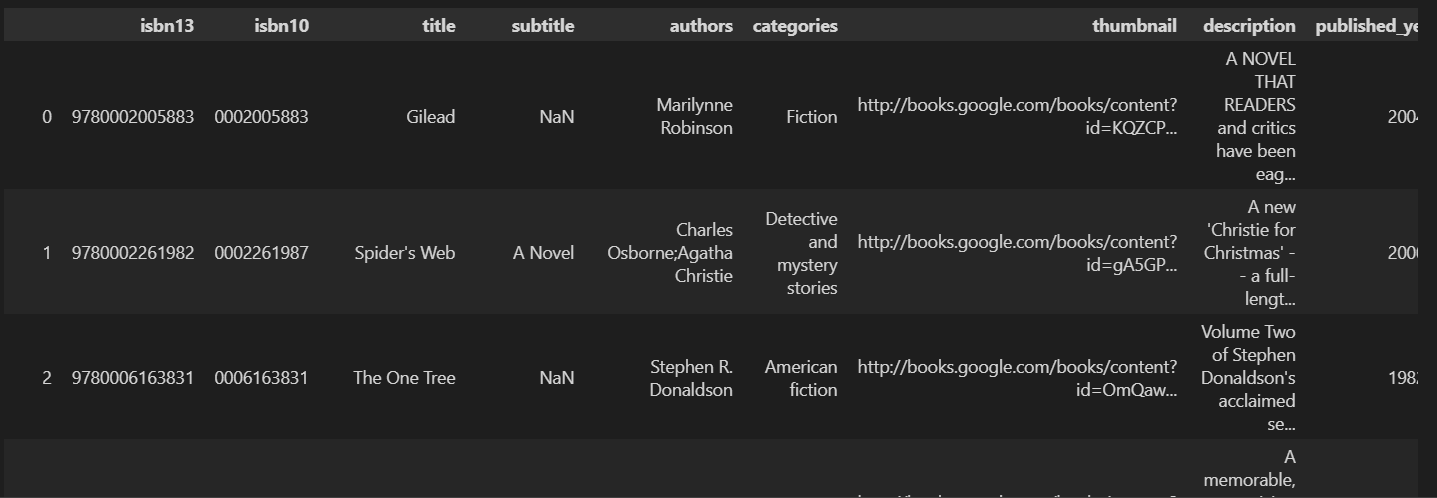
使用Gemini, LangChain, Gradio打造一个书籍推荐系统 (第一部分)
第一部分:数据处理
import kagglehub# Download latest version
path = kagglehub.dataset_download("dylanjcastillo/7k-books-with-metadata")print("Path to dataset files:", path)
自动下载该数据集的 最新版本 并返回本地保存的路径
import pandas as pd
books = pd.read_csv(f"{path}/books.csv")
books
import seaborn as sns
import matplotlib.pyplot as pltax = plt.axes()
sns.heatmap(books.isna().transpose(), cbar=False, ax=ax)plt.xlabel("Columns")
plt.ylabel("Missing values")plt.show()
创建一个 Matplotlib 的坐标轴对象(AxesSubplot),用于后续绘图。
books.isna() 会生成一个布尔矩阵,显示每个单元格是否为缺失值(NaN)。
.transpose() 将 DataFrame 转置 —— 把行列调换,使每一列(字段)显示在 y 轴,每一行(记录)显示在 x 轴。
sns.heatmap(…) 会绘制一个热力图,白色通常表示缺失,深色表示非缺失。
cbar=False 关闭颜色条(color bar)。
ax=ax 指定使用我们前面创建的坐标轴。
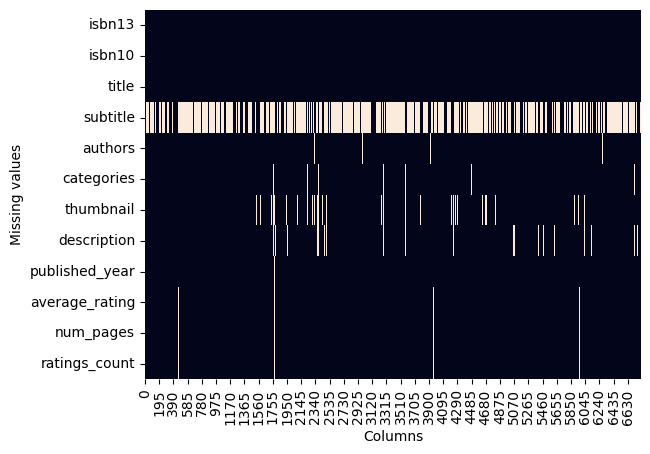
X 轴表示数据记录(行)
Y 轴表示数据字段(列)是否缺失(因为之前做了转置)
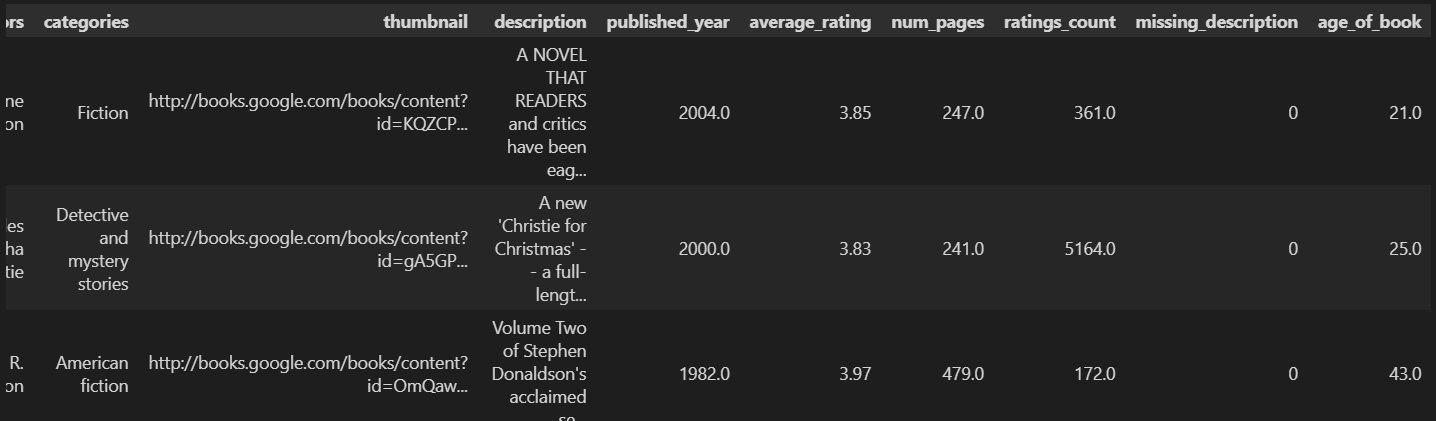
import numpy as npbooks["missing_description"] = np.where(books["description"].isna(), 1, 0)
books["age_of_book"] = 2025 - books["published_year"]
books[“description”].isna() 会返回一个布尔数组,指示每一行中 description 是否为缺失值(NaN)。
np.where(condition, x, y) 是一个三元选择函数:
- 如果 condition 为 True,则取 x(即 1)
- 否则取 y(即 0)
创建新的一列 age_of_book,表示书籍出版到 2025 年的时间跨度
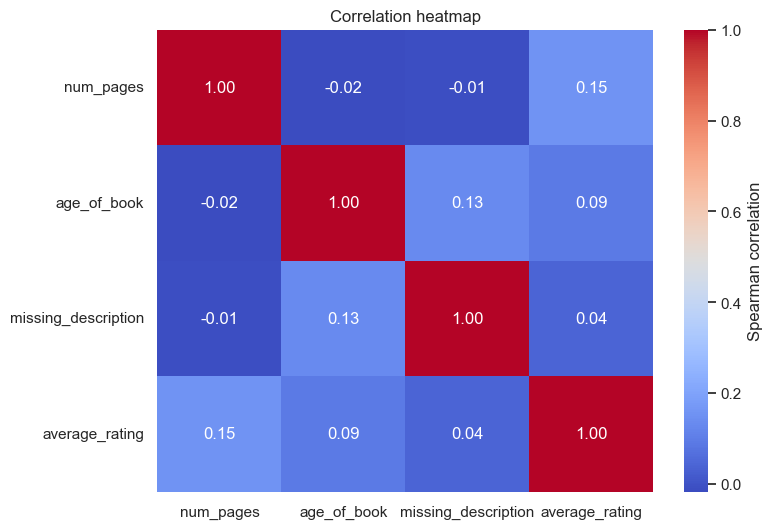
columns_of_interest = ["num_pages", "age_of_book", "missing_description", "average_rating"]correlation_matrix = books[columns_of_interest].corr(method = "spearman")sns.set_theme(style="white")
plt.figure(figsize=(8, 6))
heatmap = sns.heatmap(correlation_matrix, annot=True, fmt=".2f", cmap="coolwarm",cbar_kws={"label": "Spearman correlation"})
heatmap.set_title("Correlation heatmap")
plt.show()
定义感兴趣的字段列表:
-
“num_pages”:图书页数
-
“age_of_book”:图书出版的年限(之前计算得出)
-
“missing_description”:是否缺失描述(之前创建的标志位)
-
“average_rating”:图书的平均评分
计算这四个字段之间的 相关系数矩阵,使用 Spearman 等级相关系数
books[columns_of_interest] 提取这几个字段组成新的 DataFrame
.corr(method=“spearman”) 表示使用 Spearman 方法来计算相关性(适用于非线性或非正态分布的数据)。
结果是一个 4x4 的矩阵,数值范围在 [-1, 1] 之间,表示变量之间的相关程度:
-
1 表示完全正相关
-
-1 表示完全负相关
-
0 表示无相关性
设置 Seaborn 图表主题为白色背景。
绘制热力图:
-
correlation_matrix:输入数据为相关系数矩阵
-
annot=True:在每个格子里显示数值
-
fmt=“.2f”:格式保留两位小数
-
cmap=“coolwarm”:颜色映射(红-蓝渐变,红色代表正相关,蓝色代表负相关)
-
cbar_kws={“label”: “Spearman correlation”}:给右侧颜色条加上标签
book_missing = books[~(books["description"].isna()) &~(books["num_pages"].isna()) &~(books["average_rating"].isna()) &~(books["published_year"].isna())
]
book_missing
books[“description”].isna():检查 description 字段是否为缺失(NaN)
~(…):逻辑“非”(NOT),表示“不是缺失的”
描述、页数、评分、出版年份 四个字段都不是缺失值。
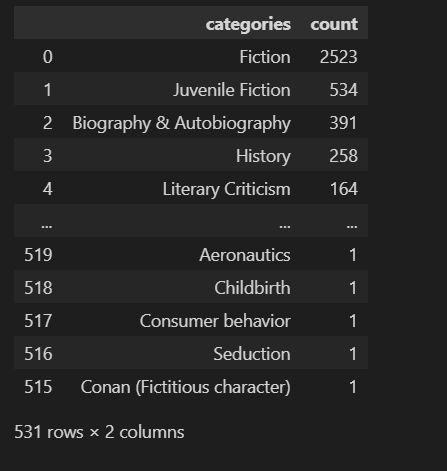
book_missing["categories"].value_counts().reset_index().sort_values("count", ascending=False)
对 book_missing 数据集中 categories 列进行 计数(统计每种类别出现的次数)
返回结果是一个 Series,索引是类别名称,值是出现次数
将 value_counts() 的结果从 Series 变成一个 DataFrame,原本的索引(分类名)被变成一列(通常是 index 列)
找出哪些图书类别最常出现
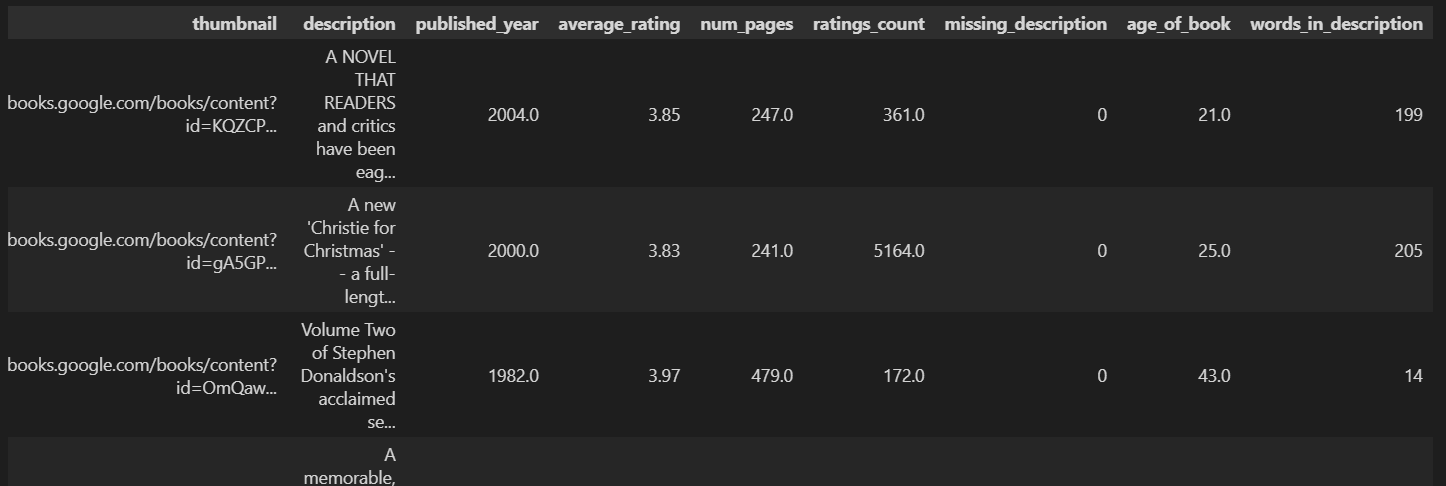
book_missing["words_in_description"] = book_missing["description"].str.split().str.len()
book_missing
计算每本书的简介(description)中包含了多少个单词,并将结果保存到一个新列 words_in_description 中。
str.split() 是 Pandas 的字符串处理方法,用于将每本书的简介字符串按空格 分割成单词列表。
对每一行分割后的列表计算长度,也就是列表中单词的数量。
创建新列 words_in_description,其值是每条 description 中的单词数(即单词总数或长度)。
book_missing_25_words = book_missing[book_missing["words_in_description"] >= 25]
book_missing_25_words
从 book_missing 数据集中筛选出简介(description)中包含 不少于 25 个单词 的图书记录,并保存到 book_missing_25_words 中。
这是一个布尔表达式,检查每本书的 words_in_description(简介的单词数)是否 大于等于 25
变量 book_missing_25_words 包含的是那些 简介长度 ≥ 25 个单词 的图书记录。
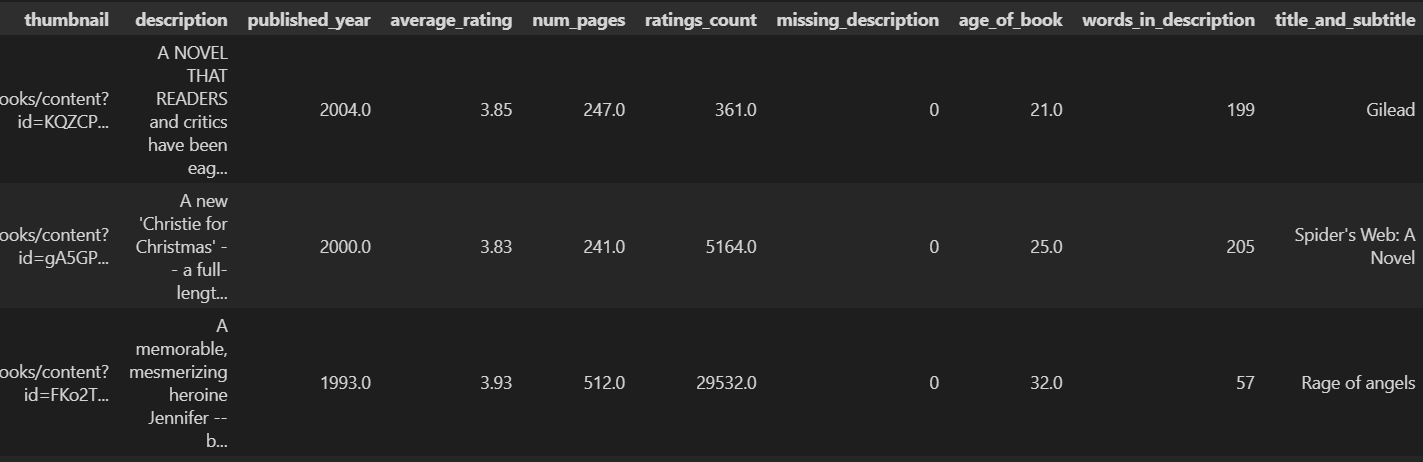
book_missing_25_words["title_and_subtitle"] = (np.where(book_missing_25_words["subtitle"].isna(), book_missing_25_words["title"],book_missing_25_words[["title", "subtitle"]].astype(str).agg(": ".join, axis=1))
)
book_missing_25_words
为每本书生成一个新的字段 title_and_subtitle,内容是“书名: 副标题”(如果有副标题),否则就只用书名。
判断副标题是否缺失(NaN),返回一个布尔序列。
这是 NumPy 的条件选择函数:np.where(condition, value_if_true, value_if_false)
- 如果 subtitle 是 NaN,就取 title
- 否则,组合 title 和 subtitle 成 “title: subtitle” 形式
对每一行(axis=1)将 title 和 subtitle 用 ": " 连接。
这段代码的目的是构建一个统一的“完整书名”字段,结合书名和副标题
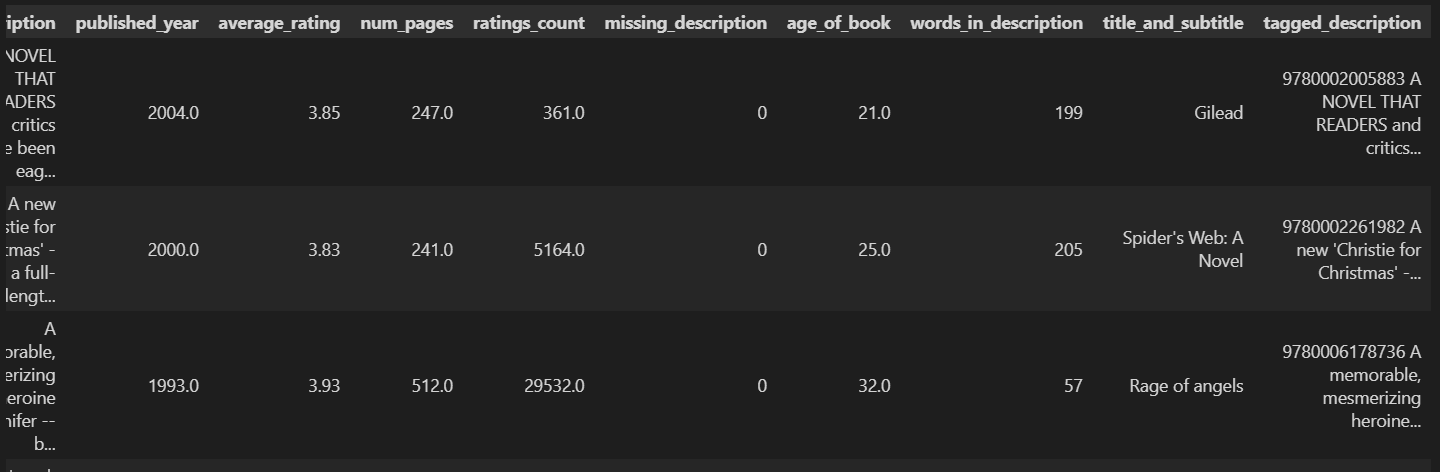
book_missing_25_words["tagged_description"] = book_missing_25_words[["isbn13", "description"]].astype(str).agg(" ".join, axis=1)
book_missing_25_words
(book_missing_25_words.drop(["subtitle", "missing_description", "age_of_book", "words_in_description"], axis=1).to_csv("books_cleaned_new.csv", index = False)
)
对 book_missing_25_words 数据框进行清理(删除一些不再需要的列),然后将结果保存为一个新的 CSV 文件 books_cleaned_new.csv。
删除指定的列:
-
“subtitle”:副标题(因为我们已经合并为 title_and_subtitle,原列可删除)
-
“missing_description”:布尔值字段(描述是否缺失),此时已无用
-
“age_of_book”:出版年份转化来的字段,不再需要
-
“words_in_description”:简介单词数,之前用于筛选,现在可以移除
.drop(…, axis=1) 表示按列(axis=1)进行删除。
将处理后的数据保存为 CSV 文件
index=False 表示不要把 DataFrame 的索引保存到文件中(只保存列和数据)
数据分析流程中 “导出清洗后的最终数据”
相关文章:
使用Gemini, LangChain, Gradio打造一个书籍推荐系统 (第一部分)
第一部分:数据处理 import kagglehub# Download latest version path kagglehub.dataset_download("dylanjcastillo/7k-books-with-metadata")print("Path to dataset files:", path)自动下载该数据集的 最新版本 并返回本地保存的路径 impo…...
大语言模型 16 - Manus 超强智能体 Prompt分析 原理分析 包含工具列表分析
写在前面 Manus 是由中国初创公司 Monica.im 于 2025 年 3 月推出的全球首款通用型 AI 智能体(AI Agent),旨在实现“知行合一”,即不仅具备强大的语言理解和推理能力,还能自主执行复杂任务,直接交付完整成…...

物联网赋能7×24H无人值守共享自习室系统设计与实践!
随着"全民学习"浪潮的兴起,共享自习室市场也欣欣向荣,今天就带大家了解下在物联网的加持下,无人共享自习室系统的设计与实际方法。 一、物联网系统整体架构 1.1 系统分层设计 层级技术组成核心功能用户端微信小程序/H5预约选座、…...

以太联Intellinet带您深度解析PoE交换机的上行链路端口(Uplink Ports)
在当今网络技术日新月异的时代,以太网供电(PoE)交换机已然成为现代网络连接解决方案中不可或缺的“利器”。它不仅能够出色地完成数据传输任务,还能为所连接的设备提供电力支持,彻底摆脱了单独电源适配器的束缚,让网络部署更加简洁…...

浏览器播放 WebRTC 视频流
源码(vue) <template><video ref"videoElement" class"video" autoplay muted playsinline></video> </template><script setup lang"ts">import { onBeforeUnmount, onMounted, ref } fr…...

从零开始:使用 PyTorch 构建深度学习网络
从零开始:使用 PyTorch 构建深度学习网络 目录 PyTorch 简介环境配置PyTorch 基础构建神经网络训练模型评估与测试案例实战:手写数字识别进阶技巧常见问题解答 PyTorch 简介 PyTorch 是一个开源的深度学习框架,由 Facebook(现…...
分类算法 Kmeans、KNN、Meanshift 实战
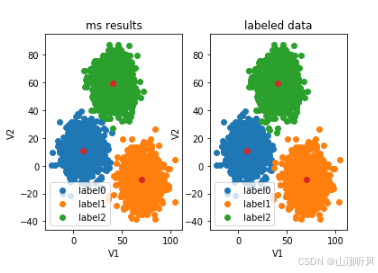
任务 1、采用 Kmeans 算法实现 2D 数据自动聚类,预测 V180,V260 数据类别; 2、计算预测准确率,完成结果矫正 3、采用 KNN、Meanshift 算法,重复步骤 1-2 代码工具:jupyter notebook 视频资料 无监督学习ÿ…...

【razor】回环结构导致的控制信令错位:例如发送端收到 SR的问题
一、razor的echo程序 根据对 yuanrongxi/razor 仓库的代码和 echo 测试程序相关实现的分析,下面详细解读 echo 程序中 RTCP sender report(SR)、receiver report(RR)回显的问题及项目的解决方式。 1. 问题背景 在 RTP/RTCP 体系下,SR(Sender Report)由发送端周期性发…...

网络安全之身份验证绕过漏洞
漏洞简介 CrushFTP 是一款由 CrushFTP LLC 开发的强大文件传输服务器软件,支持FTP、SFTP、HTTP、WebDAV等多种协议,为企业和个人用户提供安全文件传输服务。近期,一个被编号为CVE-2025-2825的严重安全漏洞被发现,该漏洞影响版本1…...
MySQL 主从复制搭建全流程:基于 Docker 与 Harbor 仓库
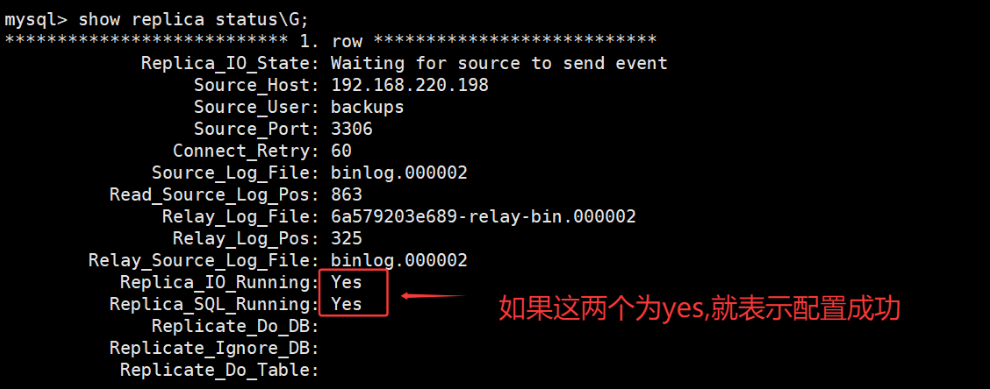
一、引言 在数据库管理中,MySQL 主从复制是一种非常重要的技术,它可以实现数据的备份、读写分离,减轻主数据库的压力。本文将详细介绍如何使用 Docker 和 Harbor 仓库来搭建 MySQL 主从复制环境,适合刚接触数据库和 Docker 的新手…...

vscode打开vue + element项目
好嘞,我帮你详细整理一个用 VS Code 来可视化开发 Vue Element UI 的完整步骤,让你能舒服地写代码、预览界面、调试和管理项目。 用 VS Code 可视化开发 Vue Element UI 全流程指南 一、准备工作 安装 VS Code 官网下载安装:https://code…...
Django框架的前端部分使用Ajax请求一
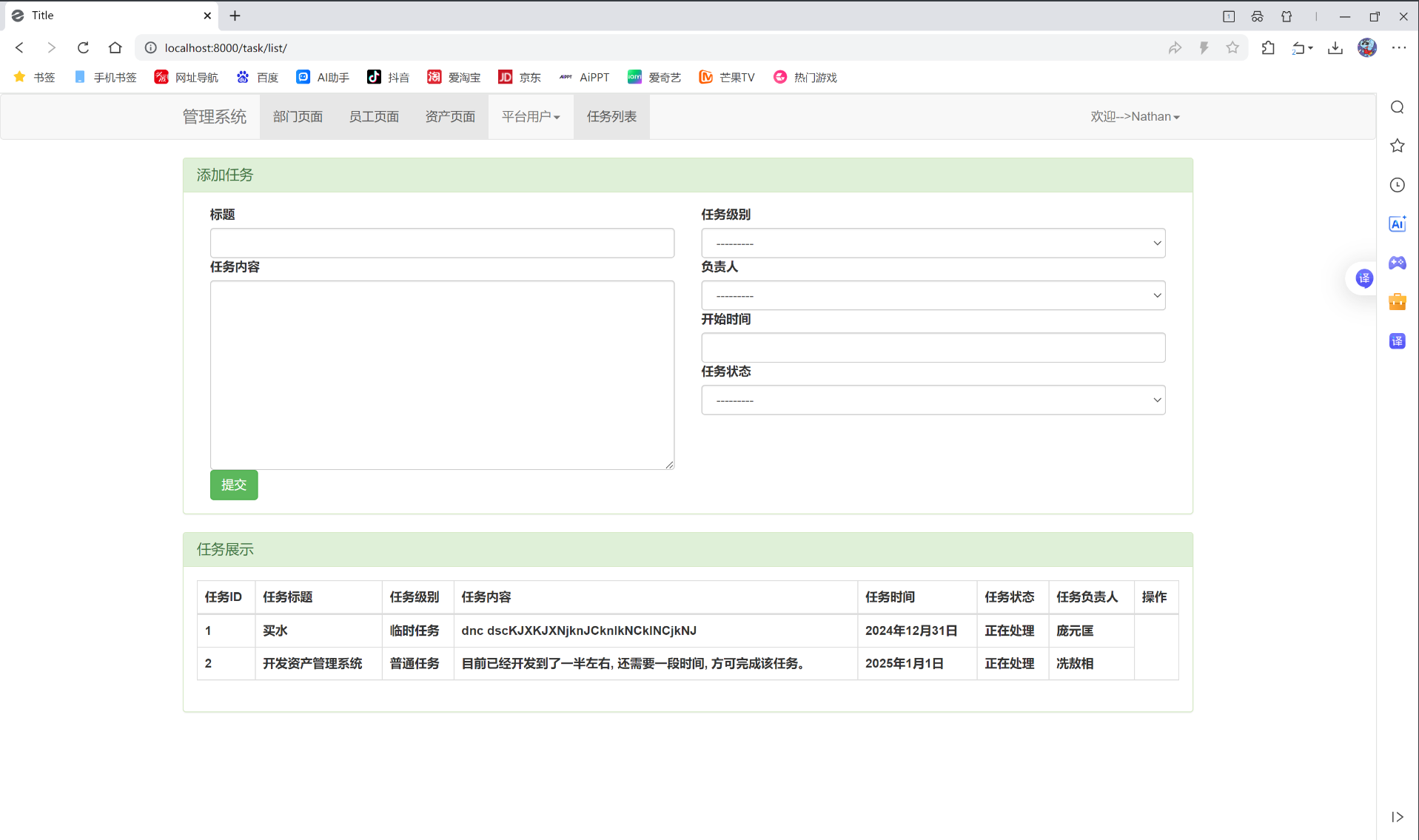
Ajax请求 目录 1.ajax请求使用 2.增加任务列表功能(只有查看和新增) 3.代码展示集合 这篇文章, 要开始讲关于ajax请求的内容了。这个和以前文章中写道的Vue框架里面的axios请求, 很相似。后端代码, 会有一些细节点, 跟前几节文章写的有些区别。 一、ajax请求使用 我们先…...

cmd如何从C盘默认路径切换到D盘某指定目录
以从C盘cmd打开后的默认目录切换到目录"D:\Program Files\MySQL\MySQL Server 8.0\bin\mysqld"为例 打开cmd 首先点击开始键,搜索cms,右键以管理员身份运行打开管理员端的命令行提示符 1、首先要先切换到D盘 直接输入D:然后回车就可以&…...

693SJBH基于.NET的题库管理系统
计算机与信息学院 本科毕业论文(设计)开题报告 论文中文题目 基于asp.net的题库管理系统设计与实现 论文英文题目 Asp.net based database management system design and Implementation 学生姓名 专业班级 XXXXXX专业08 班 ⒈选题的背景和意…...

[Vue]跨组件传值
父子组件传值 详情可以看文章 跨组件传值 Vue 的核⼼是单向数据流。所以在父子组件间传值的时候,数据通常是通过属性从⽗组件向⼦组件,⽽⼦组件通过事件将数据传递回⽗组件。多层嵌套场景⼀般使⽤链式传递的⽅式实现provideinject的⽅式适⽤于需要跨层级…...

每日Prompt:实物与手绘涂鸦创意广告
提示词 一则简约且富有创意的广告,设置在纯白背景上。 一个真实的 [真实物体] 与手绘黑色墨水涂鸦相结合,线条松散而俏皮。涂鸦描绘了:[涂鸦概念及交互:以巧妙、富有想象力的方式与物体互动]。在顶部或中部加入粗体黑色 [广告文案…...
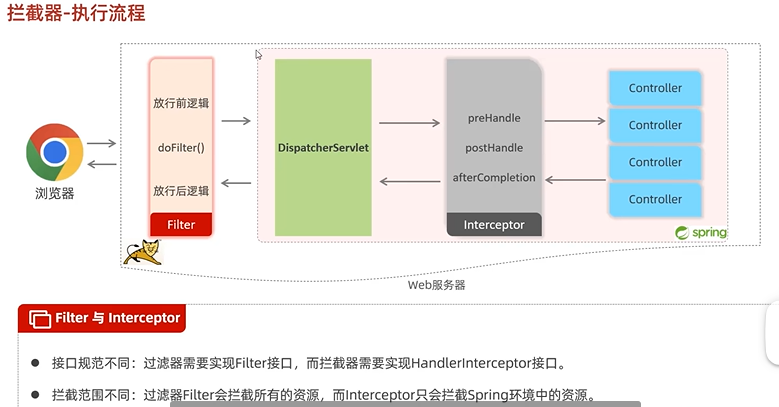
学习笔记:黑马程序员JavaWeb开发教程(2025.4.8)
12.11 登录校验-Filter-详解(过滤器链) 过滤器链及其执行顺序,一个Filter一个过滤器链,类名排名越靠前(按照ABC这样的顺序),就先执行谁 12.12 登录校验-Filter-登录校验过滤器 获取请求参数&…...

vue3 在线播放语音 mp3
播放、暂停、停止 <template><div><button click"togglePlay">{{ isPlaying ? "暂停" : "播放" }}</button><button click"stopAudio">停止</button><p>播放进度:{{ Math.rou…...
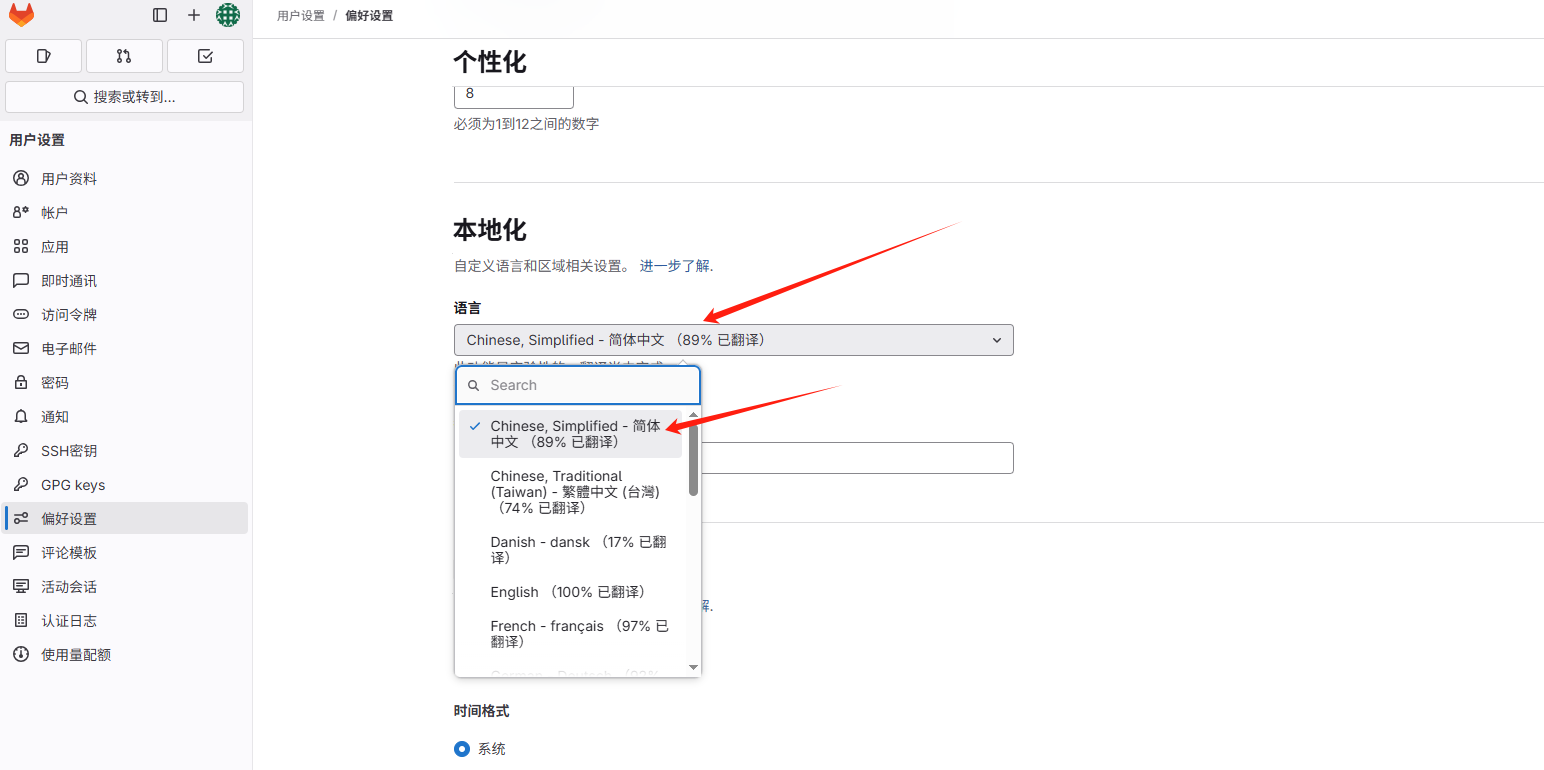
Ubuntu部署私有Gitlab
这个东西安装其实挺简单的,但是因为我这边迁移了数据目录和使用自己安装的 nginx 代理还是踩了几个坑,所以大家可以注意下 先看下安装 # 先安装必要组件 sudo apt update sudo apt install -y curl openssh-server ca-certificates tzdata perl# 添加gi…...
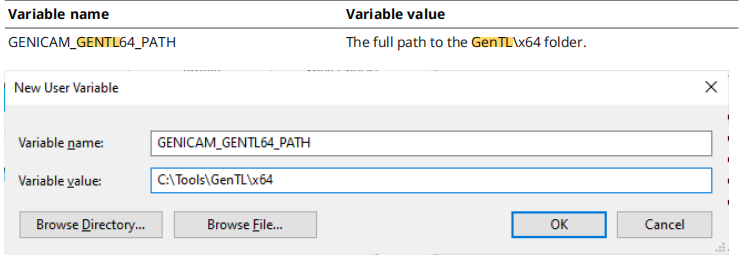
genicamtl_lmi_gocator_objectmodel3d
目录 一、在halcon中找不到genicamtl_lmi_gocator_objectmodel3d例程二、在halcon中运行genicamtl_lmi_gocator_objectmodel3d,该如何配置三、代码分段详解(一)传感器连接四、代码分段详解(二)采集图像并显示五、代码分段详解(三)坐标变换六、常见问题一、在halcon中找不…...
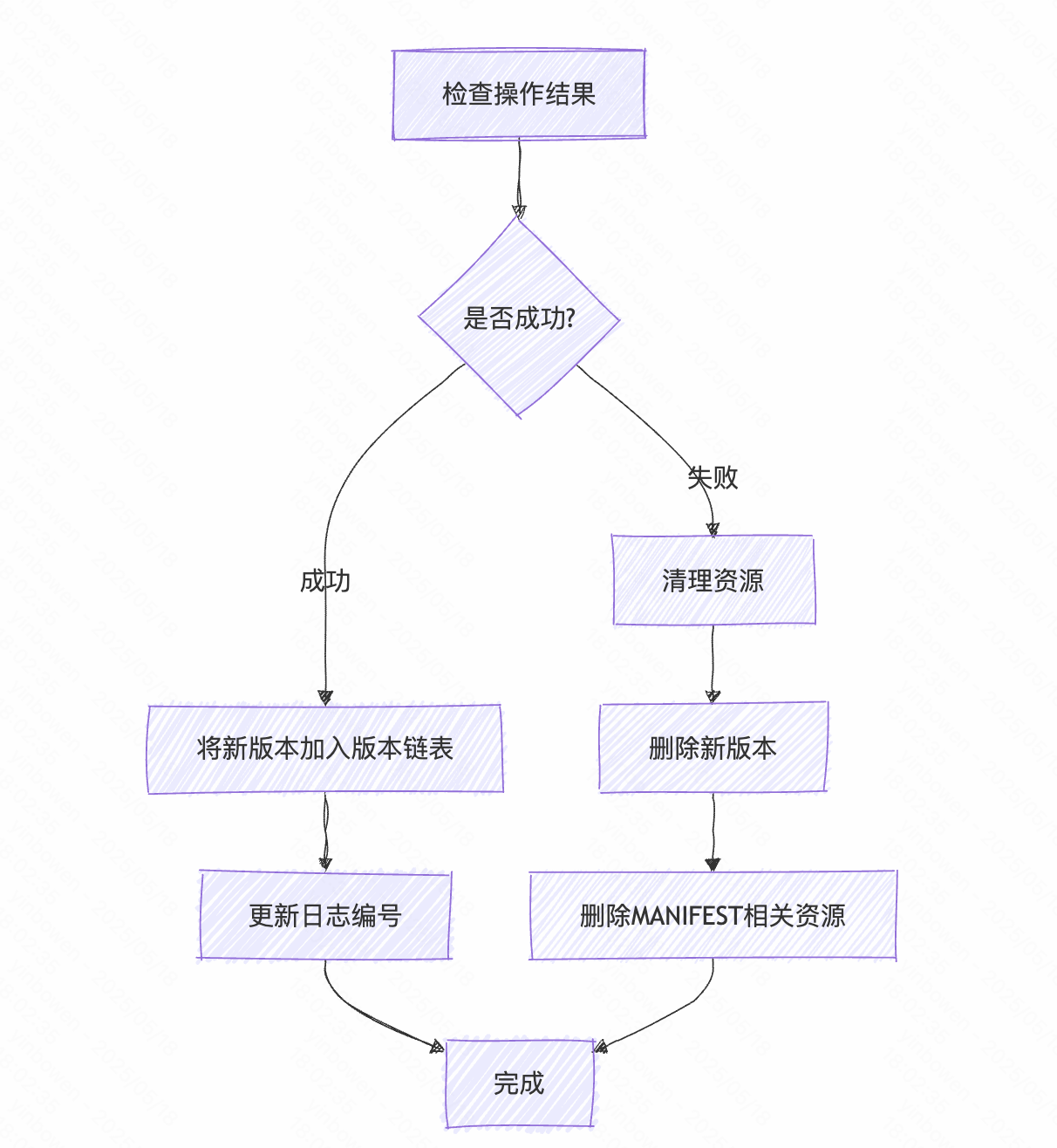
[LevelDB]LevelDB版本管理的黑魔法-为什么能在不锁表的情况下管理数据?
文章摘要 LevelDB的日志管理系统是怎么通过双链表来进行数据管理为什么LevelDB能够在不锁表的情况下进行日志新增 适用人群: 对版本管理机制有开发诉求,并且希望参考LevelDB的版本开发机制。数据库相关从业者的专业人士。计算机狂热爱好者,对计算机的…...

bisheng系列(二)- 本地部署(前后端)
一、导读 环境:Ubuntu 24.04、open Euler 23.03、Windows 11、WSL 2、Python 3.10 、bisheng 1.1.1 背景:需要bisheng二开商用,故而此处进行本地部署,便于后期调试开发 时间:20250519 说明:bisheng前后…...

【网络编程】十二、两万字详解 IP协议
文章目录 Ⅰ. 基本概念1、网络层解决的问题2、保证数据可靠的从一台主机送到另一台主机的前提3、路径选择4、主机和路由器的区别 Ⅱ. IP协议格式IP如何将报头与有效载荷进行分离?IP如何决定将有效载荷交付给上层的哪一个协议?理解socket编程 Ⅲ. 分片与组…...
Linux探秘:驾驭开源,解锁高效能——基础指令
♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥ ♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥ ♥♥♥我们一起努力成为更好的自己~♥♥♥ ♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥ ♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥ ✨✨✨✨✨✨ 个…...

WebSocket解决方案的一些细节阐述
今天我们来看看WebSocket解决方案的一些细节问题: 实际上,集成WebSocket的方法都有相关的工程挑战,这可能会影响项目成本和交付期限。在最简单的层面上,构建 WebSocket 解决方案似乎是添加接收实时更新功能的前进方向。但是&…...

大数据量下Redis分片的5种策略
随着业务规模的增长,单一Redis实例面临着内存容量、网络带宽和计算能力的瓶颈。 分片(Sharding)成为扩展Redis的关键策略,它将数据分散到多个Redis节点上,每个节点负责整个数据集的一个子集。 本文将分享5种Redis分片策略。 1. 取模分片(M…...

muduo库TcpServer模块详解
Muduo库核心模块——TcpServer Muduo库的TcpServer模块是一个基于Reactor模式的高性能TCP服务端实现,负责管理监听端口、接受新连接、分发IO事件及处理连接生命周期。 一、核心组件与职责 Acceptor 监听指定端口,接受新连接,通过epoll监听l…...

Java 代码生成工具:如何快速构建项目骨架?
Java 代码生成工具:如何快速构建项目骨架? 在 Java 项目开发过程中,构建项目骨架是一项繁琐但又基础重要的工作。幸运的是,Java 领域有许多代码生成工具可以帮助我们快速完成这一任务,大大提高开发效率。 一、代码生…...
Nginx核心服务
一.正向代理 正向代理(Forward Proxy)是一种位于客户端和原始服务器之间的代理服务器,其主要作用是将客户端的请求转发给目标服务器,并将响应返回给客户端 Nginx 的 正向代理 充当客户端的“中间人”,代…...
第22天-Python ttkbootstrap 界面美化指南
环境安装 pip install ttkbootstrap 示例1:基础主题切换器 import ttkbootstrap as ttk from ttkbootstrap.constants import *def create_theme_switcher():root = ttk.Window(title="主题切换器", themename="cosmo")def change_theme():selected = t…...