【自然语言处理与大模型】向量数据库:Chroma使用指南
Chroma是一款功能强大的开源 AI 应用数据库,专为高效数据存储与检索而设计。它不仅支持 Embedding 和 Metadata 的存储,还集成了多项核心功能,包括向量搜索、全文搜索、Document 存储、Metadata 过滤以及多模态检索。此外,Chroma 还提供了便捷的客户端-服务器(CS)模式,满足多样化的应用场景需求。
安装
# 在服务器上安装
pip install chromadb# 在客户端上安装,仅支持 HTTP 的客户端
pip install chromadb-client使用
# 导入chromadb
import chromadb# 导入embedding_functions,它可以自定义嵌入模型
from chromadb.utils import embedding_functionsmy_embedding_func = embedding_functions.OpenAIEmbeddingFunction(api_key="YOUR_API_KEY",model_name="<嵌入模型的名称>"
)# 下面三选一就行
# 创建一个临时客户端,存在内存中
chroma_client = chromadb.EphemeralClient()
chroma_client = chromadb.Client() # 默认使用内存存储模式(非持久化)# 创建一个持久客户端,若不指定则存默认路径为 .chroma
chroma_client = chromadb.PersistantClient(path="<本地存储路径>")# 创建一个集合
"""
集合是您存储嵌入、文档和任何附加元数据的地方。集合索引您的嵌入和文档,并实现高效的检索和过滤。您可以使用名称创建一个集合。
"""
collection = chroma_client.create_collection(name="my_collection","embedding_function": my_embedding_func # 指定向量模型)
collection = chroma_client.get_or_create_collection(name="my_collection") # 该方法可以避免重复创建集合# collection的几个属性
print(collection.peek()) # 返回集合中前10项的列表
print(collection.count()) # 返回集合中项目的数量# 增:向集合中添加一些文本文件
"""
Chroma 将存储您的文本并自动处理嵌入和索引。您还可以自定义嵌入模型。您必须为您的文档提供唯一的字符串 ID
"""
collection.add(documents=["This is a document about pineapple","This is a document about oranges"],metadatas=[{"source": "pineapple"}, {"source": "oranges"}]ids=["id1", "id2"]
)# 查:查询集合
"""
您可以使用查询文本列表查询集合,Chroma 将返回 n 个最相似的结果。就是这么简单!如果未提供 n_results,Chroma 默认将返回 10 个结果。默认情况下,Chroma 使用 DefaultEmbeddingFunction,它是基于 Sentence Transformers 的 MiniLM-L6-v2 模型
"""
results = collection.query(query_texts=["This is a query document about hawaii"], # Chroma会自动嵌入n_results=2 # 返回多少结果# where = {"source": "hawaii"}, # 按元数据过滤# where_document = {"$contains": "about hawaii"} # 按文档内容过滤
)# 改:如果重复执行,相同 ID 的文档会被更新
collection.upsert(documents=["This is a document about pineapple","This is a document about oranges"],ids=["id1", "id2"]
)# 删:删除某个文档,删除整个集合
collection.delete(ids=["id2"]) # 删除某个文档
client.delete_collection(name="my_collection") # 删除整个集合CS模式
服务器上运行这个命令:
# 运行chroma服务器
chroma run --path <本地持久化数据库的路径># 单独设置地址和端口
chroma run --path /db_path --host localhost --port 8000客户端上运行这个代码:
import chromadb# 下面二选一就行
# 同步客户端连接方式(阻塞式)
client = chromadb.HttpClient(host='localhost', port=8000)# 异步客户端连接方式(非阻塞式)
async def main():client = await chromadb.AsyncHttpClient(host='localhost', port=8000)# 运行异步主函数
asyncio.run(main())相关文章:

【自然语言处理与大模型】向量数据库:Chroma使用指南
Chroma是一款功能强大的开源 AI 应用数据库,专为高效数据存储与检索而设计。它不仅支持 Embedding 和 Metadata 的存储,还集成了多项核心功能,包括向量搜索、全文搜索、Document 存储、Metadata 过滤以及多模态检索。此外,Chroma …...
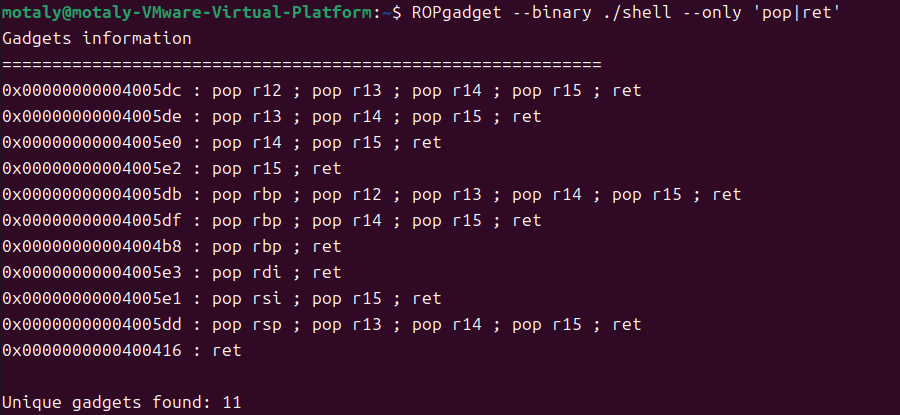
NSSCTF [GFCTF 2021]where_is_shell
889.[GFCTF 2021]where_is_shell(system($0)64位) [GFCTF 2021]where_is_shell (1) 1.准备 motalymotaly-VMware-Virtual-Platform:~$ file shell shell: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.s…...

WSL 安装 Debian 12 后,Linux 如何安装 vim ?
在 WSL 的 Debian 12 中安装 Vim 非常简单,只需使用 apt 包管理器即可。以下是详细步骤: 1. 更新软件包列表 首先打开终端,确保系统包列表是最新的: sudo apt update2. 安装 Vim 直接通过 apt 安装 Vim: sudo apt …...
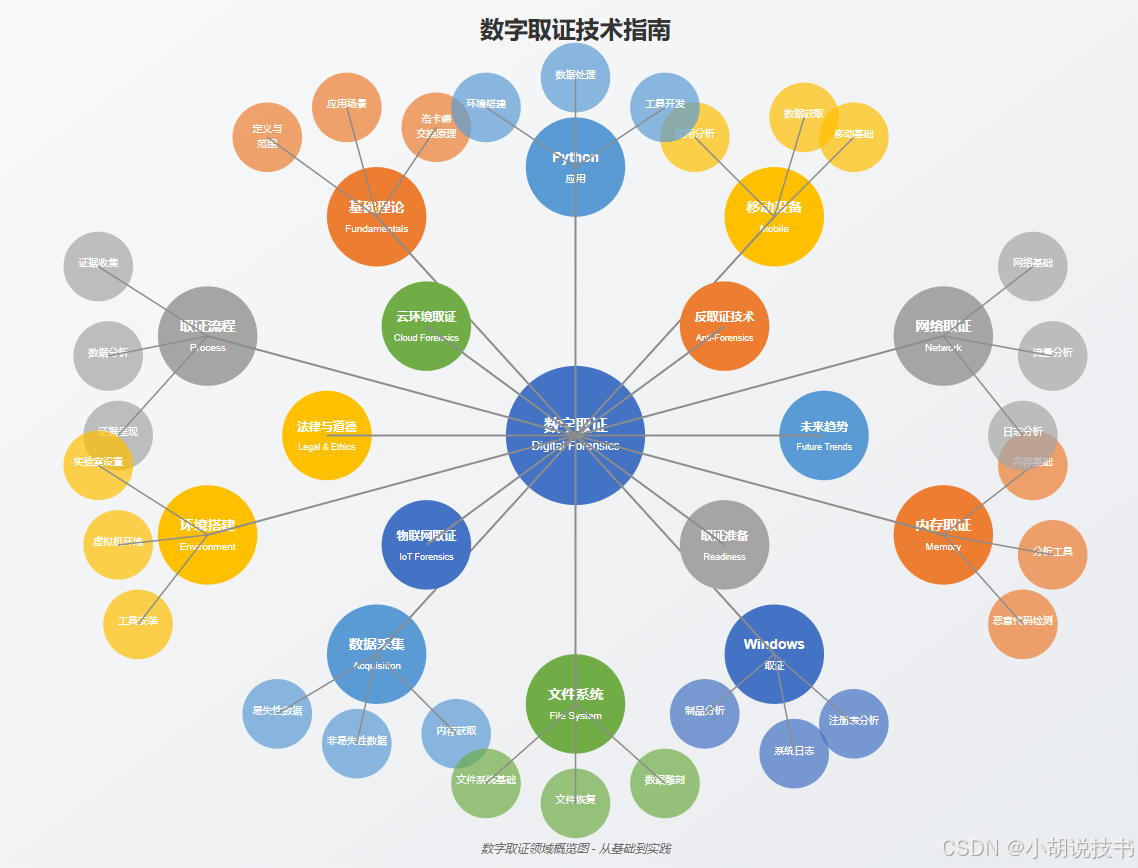
电子数据取证(数字取证)技术全面指南:从基础到实践
为了后续查阅方便,推荐工具先放到前面 推荐工具 数字取证基础工具 综合取证平台 工具名称类型主要功能适用场景EnCase Forensic商业全面的证据获取和分析、强大的搜索能力法律诉讼、企业调查FTK (Forensic Toolkit)商业高性能处理和索引、集成内存分析大规模数据处…...

Ubuntu使用Docker搭建SonarQube企业版(含破解方法)
目录 Ubuntu使用Docker搭建SonarQube企业版(含破解方法)SonarQube介绍安装Docker安装PostgreSQL容器Docker安装SonarQube容器SonarQube汉化插件安装 破解生成license配置agent 使用 Ubuntu使用Docker搭建SonarQube企业版(含破解方法ÿ…...

Spark SQL 之 Analyzer
Spark SQL 之 Analyzer // Special case for Project as it supports lateral column alias.case p: Project =>val resolvedNoOuter = p.projectList.map(resolveExpressionByPlanChildren(_, p...

c/c++数据类型转换.
author: hjjdebug date: 2025年 05月 18日 星期日 20:28:52 CST descrip: c/c数据类型转换. 文章目录 1. 为什么需要类型转换?1.1 发生的时机:1.2 常见的发生转换的类型: 2. c语言的类型转换: (Type) value2.1 c语言的类型变换是如何实现的? 规则是什么? 3. c 的static_cast…...
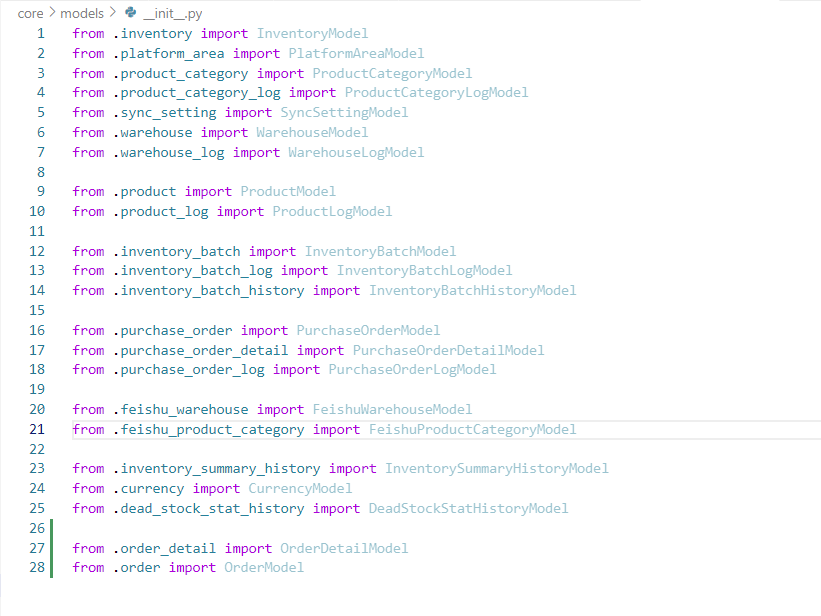
Django 项目的 models 目录中,__init__.py 文件的作用
在 Django 项目的models/init.py文件中,这些导入语句的主要作用是将各个模型类从不同的模块中导入到models包的命名空间中。这样做有以下几个目的: 简化导入路径 当你需要在项目的其他地方使用这些模型时,可以直接从models包导入,…...

实验六:FPGA序列检测器实验
FPGA序列检测器实验(远程实验系统) 文章目录 FPGA序列检测器实验(远程实验系统)一、数字电路基础知识1. 时钟与同步2. 按键消抖原理代码讲解:分频与消抖3. 有限状态机(FSM)设计代码讲解:状态机编码与转移4. 边沿检测与信号同步5. 模块化设计二、实验数字电路整体思想三…...
网络的知识的一些概念
1.什么是局域网,什么是广域网 局域网(Local area network)也可以称为本地网,内网,局域网有这几个发展经历: 最开始电脑与电之间是直接用网线连接的 再后来有了集线器() 再后来出…...

芋道项目,商城模块数据表结构
一、需求 最近公司有新的业务需求,调研了一下,决定使用芋道(yudao-cloud)框架,于是从github(https://github.com/YunaiV/yudao-cloud)上克隆项目,选用的是jdk17版本的。根据项目启动手册&#…...

yarn任务筛选spark任务,判断内存/CPU使用超过限制任务
yarn任务筛选spark任务,判断内存/CPU使用超过限制任务 curl -s “http://it-cdh-node01:8088/ws/v1/cluster/apps?statesRUNNING” | jq ‘.apps.app | map(select(.applicationType “SPARK” ) | select(.allocatedMB > 102400 or .allocatedVCores > 50)…...

【氮化镓】HfO2钝化优化GaN 器件性能
2025年,南洋理工大学的Pradip Dalapati等人在《Applied Surface Science》期刊发表了题为《Role of ex-situ HfO2 passivation to improve device performance and suppress X-ray-induced degradation characteristics of in-situ Si3N4/AlN/GaN MIS-HEMTs》的文章。该研究基…...
)
c#的内存指针操作(仅用于记录)
c#也可以直接操作内存指针,如下为示例: unsafe {byte[] a {1,2,3};fixed (byte* p1 a, p2 &a[^1]){Debugger.Log(1, "test", $"max index:{p2-p1}");Debugger.Log(1, "test", $"address:{(long)p1:X}")…...

常见机器学习算法简介:回归、分类与聚类
机器学习说到底,不就三件事: 预测一个数 —— 回归 判断归属哪个类 —— 分类 自动把数据分组 —— 聚类 别背术语,别管定义,先看问题怎么解决。 一、回归(Regression) 干嘛的? 模型输出一…...

SpringBoot项目里面发起http请求的几种方法
在Spring Boot项目中发起HTTP请求的方法 在Spring Boot项目中,有几种常用的方式可以发起HTTP请求,以下是主要的几种方法: 1. 使用RestTemplate (Spring 5之前的主流方式) // 需要先注入RestTemplate Autowired private RestTemplate restT…...

Linux下Nginx源码安装步骤详解
以下是在Linux系统下从源码安装Nginx的详细步骤及解释: 1. 下载Nginx源码 步骤: wget http://nginx.org/download/nginx-1.25.3.tar.gz tar -zxvf nginx-1.25.3.tar.gz cd nginx-1.25.3解释: wget:从官网下载Nginx源码包&#…...
SQLMesh 增量模型从入门到精通:5步实现高效数据处理
本文深入解析 SQLMesh 中的增量时间范围模型,介绍其核心原理、配置方法及高级特性。通过实际案例说明如何利用该模型提升数据加载效率,降低计算资源消耗,并提供配置示例与最佳实践建议,帮助读者在实际项目中有效应用这一强大功能。…...
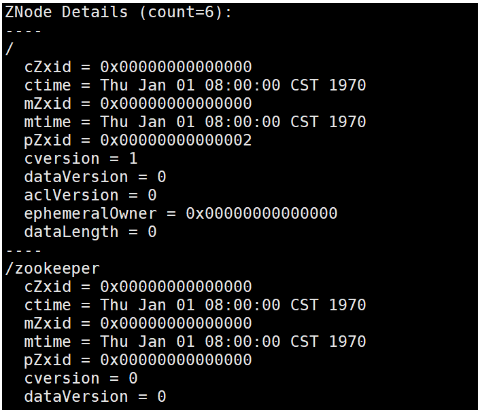
Zookeeper 入门(二)
4. Zookeeper 的 ACL 权限控制( Access Control List ) Zookeeper 的ACL 权限控制,可以控制节点的读写操作,保证数据的安全性,Zookeeper ACL 权 限设置分为 3 部分组成,分别是:权限模式(Scheme)、授权对象(…...
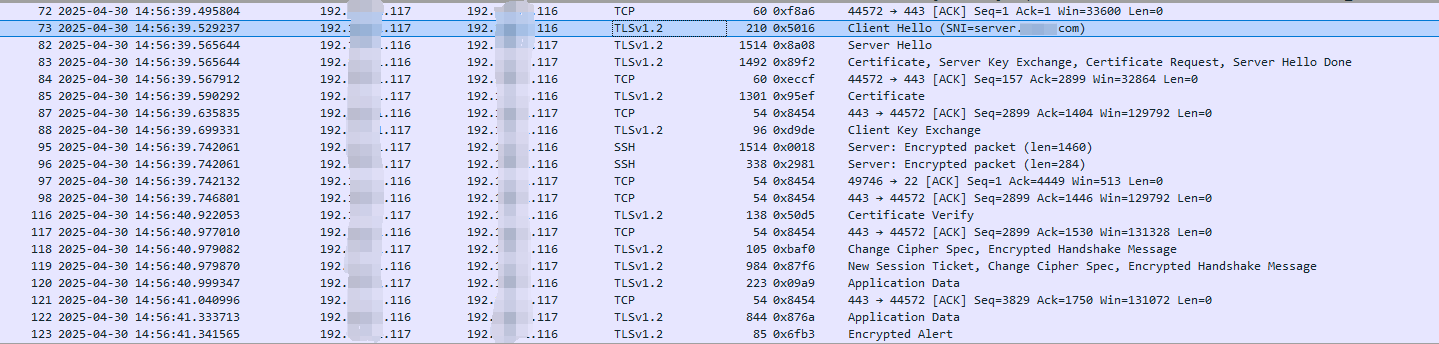
【架构篇】安全架构-双向认证
mTLS(Mutual TLS)详解:双向认证的原理、流程与实践 摘要 mTLS(Mutual TLS)是一种基于数字证书的双向身份验证协议,广泛应用于微服务通信、金融交易等高安全场景。本文深入解析mTLS的工作原理、认证流程、W…...

负载均衡—会话保持技术详解
一、会话保持的定义 会话保持(Session Persistence)是一种负载均衡策略,其核心机制是确保来自同一客户端的连续请求,在特定周期内被定向到同一台后端服务器进行处理。这种机制通过记录和识别客户端的特定标识信息,打破…...
Flask快速入门和问答项目源码
Flask基础入门 源码: gitee:我爱白米饭/Flask问答项目 - 码云 目录 1.安装环境2.【debug、host、port】3.【路由params和query】4.【模板】5.【静态文件】6.【数据库连接】6.1.安装模块6.2.创建数据库并测试连接6.3.创建数据表6.4.ORM增删改查 6.5.ORM模…...
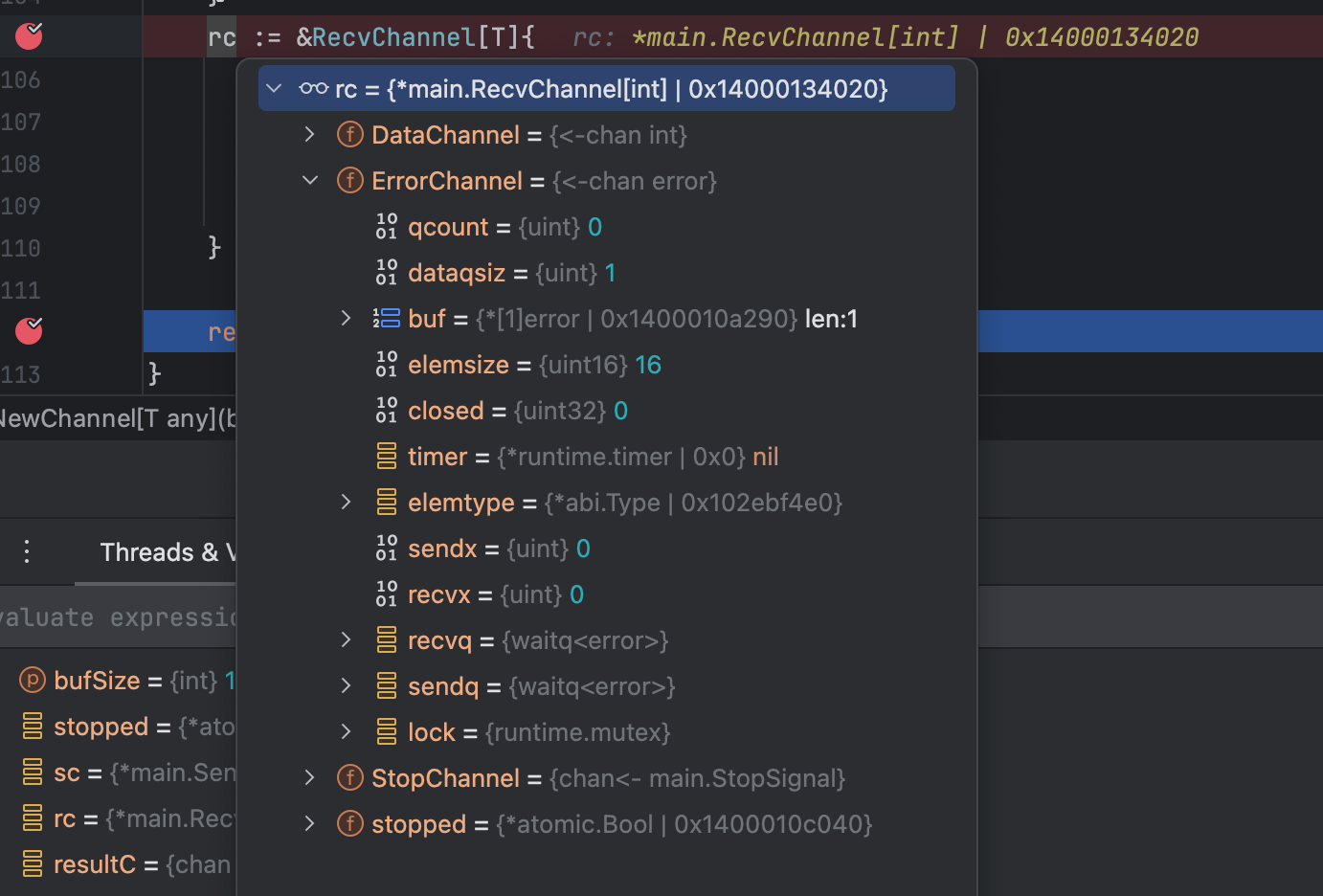
go语法大赏
前些日子单机房稳定性下降,找了好一会才找到真正的原因。这里面涉及到不少go语法细节,正好大家一起看一下。 一、仿真代码 这是仿真之后的代码 package mainimport ("fmt""go.uber.org/atomic""time" )type StopSignal…...
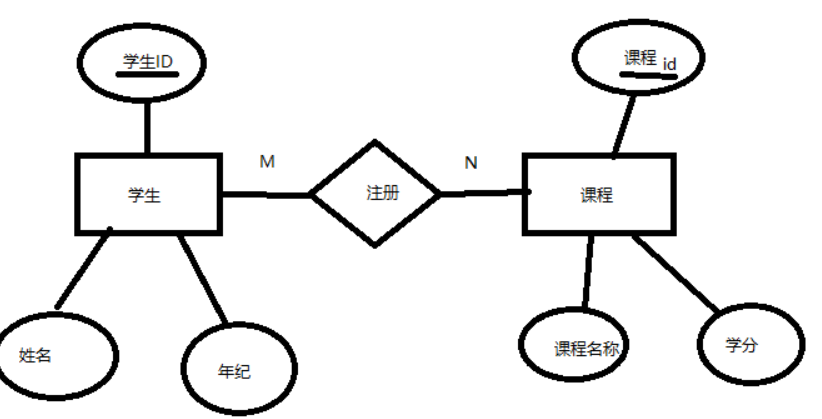
软件工程各种图总结
目录 1.数据流图 2.N-S盒图 3.程序流程图 4.UML图 UML用例图 UML状态图 UML时序图 5.E-R图 首先要先了解整个软件生命周期: 通常包含以下五个阶段:需求分析-》设计-》编码 -》测试-》运行和维护。 软件工程中应用到的图全部有:系统…...

R-tree详解
R-tree 是一种高效的多维空间索引数据结构,专为快速检索空间对象(如点、线、区域)而设计。它广泛应用于地理信息系统(GIS)、计算机图形学、数据库等领域,支持范围查询、最近邻搜索等操作。以下是其核心原理…...
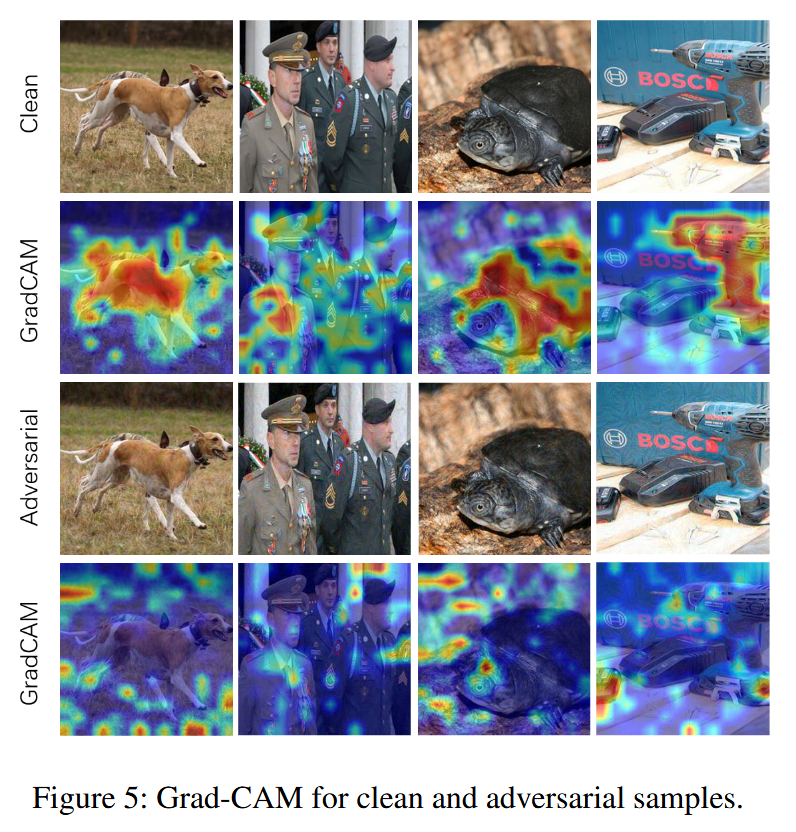
AAAI2024 | 基于特征多样性对抗扰动攻击 Transformer 模型
Attacking Transformers with Feature Diversity Adversarial Perturbation 摘要-Abstract引言-Introduction相关工作-Related Work方法-Methodology实验-Experiments结论-Conclusion 论文链接 本文 “Attacking Transformers with Feature Diversity Adversarial Perturbatio…...

关于数据湖和数据仓的一些概念
一、前言 随着各行业数字化发展的深化,数据资产和数据价值已越来越被深入企业重要发展的战略重心,海量数据已成为多数企业生产实际面临的重要问题,无论存储容量还是成本,可靠性都成为考验企业数据治理的考验。本文来看下海量数据存储的数据湖和数据仓,数据仓库和数据湖,…...
#三方框架 #Uniapp)
鸿蒙OSUniApp制作自定义的下拉菜单组件(鸿蒙系统适配版)#三方框架 #Uniapp
UniApp制作自定义的下拉菜单组件(鸿蒙系统适配版) 前言 在移动应用开发中,下拉菜单是一个常见且实用的交互组件,它能在有限的屏幕空间内展示更多的选项。虽然各种UI框架都提供了下拉菜单组件,但在一些特定场景下&…...

C++面试2——C与C++的关系
C与C++的关系及核心区别的解析 一、哲学与编程范式:代码组织的革命 过程式 vs 多范式混合 C语言是过程式编程的典范,以算法流程为中心,强调“怎么做”(How)。例如,实现链表操作需手动管理节点指针和内存。 C++则是多范式语言,支持面向对象(OOP)、泛型编程(模板)、函…...
常用的Java工具库
1. Collections 首先是 java.util 包下的 Collections 类。这个类主要用于操作集合,我个人非常喜欢使用它。以下是一些常用功能: 1.1 排序 在工作中,经常需要对集合进行排序。让我们看看如何使用 Collections 工具实现升序和降序排列&…...