Mergekit——任务向量合并算法Ties解析
Mergekit——高频合并算法 TIES解析
- Ties背景
- Ties 核心思想
- 具体流程
- 总结
mergekit项目地址
Mergekit提供模型合并方法可以概况为四大类:基本线性加权、基于球面插值、基于任务向量 以及一些专业化方法,今天我们来刷下基于任务向量的ties合并方法,熟悉原理和代码。
Ties背景
首先明确:Ties方法建立在“任务向量”的概念之上,任务向量表示参考的微调模型和基本模型之间的区别,这种方法在mergekit中非常多,Ties只是其中一种变体。
TIES-Merging ——可将多个同构不同参数的模型合并为单个多任务模型。主要解决模型合并中的两个主要挑战:
1.模型参数冗余:它识别并消除特定任务模型中的冗余参数。这是通过关注微调期间所做的更改、识别前 k% 最重要的更改并丢弃其余的来实现的。
2.参数符号之间的不一致:当不同模型对同一参数提出相反的调整时,就会出现冲突。TIES-Merging 通过创建一个统一的符号向量来解决这些冲突,该符号向量代表所有模型中最主要的变化方向。
Ties 核心思想
稀疏化密度:通过仅保留一小部分最重要的参数(密度参数)并将其余参数重置为零,减少特定于任务的模型中的冗余。
符号共识: 通过根据累积幅度的最主要方向(正或负)创建统一的符号向量,解决不同模型之间的符号冲突。
不相交合并:对与统一符号向量对齐的参数值进行平均,不包括零值。
具体表现为当多个模型进行合并时候,稀疏化密度只保留最重要的权重高化,符号共识**保留多个模型再更新方向上一致的参数。
具体流程
通过分析代码后,可以汇总为以下步骤:
- 计算任务向量——每个模型和base模型的差异,比较简单
def get_task_vectors(weight_info: WeightInfo,base_model: ModelReference,tensors: ImmutableMap[ModelReference, torch.Tensor],tensor_parameters: ImmutableMap[ModelReference, ImmutableMap[str, Any]],
) -> Tuple[List[Dict[str, Any]], torch.Tensor]:keys = list(tensors.keys())base = tensors[base_model]parameter_name = weight_info.nameres = []for model in keys:if model == base_model:continuex = tensors[model].to(base.dtype)if x.shape != base.shape:if weight_info.is_embed:x = x[: base.shape[0], : base.shape[1]]logging.warning(f"Using submatrix of {model}:{parameter_name}")else:logging.warning(f"skipping {model}:{parameter_name} due to size mismatch")continuedelta = x - basedel xdel tensors[model]d = {}d["model"] = modeld["delta"] = deltafor p in tensor_parameters[model]:d[p] = tensor_parameters[model][p]res.append(d)return res, base
- 稀疏化权重
# sparsifyif self.method.sparsification_method:for tv_info in tvs:kwargs = {}if "gamma" in tv_info:kwargs["gamma"] = tv_info["gamma"]if "epsilon" in tv_info:kwargs["epsilon"] = tv_info["epsilon"]tv_info["delta"] = sparsify(tv_info["delta"],density=tv_info["density"],method=self.method.sparsification_method,rescale_norm=self.rescale_norm,**kwargs,)
然后,如何计算权重幅度等等,在源码中sparsify具备四种稀疏化方法:
- magnitude: 基于权重大小的剪枝
- random: 随机剪枝
- magnitude_outliers: 去除极大值和极小值的剪枝
- della_magprune: 基于概率的渐进式剪枝方法
这里我们主要说ties 基于权重幅度剪枝—— 保留绝对值最大的k个元素,k=density*总元素数,简单高效
def magnitude(tensor: torch.Tensor, density: float, rescale_norm: Optional[RescaleNorm] = None
) -> torch.Tensor:"""Masks out the smallest values, retaining a proportion of `density`."""if density >= 1:return tensork = int(density * tensor.numel()) #计算保留元素数量assert k > 0, "not gonna zero out the whole tensor buddy"mask = torch.zeros_like(tensor)w = tensor.abs().view(-1)if w.device.type == "cpu":w = w.float()topk = torch.argsort(w, descending=True)[:k] #对绝对值进行降序排序,获取前k大值的索引mask.view(-1)[topk] = 1 #将掩码中对应top-k索引的位置设为1res = rescaled_masked_tensor(tensor, mask, rescale_norm) #调用辅助函数应用掩码并根据需要重新缩放,保持特定的范数特性,保证输出和反向传播计算的稳定性return res
通过上述计算,可以保留所谓权重幅度最大的参数,完成稀疏化。
3. 权重应用
deltas = torch.stack([tv["delta"] for tv in tvs], dim=0)weights = torch.tensor([tv["weight"] for tv in tvs], dtype=deltas.dtype, device=deltas.device)while len(deltas.shape) > len(weights.shape):weights.unsqueeze_(-1)weighted_deltas = deltas * weights4.符号共识
Ties提供两种方式计算符号
”sum“: 加权,考虑参数幅度
”count“,基于符号数量统计
def get_mask(delta: torch.Tensor,method: Literal["sum", "count"] = "sum",mask_dtype: Optional[torch.dtype] = None,
):"""Returns a mask determining which delta vectors should be mergedinto the final model.For the methodology described in the TIES paper use 'sum'. For asimpler naive count of signs, use 'count'."""if mask_dtype is None:mask_dtype = delta.dtypesign = delta.sign().to(mask_dtype) # 获取每个元素的符号(-1, 0, +1)if method == "sum":sign_weight = delta.sum(dim=0) # 沿模型维度求和majority_sign = (sign_weight >= 0).to(mask_dtype) * 2 - 1 # 转换为±1del sign_weightelif method == "count":majority_sign = (sign.sum(dim=0) >= 0).to(mask_dtype) * 2 - 1else:raise RuntimeError(f'Unimplemented mask method "{method}"')return sign == majority_sign #生成bool mask
在Sum方法中也是ties的论文方法,考虑差异的幅度和方向:
对每个参数位置,计算所有模型差异的总和;如果总和≥0,多数符号为+1,否则为-1,这样幅度的差异大对结果影响较大;
在count方法中,对每个参数位置,统计正负号数量,正号多则多数符号为+1,否则为-1,忽略差异幅度,只考虑方向
计算更简单但可能不够精确。
- 合并
回到主线代码,这里我们已经拿到了掩码,可以确定哪些参数变化(deltas)应该被合并
if self.method.consensus_method:mask_dtype = torch.int8 if self.int8_mask else base.dtypemask = get_mask(weighted_deltas,method=self.method.consensus_method,mask_dtype=mask_dtype,) #拿到mask后mixed_delta = (weighted_deltas * mask).sum(dim=0) #直接对所有加权deltas求和divisor = (weights * mask).sum(dim=0) #计算有效权重的和(用于归一化)divisor[divisor == 0] = 1else:mixed_delta = weighted_deltas.sum(dim=0) #只保留被掩码选中的deltas并求和divisor = weights.sum(dim=0)divisor[divisor.abs() < 1e-8] = 1if self.normalize: # 归一化mixed_delta /= divisor if self.lambda_ != 1: #系数缩放mixed_delta *= self.lambda_return (base + mixed_delta).to(base.dtype) 合并
总结
Mergekit ties的配置参考
models:- model: psmathur/orca_mini_v3_13b #参考模型1parameters:density: [1, 0.7, 0.1] # density gradient 这是稀疏化的密度列表 对应不同层的稀疏化成都weight: 1.0 #权重值- model: garage-bAInd/Platypus2-13B #参考模型2 其余同上parameters:density: 0.5 weight: [0, 0.3, 0.7, 1] # weight gradient- model: WizardLM/WizardMath-13B-V1.0 #参考模型3 其余同上parameters:density: 0.33weight:- filter: mlp #对于MLP是取0.5 其他层是0value: 0.5- value: 0
merge_method: ties
base_model: TheBloke/Llama-2-13B-fp16 #选择这个模型作为基础模型
parameters:normalize: trueint8_mask: true
dtype: float16
这里当参数为List时候,Mergekit会进行映射到不同层,在处理每个参数时候根据位置选择List中的密度或者权重值,保留嵌入层 、中间层、末尾层对应不同密度稀疏,考虑使用线性插值来计算中间层的密度。
相关文章:

Mergekit——任务向量合并算法Ties解析
Mergekit——高频合并算法 TIES解析 Ties背景Ties 核心思想具体流程总结 mergekit项目地址 Mergekit提供模型合并方法可以概况为四大类:基本线性加权、基于球面插值、基于任务向量 以及一些专业化方法,今天我们来刷下基于任务向量的ties合并方法…...

Java 应用中的身份认证与授权:OAuth2.0 实现安全的身份管理
Java 应用中的身份认证与授权:OAuth2.0 实现安全的身份管理 在当今的软件开发领域,身份认证与授权是构建安全可靠应用的关键环节。而 Java 作为广泛使用的编程语言,在实现这一功能上有着诸多成熟的框架和方案。其中,OAuth2.0 凭借…...

【氮化镓】偏置对GaN HEMT 单粒子效应的影响
2025年5月19日,西安电子科技大学的Ling Lv等人在《IEEE Transactions on Electron Devices》期刊发表了题为《Single-Event Effects of AlGaN/GaN HEMTs Under Different Biases》的文章,基于实验和TCAD仿真模拟方法,研究了单粒子效应对关断状态、半开启状态和开启状态下AlG…...
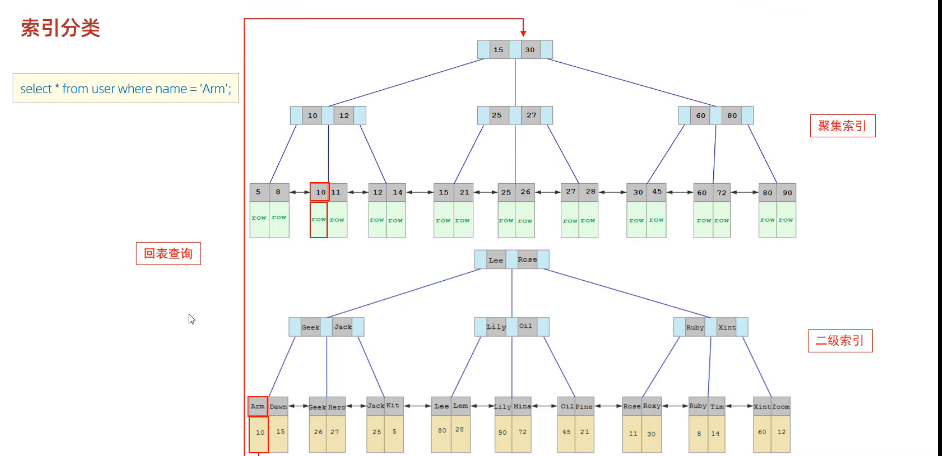
Mysql 索引概述
索引(index)是帮助Mysql高效获取数据的数据结构 索引优点:1. 提高排序效率 2. 提高查询效率 索引缺点:1.索引占用空间(可忽略)2.索引降低了更新表的速度,如进行insert,update,delette 时效率降…...

HttpServletRequest常用功能简介-笔记
javax.servlet.http.HttpServletRequest 是 ServletRequest 接口的子接口,专用于处理 HTTP 协议相关的请求。它提供了访问请求行、请求头、请求参数以及请求属性等方法。 1.请求行(Request Line) ✅ 功能说明 请求行包含客户端发送的 HTTP …...
解决RAGFlow部署中镜像源拉取的问题
报错提示 Error response from daemon: Get "https://registry-1.docker.io/v2/ ": context deadline exceeded 解决方法 这个原因是因为拉取镜像源失败,可以在/etc/docker/daemon.json文件中添加镜像加速器,例如下面所示 {"registry…...
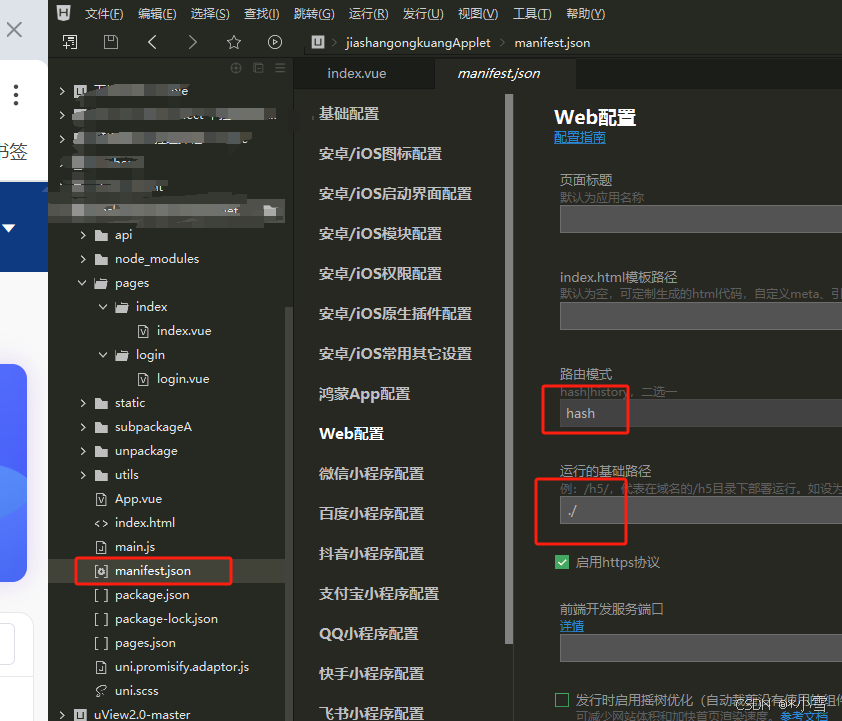
uniapp打包H5,输入网址空白情况
由于客户预算有限,最近写了两个uniapp打包成H5的案例,总结下面注意事项 1. 发行–网站-PCWeb或手机H5按钮,输入名称,网址 点击【发行】,生成文件 把这个给后端,就可以了 为什么空白呢 最重要一点…...

wsl2中Ubuntu22.04配置静态IP地址
第一步找到/etc/netplan目录下的01-netcfg.yaml文件,(如果不存在则自己创建一个)在里面配置一下代码: network:version: 2renderer: networkdethernets:eth0:dhcp4: noaddresses: [192.168.3.222/24]routes:- to: 0.0.0.0/0via: …...
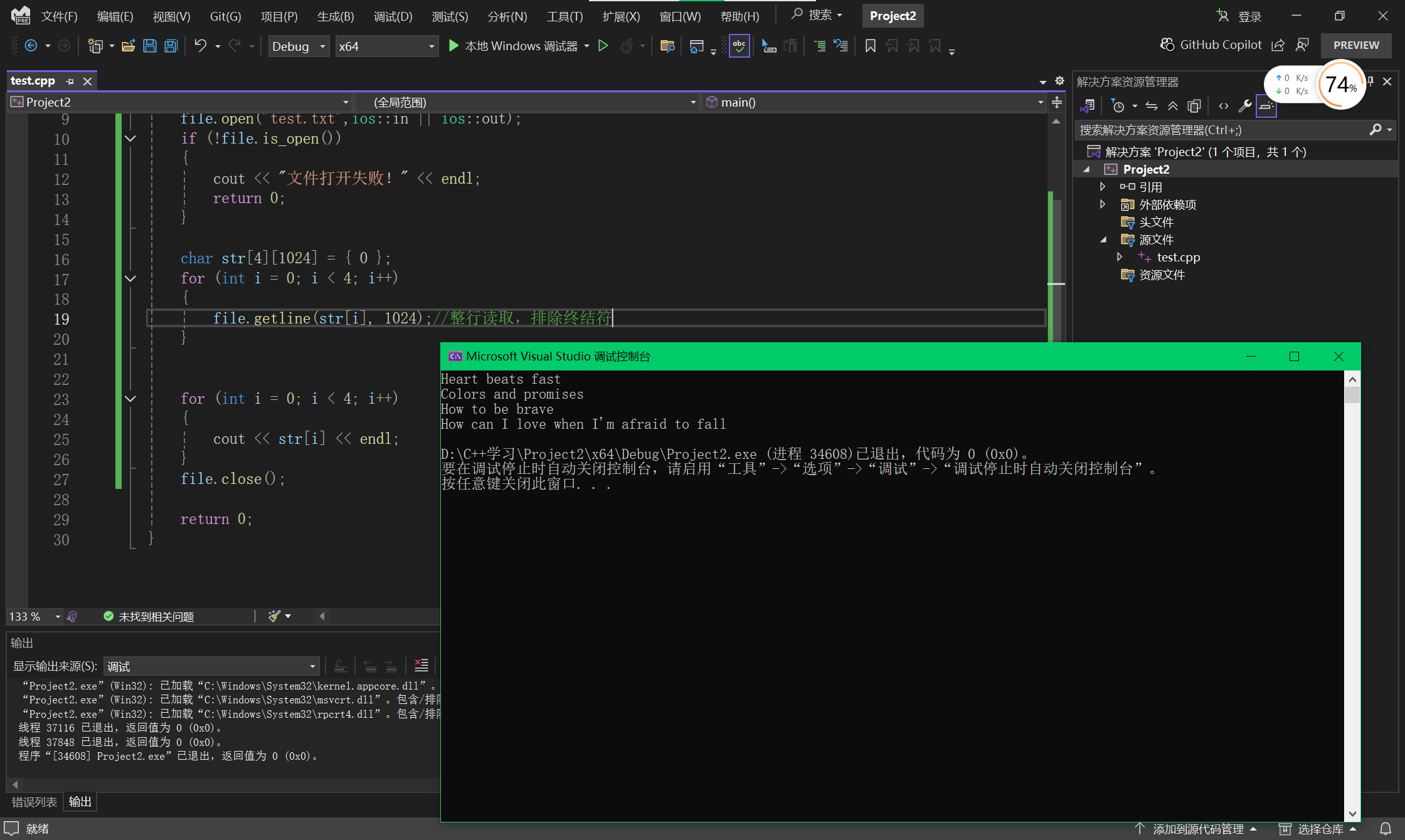
C++(21):fstream的读取和写入
目录 1 ios::out 2 ios::in和is_open 3 put()方法 4 get()方法 4.1 读取单个字符 4.2 读取多个字符 4.3 设置终结符 5 getline() 1 ios::out 打开文件用于写入数据。如果文件不存在,则新建该文件;如果文件原来就存在,则打开时清除…...
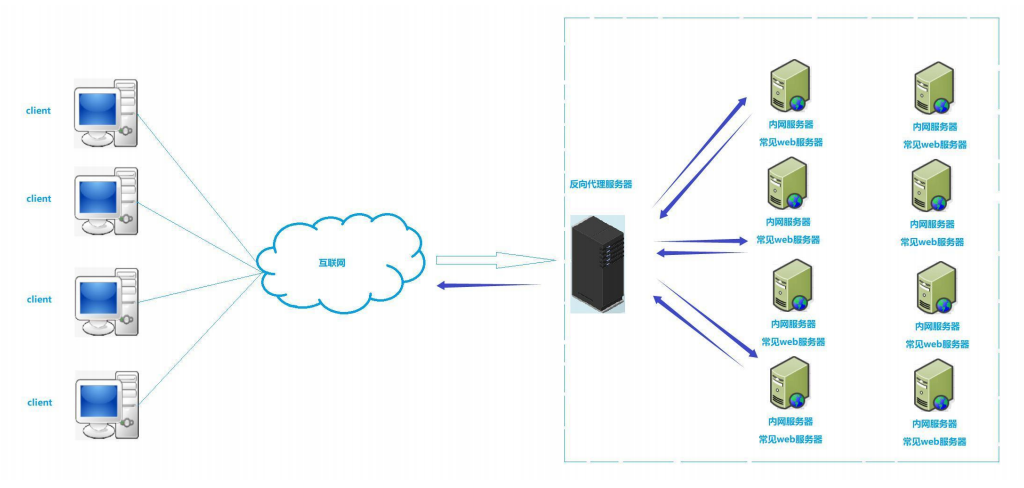
NAT/代理服务器/内网穿透
目录 一 NAT技术 二 内网穿透/内网打洞 三 代理服务器 一 NAT技术 跨网络传输的时候,私网不能直接访问公网,就引入了NAT能讲私网转换为公网进行访问,主要解决IPv4(2^32)地址不足的问题。 1. NAT原理 当某个内网想访问公网,就必…...

Unity 多时间源Timer定时器实战分享:健壮性、高效性、多线程安全与稳定性能全面解析
简介 Timer 是一个 Unity 环境下高效、灵活的定时任务调度系统,支持以下功能: •支持多种时间源(游戏时间 / 非缩放时间 / 真实时间) •支持一次性延迟执行和重复执行 •提供 ID、回调、目标对象等多种查询和销毁方式 •内建…...

深入解析Spring Boot与Spring Security的集成实践
深入解析Spring Boot与Spring Security的集成实践 引言 Spring Security是Spring生态中用于处理认证和授权的强大框架。在Spring Boot项目中集成Spring Security可以轻松实现用户认证、权限控制等功能。本文将详细介绍如何从零开始集成Spring Security,并解决实际…...
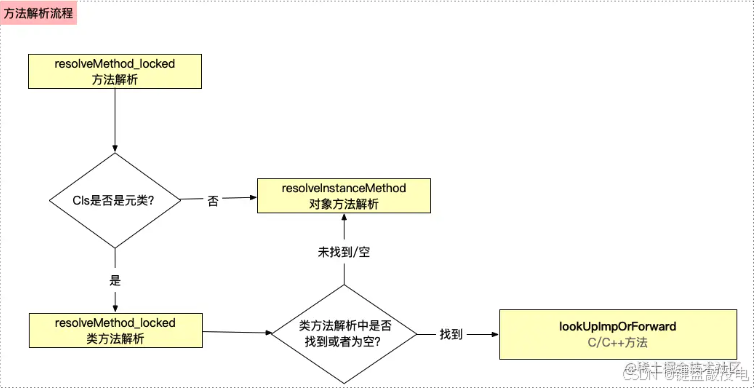
【iOS】探索消息流程
探索消息流程 Runtime介绍OC三大核心动态特性动态类型动态绑定动态语言 方法的本质代码转换objc_msgSendSELIMPMethod 父类方法在子类中的实现 消息查找流程开始查找快速查找流程慢速查找流程二分查找方法列表父类缓存查找 动态方法解析动态方法决议实例方法类方法优化 消息转发…...

用户账号及权限管理:企业安全的基石与艺术
在当今数字化时代,用户账号及权限管理已成为企业IT安全体系中不可或缺的核心组件。它不仅是保护敏感数据的第一道防线,更是确保业务运营效率和合规性的关键。本文将深入探讨用户账号及权限管理的重要性、最佳实践以及实施策略,助您构建一个安全、高效且灵活的访问控制体系。…...
413 Payload Too Large 问题定位
源头 一般是服务器或者nginx 配置导致的 nginx http {client_max_body_size 50m; # 调整为所需大小(如 50MB)# 其他配置... }nginx 不配置,默认是1M 服务器 spring 不配置也是有默认值的好像也是1M 如果出现413 可以试着修改配置来避…...

2025年渗透测试面试题总结-360[实习]安全工程师(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 1. 自我介绍 2. WAF及其绕过方式 3. IPS/IDS/HIDS 4. 云安全 5. 绕过安骑士/安全狗 6. Gopher扩展…...
Ubuntu16.04升级gcc/g++版本方法
0 前言 gcc与g分别是GNU的c和c编译器,Ubuntu16.04默认的gcc和g的版本是5.4.0,在使用一些交叉编译工具链会提示找不到GLIBC_2.27,而GLIBC_2.27又需要gcc 6.2以上版本,因此本文介绍Ubuntu16.04升级gcc/g版本的方法。 1 Ubuntu16.0…...
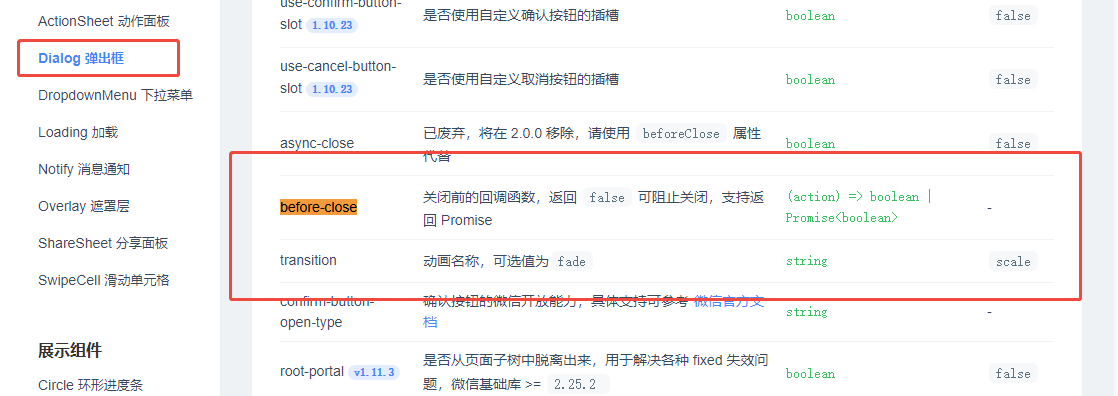
微信小程序van-dialog确认验证失败时阻止对话框的关闭
使用官方(Vant Weapp - 轻量、可靠的小程序 UI 组件库)的before-close: wxml: <van-dialog use-slot title"名称" show"{{ show }}" show-cancel-button bind:cancel"onClose" bind:confirm"getBackInfo"…...

边缘计算模块
本文来源 :腾讯元宝 边缘计算模块是一种部署在网络边缘(靠近数据源)的集成化硬件/软件设备,用于实时处理本地数据,减少云端依赖,提升响应速度与安全性。以下是其核心要点: 1. 核心组成 …...

【极兔快递Java社招】一面复盘|数据库+线程池+AQS+中间件面面俱到
【极兔快递Java社招】一面复盘|数据库线程池AQS中间件面面俱到 📍面试公司:极兔快递 👜面试岗位:Java后端开发工程师 🕐面试时长:约 60 分钟 🔄面试轮次:第 1 轮技术面&…...

OceanBase 的系统变量、配置项和用户变量有何差异
在继续阅读本文之前,大家不妨先思考一下,数据库中“系统变量”、“用户变量”以及“配置项”这三者之间有何不同。如果感到有些模糊,那么本文将是您理清这些概念的好帮手。 很多用户在使用OceanBase数据库中的“配置项”和“系统变量”&#…...

Git本地使用小Tips
要将本地仓库 d:\test 的更新推送到另一个本地仓库 e:\test,可以使用 Git 的远程仓库功能。以下是具体步骤: 在 e:\test 中添加 d:\test 作为远程仓库 在 e:\test 目录中打开 Git Bash 或命令行,执行以下命令: git remo…...
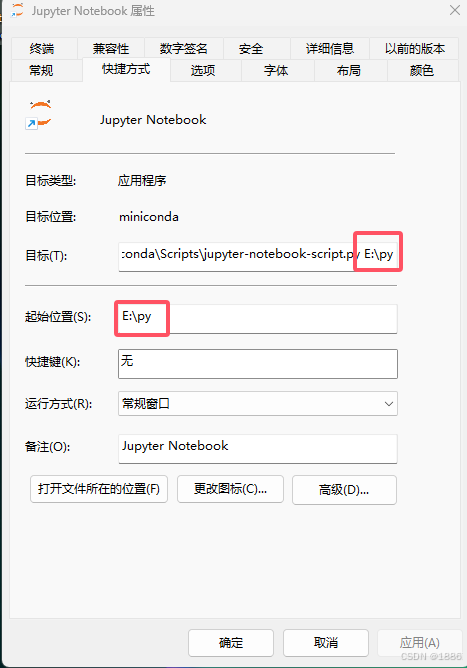
【Python】Jupyter指定具体路径
一、右键Jupyter Notebook 右击Jupyter Notebook点击属性 二、修改以下两个地方...

ThreadLocal作一个缓存工具类
1、工具类 import java.util.HashMap; import java.util.Map;public class ThreadLocalUtil {// 使用Map存储多类型数据private static final ThreadLocal<Map<String, Object>> CONTEXT_HOLDER new ThreadLocal<>();// 存储数据public static void set(Str…...

RNope:结合 RoPE 和 NoPE 的长文本建模架构
TL;DR 2025 年 Cohere 提出的一种高效且强大的长上下文建模架构——RNope-SWA。通过系统分析注意力模式、位置编码机制与训练策略,该架构不仅在长上下文任务上取得了当前最优的表现,还在短上下文任务和训练/推理效率方面实现了良好平衡。 Paper name …...
virtualbox虚拟机中的ubuntu 20.04.6安装新的linux内核5.4.293 | 并增加一个系统调用 | 证书问题如何解决
参考文章:linux添加系统调用【简单易懂】【含32位系统】【含64位系统】_64位 32位 系统调用-CSDN博客 安装新内核 1. 在火狐下载你需要的版本的linux内核压缩包 这里我因为在windows上面下载过,配置过共享文件夹,所以直接复制粘贴通过共享文…...

unity UGUI虚线框shader
Shader "Custom/DottedLineShader" {Properties{_MainTex ("Texture", 2D) "white" {}_Color("Color",COLOR) (1,1,1,1)_LineLength("虚线长度",float) 0.08}SubShader{Tags //设置支持UGUI{ "Queue""Tran…...

vue2、vue3项目打包生成txt文件-自动记录打包日期:git版本、当前分支、提交人姓名、提交日期、提交描述等信息 和 前端项目的版本号json文件
vue2 打包生成text文件 和 前端项目的版本号json文件 项目打包生成txt文件-自动记录git版本、当前分支、提交人姓名、提交日期、提交描述等信息生成版本号json文件-自动记录当前版本号、打包时间等信息新建branch-version-webpack-plugin.js文件 // 同步子进程 const execSyn…...
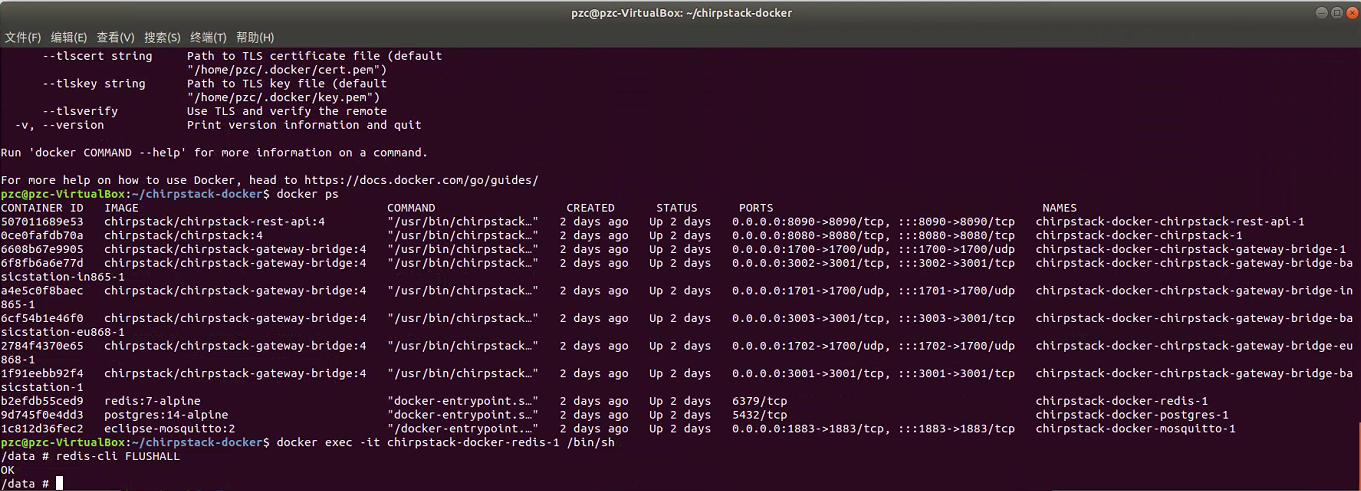
chirpstack v4版本 全流程部署[ubuntu+docker]
背景介绍 由于chirpstackv3 版本使用的是锐米提供的版本,从网络上寻找的资源大多数都是一样的v3版本,是经过别人编译好发布出来的,原本的chirpsatck项目是运行的linxu环境下的,因此我的想法是在linux服务器上部署chirpsatckv4,暂时使用linux上的chirpstack v4版本,目前编译成e…...

DeepSeek 赋能数字孪生:重构虚实共生的智能未来图景
目录 一、数字孪生技术概述1.1 数字孪生的概念1.2 技术原理剖析1.3 应用领域与价值 二、DeepSeek 技术解读2.1 DeepSeek 的技术亮点2.2 与其他模型的对比优势 三、DeepSeek 赋能数字孪生3.1 高精度建模助力3.2 实时数据处理与分析3.3 智能分析与预测 四、实际案例解析4.1 垃圾焚…...