zData X zStorage 为什么采用全闪存架构而非混闪架构?
点击蓝字 关注我们
最近有用户问到 zData X 的存储底座 zStorage 分布式存储为什么采用的是全闪存架构而非混闪架构?主要原因还是在于全闪存架构在性能和可靠性方面具有更显著的优势。zData X 的上一代产品 zData 的早期版本也使用了SSD盘作为缓存的技术架构,在当时的确是起了比较大的作用。但随着SSD技术的演进、成本大幅降低以及缓存架构本身的一些问题,zData 后期的版本就去掉了SSD缓存。所以我们对于SSD作为缓存的这种技术架构也有一些经验。这篇文章我系统地来讲一讲这两种架构的优劣势,以及为什么 zData X & zStorage 采用了全闪存架构。
混闪架构是指使用SSD盘做缓存,而主存或者说后端存储用HDD盘(机械盘);全闪存架构是指存储全部用SSD盘,没有缓存这一层。值得注意的是,有些分布式存储软件虽然基于混闪架构,但是把主存储从HDD盘换成SSD盘,即所有存储介质都是SSD盘,这种方案从架构上来说仍然是混闪架构,相比全闪存架构来说,IO性能更差但成本反而更高了,本文不讨论这种“伪全闪存架构”。
那么混闪架构相对于全闪存架构,有哪些优缺点呢?我先说在数据库场景的结论(产品或方案的优劣势都是在场景中体现,抛开场景谈优劣势都是耍流氓。本文主要讲数据库场景下两种架构的对比):
优点:相同存储容量下的成本降低。相对于全闪存架构,3存储节点300TB裸容量的情况下,混闪架构整体成本降低约10%。该优势在容量越大越突出,如果容量越小,则成本优势越不明显。但这个优点正随着SSD盘价格的持续降低而导致优势越来越小。
缺点:混闪架构在性能和可靠性方面存在不少缺陷。譬如,
①随机IO延迟高:在存储节点上,混闪架构的随机IO延迟远高于全闪存架构,全闪存架构的平均IO延迟优于混闪架构6-30倍。这会导致混闪架构在一些随机IO较多的复杂SQL执行时,时间就非常长。全闪存架构下1000个随机IO的SQL也只需要0.1s,而混闪需要0.6~3s。
②IO带宽(吞吐量)低:为了避免大量数据把缓存中的热点数据挤出,顺序IO通常不经过缓存,要从主存HDD盘读取,单存储节点的IO带宽只有1-3GB/s,而全闪存架构单存储节点的IO带宽在20GB/s以上。这会导致数据备份、批量数据处理、报表统计分析等场景下的IO性能非常差。
③性能稳定性和确定性差:全闪存架构的性能指标都是相对稳定的,在稳定的性能指标下,业务表现也是确定的。但混闪架构这方面的缺点比较明显:数据访问的性能严重依赖于缓存命中率,即数据的热点程度。热点程度差的数据,访问的性能就非常差。
某些低频但重要的业务,比如某个业务系统的某些复杂查询类功能,使用不高频,这种情况下数据不是热点,要从机械盘上读取,所以性能非常差。全闪存架构稳定执行0.5s,但是混闪架构可能需要15s。
假设一个业务80%的可能性只需要30分钟处理完,但是有20%的可能性需要3小时处理完,而出现这种情况的时间点是无法预测的,故作为一个用户也难以预先处理,那我宁愿这个业务稳定地在1小时处理完成。
④缓存的并发访问、元数据管理、缓存数据冗余保护带来的性能降低问题:缓存层要对缓存介质和主存介质的映射数据(类似于操作系统虚拟内页面和物理内存页面的映射,也是以“块”或“页面”为单位映射)、缓存块是否是脏数据等元数据在内存中的管理和并发访问,以及持久化到缓存盘上都会有非常大的性能消耗。为了避免坏单块缓存盘导致整个节点不可用,所以缓存盘通常要多个缓存盘并且进行数据镜像保护(相当于还要实现缓存数据的软RAID),为了数据冗余的一致性和缓存数据至少写2份都会带来比较大的性能损耗。
⑤重构速率和数据可靠性问题:如果1块硬盘故障,更换1块新盘,进行数据重构。混闪架构下重构速率只有全闪存架构下的1/10,具体来说是200多MB/s与3GB/s的对比。即重构1个盘所花的时间是全闪存架构的10倍长。实际系统中HDD磁盘故障重构时间往往长达1周。重构时间越长,在此期间出现另一磁盘故障的概率就越大。
⑥混闪架构下的闪存盘寿命问题:SSD盘作为缓存,一方面因为读数据时要从HDD读出来然后写入到SSD盘进行缓存,导致读IO会产生SSD盘的写操作;另一方面IO集中在1-2个缓存盘上,导致缓存盘的擦写次数远高于全闪存盘,那么混闪架构下的闪存盘寿命低,而闪存故障又会导致整个缓存失效,甚至节点不可用。
⑦运维复杂性问题:由于缓存命中率过于重要,围绕缓存命中率的运维和监控,复杂性远超于全闪存架构。
在上述问题中,由于热点数据变动导致缓存命中率降低及性能降低的情况,在90%的数据都是归档的冷数据的情况下,这个问题发生的概率比较低,但其他问题普遍存在,不太好解决。
我们来详细地说一下上述的问题:
我们先来说一说混闪架构,即使用SSD盘做缓存,HDD盘做主存这种方案的好处——很直接,就是为了省成本。我们简单来算一笔账:
按1个节点100TB左右的容量来计算(按此容量算的原因是3个节点裸容量在300TB能够满足绝大部分企业的数据库使用),7.84TB的SSD盘和8TB的HDD盘都是需要13个。
U.2接口PCIe 4.0的NVMe SSD盘,800-1000元/TB,按800元/TB计算,13个7.84TB的SSD盘共81536元。
8TB SATA 7.2K 3.5in的企业级HDD盘,180元/TB,13个8TB的HDD盘共18720元。但是要注意,还需要2个缓存盘,共计12544元。缓存盘和主存盘的总价是31264元。这里为什么要2个缓存盘?原因是要考虑冗余,否则1个缓存盘故障,整个节点不可用。
那么3个节点共300TB裸容量的规模下,全闪存架构,磁盘共需要244608元;而混闪架构,磁盘共需要93792元,比全闪磁盘少了约15万元,相对于全闪存的数据库一体机150万左右的总价,刚好节省了10%的费用。
所以混闪架构,一套系统大约节省10%总体费用。
事物都有两面性,如果混闪架构只有优点没有缺点,这个世界就不会有全闪存分布式存储,也不会有全闪存磁盘阵列。那么混闪架构相对于全闪存架构的缺点有哪些呢?我们先从技术原理上对缓存进行解析:
1. 7200转的机械盘和SSD盘的主要性能对比:
大容量HDD盘一般都是7200转,故这里用以与SSD盘对比。

2. 缓存的技术特点:
①使用高性能的存储介质作为低性能低成本存储介质的缓存,本质上是利用数据局部性原理,即在某段短时间内,某些数据会被多次地访问。在进行数据访问时,访问到热点数据,从缓存直接进行访问,称之为“缓存命中”,如果不是热点数据,很大概率要从主存即机械盘上访问。缓存命中次数/总访问次数称之为“缓存命中率”。
②由于缓存容量远低于主存容量,所以缓存只能存放一部分数据,缓存一般使用LRU算法,最近最少使用的数据会被移出缓存。
③缓存有3种策略,如下表所示:
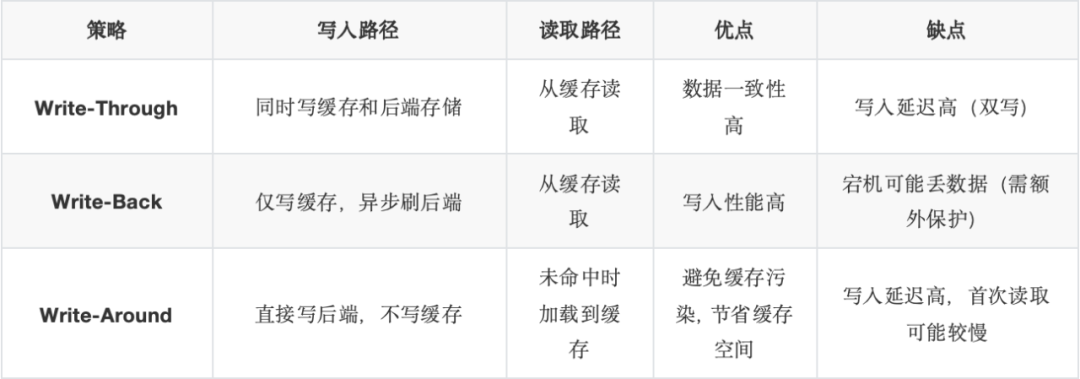
追求低延迟的数据库场景只能选择Write-Back缓存策略,否则10ms级的写延迟在数字化时代的今天是完全不可接受的。
在了解缓存的技术原理的基础上,我们再来看“混闪架构”分布式存储的问题。
1. 混闪架构IO延迟远高于全闪存架构
混闪架构下,缓存命中的IO性能达到SSD盘的水准,而缓存没有命中的IO性能就奇差无比,即IO延迟在0.1ms~10ms之间,波动范围非常大,最大值是最小值的100倍。反观全闪存架构的IO延迟“稳定在亚毫秒级”,波动范围非常小。
缓存命中率一般在70%-95%之间,假设1000个IO,几种缓存命中率下这1000个IO所花费的总时间是多长呢?我们看下表所列:
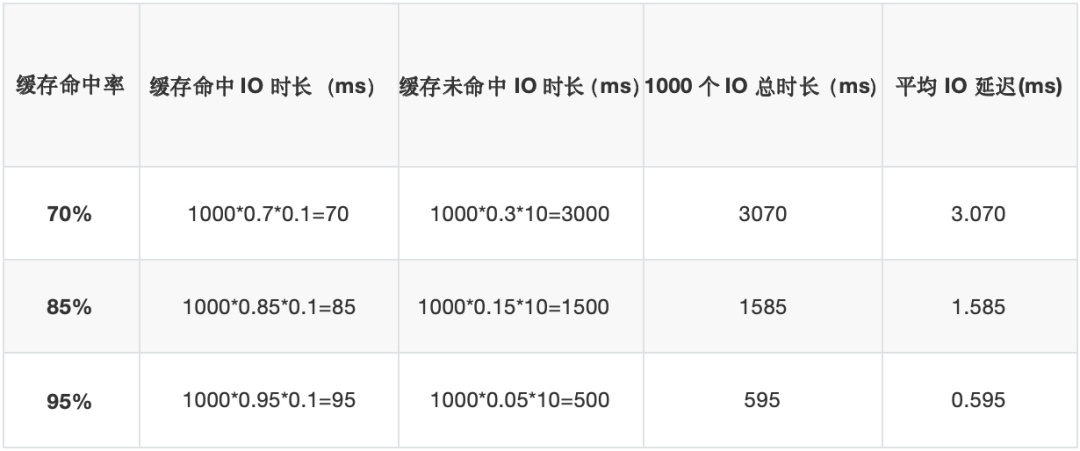
对于全闪存架构,1000个IO的总耗时基本就在100ms左右,是相对稳定和确定的。从上表的数据可以看到,即使是缓存命中率高达95%时,全闪存架构的IO延迟也只有混闪架构IO延迟的1/6,优势明显。如果某些数据缓存命中率不高,只有70%时,全闪存架构的IO延迟甚至优于混闪架构30倍。
混闪架构的这些延迟,在一些随机IO较多的复杂SQL执行时,耗费时间就非常长。全闪存架构下1000个随机IO的SQL也只需要0.1s,而混闪架构需要0.6~3s。
2. 混闪架构IO带宽(吞吐量)远低于全闪存架构
顺序读写的数据通常不会被反复访问,同时也要避免大量读写的数据把缓存中的热点数据挤出去,所以顺序读写通常是从主存储即后端的HDD盘上直接访问。这样吞吐量基本上就受限于机械盘的能力,如前所述,一个HDD盘的吞吐量仅为100-200MB/s,所以10个并发访问同时访问10个盘时,吞吐量也仅有1-2GB/s。按本文所述1个存储节点13个磁盘时,总吞吐量不足3GB/s。
在实际的业务中,顺序读写的IO吞吐量则更低。比如顺序读写128KB,如果按4K为存储的块单位,128KB就是32个4KB块。当这32个块部分数据在缓存中时,就需要把IO拆分成多个进行处理,严重影响性能。
3. “性能不稳定”导致的“不确定性”
所谓“性能不稳定”,就是在缓存命中时IO性能达到SSD盘的水准,而缓存没有命中的IO性能就奇差无比,波动范围有100倍之差,不像全闪存架构的IO延迟那样“稳定在亚毫秒级”。
那么“不确定性”是什么?是指IO性能不稳定带来的业务功能执行时间不确定。比如某个DBA每天早上都要查一个报表,这个报表大部分时间执行只需要0.6s,但是有小部分时间执行时间要5s,这就会使用户的使用体验非常不好。再比如某个批处理,需要在早上6点前完成,性能好的时候,早上4点就完成了,但是有时也会出现早上8点都完成不了。这种情况下,用户会感觉这系统随时都可能因为缓存问题而出现爆雷。出现上述业务执行时间“不确定性“的原因,主要在于该业务对应的数据的缓存命中率下降了。
早些年Exadata就是以混闪架构为主,曾出现由于A业务导致了B业务的数据被挤出缓存,而后在做B业务时缓存命中率低,导致SQL性能非常差,问题难以处理。
假设一个业务80%的可能性只需要30分钟处理完,但是有20%的可能性需要3小时处理完,而出现这种情况的时间点是无法预测的,故作为一个用户也难以预先处理,那我宁愿这个业务稳定地在1小时处理完成。或者说软件界面上的功能,80%的响应时间是0.5s,20%的响应时间是3s,那我宁愿100%的响应时间是1s。
导致缓存命中率降低,甚至缓存失效的主要原因有:
可能是新生成的数据不在缓存中,也可能是其他业务(如批处理)导致缓存中原来的“热点”数据被挤出缓存。比如计费系统出账,要访问几乎所有的账户相关数据,大量的数据进入缓存,使得缓存中原有数据被挤出。对于这个问题,如果系统中90%以上的数据是归档冷数据,出现的概率会小很多。
磁盘重构和重均衡会导致缓存的命中率大幅降低。磁盘故障进行重构和扩容增加磁盘或节点进行重均衡,都会使得后端主存储上HDD的数据进行大量的搬移,使得缓存中的数据失效。
用于缓存的SSD盘故障,导致缓存失效带来的问题更为严重,此时业务很大概率在性能上会下降到完全不可用的状态。
如果缓存元数据没有开启持久化,存储节点重启后会导致缓存数据全部失效,此时缓存相当于完全失效。
存储节点通过增加磁盘进行扩容,但是缓存盘本身没有增加容量。比如原来缓存盘与主存储的比率是1:10,增加了磁盘后变成了1:16。节点增加了磁盘,性能反而降低了;而全闪存在增加磁盘后性能是提升的。
4. 缓存的并发处理、元数据管理、缓存数据冗余保护带来的性能降低问题
缓存层要对缓存介质和主存介质进行映射,比如主存上的第N个盘的第M个8K块(也可以是其他大小的块)的缓存数据在缓存盘A的第X个8K块。除了映射信息之外,还要记录缓存块的状态:有效、无效、是否脏数据等,映射数据是元数据的一部分,一般是以hash表在内存中组织,以方便快速查找。
对于8KB大小的缓存块(标准术语称为cache line),7.84TB的缓存盘大小至少需要15~20GB的内存用于元数据。这个巨大的hash内存结构和前面提到的LRU算法需要的内存结构要进行并发访问,都会由于加锁等同步访问机制而产生性能损耗。
对于Write-Back缓存策略,在写IO时元数据一定要持久化到缓存上,否则软件或节点重启后,脏块信息丢失就会导致数据丢失。这样在写IO时还要写元数据,降低了性能。
为了考虑可用性,缓存数据需要进行冗余保护,否则1个盘故障后,Write Back的缓存上还没有写到后端主存的脏块数据,就永久性丢失了。当然分布式存储一个节点不工作,整个系统还有冗余保护,能保证数据不丢失和业务连续性,但是这会使得1个盘故障导致整个节点不可用,严重影响了系统可用性和性能。而用多个盘做缓存数据的冗余保护,则会使得冗余本身变得很复杂,影响性能。这个复杂性体现在如何用一个可靠的机制来保证两个缓存盘的数据是一致的,这个机制越复杂就越影响性能。而同时为了数据冗余,缓存数据至少写2份,也是性能较大损耗的点。
5. 重构速率和数据可靠性问题
如果1块硬盘故障,更换1块新盘,进行数据重构。为保证业务性能,最多使用30%的IO带宽用于重构,那么1个机械盘能用于重构的带宽是30-60M/s,取中间数45M/s。本文按13个盘举例,那么坏1个盘,在12个盘之间进行重构,就是45*12/2=270MB/s(除以2是因为一份数据要进行读和写)。而 zStorage 在只影响性能20%的情况下,重构速率可以达到3GB/s,因此混闪架构下重构速率只有全闪存架构下的1/10,即重构1个盘所花的时间是全闪存架构的10倍长。重构时间越长,在此期间出现另一磁盘故障的风险就越大。
1个8TB的盘,使用率假设到了75%,即存储了6TB数据,混闪架构下重构需要6小时,而 zStorage 全闪存架构只需要34分钟。
从计算来看HDD盘的重构时间还挺长,但是实际上由于业务IO的压力,导致磁盘重构的速率远低于计算值。根据经验,HDD盘故障后的重构时间往往长达一周,因此HDD磁盘故障后的风险非常大。
6. 混闪架构下的闪存盘寿命问题
SSD盘作为缓存,一方面连读IO都会在SSD盘上写数据,另一方面IO集中在1-2个缓存盘上,导致缓存盘的擦写次数远高于全闪存盘。这意味着混闪架构下的闪存盘寿命低,而闪存故障又会导致整个缓存失效,甚至节点不可用。
而对于全闪存架构来说则不存在此问题,大多数业务都是读多写少,磁盘的擦写次数少,并且写是均匀分布在所有磁盘上,基本上不会因为擦写而导致SSD盘的寿命中止和故障。
其实还有其他一些问题,包括运维复杂性问题,由于缓存命中率实在关键,混闪架构要随时关注缓存命中率,磁盘的替换操作也要比全闪存架构复杂不少。
结语
最后我们再回到缓存解决的成本问题上。云和恩墨的 zData 产品在2015年销售时,SSD盘的价格在10000元/TB以上,而十年过去了,其价格已降到约800元/TB,降幅十几倍;单盘容量从1.6TB增加到了如今主流的7.84~15.68TB;单存储节点从PCIe接口能插入2~4个SSD盘到现在可以插入超过24个U.2接口的SSD盘。
缓存作为软件系统架构中一项关键技术,在软件产品中起着非常重要的作用。在过去SSD盘价格高昂、单盘容量低、接口还是PCIe直插主板或用SATA SSD的时代,SSD缓存起到了巨大的作用。如果 Intel 没有停产Optane,那么的确还可以考虑将Optane作为缓存层使用,可以进一步降低全闪存储系统的IO延迟,在需要更低IO延迟的场景中发挥作用。
然而时至今日,随着软硬件技术的不断进步,可以预见SSD盘的价格还会持续下降。因此,在数据库场景,我们应该选择更先进的技术,而不是还采用混闪这种成本优势不大、但缺点太多的架构。这便是为什么全闪分布式存储和全闪存储阵列成为主流,zData X & zStorage 采用全闪存架构的原因。

数据驱动,成就未来,云和恩墨,不负所托!
云和恩墨创立于2011年,是业界领先的“智能的数据技术提供商”。公司以“数据驱动,成就未来”为使命,致力于将创新的数据技术产品和解决方案带给全球的企业和组织,帮助客户构建安全、高效、敏捷且经济的数据环境,持续增强客户在数据洞察和决策上的竞争优势,实现数据驱动的业务创新和升级发展。
自成立以来,云和恩墨专注于数据技术领域,根据不断变化的市场需求,创新研发了系列软件产品,涵盖数据库、数据库存储、数据库管理和数据智能等领域。这些产品已经在集团型、大中型、高成长型客户以及行业云场景中得到广泛应用,证明了我们的技术和商业竞争力,展现了公司在数据技术端到端解决方案方面的优势。

相关文章:
zData X zStorage 为什么采用全闪存架构而非混闪架构?
点击蓝字 关注我们 最近有用户问到 zData X 的存储底座 zStorage 分布式存储为什么采用的是全闪存架构而非混闪架构?主要原因还是在于全闪存架构在性能和可靠性方面具有更显著的优势。zData X 的上一代产品 zData 的早期版本也使用了SSD盘作为缓存的技术架构&#x…...

鸿蒙OSUniApp 实现精美的轮播图组件#三方框架 #Uniapp
UniApp 实现精美的轮播图组件 在移动应用开发中,轮播图是一个非常常见且重要的UI组件。本文将深入探讨如何使用UniApp框架开发一个功能丰富、动画流畅的轮播图组件,并分享一些实际开发中的经验和技巧。 一、基础轮播图实现 1.1 组件结构设计 首先&am…...

解决git中断显示中文为八进制编码问题
git config --global core.quotepath false 命令用于配置 Git 如何处理非 ASCII 字符(如中文、日文、韩文等)的文件名显示 core.quotepath Git 的一个核心配置项,控制是否对非 ASCII 文件名进行转义(quote)处理。 f…...

SQL次日留存率计算精讲:自连接与多字段去重的深度应用
一、问题拆解:理解次日留存率的计算逻辑 1.1 业务需求转换 题目:运营希望查看用户在某天刷题后第二天还会再来刷题的留存率。 关键分析点: 留存率 (第一天刷题且第二天再次刷题的用户数) / 第一天刷题的总用户数需…...

使用SQLite Studio导出/导入SQL修复损坏的数据库
使用SQLite Studio导出/导入SQL修复损坏的数据库 使用Zotero时遇到了数据库损坏,在软件中寸步难行,遂尝试修复数据库。 一、SQLite Studio简介 SQLite Studio是一款专为SQLite数据库设计的免费开源工具,支持Windows/macOS/Linux。相较于其…...

LSTM-Attention混合模型:美债危机与黄金对冲效率研究
摘要:本文依托多维度量化分析框架,结合自然语言处理(NLP)技术对地缘文本的情绪挖掘,构建包含宏观因子、风险溢价因子及技术面因子的三阶定价模型,对当前黄金市场的波动特征进行归因分析。实证结果显示&…...

了解 DDD 吗?DDD 和 MVC 的区别是什么?
简介: DDD(Domain-driven Design) 和 MVC(Model-View-Controller) 是软件后台开发两种流行的分层架构思想。 MVC 是一种设计模式,主要用来分离用户界面,业务逻辑,和数据模型。 而…...
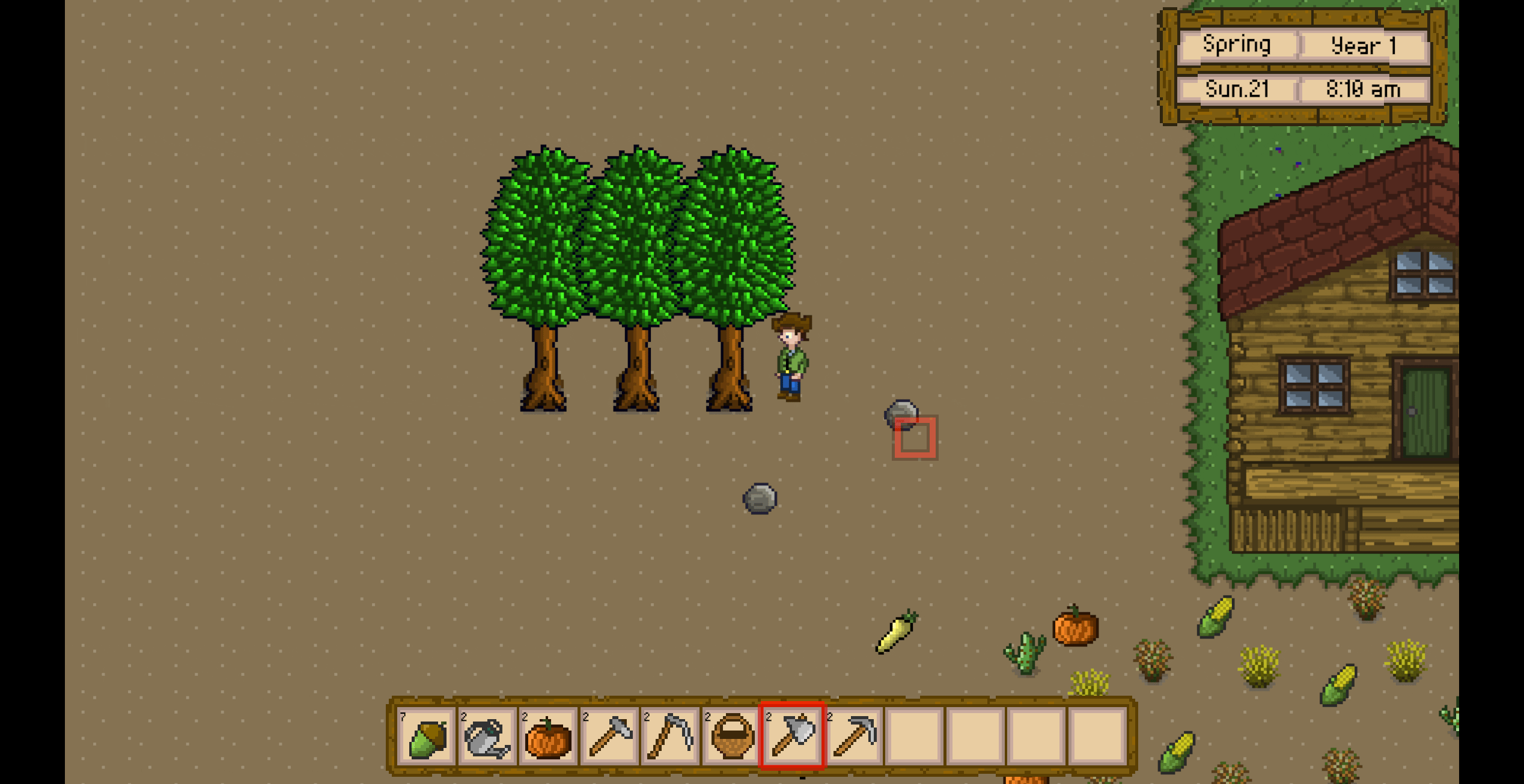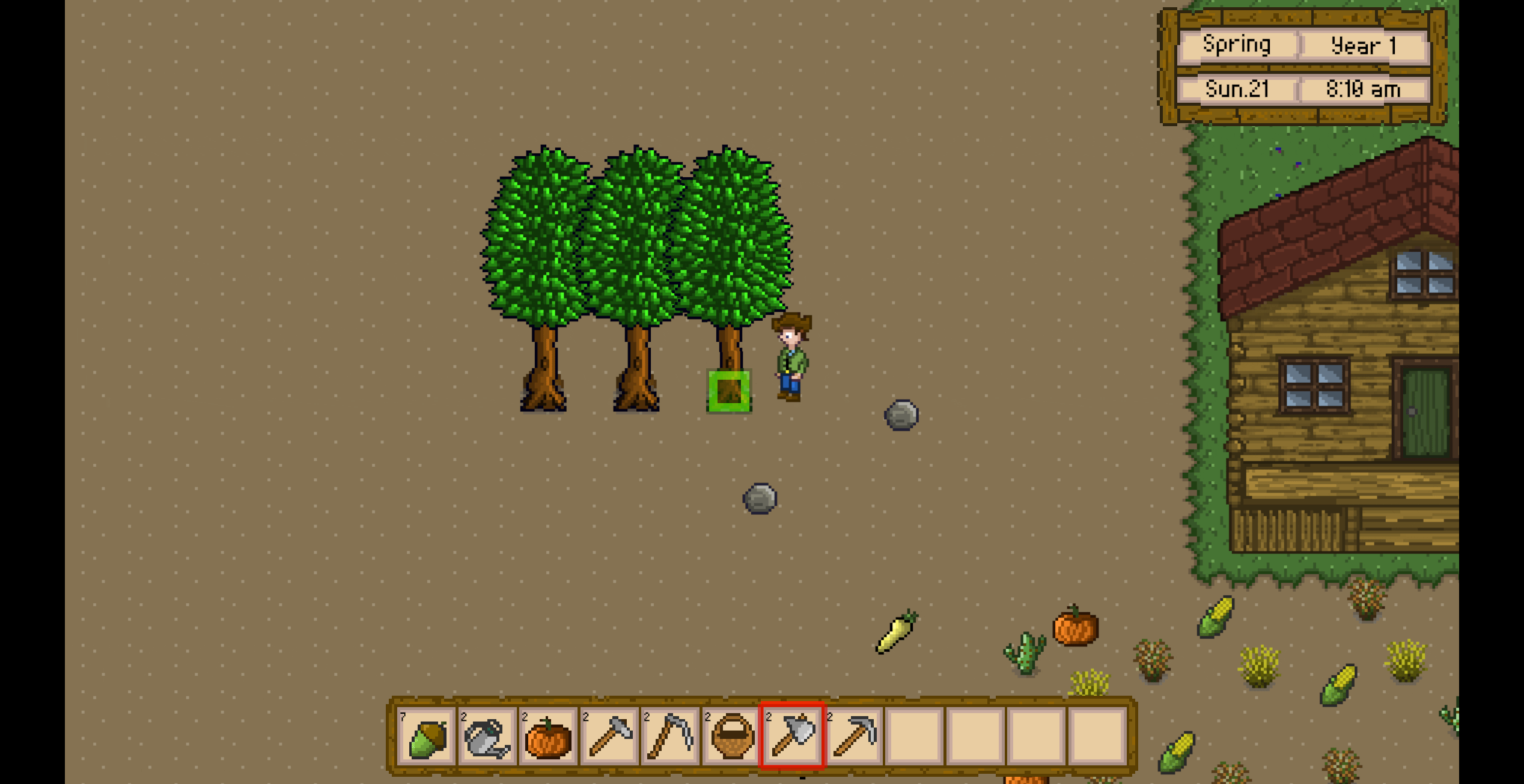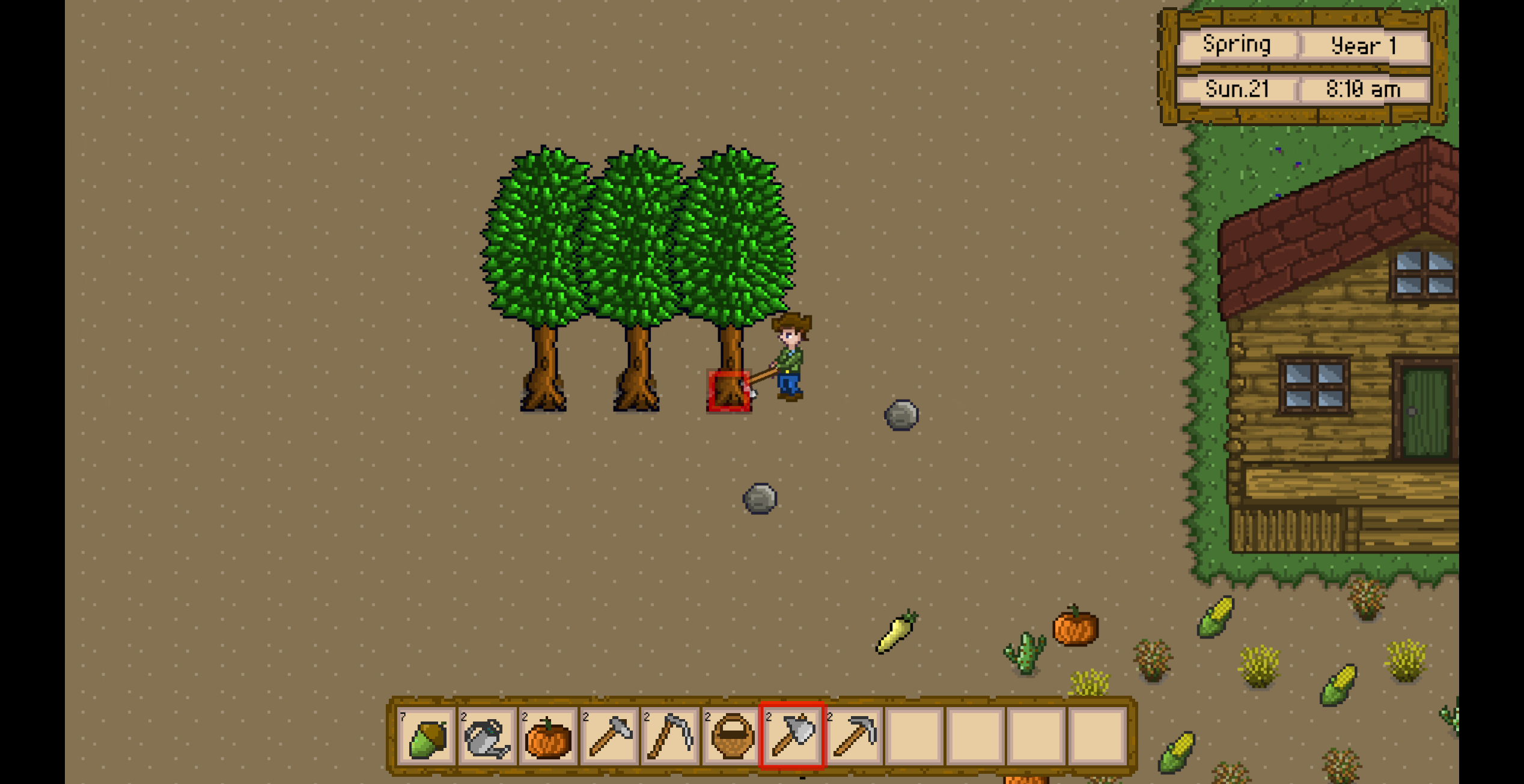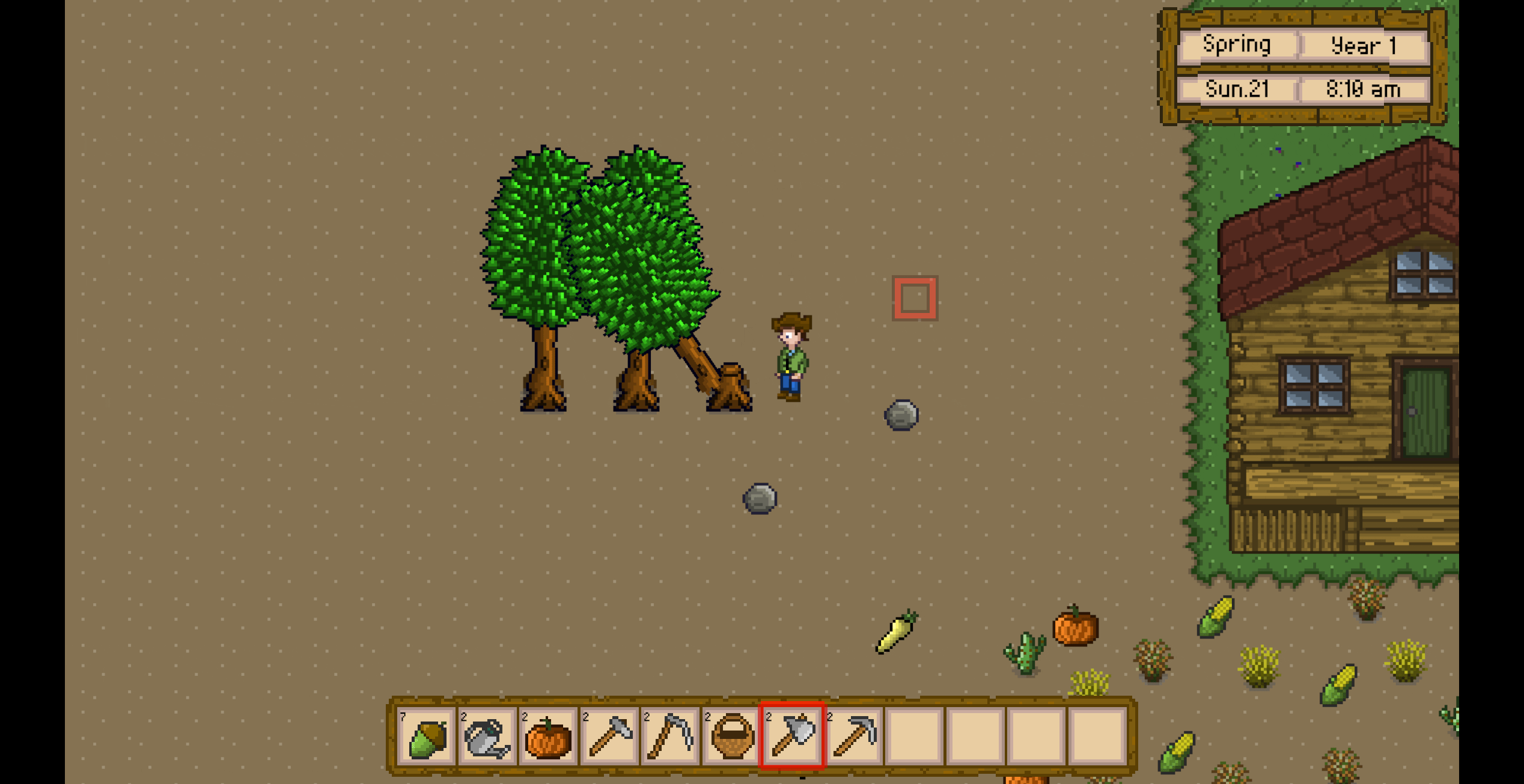
Unity3D仿星露谷物语开发46之种植/砍伐橡树
1、目标 种植一棵橡树,从种子变成大树。 然后可以使用斧头砍伐橡树。 2、删除totalGrowthDays字段 修改growthDays的含义,定义每个值为到达当前阶段的累加天数。此时最后一个阶段就是totalGrowthDays的含义。所以就可以删除totalGrowthDays字段。 &…...

STM32外设应用详解——从基础到高级应用的全面指南
目录 一、引言:为何选择STM32外设 二、主要外设类别与详细应用解析 1. GPIO(通用输入输出) 工作原理详解 高级应用设计 硬件连接建议 2. 定时器(TIM)详解 基本定时器原理 高级配置 实际应用 核心技巧 3. A…...

作业帮C++后台开发面试题及参考答案
Cookie 和 Session 的区别是什么? Cookie 和 Session 是 Web 开发中用于管理用户状态的两种机制,它们在存储位置、安全性、生命周期和数据类型等方面存在显著差异。 存储位置:Cookie 数据存储在客户端浏览器,而 Session 数据存储在服务器端。当浏览器向服务器发送请求时,…...

红队进阶实战
4.1 内网渗透(域渗透、横向移动) 域环境攻击链 初始立足点:通过钓鱼获取域用户凭据(如NTLM Hash)。信息收集: 使用BloodHound自动化分析域内关系。执行nltest /dclist:domain.com获取域控制器列表。横向移动: Pass-the-Hash:利用Mimikatz注入Hash到新会话。sekurlsa::…...

C语言中的指定初始化器
什么是指定初始化器? C99标准引入了一种更灵活、直观的初始化语法——指定初始化器(designated initializer), 可以在初始化列表中直接引用结构体或联合体成员名称的语法。通过这种方式,我们可以跳过某些不需要初始化的成员,并且可以以任意顺序对特定成员进行初始化。这…...

C/C++ 整数类型的长度
参考 cppreference.cn 在某些语言中,整数类型的长度是固定的,如java中 char 8short 16int 32long 64 可是C/C 与机器相关,整数类型长度与平台有关 先可以记一个简单的 按照C标准: char > 8short > 16int > 16long &g…...
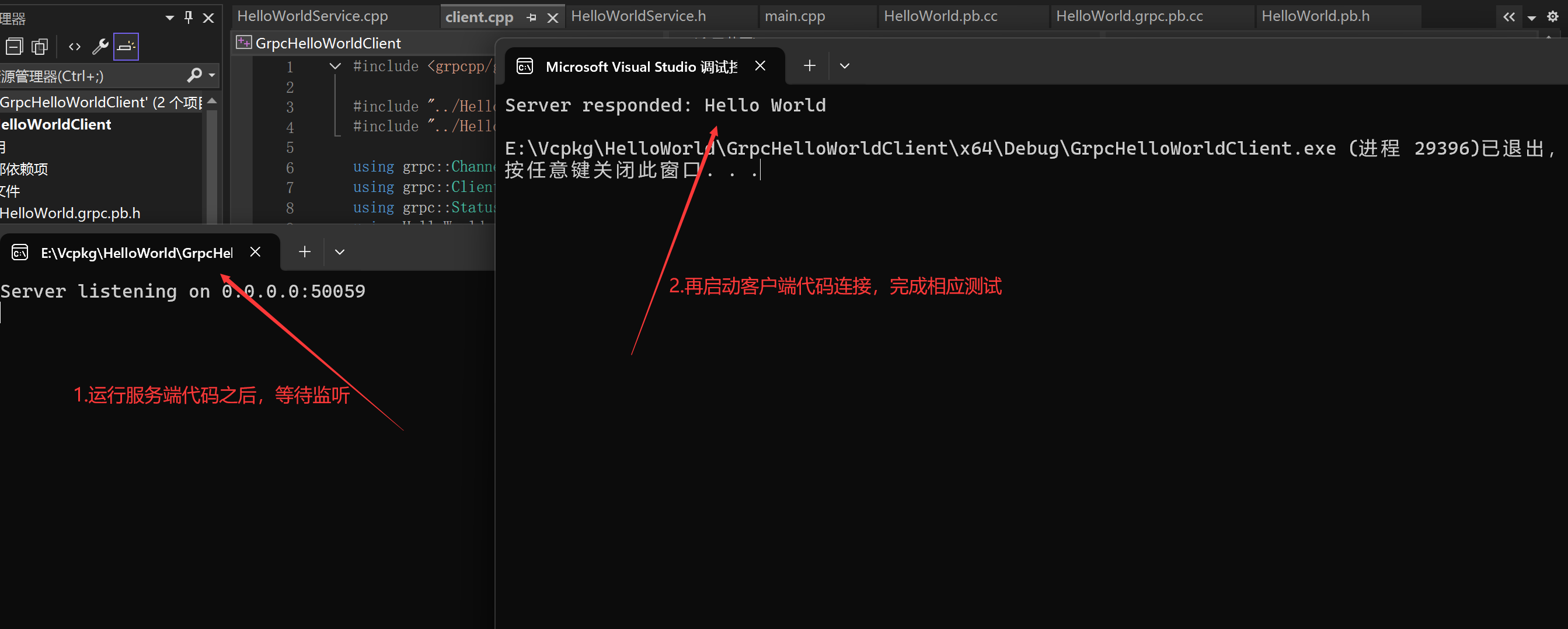
gRPC开发指南:Visual Studio 2022 + Vcpkg + Windows全流程配置
前言 gRPC作为Google开源的高性能RPC框架,在微服务架构中扮演着重要角色。本文将详细介绍在Windows平台下,使用Visual Studio 2022和Vcpkg进行gRPC开发的完整流程,包括环境配置、项目搭建、常见问题解决等实用内容。 环境准备 1. 安装必要组…...

高密度服务器机柜散热方案:高风压风机在复杂风道中的关键作用与选型要点
随着云计算、人工智能等技术的飞速发展,数据中心内服务器机柜的集成度不断攀升,高密度部署成为常态。然而,高密度意味着单位空间内服务器数量剧增,发热量呈指数级上升,传统散热方案已难以满足需求。在复杂的机柜风道环…...

Android framework 问题记录
一、休眠唤醒,很快熄屏 1.1 问题描述 机器休眠唤醒后,没有按照约定的熄屏timeout 进行熄屏,很快就熄屏(约2s~3s左右) 1.2 原因分析: 抓取相关log,打印休眠背光 相关调用栈 //具体打印调用栈…...
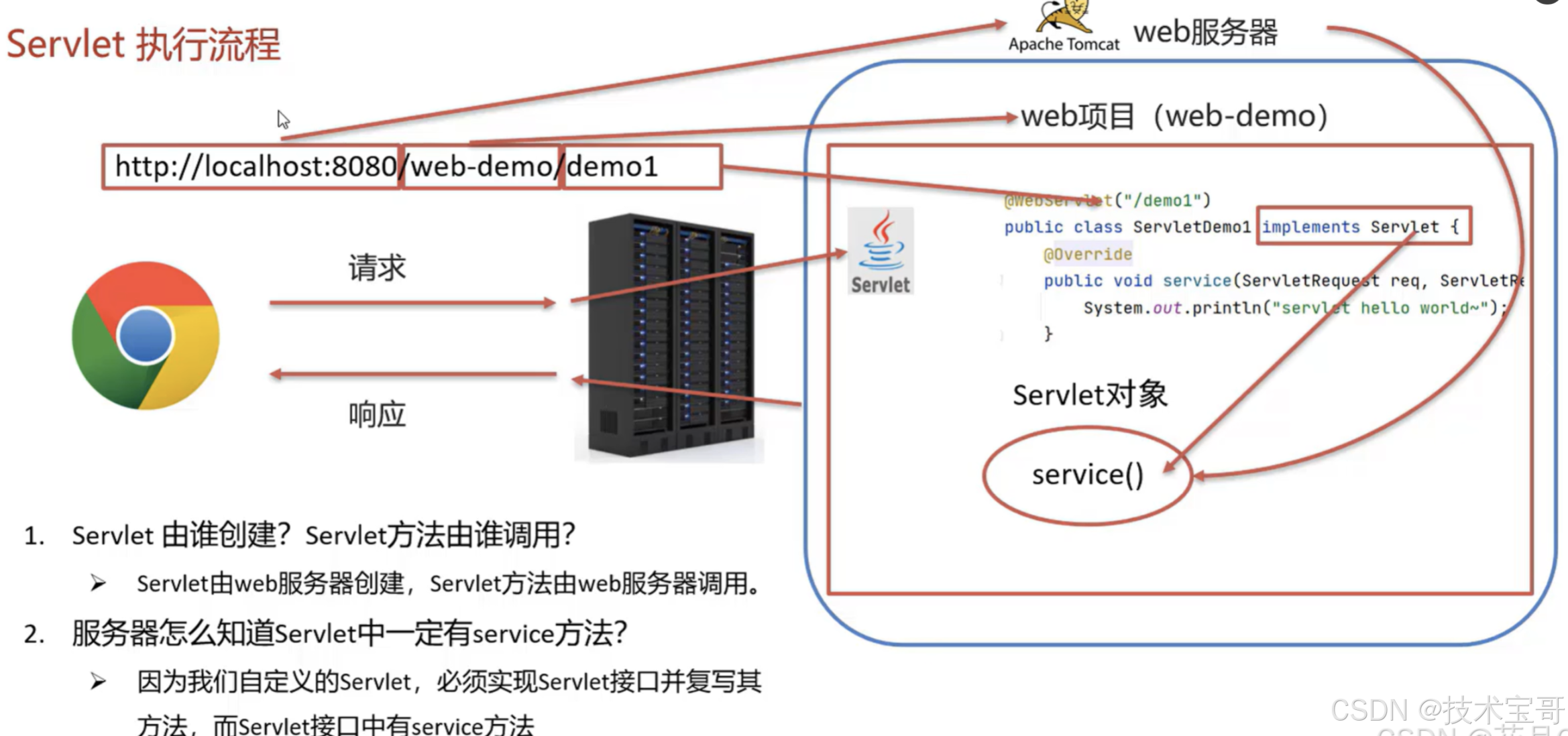
框架之下再看HTTP请求对接后端method
在当今的软件开发中,各类框架如雨后春笋般不断涌现,极大地提升了开发效率。以 Java 开发为例,Spring 框架历经多次迭代演进,而 Spring Boot 更是将开发便捷性提升到了新高度。如今,开发者只需简单引入 Maven 包&#x…...

Oracle APEX IR报表列宽调整
目录 1. 问题:如何调整Oracle APEX IR报表列宽 2. 解决办法 1. 问题:如何调整Oracle APEX IR报表列宽 1-1. 防止因标题长而数据短,导致标题行的文字都立起来了,不好看。 1-2. 防止因数据太长而且中间还没有空格,把列…...
【笔记】与PyCharm官方沟通解决开发环境问题
#工作记录 2025年5月20日 星期二 背景 在此前的笔记中,我们提到了向PyCharm官方反馈了几个关于Conda环境自动激活、远程解释器在社区版中的同步问题以及Shell脚本执行时遇到的问题。这些问题对日常开发流程产生了一定影响,因此决定联系官方支持寻求解…...

深入解析:如何基于开源OpENer开发EtherNet/IP从站服务
一、EtherNet/IP协议概述 EtherNet/IP(Industrial Protocol)是一种基于以太网的工业自动化通信协议,它将CIP(Common Industrial Protocol)封装在标准以太网帧中,通过TCP/IP和UDP/IP实现工业设备间的通信。作为ODVA(Open DeviceNet Vendors Association)组织的核心协议…...
node.js文件系统(fs) - 创建文件、打开文件、写入数据、追加数据、读取数据、创建目录、删除目录
注意:以下所有示例均是异步语法! 注意:以下所有示例均是异步语法! 创建文件 node.js 允许我们在计算机本地创建文件,例如创建一个 word 文件: // 引入核心模块(fs) var fs require(fs)// API fs.writeF…...
)
SQL:MySQL函数:空值处理函数(NULL Handling Functions)
目录 什么是空值(NULL)? 常用空值处理函数总览 1️⃣ IFNULL() – 空值替换函数(If Null) 2️⃣ COALESCE() – 多参数空值判断(返回第一个非 NULL 值) 3️⃣ NULLIF() – 相等则返回 NULL…...
利用ffmpeg截图和生成gif
从视频中截取指定数量的图片 ffmpeg -i input.mp4 -ss 00:00:10 -vframes 1 output.jpgffmpeg -i input.mp4 -ss 00:00:10 -vframes 180 output.jpg -vframes 180代表截取180帧, 实测后发现如果视频是60fps,那么会从第10秒截取到第13秒-i input.mp4:指定输入视频文…...
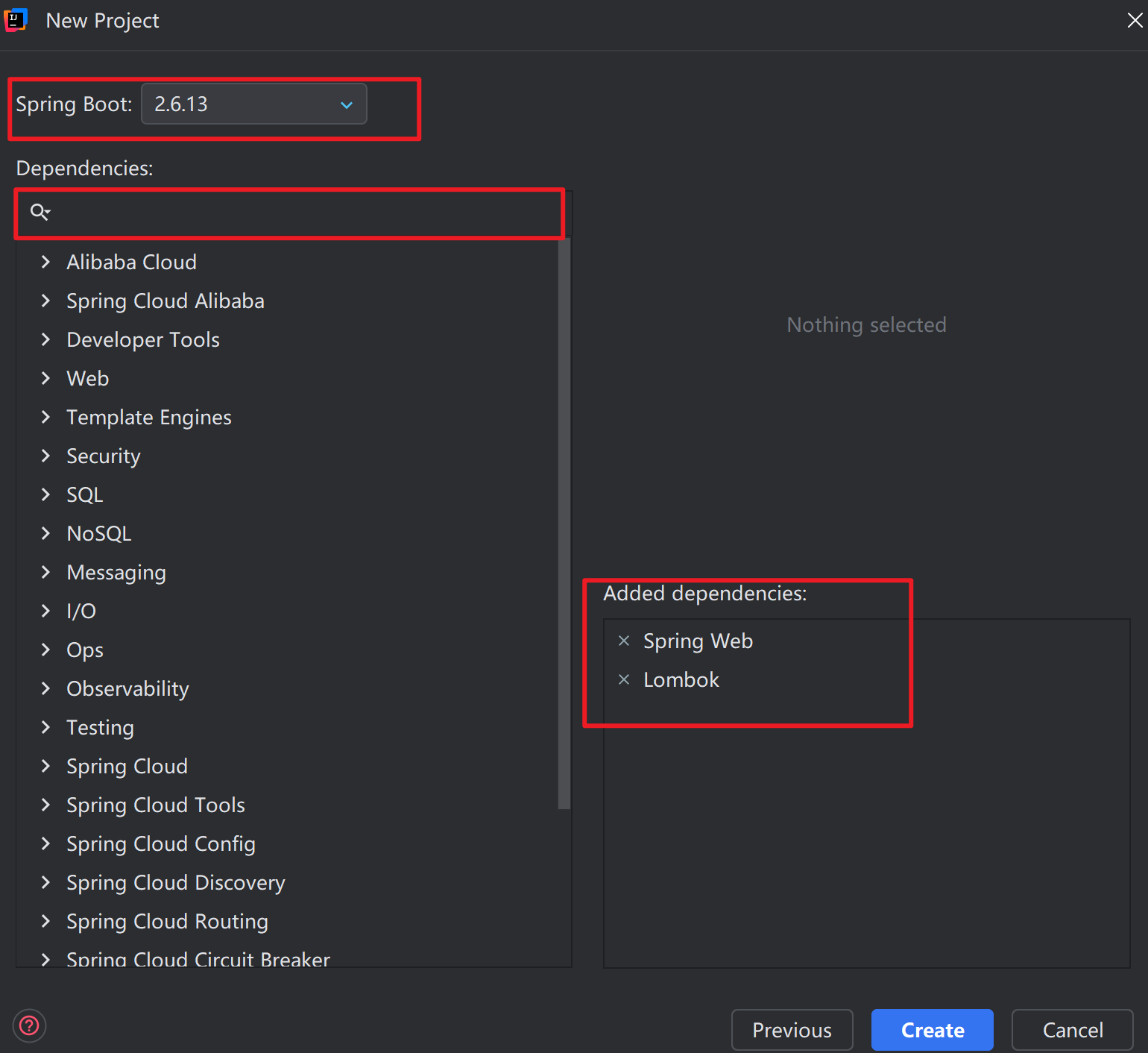
初始化一个Springboot项目
初始化一个Springboot项目 文章目录 初始化一个Springboot项目1、新建项目2、配置yml3、自定义异常4、通用相应类5、全局跨域配置6、总结 1、新建项目 首先,我们需要创建一个新的 Spring Boot 项目。这里我们使用 IntelliJ IDEA 作为开发工具,它提供了方…...

YOLOv8在单目向下多车辆目标检测中的应用
大家读完觉得我有帮助记得关注!!! 摘要 自动驾驶技术正逐步改变传统的汽车驾驶方式,标志着现代交通运输的一个重要里程碑。目标检测是自主系统的基石,在提高驾驶安全性、实现自主功能、提高交通效率和促进有效的应急…...

23种设计模式解释+记忆
一、创建型模式(5种)—— “怎么造对象?” 单例模式(Singleton) 场景:公司的CEO只能有一个。 核心:确保一个类只有一个实例,全局访问。 关键词:唯一、全局访问。 工厂方…...

Baklib构建AI就绪型知识中台实践
Baklib驱动企业知识资产重构 在数字化转型浪潮中,企业知识中台的构建已成为激活数据价值的关键路径。Baklib通过结构化存储与智能分类引擎,将分散于邮件、文档、IM工具中的碎片化信息转化为可检索、可复用的数字资产。其核心能力体现在三个维度…...

JS逆向-某易云音乐下载器
文章目录 介绍下载链接Robots文件搜索功能JS逆向**函数a:生成随机字符串****函数b:AES-CBC加密****函数c:RSA公钥加密** 歌曲下载总结 介绍 在某易云音乐中,很多歌曲听是免费的,但下载需要VIP,此程序旨在“…...

FreeRTOS全攻略:从入门到精通
目录 一、FreeRTOS 基础概念1.1 FreeRTOS 是什么1.2 为什么选择 FreeRTOS 二、与裸机开发的区别2.1 任务管理2.2 中断处理2.3 资源管理 三、FreeRTOS 入门篇3.1 内存管理3.2 任务创建3.3 任务状态3.4 任务优先级3.5 空闲任务和钩子函数3.6 同步与互斥3.7 队列3.8 信号量3…...

服务器的基础知识
什么是服务器 配置牛、运行稳、价格感人的高级计算机,家用电脑不能比拟的。 服务器的组成:电源、raid卡、网卡、内存、cpu、主板、风扇、硬盘。 服务器的分类 按计算能力分类 超级计算机 小型机AIX x86服务器(服务器cpu架构) …...