No More Adam: 新型优化器SGD_SaI

一.核心思想和创新点
2024年12月提出的SGD-SaI算法(Stochastic Gradient Descent with Scaling at Initialization)本质上是一种在训练初始阶段对不同参数块(parameter block)基于**梯度信噪比(g-SNR, Gradient Signal-to-Noise Ratio)进行局部学习率缩放的SGDM变体。**代码开源:https://github.com/AnonymousAlethiometer/SGD_SaI/
通过在训练初始化阶段针对参数分组进行一次性学习率缩放(基于g-SNR)即可实现与自适应方法类似的性能,完全不依赖于动态二阶动量,不仅保留了SGDM的高效性和简洁性,还显著提升了大模型训练的资源利用率和稳定性。这为未来深度学习模型的高效训练,特别是大规模Transformer的可扩展性提供了一条全新路径。
1.质疑自适应梯度方法的必要性
作者质疑了当前深度学习中广泛应用的自适应梯度优化器(如Adam及其变体)的必要性,认为其主要优势(即根据梯度历史动态调整每个参数的学习率以应对训练初期的梯度噪声、稀疏和不同参数组间的学习率不均衡)可以通过更简单、更高效的方法实现。
2.提出SGD-SaI优化器
作者提出了一种基于动量的随机梯度下降优化器改进版——SGD-SaI(Stochastic Gradient Descent with Scaling at Initialization),其核心做法是在训练初始阶段,利用梯度信噪比(g-SNR),对不同参数分组的学习率进行一次性分组缩放,而非每步动态自适应。这种方法完全摒弃了存储和更新每个参数的二阶动量(即方差估计),极大减少了优化器的内存开销和计算复杂度。
3.梯度信噪比(g-SNR)引导的分组缩放
g-SNR度量了参数块的梯度范数与方差之比,可以稳定反映各参数块在不同训练阶段的梯度特性。实验表明g-SNR在参数块内具有时间上的稳定性(即初始化时刻的分布基本决定整个训练过程),据此对参数分组的学习率进行归一化缩放,有效平衡了参数块间的训练进度。
4.广泛的适用性和实证优势
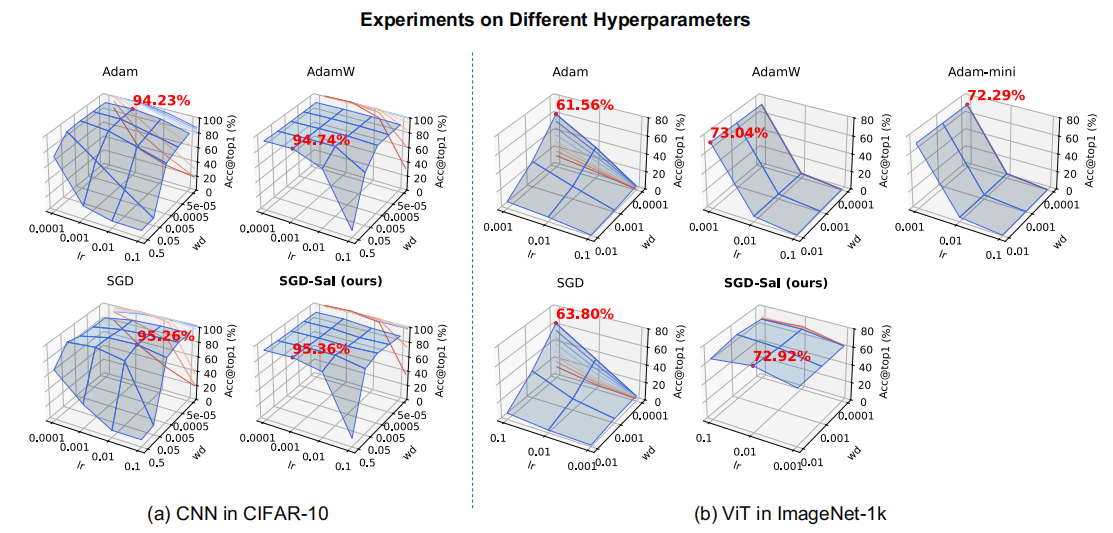
SGD-SaI方法不仅在传统卷积神经网络(CNN)任务上表现良好,在Transformer、ViT、GPT-2等参数分布高度异质的大模型任务中,也能够实现与主流自适应方法(AdamW、Adam-mini等)相当甚至更优的性能,同时具备更好的超参数鲁棒性和极低的内存占用,显著提升了大模型训练的可扩展性与资源利用效率。
5.实验验证
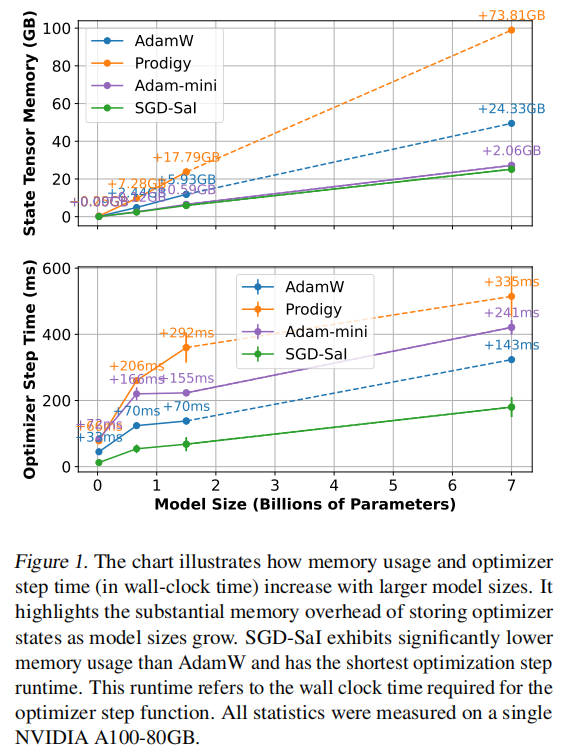
在大规模语言模型、视觉Transformer、LoRA微调、扩散模型微调以及CNN等多类任务上的实验证明,SGD-SaI在准确率、收敛稳定性、内存效率、训练速度等方面均表现优异,尤其是在Transformer类任务中,解决了传统SGD难以收敛的问题,并可节省高达50%甚至75%的优化器状态内存,显著降低了训练门槛。
二.算法流程
1.参数分块(Parameter Grouping)
神经网络的所有参数 θ \theta θ 按照网络结构分为 B B B 个参数块(如不同层、不同类型参数等),记为 θ ( i ) \theta^{(i)} θ(i)( i = 1 , 2 , . . . , B i=1,2,...,B i=1,2,...,B)。
2.计算每个参数块的梯度信噪比(g-SNR)
对于每个参数块 i i i,在第一次训练迭代时计算:
-
梯度范数:
G n o r m ( i ) = ∑ j = 1 d i ( g j ( i ) ) 2 G_{\mathrm{norm}}^{(i)}=\sqrt{\sum_{j=1}^{d_i}(g_j^{(i)})^2} Gnorm(i)=∑j=1di(gj(i))2
其中 g j ( i ) g_j^{(i)} gj(i)是第 i i i 个参数块第 j j j个参数的梯度, d i d_i di 是该参数块参数数量。
- 梯度均值:
g ˉ ( i ) = 1 d i ∑ j = 1 d i g j ( i ) \bar{g}^{(i)}=\frac{1}{d_i}\sum_{j=1}^{d_i}g_j^{(i)} gˉ(i)=di1∑j=1digj(i)
- 梯度方差:
G v a r ( i ) = 1 d i ∑ j = 1 d i ( g j ( i ) − g ˉ ( i ) ) 2 G_\mathrm{var}^{(i)}=\frac{1}{d_i}\sum_{j=1}^{d_i}(g_j^{(i)}-\bar{g}^{(i)})^2 Gvar(i)=di1∑j=1di(gj(i)−gˉ(i))2
- g-SNR定义:
G s n r ( i ) = G n o r m ( i ) G v a r ( i ) + ϵ G_{\mathrm{snr}}^{(i)}=\frac{G_{\mathrm{norm}}^{(i)}}{\sqrt{G_{\mathrm{var}}^{(i)}+\epsilon}} Gsnr(i)=Gvar(i)+ϵGnorm(i)
其中 ϵ \epsilon ϵ 是防止分母为零的小常数。
3. 归一化g-SNR得到缩放因子
对所有参数块的 G snr ( i ) G_{\text{snr}}^{(i)} Gsnr(i)做最大值归一化:
G ~ s n r ( i ) = G s n r ( i ) max k G s n r ( k ) \tilde{G}_\mathrm{snr}^{(i)}=\frac{G_\mathrm{snr}^{(i)}}{\max_kG_\mathrm{snr}^{(k)}} G~snr(i)=maxkGsnr(k)Gsnr(i)
这样归一化后的值在0到1之间。
4. 局部学习率缩放
对于每个参数块,设全局基础学习率为 η \eta η,则每个参数块的实际学习率为:
η ( i ) = G ~ s n r ( i ) ⋅ η \eta^{(i)}=\tilde{G}_{\mathrm{snr}}^{(i)}\cdot\eta η(i)=G~snr(i)⋅η
5.训练过程
- 动量项采用传统SGDM:
m t ( i ) = μ m t − 1 ( i ) + ( 1 − μ ) g t ( i ) m_t^{(i)}=\mu m_{t-1}^{(i)}+(1-\mu)g_t^{(i)} mt(i)=μmt−1(i)+(1−μ)gt(i)
- 权重更新(以decoupled weight decay为例):
θ t ( i ) = θ t − 1 ( i ) − λ η θ t − 1 ( i ) − η ( i ) m t ( i ) \theta_t^{(i)}=\theta_{t-1}^{(i)}-\lambda\eta\theta_{t-1}^{(i)}-\eta^{(i)}m_t^{(i)} θt(i)=θt−1(i)−ληθt−1(i)−η(i)mt(i)
其中 λ \lambda λ为权重衰减系数。
补充解释一下Decoupled weight decay(解耦权重衰减):
是一种针对权重衰减(weight decay)正则化项的优化策略,最早由Loshchilov和Hutter在AdamW优化器中系统提出。 其核心思想是将权重衰减正则项与梯度更新过程解耦,从而更好地控制正则化效果,提升模型泛化能力,避免对自适应梯度的干扰。
在SGD及其变体(如Adam)中,L2正则化通常被实现为在每次参数更新时,将权重衰减项( λ θ \lambda \theta λθ)加入到梯度中:
g ′ = g + λ θ g^{\prime}=g+\lambda\theta g′=g+λθ
其中, g g g 是损失函数关于参数的梯度, λ \lambda λ 是权重衰减系数, θ \theta θ是参数。
然后按照普通优化器的参数更新公式进行迭代: θ t + 1 = θ t − η g ′ \theta_{t+1}=\theta_t-\eta g^{\prime} θt+1=θt−ηg′
这种方式实际上把权重衰减项当做损失函数梯度的一部分来处理。
解耦策略下,权重衰减项不再与梯度混合计算,而是在参数更新时直接对参数进行衰减,其更新公式为:
θ t + 1 = θ t − η g − η λ θ t \theta_{t+1}=\theta_t-\eta g-\eta\lambda\theta_t θt+1=θt−ηg−ηλθt
也可以拆分为两步:
1.正常的梯度下降更新: θ t + 1 / 2 = θ t − η g \theta_{t+1/2}=\theta_t-\eta g θt+1/2=θt−ηg
2.单独进行权重衰减: θ t + 1 = θ t + 1 / 2 − η λ θ t \theta_{t+1}=\theta_{t+1/2}-\eta\lambda\theta_t θt+1=θt+1/2−ηλθt
这样做的好处是,权重衰减只针对参数本身进行缩减,而不会受梯度自适应调整的影响,能更精确地施加正则化,从而提升模型泛化效果。
SGD-SaI算法采用了decoupled weight decay,即先计算梯度用于g-SNR,再单独对参数进行衰减,这样能够保证g-SNR反映真实的梯度稀疏性和噪声特征,而不会被权重衰减项混淆,从而提升分组学习率缩放的有效性
值得强调的是:整个训练过程中每个参数块的缩放因子 G ~ snr ( i ) \tilde{G}_{\text{snr}}^{(i)} G~snr(i)只在初始化阶段计算一次,后续训练保持不变,极大降低了内存和计算开销。
三.代码解释
核心代码是sgd_sai.py,这里完整注释如下
import torch
from torch.optim.optimizer import Optimizer # PyTorch优化器基类class SGD_sai(Optimizer): # 定义SGD_sai优化器类,继承自PyTorch优化器r"""该优化器实现了论文"SGD-SaI: Stochastic Gradient Descent with Scaling at Initialization"的核心算法思想。支持标准SGD参数设置及momentum、weight_decay等常用优化选项。"""def __init__(self, params, lr=1e-2, momentum=0.9, eps=1e-8, weight_decay=0, maximize=False):# 构造函数,初始化优化器的各项参数和默认设置defaults = dict(lr=lr, momentum=momentum, eps=eps, weight_decay=weight_decay, maximize=maximize)super(SGD_sai, self).__init__(params, defaults) # 调用父类初始化self.gsnr_initialized = False # 标志变量,指示g-SNR缩放因子是否已完成初始化@torch.no_grad()def step(self, closure=None):"""执行一次优化器更新。包括g-SNR的初始化、动量累计、权重衰减和参数更新。"""loss = Noneif closure is not None:with torch.enable_grad():loss = closure() # 支持自定义loss回调(如二阶梯度)# 如果还没有初始化g-SNR缩放因子,则进行一次初始化if not self.gsnr_initialized:gsnr_list = [] # 用于存储每个参数组的g-SNRfor group in self.param_groups:for p in group['params']:if p.grad is None: # 跳过无梯度参数continuegrad = p.grad.data # 获取梯度grad_norm = grad.norm() # 计算L2范数grad_var = grad.var() # 计算方差eps = group['eps'] # 取数值稳定用小常数gsnr = grad_norm / (grad_var.sqrt() + eps) # 计算g-SNRgsnr_list.append(gsnr) # 存入列表# 将所有g-SNR按最大值归一化max_gsnr = torch.max(torch.stack(gsnr_list))norm_gsnr_list = [x / max_gsnr for x in gsnr_list]# 保存每个参数的g-SNR缩放因子idx = 0for group in self.param_groups:for p in group['params']:if p.grad is None:continuep.gsnr_scale = norm_gsnr_list[idx] # 动态添加属性idx += 1self.gsnr_initialized = True # 完成g-SNR初始化return loss # 初始化阶段不做参数更新# 正式参数更新过程for group in self.param_groups:lr = group['lr'] # 获取全局学习率momentum = group['momentum'] # 获取动量系数weight_decay = group['weight_decay'] # 获取权重衰减系数maximize = group['maximize'] # 是否最大化目标for p in group['params']:if p.grad is None:continuegrad = p.grad.dataif maximize:grad = -grad # 支持最大化模式# 解耦式权重衰减:对参数本身做缩放,不叠加到梯度if weight_decay != 0:p.data.add_(p.data, alpha=-lr * weight_decay)# 获取g-SNR缩放因子scale = getattr(p, 'gsnr_scale', 1.0)# 获取或初始化动量param_state = self.state[p]if 'momentum_buffer' not in param_state:buf = param_state['momentum_buffer'] = torch.clone(grad).detach()else:buf = param_state['momentum_buffer']buf.mul_(momentum).add_(grad, alpha=1 - momentum)# 参数更新:带g-SNR缩放的动量SGDp.data.add_(buf, alpha=-lr * scale)return loss # 返回损失值以便监控
代码中有几点重点说明:
(1)g-SNR初始化:
- 仅在第一次调用
step()时触发,遍历所有参数,依据当前梯度分布计算g-SNR,并最大归一化。 - 利用动态属性
p.gsnr_scale将每个参数的缩放因子缓存下来,后续训练反复使用。
(2)动量与权重衰减:
- 动量缓存采用PyTorch标准做法(
momentum_buffer)。 - 权重衰减采用解耦式,即直接对参数做缩放操作,避免正则项混入梯度统计,理论上等同于AdamW等现代优化器。
(3)参数更新:
- 更新公式为:基础学习率 × g-SNR缩放 × 动量项,精确实现论文中的“初始化缩放,分组局部自适应学习率”思想。
- 若未初始化g-SNR则直接跳过参数更新。
(4)max/min目标灵活性:
maximize选项用于兼容极大极小化目标。
四.使用优化器
安装:
pip install sgd-sai
使用:
from sgd_sai import SGD_sai# 初始化优化器
optimizer = SGD_sai(model.parameters(), lr=lr, momentum=0.9, eps=1e-08, weight_decay=weight_decay)for _ in range(steps):pred = model(input_ids)loss = loss_fn(pred, labels)loss.backward()optimizer.step()optimizer.zero_grad(set_to_none=True)
在每个训练step前调用
optimizer.zero_grad(),是为了清空所有参数的.grad属性,以避免梯度累积。否则多次反向传播会让梯度不断相加,导致梯度异常。当
set_to_none=False(默认值)时,会将每个参数的.grad置为与原来形状相同的全零张量当
set_to_none=True时,则会直接把.grad设为 None
set_to_none=True通常更高效,节省了将张量置零的时间与显存开销,特别适合大模型或分布式训练,且官方推荐优先使用。只要后续所有反向传播都能正确地重新分配
.grad,则功能完全等价。某些情况下(比如自定义梯度操作),如果你的代码假设
.grad一定存在且是全零tensor,才建议用默认方式。
相关文章:
No More Adam: 新型优化器SGD_SaI
一.核心思想和创新点 2024年12月提出的SGD-SaI算法(Stochastic Gradient Descent with Scaling at Initialization)本质上是一种在训练初始阶段对不同参数块(parameter block)基于**梯度信噪比(g-SNR, Gradient Signa…...

数据结构【AVL树】
AVL树 1.AVL树1.AVL的概念2.平衡因子 2.AVl树的实现2.1AVL树的结构2.2AVL树的插入2.3 旋转2.3.1 旋转的原则 1.AVL树 1.AVL的概念 AVL树可以是一个空树。 它的左右子树都是AVL树,且左右子树的高度差的绝对值不超过1。AVL树是一颗高度平衡搜索二叉树,通…...

C#将1GB大图裁剪为8张图片
C#处理超大图片(1GB)需要特别注意内存管理和性能优化。以下是几种高效裁剪方案: 方法1:使用System.Drawing分块处理(内存优化版) using System; using System.Drawing; using System.Drawing.Imaging; us…...

数据库——SQL约束窗口函数介绍
4.SQL约束介绍 (1)主键约束 A、基本内容 基本内容 p r i m a r y primary primary k e y key key约束唯一表示数据库中的每条记录主键必须包含唯一的值(UNIQUE)主键不能包含NULL值(NOT NULL)每个表都应…...

Linux系统启动相关:vmlinux、vmlinuz、zImage,和initrd 、 initramfs,以及SystemV 和 SystemD
目录 一、vmlinux、vmlinuz、zImage、bzImage、uImage 二、initrd 和 initramfs 1、initrd(Initial RAM Disk) 2、initramfs(Initial RAM Filesystem) 3、initrd vs. initramfs 对比 4. 如何查看和生成 initramfs 三、Syste…...
JSP链接MySQL8.0(Eclipse+Tomcat9.0+MySQL8.0)
所用环境 Eclipse Tomcat9.0 MySQL8.0.21(下载:MySQL Community Server 8.0.21 官方镜像源下载 | Renwole) mysql-connector-java-8.0.21(下载:MySQL :: Begin Your Download) .NET Framework 4.5.2(下…...

Python爬虫-爬取百度指数之人群兴趣分布数据,进行数据分析
前言 本文是该专栏的第56篇,后面会持续分享python爬虫干货知识,记得关注。 在本专栏之前的文章《Python爬虫-爬取百度指数之需求图谱近一年数据》中,笔者有详细介绍过爬取需求图谱的数据教程。 而本文,笔者将再以百度指数为例子,基于Python爬虫获取指定关键词的人群“兴…...

SEO长尾词与关键词优化实战
内容概要 在SEO优化体系中,长尾关键词与核心关键词的协同作用直接影响流量获取效率与用户转化路径。长尾词通常由3-5个词组构成,搜索量较低但意图明确,能精准触达细分需求用户;核心关键词则具备高搜索量与广泛覆盖能力࿰…...
机器学习-人与机器生数据的区分模型测试-数据处理1
附件为训练数据,总体的流程可以作为参考。 导入依赖 import pandas as pd import os import numpy as np from sklearn.model_selection import train_test_split,GridSearchCV from sklearn.ensemble import RandomForestClassifier,VotingClassifier from skle…...

HelloWorld
HelloWorld 新建一个java文件 文件后缀名为 .javahello.java【注意】系统可能没有显示文件后缀名,我们需要手动打开 编写代码 public class hello {public static void main(String[] args) {System.out.print(Hello,World)} }编译 javac java文件,会生…...

令牌桶和漏桶算法使用场景解析
文章目录 什么时候用令牌桶,什么时候用漏桶算法??先放结论 两个算法一眼看懂什么时候选令牌桶?什么时候选漏桶?组合用法(90% 的真实系统都会这么干)小结记忆 对令牌桶和漏桶组合用法再次详细叙述…...

轻量、优雅、高扩展的事件驱动框架——Hibiscus-Signal
在现代企业级应用中,事件驱动架构(EDA)已成为解耦系统、提升扩展性的利器。今天给大家推荐一个非常优秀的国产轻量级事件驱动框架 —— Hibiscus Signal,它不仅天然整合 Spring Boot,还提供完整的事件生命周期支持&…...
SEO 优化实战:ZKmall模板商城的 B2C商城的 URL 重构与结构化数据
在搜索引擎算法日益复杂的今天,B2C商城想要在海量信息中脱颖而出,仅靠优质商品和营销活动远远不够。ZKmall模板商城以实战为导向,通过URL 重构与结构化数据优化两大核心策略,帮助 B2C 商城实现从底层架构到搜索展示的全面升级&…...

2020CCPC河南省赛题解
A. 班委竞选 签到题,模拟。 #include <bits/stdc.h> #define x first #define y second #define int long long //#define double long doubleusing namespace std; typedef unsigned long long ULL ; typedef pair<int,int> PII ; typedef pair<d…...

数字万用表与指针万用表使用方法及注意事项
在电子测量领域,万用表是极为常用的工具,数字万用表和指针万用表各具特点。熟练掌握它们的使用方法与注意事项,能确保测量的准确性与安全性。下面为您详细介绍: 一 、数字万用表按钮功能 > 进入及退出手动量程模式 每 按 […...

虚拟主播肖像权保护,数字时代的法律博弈
首席数据官高鹏律师团队 在虚拟主播行业蓬勃发展的表象之下,潜藏着一场关乎法律边界的隐形战争。当一位虚拟偶像的3D模型被非法拆解、面部数据被批量复制,运营方惊讶地发现——传统的肖像权保护体系,竟难以完全覆盖这具由代码与数据构成的“…...
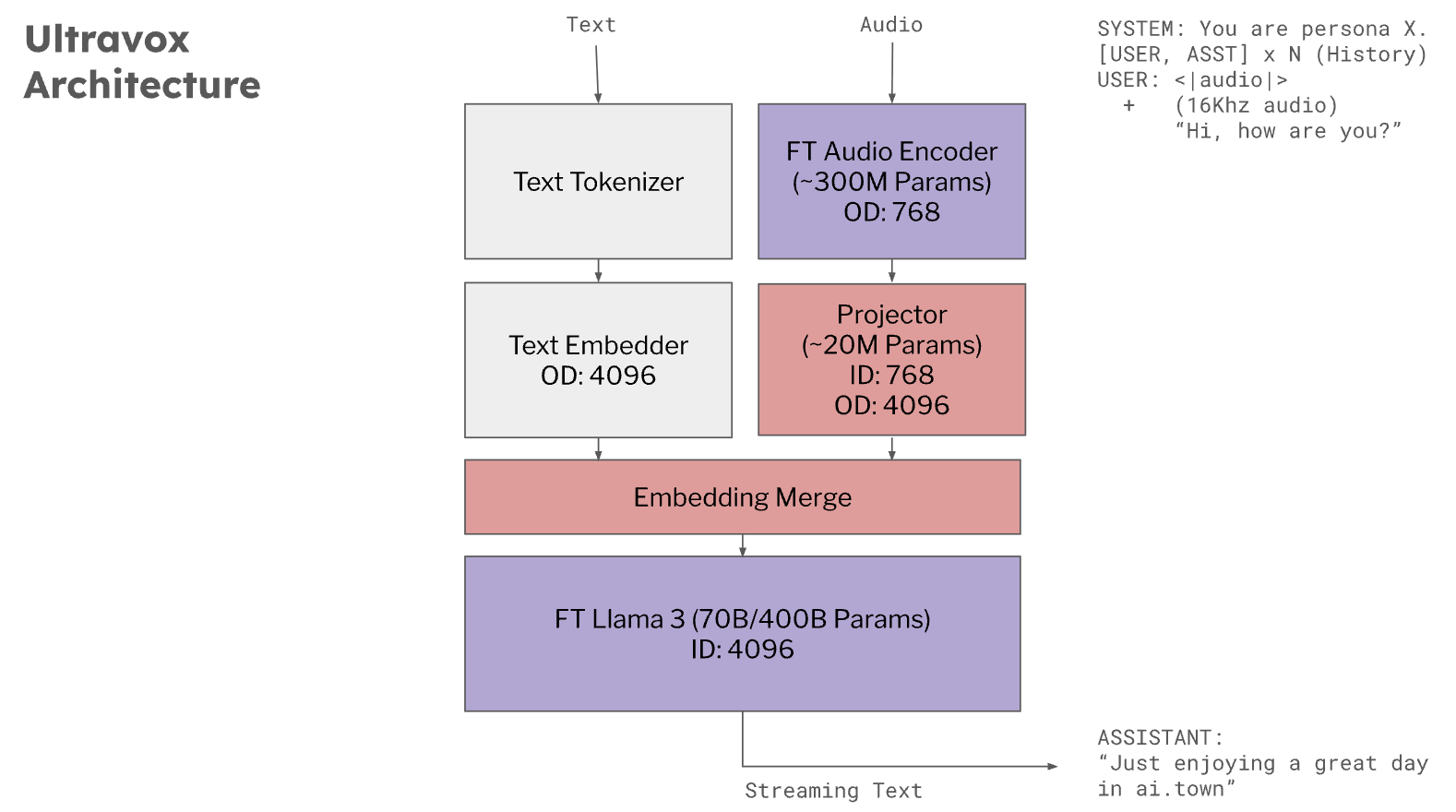
【读代码】端到端多模态语言模型Ultravox深度解析
一、项目基本介绍 Ultravox是由Fixie AI团队开发的开源多模态大语言模型,专注于实现音频-文本的端到端实时交互。项目基于Llama 3、Mistral等开源模型,通过创新的跨模态投影架构,绕过了传统语音识别(ASR)的中间步骤,可直接将音频特征映射到语言模型的高维空间。 核心优…...
RabbitMQ工作流程及使用方法
一、什么是RabbitMQ RabbitMQ 是一款基于 AMQP(高级,消息队列协议) 的开源消息中间件,专为分布式系统设计,用于实现应用程序间的异步通信,其核心功能是通过 消息代理(Message Broker&…...

Java 面向对象进阶:解锁多态、内部类与包管理
Java 面向对象进阶:解锁多态、内部类与包管理 🔑 在 Java 的面向对象编程中,多态赋予了对象“多种形态”的能力,内部类提供了更精细的代码组织方式,而包则帮助我们管理和组织大量的类。今天,我们将深入探讨…...

算法:分治法
实验内容 在一个2kⅹ2k个方格组成的棋盘中,若恰有一个方格与其他方格不同,则称该方格为特殊方格,且称该棋盘为一特殊棋盘。 显然,特殊方格出现的位置有4k 种情况,即k>0,有4k 种不同的特殊棋盘 棋盘覆盖:…...
MySQL初阶:sql事务和索引
索引(index) 可以类似理解为一本书的目录,一个表可以有多个索引。 索引的意义和代价 在MySQL中使用select进行查询时会经过: 1.先遍历表 2.将条件带入每行记录中进行判断,看是否符合 3.不符合就跳过 但当表中的…...
docker部署第一个Go项目
1.前期准备 目录结构 main.go package mainimport ("fmt""github.com/gin-gonic/gin""net/http" )func main() {fmt.Println("\n .::::.\n .::::::::.\n :::::::::::\n …...

day27 python 装饰器
目录 一、装饰器的基本概念 示例:用装饰器优化质数查找函数 二、装饰器的高级用法 1. 支持任意参数的装饰器 2. 装饰器的返回值处理 在 Python 编程中,装饰器是一个非常强大的功能,它可以让其他函数或方法在不需要做任何代码修改的前提下…...
Visual Studio2022跨平台Avalonia开发搭建
由于我已经下载并安装了 VS2022版本,这里就跳过不做阐述。 1.安装 Visual Studio 2022 安装时工作负荷Tab页勾选 “.NET 桌面开发” 和“Visual Studio扩展开发” ,这里由于不是用的微软的MAUI,所以不用选择其他的来支持跨平台开发&a…...
css iconfont图标样式修改,js 点击后更改样式
背景: 在vue项目中,通过点击/鼠标覆盖,更改选中元素的样式,可以通过js逻辑,也可以根据css样式修改。包括以下内容:iconfont图标的引入以及使用,iconfont图标样式修改【导入文件是纯白࿰…...
开源项目实战学习之YOLO11:12.4 ultralytics-models-sam-memory_attention.py源码分析
👉 点击关注不迷路 👉 点击关注不迷路 👉 另外,前些天发现了一个巨牛的AI人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。感兴趣的可以点击相关跳转链接。 点击跳转到网站。 ultralytics-models-sam 1.sam-modules-memory_attention.pyblocks.py: 定义模…...

【沉浸式求职学习day42】【算法题:滑动窗口】
沉浸式求职学习 长度最小的子数组水果成篮 关于算法题:滑动窗口的几个题目 长度最小的子数组 给定一个含有 n 个正整数的数组和一个正整数 s ,找出该数组中满足其和 ≥ s 的长度最小的 连续 子数组,并返回其长度。如果不存在符合条件的子数组…...

LIIGO ❤️ RUST 12 YEARS
LIIGO 💖 RUST 12 YEARS 今天是RUST语言1.0发布十周年纪念日。十年前的今天,2015年的今天,Rust 1.0 正式发行。这是值得全球Rust支持者隆重纪念的日子。我借此机会衷心感谢Rust语言创始人Graydon Hoare,Mozilla公司,以…...

Linux基础开发工具二(gcc/g++,自动化构建makefile)
3. 编译器gcc/g 3.1 背景知识 1. 预处理(进行宏替换/去注释/条件编译/头文件展开等) 2. 编译(生成汇编) 3. 汇编(生成机器可识别代码) 4. 连接(生成可执行文件或库文件) 3.2 gcc编译选项 格式 : gcc …...

Linux zip、unzip 压缩和解压
zip 命令用于压缩文件,压缩后的文件后缀名为 .zip 。 对应的解压命令是 unzip 。 测试用的目录结构如下, userzn:~/test$ tree . ├── folder1 │ ├── folder111 │ │ └── file1.txt │ └── main1.c ├── folder2 │ ├── …...