【YOLO(txt)格式转VOC(xml)格式数据集】以及【制作VOC格式数据集 】
1.txt—>xml转化代码
如果我们手里只有YOLO标签的数据集,我们要进行VOC格式数据集的制作首先要进行标签的转化,以下是标签转化的脚本。
其中picPath为图片所在文件夹路径;
txtPath为你的YOLO标签对应的txt文件所在路径;
xmlPath为要生成的xml的路径;
同时将脚本中的类别信息换成你自己的。
from xml.dom.minidom import Document
import os
import cv2# def makexml(txtPath, xmlPath, picPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
def makexml(picPath, txtPath, xmlPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件在自己的标注图片文件夹下建三个子文件夹,分别命名为picture、txt、xml"""# names: ['-1', 'bearing', 'bolt', 'flange', 'gear', 'nut', 'retaining_ring', 'spring', 'washer']dic = {'0': "Double hexagonal column", # 创建字典用来对类型进行转换'1': "Flange nut", # 此处的字典要与自己的classes.txt文件中的类对应,且顺序要一致'2': "Hexagon nut",'3': "Hexagon pillar",'4': "Hexagon screw",'5': "Hexagonal steel columnc",'6': "Hexagonal steel column",'7': "Keybar",'8': 'Plastic cushion pillar','9': 'Rectangular nut','10': 'Round head screw','11': 'Spring washer','12': 'T-shaped screw',}files = os.listdir(txtPath)for i, name in enumerate(files):print(f"�� [{i + 1}/{len(files)}] 正在处理:{name}")xmlBuilder = Document()annotation = xmlBuilder.createElement("annotation") # 创建annotation标签xmlBuilder.appendChild(annotation)txtFile = open(txtPath + name)txtList = txtFile.readlines()# img = cv2.imread(picPath + name[0:-4] + ".jpg")# 自动尝试读取 .jpg, .png, .jpeg 图像img = Noneimg_extensions = [".jpg", ".png", ".jpeg"]for ext in img_extensions:img_path = os.path.join(picPath, name[0:-4] + ext)if os.path.exists(img_path):img = cv2.imread(img_path)if img is not None:break# 如果图片读取失败,则跳过该文件if img is None:print(f"❌ 无法读取图片:{name[0:-4]}(支持格式:.jpg/.png/.jpeg),跳过")continueelse:print(f"✅ 成功读取图片:{name[0:-4]}")Pheight, Pwidth, Pdepth = img.shapefolder = xmlBuilder.createElement("folder") # folder标签foldercontent = xmlBuilder.createTextNode("driving_annotation_dataset")folder.appendChild(foldercontent)annotation.appendChild(folder) # folder标签结束filename = xmlBuilder.createElement("filename") # filename标签filenamecontent = xmlBuilder.createTextNode(name[0:-4] + ".jpg")filename.appendChild(filenamecontent)annotation.appendChild(filename) # filename标签结束size = xmlBuilder.createElement("size") # size标签width = xmlBuilder.createElement("width") # size子标签widthwidthcontent = xmlBuilder.createTextNode(str(Pwidth))width.appendChild(widthcontent)size.appendChild(width) # size子标签width结束height = xmlBuilder.createElement("height") # size子标签heightheightcontent = xmlBuilder.createTextNode(str(Pheight))height.appendChild(heightcontent)size.appendChild(height) # size子标签height结束depth = xmlBuilder.createElement("depth") # size子标签depthdepthcontent = xmlBuilder.createTextNode(str(Pdepth))depth.appendChild(depthcontent)size.appendChild(depth) # size子标签depth结束annotation.appendChild(size) # size标签结束for j in txtList:oneline = j.strip().split(" ")object = xmlBuilder.createElement("object") # object 标签picname = xmlBuilder.createElement("name") # name标签namecontent = xmlBuilder.createTextNode(dic[oneline[0]])picname.appendChild(namecontent)object.appendChild(picname) # name标签结束pose = xmlBuilder.createElement("pose") # pose标签posecontent = xmlBuilder.createTextNode("Unspecified")pose.appendChild(posecontent)object.appendChild(pose) # pose标签结束truncated = xmlBuilder.createElement("truncated") # truncated标签truncatedContent = xmlBuilder.createTextNode("0")truncated.appendChild(truncatedContent)object.appendChild(truncated) # truncated标签结束difficult = xmlBuilder.createElement("difficult") # difficult标签difficultcontent = xmlBuilder.createTextNode("0")difficult.appendChild(difficultcontent)object.appendChild(difficult) # difficult标签结束bndbox = xmlBuilder.createElement("bndbox") # bndbox标签xmin = xmlBuilder.createElement("xmin") # xmin标签mathData = int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)xminContent = xmlBuilder.createTextNode(str(mathData))xmin.appendChild(xminContent)bndbox.appendChild(xmin) # xmin标签结束ymin = xmlBuilder.createElement("ymin") # ymin标签mathData = int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)yminContent = xmlBuilder.createTextNode(str(mathData))ymin.appendChild(yminContent)bndbox.appendChild(ymin) # ymin标签结束xmax = xmlBuilder.createElement("xmax") # xmax标签mathData = int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)xmaxContent = xmlBuilder.createTextNode(str(mathData))xmax.appendChild(xmaxContent)bndbox.appendChild(xmax) # xmax标签结束ymax = xmlBuilder.createElement("ymax") # ymax标签mathData = int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)ymaxContent = xmlBuilder.createTextNode(str(mathData))ymax.appendChild(ymaxContent)bndbox.appendChild(ymax) # ymax标签结束object.appendChild(bndbox) # bndbox标签结束annotation.appendChild(object) # object标签结束f = open(xmlPath + name[0:-4] + ".xml", 'w')xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')f.close()print(f"✅ 已保存 XML 文件:{name[0:-4]}.xml\n")if __name__ == "__main__":picPath = "/home/yu/wz/duibi/retinanet-pytorch-master/VOCdeckit/VOC2007/JPEGImages/" # 图片所在文件夹路径,后面的/一定要带上txtPath = "/home/yu/wz/duibi/retinanet-pytorch-master/VOCdeckit/VOC2007/YOLO/" # txt所在文件夹路径,后面的/一定要带上xmlPath = "/home/yu/wz/duibi/retinanet-pytorch-master/VOCdeckit/VOC2007/Annotations/" # xml文件保存路径,后面的/一定要带上makexml(picPath, txtPath, xmlPath)
2.VOC格式数据集处理
VOC格式数据集文件夹存放格式:
ImageSets里面等会是通过脚本生成的,前期只需要整理Annotation和JPEGImages
开始时候:
import os
import random
import xml.etree.ElementTree as ETimport numpy as npfrom utils.utils import get_classes#--------------------------------------------------------------------------------------------------------------------------------#
# annotation_mode用于指定该文件运行时计算的内容
# annotation_mode为0代表整个标签处理过程,包括获得VOCdevkit/VOC2007/ImageSets里面的txt以及训练用的2007_train.txt、2007_val.txt
# annotation_mode为1代表获得VOCdevkit/VOC2007/ImageSets里面的txt
# annotation_mode为2代表获得训练用的2007_train.txt、2007_val.txt
#--------------------------------------------------------------------------------------------------------------------------------#
annotation_mode = 0
#-------------------------------------------------------------------#
# 必须要修改,用于生成2007_train.txt、2007_val.txt的目标信息
# 与训练和预测所用的classes_path一致即可
# 如果生成的2007_train.txt里面没有目标信息
# 那么就是因为classes没有设定正确
# 仅在annotation_mode为0和2的时候有效
#-------------------------------------------------------------------#
classes_path = 'model_data/voc_classes.txt'
#--------------------------------------------------------------------------------------------------------------------------------#
# trainval_percent用于指定(训练集+验证集)与测试集的比例,默认情况下 (训练集+验证集):测试集 = 9:1
# train_percent用于指定(训练集+验证集)中训练集与验证集的比例,默认情况下 训练集:验证集 = 9:1
# 仅在annotation_mode为0和1的时候有效
#--------------------------------------------------------------------------------------------------------------------------------#
trainval_percent = 1.0
train_percent = 0.8
#-------------------------------------------------------#
# 指向VOC数据集所在的文件夹
# 默认指向根目录下的VOC数据集
#-------------------------------------------------------#
VOCdevkit_path = 'VOCdevkit'VOCdevkit_sets = [('2007', 'train'), ('2007', 'val')]
classes, _ = get_classes(classes_path)#-------------------------------------------------------#
# 统计目标数量
#-------------------------------------------------------#
photo_nums = np.zeros(len(VOCdevkit_sets))
nums = np.zeros(len(classes))
def convert_annotation(year, image_id, list_file):in_file = open(os.path.join(VOCdevkit_path, 'VOC%s/Annotations/%s.xml'%(year, image_id)), encoding='utf-8')tree=ET.parse(in_file)root = tree.getroot()for obj in root.iter('object'):difficult = 0 if obj.find('difficult')!=None:difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult)==1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('ymin').text)), int(float(xmlbox.find('xmax').text)), int(float(xmlbox.find('ymax').text)))list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))nums[classes.index(cls)] = nums[classes.index(cls)] + 1if __name__ == "__main__":random.seed(0)if " " in os.path.abspath(VOCdevkit_path):raise ValueError("数据集存放的文件夹路径与图片名称中不可以存在空格,否则会影响正常的模型训练,请注意修改。")if annotation_mode == 0 or annotation_mode == 1:print("Generate txt in ImageSets.")xmlfilepath = os.path.join(VOCdevkit_path, 'VOC2007/Annotations')saveBasePath = os.path.join(VOCdevkit_path, 'VOC2007/ImageSets/Main')temp_xml = os.listdir(xmlfilepath)total_xml = []for xml in temp_xml:if xml.endswith(".xml"):total_xml.append(xml)num = len(total_xml) list = range(num) tv = int(num*trainval_percent) tr = int(tv*train_percent) trainval= random.sample(list,tv) train = random.sample(trainval,tr) print("train and val size",tv)print("train size",tr)ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w') ftest = open(os.path.join(saveBasePath,'test.txt'), 'w') ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w') fval = open(os.path.join(saveBasePath,'val.txt'), 'w') for i in list: name=total_xml[i][:-4]+'\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) ftrainval.close() ftrain.close() fval.close() ftest.close()print("Generate txt in ImageSets done.")if annotation_mode == 0 or annotation_mode == 2:print("Generate 2007_train.txt and 2007_val.txt for train.")type_index = 0for year, image_set in VOCdevkit_sets:image_ids = open(os.path.join(VOCdevkit_path, 'VOC%s/ImageSets/Main/%s.txt'%(year, image_set)), encoding='utf-8').read().strip().split()list_file = open('%s_%s.txt'%(year, image_set), 'w', encoding='utf-8')for image_id in image_ids:list_file.write('%s/VOC%s/JPEGImages/%s.jpg'%(os.path.abspath(VOCdevkit_path), year, image_id))convert_annotation(year, image_id, list_file)list_file.write('\n')photo_nums[type_index] = len(image_ids)type_index += 1list_file.close()print("Generate 2007_train.txt and 2007_val.txt for train done.")def printTable(List1, List2):for i in range(len(List1[0])):print("|", end=' ')for j in range(len(List1)):print(List1[j][i].rjust(int(List2[j])), end=' ')print("|", end=' ')print()str_nums = [str(int(x)) for x in nums]tableData = [classes, str_nums]colWidths = [0]*len(tableData)len1 = 0for i in range(len(tableData)):for j in range(len(tableData[i])):if len(tableData[i][j]) > colWidths[i]:colWidths[i] = len(tableData[i][j])printTable(tableData, colWidths)if photo_nums[0] <= 500:print("训练集数量小于500,属于较小的数据量,请注意设置较大的训练世代(Epoch)以满足足够的梯度下降次数(Step)。")if np.sum(nums) == 0:print("在数据集中并未获得任何目标,请注意修改classes_path对应自己的数据集,并且保证标签名字正确,否则训练将会没有任何效果!")print("在数据集中并未获得任何目标,请注意修改classes_path对应自己的数据集,并且保证标签名字正确,否则训练将会没有任何效果!")print("在数据集中并未获得任何目标,请注意修改classes_path对应自己的数据集,并且保证标签名字正确,否则训练将会没有任何效果!")print("(重要的事情说三遍)。")修改代码中的:

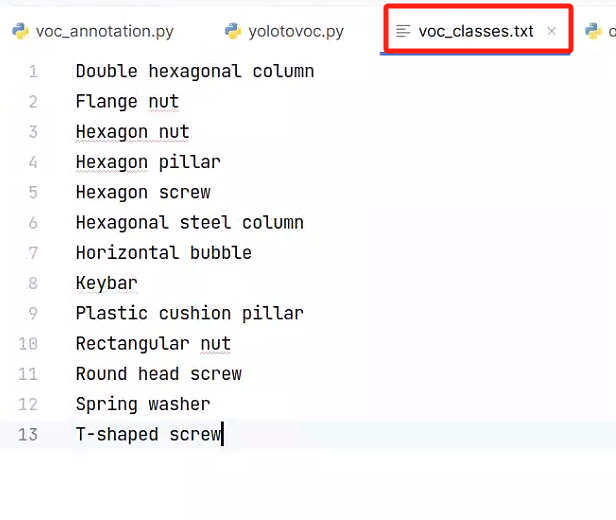
voc_classes.txt存放自己的标签:
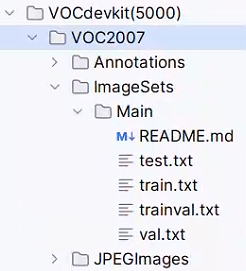
运行脚本最后生成:
控制台输出每个类别的信息则运行成功,
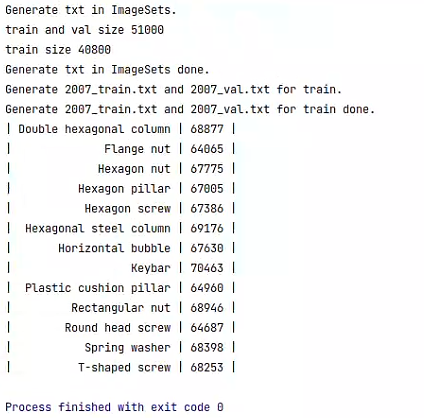
同时项目的根目录下生成:
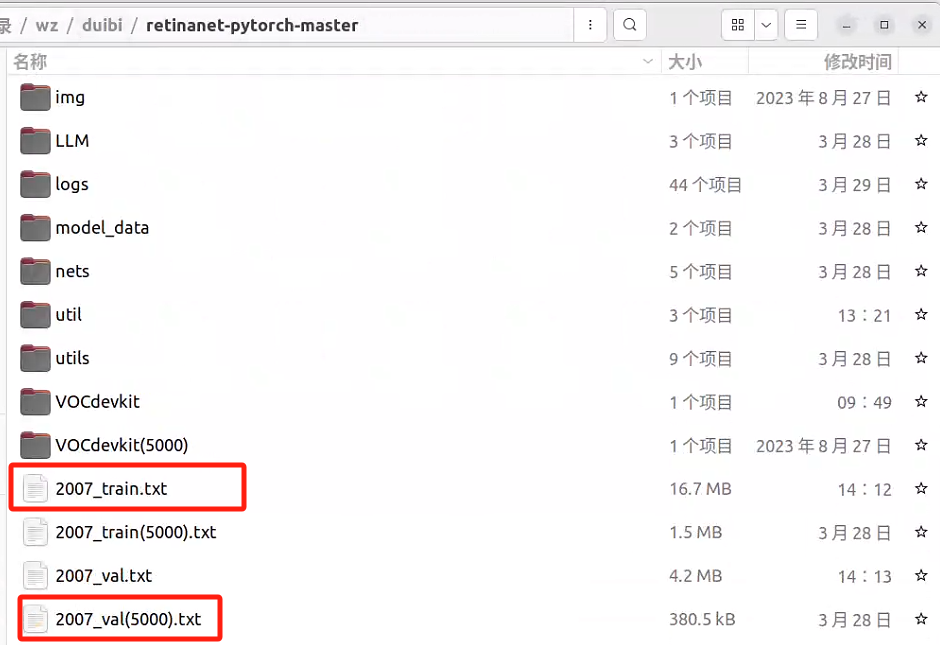
打开这两个文件夹看一下是否包含自己的数据集信息:

至此,我们的数据集就制作完毕!
相关文章:
【YOLO(txt)格式转VOC(xml)格式数据集】以及【制作VOC格式数据集 】
1.txt—>xml转化代码 如果我们手里只有YOLO标签的数据集,我们要进行VOC格式数据集的制作首先要进行标签的转化,以下是标签转化的脚本。 其中picPath为图片所在文件夹路径; txtPath为你的YOLO标签对应的txt文件所在路径; xmlPa…...

WSL 安装 Debian 12 后,如何安装图形界面 X11 ?
在 Debian Linux 系统中安装 X11(X Window System),可以按照以下步骤进行操作: 一、确认系统版本和硬件支持 首先,你需要确认自己的 Debian 系统版本,可使用以下命令: cat /etc/debian_versi…...

Linux 的 UDP 网络编程 -- 回显服务器,翻译服务器
目录 1. 回显服务器 -- echo server 1.1 相关函数介绍 1.1.1 socket() 1.1.2 bind() 1.1.3 recvfrom() 1.1.4 sendto() 1.1.5 inet_ntoa() 1.1.6 inet_addr() 1.2 Udp 服务端的封装 -- UdpServer.hpp 1.3 服务端代码 -- UdpServer.cc 1.4 客户端代码 -- UdpClient.…...
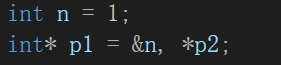
C++笔试题(金山科技新未来训练营):
题目分布: 17道单选(每题3分)3道多选题(全对3分,部分对1分)2道编程题(每一道20分)。 不过题目太多,就记得一部分了: 单选题: static变量的初始…...
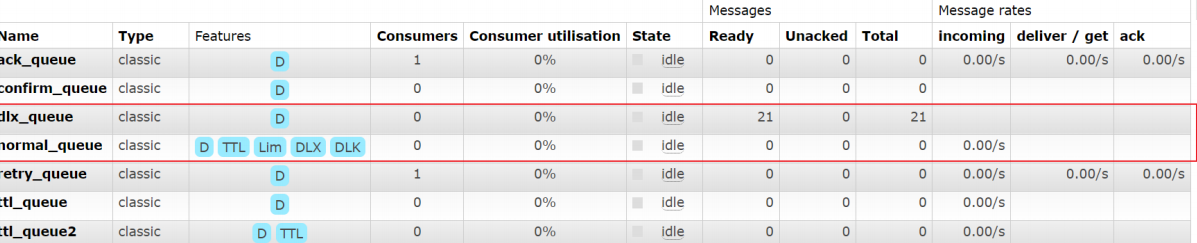
【RabbitMQ】 RabbitMQ高级特性(二)
文章目录 一、重试机制1.1、重试配置1.2、配置交换机&队列1.3、发送消息1.4、消费消息1.5、运行程序1.6、 手动确认 二、TTL2.1、设置消息的TTL2.2、设置队列的TTL2.3、两者区别 三 、死信队列6.1 死信的概念3.2 代码示例3.2.1、声明队列和交换机3.2.2、正常队列绑定死信交…...

大数据技术全景解析:HDFS、HBase、MapReduce 与 Chukwa
大数据技术全景解析:HDFS、HBase、MapReduce 与 Chukwa 在当今这个信息爆炸的时代,大数据已经成为企业竞争力的重要组成部分。从电商的用户行为分析到金融的风险控制,从医疗健康的数据挖掘到智能制造的实时监控,大数据技术无处不…...

电子电路:什么是电流离散性特征?
关于电荷的量子化,即电荷的最小单位是电子的电荷量e。在宏观电路中,由于电子数量极大,电流看起来是连续的。但在微观层面,比如纳米器件或单电子晶体管中,单个电子的移动就会引起可观测的离散电流。 还要提到散粒噪声,这是电流离散性的表现之一。当电流非常小时,例如在二…...
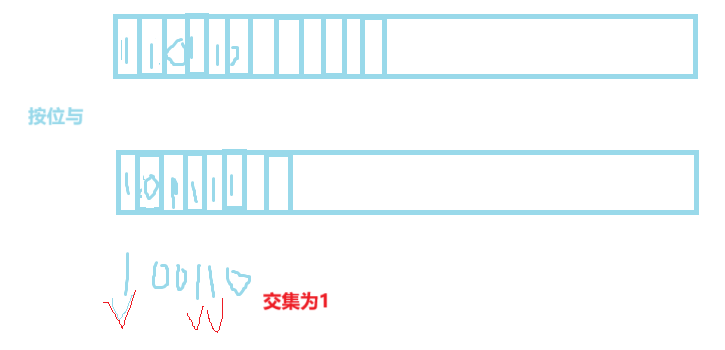
深入理解位图(Bit - set):概念、实现与应用
目录 引言 一、位图概念 (一)基本原理 (二)适用场景 二、位图的实现(C 代码示例) 三、位图应用 1. 快速查找某个数据是否在一个集合中 2. 排序 去重 3. 求两个集合的交集、并集等 4. 操作系…...
猫番阅读APP:丰富资源,优质体验,满足你的阅读需求
猫番阅读APP是一款专为书籍爱好者设计的移动阅读应用,致力于提供丰富的阅读体验和多样化的书籍资源。它不仅涵盖了小说、非虚构、杂志等多个领域的电子书,还提供了个性化推荐、书架管理、离线下载等功能,满足不同读者的阅读需求。无论是通勤路…...

Java文件读写程序
1.引言 在日常的软件开发中,文件操作是常见的功能之一。不仅要了解如何读写文件,更要知道如何安全地操作文件以避免程序崩溃或数据丢失。这篇文章将深入分析一个简单的 Java 文件读写程序 Top.java,包括其基本实现、潜在问题以及改进建议&am…...

深入解析Java事件监听机制与应用
Java事件监听机制详解 一、事件监听模型组成 事件源(Event Source) 产生事件的对象(如按钮、文本框等组件) 事件对象(Event Object) 封装事件信息的对象(如ActionEvent包含事件源信息…...
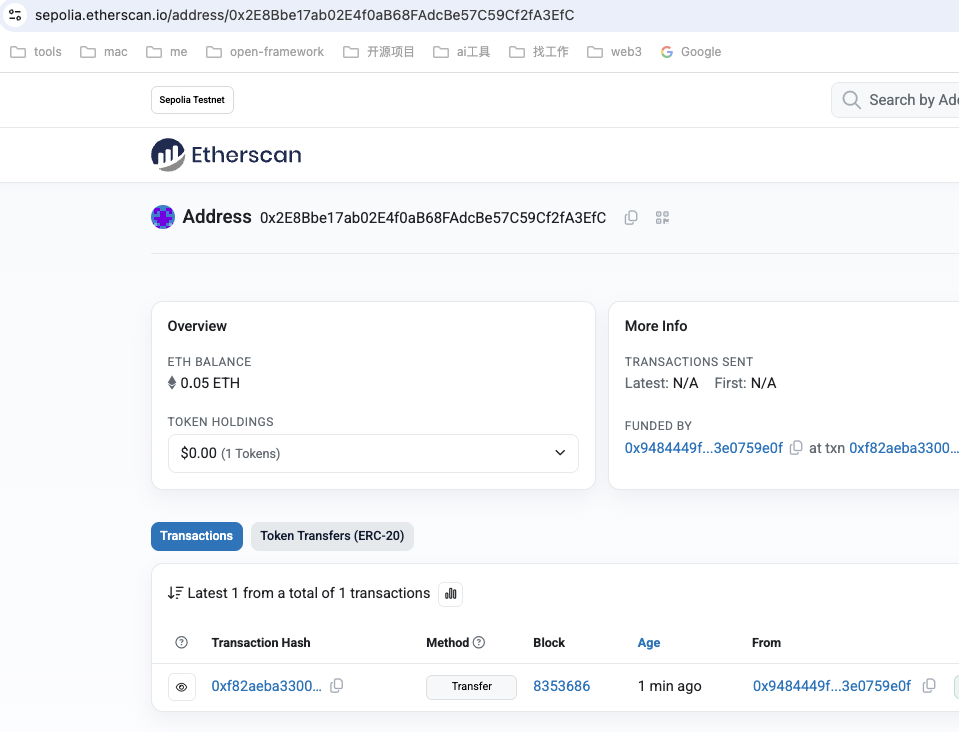
MetaMask安装及使用-使用水龙头获取测试币的坑?
常见的异常有: 1.unable to request drip, please try again later. 2.You must hold at least 1 LINK on Ethereum Mainnet to request native tokens. 3.The address provided does not have sufficient historical activity or balance on the Ethereum Mainne…...

AI:OpenAI论坛分享—《AI重塑未来:技术、经济与战略》
AI:OpenAI论坛分享—《AI重塑未来:技术、经济与战略》 导读:2025年4月24日,OpenAI论坛全面探讨了 AI 的发展趋势、技术范式、地缘政治影响以及对经济和社会的广泛影响。强调了 AI 的通用性、可扩展性和高级推理能力,以…...
Linux配置vimplus
配置vimplus CentOS的配置方案很简单,但是Ubuntu的解决方案网上也很多但是有效的很少,尤其是22和24的解决方案,在此我整理了一下我遇到的问题解决方法 CentOS7 一键配置VimForCPP 基本上不会有什么特别难解决的报错 sudo yum install vims…...

服务端HttpServletRequest、HttpServletResponse、HttpSession
一、概述 在JavaWeb 开发中,获取客户端传递的参数至关重要。http请求是客户端向服务端发起数据传输协议,主要包含包含请求行、请求头、空行和请求体四个部分,在这四部分中分别携带客户端传递到服务端的数据。常见的http请求方式有get、post、…...

实验九视图索引
设计性实验 1. 创建视图V_A包括学号,姓名,性别,课程号,课程名、成绩; 一个语句把学号103 课程号3-105 的姓名改为陆君茹1,性别为女 ,然后查看学生表的信息变化,再把上述数据改为原…...
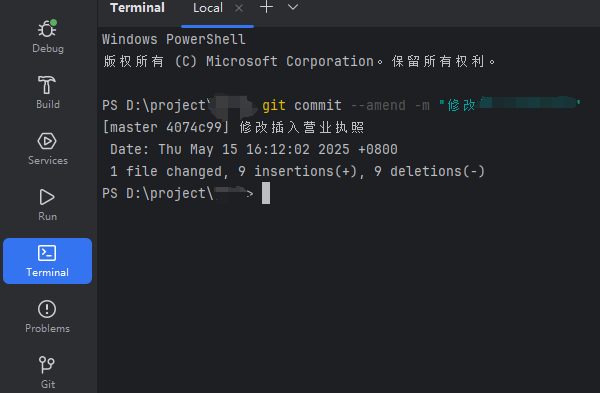
git 本地提交后修改注释
dos命令行进入目录,idea可以点击Terminal 进入命令行 git commit --amend -m "修改内容"...
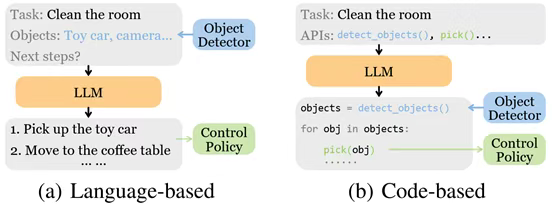
面向具身智能的视觉-语言-动作模型(VLA)综述
具身智能被广泛认为是通用人工智能(AGI)的关键要素,因为它涉及控制具身智能体在物理世界中执行任务。在大语言模型和视觉语言模型成功的基础上,一种新的多模态模型——视觉语言动作模型(VLA)已经出现&#…...

Thrust库中的Gather和Scatter操作
Thrust库中的Gather和Scatter操作 Thrust是CUDA提供的一个类似于C STL的并行算法库,其中包含两个重要的数据操作:gather(聚集)和scatter(散开)。 Gather操作 Gather操作从一个源数组中按照指定的索引收集元素到目标数组中。 函数原型: t…...

计算机发展的历程
计算机系统的概述 一, 计算机系统的定义 计算机系统的概念 计算机系统 硬件 软件 硬件的概念 计算机的实体, 如主机, 外设等 计算机系统的物理基础 决定了计算机系统的天花板瓶颈 软件的概念 由具有各类特殊功能的程序组成 决定了把硬件的性能发挥到什么程度 软件的分类…...
深度学习驱动下的目标检测技术:原理、算法与应用创新(三)
五、基于深度学习的目标检测代码实现 5.1 开发环境搭建 开发基于深度学习的目标检测项目,首先需要搭建合适的开发环境,确保所需的工具和库能够正常运行。以下将详细介绍 Python、PyTorch 等关键开发工具和库的安装与配置过程。 Python 是一种广泛应用于…...

Python爬虫实战:研究 RPC 远程调用机制,实现逆向解密
1. 引言 在网络爬虫技术的实际应用中,目标网站通常采用各种加密手段保护其数据传输和业务逻辑。这些加密机制给爬虫开发带来了巨大挑战,传统的爬虫技术往往难以应对复杂的加密算法。逆向解密作为一种应对策略,旨在通过分析和破解目标网站的加密机制,获取原始数据。 然而,…...

[学习] RTKLib详解:qzslex.c、rcvraw.c与solution.c
RTKLib详解:qzslex.c、rcvraw.c与solution.c 本文是 RTKLlib详解 系列文章的一篇,目前该系列文章还在持续总结写作中,以发表的如下,有兴趣的可以翻阅。 [学习] RTKlib详解:功能、工具与源码结构解析 [学习]RTKLib详解…...
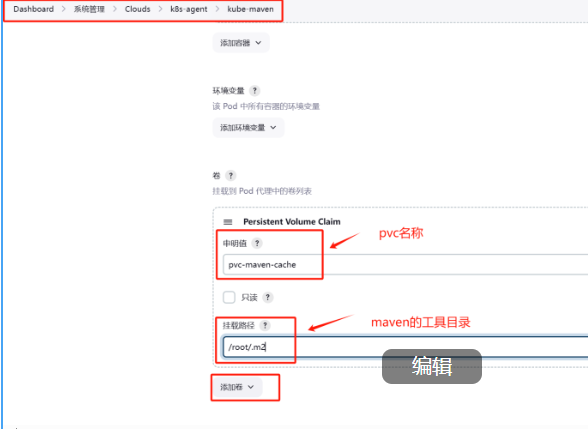
jenkins流水线常规配置教程!
Jenkins流水线是在工作中实现CI/CD常用的工具。以下是一些我在工作和学习中总结出来常用的一些流水线配置:变量需要加双引号括起来 "${main}" 一 引用无账号的凭据 使用变量方式引用,这种方式只适合只由密码,没有用户名的凭证。例…...

Java中序列化和反序列化的理解
基本概念 序列化(Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程,而反序列化(Deserialization)则是将这种形式重新转换为对象的过程。 核心作用 持久化存储:将对象状态保存到文件或数据库中 网络传输:在网络间传递对象…...

基于OpenCV的SIFT特征和FLANN匹配器的指纹认证
文章目录 引言一、概述二、代码解析1. 图像显示函数2. 核心认证函数2.1 创建SIFT特征提取器2.2 检测关键点和计算描述符(源图像)2.3 检测关键点和计算描述符(模板图像)2.4 创建FLANN匹配器2.5 使用K近邻匹配 3. 匹配点筛选4. 认证…...
)
零基础学Java——第十一章:实战项目 - 桌面应用开发(JavaFX入门)
第十一章:实战项目 - 桌面应用开发(JavaFX入门) 欢迎来到我们实战项目的桌面应用开发部分!在前面的章节中,我们可能已经接触了Swing。现在,我们将目光投向JavaFX,一个更现代、功能更丰富的用于…...
)
Milvus 视角看主流嵌入式模型(Embeddings)
嵌入是一种机器学习概念,用于将数据映射到高维空间,其中语义相似的数据被紧密排列在一起。嵌入模型通常是 BERT 或其他 Transformer 系列的深度神经网络,它能够有效地用一系列数字(称为向量)来表示文本、图像和其他数据…...
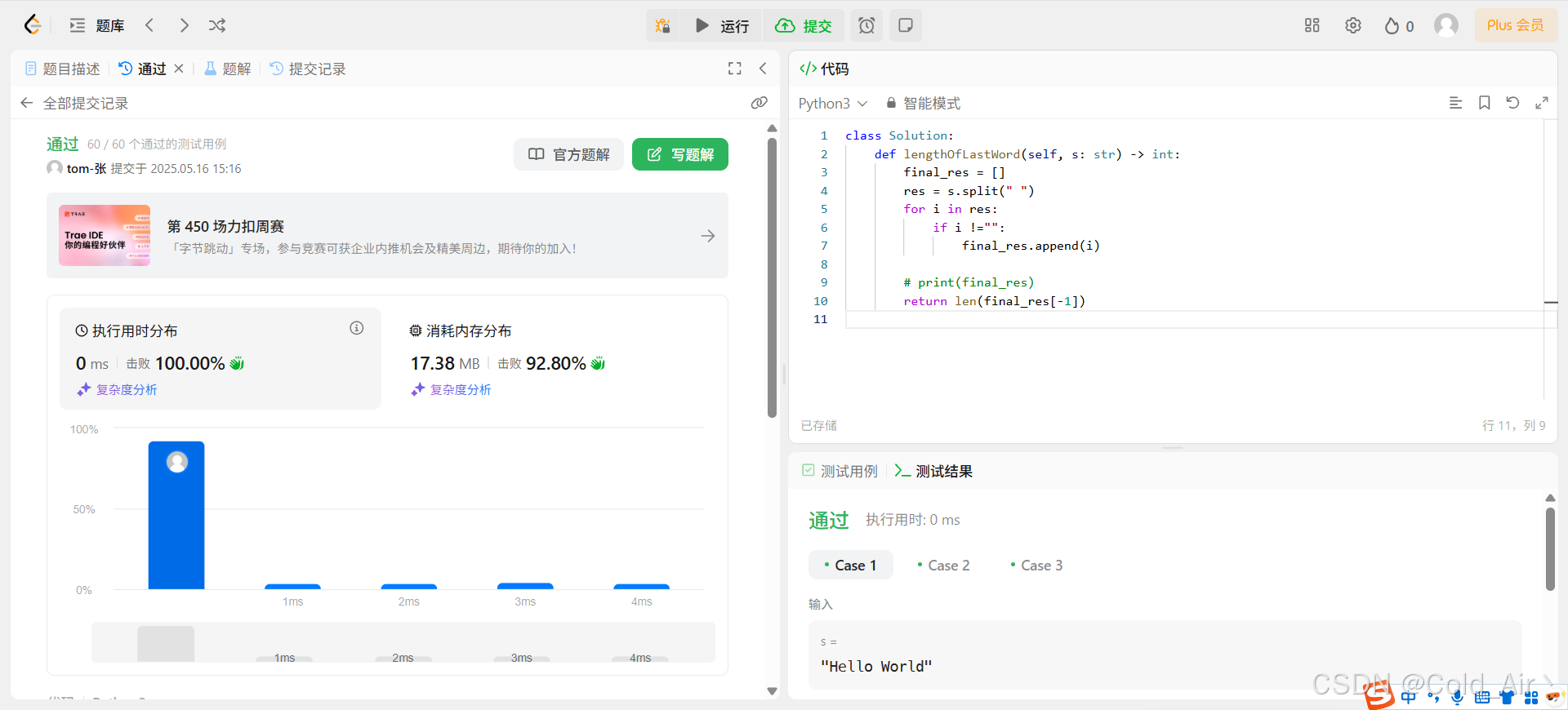
leetcode:58. 最后一个单词的长度(python3解法)
难度:简单 给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中 最后一个 单词的长度。 单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。 示例 1: 输入:s "Hello World"…...

虹科应用 | 探索PCAN卡与医疗机器人的革命性结合
随着医疗技术的不断进步,医疗机器人在提高手术精度、减少感染风险以及提升患者护理质量方面发挥着越来越重要的作用。医疗机器人的精确操作依赖于稳定且高效的数据通信系统,虹科提供的PCAN四通道mini PCIe转CAN FD卡,正是为了满足这一需求而设…...