手动实现 Transformer 模型
本文使用 Pytorch 库手动实现了传统 Transformer 模型中的多头自注意力机制、残差连接和层归一化、前馈层、编码器、解码器等子模块,进而实现了对 Transformer 模型的构建。
"""
@Title: 解析 Transformer
@Time: 2025/5/10
@Author: Michael Jie
"""import mathimport torch
import torch.nn.functional as F
from torch import nn, Tensor# 缩放点积注意力机制 (Scaled Dot-Product Attention)
class Attention(nn.Module):def __init__(self, causal: bool = True) -> None:"""注意力公式:Attention(Q, K, V) = softmax(Q · K / sqrt(d_k)) · VArgs:causal: 是否自动生成因果掩码,默认为 True"""super(Attention, self).__init__()self.causal = causaldef forward(self,q: Tensor,k: Tensor,v: Tensor,padding_mask: Tensor = None,attn_mask: Tensor = None) -> tuple[Tensor, Tensor]:"""填充掩码:处理变长序列,避免填充影响注意力计算因果掩码:防止解码器在训练时看到未来的信息Args:q: 查询 shape=(..., seq_len_q, d_k)k: 键 shape=(..., seq_len_k, d_k)v: 值 shape=(..., seq_len_k, d_v)padding_mask: 填充掩码 shape=(..., seq_len_k)attn_mask: 因果掩码 shape=(..., seq_len_q, seq_len_k)Returns:output: 输出 shape=(..., seq_len_q, d_v)weights: 注意力权重 shape=(..., seq_len_q, seq_len_k)"""# 注意力分数d_k = q.size(-1)scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)# 应用填充掩码if padding_mask is not None:# 广播 (..., 1, seq_len_k)scores = scores.masked_fill(padding_mask.unsqueeze(-2), float("-inf"))# 自动生成因果掩码,优先使用自定义的因果掩码seq_len_q, seq_len_k = q.size(-2), k.size(-2)if self.causal and attn_mask is None:attn_mask = torch.triu(torch.ones(seq_len_q, seq_len_k), diagonal=1).bool()# 应用因果掩码if attn_mask is not None:scores = scores.masked_fill(attn_mask, float("-inf"))# 注意力权重weights = F.softmax(scores, dim=-1)# 再次应用填充掩码,确保填充位置的注意力权重为 0if padding_mask is not None:weights = weights.masked_fill(padding_mask.unsqueeze(-2), 0)# 乘以 v 得到输出output = torch.matmul(weights, v)return output, weights# 自注意力机制 (Self Attention)
class SelfAttention(nn.Module):def __init__(self, d_model: int = 512) -> None:"""自注意力机制是注意力机制的一种特殊形式,其中 Q、K、V 都来自同一输入序列,其能够捕捉序列内部元素之间的关系,不依赖 RNN 或 CNN,直接建模长距离依赖。Args:d_model: 特征维度,默认为 512"""super(SelfAttention, self).__init__()self.attention = Attention() # 注意力机制# 合并 Q、K、V 的线性变换self.linear_qkv = nn.Linear(d_model, d_model * 3)self.linear_out = nn.Linear(d_model, d_model)def forward(self,x: Tensor,padding_mask: Tensor = None,attn_mask: Tensor = None) -> Tensor:"""_Args:x: 词嵌入 shape=(batch_size, seq_len, d_model)padding_mask: 填充掩码 shape=(batch_size, seq_len)attn_mask: 因果掩码 shape=(seq_len, seq_len)Returns:output: 输出 shape=(batch_size, seq_len, d_model)"""# 通过线性层同时生成 Q、K、Vqkv = self.linear_qkv(x)q, k, v = qkv.chunk(3, dim=-1) # (batch_size, seq_len, d_model)# 应用注意力机制output, weights = self.attention(q, k, v, padding_mask, attn_mask)return self.linear_out(output)# 多头自注意力机制 (Multi-Head Self Attention)
class MultiHeadSelfAttention(nn.Module):def __init__(self, d_model: int = 512, num_heads: int = 8) -> None:"""多头自注意力机制是自注意力机制的扩展,通过将输入特征分割成多个头,每个头独立计算注意力,然后将结果拼接起来,从而提高模型的多角度表达能力。Args:d_model: 特征维度,默认为 512num_heads: 头数,默认为 8"""super(MultiHeadSelfAttention, self).__init__()if d_model % num_heads != 0:raise ValueError(f"d_model must be divisible by num_heads, but got {d_model} and {num_heads}")self.num_heads = num_headsself.attention = Attention() # 注意力机制# 分别对 Q、K、V 进行线性变换self.linear_q = nn.Linear(d_model, d_model)self.linear_k = nn.Linear(d_model, d_model)self.linear_v = nn.Linear(d_model, d_model)self.linear_out = nn.Linear(d_model, d_model)def forward(self,q: Tensor,k: Tensor,v: Tensor,padding_mask: Tensor = None,attn_mask: Tensor = None) -> Tensor:"""Q、K、V 在不同的自注意力模块中的来源可能不同,在编解码器自注意力中,Q 来自解码器的输入,K、V 来自编码器的输出。Args:q: 查询 shape=(batch_size, seq_len, d_model)k: 键 shape=(batch_size, seq_len / seq_len_k, d_model)v: 值 shape=(batch_size, seq_len / seq_len_k, d_model)padding_mask: 填充掩码 shape=(batch_size, seq_len / seq_len_k)attn_mask: 因果掩码 shape=(seq_len / seq_len_k, seq_len / seq_len_k)Returns:output: 输出 shape=(batch_size, seq_len, d_model)"""q = self.linear_q(q)k = self.linear_k(k)v = self.linear_v(v)batch_size, seq_len, seq_len_k = q.size(0), q.size(1), k.size(1)# (batch_size, num_heads, seq_len, d_k)q = q.view(batch_size, seq_len, self.num_heads, -1).transpose(1, 2)k = k.view(batch_size, seq_len_k, self.num_heads, -1).transpose(1, 2)v = v.view(batch_size, seq_len_k, self.num_heads, -1).transpose(1, 2)# 调整掩码形状以匹配多头if padding_mask is not None:padding_mask = padding_mask.unsqueeze(1) # (batch_size, 1, seq_len)if attn_mask is not None:attn_mask = attn_mask.unsqueeze(0) # (1, seq_len, seq_len)# 应用注意力机制output, weights = self.attention(q, k, v, padding_mask, attn_mask)# 拼接output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, -1)return self.linear_out(output)# 残差连接和层归一化 (Add&Norm)
class AddNorm(nn.Module):def __init__(self, d_model: int = 512) -> None:"""Add&Norm 层结合了两种操作:残差连接和层归一化,可以使模型在训练过程中更加稳定,并且通过堆叠多个这样的层来构建更深的模型。Args:d_model: 特征维度,默认为 512"""super(AddNorm, self).__init__()self.norm = nn.LayerNorm(d_model) # 层归一化def forward(self, x: Tensor, y: Tensor) -> Tensor:return self.norm(x + y)# 前馈层 (FeedForward Layer)
class FeedForward(nn.Module):def __init__(self,input_dim: int = 512,hidden_dim: int = 2048,activation: str = "relu",dropout: float = 0.1) -> None:"""全连接层(扩大维度) -> 激活函数 -> 全连接层(恢复原始维度)通过非线性变换进一步提取和增强特征,使模型具备更强的模式识别和语义组合能力。Args:input_dim: 输入维度,默认为 512hidden_dim: 隐藏层维度,默认为 2048activation: 激活函数,默认为 "relu"-支持:"sigmoid", "tanh", "relu", "gelu", "leaky_relu", "elu"dropout: 丢弃率,默认为 0.1"""super(FeedForward, self).__init__()match activation: # 切换不同的激活函数case "sigmoid":activation = nn.Sigmoid()case "tanh":activation = nn.Tanh()case "relu":activation = nn.ReLU()case "gelu":activation = nn.GELU()case "leaky_relu":activation = nn.LeakyReLU()case "elu":activation = nn.ELU()case _:raise ValueError(f"Unsupported activation function: {activation}")# Linear -> activation -> Dropout -> Linearself.ffn = nn.Sequential(nn.Linear(input_dim, hidden_dim),activation,nn.Dropout(dropout),nn.Linear(hidden_dim, input_dim),)def forward(self, x: Tensor) -> Tensor:return self.ffn(x)# 编码层
class EncoderLayer(nn.Module):def __init__(self,d_model: int = 512,num_heads: int = 8,dim_feedforward: int = 2048,dropout: float = 0.1) -> None:"""MultiHeadSelfAttention -> AddNorm -> FeedForward -> AddNormArgs:d_model: 特征维度,默认为 512num_heads: 头数,默认为 8dim_feedforward: FFN 隐藏层维度,默认为 2048dropout: 丢弃率,默认为 0.1"""super(EncoderLayer, self).__init__()# 多头自注意力层self.attn = MultiHeadSelfAttention(d_model, num_heads)# Add&Norm 层self.norm1 = AddNorm(d_model)self.norm2 = AddNorm(d_model)# 前馈层self.ffn = FeedForward(d_model, dim_feedforward, dropout=dropout)# 丢弃层self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)def forward(self,x: Tensor,padding_mask: Tensor = None,attn_mask: Tensor = None) -> Tensor:x = self.norm1(x, self.dropout1(self.attn(x, x, x, padding_mask, attn_mask)))x = self.norm2(x, self.dropout2(self.ffn(x)))return x# 编码器
class Encoder(nn.Module):def __init__(self, num_layers: int = 6, **params) -> None:"""编码器由多个编码层组成,每个编码层结构相同但并不共享参数。Args:num_layers: 层数,默认为 6**params: 编码层参数,参考 EncoderLayer"""super(Encoder, self).__init__()self.layers = nn.ModuleList([EncoderLayer(**params)for _ in range(num_layers)])def forward(self,x: Tensor,padding_mask: Tensor = None,attn_mask: Tensor = None) -> Tensor:for layer in self.layers: # 逐层传递x = layer(x, padding_mask, attn_mask)return x# 解码层
class DecoderLayer(nn.Module):def __init__(self,d_model: int = 512,num_heads: int = 8,dim_feedforward: int = 2048,dropout: float = 0.1) -> None:"""MultiHeadSelfAttention -> AddNorm -> MultiHeadSelfAttention -> AddNorm -> FeedForward -> AddNormArgs:d_model: 特征维度,默认为 512num_heads: 头数,默认为 8dim_feedforward: FFN 隐藏层维度,默认为 2048dropout: 丢弃率,默认为 0.1"""super(DecoderLayer, self).__init__()# 多头自注意力层self.attn = MultiHeadSelfAttention(d_model, num_heads)self.cross_attn = MultiHeadSelfAttention(d_model, num_heads)# Add&Norm 层self.norm1 = AddNorm(d_model)self.norm2 = AddNorm(d_model)self.norm3 = AddNorm(d_model)# 前馈层self.ffn = FeedForward(d_model, dim_feedforward, dropout=dropout)# 丢弃层self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)self.dropout3 = nn.Dropout(dropout)def forward(self,y: Tensor,memory: Tensor,padding_mask_y: Tensor = None,padding_mask_memory: Tensor = None,attn_mask_y: Tensor = None,attn_mask_memory: Tensor = None) -> None:x = yx = self.norm1(x, self.dropout1(self.attn(x, x, x, padding_mask_y, attn_mask_y)))x = self.norm2(x, self.dropout2(self.attn(x, memory, memory, padding_mask_memory, attn_mask_memory)))x = self.norm3(x, self.dropout3(self.ffn(x)))return x# 解码器
class Decoder(nn.Module):def __init__(self, num_layers: int = 6, **params) -> None:"""解码器由多个解码层组成,每个解码层结构相同但并不共享参数。Args:num_layers: 层数,默认为 6**params: 解码层参数,参考 DecoderLayer"""super(Decoder, self).__init__()self.layers = nn.ModuleList([DecoderLayer(**params)for _ in range(num_layers)])def forward(self,y: Tensor,memory: Tensor,padding_mask_y: Tensor = None,padding_mask_memory: Tensor = None,attn_mask_y: Tensor = None,attn_mask_memory: Tensor = None) -> Tensor:x = yfor layer in self.layers: # 逐层传递x = layer(y, memory, padding_mask_y, padding_mask_memory, attn_mask_y, attn_mask_memory)return x# Transformer
class Transformer(nn.Module):def __init__(self,num_encoder_layers: int = 6,num_decoder_layers: int = 6,**params) -> None:"""transformer 是标准的编码器-解码器结构Args:num_encoder_layers: 编码器层数,默认为 6num_decoder_layers: 解码器层数,默认为 6**params: 编解码层参数,参考 EncoderLayer 和 DecoderLayer"""super(Transformer, self).__init__()self.encoder = Encoder(num_encoder_layers, **params) # 编码器self.decoder = Decoder(num_decoder_layers, **params) # 解码器def forward(self,x: Tensor,y: Tensor,padding_mask_x: Tensor = None,padding_mask_y: Tensor = None,padding_mask_memory: Tensor = None,attn_mask_x: Tensor = None,attn_mask_y: Tensor = None,attn_mask_memory: Tensor = None) -> Tensor:memory = self.encoder(x, padding_mask_x, attn_mask_x)output = self.decoder(y, memory, padding_mask_y, padding_mask_memory, attn_mask_y, attn_mask_memory)return outputif __name__ == '__main__':# attention = Attention(True)# t1, t2 = attention(# torch.rand((2, 3, 64)),# torch.rand((2, 5, 64)),# torch.rand((2, 5, 512)),# torch.tensor([[False, True, True, True, True],# [False, False, False, False, True]])# )# print(t1.shape, t2.shape)# self_attention = SelfAttention()# t3 = self_attention(# torch.rand((2, 5, 512)),# torch.tensor([[False, False, False, True, True],# [False, False, True, True, True]])# )# print(t3.shape)# multi_head_self_attention = MultiHeadSelfAttention(num_heads=2)# t4 = multi_head_self_attention(# torch.rand((2, 3, 512)),# torch.rand((2, 5, 512)),# torch.rand((2, 5, 512)),# torch.tensor([[False, False, False, True, True],# [False, False, True, True, True]])# )# print(t4.shape)# encoder_layer = EncoderLayer()# t5 = encoder_layer(# torch.rand((2, 5, 512)),# torch.tensor([[False, False, False, True, True],# [False, False, True, True, True]])# )# print(t5.shape)# encoder = Encoder(dropout=0.2)# t6 = encoder(# torch.rand((2, 5, 512)),# torch.tensor([[False, False, False, True, True],# [False, False, True, True, True]])# )# print(t6.shape)# decoder_layer = DecoderLayer()# t7 = decoder_layer(# torch.rand((2, 3, 512)),# torch.rand((2, 5, 512)),# torch.tensor([[False, False, False],# [False, False, True]]),# torch.tensor([[False, False, False, True, True],# [False, False, True, True, True]])# )# print(t7.shape)# decoder = Decoder()# t8 = decoder(# torch.rand((2, 3, 512)),# torch.rand((2, 5, 512)),# torch.tensor([[False, False, False],# [False, False, True]]),# torch.tensor([[False, False, False, True, True],# [False, False, True, True, True]])# )# print(t8.shape)transformer = Transformer()t9 = transformer(torch.rand((2, 5, 512)),torch.rand((2, 3, 512)),torch.tensor([[False, False, False, True, True],[False, False, True, True, True]]),torch.tensor([[False, False, False],[False, False, True]]),)print(t9.shape)
相关文章:
手动实现 Transformer 模型
本文使用 Pytorch 库手动实现了传统 Transformer 模型中的多头自注意力机制、残差连接和层归一化、前馈层、编码器、解码器等子模块,进而实现了对 Transformer 模型的构建。 """ Title: 解析 Transformer Time: 2025/5/10 Author: Michael Jie &quo…...

成功案例丨从草图到鞍座:用先进的发泡成型仿真技术变革鞍座制造
案例简介 在鞍座制造中,聚氨酯泡沫成型工艺是关键环节,传统依赖实验测试的方法耗时且成本高昂。为解决这一问题,意大利自行车鞍座制造商 Selle Royal与Altair合作,采用Altair Inspire PolyFoam软件进行发泡成型仿真。 该工具帮助团…...

BG开发者日志517:demo数据分析与修改方向
光明斗士玩法介绍预告片 1、试玩版开局不利 因为疏忽与经验不足,导致本地化出了问题,demo版本是以默认简体中文版的状态发布的, demo早就在2月就已经过审,当时客服并没有提出问题。后来多次传新版本,直接就发布了。 …...

Linux靶机网站配置:从零搭建Web靶场环境
在网络安全学习中,搭建靶机环境是进行渗透测试和防御技术研究的重要环节。本教程将详细介绍如何在Linux系统(如Kali、Debian、Ubuntu等)上配置一个基于Apache的靶机网站,支持HTTP/HTTPS、虚拟主机、SSL自签名证书、本地域名解析、…...

电机试验平台:创新科技推动电动机研究发展
电机试验平台是电机制造和研发过程中不可或缺的重要设备,其功能涵盖了电机性能测试、电机寿命测试、电机质量评估等多个方面。随着科技的不断发展和电机应用领域的日益扩大,对电机试验平台的要求也越来越高。本文将从现代化电机试验平台的设计与应用两个…...

STM32F103定时器1每毫秒中断一次
定时器溢出中断,在程序设计中经常用到。在使用TIM1和TIM8溢出中断时,需要注意“TIM_TimeBaseStructure.TIM_RepetitionCounter0;”,它表示溢出一次,并可以设置中断标志位。 TIM1_Interrupt_Initializtion(1000,72); //当arr1…...

【springcloud学习(dalston.sr1)】Zuul路由访问映射规则配置及使用(含源代码)(十二)
该系列项目整体介绍及源代码请参照前面写的一篇文章【springcloud学习(dalston.sr1)】项目整体介绍(含源代码)(一) springcloud学习(dalston.sr1)系统文章汇总如下: 【springcloud学习(dalston…...
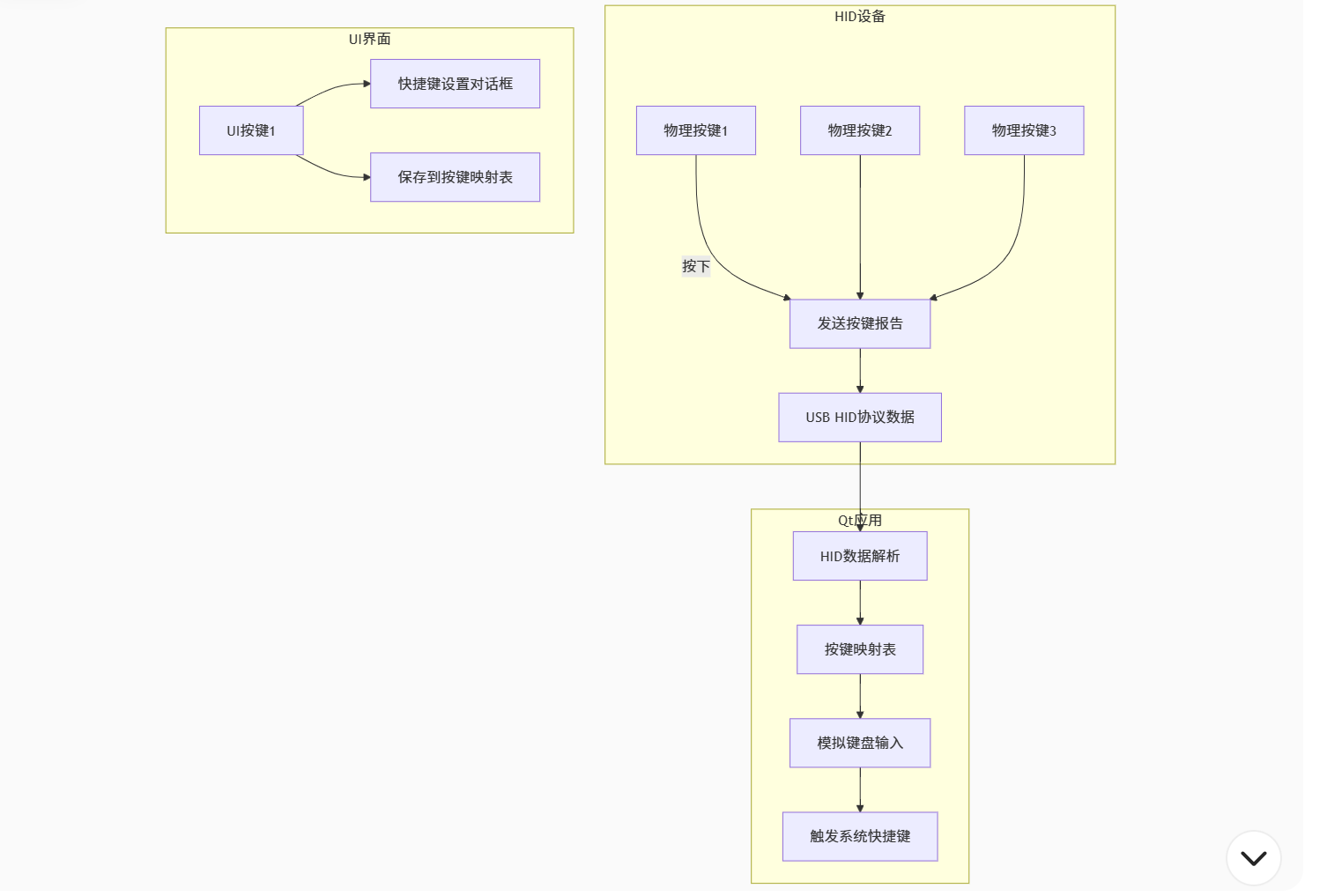
Qt与Hid设备通信
什么是HID? HID(Human Interface Device)是直接与人交互的电子设备,通过标准化协议实现用户与计算机或其他设备的通信,典型代表包括键盘、鼠标、游戏手柄等。 为什么HID要与qt进行通信? 我这里的应…...

2024 山东省ccpc省赛
目录 I(签到) 题目简述: 思路: 代码: A(二分答案) 题目简述: 思路: 代码: K(构造) 题目: 思路: 代…...
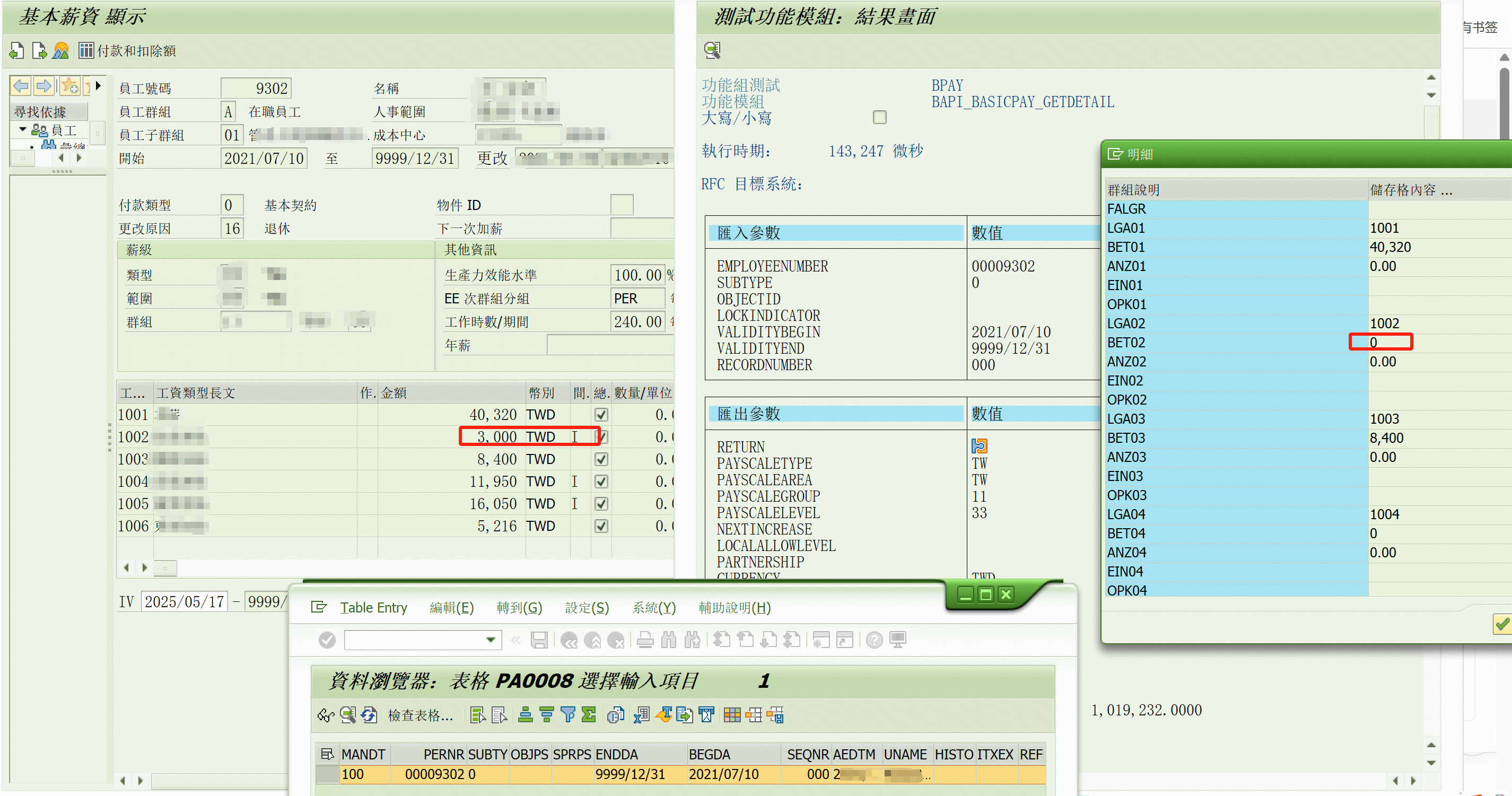
SAP HCM 0008数据存储逻辑
0008信息类型:0008信息类型是存储员工基本薪酬的地方,因为很多企业都会都薪酬带宽,都会按岗定薪,所以在上线前为体现工资体系的标准化,都会在配置对应的薪酬关系,HCM叫间接评估,今天我们就分析下…...
面试题)
Elasticsearch 查询与过滤(Query vs. Filter)面试题
Elasticsearch 查询与过滤(Query vs. Filter)面试题 🚀 目录 基础概念性能优化实战应用错误排查高级场景设计题总结基础概念 🔍 面试题1:基础概念 题目: 请解释Elasticsearch中query和filter的主要区别,并说明何时应优先使用filter。 👉 查看参考答案 核心区别…...

golang读、写、复制、创建目录、删除、重命名,文件方法总结
文章目录 一、只读文件二、写入文件三、复制文件四、创建目录五、删除目录/文件五、重命名文件 一、只读文件 file, err : os.Open("./main.go")defer file.Close() //打开文件一定要关闭关闭文件if err ! nil {fmt.Println("文件打开失败", err)}/*方案一…...
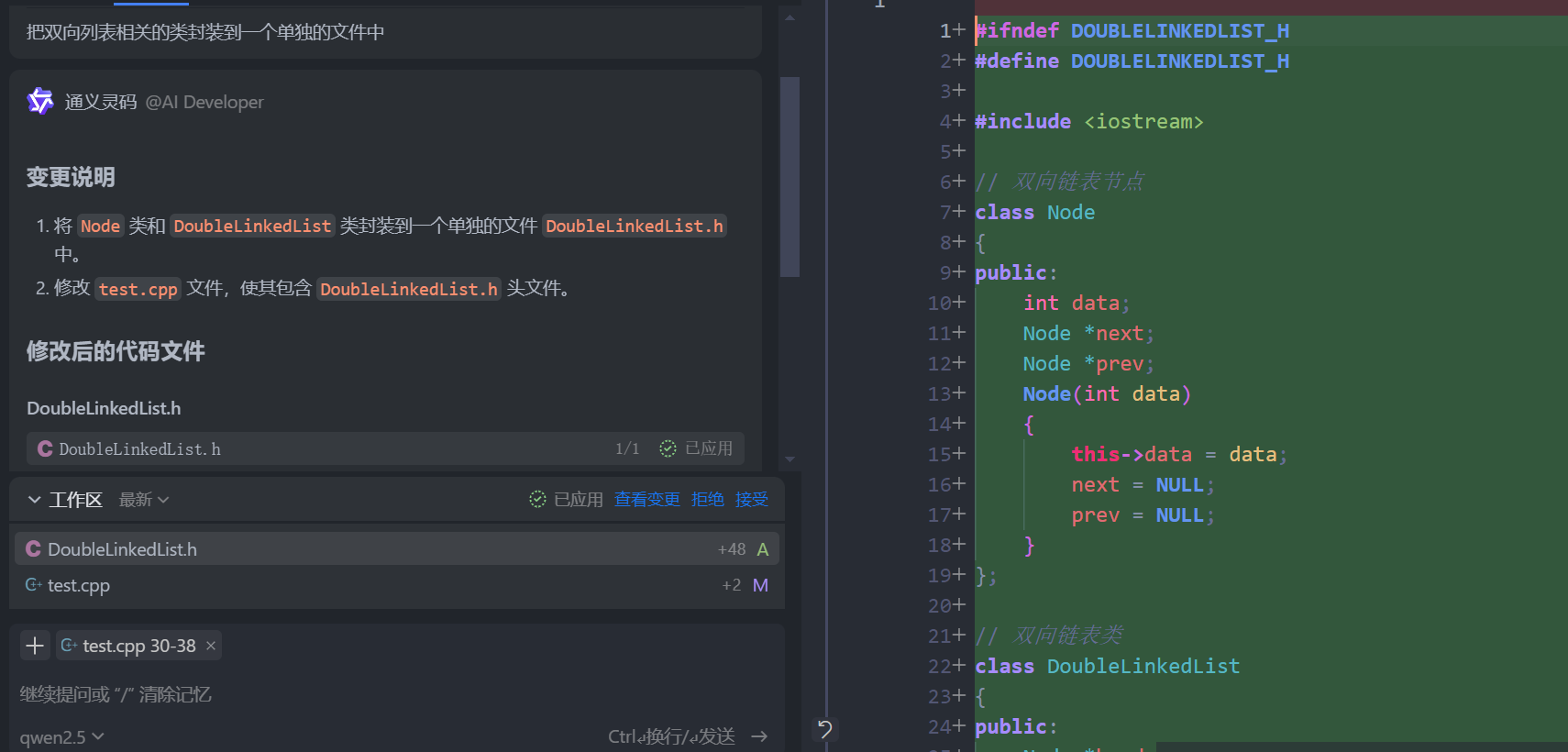
如何使用通义灵码辅助学习C++编程 - AI编程助手提升效率
一、引言 C 是一门功能强大且灵活的编程语言,在软件开发、系统编程、游戏开发等领域广泛应用。然而,其复杂的语法和丰富的特性使得学习曲线较为陡峭。对于初学者而言,在学习过程中难免会遇到各种问题,如语法理解困难、代码调试耗…...

解决LeetCode 47. 全排列 II 问题的正确姿势:深入分析剪枝与状态跟踪
文章目录 问题描述常见错误代码与问题分析错误代码示例错误分析 正确解决方案修正后的代码关键修正点 核心逻辑详解1. 为何使用 boolean[] used 而非 HashSet?2. 剪枝条件 !used[i - 1] 的作用 场景对比:何时用数组?何时用哈希表?…...

ubuntu18 设置静态ip
百度 编辑/etc/netplan/01-netcfg.yaml 系统没有就自己编写 network: version: 2 renderer: networkd ethernets: eth0: dhcp4: no addresses: [192.168.20.8/24] # 设置你的IP地址和子网掩码 gateway4: 192.168.20.1 # 网关地址 namese…...
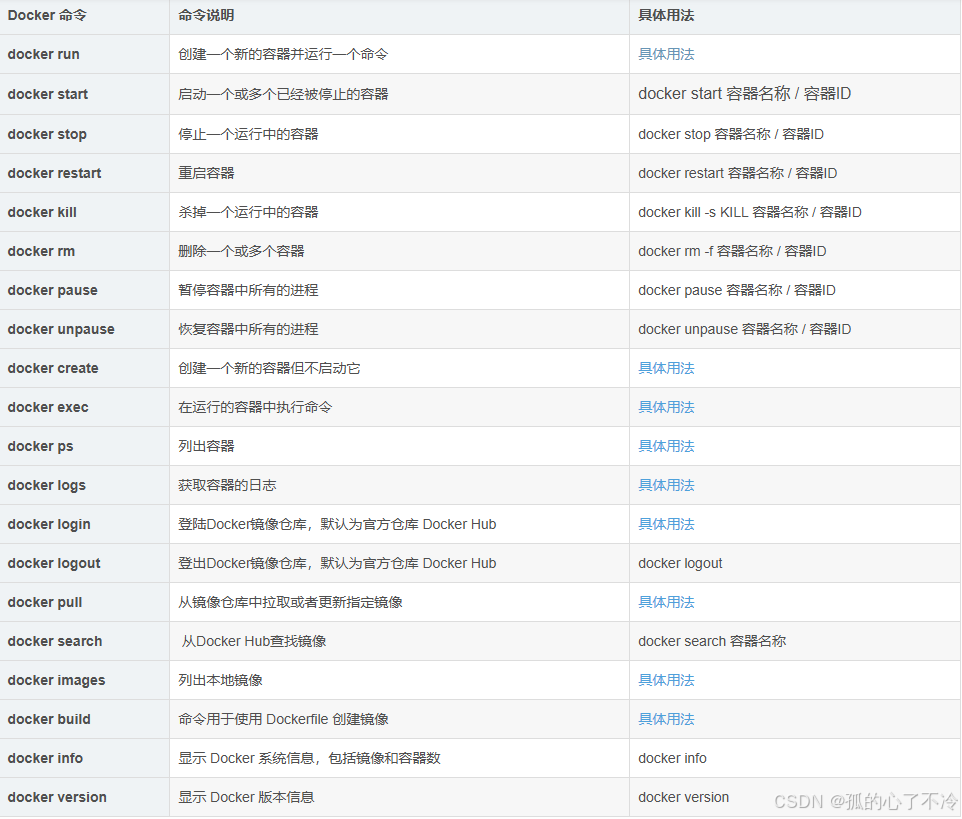
【Docker】CentOS 8.2 安装Docker教程
目录 1.卸载 2.安装依赖 3.设置yum源 4.安装Docker 5.启动Docker 6.设置Docker开机自启 7.验证Docker是否安装成功 8.配置多个国内镜像地址 9.重启Docker 10.Docker指令大全 10.1.启动与关闭Docker 10.2.Docker镜像操作 10.3.Docker容器操作 10.4.Docker Compose操作…...
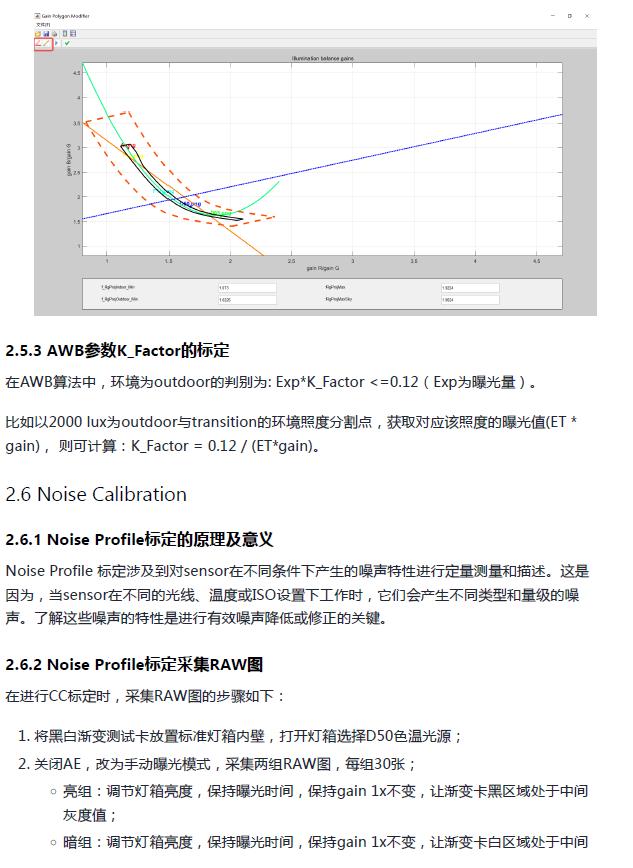
K230 ISP:一种新的白平衡标定方法
第一次遇见需要利用光谱响应曲线进行白平衡标定的方法。很好奇是如何利用光谱响应曲线进行白平衡标定的。 参考资料参考:K230 ISP图像调优指南 K230 介绍 嘉楠科技 Kendryte 系列 AIoT 芯片中的最新一代 AIoT SoC K230 芯片采用全新的多核异构单元加速计算架构&a…...

桃芯ingchips——windows HID键盘例程无法同时连接两个,但是安卓手机可以的问题
目录 环境 现象 原理及解决办法 环境 PC:windows11 安卓:Android14 例程使用的是HID Keyboard,板子使用的是91870CQ的开发板,DB870CC1A 现象 连接安卓手机时并不会出现该现象,两个开发板都可以当做键盘给手机发按…...

SQL看最多的数据,但想从小到大排列看趋势
SQL 查询:从 test 表中获取本月的数据,并对数量最多的前10个流程按数量升序排序 假设表结构 test 表包含请求信息。workflow_base 包含流程的基本信息。 CREATE TABLE test (requestid INT, -- 请求IDworkflowid INT, -- 流程IDcurr…...

Go语言 Gin框架 使用指南
Gin 是一个用 Go (Golang) 编写的 Web 框架。 它具有类似 martini 的 API,性能要好得多,多亏了 httprouter,速度提高了 40 倍。 如果您需要性能和良好的生产力,您一定会喜欢 Gin。Gin 相比于 Iris 和 Beego 而言,更倾向…...

[Linux] vim及gcc工具
目录 一、vim 1.vim的模式 2.vim的命令集 (1):命令模式 (2):底行模式 3.vim配置 二、gcc 1.gcc格式及选项 2.工作布置 三、自动化构建工具makefile 1.基本使用方法 2.配置文件解析 3.拓展 在linux操作系统的常用工具中,常用vim来进行程序的编写;…...

YOLOv11改进 | Neck篇 | 轻量化跨尺度跨通道融合颈部CCFM助力YOLOv11有效涨点
YOLOv11改进 | Neck篇 | 轻量化跨尺度跨通道融合颈部CCFM助力YOLOv11有效涨点 引言 在目标检测领域,YOLO系列算法因其卓越的速度-精度平衡而广受欢迎。YOLOv11作为该系列的最新演进版本,在Neck部分引入了创新的跨尺度跨通道融合模块(CCFM, Cross-scale…...

MySQL只操作同一条记录也会死锁吗?
大家好,我是锋哥。今天分享关于【MySQL只操作同一条记录也会死锁吗?】面试题。希望对大家有帮助; MySQL里where条件的顺序影响索引使用吗? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 在MySQL中,死锁通常发生在多…...
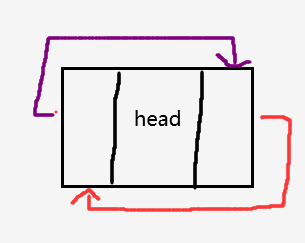
数据结构与算法——双向链表
双向链表 定义链表分类双向链表:带头双向循环链表 初始化打印尾插头插尾删头删查找在pos(指定位置)之后插入结点在pos(指定位置)之前插入结点删除pos(指定位置)的结点销毁顺序表与链表的分析 定义 链表分类 单向和双向 带头和不带头 带头是指存在一个头结点&…...
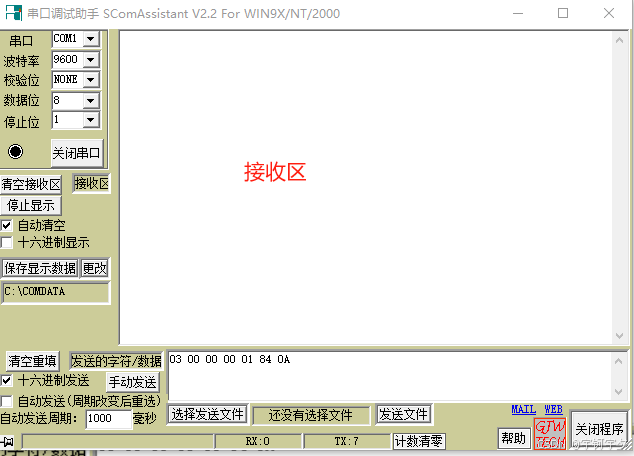
MODBUS RTU调试助手使用方法详解
一、软件简介 485调试助手是一款常用的串口通信调试工具,专门用于RS-485总线设备的测试、调试和通信监控。它支持多种串口参数设置,提供数据收发功能,是工业现场调试的必备工具之一。 二、软件安装与启动 1. 系统要求 Windows 7/10/11操作…...
自由学习记录(60)
Lecture 16 Ray Tracing 4_哔哩哔哩_bilibili 老师说的“高频采样”问题是什么? 现在考虑一个特殊情况: ❗ 一个像素内,图像信号变化很剧烈(高频): 比如: 细网格纹理 马赛克背景 很高频的…...

现代计算机图形学Games101入门笔记(三)
三维变换 具体形式缩放,平移 特殊点旋转。这里涉及到坐标系,先统一定义右手坐标系,根据叉乘和右手螺旋判定方向。这里还能法线Ry Sina 正负与其他两个旋转不一样。这里可以用右手螺旋,x叉乘z,发现大拇指朝下࿰…...
WeakAuras Lua Script <BiaoGe>
WeakAuras Lua Script <BiaoGe> 表格拍卖插件WA字符串 表格字符串代码: !WA:2!S3xA3XXXrcoE2VH9l7ZFy)C969PvDpSrRgaeuhljFlUiiSWbxaqXDx(4RDd0vtulB0fMUQMhwMZJsAO5HenLnf1LPSUT4iBrjRzSepL(pS)e2bDdWp5)cBEvzLhrMvvnAkj7zWJeO7mJ8kYiJmYiImYF0b(XR)JR9JRD…...

计算机视觉与深度学习 | LSTM应用合集
LSTM **一、时间序列预测****二、自然语言处理(NLP)****三、语音识别与合成****四、视频分析与行为识别****五、异常检测****六、医疗健康****七、推荐系统****八、金融风控****九、机器人控制****十、其他创新应用****十一、LSTM的局限性及替代方案****十二、总结**长短期记…...
和算术右移(Arithmetic Right Shift)的区别)
在Verilog中,逻辑右移(Logical Right Shift)和算术右移(Arithmetic Right Shift)的区别
在Verilog中,逻辑右移(Logical Right Shift)和算术右移(Arithmetic Right Shift)的核心区别在于左侧空位的填充方式,具体如下: 逻辑右移(>>) 操作符:&g…...