构建RAG混合开发---PythonAI+JavaEE+Vue.js前端的实践
写在前文:之所以设计这一套流程,是因为 Python在前沿的科技前沿的生态要比Java好,而Java在企业级应用层开发比较活跃;
毕竟许多企业的后端服务、应用程序均采用Java开发,涵盖权限管理、后台应用、缓存机制、中间件集成及数据库交互等方面。但是现在的AI技术生态发展得很快,而Python在科研(数据科学/机器学习领域)语言,在这方面有天然的优势;所以为了接入大模型LLMs,选择用Python接入大模型LLMs,然后通过FastAPI发布HTTP接口,让Java层负责与前端Vue.js应用及Python流接口进行交互,这样的话,前端直接访问Java应用,企业应用只需要保持现有生态即可,当前的权限、后台应用、缓存、中间件等流程都不用再Python端再次开发,省去了很多工作;
整个流程如下: python负责和模型交互---Java作为中间层负责和前端Vue以及Python流接口交互-----Vue负责展示;
技术体系
PythonAI端:
- LLM模型:本地ChatOllama+Qwen VLLm+Qwen、本地通过HF的Transformer加载- Embedding向量:OllamaEmbedding + nomic-embed-text:latest- 向量库FAISS:使用本地版本的Faiss库- 检索优化:混合(二阶段)检索:similarity_score_threshold相似性打分(向量检索)+BM25(关键字)检索构成的混合检索 结合 FlashRank重排序优化检索继续优化,多阶段检索:多查询检索(LLM扩展)、混合检索(向量检索+BM25关键字检索)、重排序优化、LLM压缩;---之所以不使用多查询LLM扩展和LLM压缩,是因为性能问题---在使用LLM压缩时,最好结合微调效果会好很多,不然可能会排除掉一些问题和答案关联性不强但实际上是一一对应的问题答案;使用单独使用混合检索的时候满足绝大多数情况;- 重排序:离线的FlashRankRerank+默认ms-marco-MultiBERT-L-12模型
- 流输出:使用StreamingResponse包装结合yield关键字;
- 性能优化:调用astream的异步执行方法/如果要使用stream同步方法,那么使用iterate_in_threadpool转异步/也可以使用async+with来管理异步执行
JavaAI端:
- 核心:Springboot
- 请求流接口:WebClient
- 返回流结果:Flux前端:vue3+vite构建项目核心接口主要包含下面的功能:
Python的流输出:Python通过yield定义一个生成器函数(可以不间断的返回数据),然后通过“StreamingResponse”包装后流式返回;
---注意:return是一次性返回;
Java请求流接口:在Java端我们使用WebClient请求Python的流接口;
Java流输出:将结果转为Flux类型的数据返回到前端页面;
--- 此时这两个接口,都是可以直接通过浏览器访问接口查看效果
--- 如果使用Postman,必须返回标准的SSE格式的数据,不然是看不到效果的;
SSE数据格式:每个数据块以"data: "开头,结尾加两个换行符
PythonAI ---- 本文主要是本地Ollama加载模型
下一篇更新:云服务通过VLLm部署模型,然后本地使用OpenAI加载云端的VLLm模型;以及“使用HuggingFace的原生Transformer加载LLM”
流式输出核心代码
主要是通过yield定义一个生成器函数,再通过StreamingResponse包装返回,注意设置media_type="text/event-stream;charset=utf-8"
def llm_astream(self, faiss_query):from fastapi.concurrency import iterate_in_threadpoolsync_generator = self.chain.astream(faiss_query)# 如果 chain.stream 是同步生成器,使用 iterate_in_threadpool 转换为异步async for chunk in iterate_in_threadpool(sync_generator):# yield chunk.content# 标准的SEE数据格式;如果不修改为下面这个,那么在使用Java的WebClient请求时,返回的是空白/报错。# # 包装成SSE格式,每个数据块以"data: "开头,结尾加两个换行符# yield f"data: {chunk.content}\n\n" # 使用String字符串返回import json# 统一返回Json格式,并且禁止Unicode编码---不然返回的就是Unicode编码后的代码yield f"data: {json.dumps({'content': chunk.content}, ensure_ascii=False)}\n\n" # # 如果 chain.stream 本身是异步生成器,直接使用:# async for chunk in self.chain.stream(faiss_query):# yield chunk.content@app.get("/stream")
async def llm_stream(query: str):from starlette.responses import StreamingResponsereturn StreamingResponse( # 使用StreamingResponse包装,流返回retriever.llm_astream(query),media_type="text/event-stream;charset=utf-8" # text/plain、text/event-stream;强制响应头charset=utf-8)注意:此种方法可以使用浏览器看到效果;但是用Postman---如果不是标准的SSE格式数据就看不到效果;
注意:我们返回数据时一定要返回SSE格式的数据,不然Java端要报错“java.lang.NullPointerException: The mapper [xxxxxxx$$Lambda$880/0x0000000801118d08] returned a null value”;
SSE标准格式,返回JSON格式版本:yield f"data: {json.dumps({'content': chunk.content})}\n\n"
Java端使用“ServerSentEvent”事件接收;
SSE标准格式,返回字符串格式版本:yield f"data: {chunk.content}\n\n"
Java端使用“String”事件接收;
完整的代码
下面关于检索优化、构建链、llm交互、rag知识入库、向量库、Ollama加载云端API等...技术知识见我之前发的几篇文章;---- 安装了依赖以后,可以直接运行下面代码;
请求地址:http://localhost:8000/astream?query=xxxxx
---还可以访问stream接口看看使用异步协程、同步返回的不同效果;
"""检索agent"""
import asynciofrom langchain_community.vectorstores import FAISS
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import ChatOllama
from langserve import add_routesdef log_retrieved_docs(ctx):# print(f"[{ctx['msgid']}] [{ctx['query']}] Retrieved documents:[{ctx['content']['content']}]")print(f"Retrieved documents:[{ctx}]")return ctx # 确保返回原数据继续链式传递class RetrieverLoad:def __init__(self):print("加载向量库...")from langchain_ollama import OllamaEmbeddingsself.faiss_persist_directory = 'faiss路径'self.embedding = OllamaEmbeddings(model='nomic-embed-text:latest')self.faiss_index_name = 'faiss_index名称'self.faiss_vector_store = self.load_embed_store()self.llm = ChatOllama(model="qwen2.5:3b")self.prompt = ChatPromptTemplate.from_template(retriver_template)self.retriever = self.retriever()self.chain = self.llm_chain()def load_embed_store(self):return FAISS.load_local(self.faiss_persist_directory,embeddings=self.embedding,index_name=self.faiss_index_name, # 需与保存时一致allow_dangerous_deserialization=True)def retriever(self, score_threshold: float = 0.5, k: int = 5):sst_retriever = self.faiss_vector_store.as_retriever(search_type='similarity_score_threshold',search_kwargs={"score_threshold": score_threshold, "k": k})# 初始化BM25检索# (使用公共方法获取文档)documents = list(self.faiss_vector_store.docstore._dict.values())from langchain_community.retrievers import BM25Retrieverbm25_retriever = BM25Retriever.from_documents(documents,k=20, # 返回数量k1=1.5, # 默认1.2,增大使高频词贡献更高b=0.8 # 默认0.75,减小以降低文档长度影响)# 混合检索:BM25+embedding的from langchain.retrievers import EnsembleRetrieverensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, sst_retriever],weights=[0.3, 0.7])# 混合检索后 重排序# 构建压缩管道:重排序 + 内容提取from flashrank import Rankerfrom langchain_community.document_compressors import FlashrankRerankflashrank_rerank = FlashrankRerank(client=Ranker(cache_dir='D://A4Project//LLM//flash_rankRerank//'),top_n=8)# 三阶段检索:粗检索、重排序、内容压缩from langchain.retrievers import ContextualCompressionRetrieverbase_retriever = ContextualCompressionRetriever(# step1. 粗检索---30% BM25+70% Embedding向量检索base_retriever=ensemble_retriever,# step2. 重排序---FlashRankbase_compressor=flashrank_rerank)# step3、内容压缩---LLM---部分场景不推荐使用LLM内容压缩,压缩可能会删除RAG里面原本Q&A对应但是答案中不包含问题,导致关联性小的数据;而且很影响性能# from langchain.retrievers.document_compressors import LLMChainExtractor# # 重排序后 压缩上下文# compressor_prompt = """# 鉴于以下问题和内容,提取与回答问题相关的背景*按原样*的任何部分。如果上下文都不相关,则返回{no_output_str}。# 记住,*不要*编辑提取上下文的部分。# 问题: {{question}}# 内容: {{context}}# 提取相关部分:# """# from langchain_core.prompts import PromptTemplate# compressor_prompt_template = PromptTemplate(# input_variables=['question', 'context'],# template=compressor_prompt.format(no_output_str='NO_OUTPUT'))# compressor = LLMChainExtractor.from_llm(prompt=compressor_prompt_template, llm=self.llm)# # compressor = LLMChainExtractor.from_llm(llm=self.llm)# pipeline_retriever = ContextualCompressionRetriever(# base_retriever=base_retriever,# base_compressor=compressor# )return base_retrieverdef llm_chain(self):# 处理检索结果的函数(将文档列表转换为字符串)from langchain_core.runnables import RunnableLambda# process_docs = RunnableLambda(lambda docs: "\n".join([doc.page_content for doc in docs]))from langchain_core.runnables import RunnablePassthroughprompt = """请根据以下内容回答问题,内容中如果没有的那就回答“请咨询人工...”,内容中如果有其他不相干的内容,直接删除即可。内容:{content}问题:{query}回答:"""prompt_template = ChatPromptTemplate.from_template(prompt)from operator import itemgetterchain = (# RunnableLambda(log_retrieved_docs) | # 直接打印传递进来的参数{# 这个content和query会继续往下传递,直到prompt --->{content}、{query}"content": RunnableLambda(lambda x: x["query"]) # 必须,不然要报错“TypeError: Expected a Runnable, callable or dict.Instead got an unsupported type: <class 'str'”| self.retriever # 检索# | RunnableLambda(log_retrieved_docs) # 打印出检索到的文档,检索后未处理# 先检索再处理文档| RunnableLambda(lambda docs: "\n".join([doc.page_content for doc in docs])),# | process_docs # 先检索再处理文档 --- 和上面方法二选一# | RunnableLambda(log_retrieved_docs), # 打印出检索后的文档 --- 这里传递的仅仅是检索到的内容且预处理后的内容"query": itemgetter("query"), # 直接传递用户原始问题"msgid": RunnableLambda(lambda x: x["msgid"]), # 显示传递msgid --- 和itemgetter同样的效果}| RunnableLambda(log_retrieved_docs) # 传递的是前面整个content、query、msgid的值到日志中| prompt_template # 组合成完整 prompt| self.llm # 传给大模型生成回答# | RunnableLambda(log_retrieved_docs) # 传递的是LLM生成的内容 --- 但是在这一步以后,系统会同步返回---不推荐在这里打印日志)return chainasync def llm_invoke(self, query):return self.chain.invoke(query)async def retriever_stream(self, query):return self.retriever.stream(query)async def llm_astream(self, query: str, msgid: str):# 直接使用astream 异步执行chunks = []result = ""async for chunk in self.chain.astream({"query": query, "msgid": msgid}):chunks.append(chunk.content)result += chunk.content# yield chunk.content# 标准的SEE数据格式;如果不修改为下面这个,那么在使用Java的WebClient请求时,返回的是空白/报错。# # 包装成SSE格式,每个数据块以"data: "开头,结尾加两个换行符import json# 统一返回Json格式,并且禁止Unicode编码---不然返回的就是Unicode编码后的代码yield f"data: {json.dumps({'content': chunk.content}, ensure_ascii=False)}\n\n"print(f"query:{query} msgid:{msgid} llm:{result}")# # 如果 chain.stream 本身是异步生成器,直接使用:# async for chunk in self.chain.stream(query):# yield chunk.contentasync def llm_stream(self, query):from fastapi.concurrency import iterate_in_threadpool# 如果 chain.stream 是同步生成器,使用 iterate_in_threadpool 转换为异步async for chunk in iterate_in_threadpool(self.chain.stream(query)):# yield chunk.content# 标准的SEE数据格式;如果不修改为下面这个,那么在使用Java的WebClient请求时,返回的是空白/报错。# # 包装成SSE格式,每个数据块以"data: "开头,结尾加两个换行符import json# 统一返回Json格式,并且禁止Unicode编码---不然返回的就是Unicode编码后的代码yield f"data: {json.dumps({'content': chunk.content}, ensure_ascii=False)}\n\n"# # 如果 chain.stream 本身是异步生成器,直接使用:# async for chunk in self.chain.stream(query):# yield chunk.contentfrom fastapi import FastAPIapp = FastAPI(title='ruozhiba', version='1.0.0', description='ruozhiba检索')
# 添加 CORS --- 跨域 中间件
from fastapi.middleware.cors import CORSMiddleware
app.add_middleware(CORSMiddleware,allow_origins=["*"], # 允许所有来源,生产环境建议指定具体域名allow_credentials=True, # 允许携带凭证(如cookies)allow_methods=["*"], # 允许所有HTTP方法(可选:["GET", "POST"]等)allow_headers=["*"], # 允许所有HTTP头
)
# 同步返回
@app.get("/invoke")
async def llm_invoke(query: str):results = await retriever.llm_invoke(query)return {"results": results.content}@app.get("/retriever")
async def retriever_stream(query: str):return await retriever.retriever_stream(query)# 流式输出——异步执行
@app.get("/astream")
async def astream(query: str, msgid: str):from starlette.responses import StreamingResponseprint(f"请求开始:query:{query} msgid:{msgid}")return StreamingResponse(retriever.llm_astream(query, msgid),media_type="text/event-stream;charset=utf-8" # text/plain、text/event-stream;强制响应头charset=utf-8)# 流式输出——同步执行
@app.get("/stream")
async def llm_stream(query: str):from starlette.responses import StreamingResponsereturn StreamingResponse(retriever.llm_stream(query),media_type="text/event-stream;charset=utf-8" # text/plain、text/event-stream;强制响应头charset=utf-8)
if __name__ == '__main__':# asyncio.run(main())import uvicornretriever = RetrieverLoad()uvicorn.run(app, host='localhost', port=8000)JavaAI
引入依赖
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.1.1</version><relativePath/> <!-- lookup parent from repository --></parent><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-webflux</artifactId></dependency></dependencies>返回Flux流 --- 测试
---浏览器访问就可以看到流效果...但是中文的话,会是乱码;
@GetMapping(value = "/chat", produces = MediaType.TEXT_EVENT_STREAM_VALUE)public Flux<String> chat() {
// Thread.sleep()会阻塞线程,改用Flux.interval实现非阻塞延迟:return Flux.interval(Duration.ofMillis(100)) // 每100ms生成一个数字.map(i -> "消息:" + i) // 转换为消息字符串.take(10); // 限制总数量为10000条
// return Flux.create(emitter -> {
// // 模拟数据流
// for (int i = 0; i < 10000; i++) {
// emitter.next("Message " + i);
// try {
// Thread.sleep(100); // 模拟延迟
// } catch (InterruptedException e) {
// emitter.error(e);
// }
// }
// emitter.complete();
// });}解决中文乱码问题
如果不使用Filter,那么在返回前端页面的时候会是中文乱码;
@Component
@Order(Ordered.HIGHEST_PRECEDENCE)
public class FluxPreProcessorFilter implements Filter {@Overridepublic void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)throws IOException, ServletException {response.setCharacterEncoding("UTF-8");chain.doFilter(request, response);}
}结合Python流接口
初始化WebClient
private final WebClient webClient;public ChatMsgController(WebClient.Builder webClientBuilder) {this.webClient = webClientBuilder.clientConnector(new ReactorClientHttpConnector(HttpClient.create().responseTimeout(Duration.ofSeconds(30)) // 第一次请求可以设置长点.compress(false) // 关闭压缩(如果开启可能缓冲)))// .codecs(configurer -> configurer.defaultCodecs().maxInMemorySize(256 * 1024 * 1024))// .defaultHeader(HttpHeaders.AUTHORIZATION, "Bearer " + openAi)// 网上说:必须设置为JSON格式;初始设置MediaType.TEXT_EVENT_STREAM_VALUE会导致请求失败,必须使用APPLICATION_JSON_VALUE// 实际测试,与这无关
// .defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE).baseUrl("http://localhost:8000") // python项目地址.build();}接收String流
public Flux<Object> stream(String query) {return webClient.get().uri("/stream?query={query}", query).accept(MediaType.TEXT_EVENT_STREAM).retrieve().bodyToFlux(String.class).doOnError(e->System.err.println("发生错误: " + e.getMessage()));}接收JSON流
public Flux<String> stream(String query) {return webClient.get().uri("/stream?query={query}", query).accept(MediaType.TEXT_EVENT_STREAM).retrieve().bodyToFlux(ServerSentEvent.class)// 解析为标准的SSE事件.mapNotNull(ServerSentEvent::data) // 提取标准的SEE数据格式的 数据部分.doOnError(e->System.err.println("发生错误: " + e.getMessage())).map(Object::toString); // 返回是否需要根据情况来定 --- 如果不需要,返回“Flux<Object>”即可}日志&错误处理
public Flux<String> stream(@PathVariable("query") String query) {String msgid = UUID.randomUUID().toString().replace("-", "");log.info("请求开始。msgid:{},query:{}", msgid, query);return webClient.get().uri("/stream?query={query}", query).accept(MediaType.TEXT_EVENT_STREAM).retrieve()// 请求失败返回错误。// 状态码 --- 当未请求成功时的异常.onStatus(HttpStatusCode::isError, response -> {log.error("错误状态码。msgid:{},query:{},errorCode:{}", msgid, query, response.statusCode());return response.bodyToMono(String.class).flatMap(body -> Mono.error(new RuntimeException("HTTP错误: " + body)));}).bodyToFlux(String.class).log() // 打印日志.doOnNext(data -> System.out.println("接收到数据块:" + data)) // 打印接收到的数据.doOnError(e -> log.error("发生错误。msgid:{},query:{},error:{}", msgid, query, e.getMessage())) // 请求成功后,返回来的异常}移除多余的前缀
@GetMapping(value = "/astream/{query}", produces = MediaType.TEXT_EVENT_STREAM_VALUE)public Flux<String> astream(@PathVariable("query") String query) {String msgid = UUID.randomUUID().toString().replace("-", "");log.info("请求开始。msgid:{},query:{}", msgid, query);return webClient.get().uri("/astream?query={query}&msgid={msgid}", query, msgid).accept(MediaType.TEXT_EVENT_STREAM).retrieve().onStatus(HttpStatusCode::isError, response -> {log.error("错误状态码。msgid:{},query:{},errorCode:{}", msgid, query, response.statusCode());return response.bodyToMono(String.class).flatMap(body -> Mono.error(new RuntimeException("HTTP错误: " + body)));}).bodyToFlux(String.class) // 转为String// 移除多余的Python返回的前缀; --- 因为我们返回给前端的也是SSE数据格式,所以返回的数据也是默认会有data:.map(x -> x.substring(0, x.length() - 2).replace("{\"content\": \"", "")) .doOnError(e -> log.error("发生错误。msgid:{},query:{},error:{}", msgid, query, e.getMessage())) // 请求成功后,返回来的异常.map(Object::toString);}保存历史记录
public Flux<String> astream(@PathVariable("query") String query) {String msgid = UUID.randomUUID().toString().replace("-", "");log.info("请求开始。msgid:{},query:{}", msgid, query);Flux<String> dataFlux = webClient.get().uri("/astream?query={query}&msgid={msgid}", query, msgid).accept(MediaType.TEXT_EVENT_STREAM).retrieve()// 通过cache()共享数据流,单独订阅以保存数据,避免重复请求,确保保存操作仅触发一次。// 必须开启,不然在后续执行"dataFlux.collectList()/ dataFlux.reduce"会再次发起请求// 不开启cache的话---相当于前端请求一次,后端发起了三次请求.cache().doOnError(e -> log.error("发生错误。msgid:{},query:{},error:{}", msgid, query, e.getMessage())) // 请求成功后,返回来的异常.map(Object::toString);// 单独订阅以收集并保存数据 --- 下面是测试方法,二选一// 使用.collectList() 收集成一个完整的 List<String>,打印出来的list是一个chunk,["你好", ",世界", "!"]// 自己拼装ListdataFlux.collectList() //.flatMap(list -> {String join = String.join("", list);log.info("触发collectList保存。msgid:{},query:{},llm:{}", msgid, query, join);return Mono.just(join);}).subscribeOn(Schedulers.boundedElastic()).subscribe(null,error -> log.error("collectList保存失败。msgid:{},query:{}", msgid, query, error),() -> log.info("collectList数据已保存。msgid:{},query:{}", msgid, query));// 使用reduce,合并ChunkdataFlux.reduce((a, b) -> a + b).flatMap(list -> {log.info("触发reduce保存。msgid:{},query:{},llm:{}", msgid, query, list);return Mono.just(list);}).subscribeOn(Schedulers.boundedElastic()).subscribe(null,error -> log.error("reduce保存失败。msgid:{},query:{}", msgid, query, error),() -> log.info("reduce数据已保存。msgid:{},query:{}", msgid, query));return dataFlux;}完整代码
SpringBoot启动---浏览器请求
@RestController
@RequestMapping("/ai")
@CrossOrigin("*")
@Slf4j
public class ChatMsgController {private final WebClient webClient;public ChatMsgController(WebClient.Builder webClientBuilder) {this.webClient = webClientBuilder.clientConnector(new ReactorClientHttpConnector(HttpClient.create().responseTimeout(Duration.ofSeconds(60)).compress(false) // 关闭压缩(如果开启可能缓冲)))
// .codecs(configurer -> configurer.defaultCodecs().maxInMemorySize(256 * 1024 * 1024))// .defaultHeader(HttpHeaders.AUTHORIZATION, "Bearer " + openAi)// ⚠️ 必须设置为JSON格式;初始设置MediaType.TEXT_EVENT_STREAM_VALUE会导致请求失败,必须使用APPLICATION_JSON_VALUE
// .defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE).baseUrl("http://localhost:8000").build();}@GetMapping(value = "/astream/{query}", produces = MediaType.TEXT_EVENT_STREAM_VALUE)public Flux<String> astream(@PathVariable("query") String query) {String msgid = UUID.randomUUID().toString().replace("-", "");log.info("请求开始。msgid:{},query:{}", msgid, query);Flux<String> dataFlux = webClient.get().uri("/astream?query={query}&msgid={msgid}", query, msgid).accept(MediaType.TEXT_EVENT_STREAM).retrieve()// 请求失败返回错误。// 状态码 --- 当未请求成功时的异常.onStatus(HttpStatusCode::isError, response -> {log.error("错误状态码。msgid:{},query:{},errorCode:{}", msgid, query, response.statusCode());return response.bodyToMono(String.class).flatMap(body -> Mono.error(new RuntimeException("HTTP错误: " + body)));}).bodyToFlux(String.class) // 转为String
// .bodyToFlux(ServerSentEvent.class) // 解析为标准的SSE事件
// .mapNotNull(ServerSentEvent::data) // 提取标准的SEE数据格式的 数据部分.map(x -> x.substring(0, x.length() - 2).replace("{\"content\": \"", ""))
// .log() // 打印日志 --- 这个日志是一个chunk一个chunk打印的.cache()// 通过cache()共享数据流,单独订阅以保存数据,避免重复请求,确保保存操作仅触发一次。必须开启,不然在后续执行"dataFlux.collectList()/ dataFlux.reduce"会再次发起请求---相当于前端请求一次,后端发起了三次请求
// .doOnNext(data -> System.out.println("接收到数据块:" + data)) // 打印接收到的数据.doOnError(e -> log.error("发生错误。msgid:{},query:{},error:{}", msgid, query, e.getMessage())) // 请求成功后,返回来的异常.map(Object::toString);// 单独订阅以收集并保存数据// 使用.collectList() 收集成一个完整的 List<String>,打印出来的list是一个chunk,["你好", ",世界", "!"]// 自己拼装ListdataFlux.collectList() //.flatMap(list -> {String join = String.join("", list);log.info("触发collectList保存。msgid:{},query:{},llm:{}", msgid, query, join);return Mono.just(join);}).subscribeOn(Schedulers.boundedElastic()).subscribe(null,error -> log.error("collectList保存失败。msgid:{},query:{}", msgid, query, error),() -> log.info("collectList数据已保存。msgid:{},query:{}", msgid, query));// 使用reduce,合并ChunkdataFlux.reduce((a, b) -> a + b).flatMap(list -> {log.info("触发reduce保存。msgid:{},query:{},llm:{}", msgid, query, list);return Mono.just(list);}).subscribeOn(Schedulers.boundedElastic()).subscribe(null,error -> log.error("reduce保存失败。msgid:{},query:{}", msgid, query, error),() -> log.info("reduce数据已保存。msgid:{},query:{}", msgid, query));return dataFlux;}
}Test/Main启动
public class StreamApiClient {public void streamData(String query) {
// WebClient client = WebClient.create("http://localhost:8000");WebClient client = WebClient.builder().clientConnector(new ReactorClientHttpConnector(HttpClient.create().responseTimeout(Duration.ofSeconds(10))
// .compress(false) // 关闭压缩(如果开启可能缓冲)))
// .defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE).baseUrl("http://localhost:8000").build();Flux<String> stream = client.get().uri("/stream?query={query}", query).accept(MediaType.TEXT_EVENT_STREAM).retrieve().onStatus(HttpStatusCode::isError, response -> { // 请求失败返回错误System.out.println("错误状态码: " + response.statusCode());return response.bodyToMono(String.class).flatMap(body -> Mono.error(new RuntimeException("HTTP错误: " + body)));}).bodyToFlux(String.class)
// .log()
// .doOnNext(data -> System.out.println("接收到数据块:" + data)).doOnError(e -> System.err.println("发生错误: " + e.getMessage()));stream.subscribe(chunk -> System.out.println("Received chunk: " + chunk),error -> System.err.println("Error: " + error),() -> System.out.println("Stream completed"));}public static void main(String[] args) throws InterruptedException {StreamApiClient streamApiClient = new StreamApiClient();streamApiClient.streamData("五块能娶几个老婆");Thread.sleep(40000); // 可以适当提升时间,不然可能程序还没得到返回就结束了,看不到效果}
}Vue前端
前端使用vue3+vite构建
创建项目
HBuilderX创建

使用命令创建
npm create vite@latest my-vue-app -- --template vue # 创建项目
cd my-vue-app # 进入到项目中
npm install # 安装依赖
npm run dev # 运行dev环境项目<!-- 其中: -->
<!-- index.html 主要是标签---包含标签页itme样式; -->
<!-- src/App.vue ---主页访问,系统 import HelloWorld from './components/HelloWorld.vue'导入了HelloWorld.vue -->
<!-- src/components/HelloWorld.vue ---刚开始是广告页,可以修改内容 -->
<!-- 所以启动成功后,访问"http://localhost:3000/index"会直接进入HelloWorld.vue; -->
<!-- 我们现在只需要修改HelloWorld.vue即可 -->修改HelloWorld.vue
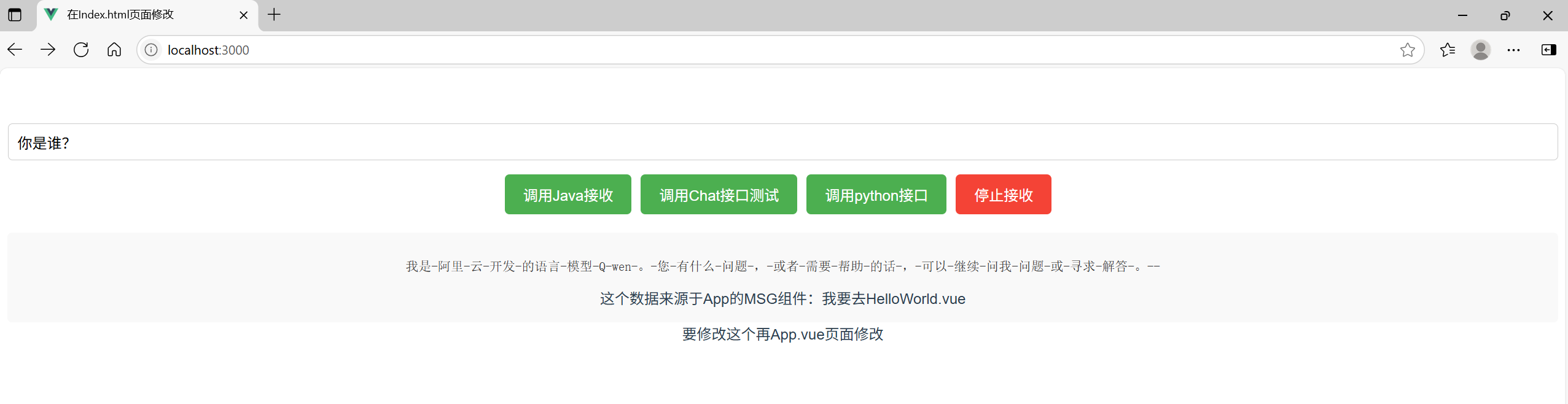
<template><div><input v-model="query" placeholder="输入查询内容" class="query-input" /><button @click="startStream" class="action-button start-button">调用Java接收流</button><button @click="chatStream" class="action-button start-button">调用Chat接口测试</button><button @click="pythonStream" class="action-button start-button">调用python接口</button><button @click="closeStream" class="action-button stop-button">停止接收</button><div class="result-container"><pre class="response-data">{{ responseData }}</pre><div>这个数据来源于App的MSG组件:{{msg}}</div></div></div>
</template>
<script setup>
import { ref, onBeforeUnmount } from 'vue'// Props 定义
const props = defineProps({msg: String
})// 响应式数据
const query = ref('为什么砍头不找死刑犯来演')
const responseData = ref('')
const eventSource = ref(null)// 方法
const pythonStream = () => {closeStream()responseData.value = ''const url = `http://localhost:8000/astream?query=${encodeURIComponent(query.value)}&msgid=123456`eventSource.value = new EventSource(url)eventSource.value.onmessage = (event) => {const data = JSON.parse(event.data)responseData.value += data.content + "\n"}eventSource.value.onerror = (error) => {console.warn("EventSource warn:", error)closeStream()}
}const chatStream = () => {closeStream()responseData.value = ''const url = `http://localhost:8080/ai/chat`eventSource.value = new EventSource(url)eventSource.value.onmessage = (event) => {responseData.value += event.data + "\n"}eventSource.value.onerror = (error) => {console.warn("EventSource warn:", error)closeStream()}
}const startStream = () => {closeStream()responseData.value = ''const url = `http://localhost:8080/ai/astream/${encodeURIComponent(query.value)}`eventSource.value = new EventSource(url)eventSource.value.onmessage = (event) => {responseData.value += event.data + "-"}eventSource.value.onerror = (error) => {console.warn("EventSource warn:", error)closeStream()}
}const closeStream = () => {if (eventSource.value) {eventSource.value.close()eventSource.value = null}
}// 生命周期钩子
onBeforeUnmount(() => {closeStream()
})
</script><style scoped>.container {max-width: 600px;margin: 50px auto;padding: 20px;border-radius: 10px;box-shadow: 0 4px 8px rgba(0, 0, 0, .1);background-color: #fff;}.query-input {width: calc(100% - 22px);padding: 10px;margin-bottom: 15px;border: 1px solid #ccc;border-radius: 5px;font-size: 16px;}.action-button {padding: 10px 20px;margin-right: 10px;border: none;border-radius: 5px;cursor: pointer;font-size: 16px;transition: all .3s ease;}.start-button {background-color: #4CAF50;color: white;}.stop-button {background-color: #f44336;color: white;}.start-button:hover {background-color: #45a049;}.stop-button:hover {background-color: #e53935;}.result-container {margin-top: 20px;padding: 15px;background: #f9f9f9;border-radius: 5px;overflow-x: auto;}.response-data {white-space: pre-wrap;word-wrap: break-word;font-size: 14px;color: #333;}
</style>请求测试
相关文章:
构建RAG混合开发---PythonAI+JavaEE+Vue.js前端的实践
写在前文:之所以设计这一套流程,是因为 Python在前沿的科技前沿的生态要比Java好,而Java在企业级应用层开发比较活跃; 毕竟许多企业的后端服务、应用程序均采用Java开发,涵盖权限管理、后台应用、缓存机制、中间件集成…...

08.webgl_buffergeometry_attributes_none ,three官方示例+编辑器+AI快速学习
本实例主要讲解内容 这个Three.js示例展示了无属性几何体渲染技术,通过WebGL 2的gl_VertexID特性和伪随机数生成算法,在着色器中动态计算顶点位置和颜色,而不需要在CPU端预先定义几何体数据。 核心技术包括: WebGL 2的顶点ID特…...
26考研 | 王道 | 计算机组成原理 | 一、计算机系统概述
26考研 | 王道 | 计算机组成原理 | 一、计算机系统概述 文章目录 26考研 | 王道 | 计算机组成原理 | 一、计算机系统概述1.1 计算机的发展1.2 计算机硬件和软件1.2.1 计算机硬件的基本组成1.2.2 各个硬件的工作原理1.2.3 计算机软件1.2.4 计算机系统的层次结构1.2.5 计算机系统…...

转换算子介绍
### 转换算子的定义与用法 #### 定义 转换算子(Transformation Operators)是指用于处理分布式数据集的操作符,在大数据框架中广泛使用,例如Apache Flink和Apache Spark。这些操作符允许开发者对数据集执行各种变换操作࿰…...
)
Android学习总结之Glide自定义三级缓存(实战篇)
一、为什么需要三级缓存 内存缓存(Memory Cache) 内存缓存旨在快速显示刚浏览过的图片,例如在滑动列表时来回切换的图片。在 Glide 中,内存缓存使用 LruCache 算法(最近最少使用),能自动清理长…...

单片机开发软件
目录 纯编码 vscode Ardunio Keil 1. 集成化开发环境(IDE) 2. 多架构芯片支持 3. 高效的代码生成与优化 4. 强大的调试与仿真功能 5. 丰富的库函数与生态系统 6. 教育与企业级适用性 典型应用场景 半编码半图形化 STM32CUBEIED 1. 图形化配置…...

LeetCode100.2 字母异位词分组
观察题目,需要把strs中的元素按照字母进行归类,一个朴素的思路是:遍历strs,对每个元素排序后插入哈希表中,随后再遍历一遍表将其转化为vector<vector<string>>。 class Solution { public:vector<vect…...

深入了解 Stable Diffusion:AI 图像生成的奥秘
一、引言 AI 艺术与图像生成技术的兴起改变了我们创造和体验视觉内容的方式。在过去几年里,深度学习模型已经能够创造出令人惊叹的艺术作品,这些作品不仅模仿了人类艺术家的风格,甚至还能创造出前所未有的新风格。在这个领域,Sta…...

Python爬虫实战:研究ajax异步渲染加密
一、引言 在当今数字化时代,数据已成为推动各行业发展的核心驱动力。网络爬虫作为一种高效的数据采集工具,能够从互联网上自动获取大量有价值的信息。然而,随着 Web 技术的不断发展,越来越多的网站采用了 AJAX(Asynchronous JavaScript and XML)异步渲染技术来提升用户体…...

大语言模型训练的两个阶段
先说结论:第一阶段在云平台训练至收敛 第二阶段本地GPU微调 一、阶段划分的核心逻辑 阶段目标资源特点典型耗时占比成本敏感度预训练获取通用表征能力需要大规模分布式计算70-90%高(追求每美元算力)微调适配特定任务需要领域数据安全/低延迟…...

显示的图标跟UI界面对应不上。
图片跟UI界面不符合。 要找到对应dp的值。UI的dp要跟代码里的xml文件里的dp要对应起来。 蓝湖里设置一个宽度给对应上。然后把对应的值填入xml. 一个屏幕上的图片到底是用topmarin来设置,还是用bottommarin来设置。 因为第一节,5,7 车厢的…...
)
OJ判题系统第6期之判题逻辑开发——设计思路、实现步骤、代码实现(策略模式)
在看这期之前,建议先看前五期: Java 原生实现代码沙箱(OJ判题系统第1期)——设计思路、实现步骤、代码实现-CSDN博客 Java 原生实现代码沙箱之Java 程序安全控制(OJ判题系统第2期)——设计思路、实现步骤…...

css中的 vertical-align与line-height作用详解
一、vertical-align 详解 作用对象:行内元素(inline/inline-block)或表格单元格内容核心功能:控制元素在行框内的垂直对齐方式常用取值: baseline(默认):基线与父元素基线对齐top&a…...

vue数据可视化开发echarts等组件、插件的使用及建议-浅看一下就行
在 Vue 项目中使用 ECharts 进行数据可视化开发时,可以结合 Vue 的响应式特性和 ECharts 的强大功能,实现动态、交互式的图表展示。 一、ECharts 基础使用 1. 安装 ECharts npm install echarts2. 在 Vue 组件中使用 ECharts <template><div…...
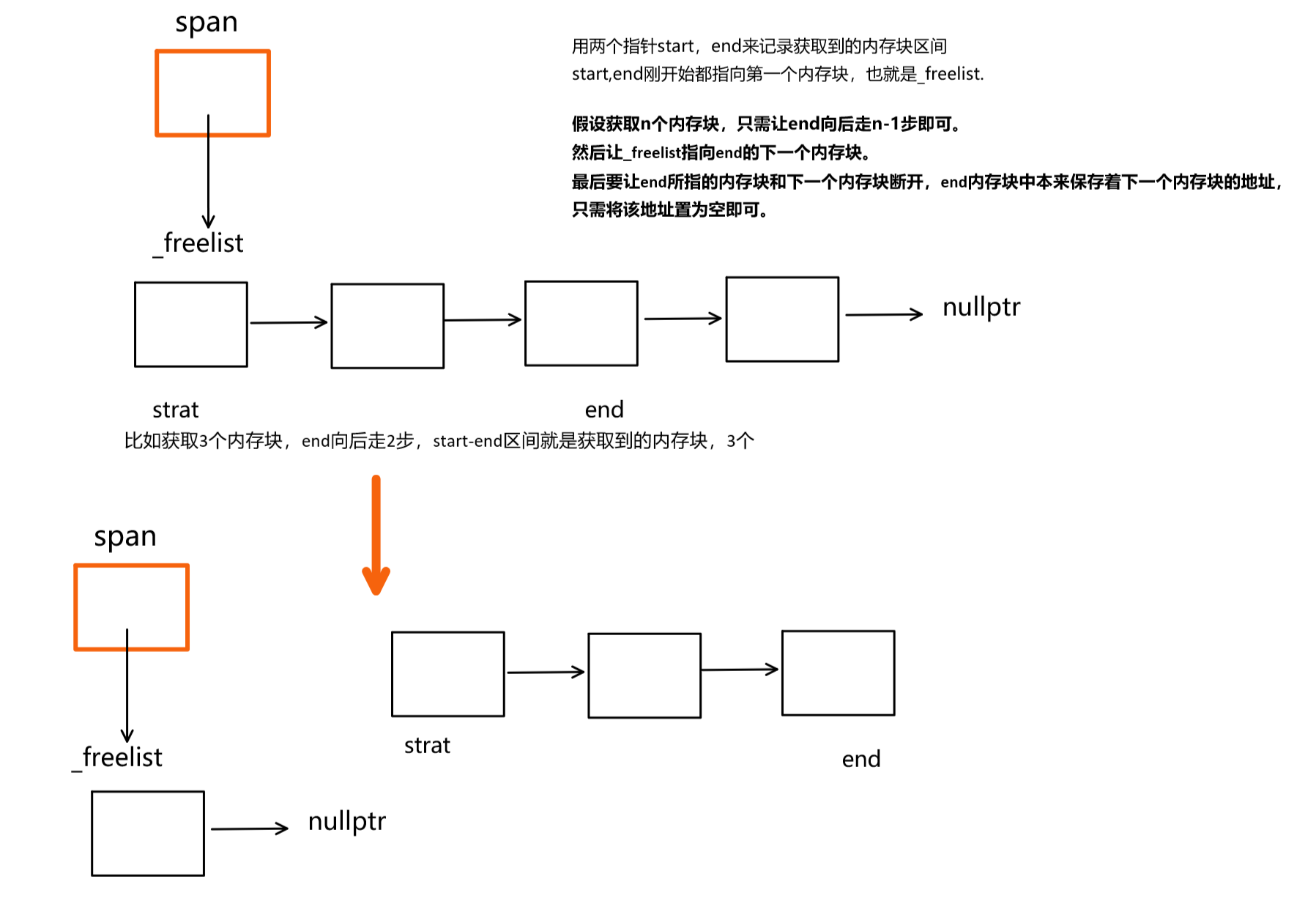
高并发内存池(三):TLS无锁访问以及Central Cache结构设计
目录 前言: 一,thread cache线程局部存储的实现 问题引入 概念说明 基本使用 thread cache TLS的实现 二,Central Cache整体的结构框架 大致结构 span结构 span结构的实现 三,Central Cache大致结构的实现 单例模式 thr…...

在Taro中开发一个跨端Svg组件,同时支持小程序、H5、React Native
Taro系列中一直没有跨端的绘图工具,小程序端支持canvas但是不支持svg,RN端有 react-native-svg 支持svg,但是没有很好原生的canvas插件,社区的canvas都是基于WebView实现的,或者skia,这个插件的书写方式和c…...
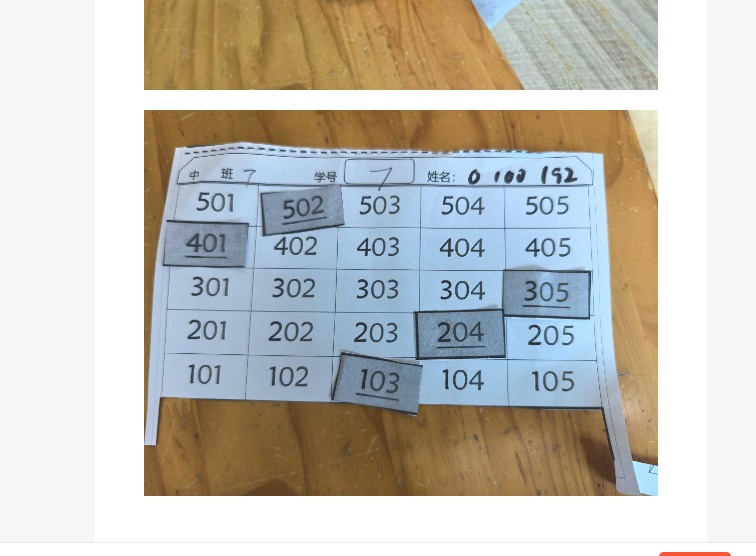
【办公类-100-01】20250515手机导出教学照片,自动上传csdn+最大化、最小化Vs界面
背景说明: 每次把教学照片上传csdn,都需要打开相册,一张张截图,然后ctrlV黏贴到CSDN内,我觉得太烦了。 改进思路: 是否可以先把所有照片都上传到csdn,然后再一张张的截图(去掉幼儿…...

SIP协议栈--osip源码梳理
文章目录 osiposip主体结构体code main函数 状态机转化结构体code状态转换 sip事务结构体code osip_dialog结构体code 创建并发送200 OK响应 osip_message结构体code osip_eventcode 打印接收到的SIP消息 osip OSIP(Open Source Implementation of SIP)…...

Python零基础入门到高手8.4节: 元组与列表的区别
目录 8.4.1 不可变数据类型 8.4.2 可变数据类型 8.4.3 元组与列表的区别 8.4.4 今天彩票没中奖 8.4.1 不可变数据类型 不可变数据类型是指不可以对该数据类型进行原地修改,即只读的数据类型。迄今为止学过的不可变数据类型有字符串,元组。 在使用[]…...

深度学习入门:深度学习(完结)
目录 1、加深网络1.1 向更深的网络出发1.2 进一步提高识别精度1.3 加深层的动机 2、深度学习的小历史2.1 ImageNet2.2 VGG2.3 GoogleNet2.4 ResNet 3、深度学习的高速化3.1 需要努力解决的问题3.2 基于GPU的高速化3.3 分布式学习3.4 运算精度的位数缩减 4、深度学习的应用案例4…...

OpenCV CUDA模块中矩阵操作------矩阵元素求和
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在OpenCV的CUDA模块中,矩阵元素求和类函数主要用于计算矩阵元素的总和、绝对值之和以及平方和。这些操作对于图像处理中的特征提取、…...
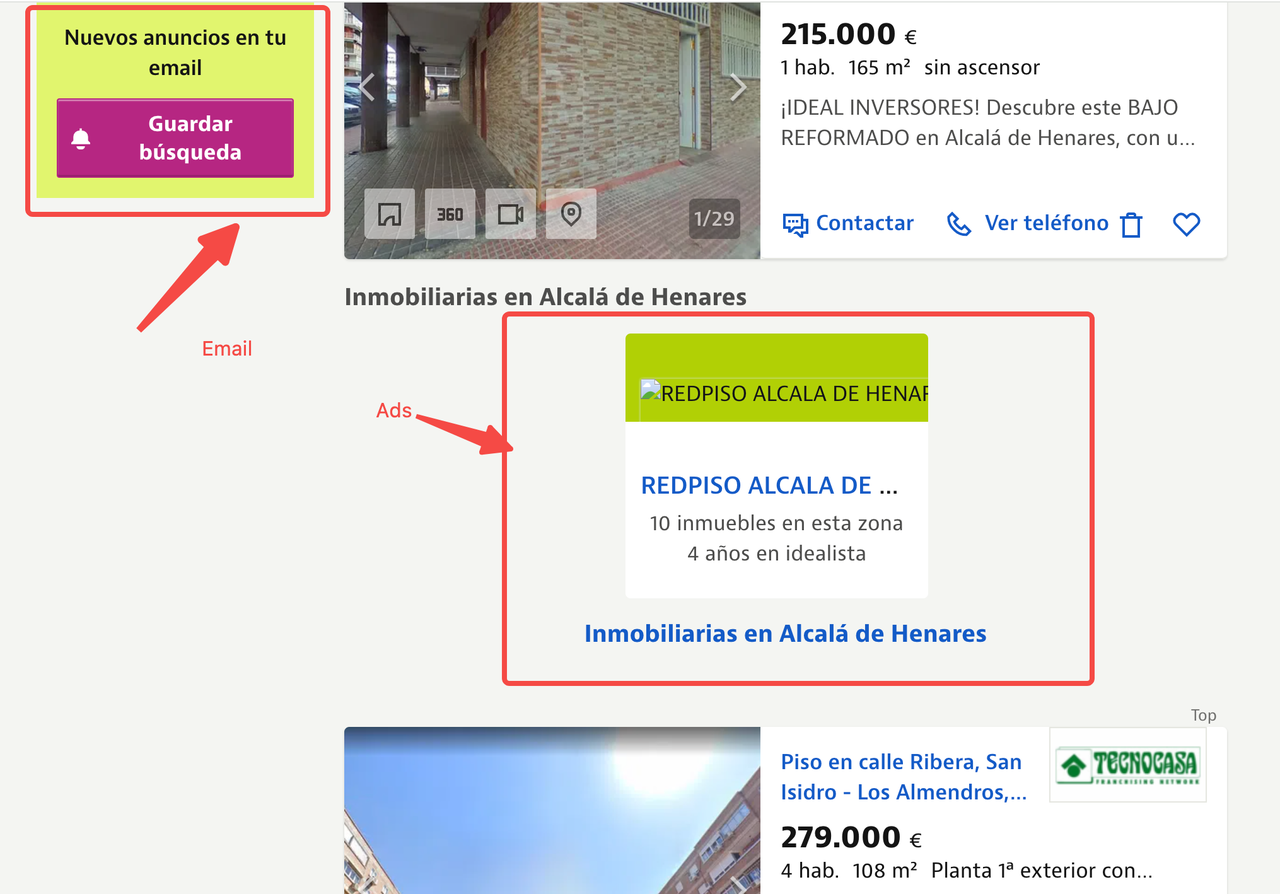
使用Scrapeless Scraping Browser的自动化和网页抓取最佳实践
引言:人工智能时代浏览器自动化和数据收集的新范式 随着生成性人工智能、人工智能代理和数据密集型应用程序的快速崛起,浏览器正在从传统的“用户互动工具”演变为智能系统的“数据执行引擎”。在这一新范式中,许多任务不再依赖单一的API端点…...
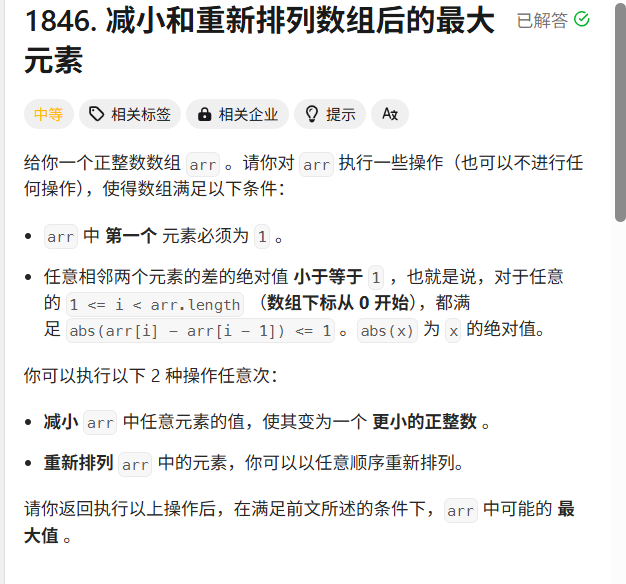
java数组题(5)
(1): 思路: 1.首先要对数组nums排序,这样两数之间的差距最小。 2.题目要求我们通过最多 k 次递增操作,使数组中某个元素的频数(出现次数)最大化。经过上面的排序,最大数…...

使用Thrust库实现异步操作与回调函数
文章目录 使用Thrust库实现异步操作与回调函数基本异步操作插入回调函数更复杂的回调示例注意事项 使用Thrust库实现异步操作与回调函数 在Thrust库中,你可以通过CUDA流(stream)来实现异步操作,并在适当的位置插入回调函数。以下是如何实现的详细说明&a…...

物联网无线传感方向专业词汇解释
涡旋电磁波(VEMW):一种具有轨道角动量的电磁波,其特性在于能够在传播过程中携带额外的相位信息,从而增加通信系统的容量和灵活性。波前:波动传播过程中,同一时刻振动相位相同的所有点构成的几何曲面,代表波…...

Maven 插件参数注入与Mojo开发详解
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

C++中void*知识详解和注意事项
一、void* 是什么? 在 C/C 中,void* 表示一个通用指针类型(generic pointer),可以指向任意类型的对象,但 不能直接解引用或进行算术运算,必须先进行类型转换。 void* ptr; // 可以指向任意类型…...
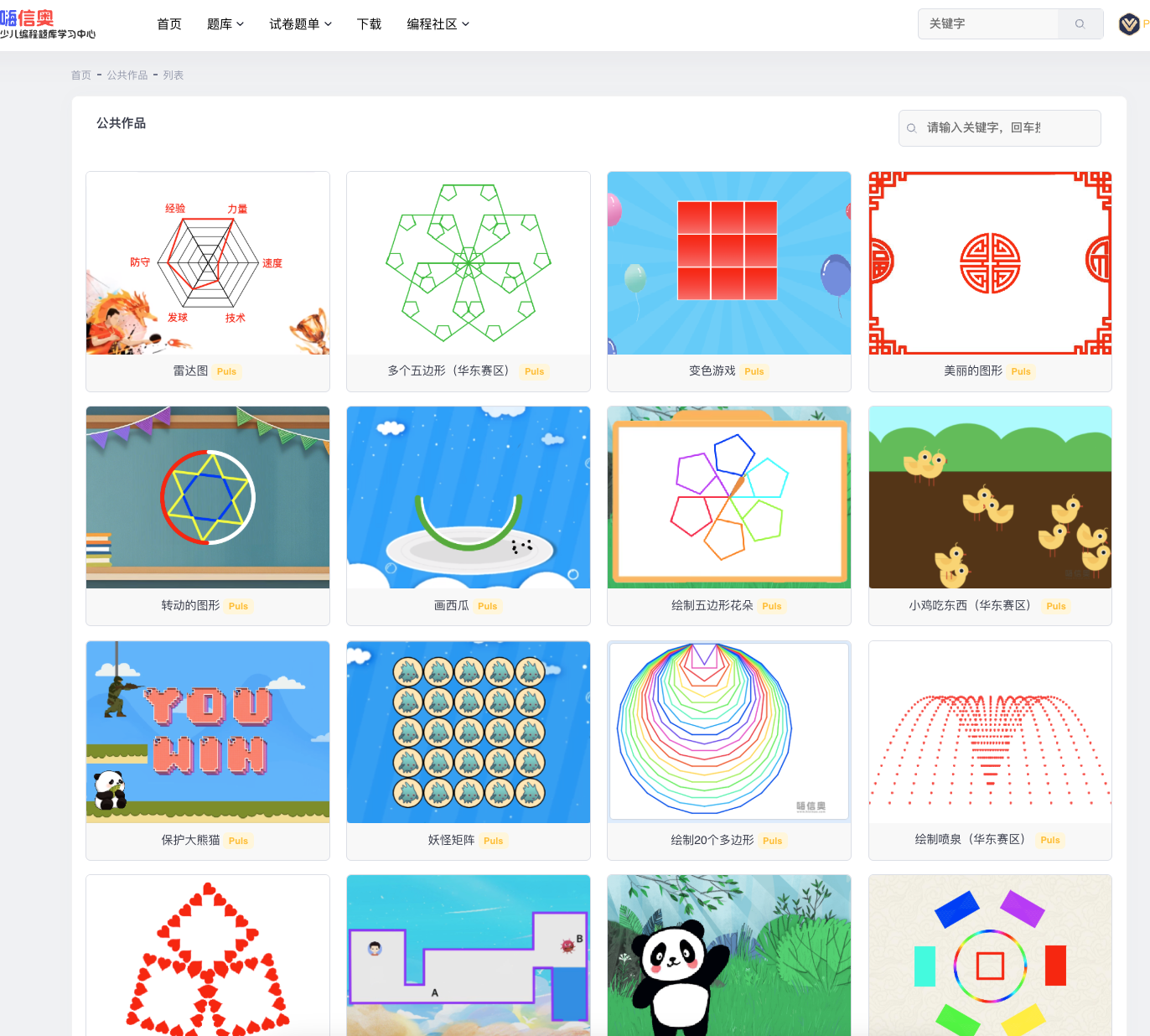
2024年全国青少年信息素养大赛——算法创意实践挑战赛复赛真题(小学组)——玫瑰花地的面积
2024年全国青少年信息素养大赛——算法创意实践挑战赛复赛真题(小学组)——玫瑰花地的面积 上面试卷可点下方,支持在线编程,在线测评~ 2024年全国信息素养大赛 算法创意实践挑战赛复赛(小学组)_c_少儿编程题库学习中心-嗨信奥 5月17号 全国青…...
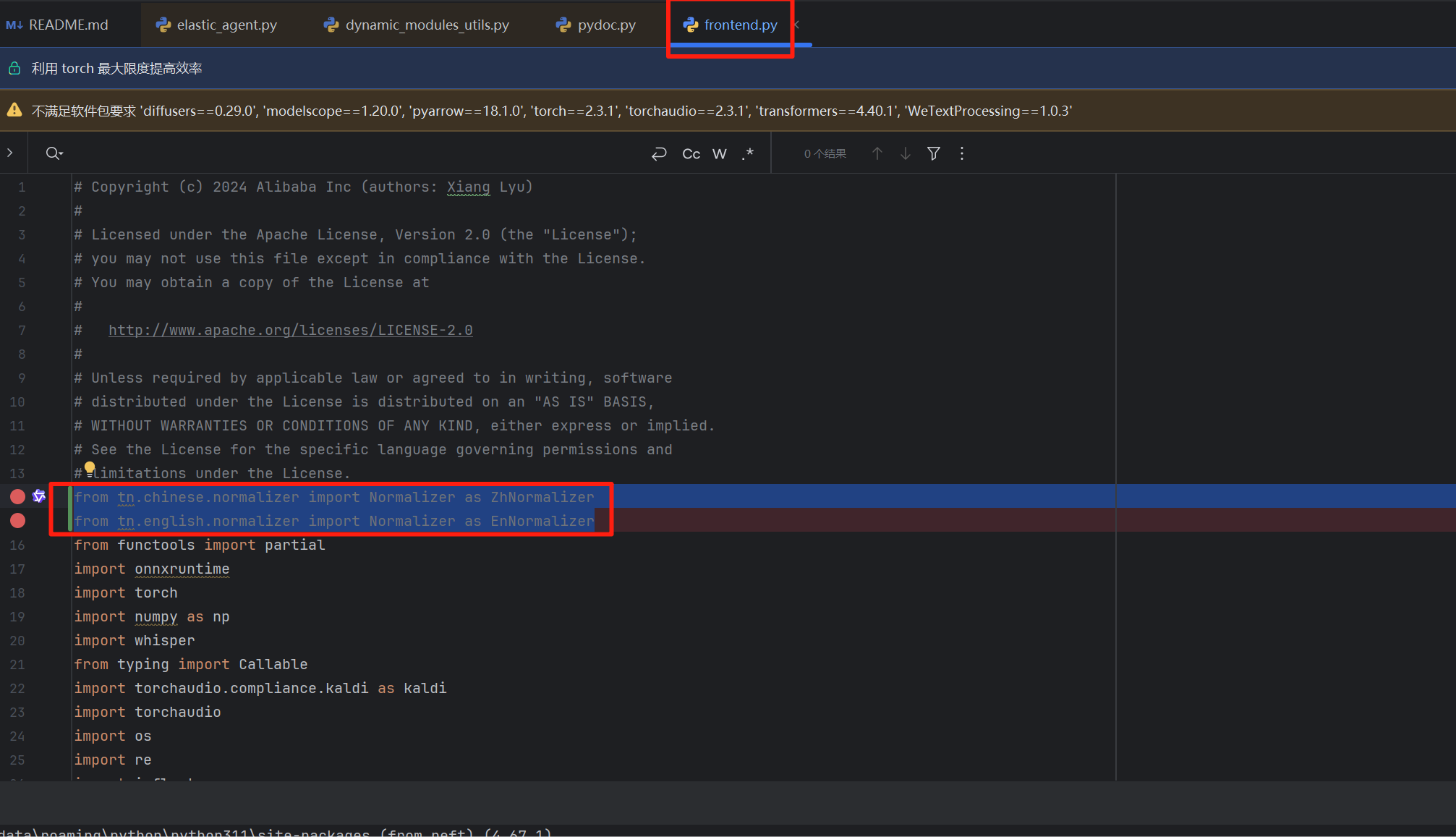
【补充笔记】修复“NameError: name ‘ZhNormalizer‘ is not defined”的直接方法
#工作记录 一、问题描述 在运行CosyVoice_For_Windows项目时,出现以下报错: File "F:\PythonProjects\CosyVoice_For_Windows\cosyvoice\cli\frontend.py", line 74, in __init__ self.zh_tn_model ZhNormalizer(remove_erhuaFalse, fu…...
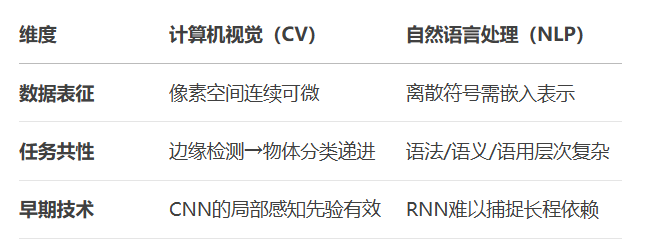
预训练模型实战手册:用BERT/GPT-2微调实现10倍效率提升,Hugging Face生态下的迁移学习全链路实践
更多AI大模型应用开发学习内容,尽在聚客AI学院。 一. 预训练模型(PTM)核心概念 1.1 什么是预训练模型? 预训练模型(Pre-trained Model, PTM)是在大规模通用数据上预先训练的模型,通过自监督学…...