预测模型开发与评估:基于机器学习的数据分析实践
在当今数据驱动的时代,预测模型已成为各行各业决策制定的核心工具。本文将分享我在COMP5310课程项目中开发预测模型的经验,探讨从数据清洗到模型优化的完整过程,并提供详细的技术实现代码。
## 研究问题与数据集
### 研究问题
我们的研究聚焦于信用卡欺诈检测,主要探讨以下问题:如何通过机器学习技术有效识别信用卡交易中的欺诈行为,并最大化检测准确率同时减少误报?
这一问题对金融机构和消费者都具有重大意义。对金融机构而言,能够及时识别欺诈交易可以减少经济损失;对消费者而言,则能保障个人财产安全并增强使用信用卡的信心。
### 数据集概述
我们使用的是信用卡交易数据集,包含了大量真实交易记录,其中少部分被标记为欺诈交易。数据集具有以下特点:
- 包含交易时间、金额及多个经PCA变换后的特征变量
- 存在严重的类别不平衡问题(欺诈交易占比不到1%)
- 原始数据中存在缺失值和异常值,需要进行预处理
## 建模准备
### 评估指标选择
考虑到欺诈检测的特殊性,我们选择以下评估指标:
1. **AUC-ROC曲线下面积**:能够全面评估模型在不同阈值下的表现
2. **精确率-召回率曲线及F1分数**:特别关注模型对少数类(欺诈交易)的识别能力
### 数据划分策略
我们采用了时间序列验证的方式划分数据:
- 训练集:70%(按时间顺序的前70%交易)
- 验证集:15%(用于超参数调优)
- 测试集:15%(用于最终评估)
这种划分方式能更好地模拟真实世界中欺诈检测的应用场景。
## 预测模型开发
### 模型选择:XGBoost算法
我选择了XGBoost作为主要模型,原因如下:
- 对类别不平衡数据集有较好的处理能力
- 能有效处理非线性关系
- 具有内置的特征重要性评估
- 在许多类似欺诈检测任务中表现优异
### 算法原理
XGBoost是梯度提升决策树(GBDT)的一种高效实现,其核心原理是通过构建多个弱学习器(决策树),每个新树都专注于修正前面树的预测误差。
XGBoost的主要算法步骤如下:
# XGBoost算法伪代码def xgboost_training(data, labels, n_estimators, learning_rate):# 初始化预测为0predictions = [0 for _ in range(len(labels))]# 迭代构建决策树for i in range(n_estimators):# 计算当前预测的残差(梯度)gradients = compute_gradients(labels, predictions)hessians = compute_hessians(labels, predictions)# 基于梯度和Hessian矩阵构建新树tree = build_tree(data, gradients, hessians)# 更新预测值tree_predictions = tree.predict(data)predictions = [pred + learning_rate * tree_predfor pred, tree_pred in zip(predictions, tree_predictions)]return final_model### 模型开发过程
首先,我进行了深入的数据预处理:
# 数据预处理代码import pandas as pdimport numpy as npfrom sklearn.preprocessing import StandardScalerfrom sklearn.model_selection import train_test_split# 加载数据df = pd.read_csv('credit_card_fraud.csv')# 处理缺失值df.fillna(df.median(), inplace=True)# 特征缩放scaler = StandardScaler()df[['Amount', 'Time']] = scaler.fit_transform(df[['Amount', 'Time']])# 时间序列划分df = df.sort_values('Time')train_size = int(0.7 * len(df))val_size = int(0.15 * len(df))train_data = df.iloc[:train_size]val_data = df.iloc[train_size:train_size+val_size]test_data = df.iloc[train_size+val_size:]X_train, y_train = train_data.drop('Class', axis=1), train_data['Class']X_val, y_val = val_data.drop('Class', axis=1), val_data['Class']X_test, y_test = test_data.drop('Class', axis=1), test_data['Class']```接下来,我训练了初始XGBoost模型:```python# XGBoost模型训练import xgboost as xgbfrom sklearn.metrics import roc_auc_score, f1_score, precision_recall_curve# 创建DMatrix数据结构dtrain = xgb.DMatrix(X_train, label=y_train)dval = xgb.DMatrix(X_val, label=y_val)# 设置初始参数params = {'objective': 'binary:logistic','eval_metric': 'auc','max_depth': 6,'eta': 0.1,'subsample': 0.8,'colsample_bytree': 0.8,'scale_pos_weight': sum(y_train == 0) / sum(y_train == 1) # 处理类别不平衡}# 训练模型watchlist = [(dtrain, 'train'), (dval, 'eval')]model = xgb.train(params, dtrain, num_boost_round=100,evals=watchlist, early_stopping_rounds=10)```## 模型评估与优化
### 模型评估
我使用了ROC曲线和精确率-召回率曲线进行全面评估:
# 模型评估代码import matplotlib.pyplot as pltfrom sklearn.metrics import roc_curve, precision_recall_curve, auc# 在测试集上进行预测dtest = xgb.DMatrix(X_test)y_pred_prob = model.predict(dtest)# 计算ROC曲线fpr, tpr, _ = roc_curve(y_test, y_pred_prob)roc_auc = auc(fpr, tpr)# 计算PR曲线precision, recall, _ = precision_recall_curve(y_test, y_pred_prob)pr_auc = auc(recall, precision)# 计算最佳阈值下的F1分数f1_scores = []thresholds = np.arange(0.1, 0.9, 0.05)for threshold in thresholds:y_pred = (y_pred_prob >= threshold).astype(int)f1_scores.append(f1_score(y_test, y_pred))best_threshold = thresholds[np.argmax(f1_scores)]y_pred_optimized = (y_pred_prob >= best_threshold).astype(int)```初始模型评估结果:
- AUC-ROC: 0.975
- PR-AUC: 0.856
- 最佳阈值下F1分数: 0.823
### 模型优化
通过网格搜索进行超参数优化:
# 超参数调优代码from sklearn.model_selection import GridSearchCV# 设置超参数搜索空间param_grid = {'max_depth': [3, 5, 7, 9],'learning_rate': [0.01, 0.05, 0.1, 0.2],'n_estimators': [50, 100, 200],'subsample': [0.6, 0.8, 1.0],'colsample_bytree': [0.6, 0.8, 1.0],'min_child_weight': [1, 3, 5]}# 创建XGBoost分类器xgb_clf = xgb.XGBClassifier(objective='binary:logistic',scale_pos_weight=sum(y_train == 0) / sum(y_train == 1))# 执行网格搜索grid_search = GridSearchCV(estimator=xgb_clf,param_grid=param_grid,scoring='f1',cv=5,verbose=1,n_jobs=-1)grid_search.fit(X_train, y_train)# 获取最佳参数best_params = grid_search.best_params_print(f"最佳参数: {best_params}")# 使用最佳参数训练最终模型final_model = xgb.XGBClassifier(**best_params)final_model.fit(X_train, y_train)```优化后模型评估结果:
- AUC-ROC: 0.991
- PR-AUC: 0.912
- 最佳阈值下F1分数: 0.887
## 结论与讨论
通过本次项目,我成功开发了一个高效的信用卡欺诈检测模型。XGBoost算法在处理类别不平衡数据集方面展现出优异性能,特别是经过超参数优化后,模型在测试集上取得了令人满意的结果。
模型的主要优势在于:
1. 高准确率:减少误报同时保持高检出率
2. 可解释性:通过特征重要性分析,了解哪些因素对欺诈检测最为关键
3. 计算效率:相比复杂的神经网络,XGBoost在实际应用中更具部署优势
未来工作方向包括:
- 融合多模型集成学习,进一步提升性能
- 探索深度学习方法在欺诈检测中的应用
- 研究基于异常检测的无监督学习方法,用于发现新型欺诈模式
通过本项目,我不仅掌握了预测模型开发的完整流程,更深入理解了在现实业务场景中应用机器学习技术的挑战与策略。
## 参考资料
1. Chen, T., & Guestrin, C. (2016). XGBoost: A Scalable Tree Boosting System.
2. Brownlee, J. (2020). Imbalanced Classification with Python.
3. Pozzolo, A. D., et al. (2015). Calibrating Probability with Undersampling for Unbalanced Classification.
相关文章:

预测模型开发与评估:基于机器学习的数据分析实践
在当今数据驱动的时代,预测模型已成为各行各业决策制定的核心工具。本文将分享我在COMP5310课程项目中开发预测模型的经验,探讨从数据清洗到模型优化的完整过程,并提供详细的技术实现代码。 ## 研究问题与数据集 ### 研究问题 我们的研究聚焦…...

提高表达能力
你遇到的这种情况其实很常见,背后的原因可能涉及思维模式、心理状态和表达习惯的综合作用。以下是具体分析和解决方案: 1. 原因分析:为什么讨论时流畅,独自表达却卡壳? 外部反馈缺失:讨论时对方的提问、反…...
【更新】全国省市县-公开手机基站数据集(2006-2025.3)
手机基站是现代通信网络中的重要组成部分,它们为广泛的通信服务提供基础设施。随着数字化进程的不断推进,手机基站的建设与布局对优化网络质量和提升通信服务水平起着至关重要的作用,本分享数据可帮助分析移动通信网络的发展和优化。本次数据…...
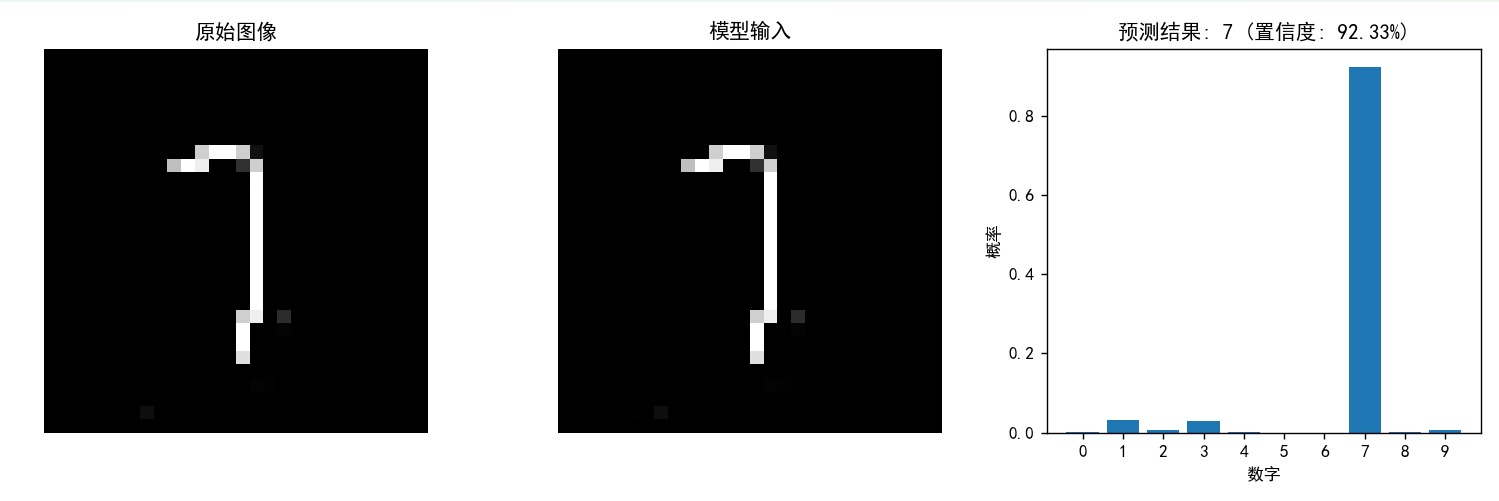
基于MNIST数据集的手写数字识别(CNN)
目录 一,模型训练 1.1 数据集介绍 1.2 CNN模型层结构 1.3 定义CNN模型 1.4 神经网络的前向传播过程 1.5 数据预处理 1.6 加载数据 1.7 初始化 1.8 模型训练过程 1.9 保存模型 二,模型测试 2.1 定义与训练时相同的CNN模型架构 2.2 图像的预处…...

MYSQL创建索引的原则
创建索引的原则包括: 表中的数据量超过10万以上时考虑创建索引。 选择查询频繁的字段作为索引,如查询条件、排序字段或分组字段。 尽量使用复合索引,覆盖SQL的返回值。 如果字段区分度不高,可以将其放在组合索引的后面。 对于…...

运行Spark程序-在shell中运行
Spark Shell运行程序步骤 启动Spark Shell 根据语言选择启动命令: Scala版本(默认):执行spark-shellPython版本:执行pyspark 数据加载示例 读取本地文本文件: // Scala版本 val textData sc.textFile(…...
idea Maven 打包SpringBoot可执行的jar包
背景:当我们需要坐联调测试的时候,需要对接前端同事,则需要打包成jar包直接运行启动服务 需要将项目中的pom文件增加如下代码配置: <build><plugins><plugin><groupId>org.springframework.boot</gr…...
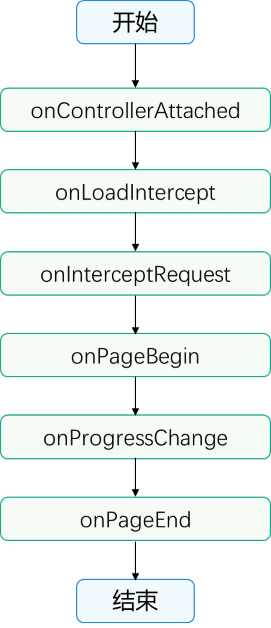
HarmonyOs开发之——— ArkWeb 实战指南
HarmonyOs开发之——— ArkWeb 实战指南 谢谢关注!! 前言:上一篇文章主要介绍HarmonyOs开发之———合理使用动画与转场:CSDN 博客链接 一、ArkWeb 组件基础与生命周期管理 1.1 Web 组件核心能力概述 ArkWeb 的Web组件支持加载本地或在线网页,提供完整的生命周期回调体…...
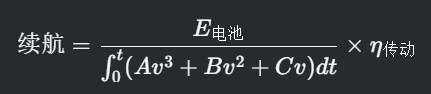
国标GB/T 12536-90滑行试验全解析:纯电动轻卡行驶阻力模型参数精准标定
摘要 本文以国标GB/T 12536-90为核心框架,深度解析纯电动轻卡滑行试验的完整流程与数据建模方法,提供: 法规级试验规范:从环境要求到数据采集全流程详解行驶阻力模型精准标定:最小二乘法求解 ( FAv^2BvC ) 的MATLAB实…...

初识——QT
QT安装方法 一、项目创建流程 创建项目 入口:通过Qt Creator的欢迎页面或菜单栏(文件→新建项目)创建新项目。 项目类型:选择「Qt Widgets Application」。 路径要求:项目路径需为纯英文且不含特殊字符。 构建系统…...

几何_平面方程表示_点+向量形式
三维平面方程可以写成: π : n ⊤ X d 0 \boxed{\pi: \mathbf{n}^\top \mathbf{X} d 0} π:n⊤Xd0 📐 一、几何直观解释 ✅ 平面是“法向量 平面上一点”定义的集合 一个平面可以由: 一个单位法向量 n ∈ R 3 \mathbf{n} \in \mat…...

学习alpha
(sign(ts_delta(volume, 1)) * (-1 * ts_delta(close, 1))) 这个先用sign操作符 sign.如果输入NaN则返回NaN 在金融领域,符号函数 sign(x) 与 “基础”(Base)的组合概念可结合具体场景解读,以下从不同金融场景分析其潜在意义&…...

Java - Junit框架
单元测试:针对最小的功能单元(方法),编写测试代码对该功能进行正确性测试。 Junit:Java语言实现的单元测试框架,很多开发工具已经集成了Junit框架,如IDEA。 优点 编写的测试代码很灵活,可以指某个测试方法…...

秒删node_modules[无废话版]
“npm install”命令带来的便利和高效让人感到畅快,但删除依赖包时却可能带来诸多困扰。特别是在项目依赖关系较为复杂的情况下,node_modules文件夹的体积往往会膨胀至数百MB甚至几个GB,手动删除时进度条长时间转圈,令人感到焦虑和…...
kkFileView文件文档在线预览镜像分享
kkFileView为文件文档在线预览解决方案,该项目使用流行的spring boot搭建,易上手和部署,基本支持主流办公文档的在线预览,如doc,docx,xls,xlsx,ppt,pptx,pdf,txt,zip,rar,图片,视频,音频等等 开源项目地址 https://gitee.com/kek…...
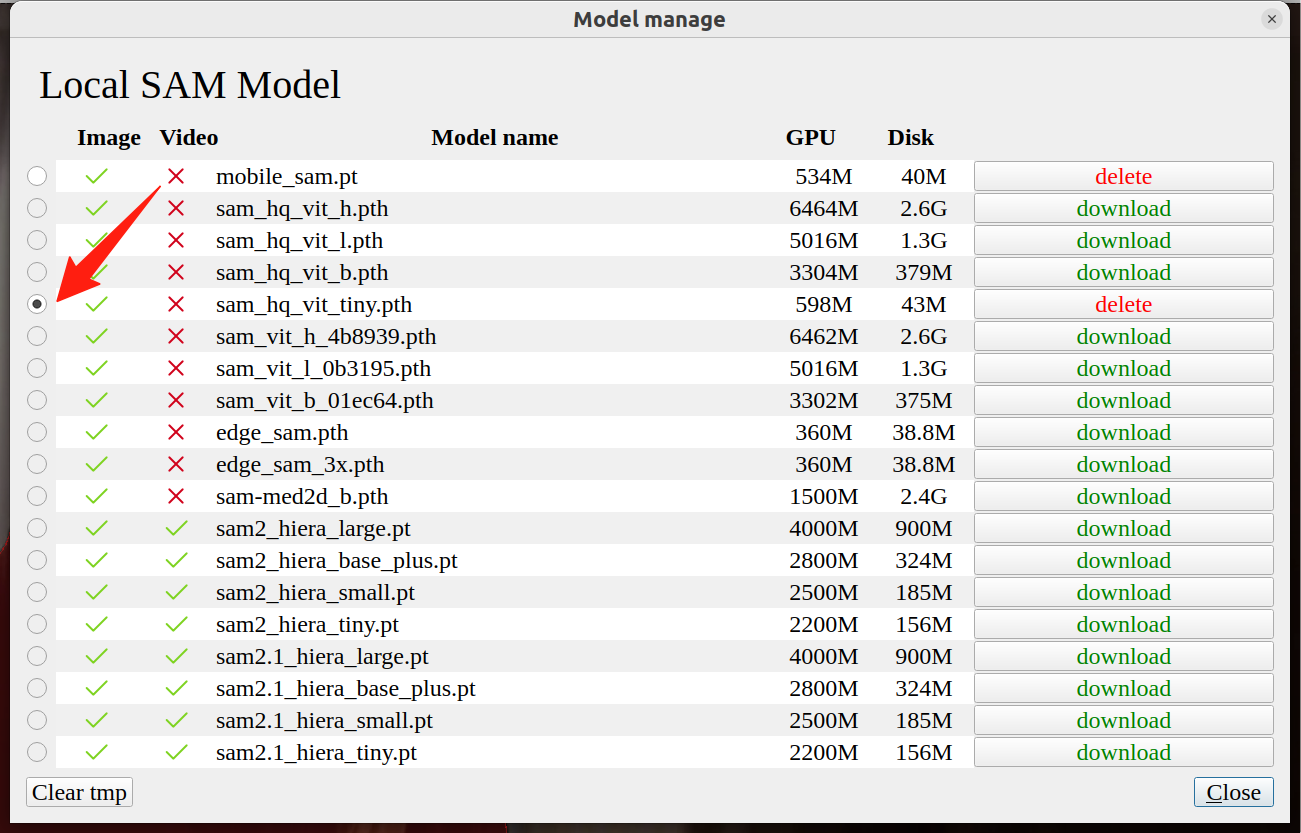
实例分割AI数据标注 ISAT自动标注工具使用方法
文章目录 🌕ISAT安装和启动方法🌕下载和使用AI分割模型🌙SAM模型性能排行🌙手动下载sam模型 & sam模型下载路径🌕使用方法🌙从file中导入图片🌙点击左上角的图标进入分割模式🌙鼠标左键点击画面中的人则自动标注🌙点击右键该区域不标注🌙一个人一个人的…...

Qt图表绘制(QtCharts)- 性能优化(13)
文章目录 1 批量替换代替追加1.1 测试11.2 测试21.3 测试3 2 开启OpenGL2.1 测试12.2 测试22.3 测试32.4 测试4 更多精彩内容👉内容导航 👈👉Qt开发 👈👉QtCharts绘图 👈👉python开发 …...

Spring Cloud动态配置刷新:@RefreshScope与@Component的协同机制解析
在微服务架构中,动态配置管理是实现服务灵活部署、快速响应业务变化的关键能力之一。Spring Cloud 提供了基于 RefreshScope 和 Component 的动态配置刷新机制,使得开发者可以在不重启服务的情况下更新配置。 本文将深入解析 RefreshScope 与 Component…...

部署docker上的redis,idea一直显示Failed to connect to any host resolved for DNS name
参考了https://blog.csdn.net/m0_74216612/article/details/144145127 这篇文章,关闭了centos的防火墙,也修改了redis.conf文件,还是一直显示Failed to connect to any host resolved for DNS name。最终发现是腾讯云服务器那一层防火墙没…...
如何在 Windows 10 或 11 上使用命令提示符安装 PHP
我们可以在 Windows 上从其官方网站下载并安装 PHP 的可执行文件,但使用命令提示符或 PowerShell 更方便。 PHP 并不是一种新的或不为人知的脚本语言,它已经存在并被全球数千名网络开发人员使用。它以开源许可并分发,广泛用于 LAMP 堆栈中。然而,与 Linux 相比,它在 Wind…...
RK3588 ADB使用
安卓adb操作介绍 adb(Android Debug Bridge)是一个用于与安卓设备进行通信和控制的工具。adb可以通过USB或无线网络连接安卓设备,执行各种命令,如安装和卸载应用,传输文件,查看日志,运行shell命…...

Vue 3.0双向数据绑定实现原理
Vue3 的数据双向绑定是通过响应式系统来实现的。相比于 Vue2,Vue3 在响应式系统上做了很多改进,主要使用了 Proxy 对象来替代原来的 Object.defineProperty。本文将介绍 Vue3 数据双向绑定的主要特点和实现方式。 1. 响应式系统 1.1. Proxy对象 Vue3 …...
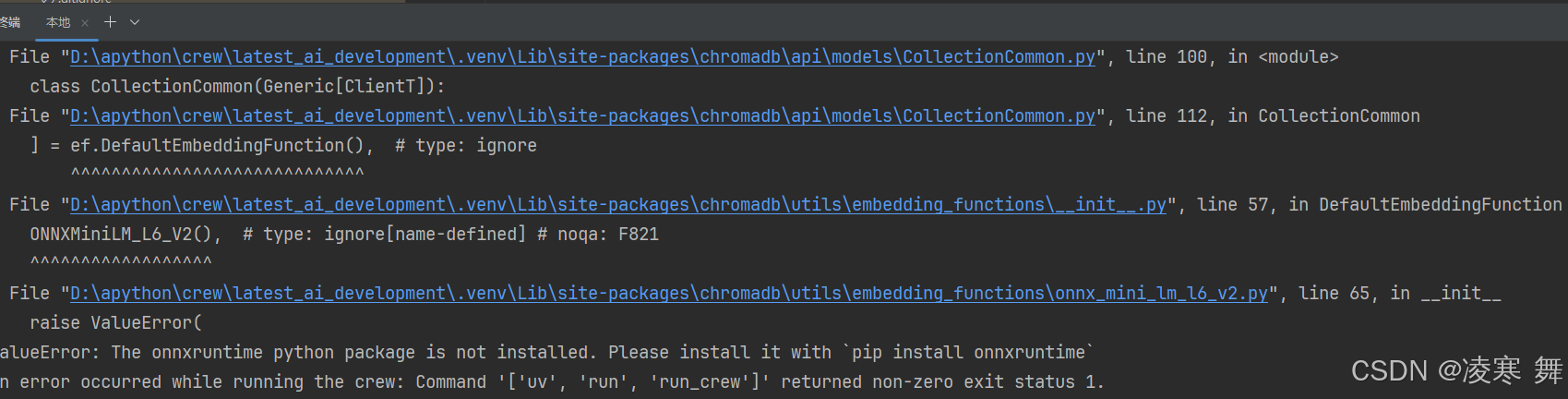
Please install it with pip install onnxruntime
无论怎么安装都是 Please install it with pip install onnxruntime 我python 版本是3.11 ,我换成3.10 解决了...

java -jar命令运行 jar包时如何运行外部依赖jar包
java -jar命令运行 jar包时如何运行外部依赖jar包 场景: 打包发不完,运行时。发现一个问题, java java.lang.NoClassDefFoundError: org/apache/commons/lang3/ArrayUtils 显示此,基本表明,没有这个依赖,如果在开发…...

低损耗高效能100G O Band DWDM 10km光模块 | 支持密集波分复用
目录 前言 一、产品概述 100G QSFP28 O Band DWDM 10km光模块核心特点包括: 二、为何选择O Band DWDM方案? 1.低色散损耗,传输更稳定 2.兼容性强 三、典型应用场景 1.数据中心互联(DCI) 2.企业园区/智慧城市组网 3.电信…...

【解决分辨数字】2021-12-16
缘由用C语言解决分辨数字-编程语言-CSDN问答 int a 0, w 0, aa[6]{};cin >> a;while (a)aa[w] a % 10, a / 10, w;cout << w << endl;while (a<w)cout << aa[a] << ends, aa[5] * 10, aa[5] aa[a];cout << endl << aa[5] <…...

el-tree结合checkbox实现数据回显
组件代码 <el-tree:data"vertiList"show-checkboxnode-key"id":props"defaultProps"ref"treeRefx"class"custom-tree"check-change"handleCheckChange"> </el-tree>获取选择的节点 handleCheckChan…...

第二十六天打卡
全局变量 global_var 全局变量是定义在函数、类或者代码块外部的变量,它在整个程序文件内都能被访问。在代码里, global_var 就是一个全局变量,下面是相关代码片段: print("\n--- 变量作用域示例 ---") global_var …...
阿里云ECS部署Dify
一:在ECS上面安装Docker 关防火墙 sudo systemctl stop firewalld 检查防火墙状态 systemctl status firewalld sudo yum install -y yum-utils device-mapper-persistent-data lvm2 设置阿里镜像源,安装并启动docker [base] nameCentOS-$releas…...

【线段树】P4588 [TJOI2018] 数学计算|普及+
本文涉及知识点 C线段树 [TJOI2018] 数学计算 题目描述 小豆现在有一个数 x x x,初始值为 1 1 1。小豆有 Q Q Q 次操作,操作有两种类型: 1 m:将 x x x 变为 x m x \times m xm,并输出 x m o d M x \bmod M…...