[模型部署] 3. 性能优化
👋 你好!这里有实用干货与深度分享✨✨ 若有帮助,欢迎:
👍 点赞 | ⭐ 收藏 | 💬 评论 | ➕ 关注 ,解锁更多精彩!
📁 收藏专栏即可第一时间获取最新推送🔔。
📖后续我将持续带来更多优质内容,期待与你一同探索知识,携手前行,共同进步🚀。

性能优化
本文介绍深度学习模型部署中的性能优化方法,包括模型量化、模型剪枝、模型蒸馏、混合精度训练和TensorRT加速等技术,以及具体的实现方法和最佳实践,帮助你在部署阶段获得更高的推理效率和更低的资源消耗。
1. 模型量化
| 量化类型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 静态量化 | - 精度损失小 - 推理速度快 - 内存占用小 | - 需要校准数据 - 实现复杂 | - 对精度要求高 - 资源受限设备 |
| 动态量化 | - 实现简单 - 无需校准数据 - 灵活性高 | - 精度损失较大 - 加速效果有限 | - 快速部署 - RNN/LSTM模型 |
| 量化感知训练 | - 精度最高 - 模型适应量化 | - 需要重新训练 - 开发成本高 | - 高精度要求 - 大规模部署 |
1.1 PyTorch静态量化
静态量化在模型推理前完成权重量化,适用于对精度要求较高的场景,需提供校准数据。
import torch
from torch.quantization import get_default_qconfig
from torch.quantization.quantize_fx import prepare_fx, convert_fxdef quantize_model(model, calibration_data):# 设置量化配置(fbgemm用于x86架构,qnnpack用于ARM架构)qconfig = get_default_qconfig('fbgemm') qconfig_dict = {"":qconfig}# 准备量化(插入观察节点)model_prepared = prepare_fx(model, qconfig_dict)# 校准(收集激活值的分布信息)for data in calibration_data:model_prepared(data)# 转换为量化模型(替换浮点运算为整数运算)model_quantized = convert_fx(model_prepared)return model_quantized# 使用示例
model = YourModel()
model.eval() # 量化前必须设置为评估模式
calibration_data = get_calibration_data() # 获取校准数据
quantized_model = quantize_model(model, calibration_data)# 保存量化模型
torch.jit.save(torch.jit.script(quantized_model), "quantized_model.pt")
1.2 动态量化
动态量化在推理过程中动态计算激活值的量化参数,操作简单,特别适用于线性层和RNN。
import torch
import torch.quantizationdef dynamic_quantize(model):# 应用动态量化(仅量化权重,激活值在运行时量化)quantized_model = torch.quantization.quantize_dynamic(model,{torch.nn.Linear, torch.nn.LSTM, torch.nn.GRU}, # 量化的层类型dtype=torch.qint8 # 量化数据类型)return quantized_model# 验证量化效果
def verify_quantization(original_model, quantized_model, test_input):# 比较输出结果with torch.no_grad():original_output = original_model(test_input)quantized_output = quantized_model(test_input)# 计算误差error = torch.abs(original_output - quantized_output).mean()print(f"平均误差: {error.item()}")# 比较模型大小original_size = get_model_size_mb(original_model)quantized_size = get_model_size_mb(quantized_model)print(f"原始模型大小: {original_size:.2f} MB")print(f"量化模型大小: {quantized_size:.2f} MB")print(f"压缩比: {original_size/quantized_size:.2f}x")return error.item()# 获取模型大小(MB)
def get_model_size_mb(model):torch.save(model.state_dict(), "temp.p")size_mb = os.path.getsize("temp.p") / (1024 * 1024)os.remove("temp.p")return size_mb
1.3 量化感知训练
量化感知训练在训练过程中模拟量化效果,使模型适应量化带来的精度损失。
import torch
from torch.quantization import get_default_qat_qconfig
from torch.quantization.quantize_fx import prepare_qat_fx, convert_fxdef quantization_aware_training(model, train_loader, epochs=5):# 设置量化感知训练配置qconfig = get_default_qat_qconfig('fbgemm')qconfig_dict = {"":qconfig}# 准备量化感知训练model_prepared = prepare_qat_fx(model, qconfig_dict)# 训练optimizer = torch.optim.Adam(model_prepared.parameters())criterion = torch.nn.CrossEntropyLoss()for epoch in range(epochs):for inputs, targets in train_loader:optimizer.zero_grad()outputs = model_prepared(inputs)loss = criterion(outputs, targets)loss.backward()optimizer.step()# 转换为量化模型model_quantized = convert_fx(model_prepared)return model_quantized
2. 模型剪枝
| 剪枝类型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 结构化剪枝 | - 硬件友好 - 实际加速效果好 - 易于实现 | - 精度损失较大 - 压缩率有限 | - 计算密集型模型 - 需要实际加速 |
| 非结构化剪枝 | - 高压缩率 - 精度损失小 - 灵活性高 | - 需要特殊硬件/库支持 - 实际加速有限 | - 存储受限场景 - 可接受稀疏计算 |
2.1 结构化剪枝
结构化剪枝移除整个卷积核或通道,可直接减少模型参数量和计算量,提升推理速度。
import torch
import torch.nn.utils.prune as prunedef structured_pruning(model, amount=0.5):# 按通道剪枝for name, module in model.named_modules():if isinstance(module, torch.nn.Conv2d):prune.ln_structured(module,name='weight',amount=amount, # 剪枝比例n=2, # L2范数dim=0 # 按输出通道剪枝)return modeldef fine_tune_pruned_model(model, train_loader, epochs=5):# 剪枝后微调恢复精度optimizer = torch.optim.Adam(model.parameters())criterion = torch.nn.CrossEntropyLoss()for epoch in range(epochs):for inputs, targets in train_loader:optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, targets)loss.backward()optimizer.step()return modeldef remove_pruning(model):# 移除剪枝,使权重永久化for name, module in model.named_modules():if isinstance(module, torch.nn.Conv2d):prune.remove(module, 'weight')return model
2.2 非结构化剪枝
非结构化剪枝(细粒度剪枝)可获得更高稀疏率,但对硬件加速支持有限。
def fine_grained_pruning(model, threshold=0.1):# 按权重大小剪枝for name, module in model.named_modules():if isinstance(module, torch.nn.Conv2d) or isinstance(module, torch.nn.Linear):# 创建掩码:保留绝对值大于阈值的权重mask = torch.abs(module.weight.data) > threshold# 应用掩码module.weight.data *= maskreturn model# 评估剪枝效果
def evaluate_sparsity(model):total_params = 0zero_params = 0for name, param in model.named_parameters():if 'weight' in name: # 只考虑权重参数total_params += param.numel()zero_params += (param == 0).sum().item()sparsity = zero_params / total_paramsprint(f"模型稀疏度: {sparsity:.2%}")print(f"非零参数数量: {total_params - zero_params:,}")print(f"总参数数量: {total_params:,}")return sparsity
3. 模型蒸馏
| 蒸馏类型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 响应蒸馏 | - 实现简单 - 效果稳定 | - 信息损失 - 依赖教师质量 | - 分类任务 - 小型模型训练 |
| 特征蒸馏 | - 传递更多信息 - 效果更好 | - 实现复杂 - 需要匹配特征 | - 复杂任务 - 深层网络 |
| 关系蒸馏 | - 保留样本关系 - 泛化性好 | - 计算开销大 | - 度量学习 - 表示学习 |
3.1 知识蒸馏
通过教师模型指导学生模型训练,实现模型压缩和加速。
import torch
import torch.nn as nn
import torch.nn.functional as Fclass DistillationLoss(nn.Module):def __init__(self, temperature=4.0, alpha=0.5):super().__init__()self.temperature = temperature # 温度参数控制软标签的平滑程度self.alpha = alpha # 平衡硬标签和软标签的权重self.ce_loss = nn.CrossEntropyLoss()self.kl_loss = nn.KLDivLoss(reduction='batchmean')def forward(self, student_logits, teacher_logits, labels):# 硬标签损失(学生模型与真实标签)ce_loss = self.ce_loss(student_logits, labels)# 软标签损失(学生模型与教师模型输出)soft_teacher = F.softmax(teacher_logits / self.temperature, dim=1)soft_student = F.log_softmax(student_logits / self.temperature, dim=1)kd_loss = self.kl_loss(soft_student, soft_teacher)# 总损失 = (1-α)·硬标签损失 + α·软标签损失total_loss = (1 - self.alpha) * ce_loss + \self.alpha * (self.temperature ** 2) * kd_lossreturn total_lossdef train_with_distillation(teacher_model, student_model, train_loader, epochs=10):teacher_model.eval() # 教师模型设为评估模式student_model.train() # 学生模型设为训练模式criterion = DistillationLoss(temperature=4.0, alpha=0.5)optimizer = torch.optim.Adam(student_model.parameters(), lr=1e-3)for epoch in range(epochs):total_loss = 0for data, labels in train_loader:optimizer.zero_grad()# 教师模型推理(不计算梯度)with torch.no_grad():teacher_logits = teacher_model(data)# 学生模型前向传播student_logits = student_model(data)# 计算蒸馏损失loss = criterion(student_logits, teacher_logits, labels)loss.backward()optimizer.step()total_loss += loss.item()print(f"Epoch {epoch+1}/{epochs}, Loss: {total_loss/len(train_loader):.4f}")return student_model
3.2 特征蒸馏
特征蒸馏通过匹配中间层特征,传递更丰富的知识。
class FeatureDistillationLoss(nn.Module):def __init__(self, alpha=0.5):super().__init__()self.alpha = alphaself.ce_loss = nn.CrossEntropyLoss()self.mse_loss = nn.MSELoss()def forward(self, student_logits, teacher_logits, student_features, teacher_features, labels):# 分类损失ce_loss = self.ce_loss(student_logits, labels)# 特征匹配损失feature_loss = 0for sf, tf in zip(student_features, teacher_features):# 可能需要调整特征维度if sf.shape != tf.shape:sf = F.adaptive_avg_pool2d(sf, tf.shape[2:])feature_loss += self.mse_loss(sf, tf)# 总损失total_loss = (1 - self.alpha) * ce_loss + self.alpha * feature_lossreturn total_loss
4. 混合精度训练与推理
混合精度使用FP16和FP32混合计算,在保持精度的同时提升性能。
# 混合精度训练
import torch
from torch.cuda.amp import autocast, GradScalerdef train_with_mixed_precision(model, train_loader, epochs=10):optimizer = torch.optim.Adam(model.parameters())criterion = torch.nn.CrossEntropyLoss()scaler = GradScaler() # 梯度缩放器,防止FP16下溢for epoch in range(epochs):for inputs, targets in train_loader:inputs, targets = inputs.cuda(), targets.cuda()optimizer.zero_grad()# 使用自动混合精度with autocast():outputs = model(inputs)loss = criterion(outputs, targets)# 缩放梯度以防止下溢scaler.scale(loss).backward()scaler.step(optimizer)scaler.update()return model# 混合精度推理
def inference_with_mixed_precision(model, test_loader):model.eval()results = []with torch.no_grad():with autocast():for inputs in test_loader:inputs = inputs.cuda()outputs = model(inputs)results.append(outputs)return results
5. TensorRT优化
TensorRT可极大提升NVIDIA GPU上的推理速度。
import tensorrt as trt
import numpy as np
import pycuda.driver as cuda
import pycuda.autoinitdef build_engine(onnx_path, engine_path, precision='fp16'):logger = trt.Logger(trt.Logger.WARNING)builder = trt.Builder(logger)network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))parser = trt.OnnxParser(network, logger)# 解析ONNX模型with open(onnx_path, 'rb') as model:if not parser.parse(model.read()):for error in range(parser.num_errors):print(parser.get_error(error))return None# 配置构建器config = builder.create_builder_config()config.max_workspace_size = 1 << 30 # 1GB# 设置精度模式if precision == 'fp16' and builder.platform_has_fast_fp16:config.set_flag(trt.BuilderFlag.FP16)elif precision == 'int8' and builder.platform_has_fast_int8:config.set_flag(trt.BuilderFlag.INT8)# 需要提供校准器进行INT8量化# config.int8_calibrator = ...# 构建引擎engine = builder.build_engine(network, config)# 保存引擎with open(engine_path, 'wb') as f:f.write(engine.serialize())print(f"TensorRT引擎已保存到: {engine_path}")return enginedef inference_with_tensorrt(engine_path, input_data):logger = trt.Logger(trt.Logger.WARNING)# 加载引擎with open(engine_path, 'rb') as f:runtime = trt.Runtime(logger)engine = runtime.deserialize_cuda_engine(f.read())# 创建执行上下文context = engine.create_execution_context()# 获取输入输出绑定信息input_binding_idx = engine.get_binding_index("input")output_binding_idx = engine.get_binding_index("output")# 分配GPU内存input_shape = engine.get_binding_shape(input_binding_idx)output_shape = engine.get_binding_shape(output_binding_idx)input_size = trt.volume(input_shape) * engine.get_binding_dtype(input_binding_idx).itemsizeoutput_size = trt.volume(output_shape) * engine.get_binding_dtype(output_binding_idx).itemsize# 分配设备内存d_input = cuda.mem_alloc(input_size)d_output = cuda.mem_alloc(output_size)# 创建输出数组h_output = cuda.pagelocked_empty(trt.volume(output_shape), dtype=np.float32)# 将输入数据复制到GPUh_input = np.ascontiguousarray(input_data.astype(np.float32).ravel())cuda.memcpy_htod(d_input, h_input)# 执行推理bindings = [int(d_input), int(d_output)]context.execute_v2(bindings)# 将结果复制回CPUcuda.memcpy_dtoh(h_output, d_output)# 重塑输出为正确的形状output = h_output.reshape(output_shape)return output
6. 最佳实践
6.1 量化策略选择
- 静态量化:精度高,需校准数据,适合CNN模型
- 动态量化:实现简单,适合RNN/LSTM/Transformer模型
- 量化感知训练:精度最高,但需要重新训练
- 选择建议:先尝试动态量化,如精度不满足再使用静态量化或量化感知训练
6.2 剪枝方法选择
- 结构化剪枝:规则性好,加速效果明显,适合计算受限场景
- 非结构化剪枝:压缩率高,但需要特殊硬件支持,适合存储受限场景
- 选择建议:优先考虑结构化剪枝,除非对模型大小有极高要求
6.3 蒸馏技巧
- 选择合适的教师模型:教师模型应比学生模型性能显著更好
- 调整温度参数:较高温度(4~10)使知识更软化,有助于传递类间关系
- 平衡硬标签和软标签损失:通常软标签权重0.5~0.9效果较好
- 特征匹配:对于深层网络,匹配中间层特征效果更佳
6.4 混合精度优化
- 训练时使用AMP:自动混合精度可显著加速训练
- 推理时选择合适精度:根据硬件和精度要求选择FP32/FP16/INT8
- 注意数值稳定性:某些操作(如归一化层)保持FP32精度
6.5 部署优化
- 使用TensorRT等推理引擎加速:可获得2~5倍性能提升
- 优化内存访问和批处理大小:根据硬件特性调整
- 模型融合:合并连续操作减少内存访问
- 量化与剪枝结合:先剪枝再量化通常效果更好
6.6 评估和监控
- 全面评估指标:不仅关注精度,还要测量延迟、吞吐量和内存占用
- 测量真实设备性能:在目标部署环境测试,而非仅在开发环境
- 监控资源使用:CPU/GPU利用率、内存占用、功耗等
- 建立性能基准:记录优化前后的各项指标,量化优化效果
6.7 优化流程建议
- 建立基准:记录原始模型性能指标
- 分析瓶颈:识别计算密集或内存密集操作
- 选择策略:根据瓶颈和部署环境选择优化方法
- 渐进优化:从简单到复杂,逐步应用优化技术
- 持续评估:每步优化后评估性能和精度变化
- 权衡取舍:根据应用需求平衡精度和性能
📌 感谢阅读!若文章对你有用,别吝啬互动~
👍 点个赞 | ⭐ 收藏备用 | 💬 留下你的想法 ,关注我,更多干货持续更新!
相关文章:
[模型部署] 3. 性能优化
👋 你好!这里有实用干货与深度分享✨✨ 若有帮助,欢迎: 👍 点赞 | ⭐ 收藏 | 💬 评论 | ➕ 关注 ,解锁更多精彩! 📁 收藏专栏即可第一时间获取最新推送🔔…...

Vue3 加快页面加载速度 使用CDN外部库的加载 提升页面打开速度 服务器分发
介绍 CDN(内容分发网络)通过全球分布的边缘节点,让用户从最近的服务器获取资源,减少网络延迟,显著提升JS、CSS等静态文件的加载速度。公共库(如Vue、React、Axios)托管在CDN上,减少…...

接触感知 钳位电路分析
以下是NG板接触感知电路的原理图。两极分别为P3和P4S,电压值P4S < P3。 电路结构分两部分,第一部分对输入电压进行分压钳位。后级电路使用LM113比较器芯片进行电压比较,输出ST接触感知信号。 钳位电路输出特性分析 输出电压变化趋势&a…...

彻底删除Docker容器中的环境变量
彻底删除Docker容器中的环境变量 前言:环境变量的重要性第一步:创建实验容器第二步:验证环境变量第三步:定位容器"身份证"第四步:修改"出生证明"(重要!)第五步:验证手术成果技术原理深度剖析更安全的替代方案常见问题解答结语:知其然更要知其所以…...
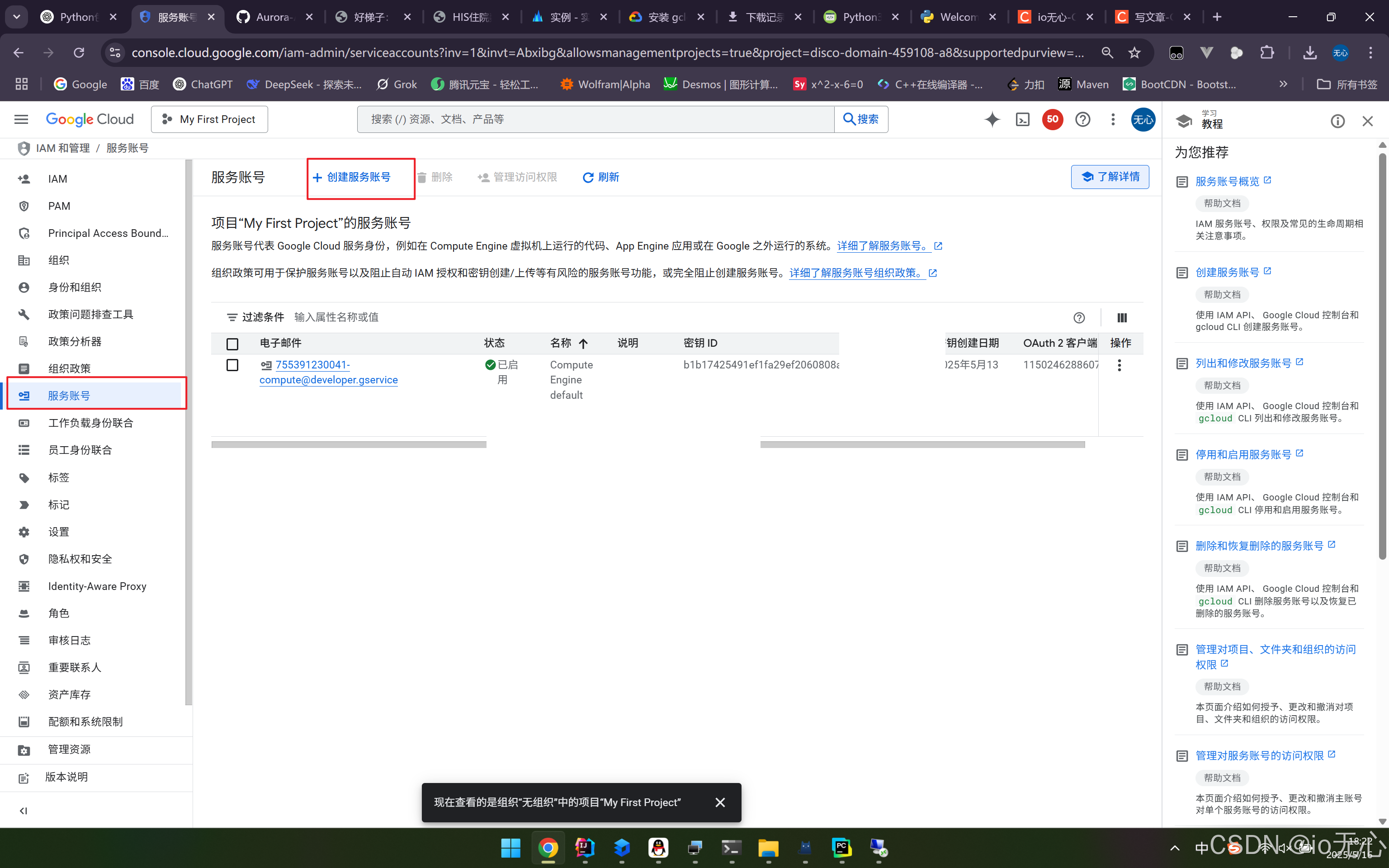
使用 gcloud CLI 自动化管理 Google Cloud 虚拟机
被操作的服务器,一定要开启API完全访问权限,你的电脑安装gcloud CLI前一定要先安装Python3! 操作步骤 下载地址,安装大概需要十分钟:https://cloud.google.com/sdk/docs/install?hlzh-cn#windows 选择你需要的版本&a…...
SQL语句,索引,视图,存储过程以及触发器
一、初识MySQL 1.数据库 按照数据结构来组织、存储和管理数据的仓库;是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合; 2.OLTP与OLAP OLTP( On-Line transaction processing )翻译为联机事务处理&am…...

在Web应用中集成Google AI NLP服务的完整指南:从Dialogflow配置到高并发优化
在当今数字化客服领域,自然语言处理(NLP)技术已成为提升用户体验的关键。Google AI提供了一系列强大的NLP服务,特别是Dialogflow,能够帮助开发者构建智能对话系统。本文将详细介绍如何在Web应用中集成这些服务,解决从模型训练到高并发处理的全套技术挑战。 一、Dialogflow…...
7. 进程控制-进程替换
目录 1. 进程替换 1.1 单进程版: 1.2 进程替换的原理 1.3 多进程版-验证各种程序替换接口 2. 进程替换的各种接口 2.1 execl 2.2 execlp 2.3 execv 2.4 execvp 2.5 execle 1. 进程替换 上图为程序替换的接口,之后会详细介绍。 1.1 单进程版&am…...
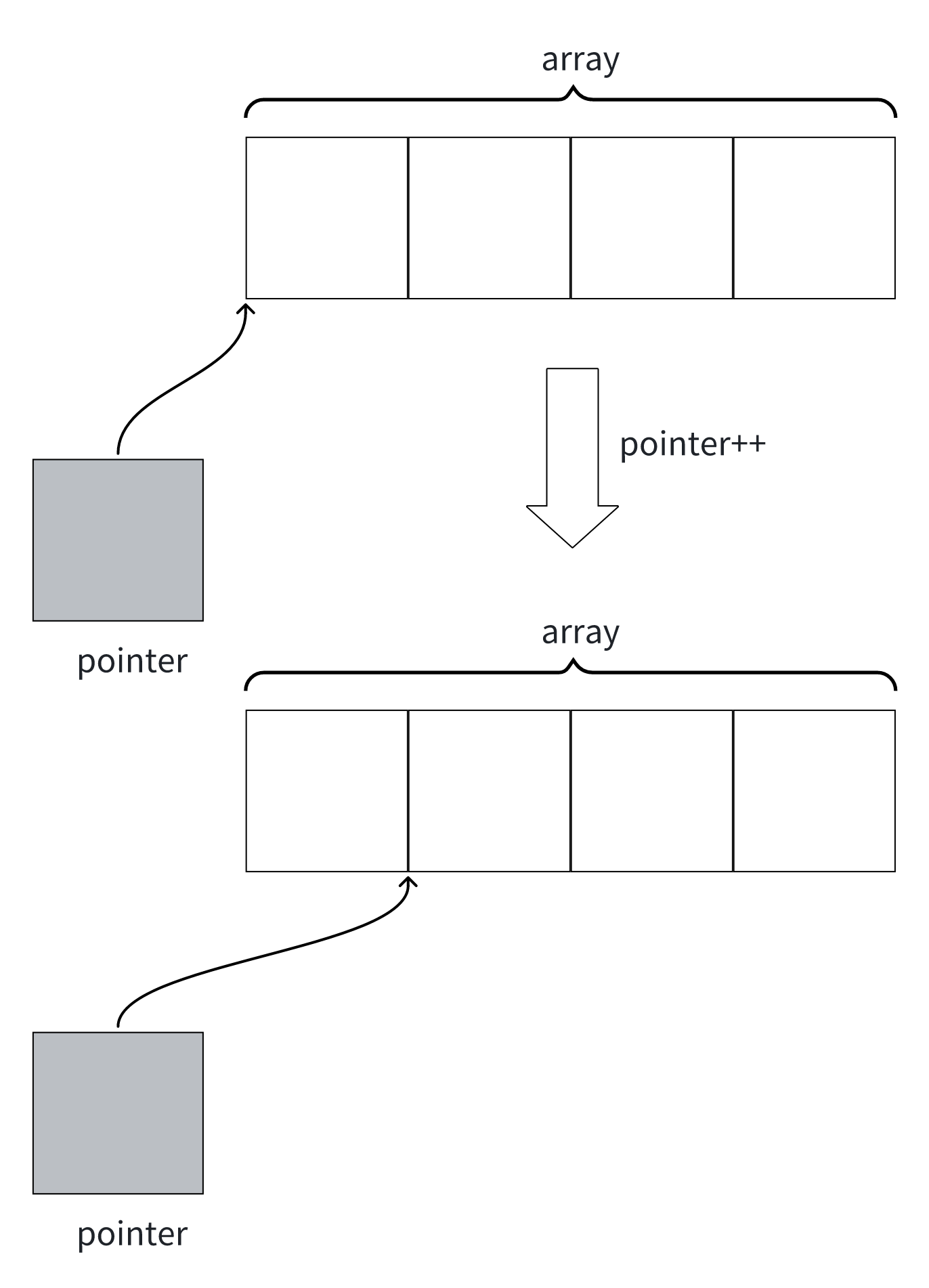
理解 C# 中的各类指针
前言 变量可以理解成是一块内存位置的别名,访问变量也就是访问对应内存中的数据。 指针是一种特殊的变量,它存储了一个内存地址,这个内存地址代表了另一块内存的位置。 指针指向的可以是一个变量、一个数组元素、一个对象实例、一块非托管内存…...

真题卷001——算法备赛
蓝桥杯2024年C/CB组国赛卷 1.合法密码 问题描述 小蓝正在开发自己的OJ网站。他要求用户的密码必须符合一下条件: 长度大于等于8小于等于16必须包含至少一个数字字符和至少一个符号字符 请计算一下字符串,有多少个子串可以当作合法密码。字符串为&am…...

Qt图表库推荐指南与分析
目录 一、核心图表库横向对比1. Qt Charts2. QCustomPlot3. QWT (Qt Widgets for Technical Applications)4. KD Chart二、性能与功能对比矩阵三、选型策略与组合方案1. 通用型需求:2. 技术型场景:3. 企业级开发:四、未来趋势与避坑指南1. 协议风险:2. 技术兼容性:3. 性能…...

【Dv3Admin】工具视图配置文件解析
在开发后台管理系统时,处理复杂的 CRUD 操作是常见的需求。Django Rest Framework(DRF)通过 ModelViewSet 提供了基础的增删改查功能,但在实际应用中,往往需要扩展更多的功能,如批量操作、权限控制、查询优化等。dvadmin/utils/viewset.py 模块通过继承并扩展 ModelViewS…...
Vue3中实现轮播图
目录 1. 轮播图介绍 2. 实现轮播图 2.1 准备工作 1、准备至少三张图片,并将图片文件名改为数字123 2、搭好HTML的标签 3、写好按钮和图片标签 编辑 2.2 单向绑定图片 2.3 在按钮里使用方法 2.4 运行代码 3. 完整代码 1. 轮播图介绍 首先,什么是…...

C#中UI线程的切换与后台线程的使用
文章速览 UI线程切换示例 后台线程使用示例 两者对比适用场景Application.Current.Dispatcher.InvokeTask.Factory.StartNew 执行同步性Application.Current.Dispatcher.InvokeTask.Factory.StartNew 一个赞,专属于你的足迹! UI线程切换 在WPF应用程序…...
微信小程序 自定义图片分享-绘制数据图片以及信息文字
一 、需求 从数据库中读取头像,姓名电话等信息,当分享给女朋友时,每个信息不一样 二、实现方案 1、先将数据库中需要的头像姓名信息读取出来加载到data 数据项中 data:{firstName:, // 姓名img:, // 头像shareImage:,// 存储临时图片 } 2…...

优艾智合机器人助力半导体智造,领跑国产化替代浪潮
在全球半导体产业加速自动化转型的背景下,传统物流已成为制约智能化升级的关键瓶颈。作为中国移动机器人行业的领军企业,优艾智合(YOUIBOT)自2017年起就敏锐洞察到"半导体设备国产化"的紧迫需求,依托在工业移…...

关于 TCP 端口 445 的用途以及如何在 Windows 10 或 11 上禁用它
TCP 端口 445 主要用于直接通过 TCP/IP 访问 Microsoft 网络,无需使用 NetBIOS 层。此服务自 Windows 2000 和 Windows XP 开始在 Windows 中提供。在 Windows NT/2K/XP 中,SMB(Server Message Block)协议用于文件共享等。它在 Windows NT 中运行在 NetBT(NetBIOS over TC…...

C语言_coredump深度解析
在 C/C++ 开发中,Core Dump 是解决程序崩溃问题的重要手段。本文将系统介绍 Core Dump 的概念、用途、常见原因及调试方法,结合具体代码示例,帮助开发者快速定位和解决问题。 一、Core Dump 是什么? Core Dump(核心转储)是操作系统在进程异常终止时,将进程的内存镜像、…...

全栈项目中是否可以实现统一错误处理链?如果可以,这条链路该如何设计?需要哪些技术支撑?是否能同时满足性能、安全性和用户体验需求?
在复杂系统中,错误一旦出现,可能不断扩散,直到让整个系统宕机。尤其在一个全栈项目中,从数据库到服务器端逻辑、再到前端用户界面,错误可能在任意一个环节产生。如果我们不能在全栈范围内实现统一的错误处理机制&#…...

Twitter数据采集新选择:twitterapi.io全面评测与实战指南
之前我在CSDN上分享过如何高效获取Twitter数据:Apify平台上的推特数据采集解决方案_tweet scraper v2 (pay per result)-CSDN博客,当时介绍了如何利用Apify平台抓取Twitter数据。虽然Apify提供了不错的解决方案,但在实际项目中我遇到了一些瓶…...

排序01:多目标模型
用户-笔记的交互 对于每篇笔记,系统记录曝光次数、点击次数、点赞次数、收藏次数、转发次数。 点击率点击次数/曝光次数 点赞率点赞次数/点击次数 收藏率收藏次数/点击次数 转发率转发次数/点击次数 转发是相对较少的,但是非常重要,例如转发…...
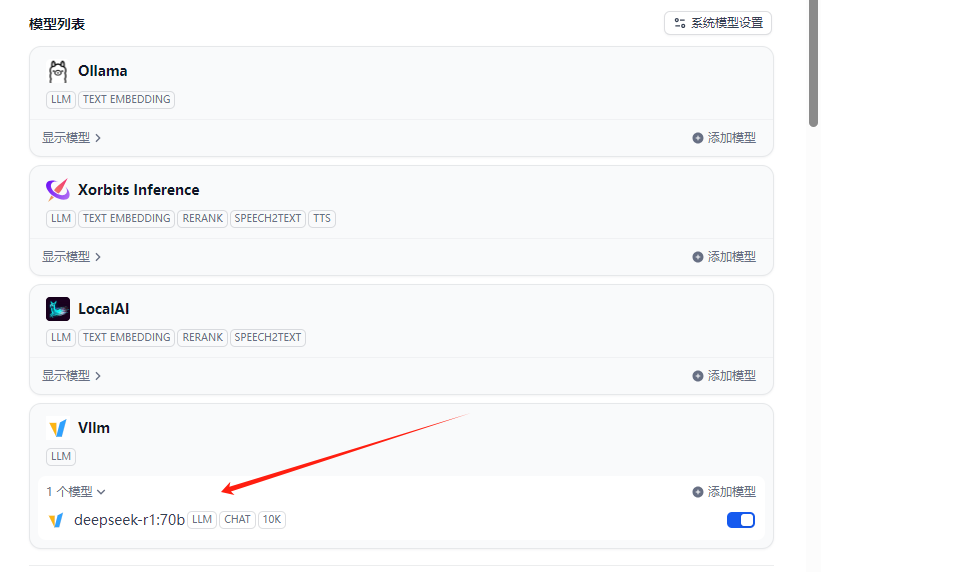
Dify中使用插件LocalAI配置模型供应商报错
服务器使用vllm运行大模型,今天在Dify中使用插件LocalAI配置模型供应商后,使用工作流的时候,报错:“Run failed: PluginInvokeError: {"args":{},"error_type":"ValueError","message":&…...
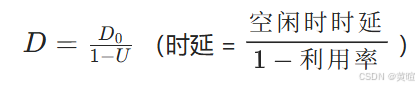
初识计算机网络。计算机网络基本概念,分类,性能指标
初识计算机网络。计算机网络基本概念,分类,性能指标 本系列博客源自作者在大二期末复习计算机网络时所记录笔记,看的视频资料是B站湖科大教书匠的计算机网络微课堂,祝愿大家期末都能考一个好成绩! 视频链接地址 一、…...

【Python 操作 MySQL 数据库】
在 Python 中操作 MySQL 数据库主要通过 pymysql 或 mysql-connector-python 库实现。以下是完整的技术指南,包含连接管理、CRUD 操作和最佳实践: 一、环境准备 1. 安装驱动库 pip install pymysql # 推荐(纯Python实现࿰…...

标贝科技:大模型领域数据标注的重要性与标注类型分享
当前,大模型作为人工智能领域的前沿技术,其强大的泛化能力和复杂任务处理能力,依赖于海量数据的训练。而数据标注,作为连接原始数据与大模型训练的关键桥梁,在这一过程中发挥着举足轻重的作用。 大模型的训练依赖海…...
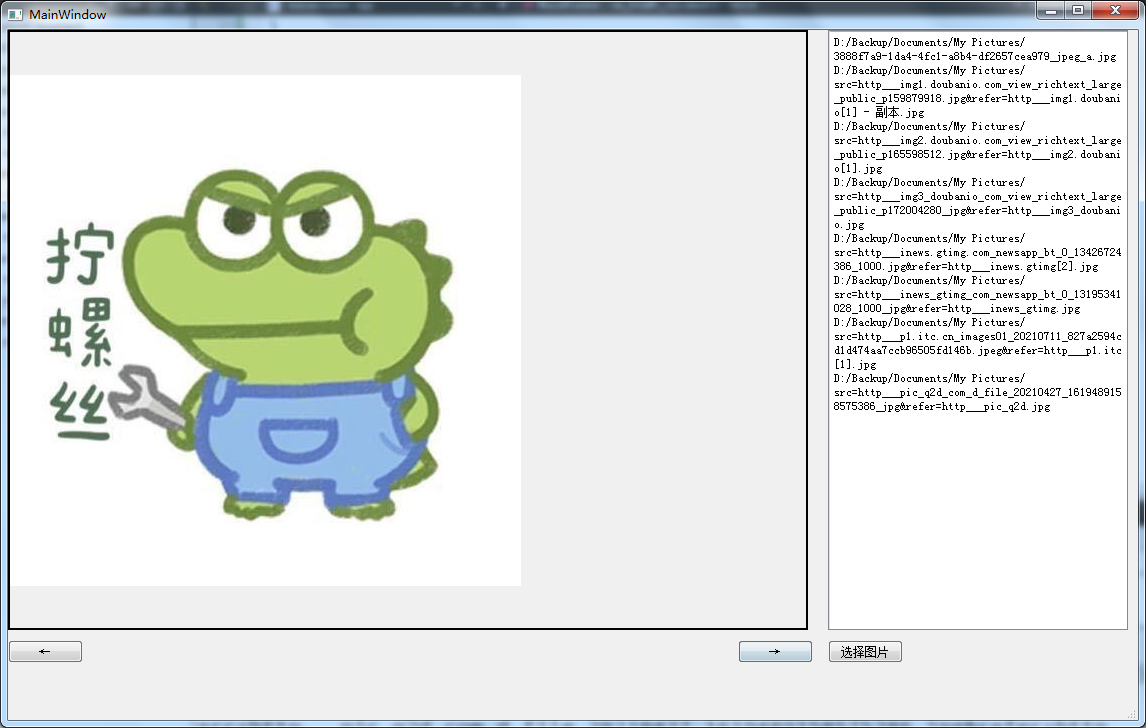
C++ QT图片查看器
private:QList<QString> fs;int i;void MainWindow::on_btnSlt_clicked() {QStringList files QFileDialog::getOpenFileNames(this,"选择图片",".","Images(*.png *.jpg *.bmp)");qDebug()<<files;ui->picList->clear();ui-…...

数据集-目标检测系列- 杨桃 数据集 Starfruit>> DataBall
数据集-目标检测系列- 杨桃 数据集 Starfruit>> DataBall * 相关项目 1)数据集可视化项目:gitcode: https://gitcode.com/DataBall/DataBall-detections-100s/overview 2)数据集训练、推理相关项目:GitH…...
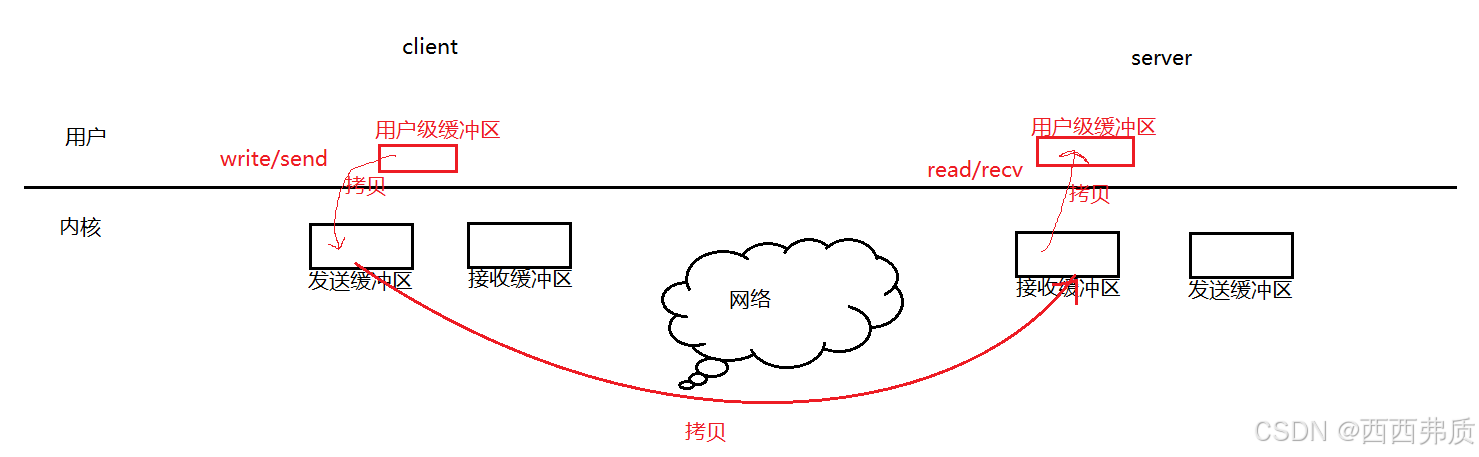
【Linux网络】网络套接字编程
套接字编程 一,理解端口号二,初识TCP/UDP协议三,网络字节序四,UDP套接字编程常用API4.1 struct sockaddr类型4.2 socket接口4.3 bind接口4.4 recvfrom4.5 sendto 五,TCP套接字常用API5.1 listen接口5.2 accept接口5.3 …...
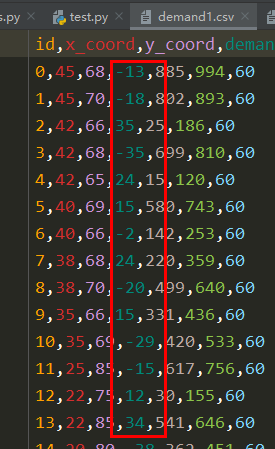
【data】上海膜拜数据
数据初始样貌 一、数据预处理 1. 数据每5分钟栅格统计 时间数据的处理 path"mobike_shanghai.csv" dfpd.read_csv(path) # 获取时间信息,对于分钟信息,5分钟取整 def time_info(df,col): df[datetime] pd.to_datetime(df[col])df[wee…...

文件相关操作
文本文件 程序运行时产生的数据都属于临时数据,程序一旦运行结束都会被释放 通过文件可以将数据持久化 C的文件操作需要包含头文件 文件分类 文本文件:文件以文本的ASCII码形式存储在计算机中 二进制文件:文件以文本的二进制形式存储在计算…...