OpenAI Chat API 详解:打造智能对话应用的基石
目录
- OpenAI Chat API 详解:打造智能对话应用的基石
- 参数概览
- 核心参数详解与实战
- 1. `model`: 选择你的 AI 大脑
- 2. `prompt`: 指引 AI 的灵魂
- 3. `max_tokens`: 控制输出的长度
- 4. `temperature` 和 `top_p`: 调控创造力
- 5. `stop`: 控制生成的结束
- 6. `presence_penalty` 和 `frequency_penalty`: 避免重复
- 实战演练:使用 REST API 调用
- 总结与展望
OpenAI Chat API 详解:打造智能对话应用的基石
OpenAI API 提供了强大的自然语言处理能力, 通过简单的 API 调用, 开发者可以将先进的语言模型集成到各种应用中。然而, 要充分发挥这些模型的潜力, 理解并灵活运用其丰富的调用参数至关重要。本文将带你深入探索 OpenAI API 的各项参数, 并结合实际案例, 助你成为驾驭语言力量的行家。
参数概览
在深入每个参数之前, 我们先通过一个表格对 OpenAI API 的常用调用参数进行概览, 其中包含了参数及其默认值, 让你对整体有一个清晰的认识。
| 参数名 | 类型 | 是否必需 | 描述 | 常用取值示例 | 默认值 |
|---|---|---|---|---|---|
model | String | 是 | 指定要使用的模型。 | "gpt-3.5-turbo", "text-davinci-003", "code-davinci-002" | 无 |
message | Array | 是 | messages 参数是一个包含消息对象的数组,用于表示到目前为止的对话历史 。每个消息对象必须包含 role 和 content 字段。role 可以是 system、user 或 assistant,分别代表系统指令、用户的输入和助手的回复。通过在 messages 数组中按时间顺序包含所有相关的先前消息,可以为模型提供必要的上下文,从而实现连贯的多轮对话。 | "请写一首关于春天的诗歌", [{"role": "user", "content": "你好"}, {"role": "assistant", "content": "你好!有什么我可以帮您?"}] | 无 |
prompt | String/Array | 否 | 在一些较旧的或基于补全的模型中,仍然会使用 prompt 参数。prompt 接受一个字符串或字符串数组,作为生成文本补全的输入 。对于构建类似 ChatGPT 的应用程序,推荐使用带有聊天补全端点的 messages 参数 。 | "你好" | 无 |
max_tokens | Integer | 否 | 生成文本的最大 token 数。限制生成文本的长度, 防止模型输出过长。 | 50, 200, 1000 | 模型默认最大值 |
temperature | Float | 否 | 控制生成文本的随机性。值越高, 输出越随机和有创造性;值越低, 输出越确定和集中。通常在 0 到 2 之间。 | 0.2, 0.7, 1.5 | 1.0 |
top_p | Float | 否 | 控制生成文本的核采样。模型会考虑概率最高的 top-p 的 token 集合。与 temperature 类似, 但以不同的方式控制随机性。建议不要同时调整 temperature 和 top_p。 | 0.5, 0.9 | 1.0 |
n | Integer | 否 | 为每个输入提示生成多少个独立的补全。 | 1, 3, 5 | 1 |
stream | Boolean | 否 | 是否启用流式传输。如果设置为 True, 模型将以数据流的形式逐个返回 token。 | True, False | False |
stop | String/Array | 否 | 模型在生成文本时遇到这些序列时会停止生成。可以是一个字符串或一个字符串数组。 | "\n", `[“###”, "< | file_separator |
presence_penalty | Float | 否 | 对模型生成新 token 的惩罚, 鼓励模型生成之前文本中没有出现过的新概念。范围通常在 -2.0 到 2.0 之间。 | -1.0, 0.5, 2.0 | 0.0 |
frequency_penalty | Float | 否 | 对模型生成已经频繁出现的 token 的惩罚, 降低模型重复输出相同内容的倾向。范围通常在 -2.0 到 2.0 之间。 | -1.0, 0.5, 2.0 | 0.0 |
logit_bias | Map | 否 | 修改特定 token 出现在完成结果中的可能性。接受一个 JSON 对象, 该对象将 token (由 tokenizer 计算) 映射到介于 -100 和 100 之间的偏差值。正偏差会增加 token 的可能性, 而负偏差会降低其可能性。 | {"50256": -100} (降低 `< | endoftext |
user | String | 否 | 代表最终用户的唯一标识符, 有助于 OpenAI 监控和检测滥用行为。 | "user-1234", "internal-app-user" | null |
注意: max_tokens 的默认值取决于所选模型的最大上下文长度。stop 和 user 默认值为 null,表示没有设置。logit_bias 默认值为空字典 {},表示没有对任何 token 的概率进行调整。
核心参数详解与实战
接下来, 我们将对一些最核心和常用的参数进行更深入的探讨, 并通过实际案例展示它们的应用。
1. model: 选择你的 AI 大脑
model 参数决定了你将使用哪个 OpenAI 模型来处理你的请求。不同的模型在能力、速度和成本上都有所不同。
gpt-3.5-turbo: 目前最流行的模型之一, 性价比高, 适用于各种文本生成和对话任务。text-davinci-003: 功能强大的文本生成模型, 擅长创意性写作、长文本生成和复杂指令理解。code-davinci-002: 专门为代码生成和理解而优化的模型。
实战案例 (Python SDK):
假设你想生成一篇关于未来旅行的短文, 你可以选择 text-davinci-003 以获得更具创意和深度的内容:
import openaiclient = openai.OpenAI(api_key="YOUR_API_KEY")response = client.completions.create(model="text-davinci-003",prompt="展望未来,人们会以怎样的方式旅行?",max_tokens=200,temperature=0.8 # 覆盖默认值 1.0
)print(response.choices[0].text.strip())
如果你想构建一个简单的聊天机器人, gpt-3.5-turbo 会是更经济实惠的选择:
response = client.chat.completions.create(model="gpt-3.5-turbo",messages=[{"role": "user", "content": "你好!"},]
)print(response.choices[0].message.content)
2. prompt: 指引 AI 的灵魂
prompt 是你提供给模型的指令或输入文本, 它直接影响着模型生成的内容。对于不同的模型, prompt 的格式有所不同:
- Completion 模型 (如
text-davinci-003):prompt是一个字符串, 包含你希望模型补全或基于其生成文本的指令。 - Chat 模型 (如
gpt-3.5-turbo):prompt是一个包含消息对象的数组, 每个消息对象都有role(可以是"user","assistant", 或"system") 和content字段, 用于构建对话历史。
实战案例 (Python SDK):
Chat 模型:
response = client.chat.completions.create(model="gpt-3.5-turbo",messages=[{"role": "system", "content": "你是一个乐于助人的翻译助手。"},{"role": "user", "content": "请翻译这句话成法语:谢谢你的帮助。"},]
)print(response.choices[0].message.content)
清晰、明确且富有上下文的 prompt 是获得高质量输出的关键。掌握 prompt engineering 的技巧将极大地提升你使用 OpenAI API 的效果。
主要区别总结。
3. max_tokens: 控制输出的长度
max_tokens 参数限制了模型在单个请求中生成的最大 token 数。一个 token 大致相当于英语文本中的一个单词或几个字符。合理设置 max_tokens 可以帮助你控制 API 的使用成本, 并防止模型生成过长的、不相关的文本。
实战案例 (Python SDK):
假设你需要生成一篇关于某个主题的摘要, 你可能希望限制输出的长度:
response = client.completions.create(model="text-davinci-003",prompt="请总结一下人工智能在医疗领域的应用。",max_tokens=150
)print(response.choices[0].text.strip())
4. temperature 和 top_p: 调控创造力
temperature 和 top_p 是控制模型输出随机性的两个重要参数。它们的默认值都是 1.0。
temperature: 值越高 (例如 0.8, 1.0), 模型在选择下一个 token 时会更加随机, 生成更具创意和多样性的文本。值越低 (例如 0.2, 0.5), 模型会更加保守和确定, 输出更符合逻辑和事实的文本。top_p: 又称核采样。模型会考虑概率最高的 top-p 的 token 集合, 并从中进行采样。例如,top_p=0.9意味着模型会考虑概率最高的 90% 的 token。
建议: 通常建议只调整其中一个参数。如果你追求更可预测和正式的输出, 降低 temperature 是一个好的选择。如果你希望模型更具创造性, 可以尝试提高 temperature。
实战案例 (Python SDK):
低 temperature (更确定):
response = client.completions.create(model="text-davinci-003",prompt="中国的首都是哪里?",temperature=0.1, # 覆盖默认值 1.0max_tokens=10
)print(response.choices[0].text.strip())
高 temperature (更具创造性):
response = client.completions.create(model="text-davinci-003",prompt="用奇幻的风格描述一片森林。",temperature=0.9, # 覆盖默认值 1.0max_tokens=100
)print(response.choices[0].text.strip())
5. stop: 控制生成的结束
stop 参数允许你指定一个或多个停止序列。当模型生成文本时遇到这些序列中的任何一个, 它将停止生成。其默认值为 null, 表示模型会一直生成直到达到 max_tokens 或自然结束。设置 stop 可以帮助你控制模型输出的范围和格式。
实战案例 (Python SDK):
假设你希望模型生成一段代码, 并希望它在生成完函数定义后停止:
response = client.completions.create(model="code-davinci-002",prompt="请用 Python 编写一个计算两个数字之和的函数。",stop=["\n\n"] # 覆盖默认值 null
)print(response.choices[0].text.strip())
6. presence_penalty 和 frequency_penalty: 避免重复
这两个惩罚参数用于控制模型生成重复文本的倾向。它们的默认值都是 0.0。
presence_penalty: 对模型生成新 token 的惩罚。值越大, 模型越不容易生成之前文本中已经出现过的 token, 从而鼓励生成新的概念和想法。frequency_penalty: 对模型生成已经频繁出现的 token 的惩罚。值越大, 模型越不容易重复使用高频词汇, 从而降低生成重复文本的可能性。
实战案例 (Python SDK):
假设你希望模型生成一篇关于某个主题的文章, 并避免过度重复关键词:
response = client.completions.create(model="text-davinci-003",prompt="谈谈人工智能的未来发展。",max_tokens=300,presence_penalty=0.5, # 覆盖默认值 0.0frequency_penalty=0.3 # 覆盖默认值 0.0
)print(response.choices[0].text.strip())
实战演练:使用 REST API 调用
为了更直观地展示 OpenAI API 的调用方式, 这里提供一个使用 Python requests 库进行 REST API 调用的全面示例。这个示例将调用 gpt-3.5-turbo 模型生成一段文本, 并包含常用的参数, 显式地设置了一些非必填参数。
import requests
import json# 替换为你的 OpenAI API 密钥
API_KEY = "YOUR_OPENAI_API_KEY"
BASE_URL = "https://api.openai.com/v1"
# 指定要使用的 OpenAI 模型, 这里选择的是对话模型 gpt-3.5-turbo
MODEL = "gpt-3.5-turbo"# 设置 HTTP 请求头, 包含授权信息和内容类型
headers = {"Authorization": f"Bearer {API_KEY}","Content-Type": "application/json"
}# 构建发送给 OpenAI API 的 JSON 数据
data = {# 指定使用的模型"model": MODEL,# 包含用户输入的消息列表。对于 chat 模型, 需要指定 role (user, assistant, system) 和 content"messages": [{"role": "user", "content": "请用一句话概括人工智能的未来。"}],# 设置生成文本的最大 token 数量, 防止输出过长"max_tokens": 50,# 控制生成文本的随机性, 值越高越随机 (0 到 2), 默认 1.0"temperature": 0.7,# 控制核采样, 与 temperature 类似但以不同的方式控制随机性 (0 到 1), 默认 1.0"top_p": 0.9,# 请求生成多少个不同的回复, 默认 1"n": 1,# 是否以流式传输响应, 设置为 False 表示等待完整响应, 默认 False"stream": False,# 定义模型在生成文本时遇到这些字符串时停止生成, 默认 null"stop": ["\n", "."],# 对生成新 token 的惩罚, 鼓励生成新的概念 (-2.0 到 2.0), 默认 0.0"presence_penalty": 0.0,# 对生成已频繁出现的 token 的惩罚, 降低重复性 (-2.0 到 2.0), 默认 0.0"frequency_penalty": 0.0,# 修改特定 token 出现在完成结果中的可能性 (字典), 默认 {}"logit_bias": {},# "user": "user-specific-id" # 可选参数, 代表最终用户的唯一标识符, 默认 null
}try:# 向 OpenAI API 的 /chat/completions 端点发送 POST 请求response = requests.post(f"{BASE_URL}/chat/completions", headers=headers, json=data)# 如果请求失败 (状态码不是 2xx), 则抛出 HTTPError 异常response.raise_for_status()# 将 API 的 JSON 响应解析为 Python 字典response_json = response.json()# 格式化打印 JSON 响应, 方便查看print(json.dumps(response_json, indent=4, ensure_ascii=False))# 检查响应中是否存在 'choices' 字段且不为空if "choices" in response_json and len(response_json["choices"]) > 0:# 提取生成的文本内容message = response_json["choices"][0]["message"]["content"]print(f"\n生成的文本:{message}")else:print("未能在响应中找到生成的内容。")except requests.exceptions.RequestException as e:print(f"API 请求失败: {e}")
except json.JSONDecodeError as e:print(f"JSON 解析失败: {e}")
总结与展望
掌握 OpenAI API 的调用参数是解锁其强大功能的关键。通过灵活调整这些参数, 并理解它们的默认行为, 你可以更精确地控制模型的行为, 使其生成符合你需求的文本。
相关文章:

OpenAI Chat API 详解:打造智能对话应用的基石
目录 OpenAI Chat API 详解:打造智能对话应用的基石参数概览核心参数详解与实战1. model: 选择你的 AI 大脑2. prompt: 指引 AI 的灵魂3. max_tokens: 控制输出的长度4. temperature 和 top_p: 调控创造力5. stop: 控制生成的结束6. presence_penalty 和 frequency_…...
:大型应用性能优化实战案例)
JavaScript性能优化实战(12):大型应用性能优化实战案例
在前面的系列文章中,我们探讨了各种JavaScript性能优化技术和策略。本篇将聚焦于实际的大型应用场景,通过真实案例展示如何综合运用这些技术,解决复杂应用中的性能挑战。 目录 电商平台首屏加载优化全流程复杂数据可视化应用性能优化案例在线协作工具的实时响应优化移动端W…...
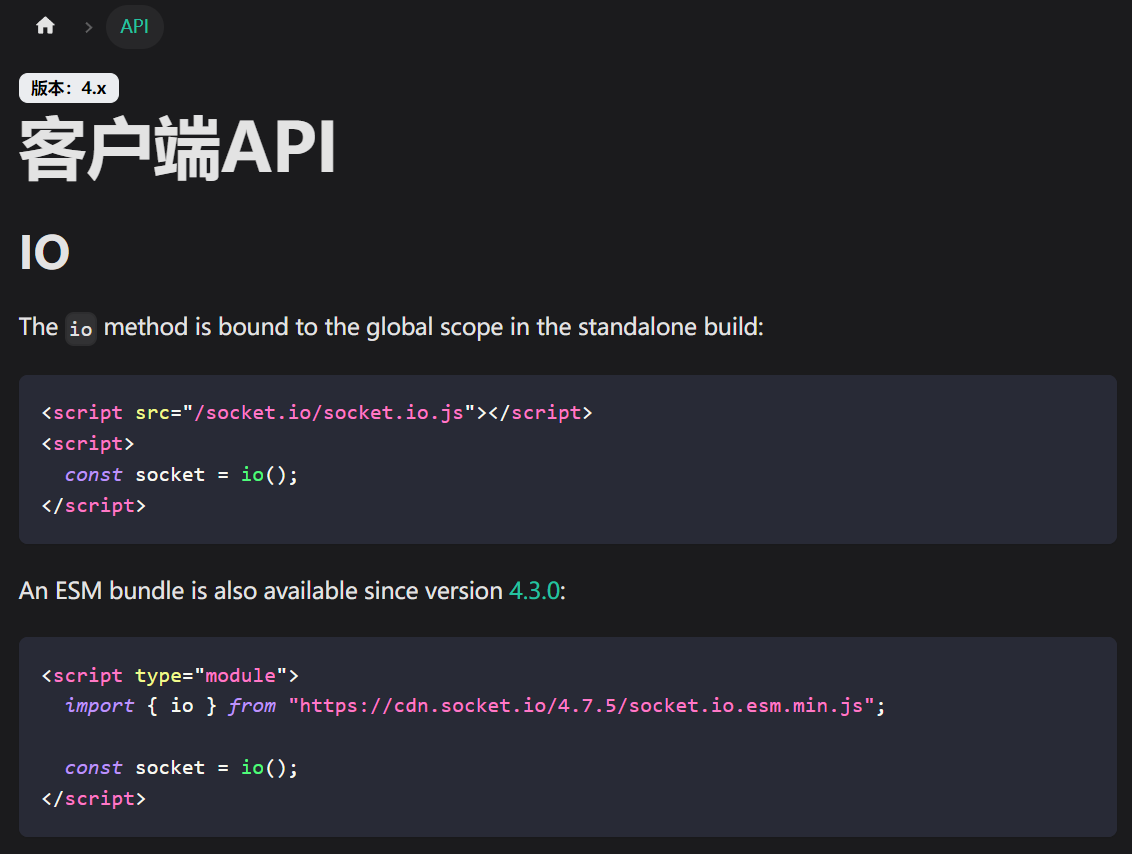
Socket.IO是什么?适用哪些场景?
Socket.IO 详细介绍及适用场景 一、Socket.IO 是什么? Socket.IO 是一个基于事件驱动的 实时通信库,支持双向、低延迟的客户端-服务器交互。它底层结合了 WebSocket 和 HTTP 长轮询 等技术,能够在不同网络环境下自动选择最优传输方式&#x…...

深度学习入门:卷积神经网络
目录 1、整体结构2、卷积层2.1 全连接层存在的问题2.2 卷积运算2.3 填充2.4 步幅2.5 3维数据的卷积运算2.6 结合方块思考2.7 批处理 3、池化层4、卷积层和池化层的实现4.1 4维数组4.2 基于im2col的展开4.3 卷积层的实现4.4 池化层的实现 5、CNN的实现6、CNN的可视化6.1 第一层权…...
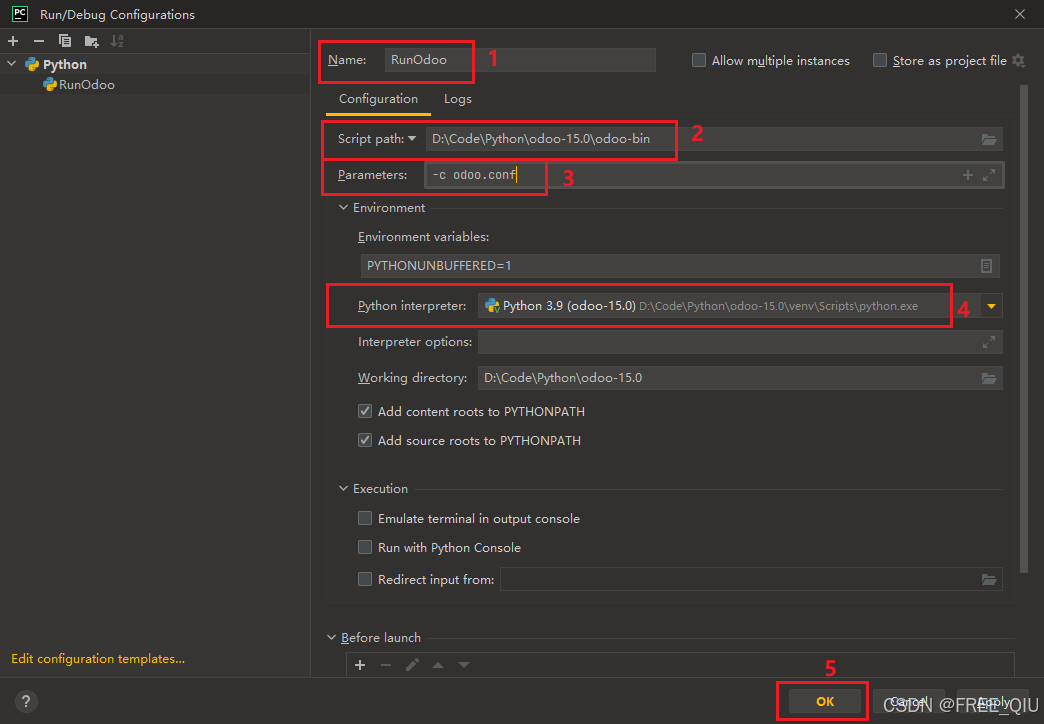
【Odoo】Pycharm导入运行Odoo15
【Odoo】Pycharm导入运行Odoo15 前置准备1. Odoo-15项目下载解压2. PsrtgreSQL数据库 项目导入运行1. 项目导入2. 设置项目内虚拟环境3. 下载项目中依赖4. 修改配置文件odoo.conf 运行Pycharm快捷运行 前置准备 1. Odoo-15项目下载解压 将下载好的项目解压到开发目录下 2. …...
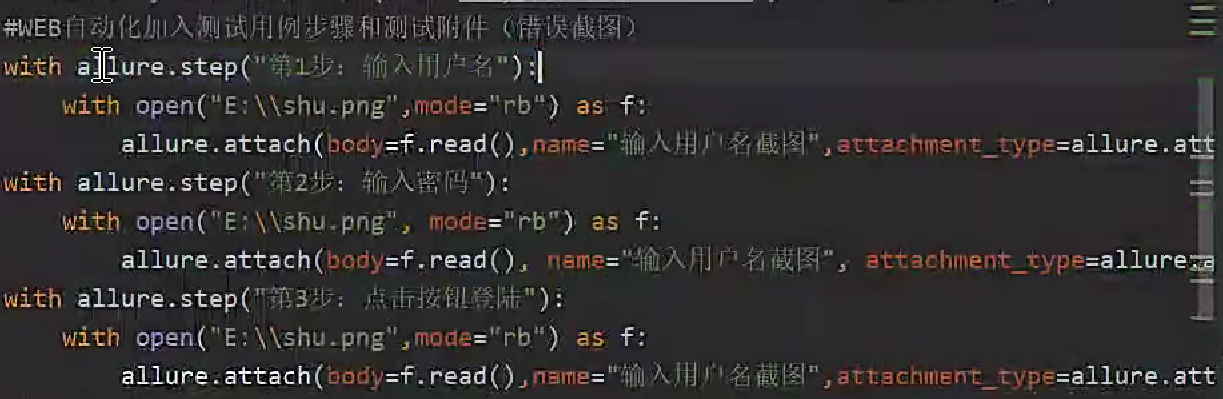
pytest框架 - 第二集 allure报告
一、断言assert 二、Pytest 结合 allure-pytest 插件生成美观的 Allure 报告 (1) 安装 allure 环境 安装 allure-pytest 插件:pip install allure-pytest在 github 下载 allure 报告文件 地址:Releases allure-framework/allure2 GitHub下载&#x…...
pycharm连接github(详细步骤)
【前提:菜鸟学习的记录过程,如果有不足之处,还请各位大佬大神们指教(感谢)】 1.先安装git 没有安装git的小伙伴,看上一篇安装git的文章。 安装git,2.49.0版本-CSDN博客 打开cmd(…...
检测的四大实现方案详解)
Android日活(DAU)检测的四大实现方案详解
引言 日活跃用户(DAU)是衡量应用健康度的核心指标之一。在Android开发中,实现DAU统计需要兼顾准确性、性能和隐私合规。本文将详细介绍四种主流实现方案,并提供完整的代码示例和选型建议。 方案一:本地检测方案 核心…...

2021ICPC四川省赛个人补题ABDHKLM
Dashboard - The 2021 Sichuan Provincial Collegiate Programming Contest - Codeforces 过题难度: A K D M H B L 铜奖 5 594 银奖 6 368 金奖 8 755 codeforces.com/gym/103117/problem/A 模拟出牌的过程,打表即可 // Code Start Here int t…...

oracle linux 95 升级openssh 10 和openssl 3.5 过程记录
1. 安装操作系统,注意如果可以选择,选择安装开发工具,主要是后续需要编译安装,需要gcc 编译工具。 2. 安装操作系统后,检查zlib 、zlib-dev是否安装,如果没有,可以使用安装镜像做本地源安装&a…...

httpx[http2] 和 httpx 的核心区别及使用场景如下
httpx[http2] 和 httpx 的核心区别在于 HTTP/2 协议支持,具体差异及使用场景如下: 1. 功能区别 命令/安装方式协议支持额外依赖适用场景pip install httpx仅 HTTP/1.1无通用请求,轻量依赖pip install httpx[http2]支持 HTTP/2需安装 h2>3…...
Text models —— BERT,RoBERTa, BERTweet,LLama
BERT 什么是BERT? BERT,全称Bidirectional Encoder Representations from Transformers,BERT是基于Transformer的Encoder(编码器)结构得来的,因此核心与Transformer一致,都是注意力机制。这种…...

【AGI】大模型微调数据集准备
【AGI】大模型微调数据集准备 (1)模型内置特殊字符及提示词模板(2)带有系统提示和Function calling微调数据集格式(3)带有思考过程的微调数据集结构(4)Qwen3混合推理模型构造微调数据…...

新能源汽车制动系统建模全解析——从理论到工程应用
《纯电动轻卡制动系统建模全解析:车速-阻力拟合、刹车力模型与旋转质量转换系数优化》 摘要 本文以纯电动轻卡为研究对象,系统解析制动系统建模核心参数优化方法,涵盖: 车速-阻力曲线拟合(MATLAB实现与模型验证&…...

【Linux驱动】Linux 按键驱动开发指南
Linux 按键驱动开发指南 1、按键驱动开发基础 1.1. 按键驱动类型 Linux下的按键驱动主要有两种实现方式: 输入子系统驱动:最常用,通过input子系统上报按键事件 字符设备驱动:较少用,需要自己实现文件操作接口 1.…...

湖北理元理律师事务所:债务管理的社会价值探索
债务问题从来不是孤立的经济事件,其背后牵涉家庭稳定、社会信用体系乃至区域经济发展。湖北理元理律师事务所通过五年服务数据发现:科学债务规划可使单个家庭挽回约23%的可支配收入,间接降低离婚率、心理健康问题发生率等社会成本。 债务优化…...
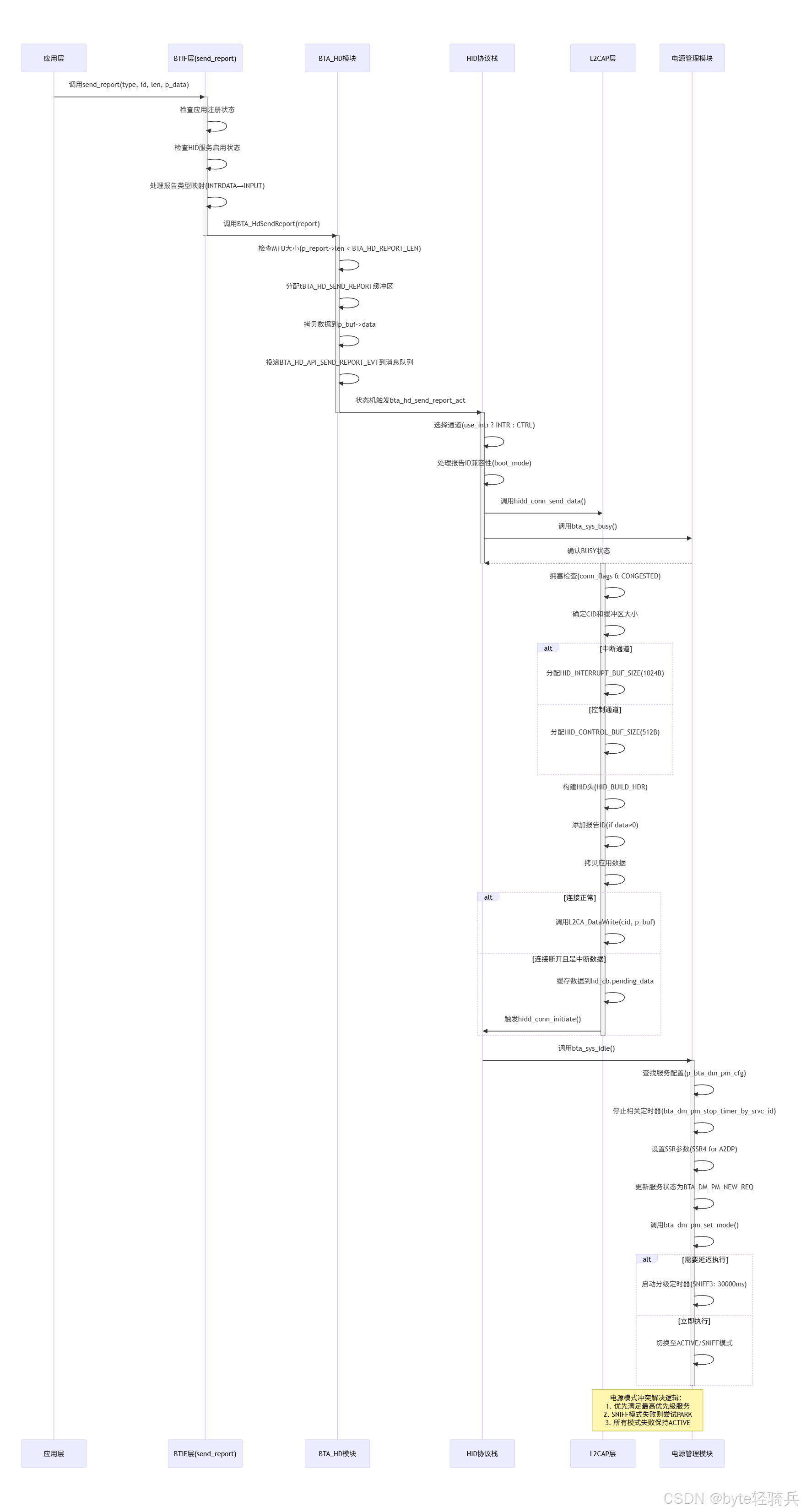
【Bluedroid】蓝牙HID DEVICE 报告发送与电源管理源码解析
本文基于Android蓝牙协议栈代码,深度解析HID设备(如键盘、鼠标)从应用层发送输入报告到主机设备的完整流程,涵盖数据封装、通道选择、L2CAP传输、电源管理四大核心模块。通过函数调用链(send_report → BTA_HdSendRepo…...

04、基础入门-SpringBoot官方文档架构
04、基础入门-SpringBoot官方文档架构 # Spring Boot官方文档架构 Spring Boot官方文档是学习和使用Spring Boot的重要资源,其架构清晰,内容全面,帮助用户从入门到精通。以下是官方文档的主要架构: ## 1. 引言 - **关于文档**&…...
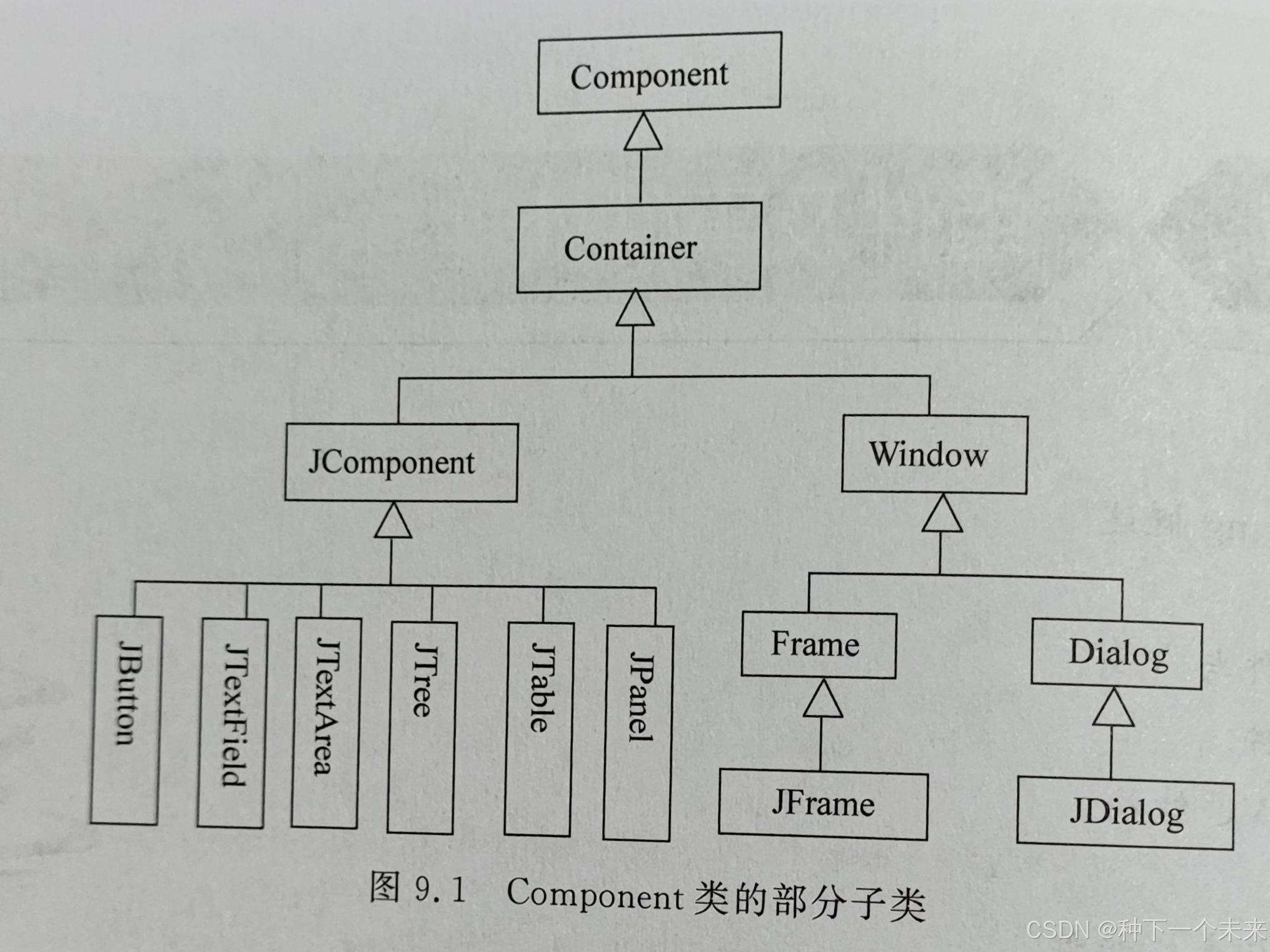
第9章 组件及事件处理
9.1 Java Swing概述 图像用户界面(GUI) java.awt包,即Java抽象窗口工具包,Button(按钮)、TextField(文本框)、List(列表) javax.swing包 容器类(…...

三、高级攻击工具与框架
高级工具与框架是红队渗透的核心利器,能够实现自动化攻击、权限维持和隐蔽渗透。本节聚焦Metasploit、Cobalt Strike及企业级漏洞利用链,结合实战演示如何高效利用工具突破防御并控制目标。 1. Metasploit框架深度解析 定位:渗透测试的“瑞…...
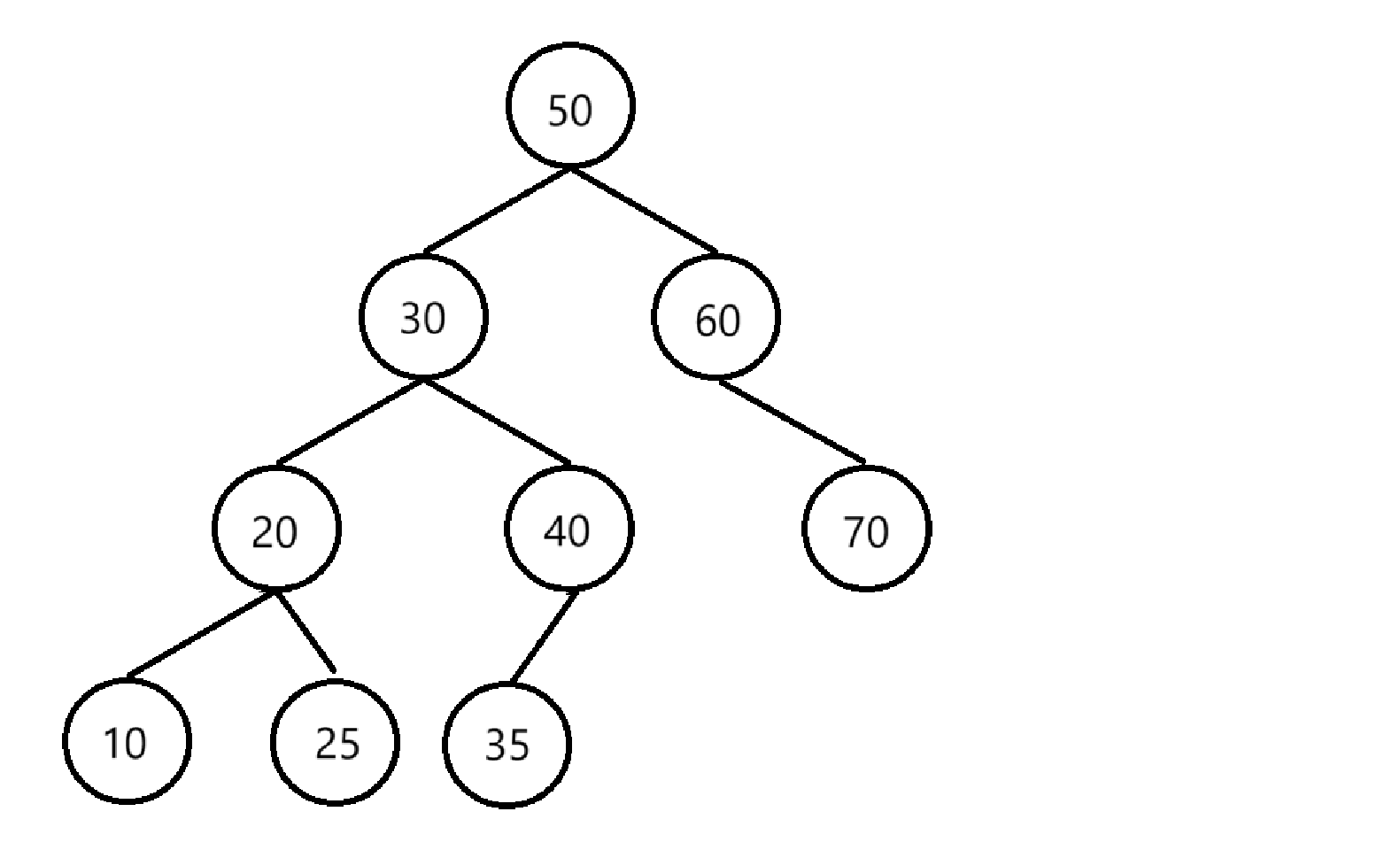
用golang实现二叉搜索树(BST)
目录 一、概念、性质二、二叉搜索树的实现1. 结构2. 查找3. 插入4. 删除5. 中序遍历 中序前驱/后继结点 一、概念、性质 二叉搜索树(Binary Search Tree),简写BST,又称为二叉查找树 它满足: 空树是一颗二叉搜索树对…...

10.13 LangChain工具调用实战:@tool装饰器+小样本提示,日处理10w+调用秘籍
LangChain 工具调用(Tool Calling)深度解析 关键词:LangChain工具调用, 函数调用与工具调用区别, @tool装饰器, ToolMessage机制, 小样本提示工程 1. Function Calling vs Tool Calling LangChain 中的工具调用系统经历了从函数调用(Function Calling)到工具调用(Tool …...

C++跨平台开发经验与解决方案
在当今软件开发领域,跨平台开发已成为一个重要的需求。C作为一种强大的系统级编程语言,在跨平台开发中扮演着重要角色。本文将分享在实际项目中的跨平台开发经验和解决方案。 1. 构建系统选择 CMake的优势 跨平台兼容性好 支持多种编译器和IDE 强大…...

【以及好久没上号的闲聊】Unity记录8.1-地图-重构与优化
最近几年越来越懒,要是能分身多好哇,大家教教我 懒得更CSDN了,所以不是很常上号,而CSDN的两周前私信显示的灰灰的 也就是虽然我每次上号都有看私信,但是搞笑的是前面四个明显的消息全是CSDN的广告,我压根没…...

C# 活动窗体截图:基于 Win32 API 的实现
1. 核心功能与技术栈 该截图功能类 ScreenShotClass 基于 Win32 API 实现了两种截图方式: CopyFromScreen 方法:利用 Graphics.CopyFromScreen 直接截取屏幕区域。BitBlt 方法:通过 GDI 的位图块传输(BitBlt)实现窗口…...
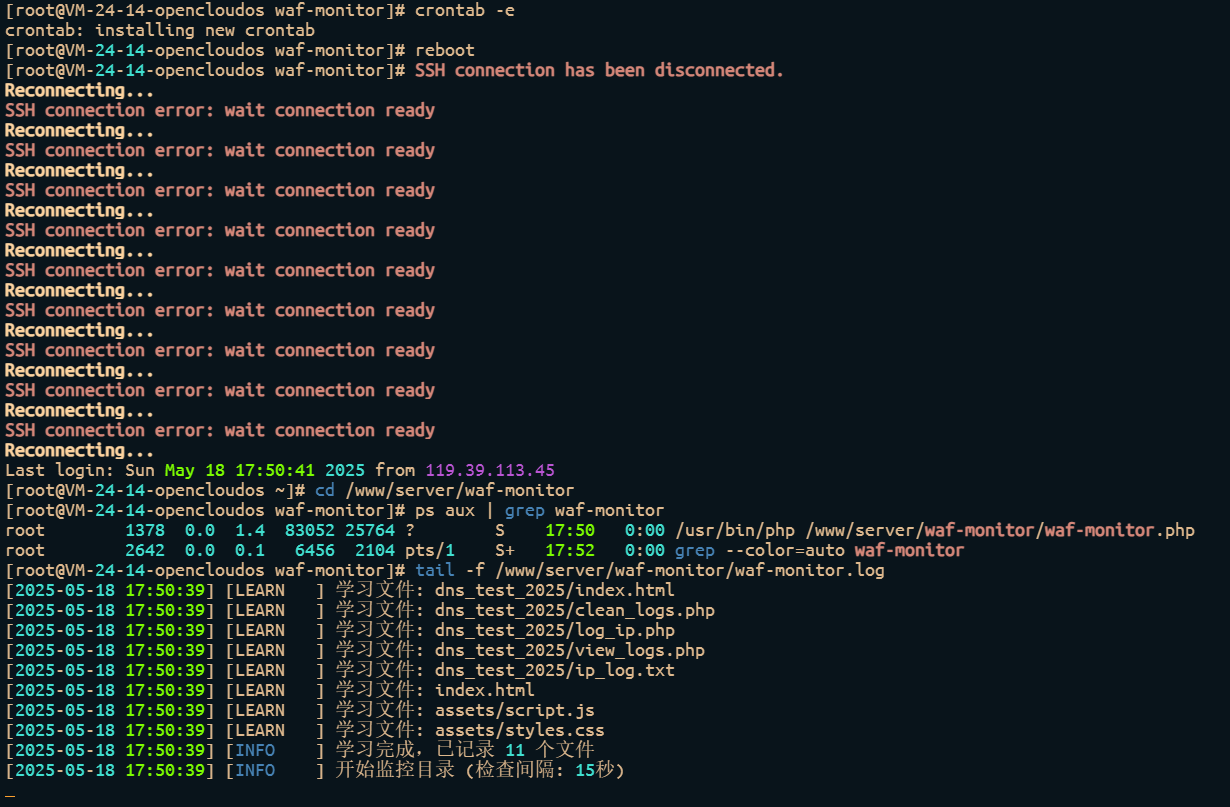
服务器防文件上传手写waf
一、waf的目录结构,根据自己目录情况进行修改 二、创建文件夹以及文件 sudo mkdir -p /www/server/waf-monitor sudo mkdir -p /www/server/waf-monitor/quarantine #创建文件夹 chmod 755 /www/server/waf-monitor #赋权cd /www/server/waf-monitor/touch waf-m…...
?)
大模型为什么学新忘旧(大模型为什么会有灾难性遗忘)?
字数:2500字 一、前言:当学霸变成“金鱼” 假设你班上有个学霸,数学考满分,英语拿第一,物理称霸全校。某天,他突然宣布:“我要全面发展!从今天起学打篮球!” 一周后&am…...
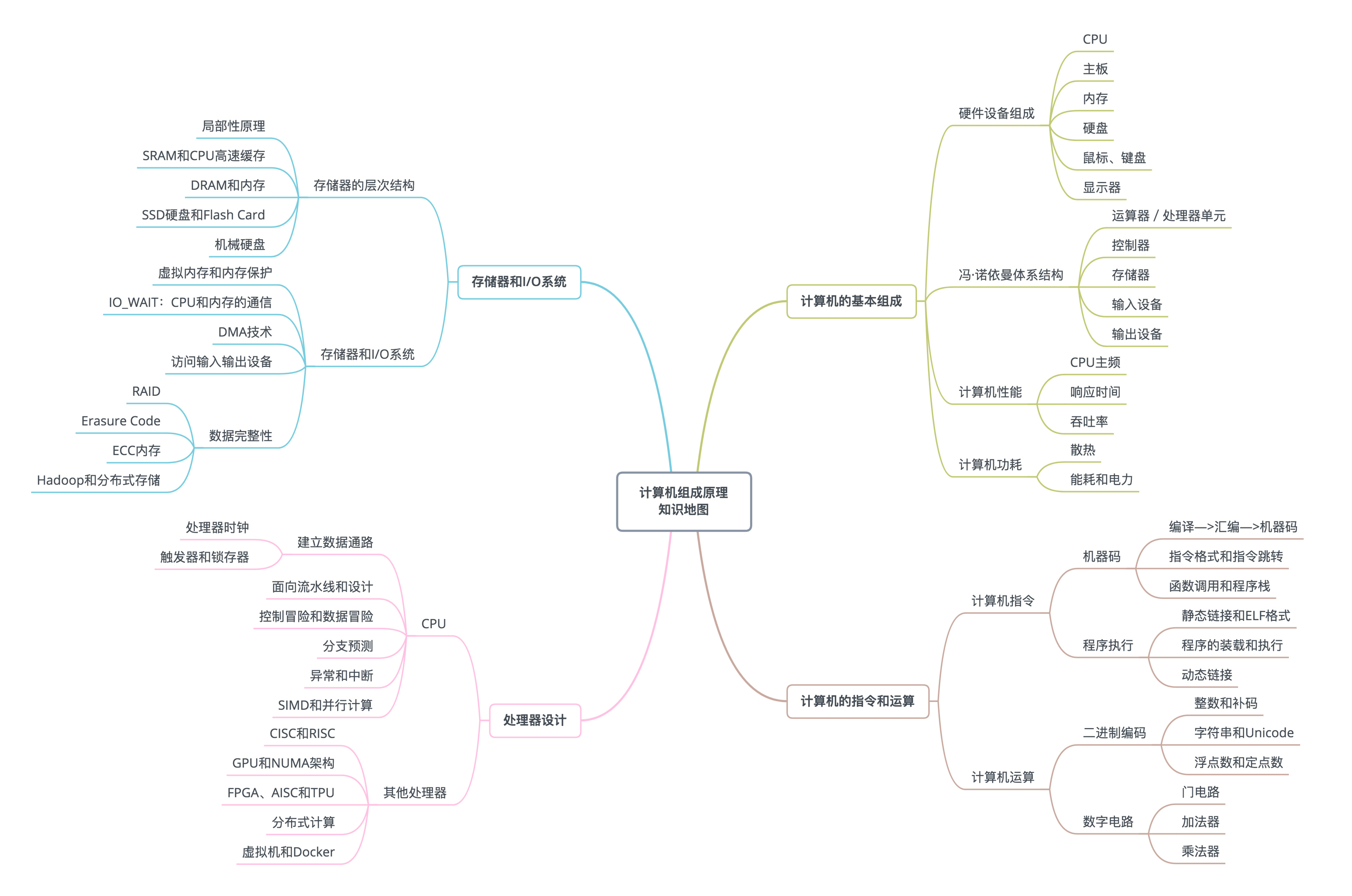
计算机的基本组成与性能
1. 冯诺依曼体系结构:计算机组成的金字塔 1.1. 计算机的基本硬件组成 1.CPU - 中央处理器(Central Processing Unit)。 2.内存(Memory)。 3.主板(Motherboard)。主板的芯片组(Ch…...

linux下编写shell脚本一键编译源码
0 前言 进行linux应用层编程时,经常会使用重复的命令对源码进行编译,然后把编译生成的可执行文件拷贝到工作目录,操作非常繁琐且容易出错。本文编写一个简单的shell脚本一键编译源码。 1 linux下编写shell脚本一键编译源码 shell脚本如下&…...
【深度学习】#12 计算机视觉
主要参考学习资料: 《动手学深度学习》阿斯顿张 等 著 【动手学深度学习 PyTorch版】哔哩哔哩跟李沐学AI 目录 目标检测锚框交并比(IoU)锚框标注真实边界框分配偏移量计算损失函数 非极大值抑制预测 多尺度目标检测单发多框检测(S…...