Qwen3 - 0.6B与Bert文本分类实验:深度见解与性能剖析
Changelog
-
[25/04/28] 新增
Qwen3-0.6B在Ag_news数据集Zero-Shot的效果。新增Qwen3-0.6B线性层分类方法的效果。调整Bert训练参数(epoch、eval_steps),以实现更细致的观察,避免严重过拟合的情况。 -
TODO:
- 利用
Qwen3-0.6Bppl、zero-shot筛选难样本,观察Qwen3-0.6B(SFT分类)在不同数据量级,不同数据难度情况下的性能变化。 ppl筛选出的难样本对Qwen33-0.6B(SFT分类)Qwen3-0.6B(线性层分类)影响是否具有同质性。- 不同尺寸模型
Think与No Think状态下Zero-Shot能力变化。 - 使用大模型蒸馏
Think数据,观察Think和No Think模式下对Qwen3-0.6B(SFT分类)性能的影响。 - 测试其他难开源分类数据集(更多分类数、多语言、长样本)。
- 利用
前言
最近在知乎上刷到一个很有意思的提问Qwen3-0.6B这种小模型有什么实际意义和用途。查看了所有回答,有人提到小尺寸模型在边缘设备场景中的优势(低延迟)、也有人提出小模型只是为了开放给其他研究者验证scaling law(Qwen2.5系列丰富的模型尺寸为开源社区验证方法有效性提供了基础)、还有人说4B、7B的Few-Shot效果就已经很好了甚至直接调用更大的LLM也能很好的解决问题。让我比较感兴趣的是有大佬提出小模型在向量搜索、命名实体识别(NER)和文本分类领域中很能打,而另一个被拿来对比的就是Bert模型。在中文文本分类中,若对TextCNN、FastText效果不满意,可能会尝试Bert系列及其变种(RoBerta等)。但以中文语料为主的类Encoder-Only架构模型其实并不多(近期发布的ModernBERT,也是以英文和Code语料为主),中文文本分类还是大量使用bert-base-chinese为基础模型进行微调,而距Bert发布已经过去了6年。Decoder-Only架构的LLM能在文本分类中击败参数量更小的Bert吗?所以我准备做一个实验来验证一下。
不想看实验细节的,可以直接看最后的结论和实验局限性部分。
实验设置
- GPU:RTX 3090(24G)
- 模型配置:
| 模型 | 参数量 | 训练方式 |
|---|---|---|
| google-bert/bert-base-cased | 0.1B | 添加线性层,输出维度为分类数 |
| Qwen/Qwen3-0.6B | 0.6B | 构造Prompt,SFT |
- 数据集配置:fancyzhx/ag_news,分类数为4,分别为World(0)、Sports(1)、Business(2)、Sci/Tech(3)。训练样本数120000,测试样本数7600,样本数量绝对均衡。数据集展示:
{"text": "New iPad released Just like every other September, this one is no different. Apple is planning to release a bigger, heavier, fatter iPad that...""label": 3
}
- 选择该数据集是在
Paper with code的Text Classification类中看到的榜单,并且该数据集元素基本上不超过510个token(以Bert Tokenizer计算)。因为Bert的最大输入长度是510个token,超过会进行截断,保留前510个token,所以为了进行公平的比较,尽量避免截断。 - 因为是多分类任务,我们以模型在测试集上的F1指标为标准,F1值越高,模型效果越好。
Bert训练细节
Bert的训练比较简单,将文本使用Tokenizer转换成input_ids后,使用Trainer进行正常训练即可。训练参数(若未单独指出,则代表使用Trainer默认值):
| 参数名称 | 值 |
|---|---|
| lr_scheduler_type(学习率衰减策略) | cosine |
| learning_rate(学习率) | 1.0e-5 |
| per_device_train_batch_size(训练batch_size) | 64 |
| gradient_accumulation_steps(梯度累积) | 1 |
| per_device_eval_batch_size(验证batch_size) | 256 |
| num_train_epochs(epoch) | 3 |
| weight_decay | 1e-6 |
| eval_steps(验证频率) | 0.05 |
- 训练过程中模型对测试集的指标变化:
| Step | Training Loss | Validation Loss | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|---|
| 282 | 0.274700 | 0.263394 | 0.909737 | 0.910311 | 0.909737 | 0.909676 |
| 564 | 0.207800 | 0.222230 | 0.922237 | 0.922701 | 0.922237 | 0.922246 |
| 846 | 0.199600 | 0.204222 | 0.931579 | 0.932552 | 0.931579 | 0.931510 |
| 1128 | 0.215600 | 0.191824 | 0.934605 | 0.935274 | 0.934605 | 0.934737 |
| 1410 | 0.190500 | 0.192846 | 0.932763 | 0.934421 | 0.932763 | 0.932937 |
| 1692 | 0.193300 | 0.180665 | 0.937895 | 0.938941 | 0.937895 | 0.937849 |
| 1974 | 0.143000 | 0.180497 | 0.940526 | 0.940945 | 0.940526 | 0.940636 |
| 2256 | 0.141500 | 0.177630 | 0.941711 | 0.941988 | 0.941711 | 0.941644 |
| 2538 | 0.147100 | 0.173602 | 0.943947 | 0.944022 | 0.943947 | 0.943908 |
| 2820 | 0.131600 | 0.176895 | 0.940658 | 0.941790 | 0.940658 | 0.940683 |
| 3102 | 0.152800 | 0.170928 | 0.945000 | 0.945140 | 0.945000 | 0.944925 |
| 3384 | 0.140000 | 0.169215 | 0.944474 | 0.944766 | 0.944474 | 0.944399 |
| 3666 | 0.149900 | 0.168865 | 0.944474 | 0.944538 | 0.944474 | 0.944483 |
| 3948 | 0.112000 | 0.172459 | 0.946184 | 0.946142 | 0.946184 | 0.946159 |
| 4230 | 0.124000 | 0.172826 | 0.945000 | 0.945254 | 0.945000 | 0.944924 |
| 4512 | 0.122300 | 0.171583 | 0.944737 | 0.944925 | 0.944737 | 0.944708 |
| 4794 | 0.104400 | 0.171969 | 0.944868 | 0.945059 | 0.944868 | 0.944854 |
| 5076 | 0.117500 | 0.171504 | 0.945395 | 0.945502 | 0.945395 | 0.945363 |
| 5358 | 0.099800 | 0.171761 | 0.945263 | 0.945510 | 0.945263 | 0.945232 |
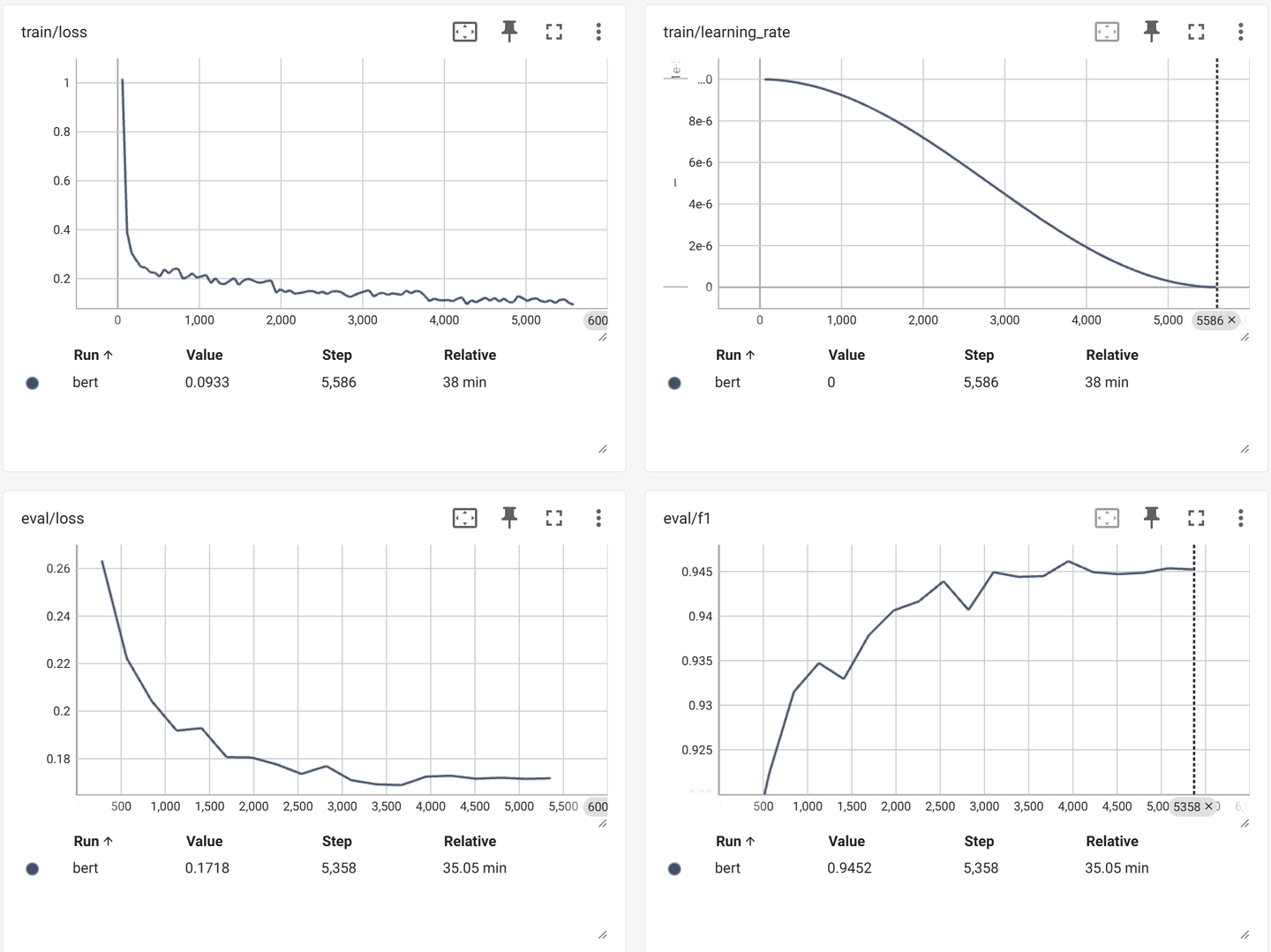
- 可以看到
Bert在测试集上最好结果是:0.945
Qwen3训练细节
- 使用
Qwen3训练文本分类模型有2种方法。第1种是修改模型架构,将模型最后一层替换为输出维度为分类数的线性层。第2种是构造Prompt,以选择题的方式创建问答对,然后进行SFT训练。
线性层分类
- 与微调Bert类似,将文本使用
Tokenizer转换成input_ids后,使用Trainer进行正常训练。训练参数(若未单独指出,则代表使用Trainer默认值):
| 参数名称 | 值 |
|---|---|
| lr_scheduler_type(学习率衰减策略) | cosine |
| learning_rate(学习率) | 1.0e-5 |
| per_device_train_batch_size(训练batch_size) | 8 |
| gradient_accumulation_steps(梯度累积) | 8 |
| per_device_eval_batch_size(验证batch_size) | 16 |
| num_train_epochs(epoch) | 1 |
| weight_decay | 1.0e-6 |
| eval_steps(验证频率) | 0.05 |
- 训练过程中模型对测试集的指标变化:
| Step | Training Loss | Validation Loss | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|---|
| 94 | 0.281800 | 0.243619 | 0.918158 | 0.918180 | 0.918158 | 0.917893 |
| 188 | 0.224100 | 0.220015 | 0.924211 | 0.925216 | 0.924211 | 0.924289 |
| 282 | 0.197700 | 0.236405 | 0.919211 | 0.920127 | 0.919211 | 0.919257 |
| 376 | 0.182800 | 0.243235 | 0.920132 | 0.925368 | 0.920132 | 0.919136 |
| 470 | 0.191500 | 0.207864 | 0.928289 | 0.929563 | 0.928289 | 0.928304 |
| 564 | 0.208400 | 0.192414 | 0.935658 | 0.935668 | 0.935658 | 0.935647 |
| 658 | 0.201900 | 0.191506 | 0.938553 | 0.938695 | 0.938553 | 0.938607 |
| 752 | 0.191900 | 0.179849 | 0.937500 | 0.937417 | 0.937500 | 0.937378 |
| 846 | 0.156100 | 0.177319 | 0.938684 | 0.938983 | 0.938684 | 0.938653 |
| 940 | 0.159900 | 0.177048 | 0.938289 | 0.939433 | 0.938289 | 0.938175 |
| 1034 | 0.159100 | 0.172280 | 0.943553 | 0.943725 | 0.943553 | 0.943455 |
| 1128 | 0.117000 | 0.168742 | 0.943026 | 0.942911 | 0.943026 | 0.942949 |
| 1222 | 0.151500 | 0.164628 | 0.943421 | 0.944371 | 0.943421 | 0.943503 |
| 1316 | 0.143600 | 0.158676 | 0.945921 | 0.946856 | 0.945921 | 0.945965 |
| 1410 | 0.183200 | 0.154356 | 0.946184 | 0.946708 | 0.946184 | 0.946221 |
| 1504 | 0.159400 | 0.153549 | 0.947763 | 0.947847 | 0.947763 | 0.947771 |
| 1598 | 0.147100 | 0.152530 | 0.948553 | 0.948609 | 0.948553 | 0.948539 |
| 1692 | 0.161400 | 0.151299 | 0.949079 | 0.949216 | 0.949079 | 0.949029 |
| 1786 | 0.150500 | 0.151270 | 0.948421 | 0.948572 | 0.948421 | 0.948363 |
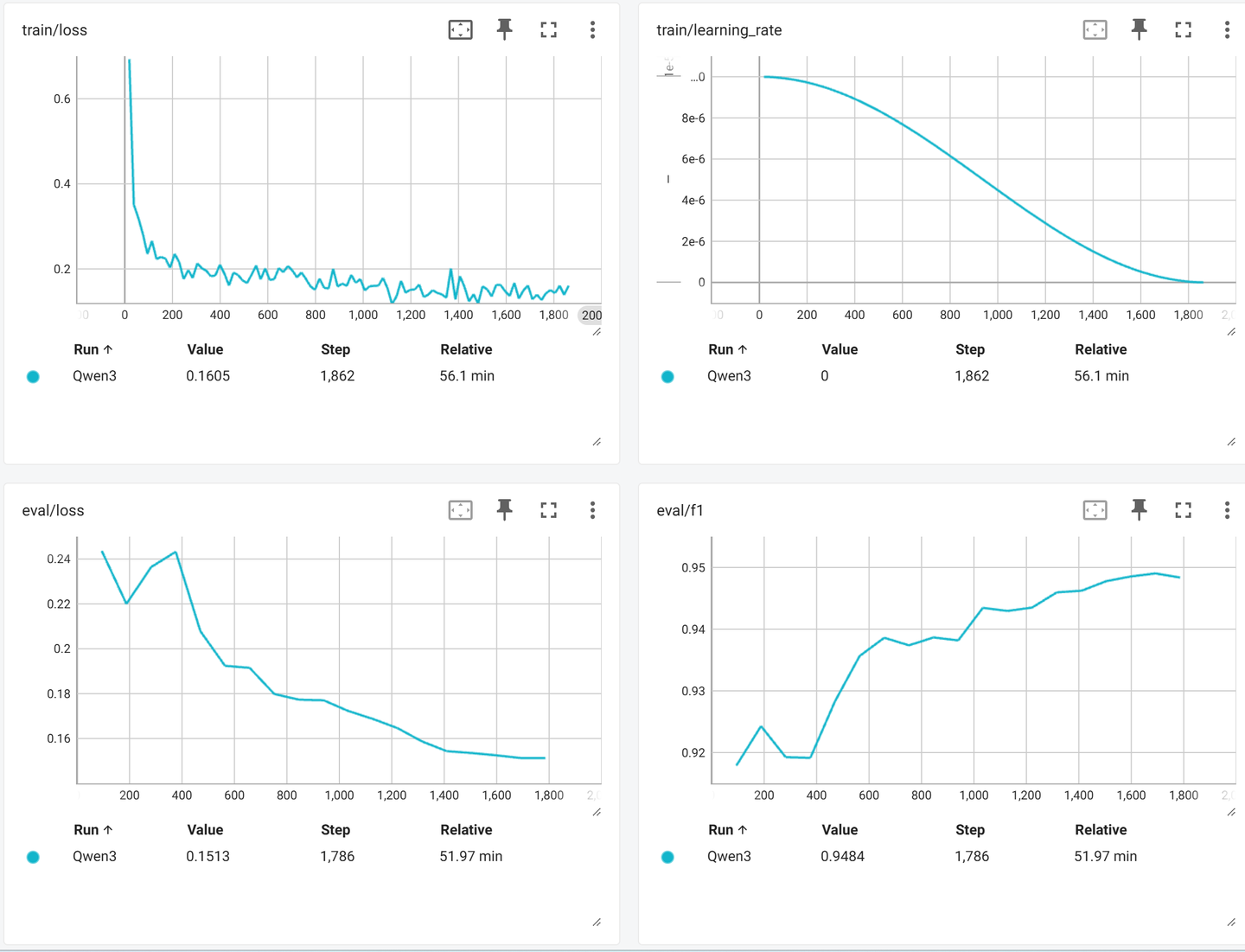
- 可以看到使用线性层分类的Qwen3-0.6B在测试集上最好结果是:0.949
SFT分类
- 我们先基于数据集写一个选择题形式的Prompt,Prompt模板为:
prompt = """Please read the following news article and determine its category from the options below.Article:
{news_article}Question: What is the most appropriate category for this news article?
A. World
B. Sports
C. Business
D. Science/TechnologyAnswer:/no_think"""answer = "<think>\n\n</think>\n\n{answer_text}"
news_article为新闻文本,answer_text表示标签。- 先测试一下Qwen3-0.6B在测试集上思考和非思考模式下的
zero-shot能力(准确率)。为获得稳定的结果,非思考模式使用手动拼接选项计算ppl,ppl最低的选项为模型答案。思考模式取<think>...</think>后的第一个选项。结果如下:
| 模型 | 思考 | 非思考 |
|---|---|---|
| Qwen3-0.6B | 0.7997 | 0.7898 |
- 训练框架使用
LLama Factory,Prompt模板与上文一致。 - 因为
Qwen3为混合推理模型,所以对非推理问答对要在模板最后加上/no_think标识符(以避免失去推理能力),并且回答要在前面加上<think>\n\n</think>\n\n。 - 按照LLama Factory SFT训练数据的格式要求组织数据,如:
{'instruction': "Please read the following news article and determine its category from the options below.\n\nArticle:\nWall St. Bears Claw Back Into the Black (Reuters) Reuters - Short-sellers, Wall Street's dwindling\\band of ultra-cynics, are seeing green again.\n\nQuestion: What is the most appropriate category for this news article?\nA. World\nB. Sports\nC. Business\nD. Science/Technology\n\nAnswer:/no_think",'output': '<think>\n\n</think>\n\nC'
}
- 训练参数配置文件:
### model
model_name_or_path: model/Qwen3-0.6B### method
stage: sft
do_train: true
finetuning_type: full### dataset
dataset: agnews_train
template: qwen3
cutoff_len: 512overwrite_cache: true
preprocessing_num_workers: 8### output
output_dir: Qwen3-0.6B-Agnews
save_strategy: steps
logging_strategy: steps
logging_steps: 0.01
save_steps: 0.2
plot_loss: true
report_to: tensorboard
overwrite_output_dir: true### train
per_device_train_batch_size: 12
gradient_accumulation_steps: 8
learning_rate: 1.2e-5
warmup_ratio: 0.01
num_train_epochs: 1
lr_scheduler_type: cosine
bf16: true
- 因为
Bert在训练2个epoch后就出现了严重的过拟合,所以对Qwen3模型,只训练1个epoch,每0.2个epoch保存一个检查点。 - 训练过程中模型对测试集的指标变化(训练结束后加载检查点对测试集进行推理,注意!为保证推理结果稳定,我们选择选项ppl低的作为预测结果):
| Step | Training Loss | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|
| 250 | 0.026 | 0.912 | 0.917 | 0.912 | 0.912 |
| 500 | 0.027 | 0.924 | 0.924 | 0.924 | 0.924 |
| 750 | 0.022 | 0.937 | 0.937 | 0.937 | 0.937 |
| 1000 | 0.022 | 0.941 | 0.941 | 0.941 | 0.941 |
| 1250 | 0.023 | 0.940 | 0.940 | 0.940 | 0.940 |
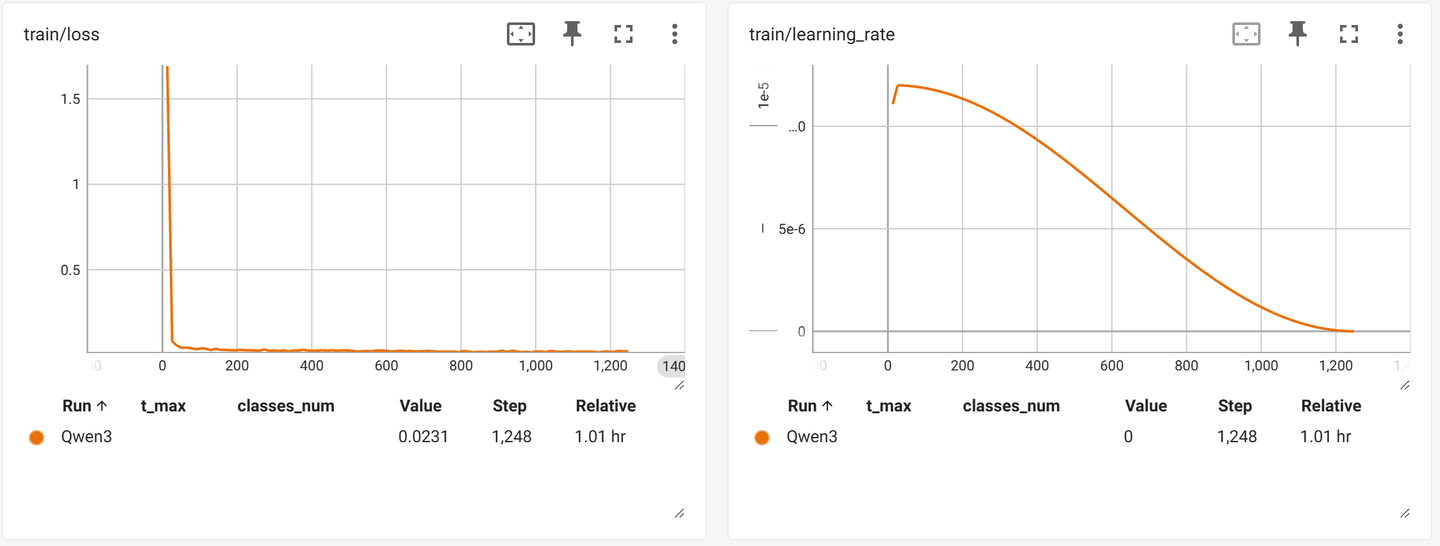
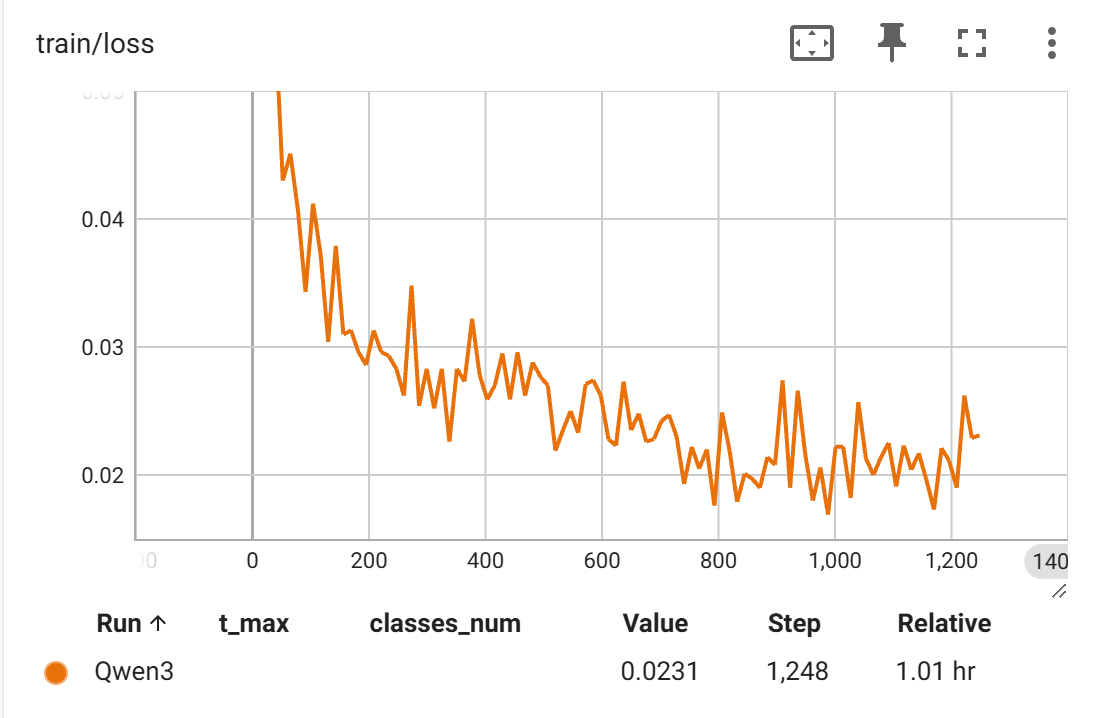
- 可以看到
Qwen3-0.6B模型Loss在一开始就急速下降,然后开始抖动的缓慢下降,如下图(纵轴范围调整0.05~0.015)。在测试集上最好结果是:0.941。
Bert和Qwen3-0.6B训练耗时
| 模型 | Epoch | 训练耗时 | 推理耗时 | 总耗时 |
|---|---|---|---|---|
| Bert | 3 | 35 min | - | 0.58 h |
| Qwen3-0.6B(线性层分类) | 1 | 52 min | - | 0.86 h |
| Qwen3-0.6B(SFT分类) | 1 | 62 min | 30 min | 1.5 h |
Bert和Qwen3-0.6B RPS测试
- 为测试
Bert和Qwen3-0.6B是否满足实时业务场景,对微调后的Bert和Qwen3-0.6B进行RPS测试,GPU为RTX 3090(24G):
| 模型 | 推理引擎 | 最大输出Token数 | RPS |
|---|---|---|---|
| Bert | HF | - | 60.3 |
| Qwen3-0.6B(SFT分类) | HF | 8 | 13.2 |
| Qwen3-0.6B(SFT分类) | VLLM | 8 | 27.1 |
| Qwen3-0.6B(线性层分类) | HF | - | 38.1 |
结论
- 在
Ag_new数据集上,各模型效果:Qwen3-0.6B(线性层分类)>Bert>Qwen3-0.6B(SFT分类)>Qwen3-0.6B(Think Zero-Shot)>Qwen3-0.6B(No Think Zero-Shot)。 - 各模型训练推理耗时:
Qwen3-0.6B(SFT分类)>Bert>Qwen3-0.6B(线性层分类)。 - 各模型
RPS:Bert>Qwen3-0.6B(线性层分类) >Qwen3-0.6B(SFT分类)。 Think模式下的Qwen3-0.6B比No Think模式下的Qwen3-0.6B准确率仅高出1%,推理时间比No Think慢20倍(HF推理引擎,Batch推理)。- 在训练
Qwen3-0.6B(线性层分类)时,Loss在前期有点抖动,或许微调一下学习率预热比率会对最终结果有微弱正向效果。
实验局限性
- 未实验在
Think模式下Qwen3-0.6B的效果(使用GRPO直接训练0.6B的模型估计是不太行的,可能还是先使用较大的模型蒸馏出Think数据,然后再进行SFT。或者先拿出一部分数据做SFT,然后再进行GRPO训练(冷启动))。 - 未考虑到长序列文本如
token数(以Bert Tokenizer为标准)超过1024的文本。 - 也许因为
AgNews分类任务比较简单,其实不管是Bert还是Qwen3-0.6B在F1超过0.94的情况下,都是可用的状态。Bert(F1:0.945)和Qwen3-0.6B线性层分类(F1:0.949)的差距并不明显。如果大家有更好的开源数据集可以用于测试,也欢迎提出。 - 未测试两模型在中文文本分类任务中的表现。
来源:https://zhuanlan.zhihu.com/p/1906768058745349565?share_code=KPTadtlbij0m&utm_psn=1907715099319312567
相关文章:
Qwen3 - 0.6B与Bert文本分类实验:深度见解与性能剖析
Changelog [25/04/28] 新增Qwen3-0.6B在Ag_news数据集Zero-Shot的效果。新增Qwen3-0.6B线性层分类方法的效果。调整Bert训练参数(epoch、eval_steps),以实现更细致的观察,避免严重过拟合的情况。 TODO: 利用Qwen3-0.6…...

4.6 sys模块
sys --- 仅作了解 面试之前冲击一下 python的垃圾回收机制 import sys # 1. api_version : 获取python的内部版本号 print(sys.api_version) #1013 # 2. copyright: 获取cpython的版本 print(sys.copyright) #3.getfilesystemencoding() getdefaultencoding():获…...

UWB定位方案在水力发电站人员安全的应用推荐
一、行业应用背景 水力发电站具有环境复杂(金属设备密集、高温高压区域多)、安全风险高(人员误入高危区域易引发事故)等特点,传统定位技术难以满足精度与可靠性要求。品铂科技基于UWB的高精度定位系统已在多…...

青少年编程与数学 02-019 Rust 编程基础 16课题、包、单元包及模块
青少年编程与数学 02-019 Rust 编程基础 16课题、包、单元包及模块 一、包1. **什么是 Crate?**2. **Crate 的类型**3. **Crate 的结构**4. **使用 Crate**5. **创建和管理 Crate**6. **发布 Crate**7. **Crate 的优势**8. **示例**创建一个 library crate 二、单元…...

bat 批处理获取日期、时间
在Windows批处理脚本编程中,获取当前日期和时间是一项常见且重要的操作。 1. 获取当前日期和时间的基本脚本 echo off for /F "tokens2" %%i in (date /t) do set mydate%%i set mytime%time% echo Current time is %mydate%:%mytime%输出示例ÿ…...
)
手写tomcat:基本功能实现(3)
TomcatRoute类 TomcatRoute类是Servlet容器,是Tomcat中最核心的部分,其本身是一个HashMap,其功能为:将路径和对象写入Servlet容器中。 package com.qcby.config;import com.qcby.Util.SearchClassUtil; import com.qcby.servlet…...

Spring Cloud Seata 快速入门及生产实战指南
文章目录 前言一、快速入门(AT模式)二、生产环境实战要点总结 前言 上一篇博客带大家深入解析Seata的核心原理及架构,理解了“为什么需要分布式事务”以及“Seata如何解决数据一致性问题”,相信大家已经对分布式事务的理论框架有…...

电商平台自动化
为什么要进行独立站自动化 纯人工测试人力成本高,相对效率低 回归测试在通用模块重复进行人工测试,测试效率低 前期调研备选自动化框架(工具): Katalon Applitools Testim 阿里云EMAS Playwright Appium Cypress 相关…...

Java微服务架构实战:Spring Boot与Spring Cloud的完美结合
Java微服务架构实战:Spring Boot与Spring Cloud的完美结合 引言 随着云计算和分布式系统的快速发展,微服务架构已成为现代软件开发的主流模式。Java作为企业级应用开发的核心语言,结合Spring Boot和Spring Cloud,为开发者提供了…...

王树森推荐系统公开课 召回11:地理位置召回、作者召回、缓存召回
GeoHash 召回 属于地理位置召回,用户可能对附近发生的事情感兴趣。GeoHash 是一种对经纬度的编码,地图上每个单位矩形的 GeoHash 的前几位是相同的,GeoHash 编码截取前几位后,将相同编码发布的内容按时间顺序(先是时间…...

无刷直流水泵构成及工作原理详解--【其利天下技术】
无刷直流水泵是相对于有刷直流泵而言的。 一:无刷直流水泵简介 无刷直流水泵即BLDC PUMP,其中“BL”意为“无刷”,DC即直流电机。 无刷直流水泵(BLDC PUMP)以电子换向器取代了机械换向器,所以无刷直流水泵既具有直流电机良好的调…...

less中使用 @supports
在Less中使用supports supports 是CSS的条件规则,用于检测浏览器是否支持特定的CSS属性或值。在Less中,你可以像在普通CSS中一样使用supports,同时还能利用Less的特性来增强它。 基本用法 /* 检测浏览器是否支持display: flex */ supports …...

大数据:新能源汽车宇宙的未来曲率引擎
** 发布日期:2025-05-14** 关键词:大数据、新能源、机器学习、碳中和、CSDN爆款 1. 大数据科普:定义、特征与技术核心 1.1 什么是大数据? 大数据(Big Data)指规模巨大、类型多样、生成速度快且价值密度低…...
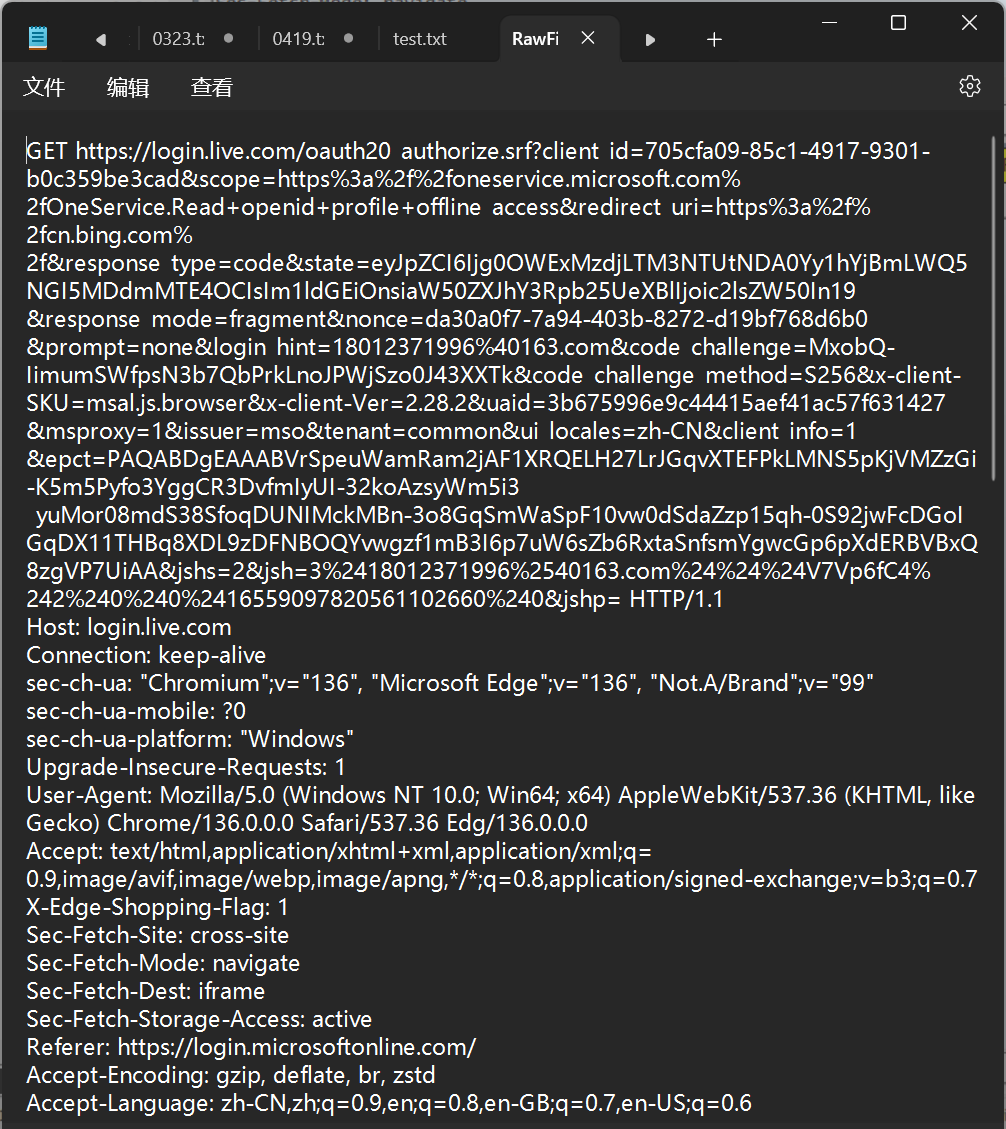
【Java ee】关于抓包软件Fiddler Classic的安装与使用
Web Debugging Proxy Tool | Fiddler Classic 安装网站↑ 下载好安装包之后,双击一路next就可以了 一、抓包软件 电脑上安装了抓包软件之后,抓包软件就可以监听你的网卡上通过的数据。 本来是你的客户端通过网卡,把数据发给目标服务器&a…...

第五部分:第五节 - Express 路由与中间件进阶:厨房的分工与异常处理
随着你的 Express 应用变得越来越大,所有的路由和中间件都写在一个文件里会变得难以管理。这时候就需要将代码进行拆分和组织。此外,一个健壮的后端应用必须能够优雅地处理错误和一些常见的 Web 开发问题,比如跨域。 路由模块化 (express.Ro…...

在 CentOS 7.9 上部署 node_exporter 并接入 Prometheus + Grafana 实现主机监控
文章目录 在 CentOS 7.9 上部署 node_exporter 并接入 Prometheus Grafana 实现主机监控环境说明node_exporter 安装与配置下载并解压 node_exporter创建 Systemd 启动服务验证服务状态验证端口监听 Prometheus 配置 node_exporter 监控项修改 prometheus.yml重新加载 Prometh…...

C++--内存管理
内存管理 1. C/C内存分布 在C语言阶段,常说局部变量存储在栈区,动态内存中的数据存储在堆区,静态变量存储在静态区(数据段),常量存储在常量区(代码段),其实这里所说的栈…...

Java实现PDF加水印功能:技术解析与实践指南
Java实现PDF加水印功能:技术解析与实践指南 在当今数字化办公环境中,PDF文件因其跨平台兼容性和格式稳定性而被广泛应用。然而,为了保护文档的版权、标记文档状态(如“草稿”“机密”等)或增加文档的可追溯性…...
)
Django + Celery 打造企业级大模型异步任务管理平台 —— 从需求到完整实践(含全模板源码)
如需完整工程文件(含所有模板),可回复获取详细模板代码。 面向人群:自动化测试工程师、企业中后台开发人员、希望提升效率的 AI 业务从业者 核心收获:掌握 Django 三表关系设计、Celery 异步任务实践、基础 Web 交互与前后端分离思路,源码可直接落地,方便二次扩展 一、系…...
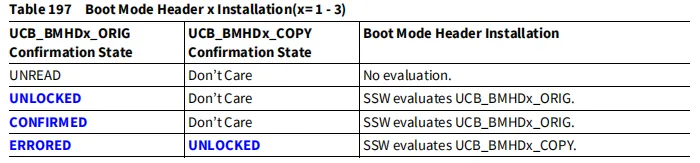
TC3xx学习笔记-UCB BMHD使用详解(二)
文章目录 前言Confirmation的定义Dual UCB: Confirmation StatesDual UCB: Errored State or ECC Error in the UCB Confirmation CodesECC Error in the UCB ContentDual Password UCB ORIG and COPY Re-programming UCB_BMHDx_ORIG and UCB_BMHDx_COPY (x 0-3)BMHD Protecti…...
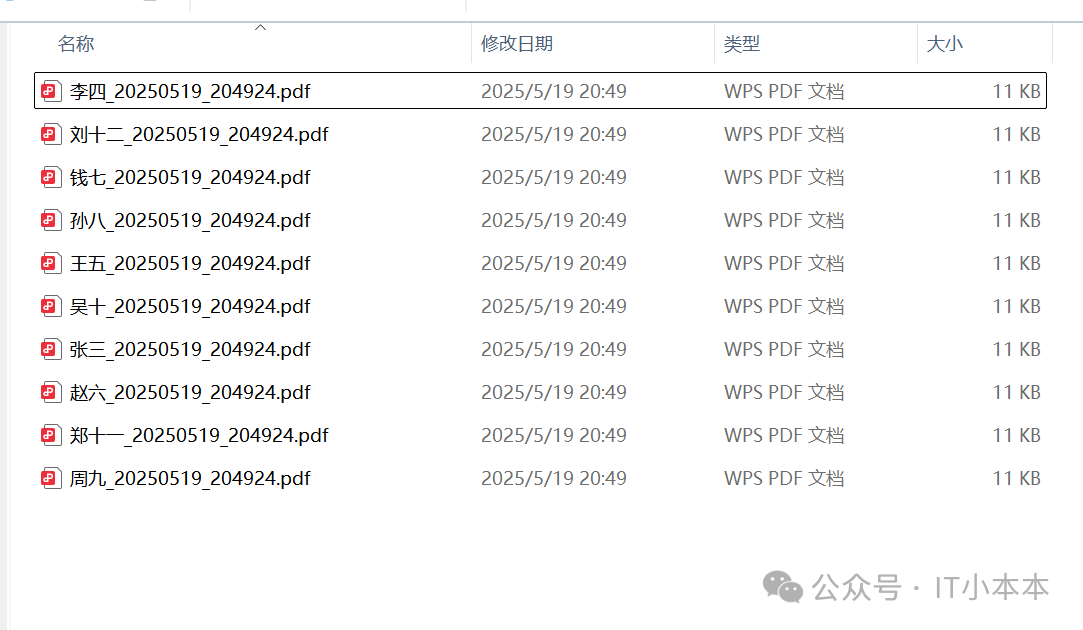
用Python实现数据库数据自动化导出PDF报告:从MySQL到个性化文档的全流程实践
本文将介绍如何使用Python构建一个自动化工具,实现从MySQL数据库提取员工数据,并为每位员工生成包含定制化表格的PDF报告。通过该方案,可显著提升数据导出效率,避免手动操作误差,同时支持灵活的格式定制。 需求&#…...

实战设计模式之状态模式
概述 作为一种行为设计模式,状态模式允许对象在其内部状态改变时,改变其行为。这种模式通过将状态逻辑从对象中分离出来,并封装到独立的状态类中来实现。每个状态类代表一种特定的状态,拥有自己的一套行为方法。当对象的状态发生变…...

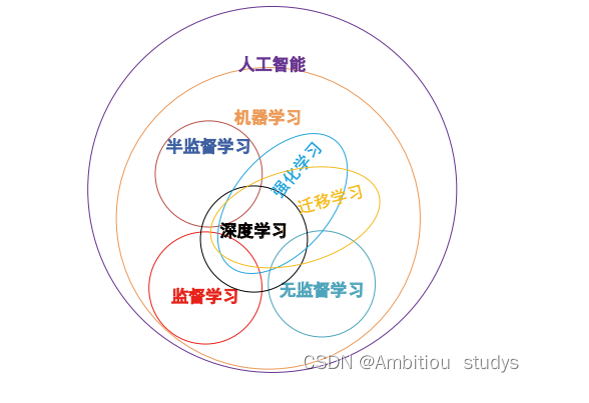
人工智能、机器学习与深度学习:概念解析与内在联系
人工智能、机器学习与深度学习:概念解析与内在联系 一、人工智能(Artificial Intelligence, AI) (一)人工智能的定义 人工智能的定义随着技术发展不断演变。从广义上讲,人工智能是指通过计算机技术实现的…...

什么是着色器 Shader
本人就是图形学结课了,对 OpenGL着色器还有很多疑问嘿嘿 文章目录 为什么要有着色器vshaderfshader 本文围绕 vshader 和 fshader 代码示例讲解。 (着色器代码取自本人简单OpenGL项目 https://github.com/DBWGLX/-OpenGL-3D-Lighting-and-Shadow-Modeli…...

Redis的主从架构
主从模式 全量同步 首先主从同步过程第一步 会先比较replication id 判断是否是第一次同步假设为第一次同步 那么就会 启动bgsave异步生成RDB 同时fork子进程记录生成期间的新数据发送RDB给从节点 清空本地数据写入RDB 增量同步 对比ReplicationID不同因此选择增量同步在Rep…...
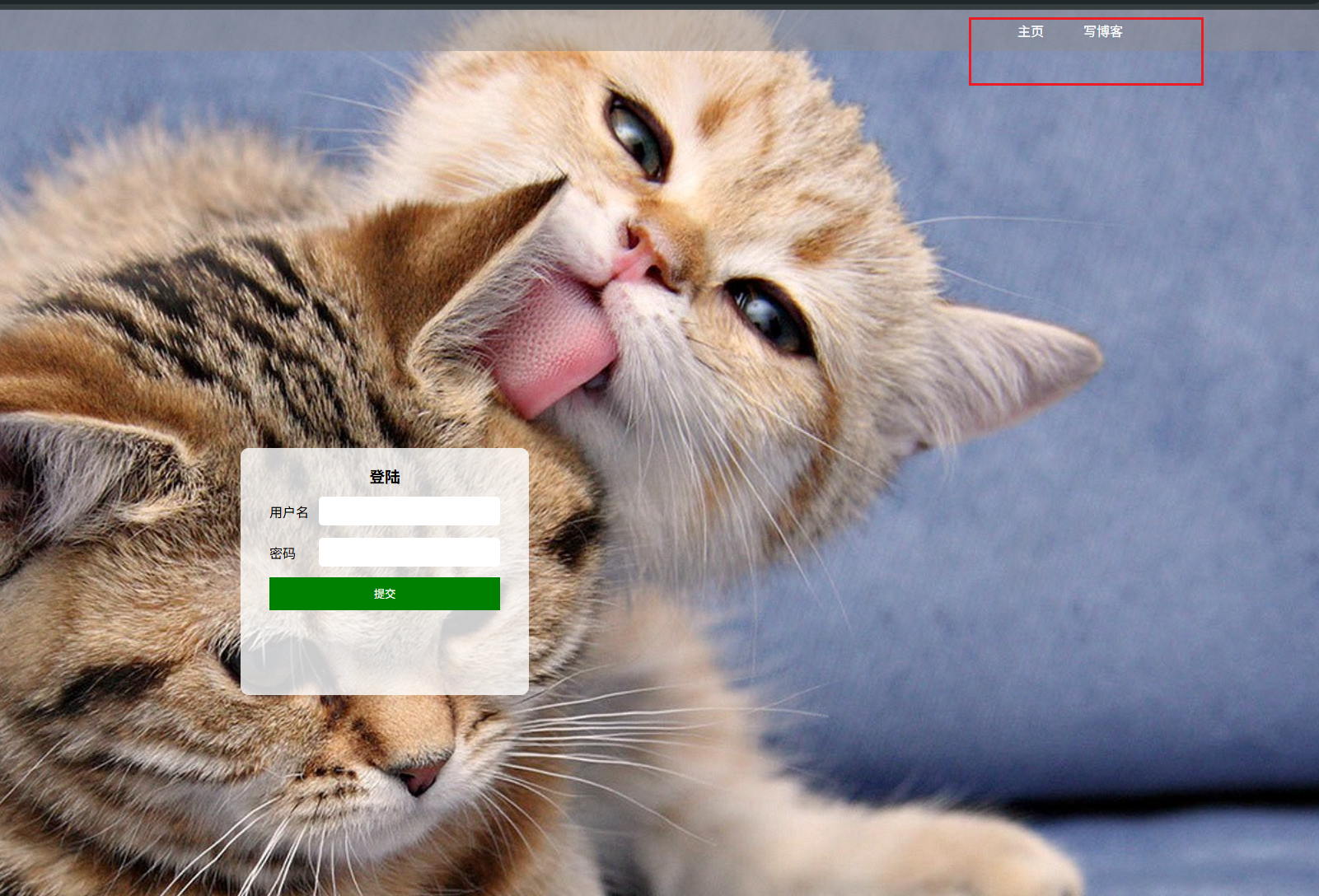
博客系统功能测试
博客系统网址:http://8.137.19.140:9090/blog_list.html 主要测试内容 功能测试、界面测试、性能测试、易用性测试、安全测试、兼容性测试、弱网测试、安装卸载测试、压力测试… 测试方法及目的 利用selenium和python编写测试脚本,对博客系统进行的相关…...

【深度学习新浪潮】什么是多模态大模型?
多模态大模型是人工智能领域的前沿技术方向,它融合了多种数据模态(如文本、图像、语音、视频、传感器数据等),并通过大规模参数模型实现跨模态的联合理解与生成。简单来说,这类模型就像人类一样,能同时“看”“听”“读”“说”,并将不同信息关联起来,完成复杂任务。 …...
机器学习前言2
1.机器学习 2.机器学习模型 3.模型评价方法 4.如何选择合适的模型 介绍 机器学习(Machine Learning, ML)是人工智能(AI)的核心分支,致力于通过数据和算法让计算机系统自动“学习”并改进性能,而无需显式编…...

【成品设计】基于Arduino的自动化农业灌溉系统
《基于STM32的单相瞬时值反馈逆变器》 硬件设计: ESP-C3最小系统板:主控芯片,内部集成wifi。土壤湿度传感器:采集土壤湿度。温度传感器:采集土壤温度。水泵模块:水泵继电器软管。按键3个:参数…...
前端页面 JavaScript数据交互
前言:学习JavaScript为前端设置动态效果,实现交互。JavaScript是一种广泛应用于网页开发的脚本语言,它能够使网页变得更加动态和交互性。作为一种客户端脚本语言,JavaScript可以被嵌入到HTML中,并且可以被所有现代的网…...