用户行为日志分析的常用架构
## 1. 经典Lambda架构
Lambda架构是一种流行的大数据处理架构,特别适合用户行为日志分析场景。
### 1.1 架构组成
Lambda架构包含三层:
- **批处理层(Batch Layer)**: 存储全量数据并进行离线批处理
- **实时处理层(Speed Layer)**: 处理最新数据,提供低延迟分析结果
- **服务层(Serving Layer)**: 整合批处理和实时处理的结果,对外提供查询服务
### 1.2 技术组件
| 层级 | 常用技术 |
|------|---------|
| 数据采集 | Flume, Kafka, Logstash, Filebeat |
| 批处理层 | Hadoop, Hive, Spark Batch |
| 实时处理层 | Flink, Spark Streaming, Storm |
| 存储层 | HDFS, HBase, Elasticsearch, Cassandra |
| 服务层 | Druid, Kylin, Presto, Impala |
| 可视化 | Superset, Tableau, PowerBI, Grafana |
### 1.3 适用场景
- 需要同时兼顾历史数据分析和实时监控的场景
- 大规模用户行为数据分析
- 对数据完整性和延迟都有一定要求的企业
## 2. Kappa架构
Kappa架构是Lambda架构的简化版,仅使用实时处理层。
### 2.1 架构组成

Kappa架构主要包含:
- **消息队列**: 持久化存储原始日志数据
- **流处理引擎**: 处理实时数据流
- **存储层**: 存储处理结果
### 2.2 技术组件
| 组件 | 常用技术 |
|------|---------|
| 消息队列 | Kafka, Pulsar |
| 流处理引擎 | Flink, Spark Streaming, Kafka Streams |
| 存储层 | Cassandra, Redis, Elasticsearch, TimescaleDB |
### 2.3 适用场景
- 实时用户行为分析和监控
- 用户实时推荐系统
- 网站流量实时监控
- 业务异常检测
## 3. 湖仓一体架构
随着数据湖和数据仓库概念的融合,湖仓一体架构成为新趋势。
### 3.1 架构组成

主要组成部分:
- **数据湖**: 存储原始数据
- **数据仓库**: 处理结构化数据
- **湖仓转换层**: 实现数据湖与数据仓库之间的数据流转
- **统一元数据管理**: 管理所有数据资产
### 3.2 技术组件
| 组件 | 常用技术 |
|------|---------|
| 数据湖 | Hudi, Iceberg, Delta Lake |
| 数据仓库 | Snowflake, Redshift, BigQuery |
| 计算引擎 | Spark, Presto, Trino |
| 元数据管理 | Hive Metastore, AWS Glue, Datahub |
### 3.3 适用场景
- 需要同时存储大量原始日志和结构化分析结果的企业
- 既需要数据探索又需要高性能分析的场景
- 数据治理要求较高的企业
## 4. 全实时数据平台架构
随着实时分析需求的增长,全实时架构逐渐流行。
### 4.1 架构组成

主要组成:
- **实时数据采集**: 采集各类用户行为日志
- **实时处理引擎**: 对数据进行实时处理
- **实时OLAP引擎**: 提供低延迟的多维分析
- **实时应用层**: 提供实时决策支持
### 4.2 技术组件
| 组件 | 常用技术 |
|------|---------|
| 实时采集 | Kafka, Pulsar, Debezium |
| 实时处理 | Flink, Spark Structured Streaming |
| 实时存储 | ClickHouse, Druid, Pinot |
| 实时应用 | Streamlit, Dash, 自定义Dashboard |
### 4.3 适用场景
- 实时用户体验优化
- 风控和反欺诈系统
- 实时推荐系统
- 实时业务监控大屏
## 5. 微服务数据分析架构
微服务架构下的数据分析需要特殊设计。
### 5.1 架构组成

主要包括:
- **服务埋点层**: 在各微服务中进行埋点
- **日志聚合层**: 收集并聚合各服务日志
- **数据处理层**: 清洗、转换、聚合数据
- **统一查询层**: 提供跨服务的统一查询能力
### 5.2 技术组件
| 组件 | 常用技术 |
|------|---------|
| 埋点 | OpenTelemetry, SkyWalking, Jaeger |
| 日志聚合 | ELK Stack, Loki, Graylog |
| 数据处理 | Spark, Flink, dbt |
| 统一查询 | Presto, Trino, Calcite |
### 5.3 适用场景
- 微服务架构下的用户行为分析
- 服务性能和用户体验关联分析
- 跨服务用户行为路径分析
## 6. SaaS化日志分析架构
利用现成的SaaS服务构建分析系统,降低开发和维护成本。
### 6.1 架构组成

主要包括:
- **埋点SDK**: 集成到应用中的埋点工具
- **日志收集API**: 接收并处理上报的日志数据
- **分析服务**: 提供预置的分析功能
- **可视化界面**: 展示分析结果
### 6.2 技术组件
| 组件 | 常用技术/产品 |
|------|--------------|
| 埋点SDK | Google Analytics, Mixpanel, 神策、GrowingIO |
| 分析服务 | Amplitude, Heap, Firebase Analytics |
| 可视化 | Looker, DataStudio, PowerBI |
| 自定义处理 | AWS Lambda, Google Cloud Functions |
### 6.3 适用场景
- 初创企业或中小型团队
- 快速验证产品假设
- 标准化用户行为分析需求
- 开发资源有限的情况
## 7. 边缘计算+云分析架构
随着IoT设备和边缘计算的发展,边云协同架构逐渐流行。
### 7.1 架构组成

主要包括:
- **边缘设备层**: 收集用户行为数据的终端设备
- **边缘计算层**: 在本地进行初步处理和聚合
- **数据同步层**: 将处理后的数据同步至云端
- **云端分析层**: 进行更复杂的分析计算
### 7.2 技术组件
| 组件 | 常用技术 |
|------|---------|
| 边缘设备 | 移动设备、IoT设备、智能终端 |
| 边缘计算 | AWS Greengrass, Azure IoT Edge |
| 数据同步 | AWS IoT Core, Azure IoT Hub |
| 云端分析 | 云原生数据湖、数据仓库 |
### 7.3 适用场景
- 移动应用用户行为分析
- IoT设备用户交互分析
- 离线场景下的用户行为捕获
- 对实时性和数据主权有较高要求的场景
## 8. 架构选型考虑因素
在选择适合自身业务的用户行为日志分析架构时,需要考虑以下因素:
### 8.1 业务需求
- **数据量**: 日志数据的规模和增长速度
- **实时性要求**: 从数据产生到可分析的最大容忍延迟
- **分析复杂度**: 是简单统计还是复杂的机器学习分析
- **查询模式**: 预定义报表vs自由查询vs即席分析
### 8.2 技术因素
- **技术栈兼容性**: 与现有技术栈的兼容程度
- **扩展性**: 应对数据量增长的能力
- **可靠性**: 系统的容错和恢复能力
- **维护成本**: 运维和升级的难度和成本
### 8.3 组织因素
- **团队技能**: 团队对特定技术的熟悉程度
- **开发资源**: 可投入的开发和运维人力
- **预算约束**: 基础设施和许可证成本
- **时间限制**: 系统上线的时间要求
## 9. 架构演进路径
大多数企业的用户行为分析架构会随业务发展而演进:
1. **初始阶段**: 使用现成SaaS解决方案快速启动
2. **成长阶段**: 构建简单的自有日志收集和分析系统
3. **扩展阶段**: 引入Lambda或Kappa架构,增强实时性
4. **成熟阶段**: 建立完整的数据湖/仓混合架构
5. **优化阶段**: 针对特定业务场景进行架构优化
## 10. 未来趋势
用户行为日志分析架构的未来发展趋势:
- **流批一体**: 流处理和批处理融合,简化架构
- **AI驱动**: 引入更多机器学习和人工智能技术
- **隐私合规**: 加强数据隐私保护和合规性设计
- **低代码平台**: 降低构建分析系统的技术门槛
- **多云/混合云**: 跨云环境的统一数据分析能力
相关文章:

用户行为日志分析的常用架构
## 1. 经典Lambda架构 Lambda架构是一种流行的大数据处理架构,特别适合用户行为日志分析场景。 ### 1.1 架构组成 Lambda架构包含三层: - **批处理层(Batch Layer)**: 存储全量数据并进行离线批处理 - **实时处理层(Speed Layer)**: 处理最新数据&…...
初识 java
目录 前言 一、jdk,JRE和JVM之间的关系 二、JVM的内存划分 前言 初步了解 jdk,JRE,JVM 之间的关系,JVM 的内存划分。 一、jdk,JRE和JVM之间的关系 jdk 是 java 开发工具集,包含JRE; JRE 是…...
简介)
3D 数据交换格式(.3DXML)简介
3DXML 是一种基于 XML 的 3D 数据交换格式,由达索系统(Dassault Systmes)开发,主要用于其 CATIA、SOLIDWORKS 和 3DEXPERIENCE 等产品中。 基本概述 全称:3D XML开发者:达索系统主要用途:3D…...
frida 配置
1.环境 1.1 下载 frida-server firda-server github下载地址 这边推荐使用最新版的上一个版本 根据虚拟机自行选择版本 我使用这个版本 frida-server-16.7.17-android-x86_64 1.2 启动 frida-server-16.7.17-android-x86_64 将文件解压至虚拟机目录 使用adb命令执行 chmo…...

16-看门狗和RTC
一、独立看门狗 1、独立看门狗概述 在由单片机构成的微型计算机系统中,由于单片机的工作常常会受到来自外界电磁场的干扰,造成程序的跑飞(不按照正常程序进行运行,如程序重启,但是如果我们填加看门狗的技术࿰…...
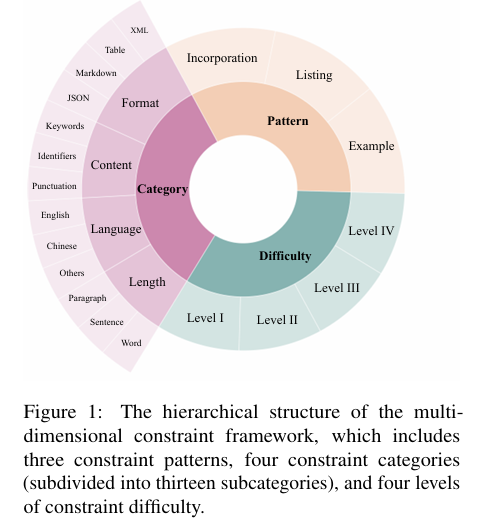
【AI论文】用于评估和改进大型语言模型中指令跟踪的多维约束框架
摘要:接下来的指令评估了大型语言模型(LLMs)生成符合用户定义约束的输出的能力。 然而,现有的基准测试通常依赖于模板化的约束提示,缺乏现实使用的多样性,并限制了细粒度的性能评估。 为了填补这一空白&…...

AUTOSAR图解==>AUTOSAR_SRS_TimeService
AUTOSAR TimeService模块详解 AUTOSAR经典平台时间服务分析与图解 目录 1. 概述2. TimeService架构分析 2.1 模块位置与组件关系2.2 模块功能职责3. TimeService组件结构 3.1 预定义定时器类型3.2 时间函数功能3.3 与GPT驱动关系4. TimeService定时器实例 4.1 实例数据结构4.2 …...

设计模式的原理及深入解析
创建型模式 创建型模式主要关注对象的创建过程,旨在通过不同的方式创建对象,以满足不同的需求。 工厂方法模式 定义:定义一个创建对象的接口,让子类决定实例化哪一个类。 解释:工厂方法模式通过定义一个创建对象的…...
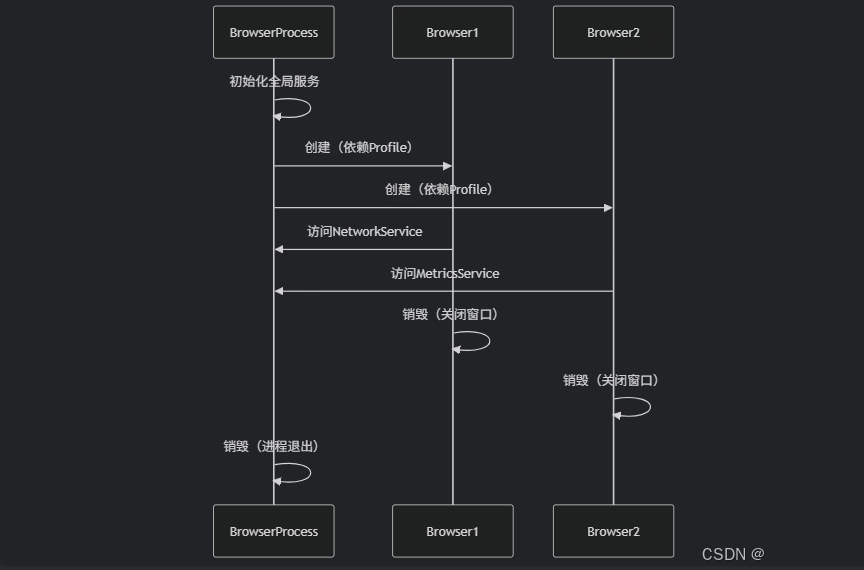
Chromium 浏览器核心生命周期剖析:从 BrowserProcess 全局管理到 Browser 窗口实例
在 Chromium 浏览器架构中,BrowserProcess 和 Browser 是两个核心类,分别管理 浏览器进程的全局状态 和 单个浏览器窗口的实例。它们的生命周期设计直接影响浏览器的稳定性和资源管理。以下是它们的详细生命周期分析: 1. BrowserProcess 的生…...
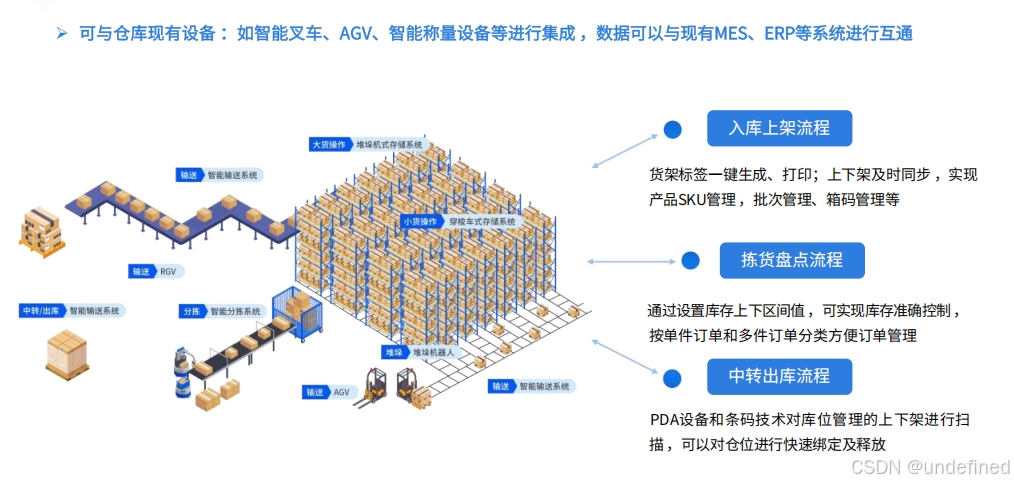
易境通海外仓系统:一件代发全场景数字化解决方案
随着全球经济一体化和消费升级,一件代发业务的跨境电商市场规模持续增长。然而,一件代发的跨境运营也面临挑战,传统海外仓管理模式更因效率低下、协同困难成为业务扩张的瓶颈。 一、一件代发跨境运营痛点 1、多平台协同:卖家往往…...

Flink 非确定有限自动机NFA
Flink 是一个用于状态化计算的分布式流处理框架,而非确定有限自动机(NFA, Non-deterministic Finite Automaton)是一种在计算机科学中广泛使用的抽象计算模型,常用于正则表达式匹配、模式识别等领域。 Apache Flink 提供了对 NFA…...

YoloV9改进策略:卷积篇|风车卷积|即插即用
论文信息 论文标题:《Pinwheel-shaped Convolution and Scale-based Dynamic Loss for Infrared Small Target Detection》 论文链接:https://arxiv.org/pdf/2412.16986 GitHub链接:https://github.com/JN-Yang/PConv-SDloss-Data 论文翻译 摘要 https://arxiv.org/pd…...

【Python训练营打卡】day30 @浙大疏锦行
DAY 30 模块和库的导入 知识点回顾: 1. 导入官方库的三种手段 2. 导入自定义库/模块的方式 3. 导入库/模块的核心逻辑:找到根目录(python解释器的目录和终端的目录不一致) 作业:自己新建几个不同路径文件尝试下如何…...

超越想象:利用MetaGPT打造高效的AI协作环境
前言 在人工智能迅速发展的今天,如何让多个大语言模型(LLM)高效协同工作成为关键挑战。MetaGPT 作为一种创新的多智能体框架,成功模拟了一个真实软件公司的运作流程,实现了从需求分析到代码实现的全流程自动化&#x…...

仿腾讯会议——添加音频
1、实现开启或关闭音频 2、 定义信号 3、实现开始暂停音频 4、实现信号槽连接 5、回收资源 6、初始化音频视频 7、 完成为每个人创建播放音频的对象 8、发送音频 使用的是对象ba,这样跨线程不会立刻回收,如果使用引用,跨线程会被直接回收掉&a…...

虚幻引擎5-Unreal Engine笔记之`GameMode`、`关卡(Level)` 和 `关卡蓝图(Level Blueprint)`的关系
虚幻引擎5-Unreal Engine笔记之GameMode、关卡(Level) 和 关卡蓝图(Level Blueprint)的关系 code review! 参考笔记: 1.虚幻引擎5-Unreal Engine笔记之GameMode、关卡(Level) 和 关卡蓝图&…...

vue3 vite 项目中自动导入图片
vue3 vite 项目中自动导入图片 安装插件配置插件使用方法 安装插件 yarn add vite-plugin-vue-images -D 或者 npm install vite-plugin-vue-images -D配置插件 在 vite.config.js 文件中配置插件 // 引入 import ViteImages from vite-plugin-vue-images;plugins: [vue(),/…...

MTK zephyr平台:系统休眠流程
一、概述: 当内核没有需要调度的东西时,就会进入空闲状态。 CONFIG_PM=y时允许内核调用PM subsys,将空闲系统置于支持的电源状态之一。 Application负责设置唤醒事件,该事件通常是由SoC外围模块触发的中断,例如: SysTick、RTC、计数器、GPIO 并非所有外设在所有电源模式…...

涨薪技术|0到1学会性能测试第71课-T-SQL调优
前面的推文我们掌握了索引调优技术,今天给大家分享T-SQL调优技术。后续文章都会系统分享干货,带大家从0到1学会性能测试。 对T-SQL语句进行调校是DBA调优数据库性能的主要任务,因为不同的查询语句,即使查询出来的结果一致,其消耗的时间和系统资源也有所不同,所以如何使查…...

Spark SQL 之 Antlr grammar 具体分析
src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBaseLexer.g4 BACKQUOTED_IDENTIFIER: ` ( ~` | `` )* `;src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBaseParser.g4 queryPrimary:...

Python----目标检测(PASCAL VOC数据集)
一、PASCAL VOC数据集 PASCAL VOC(Visual Object Classes)数据集是计算机视觉领域中广泛使用的一个 标准数据集,用于目标检测、图像分割、图像分类、动作识别等任务。该数据集由 PASCAL(Pattern Analysis, Statistical Modelling …...
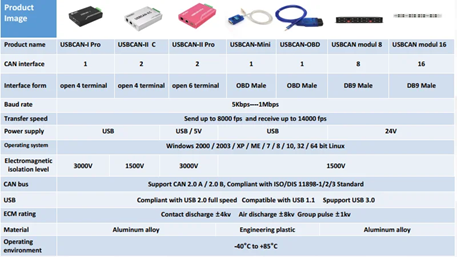
LabVIEW汽车CAN总线检测系统开发
CAN(ControllerArea Network)总线作为汽车电子系统的核心通信协议,广泛应用于动力总成、车身控制、辅助驾驶等系统。基于 LabVIEW 开发 CAN 总线检测系统,可充分利用其图形化编程优势、丰富的硬件接口支持及强大的数据分析能力&am…...
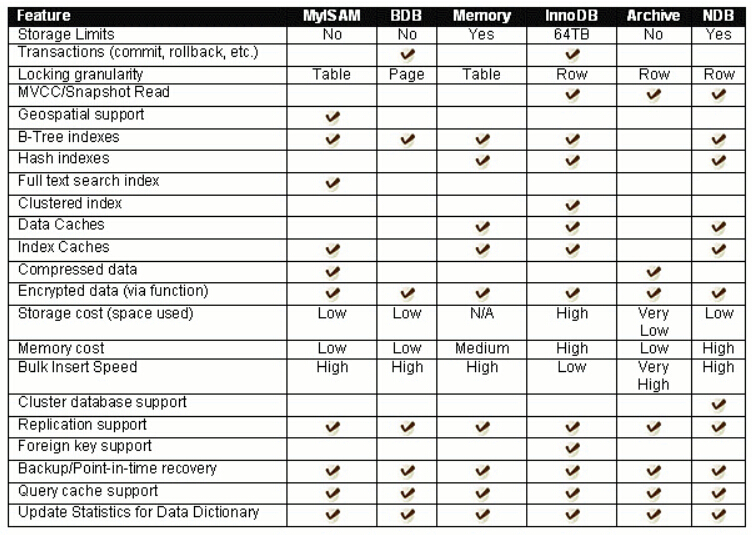
MySQL数据库基础 -- SQL 语句的分类,存储引擎
目录 1. 什么是数据库 2. 基本使用 2.1 进入 mysql 2.2 服务器、数据库以及表的关系 2.3 使用案例 2.4 数据逻辑存储 3. SQL 语句分类 4. 存储引擎 4.1 查看存储引擎 4.2 存储引擎的对比 1. 什么是数据库 安装完 MySQL 之后,会有 mysql 和 mysqld。 MySQL …...
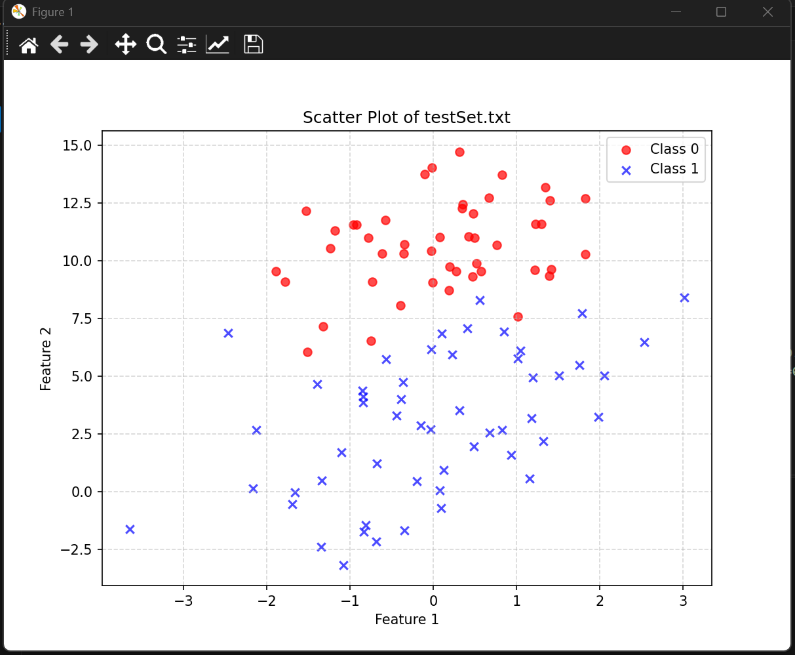
二元Logistic回归
二元Logistic回归 在机器学习领域,二元Logistic回归是一种非常经典的分类模型,广泛用于解决具有两类标签的分类问题。Logistic回归通过逻辑函数(Sigmoid函数)将预测结果映射到概率值,并进行分类。 一、Logistic回归 …...

如何从容应对面试?
引言 简历通过了,终于获得这次来之不易面试机会的你,是不是又在思考以下问题:基本礼仪都包括哪些方面?如何在群面中打动面试官?有什么注意事项?在面试的过程中,我们不单单要懂得面试技巧&#…...

如何使用GIT管理项目代码
介绍 Git是目前世界上最流行甚至最好的开源分布式版本控制系统,不论是很小的项目还是很大的项目,它都能有效并且高效的处理项目版本管理,初衷是为了帮助管理linux内核代码而开发的一个开放源码的版本控制软件。 GIT常用分支名称 分支分…...
RHCE 练习三:架设一台 NFS 服务器
一、题目要求 1、开放 /nfs/shared 目录,供所有用户查询资料 2、开放 /nfs/upload 目录,为 192.168.xxx.0/24 网段主机可以上传目录,并将所有用户及所属的组映射为 nfs-upload,其 UID 和 GID 均为 210 3.将 /home/tom 目录仅共享给 192.16…...

【android bluetooth 协议分析 01】【HCI 层介绍 9】【ReadLocalSupportedCommands命令介绍】
1. HCI_Read_Local_Supported_Commands 命令介绍 1. 命令介绍(Description) HCI_Read_Local_Supported_Commands 是 HCI 层中非常重要的查询命令。它允许 Host(如 Android 系统中的 Bluetooth stack)获取 Controller(…...

stm32实战项目:无刷驱动
目录 系统时钟配置 PWM模块初始化 ADC模块配置 霍尔接口配置 速度环定时器 换相逻辑实现 主控制循环 系统时钟配置 启用72MHz主频:RCC_Configuration()设置PLL外设时钟使能:TIM1/ADC/GPIO时钟 #include "stm32f10x.h"void RCC_Configu…...
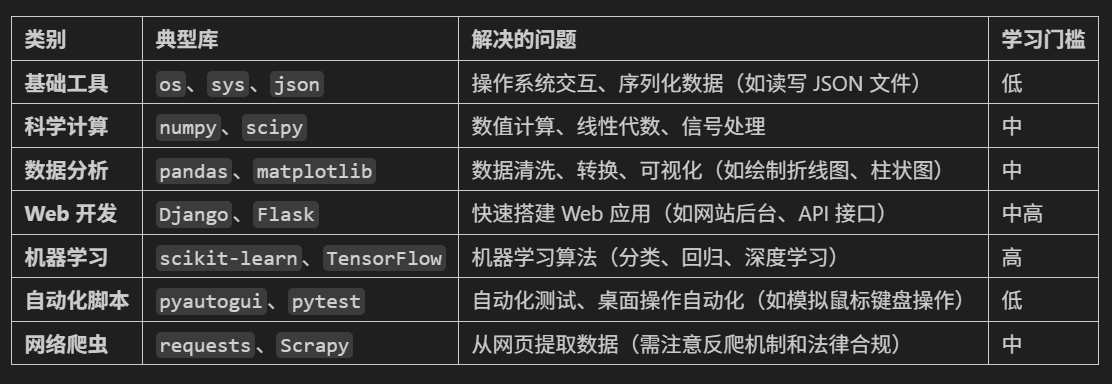
python打卡训练营打卡记录day30
一、导入官方库 我们复盘下学习python的逻辑,所谓学习python就是学习python常见的基础语法学习你所处理任务需要用到的第三方库。 1.1标准导入:导入整个库 这是最基本也是最常见的导入方式,直接使用import语句。 # 方式1:导入整…...