02_线性模型(回归分类模型)
用于分类的线性模型
线性模型也广泛应用于分类问题,可以利用下面的公式进行预测:
$ \widehat y = w[0]*x[0]+w[1]*x[1]+…+w[p]*x[p]+b > 0$
公式看起来与线性回归的公式非常相似,但没有返回特征的加权求和,而是为预测设置了阈值(0)。如果函数值小于 0,就预测类别-1;如果函数值大于 0,就预测类别 +1。对于所有用于分类的线性模型,这个预测规则都是通用的。同样,有很多种不同的方法来找出系数(w)和截距(b)。
对于用于回归的线性模型,输出 ŷ 是特征的线性函数,是直线、平面或超平面(对于更高维的数据集)。对于用于分类的线性模型,决策边界是输入的线性函数。换句话说,(二元)线性分类器是利用直线、平面或超平面来分开两个类别的分类器。
最常见的两种线性分类算法是 Logistic 回归(logistic regression)和线性支持向量机(linear support vector machine,线性 SVM)
二分类
可以将 LogisticRegression 和 LinearSVC 模型应用到 forge 数据集上,并将线性模型找到的决策边界可视化
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import mglearn
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
import warnings
warnings.filterwarnings('ignore')X,Y = mglearn.datasets.make_forge()fig, axes = plt.subplots(1, 2, figsize=(10, 3))
for model, ax in zip([LinearSVC(), LogisticRegression()], axes):clf = model.fit(X, Y)mglearn.plots.plot_2d_separator(clf, X, fill=False, eps=0.5, ax=ax, alpha=.7)mglearn.discrete_scatter(X[:, 0], X[:, 1], Y, ax=ax)ax.set_title("{}".format(clf.__class__.__name__))ax.set_xlabel("Feature 0")ax.set_ylabel("Feature 1")
axes[0].legend()
执行上例得到一张可视化的图,forge 数据集的第一个特征位于 x 轴,第二个特征位于 y 轴,与前面相同。图中分别展示了 LinearSVC 和 LogisticRegression 得到的决策边界,都是直线,将顶部归为类别 1 的区域和底部归为类别 0 的区域分开了。换句话说,对于每个分类器而言,位于黑线上方的新数据点都会被划为类别 1,而在黑线下方的点都会被划为类别 0。
注意,两个模型中都有两个点的分类是错误的。两个模型都默认使用 L2 正则化,就像 Ridge 对回归所做的那样。
对 于 LogisticRegression 和 LinearSVC, 决 定 正 则 化 强 度 的 权 衡 参 数 叫 作 C。C 值 越大,对应的正则化越弱。换句话说,如果参数 C 值较大,那么 LogisticRegression 和LinearSVC 将尽可能将训练集拟合到最好,而如果 C 值较小,那么模型更强调使系数向量(w)接近于 0。
参数 C 的作用还有另一个有趣之处。较小的 C 值可以让算法尽量适应“大多数”数据点,而较大的 C 值更强调每个数据点都分类正确的重要性。
mglearn.plots.plot_linear_svc_regularization() # 不同 C 值的线性 SVM 在 forge 数据集上的决策边界
用于分类的线性模型在低维空间中看起来可能非常受限,决策边界只能是直线或平面。同样,在高维空间中,用于分类的线性模型变得非常强大,当考虑更多特征时,避免过拟合变得越来越重要。
在乳腺癌数据集上详细分析 LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_splitcancer = load_breast_cancer()
X_train, X_test, Y_train, Y_test = train_test_split(cancer.data, cancer.target, stratify=cancer.target, random_state=42)
logreg = LogisticRegression().fit(X_train, Y_train)
print(logreg.score(X_train, Y_train),logreg.score(X_test, Y_test))
通过上例,在C=1 的(默认值)情况下,具有相当好的性能。但由于训练集和测试集的性能非常接近,所以模型很可能是欠拟合的。尝试增大 C 来拟合一个更灵活的模型:
logreg10 = LogisticRegression(C=10).fit(X_train, Y_train)
print(logreg10.score(X_train, Y_train),logreg10.score(X_test, Y_test))logreg100 = LogisticRegression(C=100).fit(X_train, Y_train)
print(logreg100.score(X_train, Y_train),logreg100.score(X_test, Y_test))logreg1000 = LogisticRegression(C=1000).fit(X_train, Y_train)
print(logreg1000.score(X_train, Y_train),logreg1000.score(X_test, Y_test))logreg10000 = LogisticRegression(C=10000).fit(X_train, Y_train)
print(logreg10000.score(X_train, Y_train),logreg10000.score(X_test, Y_test))
通过执行上例,可以看到随着C的增大,性能其实已经趋于一个稳定值(理论上应该是性能会更好,另外train_test_split中random_state取值不同,也会影响到性能,大概率是因为模型太小)
多分类的线性模型
许多线性分类模型只适用于二分类问题,不能轻易推广到多类别问题(除了 Logistic 回归)。将二分类算法推广到多分类算法的一种常见方法是“一对其余”(one-vs.-rest)方法。在“一对其余”方法中,对每个类别都学习一个二分类模型,将这个类别与所有其他类别尽量分开,这样就生成了与类别个数一样多的二分类模型。在测试点上运行所有二类分类器来进行预测。在对应类别上分数最高的分类器“胜出”,将这个类别标签返回作为预测结果。
每个类别都对应一个二类分类器,这样每个类别也都有一个系数(w)向量和一个截距(b)。下面给出的是分类置信方程,其结果中最大值对应的类别即为预测的类别标签:
$ w[0]*x[0]+w[1]*x[1]+…+w[p]*x[p]+b$
多分类 Logistic 回归背后的数学与“一对其余”方法稍有不同,但它也是对每个类别都有一个系数向量和一个截距,也使用了相同的预测方法。
from sklearn.datasets import make_blobsX,Y = make_blobs(random_state=42)mglearn.discrete_scatter(X[:, 0], X[:, 1], Y)
line = np.linspace(-15, 15)
for coef, intercept, color in zip(linear_svm.coef_, linear_svm.intercept_,['b', 'r', 'g']):plt.plot(line, -(line * coef[0] + intercept) / coef[1], c=color)plt.ylim(-10, 15)plt.xlim(-10, 8)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.legend(['Class 0', 'Class 1', 'Class 2', 'Line class 0', 'Line class 1','Line class 2'], loc=(1.01, 0.3))
执行上例可以看到,训练集中所有属于类别 0 的点都在与类别 0 对应的直线上方,这说明它们位于这个二类分类器属于“类别 0”的那一侧。属于类别 0 的点位于与类别 2 对应的直线上方,这说明它们被类别 2 的二类分类器划为“其余”。属于类别 0 的点位于与类别 1 对应的直线左侧,这说明类别 1 的二元分类器将它们划为“其余”。
图像中间有块三角形区域,3 个二类分类器都将这一区域内的点划为“其余”。落在这个范围的数据,分类方程结果最大的那个类别,即最接近的那条线对应的类别。
鸢尾花的例子
import pandas as pd
import numpy as np
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')from sklearn.model_selection import train_test_split
from sklearn.svm import LinearSVCiris = pd.read_csv(r'..\..\seaborn-data\iris.csv') # 加载数据
iris_class_dic = {'setosa':0, 'versicolor':1, 'virginica':2}
iris_class = ['setosa', 'versicolor', 'virginica']
iris_tz_array=iris.select_dtypes(include='number')
iris_class_array=iris['species'].map(iris_class_dic)X_train,X_test,Y_train,Y_test = train_test_split(iris_tz_array,iris_class_array,random_state=42)
linear_svm = LinearSVC().fit(X_train,Y_train)
print(linear_svm.score(X_train,Y_train),linear_svm.score(X_test,Y_test)) # 测试分数能拿到1,训练分数达到了0.97x_new= [[5,2.8,1,0.3]] # 预测分类
iris_class[linear_svm.predict(x_new)[0]]
总结
线性模型的主要参数是正则化参数,在回归模型中叫作 alpha,在 LinearSVC 和 Logistic-Regression 中叫作 C。alpha 值较大或 C 值较小,说明模型比较简单。特别是对于回归模型而言,调节这些参数非常重要。
目前对random_state的理解:train_test_split中的random_state可以指定不同的值,从目前的几个例子看这个值会影响到训练得分。如果存在较大差异,需要我们关注样本数据了(差异较大,很可能是样本数据太少,train_test_split随机拆分时会出现训练集与测试集存的样本比例出现较大差异)。
相关文章:
)
02_线性模型(回归分类模型)
用于分类的线性模型 线性模型也广泛应用于分类问题,可以利用下面的公式进行预测: $ \widehat y w[0]*x[0]w[1]*x[1]…w[p]*x[p]b > 0$ 公式看起来与线性回归的公式非常相似,但没有返回特征的加权求和,而是为预测设置了阈值…...

通义千问席卷日本!开源界“卷王”阿里通义千问成为日本AI发展新基石
据日本经济新闻(NIKKEI)报道,通义千问已成为日本AI开发的新基础,其影响力正逐步扩大,深刻改变着日本AI产业的格局。 同时,日本经济新闻将通义千问Qwen2.5-Max列为全球AI模型综合评测第六名,不仅…...
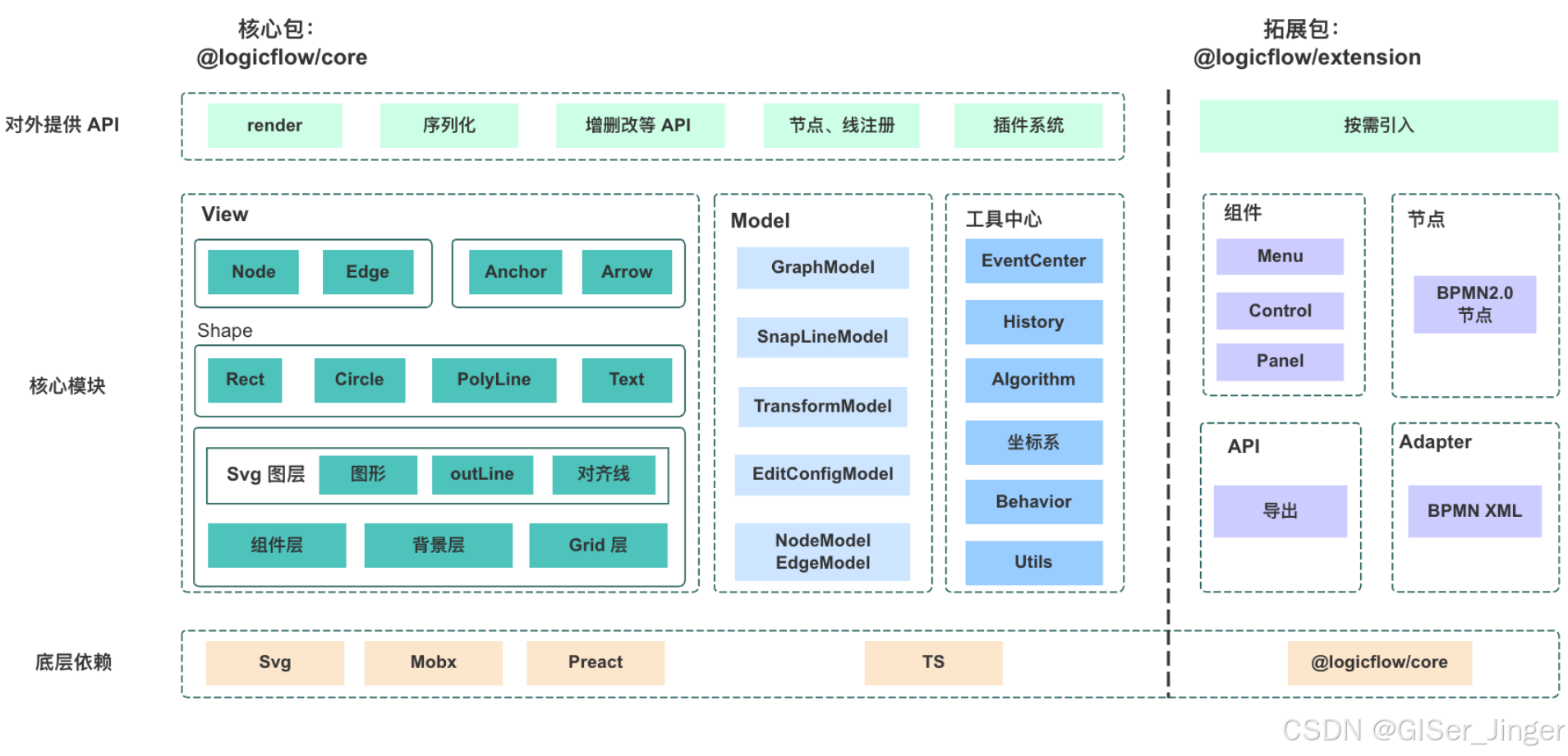
流程编辑器Bpmn与LogicFlow学习
工作流技术如何与用户交互结合(如动态表单、任务分配)处理过 XML 与 JSON 的转换自定义过 bpmn.js 的样式(如修改节点颜色、形状、图标)扩展过上下文菜单(Palette)或属性面板(Properties Panel&…...

Figma 新手教程学习笔记
📺 视频地址:Figma新手教程2025|30分钟高效掌握Figma基础操作与UI设计流程_哔哩哔哩_bilibili 🧭 课程结构 Figma 简介(00:38) 熟悉工作环境(01:49) 操作界面介绍(03:…...

RabbitMQ的工作队列模式和路由模式有什么区别?
RabbitMQ 的工作队列模式(Work Queues)和路由模式(Routing)是两种不同的消息传递模式,主要区别在于消息的分发逻辑和使用场景。以下是它们的核心差异: 1. 工作队列模式(Work Queues)…...

什么是 ANR 如何避免它
一、什么是 ANR? ANR(Application Not Responding) 是 Android 系统在应用程序主线程(UI 线程)被阻塞超过一定时间后触发的错误机制。此时系统会弹出一个对话框提示用户“应用无响应”,用户可以选择等待或强…...
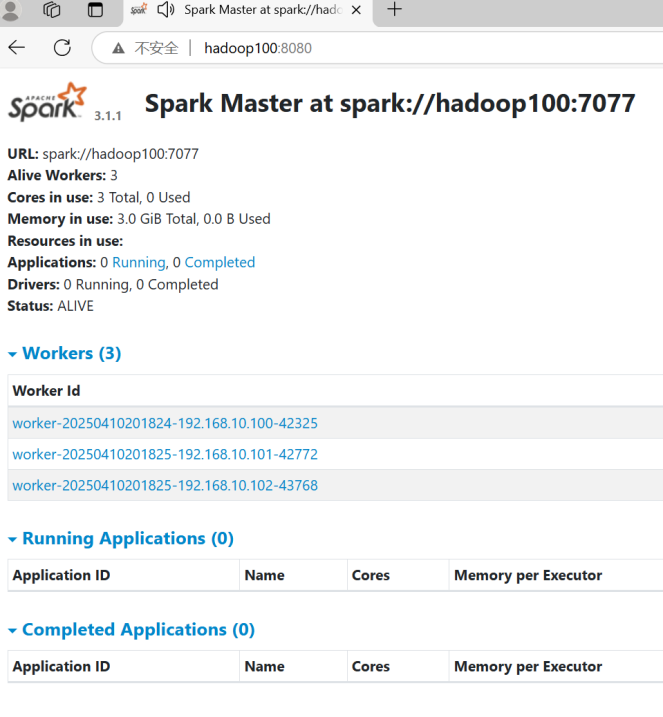
配置Spark环境
1.上传spark安装包到某一台机器(自己在finaShell上的机器)。 2.解压。 把第一步上传的安装包解压到/opt/module下(也可以自己决定解压到哪里)。对应的命令是:tar -zxvf 安装包 -C /opt/module 3.重命名。进入/opt/mo…...

嵌入式硬件篇---IIC
文章目录 前言1. IC协议基础1.1 物理层特性两根信号线SCLSDA支持多主多从 标准模式电平 1.2 通信流程起始条件(Start Condition)从机地址(Slave Address)应答(ACK/NACK)数据传输:停止条件&#…...

Window下Jmeter多机压测方法
1.概述 Jmeter多机压测的原理,是通过单个jmeter客户端,控制多个远程的jmeter服务器,使他们同步的对服务器进行压力测试。 以此方式收集测试数据的好处在于: 保存测试采样数据到本地机器通过单台机器管理多个jmeter执行引擎测试…...
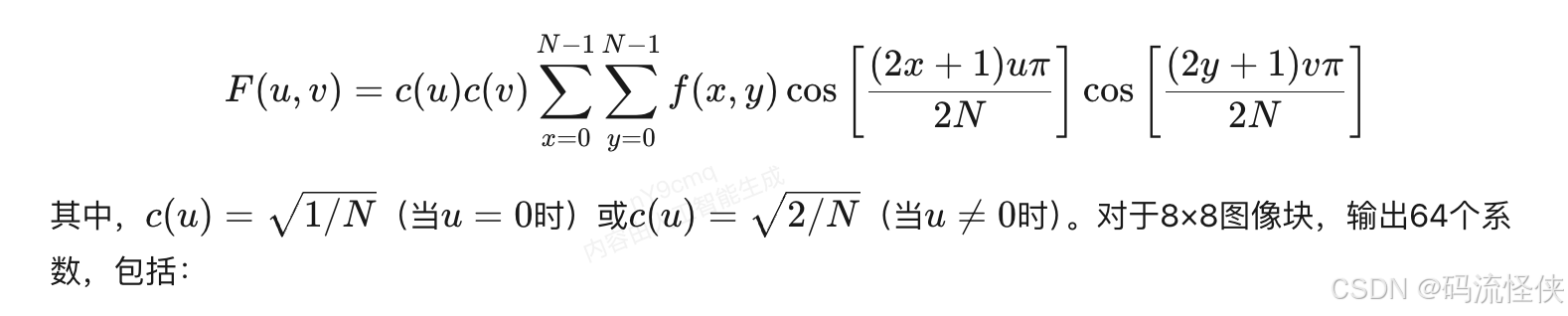
视频图像压缩领域中 DCT 的 DC 系数和 AC 系数详解
引言 在数字图像与视频压缩领域,离散余弦变换(Discrete Cosine Transform, DCT)凭借其卓越的能量集中特性,成为JPEG、MPEG等国际标准的核心技术。DCT通过将空域信号映射到频域,分离出DC系数(直流分量&…...

K8S cgroups详解
以下是 Kubernetes 中 cgroups(Control Groups) 的详细解析,涵盖其核心原理、在 Kubernetes 中的具体应用及实践操作: 一、cgroups 基础概念 1. 是什么? cgroups 是 Linux 内核提供的 资源隔离与控制机制,…...

能源设备数据采集
在全球可持续发展目标与环境保护理念日益深入人心的时代背景下,有效管理和优化能源使用已成为企业实现绿色转型、提升竞争力的关键路径。能源设备数据采集系统,作为能源管理的核心技术支撑,通过对各类能源生产设备运行数据的全面收集、深度分…...

Go语言安装proto并且使用gRPC服务(2025最新WINDOWS系统)
1.protobuf简介 protobuf 即 Protocol Buffers,是一种轻便高效的结构化数据存储格式,与语言、平台无关,可扩展可序列化。protobuf 性能和效率大幅度优于 JSON、XML 等其他的结构化数据格式。protobuf 是以二进制方式存储的,占用空…...
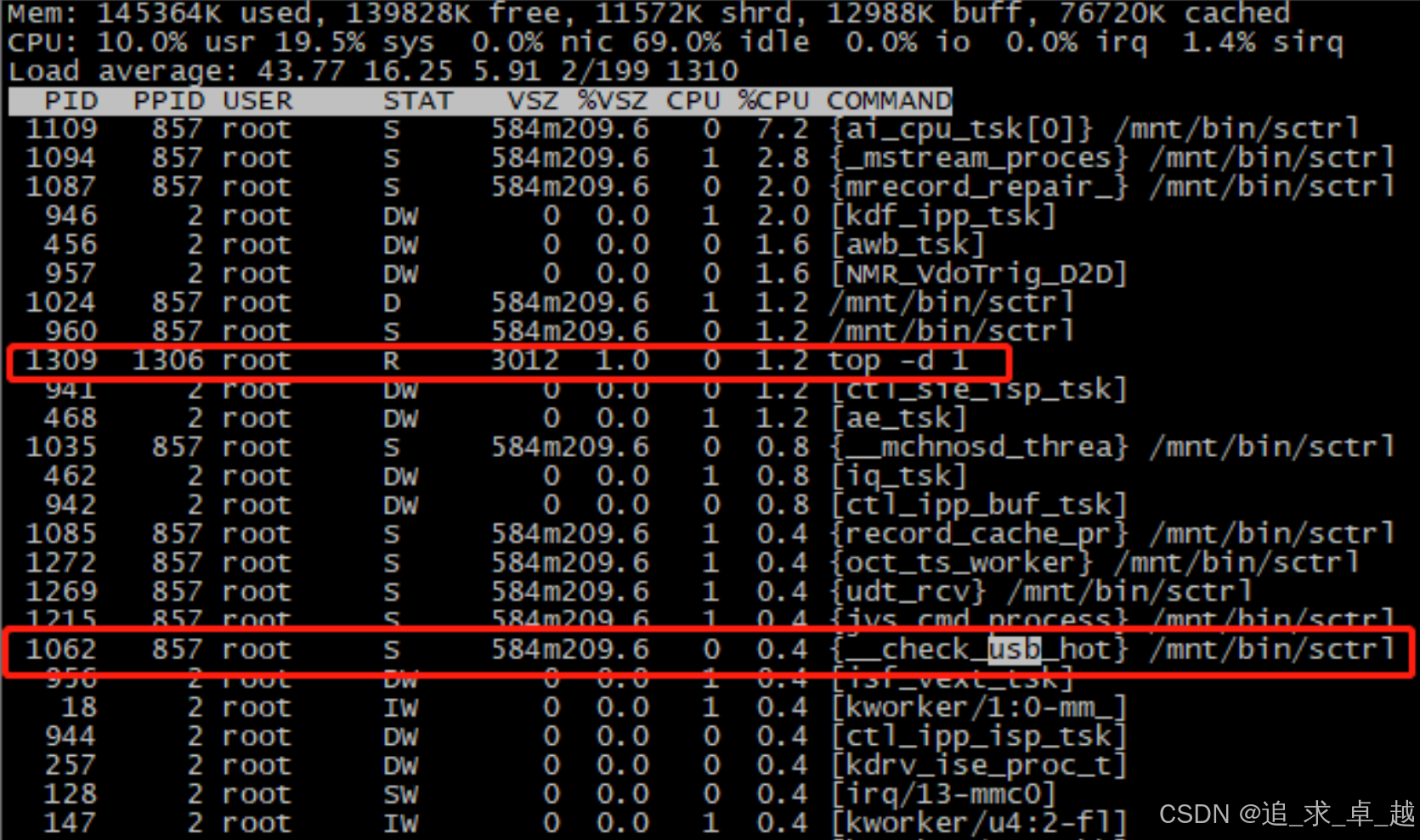
[Linux性能优化] 线程卡顿优化。Linux加入USB(HID)热插拔线程占用CPU优化。Linux中CPU使用率过高优化
文章目录 [Linux性能优化] 线程卡顿优化。0、省流版本一、问题定位:CPU 资源分析二、线程卡顿现场复现线程优化前图片 三、线程卡顿优化方向1.如果是轮询方式2.如果是事件驱动方式 四、修改方式线程优化后图片 [Linux性能优化] 线程卡顿优化。 0、省流版本 如果采…...
Ubuntu20.04下如何源码编译Carla,使用UE4源码开跑,踩坑集合
一、简介 作为一个从事算法研究的人员,无人驾驶仿真一直是比较重要的一部分,但是现在比较常见的算法验证都是在carla这个开源仿真平台上做的,所以我有二次开发carla的需求,今天就来讲讲编译CARLA。 网上的教材很多,但还是推荐大家看官网教程:Linux build - CARLA Simul…...

Java中的策略模式和模板方法模式
文章目录 1. 策略模式(Strategy Pattern)案例:支付方式选择 2. 模板方法模式(Template Method Pattern)案例:制作饮料流程 3. 策略模式 vs 模板方法模式4.总结 在Java中,策略模式和模板方法模式…...

26考研——中央处理器_数据通路的功能和基本结构(5)
408答疑 文章目录 三、数据通路的功能和基本结构数据通路的功能数据通路的组成组合逻辑元件(操作元件)时序逻辑元件(状态元件) 数据通路的基本结构CPU 内部单总线方式CPU 内部多总线方式专用数据通路方式 数据通路的操作举例通用寄…...

区块链大纲笔记
中心化出现的原因是由于网络的形成(不然就孤立了,这显然不符合现实,如,社会,计算机网路),接着由于网络中结点能力一般不对等同时为了便于管理等一系列问题,导致中心化网络的出现。&a…...

IntelliJ IDEA 集成AI编程助手全解析:从Copilot到GPT-4o Mini的实践
目录 AI编程助手的演进与核心价值GitHub Copilot深度集成指南国产新星DeepSeek配置实战GPT-4o Mini低成本接入方案三大助手对比与场景适配企业级安全与本地化部署未来发展趋势与开发者启示1. AI编程助手的演进与核心价值 1.1 技术演进图谱 #mermaid-svg-LwYPrW2Y2Pqvqgf0 {fon…...

浏览器自动化:RPA 解决方案的崛起
1. 引言 在 2025 年,浏览器自动化已成为企业和开发者不可或缺的工具。从网页数据抓取到自动化测试,这项技术不仅提高了效率,还推动了 Web 生态的发展。然而,随着浏览器指纹识别和反机器人检测的进步,传统的本地自动化…...

主流编程语言中ORM工具全解析
在不同编程语言中,ORM(Object-Relational Mapping,对象关系映射)工具的设计目标都是简化数据库操作。 以下是主流语言中最常用的 ORM 工具,按语言分类介绍其特点、适用场景和典型案例。 一、Python 生态 Python 社区…...

《数字分身进化论:React Native与Flutter如何打造沉浸式虚拟形象编辑》
React Native,依托JavaScript语言,借助其成熟的React生态系统,开发者能够快速上手,将前端开发的经验巧妙运用到移动应用开发中。它通过JavaScript桥接机制调用原生组件,实现与iOS和Android系统的深度交互,这…...

React学习———React.memo、useMemo和useCallback
React.memo React.memo是React提供的一个高阶组件,用于优化函数组件的性能,它通过记忆组件的渲染结果,避免在父组件重新渲染时,子组件不必要的重新渲染 React.memo会对组件的props进行浅比较,如果props没有变化&#…...

手机换地方ip地址会变化吗?深入解析
在移动互联网时代,我们经常带着手机穿梭于不同地点,无论是出差旅行还是日常通勤。许多用户都好奇:当手机更换使用地点时,IP地址会随之改变吗?本文将深入解析手机IP地址的变化机制,帮助您全面了解这一常见但…...

【Spring Cloud Gateway】Nacos整合遇坑记:503 Service Unavailable
一、场景重现 最近在公司进行微服务架构升级,将原有的 Spring Cloud Hoxton 版本升级到最新的 2021.x 版本,同时使用 Nacos 作为服务注册中心和配置中心。在完成基础框架搭建后,我使用 Spring Cloud Gateway 作为API 网关,通过 N…...

力扣-49.字母异位词分组
题目描述 给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。 字母异位词 是由重新排列源单词的所有字母得到的一个新单词。 class Solution {public List<List<String>> groupAnagrams(String[] strs) {Map<String…...

OpenCV光流估计:原理、实现与应用
一、什么是光流? 光流(Optical Flow)是计算机视觉中描述图像序列中像素运动模式的重要概念。它表示图像中物体在连续帧之间的表观运动,是由物体或相机的运动引起的。 光流的基本假设 亮度恒常性:同一物体点在连续帧中的亮度保持不变时间持…...
)
C语言经典笔试题目分析(持续更新)
1. 描述下面代码中两个static 各自的含义 static void func (void) {static unsigned int i; }static void func(void) 中的 static 作用对象:函数 func。 含义: 限制函数的作用域(链接属性),使其仅在当前源文件&…...
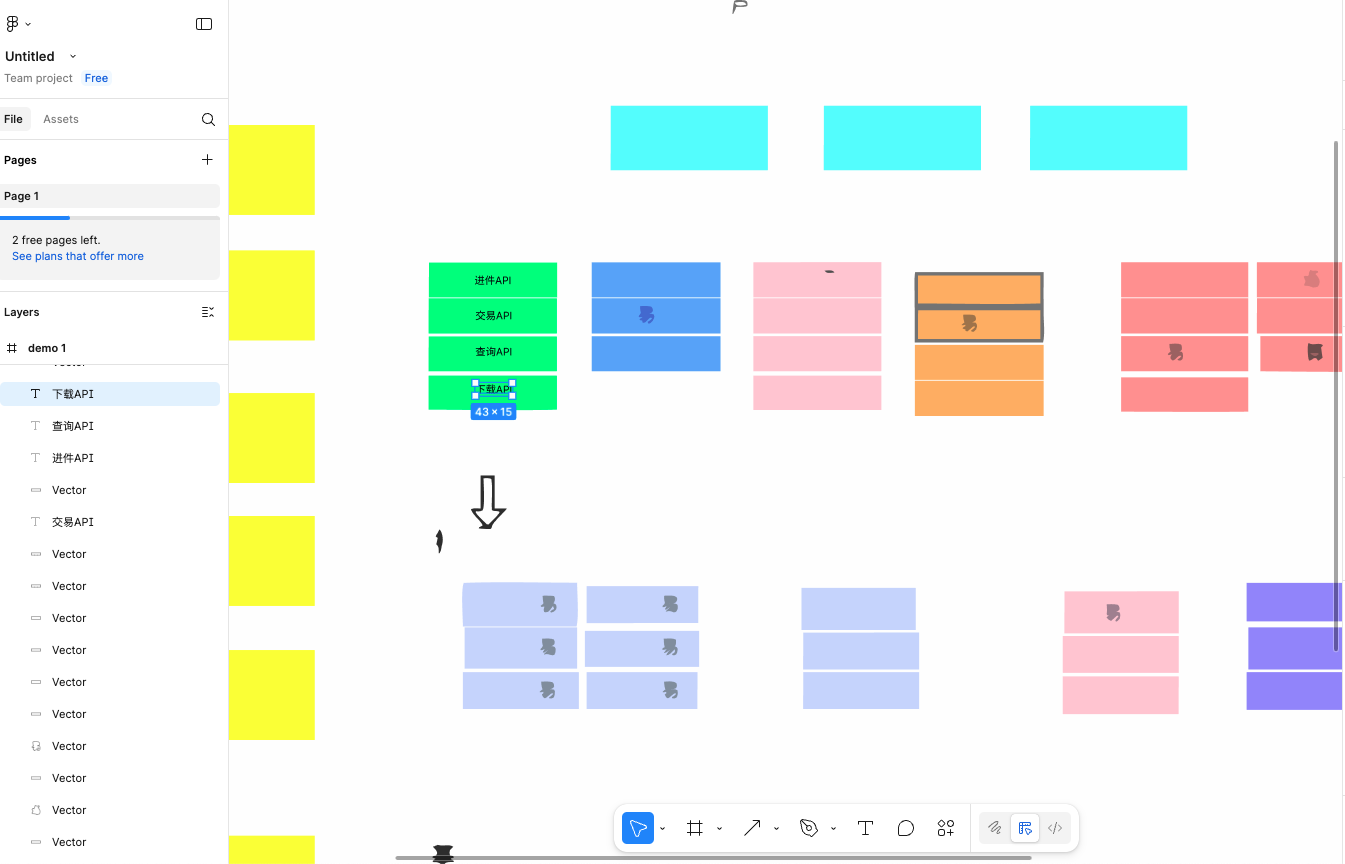
AI工具分享篇 | recraft.ai + figma 复刻技术路线图
recraft 介绍 recraft.ai 主要生成和编辑适合网站、印刷和营销的各种风格的矢量艺术、图标、3d图像和插图。其矢量化功能可将路线图转化为一个矢量图。 recraft 的注册流程非常的简单,邮箱注册即可,无需科学上网,3分钟就能搞定。看不懂英文…...
部署安装jenkins.war(2.508)
实验目的:部署jenkins,并与gitlab关联bulid 所需软件:jdk-17_linux-x64_bin.tar.gz jenkins.war apache-tomcat-10.1.40.tar.gz 实验主机:8.10具有java环境,内存最少为4G,cpu双核 目录 jdk安装 …...