构建共有语料库 - Wiki 语料库
中文Wiki语料库主要指的是从中文Wikipedia(中文维基百科)提取的文本数据。维基百科是一个自由的、开放编辑的百科全书项目,覆盖了从科技、历史到文化、艺术等广泛的主题。
对于基于RAG的应用来说,把Wiki语料作为一个公有的语料库去更新大模型的知识时效,是非常有价值的,能够极大地提升模型的性能和应用范围。
-
Step 1. 首先,准备下 中文 的Wiki语料库
中文wiki语料库链接:Index of /zhwiki/latest/
外网下载,需执行以下命令进行学术加速:
export http_proxy=http://172.168.1.240:4080export https_proxy=http://172.168.1.240:4080 
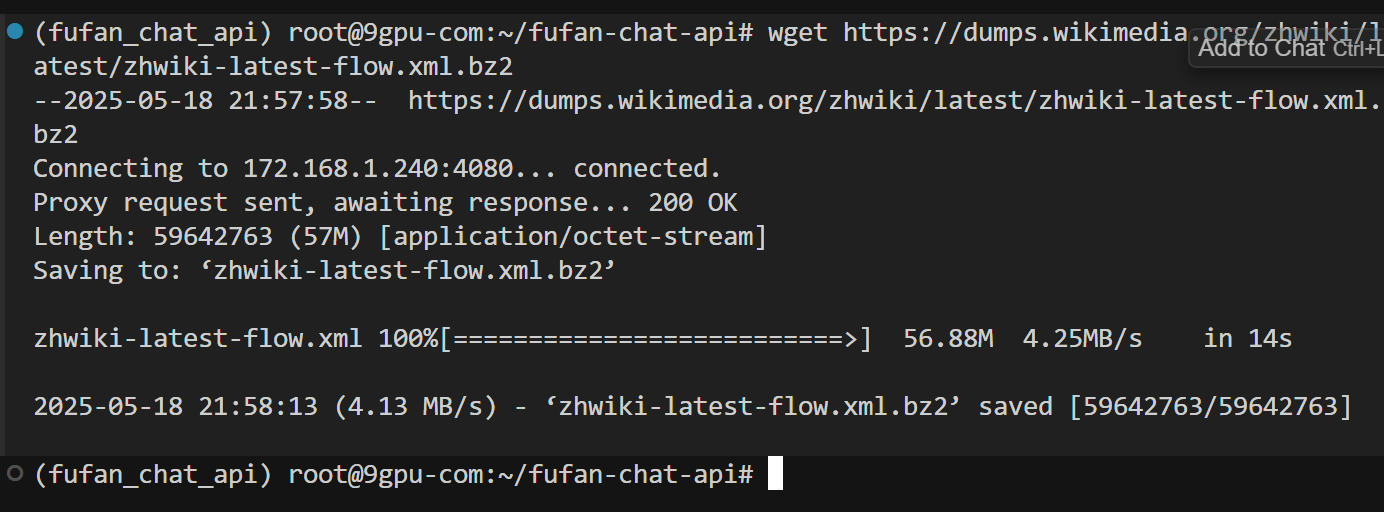
选择自己需要的压缩文件复制好下载链接后,在命令行终端执行代码:
wget https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-flow.xml.bz2文件将下载到当前目录下
-
Step 2. 执行前,安装第三方依赖包wikiextractor
WikiExtractor 是一个用于从维基百科等维基媒体项目的数据库 dumps 中提取文本的工具。做文本预处理和数据清洗。
pip install wikiextractor==0.1
-
Step 3. 下载文本处理模型
# 执行下载代码
python -m spacy download zh_core_web_lg-
Step 4. 查看数据处理脚本存放位置:/scripts/preprocess_wiki.py
import argparse
from tqdm import tqdm
import re
import html
import spacy
import os
import json
import subprocess
from pathlib import Path
import shutil
from concurrent.futures import ThreadPoolExecutor
from multiprocessing import Pool
import os
import jsondef load_corpus(dir_path):"""该函数从给定目录路径读取 .jsonl 文件,提取其文本字段中包含指定关键词的 JSON 条目。一旦语料库中的条目数量达到 设定的值 ,就停止添加。此外,它还利用多线程来加速文件处理。"""# 定义要在文本文件中查找的关键词列表keywords = ['智能教育','大模型','机器学习','深度学习','算法','自然语言处理']def iter_files(path):"""遍历位于根路径下的所有文件。"""if os.path.isfile(path):# 如果路径是文件,直接返回该文件yield pathelif os.path.isdir(path):# 如果路径是目录,遍历该目录中的每个文件for dirpath, _, filenames in os.walk(path):for f in filenames:yield os.path.join(dirpath, f)else:# 如果路径既不是目录也不是文件,抛出错误raise RuntimeError('Path %s is invalid' % path)def read_jsonl_file(file_path):"""读取 .jsonl 文件的行,并将相关数据添加到语料库中。"""with open(file_path, 'r', encoding='utf-8') as f:for line in f:json_data = json.loads(line)# 检查 JSON 数据的文本字段中是否包含任何关键词if any(keyword in json_data['text'] for keyword in keywords):corpus.append(json_data)# 如果语料库大小达到 100,停止添加if len(corpus) == 100:break# 从目录中收集所有文件路径all_files = [file for file in iter_files(dir_path)]# 初始化语料库列表corpus = []# 使用 ThreadPoolExecutor 并行读取文件with ThreadPoolExecutor(max_workers=args.num_workers) as executor:# 提交任务以读取每个文件for file_path in all_files:executor.submit(read_jsonl_file, file_path)# 返回填充好的语料库return corpusdef create_segments(doc_text, max_length, stride):"""数据预处理,在处理需要特定输入长度限制的NLP模型时,如某些类型的文本分类或语言理解模型。通过控制 max_length 和 stride 参数,可以灵活调整每个文本段的长度和重叠程度,以适应不同的处理需求。"""# 去除文档文本的首尾空白字符doc_text = doc_text.strip()# 使用NLP工具SpaCy解析文本,得到文档对象doc = nlp(doc_text)# 从文档对象中提取句子,并去除每个句子的首尾空格sentences = [sent.text.strip() for sent in doc.sents]# 初始化一个空列表,用于存储所有生成的文本段落segments = []# 使用步长 stride 遍历句子列表的索引for i in range(0, len(sentences), stride):# 将从当前索引开始的 max_length 个句子连接成一个字符串segment = " ".join(sentences[i:i + max_length])# 将构建的段落添加到列表中segments.append(segment)# 如果当前索引加上最大长度超过了句子列表的长度,停止循环if i + max_length >= len(sentences):break# 返回包含所有段落的列表return segmentsdef basic_process(title, text):# 使用html.unescape函数来解码HTML实体,恢复文本中的特殊字符title = html.unescape(title)text = html.unescape(text)# 删除文本首尾的空白字符text = text.strip()# # 如果标题含有特定的消歧义标记,则不处理这类页面if '(disambiguation)' in title.lower():return None, Noneif '(disambiguation page)' in title.lower():return None, None# 排除以列表、索引或大纲开头的页面,这些页面大多只包含链接if re.match(r'(List of .+)|(Index of .+)|(Outline of .+)',title):return None, None# 排除重定向页面if text.startswith("REDIRECT") or text.startswith("redirect"):return None, None# 如果文本以 ". References." 结尾,则删除该部分if text.endswith(". References."):text = text[:-len(" References.")].strip()# 删除文本中的特定格式标记,如引用标记text = re.sub('\{\{cite .*?\}\}', ' ', text, flags=re.DOTALL)# 替换或删除不必要的格式和标签text = text.replace(r"TABLETOREPLACE", " ")text = text.replace(r"'''", " ")text = text.replace(r"[[", " ")text = text.replace(r"]]", " ")text = text.replace(r"{{", " ")text = text.replace(r"}}", " ")text = text.replace("<br>", " ")text = text.replace(""", "\"")text = text.replace("&", "&")text = text.replace("& amp;", "&")text = text.replace("nbsp;", " ")text = text.replace("formatnum:", "")# 删除特定HTML标签内的文本,如<math>, <chem>, <score>text = re.sub('<math.*?</math>', '', text, flags=re.DOTALL)text = re.sub('<chem.*?</chem>', '', text, flags=re.DOTALL)text = re.sub('<score.*?</score>', '', text, flags=re.DOTALL)# 使用正则表达式删除样式相关的属性,例如:item_style, col_style等text = re.sub('\| ?item[0-9]?_?style= ?.*? ', ' ', text)text = re.sub('\| ?col[0-9]?_?style= ?.*? ', ' ', text)text = re.sub('\| ?row[0-9]?_?style= ?.*? ', ' ', text)text = re.sub('\| ?style= ?.*? ', ' ', text)text = re.sub('\| ?bodystyle= ?.*? ', ' ', text)text = re.sub('\| ?frame_?style= ?.*? ', ' ', text)text = re.sub('\| ?data_?style= ?.*? ', ' ', text)text = re.sub('\| ?label_?style= ?.*? ', ' ', text)text = re.sub('\| ?headerstyle= ?.*? ', ' ', text)text = re.sub('\| ?list_?style= ?.*? ', ' ', text)text = re.sub('\| ?title_?style= ?.*? ', ' ', text)text = re.sub('\| ?ul_?style= ?.*? ', ' ', text)text = re.sub('\| ?li_?style= ?.*? ', ' ', text)text = re.sub('\| ?border-style= ?.*? ', ' ', text)text = re.sub('\|? ?style=\".*?\"', '', text)text = re.sub('\|? ?rowspan=\".*?\"', '', text)text = re.sub('\|? ?colspan=\".*?\"', '', text)text = re.sub('\|? ?scope=\".*?\"', '', text)text = re.sub('\|? ?align=\".*?\"', '', text)text = re.sub('\|? ?valign=\".*?\"', '', text)text = re.sub('\|? ?lang=\".*?\"', '', text)text = re.sub('\|? ?bgcolor=\".*?\"', '', text)text = re.sub('\|? ?bg=\#[a-z]+', '', text)text = re.sub('\|? ?width=\".*?\"', '', text)text = re.sub('\|? ?height=[0-9]+', '', text)text = re.sub('\|? ?width=[0-9]+', '', text)text = re.sub('\|? ?rowspan=[0-9]+', '', text)text = re.sub('\|? ?colspan=[0-9]+', '', text)text = re.sub(r'[\n\t]', ' ', text)text = re.sub('<.*?/>', '', text)text = re.sub('\|? ?align=[a-z]+', '', text)text = re.sub('\|? ?valign=[a-z]+', '', text)text = re.sub('\|? ?scope=[a-z]+', '', text)text = re.sub('<ref>.*?</ref>', ' ', text)text = re.sub('<.*?>', ' ', text)text = re.sub('File:[A-Za-z0-9 ]+\.[a-z]{3,4}(\|[0-9]+px)?', '', text)text = re.sub('Source: \[.*?\]', '', text)# 清理可能因XML导出错误而残留的格式标签# 使用正则表达式匹配并替换各种样式相关的属性text = text.replace("Country flag|", "country:")text = text.replace("flag|", "country:")text = text.replace("flagicon|", "country:")text = text.replace("flagcountry|", "country:")text = text.replace("Flagu|", "country:")text = text.replace("display=inline", "")text = text.replace("display=it", "")text = text.replace("abbr=on", "")text = text.replace("disp=table", "")title = title.replace("\n", " ").replace("\t", " ")return title, textdef split_list(lst, n):"""将一个列表分割成 n 个大致相等的部分。"""# k 是每个部分的基本大小,m 是 len(lst) 除以 n 的余数k, m = divmod(len(lst), n)# 使用列表推导来生成子列表# 计算每个部分的起始和结束索引return [lst[i * k + min(i, m):(i + 1) * k + min(i + 1, m)] for i in range(n)]def single_worker(docs):"""处理一个文档列表,对每个文档应用清洗和格式化操作。"""# 初始化结果列表,用于存储处理后的文档results = []# 遍历文档列表,使用 tqdm 库显示进度条for item in tqdm(docs):# 应用基础处理函数 basic_process 来处理每个文档的标题和文本title, text = basic_process(item[0], item[1])# 如果处理后的标题是 None(可能因为文档不符合处理要求),则跳过当前循环if title is None:continue# 格式化标题,加上双引号title = f"\"{title}\""# 将处理和格式化后的标题和文本以元组形式添加到结果列表中results.append((title, text))return resultsif __name__ == '__main__':parser = argparse.ArgumentParser(description='Generate clean wiki corpus file for indexing.')parser.add_argument('--dump_path', type=str)parser.add_argument('--seg_size', default=None, type=int)parser.add_argument('--stride', default=None, type=int)parser.add_argument('--num_workers', default=4, type=int)parser.add_argument('--save_path', type=str, default='clean_corpus.jsonl')args = parser.parse_args()# 设置临时目录用于存储WikiExtractor的输出temp_dir = os.path.join(Path(args.save_path).parent, 'temp')# 创建临时目录os.makedirs(temp_dir)# 使用wikiextractor从维基百科转储中提取文本,输出为JSON格式,过滤消歧义页面subprocess.run(['python', '-m','wikiextractor.WikiExtractor','--json', '--filter_disambig_pages', '--quiet','-o', temp_dir,'--process', str(args.num_workers),args.dump_path])# 载入处理后的语料库corpus = load_corpus(temp_dir)# 加载Spacy中文模型nlp = spacy.load("zh_core_web_lg")# 初始化一个字典来存储文档,以避免页面重复documents = {}# 使用tqdm显示进度条for item in tqdm(corpus):title = item['title']text = item['text']# # 检查标题是否已存在于字典中,以合并同一个标题下的不同部分if title in documents:documents[title] += " " + textelse:documents[title] = text# 开始预处理文本print("Start pre-processing...")documents = list(documents.items())# 使用Python的多进程库,创建进程池进行并行处理with Pool(processes=args.num_workers) as p:result_list = list(tqdm(p.imap(single_worker, split_list(documents,args.num_workers))))result_list = sum(result_list, [])all_title = [item[0] for item in result_list]all_text = [item[1] for item in result_list]print("Start chunking...")idx = 0clean_corpus = []# 使用spaCy的pipe方法进行高效的文本处理,指定进程数和批处理大小for doc in tqdm(nlp.pipe(all_text, n_process=args.num_workers, batch_size=10), total=len(all_text)):# 获取当前文档的标题title = all_title[idx]# 索引递增,指向下一个标题idx += 1# 初始化段落列表segments = []# 初始化单词计数器word_count = 0# 初始化段落的token列表segment_tokens = []# 遍历文档中的每个tokenfor token in doc:# token(包括空格)添加到段落令牌列表segment_tokens.append(token.text_with_ws)# 如果令牌不是空格也不是标点if not token.is_space and not token.is_punct:# 单词计数加一word_count+=1# 如果单词计数达到100,则重置计数器,生成一个新段落if word_count == 100:word_count = 0segments.append(''.join([token for token in segment_tokens]))segment_tokens = []# 检查最后是否还有剩余的单词没有形成完整段落if word_count != 0:for token in doc:segment_tokens.append(token.text_with_ws)if not token.is_space and not token.is_punct:word_count+=1if word_count == 100:word_count = 0segments.append(''.join([token for token in segment_tokens]))break# 检查最后一组token是否已添加到segmentsif word_count != 0:segments.append(''.join([token for token in segment_tokens]))for segment in segments:text = segment.replace("\n", " ").replace("\t", " ")# 将处理后的标题和文本以字典形式添加到清洗后的语料库列表clean_corpus.append({"title": title, "text": text})# 删除临时目录及其内容shutil.rmtree(temp_dir)print("Start saving corpus...")# 检查保存路径的目录是否存在,如果不存在则创建os.makedirs(os.path.dirname(args.save_path), exist_ok=True)# 打开指定的文件路径进行写入,设置编码为utf-8with open(args.save_path, "w", encoding='utf-8') as f:# 遍历清洗后的语料库列表,每个元素都是一个包含标题和文本的字典for idx, item in enumerate(clean_corpus):# 将字典转换为JSON字符串格式,确保使用UTF-8编码来处理Unicode字符json_string = json.dumps({'id': idx, # 添加唯一ID'title': item['title'], # 文章标题'contents': item['text'] # 文章内容}, ensure_ascii=False) # 确保不将Unicode字符编码为ASCII# 将JSON字符串写入文件,并在每个条目后添加换行符f.write(json_string + '\n')print("Finish!")
-
Step 5. 定制化修改
-
Step 6. 执行数据处理脚本,将 wiki 数据转储处理成 JSONL 格式。
cd fufan-chat-api/scripts
conda activate fufan_chat_api
python preprocess_wiki.py# 这里是 存放 wiki 原始数据的绝对路径 --dump_path /root/fufan-chat-api/zhwiki-latest-flow.xml.bz2# 这里是 处理完文本的存储路径--save_path /root/fufan-chat-api/knowledge_base/wiki/education.jsonlpython preprocess_wiki.py --dump_path /root/fufan-chat-api/zhwiki-latest-flow.xml.bz2 --save_path /root/fufan-chat-api/knowledge_base/wiki/education.jsonl
相关文章:
构建共有语料库 - Wiki 语料库
中文Wiki语料库主要指的是从中文Wikipedia(中文维基百科)提取的文本数据。维基百科是一个自由的、开放编辑的百科全书项目,覆盖了从科技、历史到文化、艺术等广泛的主题。 对于基于RAG的应用来说,把Wiki语料作为一个公有的语料库…...
苍穹外卖项目中的 WebSocket 实战:实现来单与催单提醒功能
🚀 苍穹外卖项目中的 WebSocket 实战:实现来单与催单提醒功能 在现代 Web 应用中,实时通信成为提升用户体验的关键技术之一。WebSocket 作为一种在单个 TCP 连接上进行全双工通信的协议,被广泛应用于需要实时数据交换的场景&#…...
:移情阶段的深度博弈——如何避开客户访谈的认知陷阱)
精益数据分析(59/126):移情阶段的深度博弈——如何避开客户访谈的认知陷阱
精益数据分析(59/126):移情阶段的深度博弈——如何避开客户访谈的认知陷阱 在创业的移情阶段,客户访谈是挖掘真实需求的核心手段,但人类认知偏差往往导致数据失真。今天,我们结合《精益数据分析》的方法论…...
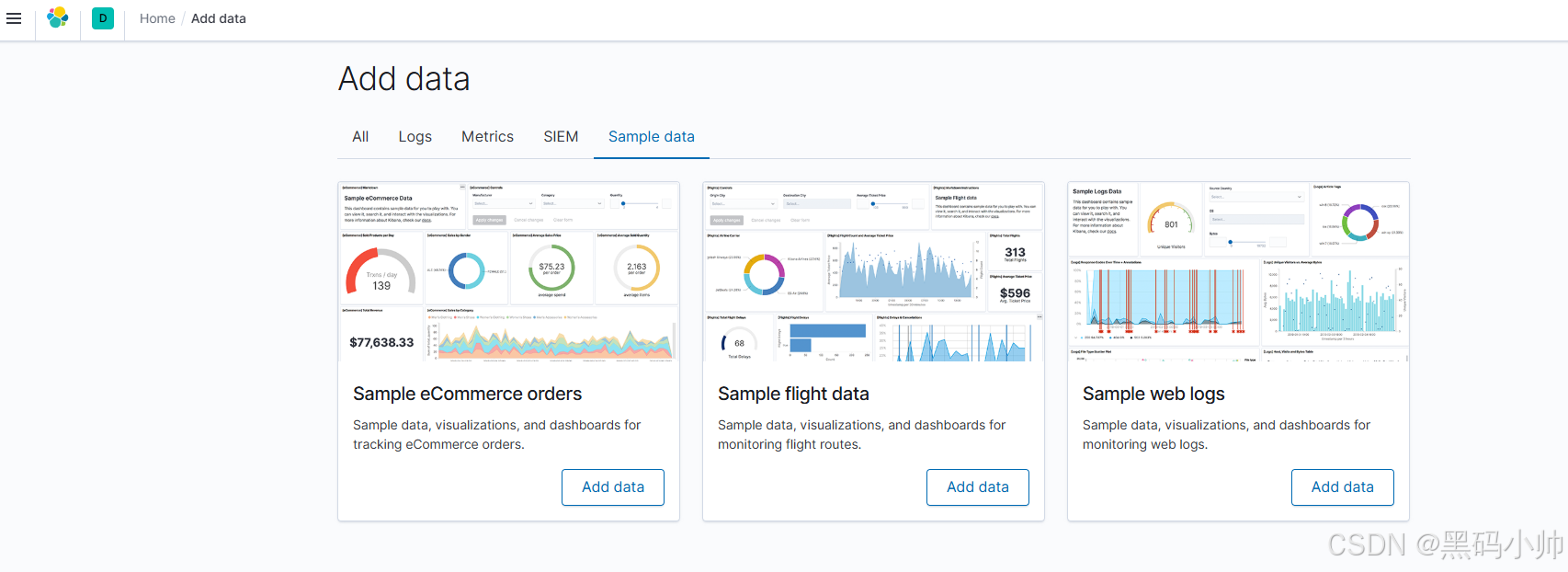
Win10 安装单机版ES(elasticsearch),整合IK分词器和安装Kibana
一. 先查看本机windows是否安装了ES(elasticsearch),检查方法如下: 检查进程 按 Ctrl Shift Esc 组合键打开 “任务管理器”。在 “进程” 选项卡中,查看是否有 elasticsearch 相关进程。如果有,说明系统安装了 ES。 检查端口…...

Ansible模块——主机名设置和用户/用户组管理
设置主机名 ansible.builtin.hostname: name:要设置的主机名 use:更新主机名的方式(默认会自动选择,不指定的话,物理机一般不会有问题,容器可能会有问题,一般是让它默认选择) syst…...

【Redis】List 列表
文章目录 初识列表常用命令lpushlpushxlrangerpushrpushxlpop & rpoplindexlinsertllen阻塞操作 —— blpop & brpop 内部编码应用场景 初识列表 列表类型,用于存储多个字符串。在操作和实现上,类似 C 的双端队列,支持随机访问(O(N)…...
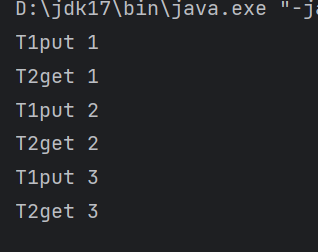
JUC入门(四)
ReadWriteLock 代码示例: package com.yw.rw;import java.util.HashMap; import java.util.Map; import java.util.concurrent.locks.ReentrantReadWriteLock;public class ReadWriteDemo {public static void main(String[] args) {MyCache myCache new MyCache…...
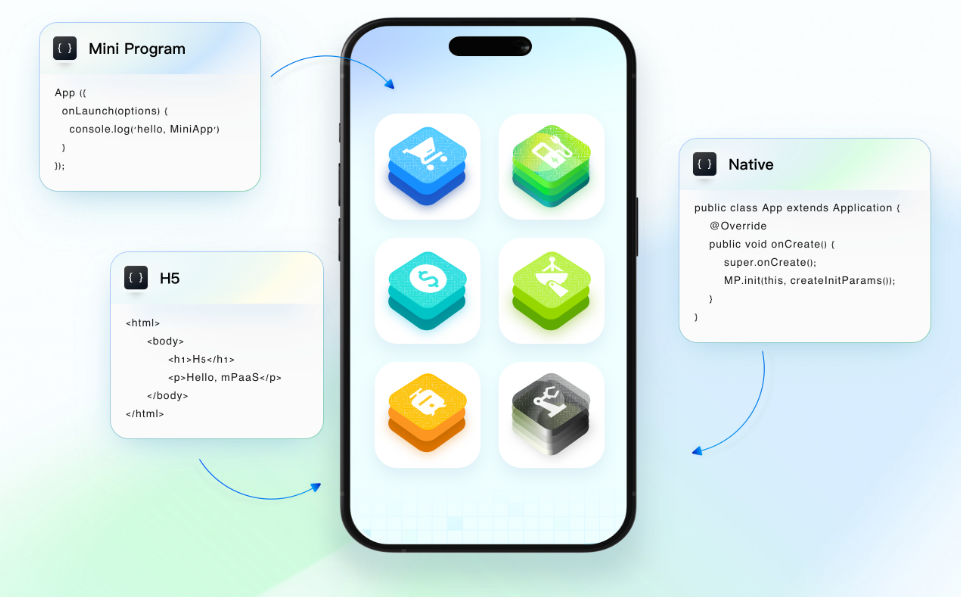
【HarmonyOS 5】鸿蒙mPaaS详解
【HarmonyOS 5】鸿蒙mPaaS详解 一、mPaaS是什么? mPaaS 是 Mobile Platform as a Service 的缩写,即移动开发平台。 蚂蚁移动开发平台mPaaS ,融合了支付宝科技能力,可以为移动应用开发、测试、运营及运维提供云到端的一站式解决…...

多线BGP服务器优化实践与自动化运维方案
背景:企业级网络架构中的线路选择难题 在分布式业务部署场景下,如何通过三网融合BGP服务器实现低延迟、高可用访问?本文以某电商平台流量调度优化为案例,解析动态BGP服务器的实战价值。 技术方案设计 核心架构:采用…...

无法加载文件 E:\Program Files\nodejs\npm.ps1,因为在此系统上禁止运行脚本
遇到“无法加载文件 E:\Program Files\nodejs\npm.ps1,因为在此系统上禁止运行脚本”这类错误,通常是因为你的 PowerShell 执行策略设置为不允许运行脚本。在 Windows 系统中,默认情况下,出于安全考虑,PowerShell 可能会阻止运行未…...
【C++模板与泛型编程】实例化
目录 一、模板实例化的基本概念 1.1 什么是模板实例化? 1.2 实例化的触发条件 1.3 实例化的类型 二、隐式实例化 2.1 隐式实例化的工作原理 2.2 类模板的隐式实例化 2.3 隐式实例化的局限性 三、显式实例化 3.1 显式实例化声明(extern templat…...

TB开拓者策略交易信号闪烁根因及解决方法
TB开拓者策略信号闪烁分析 TB开拓者策略交易信号闪烁根因 TB开拓者策略交易信号闪烁根因分析 信号闪烁是交易策略开发中常见的问题,特别是在TB(TradeBlazer)开拓者等平台上。以下是信号闪烁的主要根因分析: 主要根因 未来函数问题 使用了包含未来信息…...
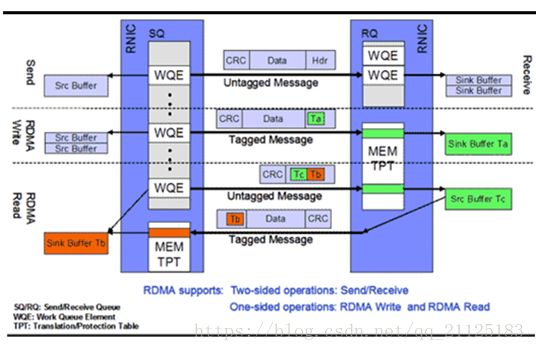
什么是RDMA?
什么是RDMA? RDMA(RemoteDirect Memory Access)技术全称远程直接内存访问,就是为了解决网络传输中服务器端数据处理的延迟而产生的。它将数据直接从一台计算机的内存传输到另一台计算机,无需双方操作系统的介入。这允许高吞吐、低延迟的网络…...

C++面试3——const关键字的核心概念、典型场景和易错陷阱
const关键字的核心概念、典型场景和易错陷阱 一、const本质:类型系统的守护者 1. 与#define的本质差异 维度#defineconst编译阶段预处理替换编译器类型检查作用域无作用域(全局污染)遵循块作用域调试可见性符号消失保留符号信息类型安全无类…...

ASIC和FPGA,到底应该选择哪个?
ASIC和FPGA各有优缺点。 ASIC针对特定需求,具有高性能、低功耗和低成本(在大规模量产时);但设计周期长、成本高、风险大。FPGA则适合快速原型验证和中小批量应用,开发周期短,灵活性高,适合初创企…...

【C++】嵌套类访问外部类成员
文章目录 C嵌套类访问外部类成员详解:权限、机制与最佳实践一、默认访问权限:并非友元二、访问外部类私有成员的方法1. 声明友元关系2. 通过公有接口访问 三、静态成员 vs. 非静态成员四、实际应用案例:Boost.Asio线程池场景需求实现关键代码…...

mac下载、使用mysql
1.如果对版本没有特别要求,那么直接使用brew install mysql安装即可。 2.使用 brew services start mysql 启动mysql。 3.使用 mysql -u root 登录mysql,这个时候还是不需要密码的 4.退出数据库:exit 5.给root设置一个密码,使用 m…...

java Lombok 对象模版和日志注解
目录 1、依赖: 2、在Idea中确认是否安装Lombok 插件 3、 Lombok常用注解 3.1 Getter 和 Setter 3.2 ToString 3.3 AllArgsConstructor 和 NoArgsConstructor 3.4 Data 3.5 FieldDefaults 4、 Slf4j 日志注解 4.2 日志级别 4.3 设置日志级别 1、依赖:…...
Python学习笔记--使用Django操作mysql
注意:本笔记基于python 3.12,不同版本命令会有些许差别!!! Django 模型 Django 对各种数据库提供了很好的支持,包括:PostgreSQL、MySQL、SQLite、Oracle。 Django 为这些数据库提供了统一的调…...

win11下,启动springboot时,提示端口被占用的处理方式
注:此操作可能存在风险!! 在启动springboot时,提示端口被占用。于是执行 #查看所有的占用的端口 netstat -ano | findStr 8080 结果发现并没有什么进程占据8080端口。再次执行: # 查看系统保留端口 netsh int ipv4…...

计算机视觉设计开发工程师学习路线
以下是一条系统化的计算机视觉(CV)学习路线,从基础到进阶,涵盖理论、工具和实践,适合逐步深入,有需要者记得点赞收藏哦: 相关学习:python深度学习,python代码定制 python…...

AI大模型从0到1记录学习numpy pandas day25
第 3 章 Pandas 3.1 什么是Pandas Pandas 是一个开源的数据分析和数据处理库,它是基于 Python 编程语言的。 Pandas 提供了易于使用的数据结构和数据分析工具,特别适用于处理结构化数据,如表格型数据(类似于Excel表格)…...
)
Opencv C++写中文(来自Gemini)
基于与Google Gemini交互获取的Opencv在图片上写汉字的实现 sudo apt-get install libfreetype6-dev sudo apt-get install fonts-wqy-zenhei CMakeLists.txt cmake_minimum_required(VERSION 3.10) # Or a more recent versionproject(OpenCVChineseText)set(CMAKE_CXX_STAN…...

下载和导出文件名称乱码问题
只对文件名称进行乱码处理,和文件中的内容无关。 import lombok.SneakyThrows; import org.springframework.web.context.request.RequestAttributes; import org.springframework.web.context.request.RequestContextHolder; import org.springframework.web.cont…...

STM32实战指南:DHT11温湿度传感器驱动开发与避坑指南
知识点1【DHT11的概述】 1、概述 DHT是一款温湿度一体化的数字传感器(无需AD转换)。 2、驱动方式 通过单片机等微处理器简单的电路连接就能实时采集本地湿度和温度。DHT11与单片机之间采用单总线进行通信,仅需要一个IO口。 相对于单片机…...
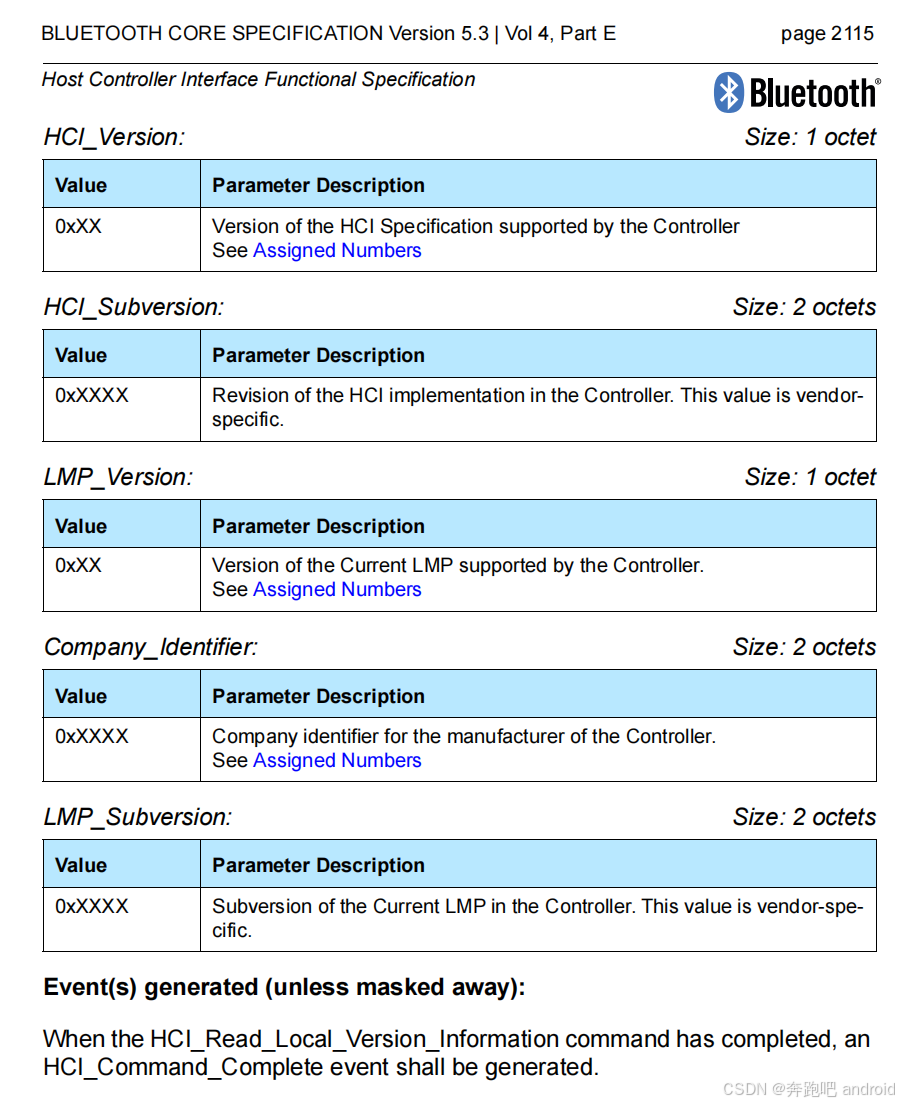
【android bluetooth 协议分析 01】【HCI 层介绍 8】【ReadLocalVersionInformation命令介绍】
1. HCI_Read_Local_Version_Information 命令介绍 1. 功能(Description) HCI_Read_Local_Version_Information 命令用于读取本地 Bluetooth Controller 的版本信息,包括 HCI 和 LMP 层的版本,以及厂商 ID 和子版本号。 这类信息用…...
esp32课设记录(四)摩斯密码的实现 并用mqtt上传
摩斯密码(Morse Code)是一种通过点(.)和划(-)组合来表示字符的编码系统。下面我将在esp32上实现摩斯密码的输入,并能够发送到mqtt的broker。 先捋一下逻辑,首先esp32的按键已经编写了短按与长按功能,这将是输出摩斯密码点和划的基础。然后当2…...
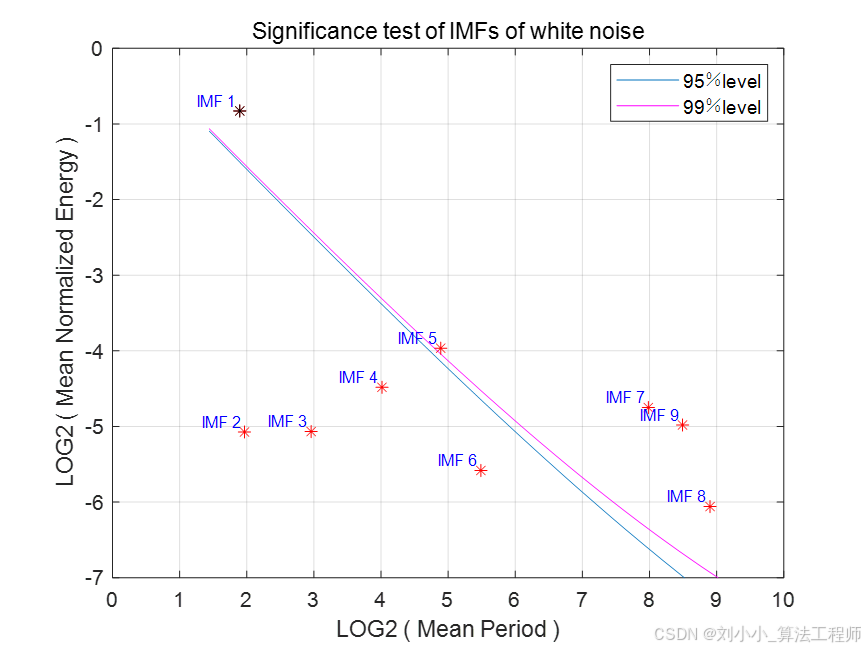
「HHT(希尔伯特黄变换)——ECG信号处理-第十三课」2025年5月19日
一、引言 心电信号(ECG)是反映心脏电活动的重要生理信号,其特征提取对于心脏疾病的诊断和监测具有关键意义。Hilbert - Huang Transform(HHT)作为一种强大的信号处理工具,在心电信号特征提取领域得到了广泛…...
前端(vue)学习笔记(CLASS 6):路由进阶
1、路由的封装抽离 将之前写在main.js文件中的路由配置与规则抽离出来,放置在router/index.js文件中,再将其导入回main.js文件中,即可实现路由的封装抽离 例如 //index.js import { createMemoryHistory, createRouter } from vue-routerim…...

GPT-4.1特点?如何使用GPT-4.1模型,GPT-4.1编码和图像理解能力实例展示
几天前,OpenAI在 API 中推出了三个新模型:GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano。这些模型的性能全面超越 GPT-4o 和 GPT-4o mini(感觉这个GPT-4.1就是GPT-4o的升级迭代版本),主要在编码和指令跟踪方面均有显著提升。还拥有更大的上下文窗口…...