【强化学习】深度强化学习 - Deep Q-Network(DQN)算法
文章目录
- 摘要
- 一、DQN核心原理
- 1. Q-learning回顾
- 2. 用深度网络逼近Q函数
- 3. 经验回放(Experience Replay)
- 4. 目标网络(Target Network)
- 5. 损失函数
- 6. ε-贪心策略(ε-greedy)
- 二、算法流程与伪代码
- 三、典型实现步骤
- 四、Python示例(PyTorch)
摘要
Deep Q-Network(DQN)将经典的Q-learning与深度神经网络相结合,使用卷积网络或多层感知机对动作价值函数进行逼近,并通过经验回放(Experience Replay)和目标网络(Target Network)两项关键技术稳定训练,从而在高维状态空间(如像素)下实现近乎人类水平的控制能力。DQN自2015年被DeepMind团队首次提出以来,已成为深度强化学习领域的基石算法之一,被广泛应用于游戏、机器人等场景。
一、DQN核心原理
1. Q-learning回顾
Q-learning是一种无模型、离线的值迭代算法,通过不断更新Q值
Q ( s t , a t ) ← Q ( s t , a t ) + α [ r t + 1 + γ max a ′ Q ( s t + 1 , a ′ ) − Q ( s t , a t ) ] Q(s_t,a_t)\leftarrow Q(s_t,a_t)+\alpha\bigl[r_{t+1} + \gamma\max_{a'}Q(s_{t+1},a') - Q(s_t,a_t)\bigr] Q(st,at)←Q(st,at)+α[rt+1+γa′maxQ(st+1,a′)−Q(st,at)]
来逼近最优动作价值函数 Q ∗ ( s , a ) Q^*(s,a) Q∗(s,a)。
2. 用深度网络逼近Q函数
DQN使用深度神经网络 Q ( s , a ; θ ) Q(s,a;\theta) Q(s,a;θ) 来近似离散系统中每对状态-动作的Q值,大幅提高了算法在高维、连续状态空间中的适用性。
3. 经验回放(Experience Replay)
训练过程中,将每次交互得到的 ( s t , a t , r t + 1 , s t + 1 ) (s_t,a_t,r_{t+1},s_{t+1}) (st,at,rt+1,st+1) 存入回放池(replay buffer),每次更新时随机抽样小批量数据,打破数据间的时序相关性,提升数据利用效率并降低方差。
4. 目标网络(Target Network)
原始Q网络的参数 θ \theta θ 会导致目标值频繁变化,DQN引入一个参数延迟更新的目标网络 Q ( s , a ; θ − ) Q(s,a;\theta^-) Q(s,a;θ−),在固定步数 C C C 后将主网络参数复制给目标网络,以稳定训练过程。
5. 损失函数
DQN的目标是最小化均方贝尔曼误差(Mean Squared Bellman Error):
L ( θ ) = E ( s , a , r , s ′ ) ∼ D [ ( r + γ max a ′ Q ( s ′ , a ′ ; θ − ) − Q ( s , a ; θ ) ) 2 ] . \mathcal{L}(\theta) = \mathbb{E}_{(s,a,r,s')\sim \mathcal{D}}\Bigl[\bigl(r + \gamma \max_{a'}Q(s',a';\theta^-) - Q(s,a;\theta)\bigr)^2\Bigr]. L(θ)=E(s,a,r,s′)∼D[(r+γa′maxQ(s′,a′;θ−)−Q(s,a;θ))2].
梯度通过反向传播计算并更新网络参数。
6. ε-贪心策略(ε-greedy)
为了兼顾探索与利用,DQN在每一步按概率 ε 随机选取动作,否则选择价值最大的动作 a = arg max a Q ( s , a ; θ ) a=\arg\max_a Q(s,a;\theta) a=argmaxaQ(s,a;θ),并随训练进程线性或指数衰减 ε。
二、算法流程与伪代码
输入:环境 Env,Q网络 Q(s,a;θ),目标网络 Q(s,a;θ⁻),回放池 D,折扣因子 γ,探索率 ε
1. 初始化 θ⁻ ← θ,D 为空
2. 对于每一集episode:a. 重置环境,获得初始状态 sb. 重复直到终止:i. 以 ε-贪心策略从 Q(s,a;θ) 选择 aii. 执行动作 a,获得 (r, s')iii. 将 (s,a,r,s') 存入 Div. 从 D 中随机抽样小批量 (s_j,a_j,r_j,s'_j)v. 计算目标 y_j = r_j + γ max_{a'} Q(s'_j,a';θ⁻)vi. 以梯度下降最小化 (y_j - Q(s_j,a_j;θ))²,更新 θvii. 每 K 步将 θ 复制到 θ⁻c. 终止或更新 ε
3. 返回训练后的 Q 网络 θ
三、典型实现步骤
-
环境与依赖
- 安装 Gym 或 Gymnasium,用于构建测试环境(如 CartPole-v1、Atari)。
- 选择深度学习框架(PyTorch、TensorFlow)并导入相应模块。
-
定义Q网络
- 对低维状态:使用全连接网络(MLP);对高维图像:使用卷积神经网络(CNN)。
- 输出维度等于动作数;前向计算返回所有动作的Q值。
-
实现Replay Buffer
- 环形队列或列表存储固定容量的过渡;实现
push(state, action, reward, next_state, done)和sample(batch_size)方法。
- 环形队列或列表存储固定容量的过渡;实现
-
训练循环
- 动作选择:ε-贪心策略;
- 存储转移:将当前交互存入回放池;
- 批量更新:当回放池样本数 ≥ 批量大小时,抽样并计算损失、反向传播更新主网络;
- 目标网络更新:每隔固定步数同步主网络参数到目标网络;
- ε衰减:逐步降低探索率至最小值。
-
超参数设置
- 回放池大小(如 10 5 10^5 105)、批量大小(如 32–128)、γ(如 0.99)、学习率(如 1e-4)、ε初始/最小值及衰减策略、目标网络更新频率 K(如 1000 步)。
-
训练与评估
- 多个随机种子、多轮训练,记录平均回报与方差;
- 根据训练曲线判断收敛性,适时调整超参数。
四、Python示例(PyTorch)
import random, numpy as np
import torch, torch.nn as nn, torch.optim as optim
from collections import dequeclass DQN(nn.Module):def __init__(self, state_dim, action_dim):super().__init__()self.net = nn.Sequential(nn.Linear(state_dim, 128), nn.ReLU(),nn.Linear(128, 128), nn.ReLU(),nn.Linear(128, action_dim))def forward(self, x):return self.net(x)# 初始化
env = gym.make('CartPole-v1')
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
policy_net = DQN(state_dim, action_dim)
target_net = DQN(state_dim, action_dim)
target_net.load_state_dict(policy_net.state_dict())
optimizer = optim.Adam(policy_net.parameters(), lr=1e-4)
replay_buffer = deque(maxlen=100000)# 训练循环
for episode in range(1000):state = env.reset()done = Falsewhile not done:if random.random() < epsilon:action = env.action_space.sample()else:with torch.no_grad():action = policy_net(torch.FloatTensor(state)).argmax().item()next_state, reward, done, _ = env.step(action)replay_buffer.append((state, action, reward, next_state, done))state = next_stateif len(replay_buffer) >= batch_size:batch = random.sample(replay_buffer, batch_size)states, actions, rewards, next_states, dones = map(lambda x: torch.FloatTensor(x), zip(*batch))q_values = policy_net(states).gather(1, actions.long().unsqueeze(1))next_q = target_net(next_states).max(1)[0].detach()target = rewards + gamma * next_q * (1 - dones)loss = nn.MSELoss()(q_values.squeeze(), target)optimizer.zero_grad(); loss.backward(); optimizer.step()# 同步目标网络if total_steps % target_update == 0:target_net.load_state_dict(policy_net.state_dict())total_steps += 1# ε衰减epsilon = max(epsilon_min, epsilon * epsilon_decay)
相关文章:
算法)
【强化学习】深度强化学习 - Deep Q-Network(DQN)算法
文章目录 摘要一、DQN核心原理1. Q-learning回顾2. 用深度网络逼近Q函数3. 经验回放(Experience Replay)4. 目标网络(Target Network)5. 损失函数6. ε-贪心策略(ε-greedy) 二、算法流程与伪代码三、典型实…...

git 修改一个老commit,再把修改应用到所有后续的 commit
找到你想修改的 commit 的哈希值(前7位即可)。 git rebase -i <commit-hash>^找到你想修改的 commit 行 将行首的 pick 改为 edit 保存并退出编辑器 进行想要的修改 git add <修改的文件> git commit --amendgit rebase --continue如果…...

docker compose 启动指定的 service
使用 Docker Compose 启动指定服务 要在 Docker Compose 中启动特定的服务而不是所有服务,可以使用以下命令: docker compose up [服务名] 基本用法 启动单个服务: docker compose up service_name 启动多个指定服务: docker …...
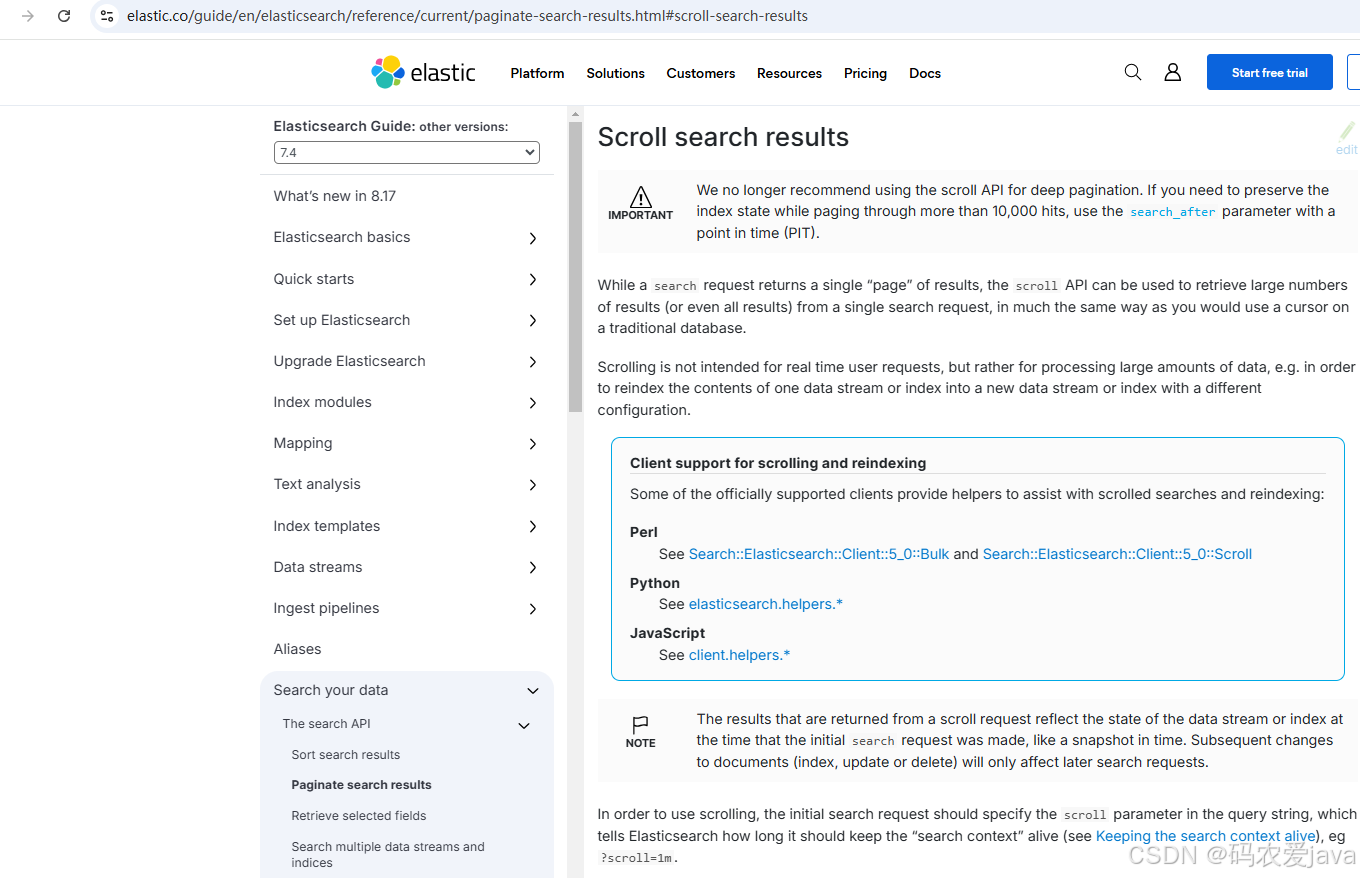
Elasticsearch 深入分析三种分页查询【Elasticsearch 深度分页】
前言: 在前面的 Elasticsearch 系列文章中,分享了 Elasticsearch 的各种查询,分页查询也分享过,本篇将再次对 Elasticsearch 分页查询进行专题分析,“深度分页” 这个名词对于我们来说是一个非常常见的业务场景&#…...
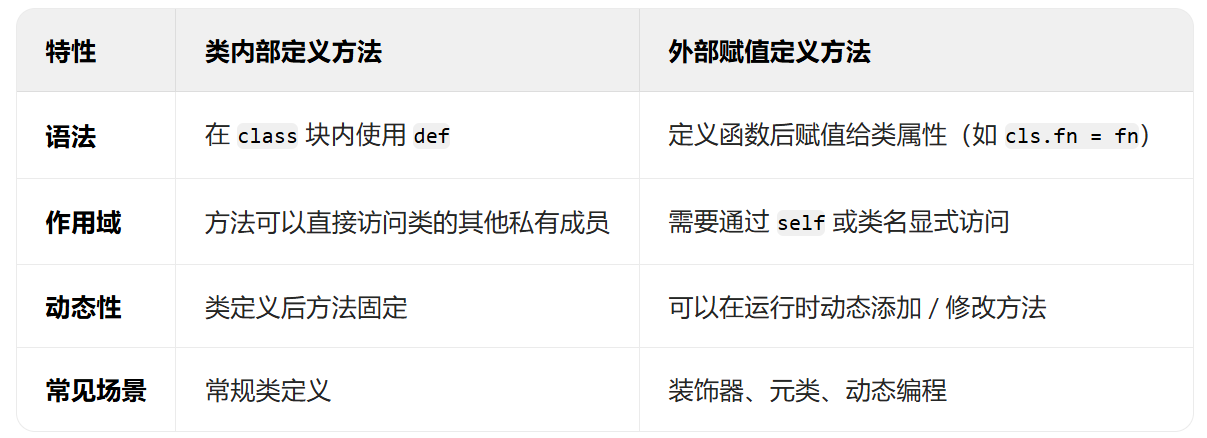
DAY29 超大力王爱学Python
知识点回顾 类的装饰器装饰器思想的进一步理解:外部修改、动态类方法的定义:内部定义和外部定义 作业:复习类和函数的知识点,写下自己过去29天的学习心得,如对函数和类的理解,对python这门工具的理解等&…...

Ubuntu 远程桌面配置指南
概述: 本文主要介绍在Ubuntu 22.04中通过VNC实现远程连接的方法。首先需安装图形化界面和VNC工具x11vnc,设置开机启动服务;然后在Windows客户端用VNC Viewer通过局域网IP和端口5900连接。 总结: 一、VNC配置与安装 安装图形化界面 在Ubuntu 22.04中需先安装: sudo apt …...

【Python装饰器深度解析】从语法糖到元编程实战
目录 🌟 前言🏗️ 技术背景与价值🩹 当前技术痛点🛠️ 解决方案概述👥 目标读者说明🧠 一、技术原理剖析📊 核心概念图解💡 核心作用讲解🔧 关键技术模块说明⚖️ 技术选型对比🛠️ 二、实战演示⚙️ 环境配置要求💻 核心代码实现案例1:基础计时装饰器案…...

推扫式高光谱相机VIX-N230重磅发布——开启精准成像新时代
随着各行业对高光谱成像技术需求的持续增长,市场对于高分辨率、高灵敏度以及快速成像的高光谱相机的需求愈发迫切。中达瑞和凭借多年的行业经验和技术积累,敏锐捕捉到这一市场趋势,正式推出全新一代推扫式可见光近红外高光谱相机——VIX-N230…...
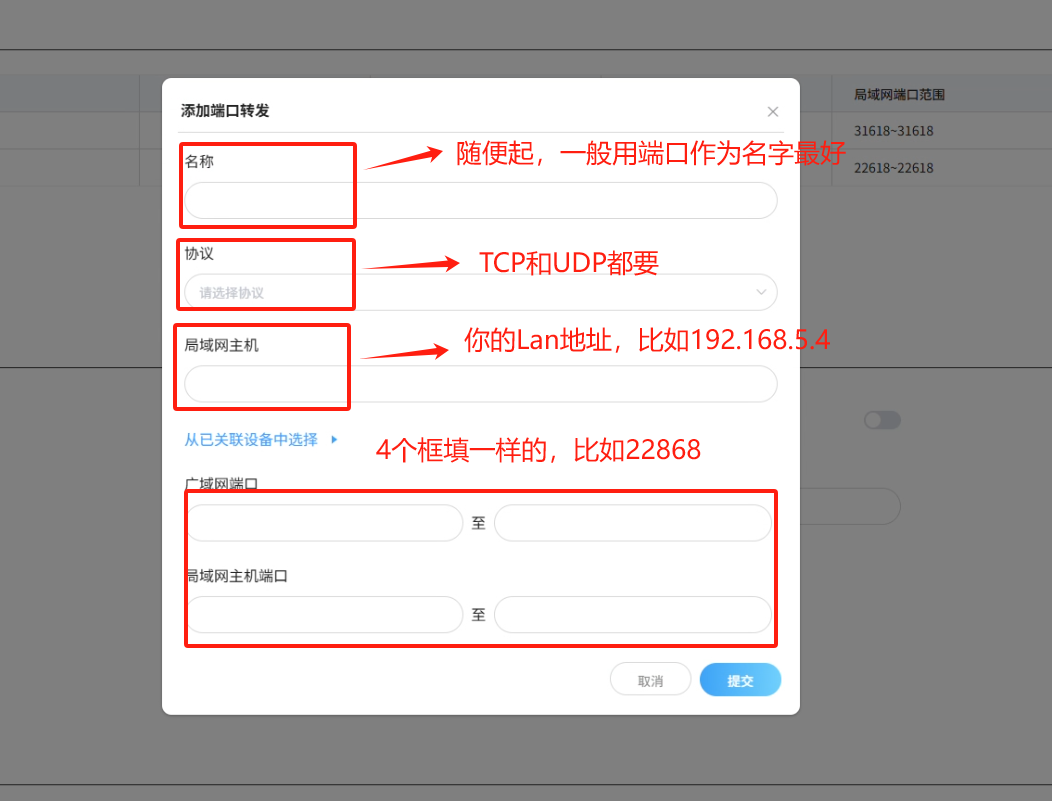
Parsec解决PnP连接失败的问题
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、准备环境二、DMZ三、端口映射1.Parsec设置固定端口2.路由器设置端口转发3.重启被控端Parsec四、多少一句1.有光猫管理员账号2.没有光猫管理员账号总结 前言…...

面试题:详细分析Arraylist 与 LinkedList 的异同
相同点 都是List接口的实现类: ArrayList和LinkedList都实现了Java集合框架中的List接口,因此它们都提供了对列表元素的操作方法。 都继承了Collection接口: 由于List接口继承了Collection接口,所以ArrayList和LinkedList也都继承…...

软件I2C
软件I2C 注意: SDA(串行数据线)和SCL(串行时钟线)都是双向I/O线,接口电路为开漏输出。需通过上拉电阻接电源VCC。 软件I2C说明 说明,有的单片机没有硬件I2C的功能,或者因为电路设计…...

通过实例讲解螺旋模型
目录 一、螺旋模型的核心概念 二、螺旋模型在电子商城系统开发中的应用示例 第 1 次螺旋:项目启动与风险初探...

Brooks Polycold快速循环水蒸气冷冻泵客户使用手含电路图,适用于真空室应用
Brooks Polycold快速循环水蒸气冷冻泵客户使用手含电路图,适用于真空室应用...

winfrom中创建webapi
参照一下两篇 Winform窗体利用WebApi接口实现ModbusTCP数据服务_winform webapi-CSDN博客 C#.NET WebApi返回各种类型(图片/json数据/字符串),.net图片转二进制流或byte - 冰封的心 - 博客园...

unity XCharts插件生成曲线图在UICanvas中
【推荐100个unity插件之22】基于UGUI的功能强大的简单易用的Unity数据可视化图表插件——XCharts3.0插件的使用_unity xcharts-CSDN博客...
)
Pichome 开源网盘程序index.php 文件读取漏洞(CVE-2025-1743)
免责声明 本文档所述漏洞详情及复现方法仅限用于合法授权的安全研究和学术教育用途。任何个人或组织不得利用本文内容从事未经许可的渗透测试、网络攻击或其他违法行为。使用者应确保其行为符合相关法律法规,并取得目标系统的明确授权。 对于因不当使用本文信息而造成的任何直…...
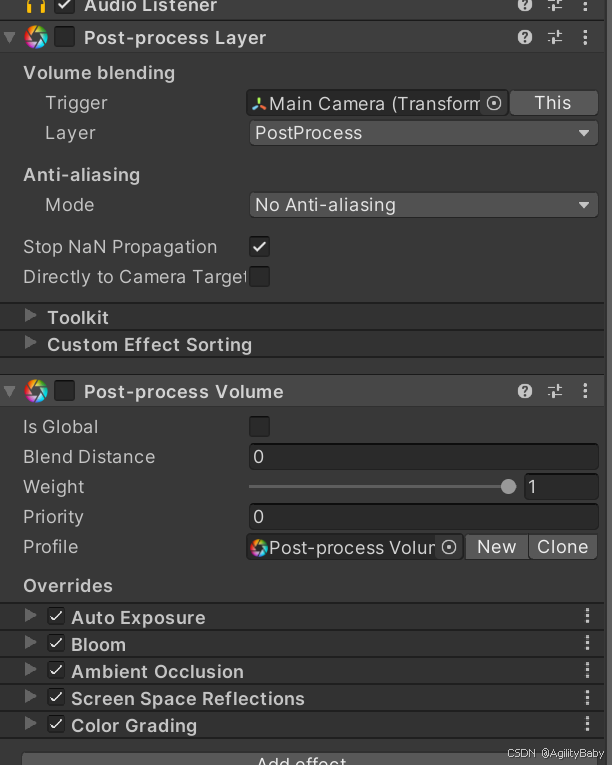
关于在Unity项目中使用Post Processing插件打包到web端出现的问题
关于在Unity项目中使用Post Processing插件打包到web端出现的问题 解决方法:是不激活摄像机上的Post Processing有关组件,拉低场景中的Directional Light平行光的强度进行web端打包。 (烘焙灯光时是可以激活。) web端支持这个Pos…...
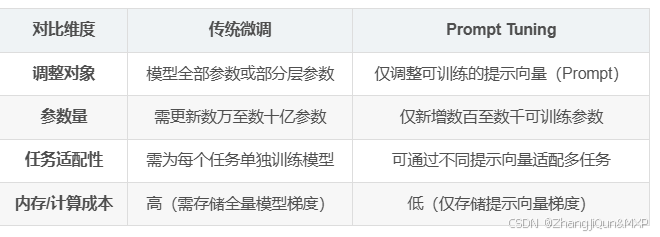
Prompt Tuning:高效微调大模型的新利器
Prompt Tuning(提示调优)是什么 Prompt Tuning(提示调优) 是大模型参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)的重要技术之一,其核心思想是通过优化 连续的提示向量(而非整个模型参数)来适配特定任务。以下是关于 Prompt Tuning 的详细解析: 一、核心概念…...
)
OpenCV 第6课 图像处理之几何变换(重映射)
1. 概述 简单来说,重映射就是把一副图像内的像素点按照规则映射到到另外一幅图像内的对应位置上去,形成一张新的图像。 因为原图像与目标图像的像素坐标不是一一对应的。一般情况下,我们通过重映射来表达每个像素的位置(x,y),像这样: g(x,y)=f(h(x,y)) 在这里g()是目标图…...

C++初阶-vector的底层
目录 1.序言 2.std::sort(了解) 3.vector的底层 3.1讲解 3.2构造函数 3.3push_back函数 3.4begin()和end()函数 3.5capacity()和size()函数和max_size函数 3.5.1size()函数 为什么这样写? 底层原理 3.5.2max_size()函数 为什么这…...

获取文件夹下所有文件的名称
一、为什么写这个程序 因为我要做一个类似于目录树的结构,需要把文件夹下的所有名字全部导出了。 二、Python和vscode的安装 先安装Python在安装vscode Python安装 vscode的安装 三、源码 import os# 定义要扫描的文件夹列表(使用原始字符串避免转义…...

C语言指针深入详解(五):回调函数、qsort函数
目录 一、回调函数 1、使用回调函数改造前 2、使用回到函数改造后 二、qsort使用举例 1、使用qsort函数排序整型数据 2、使用qsort排序结构数据 三、qsort函数模拟实现 结语 🔥个人主页:艾莉丝努力练剑 🍓专栏传送门:《…...
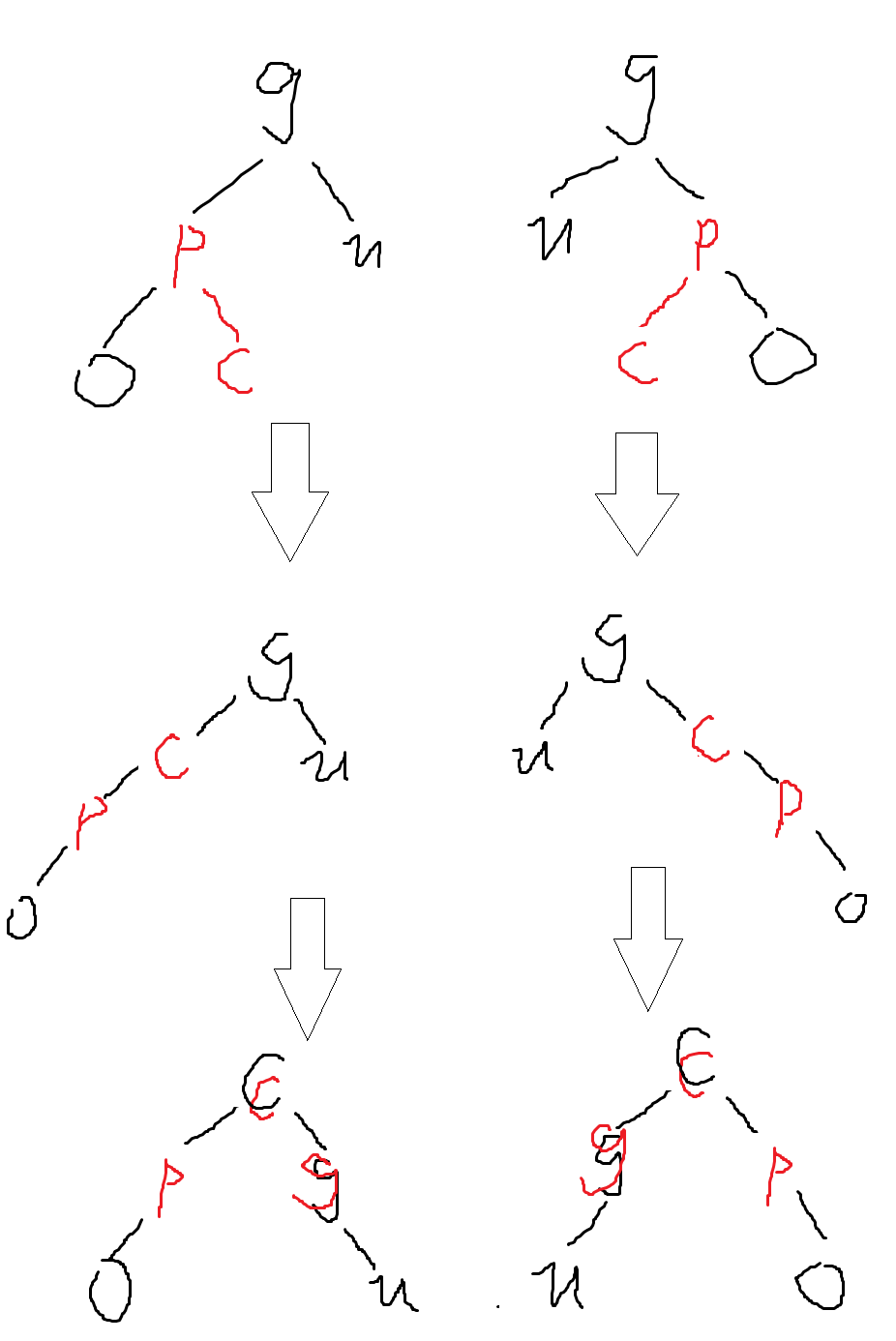
数据结构进阶:AVL树与红黑树
目录 前言 AVL树 定义 结构 插入 AVL树插入的大致过程 更新平衡因子 旋转 右单旋 左单旋 左右双旋 右左双旋 实现 红黑树 定义 性质 结构 插入 实现 总结 前言 在学习了二叉搜索树之后,我们了解到其有个致命缺陷——当树的形状呈现出一边倒…...

容器化-K8s-镜像仓库使用和应用
一、K8s 镜像仓库使用 1、启动镜像仓库 cd/usr/local/harbor ./install.sh2、配置镜像仓库地址 在 master 节点和 slaver 节点上,需要配置 Docker 的镜像仓库地址,以便能够访问本地的镜像仓库。编辑 Docker 的配置文件 vi /etc/docker/daemon.json(如果不存在则创建),添…...

基于Spring Boot + Vue的教师工作量管理系统设计与实现
一、项目简介 随着高校信息化管理的发展,教师工作量管理成为教务系统中不可或缺的一部分。为此,我们设计并开发了一个基于 Spring Boot Vue 的教师工作量管理系统,系统结构清晰,功能完备,支持管理员和教师两个角色。…...

预先学习:构建智能系统的 “未雨绸缪” 之道
一、预先学习:训练阶段的 “模型预构建” 哲学 1.1 核心定义与生物启发 预先学习的本质是模拟人类的 “经验积累 - 快速决策” 机制:如同医生通过大量病例总结诊断规则,算法在训练阶段利用全量数据提炼规律,生成固化的 “决策模型…...

完善网络安全等级保护,企业需注意:
在数字化转型加速的当下,网络安全成为企业发展的基石。网络安全等级保护作为保障网络安全的重要举措,企业必须高度重视并积极落实。以下要点,企业在完善网络安全等级保护工作中需格外关注: 一、准确开展定级备案 企业首先要依据相…...

Trae 04.22版本深度解析:Agent能力升级与MCP市场对复杂任务执行的革新
我正在参加Trae「超级体验官」创意实践征文,本文所使用的 Trae 免费下载链接:Trae - AI 原生 IDE 目录 引言 一、Trae 04.22版本概览 二、统一对话体验的深度整合 2.1 Chat与Builder面板合并 2.2 统一对话的优势 三、上下文能力的显著增强 3.1 W…...

OceanBase 开发者大会:详解 Data × AI 战略,数据库一体化架构再升级
OceanBase 2025 开发者大会与5月17日在广州举行。这是继 4 月底 OceanBase CEO 杨冰宣布公司全面进入AI 时代后的首场技术盛会。会上,OceanBase CTO 杨传辉系统性地阐述了公司的 DataAI 战略,并发布了三大产品:PowerRAG、共享存储,…...
:递归模式与条件匹配的艺术)
正则表达式进阶(三):递归模式与条件匹配的艺术
在正则表达式的高级应用中,递归模式和条件匹配是处理复杂嵌套结构和动态模式的利器。它们突破了传统正则表达式的线性匹配局限,能够应对嵌套括号、HTML标签、上下文依赖等复杂场景。本文将详细介绍递归模式((?>...)、 (?R) 等࿰…...