KNN模型思想与实现
KNN算法简介
核心思想:通过样本在特征空间中k个最相似样本的多数类别来决定其类别归属。"附近的邻居确定你的属性"是核心逻辑
决策依据:采用"多数表决"原则,即统计k个最近邻样本中出现次数最多的类别
样本相似性度量
相似性定义:样本距离越近则越相似,距离计算是核心环节
欧式距离:
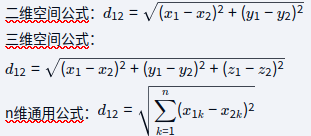
计算特点:采用"差方和开根号"的计算方式,是几何距离的直接推广
K值选择
当K值选择过小:用较小领域的训练实例进行预测
容易收到异常点的影响,K值的减小就意味着整体模型变得复杂,容易发生过拟合。
当K值选择过大:当k值过大时,参考范围过广,容易受到样本不均衡问题影响
导致欠拟合现象,模型变得过于简单,反应迟钝,可能忽略局部特征而偏向多数类
KNN算法
解决问题:分类问题、回归问题
算法思想:若一个样本在特征空间中的k个最相似的样本大多数属于某一个类别,则该样本也属于这个类别
相似性:欧式距离
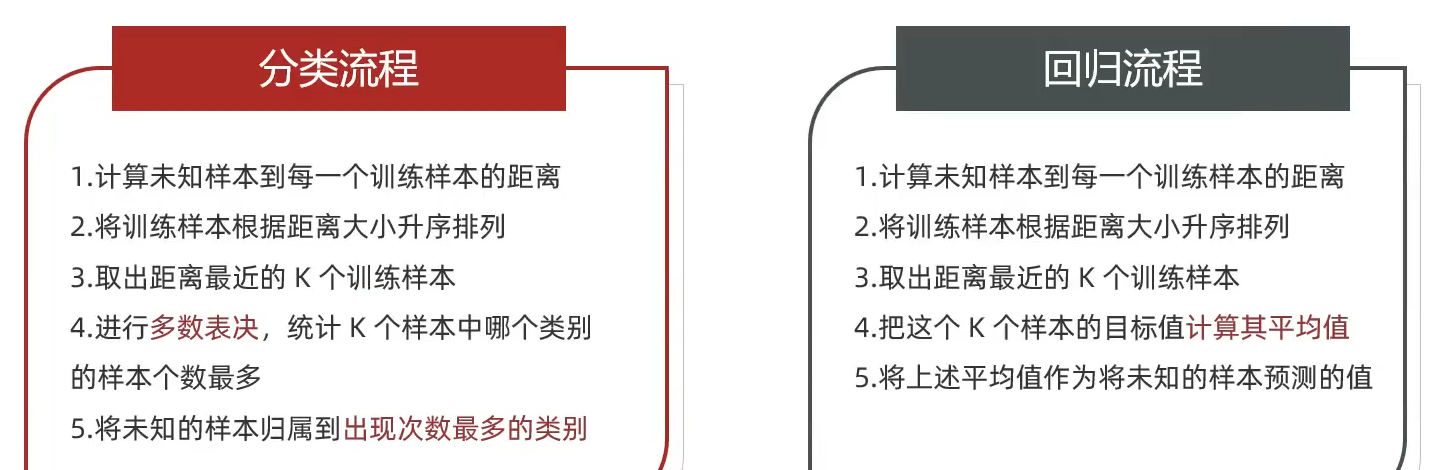
KNN概括
- 算法类型: 有监督学习,可用于分类和回归
- 核心思想: "物以类聚"——相似样本具有相似属性
- 参数选择:
- 常用交叉验证和网格搜索方法确定最优k值
- 需要平衡过拟合和欠拟合问题
- 优缺点:
- 优点:简单直观,无需训练过程
- 缺点:计算量大,对不平衡数据敏感
KNN算法API使用
KNN分类API
n_neighbors:int,可选(默认=5) 选择最大的k值
from sklearn.neighbors import KNeighborsClassifierdef dm01_knnapi_classification():estimator = KNeighborsClassifier(n_neighbors=1) # 初始化分类器x=[[0],[1],[2],[3]] y=[0,0,1,1]estimator.fit(x,y)myret=estimator.predict([[4]])print(myret)dm01_knnapi_classification()案例2
from sklearn.neighbors import KNeighborsClassifier# 数据(特征工程)
# 分类
x=[[0,2,3],[1,3,4],[3,5,6],[4,7,8],[2,3,4]]
y=[0,0,1,1,0]# 实例化模型
model=KNeighborsClassifier(n_neighbors=3)# 模型训练
model.fit(x,y)# 模型预测
print(model.predict([[4,4,5]])) KNN回归API
from sklearn.neighbors import KNeighborsRegressordef dm02_knnapi_Regression():estimator = KNeighborsRegressor(n_neighbors=2)x = [[0, 0, 1], [1, 1, 0], [3, 10, 10], [4, 11, 12]]y = [0.1, 0.2, 0.3, 0.4]estimator.fit(x, y)myret = estimator.predict([[2, 11, 10]])print(myret)dm02_knnapi_Regression()这个点与后两个点相近,就取这两个y点的平均值。
from sklearn.neighbors import KNeighborsRegressor# 数据(特征工程)
# 回归
x=[[0,1,2],[1,2,3],[2,3,4],[3,4,5]]
y=[0.1,0.2,0.3,0.4]# 实例化模型
model=KNeighborsRegressor(n_neighbors=3)# 模型训练
model.fit(x,y)# 模型预测
print(model.predict([[4,4,5]]))距离度量-常见距离公式
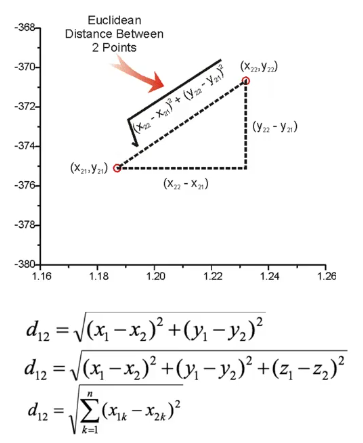
欧式距离
直观的距离度量方式,两个点在空间中的距离一般都是欧式距离
曼哈顿距离
也称为“城市街区距离”(City Block distance),曼哈顿城市特点:横平竖直

切比雪夫距离
国际象棋中国王的移动方式(可直行、横行、斜行)

闵可夫斯基距离
其不是一种新的距离的度量方式
是对多个距离度量公式的概括性的表述

特征预处理
为什么要做归一化和标准化
当特征的单位或大小相差较大时,数值较大的特征会主导模型训练结果,导致模型无法有效学习其他特征。
若某特征的方差比其他特征大几个数量级,会严重影响目标结果,使模型产生偏差。
归一化
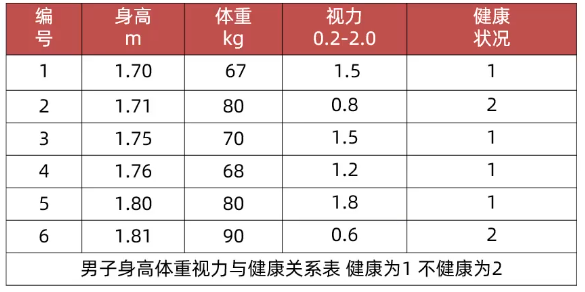
通过对原始数据进行变换把数据映射到[mi,mx](默认微[0,1]之间)
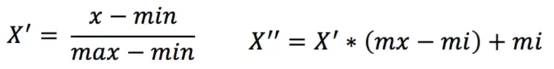
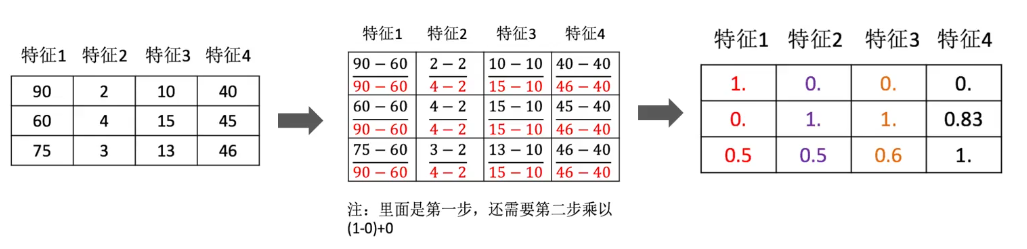
数据归一化API
sklearn.preprocessing.MinMaxScaler(feature_range=(0,1)...)
feature_range缩放区间
fit_transform(X): 同时计算统计量并执行转换
import numpy as np
from sklearn.preprocessing import MinMaxScalerdef dm01_MinMaxScaler():# 1.准备数据data=[[90,2,10,40],[60,4,15,45],[75,3,13,46]]# 2.初始化归一化对象transformer=MinMaxScaler()# 3.对原始特征进行变换data=transformer.fit_transform(data)# 4.打印归一化后的结果print(data)标准化
数据标准化:通过对原始数据进行标准化,转换为均值为0,标准差为1的标准正态分布的数据

数据标准化API
sklearn.preprocessing.StandardScaler()
fit_transform(x)将特征进行标准化缩放
from sklearn.preprocessing import StandardScaler
def dm03_StandardScaler():# 1.准备数据data=[[90,2,10,40],[60,4,15,45],[75,3,13,46]]# 2.初始化标准化对象transformer=StandardScaler()#3.对原始特征进行转换data=transformer.fit_transform(data)# 4.打印标准化后的结果print(data)# 5.打印每一列数据的均值和方差print("transformer.mean-->",transformer.mean_)print("transformer.var-->",transformer.var_)
利用KNN算法对鸢尾花分类
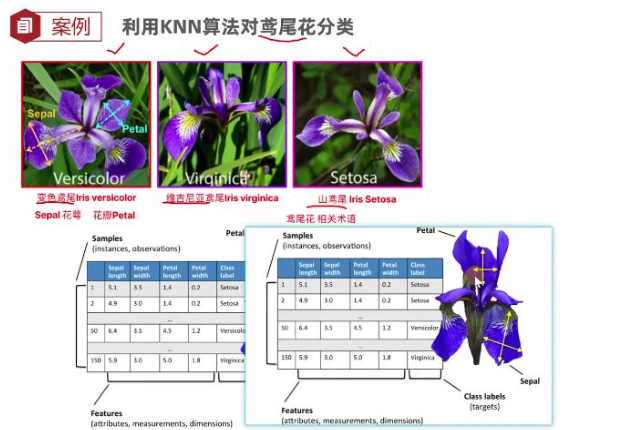
加载鸢尾花数据
# 利用KNN来对鸢尾花分类
from sklearn.datasets import load_irisdef dm01_loadiris():# 加载数据集mydataset=load_iris()# 查看数据集信息print('查看数据集信息>\n',mydataset.data[:5])# 查看目标值print("mydataset.target->\n",mydataset.target)# 查看目标值名字print('mydataset.target_names->',mydataset.target_names)# 查看特征名print('mydataset.feature_names->',mydataset.feature_names)# 查看数据集描述print('mydataset.DESCR->\n',mydataset.DESCR)鸢尾花数据展示
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd# 显示鸢尾花数据
def dm02_showiris():# 1载入鸢尾花数据集并显示特征名称feature_namesmydataset=load_iris()print(mydataset.feature_names)# 2把数据转化成dataframe格式,设置data,columns属性 目标值名称iris_d=pd.DataFrame(mydataset['data'],columns=mydataset.feature_names)iris_d['label']=mydataset.targetprint('\niris_d-->\n',iris_d)col1='sepal length (cm)'col2='sepal width (cm)'# 3sns.lmplot()显示sns.lmplot(x=col1,y=col2,data=iris_d,hue='label',fit_reg=False)plt.xlabel(col1)plt.ylabel(col2)plt.title('iris')plt.show()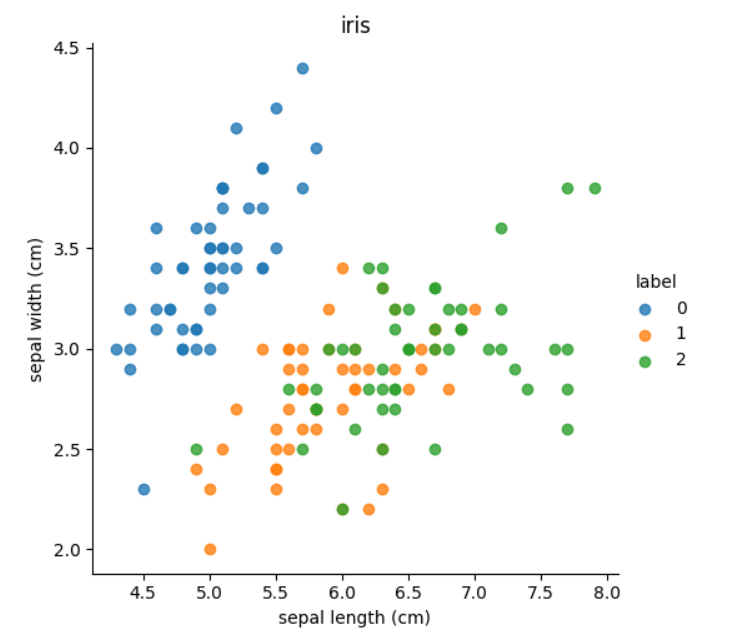
数据集划分
from sklearn.model_selection import train_test_split# 数据集划分
def dm03_traintest_split():# 1.加载数据集mydataset=load_iris()#2.划分数据集x_train,x_test,y_train,t_test=train_test_split(mydataset.data,mydataset.target,test_size=0.3,random_state=22)print("数据总数量",len(mydataset.data))print('训练集中的x-特征值',len(x_train))print('测试集中的x-特征值',len(x_test))print(y_train)模型训练和预测
def dm04():#1 获取训练集mydataset=load_iris()# 2 数据基本处理x_train,x_test,y_train,y_test=train_test_split(mydataset.data,mydataset.target,test_size=0.2,random_state=22)# 3 数据集预处理-数据标准化transfer=StandardScaler()x_train=transfer.fit_transform(x_train)x_test=transfer.transform(x_test)# 模型训练estimator=KNeighborsClassifier(n_neighbors=3)estimator.fit(x_train,y_train)# 模型评估 直接计算准确率100个样本中模型预测对了多少myscore=estimator.score(x_test,y_test)print('myscore->',myscore)#模型预测需要对带预测数据,只是标准化mydata=[[5.1,3.5,1.4,0.2],[4.6,3.1,1.5,0.2]]mydata=transfer.transform(mydata)mypred=estimator.predict(mydata)print('mypred->\n',mypred)mypred=estimator.predict_proba(mydata)print('mypred-->\n',mypred)超参数选择方法
交叉验证
是一种数据集的分割方式,将训练集划分为n份,拿一份做验证集(测试集),其他n-1份做训练集
原理
将数据集划分为cv=4份
- 第一次:第1份为验证集,其余为训练集
- 第二次:第2份为验证集,其余为训练集
- 循环完成所有划分组合(共4次训练评估)
- 取多次评估的平均值作为最终模型得分
最优模型确认:若k=5模型得分最好,则用全部数据(训练+验证集)重新训练k=5模型,最后用独立测试集评估
网格搜索
为什么需要网格搜索
模型存在大量超参数(如KNN的k值),不同参数组合性能差异显著,预先设置多组超参数(如
k=2/5/7),每组都通过交叉验证评估
- 自动化遍历预设参数空间(如循环测试k从1到20)
- 避免人工单次试验的低效性
网格搜索和交叉验证的强力组合
- 分工协作:
- 交叉验证:解决数据划分问题,确保评估可靠性
- 网格搜索:解决超参数组合优化问题
- 工程实践意义:
- 数据优化:通过交叉验证确定最佳数据划分方式
- 模型优化:通过网格搜索确定最优超参数组合
交叉验证网格搜索API介绍
sklearn.model_selection.GridSearchCV(estimator, param_grid=None, cv=None)
- estimator:需要传入实例化后的模型对象
- param_grid:以字典形式传入超参数组合,例如:{'n_neighbors':[1,3,5]}
- cv:指定交叉验证的折数(如cv=5表示五折交叉验证)
核心返回值
- best_score_:交叉验证中得到的最佳评分
- best_estimator_:包含最优参数的模型对象
- cv_results_:记录每次交叉验证的验证集和训练集准确率结果
相关文章:
KNN模型思想与实现
KNN算法简介 核心思想:通过样本在特征空间中k个最相似样本的多数类别来决定其类别归属。"附近的邻居确定你的属性"是核心逻辑 决策依据:采用"多数表决"原则,即统计k个最近邻样本中出现次数最多的类别 样本相似性度量 …...

【信息系统项目管理师】第15章:项目风险管理 - 55个经典题目及详解
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 【第1题】【第2题】【第3题】【第4题】【第5题】【第6题】【第7题】【第8题】【第9题】【第10题】【第11题】【第12题】【第13题】【第14题】【第15题】【第16题】【第17题】【第18题】【第19题】【第20题】【第…...
fscan教程1-存活主机探测与端口扫描
实验目的 本实验主要介绍fscan工具信息收集功能,对同一网段的主机进行存活探测以及常见服务扫描。 技能增长 通过本次实验的学习,了解信息收集的过程,掌握fscan工具主机探测和端口扫描功能。 预备知识 fscan工具有哪些作用? …...

蓝桥杯1447 砝码称重
问题描述 你有一架天平和 N 个砝码,这 N 个砝码重量依次是 W1,W2,⋅⋅⋅,WN。 请你计算一共可以称出多少种不同的重量? 注意砝码可以放在天平两边。 输入格式 输入的第一行包含一个整数 N。 第二行包含 N 个整数:W1,W2,W3,⋅⋅⋅,WN…...

腾讯2025年校招笔试真题手撕(三)
一、题目 今天正在进行赛车车队选拔,每一辆赛车都有一个不可以改变的速度。现在需要选取速度差距在10以内的车队(车队中速度的最大值减去最小值不大于10),用于迎宾。车队的选拔按照的是人越多越好的原则,给出n辆车的速…...
怎样通过神经网络估计股票走向
本博文将教会你如何通过神经网络建立股票模型并对其进行未来趋势估计,尽管博主已通过此方法取得一定利润,但是建议大家不要过分相信AI。本博文仅用于代码学习,请大家谨慎投资。 一、通过爬虫爬取股票往年数据 在信息爆炸的当今时代…...
【RocketMQ 生产者和消费者】- 生产者启动源码-上报生产者和消费者心跳信息到 broker(3)
文章目录 1. 前言2. sendHeartbeatToAllBrokerWithLock 上报心跳信息3. prepareHeartbeatData 准备心跳数据4. sendHearbeat 发送心跳上报请求5. broker 处理心跳请求5.1 heartBeat 处理心跳包5.2 createTopicInSendMessageBackMethod 创建重传 topic5.3 registerConsumer 注册…...
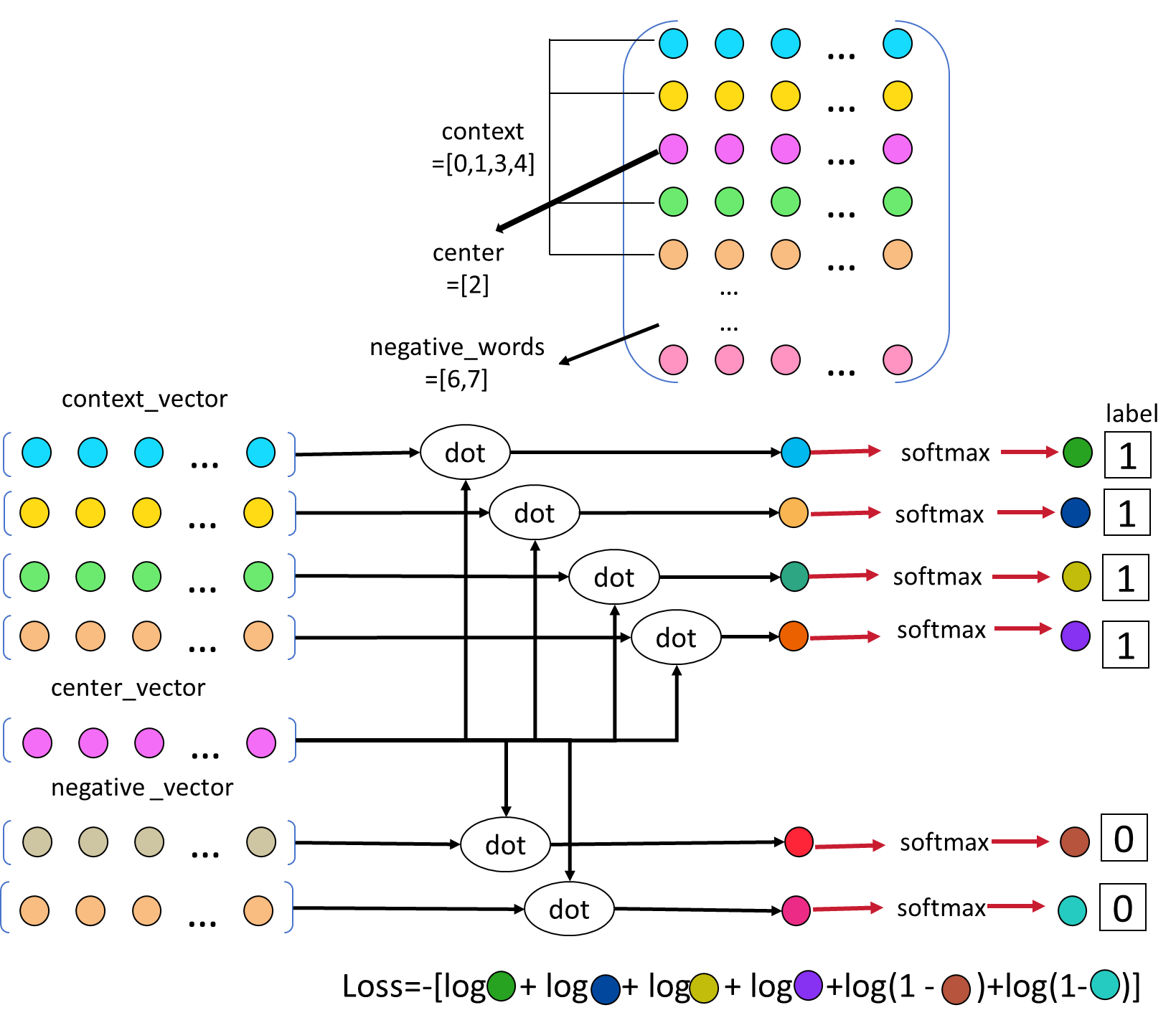
Python----循环神经网络(Word2Vec的优化)
一、负采样 基本思想: 在训练过程中,对于每个正样本(中心词和真实上下文词组成的词对),随机采样少量(如5-20个)负样本(中心词与非上下文词组成的词对)。 模型通过区分正…...

Simon J.D. Prince《Understanding Deep Learning》
学习神经网络和深度学习推荐这本书,这本书站位非常高,且很多问题都深入剖析了,甩其他同类书籍几条街。 多数书,不深度分析、没有知识体系,知识点零散、章节之间孤立。还有一些人Tian所谓的权威,醒醒吧。 …...
开搞:第四个微信小程序:图上县志
原因:我换了一个微信号来搞,因为用同一个用户,备案只能一个个的来。这样不行。所以我换了一个。原来注册过小程序。现在修改即可。注意做好计划后,速度备案和审核,不然你时间浪费不起。30元花起。 结构: -…...
)
模型评估与调优(PyTorch)
文章目录 模型评估方法混淆矩阵混淆矩阵中的指标ROC曲线(受试者工作特征)AUCR平方残差均方误差(MSE)均方根误差(RMSE)平均绝对误差(MAE) 模型调优方法交叉验证(CV&#x…...

sockaddr结构体详解
在网络编程中,sockaddr 结构体用于表示套接字的地址信息。由于不同协议(如 IPv4、IPv6、Unix 域套接字)的地址格式不同,实际使用中通常通过以下三种变体结构来处理不同类型的地址: 1. 通用地址结构:struct …...
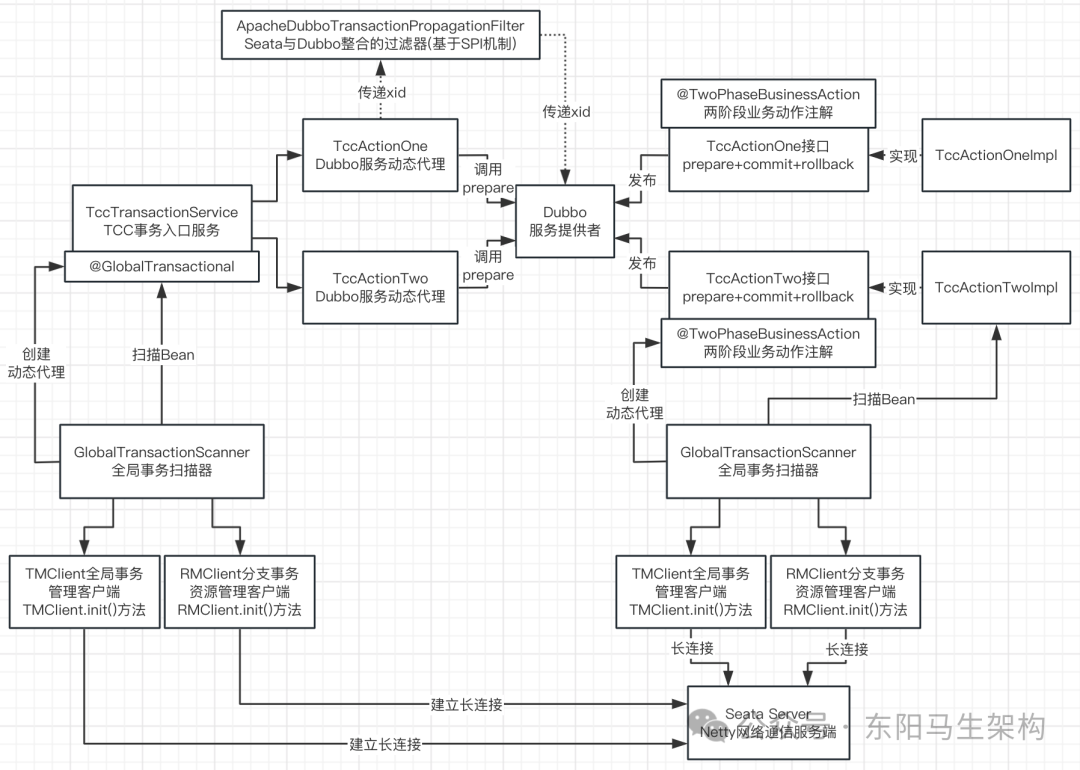
Seata源码—7.Seata TCC模式的事务处理一
大纲 1.Seata TCC分布式事务案例配置 2.Seata TCC案例服务提供者启动分析 3.TwoPhaseBusinessAction注解扫描源码 4.Seata TCC案例分布式事务入口分析 5.TCC核心注解扫描与代理创建入口源码 6.TCC动态代理拦截器TccActionInterceptor 7.Action拦截处理器ActionIntercept…...
【语法】C++的map/set
目录 平衡二叉搜索树 set insert() find() erase() swap() map insert() 迭代器 erase() operator[] multiset和multimap 在之前学习的STL中,string,vector,list,deque,array都是序列式容器,它们的…...
)
【FAQ】HarmonyOS SDK 闭源开放能力 —Live View Kit (3)
1.问题描述: 通过Push Kit创建实况窗之后,再更新实况窗失败,平台查询提示“实况窗端更新失败,通知未创建或已经过期”。 解决方案: 通过Push Kit更新实况窗内容的过程是自动更新的。客户端在创建本地实况窗后&#…...

vue vite textarea标签按下Shift+Enter 换行输入,只按Enter则提交的实现思路
注意input标签不能实现,需要用textarea标签 直接看代码 <template><textareav-model"message"keydown.enter"handleEnter"placeholder"ShiftEnter 换行,Enter 提交"></textarea> </template>&l…...

MySQL多线程备份工具mysqlpump详解!
MySQLPUMP备份工具详解 1. 概述 MySQLPump 是 MySQL 5.7 引入的一个客户端备份工具,用于替代传统的 mysqldump 工具。它提供了并行处理、进度状态显示、更好的压缩支持等新特性,能够更高效地执行 MySQL 数据库备份操作。 2. 主要特性 并行处理&#x…...

创建信任所有证书的HttpClient:Java 实现 HTTPS 接口调用,等效于curl -k
在 Java 生态中,HttpClient 和 Feign 都是调用第三方接口的常用工具,但它们的定位、设计理念和使用场景有显著差异。以下是详细对比: DIFF1. 定位与抽象层级 特性HttpClientFeign层级底层 HTTP 客户端库(处理原始请求/响应&#…...

Redisson分布式集合原理及应用
Redisson是一个用于Redis的Java客户端,它简化了复杂的数据结构和分布式服务的使用。 适用场景对比 数据结构适用场景优点RList消息队列、任务队列、历史记录分布式共享、阻塞操作、分页查询RMap缓存、配置中心、键值关联数据支持键值对、分布式事务、TTLRSet去重集…...
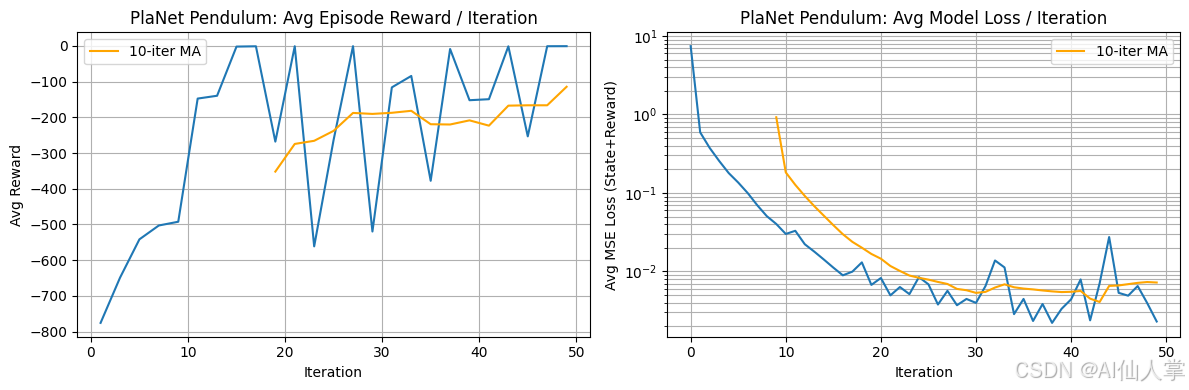
深入理解 PlaNet(Deep Planning Network):基于python从零实现
引言:基于模型的强化学习与潜在动态 基于模型的强化学习(Model-based Reinforcement Learning)旨在通过学习环境动态的模型来提高样本效率。这个模型可以用来进行规划,让智能体在不需要与真实环境进行每一次决策交互的情况下&…...
:用户反馈的科学解读与试验驱动迭代——Rally的双向验证方法论)
精益数据分析(75/126):用户反馈的科学解读与试验驱动迭代——Rally的双向验证方法论
精益数据分析(75/126):用户反馈的科学解读与试验驱动迭代——Rally的双向验证方法论 在创业的黏性阶段,用户反馈是优化产品的重要依据,但如何避免被表面反馈误导?如何将反馈转化为可落地的迭代策略&#x…...
仿腾讯会议——视频发送接收
1、 添加音频模块 2、刷新图片,触发重绘 3、 等比例缩放视频帧 4、 新建视频对象 5、在中介者内定义发送视频帧的函数 6、完成发送视频的函数 7、 完成开启/关闭视频 8、绑定视频的信号槽函数 9、 完成开启/关闭视频 10、 完成发送视频 11、 完成刷新图片显示 12、完…...
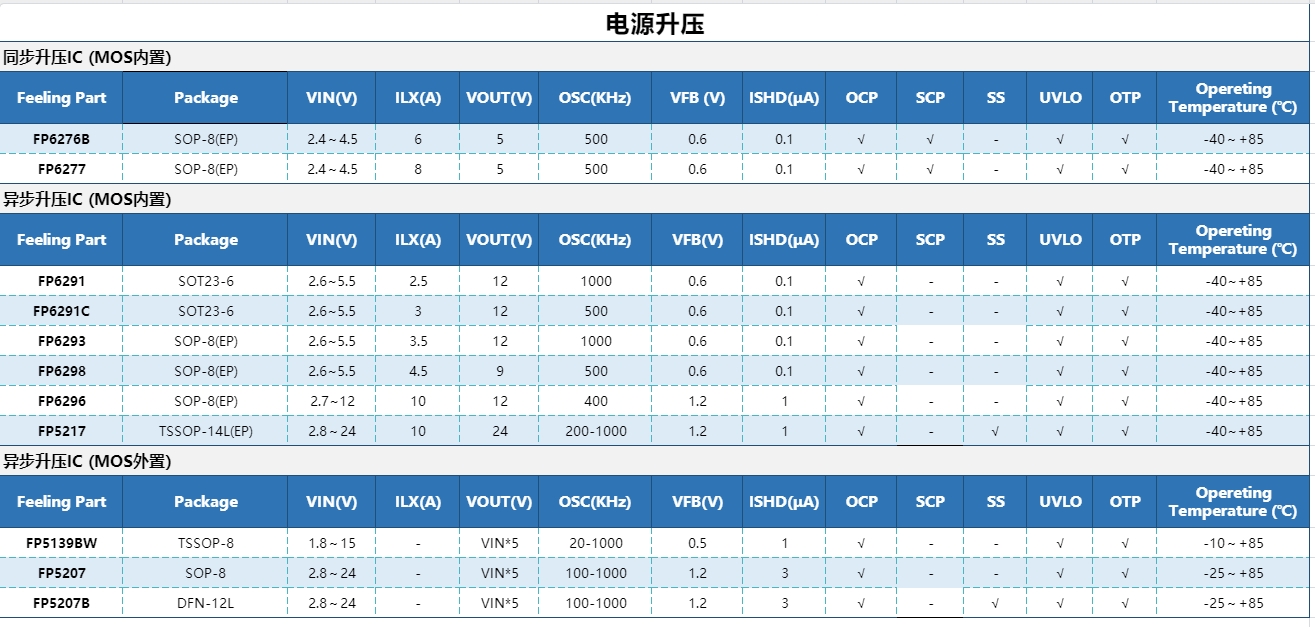
从3.7V/5V到7.4V,FP6291在应急供电智能门锁中的应用
在智能家居蓬勃发展的当下,智能门锁以其便捷、安全的特性,成为现代家庭安防的重要组成部分。在智能门锁电量耗尽的情况下,应急电源外接移动电源(USB5V输入) FP6291升压到7.4V供电可应急开锁。增强用户在锁具的安全性、…...
)
java后端-海外登录(谷歌/FaceBook)
前言 由于最近公司的项目要在海外运行,因此需要对接海外的登录,目前就是谷歌和facebook两种,后面支付也是需要的,后续再进行书写 谷歌登录 这个相对比较容易,而且只提供给安卓即可,废话就不多说了,直接贴解决方案 引入maven依赖 <dependency> <groupId>com.go…...
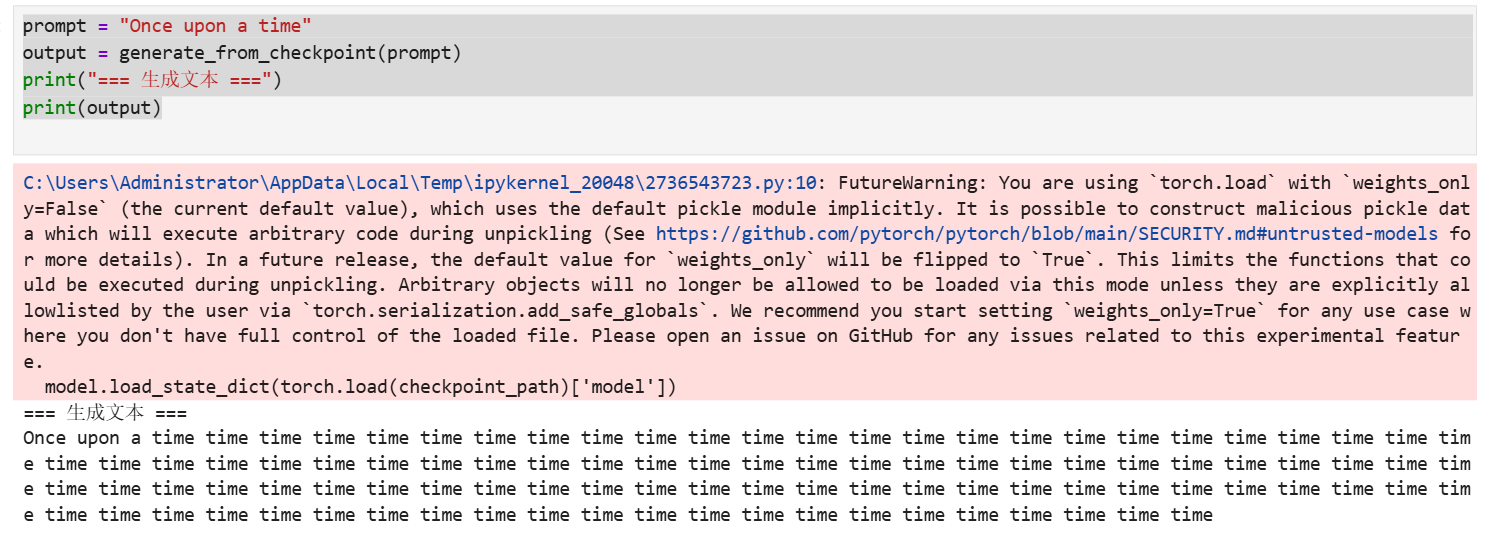
【人工智障生成日记1】从零开始训练本地小语言模型
🎯 从零开始训练本地小语言模型:MiniGPT TinyStories(4090Ti) 🧭 项目背景 本项目旨在以学习为目的,从头构建一个完整的本地语言模型训练管线。目标是: ✅ 不依赖外部云计算✅ 完全本地运行…...
Selenium-Java版(frame切换/窗口切换)
frame切换/窗口切换 前言 切换到frame 原因 解决 切换回原来的主html 切换到新的窗口 问题 解决 回到原窗口 法一 法二 示例 前言 参考教程:Python Selenium Web自动化 2024版 - 自动化测试 爬虫_哔哩哔哩_bilibili 上期文章:Sel…...
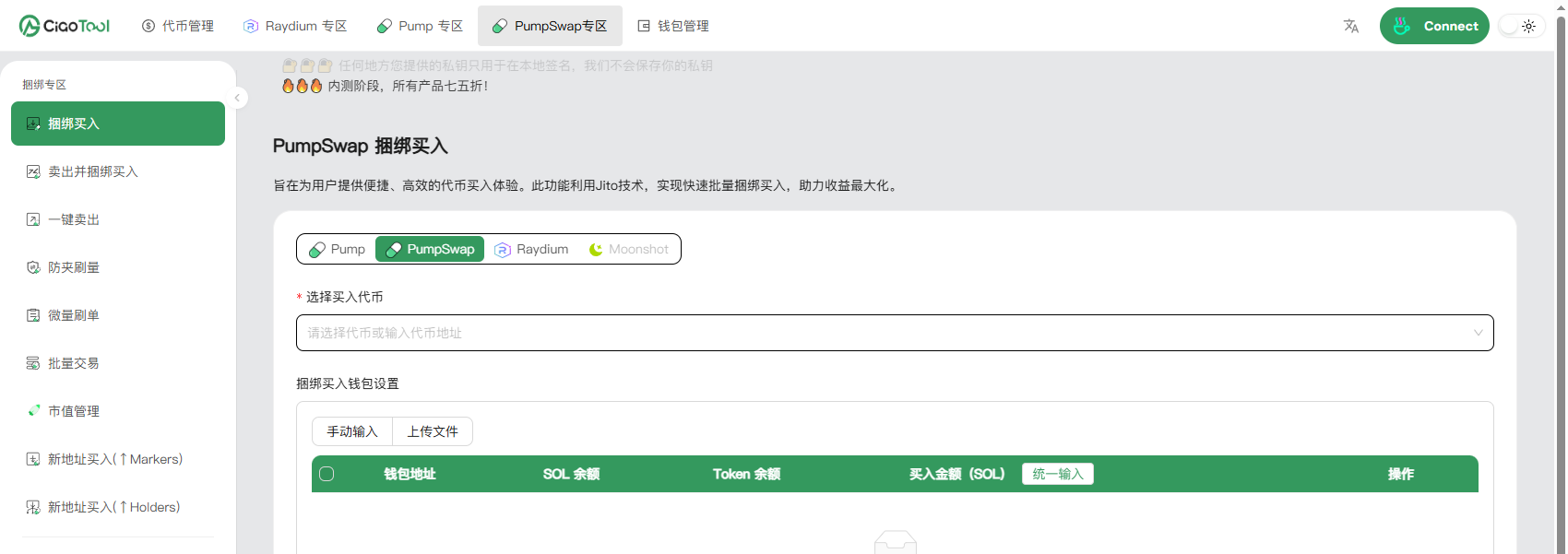
一文深度解析:Pump 与 PumpSwap 的协议机制与技术差异
在 Solana 链上,Pump.fun 和其延伸产品 PumpSwap 构成了 meme coin 发行与流通的两大核心场景。从初期的游戏化发行模型,到后续的自动迁移与交易市场,Pump 系列协议正在推动 meme coin 从“爆发性投机”走向“协议化运营”。本文将从底层逻辑…...

星云智控v1.0.0产品发布会圆满举行:以创新技术重构物联网监控新生态
星云智控v1.0.0产品发布会圆满举行:以创新技术重构物联网监控新生态 2024年5月15日,成都双流蛟龙社区党群服务中心迎来了一场备受业界瞩目的发布会——优雅草科技旗下”星云智控v1.0.0”物联网AI智控系统正式发布。本次发布会吸引了包括沃尔沃集团、新希…...
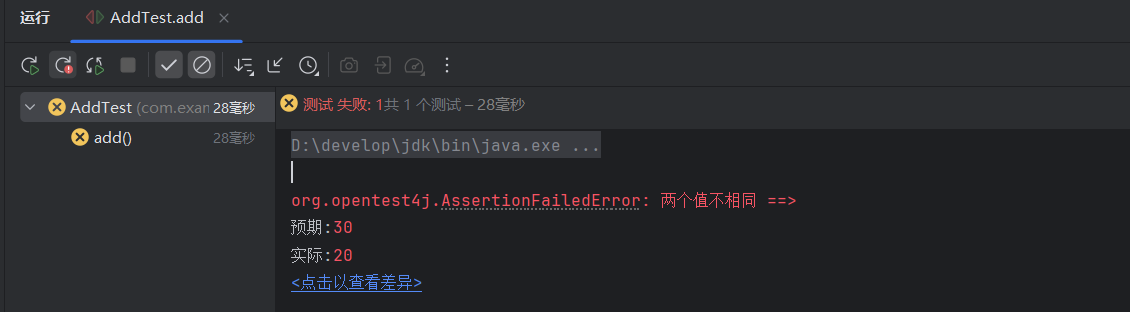
SpringBoot(一)--- Maven基础
目录 前言 一、初始Maven 1.依赖管理 2.项目构建 3.统一项目结构 二、IDEA集成Maven 1.Maven安装 2.创建Maven项目 2.1全局设置 2.2 创建SpringBoot项目 2.3 常见问题 三、单元测试 1.JUnit入门 2.断言 前言 Maven 是一款用于管理和构建Java项目的工具ÿ…...

基于FPGA控制电容阵列与最小反射算法的差分探头优化设计
在现代高速数字系统测试中,差分探头的信号完整性直接影响测量精度。传统探头存在阻抗失配导致的信号反射问题,本文提出一种通过FPGA动态控制电容阵列,结合最小反射算法的优化方案,可实时调整探头等效容抗,将信号反射损…...