数据分析_Python
1 分析内容
1.1 数据的整体概述
提供数据集的基本信息,包括数据量、时间跨度、地理范围和主要字段.
import pandas as pd# 创建示例数据
data = {'姓名': ['张三', '李四', '王五', '赵六', '钱七', '孙八', '周九', '吴十'],'年龄': [25, 30, 35, 40, 45, 50, 55, 60],'性别': ['男', '男', '女', '女', '男', '女', '男', '女'],'收入': [5000, 6000, 7500, 8000, 9000, 10000, None, 12000],'工作年限': [2, 3, 5, 7, 10, 12, 15, 18],'部门': ['销售', '销售', '研发', '研发', '市场', '市场', '财务', '财务']
}
df = pd.DataFrame(data)print("原始数据:")
print(df.head(3).to_string())# 1. 筛选年龄大于30且部门为研发的数据
print("\n1. 筛选结果:")
filtered = df[(df['年龄'] > 30) & (df['部门'] == '研发')]
print(filtered.to_string())# 2. 按收入降序排序
print("\n2. 排序结果:")
sorted_data = df.sort_values('收入', ascending=False)
print(sorted_data.to_string())# 3. 计算月收入
print("\n3. 计算新列结果:")
df['月收入'] = df['收入'] / 12
print(df[['姓名', '收入', '月收入']].to_string())# 4. 合并姓名和部门列
print("\n4. 合并列结果:")
df['信息'] = df['姓名'] + ' - ' + df['部门']
print(df[['信息', '姓名', '部门']].to_string())# 5. 转换年龄列为浮点数类型
print("\n5. 数据类型转换结果:")
df['年龄'] = df['年龄'].astype(float)
print(f"年龄列类型: {df['年龄'].dtype}")1.2 数据的基本统计信息
计算数据的核心统计指标和分布特征,以便理解数据的整体特征.分析方法有集中趋势分析、离散程度分析、分布分析.
(1) 集中趋势分析
import pandas as pddata = {'年龄': [25, 30, 30, 40, 45],'工资': [5000, 6000, 7000, 8000, 9000]
}
df = pd.DataFrame(data)# 通用描述性统计
summary = df.describe()
print("通用描述性统计:\n", summary)
# 统计单列的描述性信息
print("Age statistics:\n", df['年龄'].describe())# 特定统计量计算
sum_age = df['年龄'].sum()
print("\n年龄总和:", sum_age)count_age = df['年龄'].count()
print("年龄计数:", count_age)min_age = df['年龄'].min()
print("年龄最小值:", min_age)max_age = df['年龄'].max()
print("年龄最大值:", max_age)average_age = df['年龄'].mean()
print("平均年龄:", average_age)median_salary = df['工资'].median()
print("工资中位数:", median_salary)mode_age = df['年龄'].mode()
print("年龄众数:\n", mode_age)std_salary = df['工资'].std()
print("工资标准差:", std_salary)var_salary = df['工资'].var()
print("工资方差:", var_salary)q25_salary = df['工资'].quantile(0.25)
print("工资列的25%分位数:", q25_salary)(2) 分布分析
import pandas as pd# 创建示例数据
data = {'姓名': ['张三', '李四', '王五', '赵六', '钱七', '孙八', '周九', '吴十'],'年龄': [25, 30, 35, 40, 45, 50, 55, 60],'性别': ['男', '男', '女', '女', '男', '女', '男', '女'],'收入': [5000, 6000, 7500, 8000, 9000, 10000, None, 12000],'工作年限': [2, 3, 5, 7, 10, 12, 15, 18],'部门': ['销售', '销售', '研发', '研发', '市场', '市场', '财务', '财务']
}
df = pd.DataFrame(data)# 统计每个部门的频数(返回Series)
department_counts = df['部门'].value_counts(dropna=False)# 输出结果(按频数降序排列)
print(department_counts) 1.3 数据的分组与汇总
根据时间或业务维度对数据进行分组,并计算汇总指标,以揭示不同维度的表现分析方法有分组分析、汇总统计.
import pandas as pd# 使用你最初的数据源
data = {'姓名': ['张三', '李四', '王五', '赵六', '钱七', '孙八', '周九', '吴十'],'年龄': [25, 30, 35, 40, 45, 50, 55, 60],'性别': ['男', '男', '女', '女', '男', '女', '男', '女'],'收入': [5000, 6000, 7500, 8000, 9000, 10000, None, 12000],'工作年限': [2, 3, 5, 7, 10, 12, 15, 18],'部门': ['销售', '销售', '研发', '研发', '市场', '市场', '财务', '财务']
}
df = pd.DataFrame(data)# 输出原始数据
print("=== 原始数据 ===")
print(df.to_string())# 1. 按性别分组统计人数和平均年龄(使用agg)
print("\n=== 按性别分组的统计信息 ===")
gender_stats = df.groupby('性别').agg(人数=('姓名', 'count'),平均年龄=('年龄', 'mean'),平均收入=('收入', 'mean')
).reset_index()
print(gender_stats)# 2. 按收入区间分组(自定义分组,使用agg)
print("\n=== 按收入区间分组的统计 ===")
def income_category(x):if x < 6000:return '低收入'elif x < 9000:return '中等收入'else:return '高收入'df['收入等级'] = df['收入'].apply(income_category)
income_stats = df.groupby('收入等级').agg(人数=('姓名', 'count')
).reset_index()
print(income_stats) 1.4 数据的趋势与变化
分析数据随时间的变化趋势和周期性波动,以识别增长、下降或稳定的模式.分析方法有时间序列分析、周期性分析.
import pandas as pddata = {'date': ['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04', '2023-01-05'],'sales': [1000, 1200, 900, 1500, 1300]
}
df = pd.DataFrame(data)# 确保日期字段是日期时间格式
df['date'] = pd.to_datetime(df['date'])
# 按日期排序(确保时间序列的顺序正确)
df = df.sort_values('date')
# 设置日期为索引(方便时间序列分析)
df.set_index('date', inplace=True)# 输出处理后的数据
print("处理后的时间序列数据:\n",df)1.5 数据的对比与差异
通过同比、环比和分类对比分析,识别不同时间段或类别之间的差异.分析方法有同环比分析,分类对比分析.
1.5.1 同环比分析
import pandas as pd# 使用简单的示例数据
data = {'日期': ['2023-01-01', '2023-02-01', '2023-03-01', '2023-04-01', '2022-01-01', '2022-02-01', '2022-03-01', '2022-04-01'],'产品': ['A', 'A', 'B', 'B', 'A', 'A', 'B', 'B'],'销售额': [12000, 15000, 8000, 9500, 10000, 14000, 7000, 9000],'利润': [2000, 3000, 1500, 2000, 1800, 2500, 1200, 1800]
}
df = pd.DataFrame(data)# 将日期列转换为datetime类型
df['日期'] = pd.to_datetime(df['日期'])# 打印原始数据
print("\n=== 原始数据 ===")
print(df.to_string())# 按月聚合销售额
monthly_data = df.groupby(df['日期'].dt.to_period('M'))['销售额'].sum().reset_index()
monthly_data.columns = ['月份', '销售额']# 1. 同比分析 (YoY - Year over Year)
year_month_sales = monthly_data.copy()
year_month_sales['年月'] = year_month_sales['月份'].astype(str) # 转为字符串格式
year_month_sales['月份'] = year_month_sales['月份'].dt.month # 提取月份数字# 计算同比增长率及同期数
year_month_sales['同期销售额'] = year_month_sales.groupby('月份')['销售额'].shift(1)
year_month_sales['同比增长率(%)'] = year_month_sales.groupby('月份')['销售额'].pct_change(1) * 100print("\n=== 同比分析 ===")
print(year_month_sales[['年月', '销售额', '同期销售额', '同比增长率(%)']].to_string(index=False))# 2. 环比分析 (MoM - Month over Month)
# 计算环比增长率及环期数
monthly_data['环期销售额'] = monthly_data['销售额'].shift(1)
monthly_data['环比增长率(%)'] = monthly_data['销售额'].pct_change() * 100print("\n=== 环比分析 ===")
print(monthly_data.to_string(index=False))1.5.2 分类对比分析
import pandas as pd# 使用简单的示例数据
data = {'日期': ['2023-01-01', '2023-02-01', '2023-03-01', '2023-04-01', '2022-01-01', '2022-02-01', '2022-03-01', '2022-04-01'],'产品': ['A', 'A', 'B', 'B', 'A', 'A', 'B', 'B'],'销售额': [12000, 15000, 8000, 9500, 10000, 14000, 7000, 9000],'利润': [2000, 3000, 1500, 2000, 1800, 2500, 1200, 1800]
}
df = pd.DataFrame(data)# 按产品分类对比
product_comparison = df.groupby('产品').agg(销售额总和=('销售额', 'sum'),销售额均值=('销售额', 'mean'),利润总和=('利润', 'sum'),利润均值=('利润', 'mean')
).reset_index() # 恢复产品列为普通列# 计算销售额占比
total_sales = df['销售额'].sum()
product_comparison['销售额占比(%)'] = (product_comparison['销售额总和'] / total_sales) * 100# 计算利润率
product_comparison['利润率(%)'] = (product_comparison['利润总和'] / product_comparison['销售额总和']) * 100print("\n=== 产品分类对比(方法一)===")
print(product_comparison.to_string(index=False))1.6 异常值与关键点
识别数据中的异常值和关键点,以便关注显著变化或重要数据点.
相关文章:

数据分析_Python
1 分析内容 1.1 数据的整体概述 提供数据集的基本信息,包括数据量、时间跨度、地理范围和主要字段. import pandas as pd# 创建示例数据 data {姓名: [张三, 李四, 王五, 赵六, 钱七, 孙八, 周九, 吴十],年龄: [25, 30, 35, 40, 45, 50, 55, 60],性别: [男, 男, 女, 女, 男,…...

TCP/UDP协议原理和区别 笔记
从简单到难吧 区别就是TCP一般用于安全稳定的需求,UDP一般用于不那么需要完全数据的需求,比如说直播,视频等。 再然后就是TPC性能慢于UDP。 再然后我们看TCP的原理(三次握手,数据传输,四次挥手࿰…...

深入浅出:C++数据处理类与计算机网络的巧妙类比
深入浅出:C数据处理类与计算机网络的巧妙类比 引言 在计算机编程中,我们常常会遇到一些看似简单的代码结构,却能巧妙地映射到复杂的计算机网络概念中。本文将通过一个简单的C数据处理类,探讨其与计算机网络中硬件设备和协议的类…...

【滑动窗口】LeetCode 209题解 | 长度最小的子数组
长度最小的子数组 前言:滑动窗口一、题目链接二、题目三、算法原理解法一:暴力枚举解法二:利用单调性,用滑动窗口解决问题那么怎么用滑动窗口解决问题?分析滑动窗口的时间复杂度 四、编写代码 前言:滑动窗口…...

在RK3588上使用NCNN和Vulkan加速ResNet50推理全流程
在RK3588上使用NCNN和Vulkan加速ResNet50推理全流程 前言:为什么需要关注移动端AI推理一、环境准备与框架编译1.1 获取NCNN源码1.2 安装必要依赖1.3 编译NCNN二、模型导出与转换2.1 生成ONNX模型2.2 转换NCNN格式三、模型量化加速3.1 生成校准数据3.2 执行量化操作四、性能测试…...

【ant design】ant-design-vue 4.0实现主题色切换
官网:Ant Design Vue — An enterprise-class UI components based on Ant Design and Vue.js 我图方便,直接在 app.vue 中加入的 <div class"app-content" v-bind:class"appOption.appContentClass"><a-config-provider…...

Android 图片自动拉伸不变形,点九
要让 UI 设计师 制作 Android 用的点九图(.9.png),可以按照以下流程和要求进行: 🧩 一、什么是点九图? 点九图(NinePatch)是一种特殊的 PNG 图像,用于在 Android 中根据…...

电子电路:什么是色环电阻器,怎么识别和计算阻值?
识别和计算色环电阻的阻值需要掌握颜色编码规则和基本步骤。以下是具体方法及窍门: 一、色环电阻的基本规则 色环数量: 4环电阻:前2环为有效数字,第3环为倍乘(10ⁿ),第4环为误差。5环电阻:前3环为有效数字,第4环为倍乘,第5环为误差。6环电阻(较少见):前3环为有效数…...

LeetCode Hot100刷题——轮转数组
56. 轮转数组 给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。 示例 1: 输入: nums [1,2,3,4,5,6,7], k 3 输出: [5,6,7,1,2,3,4] 解释: 向右轮转 1 步: [7,1,2,3,4,5,6] 向右轮转 2 步: [6,7,1,2,3,4,5] 向右轮转 3 步: …...
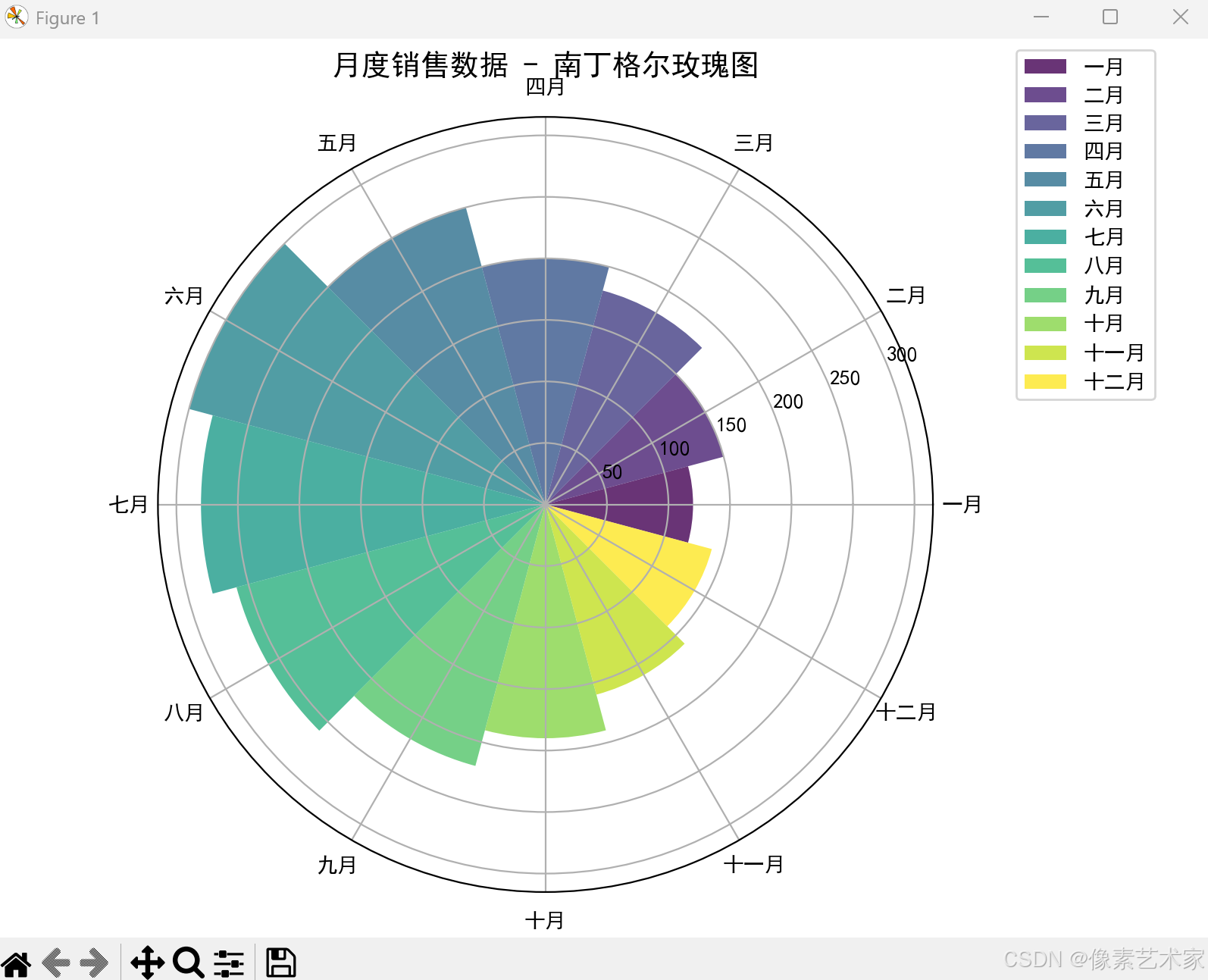
Python绘制南丁格尔玫瑰图:从入门到实战
Python绘制南丁格尔玫瑰图:从入门到实战 引言 南丁格尔玫瑰图(Nightingale Rose Chart),也被称为极区图(Polar Area Chart),是一种独特的数据可视化方式。这种图表由弗洛伦斯南丁格尔ÿ…...

概率与期望总结
一、概率 概念:无需多言;几个公式( Ω \Omega Ω 表示整个样本空间): 以下公式均有 A , B ⊆ Ω , 且 P ( A ) , P ( B ) > 0. P ( A ∪ B ) P ( A ) P ( B ) − P ( A ∩ B ) , P ( A ∣ B ) P ( A B ) P ( B…...

炼丹学习笔记3---ubuntu2004部署运行openpcdet记录
前言 环境 cuda 11.3 python 3.8 ubuntu2004 一、cuda环境检测 ylhy:~/code_ws/OpenPCDet/tools$ nvcc -V nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2021 NVIDIA Corporation Built on Sun_Mar_21_19:15:46_PDT_2021 Cuda compilation tools, release 11.3…...
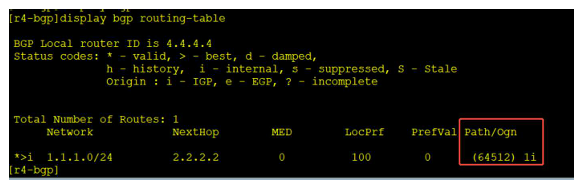
深入解析BGP路由反射器与联邦:突破IBGP全连接限制的两种方案
一、引言:大型BGP网络的挑战 在大型BGP网络架构中,传统的IBGP全连接架构会带来严重的扩展性问题。当网络中存在N台路由器时,需要维护N*(N-1)/2个IBGP连接,这对设备资源和运维管理都是巨大挑战。本文将深入解析两种主流解决方案&a…...
QT设置MySQL驱动
QSqlDatabase: QMYSQL driver not loaded QSqlDatabase: available drivers: QSQLITE QMYSQL QMYSQL3 QODBC QODBC3 QPSQL QPSQL7 第一步:下载MySQL https://dev.mysql.com/downloads/mysql/ 解压缩下载的安装包,其目录结构如下所示: 第二…...
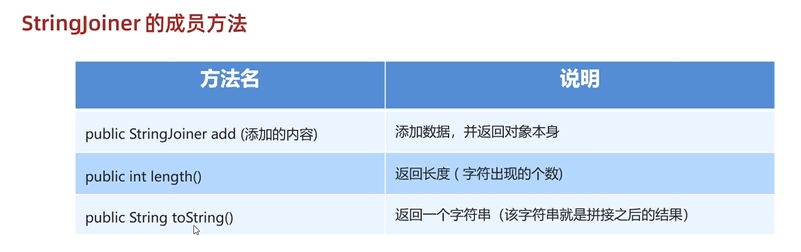
String的一些固定程序函数
append reverse length toString...
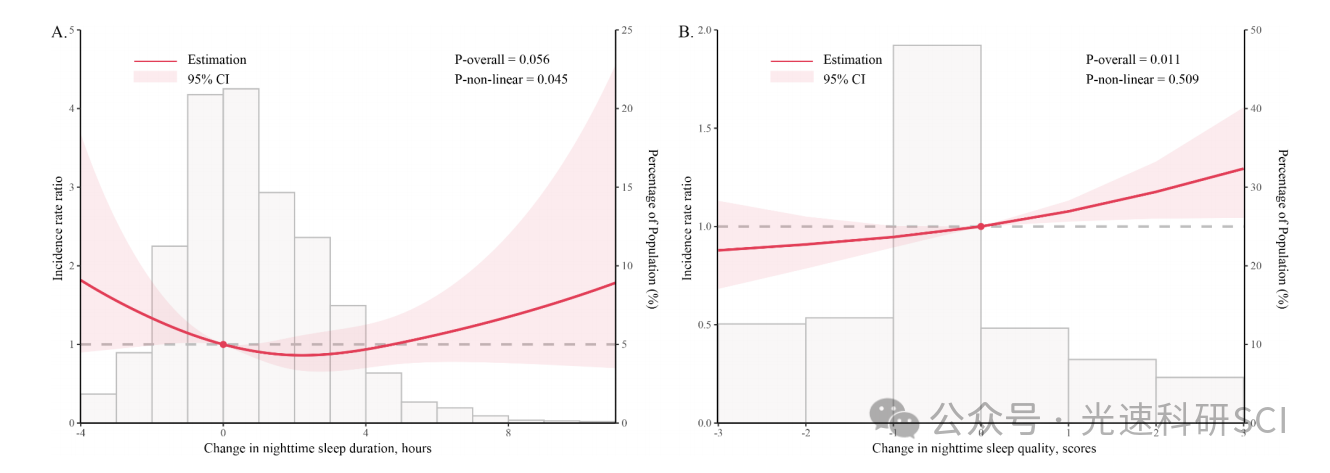
3.2/Q2,Charls最新文章解读
文章题目:Transition of nighttime sleep duration and sleep quality with incident cardiovascular disease among middle-aged and older adults: results from a national cohort study DOI:10.1186/s13690-025-01577-5 中文标题:中老年人…...
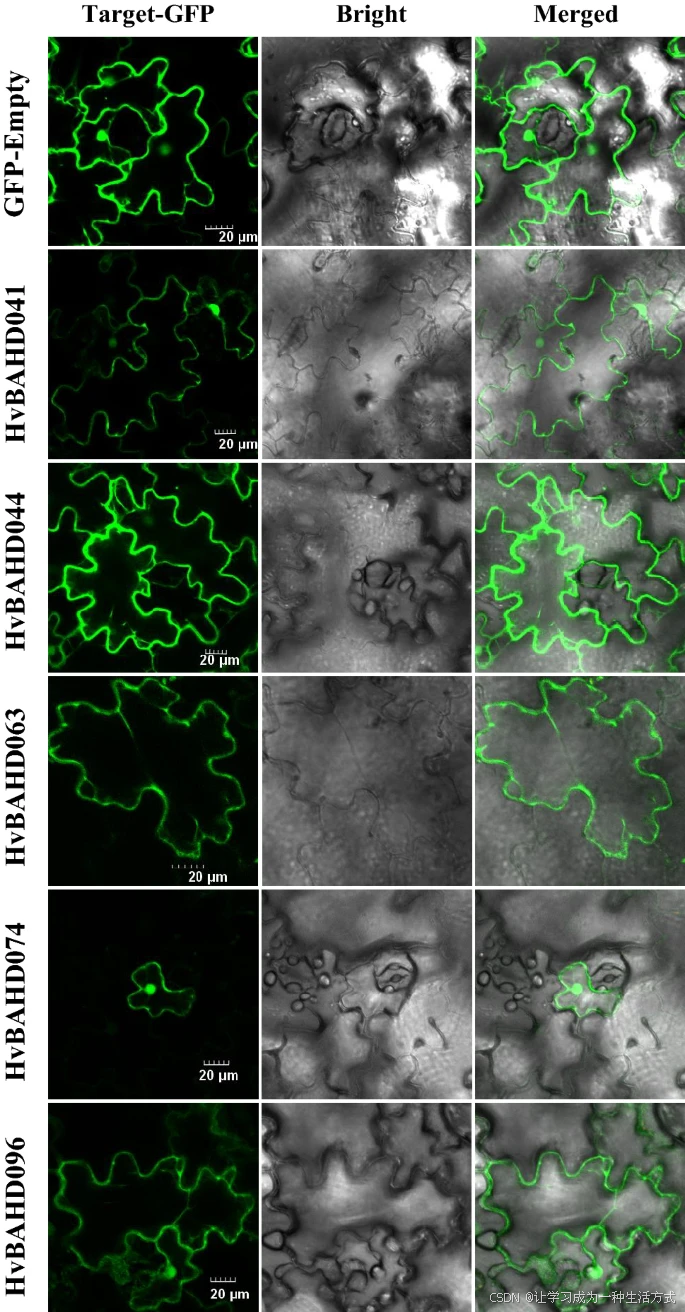
大麦(Hordeum vulgare)中 BAHD 超家族酰基转移酶-文献精读129
Systematic identification and expression profiles of the BAHD superfamily acyltransferases in barley (Hordeum vulgare) 系统鉴定与大麦(Hordeum vulgare)中 BAHD 超家族酰基转移酶的表达谱分析 摘要 BAHD 超家族酰基转移酶在植物中催化和调控次…...
docker迅雷自定义端口号、登录用户名密码
在NAS上部署迅雷,确实会带来很大的方便。但是目前很多教程都是讲怎么部署docker迅雷,鲜有将自定义配置的方法。这里讲一下怎么部署,并重点讲一下支持的自定义参数。 一、部署docker 在其他教程中,都是介绍的如下命令,…...
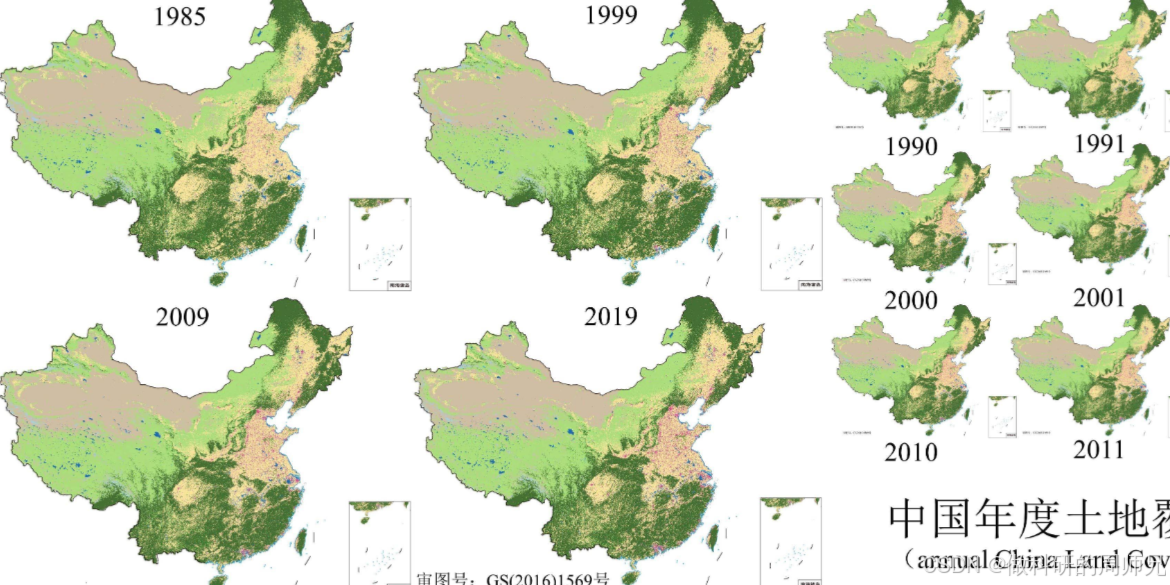
中国30米年度土地覆盖数据集及其动态变化(1985-2022年)
中文名称 中国30米年度土地覆盖数据集及其动态变化(1985-2022年) 英文名称:The 30 m annual land cover datasets and its dynamics in China from 1985 to 2022 CSTR:11738.11.NCDC.ZENODO.DB3943.2023 DOI 10.5281/zenodo.8176941 数据共享方式:…...
3D个人简历网站 5.天空、鸟、飞机
1.显示天空 models下新建文件Sky.jsx Sky.jsx // 从 React 库中导入 useRef 钩子,用于创建可变的 ref 对象 import { useRef } from "react"; // 从 react-three/drei 库中导入 useGLTF 钩子,用于加载 GLTF 格式的 3D 模型 import { useGLT…...

STM32IIC实战-OLED模板
STM32IIC实战-OLED模板 一,SSD1306 控制芯片1, 主要特性2,I2C 通信协议3, 显示原理4, 控制流程5, 开发思路 二,HAL I2C API 解析I2C 相关 API1,2,3,4…...

Sparse4D运行笔记
Sparse4D有三个版本,其中V1和V2版本的官方文档中环境依赖写得比较模糊且依赖库有版本冲突。 1. Sparse4D V1 创建环境 conda create sparse4dv1 python3.8 激活环境 conda activate sparse4dv1 安装torch, torchvision, torchaudio pip install torch1.13.0c…...

Redis设计与实现——分布式Redis
Redis Sentinel(哨兵) Sentinel 的工作机制 故障检测(Failure Detection) 主观下线(Subjective Down):单个 Sentinel 实例检测到主节点在30 秒内无响应,标记其为 SDOWN。 客观下线…...

多指标组合策略
该策略(MultiConditionStrategy)是一种基于多种技术指标和市场条件的交易策略。它通过综合考虑多个条件来生成交易信号,从而决定买入或卖出的时机。 以下是对该策略的详细分析: 交易逻辑思路 1. 条件1:星期几和价格变化判断 - 该条件根据当前日期是星期几以及价格的变化…...
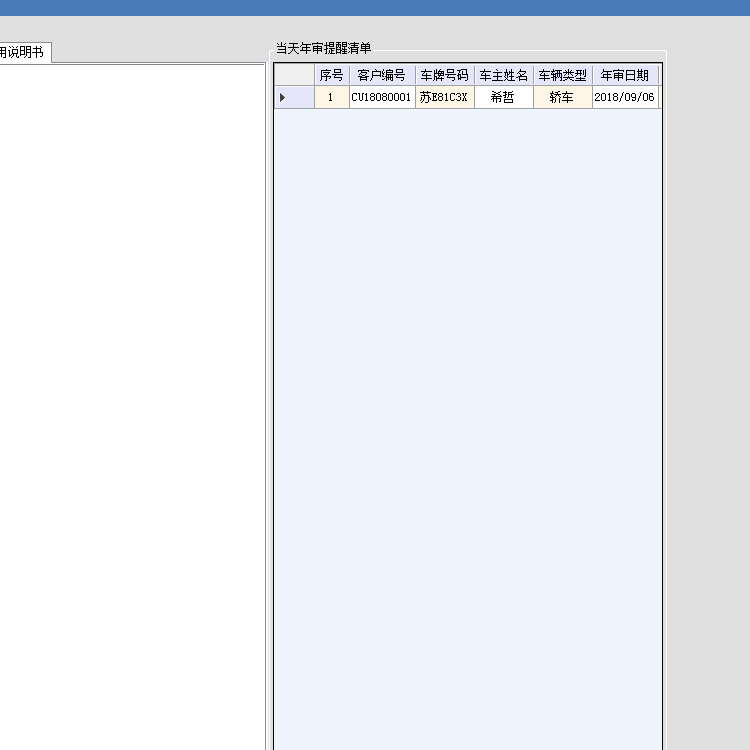
c#车检车构客户管理系统软件车辆年审短信提醒软件
# CMS_VehicleInspection 车检车构客户管理系统软件车辆年审短信提醒软件 # 开发背景 软件是给泸州某公司开发的车检车构客户管理系统软件。用于在车检年审到期前一个月给客户发送车检短信提醒 # 功能描述 主要功能:车辆年审前一个月给客户发年审短信提醒…...

Java爬虫能处理京东商品数据吗?
Java爬虫完全可以处理京东商品数据。通过Java爬虫技术,可以高效地获取京东商品的详细信息,包括商品名称、价格、图片、描述等。这些信息对于市场分析、选品上架、库存管理和价格策略制定等方面具有重要价值。以下是一个完整的Java爬虫示例,展…...

通俗版解释CPU、核心、进程、线程、协程的定义及关系
通俗版解释(比喻法) 1. CPU 和核心 CPU 一个工厂(负责干活的总部)。核心 工厂里的车间(比如工厂有4个车间,就能同时处理4个任务)。 2. 进程 进程 一家独立运营的公司(比如一家…...
大语言模型 11 - 从0开始训练GPT 0.25B参数量 MiniMind2 准备数据与训练模型 DPO直接偏好优化
写在前面 GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,…...
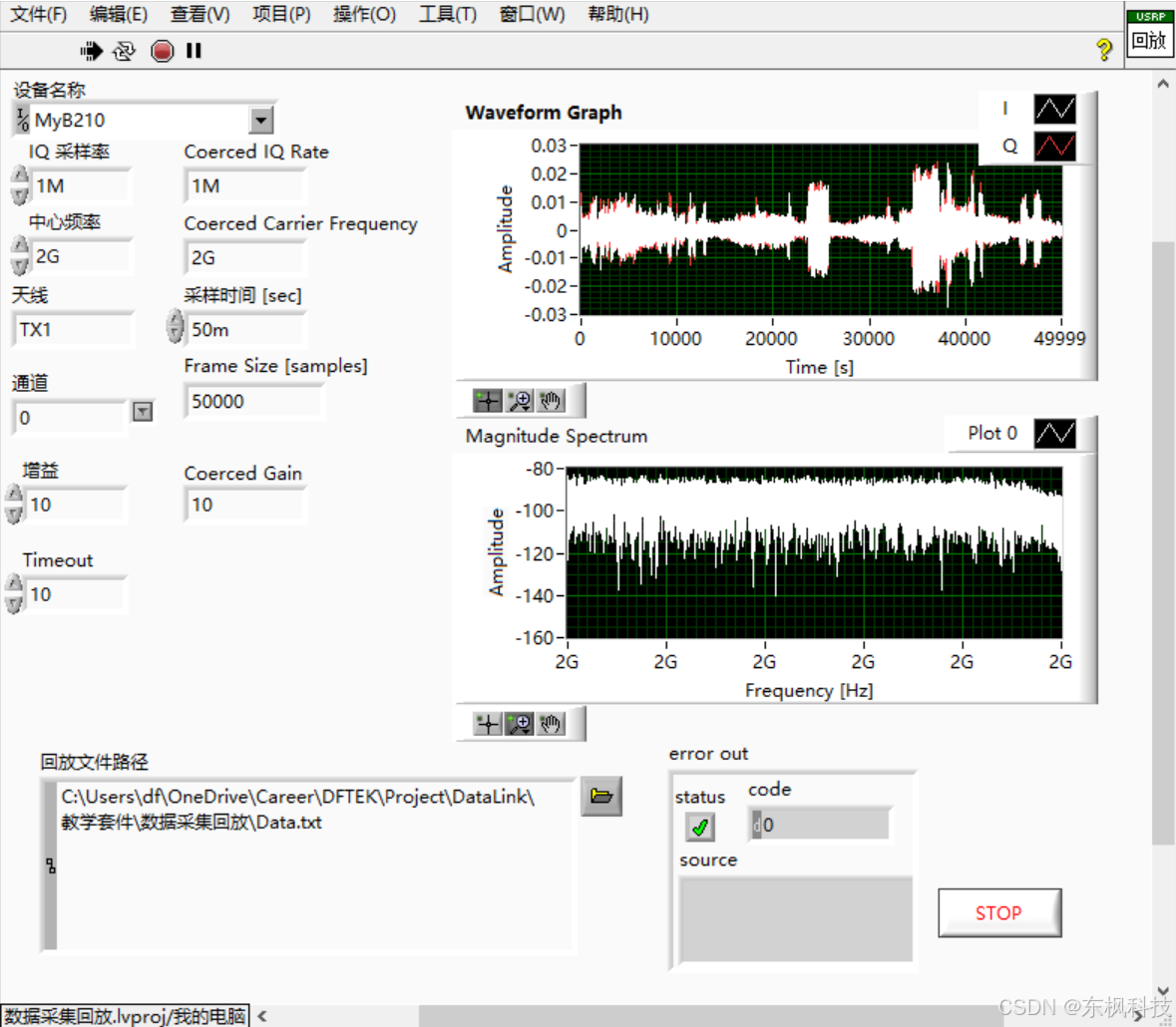
USRP 射频信号 采集 回放 系统
USRP 射频信号采集回放系统 也可以叫做: 利用宽带RF录制和回放系统实现6G技术研究超宽带射频信号采集回放系统使用NI USRP平台实现射频信号录制和回放操作演示USRP也能实现多通道宽带信号流盘回放了! 对于最简单的实现方法就是使用LabVIEW进行实现 采…...

【skywalking】index“:“skywalking_metrics-all“},“status“:404}
skywalking 启动报错 java.lang.RuntimeException: {"error":{"root_cause":[{"type":"index_not_found_exception","reason":"no such index [skywalking_metrics-all]","resource.t ype":"inde…...