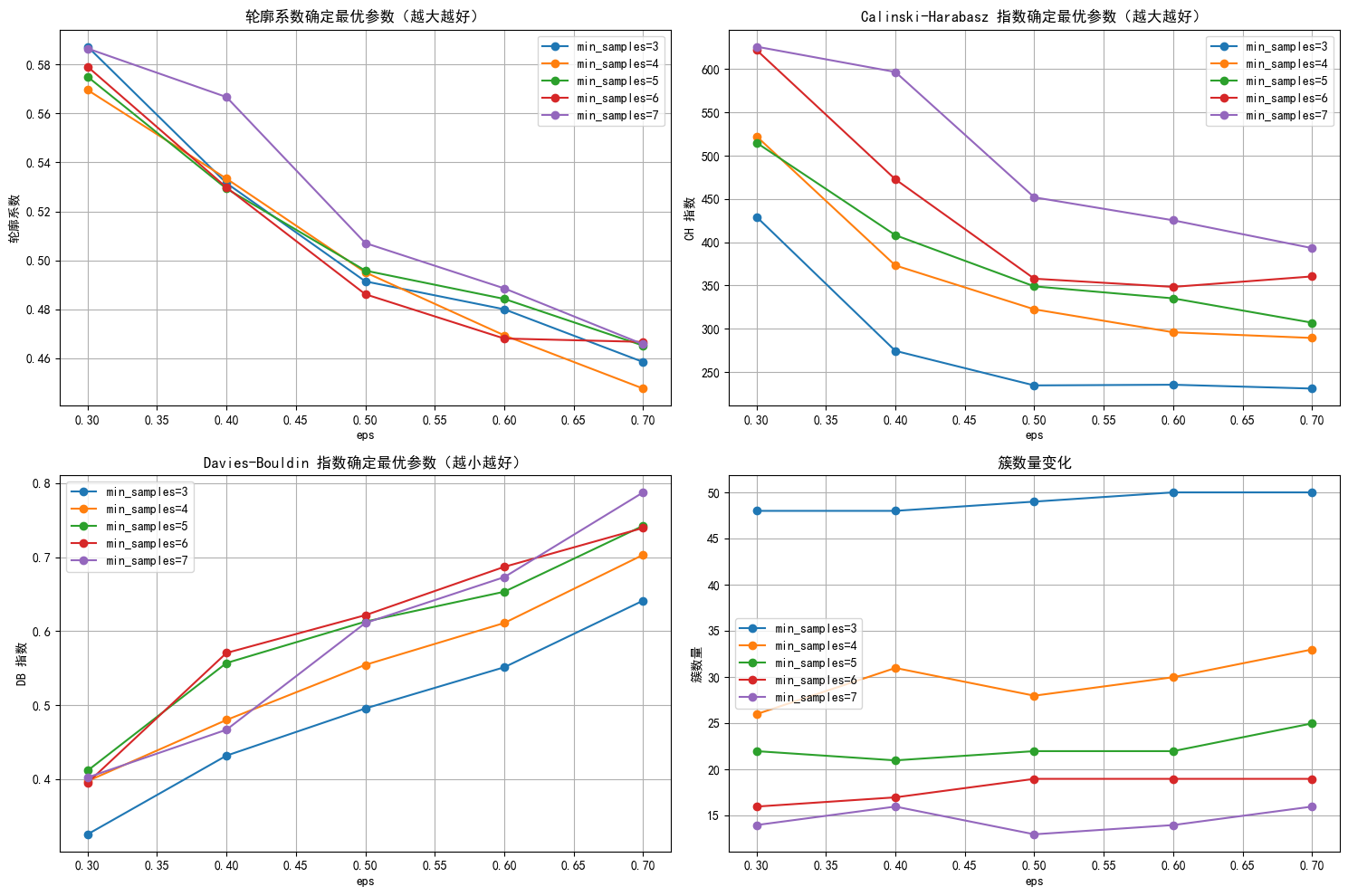
# 选择 eps 和 min_samples 值(根据图表选择最佳参数)
selected_eps = 0.4 # 根据图表调整
selected_min_samples = 7 # 根据图表调整# 使用选择的参数进行 DBSCAN 聚类
dbscan = DBSCAN(eps=selected_eps, min_samples=selected_min_samples)
dbscan_labels = dbscan.fit_predict(X_scaled)
X['DBSCAN_Cluster'] = dbscan_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# DBSCAN 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=dbscan_labels, palette='viridis')
plt.title(f'DBSCAN Clustering with eps={selected_eps}, min_samples={selected_min_samples} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 DBSCAN 聚类标签的分布
print(f"DBSCAN Cluster labels (eps={selected_eps}, min_samples={selected_min_samples}) added to X:")
print(X[['DBSCAN_Cluster']].value_counts()) 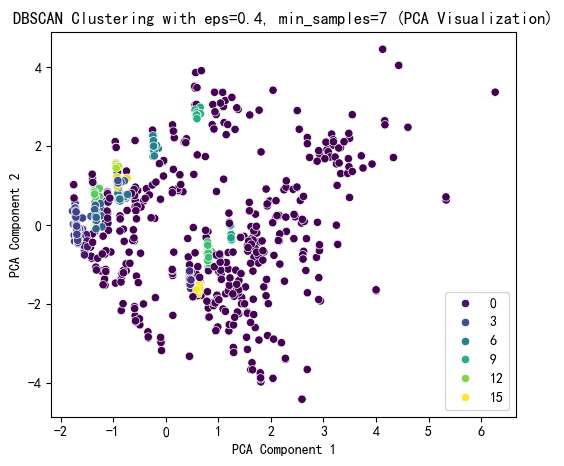
@浙大疏锦行
相关文章:
第二十二天打卡
数据预处理 import pandas as pd from sklearn.model_selection import train_test_splitdef data_preprocessing(file_path):"""泰坦尼克号生存预测数据预处理函数参数:file_path: 原始数据文件路径返回:preprocessed_data: 预处理后的数据集""&quo…...

Android Activity之间跳转的原理
一、Activity跳转核心流程 Android Activity跳转的底层实现涉及 系统服务交互、进程间通信(IPC) 和 生命周期管理,主要流程如下: startActivity() 触发请求 应用调用 startActivity() 时,通过 Inst…...

MATLAB 矩阵与数组操作基础教程
文章目录 前言环境配置一、创建矩阵与数组(一)直接输入法(二)特殊矩阵生成函数(三)使用冒号表达式创建数组 二、矩阵与数组的基本操作(一)访问元素(二)修改元…...

【Linux】第十六章 分析和存储日志
1. RHEL 日志文件保存在哪个目录中? 一般存储在 /var/log 目录中。 2. 什么是syslog消息和非syslog消息? syslog消息是一种标准的日志记录协议和格式,用于系统和应用程序记录日志信息。它规定了日志消息的结构和内容,包括消息的…...
解锁性能密码:Linux 环境下 Oracle 大页配置全攻略
在 Oracle 数据库运行过程中,内存管理是影响其性能的关键因素之一。大页内存(Large Pages)作为一种优化内存使用的技术,能够显著提升 Oracle 数据库的运行效率。本文将深入介绍大页内存的相关概念,并详细阐述 Oracle 在…...
Spark,在shell中运行RDD程序
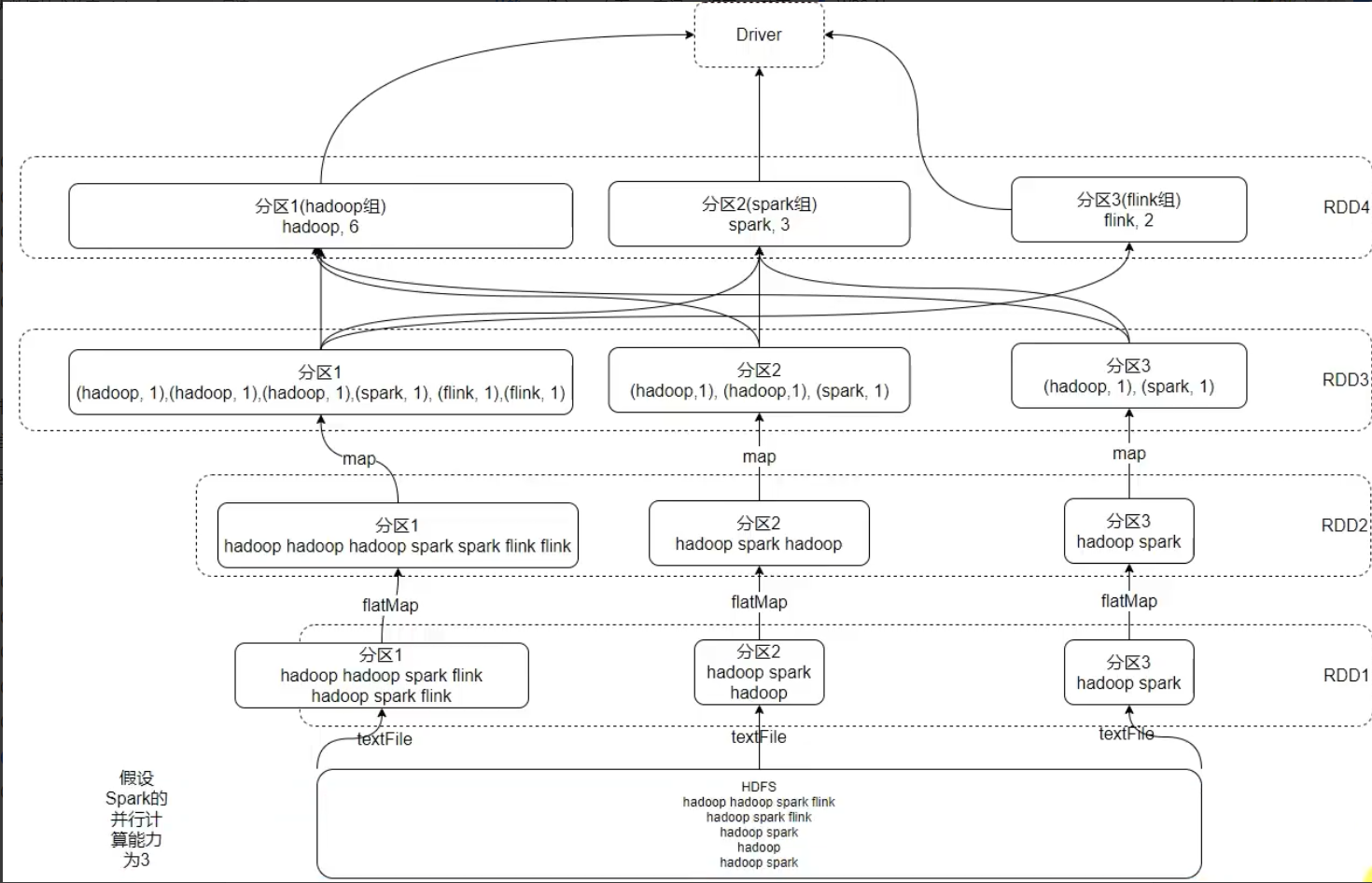
在hdfs中/wcinput中创建一个文件:word2.txt在里面写几个单词 启动hdfs集群 [roothadoop100 ~]# myhadoop start [roothadoop100 ~]# cd /opt/module/spark-yarn/bin [roothadoop100 ~]# ./spark-shell 写个11测试一下 按住ctrlD退出 进入环境:spa…...
SAP学习笔记 - 开发11 - RAP(RESTful Application Programming)简介
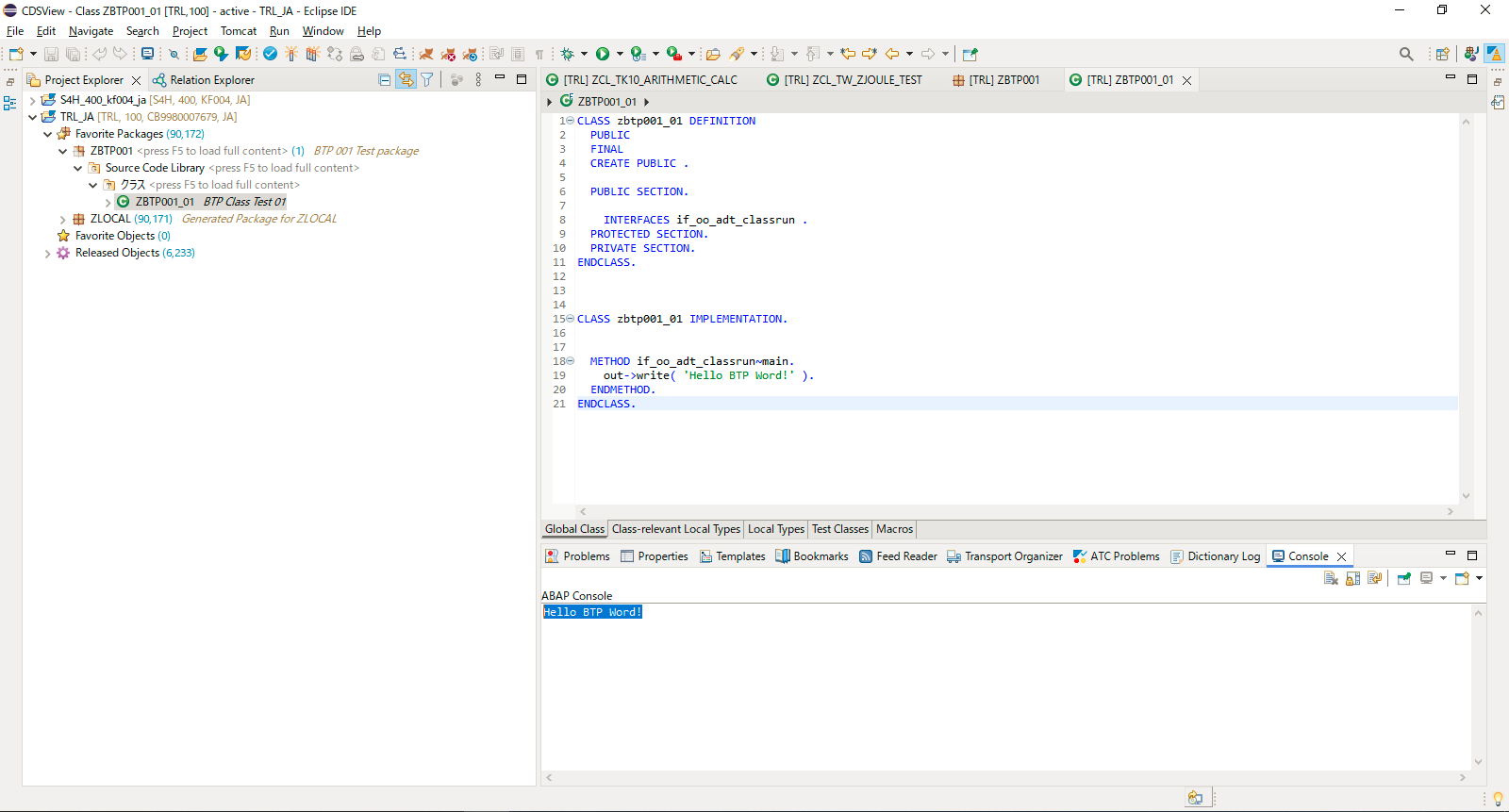
上一章学习了BTP架构图,实操创建Directory/Subaccount,BTP的内部组成,BTP Cockpit。 SAP学习笔记 - 开发10 - BTP架构图,实操创建Directory/Subaccount,BTP的内部组成,BTP Cockpit-CSDN博客 本章继续学习S…...

数据防泄密安全:企业稳健发展的守护盾
在数字化时代,数据已成为企业最核心的资产之一。无论是客户信息、财务数据,还是商业机密,一旦泄露,都可能给企业带来不可估量的损失。近年来,数据泄露事件频发,如Facebook用户数据泄露、Equifax信用数据外泄…...
MySQL之基础索引
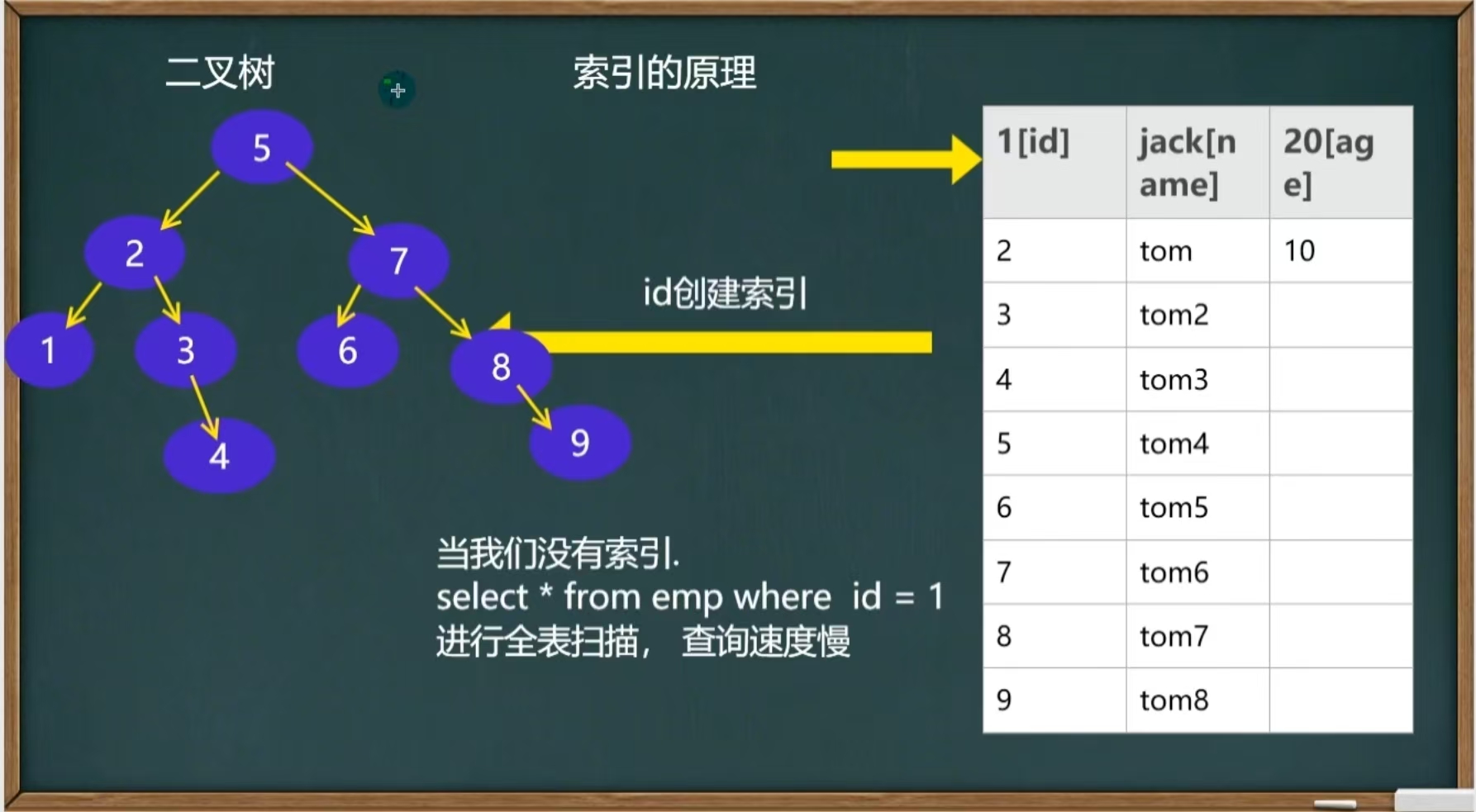
目录 引言 1、创建索引 2、索引的原理 2、索引的类型 3、索引的使用 1.添加索引 2.删除索引 3.删除主键索引 4.修改索引 5.查询索引 引言 当一个数据库里面的数据特别多,比如800万,光是创建插入数据就要十几分钟,我们查询一条信息也…...

Openshift节点Disk pressure
OpenShift 监控以下指标,并定义以下垃圾回收的驱逐阈值。请参阅产品文档以更改任何驱逐值。 nodefs.available 从 cadvisor 来看,该node.stats.fs.available指标表示节点文件系统(所在位置)上有多少可用(剩余…...
拉丁方分析
本文是实验设计与分析(第6版,Montgomery著傅珏生译)第4章随机化区组,拉丁方,以及有关的设计第4.2节的python解决方案。本文尽量避免重复书中的理论,着于提供python解决方案,并与原书的运算结果进行对比。您…...

Pomelo知识框架
一、Pomelo 基础概念 Pomelo 简介 定位:分布式游戏服务器框架(网易开源)。 特点:高并发、可扩展、多进程架构、支持多种通信协议(WebSocket、TCP等)。 适用场景:MMO RPG、实时对战、社交游戏等…...
软考软件设计师中级——软件工程笔记
1.软件过程 1.1能力成熟度模型(CMM) 软件能力成熟度模型(CMM)将软件过程改进分为以下五个成熟度级别,每个级别都定义了特定的过程特征和目标: 初始级 (Initial): 软件开发过程杂乱无章…...

基于事件驱动和策略模式的差异化处理方案
一、支付成功后事件驱动 1、支付成功事件 /*** 支付成功事件** author ronshi* date 2025/5/12 14:40*/ Getter Setter public class PaymentSuccessEvent extends ApplicationEvent {private static final long serialVersionUID 1L;private ProductOrderDO productOrderDO;…...
5.5.1 WPF中的动画2-基于路径的动画
何为动画?一般只会动。但所谓会动,还不仅包括位置移动,还包括角度旋转,颜色变化,透明度增减。动画本质上是一个时间段内某个属性值(位置、颜色等)的变化。因为属性有很多数据类型,它们变化也需要多种动画类比如: BooleanAnimationBase\ ByteAnimationBase\DoubleAnima…...

计算机网络:手机和基站之间的通信原理是什么?
手机与基站之间的通信是无线通信技术的核心应用之一,涉及复杂的物理层传输、协议交互和网络管理机制。以下从技术原理、通信流程和关键技术三个层面深入解析这一过程: 一、蜂窝网络基础架构 1. 蜂窝结构设计 基本原理:将服务区域划分为多个六边形“蜂窝小区”,每个小区由*…...

PostgreSQL常用DML操作的锁类型归纳
DML锁类型分析 本文对PostgreSQL的insert、 update、 truncate、 delete等常用DML操作的锁类型进行了归纳类比: 包括是否排他、 共享、 表级、 行级等的总结。 truncate :access exclusive mode(block all read/write)、table-le…...

Apache Flink 与 Flink CDC:概念、联系、区别及版本演进解析
Apache Flink 与 Flink CDC:概念、联系、区别及版本演进解析 在实时数据处理和流式计算领域,Apache Flink 已成为行业标杆。而 Flink CDC(Change Data Capture) 作为其生态中的重要组件,为数据库的实时变更捕获提供了强大的能力。 本文将从以下几个方面进行深入讲解: 什…...

数学复习笔记 8
前言 成为一个没有感情的刷题机器就可以变得很强了。 逆矩阵的运算 随便算一下就算出来了,没啥难的。主要是用天然可交换的矩阵来算。有三个天然可交换的矩阵,某矩阵和单位阵,该矩阵和它的伴随矩阵,该矩阵和它的逆矩阵。一定要…...

FunASR:语音识别与合成一体化,企业级开发实战详解
简介 FunASR是由阿里巴巴达摩院开源的高性能语音识别工具包,它不仅提供语音识别(ASR)功能,还集成了语音端点检测(VAD)、标点恢复、说话人分离等工业级模块,形成了完整的语音处理解决方案。 FunASR支持离线和实时两种模式,能够高效处理多语言音频,并提供高精度的识别结果。…...

rust-candle学习笔记11-实现一个简单的自注意力
参考:about-pytorch 定义ScaledDotProductAttention结构体: use candle_core::{Result, Device, Tensor}; use candle_nn::{Linear, Module, linear_no_bias, VarMap, VarBuilder, ops};struct ScaledDotProductAttention {wq: Linear,wk: Linear,wv: …...

读入csv文件写入MySQL
### 使用 Spark RDD 读取 CSV 文件并写入 MySQL 的实现方法 #### 1. 环境准备 在使用 Spark 读取 CSV 文件并写入 MySQL 数据库之前,需要确保以下环境已配置完成: - 添加 Maven 依赖项以支持 JDBC 连接。 - 配置 MySQL 数据库连接参数,包括 …...

Andorid之TabLayout+ViewPager
文章目录 前言一、效果图二、使用步骤1.主xml布局2.activity代码3.MyTaskFragment代码4.MyTaskFragment的xml布局5.Adapter代码6.item布局 总结 前言 TabLayoutViewPager功能需求已经是常见功能了,我就不多解释了,需要的自取。 一、效果图 二、使用步骤…...

C++GO语言微服务之用户信息处理②
目录 01 03-获取用户信息-上 02 04-获取用户信息-下 03 05-更新用户名实现 01 06-中间件简介和中间件类型 02 07-中间件测试和模型分析 03 08-中间件测试案例和小结 04 09-项目使用中间件 01 03-获取用户信息-上 ## Cookie操作 ### 设置Cookie go func (c *Context) …...

26考研——中央处理器_指令流水线_流水线的冒险与处理 流水线的性能指标 高级流水线技术(5)
408答疑 文章目录 六、指令流水线流水线的冒险与处理结构冒险数据冒险延迟执行相关指令采用转发(旁路)技术load-use 数据冒险的处理 控制冒险 流水线的性能指标流水线的吞吐率流水线的加速比 高级流水线技术超标量流水线技术超长指令字技术超流水线技术 …...

Java 与 Go 语言对比
Java 和 Go (Golang) 是两种流行的编程语言,各有其设计哲学和应用场景。以下是它们的详细对比: 1. 基本特性 特性JavaGo诞生时间1995 (Sun Microsystems)2009 (Google)设计目标“Write Once, Run Anywhere”简洁、高效的系统编程语言语言类型面向对象多…...

OpenUCX 库介绍与使用指南
OpenUCX 库介绍与使用指南 OpenUCX 简介 OpenUCX (Unified Communication X) 是一个高性能、开源通信框架,专为大规模分布式计算和加速计算设计。它提供了统一的API,支持多种网络硬件和协议,包括InfiniBand、RoCE、TCP等。 主要特点 高性…...
酒店旅游类数据采集API接口之携程数据获取地方美食品列表 获取地方美餐馆列表 景点评论
携程 API 接入指南 API 地址: 调用示例: 美食列表 景点列表 景点详情 酒店详情 参数说明 通用参数说明 请谨慎传递参数,避免不必要的费用扣除。 URL 说明:https://api-gw.cn/平台/API类型/ 平台:淘宝,京…...

Lora原理及实现浅析
Lora 什么是Lora Lora的原始论文为《LoRA: Low-Rank Adaptation of Large Language Models》,翻译为中文为“大语言模型的低秩自适应”。最初是为了解决大型语言模在进行任务特定微调时消耗大量资源的问题;随后也用在了Diffusion等领域,用于…...
)
GitHub 趋势日报 (2025年05月13日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1harry0703/MoneyPrinterTurbo利用ai大模型,一键生成高清短视频使用…...