显卡、Cuda和pytorch兼容问题
这里写目录标题
- 驱动与CUDA版本兼容性问题
- 1. **驱动与CUDA版本兼容性问题**
- 2. **任务特性与硬件适配差异**
- 3. **优化策略与框架配置差异**
- 4. **散热与功耗限制**
- 5. **数据传输与CPU瓶颈**
- 排查建议
- 总结
- 查询PyTorch中实际使用的CUDA版本
- **1. 查询PyTorch中实际使用的CUDA版本**
- **可能的输出结果**:
- **2. 检查系统中安装的CUDA Toolkit版本**
- **方法一:通过终端命令查询**
- **方法二:查找CUDA安装路径**
- **3. 验证PyTorch与CUDA版本对应关系**
- **示例**:
- **4. 解决版本不兼容问题**
- **步骤一:卸载当前PyTorch**
- **步骤二:安装指定CUDA版本的PyTorch**
- **步骤三:验证安装**
- **5. 特殊场景处理**
- **问题:`nvidia-smi`与`nvcc --version`显示的CUDA版本不同**
- **问题:多CUDA版本共存**
- **总结**
- 版本不兼容带来的问题
- **1. 性能严重下降**
- **2. GPU 无法被 PyTorch 识别**
- **3. 显存管理异常**
- **4. 计算内核报错或崩溃**
- **5. 框架优化完全失效**
- **6. 显存带宽无法充分利用**
- **7. 兼容性警告或日志提示**
- **如何验证问题根源?**
- **总结**
驱动与CUDA版本兼容性问题
1. 驱动与CUDA版本兼容性问题
- CUDA版本适配不当:网页1提到RTX 4060用户因PyTorch仅支持CUDA 11.8而卸载CUDA 12.0后性能正常。若4090未正确安装与PyTorch兼容的CUDA版本(如默认使用更高版本但未被框架优化),可能导致算力无法释放。
- Tensor Core未启用:4090的Tensor Core性能远超4060,但若任务未启用FP16混合精度(如未使用
.half()转换数据),则无法利用该加速单元。网页7测试显示启用Tensor Core后速度提升2.6倍,而4090若未开启可能反被4060超越。
2. 任务特性与硬件适配差异
- 小规模计算或低并行度任务:若任务为小批量数据或单线程密集型(如频繁同步操作),4090的16384个CUDA核心无法充分利用,而4060的3584核心更适配此类场景。网页3指出GPU在小数据量时可能不如CPU,而高配显卡的并行优势需大规模计算才能体现。
- 显存带宽与容量未被充分利用:4090的显存带宽(936 GB/s)远超4060(272 GB/s),但若任务显存需求低(如小于8GB),其带宽优势无法转化为实际加速。网页7测试中,矩阵计算的加速依赖数据规模,小任务下GPU优势有限。
3. 优化策略与框架配置差异
- 未启用PyTorch加速工具:网页5提到PyTorch团队通过
torch.compile、量化、推测性解码等技术实现10倍加速。若4090未启用这些优化(如未设置torch.compile(mode="reduce-overhead")),而4060因显存限制被迫启用量化或模型简化,反而可能更高效。 - 多GPU负载分配问题:若任务使用
DataParallel而非DistributedDataParallel,可能导致4090的多卡负载不均衡(如主卡显存溢出),而4060单卡运行效率更高。网页6指出DistributedDataParallel在多卡场景下更优。
4. 散热与功耗限制
- 4090的功耗墙触发降频:4090的TDP高达450W,若散热不足或电源功率受限,可能触发降频。网页5提到用户手动限制4090功耗至70%导致性能骤降,类似场景下4060的115W低功耗更易稳定运行。
- 动态频率调整差异:4090的Boost频率(2.52 GHz)较4060(2.46 GHz)更高,但持续高负载下可能因温度过高而降频。网页7测试中GPU长时间负载需依赖散热稳定性。
5. 数据传输与CPU瓶颈
- 主机到设备(H2D)延迟:若任务需频繁将数据从CPU传输至GPU,4090的高算力可能被传输延迟抵消。网页3指出,当数据传输时间占比高时,GPU加速效果会被削弱,而4060因计算时间与传输时间更平衡可能表现更好。
- CPU成为瓶颈:若任务依赖CPU预处理(如数据加载、逻辑控制),而4090的CPU配置较弱(如单核性能不足),整体效率受限。网页2提到NPU/GPU任务中CPU单核处理可能成为瓶颈。
排查建议
-
验证CUDA与驱动配置
- 检查4090的CUDA版本是否与PyTorch匹配(
print(torch.version.cuda)),确保安装官网推荐驱动。 - 对比4060与4090的
torch.cuda.is_available()和torch.backends.cudnn.enabled状态。
- 检查4090的CUDA版本是否与PyTorch匹配(
-
监控硬件利用率
- 使用
nvidia-smi或MSI Afterburner观察4090的GPU利用率、温度、功耗及核心频率是否正常。 - 通过PyTorch Profiler分析任务中内核执行时间与数据传输占比。
- 使用
-
优化策略测试
- 对4090启用混合精度(
torch.cuda.amp)与torch.compile,对比性能变化。 - 尝试禁用多卡并行(如强制单卡运行),排除负载分配问题。
- 对4090启用混合精度(
-
任务适配性调整
- 增大批量大小或数据规模,验证4090的并行优势是否显现。
- 减少CPU依赖操作(如使用GPU端数据增强),降低主机到设备的数据传输频率。
总结
此现象本质是硬件特性、框架优化、任务适配性三者不匹配的综合结果。4090的理论性能远超4060,但其潜力需特定条件(如大规模并行计算、正确优化配置、散热充足)才能释放。建议优先排查驱动兼容性、启用PyTorch加速工具,并调整任务以匹配高配显卡的硬件特性。若任务规模较小或优化成本过高,4060可能反而是更经济的选择。
若RTX 4090未正确安装与PyTorch兼容的CUDA版本,可以通过以下步骤查询和验证当前环境配置:
查询PyTorch中实际使用的CUDA版本
1. 查询PyTorch中实际使用的CUDA版本
在Python环境中运行以下代码,直接查看PyTorch绑定的CUDA版本:
import torch# 检查PyTorch是否识别到CUDA(返回True表示正常)
print("CUDA是否可用:", torch.cuda.is_available())# 查看PyTorch编译时使用的CUDA版本
print("PyTorch绑定的CUDA版本:", torch.version.cuda)# 查看当前PyTorch支持的CUDA驱动版本(需与NVIDIA驱动匹配)
print("支持的CUDA驱动版本:", torch.cuda.get_device_properties(0).driver_version)
可能的输出结果:
- 若输出类似
CUDA版本: 11.8,但系统实际安装的是CUDA 12.x,则说明PyTorch未正确绑定高版本CUDA。 - 若
torch.cuda.is_available()返回False,则可能是驱动未安装或CUDA版本完全不兼容。
2. 检查系统中安装的CUDA Toolkit版本
方法一:通过终端命令查询
# 查看系统全局CUDA版本(由环境变量PATH决定)
nvcc --version # 若返回“command not found”,则说明未安装CUDA Toolkit# 查看NVIDIA驱动支持的CUDA版本(驱动API版本)
nvidia-smi # 右上角显示的CUDA Version是驱动支持的最高版本
- 关键点:
nvidia-smi显示的CUDA版本是驱动支持的最高版本,不代表实际安装的CUDA Toolkit。nvcc --version显示的是当前激活的CUDA Toolkit版本。
方法二:查找CUDA安装路径
# Linux/MacOS
whereis cuda # 查找默认安装路径(如/usr/local/cuda)# Windows
where nvcc # 查看nvcc编译器路径(如C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.2\bin)
3. 验证PyTorch与CUDA版本对应关系
访问PyTorch官网的版本兼容性表格,检查当前安装的PyTorch版本是否支持系统中的CUDA版本。
示例:
- 若PyTorch通过以下命令安装:
则PyTorch绑定的是CUDA 12.1,需确保系统中安装了CUDA Toolkit 12.x。conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=12.1 -c pytorch -c nvidia
4. 解决版本不兼容问题
若发现PyTorch绑定的CUDA版本与系统安装的版本不一致,需重新安装PyTorch:
步骤一:卸载当前PyTorch
pip uninstall torch torchvision torchaudio
# 或使用conda
conda uninstall pytorch torchvision torchaudio
步骤二:安装指定CUDA版本的PyTorch
根据官网提供的命令安装,例如:
# 安装支持CUDA 12.1的PyTorch
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia# 或使用pip
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
步骤三:验证安装
重新运行Python检查命令:
import torch
print(torch.cuda.is_available()) # 应为True
print(torch.rand(10).to('cuda')) # 应正常输出张量
print(torch.version.cuda) # 应与安装时指定的版本一致(如12.1)
5. 特殊场景处理
问题:nvidia-smi与nvcc --version显示的CUDA版本不同
- 原因:
nvidia-smi显示的是驱动支持的CUDA版本,nvcc显示的是编译器的CUDA Toolkit版本。 - 解决方案:只需确保PyTorch的CUDA版本≤驱动支持的版本(由
nvidia-smi显示)。
问题:多CUDA版本共存
若系统安装了多个CUDA Toolkit(如11.8和12.1),需通过环境变量指定优先级:
# Linux/MacOS
export PATH=/usr/local/cuda-12.1/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64:$LD_LIBRARY_PATH# Windows
在系统环境变量中调整CUDA路径优先级(控制面板 → 系统 → 高级 → 环境变量)。
总结
通过上述步骤可明确:
- PyTorch实际绑定的CUDA版本;
- 系统中安装的CUDA Toolkit版本;
- NVIDIA驱动支持的CUDA版本;
- 三者是否匹配。若不匹配,需按需调整PyTorch或CUDA Toolkit版本。
若 RTX 4090 未正确安装与 PyTorch 兼容的 CUDA 版本,可能会引发以下问题:
版本不兼容带来的问题
1. 性能严重下降
- 表现:GPU 利用率极低(如用户描述的 20%),计算速度远低于预期,甚至不如低端显卡(如 RTX 4060)。
- 原因:
- 未启用 Tensor Core:PyTorch 若未绑定支持 Ada Lovelace 架构(RTX 40 系)的 CUDA 版本,可能无法调用 4090 的 Tensor Core(FP16/FP8 加速单元),导致算力浪费。
- 回退到低效计算模式:可能强制使用 FP32 浮点运算(而非 FP16 混合精度),导致计算效率低下。
2. GPU 无法被 PyTorch 识别
- 表现:
torch.cuda.is_available()返回False,代码无法使用 GPU。 - 原因:
- CUDA 版本完全不兼容:例如 PyTorch 安装时绑定的是 CUDA 11.x,但系统安装了 CUDA 12.x,且未正确配置环境。
- 驱动未安装或版本过低:NVIDIA 驱动版本低于 CUDA Toolkit 的最低要求(如 CUDA 12.1 需要驱动版本 ≥ 530.30)。
3. 显存管理异常
- 表现:显存分配失败(如
CUDA out of memory错误),即使任务需求远低于 4090 的 24GB 显存。 - 原因:
- 显存分配策略冲突:CUDA 版本与 PyTorch 不匹配时,显存池管理逻辑可能失效,导致碎片化或预分配失败。
- 驱动级兼容性问题:驱动未正确支持 PyTorch 的显存调用接口。
4. 计算内核报错或崩溃
- 表现:运行时报错(如
CUDA error: no kernel image is available for execution),任务直接中断。 - 原因:
- 架构不匹配:PyTorch 编译时未包含对 Ada Lovelace 架构(SM 8.9/9.0)的支持,导致无法生成适配 4090 的计算内核。
- CUDA 函数缺失:高版本 CUDA 函数(如 cuBLAS 12.x 的新 API)在低版本 PyTorch 中不可用。
5. 框架优化完全失效
- 表现:PyTorch 的高级加速功能(如
torch.compile、自动混合精度AMP)无法启用或无效。 - 原因:
- 依赖 CUDA 版本的功能受限:例如
torch.compile需要 CUDA ≥ 11.7 才能充分发挥性能。 - 算子调度异常:PyTorch 的 GPU 算子可能因版本不匹配而回退到低效的 CPU 实现。
- 依赖 CUDA 版本的功能受限:例如
6. 显存带宽无法充分利用
- 表现:4090 的显存带宽(936 GB/s)未被利用,任务速度受限于数据传输而非计算。
- 原因:
- 低效数据传输:CUDA 版本不兼容可能导致 PyTorch 使用默认的 PCIe 传输模式,而非 GPU 显存直接访问(DMA)。
- 驱动级带宽限制:驱动未正确启用显存压缩(如 NVIDIA 的 Lossless Compression 技术)。
7. 兼容性警告或日志提示
- 表现:运行代码时输出警告(如
UserWarning: CUDA initialization skipped或The installed CUDA version is newer than the latest supported version)。 - 原因:
- PyTorch 检测到 CUDA 版本高于其设计支持范围,自动回退到兼容模式,但牺牲性能。
如何验证问题根源?
-
检查 PyTorch 与 CUDA 版本绑定:
import torch print(torch.version.cuda) # PyTorch 实际使用的 CUDA 版本 print(torch.cuda.is_available()) # 是否识别到 GPU print(torch.cuda.get_device_name(0)) # 显卡型号是否识别正确 -
对比官方兼容性表格:
- 访问 PyTorch 官方版本支持表,确认安装的 PyTorch 版本是否支持当前 CUDA 版本和 RTX 4090。
总结
未正确安装兼容的 CUDA 版本会导致 RTX 4090 的硬件特性(如 Tensor Core、高显存带宽)完全无法被 PyTorch 调用,轻则性能大幅下降,重则任务无法运行。
解决方案:严格按 PyTorch 官方文档安装指定 CUDA 版本的 PyTorch(如 CUDA 12.1 对应 PyTorch 2.1+),并确保 NVIDIA 驱动版本 ≥ 530.30。
相关文章:

显卡、Cuda和pytorch兼容问题
这里写目录标题 驱动与CUDA版本兼容性问题1. **驱动与CUDA版本兼容性问题**2. **任务特性与硬件适配差异**3. **优化策略与框架配置差异**4. **散热与功耗限制**5. **数据传输与CPU瓶颈**排查建议总结 查询PyTorch中实际使用的CUDA版本**1. 查询PyTorch中实际使用的CUDA版本***…...

SseEmitter是什么
SseEmitter 是 Spring Framework 中用于实现 Server-Sent Events (SSE) 的一个类。SSE 是一种允许服务器向客户端推送实时更新的技术,特别适合需要从服务器到客户端的单向消息传递场景,如股票价格更新、社交媒体的新消息通知等。 Server-Sent Events (S…...

OBOO鸥柏丨AI数字人触摸屏查询触控人脸识别语音交互一体机上市
OBOO鸥柏丨AI数字人触摸屏查询触控人脸识别语音交互一体机上市分析 OBOO鸥柏品牌推出的AI数字人触摸屏查询触控人脸识别语音交互一体机,是其在智能交互设备领域的又一创新产品。该一体机整合了触摸屏查询、AI人脸识别、AI声源定位语音麦克风,触控交互以…...
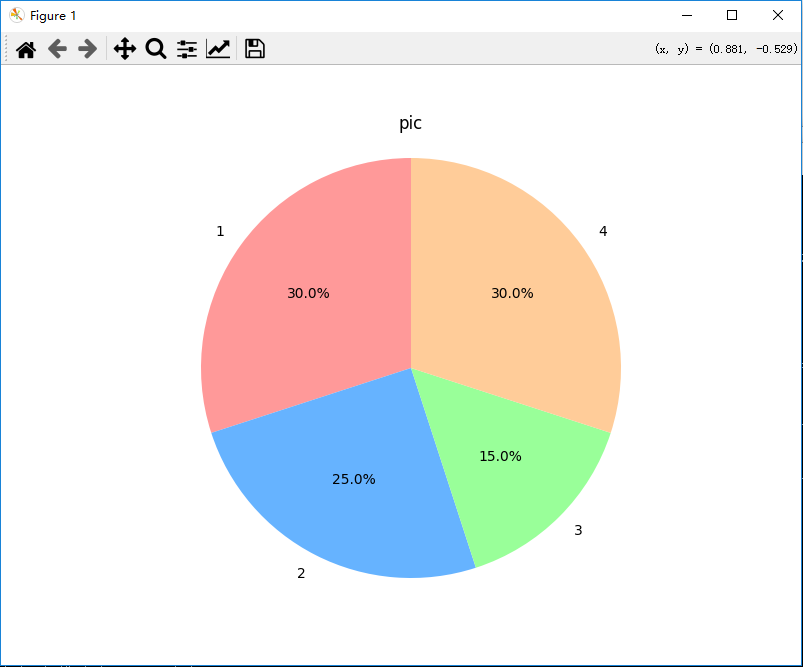
第5天-python饼图绘制
一、基础饼图绘制(Matplotlib) 1. 环境准备 python 复制 下载 pip install matplotlib numpy 2. 基础饼图代码 python 复制 下载 import matplotlib.pyplot as plt# 数据准备 labels = [1, 2, 3, 4] sizes = [30, 25, 15, 30] # 各部分占比(总和建议100) colors…...

2023 睿抗机器人开发者大赛CAIP-编程技能赛-本科组(国赛) 解题报告 | 珂学家
前言 题解 2023 睿抗机器人开发者大赛CAIP-编程技能赛-本科组(国赛)。 vp了下,题目挺好的,难度也适中,但是彻底红温了。 第二题,题意不是那么清晰, M i n ( K 1 , K 2 ) Min(K_1, K_2) Min(K1,K2)容易求&#x…...
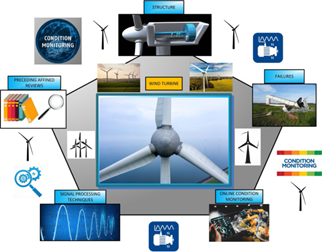
LabVIEW风机状态实时监测
在当今电子设备高度集成化的时代,设备散热成为关键问题。许多大型设备机箱常采用多个风机协同散热,确保系统稳定运行。一旦风机出现故障,若不能及时察觉,可能导致设备损坏,造成巨大损失。为满足对机箱内风机状态实时监…...
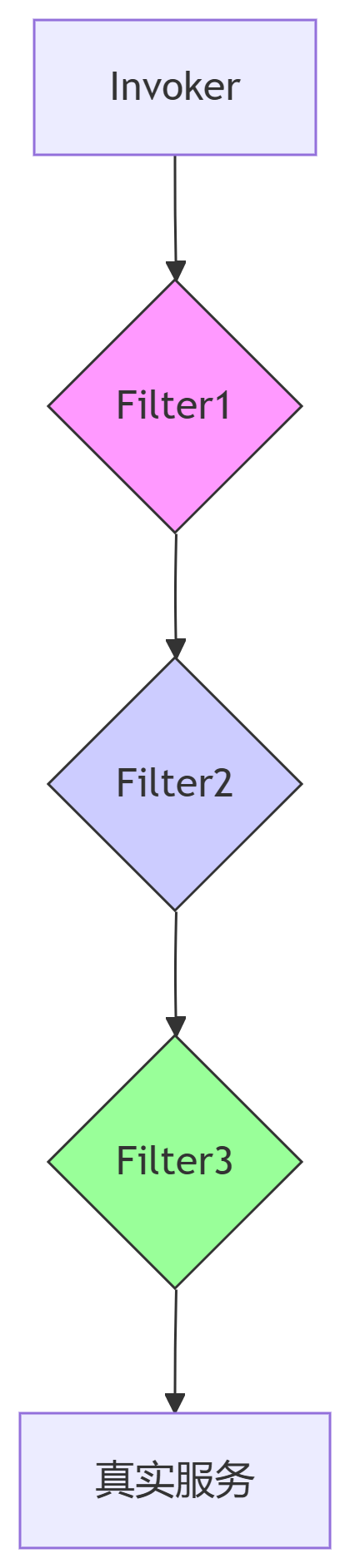
十一、面向对象底层逻辑-Dubbo过滤器Filter接口
一、引言:分布式系统中的可观测性与治理基石 在分布式服务调用链路中,如何在服务调用前后植入通用逻辑(如日志记录、权限校验、性能监控等),是构建可观测、可治理系统的关键需求。Dubbo通过Filter接口实现了面向切面编…...
单例模式)
双检锁(Double-Checked Locking)单例模式
在项目中使用双检锁(Double-Checked Locking)单例模式来管理 JSON 格式化处理对象(如 ObjectMapper 在 Jackson 库中,或 JsonParser 在 Gson 库中)是一种常见的做法。这种模式确保了对象只被创建一次,同时在…...
linux安装nginx和前端部署vue项目
1、打包前端项目 npm run build 执行完后会在根目录下生成一个dist文件夹,这个dist文件夹就是我们后面要部署到nginx的东西。 2、将dist文件夹上传到服务器中 自己建一个目录,上传即可(尽量不要在root目录下,可能涉及权限问题…...

打破次元壁,VR 气象站开启气象学习新姿势
在教育领域,VR 气象站同样发挥着巨大的作用,为气象教学带来了全新的模式,打破了传统教学的次元壁,让学生们以全新的姿势学习气象知识。 在传统的气象教学中,学生们主要通过课本、图片和老师的讲解来学习气象知识。这…...
软件设计师“数据流图”真题考点分析——求三连
数据流图考点分析 1. 考点分值占比与趋势分析 综合知识题分值统计表 年份考题数量分值分值占比考察重点2018111.33%数据流图基本元素2019222.67%数据流图绘制原则2020111.33%数据流图与控制流图的区别2021334.00%数据字典与数据流图的关系2022222.67%分层数据流图的分解原则…...

基于R语言的贝叶斯网络模型实践技术应用:开启科研新视角
在现代科研领域,变量间的因果关系推断是生态学、环境科学、医学等多学科研究的核心问题。然而,传统的统计学方法往往只能揭示变量间的相关关系,而非因果关系。贝叶斯网络作为一种结合图论与统计学理论的新型模型,不仅能够统合多种…...

用 VS Code / PyCharm 编写你的第一个 Python 程序
用ChatGPT做软件测试 编写你的第一个 Python 程序——不只是“Hello, World”,而是构建认知、习惯与未来的起点 “第一行代码,是一个开发者认知世界的方式。” 编程的入门,不只是运行一个字符串输出,更是开始用计算机思维来理解、…...

【Git】远程操作
Git 是一个分布式版本控制系统 可以简单理解为,每个人的电脑上都是一个完整的版本库,这样在工作时,就不需要联网 了,因为版本库就在自己的电脑上。 因此, 多个人协作的方式,譬如说甲在自己的电脑上改了文件…...

低代码AI开发新趋势:Dify平台化开发实战
在人工智能快速发展的今天,AI应用的开发方式也在不断演变。从传统的手写代码到如今的低代码甚至零代码开发,技术的进步让更多的非专业开发者也能轻松上手。本文将带你走进Dify平台化开发的世界,探索如何通过这一强大的低代码AI开发平台&#…...
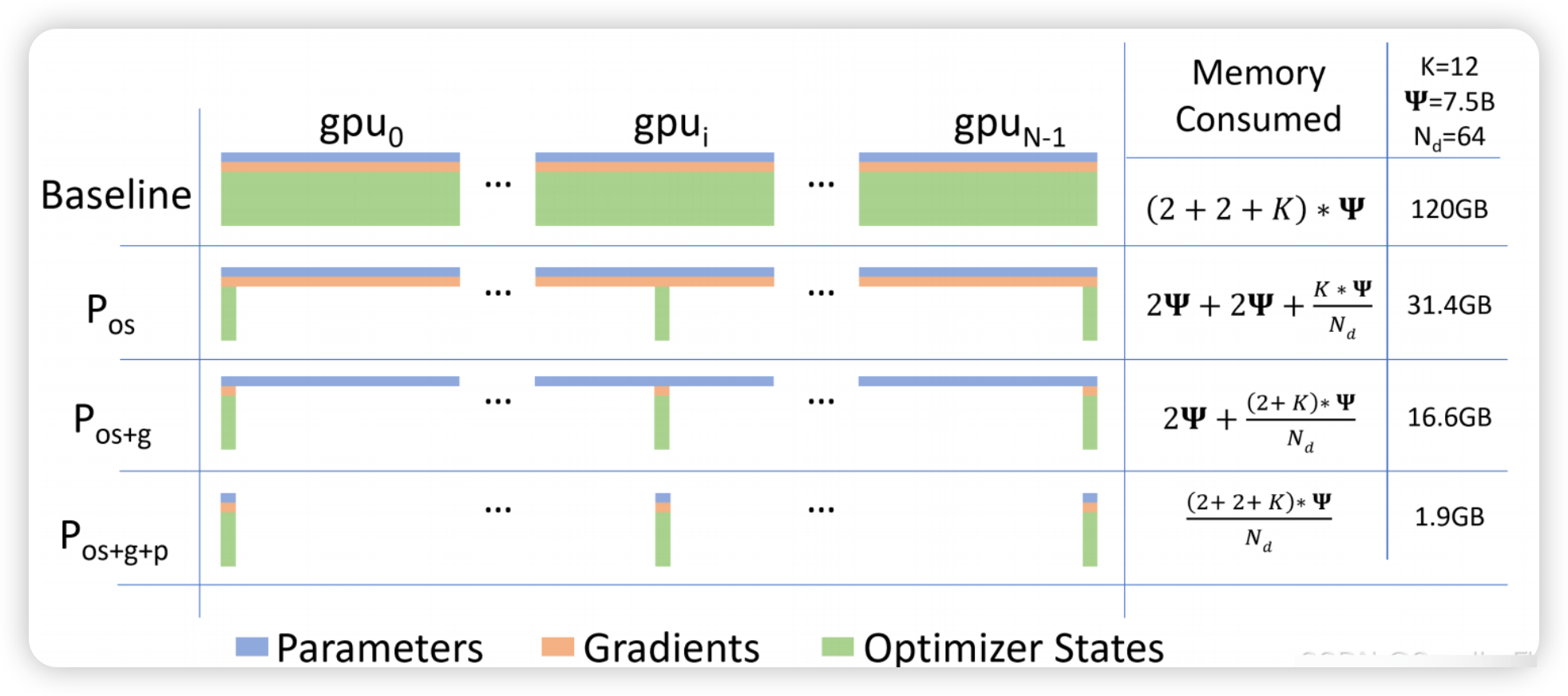
DeepSpeed简介及加速模型训练
DeepSpeed是由微软开发的开源深度学习优化框架,专注于大规模模型的高效训练与推理。其核心目标是通过系统级优化技术降低显存占用、提升计算效率,并支持千亿级参数的模型训练。 官网链接:deepspeed 训练代码下载:git代码 一、De…...
)
网络安全面试题(一)
文章目录 一、基础概念与模型1. 什么是通信协议?列举三种常见的网络通信模型?2. 解释OSI七层模型及各层功能3. TCP/IP四层模型与OSI模型的对应关系是什么?4. 五层协议体系结构与TCP/IP模型的区别?5. 什么是面向连接与非面向连接的服务&…...

Linux 内核探秘:从零构建 GPIO 设备驱动程序实战指南
在嵌入式系统开发领域,GPIO(通用输入 / 输出)作为硬件与软件交互的桥梁,是实现设备控制与数据采集的基础。编写高效、稳定的 GPIO 设备驱动程序,对于发挥硬件性能至关重要。本文将深入剖析 Linux 内核中 GPIO 驱动开发…...
openlayer:10点击地图上某些省份利用Overlay实现提示省份名称
实现点击地图上的省份,在点击经纬度坐标位置附近利用Overlay实现提示框提示相关省份名称。本文介绍了如何通过OpenLayers库实现点击地图上的省份,并在点击的经纬度坐标位置附近显示提示框,提示相关省份名称。首先,定义了两个全局变…...
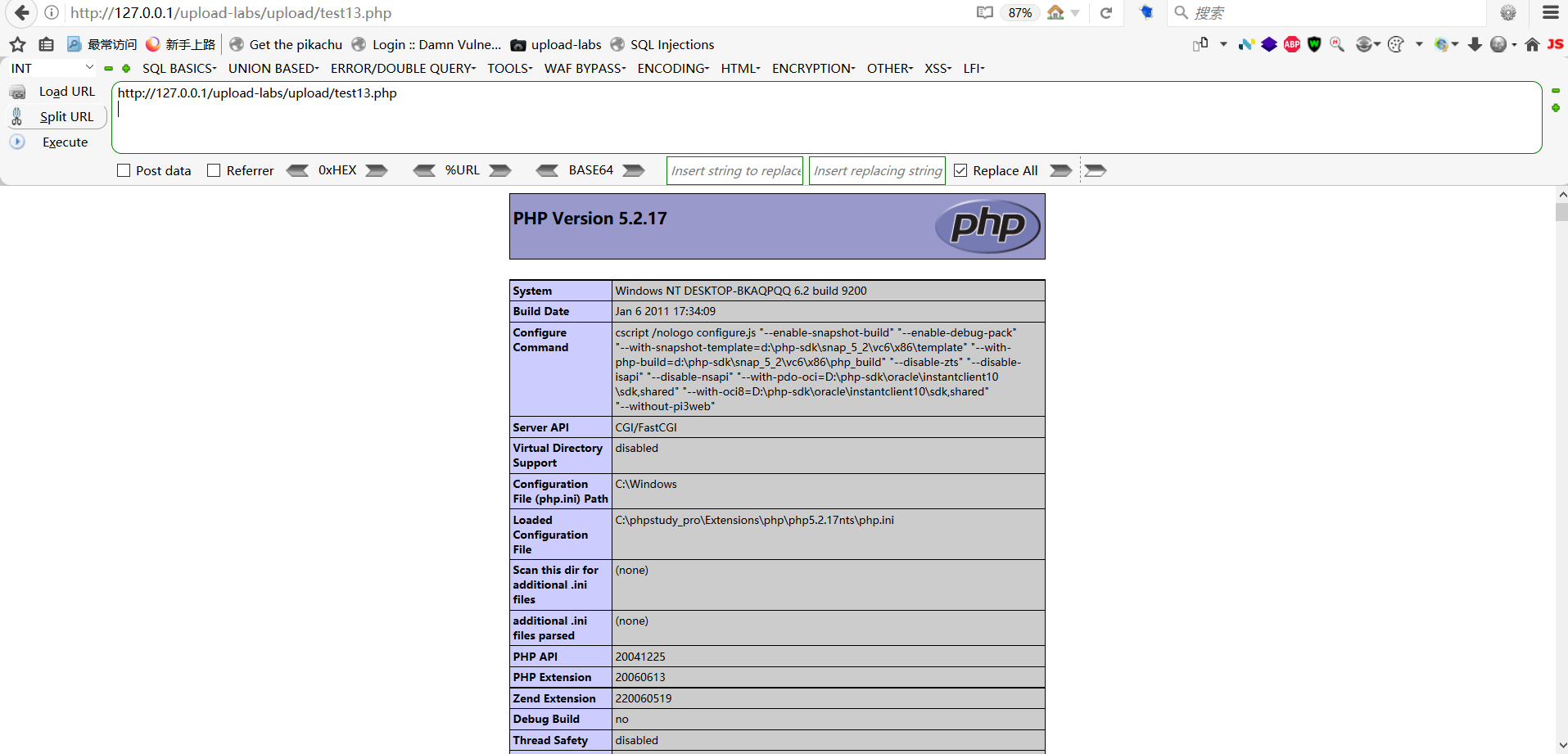
upload-labs通关笔记-第13关 文件上传之白名单POST法
目录 一、白名单过滤 二、%00截断 1.截断原理 2、截断条件 (1)PHP版本 < 5.3.4 (2)magic_quotes_gpc配置为Off (3)代码逻辑存在缺陷 三、源码分析 1、代码审计 (1)文件…...
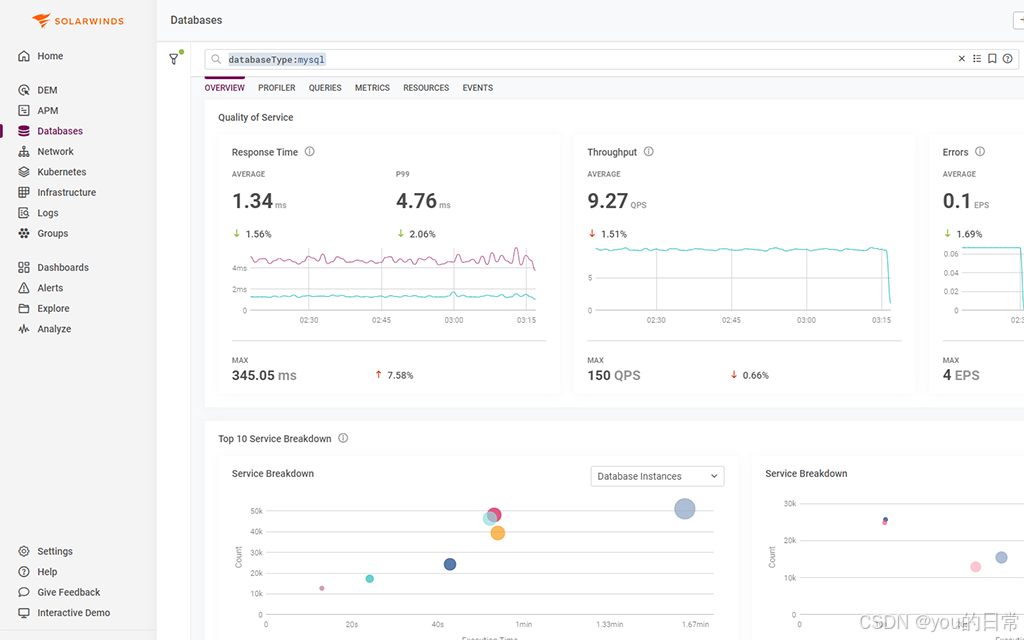
数据库健康监测器(BHM)实战:如何通过 HTML 报告识别潜在问题
在数据库运维中,健康监测是保障系统稳定性与性能的关键环节。通过 HTML 报告,开发者可以直观查看数据库的运行状态、资源使用情况与潜在风险。 本文将围绕 数据库健康监测器(Database Health Monitor, BHM) 的核心功能展开分析,结合 Prometheus + Grafana + MySQL Export…...
: 文件输入输出库 —— <fstream>)
C++(20): 文件输入输出库 —— <fstream>
目录 一、 的核心功能 二、核心类及功能 三、核心操作示例 1. 文本文件写入(ofstream) 2. 文本文件读取(ifstream) 3. 二进制文件操作(fstream) 四、文件打开模式 五、文件指针操作 六、错误处理技巧…...

使用Starrocks制作拉链表
5月1日向ods_order_info插入3条数据: CREATE TABLE ods_order_info(dt string,id string COMMENT 订单编号,total_amount decimal(10,2) COMMENT 订单金额 ) PRIMARY KEY(dt, id) PARTITION BY (dt) DISTRIBUTED BY HASH(id) PROPERTIES ( "replication_num&q…...
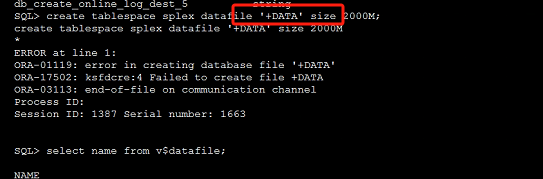
Oracle 11g 单实例使用+asm修改主机名导致ORA-29701 故障分析
解决 把服务器名修改为原来的,重启服务器。 故障 建表空间失败。 分析 查看告警日志 ORA-1119 signalled during: create tablespace splex datafile ‘DATA’ size 2000M… Tue May 20 18:04:28 2025 create tablespace splex datafile ‘DATA/option/dataf…...

Spring Boot接口通用返回值设计与实现最佳实践
一、核心返回值模型设计(增强版) package com.chat.common;import com.chat.util.I18nUtil; import com.chat.util.TraceUtil; import lombok.AllArgsConstructor; import lombok.Data; import lombok.Getter;import java.io.Serializable;/*** 功能: 通…...

DeepSeek 赋能军事:重塑现代战争形态的科技密码
目录 一、引言:AI 浪潮下的军事变革与 DeepSeek 崛起二、DeepSeek 技术原理与特性剖析2.1 核心技术架构2.2 独特优势 三、DeepSeek 在军事侦察中的应用3.1 海量数据快速处理3.2 精准目标识别追踪3.3 预测潜在威胁 四、DeepSeek 在军事指挥决策中的应用4.1 战场态势实…...

day09-新热文章-实时计算
1. 实时计算与定时计算的区别 定时计算:基于固定时间间隔(如每天/小时)处理全量数据,适用于对实时性要求不高的场景。实时计算:持续处理无界数据流,结果实时输出,适用于高实时性场景࿰…...

Elasticsearch面试题带答案
Elasticsearch面试题带答案 Elasticsearch面试题及答案【最新版】Elasticsearch高级面试题大全(2025版),发现网上很多Elasticsearch面试题及答案整理都没有答案,所以花了很长时间搜集,本套Elasticsearch面试题大全,Elasticsearch面试题大汇总,有大量经典的Elasticsearch面…...
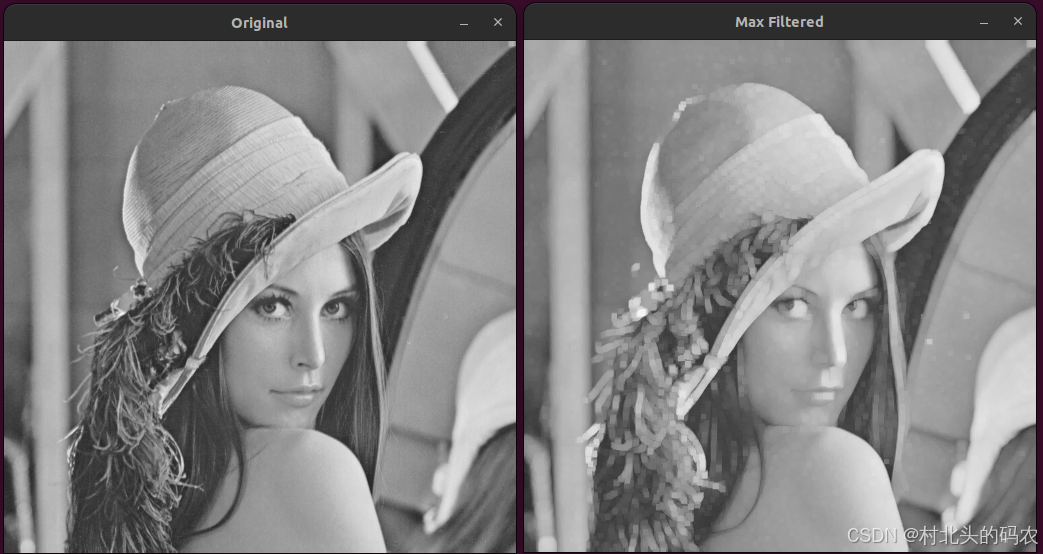
OpenCV CUDA模块图像过滤------用于创建一个最大值盒式滤波器(Max Box Filter)函数createBoxMaxFilter()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 createBoxMaxFilter()函数创建的是一个 最大值滤波器(Maximum Filter),它对图像中每个像素邻域内的像素值取最…...
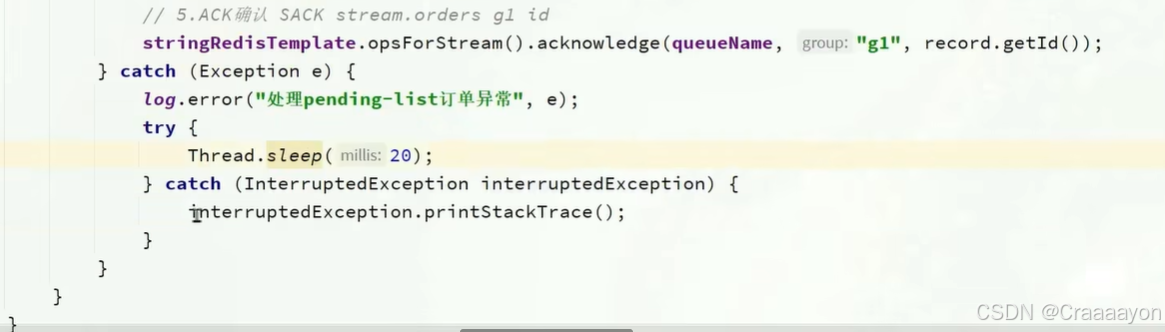
Redis数据库-消息队列
一、消息队列介绍 二、基于List结构模拟消息队列 总结: 三、基于PubSub实现消息队列 (1)PubSub介绍 PubSub是publish与subscribe两个单词的缩写,见明知意,PubSub就是发布与订阅的意思。 可以到Redis官网查看通配符的书写规则: …...