【论文阅读】A Survey on Multimodal Large Language Models
目录
- 前言
- 一、 背景与核心概念
- 1-1、多模态大语言模型(MLLMs)的定义
- 二、MLLMs的架构设计
- 2-1、三大核心模块
- 2-2、架构优化趋势
- 三、训练策略与数据
- 3-1、 三阶段训练流程
- 四、 评估方法
- 4-1、 闭集评估(Closed-set)
- 4-2、开集评估(Open-set)
- 4-3、多模态幻觉评估
- 4-4、 多模态综合能力评估
- 五、扩展方向与技术
- 5-1、模态支持扩展
- 5-2、 交互粒度扩展
- 5-3、语言与文化扩展
- 5-4、 垂直领域扩展
- 5-5、效率优化扩展
- 5-6、 新兴技术融合
- 总结
前言
这篇综述系统梳理了多模态模型的技术栈,从基础架构到前沿应用,并指出当前瓶颈(如幻觉、长上下文)和解决思路。其核心价值在于(1)方法论:三阶段训练(预训练→指令微调→对齐)成为主流范式。(2)开源生态:LLaVA、MiniGPT-4等开源模型推动社区发展。(3)跨学科应用:在医疗、机器人等领域的渗透展示通用潜力。一、 背景与核心概念
1-1、多模态大语言模型(MLLMs)的定义
核心思想:以强大的大语言模型(如GPT-4、LLaMA)为“大脑”,通过模态接口(如视觉编码器)将图像、音频、视频等非文本模态与文本模态对齐,实现跨模态理解和生成。
与传统多模态模型的区别:
- 规模:MLLMs基于百亿参数规模的LLMs,而传统模型(如CLIP、OFA)参数更小。
- 能力:MLLMs展现涌现能力(如复杂推理、指令跟随),传统模型多为单任务专用。
多模态模型发展线如下所示:
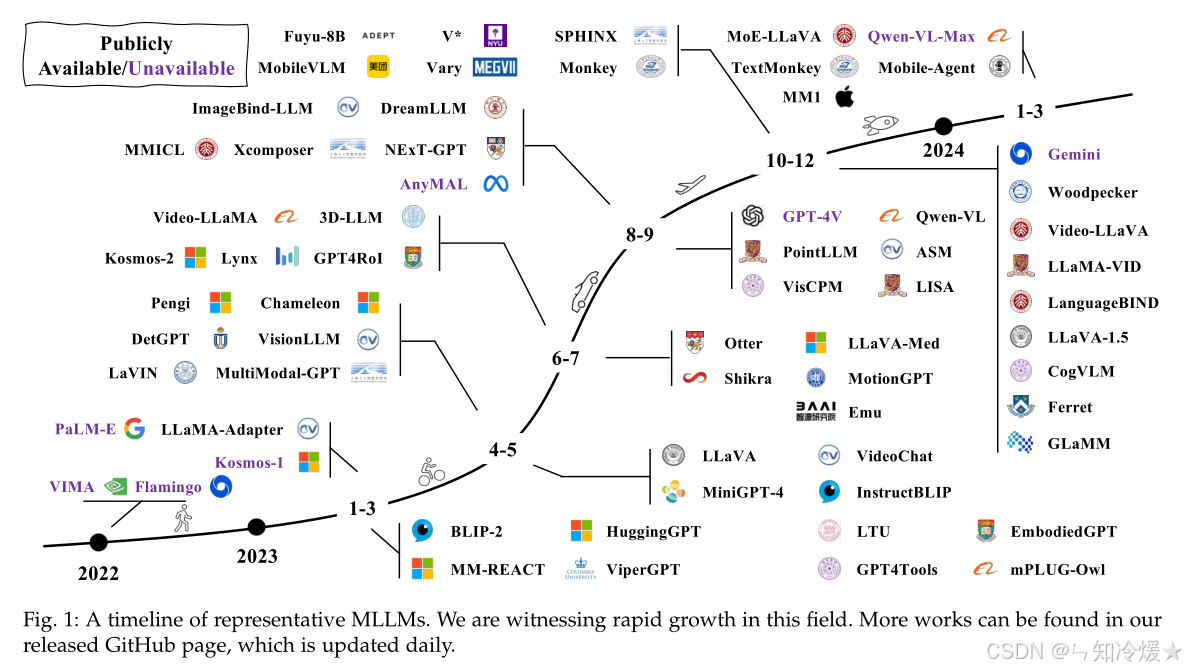
二、MLLMs的架构设计
2-1、三大核心模块
1、模态编码器(Modality Encoder)(眼睛/耳朵)
功能:将原始数据(如图像、音频、视屏等)转换为特征表示,使其能够与文本模态对其。(例如图像、音视频编码器)
常用模型:
-
图像:CLIP-ViT、EVA-CLIP(更高分辨率支持)、ConvNeXt(卷积架构)。
-
音频:CLAP、ImageBind(支持多模态统一编码)。
关键发现:输入分辨率对性能影响显著(如448x448比224x224更优)。即更高的分辨率可以获得更加显著的性能。
如图所示为常用的图像编码器:

2、大语言模型(LLM)(大脑)
功能: 作为MLLM的“大脑”,负责整合多模态信息,执行推理,生成文本输出。
-
选择:开源模型(LLaMA-2、Vicuna)或双语模型(Qwen)。
-
参数规模的影响:从13B→34B参数提升,中文零样本能力涌现(即使训练数据仅为英文)。
-
知识注入:领域适配,例如数据微调,或者工具调用,即通过指令微调教会LLM调用外部API。
如图所示为常用公开的大语言模型:

3、模态接口(Modality Interface):用于对齐不同的模态
可学习接口:
-
Token级融合:如BLIP-2的Q-Former,将视觉特征压缩为少量Token。
-
特征级融合:如CogVLM在LLM每层插入视觉专家模块。
**专家模型:**调用现成模型(如OCR工具)将图像转为文本,再输入LLM(灵活性差但无需训练)。
如图所示为典型多模态模型架构示意图:
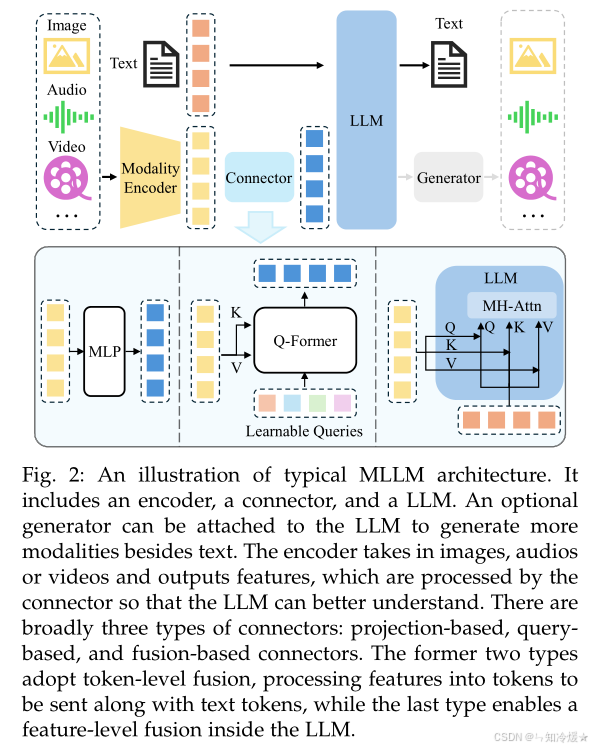
4、模块协同工作示例(以LLaVA为例)
- 图像编码:CLIP-ViT将图像编码为视觉特征。
- 特征对齐:通过两层MLP将视觉特征投影到LLaMA的文本嵌入空间。
- 指令微调:联合训练视觉-文本特征,使LLaMA能理解“描述图像中第三只猫的颜色”。
- 推理生成:LLaMA基于对齐特征生成自然语言响应。
2-2、架构优化趋势
高分辨率支持:通过分块(Monkey)、双编码器(CogAgent)处理高分辨率图像。
稀疏化:混合专家(MoE)架构(如MoE-LLaVA)在保持计算成本的同时增加参数量。
三、训练策略与数据
3-1、 三阶段训练流程
1、预训练(Pretraining)
目标:将不同模态(如图像、音频)的特征映射到统一的语义空间,通过大规模数据吸收通用知识(如物体识别、基本推理)。
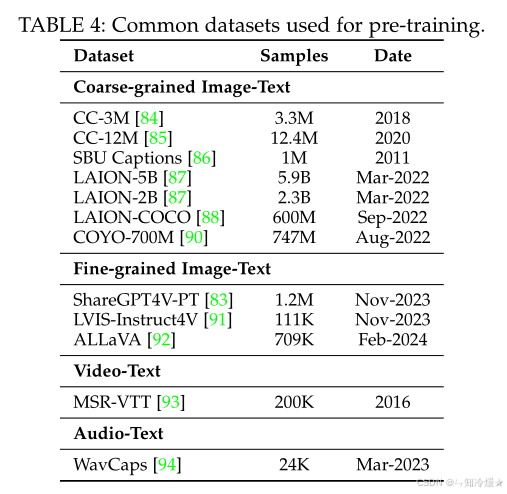
数据:大规模粗粒度图文对(如LAION-5B)或高质量细粒度数据(如GPT-4V生成的ShareGPT4V)。计算图文相似度,移除相似度太低的样本。
关键技巧:冻结编码器和LLM,仅训练接口(防止灾难性遗忘)。
如图所示为预训练所用的通用数据集:
2、指令微调(Instruction Tuning)
目标:使模型能够理解和执行多样化的用户指令(如“描述图像中的情感”),指令调优学习如何泛化到不可见的任务。
数据构建方法:
- 任务适配:将VQA数据集转为指令格式(如“Question: <问题> Answer: <答案>”)。
- 自指令生成:用GPT-4生成多轮对话数据(如LLaVA-Instruct)。
发现:
- 指令多样性(设计不同句式(疑问句、命令句)和任务类型(描述、推理、创作))比数据量更重要。
- 数据质量比数量更重要。
- 包含推理步骤的指令,可以显著提升模型的性能。
如图所示描述任务的指令(相关范例):

3、对齐微调(Alignment Tuning)
目标:减少幻觉(确保生成内容与输入模态一致(如不虚构图中未出现的物体)),使输出更符合人类偏好。(简介、安全,符合伦理)
方法:
- RLHF:通过人类偏好数据训练奖励模型,再用PPO优化策略(如LLaVA-RLHF)。
- DPO:直接优化偏好对(无需显式奖励模型)。
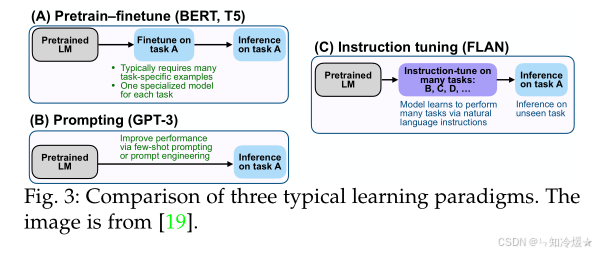
如图所示为三种典型学习范式的比较:
四、 评估方法
4-1、 闭集评估(Closed-set)
定义:在预定义任务和答案范围内测试模型性能,适用于标准化任务(如分类、问答)。
核心指标:
- 准确率(Accuracy):直接匹配模型输出与标准答案(如ScienceQA数据集)。
- CIDEr(Consensus-based Image Description Evaluation):衡量生成文本与参考描述的语义相似性(常用于图像描述任务)。
- BLEU-4:基于词重叠的机器翻译指标,适用于短文本生成(如VQA简短回答)。
4-2、开集评估(Open-set)
定义:评估模型在开放场景下的生成能力(如自由对话、创造性任务),答案不固定。
核心方法:
人工评分(Human Rating):
- 评分维度:相关性、事实性、连贯性、多样性、安全性。
- 流程:标注员按1-5分对模型输出打分(如LLaVA的对话能力评估)。
GPT-4评分(GPT-as-a-Judge):
- 方法:用GPT-4对模型输出评分(示例提示):
Instruction: 请根据相关性(1-5分)和准确性(1-5分)评价以下回答:
问题:<问题>
模型回答:<回答>
- 优点:低成本、可扩展;缺点:依赖GPT-4的偏见和文本理解能力。
4-3、多模态幻觉评估
定义:检测模型生成内容与输入模态不一致的问题(如虚构图中未出现的对象)。
评估方法:
POPE(Polling-based Object Probing Evaluation):
- 流程:生成多项选择题(如“图中是否有狗?”),统计模型回答的准确率。
- 指标:准确率、假阳性率(FP)。
CHAIR(Caption Hallucination Assessment with Image Relevance):
步骤:
- 提取生成描述中的所有名词(如“猫、桌子”)。
- 检测这些名词是否在图像中存在(通过目标检测模型)。
指标:幻觉率(错误名词占比)。
FaithScore:
方法:将生成文本拆分为原子事实(如“猫是黑色的”),用视觉模型验证每个事实是否成立。
指标:原子事实准确率。
4-4、 多模态综合能力评估
(1) 多维度基准测试
1、MME(Multimodal Evaluation Benchmark):
涵盖能力:感知(物体计数、颜色识别)、认知(推理、常识)。
任务示例:
- 感知任务:“图中红色物体的数量?”
- 认知任务:“如果移除支撑杆,积木会倒塌吗?为什么?”
指标:综合得分(感知分 + 认知分)。
2、MMBench:
特点:覆盖20+任务类型(如OCR、时序推理),使用ChatGPT将开放答案匹配到预定义选项。
指标:准确率(标准化为0-100分)。
五、扩展方向与技术
多模态大语言模型的扩展方向主要集中在提升功能多样性、支持更复杂场景、优化技术效率以及拓展垂直领域应用。以下是具体分类与技术细节
5-1、模态支持扩展
一、 输入模态扩展
1、3D点云(Point Cloud)
技术:将3D数据(如LiDAR扫描)编码为稀疏或密集特征。
案例:
- PointLLM:通过投影网络将点云特征对齐到LLM的文本空间,支持问答(如“房间中有多少把椅子?”)。
- 3D-LLM:结合视觉和3D编码器,实现跨模态推理(如分析物体空间关系)。
挑战:3D数据的高维稀疏性、计算开销大。
2、传感器融合(Sensor Fusion)
技术:整合多种传感器数据(如热成像、IMU惯性测量)。
案例:
- ImageBind-LLM:支持图像、音频、深度、热成像等多模态输入,通过统一编码器对齐特征。
应用:自动驾驶(融合摄像头、雷达、激光雷达数据)。
二、输出模态扩展
1、多模态生成:
技术:结合扩散模型(如Stable Diffusion)生成图像、音频或视频。
案例:
- NExT-GPT:输入文本生成图像+音频,或输入视频生成文本描述+配乐。
- Emu:通过视觉解码器生成高分辨率图像,支持多轮编辑(如“将图中的猫换成狗”)。
指标:生成质量(FID、CLIP Score)、跨模态一致性。
5-2、 交互粒度扩展
一、细粒度输入控制
1、区域指定(Region-specific):
技术:支持用户通过框选(Bounding Box)、点击(Point)指定图像区域。
案例:
- Ferret:接受点、框或草图输入,回答与指定区域相关的问题(如“这个红框内的物体是什么?”)。
- Shikra:输出回答时自动关联图像坐标(如“左侧的狗(坐标[20,50,100,200]在奔跑”)。
2、像素级理解(Pixel-level):
技术:结合分割模型(如Segment Anything)实现掩码级交互。
案例:
- LISA:通过文本指令生成物体掩码(如“分割出所有玻璃杯”)。
二、多轮动态交互
历史记忆增强:
技术:在对话中维护跨模态上下文缓存(如缓存前几轮的图像特征)。
案例:
- Video-ChatGPT:支持多轮视频问答(如“第三秒出现的车辆是什么品牌?”)。
5-3、语言与文化扩展
一、多语言支持
低资源语言适配:
技术:通过翻译增强(Translate-Train)或跨语言迁移学习。
案例:
- VisCPM:基于中英双语LLM,用英文多模态数据训练,通过少量中文数据微调实现中文支持。
挑战:缺乏非拉丁语系的图文对齐数据(如阿拉伯语、印地语)。
二、文化适应性
本地化内容生成:
技术:在指令数据中注入文化特定元素(如节日、习俗)。
案例:
- Qwen-VL:支持生成符合中文文化背景的描述(如“端午节龙舟赛”)。
5-4、 垂直领域扩展
一、医疗领域
技术:领域知识注入(如医学文献微调)、数据增强(合成病理图像)。
案例:
- LLaVA-Med:支持胸部X光诊断问答(如“是否存在肺炎迹象?”),准确率超放射科住院医师平均水平。
挑战:数据隐私、伦理审查。
二、自动驾驶
技术:多传感器融合、实时性优化(如模型轻量化)。
案例:
- DriveLLM:结合高精地图和摄像头数据,回答复杂驾驶场景问题(如“能否在此路口变道?”)。
三、工业检测
技术:高分辨率缺陷检测、小样本学习。
案例:
- Industrial-VLM:通过文字提示定位产品缺陷(如“检测电路板上的虚焊点”)。
5-5、效率优化扩展
一、轻量化部署
技术:
- 模型压缩:量化(INT8)、知识蒸馏(如TinyLLaVA)。
- 硬件适配:针对移动端(如NPU)优化计算图。
案例:
- MobileVLM:1.4B参数模型可在手机端实时运行,支持图像描述和简单问答。
二、混合专家(MoE)架构
技术:稀疏激活,仅调用部分专家模块处理输入。
案例:
- MoE-LLaVA:在视觉问答任务中,MoE架构比同参数规模模型准确率提升5%-10%。
5-6、 新兴技术融合
一、具身智能(Embodied AI)
技术:将MLLMs与机器人控制结合,实现“感知-推理-行动”闭环。
案例:
- PALM-E:通过视觉-语言模型控制机械臂完成复杂操作(如“把红色积木放在蓝色盒子旁边”)。
二、增强现实(AR)
技术:实时多模态交互(如语音+手势+视觉)。
案例:
- AR-LLM:在AR眼镜中叠加MLLM生成的实时导航提示(如“前方路口右转”)。
参考文章:
多模态模型综述文章
Github地址
注意: 原文内容较多,本文仅限部分内容笔记,建议直接阅读原文。
总结
好困,真的好困。🐑
相关文章:
【论文阅读】A Survey on Multimodal Large Language Models
目录 前言一、 背景与核心概念1-1、多模态大语言模型(MLLMs)的定义 二、MLLMs的架构设计2-1、三大核心模块2-2、架构优化趋势 三、训练策略与数据3-1、 三阶段训练流程 四、 评估方法4-1、 闭集评估(Closed-set)4-2、开集评估&…...
增强的YOLOv11主干网络—面向高精度目标检测的结构创新与性能优化)
基于多头自注意力机制(MHSA)增强的YOLOv11主干网络—面向高精度目标检测的结构创新与性能优化
深度学习在计算机视觉领域的快速发展推动了目标检测算法的持续进步。作为实时检测框架的典型代表,YOLO系列凭借其高效性与准确性备受关注。本文提出一种基于多头自注意力机制(Multi-Head Self-Attention, MHSA)增强的YOLOv11主干网络结构,旨在提升模型在复杂场景下的目标特征…...
vue3 elementplus tabs切换实现
Tabs 标签页 | Element Plus <template><!-- editableTabsValue 是当前tab 的 name --><el-tabsv-model"editableTabsValue"type"border-card"editableedit"handleTabsEdit"><!-- 这个是标签面板 面板数据 遍历 editableT…...

关于机器学习的实际案例
以下是一些机器学习的实际案例: 营销与销售领域 - 推荐引擎:亚马逊、网飞等网站根据用户的品味、浏览历史和购物车历史进行推荐。 - 个性化营销:营销人员使用机器学习联系将产品留在购物车或退出网站的用户,根据客户兴趣定制营销…...
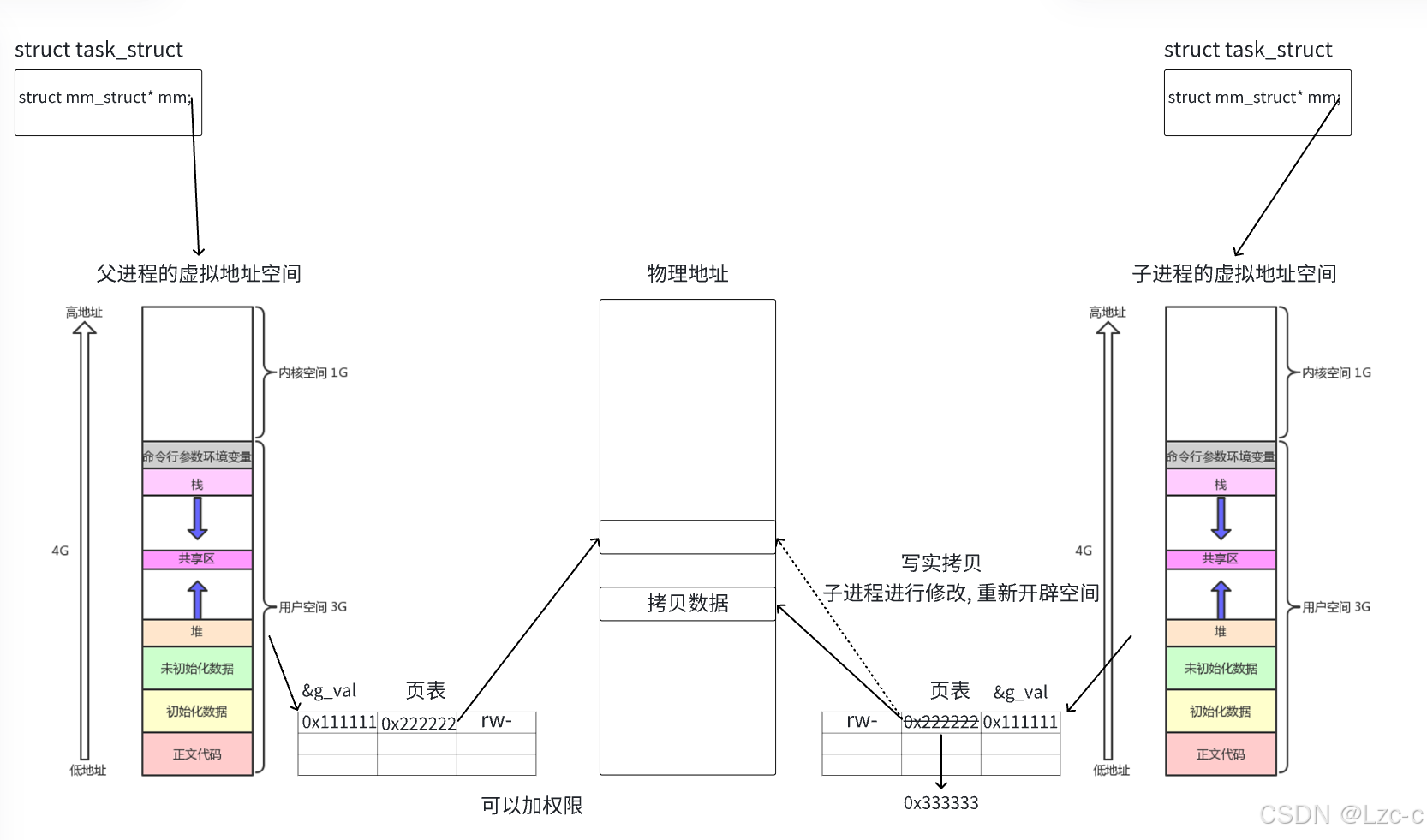
Linux的进程概念
目录 1、冯诺依曼体系结构 2、操作系统(Operating System) 2.1 基本概念 编辑 2.2 目的 3、Linux的进程 3.1 基本概念 3.1.1 PCB 3.1.2 struct task_struct 3.1.3 进程的定义 3.2 基本操作 3.2.1 查看进程 3.2.2 初识fork 3.3 进程状态 3.3.1 操作系统的进程状…...

C++ map容器: 插入操作
1. map插入操作基础 map是C STL中的关联容器,存储键值对(key-value pairs)。插入元素时有四种主要方式,各有特点: 1.1 头文件与声明 #include <map> using namespace std;map<int, string> mapStu; // 键为int,值…...

基于STC89C52的红外遥控的电子密码锁设计与实现
一、引言 电子密码锁作为一种安全便捷的门禁系统,广泛应用于家庭、办公室等场景。结合红外遥控功能,可实现远程控制开锁,提升使用灵活性。本文基于 STC89C52 单片机,设计一种兼具密码输入和红外遥控的电子密码锁系统,详细阐述硬件选型、电路连接及软件实现方案。 二、硬…...

Docker配置容器开机自启或服务重启后自启
要将一个 Docker 容器设置为开机自启,你可以使用 docker update 命令或配置 Docker 服务来实现。以下是两种常见的方法: 方法 1:使用 docker update 设置容器自动重启 使用 docker update 设置容器为开机自启 你可以使用以下命令,…...
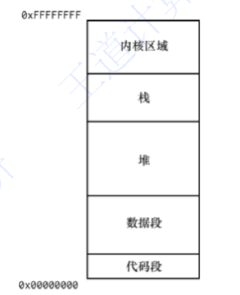
计算机单个进程内存布局的基本结构
这张图片展示了一个计算机内存布局的基本结构,从低地址(0x00000000)到高地址(0xFFFFFFFF)依次分布着不同的内存区域。 代码段 这是程序代码在内存中的存储区域。它包含了一系列的指令,这些指令是计算机执行…...

我的电赛(简易的波形发生器大一暑假回顾)
DDS算法:当时是用了一款AD9833芯片搭配外接电路实现了一个波形发生,配合stm32f103芯片实现一个幅度、频率、显示的功能; 在这个过程中,也学会了一些控制算法;就比如DDS算法,当时做了一些了解,可…...

AI工程 新技术追踪 探讨
文章目录 一、核心差异维度对比二、GitHub对AI工程师的独特价值三、需要警惕的陷阱四、推荐追踪策略五、与传统开发的平衡建议 以下内容整理来自 deepseek 作为AI工程师,追踪GitHub开源项目 对技术成长和职业发展的影响 比传统应用开发工程师 更为显著,…...
算法题(149):矩阵消除游戏
审题: 本题需要我们找到消除矩阵行与列后可以获得的最大权值 思路: 方法一:贪心二进制枚举 这里的矩阵消除时,行与列的消除会互相影响,所以如果我们先统计所有行和列的总和,然后选择消除最大的那一行/列&am…...

在 Vue 中插入 B 站视频
前言 在 Vue 项目中,有时我们需要嵌入 B 站视频来丰富页面内容,为用户提供更直观的信息展示。本文将详细介绍在 Vue 中插入 B 站视频的多种方法。 使用<iframe>标签直接嵌入,<iframe>标签是一种简单直接的方式,可将 B 站视频嵌…...
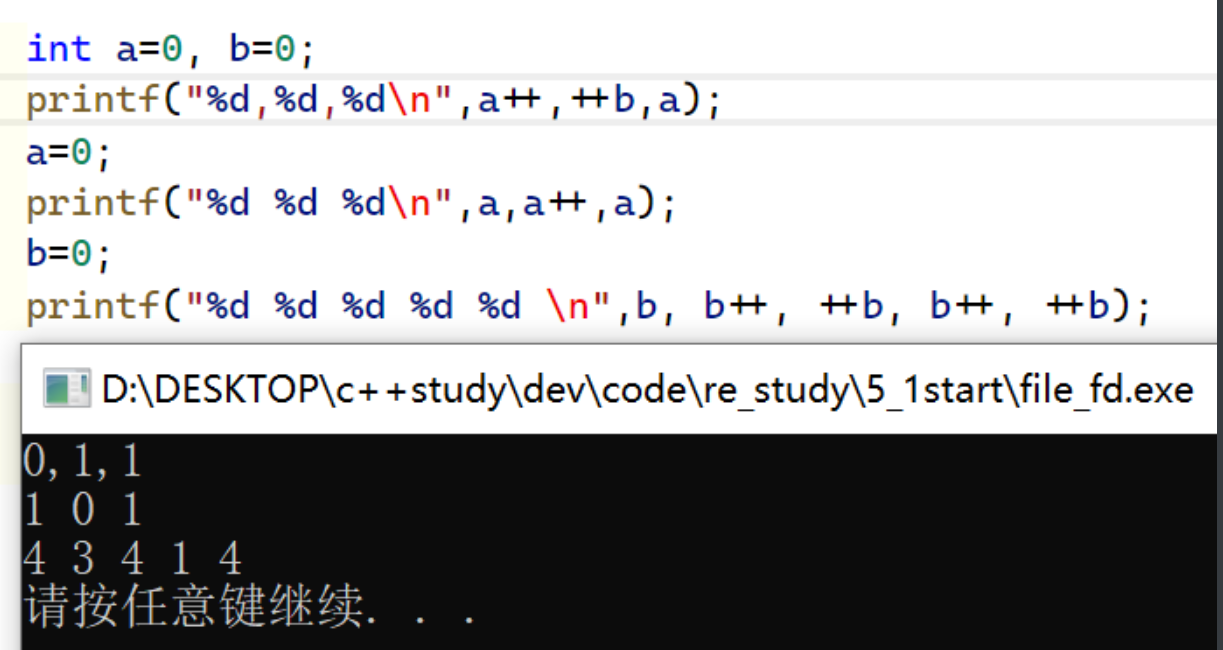
printf函数参数与入栈顺序
01. printf()的核心功能 作用:将 格式化数据 输出到 标准输出(stdout),支持多种数据类型和格式控制。 int printf(const char *format, ...);参数: format:格式字符串,字符串或%开头格式符...:…...

仿生眼机器人(人脸跟踪版)系列之一
文章不介绍具体参数,有需求可去网上搜索。 特别声明:不论年龄,不看学历。既然你对这个领域的东西感兴趣,就应该不断培养自己提出问题、思考问题、探索答案的能力。 提出问题:提出问题时,应说明是哪款产品&a…...

08、底层注解-@Configuration详解
# Configuration 注解详解 08、底层注解-Configuration详解 Configuration 是 Spring 框架中用于定义配置类的核心注解,它允许开发者以 Java 代码的形式替代传统的 XML 配置,声明和管理 Bean。 ## 一、基本作用 ### 1. 标识配置类 使用 Configuration…...
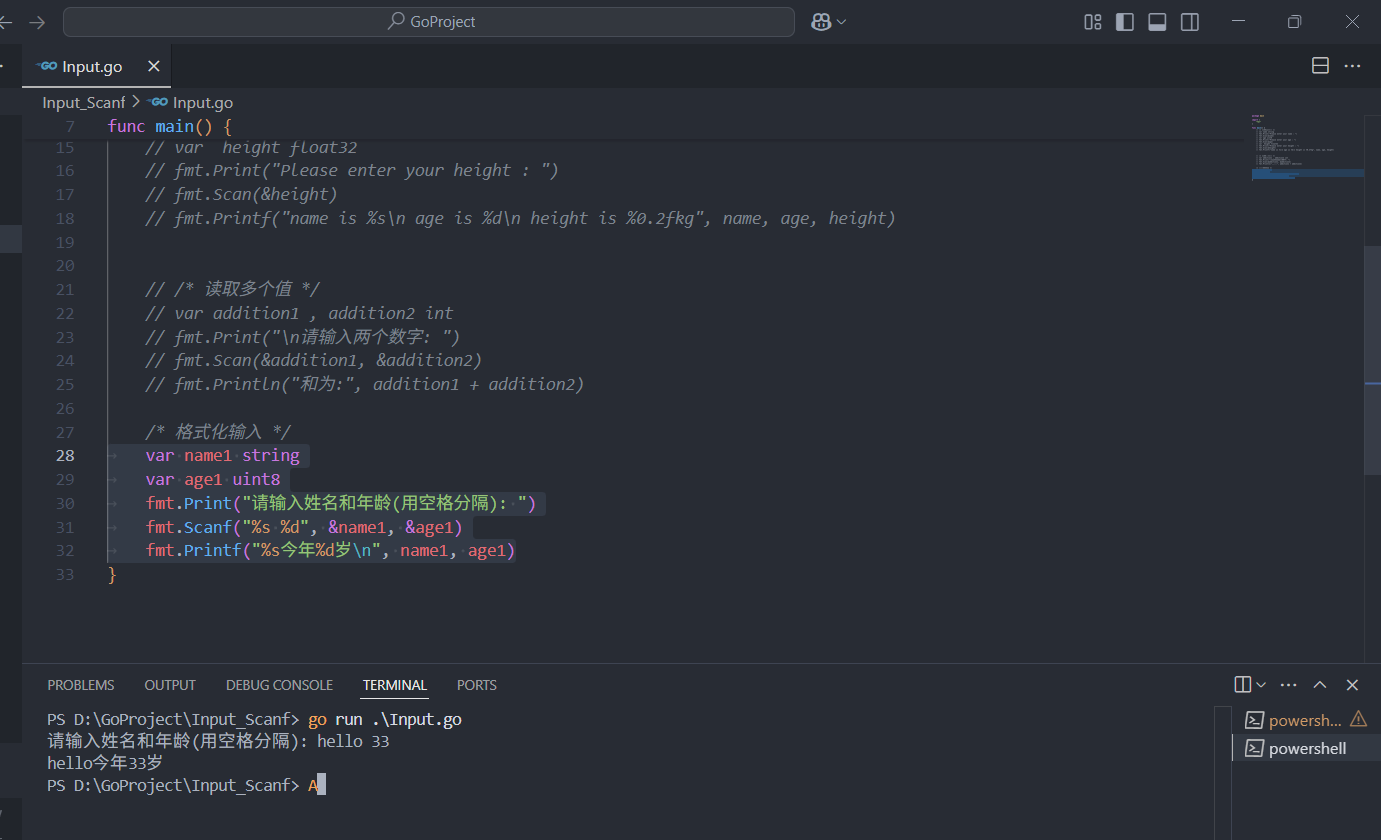
Go语言语法---输入控制
文章目录 1. fmt包读取输入1.1. 读取单个值1.2. 读取多个值 2. 格式化输入控制 在Go语言中,控制输入主要涉及从标准输入(键盘)或文件等来源读取数据。以下是几种常见的输入控制方法: 1. fmt包读取输入 fmt包中的Scan和Scanln函数都可以读取输入…...

蓝桥杯单片机按键进阶
蓝桥杯单片机按键进阶 ——基于柳离风老师模板及按键进阶教程 文章目录 蓝桥杯单片机按键进阶1、按键测试-按下生效2、按键进阶-松手生效3、按键进阶-按键禁用(未完待续) 1、按键测试-按下生效 key.c #include "key.h"/*** brief 独立按键…...

CSS- 4.3 绝对定位(position: absolute)学校官网导航栏实例
本系列可作为前端学习系列的笔记,代码的运行环境是在HBuilder中,小编会将代码复制下来,大家复制下来就可以练习了,方便大家学习。 HTML系列文章 已经收录在前端专栏,有需要的宝宝们可以点击前端专栏查看! 点…...

Flink 作业提交流程
Apache Flink 的 作业提交流程(Job Submission Process) 是指从用户编写完 Flink 应用程序,到最终在 Flink 集群上运行并执行任务的整个过程。它涉及多个组件之间的交互,包括客户端、JobManager、TaskManager 和 ResourceManager。…...

拓展运算符
拓展运算符(Spread Operator)是ES6中引入的新特性,以下是关于它的一些知识点总结: 语法 拓展运算符的语法是三个点(...),它可以将数组或对象展开成多个元素或属性。 数组中的应用 • 数组展…...
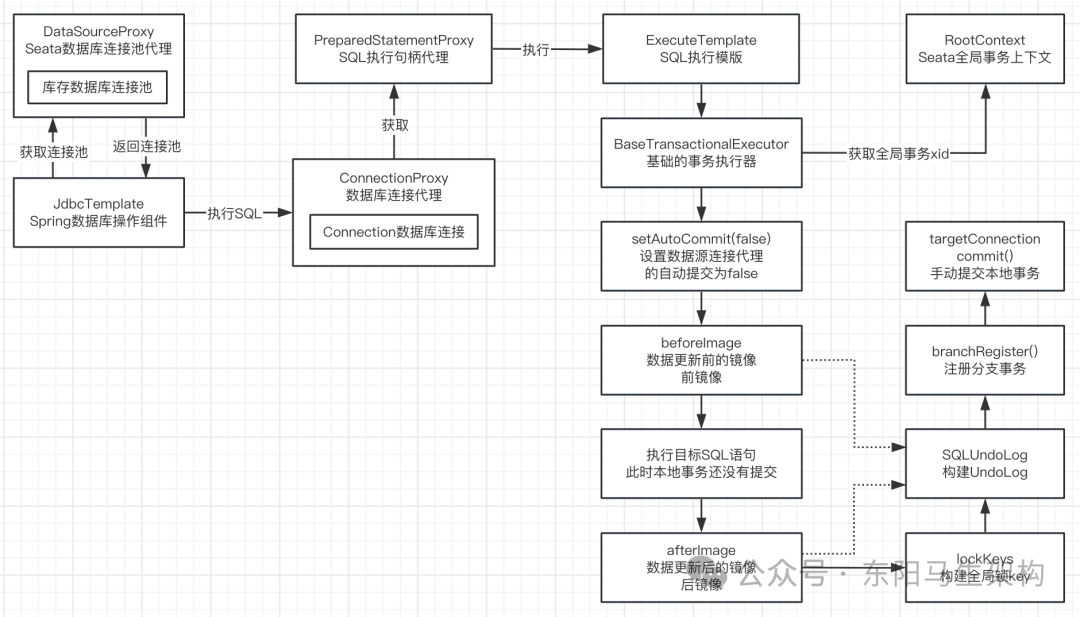
Seata源码—6.Seata AT模式的数据源代理一
大纲 1.Seata的Resource资源接口源码 2.Seata数据源连接池代理的实现源码 3.Client向Server发起注册RM的源码 4.Client向Server注册RM时的交互源码 5.数据源连接代理与SQL句柄代理的初始化源码 6.Seata基于SQL句柄代理执行SQL的源码 7.执行SQL语句前取消自动提交事务的源…...

计算机科技笔记: 容错计算机设计05 n模冗余系统 TMR 三模冗余系统
NMR(N-Modular Redundancy,N 模冗余)是一种通用的容错设计架构,通过引入 N 个冗余模块(N ≥ 3 且为奇数),并采用多数投票机制,来提升系统的容错能力与可靠性。单个模块如果可靠性小于…...

Spring Boot 与 RabbitMQ 的深度集成实践(一)
引言 ** 在当今的分布式系统架构中,随着业务复杂度的不断提升以及系统规模的持续扩张,如何实现系统组件之间高效、可靠的通信成为了关键问题。消息队列作为一种重要的中间件技术,应运而生并发挥着举足轻重的作用。 消息队列的核心价值在于其…...
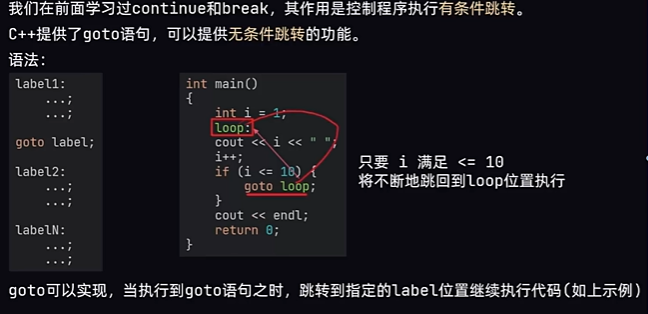
黑马程序员2024新版C++笔记 第2章 语句
1.if逻辑判断语句 语法主体: if(要执行的判断,结果是bool型){判断结果是true会执行的代码; } 2.AI大模型辅助编程 在Clion中搜索并安装对应插件: 右上角齿轮点击后找到插件(TRONGYI LINGMA和IFLYCODE)安装后重启ide即可。 重启后会有通义登…...

HTML5中的Microdata与历史记录管理详解
HTML5中的Microdata与历史记录管理解析 一、Microdata结构化数据 核心属性 itemscope 声明数据范围itemtype 指定数据词汇表(如http://schema.org/Product)itemprop 定义数据属性 <div itemscope itemtype"http://schema.org/Book">…...

上位机知识篇---涂鸦智能云平台
文章目录 前言 前言 本文简单介绍了涂鸦智能云平台。...

面试中的线程题
原文链接:线程题大全 Java 并发库同步辅助类 CountDownLatch 工作机制:初始化一个计数器,此计数器的值表示需要等待的事件数量。 提供了两个主要方法: await():当一个线程调用此方法时,它将阻塞&#…...

济南国网数字化培训班学习笔记-第三组-2-电力通信光缆网认知
电力通信光缆网认知 光缆网架构现状 基础底座 电路系统是高度复杂,实时性、安全性、可靠性要求极高的巨系统,必须建设专用通信网 相伴相生 电力系统是由发电、输电、变电、配电、用电等一次设施,及保障其正常运行的保护、自动化、通信等…...
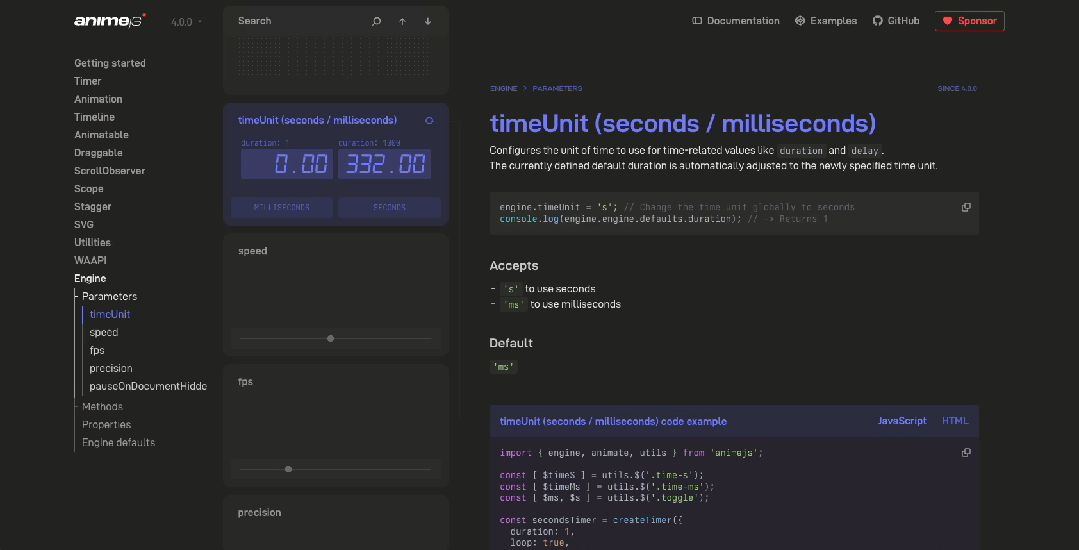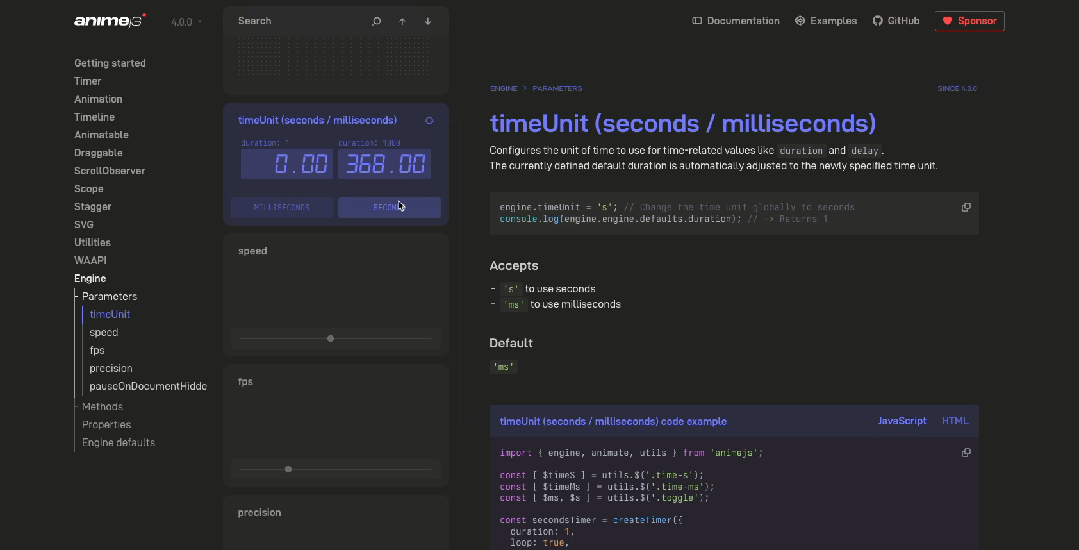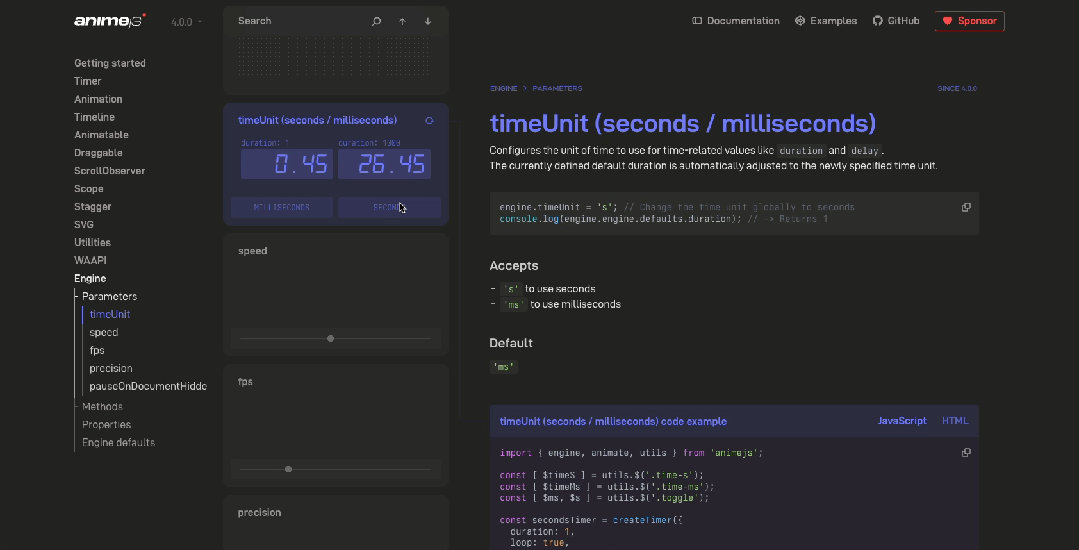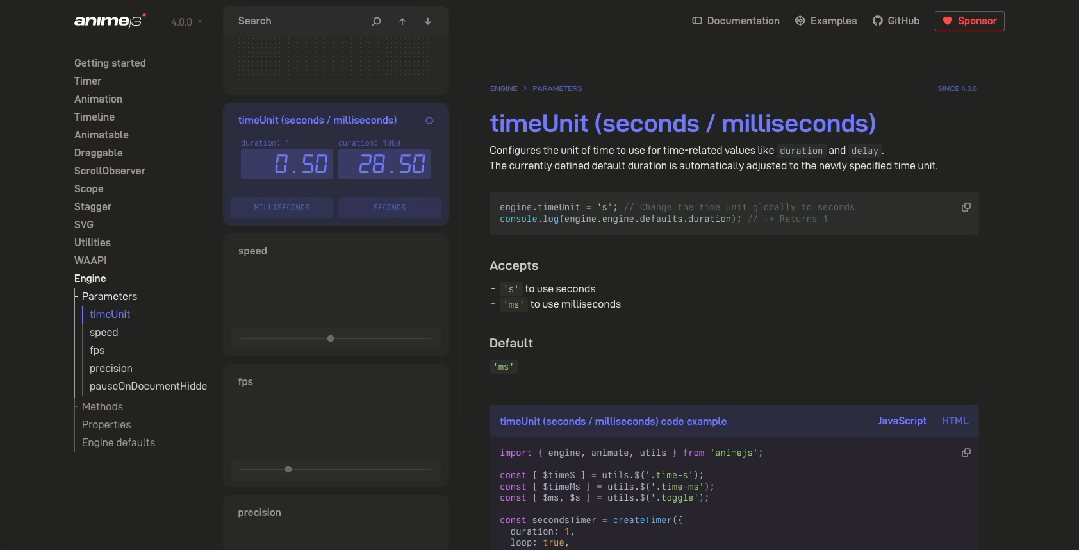
前端动画库 Anime.js 的V4 版本,兼容 Vue、React
前端动画库 Anime.js 更新了 V4 版本,并对其官网进行了全面更新,增加了许多令人惊艳的效果,尤其是时间轴动画效果,让开发者可以更精确地控制动画节奏。 这一版本的发布不仅带来了全新的模块化 API 和显著的性能提升,还…...