交叉熵损失函数,KL散度, Focal loss
目录
交叉熵损失函数(Cross-Entropy Loss)
二分类交叉熵
多分类交叉熵
KL散度(Kullback-Leibler Divergence)
交叉熵损失函数和KL散度总结
Focal loss
Focal loss 和 交叉熵损失函数 的区别
交叉熵损失函数(Cross-Entropy Loss)
交叉熵损失函数,涉及两个概念,一个是损失函数,一个是交叉熵。
首先,对于损失函数。在机器学习中,损失函数就是用来衡量我们模型的预测结果与真实结果之间“差距”的函数。这个差距越小,说明模型的表现越好;差距越大,说明模型表现越差。我们训练模型的目标,就是通过不断调整模型的参数,来最小化这个损失函数。以一个生活化的例子举例,想象一下你在教一个孩子识别猫和狗。孩子每次猜对或猜错,你都会给他一个“评分”。如果他猜对了,评分就很高(损失很小);如果他猜错了,评分就可能很低(损失很大)。
在明白完损失函数后,就要理解交叉熵了,在理解交叉熵之前我们又要了解何为熵。熵在信息论中是衡量一个随机变量不确定性(或者说信息量)的度量。不确定性越大,熵就越大。根据信息论中的香农定理,我们可以得出熵的计算公式为:
![]()
其中,P(xi)是事件xi发生的概率。- log(P(xi)) 表示信息量,根据公式我们可以知道信息量大小与概率成负相关,概率越小的时间其信息量越大,如飞机失事;概率越大的时间其信息量越小,如太阳从东边升起。
谈完熵之后,我们来开始理解何为交叉熵?
交叉熵是衡量两个概率分布之间“相似性”的度量。更准确地说,它衡量的是,当我们使用一个非真实的概率分布 Q 来表示一个真实的概率分布 P 时,所需要付出的“代价”或“信息量”。交叉熵的计算公式为:
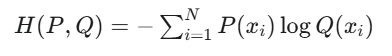
注意,这里的 P(xi) 通常是one-hot编码形式,即在分类问题中,只有真实类别对应的 P(xi) 为1,其他为0。
二分类交叉熵
在二分类问题中,当你的模型需要判断一个输入是A类还是B类(比如是猫还是狗,是垃圾邮件还是正常邮件)时,你会使用二分类交叉熵。
- 真实标签 (y): 通常用0或1表示。例如,猫是1,狗是0。
- 模型预测概率 (
): 模型输出的属于类别1的概率,通常通过Sigmoid激活函数得到,范围在0到1之间。
二分类交叉熵公式为:
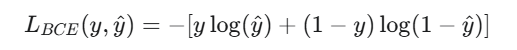
直观理解:
- 如果真实标签 y=1(比如是猫):损失函数变为 −log(
- 如果真实标签 y=0(比如是狗):损失函数变为 −log(1−
多分类交叉熵
当你的模型需要判断一个输入是N个类别中的哪一个(比如是猫、狗、还是鸟)时,你会使用多分类交叉熵。
- 真实标签 (y): 通常是one-hot编码。例如,猫是 [1,0,0],狗是 [0,1,0],鸟是 [0,0,1]。
- 模型预测概率 (
多分类交叉熵的公式为:
![]()
其中,N 是类别的数量,yi 是真实标签中第 i 个类别的指示(0或1),i 是模型预测第 i 个类别的概率。
直观理解:
- 由于真实标签 y 是one-hot编码,只有真实类别 k 对应的 yk 是1,其他 yi 都是0。所以,这个求和公式实际上只计算了真实类别对应的预测概率的负对数。
- 举例:如果真实标签是猫 [1,0,0],模型预测是 [0.8(猫),0.1(狗),0.1(鸟)]。 损失 =−(1⋅log(0.8)+0⋅log(0.1)+0⋅log(0.1))=−log(0.8)。 如果模型预测是 [0.1(猫),0.8(狗),0.1(鸟)]。 损失 =−(1⋅log(0.1)+0⋅log(0.8)+0⋅log(0.1))=−log(0.1)。 显然,−log(0.1) 比 −log(0.8) 要大很多,说明模型预测猫的概率很低时,损失会很大,这符合我们的直觉。
KL散度(Kullback-Leibler Divergence)
KL散度和交叉熵很像,只不过交叉熵是硬标签,KL散度是软标签,因此KL散度也称为相对熵,是衡量两个概率分布 P 和 Q 之间差异的非对称度量。它量化了当使用概率分布 Q 来近似概率分布 P 时所损失的信息量。KL散度主要用于拉近真实分布和近似分布的表达,去让近似分布尽可能接近真实分布,因为越近似,其除法越近于1,log()越接近于0。其计算公式为:
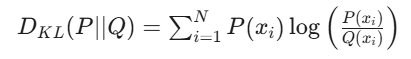
其中,P为真实分布 ,Q为近似分布 。我们将其展开,可得到以下公式:
![]()
可以看到当P(xi)为1时,这时就变成交叉熵了。
KL散度特性
- 非负性(涉及数学的非负性证明):KL(P∣∣Q)≥0(因为P和Q不相等的话,即P/Q>1),只有当 P 和 Q 是完全相同的分布时(此时P/Q = 1),KL(P∣∣Q)=0。
- 非对称性:KL(P∣∣Q) 不等于 KL(Q∣∣P) 。KL(P∣∣Q)是惩罚 Q 在 P 概率高的地方给出低概率。KL(Q∣∣P)惩罚 Q 在 P 概率低的地方给出高概率。
- 度量的是“信息损失”: 它衡量的是当你用 Q 来编码 P 时,额外需要多少比特的信息。
交叉熵损失函数和KL散度总结
- 交叉熵损失函数适用于分类任务,基于硬标签,目的是衡量模型预测的概率分布与真实标签的概率分布之间的“距离”。它的目标是让模型对真实类别的预测概率尽可能高。
- KL散度适用于衡量两个概率分布之间的差异,是非对称的,多用于概率模型,用于强制模型学习到的分布与某个先验分布接近,或衡量两个复杂分布之间的相似性。
Focal loss
Focal Loss 是一种专门设计用于处理类别不平衡问题的损失函数,特别是在CV中目标检测任务中表现出色。
为什么提出Focal loss?
在许多实际应用中,如目标检测,类别不平衡是一个常见问题。例如,在一个图像中,背景(负样本)通常占据大多数,而目标物体(正样本)很少。如果采用传统的交叉熵损失则会导致模型过度关注负样本,从而忽视正样本。
那现在就有个疑问,交叉熵损失也可为类别分配权重比,分配权重比不就可以了吗?
分配权重比确实有助于提高正样本的关注程度,但交叉熵损失函数无法让模型去具体地关注简单和困难样本,而在目标检测中,由于存在较多作为背景的负样本,因此作为目标物体的正样本在预测中被预测为正样本的概率较小,因此如果能从困难样本的角度出发的话,当被预测为正确且概率较大时,对应的loss应较小,而当被预测为正确且概率较小时,对应的loss应较大,这样的话,就起到了对困难样本的关注作用。而Focal Loss 旨在通过将注意力集中在难以分类的样本上,通过一个平衡因子和一个焦点因子来对交叉熵损失函数进行优化。
Focal loss 定义
Focal loss 的公式如下
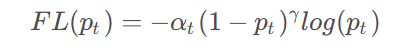
是模型对目标类的预测概率
是平衡因子,用于调整正负样本之间的影响
是焦点因子,用于调整难易样本的权重
其中,用于平衡正负样本的影响,防止负样本过多对损失的贡献。
- 假如,对于负样本
的话,那正样本
。
的值在[0,1],表示正负样本的权重比例。如果负样本占比4/5,正样本占比1/5的话,那
焦点因子用于调整简单和困难样本在损失中的贡献,是基于幂计算来进行调整的。具体地,
- 当预测概率
会非常小,从而降低了简单分类样本在损失中的贡献
- 当预测概率
焦点因子 γ 通常设为2,但可以根据具体问题调整。更大的 γ会使得模型更加专注于难分类样本,但更大的 γ 也可能会进一步使得一些困难样本被划分为简单样本了,因此在参数上的选取也不是越大越好。
Focal loss 和 交叉熵损失函数 的区别
Focal loss是基于二分类的交叉熵进行优化的,现比较二者的区别。

交叉熵损失
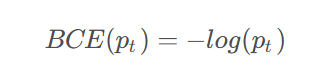
其中,是模型对正确类别的预测概率。
可以看到Focal loss与交叉熵的区别在于平衡因子和焦点因子的添加,但Focal loss重点还是在焦点因子的设计上且在这方面可解释性强,在权重因子上,交叉熵损失在具体实现的时候也能赋予不同样本的loss权重比。
下面是一个例子将说明焦点因子是如何聚焦在困难样本上的,并且探讨交叉熵和Focal loss的区别。
1. 对于一个简单样本,如预测一张图片没有猫。
- 那么真实标签y=0 (没有猫)
- 模型预测 p =0.01 (预测有猫的概率非常低,即预测没有猫的概率 非常高)。 这是一个“容易分类”的负样本,模型表现非常好。那么预测没有猫的概率就是p = 0.99,因此模型预测为与真实标签(没有猫)相同的概率是p = 0.99
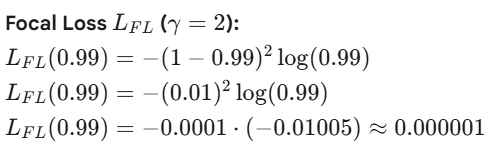

2.对于一个困难样本,如预测一张图片有猫
- 那么真实标签y=1(有猫)
- 如果模型预测p=0.1(预测有猫的概率非常低,即模型分类错误),这是一个难以分类的正样本,模型表现非常差。因此模型预测为与真实标签(有猫)相同的概率是p = 0.1
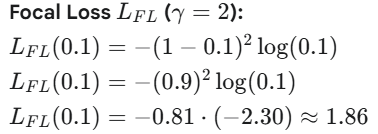

根据例子,我们可以得出以下结论
Focal loss可以有效衰减简单样本在loss中的表现,并且可以较好的保持困难样本的loss值,从而让模型关注困难样本的学习上,如上述例子中,困难样本的loss = 1.86,简单样本的loss = 0.000001,二者相差的数量级达。而在交叉熵损失中,困难样本loss = 2.30,简单样本的loss = 0.01,二者相差的数量级达
。因此Focal loss可以有效关注到困难样本的loss贡献。
相关文章:
交叉熵损失函数,KL散度, Focal loss
目录 交叉熵损失函数(Cross-Entropy Loss) 二分类交叉熵 多分类交叉熵 KL散度(Kullback-Leibler Divergence) 交叉熵损失函数和KL散度总结 Focal loss Focal loss 和 交叉熵损失函数 的区别 交叉熵损失函数(Cross-Entropy…...

php、laravel框架下如何将一个png图片转化为jpg格式
要在 PHP 的 Laravel 框架下将 PNG 图片转化为 JPG 格式,可以使用两种方法:内置的 GD 库或第三方包 Intervention/image。 方法 1:使用 GD 库 GD 库是 PHP 内置的图像处理工具,无需额外安装即可使用。 实现步骤: 使…...

足式机器人经典控制常用的ROS库介绍
一. 核心工具 & 功能 1. ros-noetic-rosbash 作用: 提供与 ROS 相关的 Shell 命令(如 roscd, rosls, roscp 等),用于快速操作 ROS 包、节点和文件。 典型场景: 快速在终端中切换 ROS 工作空间、查看或复制 ROS 包内的文件。 2. ros-noet…...

在tp6模版中加减法
实际项目中,我们经常需要标签变量加减运算的操作。但是,在ThinkPHP中,并不支持模板变量直接运算的操作。幸运的是,它提供了自定义函数的方法,我们可以利用自定义函数解决:ThinkPHP模板自定义函数语法如下&a…...
【Part 3 Unity VR眼镜端播放器开发与优化】第一节|基于Unity的360°全景视频播放实现方案
《VR 360全景视频开发》专栏 将带你深入探索从全景视频制作到Unity眼镜端应用开发的全流程技术。专栏内容涵盖安卓原生VR播放器开发、Unity VR视频渲染与手势交互、360全景视频制作与优化,以及高分辨率视频性能优化等实战技巧。 📝 希望通过这个专栏&am…...

Python打卡DAY30
知识点回顾: 导入官方库的三种手段导入自定义库/模块的方式导入库/模块的核心逻辑:找到根目录(python解释器的目录和终端的目录不一致) # 直接导入 from random import randint print(randint(1, 10)) # 导入自定义库 import modu…...
IDEA连接github(上传项目)
【前提:菜鸟学习的记录过程,如果有不足之处,还请各位大佬大神们指教(感谢)】 1.先配置好git环境。 没配置的小伙伴可以看上一篇文章教程。 安装git,2.49.0版本-CSDN博客 2.在idea设置git 打开IDEA设置-…...
重构研发效能:项目管理引领软件工厂迈向智能化
1.项目管理智能化,激活软件工厂新引擎 在高速发展的软件开发时代,企业如何高效管理多个项目、协调团队合作、优化资源配置,已成为推动技术进步的关键。尤其是在多任务、多项目并行的复杂环境下,智能项目组合管理工具正成为软件工…...

基于 STM32 单片机的实验室多参数安全监测系统设计与实现
一、系统总体设计 本系统以 STM32F103C8T6 单片机为核心,集成温湿度监测、烟雾检测、气体泄漏报警、人体移动监测等功能模块,通过 OLED 显示屏实时显示数据,并支持 Wi-Fi 远程传输。系统可对实验室异常环境参数(如高温、烟雾、燃气泄漏)及非法入侵实时报警,保障实验室安…...

Vue3 中使用 provide/inject 实现跨层级组件传值失败的原因及解决方案
1、基础用法 父组件: <script setup> import { ref, provide } from vue; import ChildComponent from ./ChildComponent.vue; const parentData ref(初始数据); // 提供数据 provide(parentData, parentData); </script>子组件: <sc…...

小白的进阶之路系列之二----人工智能从初步到精通pytorch中分类神经网络问题详解
什么是分类问题? 分类问题涉及到预测某物是一种还是另一种。 例如,你可能想要: 问题类型具体内容例子二元分类目标可以是两个选项之一,例如yes或no根据健康参数预测某人是否患有心脏病。多类分类目标可以是两个以上选项之一判断一张照片是食物、人还是狗。多标签分类目标…...

Semaphore解决高并发场景下的有限资源的并发访问问题
在高并发编程的领域中,我们常常面临着对有限资源的激烈抢夺问题。而 Java 的 java.util.concurrent 包提供的 Semaphore ,为我们提供了精准控制对有限资源并发访问的强大能力。 一、Semaphore? Semaphore,直译为 “信号量”&#…...
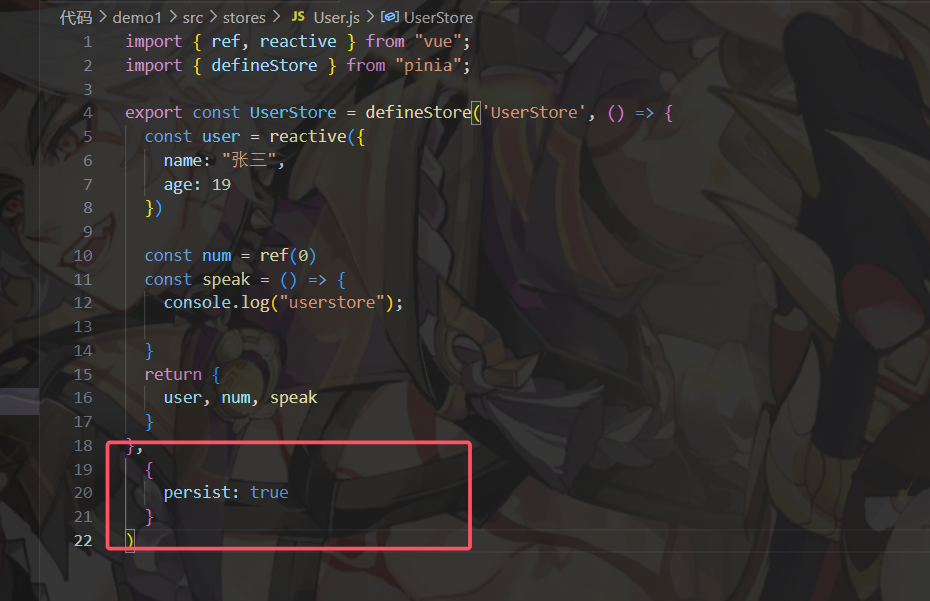
Vue3——Pinia
目录 什么是 Pinia? 为什么选择 Pinia? 基本使用 安装pinia 配置pinia 定义store 使用 持久化插件 什么是 Pinia? Pinia 是一个轻量级的状态管理库,专为 Vue 3 设计。它提供了类似 Vuex 的功能,但 API 更加简…...
02 基本介绍及Pod基础排错
01 yaml文件里的字段错误 # 多打了一个i导致的报错 [rootmaster01 yaml]# cat 01-pod.yaml apiVersion: v1 kind: Pod metadata:name: likexy spec:contaiiners:- name: aaaimage: registry.cn-hangzhou.aliyuncs.com/yinzhengjie-k8s/apps:v1 [rootmaster01 yaml]# kubectl …...

Android Edge-to-Edge
Android Edge-to-Edge显示:开发者综合指南 一、什么是Android Edge-to-Edge Android Edge-to-Edge是一种先进的用户界面(UI)设计理念,旨在最大化利用设备的显示区域。它允许应用程序的内容延伸至屏幕的各个边缘,包…...

⼆叉搜索树详解
1. ⼆叉搜索树的概念 ⼆叉搜索树⼜称⼆叉排序树,它或者是⼀棵空树,或者是具有以下性质的⼆叉树: • 若它的左⼦树不为空,则左⼦树上所有结点的值都⼩于等于根结点的值 • 若它的右⼦树不为空,则右⼦树上所有结点的值都⼤于等于根结…...
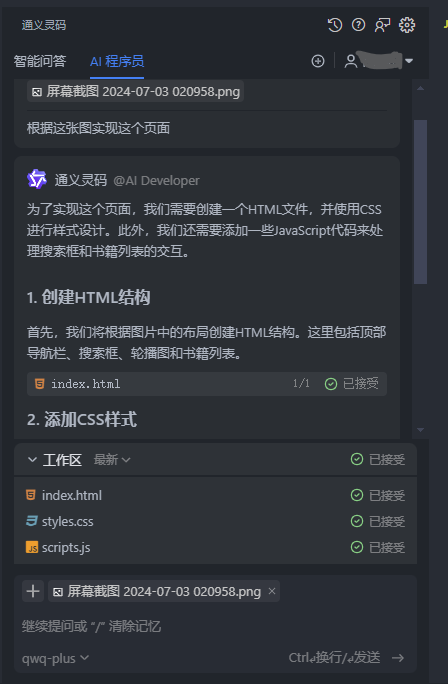
如何使用通义灵码提高前端开发效率
工欲善其事,必先利其器。对于前端开发而言,使用VSCode已经能够极大地提高前端的开发效率了。但有了AI加持后,前端开发的效率又更上一层楼了! 本文采用的AI是通义灵码插件提供的通义千问大模型,是目前AI性能榜第一梯队…...

使用 ARCore 和 Kotlin 开发 Android 增强现实应用入门指南
环境准备 1. 工具与设备要求 Android Studio:Arctic Fox 或更高版本设备:支持 ARCore 的 Android 设备(查看支持列表)依赖库:// build.gradle (Module级) dependencies {implementation com.google.ar:core:1.35.0im…...
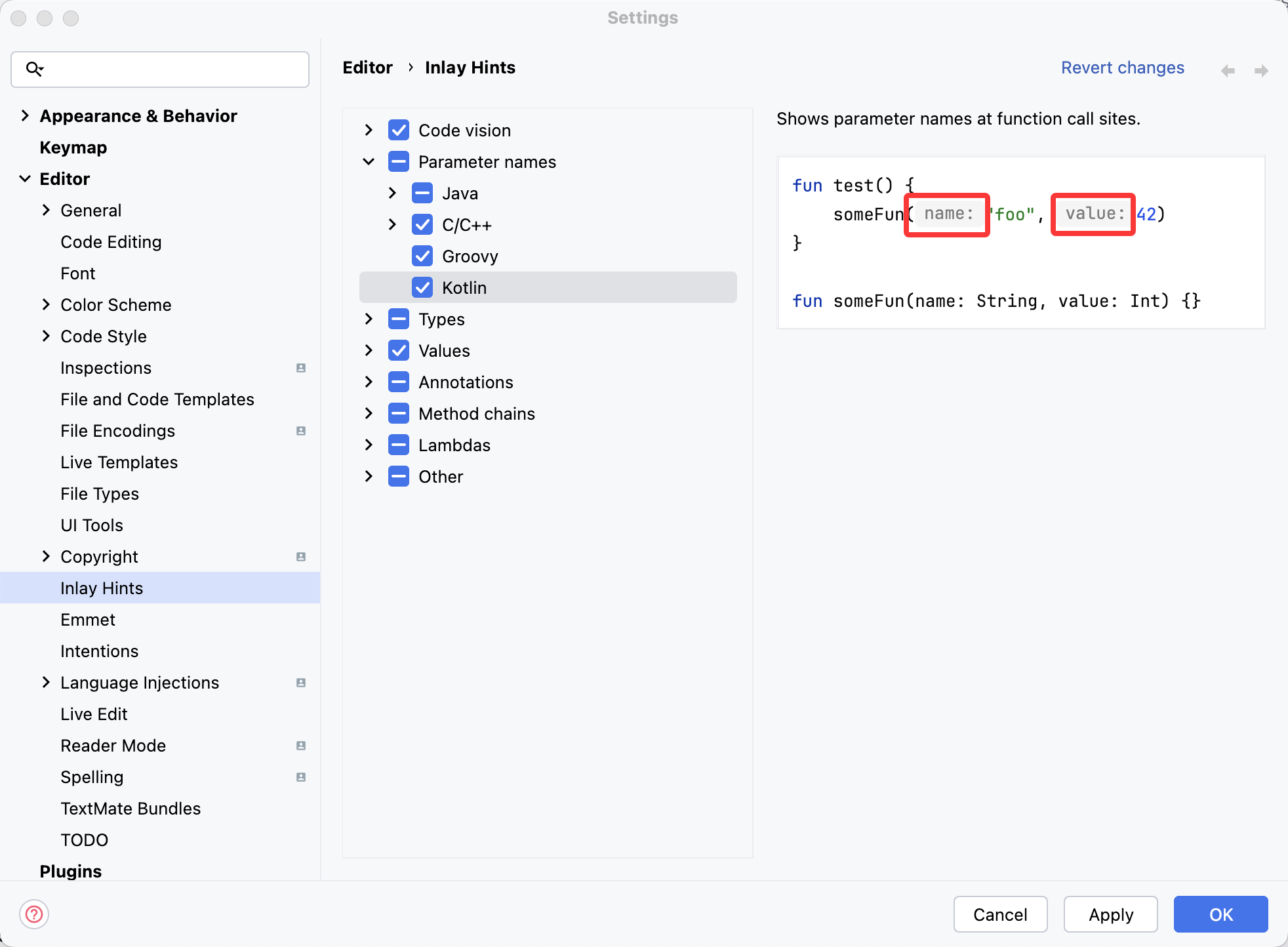
Android Studio Kotlin 中的方法添加灰色参数提示
在使用 Android Studio 时, 我发现使用 Java 编写方法后在调用方法时, 会自动显示灰色的参数。 但在 Kotlin 中没有显示, 于是找了各种方法最后找到了设置, 并且以本文章记录下来。 博主博客 https://blog.uso6.comhttps://blog.…...
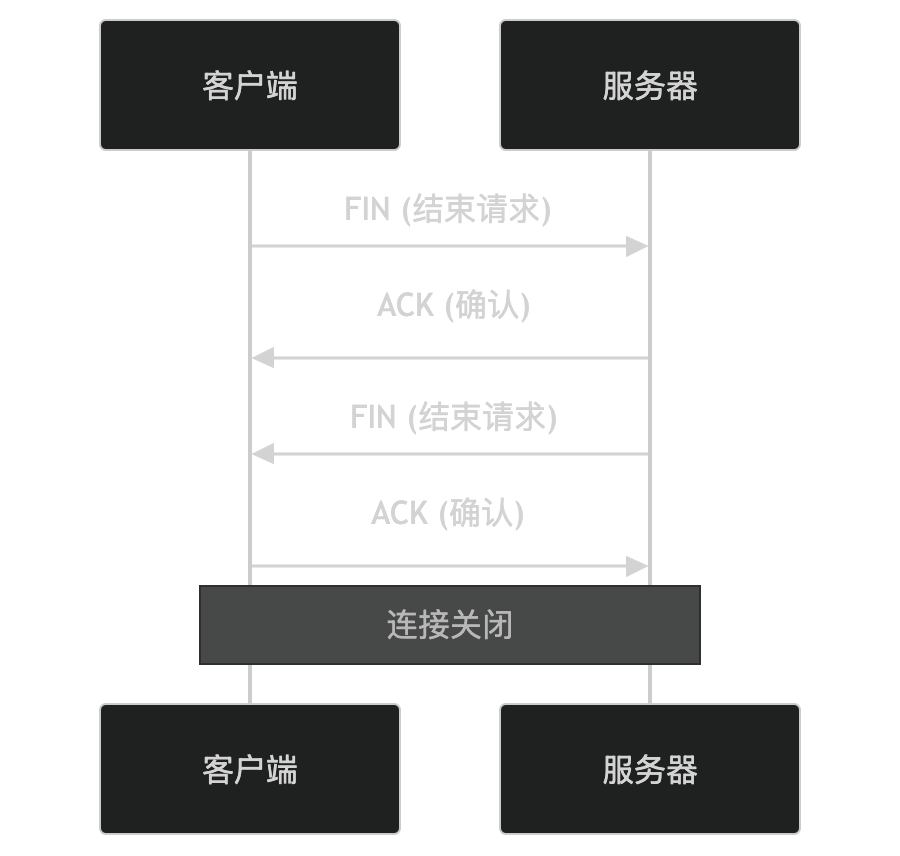
TCP协议简介
TCP 协议 TCP(Transmission Control Protocol,传输控制协议)是互联网协议套件中的核心协议之一,位于传输层。它提供了一种可靠的、面向连接的、基于字节流的数据传输服务。TCP 的主要特点是确保数据在传输过程中不丢失、不重复&a…...
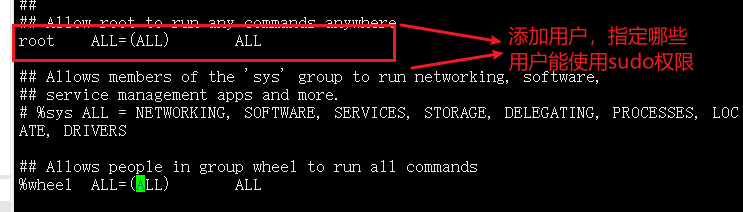
Linux学习心得问题整理(二)
day05 Linux基础入门 Linux语法解析 如何理解ssh远程连接?如何使用ssh使用远程连接服务? ssh进也称远程服务终端,常见连接方式可以包括windows和Linux两种方式 首先咱们使用windows窗口进行连接,这里就采用xshell连接工具来给大家做演示吧…...
SOC-ESP32S3部分:2-2-VSCode进行编译烧录
飞书文档https://x509p6c8to.feishu.cn/wiki/CTzVw8p4LiaetykurbTciA42nBf?fromScenespaceOverview 无论是使用Window搭建IDF开发环境,还是使用Linux Ubuntu搭建IDF开发环境,我们都建议使用VSCode进行代码编写和编译,VSCode界面友好&#x…...

数据可视化热图工具:Python实现CSV/XLS导入与EXE打包
在数据分析工作中,热图(Heatmap)是一种非常直观的可视化工具,能够清晰展示数据矩阵中的数值分布和相关性。本文将介绍如何使用Python构建一个支持CSV/XLS文件导入、热图生成并可打包为EXE的桌面应用程序。 核心功能设计 我们的热图工具将包含以下核心功能: 支持CSV和Excel…...

Python虚拟环境再PyCharm中自由切换使用方法
Python开发中的环境隔离是必不可少的步骤,通过使用虚拟环境可以有效地管理不同项目间的依赖,避免包冲突和环境污染。虚拟环境是Python官方提供的一种独立运行环境,每个项目可以拥有自己单独的环境,不同项目之间的环境互不影响。在日常开发中,结合PyCharm这样强大的IDE进行…...

使用 Terraform 创建 Azure Databricks 工作区
使用 Terraform 创建 Azure Databricks Terraform 是一种基础设施即代码(IaC)工具,允许用户通过声明式配置文件来管理和部署云资源。Azure Databricks 是一个基于 Apache Spark 的分析平台,专为数据工程和数据科学设计。通过 Terraform,可以自动化 Azure Databricks 的创…...

使用Mathematica绘制一类矩阵的特征值图像
学习过线性代数的,都知道:矩阵的特征值非常神秘,但却携带着矩阵的重要信息。 今天,我们将展示:一类矩阵,其特征值集体有着很好的分布特征。 modifiedroots[c_List] : Block[{a DiagonalMatrix[ConstantAr…...
)
GitHub 趋势日报 (2025年05月18日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1TapXWorld/ChinaTextbookPDF教材。⭐ 2027⭐ 23993Roff2public-apis/public-a…...
SpringBoot-6-在IDEA中配置SpringBoot的Web开发测试环境
文章目录 1 环境配置1.1 JDK1.2 Maven安装配置1.2.1 安装1.2.2 配置1.3 Tomcat1.4 IDEA项目配置1.4.1 配置maven1.4.2 配置File Encodings1.4.3 配置Java Compiler1.4.4 配置Tomcat插件2 Web开发环境2.1 项目的POM文件2.2 项目的主启动类2.3 打包为jar或war2.4 访问测试3 附录3…...
)
JVM 工具实战指南(jmap / jstack / Arthas / MAT)
🔍 从诊断到定位:掌握生产级 JVM 排查工具链 📖 前言:系统故障时,如何快速定位? 无论 JVM 理论多么扎实,当线上服务出现 CPU 飙高、响应超时、内存泄漏或频繁 Full GC 时,仅靠猜测…...
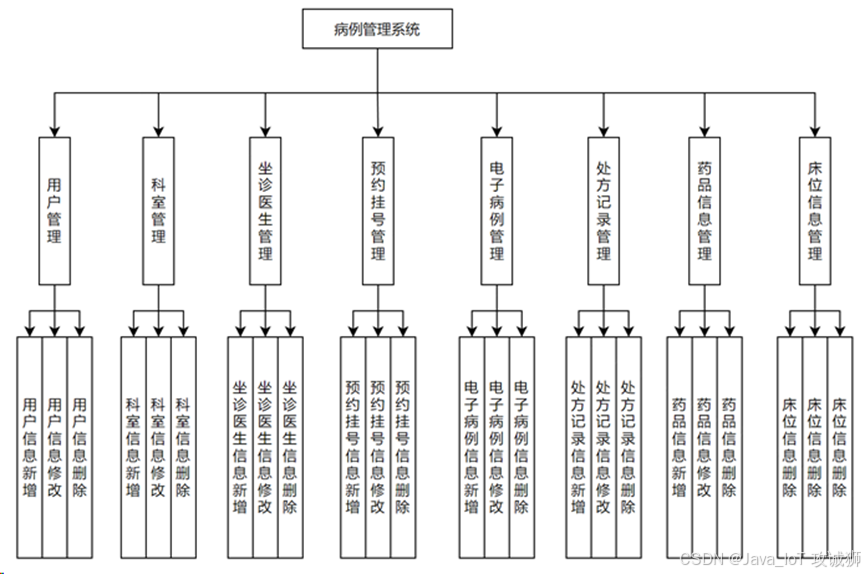
基于springboot+vue的病例管理系统
开发语言:Java框架:springbootJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7数据库工具:Navicat12开发软件:eclipse/myeclipse/ideaMaven包:Maven3.3.9 系统展示 患者信息管理 医…...