二、ZooKeeper 集群部署搭建
作者:IvanCodes
日期:2025年5月24日
专栏:Zookeeper教程

我们这次教程将以 hadoop01 (192.168.121.131), hadoop02 (192.168.121.132), hadoop03 (192.168.121.133) 三台Linux服务器为例,搭建一个ZooKeeper 3.8.4集群。
一、下载ZooKeeper软件包 (在 hadoop01 操作)
- 访问官方发布页面:
- 首先,请打开您的浏览器,访问 Apache ZooKeeper官方发布页面:
- 定位并下载指定版本:
- 在打开的页面中,找到 “Download” 部分。
- 您需要选择 Apache ZooKeeper 3.8.4 版本。点击对应的下载链接。通常,您会看到一个建议的下载镜像链接。
- 从上图所示的镜像站点下载 二进制包 (binary package),文件名通常为
apache-zookeeper-3.8.4-bin.tar.gz。 - 将下载好的
apache-zookeeper-3.8.4-bin.tar.gz文件上传到hadoop01服务器的/export/softwares目录下 (如果该目录不存在,请先创建:mkdir -p /export/softwares)。
二、解压与准备 (在 hadoop01 操作)
- 解压ZooKeeper安装包:
- 目标安装路径为
/export/server。
- 目标安装路径为
在 hadoop01 上执行:
cd /export/softwares
tar -zxvf apache-zookeeper-3.8.4-bin.tar.gz -C /export/server/
cd /export/server
mv apache-zookeeper-3.8.4-bin zookeeper
三、配置环境变量 (所有节点:hadoop01, hadoop02, hadoop03)
为了方便全局使用ZooKeeper命令,需要在所有三个节点上配置环境变量。
在 hadoop01, hadoop02, hadoop03 上分别执行以下命令:
echo 'export ZOOKEEPER_HOME=/export/server/zookeeper' >> /etc/profile
echo 'export PATH=$PATH:/export/server/zookeeper/bin' >> /etc/profile
source /etc/profile
如何查看环境变量是否配置成功? (在任一节点执行)
echo $ZOOKEEPER_HOME
# 应输出 /export/server/zookeeper
echo $PATH
# 应能看到 /export/server/zookeeper/bin 在路径中
zkServer.sh version
# 如果PATH配置正确,此命令会显示ZooKeeper版本信息
四、同步ZooKeeper至其他节点 (在 hadoop01 操作)
在 hadoop01 上完成解压后,将配置好的 /export/server/zookeeper 目录同步到 hadoop02 和 hadoop03。(其他节点此时也应已完成步骤三的环境变量配置)。
在 hadoop01 上执行:
scp -r /export/server/zookeeper root@hadoop02:/export/server/
scp -r /export/server/zookeeper root@hadoop03:/export/server/
提示:确保 hadoop01 对 hadoop02 和 hadoop03 有SSH免密登录权限,或在执行 scp 时按提示输入密码。
五、创建数据目录与配置myid (各节点分别操作)
ZooKeeper集群中每个节点都需要一个唯一的ID号 (myid),存储在其数据目录下的 myid 文件中。
在 hadoop01 上执行:
mkdir -p /export/data/zookeeper
echo "1" > /export/data/zookeeper/myid
在 hadoop02 上执行:
mkdir -p /export/data/zookeeper
echo "2" > /export/data/zookeeper/myid
在 hadoop03 上执行:
mkdir -p /export/data/zookeeper
echo "3" > /export/data/zookeeper/myid
六、修改核心配置文件zoo.cfg (在 hadoop01 操作后分发)
ZooKeeper的主要配置文件是 zoo.cfg。我们先在 hadoop01 上创建并修改,然后分发到其他节点以保持配置一致。
在 hadoop01 上执行:
cd /export/server/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
使用文本编辑器 vim 修改 /export/server/zookeeper/conf/zoo.cfg 文件,确保内容如下:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/export/data/zookeeper
clientPort=2181
# autopurge.snapRetainCount=3
# autopurge.purgeInterval=1server.1=hadoop01:2888:3888
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
4lw.commands.whitelist=stat,ruok,conf,srvr,mntr
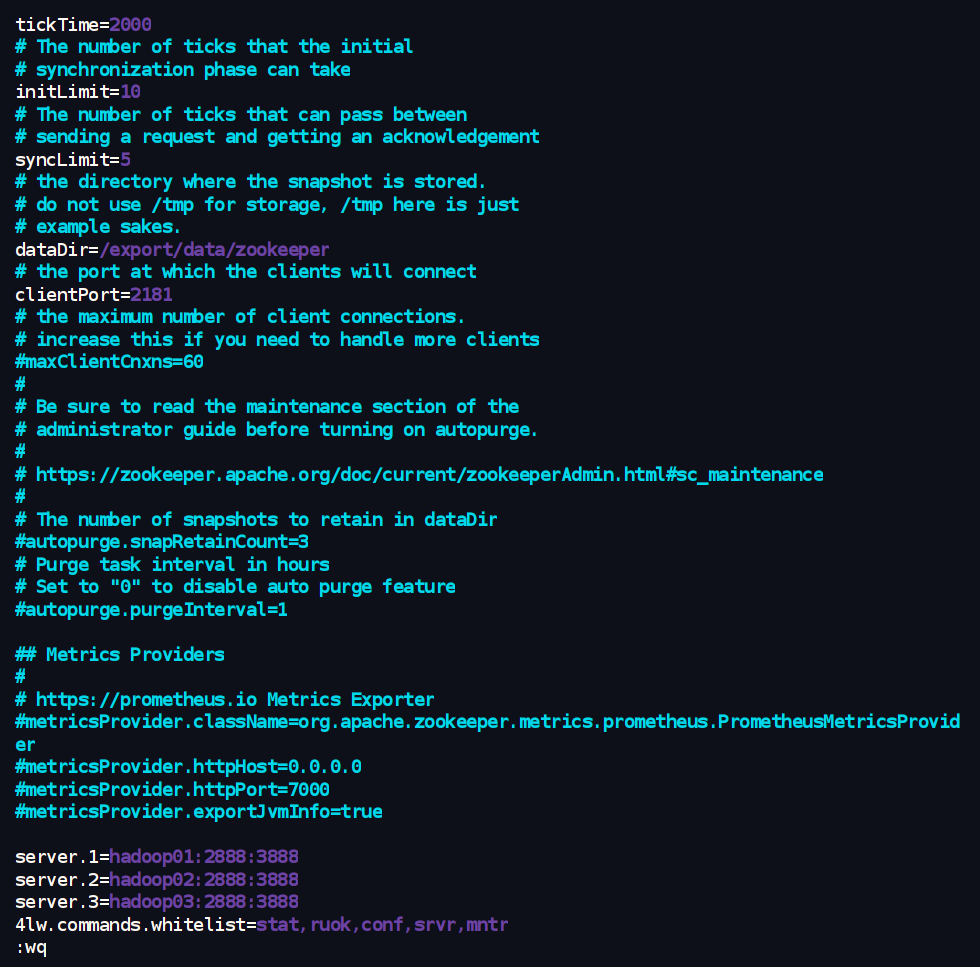
配置项重点:
dataDir=/export/data/zookeeper:指向您在步骤五中创建的数据目录。server.X=hostname:peerPort:leaderPort:X对应各节点的myid文件内容。hostname使用您的实际主机名 (hadoop01,hadoop02,hadoop03)。2888是集群内节点间通信端口。3888是Leader选举端口。
- 客户端将通过
clientPort=2181连接。
分发修改好的 zoo.cfg 文件 (在 hadoop01 上执行):
scp /export/server/zookeeper/conf/zoo.cfg root@hadoop02:/export/server/zookeeper/conf/
scp /export/server/zookeeper/conf/zoo.cfg root@hadoop03:/export/server/zookeeper/conf/
七、启动ZooKeeper集群服务 (所有节点均需操作)
在每一个节点 (hadoop01, hadoop02, hadoop03) 上启动ZooKeeper服务。
在 hadoop01, hadoop02, hadoop03 上分别执行:
zkServer.sh start
提示:建议逐个启动,并在每个节点启动后间隔几秒,以便集群有时间进行初始化和选举。
八、验证集群状态
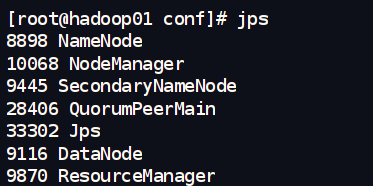
- 查看Java进程 (在任一节点执行):
jps
正常情况下,会看到一个名为 QuorumPeerMain 的Java进程。
- 查看节点角色 (在每个节点分别执行):
zkServer.sh status
此命令将显示当前节点是 Mode: leader 还是 Mode: follower。一个正常的3节点集群会有一个Leader和两个Follower。



九、常用ZooKeeper服务命令
这些命令通常在 ZOOKEEPER_HOME/bin 目录下,如果环境变量设置正确,可以直接执行。
# 启动ZooKeeper服务
zkServer.sh start
# 停止ZooKeeper服务
zkServer.sh stop
# 查看ZooKeeper服务状态(角色)
zkServer.sh status
# 重启ZooKeeper服务
zkServer.sh restart
# 在前台启动ZooKeeper服务(日志会直接输出到控制台)
zkServer.sh start-foreground
部署完成! ZooKeeper 集群现已配置完毕并准备就绪
相关文章:
二、ZooKeeper 集群部署搭建
作者:IvanCodes 日期:2025年5月24日 专栏:Zookeeper教程 我们这次教程将以 hadoop01 (192.168.121.131), hadoop02 (192.168.121.132), hadoop03 (192.168.121.133) 三台Linux服务器为例,搭建一个ZooKeeper 3.8.4集群。 一、下载…...
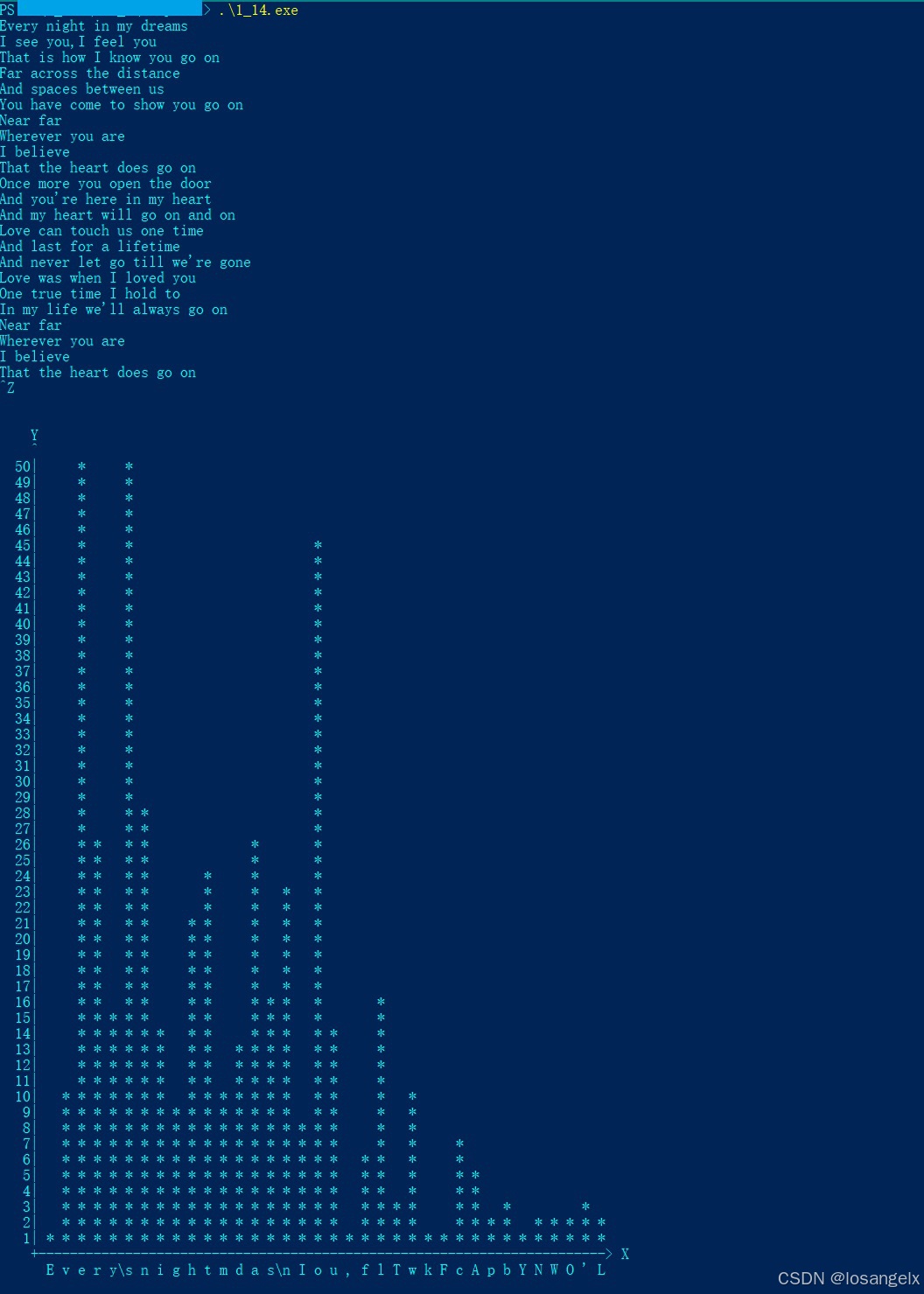
<< C程序设计语言第2版 >> 练习1-14 打印输入中各个字符出现频度的直方图
1. 前言 本篇文章是<< C程序设计语言第2版 >> 的第1章的编程练习1-14, 个人觉得还有点意思, 所以写一篇文章来记录下. 希望可以给初学C的同学一点参考. 尤其是自学的同学, 或者觉得以前学得不好, 需要自己补充学习的同学. 和我的很多其它文章一样, 不建议自己还没实…...
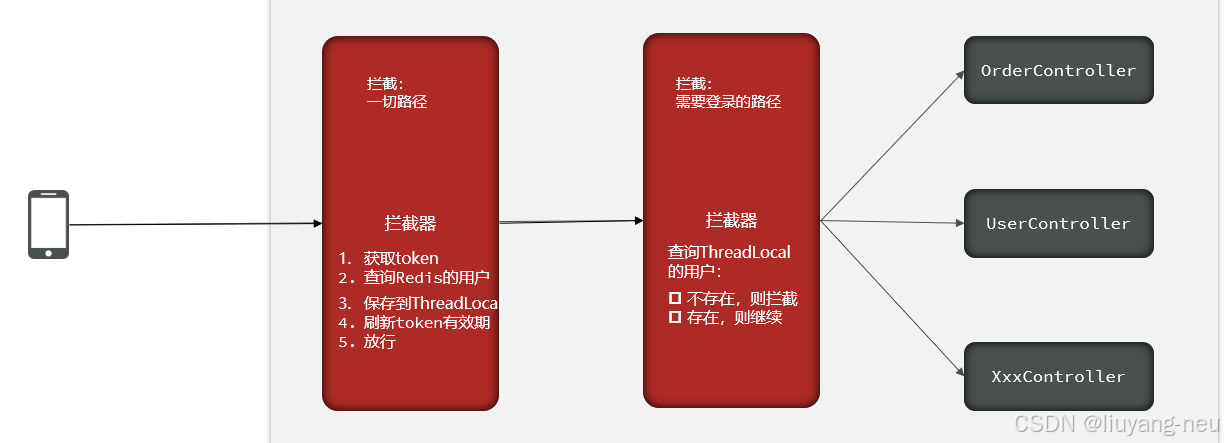
黑马点评双拦截器和Threadlocal实现原理
文章目录 双拦截器ThreadLocal实现原理 双拦截器 实现登录状态刷新的原因: 防止用户会话过期:通过动态刷新Token有效期,确保活跃用户不会因固定过期时间而被强制登出 提升用户体验:用户无需频繁重新登录,只要…...

港股IPO市场火爆 没有港卡如何参与港股打新?
据Wind资讯数据统计,今年1月1日至5月20日,港股共有23家企业IPO,较去年同期增加6家;IPO融资规模达600亿港元,较去年同期增长626.54%,IPO融资规模重回全球首位。 港股IPO市场持续火爆,不少朋友没有…...
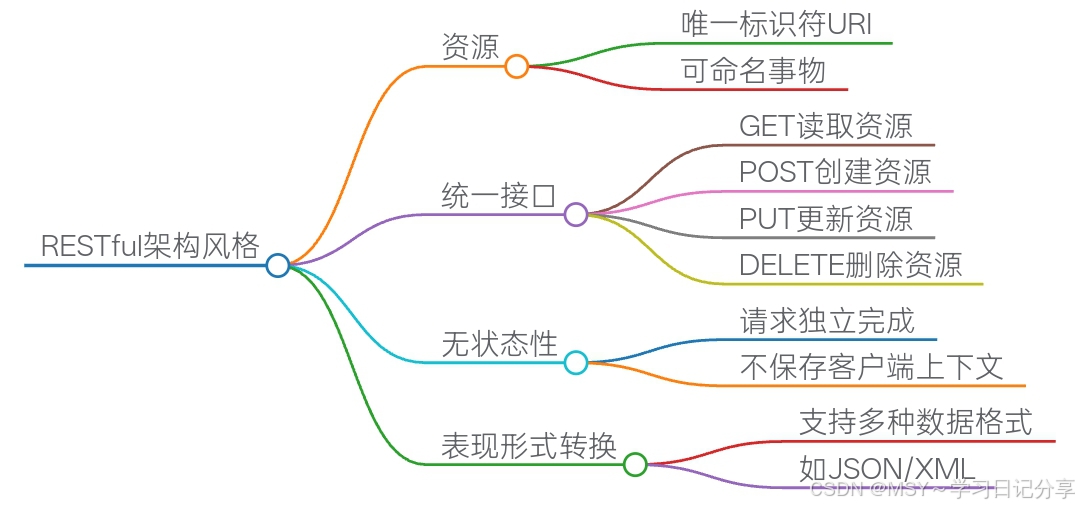
RESTful API 在前后端交互中的作用与实践
一、RESTful API 概述 RESTful(Representational State Transfer)API 是一种基于 HTTP 协议、面向资源的架构风格,旨在实现前后端的松散耦合和高效通信。它通过定义统一的资源标识、操作方法以及数据传输格式,为前后端提供了一种…...

Jenkins+Docker+Harbor快速部署Spring Boot项目详解
JenkinsDockerHarbor快速部署Spring Boot项目详解 Jenkins、Docker和Harbor是现代DevOps流程中的核心工具,结合使用可以实现自动化构建、测试和部署。下面我将详细介绍如何搭建这个集成环境。 一、各工具的核心作用 Jenkins 自动化CI/CD工具,负责拉取代…...
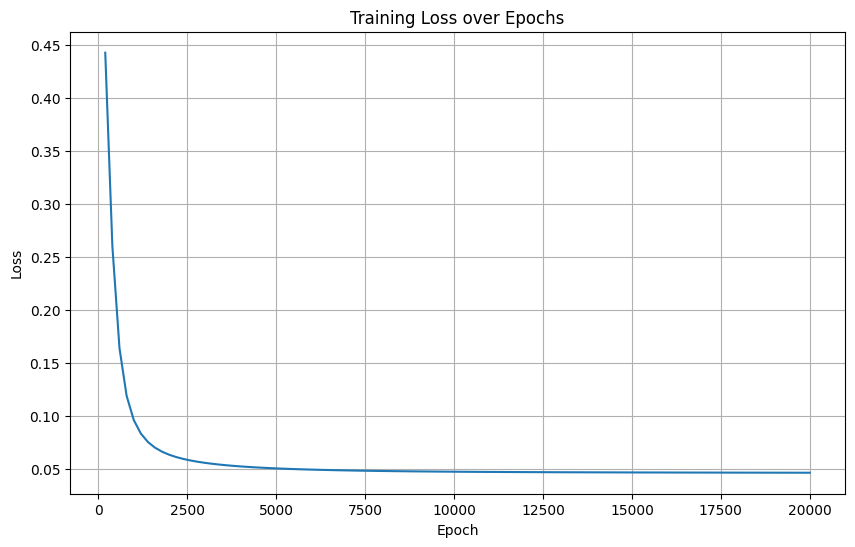
python打卡训练营打卡记录day35
知识点回顾: 三种不同的模型可视化方法:推荐torchinfo打印summary权重分布可视化进度条功能:手动和自动写法,让打印结果更加美观推理的写法:评估模式 作业:调整模型定义时的超参数,对比下效果 1…...
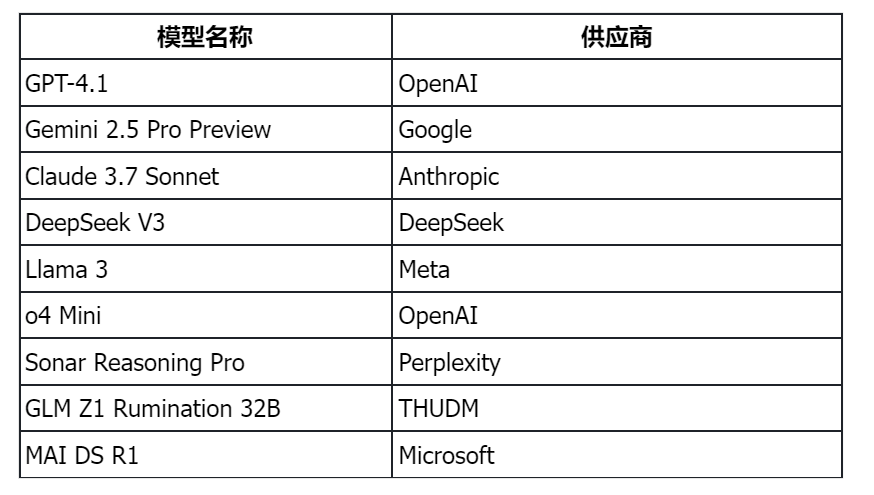
如何评价OpenRouter这样的大模型API聚合平台?
OpenRouter通过统一接口简化多模型访问与集成的复杂性,实现一站式调用。然而,这种便利性背后暗藏三重挑战:成本控制、服务稳定性、对第三方供应商的强依赖性。 现在AI大模型火得一塌糊涂,新模型层出不穷,各有各的长处。但是对于开发者来说,挨个去对接OpenAI、谷歌、Anthr…...

恢复二叉搜索树:递归与中序遍历的智慧应用
恢复二叉搜索树:递归与中序遍历的智慧应用 二叉搜索树(BST)是一种在算法世界里相当重要的数据结构,它的特性——左子树的节点值小于根节点,而右子树的节点值大于根节点——让它在查找、插入和删除操作上都能高效运行。然而,现实总是充满意外,有时候由于错误的操作或数据…...

从零开始构建一个区块链应用:技术解析与实践指南
区块链技术自比特币诞生以来,已经逐渐从金融领域扩展到更多行业,如供应链管理、物联网、智能合约等。它以其去中心化、不可篡改和透明性等特点,吸引了众多开发者的关注。然而,对于初学者来说,区块链技术的学习曲线可能…...

5.2.4 wpf中MultiBinding的使用方法
在 WPF 中,MultiBinding 允许将多个绑定(Binding)组合成一个逻辑结果,并通过一个转换器(IMultiValueConverter)处理这些值,最终影响目标属性。以下是其核心用法和示例: 核心组件: MultiBinding:定义多个绑定源的集合。 IMultiValueConverter:实现逻…...

技术服务业-首套运营商网络路由5G SA测试专网搭建完成并对外提供服务
为了更好的服务蜂窝无线技术及运营商测试认证相关业务,搭建了技术服务业少有的5G测试专网,可独立灵活配置、完整端到端5G(含RedCap、LAN)的网络架构。 通过走真正运营商网络路由的方式,使终端设备的测试和运营商网络兼…...

仿腾讯会议——音频服务器部分
1、中介者定义处理音频帧函数 2、 中介者实现处理音频帧函数 3、绑定函数映射 4、服务器定义音频处理函数 5、 服务器实现音频处理函数...

大文件上传,对接阿里oss采用前端分片技术。完成对应需求!
最近做了一个大文件分片上传的功能,记录下 1. 首先是安装阿里云 oss 扩展 composer require aliyuncs/oss-sdk-php 去阿里云 oss 获取配置文件 AccessKey ID *** AccessKey Secret *** Bucket名称 *** Endpoint *** 2. 前端上传,对文件进行分片…...

【场景分析】基于概率距离快速削减法的风光场景生成与削减方法
目录 1 主要内容 场景消减步骤 2 部分代码 3 程序结果 1 主要内容 该程序参考文献《含风光水的虚拟电厂与配电公司协调调度模型》场景消减部分模型,程序对风电场景进行生成并采用概率距离方法进行消减,程序先随机生成200个风电出力场景,然…...

【Java Web】3.SpringBootWeb请求响应
📘博客主页:程序员葵安 🫶感谢大家点赞👍🏻收藏⭐评论✍🏻 文章目录 一、请求 1.1 postman 1.2 简单参数 1.3 实体参数 1.4 数组集合参数 1.5 日期参数 1.6 JSON参数 1.7 路径参数 二、响应 2…...
单片机中断系统工作原理及定时器中断应用
文件目录 main.c #include <REGX52.H> #include "TIMER0.H" #include "KEY.H" #include "DELAY.H"//void Timer0_Init() { // TMOD 0x01; // TL0 64536 % 256; // TH0 64536 / 256; // ET0 1; // EA 1; // TR0 1; //}unsigned char…...
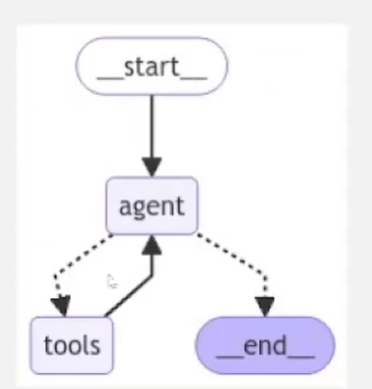
LangGraph-agent-天气助手
用于创建agent和多代理工作流 循环(有迭代次数)、可控、持久 安装langgraph包 conda create --name agent python3.12 conda activate agent pip install -U langgraph pip install langchain-openai设置 windows(>结尾) s…...
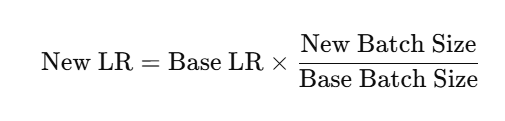
深度学习——超参数调优
第一部分:什么是超参数?为什么要调优? 一、参数 vs 超参数(Parameter vs Hyperparameter) 类型定义举例是否通过训练自动学习?参数(Parameter)是模型在训练过程中通过反向传播自动…...

阿里云API RAG全流程实战:从模型调用到多模态应用的完整技术链路
一、引言 在企业级智能应用开发中,如何让大模型高效利用动态数据并生成准确回答,是构建智能问答系统的核心挑战。阿里云提供的API RAG(检索增强生成)流程,通过整合通义千问大模型、百炼智能体平台与知识库管理体系&am…...
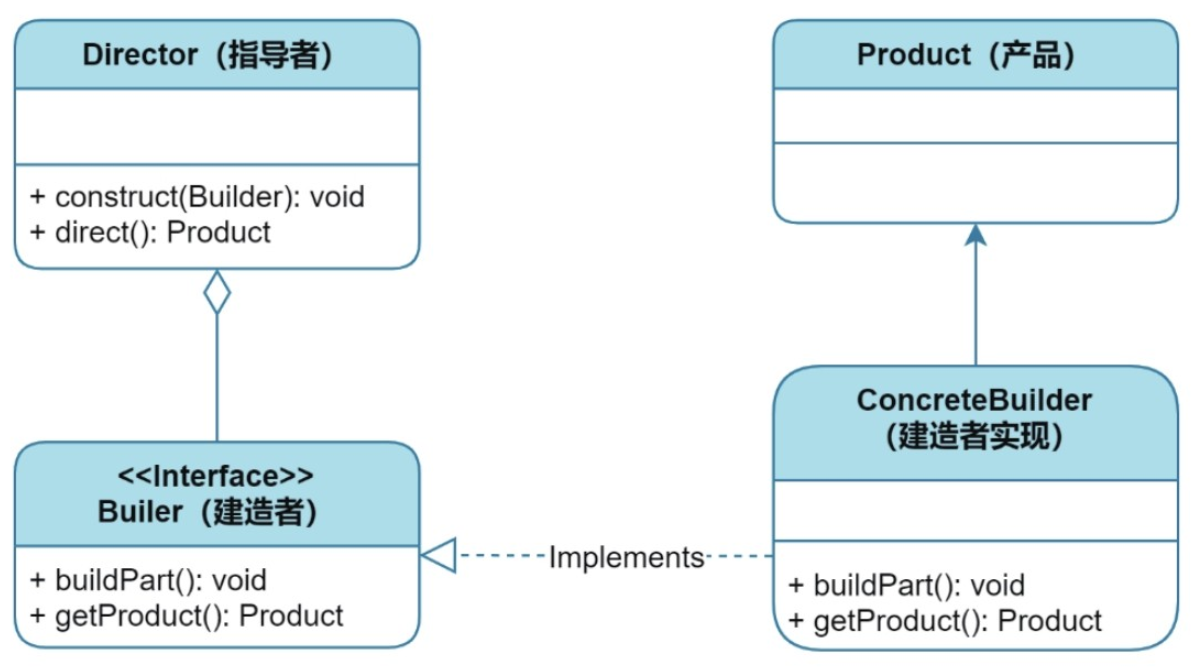
创建型:建造者模式
目录 1、核心思想 2、实现方式 2.1 模式结构 2.2 工作流程 2.3 实现案例 2.4 变体:链式建造者(常见于多参数对象,无需指挥者) 3、优缺点分析 4、适用场景 1、核心思想 目的:将复杂对象的构建过程与其表示分离…...

Jenkins集成Docker与K8S构建
Jenkins 是一个开源的持续集成和持续交付(CI/CD)工具,广泛用于自动化软件开发过程中的构建、测试和部署任务。它通过插件系统提供了高度的可扩展性,支持与多种开发工具和技术的集成。 Jenkins 的核心功能 Jenkins 的主要功能包括自动化构建、测试和部署。它能够监控版本控…...
)
redis缓存实战-19(使用 Pub/Sub 构建简单的聊天应用程序)
实践练习:使用 Pub/Sub 构建简单的聊天应用程序 Redis Pub/Sub 是一项强大的功能,可在应用程序的不同部分之间实现实时通信。这是一种消息传递范例,其中发送方(发布者)不直接向特定接收方(订阅者)发送消息,而是将消息发布到通道。订阅者对一个或多个通道表示兴趣,并且…...
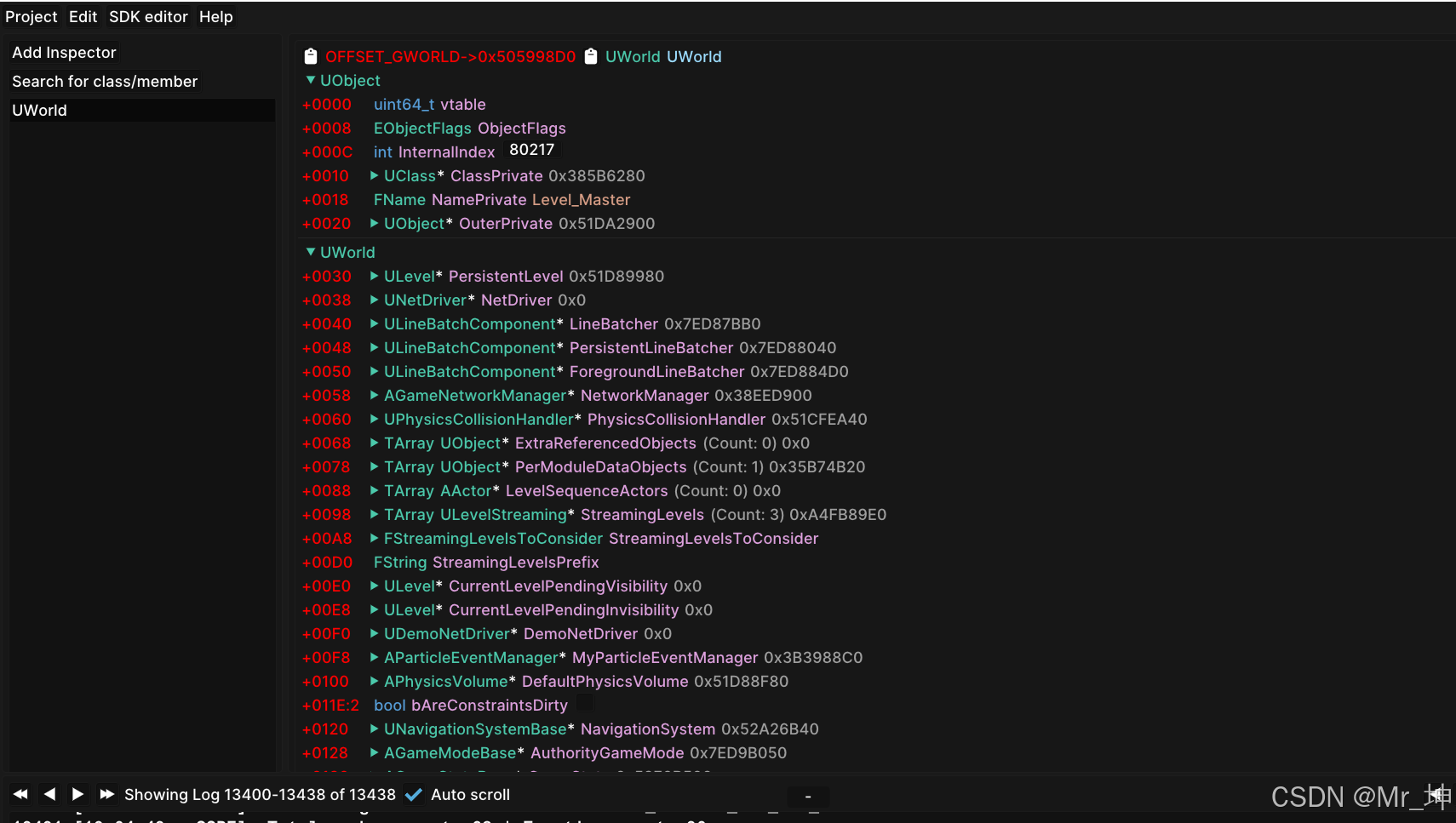
UE4游戏查找本地角色数据的方法-SDK
UE4中,玩家的表示通常涉及以下几个类: APlayerController: 代表玩家的控制逻辑,处理输入等。 APawn: 代表玩家在世界中的实体(比如一个角色、一辆车)。APlayerController 控制一个 APawn。 ACharacter: APawn 的一个…...

游园安排--最长上升子序列+输出序列
1.最长上升子序列,用二分贪心算法优化的那个 2.分割提取游客名字,与蓝肽子序列类似 3.关键是我不知道怎么输出答案序列,这里学习了一种不按序实现的,思想是倒序能凑上就加入,反正从ma开始遍历,生成一定是…...

缓存一致性与AI内容生成的幂等控制
缓存一致性与AI内容生成的幂等控制 在AI架构中,缓存系统作为提升响应速度与减少模型调用压力的关键组件,必须同时解决两个核心问题: 缓存一致性问题:数据源变动后,如何确保缓存及时更新、不过期、不脏读;…...
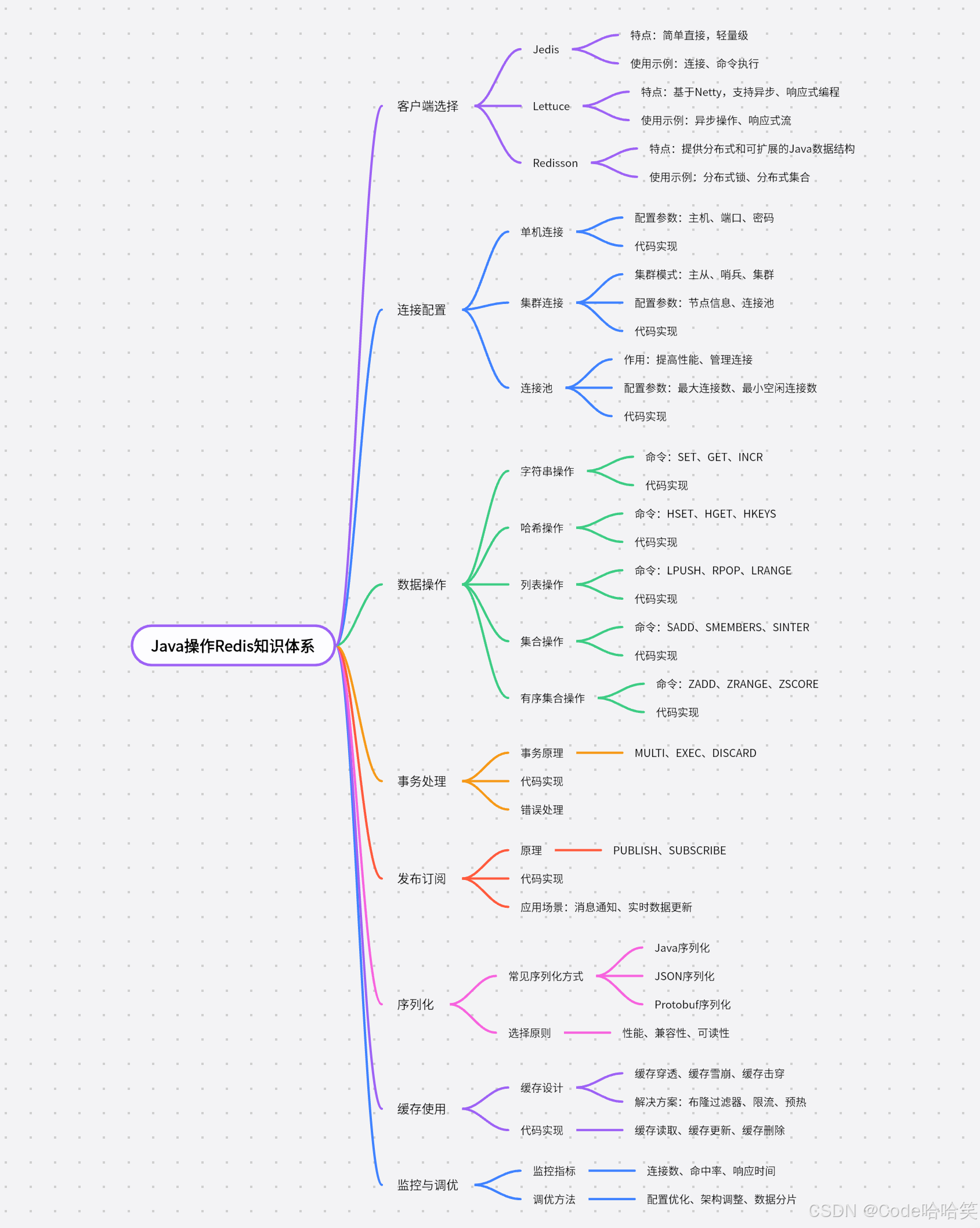
Java 连接并操作 Redis 万字详解:从 Jedis 直连到 RedisTemplate 封装,5 种方式全解析
引言 在分布式系统和高并发场景中,Redis 作为高性能内存数据库的地位举足轻重。对于 Java 开发者而言,掌握 Redis 的连接与操作是进阶必备技能。然而,从基础的 Jedis 原生客户端到 Spring 封装的 RedisTemplate,不同连接方式的原…...

python web 开发-Flask-Login使用详解
Flask-Login使用详解:轻松实现Flask用户认证 1. Flask-Login简介 Flask-Login是Flask框架的一个扩展,专门用于处理用户认证相关的功能。它提供了用户会话管理、登录/注销视图、记住我功能等常见认证需求,让开发者能够快速实现安全的用户认证…...

快速排序算法的C++和C语言对比
快速排序算法简介: 快速排序(Quick Sort)是一种高效的排序算法,采用分治法策略。它的基本思想是: 1. 从数列中挑出一个元素作为"基准" 2. 重新排序数列,所有比基准值小的元素放在基准前面,所有比基准值大的…...
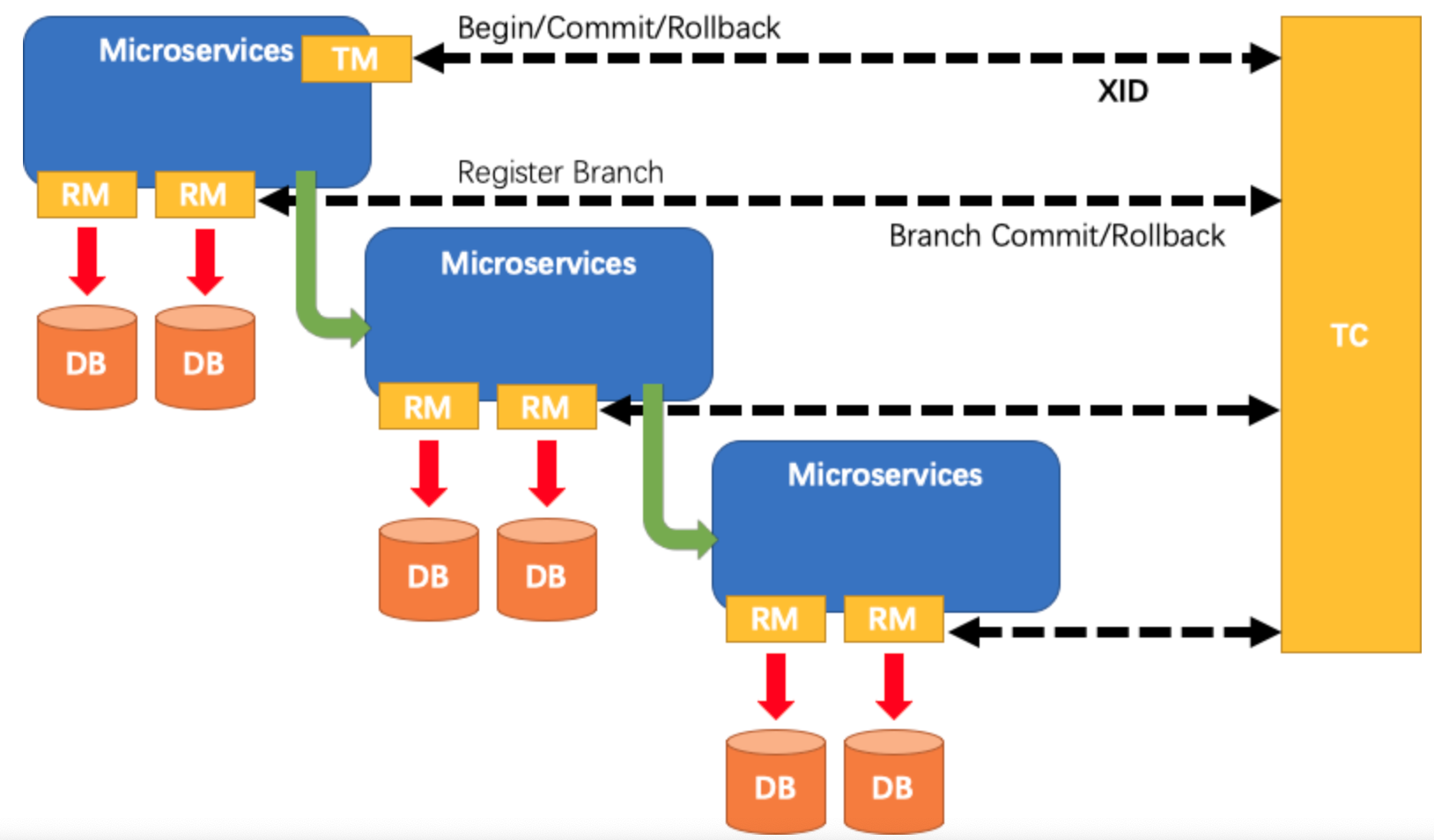
分布式事务知识点整理
目录 分布式事务问题?问题场景引入分布式事务的理论标准BASE理论附CAP理论 Two-phase Commit,2PC2PC系统组件两阶段执行过程2PC缺点 Three-Phase Commit,3PC三阶段执行过程 TTC(Try-Confirm-Cancel)seata项目以及原理how to define a Distrib…...