TPDS-2014《Efficient $k$-means++ Approximation with MapReduce》
推荐深蓝学院的《深度神经网络加速:cuDNN 与 TensorRT》,课程面向就业,细致讲解CUDA运算的理论支撑与实践,学完可以系统化掌握CUDA基础编程知识以及TensorRT实战,并且能够利用GPU开发高性能、高并发的软件系统,感兴趣可以直接看看链接:深蓝学院《深度神经网络加速:cuDNN 与 TensorRT》

核心思想
论文的核心思想是针对传统 k k k-means++算法在大规模数据处理中的低效性和初始化敏感性问题,提出了一种基于MapReduce框架的高效 k k k-means++初始化方法。传统 k k k-means++通过概率选择初始中心来提高聚类质量,但其顺序性导致在大规模数据上需要多次数据扫描,计算开销大且难以并行化。论文通过设计仅使用一次MapReduce作业的初始化算法,将标准 k k k-means++初始化(Mapper阶段)和加权 k k k-means++初始化(Reducer阶段)结合,大幅减少通信和I/O成本,同时保持较好的聚类质量。此外,论文引入了基于三角不等式的剪枝策略,进一步减少冗余距离计算,从而提升算法效率。该方法特别适合处理海量数据(如TB或PB级),并在理论上证明了其对 k k k-means最优解的 O ( α 2 ) O(\alpha^2) O(α2)近似保证。
目标函数
k k k-means算法的目标是通过最小化平方误差和(Sum of Squared Error, SSE)来划分数据点到 k k k个簇。给定数据集 X = { x 1 , x 2 , … , x n } X = \{x_1, x_2, \ldots, x_n\} X={x1,x2,…,xn},其中 x i ∈ R d x_i \in \mathbb{R}^d xi∈Rd,目标是找到 k k k个中心集合 C = { c 1 , c 2 , … , c k } C = \{c_1, c_2, \ldots, c_k\} C={c1,c2,…,ck},使SSE最小:
SSE ( C ) = ∑ x ∈ X min c ∈ C ∥ x − c ∥ 2 \operatorname{SSE}(C) = \sum_{x \in X} \min_{c \in C} \|x - c\|^2 SSE(C)=x∈X∑c∈Cmin∥x−c∥2
其中, ∥ x − c ∥ \|x - c\| ∥x−c∥表示 x x x和 c c c之间的欧几里得距离。令 C OPT C_{\text{OPT}} COPT表示最优中心集合, S S E OPT SSE_{\text{OPT}} SSEOPT为其对应的SSE。一个解 C C C被称为 α \alpha α近似解,若满足:
SSE ( C ) ≤ α ⋅ S S E OPT \operatorname{SSE}(C) \leq \alpha \cdot SSE_{\text{OPT}} SSE(C)≤α⋅SSEOPT
传统 k k k-means++通过概率选择初始中心,达到 O ( α ) O(\alpha) O(α)近似保证。论文提出的MapReduce k k k-means++算法继承了这一目标函数,但在初始化阶段通过MapReduce框架优化中心选择过程,理论上证明其达到 O ( α 2 ) O(\alpha^2) O(α2)近似保证。
目标函数的优化过程
MapReduce k k k-means++算法的优化过程主要集中在初始化阶段,通过一次MapReduce作业选择 k k k个初始中心,然后结合标准的 k k k-means迭代优化SSE。优化过程分为Mapper阶段和Reducer阶段,具体如下:
-
Mapper阶段(标准 k k k-means++初始化):
- 输入:数据集 X = { x 1 , x 2 , … , x n } X = \{x_1, x_2, \ldots, x_n\} X={x1,x2,…,xn},簇数 k k k。
- 过程:
- 随机均匀选择第一个中心 c 1 c_1 c1,加入中心集合 C C C。
- 对于剩余的 k − 1 k-1 k−1个中心,计算每个点 x ∈ X x \in X x∈X到最近已选中心的距离 D ( x ) D(x) D(x),按概率 D ( x ) 2 ∑ x ∈ X D ( x ) 2 \frac{D(x)^2}{\sum_{x \in X} D(x)^2} ∑x∈XD(x)2D(x)2选择下一个中心,加入 C C C。
- 遍历所有数据点,计算每个点到最近中心的分配,并记录每个中心 c i c_i ci代表的点数 n u m [ i ] num[i] num[i]。
- 输出:键值对 ⟨ n u m [ i ] , c i ⟩ \langle num[i], c_i \rangle ⟨num[i],ci⟩,表示每个中心的点数和中心位置。
- 时间复杂度: O ( k n d ) O(knd) O(knd),其中 n n n是数据点数, d d d是维度。
-
Reducer阶段(加权 k k k-means++初始化):
- 输入:Mapper阶段输出的 ⟨ n u m [ i ] , c i ⟩ \langle num[i], c_i \rangle ⟨num[i],ci⟩集合。
- 过程:
- 随机均匀选择第一个中心,加入 C C C。
- 对于剩余的 k − 1 k-1 k−1个中心,计算每个点 x x x(来自Mapper输出的中心)到最近已选中心的距离 D ( x ) D(x) D(x),按加权概率 n u m ⋅ D ( x ) 2 ∑ x ∈ X n u m ⋅ D ( x ) 2 \frac{num \cdot D(x)^2}{\sum_{x \in X} num \cdot D(x)^2} ∑x∈Xnum⋅D(x)2num⋅D(x)2选择下一个中心,加入 C C C。
- 输出:最终的 k k k个中心集合 C = { c 1 , c 2 , … , c k } C = \{c_1, c_2, \ldots, c_k\} C={c1,c2,…,ck}。
- 目的:通过加权概率,考虑Mapper阶段每个中心的代表性(点数),提高中心选择的质量。
-
后续 k k k-means迭代:
- 使用Reducer阶段得到的初始中心,执行标准的 k k k-means算法(Lloyd迭代),即:
- 将每个数据点分配到最近的中心,更新簇。
- 计算每个簇的质心作为新的中心。
- 重复直到中心稳定或达到最大迭代次数。
- 使用Reducer阶段得到的初始中心,执行标准的 k k k-means算法(Lloyd迭代),即:
-
剪枝策略(改进版本):
- 基于三角不等式,减少距离计算:
- 定理2:若已有中心 o o o代表点集 B B B,新中心 c c c满足 ∥ o − c ∥ 2 ≥ 2 ∥ o − b ∥ 2 \|o - c\|^2 \geq 2\|o - b\|^2 ∥o−c∥2≥2∥o−b∥2( b b b是 B B B中最远的点),则 B B B中的点无需计算到 c c c的距离,仍属于 o o o。
- 推论1:若 ∥ o − c ∥ 2 < 2 ∥ o − b ∥ 2 \|o - c\|^2 < 2\|o - b\|^2 ∥o−c∥2<2∥o−b∥2,可找到点 d ∈ B d \in B d∈B,满足 ∥ o − c ∥ 2 = 2 ∥ o − d ∥ 2 \|o - c\|^2 = 2\|o - d\|^2 ∥o−c∥2=2∥o−d∥2,则距离 o o o小于等于 ∥ o − d ∥ 2 \|o - d\|^2 ∥o−d∥2的点无需计算到 c c c的距离。
- 这些规则通过几何约束(圆形区域)避免冗余计算,显著降低计算开销。
- 基于三角不等式,减少距离计算:
-
理论保证:
- 论文证明算法的SSE满足:
∑ x ∈ X min c ∈ C ∥ x − c ∥ 2 ≤ ( α 2 + 2 α ) ∑ x ∈ X min c ∈ C OPT ∥ x − c ∥ 2 \sum_{x \in X} \min_{c \in C} \|x - c\|^2 \leq (\alpha^2 + 2\alpha) \sum_{x \in X} \min_{c \in C_{\text{OPT}}} \|x - c\|^2 x∈X∑c∈Cmin∥x−c∥2≤(α2+2α)x∈X∑c∈COPTmin∥x−c∥2
即 O ( α 2 ) O(\alpha^2) O(α2)近似。证明基于三角不等式,考虑Mapper和Reducer阶段的中心选择误差。
- 论文证明算法的SSE满足:
主要的贡献点
- 高效MapReduce初始化:
- 提出仅用一次MapReduce作业选择 k k k个初始中心的算法,相比传统 k k k-means++的 2 k 2k 2k次MapReduce作业,大幅减少通信和I/O成本。
- 理论近似保证:
- 证明算法达到 O ( α 2 ) O(\alpha^2) O(α2)近似,略低于 k k k-means++的 O ( α ) O(\alpha) O(α),但仍优于随机初始化,且适合大规模数据。
- 剪枝策略:
- 引入基于三角不等式的剪枝方法,显著减少冗余距离计算,尤其在高维和大规模数据上效果明显。
- 实验验证:
- 在真实(Oxford Buildings)和合成数据集上验证了算法的高效性和近似质量,优于随机初始化和部分并行 k k k-means++实现。
- 系统实现:
- 在Hadoop上实现,解决了全局信息通信(通过Job Configuration和Distributed Cache)和数据流处理(通过cleanup函数)等技术问题。
实验结果
实验在一个由12台机器组成的Hadoop集群上进行(1主节点,11从节点,每节点2核CPU、8GB内存),使用Hadoop 0.20.2,数据集包括:
- Oxford Buildings数据集:5062张图像,提取17M+个128维SIFT特征,5.67GB。
- 合成数据集:20M+个128维点,围绕5000个中心生成,15GB。
主要实验结果如下:
-
效率比较(MapReduce k k k-means++ vs 可扩展 k k k-means++):
- MapReduce k k k-means++仅需一次MapReduce作业,而可扩展 k k k-means++需要多次作业,导致更高的通信和I/O成本。单机迭代替换多机迭代显著提升效率。
-
近似质量(MR-KMI vs MR-RI):
- 在Oxford数据集上,MR-KMI的SSE比MR-RI低约 10 11 10^{11} 1011( k = 1000 k=1000 k=1000至5000),且更稳定。
- 在合成数据集上,MR-KMI的SSE比MR-RI低2个数量级( 10 10 10^{10} 1010 vs 10 12 10^{12} 1012),当 k = 5000 k=5000 k=5000时,MR-KMI的SSE约为MR-RI的1/13(表2)。
- MR-KMI的初始化更接近最终解,Oxford数据集上SSE初始化/SSE迭代=5为1.41(MR-KMI)vs 1.53(MR-RI),合成数据集为1.96 vs 47.39。
-
近似质量(MR-KM++ vs MR-KM):
- 在Oxford数据集上,MR-KM++的SSE在5次迭代后比MR-KM低,最大差距在第一次迭代( 3 × 10 10 3 \times 10^{10} 3×1010)。
- 在合成数据集上,MR-KM++的SSE约为MR-KM的1/10(第一次迭代),且在3-5次迭代后稳定(约 1.02 × 10 10 1.02 \times 10^{10} 1.02×1010,表3),显示更快收敛。
-
剪枝策略效率(IMR-KMI vs MR-KMI):
- 在合成数据集上,IMR-KMI在Reducer阶段减少99%的距离计算,Mapper阶段减少96%(表5)。
- 在Oxford数据集上,减少幅度较小,但随 k k k增加更显著,最大减少18.6%(Mapper, k = 5000 k=5000 k=5000)和22.4%(Reducer, k = 5000 k=5000 k=5000,表4)。
- 剪枝效果在合成数据集上更强,可能因其点分布更规则。
算法的实现过程
以下是MapReduce k k k-means++算法的详细实现过程,结合伪代码说明:
Input: 数据集 X = {x_1, x_2, ..., x_n}, 簇数 k
Output: 初始中心集合 C = {c_1, c_2, ..., c_k}1. Mapper阶段:for 每个 Mapper 任务 do// 初始化C ← ∅随机均匀选择 x ∈ X 作为第一个中心,C ← C ∪ {x}num[i] ← 0, ∀i=1,...,k// 选择 k 个中心while |C| < k do计算 D(x) = min_{c ∈ C} ||x - c||^2, ∀x ∈ X按概率 P(x) = D(x)^2 / Σ_{x ∈ X} D(x)^2 选择 xC ← C ∪ {x}// 分配点并计数for 每个 x_i ∈ X do找到最近的中心 c_j ∈ Cnum[j] ← num[j] + 1输出 <num[j], c_j>, ∀j=1,...,kend2. Reducer阶段:// 初始化C ← ∅随机均匀选择 x ∈ {<num, c>} 作为第一个中心,C ← C ∪ {x}// 选择 k 个中心while |C| < k do计算 D(x) = min_{c ∈ C} ||x - c||^2, ∀x ∈ {<num, c>}按加权概率 P(x) = num * D(x)^2 / Σ_{x} num * D(x)^2 选择 xC ← C ∪ {x}输出 C3. 剪枝策略(IMR-KMI):for 每个新中心 c dofor 每个已有中心 o 及其点集 B do找到 B 中最远点 b,满足 ||o - b||^2 最大if ||o - c||^2 ≥ 2 ||o - b||^2 thenB 中的点无需计算到 c 的距离,仍属于 oelse找到 d 满足 ||o - c||^2 = 2 ||o - d||^2对 B 中满足 ||o - x||^2 ≤ ||o - d||^2 的点,无需计算到 c 的距离endendend4. k-means迭代:使用 C 执行标准 k-means:分配每个点到最近中心,更新簇计算簇质心作为新中心重复直到收敛
实现细节:
- Hadoop实现:
- 使用Job Configuration传递小量全局信息,Distributed Cache传递大数据。
- 通过cleanup函数处理Mapper和Reducer中的顺序计算,解决数据流式处理的限制。
- Mapper阶段:
- 每个Mapper处理64MB数据块,独立运行 k k k-means++初始化。
- 输出中心及其代表点数,供Reducer使用。
- Reducer阶段:
- 使用加权概率整合Mapper结果,选择最终 k k k个中心。
- 剪枝策略:
- 在Mapper和Reducer阶段应用定理2和推论1,基于几何约束(圆形区域)跳过不必要的距离计算。
- 时间复杂度:
- Mapper阶段: O ( k n d ) O(knd) O(knd),Reducer阶段: O ( k m d ) O(kmd) O(kmd)( m m m是Mapper输出中心数, m ≪ n m \ll n m≪n)。
- 剪枝策略显著降低实际计算量,尤其在合成数据集上。
总结
MapReduce k k k-means++算法通过一次MapReduce作业实现高效初始化,结合剪枝策略和理论证明,解决了传统 k k k-means++在大规模数据上的低效问题。其在真实和合成数据集上的实验结果验证了其高效性和良好的近似质量,特别适合云计算环境下的海量数据聚类任务。
相关文章:
TPDS-2014《Efficient $k$-means++ Approximation with MapReduce》
推荐深蓝学院的《深度神经网络加速:cuDNN 与 TensorRT》,课程面向就业,细致讲解CUDA运算的理论支撑与实践,学完可以系统化掌握CUDA基础编程知识以及TensorRT实战,并且能够利用GPU开发高性能、高并发的软件系统…...

地理特征类可视化图像
目录 一、蜂窝热力地图 1. 特点 (1)优点 (2)缺点 2. 应用场景 3.python代码实现 (1)代码 (2)实现结果 二、变形地图 1. 特点 (1)优点 (2)缺点 2. 应用场景 3.python代码实现 (1)代码 (2)实现结果 三、关联地图 1. 特点 (1)优点 (2)缺点 2. 应用场景 3.pyth…...

【Java高阶面经:微服务篇】8.高可用全链路治理:第三方接口不稳定的全场景解决方案
一、第三方接口治理的核心挑战与架构设计 1.1 不稳定接口的典型特征 维度表现影响范围响应时间P99超过2秒,波动幅度大(如100ms~5s)导致前端超时,用户体验恶化错误率随机返回5xx/429,日均故障3次以上核心业务流程中断,交易失败率上升协议不一致多版本API共存,字段定义不…...
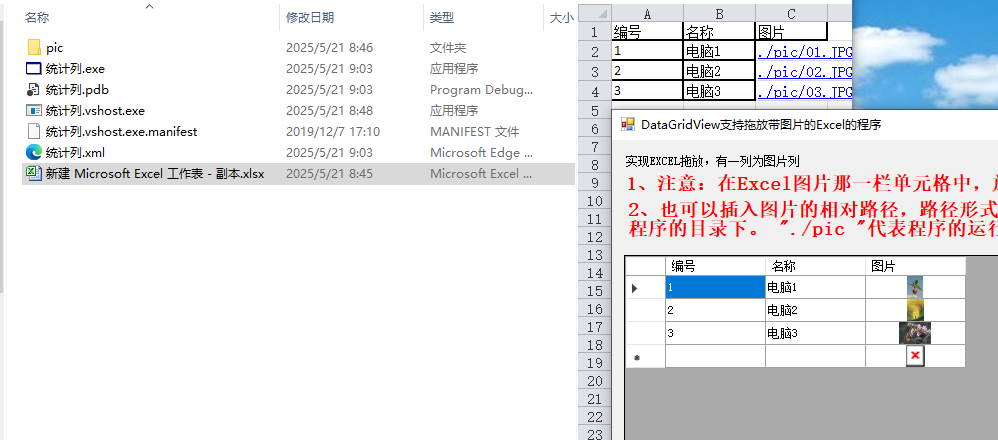
DataGridView中拖放带有图片的Excel,实现数据批量导入
1、带有DataGridView的窗体,界面如下 2、编写DataGridView支持拖放的代码 Private Sub DataGridView1_DragEnter(ByVal sender As Object, ByVal e As DragEventArgs) Handles DataGridView1.DragEnterIf e.Data.GetDataPresent(DataFormats.FileDrop) ThenDim file…...
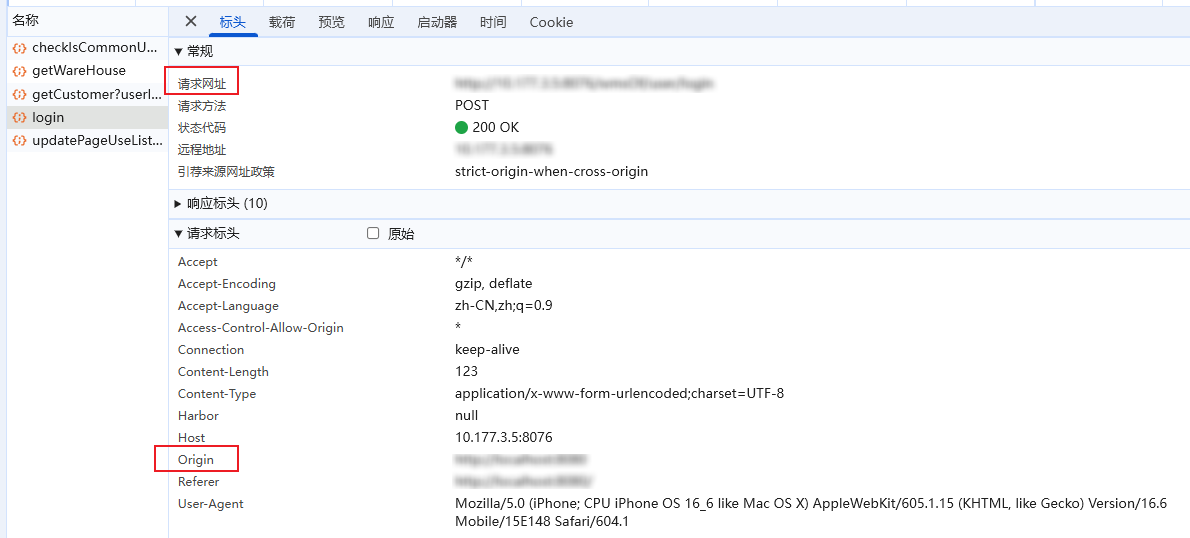
跨域_Cross-origin resource sharing
同源是指"协议域名端口"三者相同,即便两个不同的域名指向同一个ip,也非同源 1.什么是CORS? CORS是一个W3C标准,全称是"跨域资源共享"(Cross-origin resource sharing)。它允许浏览器向跨源服务器ÿ…...

Opencv常见学习链接(待分类补充)
文章目录 1.常见学习链接 1.常见学习链接 1.Opencv中文官方文档 2.Opencv C图像处理:矩阵Mat 随机数RNG 计算耗时 鼠标事件 3.Opencv C图像处理:亮度对比度饱和度高光暖色调阴影漫画效果白平衡浮雕羽化锐化颗粒感 4.OpenCV —— 频率域滤波ÿ…...
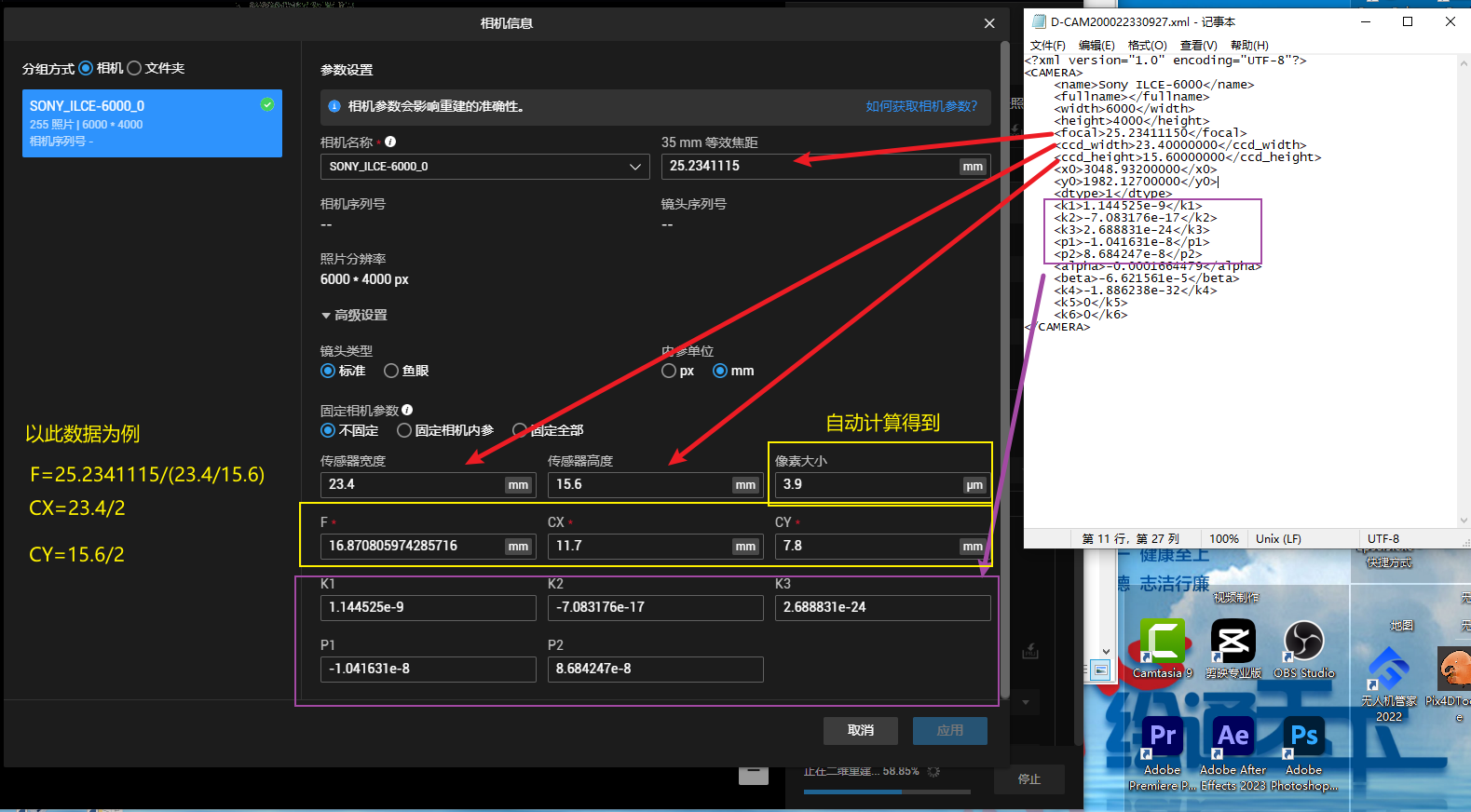
大疆制图跑飞马D2000的正射与三维模型
1 问题描述 大疆制图在跑大疆无人机飞的影像的时候,能够自动识别相机参数并且影像自带pos信息,但是用飞马无人机获取的影像pos信息与影像是分开的(飞马无人机数据处理有讲),所以在用大疆制图时需要对相机参数进行设置…...

PostgreSQL中的权限管理简介
在 PostgreSQL 中,权限管理是非常重要的,它允许管理员控制用户对数据库对象的访问权限。其中,权限管理是通过角色和权限来实现的。角色可以是用户、组或者其他角色,而权限则控制了角色对数据库对象的访问权限。 1.用户和角色 在…...

ConceptAttention:Diffusion Transformers learn highly interpretable features
ConceptAttention: Diffusion Transformers Learn Highly Interpretable Featureshttps://arxiv.org/html/2502.04320?_immersive_translate_auto_translate=1用flux的attention来做图文的显著性分析。 1.i...
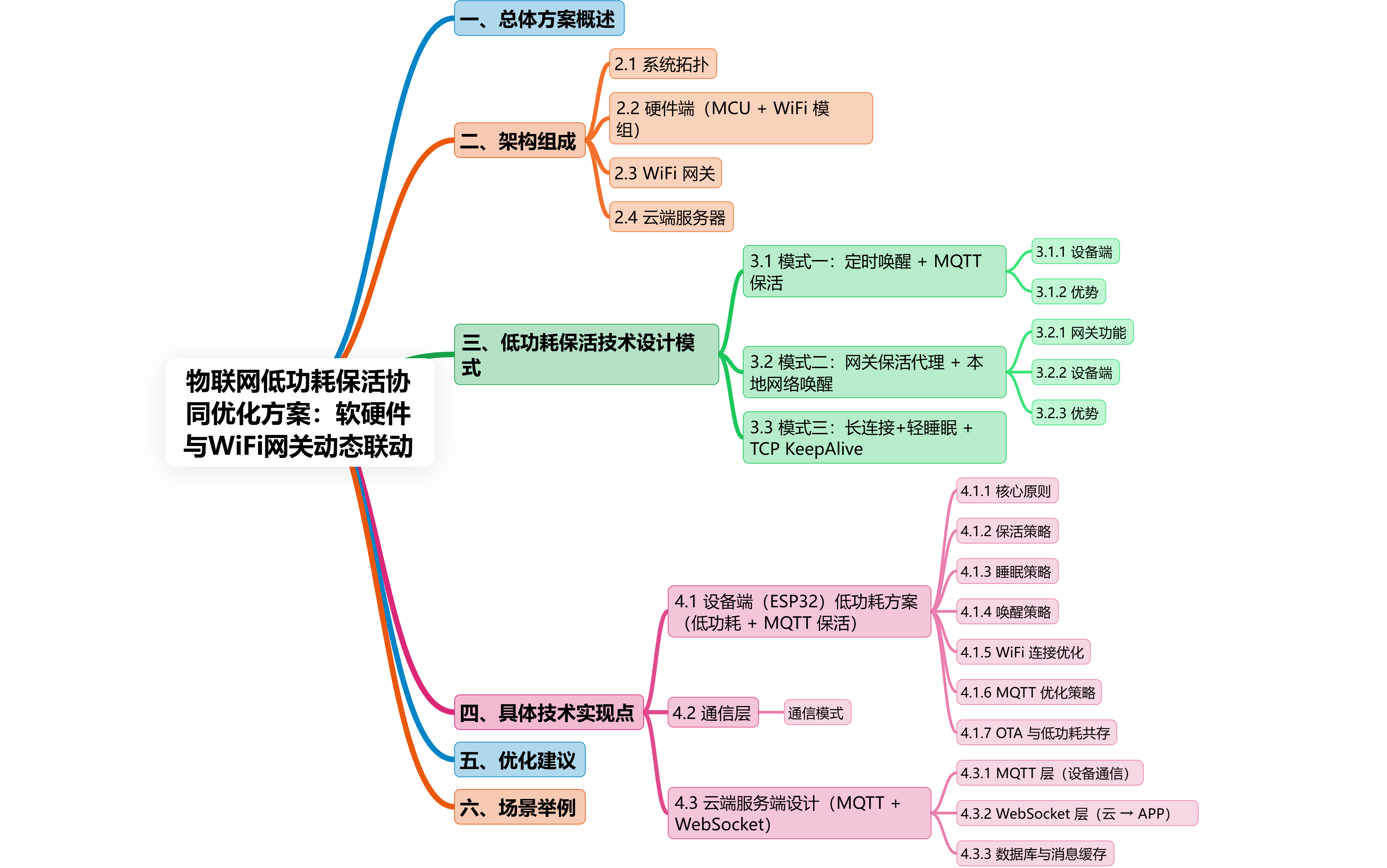
物联网低功耗保活协同优化方案:软硬件与WiFi网关动态联动
目录 一、总体方案概述 二、架构组成 2.1 系统拓扑 2.2 硬件端(MCU + WiFi 模组) 2.3 WiFi 网关 2.4 云端服务器 三、低功耗保活技术设计模式 3.1 模式一:定时唤醒 + MQTT 保活 3.1.1 设备端 3.1.2 优势 3.2 模式二:网关保活代理 + 本地网络唤醒 3.2.1 网关功能…...
LW-CTrans:一种用于三维医学图像分割的轻量级CNN与Transformer混合网络|文献速递-深度学习医疗AI最新文献
Title 题目 LW-CTrans: A lightweight hybrid network of CNN and Transformer for 3Dmedical image segmentation LW-CTrans:一种用于三维医学图像分割的轻量级CNN与Transformer混合网络 01 文献速递介绍 三维医学图像分割旨在从计算机断层扫描(CT…...

光谱相机在地质勘测中的应用
一、矿物识别与蚀变带分析 光谱特征捕捉 通过可见光至近红外(400-1000nm)的高光谱分辨率(可达3.5nm),精确识别矿物的“光谱指纹”。例如: 铜矿:在400-500nm波段反射率显著低于围…...

Autodl训练Faster-RCNN网络(自己的数据集)
参考文章: Autodl服务器中Faster-rcnn(jwyang)复现(一)_autodl faster rcnn-CSDN博客 Autodl服务器中Faster-rcnn(jwyang)训练自己数据集(二)_faster rcnn autodl-CSDN博客 环境配置 我到下载torch这一步老是即将结束的时候自动结束进程,所以还是自己…...
)
每日两道leetcode(今天开始刷基础题模块——这次是之前的修改版)
1768. 交替合并字符串 - 力扣(LeetCode) 题目 给你两个字符串 word1 和 word2 。请你从 word1 开始,通过交替添加字母来合并字符串。如果一个字符串比另一个字符串长,就将多出来的字母追加到合并后字符串的末尾。 返回 合并后的…...
)
服务器数据迁移终极指南:网站、数据库、邮件无缝迁移策略与工具实战 (2025)
嘿,各位服务器的“大管家”们!咱们在IT江湖闯荡,总有那么些时候,不得不面对一个既重要又可能让人头皮发麻的任务——服务器迁移!可能是因为旧服务器“年事已高”想给它换个“新家”,也可能是业务发展太快&a…...
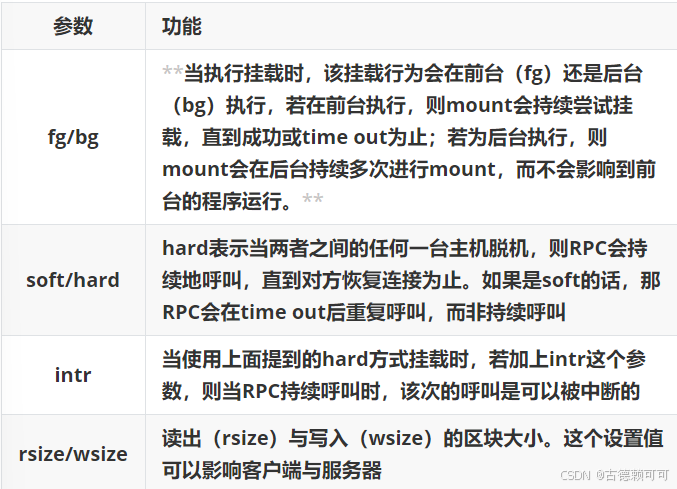
NFS服务小实验
实验1 建立NFS服务器,使的客户端顺序共享数据 第一步:服务端及客户端的准备工作 # 恢复快照 [rootserver ~]# setenforce 0 [rootserver ~]# systemctl stop firewalld [rootserver ~]# yum install nfs-utils -y # 服务端及客户端都安装 …...

vue 中的v-once
🔰 基础理解 ✅ 语法: <span v-once>{{ msg }}</span>✅ 效果: • 只渲染一次,之后无论数据如何变化,该内容都不会更新。 • 非常适用于静态内容或首次加载后不需要变化的数据。🧪 示例&…...
鸿蒙ArkTS-发请求第三方接口显示实时新闻列表页面
发请求展示新闻列表 鸿蒙ArkTS-发请求第三方接口显示实时新闻列表页面 1. 效果图 新闻首页: 点击某一新闻的详情页面(需要使用模拟器才能查看详情页面): 2. 代码 1. key准备 首先需求到聚合网申请一个key,网址如下…...

2025年开源大模型技术全景图
迈向2025年,开源大型语言模型(LLM)生态系统已不再仅仅是闭源模型的补充,而是成为推动AI创新与民主化的核心引擎。其技术全景展现了一个高度模块化、协作共生且快速演进的复杂网络。以下是对提供的蓝图进行更细致的解读,…...

【创造型模式】工厂方法模式
文章目录 工厂方法模式工厂方法模式当中的角色和职责工厂方法模式的实现工厂方法模式的优缺点 工厂方法模式 今天我们继续学习一例创造型设计模式——工厂方法模式。参考的主要资料是刘丹冰老师的《Easy 搞定 Golang 设计模式》。 工厂方法模式当中的角色和职责 简单来说&…...
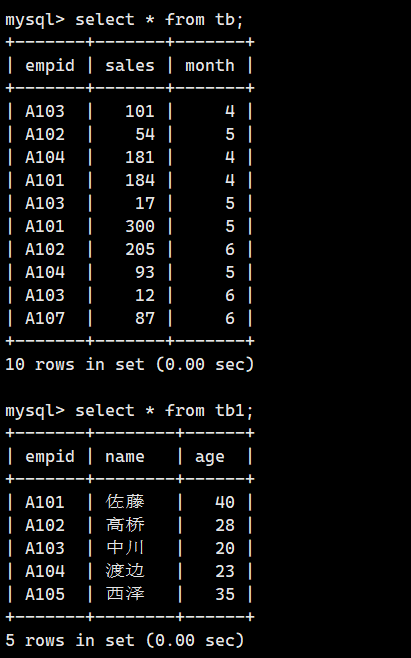
【MySQL】使用文件进行交互
目录 准备工作 1.从文本文件中读取数据(导入) 1.1.CSV 文件 1.2.设置导入导出的路径 1.3.导入文件 1.4.将数据写入文本文件(导出) 2.从文件中读取并执行SQL命令 2.1.通过mysql监视器执行编写在文件里面的SQL语句 2.2.通过…...

# 大模型的本地部署与应用:从入门到实战
大模型的本地部署与应用:从入门到实战 在当今人工智能飞速发展的时代,大模型(尤其是大型语言模型,LLMs)已经成为自然语言处理(NLP)领域的核心力量。从文本生成、机器翻译到问答系统,…...

布丁扫描高级会员版 v3.5.2.2| 安卓智能扫描 APP OCR文字识别小助手
布丁扫描高级会员版 v3.5.2.2| 安卓智能扫描 APP OCR文字识别小助手 布丁扫描APP是一款集成了先进图像处理与OCR文字识别技术的智能扫描软件。它旨在将纸质文档、照片、名片、书籍等各类实体资料快速…...

可视化大屏全屏后重载echarts图表
问题:可视化大屏点击全屏之后,但echarts图表还是之前的大小,并没有撑满该容器,所以这时候我们需要全屏之后重新加载echarts图表内容 代码如下: // 全屏或非全屏状态下重新加载图表window.onresize () > {//lineCh…...

20200201工作笔记常用命令要整理
工作笔记常用命令: 1.repo常用命令: repo sync -c -j10 2. 常用adb命令 错误: error: device unauthorized. This adbds $ADB_VENDOR_KEYS is not set; try adb kill-server if that seems wrong. Otherwise check for a confirmation dialog on your d…...

Java对象内存模型、如何判定对象已死亡?
一、Java对象内存模型 Java对象在内存中由三部分组成: 含类元数据指针(指向方法区的Class对象)和Mark Word(存储对象哈希码、锁状态、GC分代年龄等信息)。 若为数组对象,还包含数组长度数据。 1,…...

spark任务的提交流程
目录 spark任务的提交流程1. 资源申请与初始化2. 任务划分与调度3. 任务执行4. 资源释放与结果处理附:关键组件协作示意图扩展说明SparkContext介绍 spark任务的提交流程 用户创建一个 Spark Context;Spark Context 去找 Cluster Manager 申请资源同时说明需要多少 CPU 和内…...

ELK简介和docker版安装
使用场景 主要还是给开发人员“打捞日志”用的。 ELK 是由三个开源工具组成的套件(Elasticsearch、Logstash 和 Kibana),主要用于日志的收集、分析和可视化。以下是 ELK 常见的使用场景: 日志集中化管理 收集来自多个服务器或服…...

利用条件编译实现RTT可控的调试输出
在嵌入式开发中,调试信息的输出通常对定位问题至关重要。然而,为了保证代码在正式发布时的性能和体积,调试信息往往需要在不修改主逻辑代码的前提下禁用。 代码一览 // debug.h #pragma once// #define DEBUG#ifdef DEBUG#include "SEG…...

【软件设计师】计算机网络考点整理
以下是软件设计师考试中 计算机网络 的核心考点总结,帮助您高效备考: 一、网络体系结构与协议 OSI七层模型 & TCP/IP四层模型 各层功能(物理层-数据链路层-网络层-传输层-会话层-表示层-应用层)对应协…...