【程序员AI入门:模型】19.开源模型工程化全攻略:从选型部署到高效集成,LangChain与One-API双剑合璧

一、模型选型与验证:精准匹配业务需求
(一)多维度评估体系
通过量化指标权重实现科学选型,示例代码计算模型综合得分:
# 评估指标权重与模型得分
requirements = {"accuracy": 0.4, "latency": 0.3, "ram_usage": 0.2, "license": 0.1}
model_scores = {"bert-base": [0.85, 120, 1.2, 1.0], # 精度、延迟(ms)、内存(GB)、许可证合规"distilbert": [0.82, 80, 0.8, 1.0],"albert-xxlarge": [0.88, 250, 3.1, 0.8]
}
# 综合得分计算
for model, metrics in model_scores.items():score = sum(w * m for w, m in zip(requirements.values(), metrics))print(f"模型: {model}, 综合得分: {score:.2f}")
(二)快速验证方案
利用Hugging Face Inference API秒级测试模型效果:
# cURL快速验证文本填充任务
curl https://api-inference.huggingface.co/models/bert-base-uncased \-X POST \-H "Authorization: Bearer YOUR_API_KEY" \-d '{"inputs": "The movie was [MASK]."}'
二、工程化集成:构建生产级模型服务
(一)依赖管理最佳实践
通过requirements.yaml锁定环境版本,避免依赖冲突:
# requirements.yaml
channels:- pytorch- defaults
dependencies:- python=3.8- pytorch=1.13.1- transformers=4.26.0- onnxruntime=1.14.0- docker=20.10.0
(二)服务化封装(FastAPI示例)
实现模型动态加载与API标准化:
# app/api_wrapper.py
from fastapi import APIRouter, HTTPException
from pydantic import BaseModelclass ModelRequest(BaseModel):model_name: str # 模型名称(如bert-base/distilbert)input: str # 输入文本router = APIRouter()@router.post("/predict")
async def model_predict(request: ModelRequest):model = get_model(request.model_name) # 自定义模型加载函数preprocessed = preprocess(request.input) # 预处理文本with torch.inference_mode():output = model(**preprocessed)return {"result": postprocess(output)} # 后处理输出结果
三、性能优化:突破算力与延迟瓶颈
(一)计算图优化技术
- TorchScript编译:提升PyTorch模型推理速度
# 追踪模型并保存优化版本
traced_model = torch.jit.trace(model, example_inputs)
torch.jit.save(traced_model, "optimized_model.pt")
- ONNX Runtime加速:跨框架高效推理
# 转换为ONNX格式并运行
ort_session = ort.InferenceSession("model.onnx")
ort_inputs = {ort_session.get_inputs()[0].name: numpy_input}
ort_outputs = ort_session.run(None, ort_inputs)
(二)量化压缩策略
- 动态量化:在不显著损失精度的前提下减少显存占用
# 对线性层进行8位动态量化
quantized_model = torch.quantization.quantize_dynamic(model,{torch.nn.Linear},dtype=torch.qint8
)
- 训练后量化(PTQ):基于校准数据集优化量化效果
from transformers.quantization import QuantConfig, DatasetCalibratorcalibrator = DatasetCalibrator(calib_dataset) # 校准数据集
quant_config = QuantConfig(activation=QuantFormat.QDQ)
quant_model = quantize(model, quant_config, calibrator)
四、持续维护:构建自动化运维体系
(一)实时监控与指标采集
利用Prometheus实现性能指标可视化:
# prometheus_client监控中间件
from prometheus_client import Histogram, GaugeREQUEST_LATENCY = Histogram('model_latency_seconds', '请求延迟分布')
MODEL_ACCURACY = Gauge('model_accuracy', '当前模型精度')@app.middleware("http")
async def monitor_requests(request: Request, call_next):start_time = time.time()response = await call_next(request)latency = time.time() - start_timeREQUEST_LATENCY.observe(latency) # 记录延迟if request.url.path == "/evaluate":MODEL_ACCURACY.set(parse_accuracy(response)) # 更新精度指标return response
(二)自动化更新流水线
通过GitHub Actions实现模型版本管理:
# .github/workflows/model_updater.yml
name: 模型自动更新
on:schedule:- cron: '0 3 * * 1' # 每周一凌晨3点执行jobs:check-updates:runs-on: ubuntu-lateststeps:- name: 检查模型更新run: |python check_model_update.py \--model bert-base-uncased \--current-sha $(git rev-parse HEAD:models/)- name: 重新训练与部署if: steps.check-updates.outputs.new_version == 'true'run: |python retrain.py # 触发再训练docker build -t model-service:latest . # 构建最新镜像kubectl rollout restart deployment/model-service # 滚动更新K8s部署
五、高级集成方案:LangChain与One-API深度融合
(一)LangChain生态适配
通过ChatHuggingFace实现Hugging Face模型无缝接入:
# LangChain集成Hugging Face模型
from langchain_huggingface import HuggingFacePipeline, ChatHuggingFacellm = HuggingFacePipeline.from_model_id(model_id="Qwen/Qwen2.5-0.5B-Instruct",task="text-generation",device="cuda" if torch.cuda.is_available() else "cpu",pipeline_kwargs={"max_new_tokens": 512, "temperature": 0.8}
)
chat_model = ChatHuggingFace(llm=llm)
response = chat_model.invoke("写一首关于AI的诗")
print("AI诗歌:", response.content)
(二)One-API统一代理管理
兼容OpenAI接口实现多模型供应商无缝切换:
# Ollama快速启动本地模型
ollama pull qwen2.5:0.5b # 拉取模型
ollama run qwen2.5:0.5b --listen 0.0.0.0:3000 # 启动服务
# 模拟OpenAI接口调用本地模型
from openai import OpenAI
client = OpenAI(base_url="http://localhost:3000/v1") # 指向One-API代理response = client.chat.completions.create(model="qwen2.5:0.5b", # 模型名称与Ollama一致messages=[{"role": "user", "content": "解释Transformer架构"}]
)
print("模型回答:", response.choices[0].message.content)
(三)本地化部署优势
- 数据安全:敏感数据无需上传云端,满足GDPR/等保三级要求
- 成本控制:消除API调用费用,适合高频推理场景(如客服系统)
- 低延迟:局域网内响应速度提升70%,支持实时交互业务
六、典型场景解决方案
(一)有限资源环境部署(移动端案例)
# MobileBERT + TFLite轻量化部署
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT] # 启用默认优化
converter.target_spec.supported_types = [tf.float16] # 支持半精度计算
tflite_model = converter.convert() # 生成TFLite模型# 安卓端推理示例
Interpreter interpreter = new Interpreter(tflite_model);
interpreter.allocateTensors();
interpreter.setInputTensorData(0, inputBuffer);
interpreter.invoke();
interpreter.getOutputTensorData(0, outputBuffer);
(二)多模型协同工作流
构建模型 ensemble 实现复杂逻辑处理:
class ModelEnsemble:def __init__(self):# 加载多任务模型self.models = {'keyword': load_keyword_model(), # 关键词提取模型'sentiment': load_sentiment_model(), # 情感分析模型'ner': load_ner_model() # 命名实体识别模型}def process(self, text):keyword_result = self.models['keyword'](text)if 'emergency' in keyword_result:return self._handle_emergency(text) # 紧急情况专属流程else:return {'sentiment': self.models['sentiment'](text),'entities': self.models['ner'](text)}def _handle_emergency(self, text):# 触发紧急响应模型或外部系统return {"priority": "high", "action": "转接人工客服"}
七、成本控制与安全合规
(一)全链路成本优化策略
| 策略 | 实施方法 | 预期节省 |
|---|---|---|
| 模型蒸馏 | 大模型指导小模型训练 | 40%-60%计算成本 |
| 动态冷热分层 | 高频模型热加载,低频按需加载 | 30%-50%内存占用 |
| 请求合并 | 批量处理多个请求 | 25%-40%延迟 |
| 边缘计算 | 端侧设备执行初步推理 | 50%-70%流量成本 |
| 混合精度 | 使用FP16/BF16训练与推理 | 35%-50%显存占用 |
(二)安全合规实践
- 数据隐私保护:通过同态加密实现密态推理
# 同态加密推理(Concrete ML示例)
from concrete.ml.deployment import FHEModelClient# 初始化客户端(加载加密模型与密钥)
client = FHEModelClient("model.zip", key_dir="./keys")# 加密输入并推理
encrypted_input = client.encrypt(input_data)
encrypted_pred = model.predict(encrypted_input)# 解密结果
result = client.decrypt(encrypted_pred)
- 模型完整性验证:通过GPG签名与哈希校验防止篡改
# GPG签名校验
gpg --verify model_weights.pth.sig model_weights.pth# SHA-256哈希校验
echo "d41d8cd98f00b204e9800998ecf8427e model_weights.pth" > checksums.txt
sha256sum -c checksums.txt
八、实战效果:全流程效率提升
- 开发周期:从传统2周缩短至3天(模型集成效率提升80%)
- 资源消耗:推理内存占用减少65%,单卡V100支持同时运行3个千亿级模型
- 运维成本:自动化监控与更新节省80%人力投入,故障响应时间从30分钟缩短至5分钟
- 安全合规:通过本地化部署与加密技术,满足金融/医疗等行业的数据不出域要求
某金融风控系统实践显示:通过模型蒸馏与量化,欺诈检测准确率提升15%的同时,单次推理成本从$0.002降至$0.0004,年算力成本节省超$50万。
相关文章:
【程序员AI入门:模型】19.开源模型工程化全攻略:从选型部署到高效集成,LangChain与One-API双剑合璧
一、模型选型与验证:精准匹配业务需求 (一)多维度评估体系 通过量化指标权重实现科学选型,示例代码计算模型综合得分: # 评估指标权重与模型得分 requirements {"accuracy": 0.4, "latency": …...

北斗导航 | 基于深度学习的卫星导航数据训练——检测识别故障卫星
深度学习+故障卫星识别 **1. 数据准备与预处理****2. 模型选择与设计****3. 训练策略****4. 模型优化与验证****5. 实时部署与集成****6. 持续学习与更新****示例模型架构(LSTM + Attention)****挑战与解决方案**🥦🥦🥦🥦🥦🥦🥦🥕🥦🥦🥦🥦🥦🥦�…...

ARM Cortex-M3内核详解
目录 一、ARM Cortex-M3内核基本介绍 (一)基本介绍 (二)主要组成部分 (三)调试系统 二、ARM Cortex-M3内核的内核架构 三、ARM Cortex-M3内核的寄存器 四、ARM Cortex-M3内核的存储结构 五、ARM Co…...

基于Unity的简单2D游戏开发
基于Unity的简单2D游戏开发 摘要 本文围绕基于Unity的简单2D游戏开发进行深入探讨,旨在分析其开发过程中的技术架构与实现策略。通过文献综述与市场分析,研究发现,近年来Unity引擎因其优秀的跨平台特性及可视化编程理念,成为2D游戏开发的主要工具。文章首先梳理了游戏开发的…...

Linux系统编程——exec族函数
我们来完整、系统、通俗地讲解 Linux 系统编程中非常重要的一类函数:exec 族函数(也叫 exec family)。 一、什么是 exec? exec 系列函数的作用是: 用一个新的程序,替换当前进程的内容。 也就是说…...

ThinkStation图形工作站进入BIOS方法
首先视频线需要接在独立显卡上,重新开机,持续按F1,或者显示器出来lenovo的logo的时候按F1,这样就进到bios里了。联*想*坑,戴尔贵。靠。...
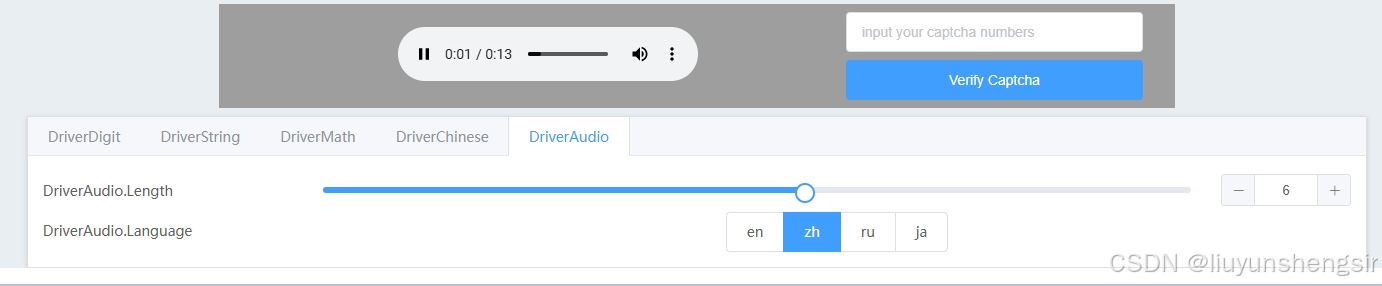
go 集成base64Captcha 支持多种验证码
base64Captcha 是一个基于 Go 语言开发的验证码生成库,主要用于在 Web 应用中集成验证码功能,以增强系统的安全性。以下是其主要特点和简介: base64Captcha主要功能 验证码类型丰富:支持生成多种类型的验证码,包括纯…...

【C语言字符函数和字符串函数(一)】--字符分类函数,字符转换函数,strlen,strcpy,strcat函数的使用和模拟实现
目录 一.字符分类函数 1.1--字符分类函数的理解 1.2--字符分类函数的使用 二.字符转换函数 2.1--字符转换函数的理解 2.2--字符转换函数的使用 三.strlen的使用和模拟实现 3.1--strlen的使用演示 3.2--strlen的返回值 3.3--strlen的模拟实现 四.strcpy的使用和模拟实现…...
deepseek问答记录:请讲解一下hugingface transformers中的AutoProcessor
Hugging Face Transformers库中的AutoProcessor是一个用于自动加载与预训练模型配套的处理器的工具类。它简化了预处理流程,特别适用于多模态模型(如同时处理文本、图像、音频的模型)。以下是详细讲解: 1. AutoProcessor的功能 •…...
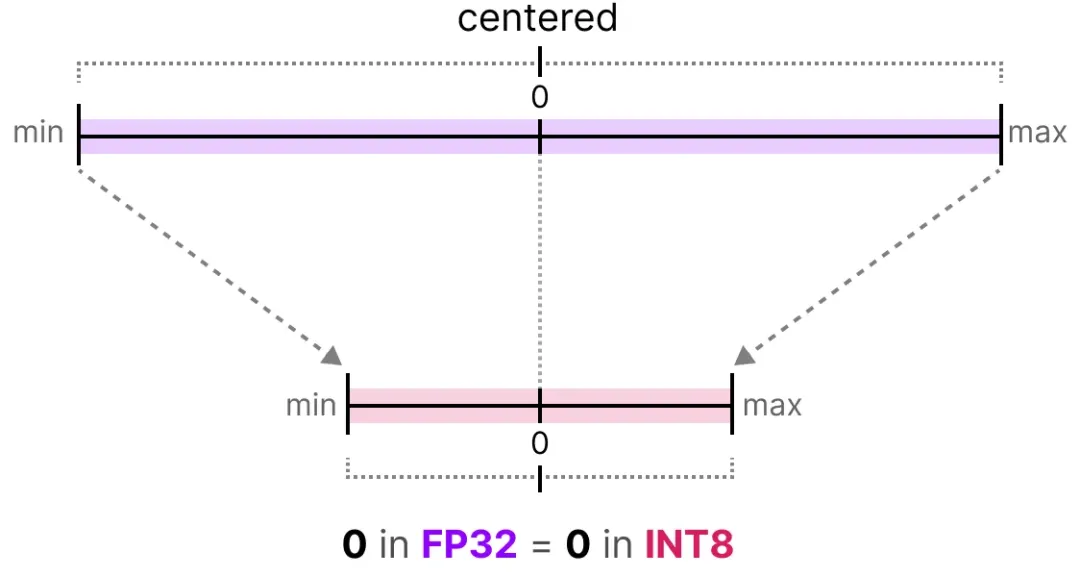
大模型基础之量化
概述 量化,Quantization,机器学习和深度学习领域是一种用于降低计算复杂度、减少内存占用、加速推理的优化方法。定义:将模型中的数据从高精度表示转换为低精度表示。主要目的是为了减少模型的存储需求和计算复杂度,同时尽量减少…...

游戏引擎学习第286天:开始解耦实体行为
回顾并为今天的内容定下基调 我们目前正在进入实体系统的一个新阶段,之前我们已经让实体的移动系统变得更加灵活,现在我们想把这个思路继续延伸到实体系统的更深层次。今天的重点,是重新审视我们处理实体类型(entity type&#x…...
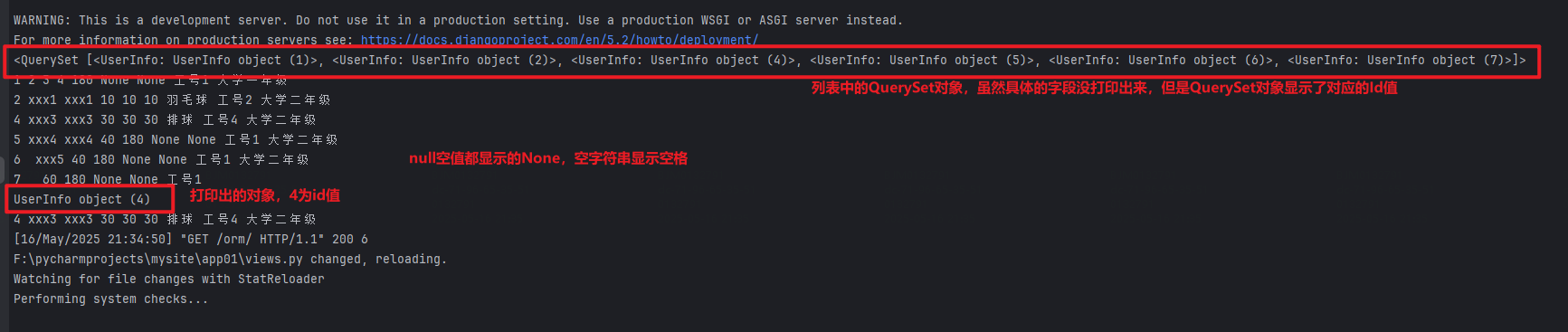
win10-django项目与mysql的基本增删改查
以下都是在win10系统下,django项目的orm框架对本地mysql的表的操作 models.py----->即表对应的类所在的位置 在表里新增数据 1.引入表对应的在models.py中的类class 2.在views.py中使用函数:类名.objects.create(字段名值,字段名"值"。。。…...

Windows 本地部署MinerU详细教程
📖 项目概述 MinerU是一款由OpenDataLab开发的开源PDF转Markdown工具,可以高质量地提取PDF文档内容,生成结构化的Markdown格式文本。本指南将帮助您在本地部署并使用MinerU。 ⭐ 功能特性 MinerU具有以下核心功能: ✨ 文档处理…...

动态范围调整(SEF算法实现)
一、背景介绍 继续在整理对比度调整相关算法,发现一篇单帧动态范围提升的算法:Simulated Exposure Fusion,论文表现看起来很秀,这里尝试对它进行了下效果复现。 二、实现流程 1、基本原理 整体来说,大致可以分为两步…...
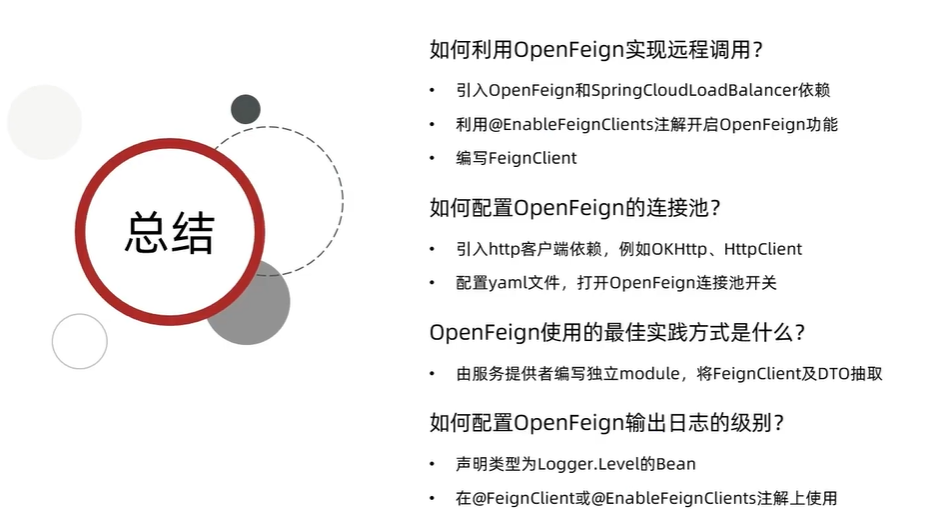
SpringCloud微服务开发与实战
本节内容带你认识什么是微服务的特点,微服务的拆分,会使用Nacos实现服务治理,会使用OpenFeign实现远程调用(通过黑马商城来带你了解实际开发中微服务项目) 前言:从谷歌搜索指数来看,国内从自201…...
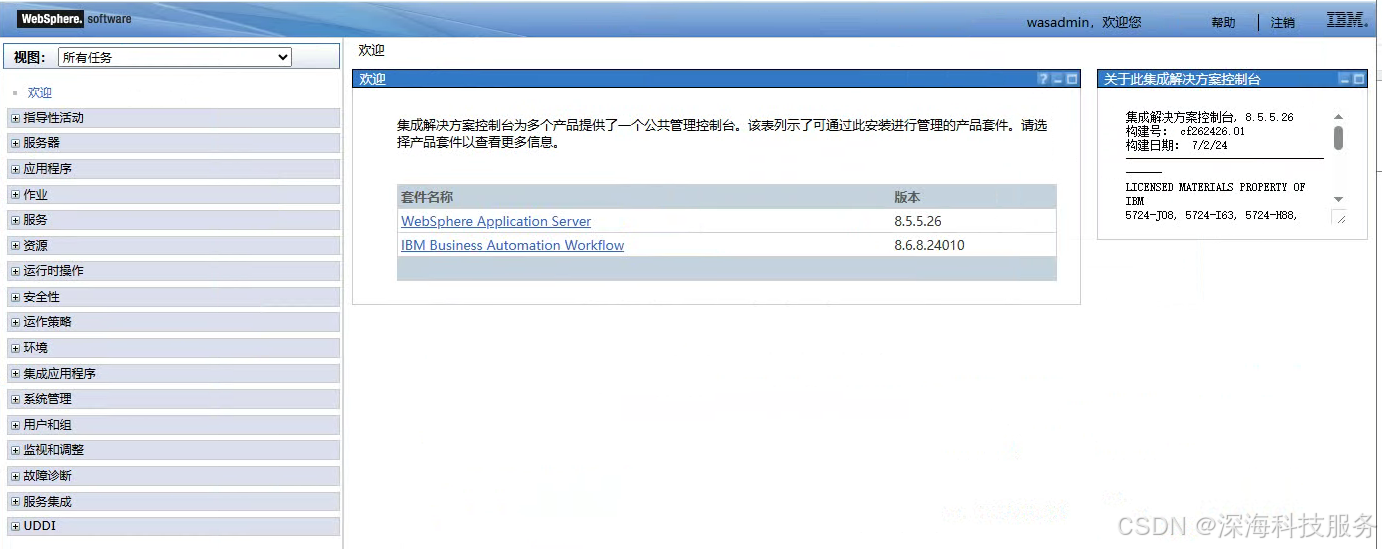
WAS和Tomcat的对比
一、WAS和Tomcat的对比 WebSphere Application Server (WAS) 和 Apache Tomcat 是两款常用的 Java 应用服务器,但它们有许多显著的区别。在企业级应用中,它们扮演不同的角色,各自有其特点和适用场景。以下是它们在多个维度上的详细对比&…...

Rust 数据结构:String
Rust 数据结构:String Rust 数据结构:String什么是字符串?创建新字符串更新字符串将 push_str 和 push 附加到 String 对象后使用 运算符和 format! 宏 索引到字符串字符串在内存中的表示字节、标量值和字形簇 分割字符串遍历字符串的方法 R…...
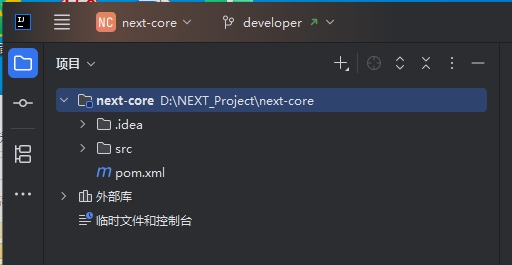
IntelliJ IDEA打开项目后,目录和文件都不显示,只显示pom.xml,怎样可以再显示出来?
检查.idea文件夹 如果项目目录中缺少.idea文件夹,可能导致项目结构无法正确加载。可以尝试删除项目根目录下的.idea文件夹,然后重新打开项目,IDEA会自动生成新的.idea文件夹和相关配置文件,从而恢复项目结构。 问题解决࿰…...
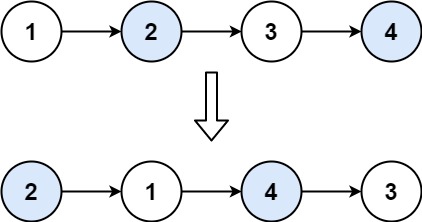
Hot100-链表-JS
160.相交链表 160. 相交链表 已解答 简单 相关标签 相关企业 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交: 题目数据 保证 整…...
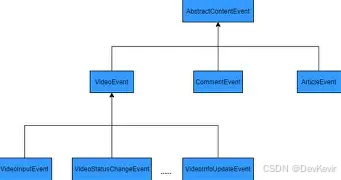
事件驱动架构:从传统服务到实时响应的IT新风潮
文章目录 事件驱动架构的本质:从请求到事件的范式转变在EDA中: 事件驱动架构的演进:从消息队列到云原生标配核心技术:事件驱动架构的基石与工具链1. 消息队列:事件传递的枢纽2. 消费者:异步处理3. 事件总线…...

网络流量分析 | NetworkMiner
介绍 NetworkMiner 是一款适用于Windows(也适用于Linux/Mac)的开源网络取证分析工具。它可被用作被动网络嗅探器/数据包捕获工具,也可被用于检测操作系统、会话、主机名、开放端口等,还能被用于解析pcap文件进行离线分析。点击此…...

弦理论的额外维度指的是什么,宇宙中有何依据
弦理论中的额外维度是解释微观世界与宏观宇宙矛盾的关键假设之一。它们并非科幻中的平行宇宙,而是通过严谨的数学框架提出,并可能留下可观测的宇宙学痕迹。以下是具体解析: 一、弦理论为何需要额外维度? 数学自洽性要求 弦理论中…...

std::tuple 用法
std::tuple 是 C11 引入的模板类,用来存储多个不同类型的值,类似于 Python 的元组。你可以把它看作是一种“组合多个变量在一个对象中”的方式。 ✅ 基本用法 #include <tuple> #include <iostream>int main() {std::tuple<int, std::st…...
深入理解 Git 分支操作的底层原理
在软件开发的世界里,Git 已经成为了版本控制的标配工具。而 Git 分支功能,更是极大地提升了团队协作和项目开发的效率。我们在日常开发中频繁地创建、切换和合并分支,但是这些操作背后的底层原理是怎样的呢?在之前的博客探秘Git底…...
Excel MCP: 自动读取、提炼、分析Excel数据并生成可视化图表和分析报告
最近,一款Excel MCP Server的开源工具火了,看起来功能很强大,咱们今天来一探究竟。 基础环境 最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个&…...

C语言:深入理解指针(4)
目录 一、字符指针变量 二、数组指针变量 三、二维数组传参的本质 四、函数指针变量 五、typedef 类型重命名 六、函数指针数组 一、字符指针变量 我们常见的字符指针变量是这样的: char a w; char* p &a; char arr[] "abcd"; char* pa ar…...

Gensim 是一个专为 Python 设计的开源库
Gensim 是一个专为 Python 设计的开源库,其核心代码和生态系统均基于 Python 构建,目前官方仅支持 Python 语言。如果你需要在其他编程语言中实现类似功能(如词向量训练、主题模型等),通常需要使用对应语言的替代库或通…...

质量管理工程师面试总结
今天闲着无聊参加了学校招聘会的一家双选会企业,以下是面试的过程。 此次面试采用的是一对多的形式。(此次三个求职者,一个面试官) 面试官:开始你们每个人先做个自我介绍吧。 哈哈哈哈哈哈哈哈,其实我们…...

python 爬虫框架介绍
文章目录 前言一、Requests BeautifulSoup(基础组合)二、Scrapy(高级框架)三、PySpider(可视化爬虫)四、Selenium(浏览器自动化)五、Playwright(新一代浏览器自动化&…...

window 显示驱动开发-使用有保证的协定 DMA 缓冲区模型
Windows Vista 的显示驱动程序模型保证呈现设备的 DMA 缓冲区和修补程序位置列表的大小。 修补程序位置列表包含 DMA 缓冲区中命令引用的资源的物理内存地址。 在有保证的协定模式下,用户模式显示驱动程序知道 DMA 缓冲区和修补程序位置列表的确切大小,…...