九、HQL DQL七大查询子句
作者:IvanCodes
日期:2025年5月15日
专栏:Hive教程
Apache Hive 的强大之处在于其类 SQL 的查询语言 HQL,它使得熟悉 SQL 的用户能够轻松地对存储在大规模分布式系统(如 HDFS)中的数据进行复杂的查询和分析。一个典型且完整的 HQL 查询语句,通常由一系列有序的子句构成。理解并熟练运用这些核心子句,是高效进行数据探索和提取的基础。我们这次重点剖析 HQL 中最常用也最核心的七个查询子句及其执行顺序。
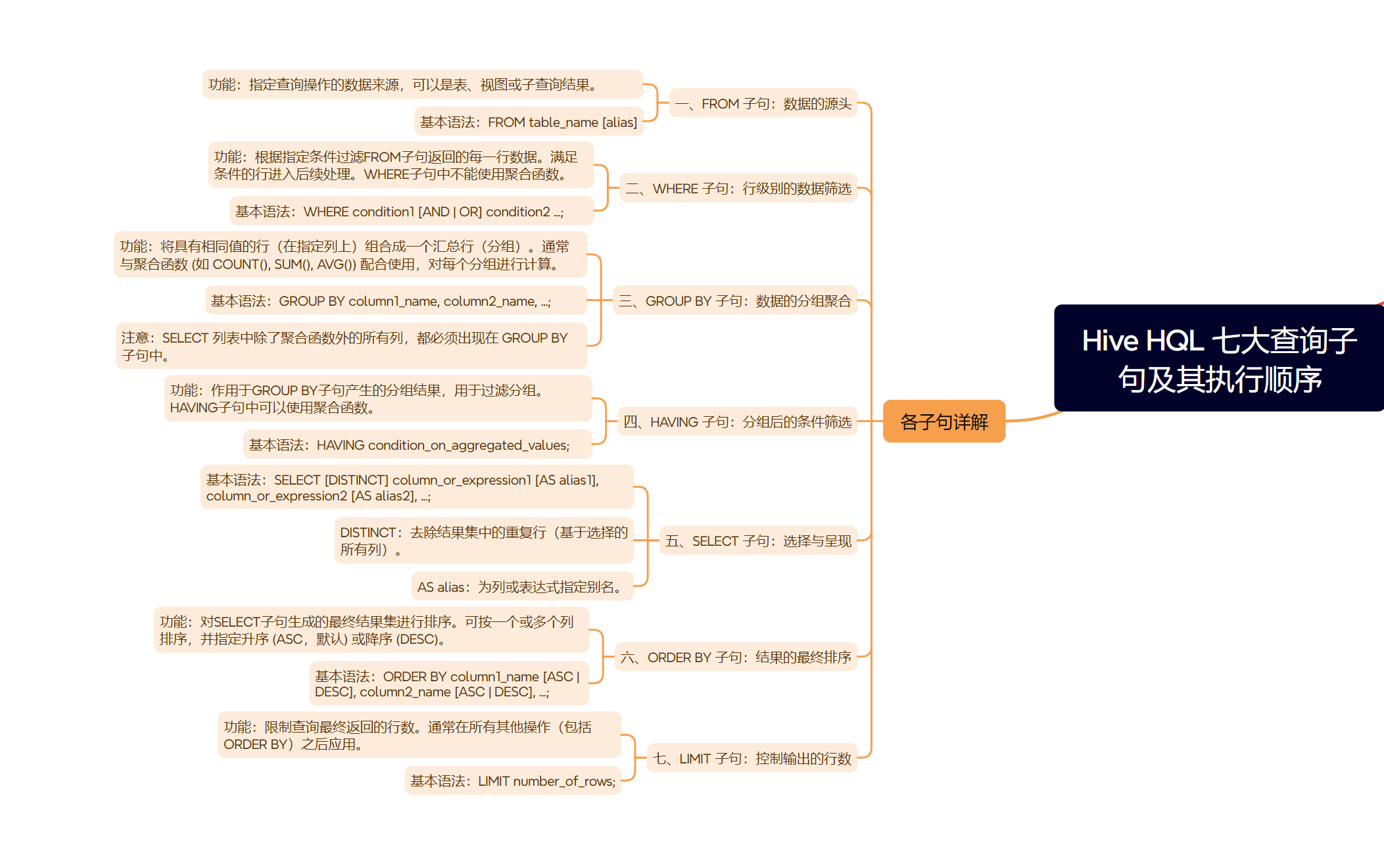
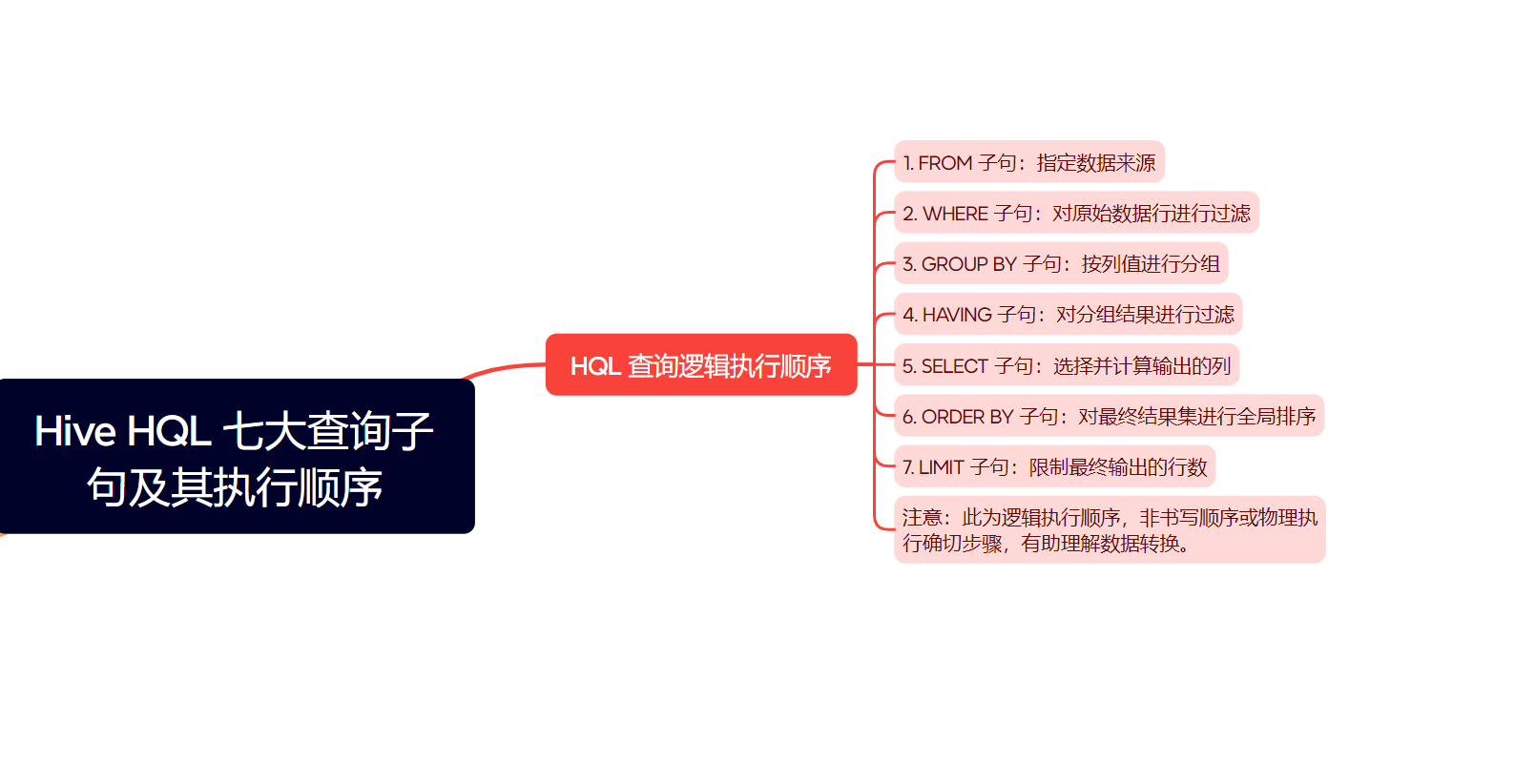
Hive HQL 七大查询子句及其执行顺序概述
一个完整的 HQL 查询语句,其逻辑上的执行顺序(注意:这不完全等同于SQL 语句的书写顺序,也不代表 Hive 引擎物理执行的确切步骤,但有助于理解数据如何被逐步筛选和转换)通常如下:
FROM子句:指定数据来源的表或视图。WHERE子句:对FROM子句中产生的原始数据行进行过滤。GROUP BY子句:将经过WHERE过滤后的数据行,按照一个或多个列的值进行分组。HAVING子句:对GROUP BY子句产生的分组结果进行过滤。SELECT子句:选择并计算最终要输出的列。ORDER BY子句:对SELECT子句产生的最终结果集进行全局排序。LIMIT子句:限制ORDER BY排序后(或未排序时)最终输出的行数。
接下来,我们将逐一详细解析这些子句。
一、FROM 子句:数据的源头
功能:指定查询操作的数据来源。可以是一个表,或者是一个子查询的结果(尽管我们这次练习题会尽量避免复杂子查询)。
基本语法:
FROM table_name [alias]
案例:
-- 从单个表查询所有列
SELECT * FROM employees;-- 从单个表查询,并给表起别名
SELECT e.name FROM employees e;
二、WHERE 子句:行级别的数据筛选
功能:根据指定的条件过滤 FROM 子句返回的每一行数据。只有满足条件的行才会进入后续的处理阶段。WHERE 子句中不能使用聚合函数。
基本语法:
WHERE condition1 [AND | OR] condition2 ...;
案例:查询部门为 ‘Sales’ 或 ‘Marketing’ 的员工
SELECT name, department
FROM employees
WHERE department = 'Sales' OR department = 'Marketing';
案例:查询薪水在 50000 到 70000 之间(包含边界)的员工
SELECT name, salary
FROM employees
WHERE salary >= 50000 AND salary <= 70000;
-- 或者使用 BETWEEN
-- WHERE salary BETWEEN 50000 AND 70000;
三、GROUP BY 子句:数据的分组聚合
功能:将具有相同值的行(在指定的列上)组合成一个汇总行(一个分组)。通常与聚合函数(如 COUNT(), SUM(), AVG(), MAX(), MIN())配合使用,对每个分组进行计算。
基本语法:
GROUP BY column1_name, column2_name, ...;
案例:统计每个部门的员工数量
SELECT department, COUNT(*) AS num_employees
FROM employees
GROUP BY department;
注意:SELECT 列表中除了聚合函数外的所有列,都必须出现在 GROUP BY 子句中。
四、HAVING 子句:分组后的条件筛选
功能:与 WHERE 子句类似,但 HAVING 作用于 GROUP BY 子句产生的分组结果。它用于过滤分组,只有满足 HAVING 条件的分组才会被保留。HAVING 子句中可以使用聚合函数。
基本语法:
HAVING condition_on_aggregated_values;
案例:找出员工数量超过10人的部门
SELECT department, COUNT(*) AS num_employees
FROM employees
GROUP BY department
HAVING COUNT(*) > 10;
总结:WHERE 先过滤行,再 GROUP BY 分组;HAVING 后过滤分组。
五、SELECT 子句:选择与呈现
功能:指定最终查询结果中包含哪些列。可以直接选择表中的列,也可以使用表达式、函数(包括聚合函数)来计算新的列。SELECT 子句在逻辑上是在 FROM, WHERE, GROUP BY, HAVING 之后执行的。
基本语法:
SELECT [DISTINCT] column_or_expression1 [AS alias1], column_or_expression2 [AS alias2], ...;
DISTINCT: 去除结果集中的重复行(基于选择的所有列)。AS alias: 为列或表达式指定别名。
案例:查询员工姓名,并将薪水乘以1.1作为“预期薪水”显示
SELECT
name,
salary,
salary * 1.1 AS expected_salary
FROM employees;
案例:查询所有不同的部门名称
SELECT DISTINCT department
FROM employees;
六、ORDER BY 子句:结果的最终排序
功能:对 SELECT 子句生成的最终结果集进行排序。可以按一个或多个列排序,并指定升序 (ASC,默认) 或降序 (DESC)。ORDER BY 通常是查询中资源消耗较大的操作之一,因为它需要对所有结果数据进行全局排序。
基本语法:
ORDER BY column1_name [ASC | DESC], column2_name [ASC | DESC], ...;
案例:查询所有员工,按入职日期 (hire_date) 从新到旧排列
SELECT name, hire_date
FROM employees
ORDER BY hire_date DESC;
七、LIMIT 子句:控制输出的行数
功能:限制查询最终返回的行数。它通常在所有其他操作(包括 ORDER BY)之后应用。
基本语法:
LIMIT number_of_rows;
案例:查询薪水最低的3名员工的信息
SELECT name, salary, department
FROM employees
ORDER BY salary ASC
LIMIT 3;
结语:七子句的协同与威力
HQL 的这七个核心查询子句,通过不同的组合和嵌套,构成了数据查询和分析的强大能力。理解每个子句的功能及其大致的执行顺序,是编写高效、准确的 HQL 查询的前提。虽然 Hive 底层会通过 MapReduce 或 Tez 对查询进行优化,但清晰的逻辑结构和合理的子句使用,仍然是提升查询性能和可读性的关键。
练习题
假设我们有一个名为 products 的表,其结构如下:
products 表:
product_id INT(产品ID)product_name STRING(产品名称)category STRING(产品类别, 例如: ‘Electronics’, ‘Books’, ‘Clothing’, ‘Home Goods’)price DECIMAL(10,2)(价格)stock_quantity INT(库存数量)release_date DATE(发布日期)
-
题目一:
FROM和SELECT的基本使用
要求:从products表中查询所有产品的产品名称 (product_name) 和价格 (price)。 -
题目二:
WHERE子句筛选
要求:查询products表中所有类别为 ‘Books’ 且价格低于 20.00 的产品信息(所有列)。 -
题目三:
GROUP BY与聚合函数
要求:查询products表,统计每个产品类别 (category) 下有多少种不同的产品(即产品数量num_products)以及这些产品的平均价格 (avg_price)。 -
题目四:
HAVING子句过滤分组结果
要求:基于上一题的结果,只显示那些产品数量超过 5 种,并且平均价格高于 50.00 的产品类别及其统计信息。 -
题目五:
ORDER BY排序输出
要求:查询products表中所有库存数量 (stock_quantity) 大于 0 的产品,按其发布日期 (release_date) 从最新到最旧排序,如果发布日期相同,则按产品名称 (product_name) 字母顺序升序排序。显示产品名称、发布日期和库存数量。 -
题目六:
LIMIT限制结果数量
要求:查询products表中价格最高的前5款产品。显示产品名称和价格。 -
题目七:综合运用所有七个子句(尽可能)
要求:从products表中找出类别为 ‘Electronics’ 或 ‘Home Goods’,且库存数量 (stock_quantity) 少于 10 件的产品。然后,按类别分组,计算每个类别下这类产品的平均价格。只显示那些平均价格大于 100.00 的类别。最后,将结果按平均价格降序排列,只取排名第一的类别信息(类别名称和平均价格)。
练习题答案
- 题目一答案:
SELECT product_name, price
FROM products;
- 题目二答案:
SELECT *
FROM products
WHERE category = 'Books' AND price < 20.00;
- 题目三答案:
SELECT category, COUNT(product_id) AS num_products, AVG(price) AS avg_price
FROM products
GROUP BY category;
- 题目四答案:
SELECT category, COUNT(product_id) AS num_products, AVG(price) AS avg_price
FROM products
GROUP BY category
HAVING COUNT(product_id) > 5 AND AVG(price) > 50.00;
- 题目五答案:
SELECT product_name, release_date, stock_quantity
FROM products
WHERE stock_quantity > 0
ORDER BY release_date DESC, product_name ASC;
- 题目六答案:
SELECT product_name, price
FROM products
ORDER BY price DESC
LIMIT 5;
- 题目七答案:
SELECT
category,
AVG(price) AS avg_category_price
FROM
products
WHERE
(category = 'Electronics' OR category = 'Home Goods') AND stock_quantity < 10
GROUP BY
category
HAVING
AVG(price) > 100.00
ORDER BY
avg_category_price DESC
LIMIT 1;
相关文章:
九、HQL DQL七大查询子句
作者:IvanCodes 日期:2025年5月15日 专栏:Hive教程 Apache Hive 的强大之处在于其类 SQL 的查询语言 HQL,它使得熟悉 SQL 的用户能够轻松地对存储在大规模分布式系统(如 HDFS)中的数据进行复杂的查询和分析…...

基于中心点预测的视觉评估与可视化流程
基于中心点预测的视觉评估与可视化流程 基于中心点预测的视觉评估与可视化流程一、脚本功能概览二、可视化与评分机制详解1. 真实框解析2. 调用模型处理帧3. 预测中心点与真实值的对比4. 打分策略5. 图像可视化三、目录结构要求四、运行方式五、应用场景与拓展思路六、总结七,…...
RTSP 播放器技术探究:架构、挑战与落地实践
RTSP 播放器为什么至今无法被淘汰? 在实时视频传输领域,RTSP(Real-Time Streaming Protocol)作为最基础、最常见的协议之一,至今依然被广泛用于监控设备、IP Camera、视频服务器等设备中。然而,要构建一个稳…...

实验5 DNS协议分析与测量
实验5 DNS协议分析与测量 1、实验目的 了解互联网的域名结构、域名系统DNS及其域名服务器的基本概念 熟悉DNS协议及其报文基本组成、DNS域名解析原理 掌握常用DNS测量工具dig使用方法和DNS测量的基本技术 2、实验环境 硬件要求:阿里云云主机ECS 一台。 软件要…...

编程日志5.8
二叉树练习题 1.965. 单值二叉树 - 力扣(LeetCode) /** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode() : val(0), left(nullptr), right(nullptr) {} * TreeNode(int x) :…...

【鸿蒙开发】性能优化
语言层面的优化 使用明确的数据类型,避免使用模糊的数据类型,例如ESObject。 使用AOT模式 AOT就是提前编译,将字节码提前编译成机器码,这样可以充分优化,从而加快执行速度。 未启用AOT时,一边运行一边进…...

2025-05-13 学习记录--Python-循环:while循环 + while-else循环 + for循环 + 循环控制
合抱之木,生于毫末;九层之台,起于累土;千里之行,始于足下。💪🏻 一、循环 ⭐️ (一)、while循环 🍭 初始条件设置 -- 通常是重复执行的 计数器while 条件(判…...
Vue3学习(组合式API——生命周期函数基础)
目录 一、Vue3组合式API中的生命周期函数。 (1)各阶段生命周期涉及函数简单介绍。 <1>创建挂载阶段的生命周期函数。 <2>更新阶段的生命周期函数。 <3>卸载阶段的生命周期函数。 <4>错误处理的生命周期函数。 (2&…...

全面指南:Xinference大模型推理框架的部署与使用
全面指南:Xinference大模型推理框架的部署与使用 Xinference(Xorbits Inference)是一个功能强大的分布式推理框架,专为简化各种AI模型的部署和管理而设计。本文将详细介绍Xinference的核心特性、版本演进,并提供多种部署方式的详细指南,包括本地部署、Docker-Compose部署…...
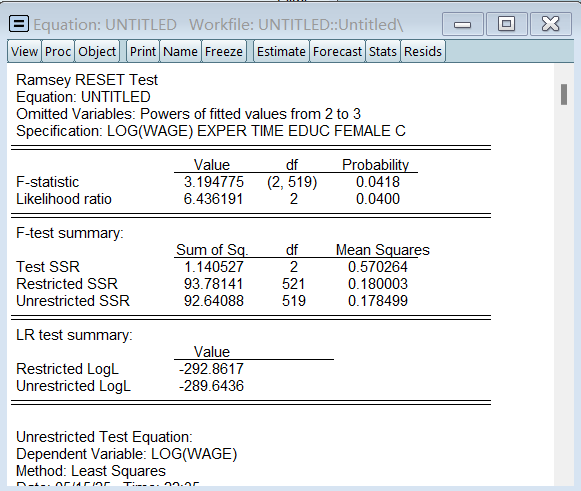
计量——检验与代理变量
1.非嵌套模型的检验 1Davidson-Mackinnon test 判断哪个模型好 log(y)β0β1x1β2x2β3x3u log(y)β0β1log(x1)β2log(x2)β3log(x3)u 1.对logÿ…...

Cocos Creator 3.8.5 构建依赖环境配置文档
Cocos Creator 3.8.5 构建依赖环境配置文档 文章目录 Cocos Creator 3.8.5 构建依赖环境配置文档✅ 构建依赖汇总表✅ 构建平台配置说明👉 Windows 构建👉 Android 构建 ✅ 推荐构建环境组合(稳定)✅ 常见问题提示 适用于打包 An…...
)
实验五:以太网UDP全协议栈的实现(通过远程实验系统)
文章目录 FPGA以太网:从ARP到UDP的完整协议栈一、引言二、核心模块详解1. ARP协议处理模块1.1 `arp_cache`:ARP缓存模块1.2 `arp_tx`:ARP请求与应答发送模块1.3 `arp_rx`:ARP接收与解析模块2. MAC层处理模块2.1 `mac_layer`:MAC层顶层模块2.2 `mac_tx_mode`:MAC发送模式选…...

HTML-实战之 百度百科(影视剧介绍)
本系列可作为前端学习系列的笔记,代码的运行环境是在HBuilder中,小编会将代码复制下来,大家复制下来就可以练习了,方便大家学习。 系列文章目录 HTML-1.1 文本字体样式-字体设置、分割线、段落标签、段内回车以及特殊符号 HTML…...

了解光学影像
本文来源 : 腾讯元宝 光学影像是一种通过光学技术捕捉、记录和处理图像的技术,广泛应用于医学、工业、安防、科研等多个领域。以下是关于光学影像的详细介绍: 1. 基本原理 光学影像基于光的传播、反射、折射和散射等物理现象。通过…...

计算机视觉---目标追踪(Object Tracking)概览
一、核心定义与基础概念 1. 目标追踪的定义 定义:在视频序列或连续图像中,对一个或多个感兴趣目标(如人、车辆、物体等)的位置、运动轨迹进行持续估计的过程。核心任务:跨帧关联目标,解决“同一目标在不同…...
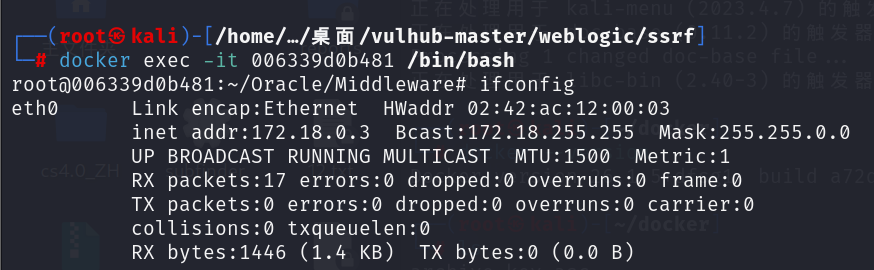
Weblogic SSRF漏洞复现(CVE-2014-4210)【vulhub靶场】
漏洞概述: Weblogic中存在一个SSRF漏洞,利用该漏洞可以发送任意HTTP请求,进而攻击内网中redis、fastcgi等脆弱组件。 漏洞形成原因: WebLogic Server 的 UDDI 组件(uddiexplorer.war)中的 SearchPublicR…...

fakeroot 在没有超级用户权限的情况下模拟文件系统的超级用户行为
fakeroot 是一个在 Linux 环境中使用的工具,它允许用户在没有超级用户权限的情况下模拟文件系统的超级用户行为。它是一个在 Linux 环境中广泛使用的工具,通常包含在大多数 Linux 发行版的软件仓库中。 主要功能 模拟 root 权限:fake…...

AI大模型应用:17个实用场景解锁未来
任何新技术的普及都需要经历一段漫长的过程,人工智能大模型也不例外。 尽管某些行业的从业者已经开始将大模型融入日常工作,但其普及程度仍远未达到“人手必备”的地步。 那么,究竟是什么限制了它的广泛应用?普通人如何才能用好…...

激光雷达点云畸变消除:MCU vs CPU 方案详解
在移动机器人、自动驾驶等场景中,激光雷达(LiDAR)用于获取高精度的空间点云数据。然而,当雷达在运动中扫描时,不同点的采集时刻对应的位置不同,就会出现“运动畸变(Motion Distortion࿰…...

java17
1.常见API之BigDecimal 底层存储方式: 2.如何分辨过时代码: 有横线的代码表示该代码已过时 3.正则表达式之字符串匹配 注意:如果X不是单一字符,需要加[]中括号 注意:1.想要表达正则表达式里面的.需要\\. 2.想要表…...

深度学习中的提示词优化:梯度下降全解析
深度学习中的提示词优化:梯度下降全解析 在您的代码中,提示词的更新方向是通过梯度下降算法确定的,这是深度学习中最基本的优化方法。 一、梯度下降与更新方向 1. 核心公式 对于可训练参数 θ \theta θ(这里是提示词嵌入向量),梯度下降的更新公式为:...

多智能体Multi-Agent应用实战与原理分析
一:Agent 与传统工具调用的对比 在当今的开发环境中,Agent 的出现极大地简化了工作流程。其底层主要基于提示词、模型和工具。用户只需向 Agent 输入需求,Agent 便会自动分析需求,并利用工具获取最终答案。而传统方式下,若没有 Agent,我们则需要手动编码来执行工具,还要…...
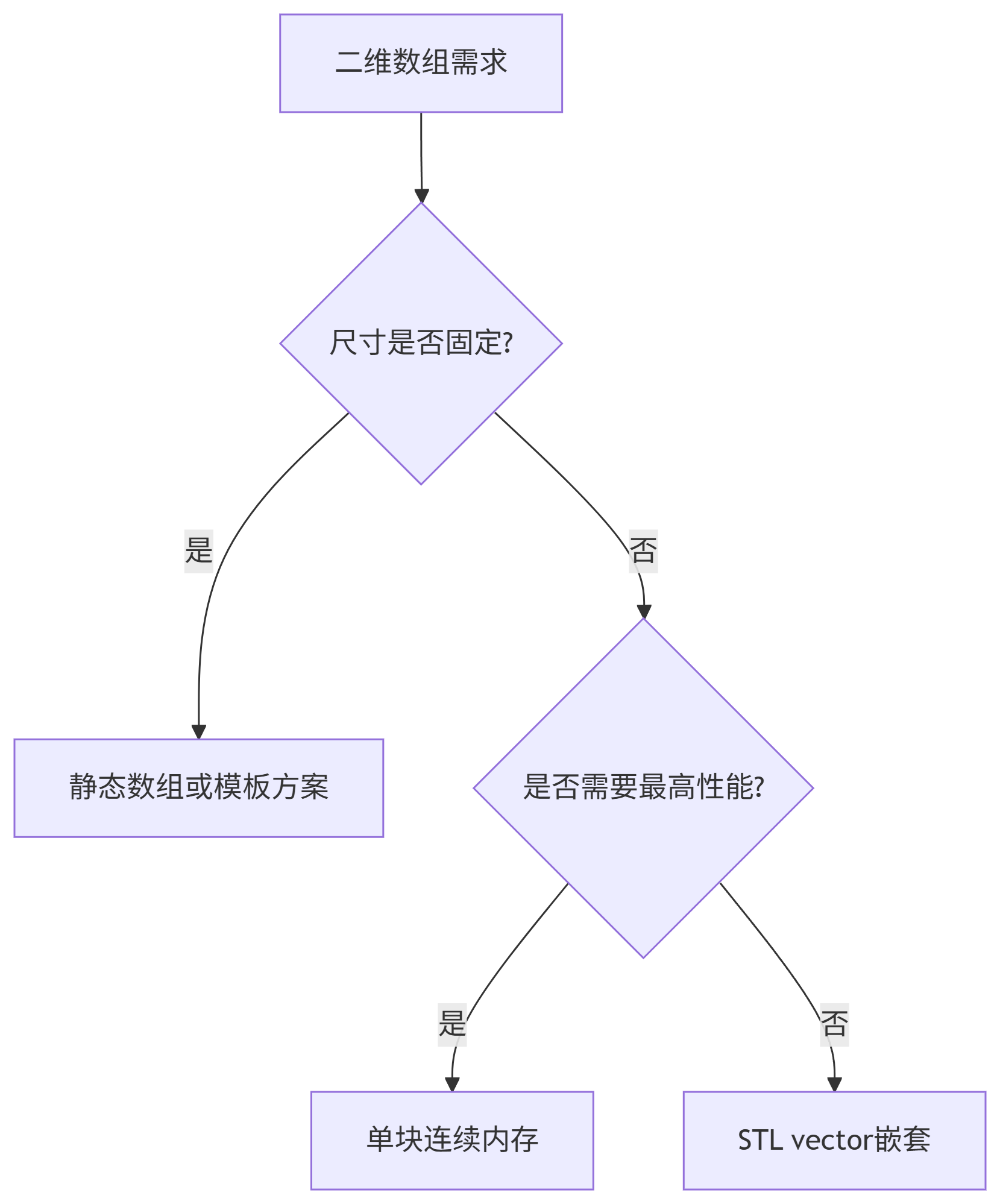
C++算法(22):二维数组参数传递,从内存模型到高效实践
引言 在C程序设计中,二维数组的参数传递是许多开发者面临的棘手问题。不同于一维数组的相对简单性,二维数组在内存结构、类型系统和参数传递机制上都存在独特特性。本文将深入探讨静态数组、动态数组以及STL容器三种实现方式,通过底层原理分…...

ProceedingJoinPoint的认识
ProceedingJoinPoint 是 Spring AOP(面向切面编程) 中的核心接口,用于在 环绕通知(Around) 中拦截方法调用并控制其执行流程。以下是对其功能和用法的详细解释: 核心作用 拦截目标方法 在方法执行前后插…...

鸿蒙OSUniApp 制作动态加载的瀑布流布局#三方框架 #Uniapp
使用 UniApp 制作动态加载的瀑布流布局 前言 最近在开发一个小程序项目时,遇到了需要实现瀑布流布局的需求。众所周知,瀑布流布局在展示不规则尺寸内容(如图片、商品卡片等)时非常美观和实用。但在实际开发过程中,我…...

Lightpanda开源浏览器:专为 AI 和自动化而设计的无界面浏览器
一、软件介绍 文末提供程序和源码下载 Lightpanda开源浏览器:专为 AI 和自动化而设计的无界面浏览器; Javascript execution Javascript 执行Support of Web APIs (partial, WIP)支持 Web API(部分、WIP)Compatible with Pla…...
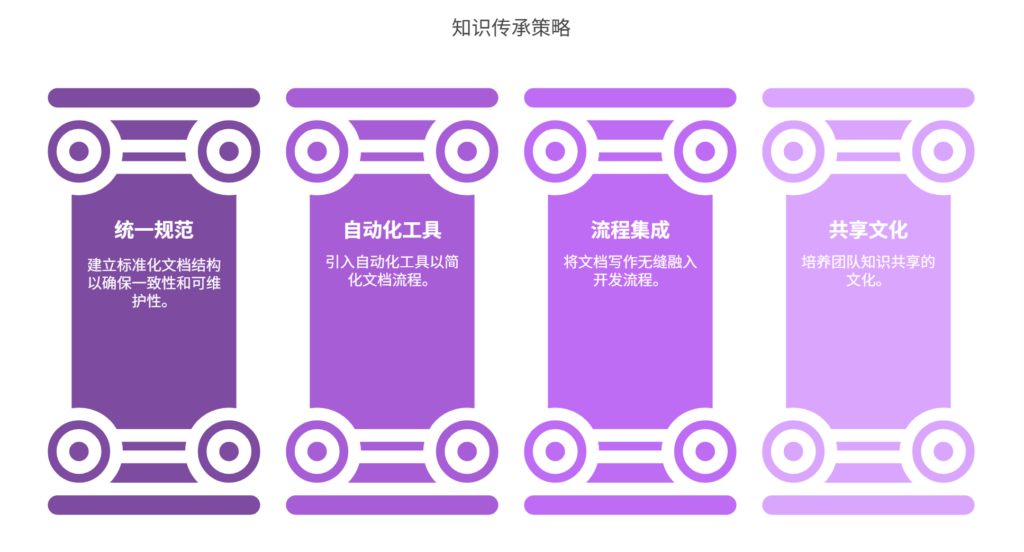
技术文档不完善,如何促进知识传承
建立统一的技术文档规范、引入文档自动化工具、将文档写作融入开发流程、建设团队知识共享文化 是促进知识传承的关键策略。在其中,尤应重视建立统一的技术文档规范,通过标准化文档结构、命名、版本管理等方式,提升文档质量和可维护性&#x…...

LLMs之MCP:2025年5月2日,Anthropic 宣布 Claude 重大更新:集成功能上线,研究能力大幅提升
LLMs之MCP:2025年5月2日,Anthropic 宣布 Claude 重大更新:集成功能上线,研究能力大幅提升 导读:2025年5月2日,Anthropic 宣布 Claude 推出 Integrations 集成功能和增强型高级研究功能。Integrations 基于 …...

Linux基础 -- 在内存中使用chroot修复eMMC
Linux基础 – 在内存中使用chroot修复eMMC 概述 本教程将介绍如何在Linux系统中,使用chroot在内存中构建一个临时系统,并在不依赖原有系统的情况下修复eMMC(如/dev/mmcblk2)磁盘。该方法适用于嵌入式系统修复、磁盘清理以及离线…...

Windows平台OpenManus部署及WebUI远程访问实现
前言:继DeepSeek引发行业震动后,Monica.im团队最新推出的Manus AI 产品正席卷科技圈。这款具备自主思维能力的全能型AI代理,不仅能精准解析复杂指令并直接产出成果,更颠覆了传统人机交互模式。尽管目前仍处于封闭测试阶段…...