Elasticsearch性能调优全攻略:从日志分析到集群优化
#作者:猎人
文章目录
- 前言
- 搜索慢查询日志
- 索引慢写入日志
- 性能调优之基本优化建议
- 性能调优之索引写入性能优化
- 提升es集群写入性能方法:
- 性能调优之集群读性能优化
- 性能调优之搜索性能优化
- 性能调优之GC优化
- 性能调优之路由优化
- 性能调优之分片优化
前言
es里面的操作,主要分为两种,一种写入(增删改),另一种是查询(搜索)。分别要识别出来哪些写入操作性能比较慢,哪些查询操作性能比较慢,先要识别出来有性能问题的这些慢查询,慢写入,然后才能去考虑如何优化写入性能,如何优化搜索性能。如果一次搜索,或者一次聚合,一下子就要10s,或者十几秒,不能接受。
搜索慢查询日志
无论是慢查询日志,还是慢写入日志,都是针对shard级别的,无论执行增删改,还是执行搜索,都是对某个数据执行写入或者是搜索,其实都是到某个shard上面去执行。 shard上面执行的慢的写入或者是搜索,都会记录在针对这个shard的日志中。比如设置一个阈值,5s就是搜索的阈值,5s就叫做慢,那么一旦一个搜索请求超过了5s之后,就会记录一条慢搜索日志到日志文件中。
shard level的搜索慢查询日志,辉将搜索性能较慢的查询写入一个专门的日志文件中。可以针对query phase和fetch phase单独设置慢查询的阈值,而具体的慢查询阈值设置如下所示:
vim elasticsearch.yml
index.search.slowlog.threshold.query.warn: 10s
index.search.slowlog.threshold.query.info: 5s
index.search.slowlog.threshold.query.debug: 2s
index.search.slowlog.threshold.query.trace: 500msindex.search.slowlog.threshold.fetch.warn: 1s
index.search.slowlog.threshold.fetch.info: 800ms
index.search.slowlog.threshold.fetch.debug: 500ms
index.search.slowlog.threshold.fetch.trace: 200ms
而慢查询日志具体的格式,都是在log4j2.properties中配置的,比如下面的配置:
appender.index_search_slowlog_rolling.type = RollingFile
appender.index_search_slowlog_rolling.name = index_search_slowlog_rolling
appender.index_search_slowlog_rolling.fileName = ${sys:es.logs}_index_search_slowlog.log
appender.index_search_slowlog_rolling.layout.type = PatternLayout
appender.index_search_slowlog_rolling.layout.pattern = [%d{ISO8601}][%-5p][%-25c] %.10000m%n
appender.index_search_slowlog_rolling.filePattern = ${sys:es.logs}_index_search_slowlog-%d{yyyy-MM-dd}.log
appender.index_search_slowlog_rolling.policies.type = Policies
appender.index_search_slowlog_rolling.policies.time.type = TimeBasedTriggeringPolicy
appender.index_search_slowlog_rolling.policies.time.interval = 1
appender.index_search_slowlog_rolling.policies.time.modulate = truelogger.index_search_slowlog_rolling.name = index.search.slowlog
logger.index_search_slowlog_rolling.level = trace
logger.index_search_slowlog_rolling.appenderRef.index_search_slowlog_rolling.ref = index_search_slowlog_rolling
logger.index_search_slowlog_rolling.additivity = false
索引慢写入日志
可以用如下的配置来设置索引写入慢日志的阈值:
index.indexing.slowlog.threshold.index.warn: 10s
index.indexing.slowlog.threshold.index.info: 5s
index.indexing.slowlog.threshold.index.debug: 2s
index.indexing.slowlog.threshold.index.trace: 500ms
index.indexing.slowlog.level: info
index.indexing.slowlog.source: 1000
用下面的log4j.properties配置就可以设置索引慢写入日志的格式:
appender.index_indexing_slowlog_rolling.type = RollingFile
appender.index_indexing_slowlog_rolling.name = index_indexing_slowlog_rolling
appender.index_indexing_slowlog_rolling.fileName = ${sys:es.logs}_index_indexing_slowlog.log
appender.index_indexing_slowlog_rolling.layout.type = PatternLayout
appender.index_indexing_slowlog_rolling.layout.pattern = [%d{ISO8601}][%-5p][%-25c] %marker%.10000m%n
appender.index_indexing_slowlog_rolling.filePattern = ${sys:es.logs}_index_indexing_slowlog-%d{yyyy-MM-dd}.log
appender.index_indexing_slowlog_rolling.policies.type = Policies
appender.index_indexing_slowlog_rolling.policies.time.type = TimeBasedTriggeringPolicy
appender.index_indexing_slowlog_rolling.policies.time.interval = 1
appender.index_indexing_slowlog_rolling.policies.time.modulate = truelogger.index_indexing_slowlog.name = index.indexing.slowlog.index
logger.index_indexing_slowlog.level = trace
logger.index_indexing_slowlog.appenderRef.index_indexing_slowlog_rolling.ref = index_indexing_slowlog_rolling
logger.index_indexing_slowlog.additivity = false
正常情况下,慢查询应该是比较少数的。如果发现某个查询特别慢,就要通知写这个查询的开发人员,让他们去优化一下性能。
设置 Slowlogs,发现一些性能不好,甚至是错误的使用 Pattern。例如:错误的将网址映射成 keyword,然后用通配符查询。应该使用 Text,结合 URL 分词器。严禁一切“x”开头的通配符查询
性能调优之基本优化建议
-
搜索结果不要返回过大的结果集
es是一个搜索引擎,所以如果用这个搜索引擎对大量的数据进行搜索,并且返回搜索结果中排在最前面的少数结果,是非常合适的。然而,如果要做成类似数据库的东西,每次都进行大批量的查询,是很不合适的。如果真的要做大批量结果的查询,记得考虑用scroll api,批量滚动查询。 -
避免超大的document
http.max_context_length的默认值是100mb,意味着一次document写入时,document的内容不能超过100mb,否则es就会拒绝写入。也许可以将这个参数设置的更大,从而让超大的documdent可以写入es,但是es底层的lucene引擎还是有一个2gb的最大限制。
即使不考虑引擎层的限制,超大的document在实际生产环境中是很不好的。超大document会耗费更多的网络资源,内存资源和磁盘资源,甚至对那些不要求获取_source的请求,也是一样,因为es需要从_source中提取_id字段,对于超大document这个获取_id字段的过程的资源开销也是很大的。而将这种超大document写入es也会使用大量的内存,占用内存空间的大小甚至会是documdent本身大小的数倍。近似匹配的搜索,比如phrase query,以及高亮显示,对超大document的资源开销会更大,因为这些操作的性能开销直接跟document的大小成正比。
因此对于超大document,我们需要考虑一下,我们到底需要其中的哪些部分。举例来说,如果我们要对一些书进行搜索,那么我们并不需要将整本书的内容就放入es中。可以仅仅使用每一篇章或者一个段落作为一个document,然后给一个field标识出来这些document属于哪本书,这样每个document的大小就变小了。可以避免超大document导致的各种开销,同时可以优化搜索的体验。
- 避免稀疏的数据
lucene的内核结构,跟稠密的数据配合起来,性能会更好, 原因就是,lucene在内部会通过doc id来唯一标识一个document,这个doc id是integer类型,范围在0到索引中含有的document数量之间。这些doc id是用来在lucene内部的api之间进行通信的,比如说,对一个term用一个match query来进行搜索,就会产生一个doc id集合,然后这些doc id会用来获取对应的norm值,以用来计算每个doc的相关度分数。而根据doc id查找norm的过程,是通过每个document的每个field保留一个字节来进行的一个算法,这个过程叫做norm查找,norm就是每个document的每个field保留的一个字节。对于每个doc id对应的那个norm值,可以通过读取es一个内置索引,叫做doc_id的索引,中的一个字节来获取。这个过程是性能很高的,而且可以帮助lucene快速的定位到每个document的norm值,但是同时这样的话document本身就不需要存储这一个字节的norm值了。
在实际运行过程中,这就意味着,如果一个索引有100个document,对于每个field,就需要100个字节来存储norm值,即使100个document中只有10个document含有某个field,但是对那个field来说,还是要100个字节来存储norm值。这就会对存储产生更大的开销,存储空间被浪费的一个问题,而且也会影响读写性能。
下面有一些避免稀疏数据的办法:
(1)避免将没有任何关联性的数据写入同一个索引
必须避免将结构完全不一样的数据写入同一个索引中,因为结构完全不一样的数据,field是完全不一样的,会导致index数据非常稀疏。最好将这种数据写入不同的索引中,如果这种索引数据量比较少,那么可以考虑给其很少的primary shard,比如1个,避免资源浪费。
(2)对document的结构进行规范化/标准化
即使要将不同类型的document写入相同的索引中,可对不同类型的document进行标准化。如果所有的document都有一个时间戳field,不过有的叫做timestamp,有的叫做creation_date,那么可以将不同document的这个field重命名为相同的字段,尽量让documment的结构相同。另外一个,就是比如有的document有一个字段,叫做goods_type,但是有的document没有这个字段,此时可以对没有这个字段的document,补充一个goods_type给一个默认值,比如default。
(3)避免使用多个types存储不一样结构的document
不建议在一个index中放很多个types来存储不同类型的数据。但是其实不是这样的,最好不要这么干,如果你在一个index中有多个type,但是这些type的数据结构不太一样,那么这些type实际上底层都是写到这个索引中的,还是会导致稀疏性。如果多个type的结构不太一样,最好放入不同的索引中,不要写入一个索引中。
(4)对稀疏的field禁用norms和doc_values
如果上面的步骤都没法做,那么只能对那种稀疏的field,禁止norms和doc_values字段,因为这两个字段的存储机制类似,都是每个field有一个全量的存储,对存储浪费很大。如果一个field不需要考虑其相关度分数,那么可以禁用norms,如果不需要对一个field进行排序或者聚合,那么可以禁用doc_values字段。
性能调优之索引写入性能优化
提高写入性能就是提高吞吐量
- 用bulk批量写入
调整bulk线程池和队列。
如果要往es里面灌入数据的话,那么根据业务场景来,如果业务场景可以支持,,将一批数据聚合起来,一次性写入es,那么就尽量采用bulk的方式,每次批量写个几百条这样子。
bulk批量写入的性能比一条一条写入大量的document的性能要好很多。如果要知道一个bulk请求最佳的大小,需要对单个es node的单个shard做压测。先bulk写入100个document,然后200个,400个,以此类推,每次都将bulk size加倍一次。如果bulk写入性能开始变平缓的时候,那么这个就是最佳的bulk大小。并不是bulk size越大越好,而是根据集群等环境具体要测试出来的,因为越大的bulk size会导致内存压力过大,因此最好一个请求不要发送超过10mb的数据量。
之前测试这个bulk写入,上来就是多线程并发写bulk,先确定一个是bulk size,此时就尽量是用你的程序,单线程,一个es node,一个shard,测试。看看单线程最多一次性写多少条数据,性能是比较好的。
Bulk、线程池、队列大小:
1)客户端:
单个 bulk 请求体的数据量不要太大,官方建议大约5-15mb
写入端的 bulk 请求超时需要足够长,建议60s 以上
写入端尽量将数据轮询打到不同节点
2)服务器端:
索引创建属于计算密集型任务,应该使用固定大小的线程池来配置。来不及处理的放入队列,线程数应该配置成CPU 核心数 +1,避免过多的上下文切换
队列大小可以话当增加 不要过大 否则占用的内存会成为 GC 的负担
-
使用多线程将数据写入es
单线程发送bulk请求是无法最大化es集群写入的吞吐量的。如果要利用集群的所有资源,就需要使用多线程并发将数据bulk写入集群中。为了更好的利用集群的资源,这样多线程并发写入,可以减少每次底层磁盘fsync的次数和开销。一样,可以对单个es节点的单个shard做压测,比如说,先是2个线程,然后是4个线程,然后是8个线程,16个,每次线程数量倍增。一旦发现es返回了TOO_MANY_REQUESTS的错误,JavaClient也就是EsRejectedExecutionException,之前有学员就是做多线程的bulk写入的时候,就发生了。此时那么就说明es是说已经到了一个并发写入的最大瓶颈了,此时我们就知道最多只能支撑这么高的并发写入了。 -
降低IO操作,增加refresh间隔和时长,降低refresh频率
默认的refresh间隔是1s,用index.refresh_interval参数可以设置,这样会其强迫es每秒中都将内存中的数据写入磁盘中,创建一个新的segment file。正是这个间隔,让我们每次写入数据后,1s以后才能看到。但是如果我们将这个间隔调大,比如30s,可以接受写入的数据30s后才看到,那么我们就可以获取更大的写入吞吐量,因为30s内都是写内存的,每隔30s才会创建一个segment file。
增加 refresh interval 的数值。默认为 1s,如果设置成-1,会禁止自动 refresh。避免过于频繁的 refresh,而生成过多的 segment 文件。但是会降低搜索的实时性
增大静态配置参数indices.memory.index buffer_size,默认是 10%,会导致自动触发 refresh -
禁止refresh和replia
如果要一次性加载大批量的数据进es,可以先禁止refresh和replia复制,将index.refresh_interval设置为-1,将index.number_of_replicas设置为0即可。这可能会导致数据丢失,因为没有refresh和replica机制了。但是不需要创建segment file,也不需要将数据replica复制到其他的replica shasrd上面去。一旦写完之后,可以将refresh和replica修改回正常的状态。 -
禁止swapping交换内存
可以将swapping禁止掉,有的时候,如果要将es jvm内存交换到磁盘,再交换回内存,大量磁盘IO,性能很差。 -
给filesystem cache更多的内存
filesystem cache被用来执行更多的IO操作,如果能给filesystem cache更多的内存资源,那么es的写入性能会好很多。 -
使用es自动生成的文档id
如果要手动给es document设置一个id,那么es需要每次都去确认一下那个id是否存在,这个过程是比较耗费时间的。如果我们使用自动生成的id,那么es就可以跳过这个步骤,写入性能会更好。对于你的业务中的表id,可以作为es document的一个field。 -
用性能更好的硬件
我们可以给filesystem cache更多的内存,也可以使用SSD替代机械硬盘,避免使用NAS等网络存储,考虑使用RAID 0来条带化存储提升磁盘并行读写效率,等等。 -
index buffer
如果要进行非常重的高并发写入操作,那么最好将index buffer调大一些,indices.memory.index_buffer_size,这个可以调节大一些,设置的这个index buffer大小,是所有的shard公用的,但是如果除以shard数量以后,算出来平均每个shard可以使用的内存大小,一般建议,但是对于每个shard来说,最多给512mb。es会将这个设置作为每个shard共享的index buffer,那些特别活跃的shard会更多的使用这个buffer。默认这个参数的值是10%,也就是jvm heap的10%,如果我们给jvm heap分配10gb内存,那么这个index buffer就有1gb,对于两个shard共享来说,是足够的了。
提升es集群写入性能方法:
写性能优化的目标: 增大写吞吐量 (Events Per Second) ,越高越好
- 客户端: 多线程,批量写
可以通过性能测试,确定最佳文档数量
多线程:需要观察是否有 HTTP 429 返回,实现 Retry 以及线程数量的自动调节 - 服务器端: 单个性能问题,往往是多个因素造成的。需要先分解问题,在单个节点上进行调整并且结合测试,尽可能压榨硬件资源,以达到最高吞吐量
使用更好的硬件。观察 CPU /IO Block0
线程切换、堆栈情况
降低 CPU 和存储开销,减少不必要分词 /避免不需要的 doc values /文档的字段尽量保证相同的顺序,可以提高文档的压缩率
尽可能做到写入和分片的均衡负载,实现水平扩展,0Shard FilteringWrite Load Balancer
关闭无关的功能:
只需要聚合不需要搜索,lndex 设置成 false
不需要算分,Norms 设置成 false
不要对字符串使用默认的 dynamic mapping。因为索引字段数量过多,会对性能产生比较大的影响
Index_options 控制在创建倒排索引时,哪些内容会被添加到倒排索引中。优化这些设置,一定程度可以节约 CPU
关闭_source,减少IO 操作;(适合指标型数据)
针对性能的取舍:
如果需要追求极致的写入速度,可以牺牲数据可靠性及搜索实时性以换取性能
牺牲可靠性: 将副本分片设置为 0,写入完毕再调整回去
牺牲搜索实时性: 增加 Refresh interval 的时间
牺牲可靠性: 修改 Translog 的配置
ES 的默认设置,已经综合考虑了数据可靠性,搜索的实时性质,写入速度,一般不要盲目修改。一切优化,都要基于高质量的数据建模
性能调优之集群读性能优化
尽量 Denormalize 数据:避免嵌套和父子关系
Elasticsearch != 关系型数据库
尽可能Denormalize 数据,从而获取最佳的性能
使用 Nested 类型的数据。查询速度会慢几倍
使用 Parent /Child 关系。查询速度会慢几百倍
数据建模:
尽量将数据先行计算,然后保存到 Elasticsearch 中。尽量避免查询时的 Script 脚本计算
尽量使用 Filter Context,利用缓存机制,减少不必要的算分
结合 profile,explain API 分析慢查询的问题,持续优化数据模型。严禁使用*开头通配符 Terms 查询
左侧可以优化为右侧,filter方式查询,避免使用query context
聚合查询中使用query方式控制聚合数据量
避免使用*星号开头查询
优化分片:
避免 Over Sharing。一个查询需要访问每一个分片,分片过多,会导致不必要的查询开销
结合应用场景,控制单个分片的尺寸
Search: 20GB
Logging:40GB
Force-merge Read-only 索引。使用基于时间序列的索引,将只读的索引进行 force merge,减少 segment 数量
性能调优之搜索性能优化
-
给filesysgtem cache更多的内存
es的搜索引擎严重依赖于底层的filesystem cache,如果给filesystem cache更多的内存,尽量让内存可以容纳所有的indx segment file索引数据文件,那么搜索的时候就基本都是走内存的,性能会非常高。
如果最佳的情况下,生产环境实践经验,最好是用es就存少量的数据,就是要用来搜索的那些索引,内存留给filesystem cache的,就100G,那么你就控制在100gb以内,相当于数据几乎全部走内存来搜索,性能非常之高,一般可以在1秒以内。所以尽量在es里,就存储必须用来搜索的数据,比如现在有一份数据,有100个字段,其实用来搜索的只有10个字段,建议是将10个字段的数据,存入es,剩下90个字段的数据,可以放mysql,hadoop hbase,都可以。这样的话,es数据量很少,10个字段的数据,都可以放内存,就用来搜索,搜索出来一些id,通过id去mysql,hbase里面去查询明细的数据。 -
用更快的硬件资源
(1)给filesystem cache更多的内存资源
(2)用SSD固态硬盘
(3)使用本地存储系统,不要用NFS等网络存储系统
(4)给更多的CPU资源 -
document模型设计
document模型设计是非常重要的,尽量在document模型设计的时候,写入的时候就完成。另外对于一些太复杂的操作,比如join,nested,parent-child搜索都要尽量避免,性能都很差的。
在搜索/查询的时候,要执行一些业务强相关的特别复杂的操作:
(1)在写入数据的时候,就设计好模型,加几个字段,把处理好的数据写入加的字段里面
(2)自己用java程序封装,es能做的用es来做,搜索出来的数据,在java程序里面去做,比如说我们基于es,用java封装一些特别复杂的操作 -
预先index data
为了性能,提前优化data index时的数据模型,比如说document有一个price field,然后大多数查询都对一个固定的范围,对这个field使用range范围查询,那么可以提前将这个price的范围处理出来,写入一个字段中。 -
预热filesystem cache
如果重启了es,那么filesystem cache是空壳的,就需要不断的查询才能重新让filesystem cache热起来,可以先对一些数据进行查询。比如一个查询,要用户点击以后才执行,才能从磁盘加载到filesystem cache里,第一次执行要10s,以后每次就几百毫秒。
完全可以程序执行那个查询,预热,数据就加载到filesystem cahce,程序执行的时候是10s,以后用户真的来看的时候就才几百毫秒。 -
避免使用script脚本
一般是避免使用es script的,实际生产中更是少用,性能不高,尽量不要使用。 -
使用固定范围的日期查询
尽量不要使用now这种内置函数来执行日期查询,因为默认now是到毫秒级的,是无法缓存结果,尽量使用一个阶段范围,比如now/m,就是到分钟级。那么如果一分钟内,都执行这个查询,是可以取用查询缓存的。
性能调优之GC优化
ElasticSearch本质上是个Java程序,所以配置JVM垃圾回收器本身也是一个很有意义的工作。使用JVM的Xms和Xmx参数来提供指定内存大小,本质上提供的是JVM的堆空间大小,当JVM的堆空间不足的时候就会触发致命的OutOfMemoryException。这意味着要么内存不足,要么出现了内存泄露。处理GC问题,首先要确定问题的源头,一般有两种方案:
- 开启ElasticSearch上的GC日志
- 使用jstat命令
- 生成内存Dump
关于第一条,在ES的配置文件elasticsearch.yml中有相关的属性可以配置,关于每个属性的用途这里当然说不完。
第二条,jstat命令可以帮助查看JVM堆中各个区的使用情况和GC的耗时情况。
第三条,最后就是将JVM的堆空间转储到文件中去,实质上是对JVM堆空间的一个快照。
想了解更多关于JVM本身GC调优方法请参考:http://www.oracle.com/technetwork/java/javase/gc-tuning-6-140523.html
另外,通过修改ES节点的启动参数,也可以调整GC的方式,但是实质上和上述方法是等同的。
性能调优之路由优化
ES中所谓的路由和IP网络不同,是一个类似于Tag的东西。在创建文档的时候,可以通过字段为文档增加一个路由属性的Tag。ES内在机制决定了拥有相同路由属性的文档,一定会被分配到同一个分片上,无论是主分片还是副本。那么,在查询的过程中,一旦指定了感兴趣的路由属性,ES就可以直接到相应的分片所在的机器上进行搜索,而避免了复杂的分布式协同的一些工作,从而提升了ES的性能。于此同时,假设机器1上存有路由属性A的文档,机器2上存有路由属性为B的文档,那么在查询的时候一旦指定目标路由属性为A,即使机器2故障瘫痪,对机器1构不成很大影响,所以这么做对灾况下的查询也提出了解决方案。所谓的路由,本质上是一个分桶(Bucketing)操作。当然,查询中也可以指定多个路由属性,机制大同小异。
性能调优之分片优化
选择合适的分片数和副本数。ES的分片分为两种,主分片(Primary Shard)和副本(Replicas)。默认情况下,ES会为每个索引创建5个分片,即使是在单机环境下,这种冗余被称作过度分配(OverAllocation),目前看来这么做完全没有必要,仅在散布文档到分片和处理查询的过程中就增加了更多的复杂性,好在ES的优秀性能掩盖了这一点。假设一个索引由一个分片构成,那么当索引的大小超过单个节点的容量的时候,ES不能将索引分割成多份,因此必须在创建索引的时候就指定好需要的分片数量。此时所能做的就是创建一个新的索引,并在初始设定之中指定这个索引拥有更多的分片。反之如果过度分配,就增大了Lucene在合并分片查询结果时的复杂度,从而增大了耗时,所以我们得到了以下结论:
应该使用最少的分片!
主分片,副本和节点最大数之间数量存在以下关系:
节点数<=主分片数*(副本数+1)
控制分片分配行为。以上是在创建每个索引的时候需要考虑的优化方法,然而在索引已创建好的前提下,是否就是没有办法从分片的角度提高了性能了呢?当然不是,首先能做的是调整分片分配器的类型,具体是在elasticsearch.yml中设置cluster.routing.allocation.type属性,共有两种分片器even_shard,balanced(默认)。even_shard是尽量保证每个节点都具有相同数量的分片,balanced是基于可控制的权重进行分配,相对于前一个分配器,它更暴漏了一些参数而引入调整分配过程的能力。
每次ES的分片调整都是在ES上的数据分布发生了变化的时候进行的,最有代表性的就是有新的数据节点加入了集群的时候。当然调整分片的时机并不是由某个阈值触发的,ES内置十一个裁决者来决定是否触发分片调整,这里暂不赘述。另外,这些分配部署策略都是可以在运行时更新的。
相关文章:

Elasticsearch性能调优全攻略:从日志分析到集群优化
#作者:猎人 文章目录 前言搜索慢查询日志索引慢写入日志性能调优之基本优化建议性能调优之索引写入性能优化提升es集群写入性能方法:性能调优之集群读性能优化性能调优之搜索性能优化性能调优之GC优化性能调优之路由优化性能调优之分片优化 前言 es里面…...
嵌入式学习的第二十天-数据结构-调试+链表的一般操作
一、调试 1.一般调试 2.找段错误 二、链表的一般操作 1.单链表的修改 int ModifyLinkList(LinkList*ll,char*name,DATATYPE*data) {DATATYPE * tmp FindLinkList(ll, name);if(NULL tmp){return 1;}memcpy(tmp,data,sizeof(DATATYPE));return 0; } 2.单链表的销毁 int D…...

Leetcode 3548. Equal Sum Grid Partition II
Leetcode 3548. Equal Sum Grid Partition II 1. 解题思路2. 代码实现 题目链接:3548. Equal Sum Grid Partition II 1. 解题思路 这一题是题目3546. Equal Sum Grid Partition I的进阶版本,不过本质上还是差不多的。 相较于题目3546,这里…...

家具制造行业的现状 质检LIMS如何赋能家具制造企业质检升级
在家具制造行业,从原木切割到成品出厂,质检环节贯穿始终 —— 木材含水率是否达标、板材甲醛释放量是否合规、涂层耐磨性能否通过标准…… 这些看似琐碎的检测项目,实则是企业把控产品品质、规避市场风险的核心关卡。传统人工质检模式在效率、…...
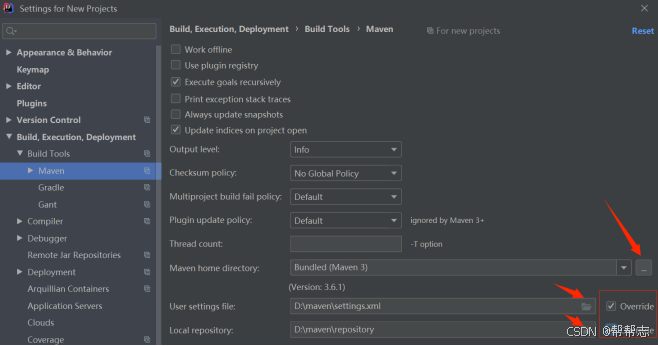
idea整合maven环境配置
idea整合maven 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是springboot的使用。前后每一小节的内容是存在的有:学习and理解的关联性。【帮帮志系列文章】:每个知识点,都是写出代码…...

无偿帮写毕业论文(看不懂的可以私信博主)
以下教程教你如何利用相关网站和AI免费帮你写一个毕业论文。毕竟毕业论文只要过就行,脱产学习这么多年,终于熬出头了,完成毕设后有空就去多看看亲人好友,祝好! 一、找一个论文模板 废话不多说,先上干货Ov…...
小白成长之路-vim编辑
文章目录 Vim一、命令模式二、插入模式3.a:进入插入模式,在当前光标的后一个字符插入4.o: 在当前光标的下一行插入5.i:在当前光标所在字符插入,返回命令模…...

Java 开源报表系统全解析:免费工具、企业案例与集成实践
在企业级数据可视化与报表开发中,选择一款功能强大且完全免费的开源报表系统至关重要。本文深度剖析 5 款经过权威验证的免费开源 Java 报表工具,涵盖图表展示、定制化及第三方集成能力,附企业级案例与技术实践,助您高效选型。 一…...

【常用算法:排序篇】7.算法魔法与面试秘籍:从趣味排序到实战通关
一、趣味排序算法:突破常规的思维火花 1. 睡眠排序(Sleep Sort)—— 时间维度的魔法 核心思想:利用多线程休眠时间模拟数值大小,自然输出有序结果。Python示例:import threading import timedef sleep_so…...

前端npm的核心作用与使用详解
一、npm是什么? npm(Node Package Manager) 是 Node.js 的默认包管理工具,也是全球最大的开源代码库生态系统。虽然它最初是为 Node.js 后端服务设计的,但如今在前端开发中已成为不可或缺的基础设施。通过npm,开发者可以轻松安装、管理和共享代码模块。 特性: 依赖管理…...
Android | IOS — Solox性能测试
文章目录 Solox性能测试1. 前置条件2. 软件图片 Solox性能测试 1. 前置条件 安装Python:3.10.0以上版本: Windows:Python官网 安装 SoloX python -m solox2. 软件图片 软件图片 报告分析:...

Rust 数据结构:Vector
Rust 数据结构:Vector Rust 数据结构:Vector创建数组更新数组插入元素删除元素 获取数组中的元素迭代数组中的值使用枚举存储多个类型删除一个数组会删除它的元素 Rust 数据结构:Vector vector 来自标准库,在内存中连续存储相同类…...

探索Turn.js:打造惊艳的3D翻页效果
目录 简介与特性 环境准备与安装 基础用法与初始化 配置参数详解 事件监听与交互 动态加载与页面管理 兼容性与性能优化 常见问题与解决方案 完整示例代码 1. 简介与特性 Turn.js 是一个基于 jQuery 的 JavaScript 库,专注于实现类书籍翻页的 3D 动画效果…...

Midjourney 最佳创作思路与实战技巧深度解析【附提示词与学习资料包下载】
引言 在人工智能图像生成领域,Midjourney 凭借其强大的艺术表现力和灵活的创作模式,已成为设计师、艺术家和创意工作者的核心工具。作为 CSDN 博主 “小正太浩二”,我将结合多年实战经验,系统分享 Midjourney 的创作方法论&#x…...

OPC UA + ABP vNext 企业级实战:高可用数据采集框架指南
🚀📊 OPC UA ABP vNext 企业级实战:高可用数据采集框架指南 🚀 📑 目录 🚀📊 OPC UA ABP vNext 企业级实战:高可用数据采集框架指南 🚀一、前言 🎯二、系统…...

MySQL库级管理:数据库管理与存储引擎剖析
引言 各位数据库爱好者们好!今天我们要深入探讨MySQL数据库的基本操作,这是每位开发者必须掌握的"内功心法" 💪。无论你是刚接触MySQL的小白,还是需要复习基础的老手,这篇教程都将带你系统学习数据库的核心…...

LeetCode 2094.找出 3 位偶数:遍历3位偶数
【LetMeFly】2094.找出 3 位偶数:遍历3位偶数 力扣题目链接:https://leetcode.cn/problems/finding-3-digit-even-numbers/ 给你一个整数数组 digits ,其中每个元素是一个数字(0 - 9)。数组中可能存在重复元素。 你…...

机器学习-计量经济学
机器学习 不要事前决定变量关系,关键是谁也不知道啊,机器学习学习的模型(那也不是真实的关系啊) 这就是自然学科的好处:只要不断的优化这个未知的东西(函数),然后在数据上ÿ…...
工具篇-扣子空间MCP,一键做游戏,一键成曲
一、登陆扣子空间 地址如下: 扣子空间 打开,然后登陆扣子 登陆之后快速开始: 二、生成游戏 小试牛刀,我们让它做一个打地鼠的游戏: 已经开始设计制作: 制作完成: 三、制作音乐 新…...

5.6 - 5.9 MySQL
数据库:存储和管理数据的仓库DB。 数据库管理系统:操纵和管理数据库的大型软件DBMS。 关系型数据库 一个数据库内可以创建多张表,在一个表内能存放多个数据。 SQL语句: DDL: 存储字符串用varchar。(类似于…...
C# WinForm 如何高效地将大量数据从 CSV 文件导入 DataGridView
如果你有非常多的csv文件,每个文件包含N多行与M多列,如:18000 行和 27 列。现在,想制作一个 Windows 窗体应用程序,导入它们并在 datagridview 中显示,然后进行一些数学运算。可是,发现数据导入…...

【redis】redis常见数据结构及其底层,redis单线程读写效率高于多线程的理解,
redis常用数据结构及底层 string字符串、list链表、set无序集合、zset有序集合、hash哈希 1.string 底层结构是SDS简单动态字符串 struct sdshdr {int len; // 已用长度(字符串实际长度)int free; // 剩余可用空间char buf[]; // 数组&#…...
:AGI研究进入关键验证期 具身智能开启物理世界交互新范式)
2025年5月AI科技领域周报(5.5-5.11):AGI研究进入关键验证期 具身智能开启物理世界交互新范式
2025年5月AI科技领域周报(5.5-5.11):AGI研究进入关键验证期 具身智能开启物理世界交互新范式 一、本周热点回顾1. OpenAI发布GPT-5多模态大模型 突破通用智能关键阈值2. 特斯拉Optimus机器人量产版发布 具身智能进入工业场景3. 百度文心ERNIE…...
SQLPub:一个提供AI助手的免费MySQL数据库服务
给大家介绍一个免费的 MySQL 在线数据库环境:SQLPub。它提供了最新版本的 MySQL 服务器测试服务,可以方便开发者和测试人员验证数据库功能,也可以用于学习 MySQL。 免费申请 在浏览器中输入以下网址: https://sqlpub.com/ SQLP…...
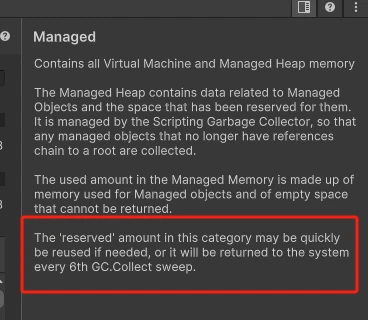
URP相机如何将场景渲染定帧模糊绘制
1)URP相机如何将场景渲染定帧模糊绘制 2)为什么Virtual Machine会随着游戏时间变大 3)出海项目,打包时需要勾选ARMv7吗 4)Unity是手动还是自动调用GC.Collect 这是第431篇UWA技术知识分享的推送,精选了UWA社…...
WeakAuras Lua Script ICC (BarneyICC)
WeakAuras Lua Script ICC (BarneyICC) https://wago.io/BarneyICC/69 全量英文字符串: !WA:2!S33c4TXX5bQv0kobjnnMowYw2YAnDKmPnjnb4ljzl7sqcscl(YaG6HvCbxaSG7AcU76Dxis6uLlHNBIAtBtRCVM00Rnj8Y1M426ZH9XDxstsRDR)UMVCTt0DTzVhTjNASIDAU…...

为什么 mac os .bashrc 没有自动加载?
原因说明 在macOS中,默认情况下,终端使用的是Bash或Zsh作为shell。对于较新版本的macOS(从Catalina开始),默认的shell已经切换为Zsh。因此,如果你正在使用Zsh,.bashrc文件不会自动生效…...
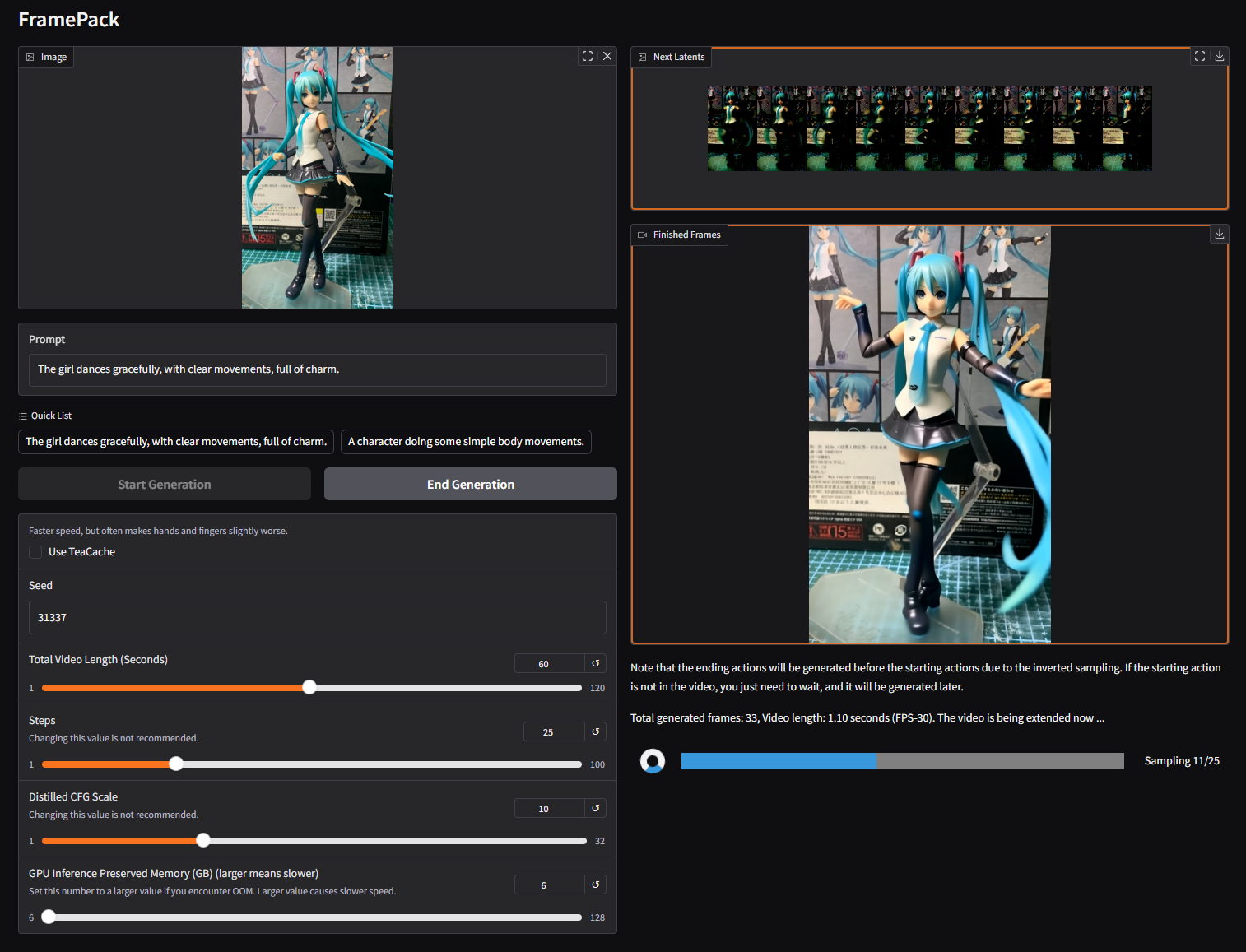
FramePack - 开源 AI 视频生成工具
🎬 项目简介 由开发者 lllyasviel 创建的一个轻量级动画帧处理工具库,专门用于游戏开发、动画制作和视频处理中的帧序列打包与管理。该项目采用高效的算法实现,能够显著提升动画资源的处理效率。 此 AI 视频生成项目,旨在通过低显…...

断点续传使用场景,完整前后端实现示例,包括上传,下载,验证
断点续传在多个场景中非常有用,包括但不限于大文件上传、跨国或跨区域文件传输、移动设备文件传输、备份和同步以及软件更新等。接下来,我将为你提供一个基于Java的后端实现示例,结合前端逻辑来完成整个断点续传的功能,包括上传、…...

【行为型之迭代器模式】游戏开发实战——Unity高效集合遍历与场景管理的架构精髓
文章目录 🔄 迭代器模式(Iterator Pattern)深度解析一、模式本质与核心价值二、经典UML结构三、Unity实战代码(背包系统遍历)1. 定义迭代器与聚合接口2. 实现具体聚合类(背包物品集合)3. 实现具…...