《Python星球日记》 第94天:走近自动化训练平台
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、自动化训练平台简介
- 1. Kubeflow Pipelines
- 2. TensorFlow Extended (TFX)
- 二、自动化训练流程
- 1. 数据预处理
- 2. 模型训练
- 3. 评估与部署
- 三、构建简单自动化训练流水线
- 1. 环境准备
- 2. 流水线组件定义
- 3. 数据处理模块
- 4. 模型训练模块
- 5. 构建完整流水线
- 6. 执行流水线
- 四、自动化训练平台的优势与挑战
- 1. 自动化训练的优势
- 2. 实施挑战与解决方案
- 五、结语与展望
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第93天:MLOps 入门
欢迎回到Python星球🪐日记!今天是我们旅程的第94天。
一、自动化训练平台简介
在机器学习和深度学习项目中,从数据准备到模型部署的流程通常包含多个复杂环节。随着项目规模扩大,手动管理这些流程变得困难且容易出错。自动化训练平台就是为了解决这一问题而生的强大工具,它能帮助我们自动化整个机器学习工作流程,提高效率和可靠性。
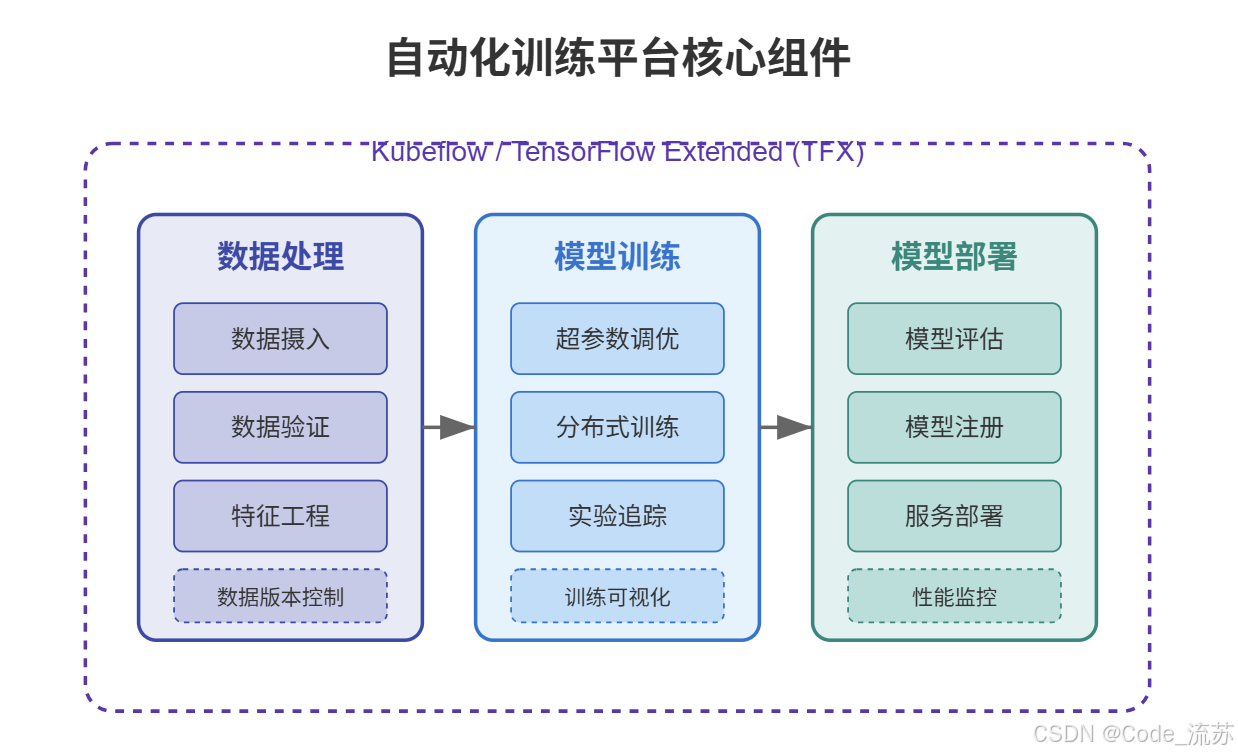
1. Kubeflow Pipelines
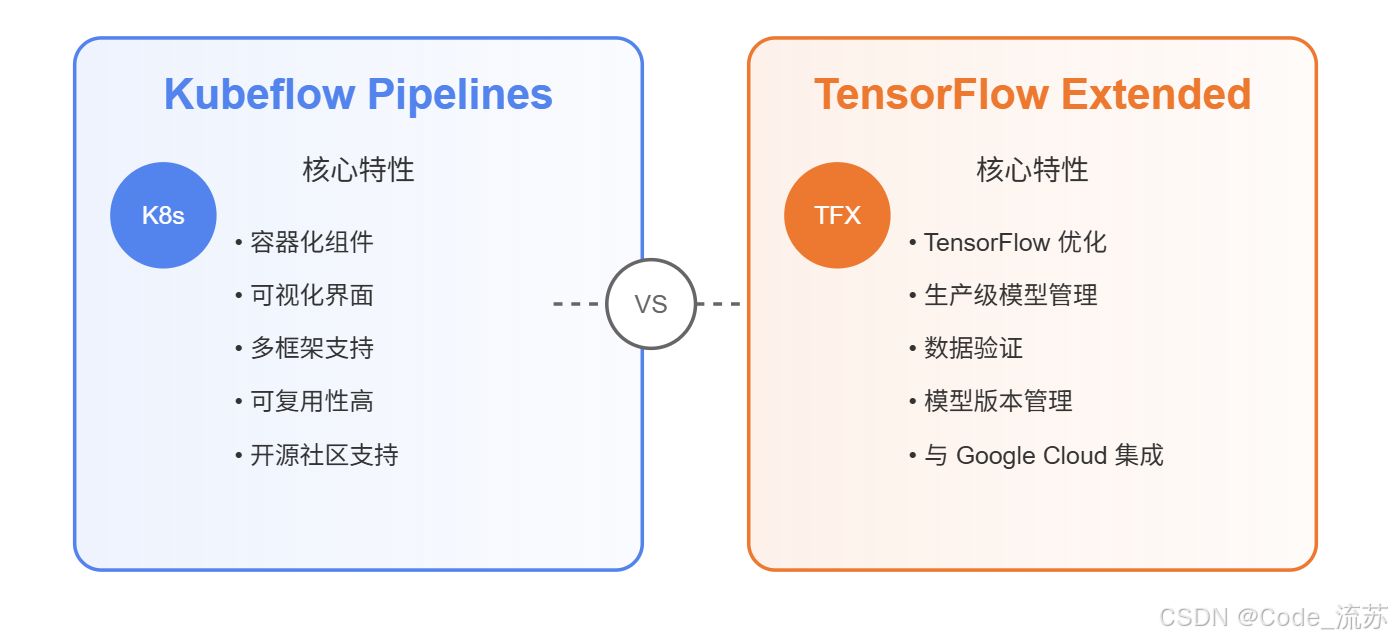
Kubeflow Pipelines 是基于 Kubernetes 的端到端机器学习工作流编排工具,它允许数据科学家构建和自动化可重复的机器学习工作流。
图片来源:Kubeflow Pipelines官方
Kubeflow Pipelines 的核心优势:
- 可复现性:将整个工作流定义为代码,确保实验可以精确复现
- 可组合性:将复杂流程拆分为可重用组件
- 可视化:提供直观的界面监控和管理工作流
- 可扩展性:无缝扩展到大规模数据和模型处理
2. TensorFlow Extended (TFX)
TensorFlow Extended (TFX) 是 Google 开发的端到端平台,用于部署生产级机器学习流水线。它专为 TensorFlow 模型优化,但也支持其他框架。
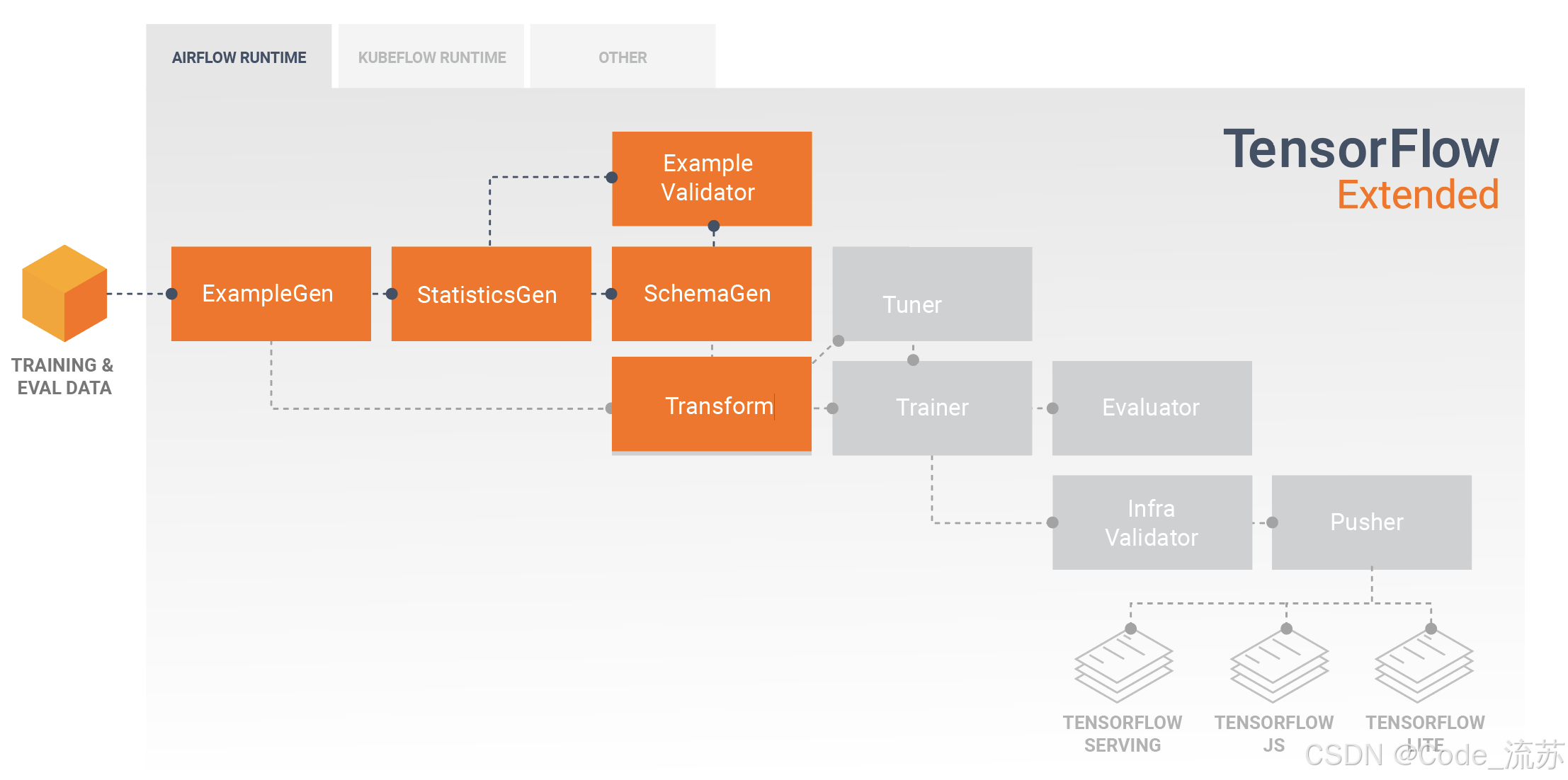
图片来源:TensorFlow Extended官方
TFX 的主要特点:
- 全生命周期管理:覆盖从数据摄入到模型服务的所有阶段
- 强大的验证机制:自动验证数据和模型质量
- 模型版本控制:追踪和管理不同版本的模型
- 与 Google Cloud 深度集成:可以利用 Google 云平台的强大功能
二、自动化训练流程
机器学习项目的自动化流程通常包含多个关键阶段,每个阶段都有特定的任务和目标。理解这些阶段对于构建有效的自动化流水线至关重要。
1. 数据预处理
数据预处理是任何机器学习流水线的第一个关键步骤,它解决了数据质量和格式的问题:
- 数据验证:确保数据符合预期的模式和分布
- 数据清洗:处理缺失值、异常值和重复记录
- 特征工程:创建、选择和转换特征以提高模型性能
- 数据拆分:将数据划分为训练集、验证集和测试集
在自动化流水线中,这些步骤被编码为可重用组件,能够一致地处理新数据。
2. 模型训练
模型训练阶段涉及选择和优化算法以从数据中学习模式:
- 超参数调优:自动化搜索最佳模型参数
- 训练监控:跟踪损失函数、准确率等指标
- 分布式训练:利用多个计算资源加速训练过程
- 实验追踪:记录每次训练运行的所有相关信息
自动化平台允许设置触发器来启动新的训练作业,例如当新数据到达或按照预定的时间表。
3. 评估与部署
训练完成后,模型需要经过彻底评估并准备部署:
- 模型评估:在测试数据上评估性能指标
- A/B测试:对比新模型与当前生产模型
- 模型注册:将经过批准的模型添加到模型注册表
- 模型服务:打包和部署模型用于推理
- 监控:跟踪生产环境中的模型性能
自动化平台确保这些步骤以可重复和可靠的方式执行,减少了手动干预的需要。
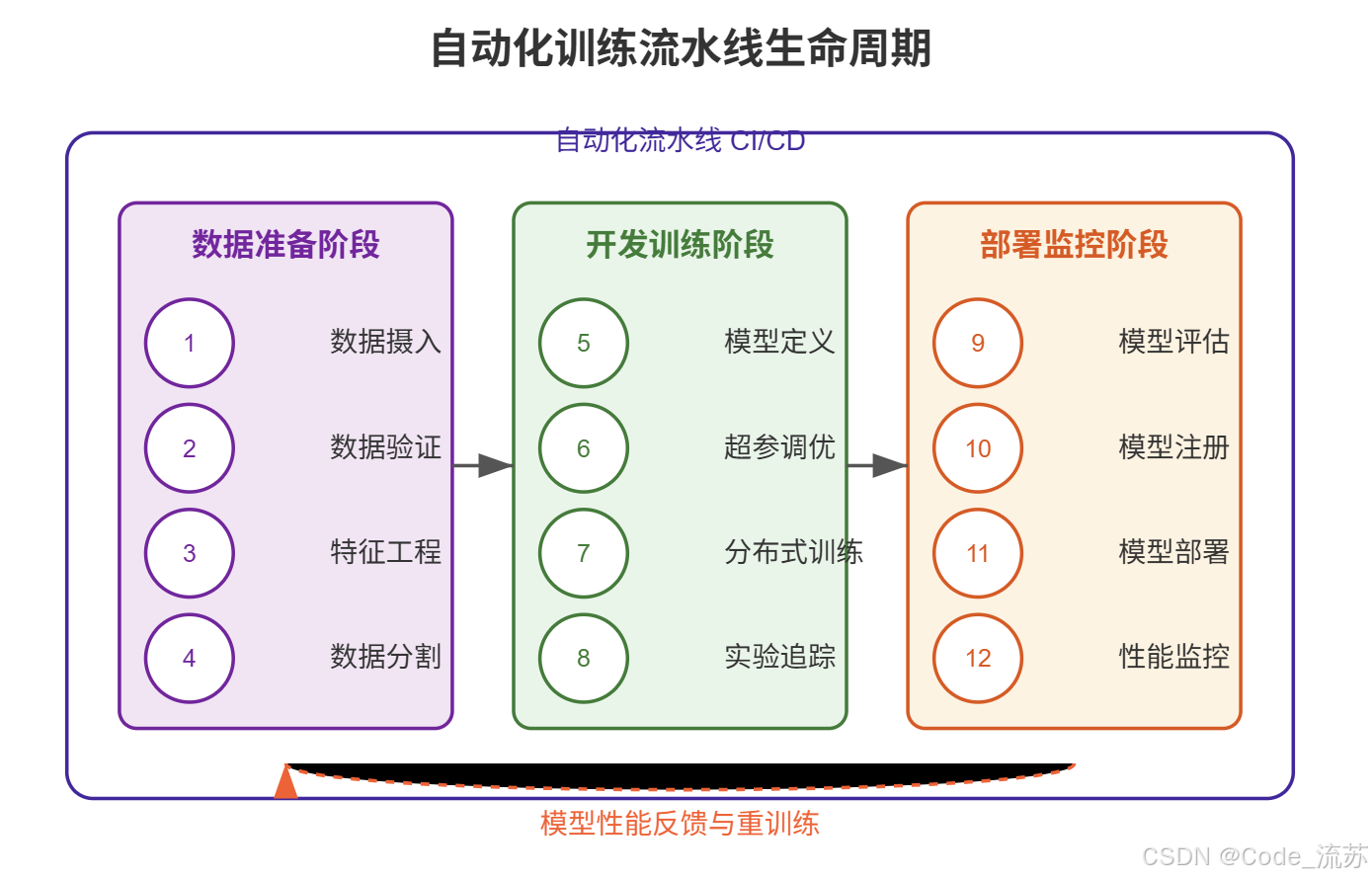
三、构建简单自动化训练流水线
现在让我们通过实际代码示例来了解如何构建一个简单的自动化训练流水线。我们将使用 TFX 框架来实现一个基础的流水线,适合初学者理解和扩展。
1. 环境准备
首先,我们需要安装必要的包和依赖:
# 安装TFX
!pip install tfx
# 安装相关依赖
!pip install tensorflow==2.12.0
!pip install apache-beam
2. 流水线组件定义
TFX 流水线由多个组件组成,每个组件负责特定的任务。下面我们定义一个简单的流水线,包含数据摄入、验证、预处理、训练和评估组件:
import tensorflow as tf
import tensorflow_model_analysis as tfma
from tfx import v1 as tfx
from tfx.components import (CsvExampleGen, # 数据摄入StatisticsGen, # 数据统计SchemaGen, # 数据模式生成ExampleValidator, # 数据验证Transform, # 特征转换Trainer, # 模型训练Evaluator, # 模型评估Pusher # 模型部署
)
from tfx.orchestration import pipeline
from tfx.orchestration.local.local_dag_runner import LocalDagRunner
3. 数据处理模块
接下来,我们需要创建预处理模块,定义如何转换原始特征:
# 创建 preprocessing_fn.py 文件
def preprocessing_fn(inputs):"""预处理函数:定义特征工程逻辑Args:inputs: 包含特征的字典Returns:转换后的特征字典"""# 获取输入特征features = {}# 对数值特征进行标准化for feature_name in ['feature1', 'feature2', 'feature3']:features[feature_name] = tf.feature_column.numeric_column(feature_name, normalizer_fn=lambda x: (x - mean) / stddev)# 对类别特征进行独热编码for feature_name in ['category1', 'category2']:features[feature_name] = tf.feature_column.categorical_column_with_vocabulary_list(feature_name, vocabulary_list=vocabulary_dict[feature_name])return features
4. 模型训练模块
我们还需要定义模型训练逻辑:
# 创建 trainer.py 文件
def run_fn(fn_args):"""训练函数:定义模型架构和训练逻辑Args:fn_args: 包含训练所需参数的对象"""# 加载转换后的数据tf_transform_output = tft.TFTransformOutput(fn_args.transform_output)train_dataset = input_fn(fn_args.train_files, tf_transform_output)eval_dataset = input_fn(fn_args.eval_files, tf_transform_output)# 构建模型model = tf.keras.Sequential([tf.keras.layers.Dense(64, activation='relu'),tf.keras.layers.Dense(32, activation='relu'),tf.keras.layers.Dense(1) # 根据任务类型调整输出层])# 编译模型model.compile(optimizer='adam',loss='mse', # 根据任务类型选择损失函数metrics=['mae'])# 训练模型model.fit(train_dataset,epochs=10,validation_data=eval_dataset)# 保存模型model.save(fn_args.serving_model_dir, save_format='tf')
5. 构建完整流水线
最后,我们将所有组件组合成一个完整的流水线:
def create_pipeline(pipeline_name,pipeline_root,data_root,module_file,serving_model_dir,metadata_path
):"""创建完整的TFX流水线Args:pipeline_name: 流水线名称pipeline_root: 流水线根目录data_root: 数据根目录module_file: 包含预处理和训练函数的模块serving_model_dir: 模型部署目录metadata_path: 元数据存储路径Returns:构建好的流水线"""# 1. 数据摄入组件example_gen = CsvExampleGen(input_base=data_root)# 2. 数据统计组件statistics_gen = StatisticsGen(examples=example_gen.outputs['examples'])# 3. 模式推断组件schema_gen = SchemaGen(statistics=statistics_gen.outputs['statistics'])# 4. 数据验证组件example_validator = ExampleValidator(statistics=statistics_gen.outputs['statistics'],schema=schema_gen.outputs['schema'])# 5. 特征转换组件transform = Transform(examples=example_gen.outputs['examples'],schema=schema_gen.outputs['schema'],module_file=module_file # 包含预处理函数的文件)# 6. 模型训练组件trainer = Trainer(module_file=module_file, # 包含训练函数的文件examples=transform.outputs['transformed_examples'],transform_graph=transform.outputs['transform_graph'],schema=schema_gen.outputs['schema'],train_args=tfx.proto.TrainArgs(num_steps=1000),eval_args=tfx.proto.EvalArgs(num_steps=500))# 7. 模型评估组件eval_config = tfma.EvalConfig(model_specs=[tfma.ModelSpec(label_key='target')],metrics_specs=[tfma.MetricsSpec(metrics=[tfma.MetricConfig(class_name='MeanSquaredError'),tfma.MetricConfig(class_name='MeanAbsoluteError')])],slicing_specs=[tfma.SlicingSpec()])evaluator = Evaluator(examples=example_gen.outputs['examples'],model=trainer.outputs['model'],eval_config=eval_config)# 8. 模型部署组件pusher = Pusher(model=trainer.outputs['model'],model_blessing=evaluator.outputs['blessing'],push_destination=tfx.proto.PushDestination(filesystem=tfx.proto.PushDestination.Filesystem(base_directory=serving_model_dir)))# 构建流水线components = [example_gen,statistics_gen,schema_gen,example_validator,transform,trainer,evaluator,pusher]return pipeline.Pipeline(pipeline_name=pipeline_name,pipeline_root=pipeline_root,components=components,metadata_connection_config=tfx.orchestration.metadata.sqlite_metadata_connection_config(metadata_path))
6. 执行流水线
最后一步是配置和执行流水线:
# 定义路径和配置
PIPELINE_NAME = "my_automl_pipeline"
PIPELINE_ROOT = "pipeline_output"
DATA_ROOT = "data/my_dataset"
MODULE_FILE = "my_pipeline_modules.py" # 包含预处理和训练函数的文件
SERVING_MODEL_DIR = "serving_model"
METADATA_PATH = "metadata.db"# 构建流水线
my_pipeline = create_pipeline(pipeline_name=PIPELINE_NAME,pipeline_root=PIPELINE_ROOT,data_root=DATA_ROOT,module_file=MODULE_FILE,serving_model_dir=SERVING_MODEL_DIR,metadata_path=METADATA_PATH
)# 执行流水线
LocalDagRunner().run(my_pipeline)
四、自动化训练平台的优势与挑战
1. 自动化训练的优势
自动化训练平台为机器学习项目带来了许多显著优势:
| 优势 | 描述 |
|---|---|
| 可重复性 | 流水线确保每次运行都遵循相同的流程,消除手动操作的不一致性 |
| 可追溯性 | 自动记录每次运行的所有步骤、参数和结果,便于审计和调试 |
| 效率提升 | 自动化重复任务,解放数据科学家专注于更有价值的工作 |
| 协作改进 | 标准化流程使团队成员更容易理解和贡献代码 |
| 扩展能力 | 能够处理更大规模的数据和更复杂的模型 |
| 快速迭代 | 缩短从实验到生产的时间,加速模型开发周期 |
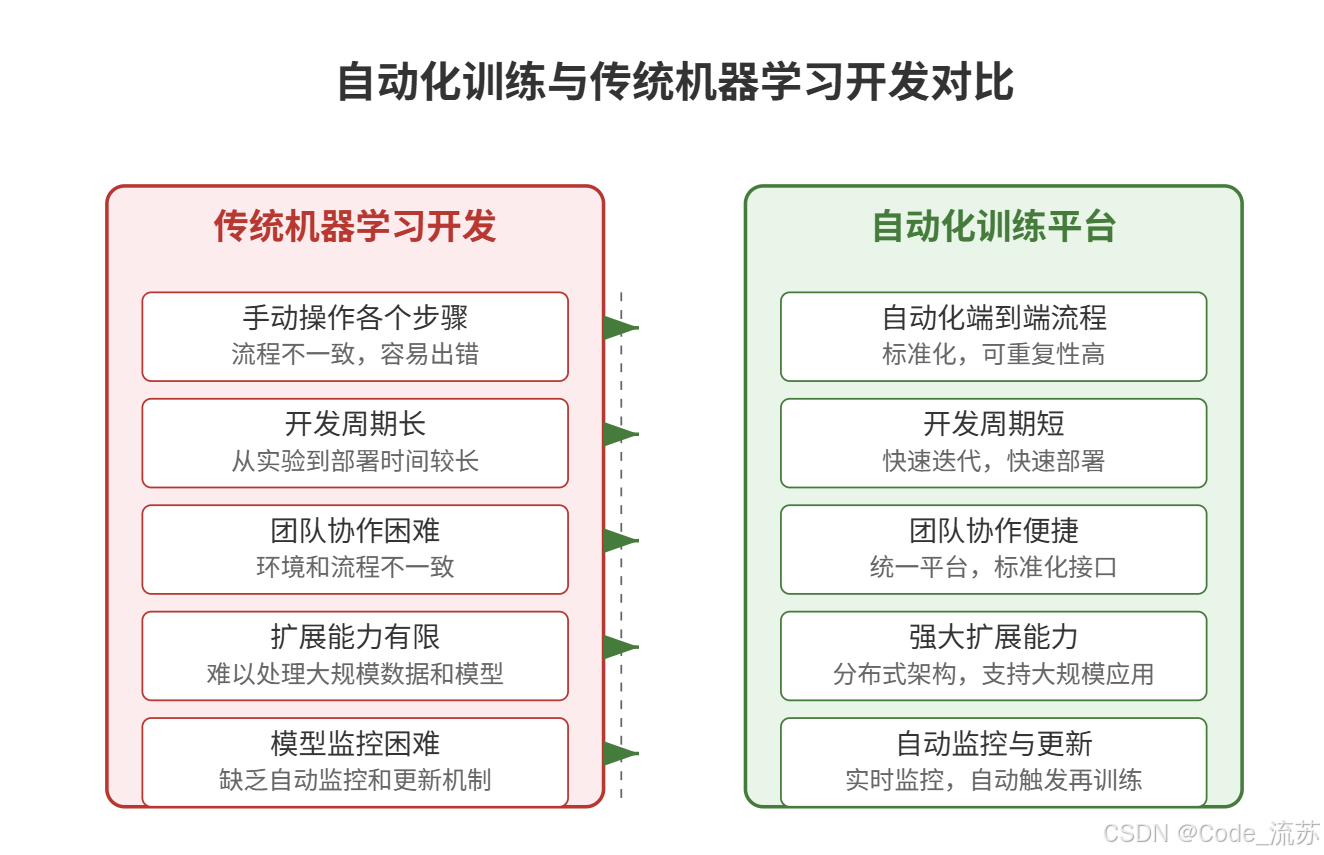
2. 实施挑战与解决方案
尽管自动化训练平台带来了巨大好处,但实施过程中也会面临一些挑战:
-
学习曲线陡峭:Kubeflow和TFX等平台需要时间掌握
解决方案:从简单流水线开始,逐步增加复杂性;利用官方教程和示例
-
环境配置复杂:设置和维护基础设施可能很困难
解决方案:考虑使用托管服务如Google Cloud AI Platform或AWS SageMaker
-
版本兼容性问题:依赖项和框架版本冲突常见
解决方案:使用容器化技术如Docker隔离环境;详细记录依赖版本
-
调试困难:分布式流水线的错误可能难以诊断
解决方案:实现全面的日志记录;分阶段测试流水线组件
五、结语与展望
自动化训练平台正在彻底改变机器学习项目的开发和部署方式。通过将复杂的工作流程自动化,数据科学家可以专注于创造性工作,而不是繁琐的手动任务。
随着技术的发展,我们可以期待自动化平台变得更加易用、功能更强大。AutoML和低代码/无代码解决方案的兴起将进一步降低构建自动化流水线的门槛,使更多人能够参与到AI应用开发中。
今天我们学习了自动化训练平台的基础知识,包括Kubeflow Pipelines和TFX的介绍,以及如何构建一个简单的自动化流水线。在未来的章节中,我们将深入探讨更复杂的自动化训练场景和高级技术。
思考问题:你能想到在你当前的机器学习项目中,哪些环节最适合自动化?自动化这些环节可能会带来哪些好处和挑战?
祝你学习愉快,勇敢的Python星球探索者!👨🚀🌠
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!
相关文章:
《Python星球日记》 第94天:走近自动化训练平台
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、自动化训练平台简介1. Kubeflow Pipelines2. TensorFlow Extended (TFX) 二…...
S7 200 smart连接Profinet转ModbusTCP网关与西门子1200PLC配置案例
控制要求:使用MODBUSTCP通信进行两台PLC之间的数据交换,由于改造现场不能改动程序,只留出了对应的IQ地址。于是客户决定使用网关进行通讯把数据传到plc。 1、读取服务器端40001~40005地址中的数据,放入到VW200~VW208中࿱…...

React中巧妙使用异步组件Suspense优化页面性能。
文章目录 前言一、为什么需要异步组件?1. 性能瓶颈分析2. 异步组件的价值 二、核心实现方式1. React.lazy Suspense(官方推荐)2. 路由级代码分割(React Router v6) 总结 前言 在 React 应用中,随着功能复…...

学习笔记:黑马程序员JavaWeb开发教程(2025.4.7)
12.9 登录校验-Filter-入门 /*代表所有,WebFilter(urlPatterns “/*”)代表拦截所有请求 Filter是JavaWeb三大组件,不是SpringBoot提供的,要在SpringBoot里面使用JavaWeb,则需要加上ServletComponentScan注…...

11 web 自动化之 DDT 数据驱动详解
文章目录 一、DDT 数据驱动介绍二、实战 一、DDT 数据驱动介绍 数据驱动: 现在主流的设计模式之一(以数据驱动测试) 结合 unittest 框架如何实现数据驱动? ddt 模块实现 数据驱动的意义: 通过不同的数据对同一脚本实现…...

OpenCV-python灰度变化和直方图修正类型
实验1 实验内容 该段代码旨在读取名为"test.png"的图像,并将其转换为灰度图像。使用加权平均值法将原始图像的RGB值转换为灰度值。 代码注释 image cv.imread("test.png")h np.shape(image)[0] w np.shape(image)[1] gray_img np.zeros…...

从 Excel 到 Data.olllo:数据分析师的提效之路
背景:Excel 的能力边界 对许多数据分析师而言,Excel 是入门数据处理的第一工具。然而,随着业务数据量的增长,Excel 的一些固有限制逐渐显现: 操作容易出错,难以审计; 打开或操作百万行数据时&…...

图像定制大一统?字节提出DreamO,支持人物生成、 ID保持、虚拟试穿、风格迁移等多项任务,有效解决多泛化性冲突。
字节提出了一个统一的图像定制框架DreamO,支持人物生成、 ID保持、虚拟试穿、风格迁移等多项任务,不仅在广泛的图像定制场景中取得了高质量的结果,而且在适应多条件场景方面也表现出很强的灵活性。现在已经可以支持消费级 GPU(16G…...
Nginx 动静分离在 ZKmall 开源商城静态资源管理中的深度优化
在 B2C 电商高并发场景下,静态资源(图片、CSS、JavaScript 等)的高效管理直接影响页面加载速度与用户体验。ZKmall开源商城通过对 Nginx 动静分离技术的深度优化,将静态资源响应速度提升 65%,带宽成本降低 40%…...
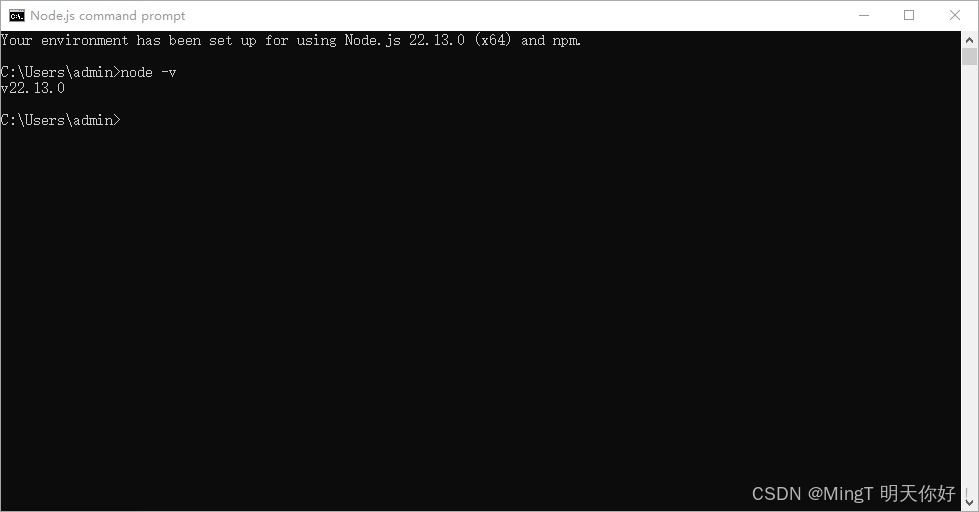
在vs code 中无法运行npm并报无法将“npm”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查
问题: npm : 无法将“npm”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查 原因: 可能是环境变量未正确继承或终端配置不一致 解决方法: 1.找到自己的node.js的版本号 2.重新下载node.js 下载 node.js - https://nodejs.p…...
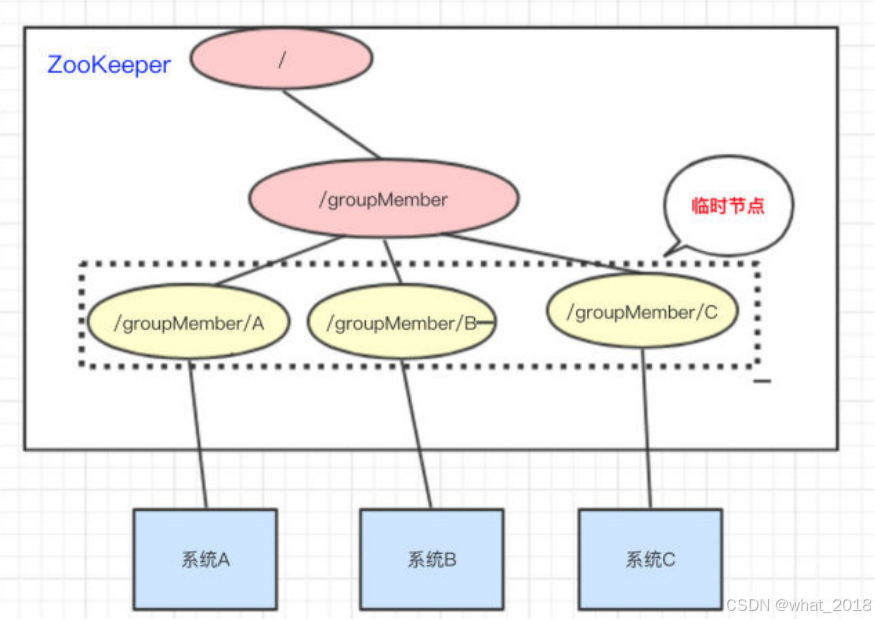
分布式2(限流算法、分布式一致性算法、Zookeeper )
目录 限流算法 固定窗口计数器(Fixed Window Counter) 滑动窗口计数器(Sliding Window Counter) 漏桶算法(Leaky Bucket) 令牌桶算法(Token Bucket) 令牌桶与漏桶的对比 分布式…...
做法!)
2089. 找出数组排序后的目标下标——O(n)做法!
本题要求在一个已排序的数组 nums 中,找出所有等于目标值 target 的元素下标。若不存在这样的元素,则返回 {-1, -1}。解决该问题有两种主要方法:二分查找法和统计计数法。 二分查找法:首先对数组进行排序,然后通过二分…...

ARM A64 LDR指令
ARM A64 LDR指令 1 LDR (immediate)1.1 Post-index1.2 Pre-index1.3 Unsigned offset 2 LDR (literal)3 LDR (register)4 其他LDR指令变体4.1 LDRB (immediate)4.1.1 Post-index4.1.2 Pre-index4.1.3 Unsigned offset 4.2 LDRB (register)4.3 LDRH (immediate)4.3.1 Post-index…...

给大模型“贴膏药”:LoRA微调原理说明书
一、前言:当AI模型开始“叛逆” 某天,我决定教deepseek说方言。 第一次尝试(传统微调): 我:给deepseek灌了100G东北小品数据集,训练三天三夜。结果:AI确实会喊“老铁666”了…但英…...

Spring-messaging-MessageHandler接口实现类ServiceActivatingHandler
ServiceActivatingHandler实现了MessageHandler接口,所以它是一个MessageHandler,在spring-integration中,它也叫做服务激活器(Service Activitor),因为这个类是依赖spring容器BeanFactory的,所…...

asp.net core api RESTful 风格控制器
在 ASP.NET Core API 中,遵循 RESTful 风格的控制器一般具备以下几个关键特征: ✅ RESTful 风格控制器的命名规范 控制器命名 使用 复数名词,表示资源集合,如 ProductsController、UsersController。 路由风格 路由使用 [Rout…...

【甲方安全建设】Python 项目静态扫描工具 Bandit 安装使用详细教程
文章目录 一、工具简介二、工具特点1.聚焦安全漏洞检测2.灵活的扫描配置3.多场景适配4.轻量且社区活跃三、安装步骤四、使用方法场景1:扫描单个Python文件场景2:递归扫描整个项目目录五、结果解读六、总结一、工具简介 Bandit 是由Python官方推荐的静态代码分析工具(SAST)…...

实习记录小程序|基于SSM+Vue的实习记录小程序设计与实现(源码+数据库+文档)
实习记录小程序 目录 基于SSM的习记录小程序设计与实现 一、前言 二、系统设计 三、系统功能设计 1、小程序端: 2、后台 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂码…...

老旧设备升级利器:Modbus TCP转 Profinet让能效监控更智能
在工业自动化领域,ModbusTCP和Profinet是两种常见的通讯协议。Profinet是西门子公司推出的基于以太网的实时工业以太网标准,而Modbus则是由施耐德电气提出的全球首个真正开放的、应用于电子控制器上的现场总线协议。这两种协议各有各的优点,但…...

【从基础到模型网络】深度学习-语义分割-ROI
在语义分割中,ROI(Region of Interest,感兴趣区域)是图像中需要重点关注的部分。其作用包括:提高效率,减少高分辨率图像的计算量;增强分割精度,聚焦关键语义信息;减少背景…...

Qt控件:交互控件
交互控件 1. QAction核心功能API 1.2 实例应用情况应用场景 1.3 QAction与QPushButton/QToolButton关系QActionQPushButtonQToolButton三者关系 1. QAction ##1. 1简介与API QAction 是一个核心类,用于表示应用程序中的一个操作(如菜单项、工具栏按钮或…...

前端下载ZIP包方法总结
在前端实现下载 ZIP 包到本地,通常有以下几种方法,具体取决于 ZIP 包的来源(静态文件、后端生成、前端动态生成等): 方法 1:直接下载静态文件(最简单) 如果 ZIP 包是服务器上的静态…...

掌握Docker:从运行到挂载的全面指南
目录 1. Docker的运行2. 查看Docker的启动日志3. 停止容器4. 容器的启动5. 删除容器6. 查看容器的详细信息7.一条命令关闭所有容器拓展容器的复制(修改数据不会同步)容器的挂载(修改数据可以同步)挂载到现有容器 1. Docker的运行 …...

Pandas pyecharts数据可视化基础③
pyecharts基础绘图案例解析 引言思维导图代码案例分析 提前安装依赖同样操作安装完重新启动Jupyter Notebook三维散点图(代码5 - 40) 代码结果代码解析 漏斗图(代码5 - 41)结果代码解析 词云图(代码5 - 42)…...
)
QMK固件OLED显示屏配置教程:从零开始实现个性化键盘显示(实操部分)
QMK固件OLED显示屏配置教程:从零开始实现个性化键盘显示 📢 前言: 作为一名键盘爱好者,近期研究了QMK固件的OLED显示屏配置,发现网上的教程要么太过复杂,要么过于简单无法实际操作。因此决定写下这篇教程,从零基础出发,带大家一步步实现键盘OLED屏幕的配置与个性化显示…...
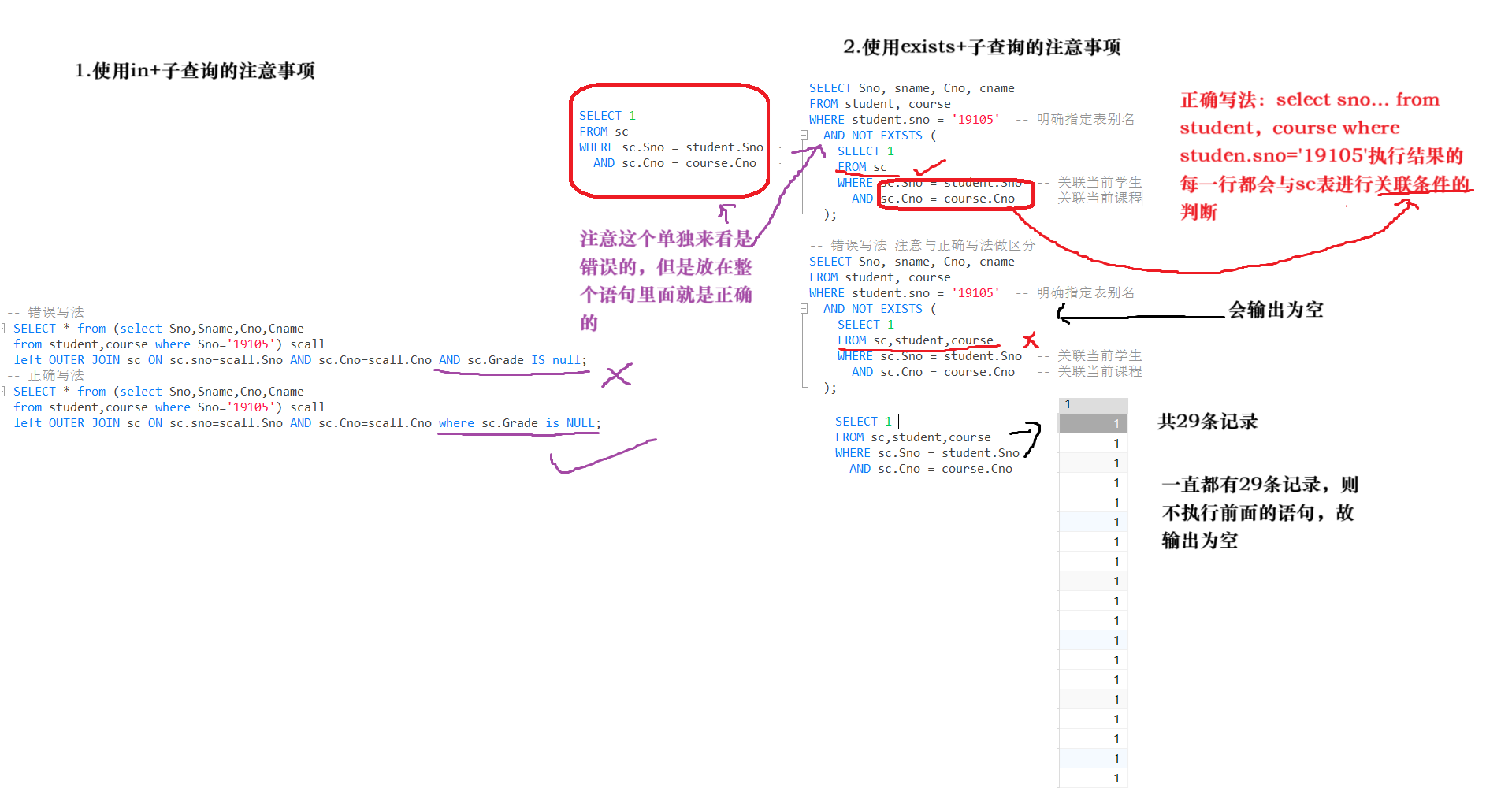
数据库中关于查询选课问题的解法
前言 今天上午起来复习了老师上课讲的选课问题。我总结了三个解法以及一点注意事项。 选课问题介绍 简单来说就是查询某某同学没有选或者选了什么课。然后查询出该同学的姓名,学号,课程号,课程名之类的。 sql文件我上传了。大家可以尝试练…...
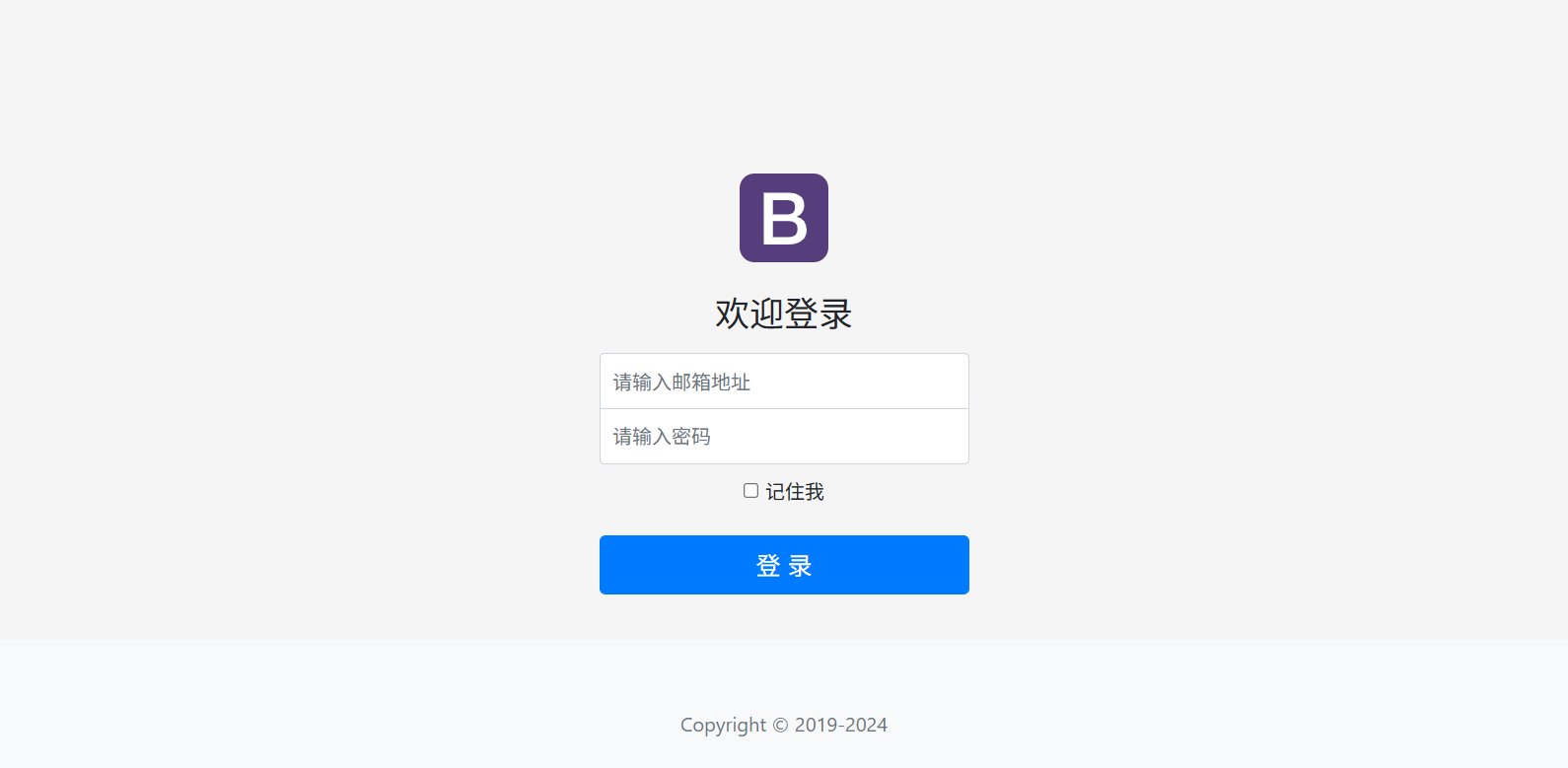
基于Bootstrap 的网页html css 登录页制作成品
目录 前言 一、网页制作概述 二、登录页面 2.1 HTML内容 2.2 CSS样式 三、技术说明书 四、页面效果图 前言 Bootstrap是一个用于快速开发Web应用程序和网站的前端框架,由Twitter的设计师Mark Otto和Jacob Thornton合作开发。 它基于HTML、CSS和JavaScri…...

python中http.cookiejar和http.cookie的区别
在Python中,http.cookiejar和http.cookie(通常指http.cookies模块)是两个不同的模块,它们的主要区别如下: 1. 功能定位 http.cookiejar 用于管理HTTP客户端的Cookie,提供自动化的Cookie存储、发送和接收功…...

【NLP 71、常见大模型的模型结构对比】
三到五年的深耕,足够让你成为一个你想成为的人 —— 25.5.8 模型名称位置编码Transformer结构多头机制Feed Forward层设计归一化层设计线性层偏置项激活函数训练数据规模及来源参数量应用场景侧重GPT-5 (OpenAI)RoPE动态相对编码混合专家架构(MoE&#…...
组件导航 (Navigation)+flutter项目搭建-混合开发+分栏
组件导航 (Navigation)flutter项目搭建 接上一章flutter项目的环境变量配置并运行flutter 上一章面熟了搭建flutter并用编辑器运行了ohos项目,这章主要是对项目的工程化改造 先创建flutter项目,再配置Navigation 1.在开发视图的resources/base/profi…...