【Java微服务组件】分布式协调P1-数据共享中心简单设计与实现
欢迎来到啾啾的博客🐱。
记录学习点滴。分享工作思考和实用技巧,偶尔也分享一些杂谈💬。
欢迎评论交流,感谢您的阅读😄。
目录
- 引言
- 设计一个共享数据中心
- 选择数据模型
- 键值对设计
- 数据可靠性设计
- 持久化
- 快照 (Snapshotting/RDB-like)
- 操作日志(Write-Ahead Log -WAL /Append-Only File AOF-like)
- 快照与日志融合使用(Snapshot + WAL)
- 一致性
- 监控数据状态
- 状态通知机制
- 集群间数据同步
- 实现一个共享数据中心
引言
分布式微服务架构中,有一些常见的分布式协调问题,如配置管理、命名服务(共享服务实例的地址信息)、分布式锁、集群管理、Master选举等。
这些协调问题可以简单归纳为数据的共享与状态监控,我们需要解决这些问题来保障架构的可用、性能,同时降低耦合、开放拓展等。
为此,我们的框架需要一个可靠的、一致的、可观察的共享数据存储。
ZooKeeper就是这样的一个存在。
不过在深入了解ZooKeeper之前,我们先就这些特性来简单实现一下共享数据存储。
在上篇注册中心中,我们设计了主从读写分离、数据安全结构与读写锁,实现了简单的注册中心。其数据共享主要是集群内数据共享。
本篇共享数据存储是面对整个架构的所有服务的。
设计一个共享数据中心
首先,我们需要考虑数据以什么样的形式、什么样的结构存在。
是仅存在于内存还是需要持久化,持久化是否需要进行事务特性实现以确保一致性……等等。
需要考虑的问题很多,首先,让我们来进行数据结构的选型、决定数据以什么样的形式存在。
选择数据模型
数据模型可以简单分为以下几种:
| 数据模型类型 | 说明 |
|---|---|
| 键值对(Key-Value) | 这是最简单和最常见的数据模型。 比如Redis。 key一般为String类型、value的值灵活多变。 这样的结构易于实现,但查询能力优先,只能按键查找。 |
| 文档型(Document-Oriented) | 比如MongoDB。 数据以类似JSON或BSON的文档形式存储。 适合存储半结构化数据(不完全符合严格的表结构,但包含一些内部组织标记或元数据的数据),结构灵活、具备层次结构、可解析、字描述。 这样的结构易于解析和传输大量数据,但查询更难。 |
| 列式(Columnar) | 比如HBase或Cassandra。 适合大规模数据分析。 |
| 关系型(Relational) | 比如MySQL。 适合数据间有复杂关系,有事务需求时的选择。 实现一个完整的关系型数据库非常困难。 |
| 图(Graph) | 比如 Neo4j。 适合数据之前关系非常重要复杂的情况。 显然实现起来更复杂。 |
对于一个共享数据存储中心,它需要能存储各式各样的值,且用户服务可以很快速地获取共享的值。
那么选择“键值对”作为数据存储的结构是个很合理的选择。
键值对设计
键值对应该如何设计呢?
了解基本数据结构的我们很容易想到使用Hash计算的方式映射,用数组进行存储。
在Java中简单来说就是使用HashMap。共享数据存储中心需要考虑多个用户服务同时调用的情况,因此,我们的结构应当是线程安全的,即使用ConcurrentHashMap,或者对普通的HashMap使用锁,如读写锁。
数据可靠性设计
数据是仅内存(In-Memory Only)还是需要持久化(Persistence)呢?
-
仅内存
仅内存性能高,但共享数据存储中心一旦重启或崩溃,数据容易丢失。 -
持久化
持久化虽然更可靠,但是复杂度显著提升。
需要以什么形式持久化?
持久化是否需要事务来确保一致性(内存和持久化存储的一致性、并发访问的一致性)?
以什么样的方式持久化?
等,有很多需要考虑的地方,越可靠越复杂。
因此必须在复杂度和可靠中做取舍,这往往也取决于对数据丢失的容忍度和数据的重要性。
持久化
持久化设计需要考虑持久化方式(Durability)与崩溃恢复(Crash Recovery)。从内存到磁盘的持久化有3种方式。
快照 (Snapshotting/RDB-like)
定期将内存中的整个数据结构完整地序列化到磁盘(分布式的“状态转移”)。
快照时,系统会创建一个当前内存数据结构的副本,对副本进行序列化操作。快照文件通常是二进制格式,考虑存储效率和加载速度。例如Redis的RDB文件。
快照操作后台线程执行,对正在运行的操作影响小。
但如果两次快照之间发生故障,快照之间的部分数据会丢失。且快照过程比较耗时且消耗I/O,尤其数据量大时。
快照可以设置的触发策略如下:
- 基于时间的策略 (Time-based)
- 基于操作数量\数据变化的策略(Change-based)
- 基于日志文件大小(Log-size-based - 通常与WAL/AOF结合
- 手动触发 (Manual Trigger)
- 系统关闭 (On Shutdown)
操作日志(Write-Ahead Log -WAL /Append-Only File AOF-like)
数据操作日志 是一种按时间顺序记录所有对数据产生修改的“操作”的日志文件。 它记录的是如何达到当前数据状态的过程,而不是数据状态本身(分布式的“操作转移”)。
数据需要先记录到日志,然后再更新到内存中。
- 追加写入(Append-Only)
新的操作日志条目总是被添加到日志文件的末尾。顺序写入的方式通常比随机写入磁盘效率高。 - 预写(Write-Ahead)
在数据真正被修改到内存中的持久化结构(在数据被刷到数据文件)之前,描述该修改的日志条目必须首先被安全地写入到持久化的操作日志中并刷盘 (fsync)。
日志条目内容一般包含:操作类型、操作参数、事务信息、时间戳或其他序列号(LSN)。
操作日志恢复数据时,会从日志头开始读取文件并按顺序重新执行,从而在内存中重建数据状态。
这种方式数据持久性更好,崩溃时只丢失最后未刷盘的少量操作。缺点是恢复时需要重放所有日志,可能较慢,日志文件会不断增长,需要定期进行压缩或与快照结合。
快照与日志融合使用(Snapshot + WAL)
快照只能恢复数据的最终状态,且两次快照之间数据会丢失,虽然效率高,但是数据量大时I/O消耗大。
而日志模式虽然不会丢失太多数据,但是重放日志效率更低,日志数量多时恢复效率会显著下降。
因此,生产级方案往往是快照与日志融合。
- 融合方案
定期做快照,同时记录快照之后的WAL。恢复时先加载最近的快照,再重放后续的WAL。
比如Redis和MySQL(InnoDB)就是用的融合方案。
-
MySQL
MySQL的InnoDB设计有重做日志Redo Log,在数据被刷入磁盘之前,数据修改的记录(Redo Log)必须先被写入到Redo Log Buffer,并从Buffer刷到磁盘的Redo Log文件中。
在InnoDB中,Redo Log有一个概念为检查点(Checkpoint),它记录一个LSN(Log Sequence Number)。
数据恢复时不需要重放所有的Redo Log,只需要从最近的Checkpoint开始重放。
Checkpoint 确保了其记录点之前的所有脏页都已刷盘,因此Checkpoint之前的Redo Log文件都可以被覆盖。。这个机制解决了日志文件不断增长的问题。 -
Redis
Redis有两种持久化方案:RDB与AOF,且可以同时开启。
RDB对应快照,AOF对应操作日志。
Redis应对操作日志不断增大的机制是 AOF重写(AOF Rewrite)。AOF重写在不中断服务的情况下,创建一个新的更小的AOF文件,新文件包含达到当前数据集状态所需的最小命令集。即去掉数据状态变更过程,只保留最新数据状态。
Redis从4.0开始RDB-AOF混合持久化。AOF重写时,新的AOF文件可以配置为以RDB格式开头,后跟增量的AOF命令(aof-use-rdb-preamble yes)。
新的 AOF 文件首先包含一个 RDB 快照部分(记录重写开始时的数据状态),然后是重写期间发生的增量写命令。
这使得恢复时可以先加载 RDB 部分,然后只重放少量的 AOF 命令,大大加快了恢复速度,同时保留了 AOF 的高持久性。
比如我们计划使用ConcurrentHashMap,那么快照时就需要将这个ConcurrentHashMap序列化。
常见的方式是快照方式是非阻塞式的后台复制——写时复制(Copy-on-Write COW)。快照策略选择按数据量进行触发。
快照与日志融合方案使用MySQL的更为简单。
一致性
在通过持久化的方式来保证数据的可靠后,我们的共享数据存储中心有了一定的可用性保障。这时我们需要开始考虑数据的一致性。
但一个完整的ACID事务系统是极其困难的,设计到并发控制、恢复管理、日志管理等多个复杂的子系统。
因此,简单实现可以暂不追求完整的ACID事务。
仅先考虑基本的一致性,如简单原子性,批量操作提交视为一个整体。集群数据同步的一致性。
监控数据状态
状态通知机制
当数据发生变更时,我们需要一个机制能可靠地通知所有相关节点,并保证它们获取到的最新的、一致性的数据。
我们很容易想到观察者模式。当数据被修改时,告诉共享数据的订阅者数据已更改。
因此通知机制的前提是需要有一张注册表。
在上篇的注册中心我们已经知道,注册表可以通过心跳来维持其有效性。
但还有另一种做法,就是ZooKeeper的的Watcher机制。
每次修改数据通知完订阅者后,删除其在注册表中的信息,每次getData()时再重新注册。即一次性触发 (One-time Trigger)。
这样可以精简设计,省去心跳机制。
集群间数据同步
简单追求集群数据同步的强一致性,共享数据做读写分离处理提升性能。
实现一个共享数据中心
简单实现两个model类,用于存储在内存的共享数据对象ShareData
import lombok.Data;/*** 内存中的共享数据** @author crayon* @version 1.0* @date 2025/5/14*/
@Data
public class ShareData {private String id;/*** 数据更新时间戳*/private Long lsn;/*** 数据*/private Object data;/*** 数据版本*/private int version;public ShareData(String id1, String initialValueForKey1, int version) {this.id = id1;this.data = initialValueForKey1;this.version = version;this.lsn = System.currentTimeMillis();}public void incrementVersion() {this.version++;}
}与用于序列化的PersistenceData
package com.crayon.datashare.model;import lombok.Data;import java.io.Serializable;/*** 内存共享数据的序列化对象** @author crayon* @version 1.0* @date 2025/5/15*/
@Data
public class PersistenceData implements Serializable {/*** 数据序列化时间*/private Long serialDateTime;/*** 操作类型*/private String operaType;/*** 数据key*/private String key;/*** 共享数据*/private ShareData shareData;public PersistenceData(Builder builder) {this.key = builder.key;this.shareData = builder.shareData;this.operaType = builder.operaType;this.serialDateTime = System.currentTimeMillis();}@Overridepublic String toString() {return "PersistenceData{" +"serialDateTime=" + serialDateTime +", operaType='" + operaType + '\'' +", key='" + key + '\'' +", shareData=" + shareData +'}';}// 建造者模式public static class Builder {private String key;private ShareData shareData;private String operaType;public Builder key(String key) {this.key = key;return this;}public Builder shareData(ShareData shareData) {this.shareData = shareData;return this;}public Builder operaType(String operaType) {this.operaType = operaType;return this;}public PersistenceData build() {return new PersistenceData(this);}}}实现最重要的数据共享中心服务端
import com.crayon.datashare.model.ShareData;import java.util.Random;
import java.util.Set;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.locks.ReentrantReadWriteLock;/*** 简单的共享数据存储中心** <p>* 功能如下:* <p>* API-获取数据* API-存储数据* API-注册信息* <p>* 数据量到了应规模时进行序列化快照,存储数据时日志追加** @author crayon* @version 1.0* @date 2025/5/14*/
public class ShareDataServer {/*** 使用ConcurrentHashMap存储共享数据* <p>* keyName -> ShareData* </p>* <p>* 集群做读写分离设计,Leader-Follower 模型 。* master写同步到slave,slave节点读,负载均衡采用随机策略。* </p>* <p>* 数据容量暂不设置上限与对应清理机制。* </p>* <p>* 没有选举机制,也没有逻辑时钟* </p>*/private static ConcurrentHashMap<String, ShareData> shareDataMaster = new ConcurrentHashMap<>();private static ConcurrentHashMap<String, ShareData> shareDataSlave1 = new ConcurrentHashMap<>();private static ConcurrentHashMap<String, ShareData> shareDataSlave2 = new ConcurrentHashMap<>();/*** 用于随机获取从节点*/private static Random random = new Random();/*** <p>* keyName -> ReentrantReadWriteLock* </p>* 线程安全方案一:* <p>* 使用读写锁控制共享数据安全。* ConcurrentHashMap 操作数据是安全的,但是共享数据内容是可变的(Mutable)。* 当需要组合多个ConcurrentHashMap操作时,其是不安全的。* 其他线程可能在ConcurrentHashMap多个操作之间,对可变对象进行更改。* <p>* 因此需要读写锁来保证写入时候数据安全。* 在共享数据中,因为原子操作为:写数据+日志追加,所以更需要使用锁来控制。* <p>* 在分布式系统中,共享数据中心本身常被作为分布式锁使用。* <p>* 如果不是需要WAL,其实可以通过不可变对象(Immutable Objects)来消除数据共享来简化并发问题* </p>*/private static ConcurrentHashMap<String, ReentrantReadWriteLock> readWriteLocks = new ConcurrentHashMap<>();/*** 订阅者集合* <p>* 采取一次性触发机制(One-time Trigger),省去心跳检测的麻烦* 每次通知订阅者时,会从集合中移除订阅者,订阅者每次需要重新注册* 比如在调用get时重新注册* <p>* 订阅者也可以封装成一个对象,这里简单一点=ip:port* <p>* keyName -> Set<ip:port>* 使用线程安全的Set,如 ConcurrentHashMap.newKeySet()* </p>*/private static ConcurrentHashMap<String, Set<String>> subscribers = new ConcurrentHashMap<>();/*** Watcher*/private static Notifier notifier = new Notifier();/*** 序列化服务* 日志操作,数据恢复(暂无)等*/private static SerializableService serializableService = new SerializableService();/*** 获取共享数据* 采取一次性触发机制(One-time Trigger)由Server完成** @param key* @param ipPort (可选) 客户端标识,用于重新注册Watcher* @param watch (可选) 是否要设置Watcher* @return*/public ShareData get(String key, String ipPort, boolean watch) {ReentrantReadWriteLock readWriteLock = readWriteLocks.computeIfAbsent(key, k -> new ReentrantReadWriteLock());readWriteLock.readLock().lock();try {ConcurrentHashMap<String, ShareData> readNode = getReadNode();ShareData shareData = readNode.get(key);if (watch && null != ipPort && !"".equals(ipPort) && null != shareData) {register(key, ipPort);}return shareData;} finally {readWriteLock.readLock().unlock();}}/*** 注册订阅者** @param key* @param ipPort*/public void register(String key, String ipPort) {// 使用ConcurrentHashMap.newKeySet() 创建一个线程安全的Setsubscribers.computeIfAbsent(key, k -> ConcurrentHashMap.newKeySet()).add(ipPort);}/*** 添加共享数据* 组合 日志追加 + 添加 + 集群同步* <p>* 原子操作设计:* 一般这种带集群同步的标准方案是共识算法(Consensus Algorithm)。太复杂了,搞不来。** </p>** @param key* @param value*/public boolean set(String key, ShareData value) {ReentrantReadWriteLock readWriteLock = readWriteLocks.computeIfAbsent(key, k -> new ReentrantReadWriteLock());readWriteLock.writeLock().lock();try {// 1、写入日志 WALboolean logSuccess = serializableService.appendLog(OperaTypeEnum.SET.getType(), key, value);if (!logSuccess) {return false;}// 2、写入内存MastershareDataMaster.put(key, value);/*** 3、集群同步* 简单模拟,没有处理网络失败、异步、其他复杂ack机制等*/syncToSlave(key, value);// 4、通知订阅者,从注册表移除// 获取并移除,实现一次性触发Set<String> currentSubscribers = subscribers.remove(key);if (currentSubscribers != null && !currentSubscribers.isEmpty()) {for (String subscriberIpPort : currentSubscribers) {// 实际应用中,这里会通过网络连接向客户端发送通知notifier.notify(subscriberIpPort, key, OperaTypeEnum.CHANGE.getType());}}} catch (Exception e) {// 实际生产需要回滚等事务操作、日志记录等return false;} finally {readWriteLock.writeLock().unlock();}return true;}/*** 集群同步* <p>* 只在set操作中调用** @param key* @param value*/private void syncToSlave(String key, ShareData value) {shareDataSlave1.put(key, value); // 模拟同步到slave1shareDataSlave2.put(key, value); // 模拟同步到slave2}/*** 50%概率随机取节点** @return*/private ConcurrentHashMap<String, ShareData> getReadNode() {return random.nextBoolean() ? shareDataSlave1 : shareDataSlave2;}}封装操作类型枚举
/*** 操作类型枚举*/
public enum OperaTypeEnum {GET("GET"),SET("SET"),CHANGE("CHANGE");private String type;OperaTypeEnum(String type) {this.type = type;}public String getType() {return type;}}实现序列化方法
import com.crayon.datashare.model.PersistenceData;
import com.crayon.datashare.model.ShareData;import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;/*** 序列化服务** <p>* 序列化:采用快照+日志方式* 按数据量策略进行快照* <p>* 文件内容:类Redis融合方案* 快照内容+日志内容。文件前面是RDB格式,后面是AOF格式* <p>* RDB格式:* AOF格式* <p>* 文件大小处理:采用保留数据最终状态的压缩方案** <p>* 恢复机制:** @author crayon* @version 1.0* @date 2025/5/15*/
public class SerializableService {/*** 假设的日志文件名*/private static final String MASTER_LOG_FILE = System.getProperty("user.dir") + "/wal/master_wal.log";/*** 日志追加* <p>* 简化的日志格式,实际应该至少有操作类型、时间戳、序列号、状态码,* 数据库的话会有数据库的一些信息,如数据库名字、server id等* </p>* 生产日志会有压缩、刷盘等操作,这里简化了*/public boolean appendLog(String operaType, String key, ShareData value) {PersistenceData persistenceData = new PersistenceData.Builder().operaType(operaType).key(key).shareData(value).build();try (PrintWriter out = new PrintWriter(new BufferedWriter(new FileWriter(MASTER_LOG_FILE, true)))) {// out.flush(); // 可以考虑更频繁的flush或根据策略fsyncout.println(persistenceData.toString());return true;} catch (IOException e) {System.err.println("Error writing to WAL: " + e.getMessage());return false;}}
}
封装一个用于通知的监视者Watcher
/*** @author crayon* @version 1.0* @date 2025/5/16*/
public class Notifier {/*** 通知订阅者** @param subscriberIpPort* @param key* @param operaType*/public void notify(String subscriberIpPort, String key, String operaType) {// 调用订阅者的接口,让订阅者进行相应的处理}
}封装一个客户端
/*** 简单模拟客户端* <p>* 订阅和获取、更新数据等操作* </p>* * @author crayon* @version 1.0* @date 2025/5/16*/
public class SubscriberClient {private String ipPort;private ShareDataServer shareDataServer = new ShareDataServer();public SubscriberClient(String ipPort) {this.ipPort = ipPort;}public void subscribe(String key) {shareDataServer.register(key, ipPort);}public ShareData get(String key, String ipPort) {return shareDataServer.get(key, ipPort, true);}}test
import com.crayon.datashare.client.SubscriberClient;
import com.crayon.datashare.model.ShareData;
import com.crayon.datashare.server.ShareDataServer;/*** 简单数据共享中心演示** @author crayon* @version 1.0* @date 2025/5/14*/
public class Demo {public static void main(String[] args) {ShareDataServer shareDataServer = new ShareDataServer();// 模拟客户端1注册对 key1 的订阅SubscriberClient subscriberClient8080 = new SubscriberClient("127.0.0.1:8080");subscriberClient8080.subscribe("key1");SubscriberClient subscriberClient8081 = new SubscriberClient("127.0.0.1:8081");subscriberClient8081.subscribe("key1");// 模拟客户端2注册对 key2 的订阅subscriberClient8081.subscribe("key2");System.out.println("\n Setting data for key1...");shareDataServer.set("key1", new ShareData("id1", "Initial Value for key1", 1));System.out.println("\n Getting data for key1 by client1 (will re-register watcher)...");ShareData data1 = shareDataServer.get("key1", "client1_ip:port", true);System.out.println("Client1 got: " + data1);System.out.println("\n Setting data for key1 again (client1 should be notified)...");shareDataServer.set("key1", new ShareData("id1", "Updated Value for key1", 2));System.out.println("\n Setting data for key2...");shareDataServer.set("key2", new ShareData("id2", "Value for key2", 1));System.out.println("\n Client2 getting data for key1 (not subscribed initially, but sets a watch now)...");ShareData data1_by_client2 = shareDataServer.get("key1", "client2_ip:port", true);System.out.println("Client2 got (for key1): " + data1_by_client2);System.out.println("\n Simulating a read from a random slave for key1:");ShareData slaveData = shareDataServer.get("key1", null, false); // No re-registerSystem.out.println("Read from slave for key1: " + slaveData);}}结果展示如下

相关文章:
【Java微服务组件】分布式协调P1-数据共享中心简单设计与实现
欢迎来到啾啾的博客🐱。 记录学习点滴。分享工作思考和实用技巧,偶尔也分享一些杂谈💬。 欢迎评论交流,感谢您的阅读😄。 目录 引言设计一个共享数据中心选择数据模型键值对设计 数据可靠性设计持久化快照 (…...

[Harmony]大文件持久化
1.添加权限 在module.json5文件中添加权限 "requestPermissions": [{"name": "ohos.permission.READ_WRITE_USER_FILE", // 读写用户数据"reason": "$string:read_write_user_file_reason","usedScene": {"…...

pgsql14自动创建表分区
最近有pgsql的分区表功能需求,没想到都2025年了,pgsql和mysql还是没有自身支持自动创建分区表的功能 现在pgsql数据库层面还是只能用老三样的办法来处理这个问题,每个方法各有优劣 1. 触发器 这是最传统的方法,通过创建一个触发…...
cursor/vscode启动项目connect ETIMEDOUT 127.0.0.1:xx
现象: 上午正常使用cursor/vscode,因为需要写前端安装了nodejs16.20和vue2,结果下午启动前端服务无法访问,浏览器一直转圈。接着测试运行最简单的flask服务,vscode报错connect ETIMEDOUT 127.0.0.1:xx,要么…...

Leetcode 3553. Minimum Weighted Subgraph With the Required Paths II
Leetcode 3553. Minimum Weighted Subgraph With the Required Paths II 1. 解题思路2. 代码实现 题目链接:3553. Minimum Weighted Subgraph With the Required Paths II 1. 解题思路 这一题很惭愧,并没有自力搞定,是看了大佬们的解答才有…...

兼顾长、短视频任务的无人机具身理解!AirVista-II:面向动态场景语义理解的无人机具身智能体系统
作者:Fei Lin 1 ^{1} 1, Yonglin Tian 2 ^{2} 2, Tengchao Zhang 1 ^{1} 1, Jun Huang 1 ^{1} 1, Sangtian Guan 1 ^{1} 1, and Fei-Yue Wang 2 , 1 ^{2,1} 2,1单位: 1 ^{1} 1澳门科技大学创新工程学院工程科学系, 2 ^{2} 2中科院自动化研究所…...

springboot踩坑记录
之前运行好端端的项目,今天下午打开只是添加了一个文件之后 再运行都报Failed to configure a DataSource: url attribute is not specified and no embedded datasource could be configured.Reason: Failed to determine a suitable driver class Action: Conside…...

SparkSQL基本操作
以下是 Spark SQL 的基本操作总结,涵盖数据读取、转换、查询、写入等核心功能: 一、初始化 SparkSession scala import org.apache.spark.sql.SparkSession val spark SparkSession.builder() .appName("Spark SQL Demo") .master("…...

Web 架构之动静分离
文章目录 一、引言二、动静分离的原理2.1 什么是动静分离2.2 为什么要进行动静分离 三、动静分离的实现方式3.1 基于 Nginx 的动静分离3.2 基于 CDN 的动静分离 四、常见问题及解决方法4.1 缓存问题4.2 跨域问题4.3 性能监控问题 五、思维导图六、总结 一、引言 在当今的 Web 应…...
20250515配置联想笔记本电脑IdeaPad总是使用独立显卡的步骤
20250515配置联想笔记本电脑IdeaPad总是使用独立显卡的步骤 2025/5/15 19:55 百度:intel 集成显卡 NVIDIA 配置成为 总是用独立显卡 百度为您找到以下结果 ?要将Intel集成显卡和NVIDIA独立显卡配置为总是使用独立显卡,可以通过以下步骤实现?ÿ…...
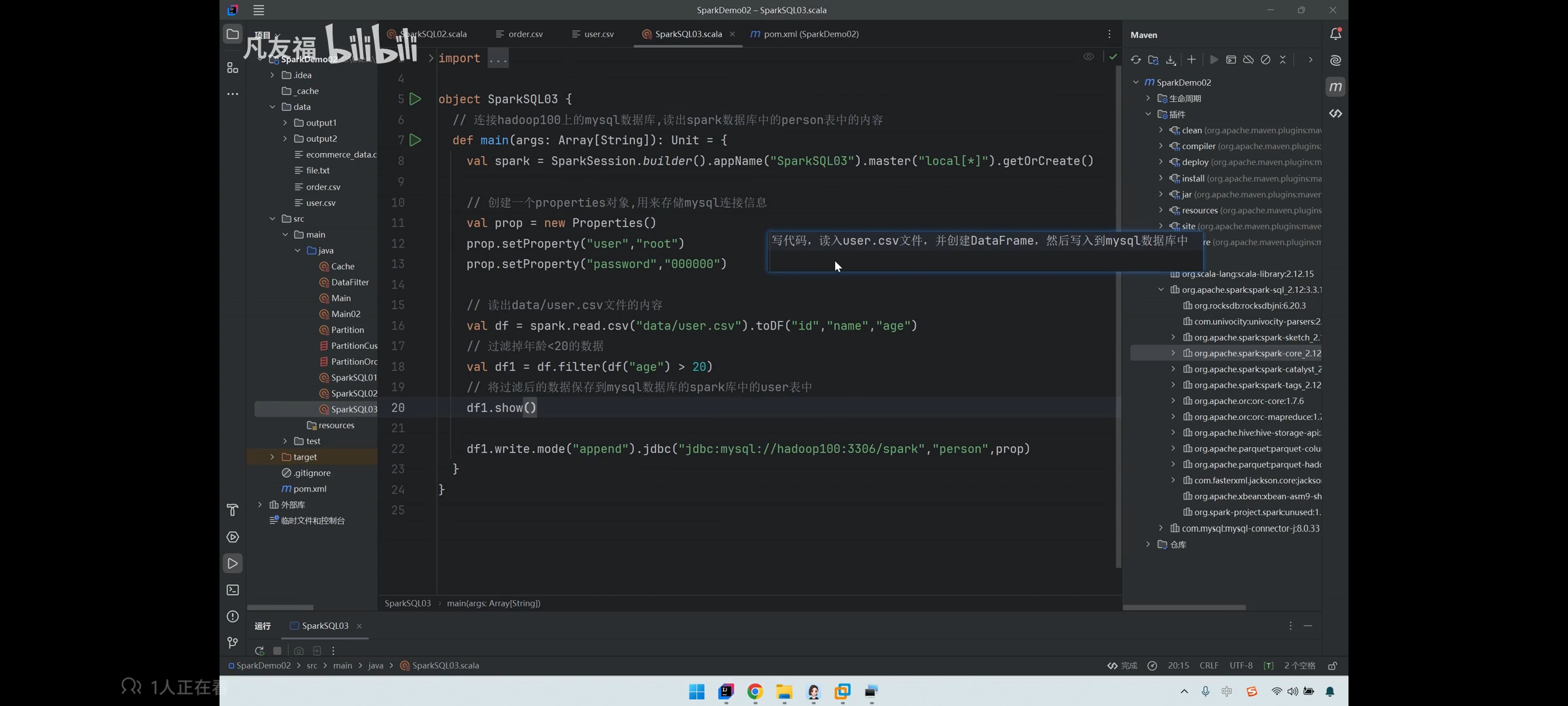
sparkSQL读入csv文件写入mysql
思路 示例 (年龄>18改成>20) mysql的字符集问题 把user改成person “让字符集认识中文”...

大涡模拟实战:从区域尺度到街区尺度的大气环境模拟
前言: 随着低空经济的蓬勃发展,无人机、空中出租车等新型交通工具正在重塑我们的城市空间。这场静默的革命不仅带来了经济机遇,更对城市大气环境提出了全新挑战。在距离地面200米以下的城市冠层中,建筑物与大气的复杂相互作用、人…...

centos安装方式的aarch64架构下的kylinv10安装docker23.0.0
以下通过压缩包方式安装docker 因为yum方式配置各种依赖仓库太麻烦了,如果你不想执行 yum repolist yum clean all yum makecache那可以按照以下压缩包的方式安装任何版本的docker 1.查看glibc版本 ldd --version我这里显示2.28,安装docker23.0.0没问…...
单目测距和双目测距 bev 3D车道线
单目视觉测距原理 单目视觉测距有两种方式。 第一种,是通过深度神经网络来预测深度,这需要大量的训练数据。训练后的单目视觉摄像头可以认识道路上最典型的参与者——人、汽车、卡车、摩托车,或是其他障碍物(雪糕桶之类…...

鸿蒙OSUniApp 实现一个精致的日历组件#三方框架 #Uniapp
使用 UniApp 实现一个精致的日历组件 前言 最近在开发一个约会小程序时,需要实现一个既美观又实用的日历组件。市面上虽然有不少现成的组件库,但都不太符合我们的设计需求。于是,我决定从零开始,基于 UniApp 自己实现一个功能完…...

【爬虫】DrissionPage-3
安装:4.1最新版本 pip install drissionpage --upgrade 官方文档:🛰️ 连接浏览器 | DrissionPage官网 1 Chromium对象 Chromium对象用于连接和管理浏览器。标签页的开关和获取、整体运行参数配置、浏览器信息获取等都由它进行。 1.1 默认…...
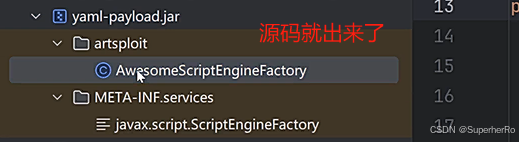
Web开发-JavaEE应用SpringBoot栈SnakeYaml反序列化链JARWAR构建打包
知识点: 1、安全开发-JavaEE-WAR&JAR打包&反编译 2、安全开发-JavaEE-SnakeYaml反序列化&链 一、演示案例-WEB开发-JavaEE-项目-SnakeYaml序列化 常见的创建的序列化和反序列化协议 • (已讲)JAVA内置的writeObject()/readObje…...
项目复习(2)
第四天 高并发优化 前端每隔15秒就发起一次请求,将播放记录写入数据库。 但问题是,提交播放记录的业务太复杂了,其中涉及到大量的数据库操作:在并发较高的情况下,会给数据库带来非常大的压力 使用Redis合并写请求 一…...
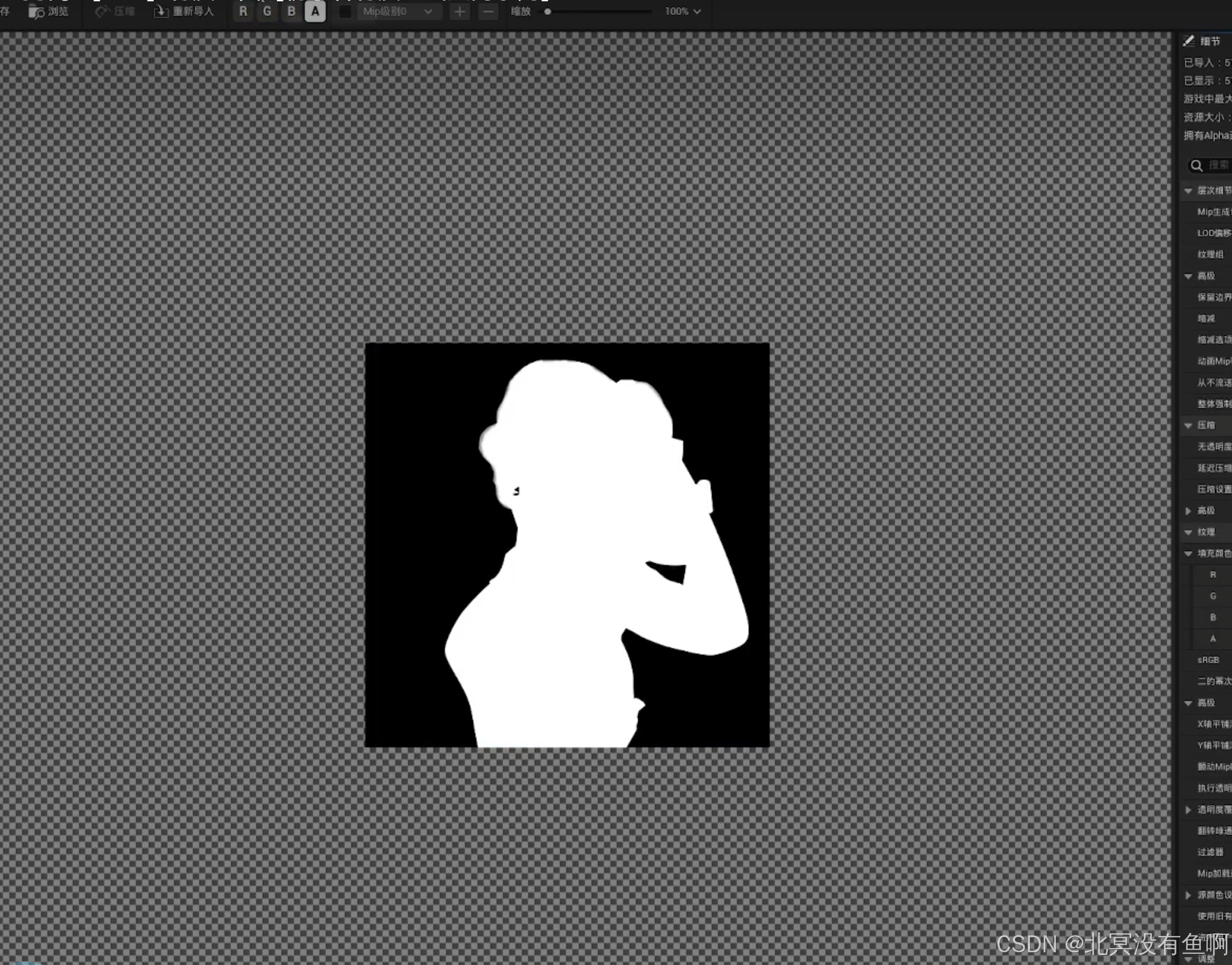
UE 材质基础 第一天
课程:虚幻引擎【UE5】材质宝典【初学者材质基础入门系列】-北冥没有鱼啊_-稍后再看-哔哩哔哩视频 随便记录一些 黑色是0到负无穷,白色是1到无穷 各向异性 有点类似于高光,可以配合切线来使用,R G B 相当于 X Y Z轴,切…...

短剧小程序系统开发源码上架,短剧项目市场分析
引言 随着短视频内容消费的爆发式增长,短剧小程序凭借其碎片化、强互动、低成本的特点,成为内容创业与资本布局的新风口。2024年以来,行业规模突破500亿元,预计2027年将超千亿17。本文将深度解析短剧小程序系统开发的技术优势、市…...
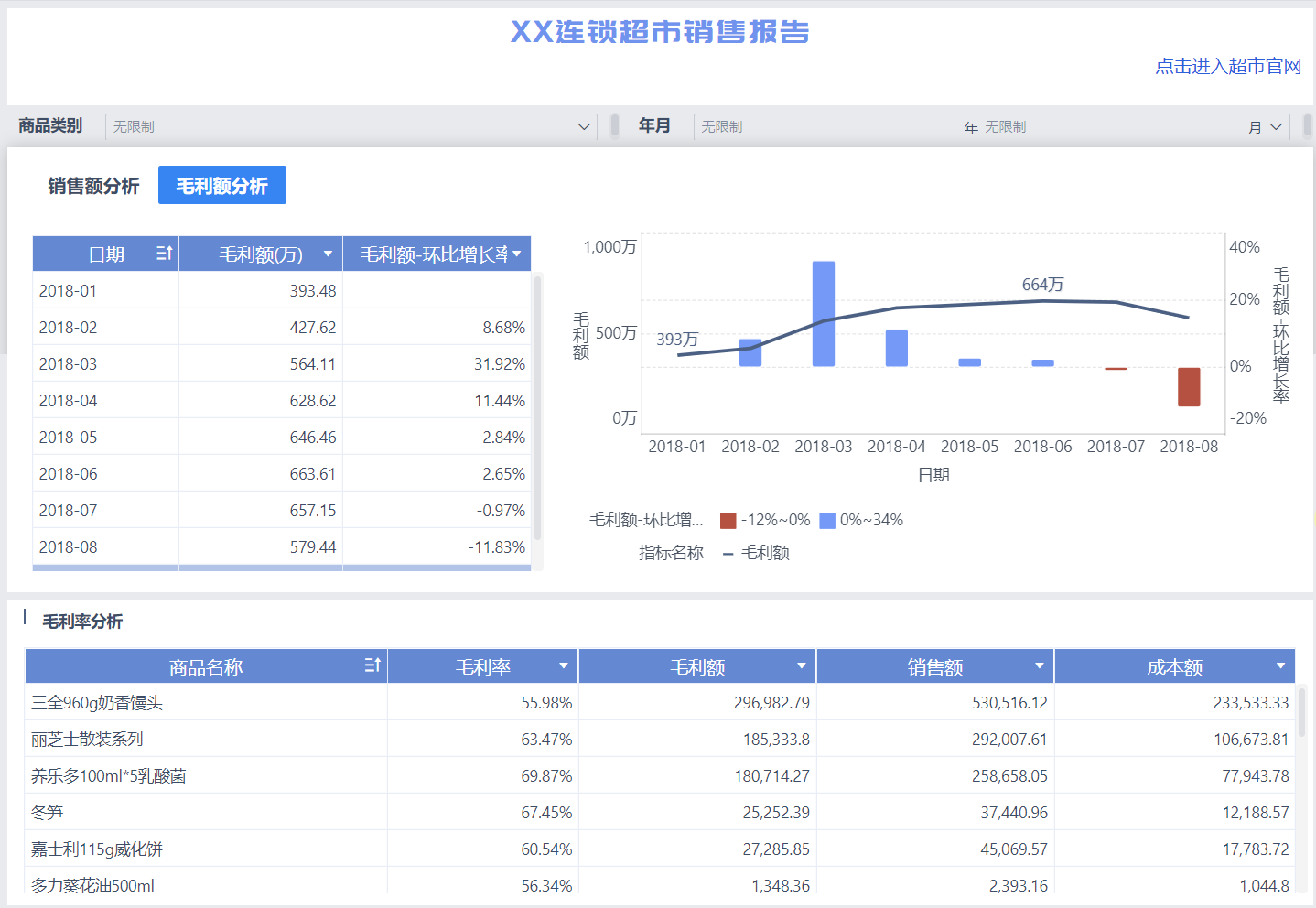
学习FineBI
FineBI 第一章 FineBI 介绍 1.1. FineBI 概述 FineBI 是帆软软件有限公司推出的一款商业智能 (Business Intelligence) 产品 。 FineBI 是新一代大数据分析的 BI 工具 , 旨在帮助企业的业务人员充分了解和利用他们的数据 。FineBI 凭借强…...

Oracle日期计算跟Mysql计算日期差距问题-导致两边计算不一致
Oracle数据库对日期做加法时,得到的时间是某天的12:00:00 例: Oracle计算 select (TO_DATE(2025-04-14, YYYY-MM-DD)1.5*365) from dual; 结果:2026/10/13 12:00:00Mysql计算 select DATE_ADD( str_to_date( 2025-04-14, %Y-%m-%d ), INTER…...
深入剖析某App视频详情逆向:聚焦sig3参数攻克
深入剖析某手App视频详情逆向:聚焦sig3参数攻克 一、引言 在当今互联网信息爆炸的时代,短视频平台如某手,已成为人们获取信息、娱乐消遣的重要渠道。对于技术爱好者和研究人员而言,深入探索其内部机制,特别是视频详情…...

Java求职面试揭秘:从Spring到微服务的技术挑战
文章简述 在这篇文章中,我们将通过一个幽默的面试场景,揭秘互联网大厂Java求职者在面试中面对的技术挑战。面试官将从Spring框架、微服务架构到大数据处理等多个维度进行提问,并详细讲解这些技术点的应用场景和解决方案,帮助小白…...

【Linux】Linux安装并配置MongoDB
目录 1.添加仓库 2.安装 MongoDB 包 3.启动 MongoDB 服务 4. 验证安装 5.配置 5.1.进入无认证模式 5.2.1创建用户 5.2.2.开启认证 5.2.3重启 5.2.4.登录 6.端口变更 7.卸载 7.1.停止 MongoDB 服务 7.2.禁用 MongoDB 开机自启动 7.3.卸载 MongoDB 包 7.4.删除数…...

HANA数据库死锁
死锁是两个或多个事务相互交叉锁定的情况,因此任何事务都无法继续进行。 通常死锁是由应用程序设计缺陷引起的,但在主键约束的上下文中也可能存在更多的技术死锁(这种情况请参考 SAP note 2429521)。 当 HANA 数据库出现死锁时&am…...

STC32G12K128实战:串口通信
STC32G12K128芯片写一个按键通过串口1发送字符串的程序。首先,确认芯片的串口1配置。STC32G系列通常使用UART1,相关的寄存器是P_SW1来选择引脚。默认情况下,UART1的TX是P3.1。 接下来是设置定时器作为波特率发生器。通常用定时器2,…...

Kotlin Multiplatform与Flutter、Compose共存:构建高效跨平台应用的完整指南
简介 在移动开发领域,跨平台技术正在重塑开发范式。Kotlin Multiplatform (KMP) 作为 JetBrains 推出的多平台开发框架,结合了 Kotlin 的简洁性与原生性能优势,使开发者能够高效共享业务逻辑。而 Flutter 凭借其高性能渲染引擎(Skia)和丰富的组件库,成为混合开发的首选方…...
:聚合——分桶聚合、指标聚合、管道子聚合)
ElasticSearch深入解析(十二):聚合——分桶聚合、指标聚合、管道子聚合
文章目录 一、分桶聚合1. 分桶聚合的核心逻辑与核心类型2. 分桶聚合的高级特性 二、指标聚合1. 指标聚合的核心逻辑与基础类型(1)基础统计指标(单值输出)(2)复合统计指标(多值输出) …...

spark小任务
import org.apache.spark.{Partitioner, SparkConf, SparkContext}object PartitionCustom {// 分区器决定哪一个元素进入某一个分区// 目标: 把10个分区器,偶数分在第一个分区,奇数分在第二个分区// 自定义分区器// 1. 创建一个类继承Partitioner// 2. …...