如何计算VLLM本地部署Qwen3-4B的GPU最小配置应该是多少?多人并发访问本地大模型的GPU配置应该怎么分配?
本文一定要阅读我上篇文章!!!
超详细VLLM框架部署qwen3-4B加混合推理探索!!!-CSDN博客
本文是基于上篇文章遗留下的问题进行说明的。
一、本文解决的问题
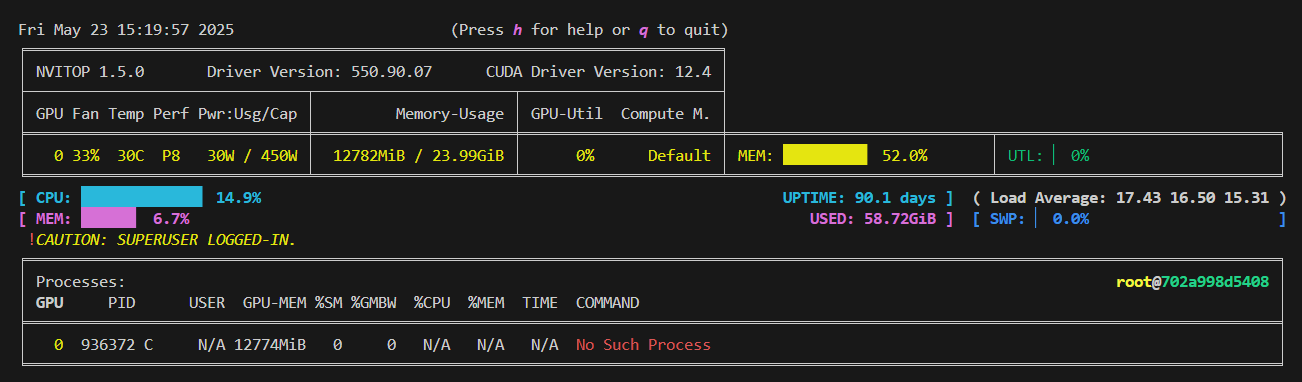
问题1:我明明只部署了qwen3-4B的模型,为什么启动VLLM推理框架后能占到显存的0.9,占了22GB显存?
问题2:VLLM框架部署Qwen3-4B的GPU最小配置应该是多少,怎么计算?
问题3:VLLM框架预留更多的GPU资源对模型推理速度影响多大?
问题4:并发处理10-20人的访问本地模型请求,GPU配置应该怎么计算,怎么分配?
二、解决问题1
问题1:我明明只部署了qwen3-4B的模型,为什么启动VLLM推理框架后能占到显存的0.9,占了22GB显存?
官网回答图片,可以知道VLLM框架是预置了0.9的显存给这个模型,但是模型实际不一定需要要那么多显存。还有最大输入的token默认值是40960,正常我们输入的长文本不需要那么大。

因此可以自定义分配GPU显存给VLLM服务,测试一下,当然你分配的显存越少,推理速度越慢。
比如我分配了0.5的显存重启VLLM服务,就可以看到分配的显存就是0.5左右。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.5
三、解决问题2
问题2:VLLM框架部署Qwen3-4B的GPU最小配置应该是多少,怎么计算?
执行完下述命令后
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.5
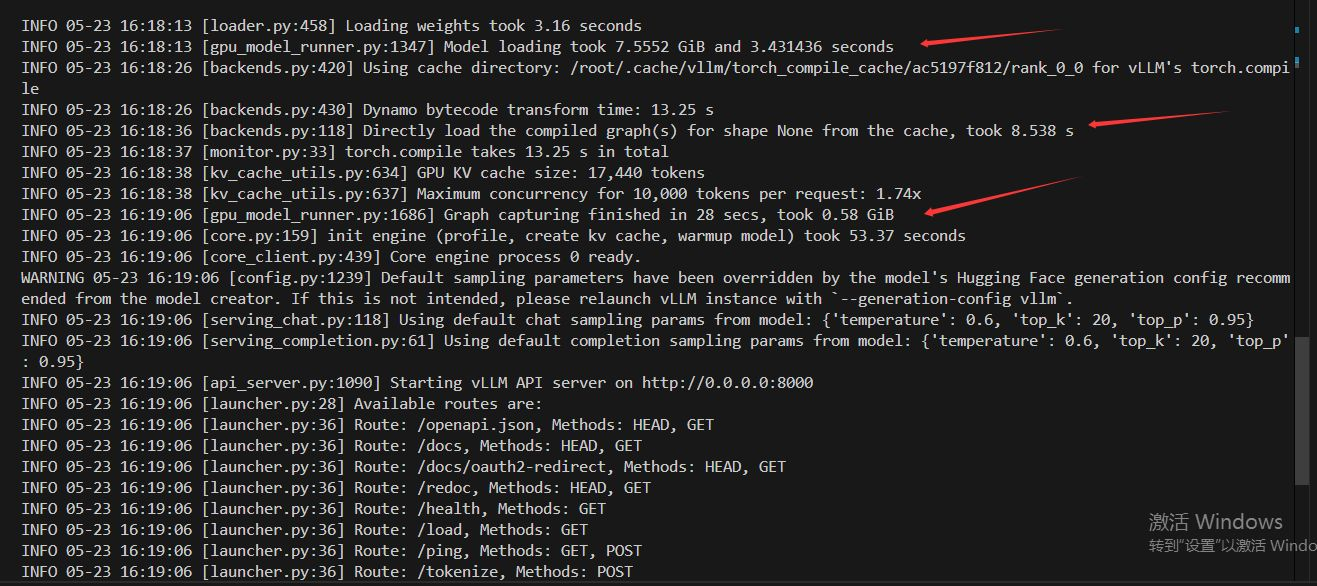
首先先分析配置日志
-
显存占用
- 模型加载:7.552 GiB(主模型权重)。
- KV缓存:17,440 tokens(具体显存需结合模型参数,但日志未直接给出数值)。
- 图捕获阶段:0.58 GiB(动态编译优化时的临时占用)。
- 总计显存:主模型+临时操作约为 8.13 GiB左右(KV缓存需额外计算,但日志未明确)。
- 总计显存:主模型+临时操作约为 8.13 GiB左右
也就是说,除了自定义的KV缓存,至少8.13GB
我们还可以自己计算KV显存,根据模型的配置文件和下述公式,得到缓存是1.37GB,也可以直接把模型配置发给deepseek叫它计算。

KV缓存总量 = batch_size × 序列长度 × 模型层数 × 2 × d_model × sizeof(float16)
因此VLLM部署Qwen3-4B的在--max-model-len 10000GPU的情况下模型占用的GPU资源是,8.13GB+1.37GB=9.5GB
如果是默认情况--max-model-len 40960,模型占用的GPU资源是,8.13GB+5.62GB=13.75GB
小技巧,如果你不相信AI计算的结果,可以执行默认的最长输入命令。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --gpu-memory-utilization 0.5
发现报错
raise ValueError( ValueError: To serve at least one request with the models's max seq len (40960), (5.62 GiB KV cache is needed, which is larger than the available KV cache memory (2.39 GiB). Based on the available memory, Try increasing `gpu_memory_utilization` or decreasing `max_model_len` when initializing the engine.
错误提示显示5.62 GiB KV cache is needed,而当前可用显存仅2.39 GiB。KV缓存用于存储Transformer模型中各层的键值向量。
我们就可以自己计算,10000的token所占用的应该KV缓存的GPU大小,10000/40960*5.62GB=1.37GB。说明AI计算的是正确的。
四、解决问题3
问题3:VLLM框架预留更多的GPU资源对模型推理速度影响多大?
使用下面代码进行测试分配不同的GPU,推理时间变化多少。因为每次生成的token数量不一样,所以我们主要是以tokens/s为衡量标准进行测试。
import time
from openai import OpenAI# 初始化客户端
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)# 使用高精度计时器
start_time = time.perf_counter() # 比time.time()精度更高[3](@ref)chat_response = client.chat.completions.create(
model="/root/lanyun-tmp/modle/Qwen3-4B",
messages=[
{"role": "user", "content": "你有什么功能"},
],
max_tokens=8192,
temperature=0.7,
top_p=0.8,
presence_penalty=1.5,
extra_body={
"top_k": 20,
"chat_template_kwargs": {"enable_thinking": True},
},
)end_time = time.perf_counter()
elapsed = end_time - start_timeprint("Chat response:", chat_response)
print(f"\n[性能报告] 请求耗时: {elapsed:.4f}秒")
print(f"生成token数: {chat_response.usage.completion_tokens} tokens")
print(f"每秒生成速度: {chat_response.usage.completion_tokens/elapsed:.2f} tokens/s")
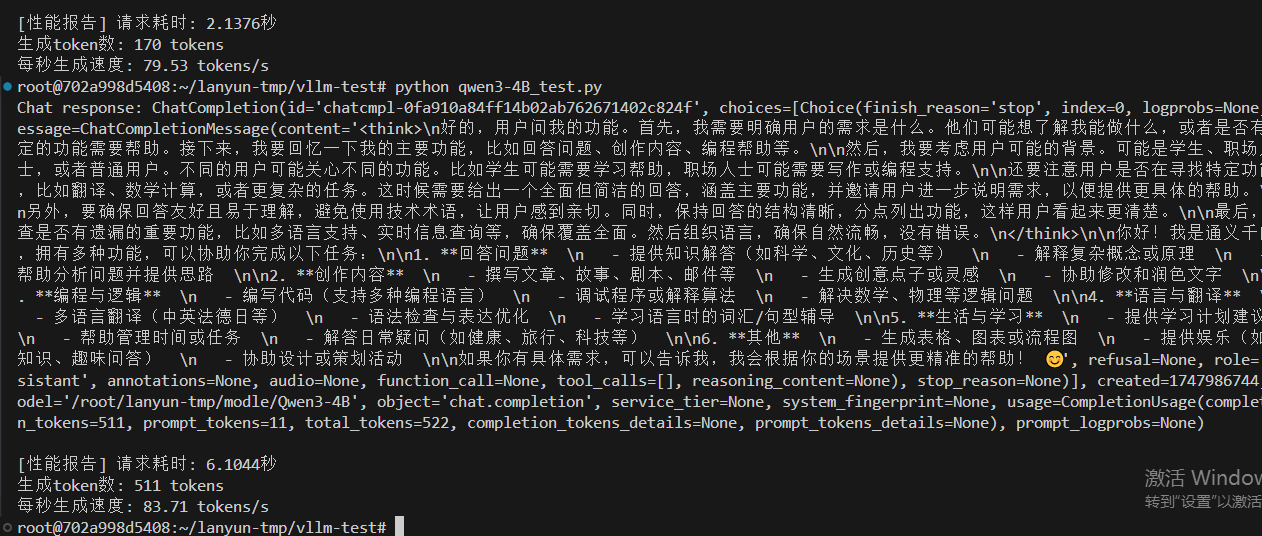
情况一,设置最大10000token数量,分配0.5GPU,12.7GB给VLLM服务,除去大模型的启动占用9.5GB,还给VLLM服务预留空间为3.2GB。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.5
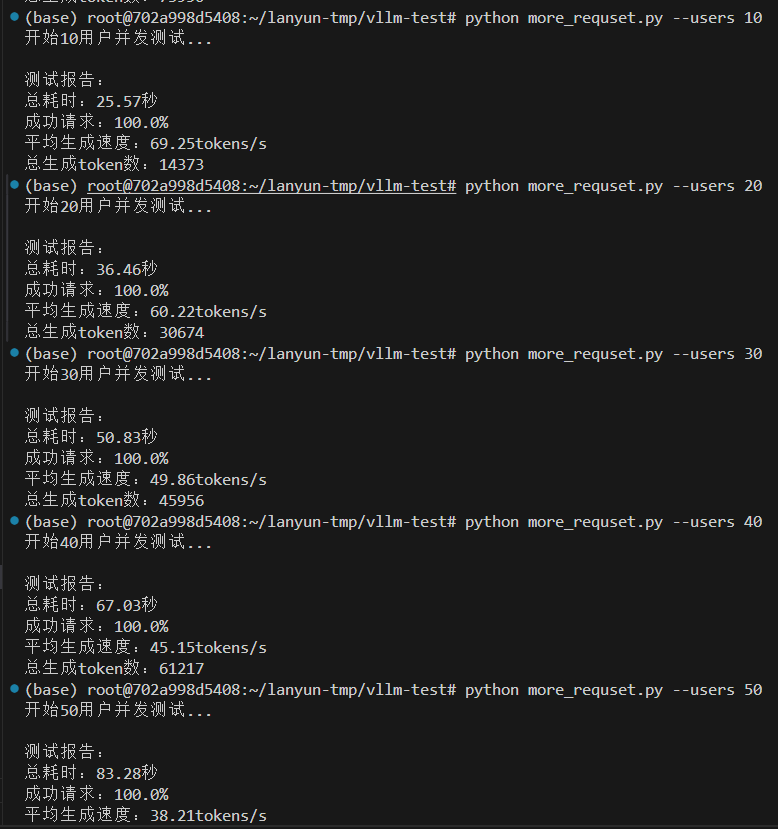
有思考83.71 tokens/s,无思考79.53 tokens/s
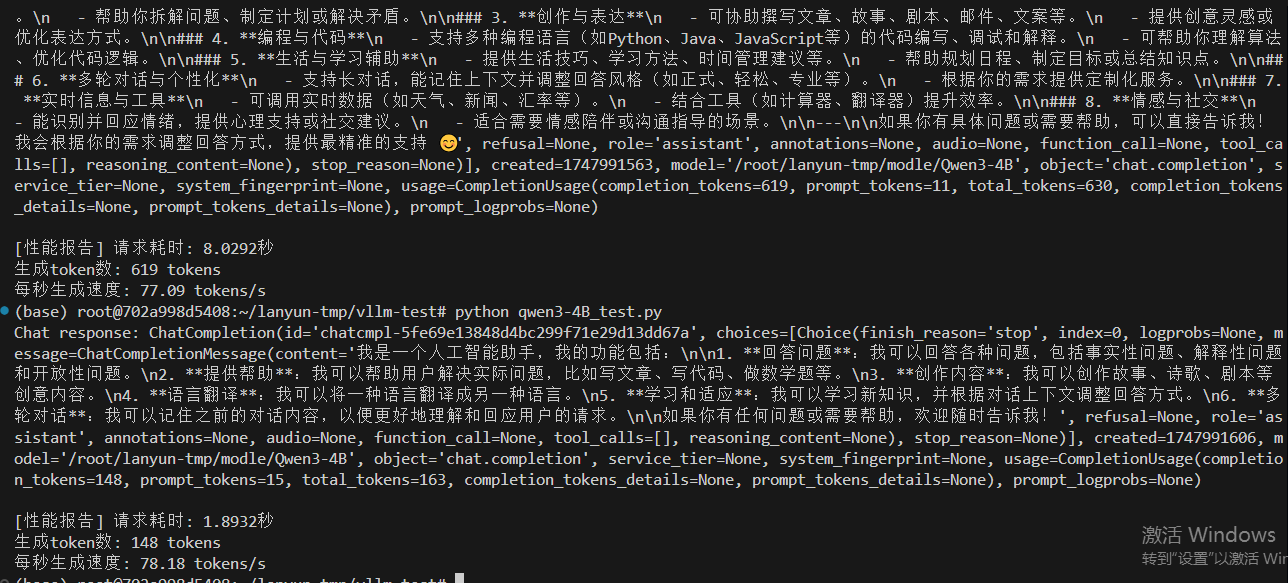
情况二,设置最大10000token数量,分配0.8GPU,20GB给VLLM服务,除去大模型的启动占用9.5GB,还给VLLM服务预留空间为10.5GB。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.8
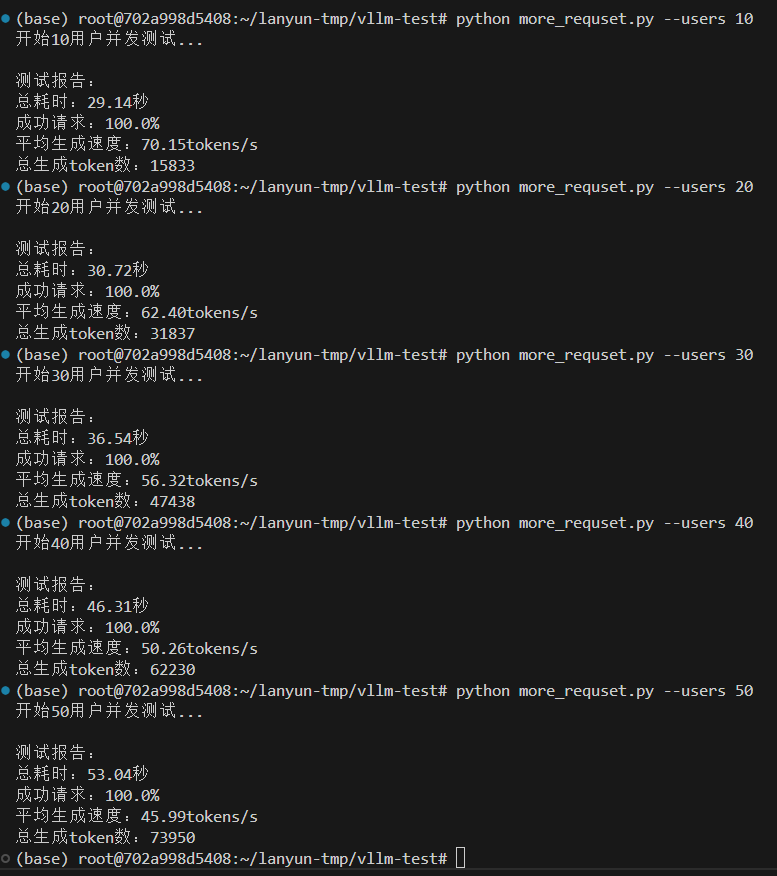
有思考77.09 tokens/s,无思考 78.18 tokens/s
通过两个情况的对比,预留给VLLM服务的GPU空间大小没有对速度有太大影响,甚至空间小一定,生成速度还更多,但是多运行几次,发现速度是差不多的。
五、解决问题4
问题4:如何测试多人并发访问大模型服务,多少人是上限,生成的速度变化是怎么样的?
我们可以创建一个并发测试的代码concurrency_test.py
# concurrency_test.py
import argparse
import threading
import time
from queue import Queue
# qwen3-4B_test.py
import time
from openai import OpenAI
def send_request(prompt="你有什么功能", max_tokens=8192, temperature=0.7):
"""单次请求测试函数"""
client = OpenAI(
api_key="EMPTY",
base_url="http://localhost:8000/v1",
)
start_time = time.perf_counter()
try:
response = client.chat.completions.create(
model="/root/lanyun-tmp/modle/Qwen3-4B",
messages=[{"role": "user", "content": prompt}],
max_tokens=max_tokens,
temperature=temperature,
extra_body={"top_k": 20}
)
elapsed = time.perf_counter() - start_time
return {
"success": True,
"time": elapsed,
"tokens": response.usage.completion_tokens,
"speed": response.usage.completion_tokens/elapsed,
"response": response.choices[0].message.content
}
except Exception as e:
return {
"success": False,
"error": str(e),
"time": time.perf_counter() - start_time
}
class ConcurrentTester:
def __init__(self, num_users):
self.num_users = num_users
self.results = Queue()
self.start_barrier = threading.Barrier(num_users + 1) # 同步所有线程同时启动
def _worker(self, user_id):
"""单个用户的请求线程"""
self.start_barrier.wait() # 等待所有线程就绪
result = send_request(prompt=f"测试用户{user_id}的并发请求")
self.results.put((user_id, result))
def run(self):
# 创建并启动所有线程
threads = []
for i in range(self.num_users):
t = threading.Thread(target=self._worker, args=(i+1,))
t.start()
threads.append(t)
# 等待所有线程准备就绪
self.start_barrier.wait()
start_time = time.perf_counter()
# 等待所有线程完成
for t in threads:
t.join()
total_time = time.perf_counter() - start_time
# 统计结果
success = 0
total_tokens = 0
speeds = []
errors = []
while not self.results.empty():
user_id, res = self.results.get()
if res['success']:
success += 1
total_tokens += res['tokens']
speeds.append(res['speed'])
else:
errors.append(f"用户{user_id}错误:{res['error']}")
return {
"total_time": total_time,
"success_rate": success/self.num_users,
"avg_speed": sum(speeds)/len(speeds) if speeds else 0,
"total_tokens": total_tokens,
"errors": errors
}
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--users", type=int, required=True,
help="并发用户数量")
args = parser.parse_args()
tester = ConcurrentTester(args.users)
print(f"开始{args.users}用户并发测试...")
results = tester.run()
print("\n测试报告:")
print(f"总耗时:{results['total_time']:.2f}秒")
print(f"成功请求:{results['success_rate']*100:.1f}%")
print(f"平均生成速度:{results['avg_speed']:.2f}tokens/s")
print(f"总生成token数:{results['total_tokens']}")
if results['errors']:
print("\n错误列表:")
for err in results['errors']:
print(f"• {err}")
分别测试上述两个情况:
情况一,设置最大10000token数量,分配0.5GPU,12.7GB给VLLM服务,除去大模型的启动占用9.5GB,还给VLLM服务预留空间为3.2GB。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.5
情况二,设置最大10000token数量,分配0.8GPU,20GB给VLLM服务,除去大模型的启动占用9.5GB,还给VLLM服务预留空间为10.5GB。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.8
情况三,设置最大10000token数量,分配0.5GPU,12.7GB给VLLM服务,除去大模型的启动占用9.5GB,还给VLLM服务预留空间为3.2GB。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.5
终极测试500个并发请求,可以看到VLLM框架一次性是处理11个请求,然后分批次排队处理这么多的并发请求。然后越到后面处理的请求越少。
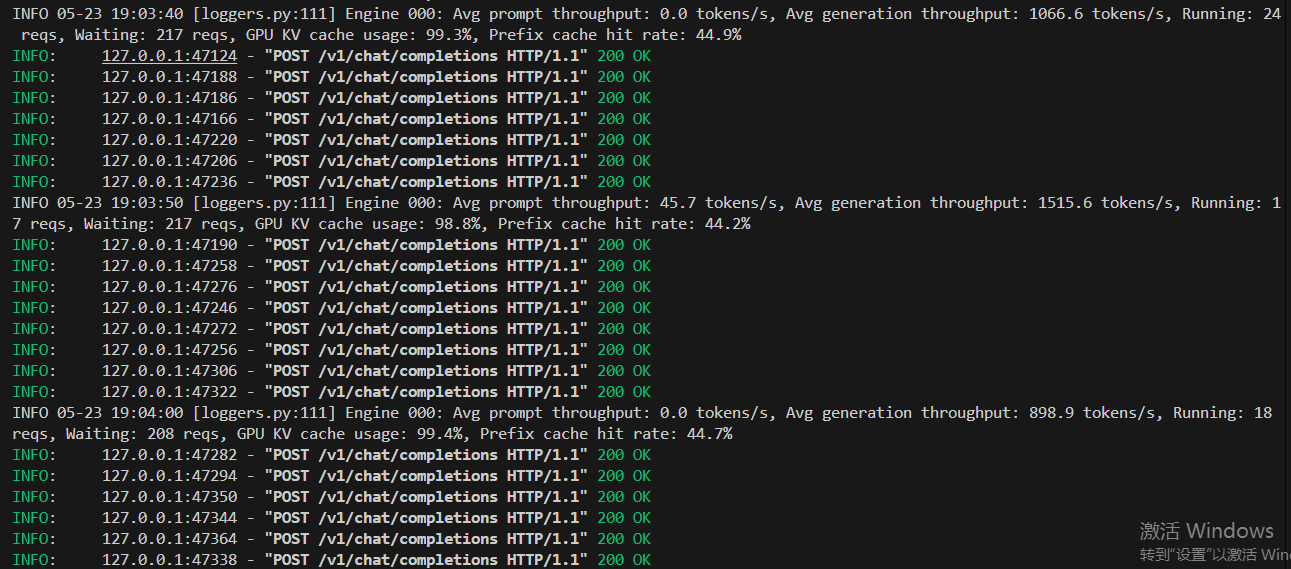
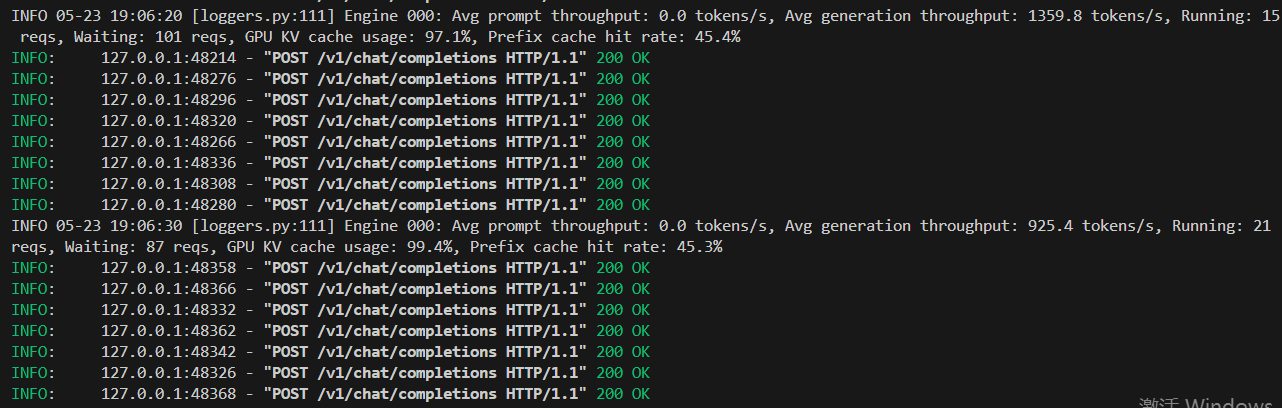
结论,VLLM处理框架处理并发的能力是可以的,它是通过并发处理11给请求,别的请求是排队处理。所以只要模型通过VLLM部署起来,理论上它解决无上限的并发请求,就是要排队等着大模型回复。
相关文章:
如何计算VLLM本地部署Qwen3-4B的GPU最小配置应该是多少?多人并发访问本地大模型的GPU配置应该怎么分配?
本文一定要阅读我上篇文章!!! 超详细VLLM框架部署qwen3-4B加混合推理探索!!!-CSDN博客 本文是基于上篇文章遗留下的问题进行说明的。 一、本文解决的问题 问题1:我明明只部署了qwen3-4B的模型…...

PostgreSQL日常维护
目录 一:基本使用 1.登录数据库 2.数据库操作 2.1列出库 2.2创建库 2.3删除库 2.4切换库 2.5查看库大小 3.数据表操作 3.1 列出表 3.2创建表 3.3复制表 3.4删除表 4.模式操作命令 4.1创建模式 4.2默认模式 4.3删除模式 4.4查看所有模式 4.5 在指定…...
Attu下载 Mac版与Win版
通过Git地址下载 Mac 版选择对于的架构进行安装 其中遇到了安装不成功,文件损坏等问题 一般是两种情况导致 1.安装版本不对 2.系统权限限制 https://www.cnblogs.com/similar/p/11280162.html打开terminal执行以下命令 sudo spctl --master-disable安装包Git下载地…...
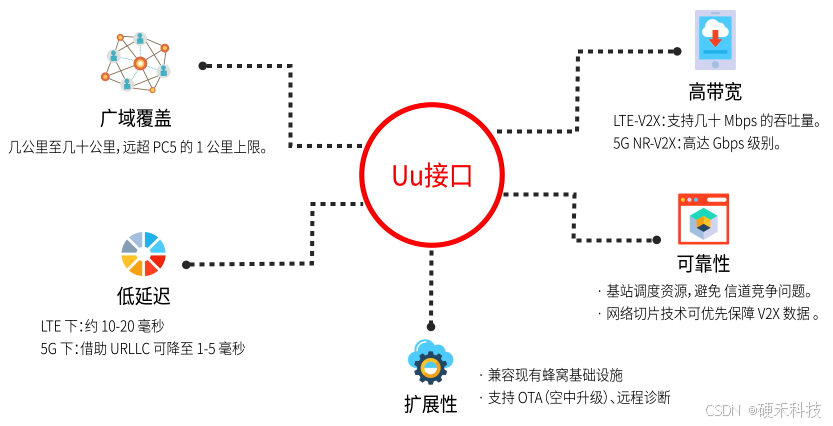
V2X协议|如何做到“车联万物”?【无线通信小百科】
1、什么是V2X V2X(Vehicle-to-Everything)即“车联万物”,是一项使车辆能够与周围环境实现实时通信的前沿技术。它允许车辆与其他交通参与者和基础设施进行信息交互。通过V2X,车辆不仅具备“远程感知”能力,还能在更大…...

【zookeeper】--部署3.6.3
文章目录 下载解压创建data和logs配置文件1)创建目录并且编辑 zoo.cfg2)接下来将 node01 的 ZooKeeper 所有文件拷贝至 node02 和 node03。推荐从 node02 和 node03 拷贝4)最后 vim /etc/profile 配置环境变量,环境搭建结束。配完环境变量后 source /etc…...
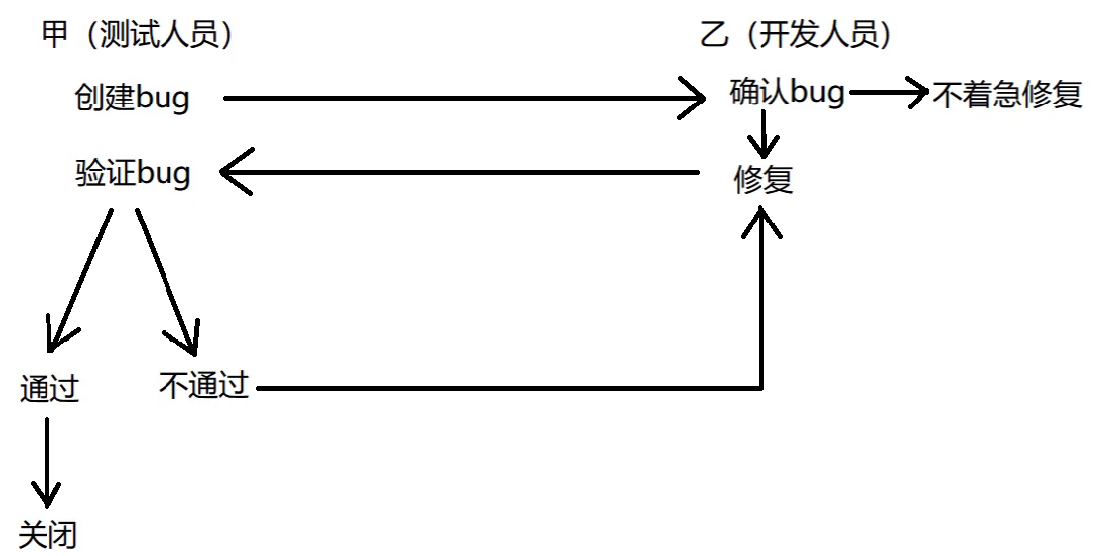
[测试_3] 生命周期 | Bug级别 | 测试流程 | 思考
目录 一、软件测试的生命周期(重点) 1、软件测试 & 软件开发生命周期 (1)需求分析 (2)测试计划 (3)测试设计与开发 (4)测试执行 (5&am…...
智能项目全景指南:技术构架、实现细节与应用实践)
物联网(IoT)智能项目全景指南:技术构架、实现细节与应用实践
目录 一、物联网项目的核心组成和发展方向 1. 核心组成 2. 发展趋势 二、系统设计的详细流程 1. 需求分析与方案规划 2. 硬件方案深度设计 3. 软件架构设计 4. 方案示意图(架构图) 三、关键技术深度剖析 1. 传感器及其接口技术 2. 嵌入式MCU选…...

【Go】1、Go语言基础
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言的特点 Go语言由Google团队设计,以简洁、高效、并发友好为核心目标。 具有以下优点: 语法简单、学习曲线平缓:语法关键字很少,且…...

RabbitMQ ⑤-顺序性保障 || 消息积压 || 幂等性
幂等性保障 幂等性(Idempotency) 是计算机科学和网络通信中的一个重要概念,指的是某个操作无论被执行多少次,所产生的效果与执行一次的效果相同。 应用程序的幂等性: 在应用程序中,幂等性就是指对一个系统…...
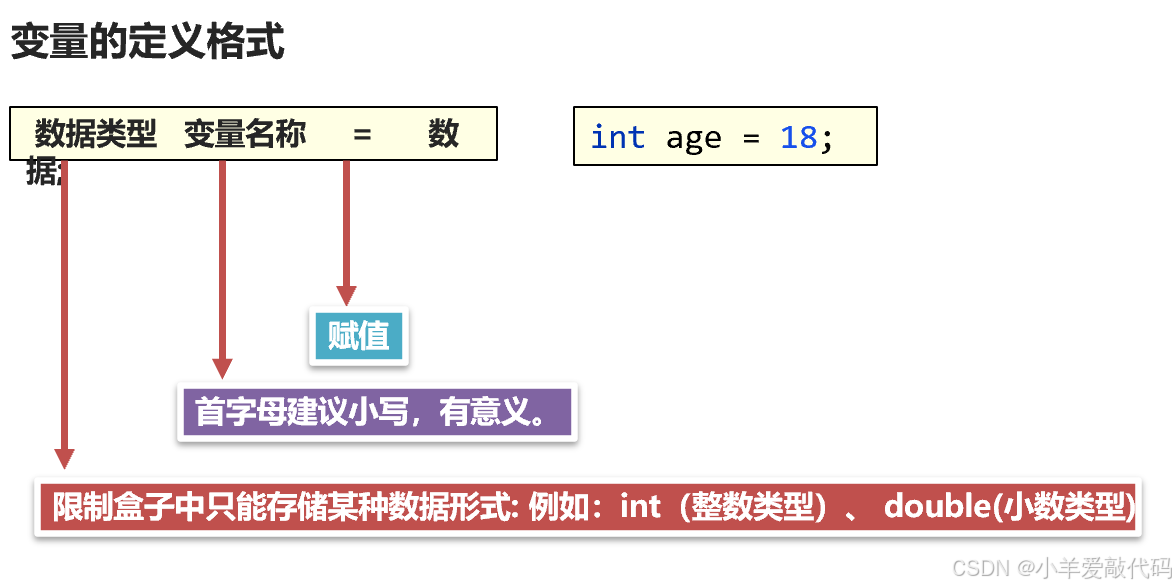
java基础知识回顾1(可用于Java基础速通)考前,面试前均可用!
目录 一、初识java 二、基础语法 1.字面量 2.变量 3.关键字 4.标识符 声明:本文章根据黑马程序员b站教学视频做的笔记,可对应课程听,课程链接如下: 02、Java入门:初识Java_哔哩哔哩_bilibili 一、初识java Java是美国 sun 公…...
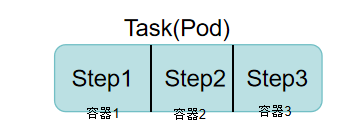
云原生CICD-Tekton入门到精通
文章目录 一、Tekton介绍二、Tekton组件介绍三、执行流程四、安装Tekton管道五、安装Tekton Dashboard六、安装Tekton Cli七、运行单Task八、运行流水线九、在流水线中使用secret十、taskSpec、taskRef、pipelineRef、pipelineSpec使用pipelineRef与taskRef结合使用(推荐)pipel…...

CMake跨平台编译生成:从理论到实战
一、引言 在当今软件开发中,跨平台开发已成为常态。无论是需要在Windows、Linux、macOS等多操作系统上运行,还是在不同的硬件架构(如x86、ARM等)间部署,跨平台编译生成都是一个无法回避的关键问题。CMake,…...

MCP 协议传输机制大变身:抛弃 SSE,投入 Streamable HTTP 的怀抱
在技术的江湖里,变革的浪潮总是一波接着一波。最近,模型上下文协议(MCP)的传输机制就搞出了大动静,决定和传统的服务器发送事件(SSE)说拜拜,转身拥抱 Streamable HTTP,这…...

opencv 图像的平移和旋转
warpAffine函数讲解,图片可自行下载,也可用自己的图片 原图im 平移im_shifted 旋转im_rotated # 图像仿射变换 # 步骤: 读取图像 -> 创建仿射变换矩阵 -> 仿射变换计算 # 平移变换矩阵:一种写法,直接写死 # 旋转变…...
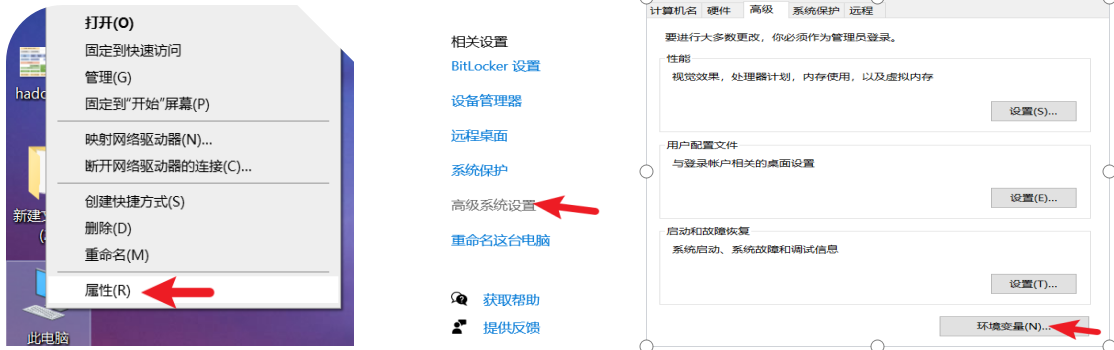
IDEA2025版本使用Big Data Tools连接Linux上Hadoop的HDFS
目录 Windows的准备 1. 将与Linux上版本相同的hadoop压缩包解压到本地 编辑2.设置$HADOOP HOME环境变量指向:E:\hadoop-3.3.4 3.下载hadoop.dll和winutils.exe文件 4.将hadoop.dll和winutils.exe放入$HADOOP HOME/bin中 IDEA中操作 1.下载Big Data Tools插件 2.添加并连…...

hysAnalyser特色的TS流编辑、剪辑和转存MP4功能说明
摘要 hysAnalyser 是一款特色的 MPEG-TS 数据分析工具,融合了常规TS文件的剪辑,转存功能,可用于平常的视频开发和测试。 本文详细阐述了对MPEG-TS 流的节目ID,名称,PID,时间戳,流类型ÿ…...

Day125 | 灵神 | 二叉树 | 二叉树中的第K大层和
Day125 | 灵神 | 二叉树 | 二叉树中的第K大层和 2583.二叉树中的第K大层和 2583. 二叉树中的第 K 大层和 - 力扣(LeetCode) 思路: 把每层的结果都放到一个vector数组里面,然后排序这个vector数组,返回第K大的元素即…...
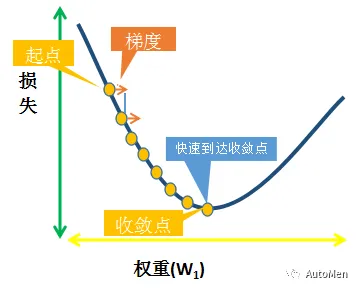
Google机器学习实践指南(学习速率篇)
🔥Google机器学习核心概念精讲(学习速率) Google机器学习实战(7)-5分钟掌握学习速率。 学习速率:模型训练的关键超参数 学习速率是指在训练模型时用于梯度下降的一个标量。在每次迭代期间,梯度下降法都会将学习速率…...

JS实现直接下载PDF文件
pdf文件通过a标签直接下载会打开页面,所以,请求该文件的blob文件流数据,再通过window.URL.createObjectURL转成链接,就可以直接下载了。 只需要替换url和文件名称就行,文件名的后缀记得要写上pdf,不然会变成…...
使用KubeKey快速部署k8s v1.31.8集群
实战环境涉及软件版本信息: 使用kubekey部署k8s 1. 操作系统基础配置 设置主机名、DNS解析、时钟同步、防火墙关闭、ssh免密登录等等系统基本设置 dnf install -y curl socat conntrack ebtables ipset ipvsadm 2. 安装部署 K8s 2.1 下载 KubeKey ###地址 https…...

FreeSWITCH 纯内网配置
纯内网,且同一个网段,Fs 可简化配置,要点是: 1. 不需要事先配置 directory,任意号码都可以注册,且无挑战 2. 呼叫无挑战 不需要考虑那么多安全问题 配置如下: 1. 全局变量 <X-PRE-PROCESS cmd"…...

leetcode hot100:十四、解题思路大全:真·大全!
因为某大厂的算法没有撕出来,怒而整理该贴。部分题目有python版本的AC代码。本贴耗时4天呜呜呜 1.哈希 两数之和 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下…...

kali的简化安装
首先点击kali的官网 https://www.kali.org/get-kali/#kali-platforms 点击虚拟机版本 下载VMware版本的压缩包 解压后 点击 后缀名为 .vmx的文件 原始账号密码为 kali kali 这样安装 就不需要我们再去配置镜像 等等复杂操作了...

交换机的连接方式堆叠和级联
以下是交换机的堆叠和级联各自的优缺点总结,帮助快速对比选择: 一、堆叠(Stacking) 优点 高性能 堆叠链路带宽高(如10G/40G/100G),成员间数据通过背板直连,无带宽瓶颈。支…...
Vortex GPGPU的github流程跑通与功能模块波形探索(三)
文章目录 前言一、./build/ci下的文件结构二、基于驱动进行仿真过程牵扯的文件2.1 blackbox.sh文件2.2 demo文件2.3 额外牵扯到的ramulator2.3.1 ramulator简单介绍2.3.2 ramulator使用方法2.3.3 ramulator的输出2.3.4 ramulator的复现2.3.4.1 调试与验证(第 4.1 节…...

React深度解析:Hooks体系与Redux Toolkit现代状态管理实践
前言 React作为当今最流行的前端框架之一,其生态体系不断演进,为开发者提供了更高效、更优雅的解决方案。本文将深入探讨React的两大核心主题:Hooks体系(特别是useState和useEffect)以及Redux Toolkit现代状态管理方案…...

实用蓝牙耳机哪款好?先做好使用场景分析!
市面上的蓝牙耳机款式繁多,618到来之际,消费者如何选择适合自己的蓝牙耳机?实用蓝牙耳机哪款好?关键在于做好使用场景分析!今天,就带大家结合不同的使用场景,分享三款倍思音频的精品蓝牙耳机。 …...

Rules and Monetization
The system creates rules that allow them to monetize. The system doesn’t just enforce rules — it creates them strategically to monetize control. 🔧 How It Works: Invent a rule (e.g., “You need a permit to sell food.”)Claim it’s for safety …...
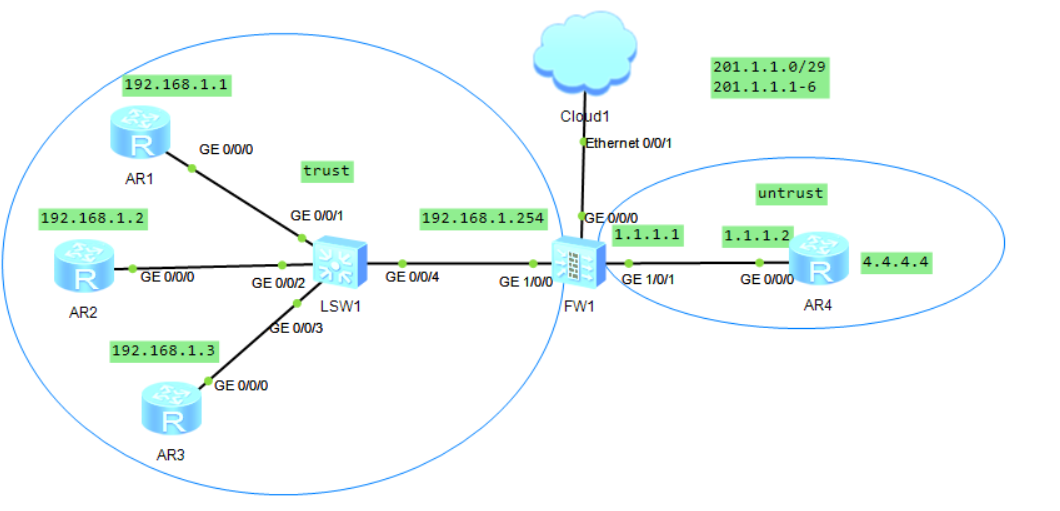
防火墙NAT地址组NAT策略安全策略
本文仅供学习交流,所涉及的知识技术产权归属华为技术有限公司所有!!! 本文仅供学习交流,所涉及的知识技术产权归属华为技术有限公司所有!!! 本文仅供学习交流,所涉及的…...

python开发环境管理和包管理
在 Python 开发中,环境管理 和 包管理 是两个非常重要的概念。它们帮助开发者: 这里写目录标题 一、什么是 Python 环境管理?二、什么是 Python 包管理?三、常见文件说明(用于包管理和环境配置)四、典型流程…...