【HBase整合Hive】HBase-1.4.8整合Hive-2.3.3过程
HBase-1.4.8整合Hive-2.3.3过程
- 一、摘要
- 二、整合过程
- 三、注意事项
一、摘要
-
HBase集成Hive,由Hive来编写SQL语句操作HBase有以下好处:
- 简化操作:Hive提供了类SQL的查询语言HiveQL,对于熟悉SQL的用户来说,无需学习HBase的原生Java API或其他复杂的操作方式,就可以方便地对HBase中的数据进行查询、插入、更新等操作。这大大降低了开发和使用的门槛,提高了数据操作的效率。
- 支持复杂查询:Hive具有强大的查询处理能力,能够支持复杂的SQL查询,如多表关联、分组、聚合等操作。而HBase本身主要是一个列存储的NoSQL数据库,对于复杂查询的支持相对有限。通过Hive集成,可以利用Hive的查询优化器和执行引擎来处理这些复杂查询,方便用户从HBase中获取更有价值的信息。
- 数据处理和分析:Hive通常与Hadoop生态系统中的其他组件紧密集成,如HDFS、MapReduce等,这使得它能够方便地进行大规模数据的处理和分析。当Hive与HBase集成后,可以将HBase中的数据与Hadoop生态系统中的其他数据结合起来进行综合分析,充分发挥Hadoop生态系统的优势。
- 数据抽象和统一管理:Hive为HBase数据提供了一种抽象层,将HBase表映射为Hive表,使得用户可以将HBase数据视为传统的关系型表进行管理和操作。这样可以在一定程度上统一数据的管理和访问方式,方便用户在不同的应用场景中使用HBase数据。
- 支持数据仓库功能:Hive最初是为数据仓库应用而设计的,它支持数据的ETL(提取、转换、加载)操作、数据分区、数据存储格式管理等功能。通过集成HBase,可以将HBase作为数据仓库的底层存储之一,利用Hive的数据仓库功能来管理和维护HBase中的数据,实现更高效的数据管理和分析。
-
HBase集成Hive,由Hive编写SQL语句操作HBase也存在一些弊端,主要体现在以下几个方面:
- 性能损耗
- Hive在执行SQL语句时,通常会将其转换为MapReduce任务或其他计算框架的任务来执行,这中间涉及到复杂的解析、优化和任务调度过程,会带来一定的性能开销。而HBase本身具有高效的实时读写能力,集成Hive后,可能无法充分发挥HBase的实时性优势,对于一些对实时性要求较高的查询,性能可能不如直接使用HBase原生API。
- Hive的查询优化器主要是针对传统的关系型数据模型和磁盘存储设计的,对于HBase这种列存储、基于内存和分布式文件系统的存储结构,优化效果可能不理想。例如,Hive可能无法很好地利用HBase的列族、数据块缓存等特性来提高查询性能。
- 功能限制
- Hive的SQL语法虽然功能强大,但并不能完全覆盖HBase的所有功能。例如,HBase的一些高级特性,如协处理器、分布式计数器等,很难通过Hive SQL来直接使用。如果应用程序需要使用这些特性,就需要在Hive和HBase之间进行切换,增加了开发和维护的复杂性。
- Hive对HBase数据类型的支持存在一定限制。HBase的数据类型较为灵活,而Hive有自己固定的数据类型体系,在数据集成时可能会出现类型转换问题,导致数据精度丢失或查询结果不准确。
- 架构复杂性
- 集成Hive和HBase增加了系统架构的复杂性。需要同时维护Hive和HBase两个系统的正常运行,包括它们各自的配置、版本兼容性、集群资源管理等。任何一个组件出现问题,都可能影响到整个系统的正常运行,增加了运维的难度和成本。
- 在数据处理流程中,数据可能需要在Hive和HBase之间进行多次转换和传输,这不仅增加了数据处理的时间和网络开销,还可能导致数据一致性问题。如果在集成过程中没有合理设计数据同步和一致性维护机制,可能会出现数据不一致的情况,影响数据分析的准确性。
- 性能损耗
-
尽管HBase集成Hive存在一些弊端,但两者进行集成仍然具有重要意义,主要原因如下:
- 技术互补
- HBase擅长处理大规模的实时数据存储和随机读写,能够在海量数据中快速定位和查询数据,适用于对实时性要求高的场景,如实时监控、金融交易等。而Hive在处理复杂的SQL查询、数据仓库管理和批处理分析方面具有优势,能够方便地进行数据汇总、统计分析和报表生成。通过集成,可将HBase的实时数据处理能力与Hive的数据分析能力相结合,满足不同业务场景下的需求。
- Hive可以将结构化的数据以表的形式进行管理,提供了一种类似于关系型数据库的操作方式,方便用户进行数据定义、查询和管理。HBase则以其灵活的列存储结构和分布式架构,能够存储半结构化或非结构化数据。两者集成后,可以在Hive中对HBase中的半结构化或非结构化数据进行处理和分析,拓展了数据处理的范围。
- 保护投资和技术栈整合
- 许多企业已经在Hadoop生态系统上进行了大量投资,Hive是Hadoop生态中常用的数据仓库工具,而HBase作为高性能的分布式数据库也被广泛应用。集成两者可以充分利用企业现有的技术栈和基础设施,避免重复建设和资源浪费,保护企业在大数据领域的前期投资。
- 对于已经熟悉Hive SQL的开发人员和数据分析师来说,通过集成HBase和Hive,他们可以在不学习新的复杂API的情况下,利用现有的技能和知识来处理HBase中的数据,降低了学习成本和开发难度,提高了工作效率。
- 支持多样化的业务需求
- 在实际业务中,往往既需要对实时数据进行快速查询和处理,又需要对历史数据进行复杂的分析和挖掘。HBase集成Hive可以同时满足这两类需求,为企业提供更全面的数据处理和分析解决方案。例如,在电商领域,HBase可以用于实时记录用户的行为数据,如点击、购买等,而Hive可以对这些数据进行分析,挖掘用户的消费习惯、购买趋势等,为企业的营销策略提供支持。
- 随着业务的发展,数据量和数据类型不断增加,对数据处理的要求也越来越多样化。集成HBase和Hive可以更好地应对这些变化,提供更灵活的数据处理和分析能力,帮助企业更好地利用数据资产,提升竞争力。
- 技术互补
二、整合过程
HBase1.4.8和Hive-2.3.3各种的安装步骤请参考基于OpenEuler国产操作系统大数据实验环境搭建。两者集成的步骤如下:
- 修改hive-site.xml
添加zookeeper的连接配置项:<!-- 与HBase集成 --><!-- 指定zookeeper集群地址 --><property><name>hive.zookeeper.quorum</name><value>s1,s2,s3</value></property><property><name>hive.zookeeper.client.port</name><value>2181</value></property> - 将hbase-site.xml复制到$HIVE_HOME/conf/目录
cp $HBASE_HOME/conf/hbase-site.xml $HIVE_HOME/conf/ - 验证
- 确保zookeeper和hbase处于启动状态
- 执行hive 命令,进程hive的CLI界面中
[root@s1 hive]# hive …… Logging initialized using configuration in jar:file:/mysoft/hive/lib/hive-common-2.3.3.jar!/hive-log4j2.properties Async: true Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine 1.X releases. hive> - 在hive的CLI中创建一张表:
执行上述SQL,结果如下:create table hive_to_hbase_emp_table( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties ("hbase.columns.mapping"=":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno") tblproperties("hbase.table.name"="hive_to_hbase_emp_table");
说明Hive与HBase集成已经正常。hive> create table hive_to_hbase_emp_table(> empno int,> ename string,> job string,> mgr int,> hiredate string,> sal double,> comm double,> deptno int)> stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties ("hbase.columns.mapping"=":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno") tblproperties("hbase.table.name"="hive_to_hbase_emp_table"); OK Time taken: 4.958 seconds hive> - 在hbase shell中查看是否由hive创建的表:
hbase(main):001:0> list TABLE hive_to_hbase_emp_table 1 row(s) in 0.8890 seconds => ["hive_to_hbase_emp_table"] hbase(main):002:0> - 在hive的cli中,创建一张hive的内部表hive_inner_emp,用于将本地文件的数据加载到该表,为后面往hbase中的表做准备(这里仅仅学习和测试演示使用):
执行上述SQL完成hive_inner_emp表创建。create table hive_inner_emp( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int) row format delimited fields terminated by ',';
然后加载将本地的emp.csv文件的数据到该表中:
命令执行正常时,数据已经添加到hive_inner_emp表中:load data local inpath '/tools/emp.csv' into table hive_inner_emp;hive> select * from hive_inner_emp; OK 7369 SMITH CLERK 7902 1980/12/17 800.0 NULL 20 7499 ALLEN SALESMAN 7698 1981/2/20 1600.0 300.0 30 7521 WARD SALESMAN 7698 1981/2/22 1250.0 500.0 30 7566 JONES MANAGER 7839 1981/4/2 2975.0 NULL 20 7654 MARTIN SALESMAN 7698 1981/9/28 1250.0 1400.0 30 7698 BLAKE MANAGER 7839 1981/5/1 2850.0 NULL 30 7782 CLARK MANAGER 7839 1981/6/9 2450.0 NULL 10 7788 SCOTT ANALYST 7566 1987/4/19 3000.0 NULL 20 7839 KING PRESIDENT NULL 1981/11/17 5000.0 NULL 10 7844 TURNER SALESMAN 7698 1981/9/8 1500.0 0.0 30 7876 ADAMS CLERK 7788 1987/5/23 1100.0 NULL 20 7900 JAMES CLERK 7698 1981/12/3 9500.0 NULL 30 7902 FORD ANALYST 7566 1981/12/3 3000.0 NULL 20 7934 MILLER CLERK 7782 1982/1/23 1300.0 NULL 10 Time taken: 0.668 seconds, Fetched: 14 row(s) - 将
hive_inner_emp表数据插入到hive_to_hbase_emp_table表中:
正常执行结果如下所示:insert into hive_to_hbase_emp_table select * from hive_inner_emp;hive> insert into hive_to_hbase_emp_table select * from hive_inner_emp; WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. Query ID = root_20250513134124_d0a93e1f-e852-405e-ad52-2ddaae763d9f Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks is set to 0 since there's no reduce operator Starting Job = job_1747100297537_0014, Tracking URL = http://s1:8088/proxy/application_1747100297537_0014/ Kill Command = /mysoft/hadoop/bin/hadoop job -kill job_1747100297537_0014 Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0 2025-05-13 13:41:56,018 Stage-3 map = 0%, reduce = 0% 2025-05-13 13:42:17,910 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 4.98 sec MapReduce Total cumulative CPU time: 4 seconds 980 msec Ended Job = job_1747100297537_0014 MapReduce Jobs Launched: Stage-Stage-3: Map: 1 Cumulative CPU: 4.98 sec HDFS Read: 5951 HDFS Write: 0 SUCCESS Total MapReduce CPU Time Spent: 4 seconds 980 msec OK Time taken: 55.57 seconds hive> - 在hbase shell中执行scan命令查看该表数据:
hbase(main):002:0> scan 'hive_to_hbase_emp_table' ROW COLUMN+CELL7369 column=info:deptno, timestamp=1747114968171, value=207369 column=info:ename, timestamp=1747114968171, value=SMITH7369 column=info:hiredate, timestamp=1747114968171, value=1980/12/177369 column=info:job, timestamp=1747114968171, value=CLERK7369 column=info:mgr, timestamp=1747114968171, value=79027369 column=info:sal, timestamp=1747114968171, value=800.07499 column=info:comm, timestamp=1747114968171, value=300.07499 column=info:deptno, timestamp=1747114968171, value=307499 column=info:ename, timestamp=1747114968171, value=ALLEN7499 column=info:hiredate, timestamp=1747114968171, value=1981/2/207499 column=info:job, timestamp=1747114968171, value=SALESMAN7499 column=info:mgr, timestamp=1747114968171, value=76987499 column=info:sal, timestamp=1747114968171, value=1600.07521 column=info:comm, timestamp=1747114968171, value=500.07521 column=info:deptno, timestamp=1747114968171, value=307521 column=info:ename, timestamp=1747114968171, value=WARD7521 column=info:hiredate, timestamp=1747114968171, value=1981/2/227521 column=info:job, timestamp=1747114968171, value=SALESMAN7521 column=info:mgr, timestamp=1747114968171, value=76987521 column=info:sal, timestamp=1747114968171, value=1250.07566 column=info:deptno, timestamp=1747114968171, value=207566 column=info:ename, timestamp=1747114968171, value=JONES7566 column=info:hiredate, timestamp=1747114968171, value=1981/4/27566 column=info:job, timestamp=1747114968171, value=MANAGER7566 column=info:mgr, timestamp=1747114968171, value=78397566 column=info:sal, timestamp=1747114968171, value=2975.07654 column=info:comm, timestamp=1747114968171, value=1400.07654 column=info:deptno, timestamp=1747114968171, value=307654 column=info:ename, timestamp=1747114968171, value=MARTIN7654 column=info:hiredate, timestamp=1747114968171, value=1981/9/287654 column=info:job, timestamp=1747114968171, value=SALESMAN7654 column=info:mgr, timestamp=1747114968171, value=76987654 column=info:sal, timestamp=1747114968171, value=1250.07698 column=info:deptno, timestamp=1747114968171, value=307698 column=info:ename, timestamp=1747114968171, value=BLAKE7698 column=info:hiredate, timestamp=1747114968171, value=1981/5/17698 column=info:job, timestamp=1747114968171, value=MANAGER7698 column=info:mgr, timestamp=1747114968171, value=78397698 column=info:sal, timestamp=1747114968171, value=2850.07782 column=info:deptno, timestamp=1747114968171, value=107782 column=info:ename, timestamp=1747114968171, value=CLARK7782 column=info:hiredate, timestamp=1747114968171, value=1981/6/97782 column=info:job, timestamp=1747114968171, value=MANAGER7782 column=info:mgr, timestamp=1747114968171, value=78397782 column=info:sal, timestamp=1747114968171, value=2450.07788 column=info:deptno, timestamp=1747114968171, value=207788 column=info:ename, timestamp=1747114968171, value=SCOTT7788 column=info:hiredate, timestamp=1747114968171, value=1987/4/197788 column=info:job, timestamp=1747114968171, value=ANALYST7788 column=info:mgr, timestamp=1747114968171, value=75667788 column=info:sal, timestamp=1747114968171, value=3000.07839 column=info:deptno, timestamp=1747114968171, value=107839 column=info:ename, timestamp=1747114968171, value=KING7839 column=info:hiredate, timestamp=1747114968171, value=1981/11/177839 column=info:job, timestamp=1747114968171, value=PRESIDENT7839 column=info:sal, timestamp=1747114968171, value=5000.07844 column=info:comm, timestamp=1747114968171, value=0.07844 column=info:deptno, timestamp=1747114968171, value=307844 column=info:ename, timestamp=1747114968171, value=TURNER7844 column=info:hiredate, timestamp=1747114968171, value=1981/9/87844 column=info:job, timestamp=1747114968171, value=SALESMAN7844 column=info:mgr, timestamp=1747114968171, value=76987844 column=info:sal, timestamp=1747114968171, value=1500.07876 column=info:deptno, timestamp=1747114968171, value=207876 column=info:ename, timestamp=1747114968171, value=ADAMS7876 column=info:hiredate, timestamp=1747114968171, value=1987/5/237876 column=info:job, timestamp=1747114968171, value=CLERK7876 column=info:mgr, timestamp=1747114968171, value=77887876 column=info:sal, timestamp=1747114968171, value=1100.07900 column=info:deptno, timestamp=1747114968171, value=307900 column=info:ename, timestamp=1747114968171, value=JAMES7900 column=info:hiredate, timestamp=1747114968171, value=1981/12/37900 column=info:job, timestamp=1747114968171, value=CLERK7900 column=info:mgr, timestamp=1747114968171, value=76987900 column=info:sal, timestamp=1747114968171, value=9500.07902 column=info:deptno, timestamp=1747114968171, value=207902 column=info:ename, timestamp=1747114968171, value=FORD7902 column=info:hiredate, timestamp=1747114968171, value=1981/12/37902 column=info:job, timestamp=1747114968171, value=ANALYST7902 column=info:mgr, timestamp=1747114968171, value=75667902 column=info:sal, timestamp=1747114968171, value=3000.07934 column=info:deptno, timestamp=1747114968171, value=107934 column=info:ename, timestamp=1747114968171, value=MILLER7934 column=info:hiredate, timestamp=1747114968171, value=1982/1/237934 column=info:job, timestamp=1747114968171, value=CLERK7934 column=info:mgr, timestamp=1747114968171, value=77827934 column=info:sal, timestamp=1747114968171, value=1300.0 14 row(s) in 0.9040 secondshbase(main):003:0> - 在hive的cli中向hive_to_hbase_emp_table表中写入一条数据,验证是否正常写入:
hive> INSERT INTO TABLE hive_to_hbase_emp_table VALUES (7935, 'Alice', 'Engineer', null, '2023-01-01', 10000.0, null, 10); WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. Query ID = root_20250513134721_628fd4af-a8f7-4c6e-b9c1-9e8f22e78c03 Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks is set to 0 since there's no reduce operator Starting Job = job_1747100297537_0015, Tracking URL = http://s1:8088/proxy/application_1747100297537_0015/ Kill Command = /mysoft/hadoop/bin/hadoop job -kill job_1747100297537_0015 Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0 2025-05-13 13:47:49,256 Stage-3 map = 0%, reduce = 0% 2025-05-13 13:48:06,096 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 6.2 sec MapReduce Total cumulative CPU time: 6 seconds 200 msec Ended Job = job_1747100297537_0015 MapReduce Jobs Launched: Stage-Stage-3: Map: 1 Cumulative CPU: 6.2 sec HDFS Read: 6082 HDFS Write: 0 SUCCESS Total MapReduce CPU Time Spent: 6 seconds 200 msec OK Time taken: 47.183 seconds hive> - 在hbase shell中执行get命令查看该条数据:
到此,说明Hive-2.3.3和HBase-1.4.8集成完毕。hbase(main):006:0> get 'hive_to_hbase_emp_table','7935' COLUMN CELLinfo:deptno timestamp=1747115316165, value=10info:ename timestamp=1747115316165, value=Aliceinfo:hiredate timestamp=1747115316165, value=2023-01-01info:job timestamp=1747115316165, value=Engineerinfo:sal timestamp=1747115316165, value=10000.0 5 row(s) in 0.1260 seconds
三、注意事项
- Hive和HBase的版本务必兼容,请查看官网获取HBase和Hive的兼容版本。否则,会有各种意想不到的错误产生。
- 在hive创建的
hive_to_hbase_emp_table表,hive只保存该表的元信息,该表所在hdfs上的路径为:
真实数据是存储在hbase路径下:drwxr-xr-x - root supergroup 0 2025-05-13 15:47 /user/hive/warehouse/hive_to_hbase_emp_table[root@s1 conf]# hdfs dfs -ls -R /hbase/data/default/hive_to_hbase_emp_table drwxr-xr-x - root supergroup 0 2025-05-13 15:26 /hbase/data/default/hive_to_hbase_emp_table/.tabledesc -rw-r--r-- 3 root supergroup 303 2025-05-13 15:26 /hbase/data/default/hive_to_hbase_emp_table/.tabledesc/.tableinfo.0000000001 drwxr-xr-x - root supergroup 0 2025-05-13 15:26 /hbase/data/default/hive_to_hbase_emp_table/.tmp drwxr-xr-x - root supergroup 0 2025-05-13 15:26 /hbase/data/default/hive_to_hbase_emp_table/14a4000780edafd6a8b46b52f046f863 -rw-r--r-- 3 root supergroup 58 2025-05-13 15:26 /hbase/data/default/hive_to_hbase_emp_table/14a4000780edafd6a8b46b52f046f863/.regioninfo drwxr-xr-x - root supergroup 0 2025-05-13 15:26 /hbase/data/default/hive_to_hbase_emp_table/14a4000780edafd6a8b46b52f046f863/info drwxr-xr-x - root supergroup 0 2025-05-13 15:26 /hbase/data/default/hive_to_hbase_emp_table/14a4000780edafd6a8b46b52f046f863/recovered.edits -rw-r--r-- 3 root supergroup 0 2025-05-13 15:26 /hbase/data/default/hive_to_hbase_emp_table/14a4000780edafd6a8b46b52f046f863/recovered.edits/2.seqid [root@s1 conf]#
相关文章:

【HBase整合Hive】HBase-1.4.8整合Hive-2.3.3过程
HBase-1.4.8整合Hive-2.3.3过程 一、摘要二、整合过程三、注意事项 一、摘要 HBase集成Hive,由Hive来编写SQL语句操作HBase有以下好处: 简化操作:Hive提供了类SQL的查询语言HiveQL,对于熟悉SQL的用户来说,无需学习HBas…...

图像对比度调整(局域拉普拉斯滤波)
一、背景介绍 之前刷对比度相关调整算法,找到效果不错,使用局域拉普拉斯做图像对比度调整,尝试复现和整理了下相关代码。 二、实现流程 1、基本原理 对输入图像进行高斯金字塔拆分,对每层的每个像素都针对性处理,生产…...

如何在本地打包 StarRocks 发行版
字数 615,阅读大约需 4 分钟 最近我们在使用 StarRocks 的时候碰到了一些小问题: • 重启物化视图的时候会导致视图全量刷新,大量消耗资源。- 修复 PR:https://github.com/StarRocks/starrocks/pull/57371• excluded_refresh_tab…...

git使用的DLL错误
安装好git windows客户端打开git bash提示 Error: Could not fork child process: Resource temporarily unavailable (-1). DLL rebasing may be required; see ‘rebaseall / rebase –help’. 提示 MINGW64的DLL链接有问题,其实是Windows的安全中心限制了&…...

Elasticsearch倒排索引核心原理面试题
倒排索引核心原理面试题 🚀 目录 基础概念性能优化应用场景数据结构设计问题排查扩展思考基础概念 🔍 面试题1:基础概念 题目:Elasticsearch/Lucene的倒排索引(Inverted Index)是如何工作的?请描述从关键词搜索到返回文档的完整流程。 👉 查看参考答案 倒排索引…...

区块链blog1__合作与信任
🍂我们的世界 🌿不是孤立的,而是网络化的 如果是单独孤立的系统,无需共识,而我们的社会是网络结构,即结点间不是孤立的 🌿网络化的原因 而目前并未发现这样的理想孤立系统,即现实中…...
从数据包到可靠性:UDP/TCP协议的工作原理分析
之前我们已经使用udp/tcp的相关接口写了一些简单的客户端与服务端代码。也了解了协议是什么,包括自定义协议和知名协议比如http/https和ssh等。现在我们再回到传输层,对udp和tcp这两传输层巨头协议做更深一步的分析。 一.UDP UDP相关内容很简单…...

【CanMV K230】AI_CUBE1.4
《k230-AI 最近小伙伴有做模型的需求。所以我重新捡起来了。正好把之前没测过的测一下。 这次我们用的是全新版本。AICUBE1.4.dotnet环境9.0 注意AICUBE训练模型对硬件有所要求。最好使用独立显卡。 有小伙伴说集显也可以。emmmm可以试试哈 集显显存2G很勉强了。 我们依然用…...

vscode 默认环境路径
目录 1.下面放在项目根目录上: 2.settings.json内容: 自定义conda环境断点调试 启动默认参数: 1.下面放在项目根目录上: .vscode/settings.json 2.settings.json内容: {"python.analysis.extraPaths"…...
支付宝授权登录
支付宝授权登录 一、场景 支付宝小程序登录,获取用户userId 二、注册支付宝开发者账号 1、支付宝开放平台 2、点击右上角–控制台,创建小程序 3、按照步骤完善信息,生成密钥时会用到的工具 4、生成的密钥,要保管好ÿ…...

Fabric 服务端插件开发简述与聊天事件监听转发
原文链接:Fabric 服务端插件开发简述与聊天事件监听转发 < Ping通途说 0. 引言 以前写过Spigot的插件,非常简单,仅需调用官方封装好的Event类即可。但Fabric这边在开发时由于官方文档和现有互联网资料来看,可能会具有一定的误…...

认识Docker/安装Docker
一、认识Docker Docker的定义 Docker 是一个开源的应用容器引擎,允许开发者将应用及其依赖打包到一个轻量级、可移植的容器中。容器化技术使得应用可以在任何支持 Docker 的环境中运行,确保环境一致性。 Docker的核心组件 Docker Engine:负责…...
电商物流管理优化:从网络重构到成本管控的全链路解析
大家好,我是沛哥儿。作为电商行业,我始终认为物流是电商体验的“最后一公里”,更是成本控制的核心战场。随着行业竞争加剧,如何通过物流网络优化实现降本增效,已成为电商企业的必修课。本文将从物流网络的各个环节切入…...

Unity:延迟执行函数:Invoke()
目录 Unity 中的 Invoke() 方法详解 什么是 Invoke()? 基本使用方法 使用要点 延伸功能 ❗️Invoke 的局限与注意事项 在Unity中,延迟执行函数是游戏逻辑中常见的需求,比如: 延迟切换场景 延迟播放音效或动画 给玩家时间…...

移植RTOS,发现任务栈溢出怎么办?
目录 1、硬件检测方法 2、软件检测方法 3、预防堆栈溢出 4、处理堆栈溢出 在嵌入式系统中,RTOS通过管理多个任务来满足严格的时序要求。任务堆栈管理是RTOS开发中的关键环节,尤其是在将RTOS移植到新硬件平台时。堆栈溢出是嵌入式开发中常见的错误&am…...

k8s部署实战-springboot应用部署
在 Kubernetes 上部署 SpringBoot 应用实战指南 前言 本文将详细介绍如何将一个 SpringBoot 应用部署到 Kubernetes 集群中,包括制作镜像、编写部署文件、创建服务等完整步骤。 准备工作 1. 示例 SpringBoot 应用 假设我们有一个简单的 SpringBoot 应用,提供 REST API 服…...

【设计模式】- 结构型模式
代理模式 给目标对象提供一个代理以控制对该对象的访问。外界如果需要访问目标对象,需要去访问代理对象。 分类: 静态代理:代理类在编译时期生成动态代理:代理类在java运行时生成 JDK代理CGLib代理 【主要角色】: 抽…...
 中)
《Vuejs设计与实现》第 5 章(非原始值响应式方案) 中
目录 5.4 合理触发响应 5.5 浅响应与深响应 5.6 只读和浅只读 5.4 合理触发响应 为了合理触发响应,我们需要处理一些问题。 首先,当值没有变化时,我们不应该触发响应: const obj = { foo: 1 } const p = new Proxy(obj, { /* ... */ })effect(() => {console.log(p…...

rk3576 gstreamer opencv
安装gstreamer rk3588使用gstreamer推流_rk3588 gstreamer-CSDN博客 rk3588使用gstreamer推流_rk3588 gstreamer-CSDN博客 Installing on Linux sudo apt-get install libgstreamer1.0-dev libgstreamer-plugins-base1.0-dev libgstreamer-plugins-bad1.0-dev gstreamer1.0-pl…...
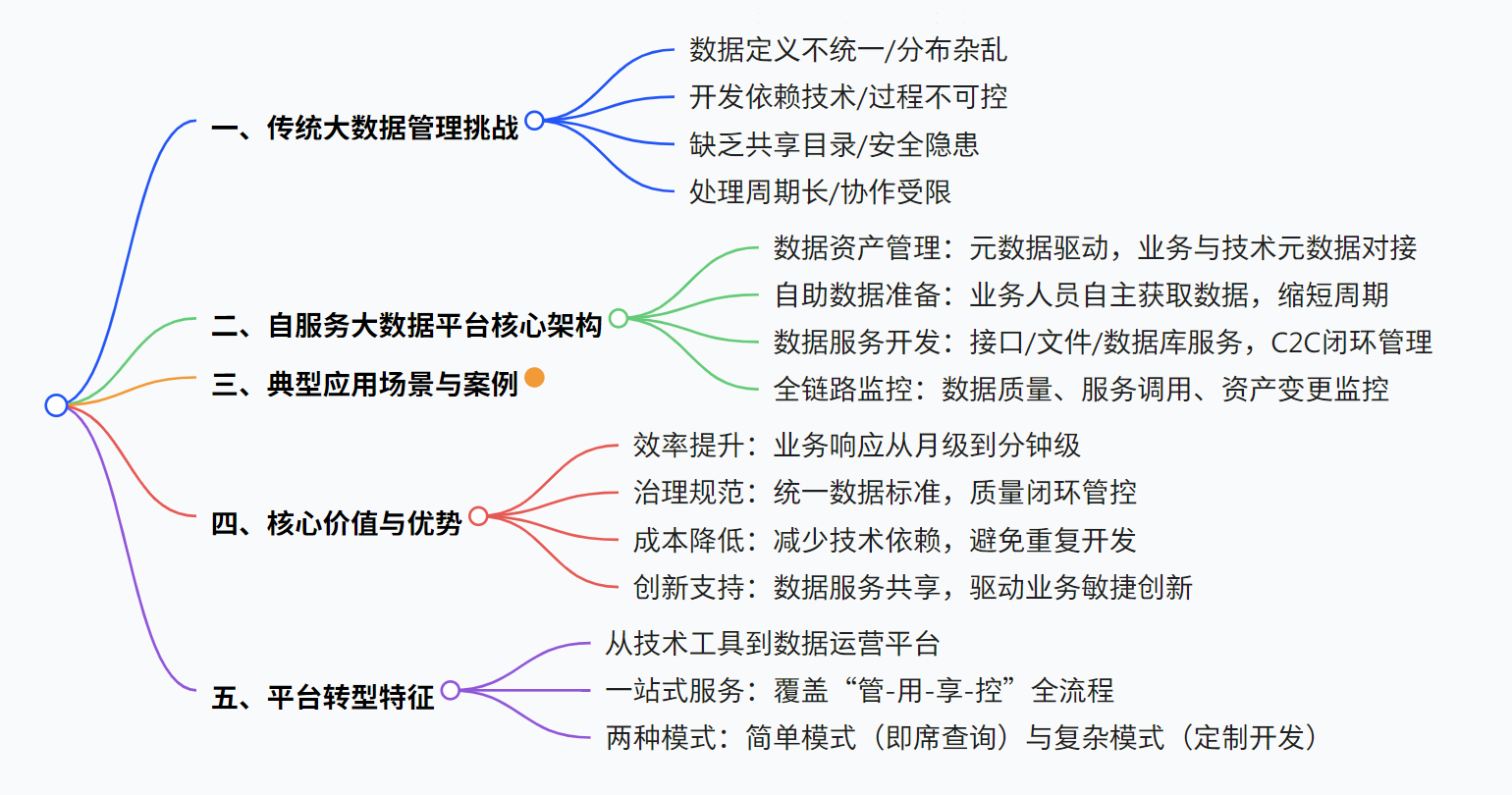
数据服务共享平台方案
该文档聚焦数据服务共享平台方案,指出传统大数据管理存在数据定义不统一、开发困难、共享不足等挑战,提出通过自服务大数据平台实现数据 “采、存、管、用” 全流程优化,涵盖数据资产管理、自助数据准备、服务开发与共享、全链路监控等功能,并通过国家电网、东方航空、政府…...
skywalking使用教程
skywalking使用教程 一、介绍 skywalking 1.1 概念 skywalking是分布式系统的应用程序性能监视工具,专为微服务、云原生架构和基于容器(Docker、K8s、Mesos)架构而设计。SkyWalking 是观察性分析平台和应用性能管理系统,提供分布…...

C 语 言 - - - 简 易 通 讯 录
C 语 言 - - - 简 易 通 讯 录 代 码 全 貌 与 功 能 介 绍通 讯 录 的 功 能 说 明通 讯 录 效 果 展 示代 码 详 解contact.hcontact.ctest.c 总 结 💻作 者 简 介:曾 与 你 一 样 迷 茫,现 以 经 验 助 你 入 门 C 语 言 💡个 …...

大模型MCP之UV安装使用
1.Windows安装 1.1 pip安装 pip install uv -i https://pypi.tuna.tsinghua.edu.cn/simple如果需要centos安装pip sudo yum install python3-pipCentOS 8开始使用dnf作为包管理器: sudo dnf install python3-pip对于基于Debian的系统(如Ubuntu&#…...

【C++】多线程和多进程
在C++中,多线程通信(同一进程内的线程间交互)和进程间通信(IPC,不同进程间的数据交换)是构建并发系统的核心技术。以下是两种通信机制的详细介绍和典型实现: 一、多线程通信(线程间同步与数据共享) 1. 共享内存与同步原语 通过全局变量或对象成员变量实现数据共享,…...

Vue百日学习计划Day16-18天详细计划-Gemini版
重要提示: 番茄时钟: 每个番茄钟为25分钟学习,之后休息5分钟。每完成4个番茄钟,进行一次15-30分钟的长休息。动手实践: DOM 操作和事件处理的理解高度依赖于实际编码。请务必在浏览器中创建 HTML 页面,并配…...

从验证码绕过到信息轰炸:全面剖析安全隐患与防范策略
在数字化交互场景中,验证码作为区分人类操作与自动化程序的核心屏障,广泛应用于用户身份核验、操作权限确认等关键环节。其设计初衷是通过人机识别机制,保障信息系统交互的安全性与可控性。然而,当验证码验证机制出现异常突破&…...

机器学习知识自然语言处理入门
一、引言:当文字遇上数学 —— 自然语言的数字化革命 在自然语言处理(NLP)的世界里,计算机要理解人类语言,首先需要将文字转化为数学向量。早期的 One-Hot 编码如同给每个词语分配一个唯一的 “房间号”,例…...

LeetCode 820 单词的压缩编码题解
LeetCode 820 单词的压缩编码题解 题目描述 题目链接 给定一个单词列表,将其编码为一个索引字符串S,格式为"单词1#单词2#…"。要求当某个单词是另一个单词的后缀时,该单词可以被省略。求最终编码字符串的最小长度。 解题思路 逆…...

论信息系统项目的范围管理
论信息系统项目的范围管理 前言一、规划范围管理,收集需求二、定义范围三、创建工作分解结构四、确认范围五、控制范围 前言 为了应对烟草零售客户数量大幅度增长所带来的问题,切实履行控烟履约的相关要求,同时也为了响应国务院“放管服”政策…...
MySQL数据库——支持远程IP访问的设置方法总结
【系列专栏】:博主结合工作实践输出的,解决实际问题的专栏,朋友们看过来! 《项目案例分享》 《极客DIY开源分享》 《嵌入式通用开发实战》 《C语言开发基础总结》 《从0到1学习嵌入式Linux开发》 《QT开发实战》 《Android开发实…...