Pandas:数据分析中的缺失值检测、加载、设置、可视化与处理
本文目录:
- 一、检测数据集中的缺失值
- (一)缺失值的判断规则:
- (二)代码如下:
- 二、缺失值加载处理&缺失值设置
- (一)缺失值加载处理
- (二)缺失值设置
- 三、缺失值可视化
- 四、缺失值的处理
- (一)删除缺失值
- (二)缺失值填充
- 1.非时间序列数据缺失值填充**
- 2.时间序列数据缺失值填充**
- 最后,关于数据集缺失值~三两话
前言:实际业务中的数据集常常存在缺失值,这时就需要对缺失值进行了解和处理,不然会影响到我们整体的数据分析。
数据库中缺失值表示为NULL,有些编程语言中缺失值表示为NA,缺失值也可能是空字符串(‘’)或数值,在Pandas中使用NaN(来自NumPy库)表示缺失值。
一、检测数据集中的缺失值
(一)缺失值的判断规则:
(1)不可通过==判断,只可以通过API(方法)判断;
(2)pandas有 isnull() / isna()等两个方法用于判断缺失值,结果返回True或者False;
(3)pandas有notnull() / notna()等两个方法用于判断是否是缺失值,结果返回True或者False。
(二)代码如下:
# 导包
import numpy as np# 1. 缺失值不是 True, False, 空字符串, 0等, 它"毫无意义"
print(np.NaN == False)
print(np.NaN == True)
print(np.NaN == 0)
print(np.NaN == '')# 2. np.nan np.NAN np.NaN 都是缺失值, 这个类型比较特殊, 不同通过 == 方式判断, 只能通过API
print(np.NaN == np.nan)
print(np.NaN == np.NAN)
print(np.nan == np.NAN)# 3. Pandas 提供了 isnull() / isna()方法, 用于测试某个值是否为缺失值
import pandas as pdprint(pd.isnull(np.NaN)) # True
print(pd.isnull(np.nan)) # True
print(pd.isnull(np.NAN)) # Trueprint(pd.isna(np.NaN)) # True
print(pd.isna(np.nan)) # True
print(pd.isna(np.NAN)) # True# isnull() / isna()方法判断数据.
print(pd.isnull(20)) # False
print(pd.isnull('abc')) # False
#实例:
df = pd.DataFrame({'A': [1, np.nan, 3],'B': ['x', None, pd.NA],'C': [pd.Timestamp('2023-01-01'), pd.NaT, 2]
})
# 使用isnull()或isna()结果相同
print(df.isnull()) # 等价于 df.isna()
实例运行结果:A B C
0 False False False
1 True True True
2 False True False#Pandas的notnull() / notna() 方法可以用于判断某个值是否为缺失值
print(pd.notnull(np.NaN)) #np.NaN是缺失值,返回False
print(pd.notnull('abc')) # 'abc'不是缺失值,返回True
二、缺失值加载处理&缺失值设置
(一)缺失值加载处理
keep_default_na=False:设置后将禁用默认识别缺失值并转化为NaN,null、NULL、空值等将保持原样;
代码如下:
例:
import pandas as pd #导包**#1.默认时(keep_default_na=True)**
file1=pd.read_csv(r"D:\weight_loss.csv")
print(file1)运行结果:Name Month Week Weight
0 Bob Jan Week 1 291.0
1 Amy Jan Week 1 197.0
2 Bob Jan NaN NaN #null、空值都转为NaN
3 Amy Jan Week 2 189.0
4 Bob Jan Week 3 NaN #NA转为NaN
5 Amy Jan NaN 189.0 #NULL转为NaN
6 Bob Jan Week 4 283.0**#2.设置keep_default_na=False**
file2=pd.read_csv(r"D:\weight_loss.csv",keep_default_na=False)
print(file2)运行结果:
0 Bob Jan Week 1 291
1 Amy Jan Week 1 197
2 Bob Jan null #null、空值均保持不变,未转为NaN
3 Amy Jan Week 2 189
4 Bob Jan Week 3 NA #NA保持不变,未转为NaN
5 Amy Jan NULL 189 #NULL保持不变,未转为NaN
6 Bob Jan Week 4 283
(二)缺失值设置
na_values=[值1, 值2…]:表示加载数据时, 设定哪些值为缺失值。
代码如下:
例:
# 仅将 "MISSING" 和空值视为缺失值
df = pd.read_csv(data.csv, keep_default_na=False, na_values=["MISSING", ""])
备注:keep_default_na=False + na_values代表严格自定义缺失值标记。
三、缺失值可视化
顾名思义,也就是通过画图的方式将缺失值呈现出来,运用的是missingno模块(专门呈现缺失值)。
代码如下:
例:
# 1. 加载数据
train = pd.read_csv('data/titanic_train.csv')
test = pd.read_csv('data/titanic_test.csv')
train.shape
train.head()# 2. 查看是否获救数据.
train['Survived'].value_counts() # 0: 没获救. 1: 获救# 3. 缺失值可视化(了解)
# 如果没有安装这个包, 需要先装一下.
# pip install missingnode# 导包
import missingno as msno# 柱状图, 展示: 每列的 非空值(即: 非缺失值)个数.
msno.bar(train) # 绘制缺失值热力图, 发现缺失值之间是否有关联, 是不是A这一列缺失, B这一列也会缺失.
msno.heatmap(train)
四、缺失值的处理
发现缺失值后,通常需要处理缺失值:删除(dropna)或者填充(fillna、interpolate等)。
(一)删除缺失值
dropna()函数, 参数介绍如下:
-
subset=None :默认是删除有缺失值的行, 如果要删除列,可以通过参数来指定,如: subset = [‘Age’] ,即当“Age”列有缺失值时会被删除;
-
inplace=False :通用参数, 是否修改原始数据默认False;
-
axis=0 :通用参数,按行或按列删除,默认按行(axis=0);
-
how=‘any’ :只要有缺失就会删除 还可以传入’all’ ,即全部都是缺失值才会被删除。
代码如下:
例:
train.shape # 原始数据, 891行, 12列# 方式1: 删除缺失值
# 删除缺失值会损失信息,并不推荐删除,当缺失数据占比较低的时候,可以尝试使用删除缺失值
# 按行删除: 删除包含缺失值的记录
# train.dropna().shape # 默认按行删(该行只要有空值, 就删除该行), 结果为: 183行, 12列
train.loc[:10].dropna() # 获取前11行数据, 删除包含空值的行. # any: 只要有空值就删除该行|列, all: 该行|列 全为空才删除 subset: 参考哪些列的空值. inplace=True 在原表修改
train.dropna(subset=['Age'], how='any')# 该列值只要有空, 就删除该列值.
train.dropna(how='any', axis=1) # 0(默认): 行, 1: 列 train.isnull().sum() # 快速计算是否包含缺失值
(二)缺失值填充
我们的数据分为时间序列数据和非时间序列数据,而它们的缺失值填充方法不同。
两种数据的特点:
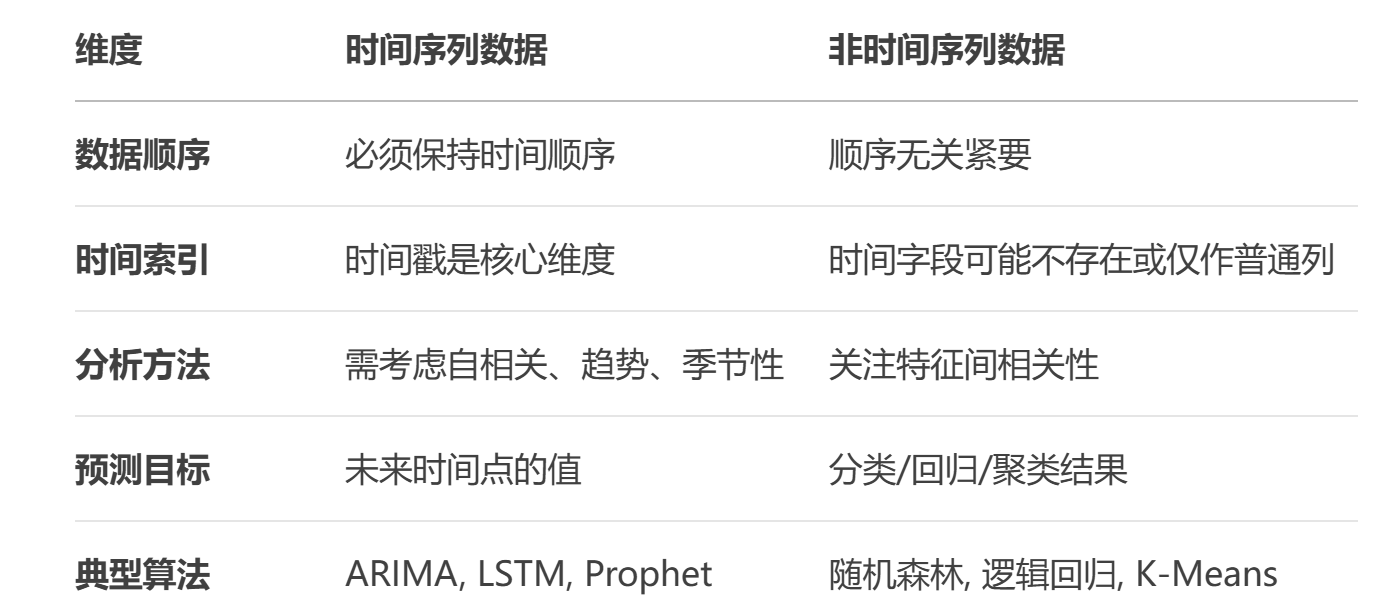
1.非时间序列数据缺失值填充**
非时序数据的缺失值填充, 直接使用fillna(值, inplace=True)
- 可以使用统计量 众数 , 平均值, 中位数 …
- 也可以使用默认值来填充 。
代码如下:
# 填充缺失值是指用一个估算的值来去替代缺失数
# 非时间序列数据, 可以使用常量来替换(默认值)# 用 0 来填充 空值.
train.fillna(0)
# 查看填充后, 每列缺失值情况.
train.fillna(0).isnull().sum()# 用平均年龄, 来替换年龄列的空值.
train['Age'].fillna(train['Age'].mean())2.时间序列数据缺失值填充**
时序数据的缺失值填充, 可以使用fillna( method=ffill),表示使用前一个值填充;
- 也可以使用fillna( method=bfill),表示使用后一个值填充;
- 还可以使用统计量 众数 , 平均值, 中位数 …
- 最后也可以使用线性插值方法:interpolate()填充缺失值。
代码如下:
# 1. 加载时间序列数据,数据集为印度城市空气质量数据(2015-2020)
# parse_dates: 把某些列转成时间列.
# index_col: 设置指定列为 索引列
city_day = pd.read_csv('data/city_day.csv', parse_dates=['Date'], index_col='Date')# 2. 查看缺失值情况.
city_day.isnull().sum()# 3. 数据中有很多缺失值,比如 Xylene(二甲苯)和 PM10 有超过50%的缺失值
# 3.1 查看包含缺失数据的部分
city_day['Xylene'][50:64]# 3.2 用固定值填充, 例如: 该列的平均值.
# 查看平均值.
city_day['Xylene'].mean() # 3.0701278234985114
# 用平均值来填充.
city_day.fillna(city_day['Xylene'].mean())[50:64]['Xylene']# 3.3 使用ffill 填充,用时间序列中空值的上一个非空值填充
# NaN值的前一个非空值是0.81,可以看到所有的NaN都被填充为0.81
city_day.fillna(method='ffill')[50:64]['Xylene']# 3.4 使用bfill填充,用时间序列中空值的下一个非空值填充
# NaN值的后一个非空值是209,可以看到所有的NaN都被填充为209
city_day.fillna(method='bfill')[50:64]['Xylene']# 3.5 线性插值方法填充缺失值
# 时间序列数据,数据随着时间的变化可能会较大。使用bfill和ffill进行插补并不是解决缺失值问题的最优方案。
# 线性插值法是一种插补缺失值技术,它假定数据点之间存在线性关系,利用相邻数据点中的非缺失值来计算缺失数据点的值。
# 参数limit_direction: 表示线性填充时, 参考哪些值(forward: 向前, backward:向后, both:前后均参考)
city_day.interpolate(limit_direction="both")[50:64]['Xylene']
最后,关于数据集缺失值~三两话
- 1.能不删就不删 , 如果某列数据有大量的缺失值(50% 以上是缺失值), 具体情况具体分析;
- 2.如果是类别型的缺失值,可以考虑使用字段 ‘缺失’ 来进行填充;
- 3.如果是数值型的缺失值,可以用一些统计量 (均值/中位数/众数) 或者业务的默认值来填充。
今天的分享到此结束。
相关文章:
Pandas:数据分析中的缺失值检测、加载、设置、可视化与处理
本文目录: 一、检测数据集中的缺失值(一)缺失值的判断规则:(二)代码如下: 二、缺失值加载处理&缺失值设置(一)缺失值加载处理(二)缺失值设置 …...

【Linux系列】EVS 与 VBD 的对比
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...
56 在standby待机打通uart调试的方法
修改点如下: 一,进入standby保证uart通 1, 去掉串口进入休眠RT_DEVICE_CTRL_SUSPEND:关闭uart,保证BSP_IO_Power_Down函数执行完前,串口都可以打印,和通过SifliUsartServer工具串口连接,并debug死机问题&…...
OceanBase 共享存储:云原生数据库的存储
目录 探会——第三届 OceanBase 开发者大会 重磅发布:OceanBase 4.3 开发者生态全面升级 实战演讲:用户案例与行业落地 OceanBase 共享存储架构解析 什么是共享存储架构? 云原生数据库的架构 性能、弹性与多云的统一 为何OceanBase能…...
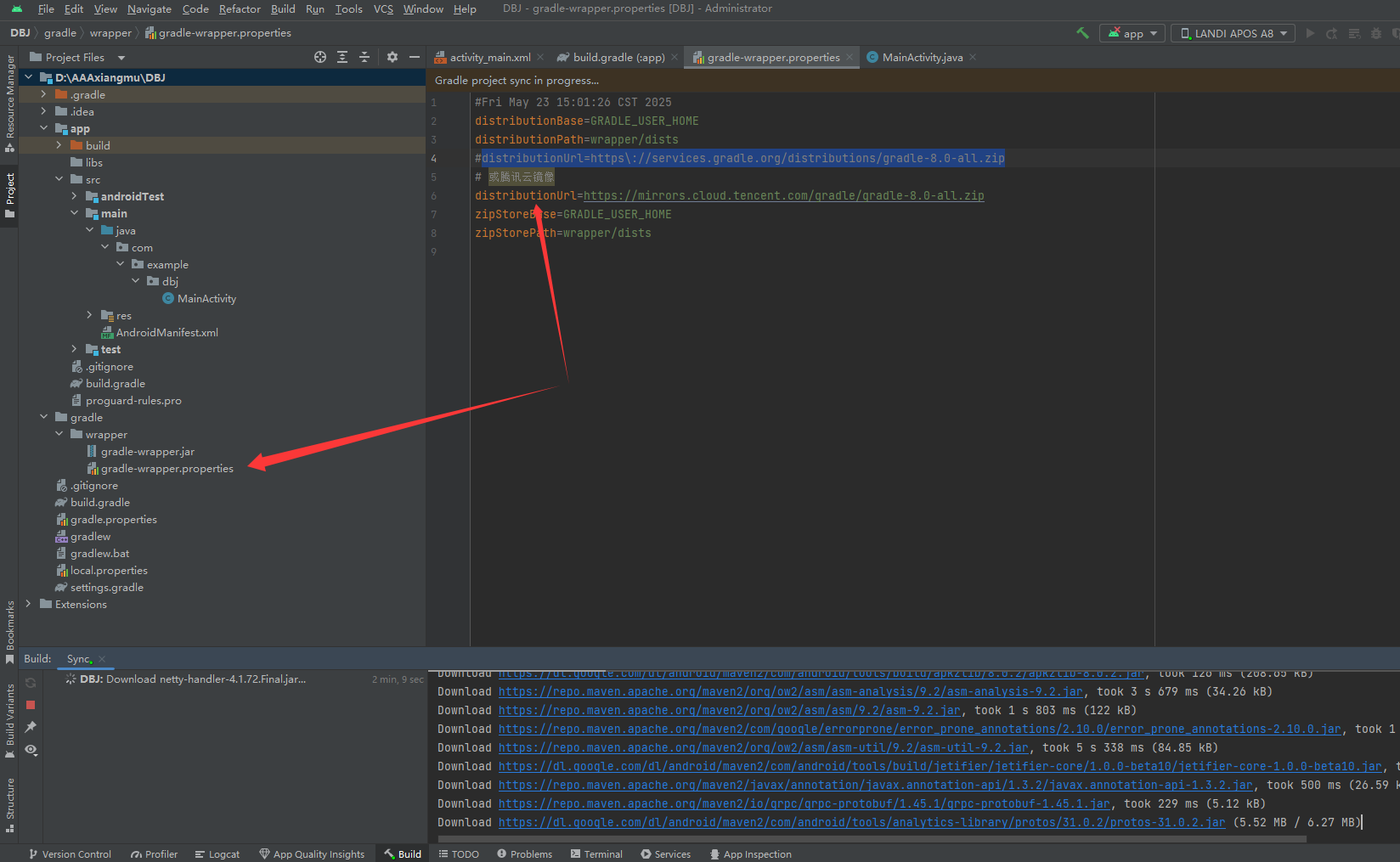
安卓新建项目时,Gradle下载慢下载如何用国内的镜像
方法 1:修改 gradle-wrapper.properties 使用国内镜像 Gradle 的下载地址可以在 gradle-wrapper.properties 中修改,替换为国内镜像地址(如阿里云、腾讯云等)。 步骤 打开项目中的 gradle-wrapper.properties 文件(路…...

讯联文库开发日志(五)登录拦截校验
零 在此之前,由于主播一直缺乏session,这次两个小时的寻找bug之旅也让我受益颇多 罪魁祸首:key值写错了,导致一直报错,不过这也让我了解了更多关于session的k-v结构 参数校验 我们需要在全局拦截器注解里面加两个方…...
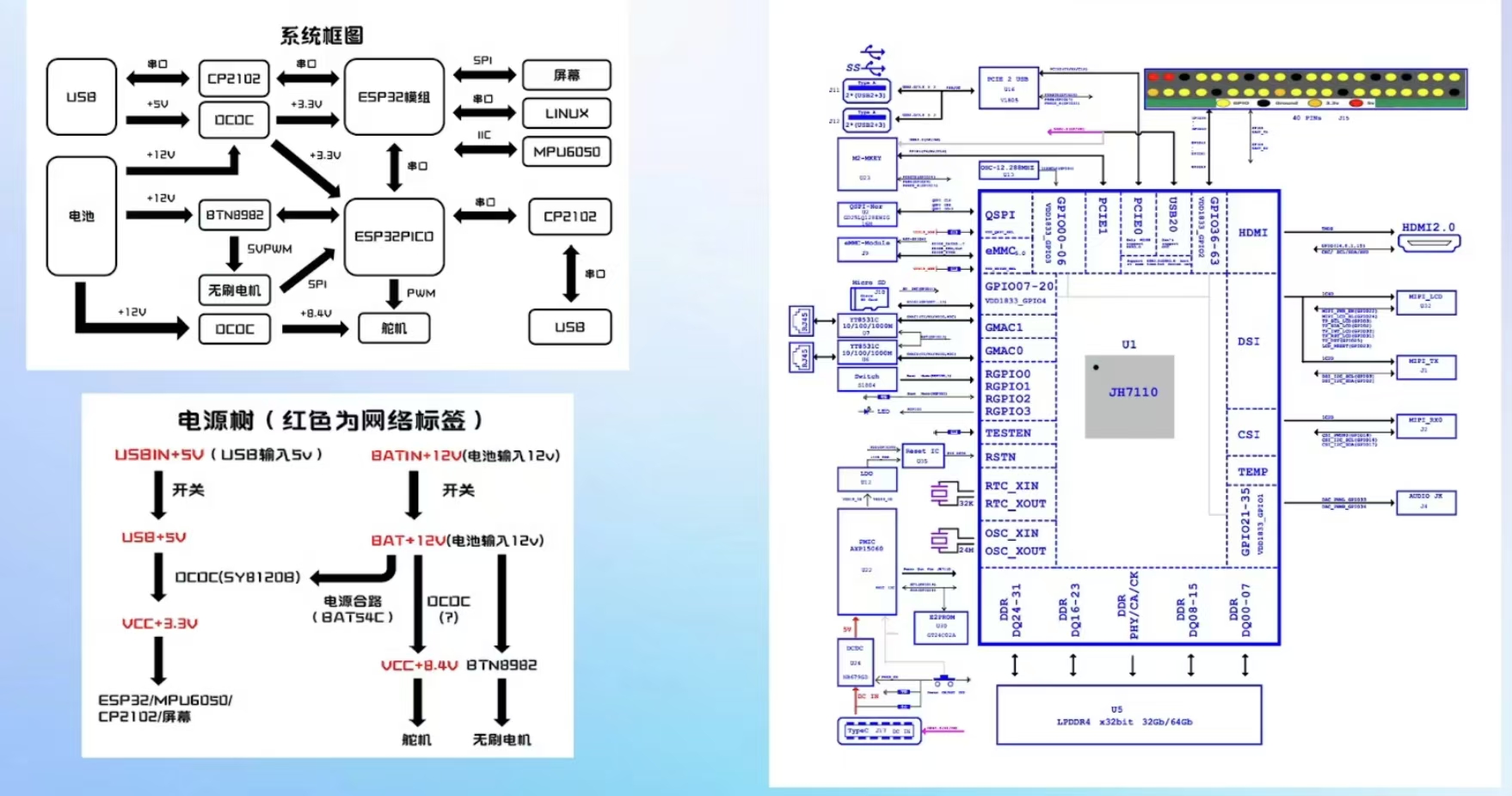
PCB设计教程【入门篇】——电路分析基础-读懂原理图
前言 本教程基于B站Expert电子实验室的PCB设计教学的整理,为个人学习记录,旨在帮助PCB设计新手入门。所有内容仅作学习交流使用,无任何商业目的。若涉及侵权,请随时联系,将会立即处理 目录 前言 一、原理图核心要素…...

C语言数据结构
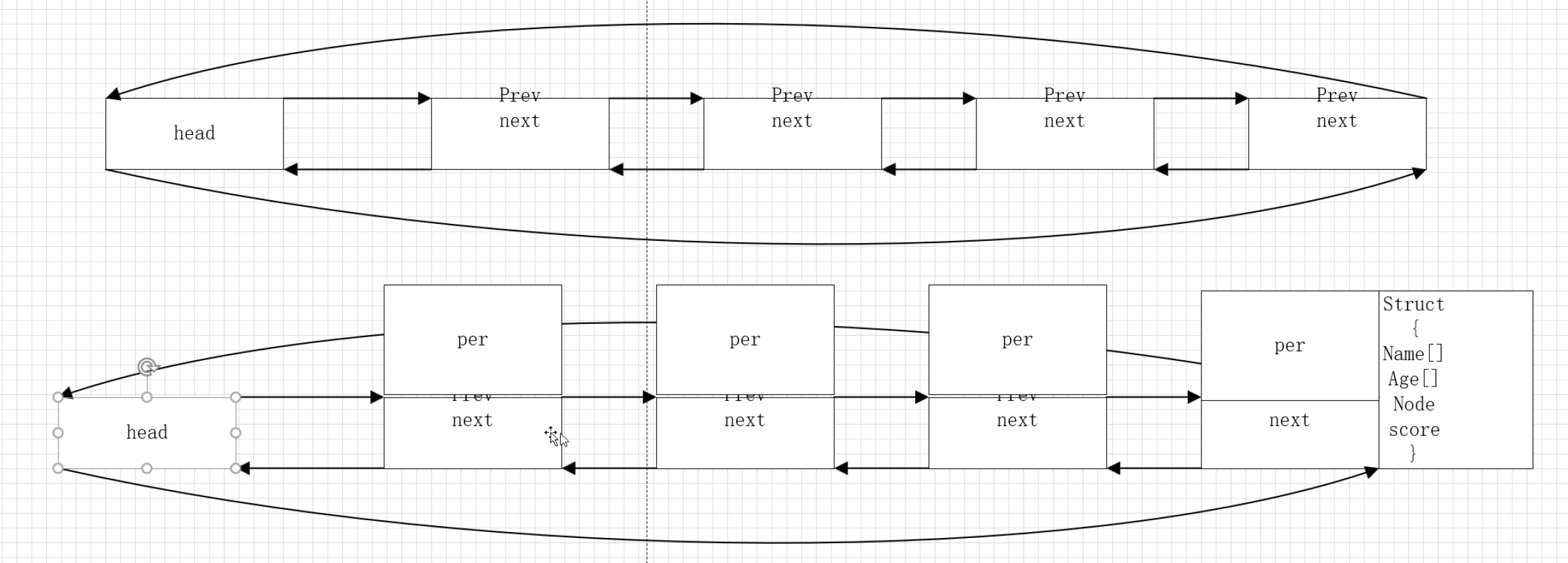
单链表 头文件:lin.h #ifndef __LINK_H__ #define __LINK_H__ #include <stdio.h> #include <stdlib.h> typedef int DataType; /*节点数据类型*/ typedef struct node { DataType data; //数据域 struct node *pNext; …...

湖北理元理律师事务所债务优化方案:让还款与生活平衡成为可能
在现代社会,债务问题已经成为影响许多家庭生活质量的重要因素。如何在不影响基本生活的前提下合理规划还款,是众多债务人面临的实际难题。湖北理元理律师事务所推出的债务优化服务,正是针对这一需求而设计的专业解决方案。 该所的债务优化方…...

Java对象内存分配优化教学
用 “停车位” 的比喻理解这个问题 🚗💨 假设你是一个停车场管理员(JVM),现在有人(程序员)要停车(new 对象)。传统认知是: 堆内存 公共停车场 栈内存 临时…...

精度再升级,可到微米!单位自动换算平米和米
CAD图纸单位怎么看?精度怎么调? 长度测出来是什么单位? 面积一大串怎么回事? 坐标小数点位置不对怎么办? 点击直接获取CAD快速看图 首先说原理 CAD图纸在绘制时,一般情况下单位是: 长度---…...
 使用文档)
【学习笔记】Sophus (Python) 使用文档
以下是一份针对 Sophus 库的 Python 使用文档,涵盖基础概念、安装方法、核心功能及代码示例。内容围绕 SO3(3D旋转群)和 SE3(3D刚体变换群)展开,适合机器人学、SLAM、三维几何等领域。 Sophus (Python) 使用…...

常见算法题目2 - 给定一个字符串,找出其中最长的不重复子串
算法题目2 - 给定一个字符串,找出其中最长的不重复子串 1. 问题描述 给定一个字符串,输出其最长的不重复子串,例如: String str "ababc"; 输出: abc以下根据两种搜索算法。 2. 算法解决 2.1 暴力循环法…...
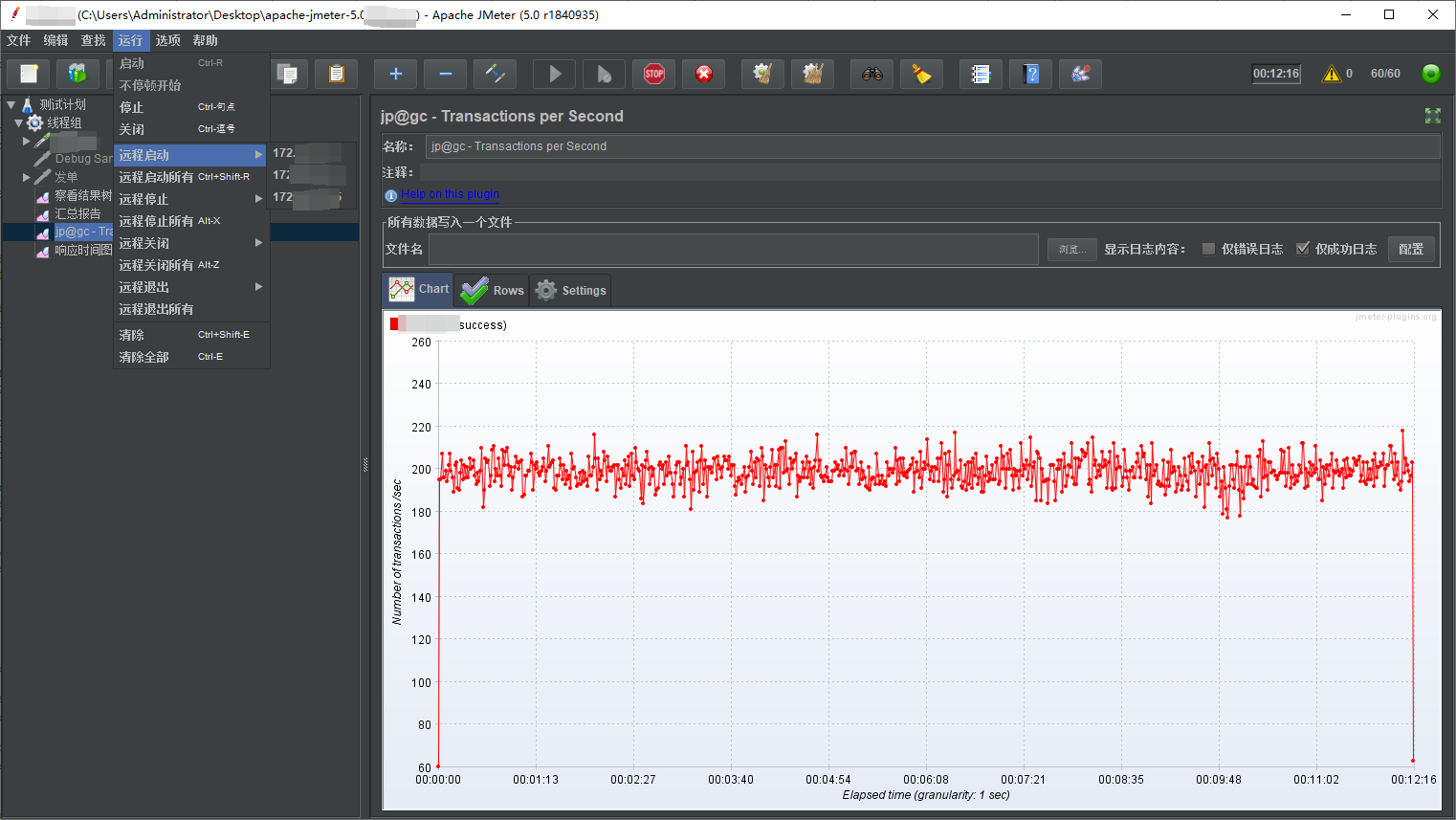
如何配置jmeter做分布式压测
问:为何需要做分布式 答:当我们本地机器jmeter进行压测时,单台JMeter机器通常无法稳定生成2000 QPS(受限于CPU、内存、网络带宽),本地端口耗尽:操作系统可用的临时端口(Ephemeral P…...

Django 中的 ORM 基础语法
深入剖析 Django 中的 ORM 语法:从基础到实战进阶 在 Django 开发领域,ORM(对象关系映射)是开发者高效操作数据库的得力工具。它以简洁直观的 Python 代码,替代繁琐的 SQL 语句,极大提升了开发效率。本文将…...

C#对象初始化语句:优雅创建对象的黑科技
📌 核心概念速览 对象初始化语句(Object Initializer)是C#中一种简洁高效的语法糖,允许在创建对象时直接初始化其公有字段或属性,无需依赖构造函数的重载。它的本质是对构造过程的扩展,尤其适合需要灵活设…...
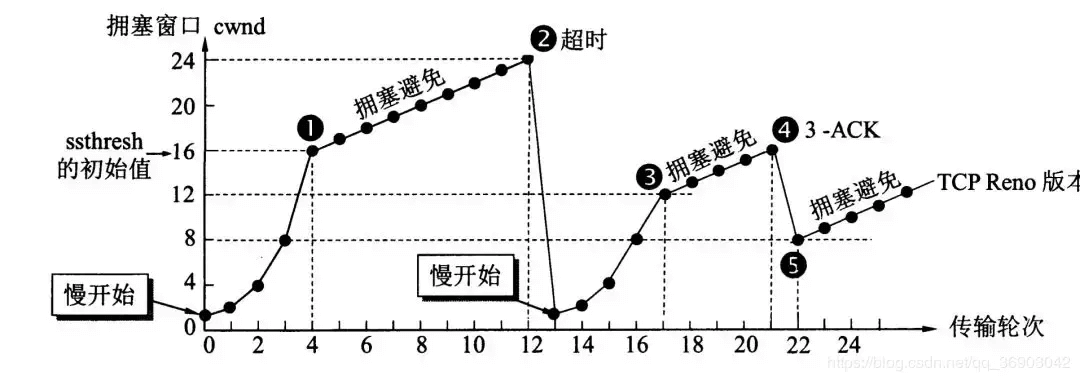
【计算机网络】TCP如何保障传输可靠性_笔记
文章目录 一、传输可靠性的6方面保障二、分段机制三、超时重传机制四、流量控制五、拥塞控制 提示:以下是本篇文章正文内容,下面案例可供参考 源网站 按TCP/IP 4层体系,TCP位于传输层,为应用层提供服务 一、传输可靠性的6方面保障…...

Robust Kernel Estimation with Outliers Handling for Image Deblurring论文阅读
Robust Kernel Estimation with Outliers Handling for Image Deblurring 1. 论文的研究目标与实际问题意义1.1 研究目标1.2 实际问题与产业意义2. 论文的创新方法、模型与优势2.1 核心思路2.2 关键公式与技术细节2.2.1 非线性模糊模型与能量函数2.2.2 中间潜像更新与IRLS2.2.3…...
)
Android Studio 开发环境兼容性检索(AGP / Gradle / Kotlin / JDK)
本表检索了 Android 项目中常用构建工具的兼容性关系,包括: AGP(Android Gradle Plugin)Gradle(构建工具)KGP(Kotlin Gradle Plugin)JDK(Java Development Kitÿ…...

html主题切换小demo
主题切换功能为网页和应用程序提供了多样化的视觉风格与使用体验。实现多主题切换的技术方案丰富多样,其中 CSS 变量和 JavaScript 样式控制是较为常见的实现方式。 以下是一个简洁的多主题切换示例,愿它能为您的编程之旅增添一份趣味。 代码展示 <…...
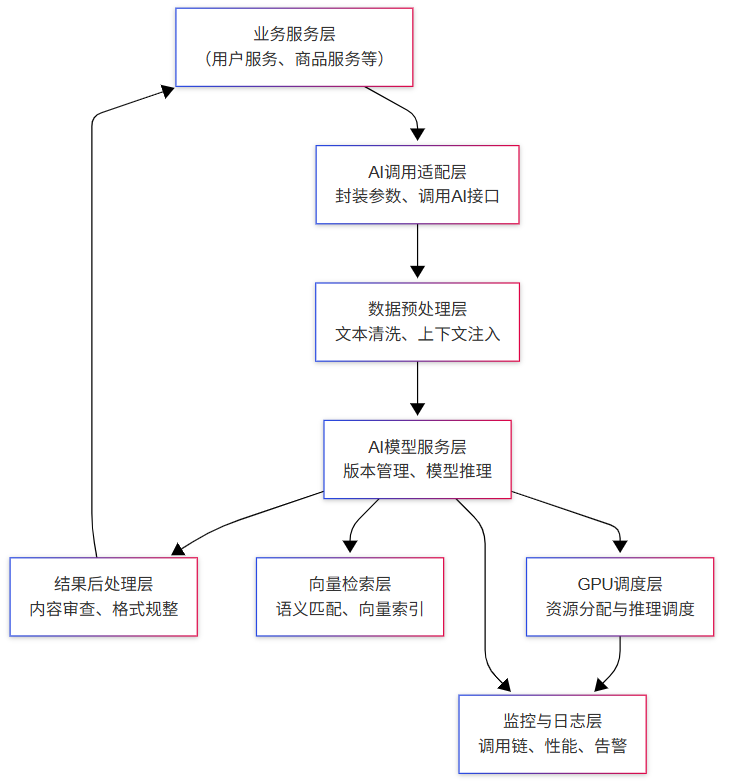
AI架构职责分配——支持AI模块的职责边界设计
职责分配——支持AI模块的职责边界设计 在传统系统中,职责分配通常围绕“控制层处理逻辑、服务层执行业务、数据层持久化”进行划分。这种分工逻辑在纯业务系统中足以支撑高效协作与系统演进。然而,随着AI模块的引入,系统中新增了如模型推理…...
. fatal: 无法读取远程仓库)
git@gitee.com: Permission denied (publickey). fatal: 无法读取远程仓库
错误信息: gitgitee.com: Permission denied (publickey). fatal: 无法读取远程仓库。  说明 Git 无法通过 SSH 密钥成功连接到 Gitee(码云)仓库。这通常是由于 SSH 密钥未正确配置或未添加到 Gitee 账户所致。 &am…...
CARIS HIPS and SIPS 12.1是专业的多波束水深数据和声呐图像处理软件
CARIS HIPS 和 SIPS 是一套综合水文处理软件,主要用于海洋水道处理和测量领域。该软件集成了测深、水柱和海底图像处理功能,能够提高业务处理的精确度和效率。 主要功能和应用场景 测深数据处理:HIPS主要用于处理大型测深数据。 …...

Docker端口映射与容器互联
Docker端口映射与容器互联 1. 端口映射实现容器访问 1.1 从外部访问容器应用 # 基础端口映射语法 docker run -d -p [宿主机端口]:[容器端口] [镜像名称]# 示例:容器80端口→宿主机8080 docker run -d -p 8080:80 nginx1.2 高级映射配置 映射类型命令示例说明文档…...

在 Ubuntu 24.04 LTS 上 Docker 部署 DB-GPT
一、DB-GPT 简介 DB-GPT 是一个开源的AI原生数据应用开发框架(AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents)。目的是构建大模型领域的基础设施,通过开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及…...

使用 Docker 搭建 PyWPS 2.0 服务全流程详解
使用 Docker 搭建 PyWPS 2.0 服务全流程详解 近年来,随着地理信息系统(GIS)和在线空间分析服务的兴起,OGC标准下的Web Processing Service(WPS)逐渐成为地理数据服务的重要组件。PyWPS 是一个基于 Python …...
Axure高保真CRM客户关系管理系统原型
一套出色的CRM(客户关系管理)系统,无疑是企业管理者掌控客户动态、提升销售业绩的得力助手。今天,就为大家介绍一款精心打造的Axure高保真CRM客户关系管理系统原型模板,助你轻松开启高效客户管理之旅。 这款CRM原型模…...
自学嵌入式 day 23 - 数据结构 树状结构 哈希表
一、树状结构 1.特征:在任意一个非空树中, (1),有且仅有一个特定的根结点 (2),当n>1 时,其余结点可分为m个互不相交的有限集合T1,T2,T3.。。。。Tm&…...
JavaScript进阶(十二)
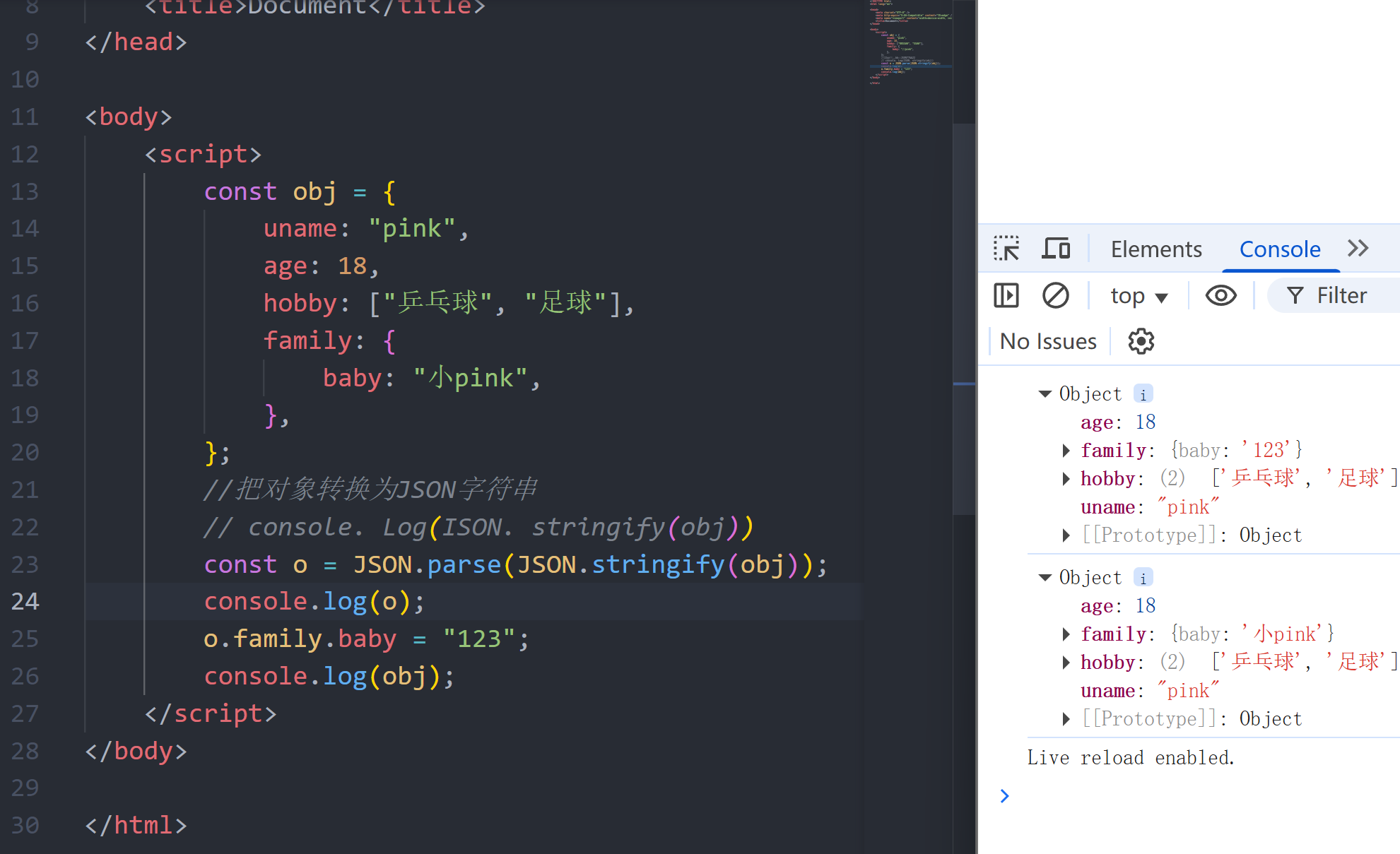
第三部分:JavaScript进阶 目录 第三部分:JavaScript进阶 十二、深浅拷贝 12.1 浅拷贝 12.2 深拷贝 1. 通过递归实现深拷贝 2. js库lodash里面cloneDeep内部实现了深拷贝 3. 通过JSON.stringify()实现 十三、异常处理 13.1 throw抛异常 13.2 try /catch捕获异常 1…...

Honeywell CV-DINA-DI1624-2A 数字输入模块
概述 型号:CV-DINA-DI1624-2A 类型:数字输入模块(16通道,24V DC) 制造商:霍尼韦尔(Honeywell),属于其工业自动化或楼宇控制系统产品线。 主要功能: 采集16路数…...