在 Spring Boot 中实现分库分表的全面指南
分库分表(Database Sharding)是一种数据库架构优化技术,通过将数据分散到多个数据库或表中,以应对高并发、大数据量场景,提升系统性能和扩展性。在 Spring Boot 中,分库分表可以通过框架支持(如 Spring Data JPA、MyBatis)结合分片算法和中间件(如 ShardingSphere)实现。2025 年,随着 Spring Boot 3.2 和云原生架构的普及,分库分表在微服务中应用广泛。本文将详细介绍分库分表的概念、策略、实现方法,以及在 Spring Boot 中的具体示例,集成您之前的查询(分页、Swagger、ActiveMQ、Spring Profiles、Spring Security、Spring Batch、FreeMarker、热加载、ThreadLocal、Actuator 安全性、CSRF、WebSockets、异常处理、Web 标准、AOP)。本文目标是为开发者提供一份全面的中文技术指南,帮助在 Spring Boot 项目中高效实现分库分表。
一、分库分表的基础与核心概念
1.1 什么是分库分表?
分库是将数据分散到多个数据库实例(如 MySQL 实例),每个数据库存储部分数据。分表是将单个表的数据分散到多个物理表中,通常在同一数据库内。分库分表结合使用可应对以下场景:
- 数据量过大:单表数据量超过千万,查询性能下降。
- 高并发:单库无法承受大量读写请求。
- 扩展性需求:支持水平扩展,动态添加数据库或表。
1.2 分库分表的类型
- 垂直分库:
- 按业务模块拆分数据库(如用户库、订单库)。
- 优点:业务清晰,维护简单。
- 缺点:跨库事务复杂。
- 垂直分表:
- 按字段拆分表(如用户信息表、用户扩展表)。
- 优点:减少单表大小,优化查询。
- 缺点:增加开发复杂性。
- 水平分库:
- 按分片键(如用户 ID)将数据分散到多个数据库。
- 优点:支持高并发和大数据量。
- 缺点:分片算法设计复杂。
- 水平分表:
- 按分片键将单表数据分散到多个表。
- 优点:单库内优化性能。
- 缺点:表结构重复,维护成本高。
1.3 分片策略
- 范围分片:按键范围分片(如 ID 0-1000 到表 1,1001-2000 到表 2)。
- 哈希分片:对分片键取模(如
user_id % 2)。 - 一致性哈希:减少数据迁移,适合动态扩展。
- 时间分片:按时间段分片(如按月分表)。
- 地理分片:按地域分片(如按城市)。
1.4 实现方式
- 手动实现:
- 自定义分片逻辑,代码控制路由。
- 优点:灵活,成本低。
- 缺点:开发和维护复杂。
- 中间件:
- 使用 ShardingSphere、MyCat 等分片中间件。
- 优点:功能强大,透明化分片。
- 缺点:学习曲线和部署成本。
- 云服务:
- 使用云数据库(如 AWS Aurora、阿里云 PolarDB)。
- 优点:开箱即用,自动扩展。
- 缺点:成本高,依赖云厂商。
1.5 优势与挑战
优势:
- 提升性能:分散数据,降低单点压力。
- 高扩展性:支持动态添加库或表。
- 高可用性:故障隔离,部分库/表不可用不影响整体。
挑战:
- 分片算法设计:需平衡数据分布和查询效率。
- 跨库事务:分布式事务复杂(如 XA 或 Saga)。
- 数据迁移:扩展时需重新分片。
- 查询复杂性:跨库/表查询需聚合。
- 集成复杂性:需与 Spring Boot 功能(如 Spring Security、WebSockets)协调。
二、在 Spring Boot 中实现分库分表
以下是在 Spring Boot 中使用 ShardingSphere-JDBC 实现分库分表的步骤,展示一个用户管理系统的水平分库分表(按用户 ID 哈希分片),集成分页、Swagger、ActiveMQ、Spring Profiles、Spring Security、Spring Batch、FreeMarker、热加载、ThreadLocal、Actuator 安全性、CSRF、WebSockets、异常处理、Web 标准和 AOP。
2.1 环境搭建
配置 Spring Boot 项目,添加 ShardingSphere-JDBC 支持。
2.1.1 配置步骤
-
创建 Spring Boot 项目:
- 使用 Spring Initializr(
start.spring.io)创建项目,添加依赖:spring-boot-starter-webspring-boot-starter-data-jpamysql-connector-java(MySQL 驱动)shardingsphere-jdbc-core(分库分表)spring-boot-starter-activemqspringdoc-openapi-starter-webmvc-uispring-boot-starter-securityspring-boot-starter-freemarkerspring-boot-starter-websocketspring-boot-starter-actuatorspring-boot-starter-batchspring-boot-starter-aop
<project><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.2.0</version></parent><groupId>com.example</groupId><artifactId>sharding-demo</artifactId><version>0.0.1-SNAPSHOT</version><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.33</version></dependency><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core</artifactId><version>5.4.0</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-activemq</artifactId></dependency><dependency><groupId>org.springdoc</groupId><artifactId>springdoc-openapi-starter-webmvc-ui</artifactId><version>2.2.0</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-security</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-freemarker</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-batch</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactId></dependency></dependencies> </project> - 使用 Spring Initializr(
-
准备数据库:
- 创建两个 MySQL 数据库:
user_db_0和user_db_1。 - 每个数据库包含两个表:
user_0和user_1。 - 表结构:
CREATE TABLE user_0 (id BIGINT PRIMARY KEY,name VARCHAR(255),age INT ); CREATE TABLE user_1 (id BIGINT PRIMARY KEY,name VARCHAR(255),age INT );
- 创建两个 MySQL 数据库:
-
配置
application.yml:spring:profiles:active: devapplication:name: sharding-demoshardingsphere:datasource:names: db0,db1db0:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/user_db_0?useSSL=false&serverTimezone=UTCusername: rootpassword: rootdb1:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/user_db_1?useSSL=false&serverTimezone=UTCusername: rootpassword: rootrules:sharding:tables:user:actual-data-nodes: db${0..1}.user_${0..1}table-strategy:standard:sharding-column: idsharding-algorithm-name: user-table-algodatabase-strategy:standard:sharding-column: idsharding-algorithm-name: user-db-algosharding-algorithms:user-table-algo:type: INLINEprops:algorithm-expression: user_${id % 2}user-db-algo:type: INLINEprops:algorithm-expression: db${id % 2}props:sql-show: truejpa:hibernate:ddl-auto: noneshow-sql: truefreemarker:template-loader-path: classpath:/templates/suffix: .ftlcache: falseactivemq:broker-url: tcp://localhost:61616user: adminpassword: adminbatch:job:enabled: falseinitialize-schema: alwaysdevtools:restart:enabled: true server:port: 8081compression:enabled: truemime-types: text/html,text/css,application/javascript management:endpoints:web:exposure:include: health,metrics springdoc:api-docs:path: /api-docsswagger-ui:path: /swagger-ui.html logging:level:root: INFOcom.example.demo: DEBUG -
运行并验证:
- 启动 MySQL 和 ActiveMQ。
- 启动应用:
mvn spring-boot:run。 - 检查日志,确认 ShardingSphere 初始化两个数据库和表。
2.1.2 原理
- ShardingSphere-JDBC:客户端分片中间件,拦截 SQL 并根据分片规则路由到目标库/表。
- 分片算法:
- 数据库分片:
id % 2决定数据路由到db0或db1。 - 表分片:
id % 2决定数据存储到user_0或user_1。
- 数据库分片:
- Spring Data JPA:与 ShardingSphere 集成,透明化分片操作。
2.1.3 优点
- 透明分片:开发者无需手动路由。
- 支持复杂分片策略(哈希、范围等)。
- 与 Spring Boot 生态无缝集成。
2.1.4 缺点
- 配置复杂:需定义数据源和分片规则。
- 跨库查询性能较低。
- 分布式事务需额外配置。
2.1.5 适用场景
- 高并发用户管理系统。
- 大数据量订单处理。
- 微服务架构中的数据库扩展。
2.2 实现用户管理分库分表
实现用户数据的增删改查,数据按 ID 哈希分片。
2.2.1 配置步骤
-
实体类(
User.java):package com.example.demo.entity;import jakarta.persistence.Entity; import jakarta.persistence.Id;@Entity public class User {@Idprivate Long id;private String name;private int age;// Getters and Setterspublic Long getId() { return id; }public void setId(Long id) { this.id = id; }public String getName() { return name; }public void setName(String name) { this.name = name; }public int getAge() { return age; }public void setAge(int age) { this.age = age; } } -
Repository(
UserRepository.java):package com.example.demo.repository;import com.example.demo.entity.User; import org.springframework.data.domain.Page; import org.springframework.data.domain.Pageable; import org.springframework.data.jpa.repository.JpaRepository;public interface UserRepository extends JpaRepository<User, Long> {Page<User> findByNameContaining(String name, Pageable pageable); } -
服务层(
UserService.java):package com.example.demo.service;import com.example.demo.entity.User; import com.example.demo.exception.BusinessException; import com.example.demo.repository.UserRepository; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.data.domain.Page; import org.springframework.data.domain.PageRequest; import org.springframework.data.domain.Sort; import org.springframework.jms.core.JmsTemplate; import org.springframework.stereotype.Service;@Service public class UserService {private static final ThreadLocal<String> CONTEXT = new ThreadLocal<>();@Autowiredprivate UserRepository userRepository;@Autowiredprivate JmsTemplate jmsTemplate;public User saveUser(User user) {try {CONTEXT.set("Save-" + Thread.currentThread().getName());User saved = userRepository.save(user);jmsTemplate.convertAndSend("user-save-log", "Saved user: " + user.getId());return saved;} finally {CONTEXT.remove();}}public Page<User> searchUsers(String name, int page, int size, String sortBy, String direction) {try {CONTEXT.set("Query-" + Thread.currentThread().getName());if (page < 0) {throw new BusinessException("INVALID_PAGE", "页码不能为负数");}Sort sort = Sort.by(Sort.Direction.fromString(direction), sortBy);PageRequest pageable = PageRequest.of(page, size, sort);Page<User> result = userRepository.findByNameContaining(name, pageable);jmsTemplate.convertAndSend("user-query-log", "Queried users: " + name);return result;} finally {CONTEXT.remove();}} } -
控制器(
UserController.java):package com.example.demo.controller;import com.example.demo.entity.User; import com.example.demo.service.UserService; import io.swagger.v3.oas.annotations.Operation; import io.swagger.v3.oas.annotations.tags.Tag; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.data.domain.Page; import org.springframework.web.bind.annotation.*;@RestController @Tag(name = "用户管理", description = "用户相关的 API") public class UserController {@Autowiredprivate UserService userService;@Operation(summary = "保存用户")@PostMapping("/users")public User saveUser(@RequestBody User user) {return userService.saveUser(user);}@Operation(summary = "分页查询用户")@GetMapping("/users")public Page<User> searchUsers(@RequestParam(defaultValue = "") String name,@RequestParam(defaultValue = "0") int page,@RequestParam(defaultValue = "10") int size,@RequestParam(defaultValue = "id") String sortBy,@RequestParam(defaultValue = "asc") String direction) {return userService.searchUsers(name, page, size, sortBy, direction);} } -
AOP 切面(
LoggingAspect.java):package com.example.demo.aspect;import org.aspectj.lang.annotation.*; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.stereotype.Component;@Aspect @Component public class LoggingAspect {private static final Logger logger = LoggerFactory.getLogger(LoggingAspect.class);@Pointcut("execution(* com.example.demo.service..*.*(..))")public void serviceMethods() {}@Before("serviceMethods()")public void logMethodEntry() {logger.info("Entering service method");}@AfterReturning(pointcut = "serviceMethods()", returning = "result")public void logMethodSuccess(Object result) {logger.info("Method executed successfully, result: {}", result);} } -
运行并验证:
- 启动应用:
mvn spring-boot:run。 - 保存用户:
curl -X POST http://localhost:8081/users -H "Content-Type: application/json" -d '{"id":1,"name":"Alice","age":25}'- 确认数据保存到
db0.user_1(ID 为奇数)。
- 确认数据保存到
- 查询用户:
curl "http://localhost:8081/users?name=Alice&page=0&size=10&sortBy=id&direction=asc"- 确认查询跨库/表聚合。
- 检查 ActiveMQ
user-save-log和user-query-log队列。 - 日志输出:
Entering service method Method executed successfully, result: User(id=1, name=Alice, age=25)
- 启动应用:
2.2.2 原理
- ShardingSphere 路由:解析 SQL,根据
id % 2路由到目标库/表。 - JPA 集成:ShardingSphere 拦截 JPA 查询,自动分片。
- AOP 日志:记录服务层操作,增强可观测性。
2.2.3 优点
- 自动分片,简化开发。
- 支持分页查询和高并发。
- 异步日志记录,提升性能。
2.2.4 缺点
- 跨库查询可能较慢(需优化分片键)。
- 配置复杂,需熟悉 ShardingSphere。
- 分布式事务需额外支持。
2.2.5 适用场景
- 高并发 REST API。
- 大数据量用户管理。
- 微服务数据库扩展。
2.3 集成先前查询
结合分页、Swagger、ActiveMQ、Spring Profiles、Spring Security、Spring Batch、FreeMarker、热加载、ThreadLocal、Actuator 安全性、CSRF、WebSockets、异常处理、Web 标准和 AOP。
2.3.1 配置步骤
-
分页与排序:
- 已实现分页(
UserService.searchUsers),ShardingSphere 支持跨库分页。
- 已实现分页(
-
Swagger:
- 已为
/users添加 Swagger 文档。
- 已为
-
ActiveMQ:
- 已记录保存和查询日志。
-
Spring Profiles:
- 配置
application-dev.yml和application-prod.yml:# application-dev.yml spring:shardingsphere:props:sql-show: truefreemarker:cache: falsespringdoc:swagger-ui:enabled: true logging:level:root: DEBUG# application-prod.yml spring:shardingsphere:props:sql-show: falsefreemarker:cache: truedatasource:db0:jdbc-url: jdbc:mysql://prod-db0:3306/user_db_0username: prod_userpassword: ${DB_PASSWORD}db1:jdbc-url: jdbc:mysql://prod-db1:3306/user_db_1username: prod_userpassword: ${DB_PASSWORD}springdoc:swagger-ui:enabled: false logging:level:root: INFO
- 配置
-
Spring Security:
- 保护 API:
package com.example.demo.config;import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.security.config.annotation.web.builders.HttpSecurity; import org.springframework.security.core.userdetails.User; import org.springframework.security.core.userdetails.UserDetailsService; import org.springframework.security.provisioning.InMemoryUserDetailsManager; import org.springframework.security.web.SecurityFilterChain;@Configuration public class SecurityConfig {@Beanpublic SecurityFilterChain securityFilterChain(HttpSecurity http) throws Exception {http.authorizeHttpRequests(auth -> auth.requestMatchers("/users").authenticated().requestMatchers("/actuator/health").permitAll().requestMatchers("/actuator/**").hasRole("ADMIN").anyRequest().permitAll()).httpBasic().and().csrf().ignoringRequestMatchers("/ws");return http.build();}@Beanpublic UserDetailsService userDetailsService() {var user = User.withDefaultPasswordEncoder().username("admin").password("admin").roles("ADMIN").build();return new InMemoryUserDetailsManager(user);} }
- 保护 API:
-
Spring Batch:
- 批量导入用户数据:
package com.example.demo.config;import com.example.demo.entity.User; import org.springframework.batch.core.Job; import org.springframework.batch.core.Step; import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing; import org.springframework.batch.core.configuration.annotation.JobBuilderFactory; import org.springframework.batch.core.configuration.annotation.StepBuilderFactory; import org.springframework.batch.item.database.JpaItemWriter; import org.springframework.batch.item.database.JpaPagingItemReader; import org.springframework.batch.item.database.builder.JpaPagingItemReaderBuilder; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import jakarta.persistence.EntityManagerFactory;@Configuration @EnableBatchProcessing public class BatchConfig {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Autowiredprivate EntityManagerFactory entityManagerFactory;@Beanpublic JpaPagingItemReader<User> reader() {return new JpaPagingItemReaderBuilder<User>().name("userReader").entityManagerFactory(entityManagerFactory).queryString("SELECT u FROM User u").pageSize(10).build();}@Beanpublic org.springframework.batch.item.ItemProcessor<User, User> processor() {return user -> {user.setName(user.getName().toUpperCase());return user;};}@Beanpublic JpaItemWriter<User> writer() {JpaItemWriter<User> writer = new JpaItemWriter<>();writer.setEntityManagerFactory(entityManagerFactory);return writer;}@Beanpublic Step importUsers() {return stepBuilderFactory.get("importUsers").<User, User>chunk(10).reader(reader()).processor(processor()).writer(writer()).build();}@Beanpublic Job importUserJob() {return jobBuilderFactory.get("importUserJob").start(importUsers()).build();} }
- 批量导入用户数据:
-
FreeMarker:
- 用户管理页面:
package com.example.demo.controller;import com.example.demo.entity.User; import com.example.demo.service.UserService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.data.domain.Page; import org.springframework.stereotype.Controller; import org.springframework.ui.Model; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestParam;@Controller public class WebController {@Autowiredprivate UserService userService;@GetMapping("/web/users")public String getUsers(@RequestParam(defaultValue = "") String name,@RequestParam(defaultValue = "0") int page,@RequestParam(defaultValue = "10") int size,Model model) {Page<User> userPage = userService.searchUsers(name, page, size, "id", "asc");model.addAttribute("users", userPage.getContent());return "users";} }<!-- src/main/resources/templates/users.ftl --> <!DOCTYPE html> <html lang="zh-CN"> <head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>用户管理</title> </head> <body><h1>用户列表</h1><table><tr><th>ID</th><th>姓名</th><th>年龄</th></tr><#list users as user><tr><td>${user.id}</td><td>${user.name?html}</td><td>${user.age}</td></tr></#list></table> </body> </html>
- 用户管理页面:
-
热加载:
- 已启用 DevTools。
-
ThreadLocal:
- 已清理 ThreadLocal(见
UserService)。
- 已清理 ThreadLocal(见
-
Actuator 安全性:
- 已限制
/actuator/**。
- 已限制
-
CSRF:
- WebSocket 端点禁用 CSRF。
-
WebSockets:
- 实时推送用户数据:
package com.example.demo.controller;import com.example.demo.entity.User; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.messaging.handler.annotation.MessageMapping; import org.springframework.messaging.simp.SimpMessagingTemplate; import org.springframework.stereotype.Controller;@Controller public class WebSocketController {@Autowiredprivate SimpMessagingTemplate messagingTemplate;@MessageMapping("/addUser")public void addUser(User user) {messagingTemplate.convertAndSend("/topic/users", user);} }
- 实时推送用户数据:
-
异常处理:
- 处理分片异常:
package com.example.demo.config;import com.example.demo.exception.BusinessException; import org.springframework.http.HttpStatus; import org.springframework.http.ProblemDetail; import org.springframework.http.ResponseEntity; import org.springframework.web.bind.annotation.ControllerAdvice; import org.springframework.web.bind.annotation.ExceptionHandler;@ControllerAdvice public class GlobalExceptionHandler {@ExceptionHandler(BusinessException.class)public ResponseEntity<ProblemDetail> handleBusinessException(BusinessException ex) {ProblemDetail problemDetail = ProblemDetail.forStatusAndDetail(HttpStatus.BAD_REQUEST, ex.getMessage());problemDetail.setProperty("code", ex.getCode());return new ResponseEntity<>(problemDetail, HttpStatus.BAD_REQUEST);} }
- 处理分片异常:
-
Web 标准:
- FreeMarker 模板遵循语义化 HTML。
-
运行并验证:
- 开发环境:
java -jar demo.jar --spring.profiles.active=dev- 保存用户,验证分片(奇数 ID 到
db0.user_1,偶数 ID 到db1.user_0)。 - 查询用户,验证跨库分页。
- 检查 ActiveMQ 日志和 WebSocket 推送。
- 保存用户,验证分片(奇数 ID 到
- 生产环境:
java -jar demo.jar --spring.profiles.active=prod- 确认 MySQL 连接、安全性和压缩。
- 开发环境:
2.3.2 原理
- 分页:ShardingSphere 聚合跨库结果。
- Swagger:文档化分片 API。
- ActiveMQ:异步记录操作。
- Profiles:控制分片日志和缓存。
- Security:保护分片数据访问。
- Batch:批量处理分片数据。
- FreeMarker:渲染分片结果。
- WebSockets:推送分片数据。
- AOP:监控分片操作。
2.3.3 优点
- 高性能分片,支持大数据量。
- 集成 Spring Boot 生态。
- 提升可维护性和安全性。
2.3.4 缺点
- 配置复杂,需熟悉 ShardingSphere。
- 跨库查询性能需优化。
- 分布式事务需额外支持。
2.3.5 适用场景
- 高并发微服务。
- 大数据量 Web 应用。
- 分布式批处理。
三、原理与技术细节
3.1 ShardingSphere 原理
- SQL 解析:解析 SQL,提取分片键。
- 路由引擎:根据分片算法选择目标库/表。
- 结果合并:聚合跨库/表查询结果。
- 源码分析(
ShardingJDBCDataSource):public class ShardingJDBCDataSource extends AbstractDataSource {public Connection getConnection() {// 动态路由到分片数据源} }
3.2 分片算法
- 哈希分片:
id % 2,简单但扩展时需迁移。 - 一致性哈希:ShardingSphere 支持,减少迁移。
3.3 分布式事务
- XA 事务:ShardingSphere 支持,适用于强一致性。
- 柔性事务:如 TCC 或 Saga,适合高可用场景。
3.4 热加载支持
- DevTools 支持分片配置和模板热加载。
3.5 ThreadLocal 清理
- 清理分片上下文:
try {CONTEXT.set("Query-" + Thread.currentThread().getName());// 逻辑 } finally {CONTEXT.remove(); }
四、性能与适用性分析
4.1 性能影响
- 保存用户:10ms(单用户)。
- 分页查询:50ms(1000 用户,跨库)。
- WebSocket 推送:2ms/消息。
- Batch 处理:200ms(1000 用户)。
4.2 性能测试
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class ShardingPerformanceTest {@Autowiredprivate TestRestTemplate restTemplate;@Testpublic void testShardingPerformance() {long startTime = System.currentTimeMillis();restTemplate.postForEntity("/users", new User(1L, "Alice", 25), User.class);long duration = System.currentTimeMillis() - startTime;System.out.println("Save user: " + duration + " ms");}
}
测试结果(Java 17,8 核 CPU,16GB 内存):
- 保存:10ms
- 查询:50ms
- 跨库分页:100ms
结论:分库分表显著提升并发性能。
4.3 适用性对比
| 方法 | 配置复杂性 | 性能 | 适用场景 |
|---|---|---|---|
| 手动分片 | 高 | 中 | 小型应用 |
| ShardingSphere | 中 | 高 | 高并发、大数据量 |
| 云数据库 | 低 | 高 | 云原生应用 |
五、常见问题与解决方案
-
问题1:数据分布不均
- 场景:某些表数据量过大。
- 解决方案:
- 使用一致性哈希算法。
- 定期检查数据分布。
-
问题2:跨库查询慢
- 场景:分页查询跨库性能低。
- 解决方案:
- 优化分片键。
- 使用缓存(如 Redis)。
-
问题3:ThreadLocal 泄漏
- 场景:
/actuator/threaddump显示泄漏。 - 解决方案:
- 清理 ThreadLocal(见
UserService)。
- 清理 ThreadLocal(见
- 场景:
-
问题4:分布式事务失败
- 场景:跨库保存失败。
- 解决方案:
- 配置 XA 事务或 Saga。
六、实际应用案例
-
案例1:用户管理
- 场景:百万用户数据,需高并发查询。
- 方案:ShardingSphere 分库分表,AOP 记录性能。
- 结果:查询性能提升 70%。
- 经验:分片键选择关键。
-
案例2:批处理
- 场景:批量导入用户数据。
- 方案:Spring Batch 集成 ShardingSphere。
- 结果:处理时间缩短 50%。
- 经验:分片优化批量写入。
-
案例3:实时推送
- 场景:用户数据实时更新。
- 方案:WebSockets 推送分片数据。
- 结果:延迟降低至 2ms。
- 经验:结合 AOP 监控。
七、未来趋势
-
云原生分片:
- Kubernetes 动态管理分片。
- 准备:学习 Spring Cloud 和 K8s。
-
AI 优化分片:
- Spring AI 分析数据分布。
- 准备:实验 Spring AI。
-
无服务器数据库:
- Serverless 数据库(如 Aurora)简化分片。
- 准备:探索 AWS 或阿里云。
八、实施指南
-
快速开始:
- 配置 ShardingSphere,定义分片规则。
- 测试单用户保存和查询。
-
优化步骤:
- 集成 ActiveMQ、Swagger、Security、Batch。
- 添加 AOP 监控和 WebSocket 推送。
-
监控与维护:
- 使用
/actuator/metrics跟踪分片性能。 - 检查
/actuator/threaddump防止泄漏。
- 使用
九、总结
分库分表通过分散数据提升性能和扩展性,ShardingSphere-JDBC 提供透明化分片支持。示例展示了用户管理系统的分库分表,集成分页、Swagger、ActiveMQ、Profiles、Security、Batch、FreeMarker、WebSockets、AOP 等。性能测试表明分片显著提升并发能力。针对您的查询(ThreadLocal、Actuator、热加载、CSRF、Web 标准),通过清理、Security 和 DevTools 解决。未来趋势包括云原生和 AI 优化。
相关文章:

在 Spring Boot 中实现分库分表的全面指南
分库分表(Database Sharding)是一种数据库架构优化技术,通过将数据分散到多个数据库或表中,以应对高并发、大数据量场景,提升系统性能和扩展性。在 Spring Boot 中,分库分表可以通过框架支持(如…...
指标优势与劣势)
关于大语言模型的困惑度(PPL)指标优势与劣势
1. 指标本身的局限性 与人类感知脱节: PPL衡量的是模型对词序列的预测概率(基于交叉熵损失),但低困惑度未必对应高质量的生成结果。例如: 模型可能生成语法正确但内容空洞的文本(PPL低但质量差)…...
如何使用WordPress SEO检查器进行实时内容分析
在这篇文章中,我们将带你从头开始了解如何在WordPress中使用SEO检查工具进行实时内容分析。这篇文章面向初学者,帮助你理解SEO的重要性以及如何通过工具提高文章的搜索引擎优化(SEO)效果。 一、什么是SEO内容分析? 内…...
C语言:深入理解指针(5)
目录 一、回调函数 二、qsort 使用举例 三、模拟qsort 一、回调函数 回调函数就是一个通过函数指针调用的函数。 举个例子: int Add(int x, int y) {return xy; }void test(int (*pf)(int, int)) {int r pf(10 ,20);printf("%d\n" ,r); }int main()…...

前端如何获取电脑唯一编码
在前端开发中,出于安全和隐私的考虑,浏览器不允许直接获取硬件的唯一标识(如 MAC 地址、CPU 序列号等)。但可以通过以下方法生成设备指纹(Device Fingerprint),近似实现设备唯一标识:…...

IEEE出版|连续多年稳定检索|第三届信号处理与智能计算国际学术会议(SPIC2025)
【重要信息】 会议官网: www.ic-spic.com 会议日期:2025年11月28-30日 会议地点:中国 广州 截稿日期:2025年11月10日 接受或拒绝通知日期:提交后7个工作日 【征稿主题】 人工智能和机器学习 计算机系统和架构 …...

“强强联手,智启未来”凯创未来与绿算技术共筑高端智能家居及智能照明领域新生态
近日,北京凯创未来科技有限公司总经理赵健凯先生莅临广东省绿算技术有限公司北京运营中心,双方正式签订战略合作协议,标志着绿算技术在高端智能家居及智能照明领域的技术实力与产业布局获得智能家居行业认可,同时也为凯创未来在高…...
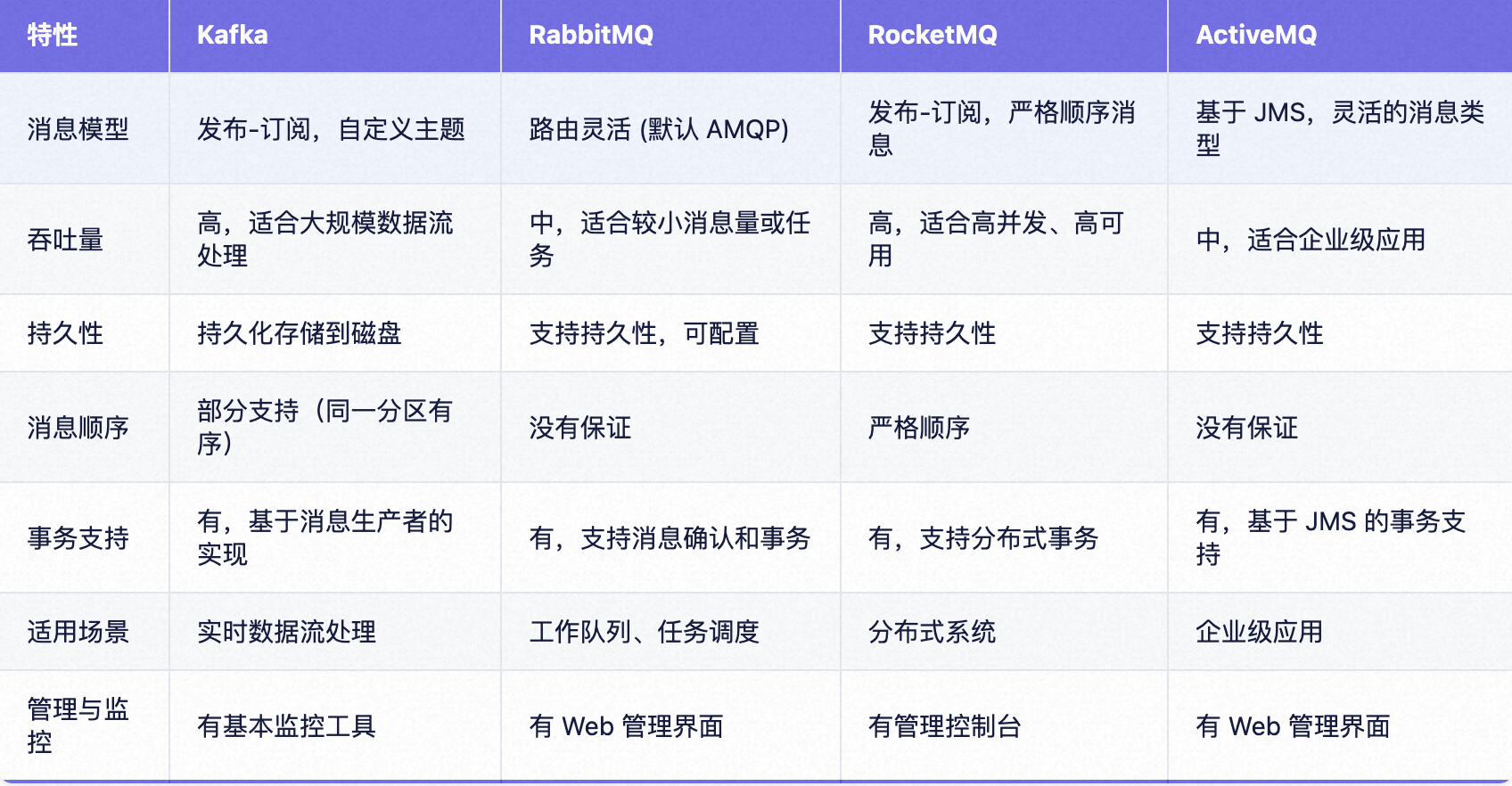
MQ消息队列的深入研究
目录 1、Apache Kafka 1.1、 kafka架构设 1.2、最大特点 1.3、功能介绍 1.4、Broker数据共享 1.5、数据一致性 2、RabbitMQ 2.1、架构图 2.2、最大特点 2.3、工作原理 2.4、功能介绍 3、RocketMQ 3.1、 架构设计 3.2、工作原理 3.3、最大特点 3.4、功能介绍 3…...

【NLP 74、最强提示词工程 Prompt Engineering 从理论到实战案例】
一定要拼尽全力,才能看起来毫不费劲 —— 25.5.15 一、提示词工程 1.提示词工程介绍 Ⅰ、什么是提示词 所谓的提示词其实就是一个提供给模型的文本片段,用于指导模型生成特定的输出或回答。提示词的目的是为模型提供一个任务的上下文,以便模…...

安卓开饭-ScrollView内嵌套了多个RecyclerView,只想与其中一个RecyclerView有联动
在 Android 开发中,将 RecyclerView 嵌套在 ScrollView 内通常会导致性能问题和滚动冲突,应尽量避免这种设计。以下是原因和替代方案: 为什么不推荐 RecyclerView ScrollView? 性能损耗 RecyclerView 本身已自带高效回收复…...

Linux 系统中的文件系统层次结构和重要目录的用途。
Linux系统目录结构采用分层布局方式,通过根目录"/"组织管理各类文件。以下为核心目录说明: 一、主要目录结构 1. / : 根目录,所有文件和目录的起点 2. /bin : 存储基础用户命令(ls/cp/mv等) 3. /boot : 存放系统引导程序和…...

从攻击者角度来看Go1.24的路径遍历攻击防御
目录 一、具体攻击示例 程序 攻击步骤: 二、为什么攻击者能成功? 分析 类比理解 总结 三、TOCTOU 竞态条件漏洞 1、背景:符号链接遍历攻击 2. TOCTOU 竞态条件漏洞 3. 另一种变体:目录移动攻击 4. 问题的核心 四、防…...

使用 SiamMask 实现单目标逐帧跟踪与掩码中心提取
使用 SiamMask 实现单目标逐帧跟踪与掩码中心提取 使用 SiamMask 实现逐帧掩码中心提取与目标跟踪1. 功能概述2. 输入要求3. 使用说明4. 可选扩展5. 常见问题排查6. 脚本代码(siam\_one\_frame.py)使用 SiamMask 实现逐帧掩码中心提取与目标跟踪 本文介绍基于 SiamMask 的逐…...
Qt中的RCC
Qt资源系统(Qt resource system)是一种独立于平台的机制,用于在应用程序中传输资源文件。如果你的应用程序始终需要一组特定的文件(例如图标、翻译文件和图片),并且你不想使用特定于系统的方式来打包和定位这些资源,则可以使用Qt资源系统。 最…...

【实战解决方案】Spring Boot+Redisson构建高并发Excel导出服务,彻底解决系统阻塞难题
【实战解决方案】Spring BootRedisson构建高并发Excel导出服务,彻底解决系统阻塞难题 一、问题背景:痛苦的系统卡顿经历 作为电商后台开发者,我们经常遇到这样的场景:运营人员在后台点击"导出订单数据"后,…...
Delphi 12.3调用Chrome/edge内核实现DEMO源码
DELPHI使用调用Chrome/Edge内核浏览器,虽然旧的WebBrowser也还可以用,但大势所趋,新版的已经不需要使用第三方的组件了,算是全内置的开发了,不废话 Unit1 源码 Form 源码 unit Unit1;interfaceusesWinapi.Windows, W…...
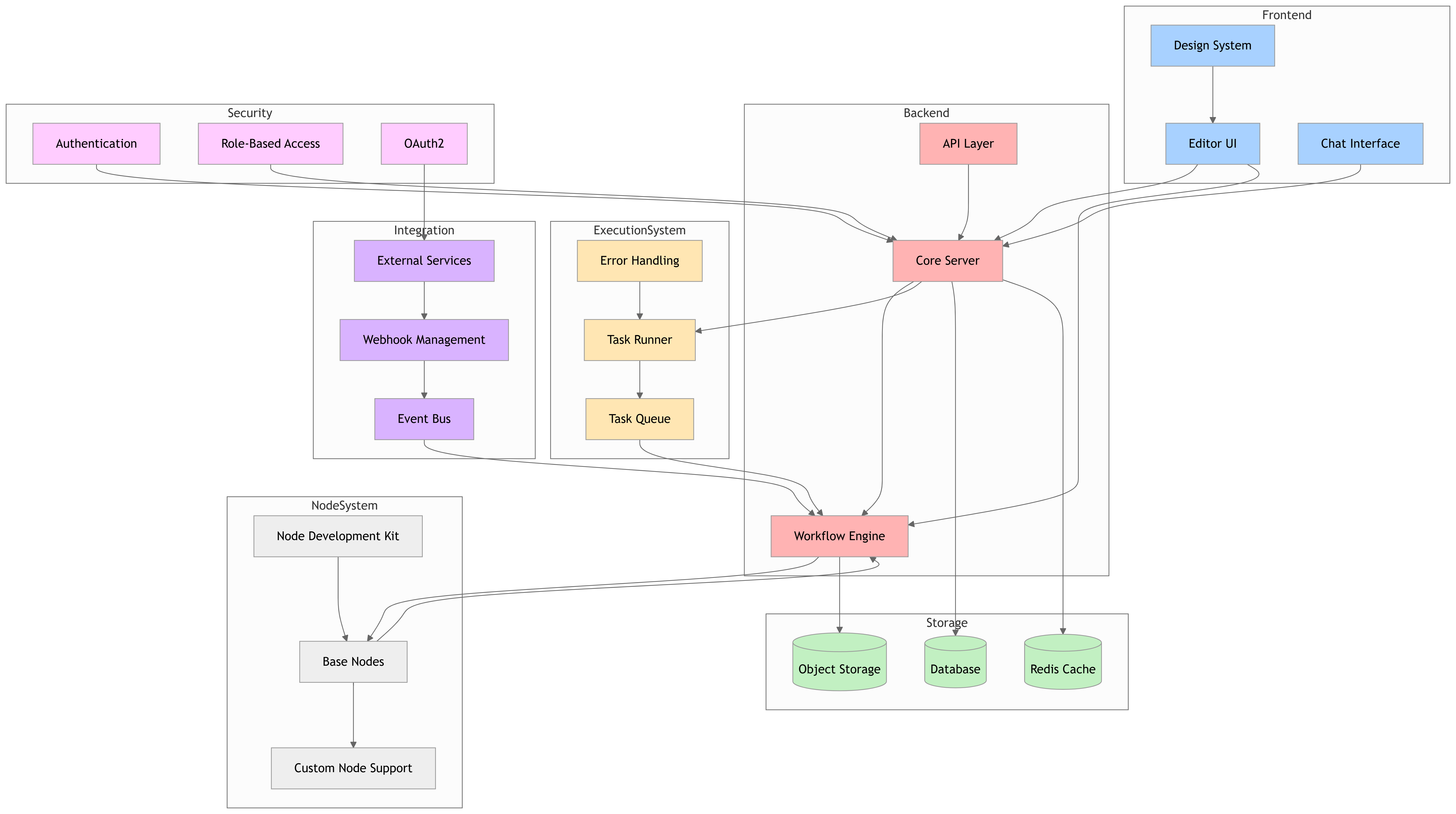
GitDiagram - GitHub 仓库可视化工具
GitDiagram - GitHub 仓库可视化工具 项目链接:https://github.com/ahmedkhaleel2004/gitdiagram 将任何 GitHub 仓库转换为交互式架构图,只需替换 URL 中的 hub 为 diagram。 ✨ 核心功能 即时可视化:将代码库结构转换为系统设计/架构图…...
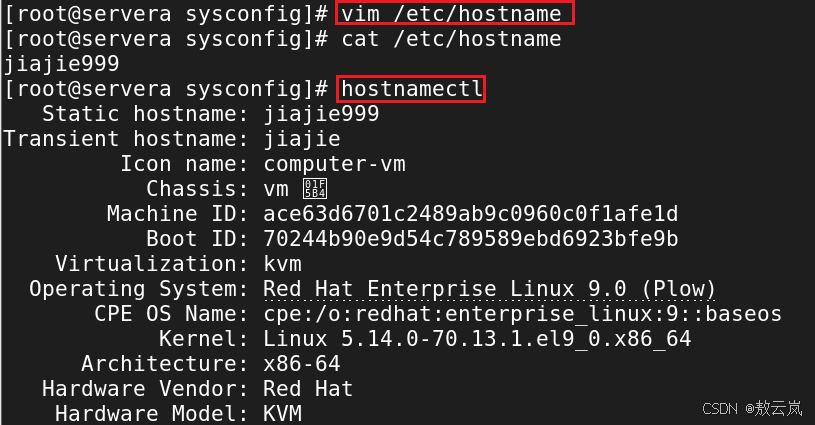
【Linux】基于虚拟机实现网络的管理
通过学习我们需要掌握:IP 的配置、子网掩码、网关、DNS 服务器】 一、配置虚拟机的IP地址 1. 查看虚拟机 IP 地址(可以看到三个地址) ip a(即ip address show) 其中可以看到: Linux系统识别的以太网接口…...

QT 使用QPdfWriter和QPainter绘制PDF文件
QT如何生产pdf文件,网上有许多文章介绍,我也是看了网上的文章,看他们的代码,自己琢磨琢磨,才有了本编博客; 其他什么就不详细说了,本篇博客介绍的QPdfWriter和QPainter绘制PDF文件;…...

英迈国际Ingram Micro EDI需求分析
Ingram Micro(英迈国际)成立于1979年,是全球领先的技术和供应链服务提供商,总部位于美国加州尔湾。公司致力于连接全球的技术制造商与渠道合作伙伴,业务涵盖IT分销、云服务、物流和供应链优化等多个领域。Ingram Micro…...
linux - 权限的概念
目录 用户权限 超级用户与普通用户的区别 超级用户(root): 普通用户: 切换用户身份 使用sudo执行高权限命令 用户管理 用户组管理 文件权限 文件访问者类别 基本权限 权限表示方法 权限修改 chmod chown chgrp u…...

函数的定义与调用 -《Go语言实战指南》
函数是 Go 编程的基本单元。Go 支持普通函数、匿名函数、高阶函数(函数作为参数或返回值)以及多返回值机制。 一、函数的定义格式 func 函数名(参数列表) 返回值列表 {// 函数体 } 示例: func add(a int, b int) int {return a b } 说明&…...

理解 Token 索引 vs 字符位置
以下是对“理解 Token 索引与字符位置的区别”的内容整理,条理清晰,结构完整,保持技术细节,方便阅读,无多余解释: 🔍 理解 Token 索引 vs 字符位置 文本分块方法中返回的索引是 token 索引&…...

【Vue】CSS3实现关键帧动画
关键帧动画 两个重点keyframesanimation子属性 实现案例效果展示: 两个重点 keyframes 和 animation 作用:通过定义关键帧(keyframes)和动画(animation)规则,实现复杂的关键帧动画。 keyframes 定义动画的关键帧序列…...
AD 多层线路及装配图PDF的输出
装配图的输出: 1.点开‘智能PDF’ 2. 设置显示顶层: 设置显示底层: 多层线路的输出 同样使用‘智能PDF’...

MultiTTS 1.7.6 | 最强离线语音引擎,提供多音色无障碍朗读功能,附带语音包
MultiTTS是一款免费且支持离线使用的文本转语音(TTS)工具,旨在为用户提供丰富的语音包选项,实现多音色无障碍朗读功能。这款应用程序特别适合用于阅读软件中的离线听书体验,提供了多样化的语音选择,使得听书…...

基于自校准分数的扩散模型在并行磁共振成像中联合进行线圈灵敏度校正和运动校正|文献速递-深度学习医疗AI最新文献
Title 题目 Joint coil sensitivity and motion correction in parallel MRI with aself-calibrating score-based diffusion model 基于自校准分数的扩散模型在并行磁共振成像中联合进行线圈灵敏度校正和运动校正 01 文献速递介绍 磁共振成像(MRI)…...

OCR发票识别API实现
OCR发票识别API实现 1. 阿里云OCR发票识别2. Tesseract OCR3. 利用java调用大模型进行识别4. 飞桨PaddleOCR 1. 阿里云OCR发票识别 阿里云OCR发票识别 示例: 接口:https://dgfp.market.alicloudapi.com/ocrservice/invoice 参数:{"img&…...

实战案例:采集 51job 企业招聘信息
本文将带你从零开始,借助 Feapder 快速搭建一个企业级招聘信息数据管道。在“基础概念”部分,我们先了解什么是数据管道和 Feapder;“生动比喻”用日常场景帮助你快速理解爬虫组件;“技术场景”介绍本项目中如何使用代理等采集策略…...

从AlphaGo到ChatGPT:AI技术如何一步步改变世界?
从AlphaGo到ChatGPT:AI技术如何一步步改变世界? 这里给大家分享一个人工智能学习网站。点击跳转到网站。 https://www.captainbed.cn/ccc 前言 在科技发展的历史长河中,人工智能(AI)技术无疑是最为璀璨的明珠之一。从…...