多模态大语言模型arxiv论文略读(八十八)

MammothModa: Multi-Modal Large Language Model
➡️ 论文标题:MammothModa: Multi-Modal Large Language Model
➡️ 论文作者:Qi She, Junwen Pan, Xin Wan, Rui Zhang, Dawei Lu, Kai Huang
➡️ 研究机构: ByteDance, Beijing, China
➡️ 问题背景:多模态大型语言模型(MLLMs)在理解视觉输入并生成语言方面表现出色,广泛应用于图像描述、视觉问答和视频分析等领域。然而,这些模型在处理高分辨率和长时间视觉输入时,仍面临有效结合复杂语言理解的挑战。
➡️ 研究动机:为了克服现有MLLMs的局限,研究团队设计了MammothModa,通过三个关键设计洞察来提升模型性能:1) 整合视觉能力同时保持复杂的语言理解;2) 扩展上下文窗口以处理高分辨率和长时间视觉特征;3) 使用高质量的双语数据集减少视觉幻觉。
➡️ 方法简介:MammothModa的架构包括三个主要组件:高分辨率输入的视觉编码器和视觉合并模块、投影层,以及带有视觉注意力专家(VE)和共享帧位置ID的大型语言模型(LLM)。视觉合并模块通过平均池化减少特征图的大小,而共享帧位置ID则通过为每个视频帧分配共享的位置编码来避免位置插值问题。
➡️ 实验设计:研究团队在多个公开数据集上进行了实验,包括视觉语言理解(VLP)和图像到图像(I2I)任务。实验设计了不同的动态分割方法、视觉合并窗口大小和帧位置ID的使用,以评估模型在不同条件下的性能。实验结果表明,MammothModa在多个基准测试中表现出色,特别是在处理高分辨率图像和长时间视频时,显著提高了效率和性能。
CharXiv: Charting Gaps in Realistic Chart Understanding in Multimodal LLMs
➡️ 论文标题:CharXiv: Charting Gaps in Realistic Chart Understanding in Multimodal LLMs
➡️ 论文作者:Zirui Wang, Mengzhou Xia, Luxi He, Howard Chen, Yitao Liu, Richard Zhu, Kaiqu Liang, Xindi Wu, Haotian Liu, Sadhika Malladi, Alexis Chevalier, Sanjeev Arora, Danqi Chen
➡️ 研究机构: Princeton Language and Intelligence (PLI), Princeton University, University of Wisconsin, Madison, The University of Hong Kong
➡️ 问题背景:当前的多模态大语言模型(Multimodal Large Language Models, MLLMs)在处理现实世界任务时表现出色,尤其是在分析科学论文或财务报告中的图表理解方面。然而,现有的评估基准往往过于简化和同质化,导致对模型性能的过度乐观估计。研究表明,即使在图表或问题稍作修改的情况下,开源模型的性能也可能大幅下降,最高可达34.5%。
➡️ 研究动机:为了更准确地评估MLLMs的图表理解能力,研究团队提出了CharXiv,这是一个包含2,323个自然、具有挑战性和多样性的图表的全面评估套件。CharXiv旨在通过提供更现实和忠实的评估标准,促进未来对MLLMs图表理解的研究。
➡️ 方法简介:CharXiv的数据集从arXiv论文中手动挑选了8个主要学科的图表,确保了图表的视觉多样性和复杂性。数据集包括两种类型的问题:描述性问题(涉及基本图表信息的提取和聚合)和推理问题(涉及复杂的视觉和数值推理)。所有问题和答案都经过人工专家的精心挑选和验证,确保了数据集的高质量。
➡️ 实验设计:研究团队评估了13个开源模型和11个专有模型在CharXiv上的表现,特别是在描述性和推理问题上的表现。实验结果揭示了开源模型和专有模型之间存在显著的性能差距,尤其是在推理问题上,最强的专有模型GPT-4o的准确率为47.1%,而最强的开源模型InternVL Chat V1.5的准确率仅为29.2%。所有模型的表现都远低于人类的80.5%。此外,研究还对模型在不同类型任务和图表上的表现进行了细粒度分析,揭示了现有MLLMs在图表理解方面的弱点。
DocKylin: A Large Multimodal Model for Visual Document Understanding with Efficient Visual Slimming
➡️ 论文标题:DocKylin: A Large Multimodal Model for Visual Document Understanding with Efficient Visual Slimming
➡️ 论文作者:Jiaxin Zhang, Wentao Yang, Songxuan Lai, Zecheng Xie, Lianwen Jin
➡️ 研究机构: 华南理工大学、华为云
➡️ 问题背景:当前的多模态大语言模型(MLLMs)在视觉文档理解(VDU)任务中面临重大挑战,主要由于文档图像的高分辨率、密集文本和复杂布局。这些特性要求MLLMs具备高度的细节感知能力。虽然提高输入分辨率可以改善细节感知能力,但也会导致视觉标记序列变长,增加计算成本,并对模型处理长上下文的能力构成压力。
➡️ 研究动机:为了应对这些挑战,研究团队提出了DocKylin,这是一种以文档为中心的MLLM,通过在像素和标记级别进行视觉内容瘦身,减少VDU场景中的标记序列长度。研究旨在通过引入自适应像素瘦身(APS)和动态标记瘦身(DTS)模块,提高模型的性能和效率。
➡️ 方法简介:研究团队提出了一种系统的方法,通过构建自适应像素瘦身(APS)预处理模块,利用梯度信息识别并消除文档图像中的冗余区域,减少冗余像素的比例,提高计算效率。此外,团队还引入了一种基于双中心聚类的动态标记瘦身(DTS)方法,高效地从大量视觉标记中过滤出信息标记,生成更紧凑的视觉序列。
➡️ 实验设计:实验在多个公开数据集上进行,包括DocVQA、InfoVQA、ChartQA、FUNSD、SROIE和POIE等。实验设计了不同因素的变化,如输入图像的分辨率、文本密度和布局复杂性,以全面评估DocKylin在不同条件下的表现。实验结果表明,DocKylin在多个VDU基准测试中表现出色,显著优于现有的方法。
Read Anywhere Pointed: Layout-aware GUI Screen Reading with Tree-of-Lens Grounding
➡️ 论文标题:Read Anywhere Pointed: Layout-aware GUI Screen Reading with Tree-of-Lens Grounding
➡️ 论文作者:Yue Fan, Lei Ding, Ching-Chen Kuo, Shan Jiang, Yang Zhao, Xinze Guan, Jie Yang, Yi Zhang, Xin Eric Wang
➡️ 研究机构: University of California, Santa Cruz、eBay Inc.、Cybever
➡️ 问题背景:当前,图形用户界面(GUI)在数字设备的交互中占据核心地位,越来越多的努力被投入到构建各种GUI理解模型中。然而,这些努力大多忽略了基于用户指示点的屏幕阅读任务(Screen Point-and-Read, ScreenPR),这一任务对于辅助技术尤为重要,能够为视觉障碍用户提供有价值的帮助。
➡️ 研究动机:为了应对ScreenPR任务的挑战,研究团队开发了Tree-of-Lens (ToL) 代理,利用先进的多模态大语言模型(MLLMs)的泛化能力,处理来自不同领域的GUI截图,并根据用户指示的屏幕上的任意点生成自然语言描述。ToL代理不仅描述了指示区域的内容,还详细说明了屏幕布局,从而帮助用户全面理解界面并避免歧义。
➡️ 方法简介:研究团队提出了ToL接地机制,通过构建层次布局树(Hierarchical Layout Tree)来表示截图的层次结构。该树的节点代表不同尺度的区域,通过训练的GUI区域检测模型自动提取局部和全局区域,形成层次布局树。然后,根据兴趣区域选择目标路径,生成不同视野宽度的镜头作为视觉提示,模拟人类逐步细化的注意力过程,以生成内容和布局描述。
➡️ 实验设计:研究团队在新提出的ScreenPR基准上评估了ToL代理,该基准包括来自网页、移动和操作系统GUI的650张截图,手动标注了1,500个目标点和区域。实验设计了多种评估指标,包括人类评价和自动循环一致性评价,以全面评估ToL代理在内容和布局描述上的准确性和抗干扰能力。实验结果表明,ToL代理在内容和布局描述的准确性上分别比基线模型提高了15%和30%以上。此外,ToL代理还被应用于移动GUI导航任务中,展示了其在识别执行路径中不正确动作方面的实用性。
HuatuoGPT-Vision, Towards Injecting Medical Visual Knowledge into Multimodal LLMs at Scale
➡️ 论文标题:HuatuoGPT-Vision, Towards Injecting Medical Visual Knowledge into Multimodal LLMs at Scale
➡️ 论文作者:Junying Chen, Chi Gui, Ruyi Ouyang, Anningzhe Gao, Shunian Chen, Guiming Hardy Chen, Xidong Wang, Ruifei Zhang, Zhenyang Cai, Ke Ji, Guangjun Yu, Xiang Wan, Benyou Wang
➡️ 研究机构: 深圳大数据研究院、香港中文大学(深圳)、深圳国家健康数据研究院
➡️ 问题背景:多模态大语言模型(MLLMs)如GPT-4V在医疗应用中表现出有限的性能,尤其是在缺乏特定于医疗领域的视觉知识方面。尽管存在一些高质量的小规模医疗视觉知识数据集,但扩展这些数据集面临隐私和许可问题。现有方法利用PubMed的大规模去标识化医疗图像-文本对,但数据噪声问题仍然影响模型性能。
➡️ 研究动机:为了提高医疗多模态模型的性能,研究团队提出了一种新的方法,通过利用“非盲”多模态大语言模型(MLLMs)来重新格式化PubMed的图像-文本对,以减少数据噪声并生成更高质量的医疗视觉问答(VQA)数据集。该方法旨在提高模型的医疗多模态能力,并为未来的医疗多模态研究提供高质量的数据资源。
➡️ 方法简介:研究团队从PubMed中筛选出高质量的医疗图像-文本对,并使用GPT-4V作为“非盲”重新格式化工具,生成了包含130万个医疗VQA样本的PubMedVision数据集。该数据集通过多种对话场景和任务类型(如对齐VQA和指令调优VQA)来增强模型的多模态能力。
➡️ 实验设计:研究团队在多个基准测试上进行了实验,包括医疗VQA基准、多模态基准MMMU Health & Medicine轨道以及传统医疗影像任务。实验结果表明,使用PubMedVision数据集训练的模型在多个医疗多模态任务上显著优于现有的开源模型。特别是,HuatuoGPT-Vision在多个医疗多模态基准测试中表现出色,显著提升了模型的医疗多模态能力。
相关文章:
多模态大语言模型arxiv论文略读(八十八)
MammothModa: Multi-Modal Large Language Model ➡️ 论文标题:MammothModa: Multi-Modal Large Language Model ➡️ 论文作者:Qi She, Junwen Pan, Xin Wan, Rui Zhang, Dawei Lu, Kai Huang ➡️ 研究机构: ByteDance, Beijing, China ➡️ 问题背景…...

创建Workforce
创建你的Workforce 3.3.1 简单实践 1. 创建 Workforce 实例 想要使用 Workforce,首先需要创建一个 Workforce 实例。下面是最简单的示例: from camel.agents import ChatAgent from camel.models import ModelFactory from camel.types import Model…...

Cribl 中 Parser 扮演着重要的角色 + 例子
先看文档: Parser | Cribl Docs Parser The Parser Function can be used to extract fields out of events or reserialize (rewrite) events with a subset of fields. Reserialization will preserve the format of the events. For example, if an event contains comma…...

WebSocket 从入门到进阶实战
好记忆不如烂笔头,能记下点东西,就记下点,有时间拿出来看看,也会发觉不一样的感受. 聊天系统是WebSocket的最佳实践,以下是使用WebSocket技术实现的一个聊天系统的关键代码,可以通过这些关键代码ÿ…...

CSS:vertical-align用法以及布局小案例(较难)
文章目录 一、vertical-align说明二、布局案例 一、vertical-align说明 上面的文字介绍,估计大家也看不懂 二、布局案例...

Linux 正则表达式 扩展正则表达式 gawk
什么是正则表达式 正则表达式是我们所定义的模式模板(pattern template),Linux工具用它来过滤文本。Linux工具(比如sed编辑器或gawk程序)能够在处理数据时,使用正则表达式对数据进行模式匹配。如果数据匹配…...
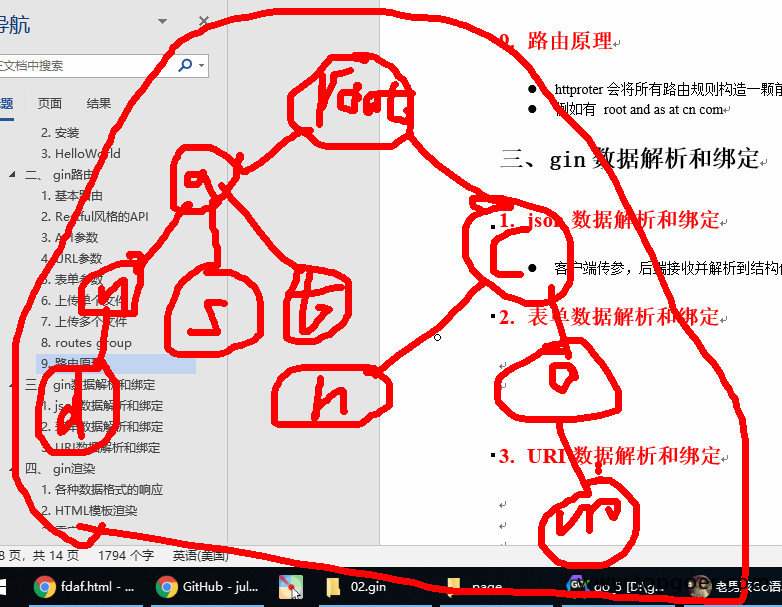
Java转Go日记(五十四):gin路由
1. 基本路由 gin 框架中采用的路由库是基于httprouter做的 地址为:https://github.com/julienschmidt/httprouter package mainimport ("net/http""github.com/gin-gonic/gin" )func main() {r : gin.Default()r.GET("/", func(c …...
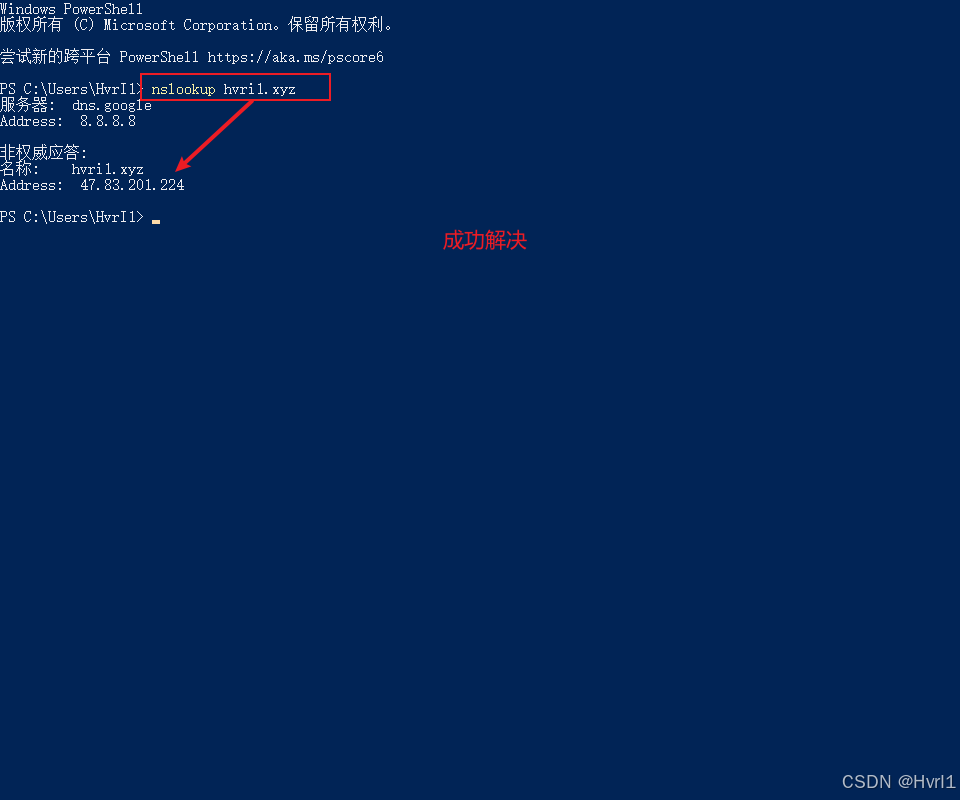
【解决】自己的域名任何端口都访问不到,公网地址正常访问,服务器报错500。
一、问题描述 后端项目部署在服务器上,通过域名访问接口服务器报错500,通过浏览器访问域名的任何端口都是无法访问此网站。 但是通过公网地址访问是可以正常访问到的,感觉是域名出现了问题 二、解决过程 先说结论:问题原因是…...

探秘鸿蒙 HarmonyOS NEXT:Navigation 组件的全面解析
鸿蒙 ArkTS 语言中 Navigation 组件的全面解析 一、引言 本文章基于HarmonyOS NEXT操作系统,API12以上的版本。 在鸿蒙应用开发中,ArkTS 作为一种简洁、高效的开发语言,为开发者提供了丰富的组件库。其中,Navigation 组件在构建…...
)
订单导入(常见问题和sql)
1.印章取行,有几行取几行 union select PARAM07 name, case when regexp_count(PO_PARAM_20, chr(10)) > 0 then substr(PO_PARAM_20, 0, instr(PO_PARAM_20, chr(10)) - 1) else PO_PARAM_20 end value,PO_ID …...
PyTorch中diag_embed和transpose函数使用详解
torch.diag_embed 是 PyTorch 中用于将一个向量(或批量向量)**嵌入为对角矩阵(或批量对角矩阵)**的函数。它常用于图神经网络(GNN)或线性代数中生成对角矩阵。 函数原型 torch.diag_embed(input, offset0,…...

算法分析与设计实验:找零钱问题的贪心算法与动态规划解决方案
在计算机科学中,贪心算法和动态规划是两种常用的算法设计策略。本文将通过一个经典的找零钱问题,详细讲解这两种算法的实现和应用。我们将会提供完整的C代码,并对代码进行详细解释,帮助读者更好地理解和掌握这两种算法。 问题描述…...
制作 MacOS系统 の Heic动态壁纸
了解动态桌面壁纸 当macOS 10.14发布后,会发现系统带有动态桌面壁纸,设置后,我们的桌面背景将随着一天从早上、到下午、再到晚上的推移而发生微妙的变化。 虽然有些软件也有类似的动态变化效果,但是在新系统中默认的HEIC格式的动…...
大数据 笔记
kafka kafka作为消息队列为什么发送和消费消息这么快? 消息分区:不受单台服务器的限制,可以不受限的处理更多的数据顺序读写:磁盘顺序读写,提升读写效率页缓存:把磁盘中的数据缓存到内存中,把…...

js中encodeURIComponent函数使用场景
encodeURIComponent 是 JavaScript 中的一个内置函数,它的作用是: 将字符串编码为可以安全放入 URL 的形式。 ✅ 为什么需要它? URL 中有一些字符是有特殊意义的,比如: ? 用来开始查询参数 & 分隔多个参数 连接…...

iOS工厂模式
iOS工厂模式 文章目录 iOS工厂模式简单工厂模式(Simple Factory)工厂方法模式(Factory Method)抽象工厂模式(Abstract Factory)三种模式对比 简单工厂模式(Simple Factory) 定义&am…...
【数据库】-1 mysql 的安装
文章目录 1、mysql数据库1.1 mysql数据库的简要介绍 2、mysql数据库的安装2.1 centos安装2.2 ubuntu安装 1、mysql数据库 1.1 mysql数据库的简要介绍 MySQL是一种开源的关系型数据库管理系统(RDBMS),由瑞典MySQL AB公司开发,目前…...

【缓存】JAVA本地缓存推荐Caffeine和Guava
🌟 引言 在软件开发过程中,缓存是提升系统性能的常用手段。对于基础场景,直接使用 Java集合框架(如Map/Set/List)即可满足需求。然而,当面对更复杂的缓存场景时: 需要支持多种过期策略&#x…...

Prometheus的服务命令和配置文件
一、Prometheus的服务端命令和启动方式 1.服务端命令(具体详情可以--help查看) --config.file“prometheus.yml”指定配置文件,默认是当前目录下的prometheus.yml--web.listen-address"0.0.0.0:9090"web页面的地址与端口…...
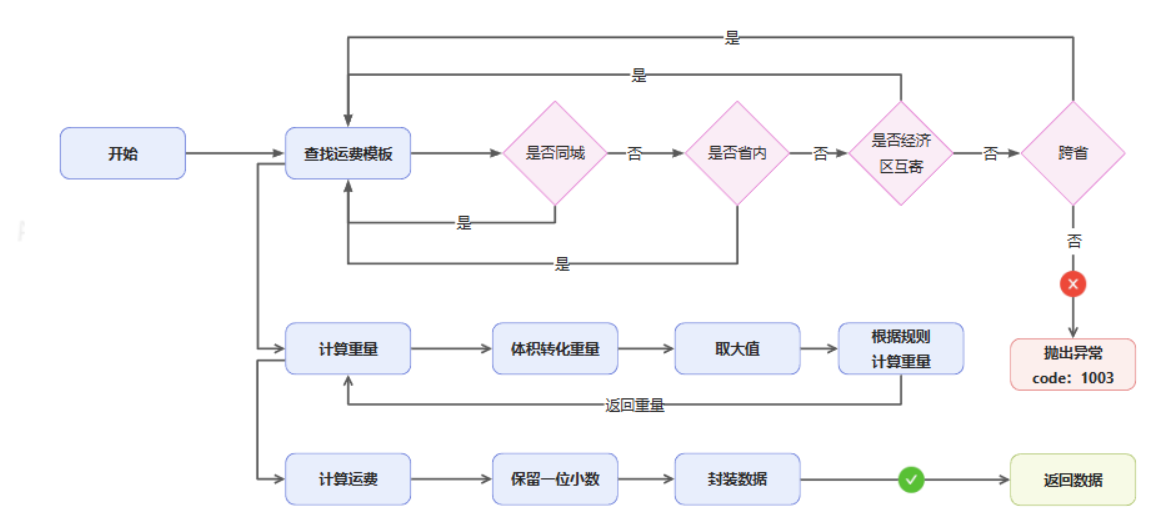
物流项目第五期(运费计算实现、责任链设计模式运用)
前四期: 物流项目第一期(登录业务)-CSDN博客 物流项目第二期(用户端登录与双token三验证)-CSDN博客 物流项目第三期(统一网关、工厂模式运用)-CSDN博客 物流项目第四期(运费模板列…...

前端JavaScript-嵌套事件
点击 如果在多层嵌套中,对每层都设置事件监视器,试试看 <!DOCTYPE html> <html lang"cn"> <body><div id"container"><button>点我!</button></div><pre id"output…...

X 下载器 2.1.42 | 国外媒体下载工具 网页视频嗅探下载
X 下载器让你能够轻松地从社交应用如Facebook、Instagram、TikTok等下载视频和图片。通过内置浏览器访问网站,它能自动检测视频和图片,只需点击下载按钮即可完成下载。去除广告,解锁本地会员,享受无广告打扰的下载体验。 大小&am…...
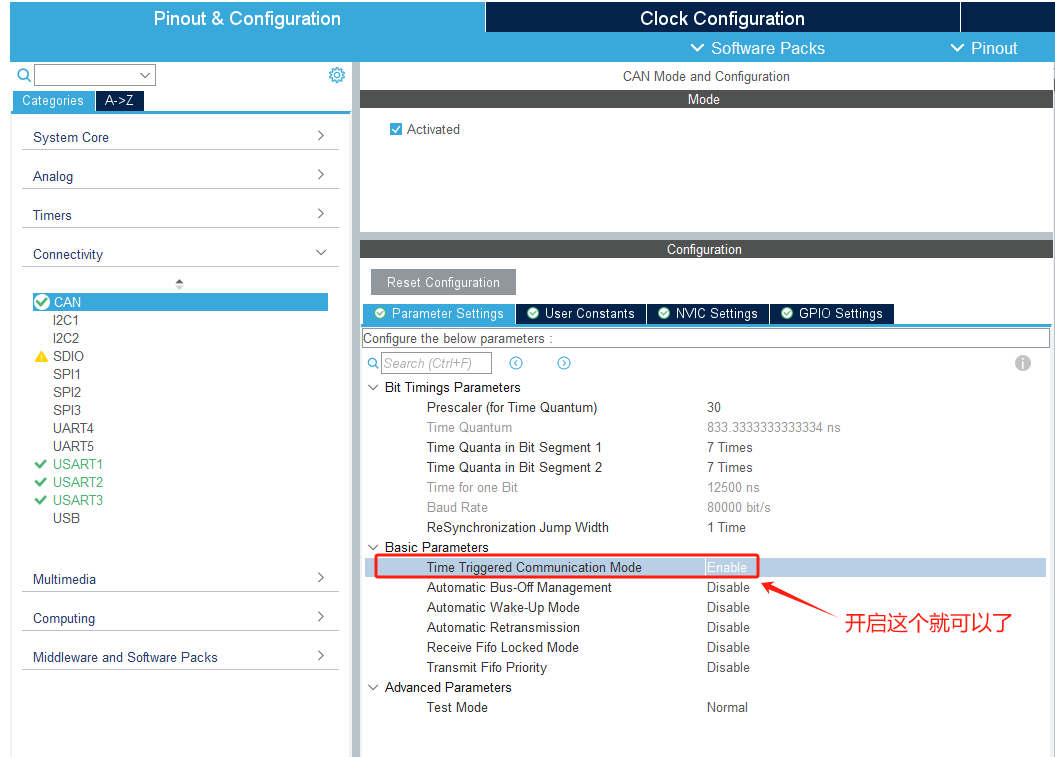
STM32 CAN CANAerospace
STM32的CAN模块对接CANAerospace 刚开始报错如下. 设备开机后整个CAN消息就不发了. USB_CAN调试器报错如下. index time Name ID Type Format Len Data00000001 000.000.000 Event 总线错误 DATA STANDARD 8 接收过程错误-格…...
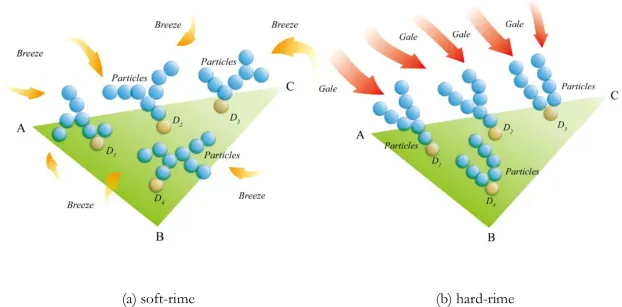
完整改进RIME算法,基于修正多项式微分学习算子Rime-ice增长优化器,完整MATLAB代码获取
1 简介 为了有效地利用雾状冰生长的物理现象,最近开发了一种优化算法——雾状优化算法(RIME)。它模拟硬雾状和软雾状过程,构建硬雾状穿刺和软雾状搜索机制。在本研究中,引入了一种增强版本,称为修改的RIME…...
服务器安装xfce桌面环境并通过浏览器操控
最近需要运行某个浏览器的脚本,但是服务器没有桌面环境,无法使用,遂找到了KasmVNC,并配合xfce实现低占用的桌面环境,可以直接使用浏览器进行操作 本文基于雨云——新一代云服务提供商的Debian11服务器操作,…...
)
Java设计模式之组合模式:从入门到精通(保姆级教程)
文章目录 1. 组合模式概述1.1 专业定义1.2 通俗解释1.3 模式结构2. 组合模式详细解析2.1 模式优缺点2.2 适用场景3. 组合模式实现详解3.1 基础实现3.2 代码解析4. 组合模式进阶应用4.1 透明式 vs 安全式组合模式4.2 组合模式与递归4.3 组合模式与迭代器5. 组合模式在实际开发中…...
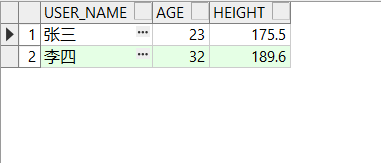
Oracle 创建外部表
找别人要一下数据,但是他发来一个 xxx.csv 文件,怎么办? 1、使用视图化工具导入 使用导入工具导入,如 DBeaver,右击要导入的表,选择导入数据。 选择对应的 csv 文件,下一步就行了(如…...

大语言模型 17 - MCP Model Context Protocol 介绍对比分析 基本环境配置
MCP 基本介绍 官方地址: https://modelcontextprotocol.io/introduction “MCP 是一种开放协议,旨在标准化应用程序向大型语言模型(LLM)提供上下文的方式。可以把 MCP 想象成 AI 应用程序的 USB-C 接口。就像 USB-C 提供了一种…...

【软考向】Chapter 9 数据库技术基础
基本概念数据库的三级模式结构 数据模型E-R 模型关系模型各种键完整性约束 关系代数5 种基本的关系代数运算:并、差、笛卡儿积、投影和选择扩展的关系代数运算:交(Intersection)、连接(Join)、除(Division)、广义投影(Generalized Projection)、外连接(O…...
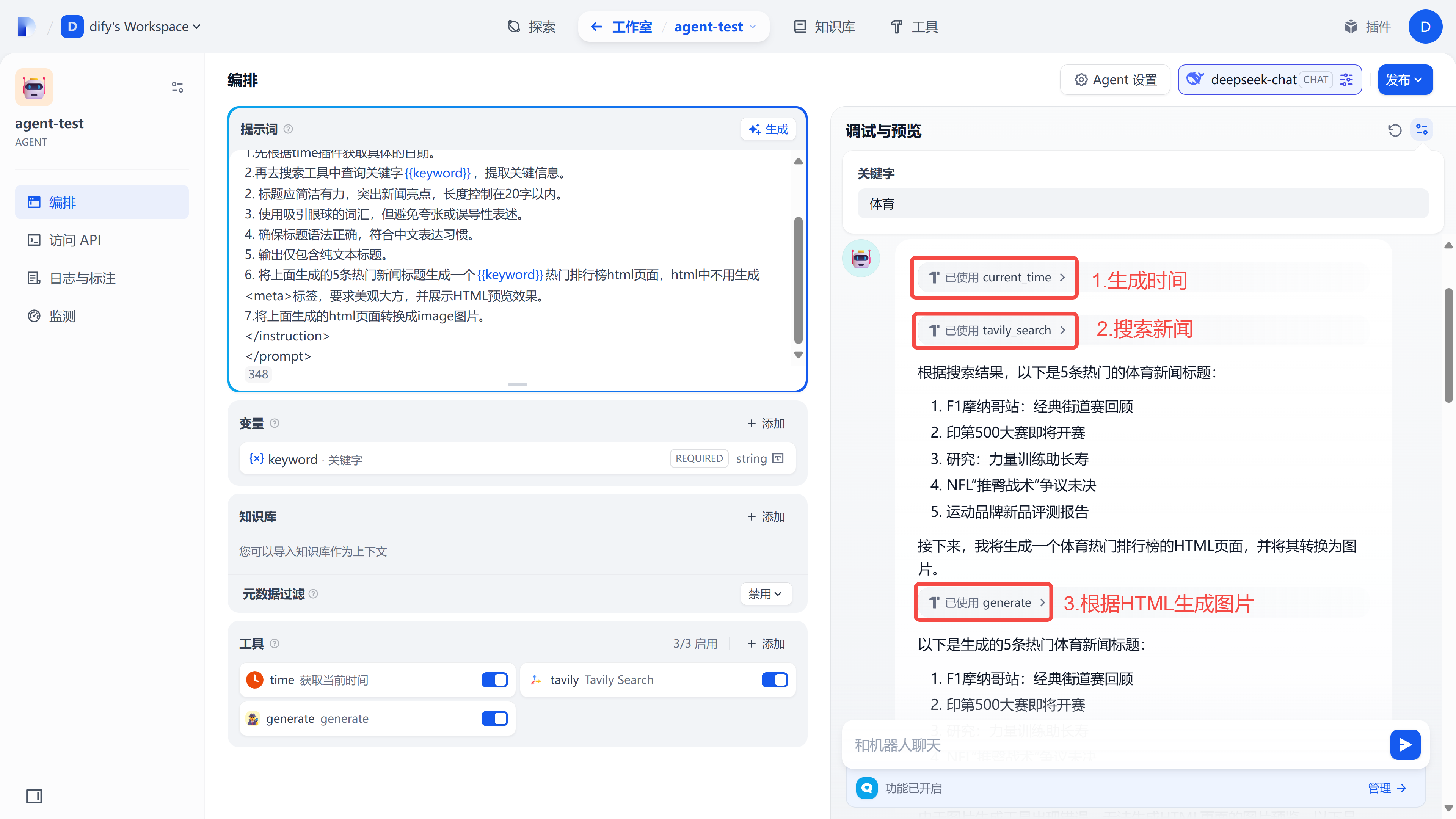
实战:Dify智能体+Java=自动化运营工具!
我们在运营某个圈子的时候,可能每天都要将这个圈子的“热门新闻”发送到朋友圈或聊天群里,但依靠传统的实现手段非常耗时耗力,我们通常要先收集热门新闻,再组装要新闻内容,再根据内容设计海报等。 那怎么才能简化并高…...