文件夹图像批处理教程
前言
因为经常对图像要做数据清洗,又很费时间去重新写一个,我一直在想能不能写一个通用的脚本或者制作一个可视化的界面对文件夹图像做批量的修改图像大小、重命名、划分数据训练和验证集等等。这里我先介绍一下我因为写过的一些脚本,然后我们对其进行绘总,并制作成一个可视化界面。
脚本
获取图像路径
我们需要一个函数去读取文件夹下的所有文件,获取其文件名,而关于这一部分我很早以前就做过了,详细可以看这里:解决Python读取图片路径存在转义字符
import osdef get_image_path(path):imgfile = []file_list = os.listdir(path)for i in file_list:new_path = os.path.join(path, i).replace("\\", "/")_, file_ext = os.path.splitext(new_path)if file_ext[1:] in ('bmp', 'dng', 'jpeg', 'jpg', 'mpo', 'png', 'tif', 'tiff', 'webp', 'pfm'):imgfile.append(new_path)return natsorted(imgfile)if __name__=="__main__":images_path = r'E:\PythonProject\img_processing_techniques_main\document\images'images_path_list = get_image_path(images_path)print(images_path_list)我们在这里进行了重命名,请以此篇为准。
批量修改图像大小
def modify_images_size(target_path, target_hwsize, save_path=None):"""批量修改图像大小"""h, w = target_hwsizeimages_paths = get_image_path(target_path)os.makedirs(save_path, exist_ok=True)for i, one_image_path in enumerate(images_paths):try:image = Image.open(one_image_path)resized_image = image.resize((w, h))base_name = os.path.basename(one_image_path)if save_path is not None:new_path = os.path.join(save_path, base_name)else:new_path = one_image_pathresized_image.save(new_path)print(f"Resized {one_image_path} to {new_path}")except Exception as e:print(f"Error resizing {one_image_path}: {e}")这里的脚本用于图像的批量修改,如果不给保存路径,那么就会修改本地的文件,我们是不推荐这里的,最好还是做好备份。
划分数据集与验证集
def split_train_val_txt(target_path, train_ratio=.8, val_ratio=.2, onlybasename=False):"""如果 train_ratio + val_ratio = 1 表示只划分训练集和验证集, train_ratio + val_ratio < 1表示将剩余的比例划分为测试集"""assert train_ratio + val_ratio <= 1test_ratio = 1. - (train_ratio + val_ratio)images_paths = get_image_path(target_path)num_images = len(images_paths)num_train = round(num_images * train_ratio)num_val = num_images - num_train if test_ratio == 0 else math.ceil(num_images * val_ratio)num_test = 0 if test_ratio == 0 else num_images - (num_train + num_val)with open(os.path.join(target_path, 'train.txt'), 'w') as train_file, \open(os.path.join(target_path, 'val.txt'), 'w') as val_file, \open(os.path.join(target_path, 'test.txt'), 'w') as test_file:for i, image_path in enumerate(images_paths):if onlybasename:image_name, _ = os.path.splitext(os.path.basename(image_path))else:image_name = image_pathif i < num_train:train_file.write(f"{image_name}\n")elif i < num_train + num_val:val_file.write(f"{image_name}\n")else:test_file.write(f"{image_name}\n")print(f"Successfully split {num_images} images into {num_train} train, {num_val} val, and {num_test} test.")
我在这里修改了划分测试集的逻辑,根据划分比例来评判,以免出现使用向上取整或向下取整导致出现的问题(测试集比例不为0,验证集比例按照向上取整划分)。
复制图像到另外一个文件夹
def copy_images_to_directory(target_path, save_folder, message=True):"""复制整个文件夹(图像)到另外一个文件夹"""try:os.makedirs(save_folder, exist_ok=True)source_path = get_image_path(target_path)for img_path in source_path:base_file_name = os.path.basename(img_path)destination_path = os.path.join(save_folder, base_file_name)shutil.copy2(img_path, destination_path)if message:print(f"Successfully copied folder: {img_path} to {save_folder}")except Exception as e:print(f"Error copying folder, {e}")这个本来是一个小功能,但是我想的是有时候如果要做每张图的匹配,可以修改为将符合条件的路径复制到目标文件夹中。修改也只需加一个列表的判断即可。
获取数据集的均值标准化
def get_dataset_mean_std(train_data):train_loader = DataLoader(train_data, batch_size=1, shuffle=False, num_workers=0,pin_memory=True)mean = torch.zeros(3)std = torch.zeros(3)for im, _ in train_loader:for d in range(3):mean[d] += im[:, d, :, :].mean()std[d] += im[:, d, :, :].std()mean.div_(len(train_data))std.div_(len(train_data))return list(mean.numpy()), list(std.numpy())def get_images_mean_std(target_path):images_paths = get_image_path(target_path)num_images = len(images_paths)mean_sum = np.zeros(3)std_sum = np.zeros(3)for one_image_path in images_paths:pil_image = Image.open(one_image_path).convert("RGB")img_asarray = np.asarray(pil_image) / 255.0individual_mean = np.mean(img_asarray, axis=(0, 1))individual_stdev = np.std(img_asarray, axis=(0, 1))mean_sum += individual_meanstd_sum += individual_stdevmean = mean_sum / num_imagesstd = std_sum / num_imagesreturn mean.astype(np.float32), std.astype(np.float32)都是相同的方法获取RGB图像的均值标准化,我们更建议直接使用第二个。
批量修改图像后缀名
def modify_images_suffix(target_path, format='png'):"""批量修改图像文件后缀"""images_paths = get_image_path(target_path)for i, one_image_path in enumerate(images_paths):base_name, ext = os.path.splitext(one_image_path)new_path = base_name + '.' + formatos.rename(one_image_path, new_path)print(f"Converting {one_image_path} to {new_path}")这里仅仅是修改图像的后缀,至于这种强力的修改是否会对图像的格式造成影响我们不做考虑。
批量重命名图像
def batch_rename_images(target_path,save_path,start_index=None,prefix=None,suffix=None,format=None,num_type=1,
):"""重命名图像文件夹中的所有图像文件并保存到指定文件夹:param target_path: 目标文件路径:param save_path: 文件夹的保存路径:param start_index: 默认为 1, 从多少号开始:param prefix: 重命名的通用格式前缀, 如 rename001.png, rename002.png...:param suffix: 重命名的通用格式后缀, 如 001rename.png, 002rename.png...:param format (str): 新的后缀名,不需要包含点(.):param num_type: 数字长度, 比如 3 表示 005:param message: 是否打印修改信息"""os.makedirs(save_path, exist_ok=True)images_paths = get_image_path(target_path)current_num = start_index if start_index is not None else 1for i, image_path in enumerate(images_paths):image_name = os.path.basename(image_path)name, ext = os.path.splitext(image_name)if format is None:ext = extelse:ext = f'.{format}'padded_i = str(current_num).zfill(num_type)if prefix and suffix:new_image_name = f"{prefix}{padded_i}{suffix}{ext}"elif prefix:new_image_name = f"{prefix}{padded_i}{ext}"elif suffix:new_image_name = f"{padded_i}{suffix}{ext}"else:new_image_name = f"{padded_i}{ext}"new_path = os.path.join(save_path, new_image_name)current_num += 1print(f"{i + 1} Successfully rename {image_path} to {new_path}")shutil.copy(image_path, new_path)print("Batch renaming and saving of files completed!")我们在这里添加了重命名的功能,其实发现很多都可以套在这里面来,所以后面我们修改过后会做成ui进行显示。
完整脚本
下面是我经过测试后的一个脚本,大家可以直接拿去使用。
import os
import math
import torch
import numpy as np
from PIL import Image
import shutil
from torch.utils.data import DataLoader
from natsort import natsorteddef get_image_path(path):imgfile = []file_list = os.listdir(path)for i in file_list:new_path = os.path.join(path, i).replace("\\", "/")_, file_ext = os.path.splitext(new_path)if file_ext[1:] in ('bmp', 'dng', 'jpeg', 'jpg', 'mpo', 'png', 'tif', 'tiff', 'webp', 'pfm'):imgfile.append(new_path)return natsorted(imgfile)def modify_images_size(target_path, target_hwsize, save_path=None):"""批量修改图像大小"""h, w = target_hwsizeimages_paths = get_image_path(target_path)os.makedirs(save_path, exist_ok=True)for i, one_image_path in enumerate(images_paths):try:image = Image.open(one_image_path)resized_image = image.resize((w, h))base_name = os.path.basename(one_image_path)if save_path is not None:new_path = os.path.join(save_path, base_name)else:new_path = one_image_pathresized_image.save(new_path)print(f"Resized {one_image_path} to {new_path}")except Exception as e:print(f"Error resizing {one_image_path}: {e}")def split_train_val_txt(target_path, train_ratio=.8, val_ratio=.2, onlybasename=False):"""如果 train_ratio + val_ratio = 1 表示只划分训练集和验证集, train_ratio + val_ratio < 1表示将剩余的比例划分为测试集"""assert train_ratio + val_ratio <= 1test_ratio = 1. - (train_ratio + val_ratio)images_paths = get_image_path(target_path)num_images = len(images_paths)num_train = round(num_images * train_ratio)num_val = num_images - num_train if test_ratio == 0 else math.ceil(num_images * val_ratio)num_test = 0 if test_ratio == 0 else num_images - (num_train + num_val)with open(os.path.join(target_path, 'train.txt'), 'w') as train_file, \open(os.path.join(target_path, 'val.txt'), 'w') as val_file, \open(os.path.join(target_path, 'test.txt'), 'w') as test_file:for i, image_path in enumerate(images_paths):if onlybasename:image_name, _ = os.path.splitext(os.path.basename(image_path))else:image_name = image_pathif i < num_train:train_file.write(f"{image_name}\n")elif i < num_train + num_val:val_file.write(f"{image_name}\n")else:test_file.write(f"{image_name}\n")print(f"Successfully split {num_images} images into {num_train} train, {num_val} val, and {num_test} test.")def copy_images_to_directory(target_path, save_folder):"""复制整个文件夹(图像)到另外一个文件夹"""try:os.makedirs(save_folder, exist_ok=True)source_path = get_image_path(target_path)for img_path in source_path:base_file_name = os.path.basename(img_path)destination_path = os.path.join(save_folder, base_file_name)shutil.copy2(img_path, destination_path)print(f"Successfully copied folder: {img_path} to {save_folder}")except Exception as e:print(f"Error copying folder, {e}")def get_dataset_mean_std(train_data):train_loader = DataLoader(train_data, batch_size=1, shuffle=False, num_workers=0,pin_memory=True)mean = torch.zeros(3)std = torch.zeros(3)for im, _ in train_loader:for d in range(3):mean[d] += im[:, d, :, :].mean()std[d] += im[:, d, :, :].std()mean.div_(len(train_data))std.div_(len(train_data))return list(mean.numpy()), list(std.numpy())def get_images_mean_std(target_path):images_paths = get_image_path(target_path)num_images = len(images_paths)mean_sum = np.zeros(3)std_sum = np.zeros(3)for one_image_path in images_paths:pil_image = Image.open(one_image_path).convert("RGB")img_asarray = np.asarray(pil_image) / 255.0individual_mean = np.mean(img_asarray, axis=(0, 1))individual_stdev = np.std(img_asarray, axis=(0, 1))mean_sum += individual_meanstd_sum += individual_stdevmean = mean_sum / num_imagesstd = std_sum / num_imagesreturn mean.astype(np.float32), std.astype(np.float32)def modify_images_suffix(target_path, format='png'):"""批量修改图像文件后缀"""images_paths = get_image_path(target_path)for i, one_image_path in enumerate(images_paths):base_name, ext = os.path.splitext(one_image_path)new_path = base_name + '.' + formatos.rename(one_image_path, new_path)print(f"Converting {one_image_path} to {new_path}")def batch_rename_images(target_path,save_path,start_index=None,prefix=None,suffix=None,format=None,num_type=1,
):"""重命名图像文件夹中的所有图像文件并保存到指定文件夹:param target_path: 目标文件路径:param save_path: 文件夹的保存路径:param start_index: 默认为 1, 从多少号开始:param prefix: 重命名的通用格式前缀, 如 rename001.png, rename002.png...:param suffix: 重命名的通用格式后缀, 如 001rename.png, 002rename.png...:param format (str): 新的后缀名,不需要包含点(.):param num_type: 数字长度, 比如 3 表示 005:param message: 是否打印修改信息"""os.makedirs(save_path, exist_ok=True)images_paths = get_image_path(target_path)current_num = start_index if start_index is not None else 1for i, image_path in enumerate(images_paths):image_name = os.path.basename(image_path)name, ext = os.path.splitext(image_name)if format is None:ext = extelse:ext = f'.{format}'padded_i = str(current_num).zfill(num_type)if prefix and suffix:new_image_name = f"{prefix}{padded_i}{suffix}{ext}"elif prefix:new_image_name = f"{prefix}{padded_i}{ext}"elif suffix:new_image_name = f"{padded_i}{suffix}{ext}"else:new_image_name = f"{padded_i}{ext}"new_path = os.path.join(save_path, new_image_name)current_num += 1print(f"{i + 1} Successfully rename {image_path} to {new_path}")shutil.copy(image_path, new_path)print("Batch renaming and saving of files completed!")
if __name__=="__main__":images_path = r'E:\PythonProject\img_processing_techniques_main\document\images'images_path_list = get_image_path(images_path)save_path =r'./save_path'# modify_images_size(images_path, (512, 512), save_path)# print(images_path_list)# split_train_val_txt(images_path, .8, .2)# copy_images_to_directory(images_path, save_folder='./save_path2')# mean, std = get_images_mean_std(images_path)# print(mean, std)# modify_images_suffix('./save_path2')BatchVision的可视化设计
我将前面的一些脚本制作成了一个批量文件处理系统 BatchVision,可实现批量修改图像大小,划分训练集和验证集,以及批量重命名,其他的一些小功能例如灰度化处理和计算均值标准化。
完整项目请看此处:UI-Design-System-Based-on-PyQt5
这里通过网盘链接分享的离线使用文件exe,无需安装环境: BatchVision
我们设计的可视化界面如下图所示:
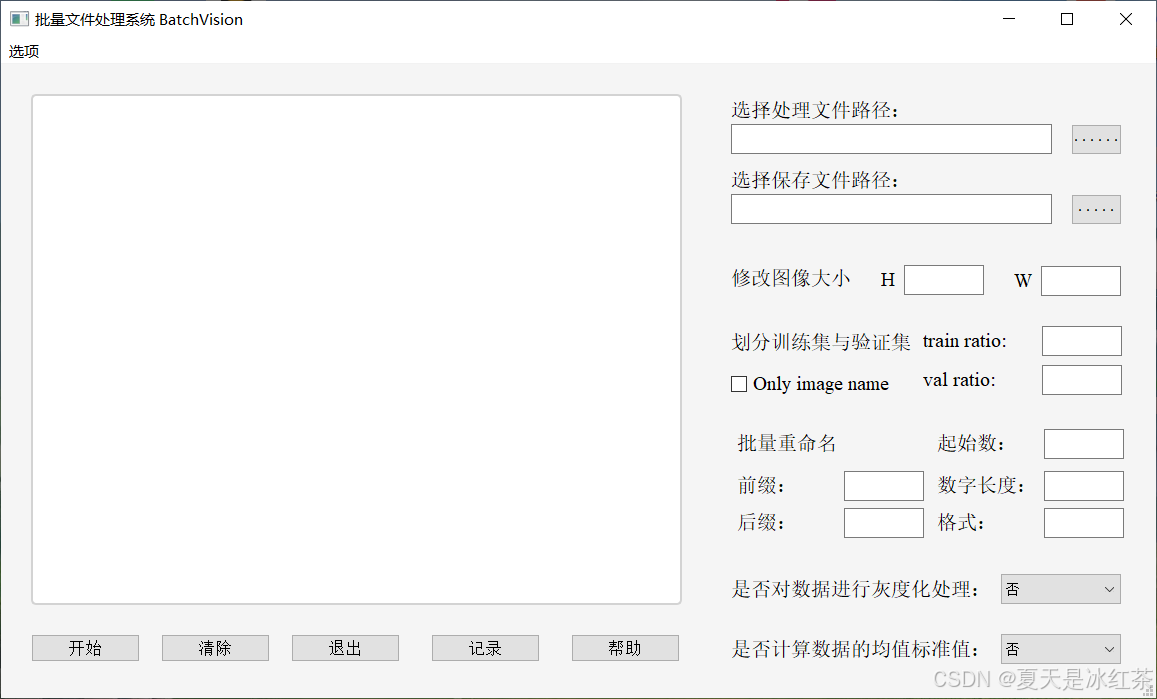
其中的一些设定我都是经过严格的判断,如果还有问题可以联系我修改。
相关文章:
文件夹图像批处理教程
前言 因为经常对图像要做数据清洗,又很费时间去重新写一个,我一直在想能不能写一个通用的脚本或者制作一个可视化的界面对文件夹图像做批量的修改图像大小、重命名、划分数据训练和验证集等等。这里我先介绍一下我因为写过的一些脚本,然后我…...
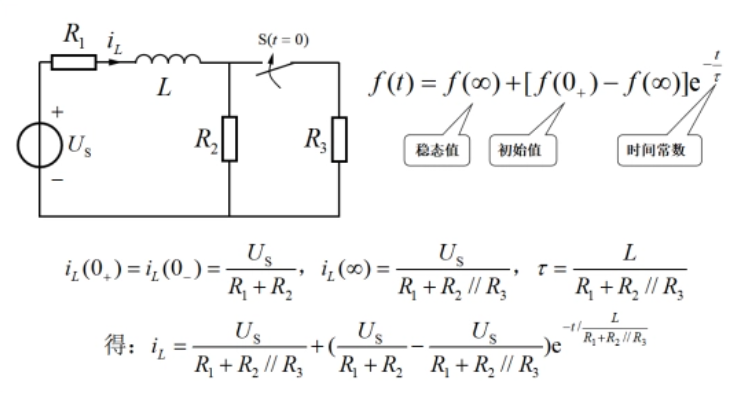
RL电路的响应
学完RC电路的响应,又过了一段时间了,想必很多人都忘了RC电路响应的一些内容。我们这次学习RL电路的响应,以此同时,其实也是带大家一起回忆一些之前所学的RC电路的响应的一些知识点。所以,这次的学习,其实也…...
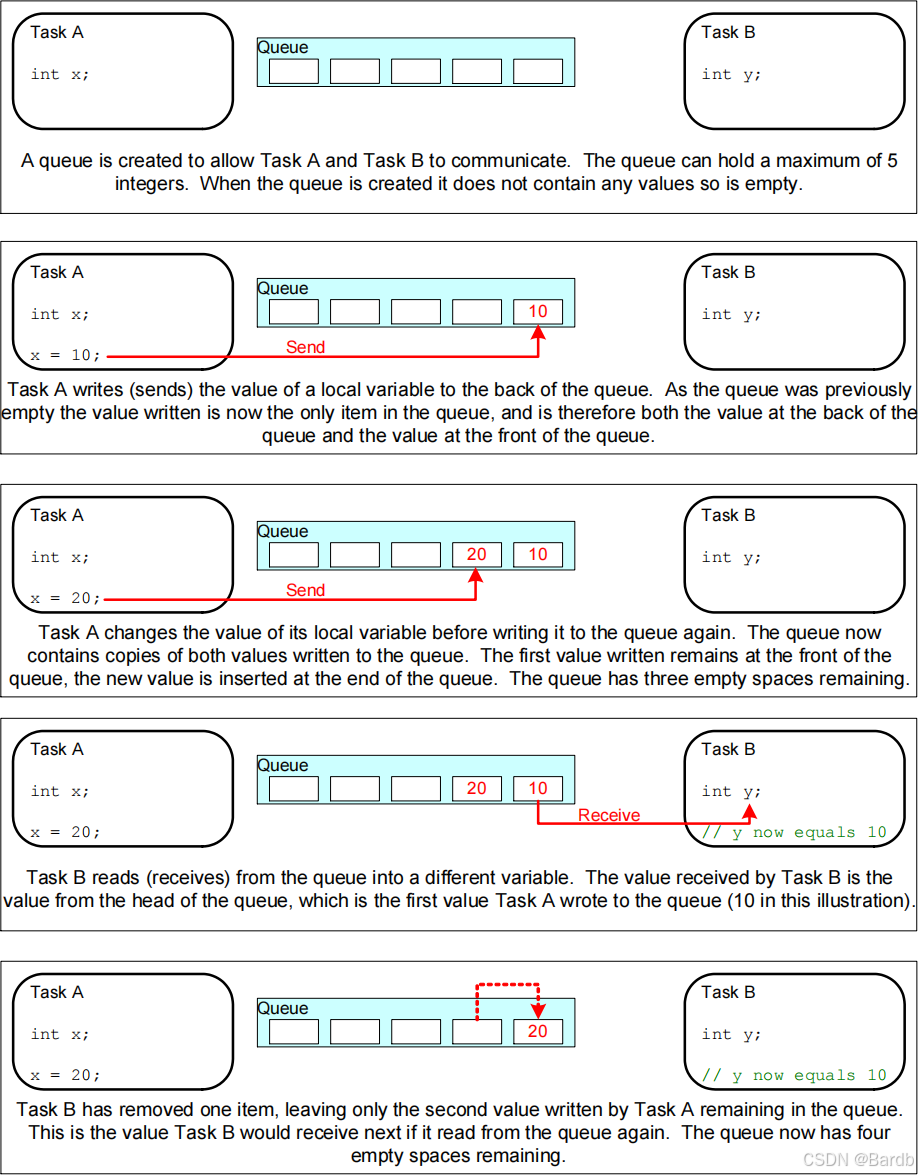
30-消息队列
一、消息队列概述 队列又称消息队列,是一种常用于任务间通信的数据结构,队列可以在任务与任务间、 中断和任务间传递信息,实现了任务接收来自其他任务或中断的不固定长度的消息,任务能够从队列里面读取消息,当队列中的…...

跨域解决方案之JSONP
目录 一、JSONP 核心原理 二、JSONP 实现步骤 (一)客户端代码 (二)服务器端代码(ASP.NET实现) 1. ASP.NET Web Forms 实现 2. ASP.NET Core 实现 三、JSONP 优缺点 (一)优点 …...

【AI测试革命】第七期:AI性能测试的深度实践——从智能建模到自动化调优的全链路升级
在微服务架构与高并发场景普及的当下,性能测试作为保障系统稳定性和用户体验的核心环节,正面临负载模型构建复杂、脚本维护成本高、瓶颈定位效率低等挑战。Copilot凭借代码生成、数据分析和智能决策能力,为性能测试全流程注入新动能ÿ…...
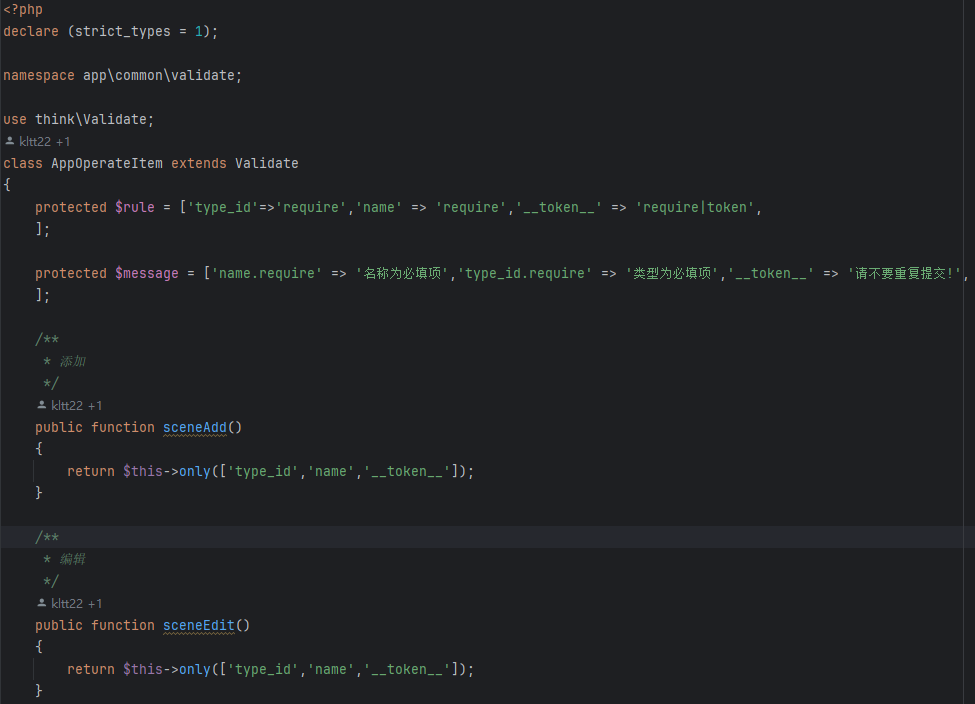
Thinkphp6使用token+Validate验证防止表单重复提交
htm页面加 <input type"hidden" name"__token__" value"{:token()}" /> Validate 官方文档 ThinkPHP官方手册...

AppAgentx 开源AI手机操控使用分享
项目地址: https://appagentx.github.io/?utm_sourceai-bot.cn GitHub仓库: https://github.com/Westlake-AGI-Lab/AppAgentX/tree/main arXiv技术论文:https://arxiv.org/pdf/2503.02268 AppAgentx是什么: AppAgentX 是西湖大学推出的一种自我进化式 GUI 代理框架。它通过…...
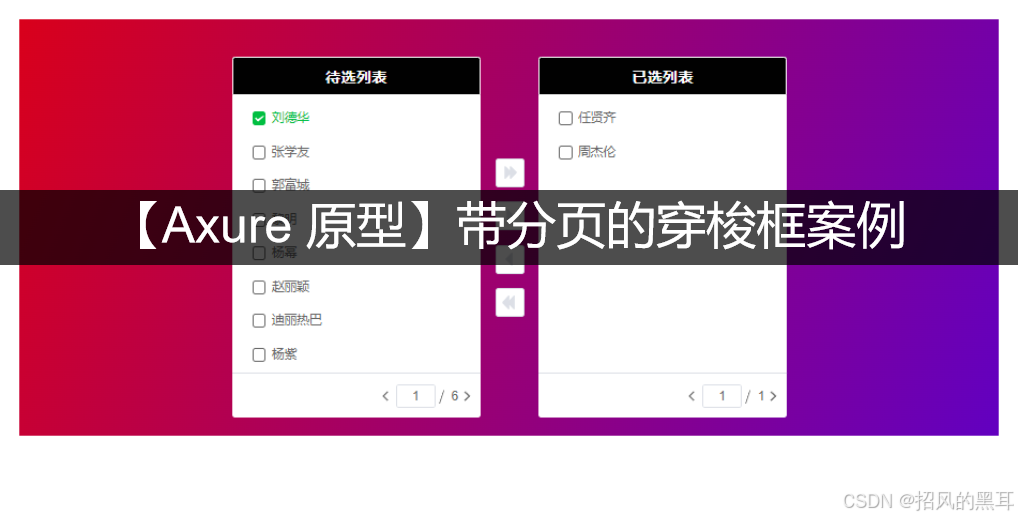
Axure设计之带分页的穿梭框原型
穿梭框(Transfer)是一种常见且实用的交互组件,广泛应用于需要批量选择或分配数据的场景。 一、应用场景 其典型应用场景包括: 权限管理系统:批量分配用户角色或系统权限数据筛选工具:在大数据集中选择特…...

嵌入式硬件篇---陀螺仪|PID
文章目录 前言1. 硬件准备主控芯片陀螺仪模块电机驱动电源其他2. 硬件连接3. 软件实现步骤(1) MPU6050初始化与数据读取(2) 姿态解算(互补滤波或DMP)(3) PID控制器设计(4) 麦克纳姆轮协同控制4. 主程序逻辑5. 关键优化与调试技巧(1) 传感器校准(2) PID参数整定先调P再调D最后…...
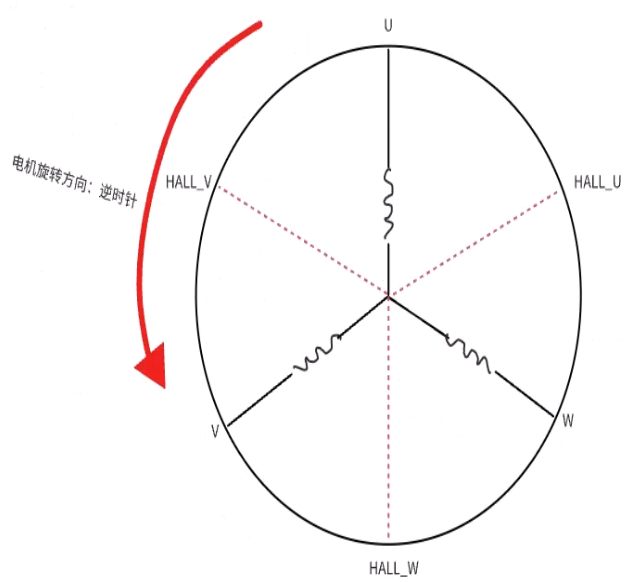
电机控制储备知识学习(五) 三项直流无刷电机(BLDC)学习(四)
目录 电机控制储备知识学习(五)一、三项直流无刷电机(BLDC)学习(四)1)软件方法控制电机转速2)PWM概念和PWM的产生3)转子位置检测和霍尔传感器的工作原理分析4)霍尔传感器安装角度和电…...

Java—— 网络爬虫
案例要求 https://hanyu.baidu.com/shici/detail?pid0b2f26d4c0ddb3ee693fdb1137ee1b0d&fromkg0 http://www.haoming8.cn/baobao/10881.html http://www.haoming8.cn/baobao/7641.html上面三个网址分别表示百家姓,男生名字,女生名字,如…...

Baklib内容中台的主要构成是什么?
Baklib内容中台核心架构 Baklib作为一站式知识管理平台的核心载体,其架构设计围绕智能搜索引擎优化技术与多终端适配响应系统展开。通过模块化内容组件的灵活配置,企业可快速搭建知识库、FAQ页面及帮助中心等标准化场景,同时借助可视化数据看…...
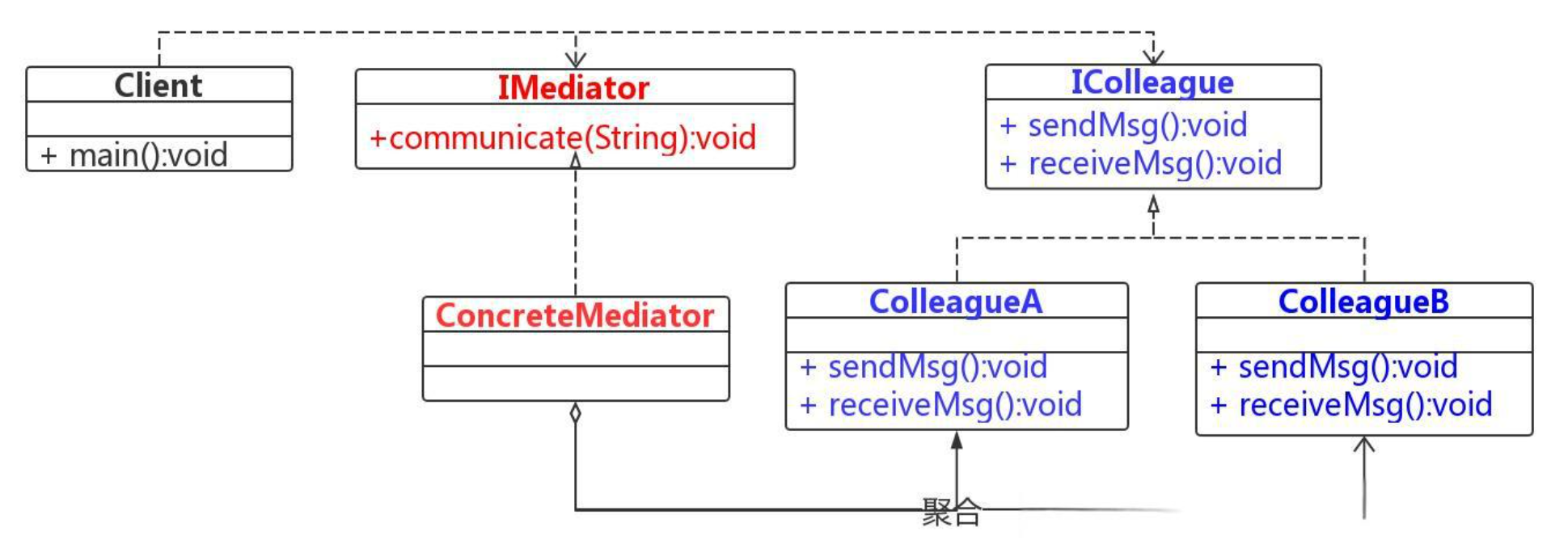
深度解析 Java 中介者模式:重构复杂交互场景的优雅方案
一、中介者模式的核心思想与设计哲学 在软件开发的历史长河中,对象间的交互管理一直是架构设计的核心难题。当多个对象形成复杂的网状交互时,系统会陷入 "牵一发而动全身" 的困境。中介者模式(Mediator Pattern)作为行…...
)
家用和类似用途电器的安全 第1部分:通用要求 与2005版差异(7)
文未有本标准免费下载链接。 ——增加了“对峰值电压大于15kV的,其放电电能应不超过350mJ”的要求(见8.1.4) 1. GB/T4706.1-2024: 8.1.4 如果易触及部件为下述情况,则不认为其是带电的。 ——该部件由安全特低电压供电,且: 对…...

HTTP Digest 认证:原理剖析与服务端实现详解
HTTP Digest 认证:原理剖析与服务端实现详解 HTTP 协议中的 Digest 认证(摘要认证)是一种比 Basic 认证更安全的身份验证机制,其核心设计是避免密码明文传输,并通过动态随机数(Nonce)防范重放攻…...
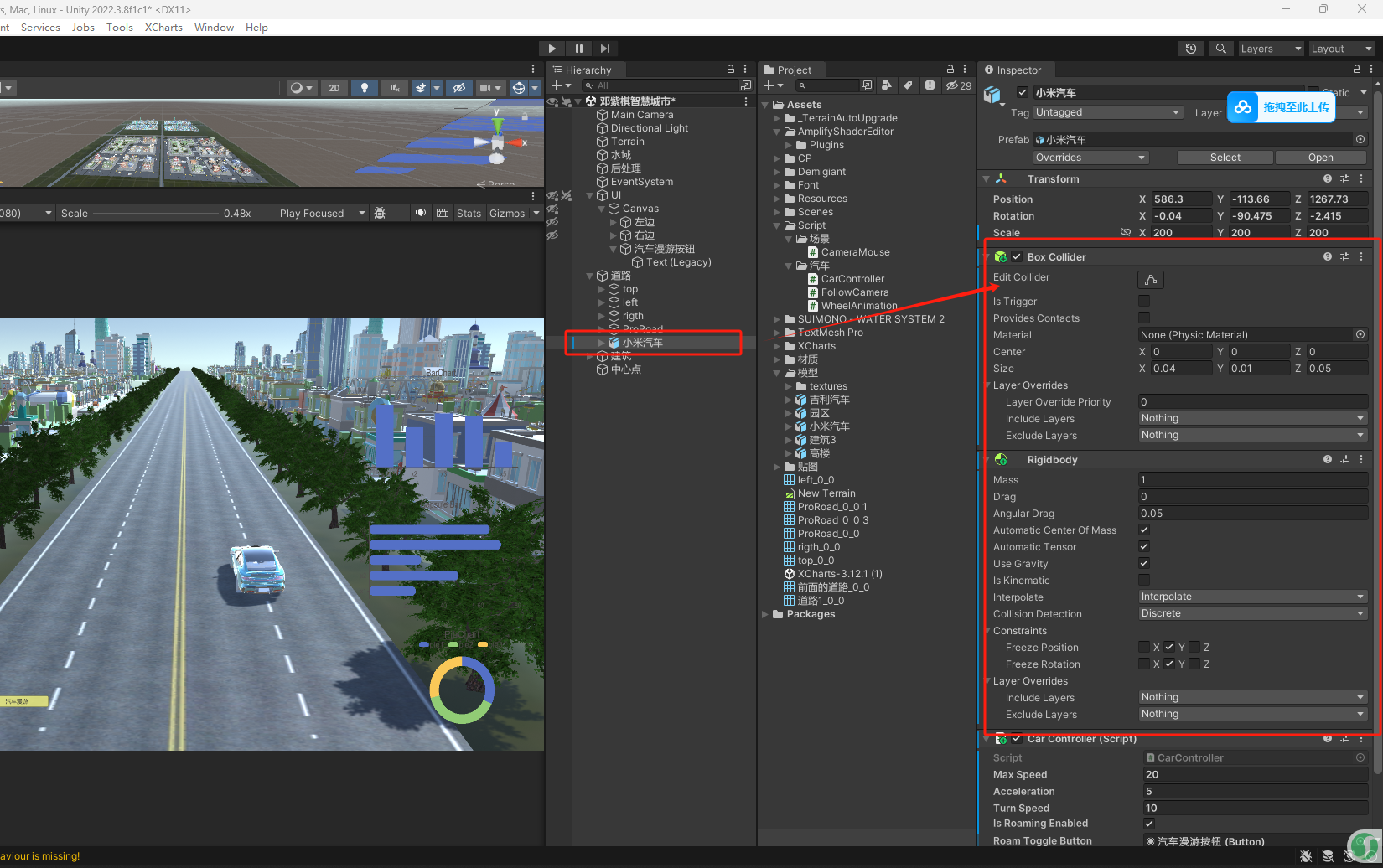
untiy实现汽车漫游
实现效果 汽车漫游 1.创建汽车模型 导入汽车模型(FBX格式或其他3D格式),确保模型包含车轮、车身等部件。 为汽车添加碰撞体(如 Box Collider 或 Mesh Collider),避免穿透场景物体。 添加 Rigidbody 组件,启用重力并调整质量(Mass)以模拟物理效果。 2.编写汽车控制脚本…...
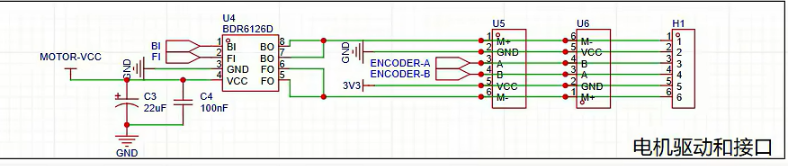
PID项目---硬件设计
该项目是立创训练营项目,这些是我个人学习的记录,记得比较潦草 1.硬件-电路原理电赛-TI-基于MSPM0的简易PID项目_哔哩哔哩_bilibili 这个地方接地是静电的考量 这个保护二极管是为了在电源接反的时候保护电脑等设备 大电容的作用:当电机工作…...

Pluto实验报告——基于FM的音频信号传输并解调恢复
目录 一、实验目的 ................................ ................................ ................................ .................. 3 二、实验内容 ................................ ................................ ................................ ......…...

【Redis】AOF日志
目录 1、背景2、工作原理3、核心配置参数4、优缺点5、AOF文件内容 1、背景 AOF(Append Only File)是redis提供的持久化机制之一,它通过记录所有修改数据库状态的写命令来实现数据库持久化。与RDB(快照)方式不同&#…...
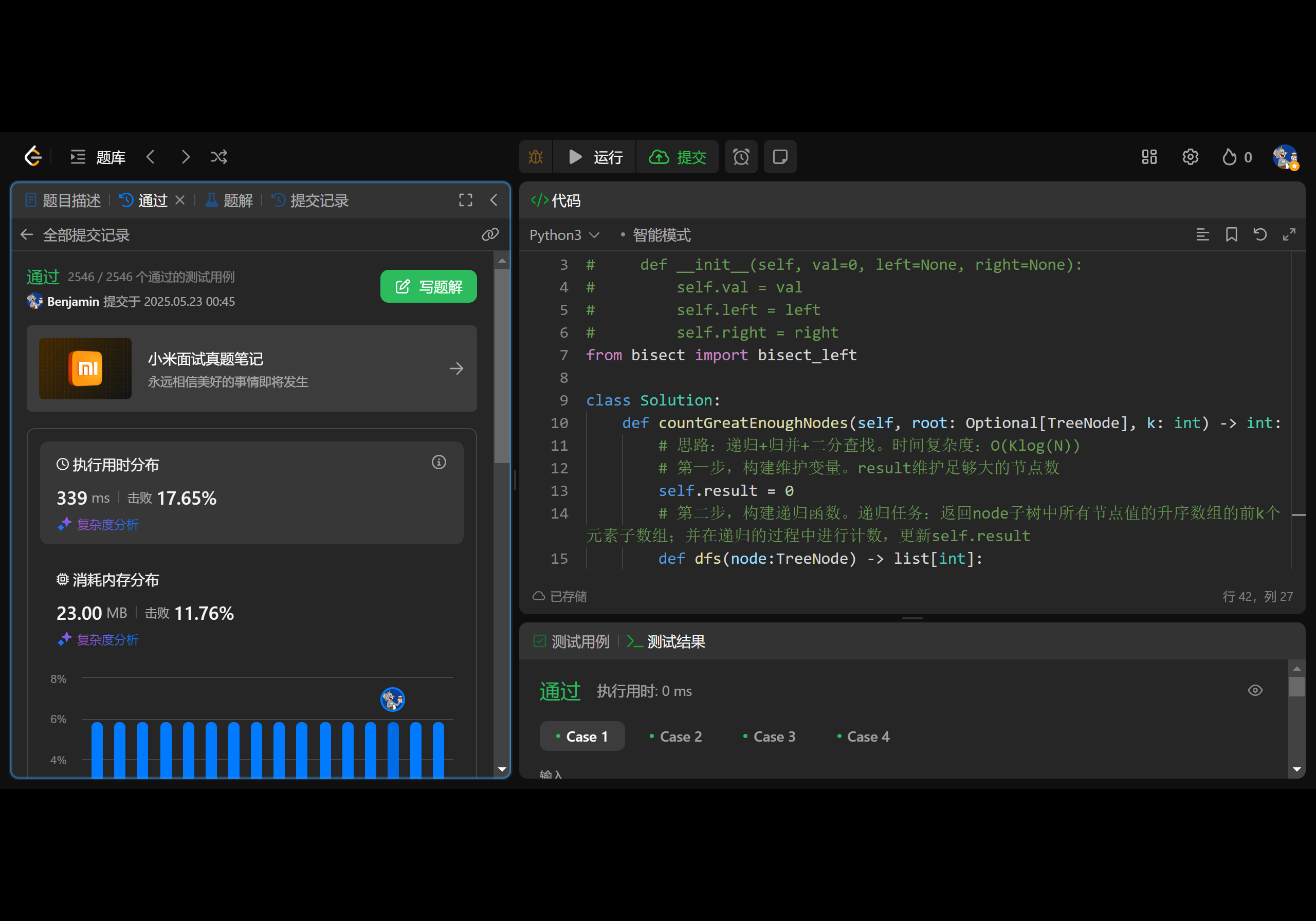
Leetcode 2792. 计算足够大的节点数
1.题目基本信息 1.1.题目描述 给定一棵二叉树的根节点 root 和一个整数 k 。如果一个节点满足以下条件,则称其为 足够大 : 它的子树中 至少 有 k 个节点。 它的值 大于 其子树中 至少 k 个节点的值。返回足够大的节点数。 如果 u v 或者 v 是 u 的…...

《关于浔川社团退出DevPress社区及内容撤回的声明》
《关于浔川社团退出DevPress社区及内容撤回的声明》 尊敬的DevPress社区及读者: 经浔川社团内部决议,我社决定自**2025年5月26日**起正式退出DevPress社区,并撤回所有由我社成员在该平台发布的原创文章。相关事项声明如下: …...

Windows逆向工程提升之IMAGE_RESOURCE_DIRECTORY
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 目录 资源目录概述 什么是资源目录? 资源目录的作用 资源目录的位置 资源目录核心结构 IMAGE_RESOURCE_DIRECTORY IMAGE_RESOURCE_DIRECTORY_ENTRY IMAGE_RESOURCE_DATA_EN…...

使用ps为图片添加水印
打开图片 找到文字工具 输入想要添加的水印 使用移动工具移动到合适的位置 选中文字图层 设置不透明度 快捷键ctrlt可以旋转 另存为png格式图片...
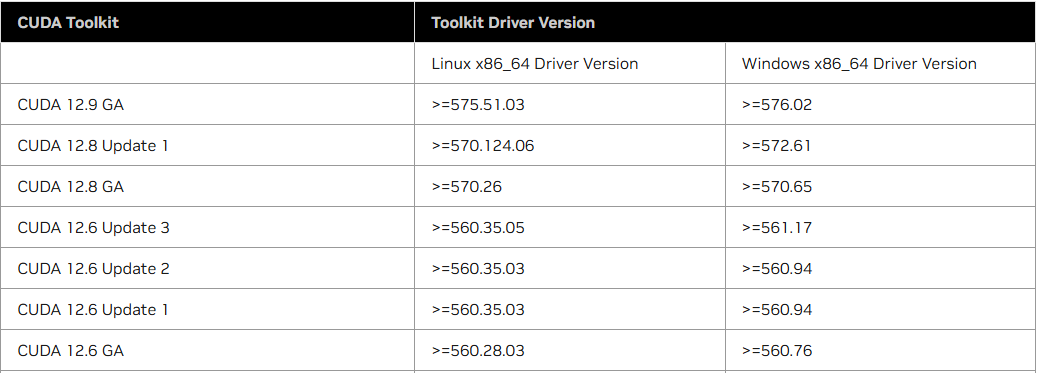
x64_ubuntu22.04.5安装:cuda driver + cuda toolkit
引言 本文操作均已实践验证,安装流程来自nvidia官方文档,验证平台显卡:RTX4070。 验证日期:2025.5.24. 1.安装cuda driver 1.1.安装方式有2种,这里选择方式1: 从apt安装最省事💖,…...
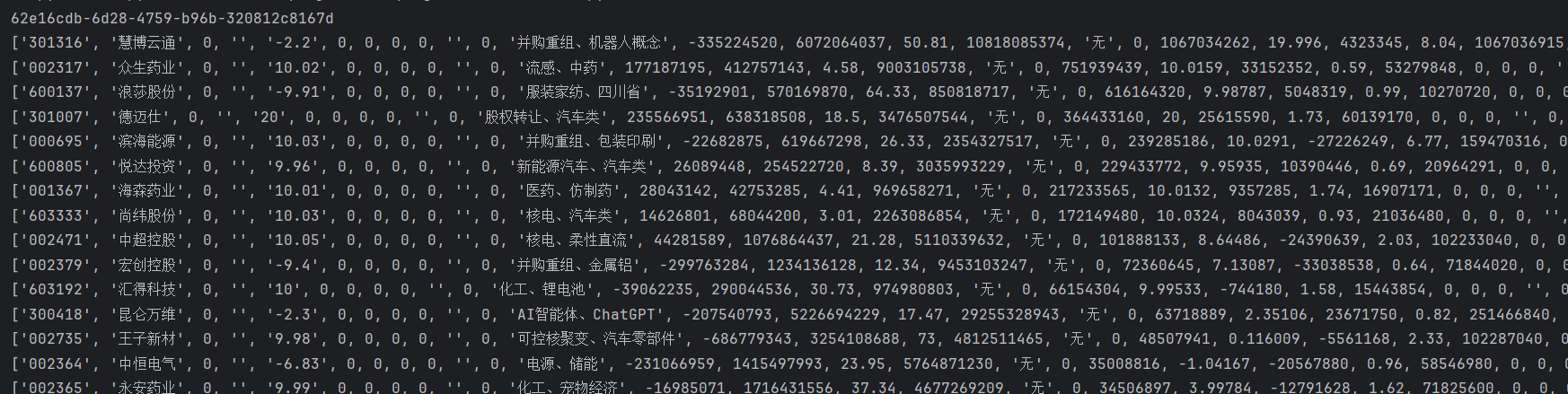
开盘啦 APP 抓包 逆向分析
声明: 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 抓包 这是一个记录贴。 这个APP是数…...
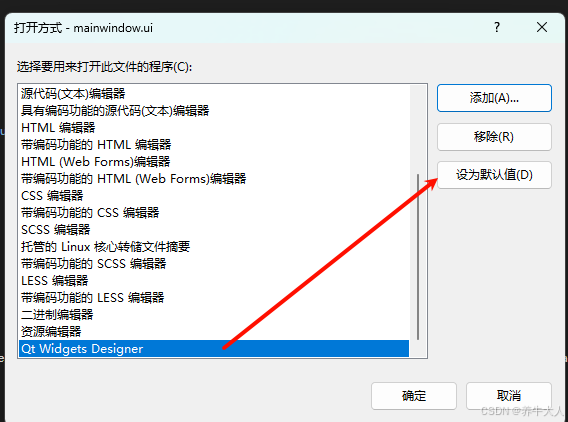
vs2022 Qt Visual Studio Tools插件设置
安装之后,需要指定QT中msvc编译器的位置,点击下图Location右边的按钮即可 选择msvc2022_64\bin目录下的 qmake.exe 另一个问题,双击UI文件不能打开设计界面 设置打开方式 选择msvc2022_64\bin目录下的designer.exe 确定即可 然后设置为默认值即可 确定…...

Python包__init__.py标识文件解析
在 Python 中,__init__.py 文件是包(Package)的核心标识文件,它的存在使一个目录被 Python 解释器识别为「包」。这个文件有以下核心作用: 核心作用 标识包的存在 任何包含 __init__.py 的目录都会被 Python 视为一个包…...
)
【MySQL】第8节|Innodb底层原理与Mysql日志机制深入剖析(一)
MySQL 的 redo log(重做日志) redo log 是 MySQL 中 InnoDB 存储引擎实现事务持久性的关键机制,用于记录数据库数据的变更,确保事务提交后数据不丢失,即使发生宕机也能通过日志恢复数据。 核心作用 1. 实现事务的持…...
电商ERP管理系统,Java+Vue,含源码与文档,统筹订单、库存等,助力电商企业高效运营
前言: 在当今数字化飞速发展的电商时代,电商企业面临着日益激烈的市场竞争和复杂的业务运营环境。为了提升运营效率、降低成本、优化客户体验,一套高效、全面的电商ERP管理系统显得尤为重要。电商ERP管理系统整合了企业内部的各项业务流程&a…...

Spring Boot微服务架构(四):微服务的划分原则
微服务划分原则(CRM系统案例说明) 一、微服务划分的核心原则 单一职责原则(SRP) 每个微服务只负责一个明确的业务功能服务边界清晰,避免功能混杂便于独立开发、测试和部署 业务领域驱动设计(DDD࿰…...