python爬虫实战训练
前言:哇,今天终于能访问豆瓣了,前几天爬太多次了,网页都不让我访问了(要登录)。
先来个小练习试试手吧!
爬取豆瓣第一页(多页同上篇文章)所有电影的排名、电影名称、星级和评分,并用Excel存储
网址是:豆瓣电影 Top 250 大家先自己尝试一下吧,还是简单的,我就直接放代码了
import requests
from bs4 import BeautifulSoup
import pandas as pd
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"}
r=requests.get("https://movie.douban.com/top250",headers=headers)
if r.status_code!=200:raise Exception("error")
soup=BeautifulSoup(r.text,"html.parser")
datas=[['排名','电影名称','星级','评分']]
articles=soup.find_all('div',class_='item')
for article in articles:rank=article.find('em').get_text()title=article.find('span',class_='title').get_text() #星级在class属性里,get('class')返回的是列表,因为HTML的class属性可以包含多个类名,因此BeautifulSoup将其存储为一个列表star=article.find('div',class_='bd').find('span').get('class')[0].replace('rating','').replace('-t','') #string的replace方法,只保留数字score=article.find('span',class_='rating_num').get_text()datas.append([rank,title,star,score])
df=pd.DataFrame(datas)
df.to_excel('doubanTop25.xlsx')
easy吧,不过,值得提一下的是,网页带小数星级的表示不准确,4.5星级为45

可以观察到star与score都在同一个div标签下,所以还可以用这两行代码代替
data=article.find('div',class_='bd').find('div').find_all('span')
star,score=data[0]['class'][0],data[1].get_text() #这样star就是一整个字符爬取动态加载的网页
我们来试着爬取杭州今年5个月的天气数据(最近都是下雨,有点不喜欢哦,小小的毛毛细雨我觉得还好,但是大暴雨真是什么都不方便)
我们选择不同的月份,可以发现网页的url都没有发生改变,说明这个网页不是静态网页,它是后台异步加载的动态网页,我们表面不能知道它实际的链接的,那么我们需要抓包来进行分析。
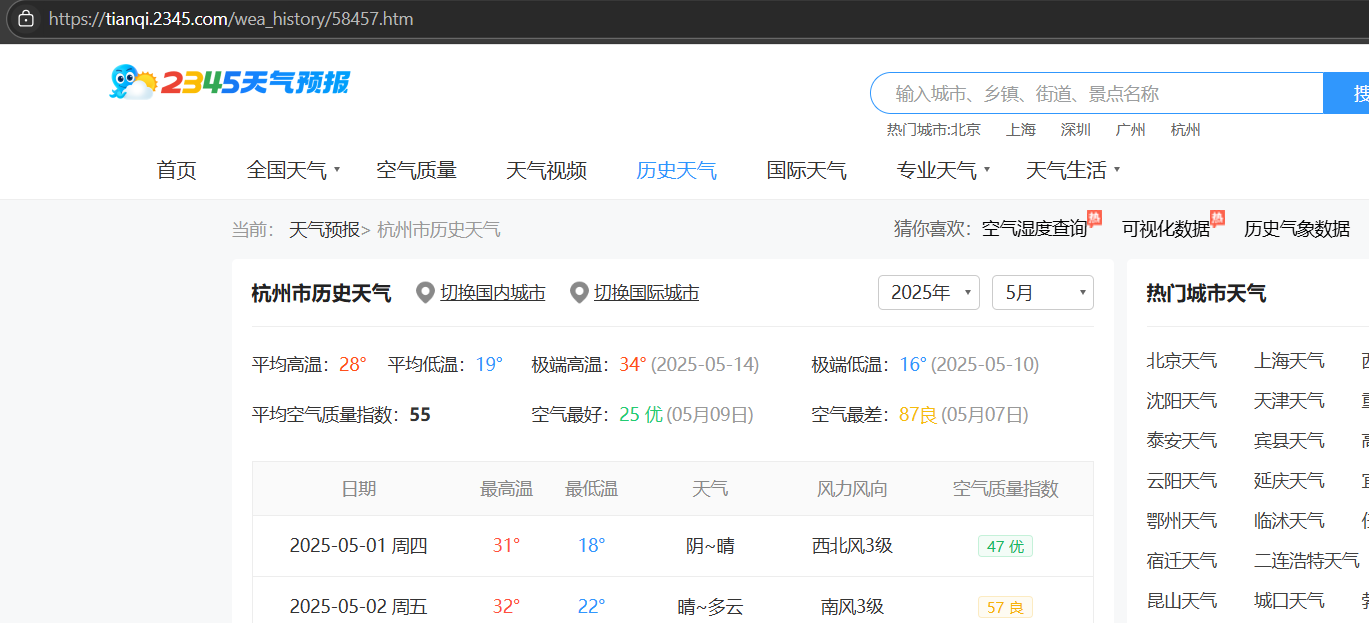
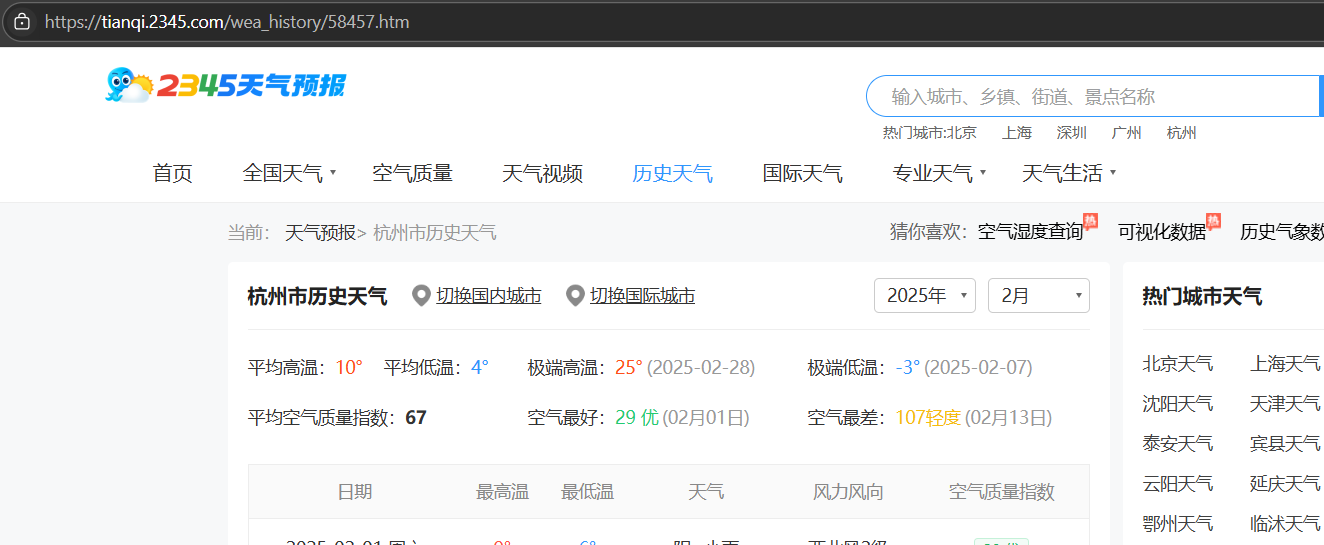
右键,点击“检查”,点击“网络”
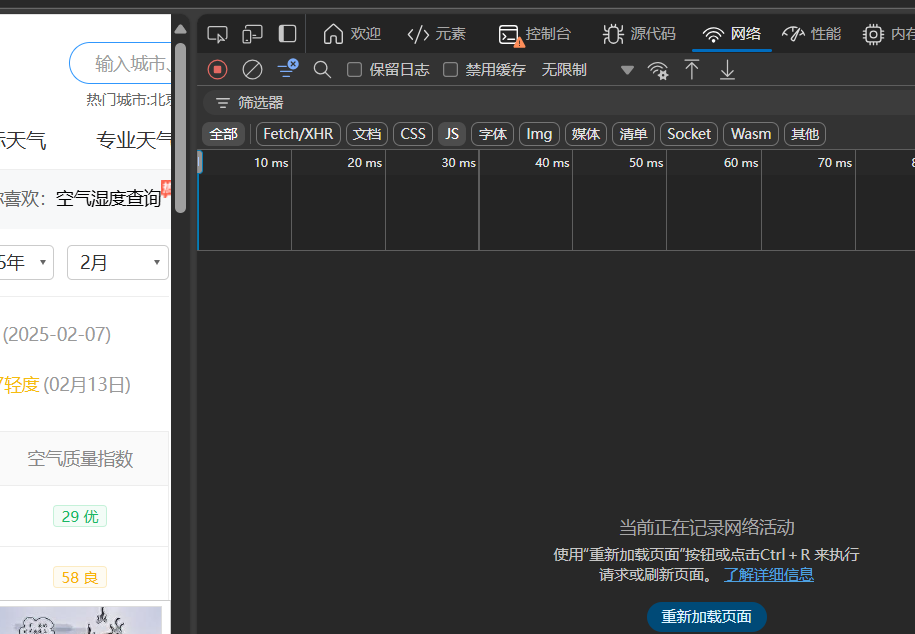
不要直接点击“重新加载页面”,那会加载大量页面弹出来一大堆。我们再次查询一个月份信息,发现后台会发送一个请求“GetHistoty……”(或者点击Fecth/XHR这是发送异步请求的意思,里面就是我们要抓的包)
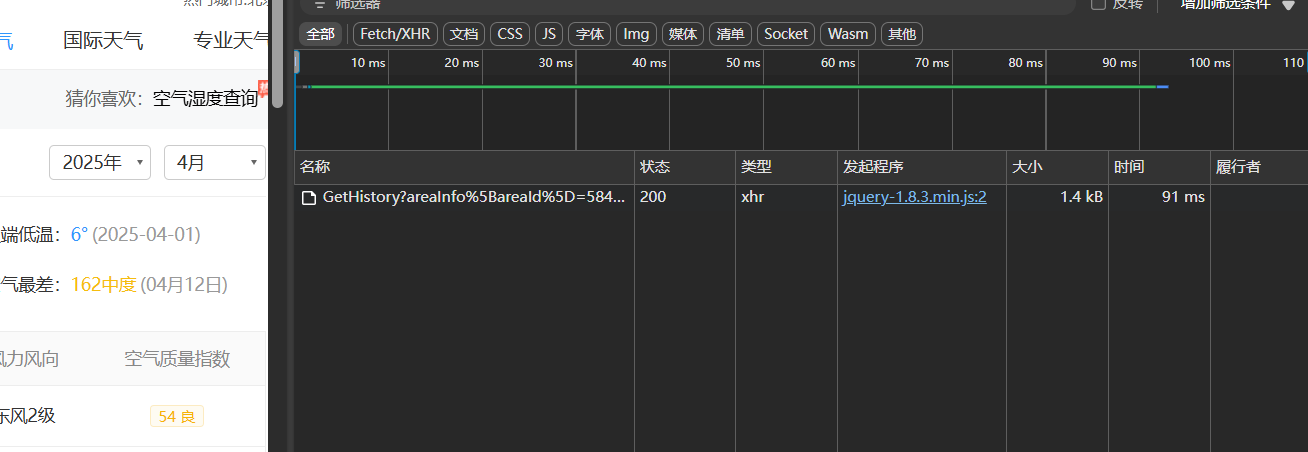 点击“请求”进去看一下,可以发现“请求URL”与网页上方的url不是同一个,这个就是异步加载的,请求方式为“GET”。复制URL“?”前面的部分(后面是参数部分,都在负载里)为url
点击“请求”进去看一下,可以发现“请求URL”与网页上方的url不是同一个,这个就是异步加载的,请求方式为“GET”。复制URL“?”前面的部分(后面是参数部分,都在负载里)为url
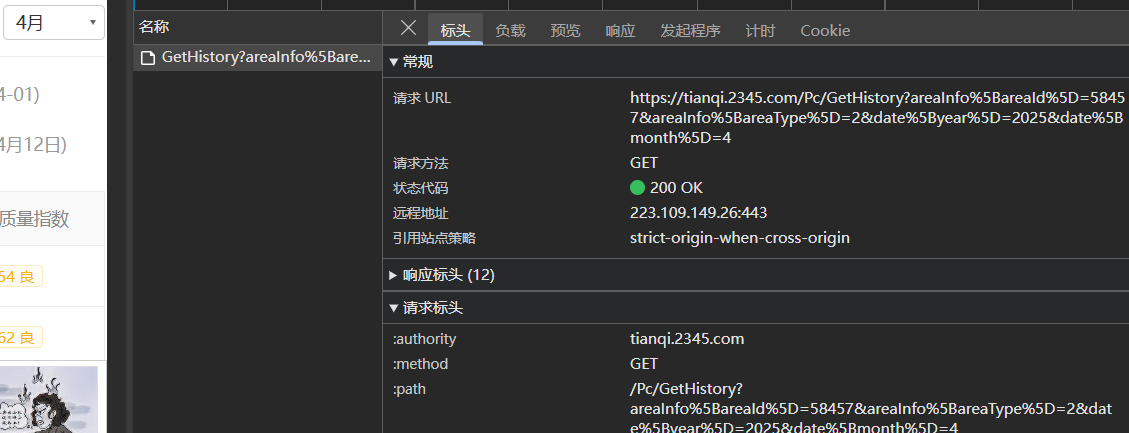
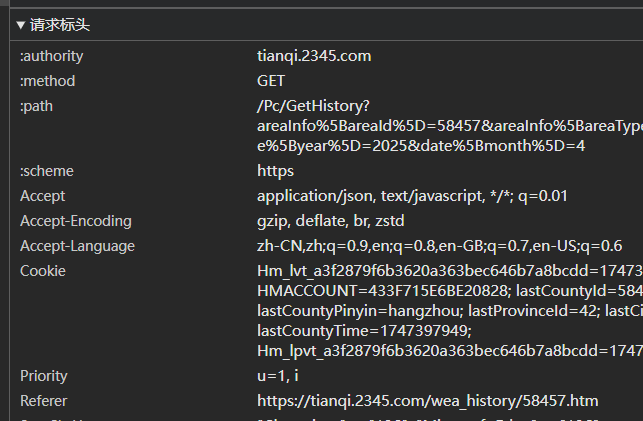
复制“请求标头”里的User-Agent,设置为headers用于反爬

这个网站的反爬做的有点好啊,还需要设置headers的Referer属性 ,也在请求标头里面,复制下来
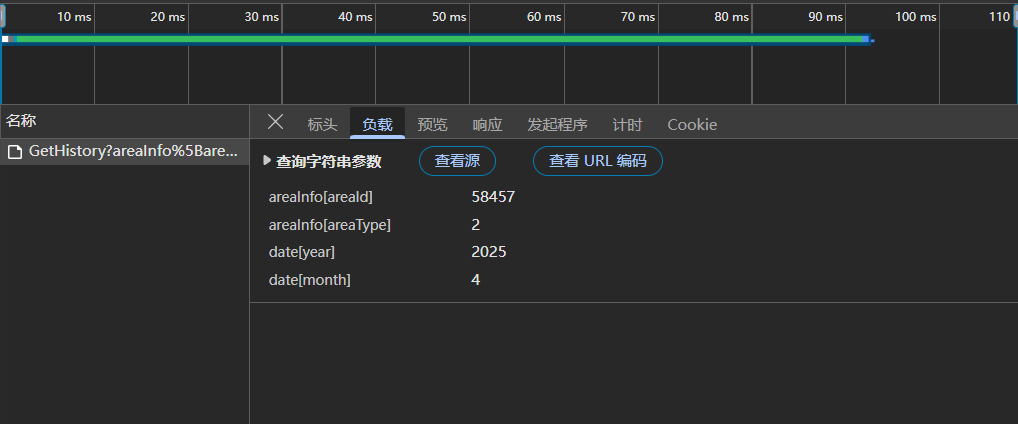
点击“负载”,前两项是杭州地区有关的编码,都是不会变的,下面两项就是查询的year与month。复制里面的内容为请求的参数(设为字典类型)
点击“响应”,看一下返回的结果是怎样的
可以看到响应是json类型的数据(JSON (JavaScript Object Notation)数据由键值对组成,类似于字典,是一种轻量级的数据交换格式)
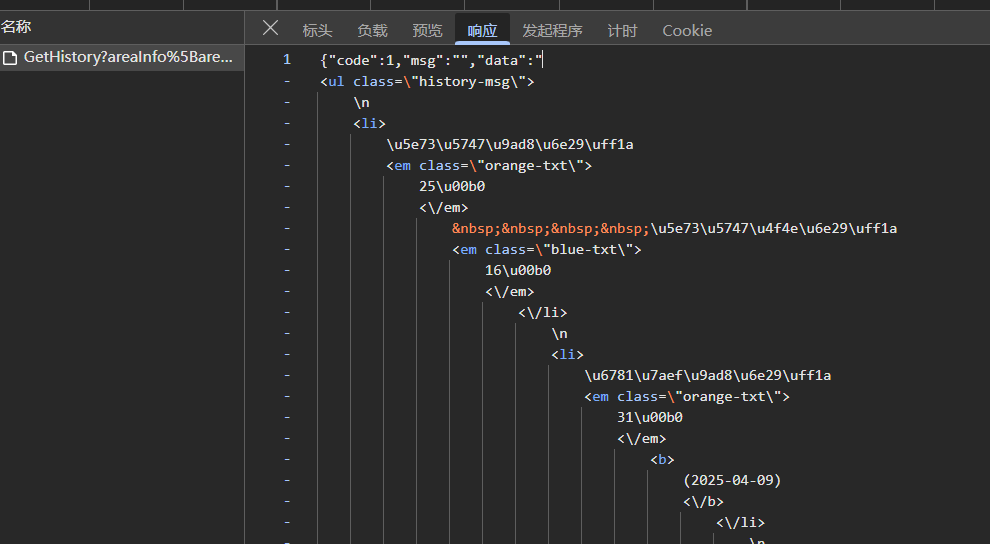
点击“预览”,可以看到格式化的展示,将鼠标移到data的值可以看到html的数据(截图没法展示,自行看),可以发现里面有个<table>标签
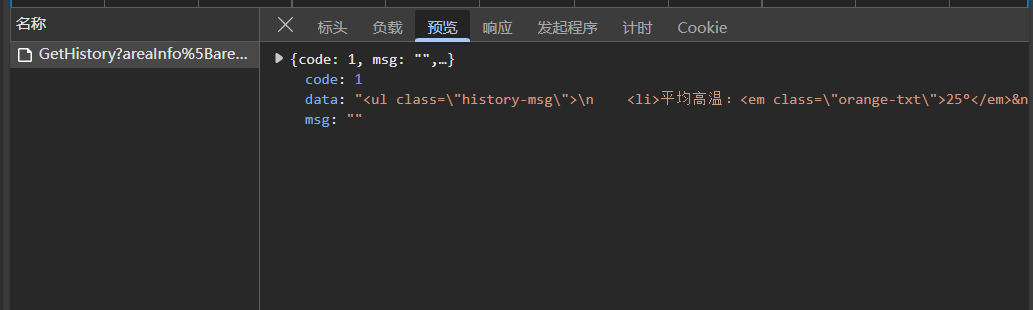
“响应”里也能看到,不过“预览”可视化更好
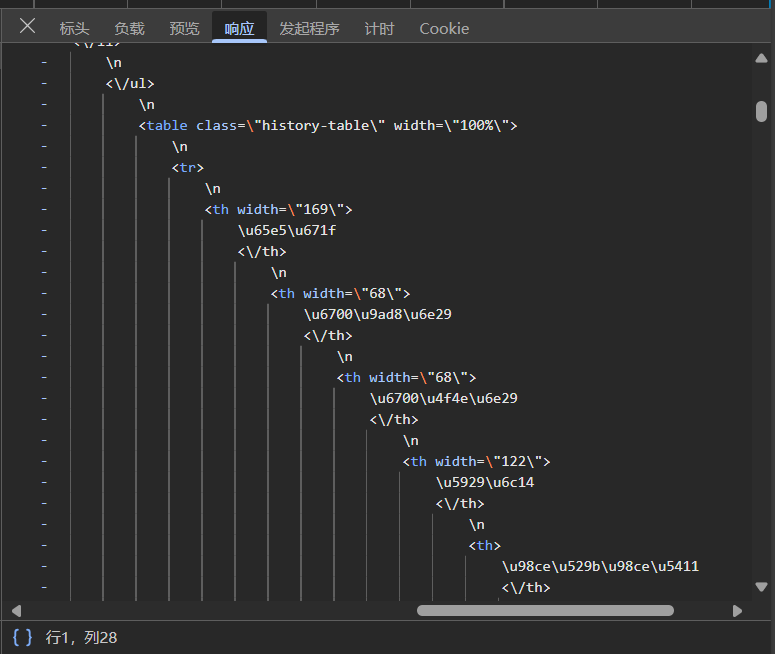
表格数据用pandas可以很容易地解析
import requests
import pandas as pd
from io import StringIO
url='https://tianqi.2345.com/Pc/GetHistory'
headers={"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0','Referer':'https://tianqi.2345.com/wea_history/58457.htm'}
params={
"areaInfo[areaId]":58457,
"areaInfo[areaType]":2,
"date[year]":2025,
"date[month]":4
}
r=requests.get(url,headers=headers,params=params) #请求头和参数都为字典类型
if r.status_code!=200:raise Exception('error')
data=r.json()["data"] #r.json()方法会将返回的JSON格式的响应解析为一个Python对象(一般为字典/列表),我们取出‘data’键的值(是字符串)
data=StringIO(data) #使用StringIO对象来包装HTML字符串,可以将字符串视为文件来读取
df=pd.read_html(data)[0] #pd.read_html()方法可以解析一个网页中所有的表格,返回一个列表,里面的元素是DataFrame的数据结构
print(df)这样我们单个的网页就爬取成功了,输出如下

我们现在来爬取1-5月的数据,根据前面的分析,只需要将参数改一下就可以了
import requests
import pandas as pd
from io import StringIO
url='https://tianqi.2345.com/Pc/GetHistory'
headers={"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0','Referer':'https://tianqi.2345.com/wea_history/58457.htm'}
def craw_weather(month):params={"areaInfo[areaId]":58457,"areaInfo[areaType]":2,"date[year]":2025,"date[month]":month}r=requests.get(url,headers=headers,params=params) if r.status_code!=200:raise Exception('error')data=r.json()["data"]data=StringIO(data) df=pd.read_html(data)[0] return df
lst=[] #里面是每个月的df数据
for n in range(1,6):df=craw_weather(n)lst.append(df)
datas=pd.concat(lst) #pd.concat()方法用于将多个Pandas对象(DataFrame或Series)沿着特定轴连接起来,非常灵活,可以用于行连接、列连接等多种操作
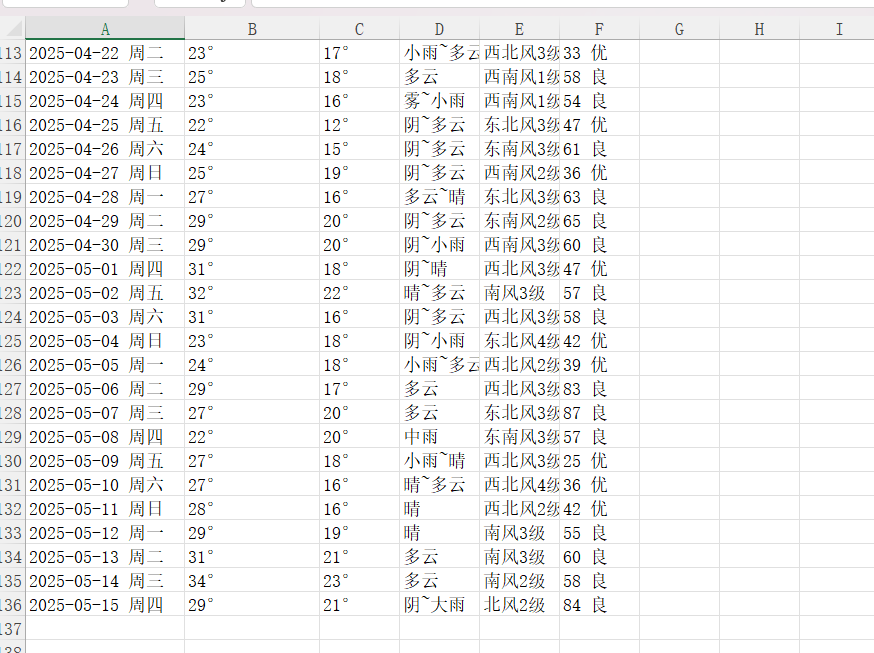
datas.to_excel('杭州1-5月天气数据.xlsx',index=False) #Pandas在将df保存为Excel时,会将df的索引作为单独的一列写入文件,设置index=False可以不包含索引列
展示如下,昨天的数据都有了
批量爬取正本小说
整本小说稍微有点多了,我们就拿番茄小说的top1为例吧,爬取前10章的内容,先批量爬取每一章的链接和章节名称,再根据链接爬取正文,最后将文章写到文件中去
网页地址为十日终焉完整版在线免费阅读_十日终焉小说_番茄小说官网
直接检索元素哈,可以发现所有章节都在特定的<div>标签下
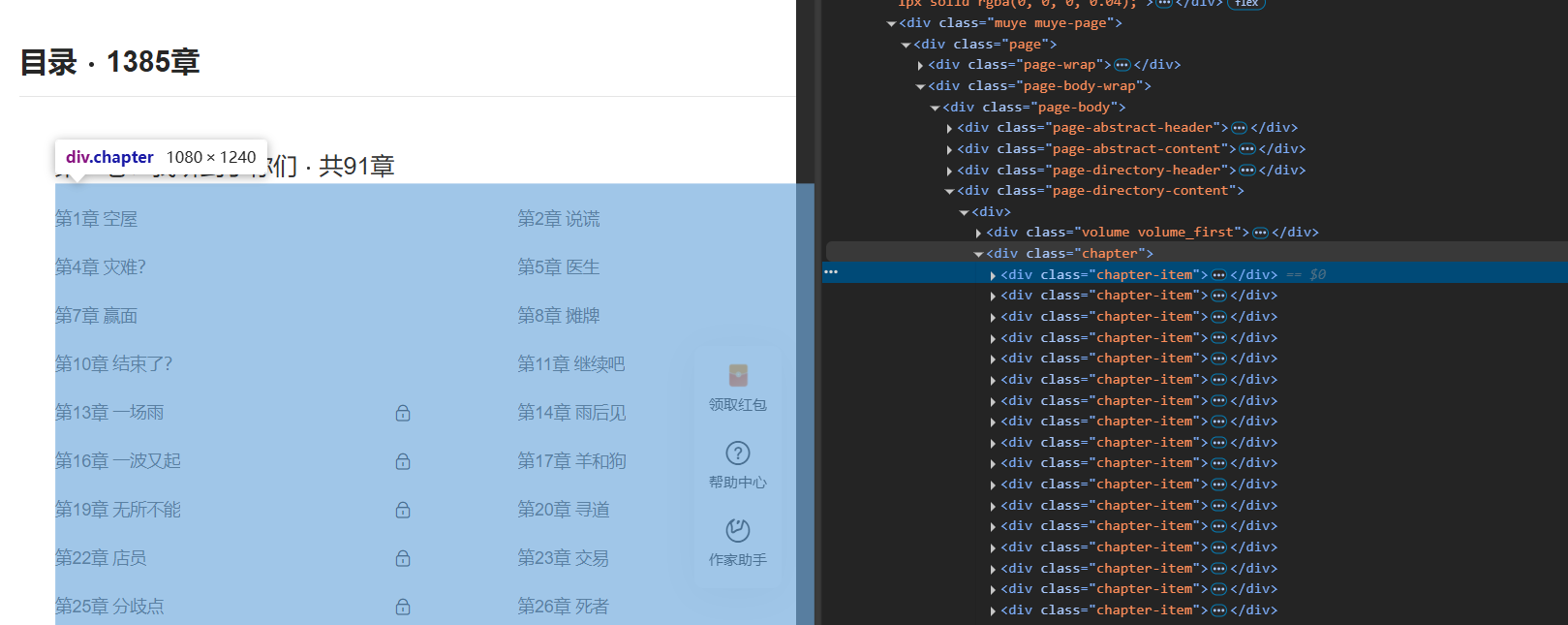
文章内容也在特定<div>标签下
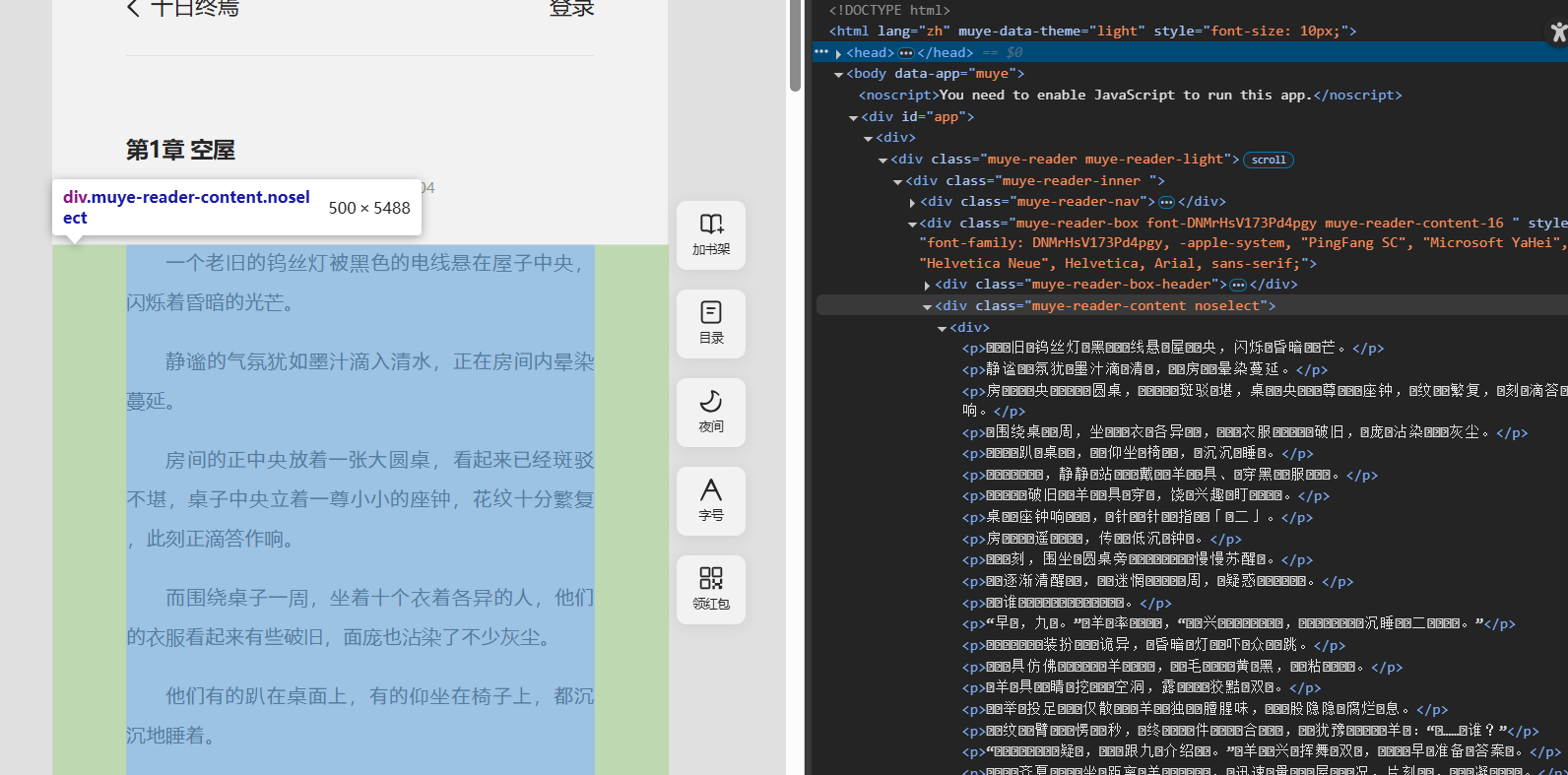 代码如下
代码如下
import requests
from bs4 import BeautifulSoup
def get_urls():root_url='https://fanqienovel.com/page/7143038691944959011'r=requests.get(root_url)if r.status_code!=200:raise Exception('error')soup=BeautifulSoup(r.text,"html.parser")datas=[]n=0for chapter in soup.find('div',class_='chapter').find_all('a'):if n==10:breakdatas.append(['https://fanqienovel.com'+chapter['href'],chapter.get_text()])n+=1return datas
def get_chapter(url):r=requests.get(url)if r.status_code!=200:raise Exception('error')soup=BeautifulSoup(r.text,"html.parser")content=soup.find('div',"muye-reader-content noselect").get_text()return content
for urls in get_urls():url,title=urlswith open(f'{title}.txt','w',encoding='utf-8') as ch: #写入文件ch.write(get_chapter(url))展示如下

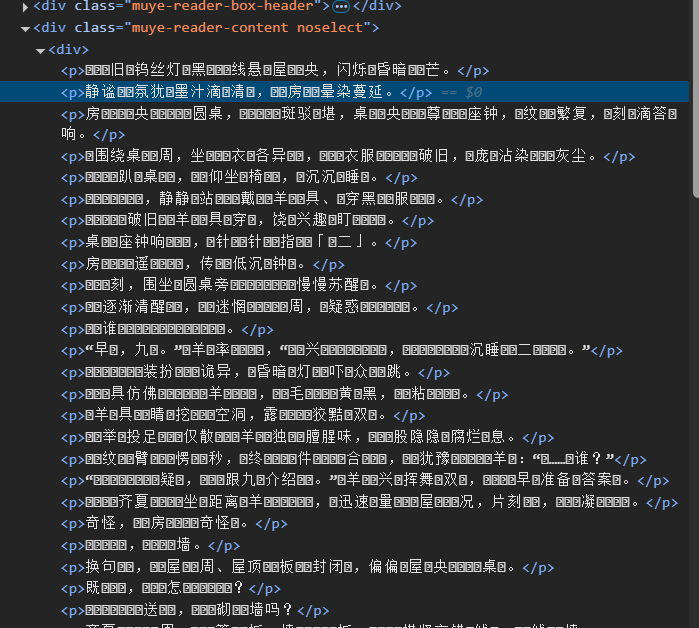
最后文章字符是乱码,因为网页源代码就是乱码的,查看<head>标签里的charset,编码就是‘utf-8’每错,主包也尝试了几种方法还是不能正常显示,可能浏览器可能会对显示的内容进行一些渲染或转换,我们讲到后面再来尝试
 那爬这个有什么用呢? 有些盗版网站不是小广告很多嘛,那你就可以把文章爬下来看咯~
那爬这个有什么用呢? 有些盗版网站不是小广告很多嘛,那你就可以把文章爬下来看咯~
相关文章:
python爬虫实战训练
前言:哇,今天终于能访问豆瓣了,前几天爬太多次了,网页都不让我访问了(要登录)。 先来个小练习试试手吧! 爬取豆瓣第一页(多页同上篇文章)所有电影的排名、电影名称、星…...
)
[特殊字符]CentOS 7.6 安装 JDK 11(适配国内服务器环境)
在国内服务器(如阿里云、腾讯云)中安装 JDK 11 时,可能由于访问 Oracle 官网较慢导致下载不便。本文将详细介绍如何在 CentOS 7.6 上安装 OpenJDK 11 和 Oracle JDK 11,并推荐使用国内镜像源加速安装过程。 🧩 目录 一…...
Redis(三) - 使用Java操作Redis详解
文章目录 前言一、创建项目二、导入依赖三、键操作四、字符串操作五、列表操作六、集合操作七、哈希表操作八、有序集合操作九、完整代码1. 完整代码2. 项目下载 前言 本文主要介绍如何使用 Java 操作 Redis 数据库,涵盖项目创建、依赖导入及 Redis 各数据类型&…...

【全网首发】解决coze工作流批量上传excel数据文档数据重复的问题
注意:目前方法将基于前一章批量数据库导入的修改!!!!请先阅读上篇文章的操作。抄袭注明来源 背景 上一节说的方法可以批量导入文件到数据库,但是无法解决已经上传的条目更新问题。简单来说,不…...

高效异步 TCP/UDP 服务器设计:低延迟与高吞吐量实现指南
高效异步 TCP/UDP 服务器设计:低延迟与高吞吐量实现指南 1. 引言 在现代高并发网络环境中,如何设计一个低延迟且高吞吐量的 TCP/UDP 服务器成为了关键问题。从游戏服务器、实时数据处理,到高性能 API 网关,异步编程架构的选择至关重要。 在这篇文章中,我们将深入探讨如…...
xss-labs靶场第11-14关基础详解
前言: 目录 第11关 第12关 第13关前期思路: 第十四关 内容: 第11关 也和上一关一样,什么输入框都没有,也就是 也是一样的操作,先将这里的hidden属性删掉一个,注意是删掉一个 输入1111&a…...
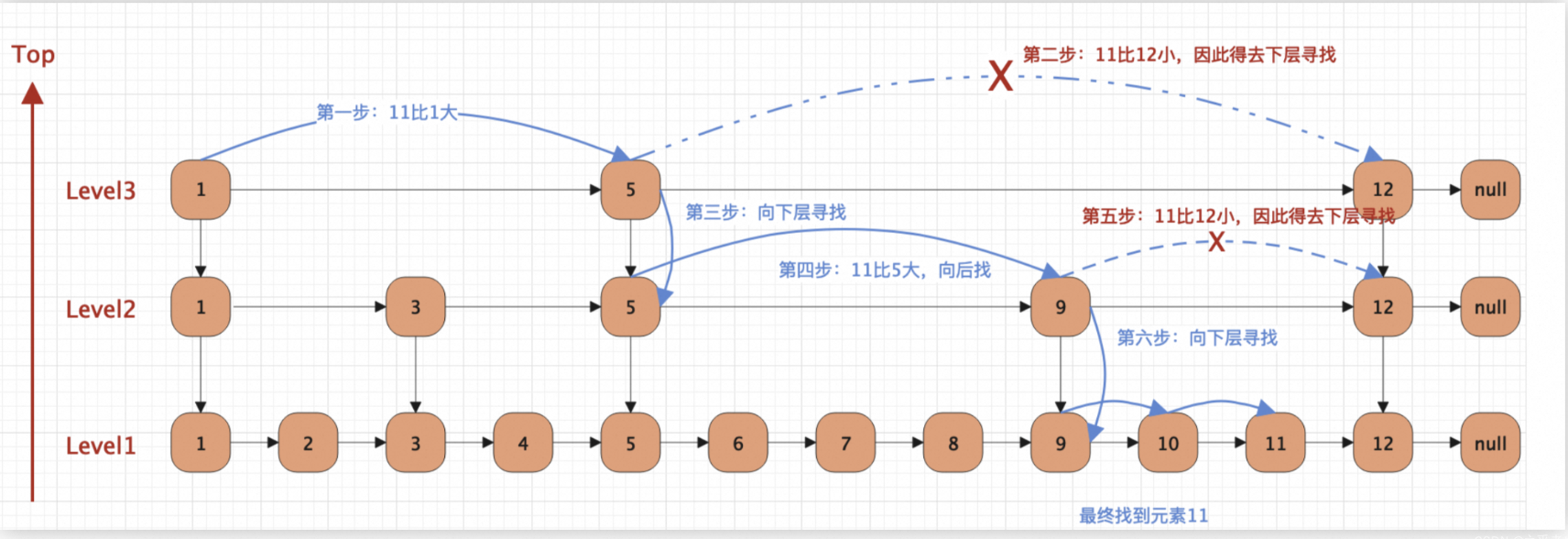
ConcurrentSkipListMap的深入学习
目录 1、介绍 1.1、线程安全 1.2、有序性 1.3、跳表数据结构 1.4、API 提供的功能 1.5、高效性 1.6、应用场景 2、数据结构 2.1、跳表(Skip List) 2.2、节点类型: 1.Node 2.Index 3.HeadIndex 2.3、特点 3、选择层级 3.1、随…...

XML简要介绍
实际上现在的Java Web项目中更多的是基于springboot开发的,所以很少再使用xml去配置项目。所以我们的目的就是尽可能快速的去了解如何读懂和使用xml文件,对于DTD,XMLSchema这类约束的学习可以放松,主要是确保自己知道这里面的大致…...

什么是直播美颜SDK?美颜技术底层算法科普
当下,不论是社交直播、电商直播,还是线上教学、虚拟主播场景,都离不开美颜技术的加持。虽然大家在日常使用直播APP时经常体验到美颜效果,但背后的技术原理却相对复杂。本篇文章小编将为大家揭开直播美颜SDK的神秘面纱,…...
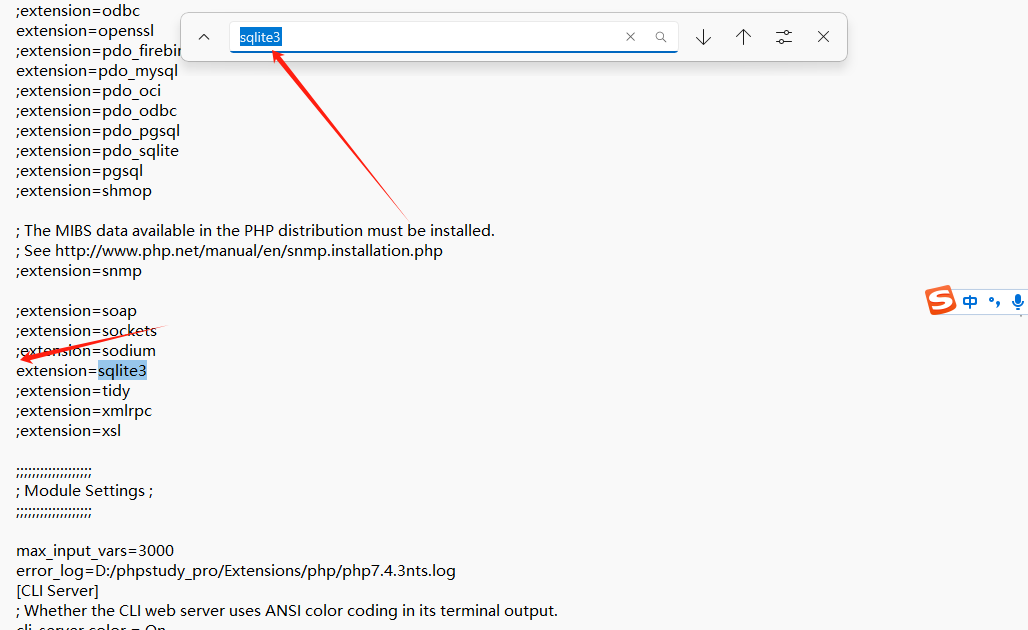
【pbootcms】打开访问首页显示未检测到您服务器环境的sqlite3数据库拓展,请检查php.ini中是否已经开启该拓展
【pbootcms】新建网站,新放的程序,打开访问首页显示未检测到您服务器环境的sqlite3数据库拓展,请检查php.ini中是否已经开启该拓展。 检查目前网站用到哪个版本的php,然后打开相关文件。 修改一下内容: 查找sqlite3,…...

MySQL——十、InnoDB引擎
MVCC 当前读: 读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。 -- 当前读 select ... lock in share mode(共享锁) select ... for update update insert delete (排他锁)快照读:…...
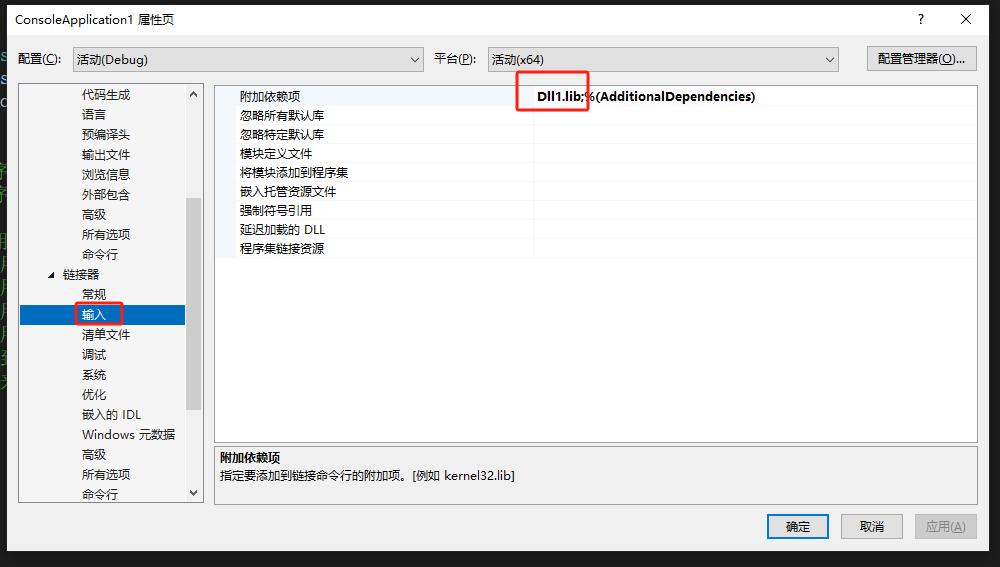
visual studio生成动态库DLL
visual studio生成动态库DLL 创建动态库工程 注意 #include “pch.h” 要放在上面 完成后点击生成 创建一个控制台项目 设置项目附加目录为刚才创建的动态库工程Dll1: 配置附加库目录: 配置动态库的导入库(.lib):链…...
IDEA中git对于指定文件进行版本控制
最近在自己写代码的时候遇到了和公司里面不一样的,自己写的代码推到码云上是,会默认对于所有修改都进行提交,这样再提交的时候很不方便。 问了问ai,表示可以手动创建脚本实现,但是ai曲解了我的意思,它实现…...

用Python绘制梦幻星空
用Python绘制梦幻星空 在这篇教程中,我们将学习如何使用Python创建一个美丽的星空场景。我们将使用Python的图形库Pygame和随机库来创建闪烁的星星、流星和月亮,打造一个动态的夜空效果。 项目概述 我们将实现以下功能: 创建深蓝色的夜…...
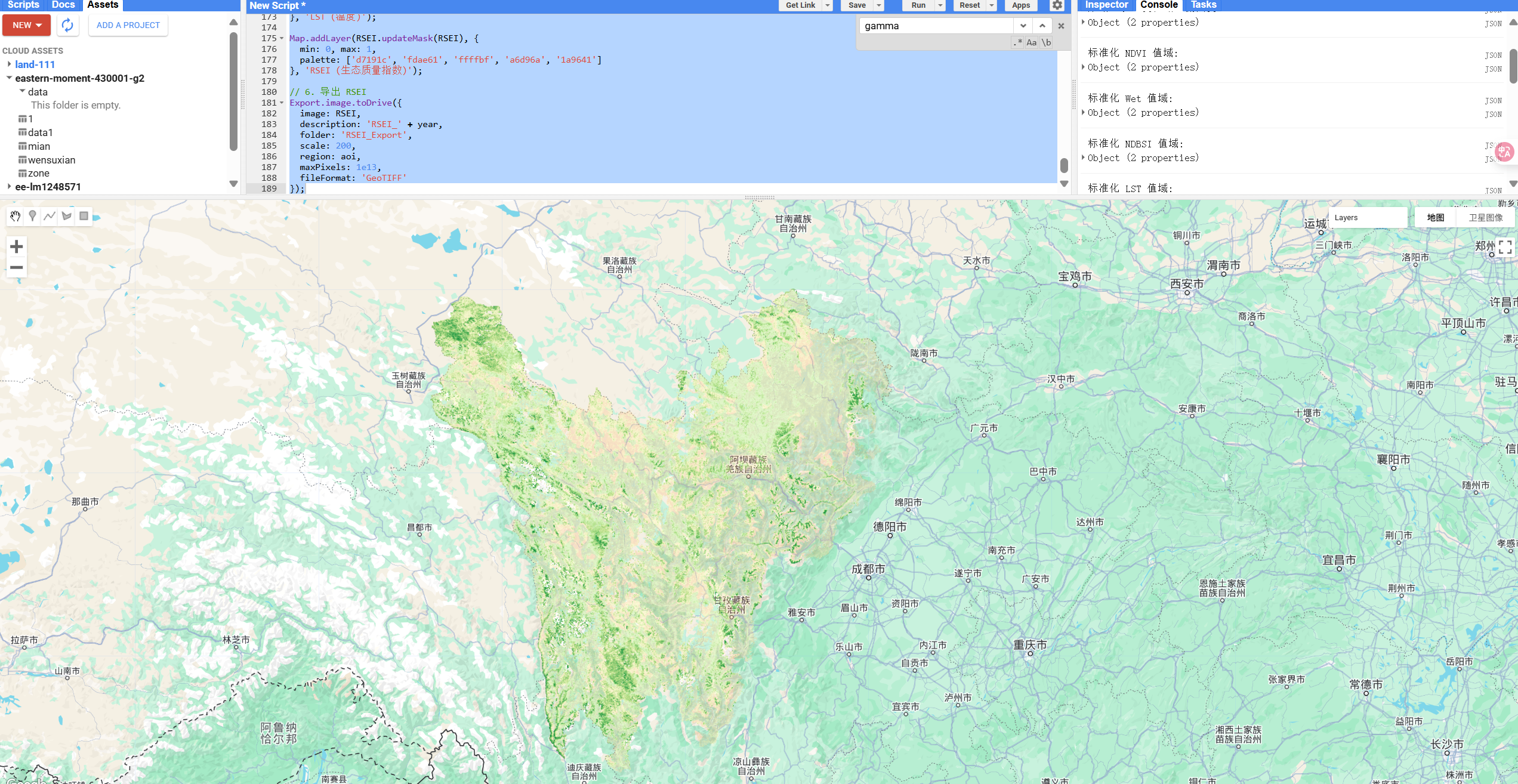
GEE计算 RSEI(遥感生态指数)
🛰️ 什么是 RSEI?为什么要用它评估生态环境? RSEI(遥感生态指数,Remote Sensing Ecological Index) 是一种通过遥感数据计算得到的、综合反映区域生态环境质量的指标体系。 它的设计初衷是用最少的变量&…...

Java 泛型与类型擦除:为什么解析对象时能保留泛型信息?
引言:泛型的“魔术”与类型擦除的困境 在 Java 中,泛型为开发者提供了类型安全的集合操作,但其背后的**类型擦除(Type Erasure)**机制却常常让人困惑。你是否遇到过这样的场景? List<String> list …...
_yxy)
达梦数据库多版本并发控制(MVCC)_yxy
达梦数据库多版本并发控制 1 多版本并发控制解决了什么问题?2 达梦MVCC实现方式2.1 版本链结构2.1.1 物理记录2.1.2 回滚记录2.1.3 版本链实现方式 2.2 可见性原则2.3 历史数据获取 1 多版本并发控制解决了什么问题? MVCC(Multi-Version Con…...

math.js 加/减/乘/除 使用
math.js 加/减/乘/除 使用 安装 npm install mathjs引入 import * as math from "mathjs";使用 // 加法 let addNumber math.add( math.bignumber(0.1), math.bignumber(0.3)) // 加法 保留两位小数 let addNumber1 math.format(math.add( math.bignumber(0.1…...
python的家教课程管理系统
目录 技术栈介绍具体实现截图系统设计研究方法:设计步骤设计流程核心代码部分展示研究方法详细视频演示试验方案论文大纲源码获取/详细视频演示 技术栈介绍 Django-SpringBoot-php-Node.js-flask 本课题的研究方法和研究步骤基本合理,难度适中…...

计算机组成原理——数据的表示
2.1数据的表示 整理自Beokayy_ 1.进制转换 十六进制与二进制的转换 一位十六进制等于四位二进制 四位二进制等于一位十六进制 0x173A4C0001 0111 0011 1010 0100 1100 十六进制与十进制的转换 十六转十:每一位数字乘以相应的16的幂再相加 十转十六:…...
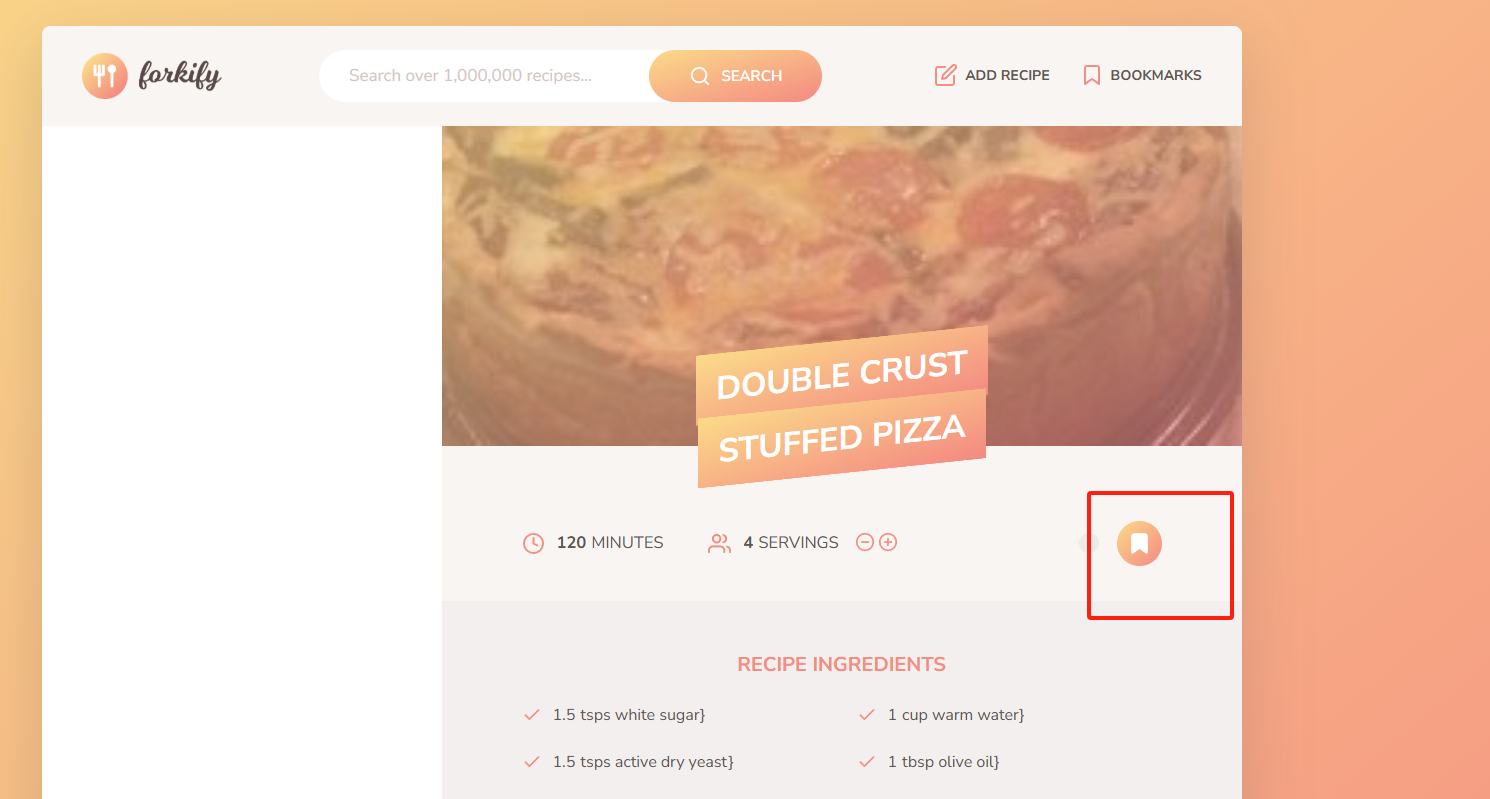
实现书签-第一部分
实现书签-第一部分 本节我们将实现书签功能,为菜谱点击类似于收藏的功能,然后可以在上方的书签找到我们所有收藏的书签; 在此之前,让我们修复一下之前的功能BUG,当我们搜索的时候,下面分页始终保持在上一…...
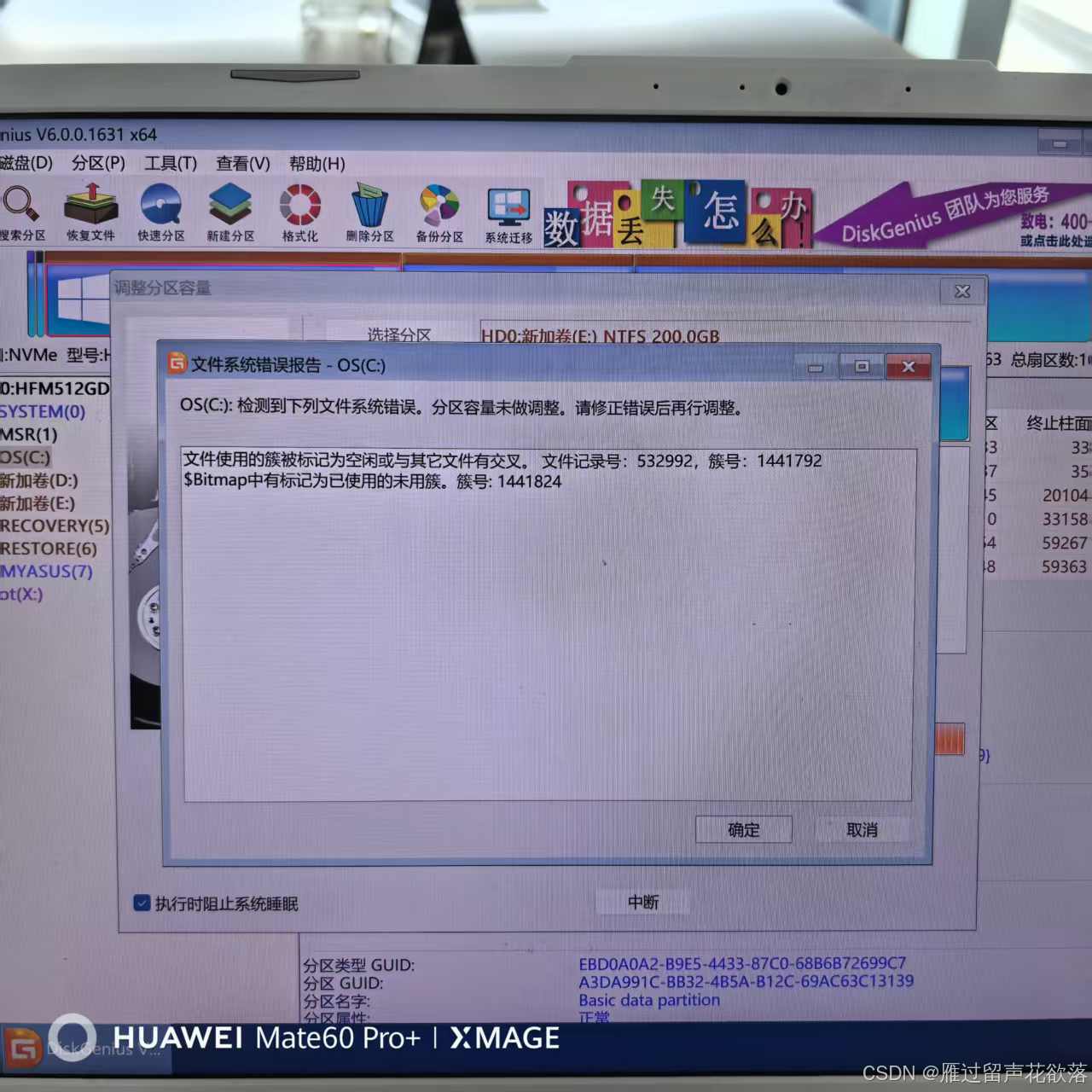
解决将其他盘可用空间,移植到C盘
第一步首先下载安装 用来扩内存盘的实用工具资源-CSDN文库 第二步打开diskgenius.exe 第三步选中想扩容的盘 右击-》选择扩容分区-》选择要缩小的分区-》然后确定 第四步拖拽对勾的地方 或者在箭头地方输入想阔的大小,然后开始,一直确定,就…...
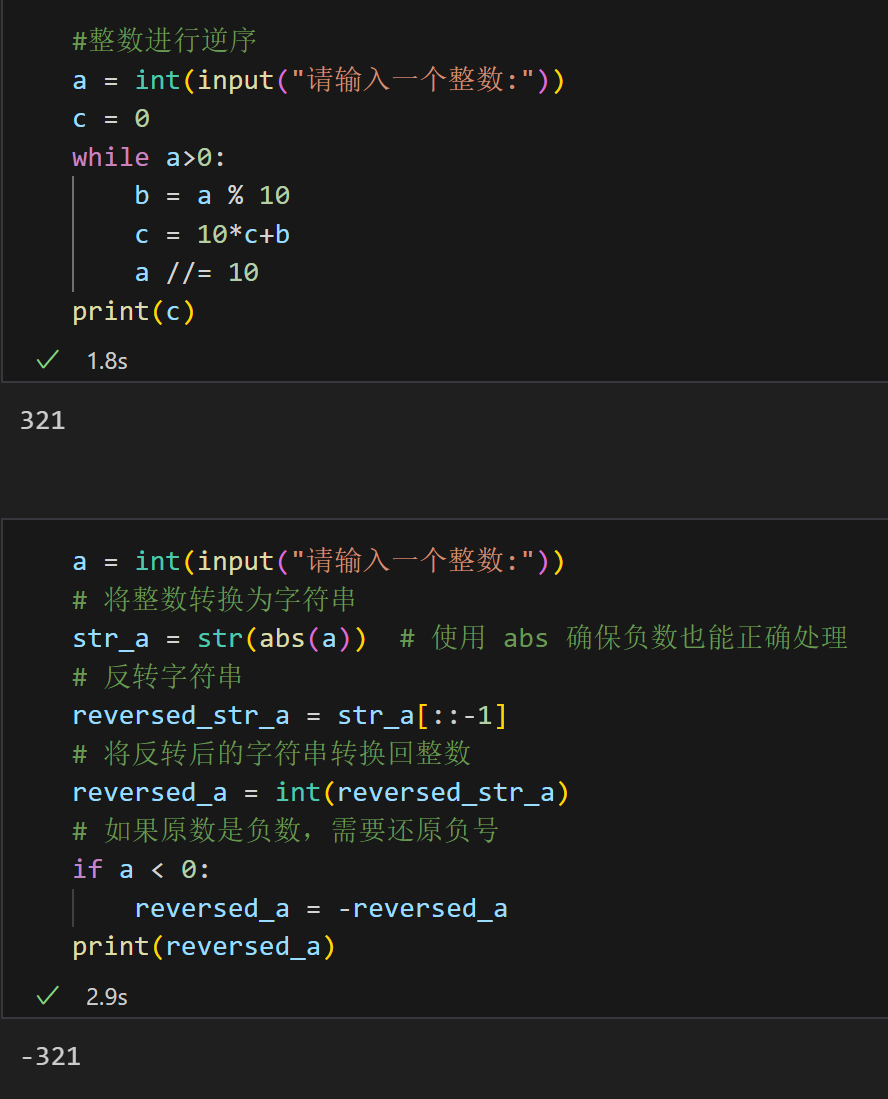
第二天的尝试
目录 一、每日一言 二、练习题 三、效果展示 四、下次题目 五、总结 一、每日一言 清晰的明白自己想要的是什么,培养兴趣也好,一定要有自己的一技之长。我们不说多优秀,但是如果父母需要我们出力,不要只有眼泪。 二、练习题 对…...
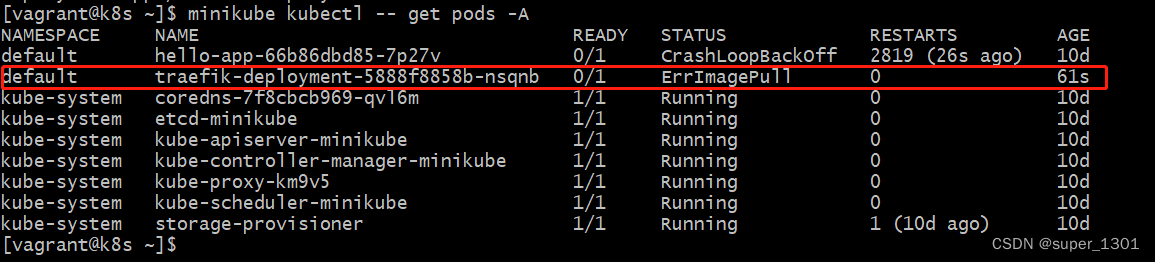
k8s灰度发布
基于 Traefik 的加权灰度发布-腾讯云开发者社区-腾讯云 Traefik | Traefik | v1.7 Releases traefik/traefik GitHub 从上面连接下载后上传到harbor虚拟机 vagrant upload /C/Users/HP280/Downloads/traefik 下载配置文件 wget -c http://raw.githubusercontent.com/conta…...

前端面经 9 JS中的继承
借用Class实现继承 实现继承 extends super extends 继承父类 super调用父类的构造函数 子类中存在方法采取就近原则 ,子类构造函数需要使用super()调用父类的构造函数 JS 静态属性和私有属性 寄生组合式继承...
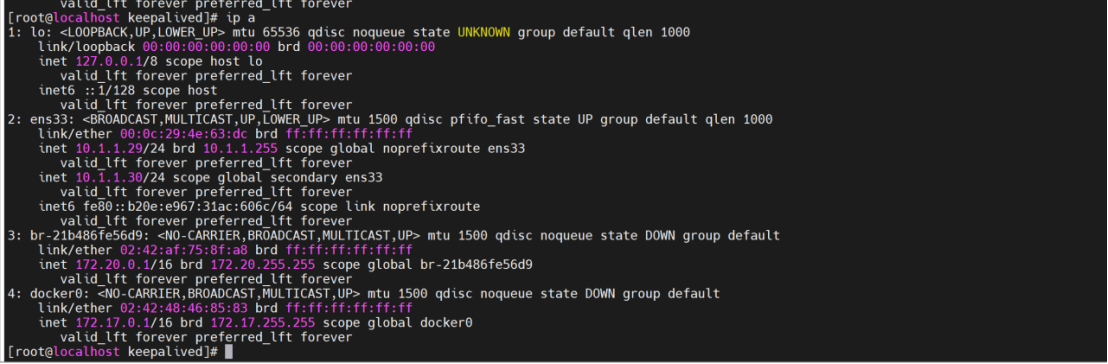
memcached主主复制+keepalive
一、Memcached主主复制技术原理 Memcached原生不支持复制,需通过repcached分支实现双向同步。其关键机制包括: 双向同步架构 两节点互为主备(Master-Master),任意节点写入的数据会同步至对端。同步基于TCP协议&#x…...

光学设计核心
光学设计核心技术全流程教学:从理论建模到工程实践 一、光学设计基础理论体系构建 1.1 光线传播核心定律 • 斯涅尔定律:n_1\sin\theta_1 n_2\sin\theta_2,通过编程实现折射角动态计算(Python示例): im…...

使用 `aiohttp` 构建高效的异步网络爬虫系统
使用 aiohttp 构建高效的异步网络爬虫系统 引言 在爬取大量网页时,传统同步方法(如 requests)可能面临网络 I/O 阻塞问题,导致性能低下。而 Python 的 aiohttp 结合 asyncio 提供了一种高效的解决方案,使得爬虫可以同时处理多个请求,大幅提升数据抓取速度。 本文将详细…...

Microsoft Azure 服务4月更新告示
由世纪互联运营的 Microsoft Azure 重要更新 名称变更 Azure Stack HCI现已正式更名为Azure Local,并成为其重要组成部分。Azure Local是一种超融合基础设施(HCI)解决方案,专为托管Windows和Linux虚拟机(VMÿ…...
idea运行
各种小kips Linuxidea上传 Linux 部署流程 1、先在idea打好jar包,clean之后install 2、在Linux目录下,找到对应项目目录,把原来的jar包放在bak文件夹里面 3、杀死上一次jar包的pid ps -ef|grep cliaidata.jar kill pid 4、再进行上传新的jar…...