数据结构*优先级队列(堆)
什么是优先级队列(堆)
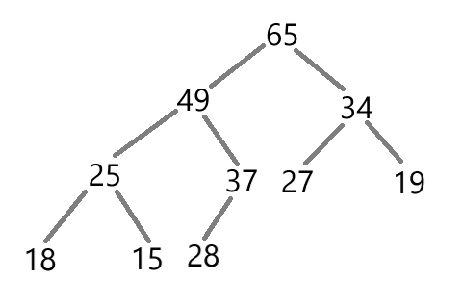
优先级队列一般通过堆(Heap)这种数据结构来实现,堆是一种特殊的完全二叉树,其每个节点都满足堆的性质。如下图所示就是一个堆:
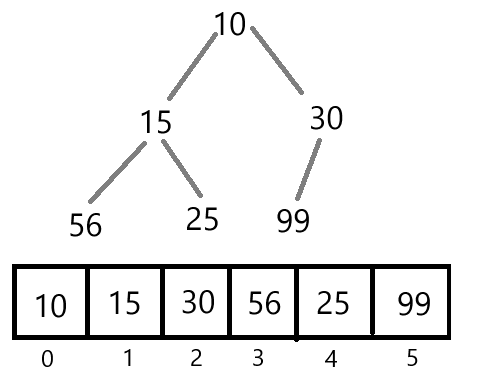
堆的存储方式
由于堆是一棵完全二叉树,所以也满足二叉树的性质:
1、 一颗非空二叉树的第i层上最多有2^(i-1)个结点。
2、 一颗深度为k的二叉树,其树的最大结点为2^k-1
3、 由第二条性质推出,具有n个结点的完全二叉树的深度k = log(n+1) [以2为底的log] 向上取整。
4、 对于任意一颗二叉树,其叶子结点为n0(结点度为0),度为2的结点个数为n2,则n0 = n2 + 1。
5、 对于具有n个结点的完全二叉树,按照从上到下、从左到右的顺序从0开始编号,则对于序号i的结点:
左孩子结点下标为2i + 1,当2i + 1 > n 时,就不存在左孩子结点。
右孩子结点下标为2i + 2,当2i + 2 > n 时,就不存在右孩子结点。
其父亲结点的下标为(i - 1) / 2。i == 0时,其结点为根节点,没有父亲结点。
当元素存入数组后,需要利用性质5来完成一些功能,完成对数组的访问。
最大堆或最小堆
对于一个完全二叉树来说:每个节点的值都大于或等于其子节点的值,堆顶元素是整个堆中的最大值,被称为最大堆;
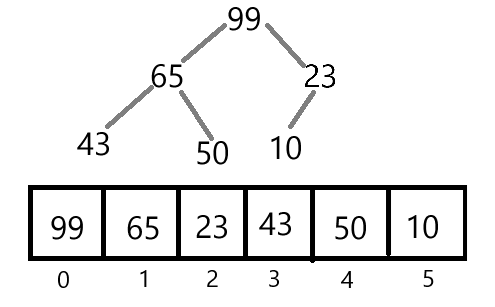
每个节点的值都小于或等于其子节点的值,堆顶元素就是堆中的最小值,被称为最小堆。
对于最大堆或者最小堆来说,数组是最常用的实现方式。数组存储堆中的值是以层序遍历的方式来存储的。
最大堆或最小堆的创建
根据数组来创建最大堆或最小堆。以下图为例:
下面代码实现了最大堆
public void createHeapMAX() {//需要对每棵子树进行调整,调整方式是一样的。//parent是从最后一个孩子的父亲结点开始的,每次parent--来访问其他的树。//当parent为根节点调整完了,说明完成了最大堆的创建for (int parent = ((useSize - 1) - 1) / 2; parent >= 0; parent--) {//每个初始parent的树的向下调整siftDownMAX(parent,useSize);//传useSize的目的是为了,在parent和child交换后,parent需要到child位置在判断下一个结点是否满足最大堆,//对应的每棵树结束的标志是child下标超过useSize}
}
/*** 向下调整,让节点的值不断向下调整* @param parent* @param useSize*/
private void siftDownMAX(int parent,int useSize){//1、定义child下标int child = parent * 2 + 1;while(child < useSize) {//2、比较左右子树的值,child谁是最大值if(child + 1 < useSize && elem[child + 1] > elem[child]) {child++;}//3、判断是否交换if(elem[parent] < elem[child]) {swap(parent,child);//当前父节点变为子节点,继续检查其新的子节点(检查子树的子树)parent = child;child = parent * 2 + 1;}else {return;//如果当前父节点已经大于其子节点,那么其子树必然已经是合法的最大堆(因为构建过程是自底向上的)}}
}
private void swap(int parent,int child){int temp = elem[parent];elem[parent] = elem[child];elem[child] = temp;
}
和上述逻辑差不多,就是更改了比较符号。下面是实现最小堆的代码:
public void createHeapMIN() {for (int parent = ((useSize - 1) - 1) / 2; parent >= 0; parent--) {siftDownMIN(parent,useSize);}
}
private void siftDownMIN(int parent,int useSize){int child = parent * 2 + 1;while(child < useSize) {if(child + 1 < useSize && elem[child + 1] < elem[child]) {child++;}if(elem[parent] > elem[child]) {swap(parent,child);parent = child;child = parent * 2 + 1;}else {return;}}
}
private void swap(int parent,int child){int temp = elem[parent];elem[parent] = elem[child];elem[child] = temp;
}
上述代码的总时间复杂度为O(N)。单个siftDownMAX和siftDownMIN的时间复杂度为O(logN)
堆的删除与插入
堆的删除
在堆中删除一定是删除堆顶的元素,也就是根节点。
实现的方法是:
1、将最后一个叶子节点和根节点交换。
2、此时再删除最后一个叶子节点(原根节点)。
3、进行向下调整
public int poll() {if(isEmpty()) {return -1;}swap(0,useSize - 1);useSize--;siftDownMAX(0,useSize);return elem[0];
}
堆的插入
实现的方法是:
1、将添加的数据放在最底层。
2、在进行向上调整
public void offer(int value) {if(isFull()){elem = Arrays.copyOf(elem,2*elem.length);}elem[useSize] = value;useSize++;int child = useSize - 1;siftUp(child);
}
/*** 实现的是最大堆* @param child*/
private void siftUp(int child){int parent = (child - 1) / 2;while (child > 0) {if(elem[parent] < elem[child]) {swap(parent,child);child = parent;//向上调整parent = (child - 1) / 2;}else {break;}}
}
private void swap(int parent,int child){int temp = elem[parent];elem[parent] = elem[child];elem[child] = temp;
}上述代码的总时间复杂度为O(N*logN)。单个siftUp的时间复杂度为O(logN)。
显然较上面创建的最大堆的时间复杂度大一些。
获取堆顶元素
实现的方法是:
直接返回数组首元素即可
public int peek() {if(isEmpty()) {return -1;}return elem[0];
}
private boolean isEmpty() {return useSize == 0;
}
堆的集合类
对于堆的集合类有两种PriorityQueue 和 PriorityBlockingQueue。PriorityBlockingQueue属于线程安全的,PriorityQueue属于线程不安全的。
我们先学习PriorityQueue类
1、由于在堆的实现过程中需要进行比较,所以放置的元素一定要能比较。像对象就不能进行比较,也就不能成为元素。
2、不能传入null
3、可以任意插入多个元素,类有自动扩容的机制
public class TestPriorityQueue {public static void main(String[] args) {PriorityQueue<Student> priorityQueue = new PriorityQueue<>();PriorityQueue<Integer> priorityQueueAge = new PriorityQueue<>();Student student = new student();priorityQueueAge.offer(Student.age);//没有错误,比较的是int类型priorityQueue.offer(new Student());//会抛出ClassCastException异常priorityQueue.offer(null);//会抛出NullPointerException异常}
}
class Student {public int age;
}
构造方法
| 构造方法 | 功能 |
|---|---|
| PriorityQueue() | 创建一个空的优先级队列,初始容量为11 |
| PriorityQueue(int initialCapacity) | 初始优先级队列的容量,但不能传小于1的数字 |
| PriorityQueue(Collection<? extends E> c) | 传入一个集合类来创建堆 |
| PriorityQueue(Comparator<? super E> comparator) | 传入比较器,按照比较器的方法完成堆的排序 |
| PriorityQueue(int initialCapacity,Comparator<? super E> comparator) | 传入比较器和初始容量 |
public static void main(String[] args) {PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();priorityQueue.offer(10);priorityQueue.offer(3);priorityQueue.offer(4);System.out.println(priorityQueue.peek());//输出:3
}
//传入一个集合类
public static void main(String[] args) {ArrayList<Integer> arrayList = new ArrayList<>();arrayList.add(10);arrayList.add(3);arrayList.add(4);PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(arrayList);System.out.println(priorityQueue.peek());//输出:3
}
通过上述代码和PriorityQueue类的源码,发现,当没有传入比较器时,堆默认是按最小堆来排的。要实现最大堆就需要传入一个比较器。
1、通过实现Comparator接口(完整类),来创建一个比较器
class Compare implements Comparator<Integer> {@Overridepublic int compare(Integer o1, Integer o2) {return o2 - o1;//此时是按最大堆来建立的//return o2.compareTo(o1);//此时也是按最大堆来建立的//Integer类继承了Comparable接口//return o1 - o2;就是按最小堆来建立的}
}
public static void main(String[] args) {Compare compare = new Compare();PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(compare);priorityQueue.offer(10);priorityQueue.offer(3);priorityQueue.offer(4);System.out.println(priorityQueue.peek());//输出:10
}
2、使用匿名内部类,在需要比较器的地方直接创建匿名内部类,无需定义独立的类。
public static void main(String[] args) {PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return o2 - o1;}});priorityQueue.offer(10);priorityQueue.offer(3);priorityQueue.offer(4);System.out.println(priorityQueue.peek());//输出:10
}
常用方法
| 方法 | 功能 |
|---|---|
| boolean offer(E e) | 添加数据 |
| E peek() | 获取堆顶的元素 |
| E poll() | 删除优先级最高的元素并返回 |
| int size() | 获取有效元素个数 |
| void clear() | 清空元素 |
| boolean isEmpty() | 判断是否为空 |
在官方中插入元素(offer())的时间复杂度为O(logN),用的是向上调整,创建堆(批量插入N个元素)的时间复杂度为O(N*logN)。使用构造方法传入集合类时,时间复杂度为O(N),用的是向下调整。
删除堆顶的元素(poll())的时间复杂度为O(logN),用的是向下调整。
关于堆的一些问题
top-K问题
代码展示:
代码一:
/*** 总时间复杂度为:O((N+k)*logN)* @param array* @param k* @return*/
public int[] topK1(int[] array,int k) {int[] ret = new int[k];if(array == null || k <= 0) {return ret;}PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(array.length);//将所有元素放到堆中,offer方法自动按照最小堆排序for (int i = 0;i < array.length;i++) {priorityQueue.offer(array[i]);}//将堆中前三个元素放到ret数组中。for (int i = 0;i < k;i++) {ret[i] = priorityQueue.poll();}return ret;
}
代码二:
/*** 总时间复杂度为:O(N*logK)* @param array* @param k* @return*/
public int[] topK(int[] array,int k) {int[] ret = new int[k];if(array == null || k <= 0) {return ret;}//根据最大根创建优先级队列PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(k, new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return o2 - o1;}});//创建有K个元素的堆//时间复杂度为:O(K * logK)for (int i = 0; i < k; i++) {priorityQueue.offer(array[i]);}//遍历后面的数组元素//时间复杂度为:O((N-K) * logK)for (int i = k; i < array.length; i++) {//当数组元素大于堆顶的元素,说明这个元素不是前K个最小的元素if(array[i] < priorityQueue.peek()){priorityQueue.poll();priorityQueue.offer(array[i]);}}//将堆中的前k放到ret数组中//时间复杂度为:O(K * logK) 几乎可以忽略for (int i = 0; i < k; i++) {ret[i] = priorityQueue.poll();}return ret;
}
代码解释:
对于代码一来说,是将所有元素全部放到堆中,进行堆排。如果有大量数据,会导致有很多次进行调整,时间复杂度高,为O((N+k)logN)。
对于代码二来说,只是对前K个元素进行了堆排,降低了时间复杂度,为O(NlogK)。
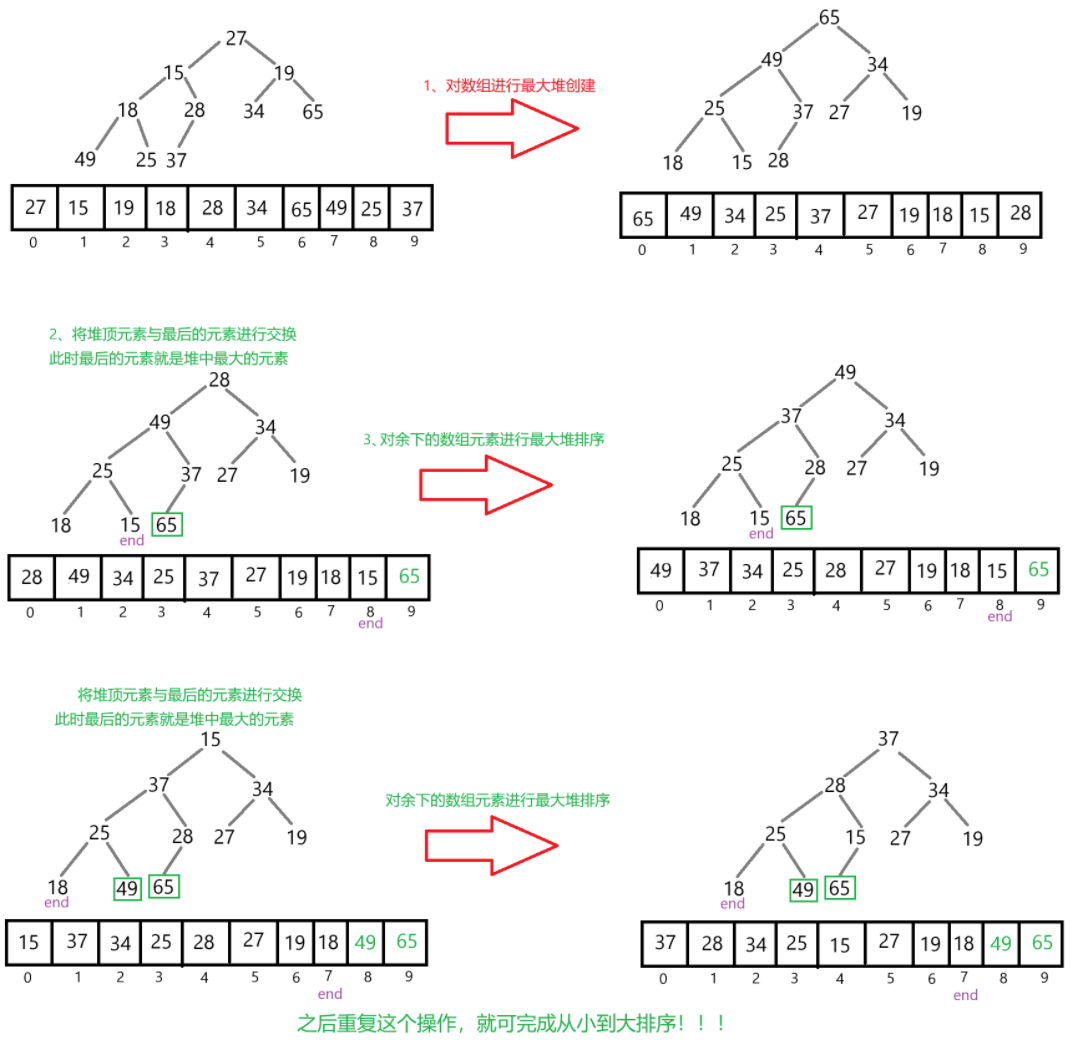
堆排序
如果是按照从小到大来排序,是要创建最大堆,反之创建最小堆。
以从小到大来排序为例。当创建最大堆后,将堆顶的元素和最后一个元素交换,再对剩余元
素进行调整为最大堆。重复这操作,直到整个数组有序。
这里为什么不创建最小堆呢?
当创建的是最小堆时,需要再创建一个数组,用来存放最小堆的堆顶,再对剩余元
素进行调整为最小堆。这样相比于创建最大堆,其空间复杂就会大一些。
代码展示:
/*** 从小到大排序* 时间复杂度为:O(N*logN)* 空间复杂度为:O(1)* @param array*/
public void heapSort(int[] array) {//先创建一个最大堆,时间复杂度为:O(N)for (int parent = ((array.length - 1) - 1) / 2; parent >= 0 ; parent--) {shiftDown(array,parent,array.length);}int end = array.length - 1;//进行排序,时间复杂度为:O(N*logN) <---- 有N次调整,每次调整的时间复杂度为:O(logN)while (end > 0) {swap(array,0,end);end--;shiftDown(array,0,end + 1);}
}
private void swap(int[] array,int a,int b) {int temp = array[a];array[a] = array[b];array[b] = temp;
}
private void shiftDown(int[] array ,int parent,int useSize) {int child = 2 * parent + 1;while (child < useSize) {if(child + 1 <useSize && array[child] < array[child + 1]) {child++;}if(array[parent] < array[child]) {swap(array,parent,child);parent = child;child = 2 * parent + 1;}else {break;}}
}
代码解释:
相关文章:
数据结构*优先级队列(堆)
什么是优先级队列(堆) 优先级队列一般通过堆(Heap)这种数据结构来实现,堆是一种特殊的完全二叉树,其每个节点都满足堆的性质。如下图所示就是一个堆: 堆的存储方式 由于堆是一棵完全二叉树,所以也满足二…...

汽车Wafer连接器:工业设备神经网络的隐形革命者
汽车Wafer连接器正在突破传统车载场景的边界,以毫米级精密结构重构工业设备的连接范式。这款厚度不足3毫米的超薄连接器,在新能源电池模组中承载200A持续电流的同时,仍能保持85℃温升的稳定表现,其每平方厘米高达120针的触点密度&…...
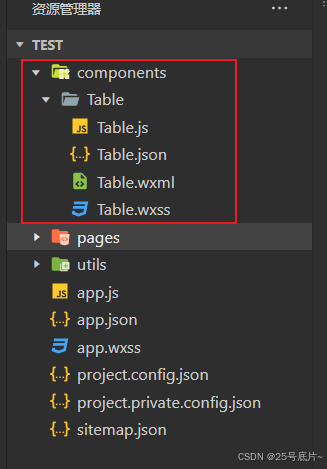
微信小程序:封装表格组件并引用
一、效果 封装表格组件,在父页面中展示表格组件并显示数据 二、表格组件 1、创建页面 创建一个components文件夹,专门用于存储组件的文件夹 创建Table表格组件 2、视图层 (1)表头数据 这里会从父组件中传递表头数据,这里为columns,后续会讲解数据由来 循环表头数组,…...

湖北理元理律师事务所:债务优化中的双维支持实践解析
在债务压力与生活质量失衡的社会议题下,法律服务机构的功能边界正在从单一的法律咨询向复合型支持延伸。湖北理元理律师事务所通过“法律心理”双维服务模式,探索债务优化与生活保障的平衡路径,其方法论或为行业提供实践参考。 法律框架&…...

uniapp在APP上如何使用websocket--详解
UniApp 在 APP 端如何使用 WebSocket以及常见问题 一、WebSocket 基础概念 WebSocket 是一种在单个TCP连接上进行全双工通信的协议,适用于实时数据传输场景(如聊天室、实时游戏、股票行情等)。 与传统HTTP对比 特性WebSocketHTTP连接方式…...
)
计网| 网际控制报文协议(ICMP)
目录 网际控制报文协议(ICMP) 一、ICMP 基础特性 二、ICMP 报文分类及作用 差错报告报文 询问报文 网际控制报文协议(ICMP) ICMP(Internet Control Message Protocol,网际控制报文协议)是 …...

Conda 完全指南:从环境管理到工具集成
Conda 完全指南:从环境管理到工具集成 在数据科学、机器学习和 Python 开发领域,环境管理一直是令人头疼的问题。不同项目依赖的库版本冲突、Python 解释器版本不兼容等问题频繁出现,而 Conda 的出现彻底解决了这些痛点。作为目前最流行的跨…...
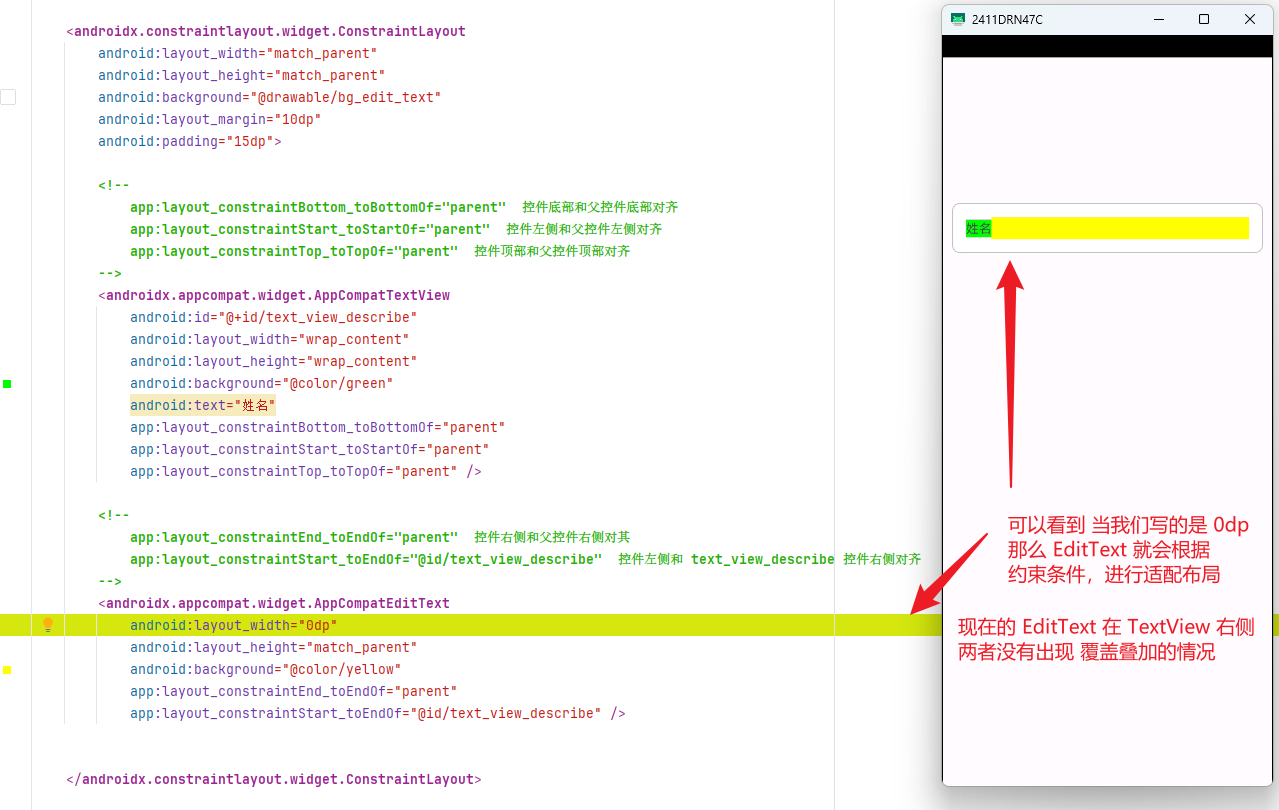
安卓中0dp和match_parent区别
安卓中的 0dp 和 match_parent 的区别? 第一章 前言 有段时间,看到同事在编写代码的时候,写到的是 0dp 有时候自己写代码的时候,编写的是 match_parent 发现有时候效果很类似。 后来通过一个需求案例,才发现两者有着…...

蓝桥杯-不完整的算式
问题描述 小蓝在黑板上写了一个形如 AopBCAopBC 的算式,其中 AA、BB、CC 都是非负整数,opop 是 、-、*、/、-、*、/(整除)四种运算之一。不过 AA、opop、BB、CC 这四部分有一部分被不小心的同学擦掉了。 给出这个不完整的算式&a…...
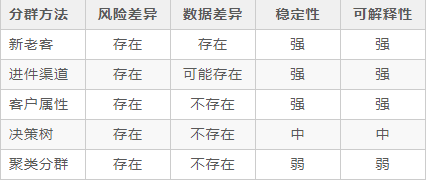
信贷风控笔记4——贷前策略之额度、定价(面试准备12)
1.贷前模型的策略应用 分类:审批准入(对头尾部区分度要求高):单一规则(找lift>3的分数做规则);二维交叉;拒绝回捞 额度定价(对排序性要求高)&am…...
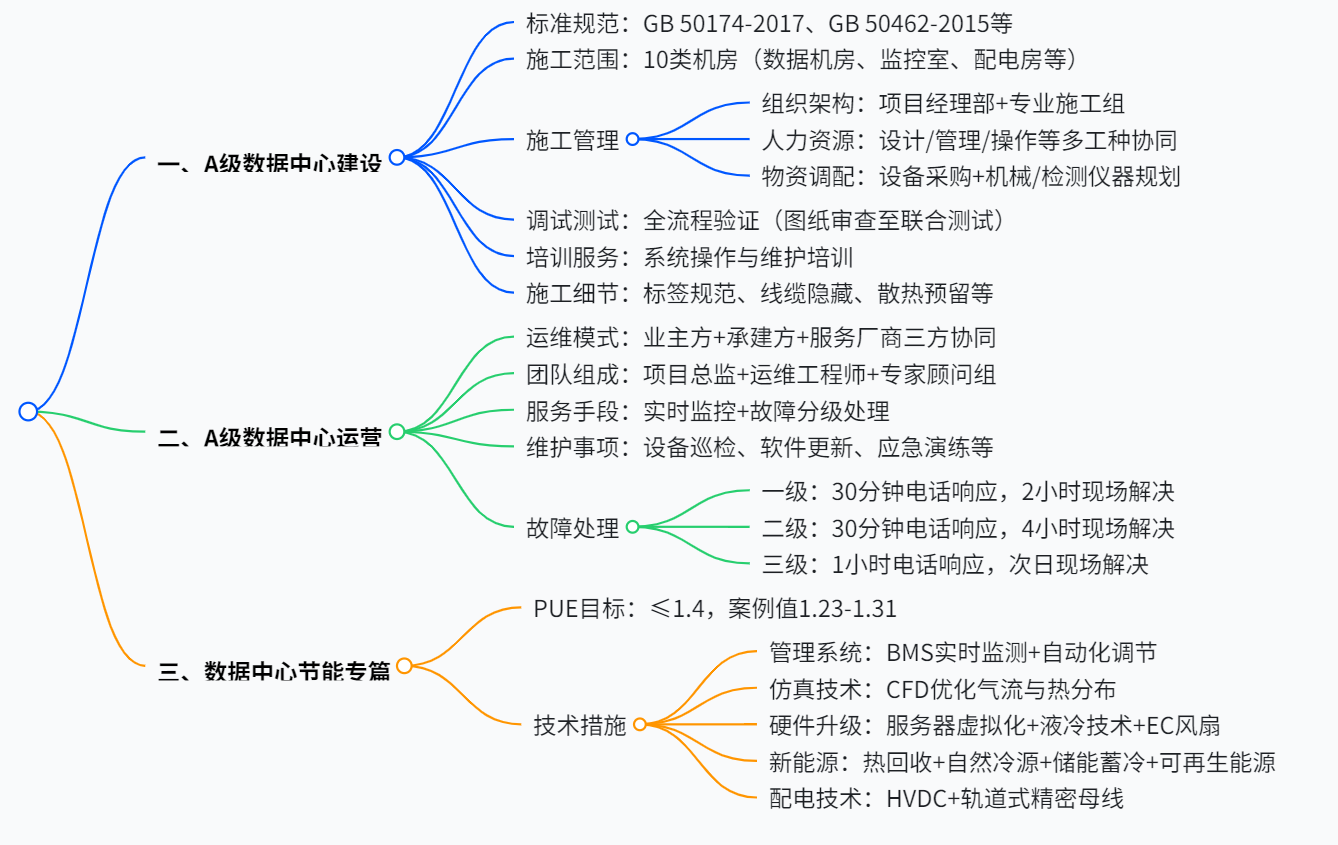
A级、B级弱电机房数据中心建设运营汇报方案
该方案围绕A 级、B 级弱电机房数据中心建设与运营展开,依据《数据中心设计规范》等标准,施工范围涵盖 10 类机房及配套设施,采用专业化施工团队与物资调配体系,强调标签规范、线缆隐藏等细节管理。运营阶段建立三方协同运维模式,针对三级故障制定30 分钟至 1 小时响应机制…...
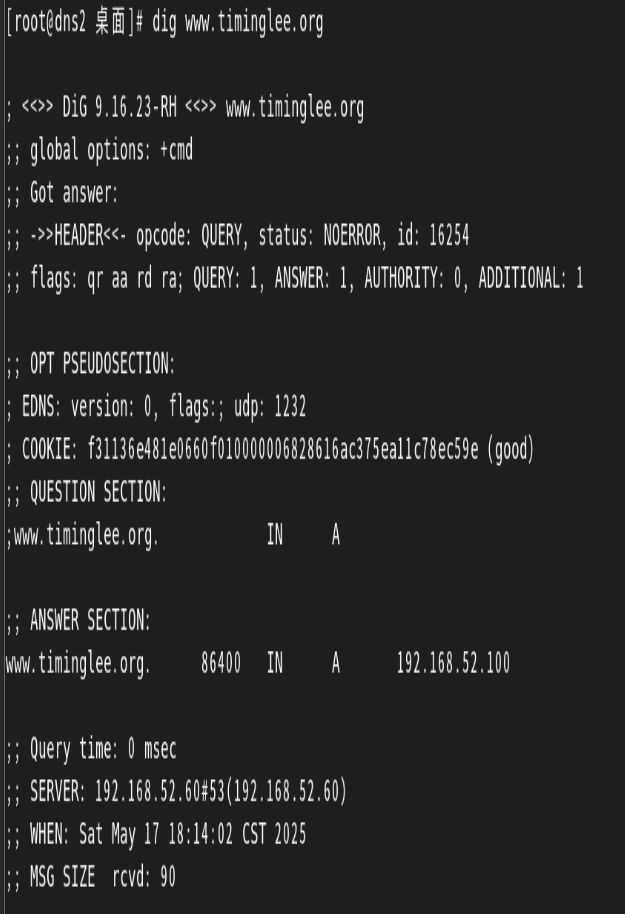
Linux中的域名解析服务器
一、DNS(域名系统)详解 1. 核心功能与特点 特性说明核心作用将域名(如 www.example.com)转换为 IP 地址(如 192.168.1.1),实现人类可读地址与机器可读地址的映射。端口与协议- 默认端口&#…...

如何优化Java中十进制字符串转十六进制的性能
在 Java 中优化十进制字符串转十六进制的性能,可以从减少对象创建、避免正则表达式、使用高效数据结构等方面入手。以下是具体的优化方案: 1. 避免字符串分割,直接遍历字符数组 原始方法(频繁创建子字符串)࿱…...
CycleISP: Real Image Restoration via Improved Data Synthesis通过改进数据合成实现真实图像恢复
摘要 大规模数据集的可用性极大释放了深度卷积神经网络(CNN)的潜力。然而,针对单图像去噪问题,获取真实数据集成本高昂且流程繁琐。因此,图像去噪算法主要基于合成数据开发与评估,这些数据通常通过广泛假设的加性高斯白噪声(AWGN)生成。尽管CNN在合成数据集上表现优异…...
Day28 Python打卡训练营
知识点回顾: 1. 类的定义 2. pass占位语句 3. 类的初始化方法 4. 类的普通方法 5. 类的继承:属性的继承、方法的继承 作业 题目1:定义圆(Circle)类 要求: 1. 包含属性:半径 radius。 2. …...

【OpenCV】基本数据类型及常见图像模式
是什么?能做什么?解决什么问题?为什么用它? OpenCV:是一个基于开源发行的跨平台计算机视觉库,实现 一、应用场景: 目标识别:人脸、车辆、车牌...自动驾驶医学影像分析视频内容理解与分析&…...
Linux之Nginx安装及配置原理篇(一)
Nginx安装及配置 前情回顾 首先针对Nginx进程模型,我们回顾一下它的原理机制,我们知道它是通过Master通过fork分发任务节点给予work节点,然后work节点触发了event事件,之后通过一个access_muttex互斥锁,来单线程调用我…...
【Linux网络】NAT和代理服务
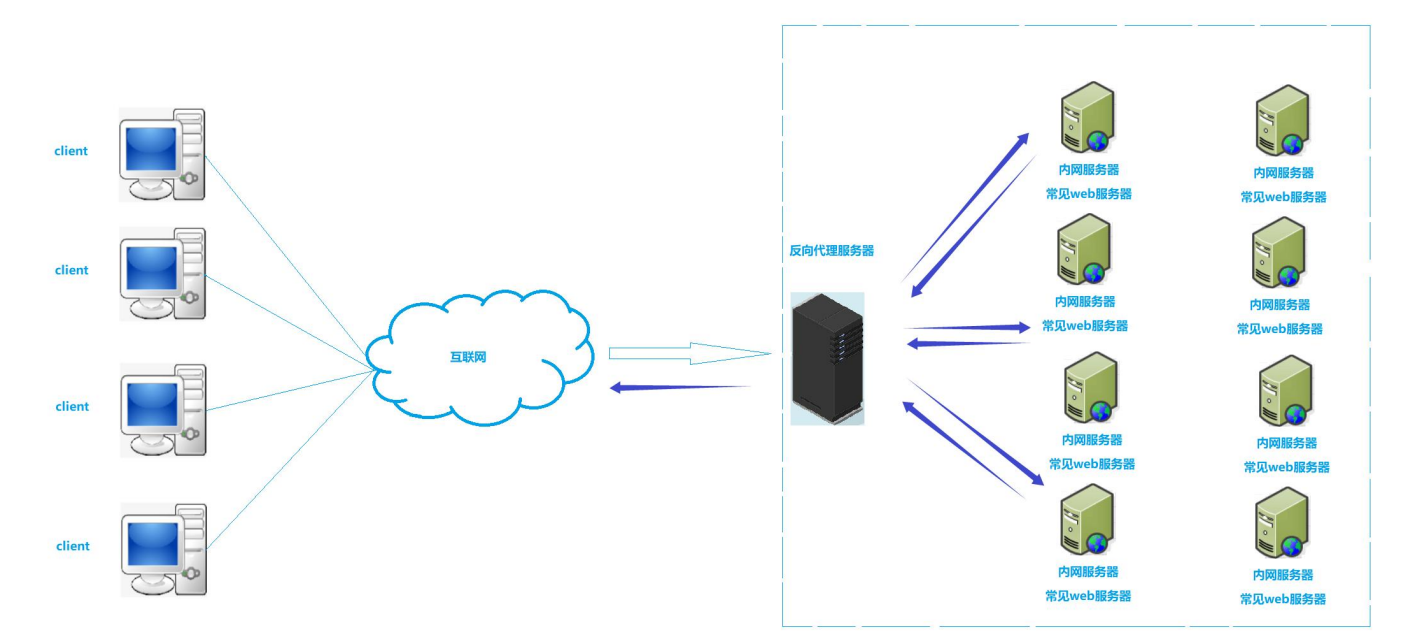
NAT 之前我们讨论了,IPv4协议中,IP地址数量不充足的问题。 原始报文途径路由器WAN口时,对报文中的源IP进行替换的过程,叫做NAT。 NAT技术当前解决IP地址不够用的主要手段,是路由器的一个重要功能: NAT能…...
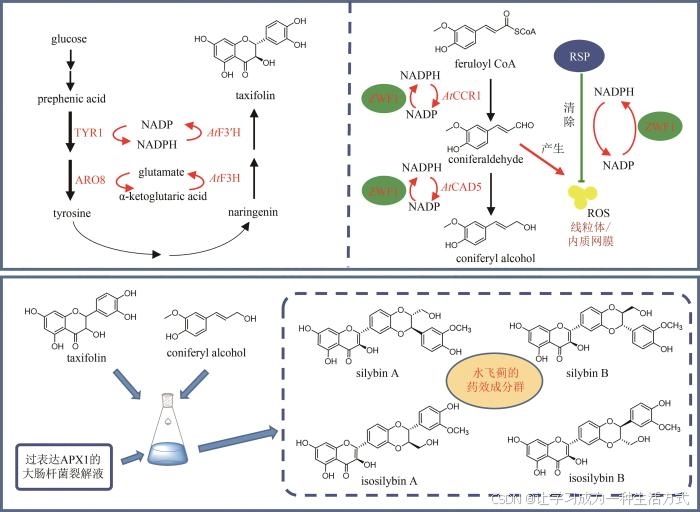
中药药效成分群的合成生物学研究进展-文献精读130
Advances in synthetic biology for producing potent pharmaceutical ingredients of traditional Chinese medicine 中药药效成分群的合成生物学研究进展 摘要 中药是中华民族的文化瑰宝,也是我国在新药创制领域的重要驱动力。许多中药材来源于稀缺物种…...
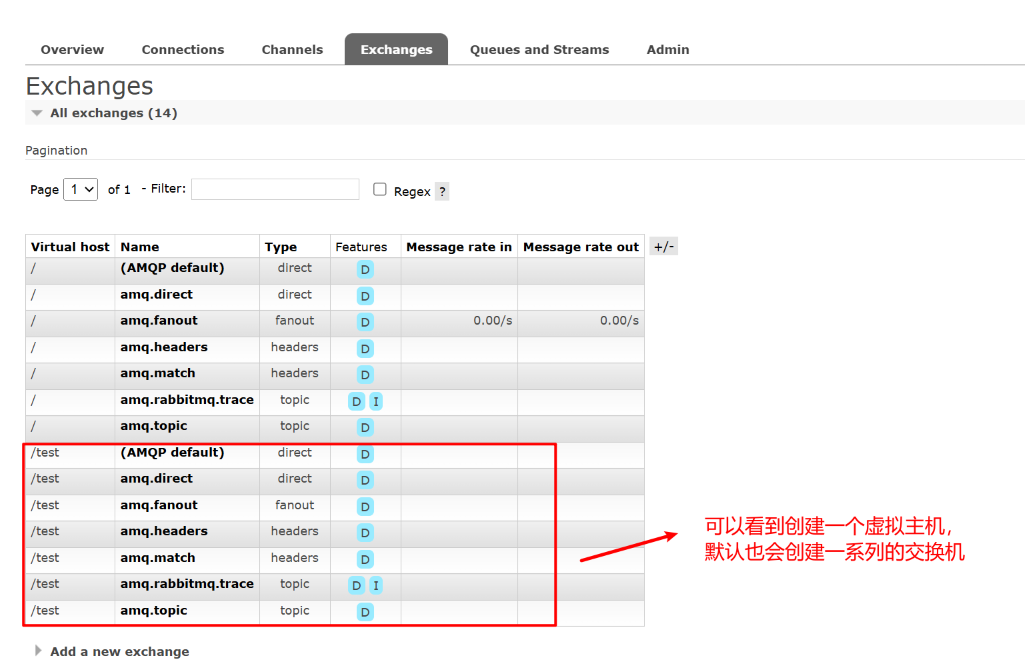
【消息队列】RabbitMQ基本认识
目录 一、基本概念 1. 生产者(Producer) 2. 消费者(Consumer) 3. 队列(Queue) 4. 交换器(Exchange) 5. 绑定(Binding) 6. 路由键(Routing …...

OCCT知识笔记之OCAF框架详解
OCAF框架在OCCT项目中的构建与使用指南 Open CASCADE Application Framework (OCAF)是Open CASCADE Technology (OCCT)中用于管理CAD数据的核心框架,它提供了一种结构化方式来组织和管理复杂的CAD数据,如装配体、形状、属性(颜色、材料)和元数据等。本文…...

蓝桥杯 16. 外卖店优先级
外卖店优先级 原题目链接 题目描述 “饱了么” 外卖系统中维护着 N 家外卖店,编号 1 ∼ N。每家外卖店都有一个优先级,初始时(0 时刻)优先级都为 0。 每经过 1 个时间单位: 如果外卖店没有订单,则优先…...

1T 服务器租用价格解析
服务器作为数据存储与处理的核心设备,对于企业和个人开发者而言至关重要。当涉及到租用 1T 服务器时,价格是大家很为关注的要点。然而,1T 服务器租用一个月的费用并非固定不变,而是受到诸多因素的综合影响。 影响 1T 服务器租用…...
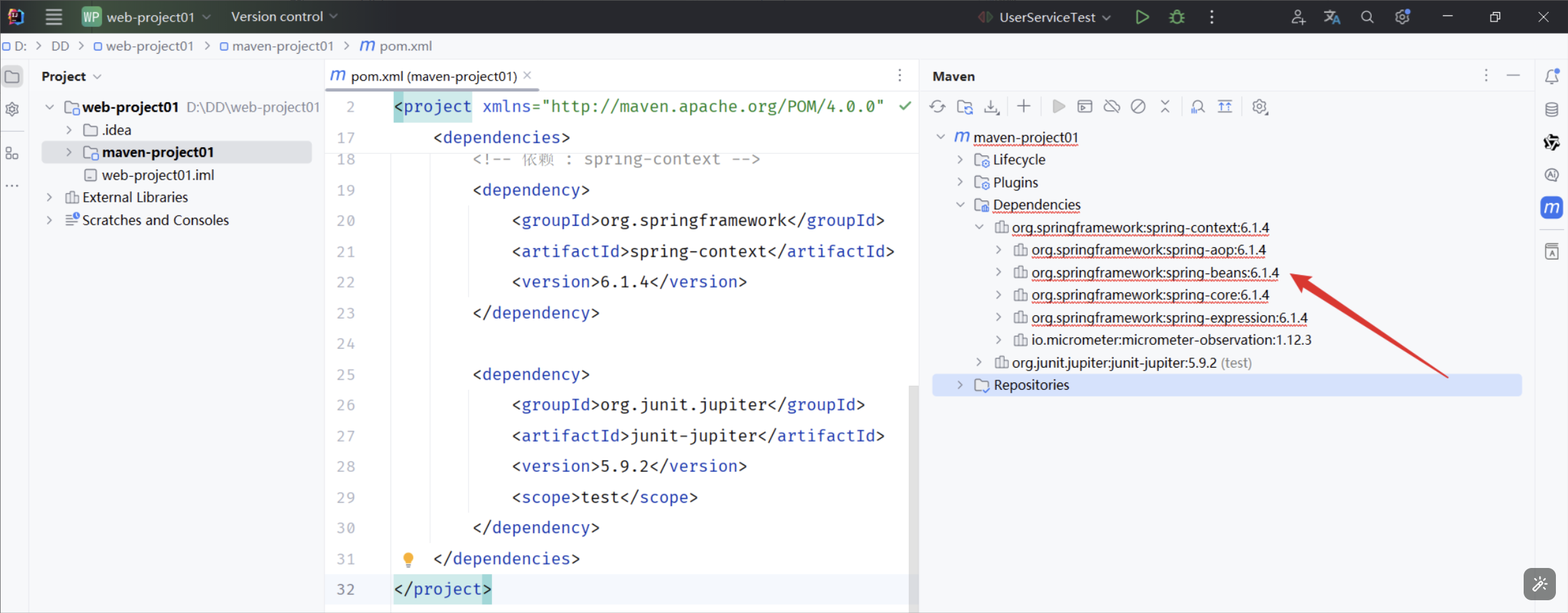
【JavaWeb】Maven(下)
1 依赖管理 1.1 依赖配置 1.1.1 基本配置 依赖:指当前项目运行所需要的jar包。 一个项目中可以引入多个依赖: 例如:在当前工程中,我们需要用到logback来记录日志,此时就可以在maven工程的pom.xml文件中,引…...

java.lang.ArithmeticException
ArithmeticException算术异常类在java.lang包下,继承RuntimeException运行期异常,算术异常类在Java1.0就有,当发生异常算术条件时抛出算术异常类,譬如除数为0的情况,除数除不尽的情况。 一 异常出现场景 1.1 除数为零…...
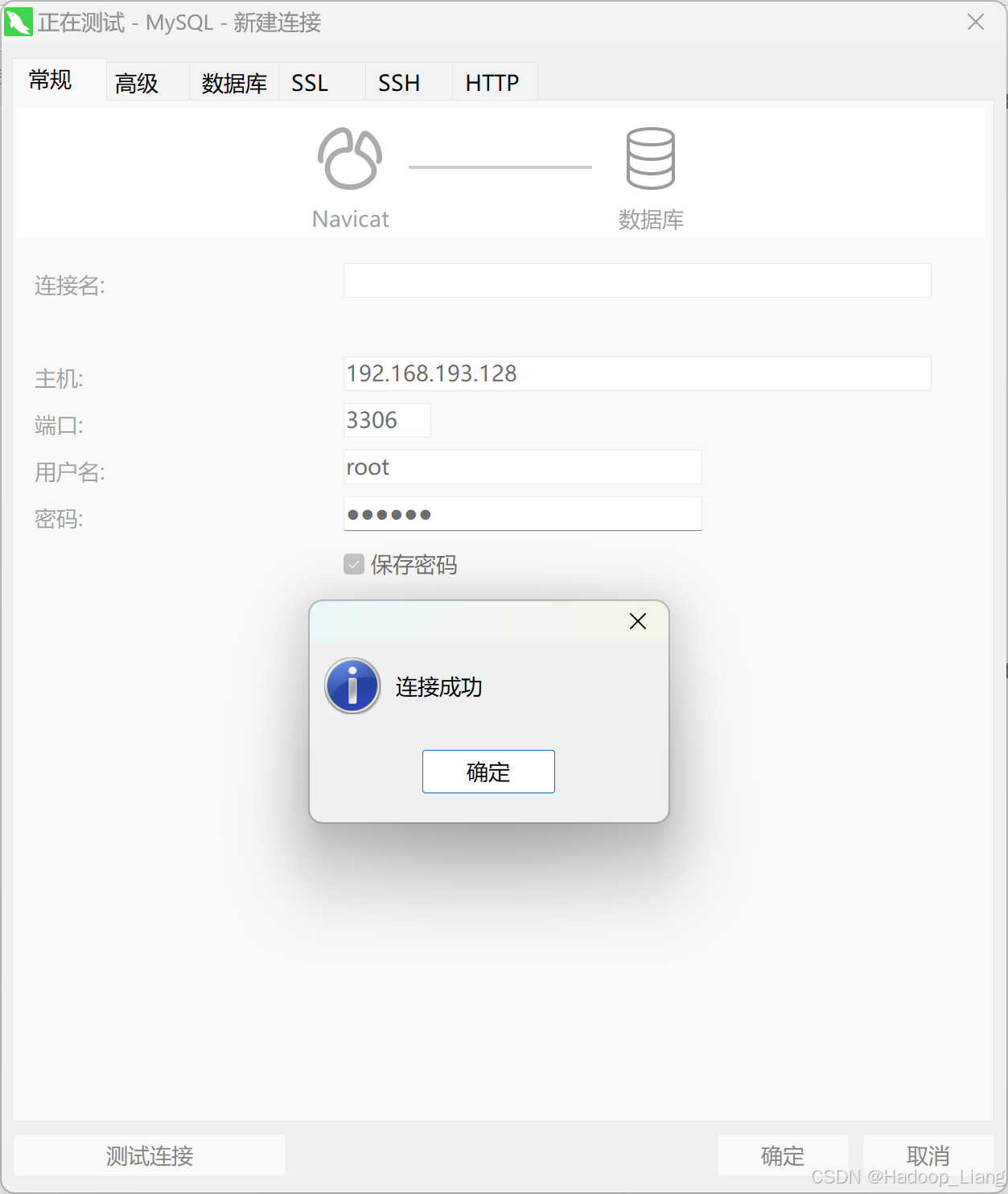
openEuler24.03 LTS下安装MySQL8.0.42
目录 前提步骤 删除原有mysql及maridb数据库 安装MySQL 启动MySQL 启动查看MySQL状态 设置MySQL开机自启动 查看登录密码 登录MySQL 修改密码及支持远程连接 远程连接MySQL 前提步骤 拥有openEuler24.03 LTS环境,可参考:Vmware下安装openEule…...

gflags 安装及使用
目录 引言 安装 如何用 gflags 库写代码 如何用命令行使用 gflags 库 gflags 库的其他命令行参数 引言 gflags 是 Google 开发的一个开源库,用于 C 应用程序中命令行参数的声明、定义 和解析。 gflags 库提供了一种简单的方式来添加、解析和文档化命令行标…...
Linux面试题集合(2)
查看系统磁盘使用,当前目录下所有文件夹的使用情况 df -h du -h 更改目录所有人和所有组,包括里面的文件夹下的文件,递归更改 chown -R newowner:newgroup 目录名 只更改文件所有人或者只更改文件所有组 chown newowner file chgrp newgroup …...
致敬经典 << KR C >> 之打印输入单词水平直方图和以每行一个单词打印输入 (练习1-12和练习1-13)
1. 前言 不知道有多少同学正在自学C/C, 无论你是一个在校学生, 还是已经是上班族. 如果你想从事或即将从事软件开发这个行业, C/C都是一个几乎必须要接触的系统级程序开发语言. 虽然现在有Rust更安全的系统级编程语言作为C/C的替代, 但作为入门, C应该还是要好好学的. C最早由B…...

std::ratio<1,1000> 是什么意思?
author: hjjdebug date: 2025年 05月 14日 星期三 09:45:24 CST description: std::ratio<1,1000> 是什么意思? 文章目录 1. 它是一种数值吗?2. 它是一种类型吗?3. std:ratio 是什么呢?4. 分析一个展开后的模板函数5.小结: …...