多模态大语言模型arxiv论文略读(八十七)

MG-LLaVA: Towards Multi-Granularity Visual Instruction Tuning
➡️ 论文标题:MG-LLaVA: Towards Multi-Granularity Visual Instruction Tuning
➡️ 论文作者:Xiangyu Zhao, Xiangtai Li, Haodong Duan, Haian Huang, Yining Li, Kai Chen, Hua Yang
➡️ 研究机构: Shanghai Jiaotong University, Shanghai AI Laboratory, S-Lab, Nanyang Technological University
➡️ 问题背景:多模态大语言模型(MLLMs)在各种视觉理解任务中取得了显著进展。然而,大多数这些模型受限于处理低分辨率图像,这限制了它们在需要详细视觉信息的感知任务中的有效性。研究团队提出了MG-LLaVA,通过引入多粒度视觉流(包括低分辨率、高分辨率和对象中心特征)来增强模型的视觉处理能力。
➡️ 研究动机:现有的MLLMs在处理低分辨率图像时表现不佳,尤其是在识别小对象方面。为了克服这一限制,研究团队设计了MG-LLaVA,该模型通过整合高分辨率视觉编码器和对象级特征,显著提高了模型的感知能力和视觉理解能力。
➡️ 方法简介:MG-LLaVA的架构包括两个关键组件:(1)多粒度视觉流框架,用于提取不同分辨率和粒度的视觉特征,并有效整合这些特征以确保无缝交互;(2)大型语言模型,用于生成连贯且上下文相关的响应。研究团队通过引入卷积门融合网络(Conv-Gate Fusion)来整合低分辨率和高分辨率特征,并通过区域对齐(RoI Align)提取对象级特征。
➡️ 实验设计:研究团队在多个公开数据集上进行了广泛的实验,包括视觉-语言感知(VLP)和视频理解任务。实验设计了不同参数规模的语言编码器(从3.8B到34B),以全面评估MG-LLaVA的性能。实验结果表明,MG-LLaVA在多个基准测试中显著优于现有的MLLMs,尤其是在多模态感知和视觉问答任务中表现出色。
MOSSBench: Is Your Multimodal Language Model Oversensitive to Safe Queries?
➡️ 论文标题:MOSSBench: Is Your Multimodal Language Model Oversensitive to Safe Queries?
➡️ 论文作者:Xirui Li, Hengguang Zhou, Ruochen Wang, Tianyi Zhou, Minhao Cheng, Cho-Jui Hsieh
➡️ 研究机构: University of California, LA, University of Maryland, Pennsylvania State University, University of California, LA
➡️ 问题背景:多模态大语言模型(Multimodal Large Language Models, MLLMs)在多种任务中展现了卓越的能力,尤其是在视觉-语言理解和生成任务中。然而,研究发现,这些模型在处理某些视觉刺激时,会表现出过度敏感的行为,即在面对无害查询时,模型可能会错误地拒绝处理,这种行为类似于人类的认知扭曲。
➡️ 研究动机:现有的研究已经揭示了MLLMs在处理某些视觉刺激时的过度敏感问题。为了进一步理解这一现象,并探索其背后的原因,研究团队开发了多模态过度敏感基准(MOSSBench),旨在系统地评估MLLMs在面对不同类型的视觉刺激时的过度敏感程度,为未来的安全机制改进提供有价值的见解。
➡️ 方法简介:研究团队提出了一种系统的方法,通过构建MOSSBench,来评估MLLMs在处理不同类型的视觉刺激时的过度敏感行为。MOSSBench包含300个高质量的图像-文本对,涵盖了多种日常场景,这些场景被分为三类:夸大风险、否定伤害和反直觉解释。这些样本经过人工和模型的双重筛选,确保其真实性和无害性。
➡️ 实验设计:研究团队在20个不同的MLLMs上进行了大规模的实证研究,包括主要的闭源模型(如GPT、Gemini、Claude)和开源模型(如IDEFICS-9b-Instruct、Qwen-VL、InternLMXComposer2等)。实验设计了不同类型的视觉刺激,并评估了模型在处理这些刺激时的拒绝率。此外,研究团队还构建了一个对比集,通过引入明确的恶意内容来评估模型的安全机制。
➡️ 主要发现:
- 过度敏感在当前的MLLMs中普遍存在,尤其是最先进的闭源模型,如Claude 3 Opus(web)和Gemini Advanced,其平均拒绝率分别高达76.33%和63.67%。
- 安全性更高的模型往往更加过度敏感,这表明增加安全性可能会无意中提高模型的谨慎性和保守性。
- 不同类型的视觉刺激会影响模型推理过程中的不同阶段,如感知、意图推理和安全判断。
MLLM as Video Narrator: Mitigating Modality Imbalance in Video Moment Retrieval
➡️ 论文标题:MLLM as Video Narrator: Mitigating Modality Imbalance in Video Moment Retrieval
➡️ 论文作者:Weitong Cai, Jiabo Huang, Shaogang Gong, Hailin Jin, Yang Liu
➡️ 研究机构: Queen Mary University of London、Adobe Research、WICT, Peking University
➡️ 问题背景:视频时刻检索(Video Moment Retrieval, VMR)旨在根据自然语言查询在未剪辑的长视频中定位特定的时间段。现有方法通常因训练注释不足而受限,即句子通常只与视频内容的一部分匹配,且词汇多样性有限。这种模态不平衡问题导致了视觉和文本信息的不完全对齐,限制了跨模态对齐知识的学习,从而影响模型的泛化能力。
➡️ 研究动机:为了缓解模态不平衡问题,研究团队提出了一种基于多模态大语言模型(MLLM)的视频叙述方法,通过生成与视频内容相关的丰富文本描述,增强视觉和文本信息的对齐,提高视频时刻检索的准确性和泛化能力。
➡️ 方法简介:研究团队提出了一种名为文本增强对齐(Text-Enhanced Alignment, TEA)的新框架。该框架利用MLLM作为视频叙述者,生成与视频时间戳对齐的结构化文本段落,以增强视觉和文本信息的语义完整性和多样性。通过视频-叙述知识增强模块和段落-查询并行交互模块,TEA能够生成更具有区分性的语义增强视频表示,从而提高跨模态对齐的精度和模型的泛化能力。
➡️ 实验设计:研究团队在两个流行的VMR基准数据集上进行了广泛的实验,验证了TEA方法的有效性和泛化能力。实验设计包括生成与视频时间戳对齐的结构化文本段落,通过多模态注意力机制进行视频-叙述知识增强,以及通过段落-查询并行交互模块进行单模态视频-查询对齐。实验结果表明,TEA在多个评估指标上均优于现有方法,显著提高了视频时刻检索的性能。
LOOK-M: Look-Once Optimization in KV Cache for Efficient Multimodal Long-Context Inference
➡️ 论文标题:LOOK-M: Look-Once Optimization in KV Cache for Efficient Multimodal Long-Context Inference
➡️ 论文作者:Zhongwei Wan, Ziang Wu, Che Liu, Jinfa Huang, Zhihong Zhu, Peng Jin, Longyue Wang, Li Yuan
➡️ 研究机构: The Ohio State University、Peking University、Imperial College London、Tencent AI Lab
➡️ 问题背景:多模态大型语言模型(MLLMs)在处理长上下文多模态输入时面临显著的计算资源挑战,尤其是多模态键值(KV)缓存的快速增长,导致内存和时间效率的下降。与仅处理文本的单模态大型语言模型(LLMs)不同,MLLMs的KV缓存包含来自多个图像的表示及其时空关系,以及相关的文本上下文。这种多模态KV缓存的特点使得传统的LLMs KV缓存优化方法不再适用,且目前尚无针对这一挑战的解决方案。
➡️ 研究动机:现有的KV缓存优化方法主要集中在文本模态上,而忽略了多模态KV缓存中图像和文本之间的交互。为了提高多模态长上下文任务的效率,研究团队提出了一种新的方法LOOK-M,旨在通过压缩KV缓存来减少内存使用,同时保持或提高模型性能。
➡️ 方法简介:LOOK-M是一种无需微调的高效框架,专门针对多模态长上下文场景下的KV缓存压缩。该方法通过在提示预填充阶段优先保留文本KV对,并基于注意力权重动态地排除不重要的图像KV对,来实现KV缓存的压缩。此外,为了保持全局上下文信息,LOOK-M还引入了多种合并策略,将被排除的KV对合并到保留的KV对中,以减少潜在的幻觉和上下文不一致问题。
➡️ 实验设计:研究团队在四个最近的MLLM骨干模型(LLaVA-v1.5-7B/13B、MobileVLM-v2、InternVL-v1.5)上进行了实验,涵盖了MileBench基准中的多个多模态长上下文任务,包括时间多图像任务、语义多图像任务、针在草堆任务和图像检索任务。实验结果表明,LOOK-M在固定KV缓存预算下,实现了最小的性能下降,并将模型推理解码延迟提高了1.3倍至1.5倍,同时将KV缓存内存占用减少了80%至95%。
A Refer-and-Ground Multimodal Large Language Model for Biomedicine
➡️ 论文标题:A Refer-and-Ground Multimodal Large Language Model for Biomedicine
➡️ 论文作者:Xiaoshuang Huang, Haifeng Huang, Lingdong Shen, Yehui Yang, Fangxin Shang, Junwei Liu, Jia Liu
➡️ 研究机构: Baidu Inc, Beijing、China Agricultural University、Institute of Automation, Chinese Academy of Sciences (CASIA)
➡️ 问题背景:尽管多模态大语言模型(MLLMs)在视觉语言任务中取得了显著进展,但在生物医学领域,这些模型的能力仍存在显著差距,尤其是在指代和定位(referring and grounding)方面。当前缺乏专门针对生物医学图像的指代和定位数据集,这限制了模型在该领域的应用和发展。
➡️ 研究动机:为了填补这一空白,研究团队开发了Med-GRIT-270k数据集,该数据集包含27万个问题-回答对,涵盖了8种不同的医学成像模态。此外,团队还提出了BiRD模型,这是一个专门针对生物医学领域的多模态大语言模型,旨在提高模型在指代和定位任务中的表现。
➡️ 方法简介:研究团队通过从医学分割数据集中采样大规模的生物医学图像-掩码对,并利用chatGPT生成指令数据集,构建了Med-GRIT-270k数据集。BiRD模型基于Qwen-VL模型进行多任务指令学习,以适应生物医学领域的特定需求。
➡️ 实验设计:研究团队在Med-GRIT-270k数据集的测试集上进行了广泛的实验,评估了BiRD模型在视觉定位(VG)、指代对象分类(ROC)、指代描述(RC)和医学图像分析(MIA)等任务中的表现。实验结果表明,随着训练数据规模的增加,模型在所有任务上的表现均有显著提升,特别是在Dermoscopy模态上表现尤为突出。
相关文章:
多模态大语言模型arxiv论文略读(八十七)
MG-LLaVA: Towards Multi-Granularity Visual Instruction Tuning ➡️ 论文标题:MG-LLaVA: Towards Multi-Granularity Visual Instruction Tuning ➡️ 论文作者:Xiangyu Zhao, Xiangtai Li, Haodong Duan, Haian Huang, Yining Li, Kai Chen, Hua Ya…...

《棒球百科》长寿运动排名·棒球1号位
关于长寿运动的排名,运动长寿秘诀: 一、全球公认的「长寿运动」排名 游泳(低冲击、强化心肺) 快走/健走(每日30分钟降低15%早逝风险) 太极拳(平衡力减压,哈佛研究称可延缓衰老&am…...

Maven 项目打包时添加本地 Jar 包
在 Maven 项目开发中,我们经常会遇到需要引入本地 Jar 包的场景,比如使用未发布到中央仓库的第三方库、公司内部自定义工具包,或者处理版本冲突的依赖项。本文将详细介绍如何通过 Maven 命令将本地 Jar 包安装到本地仓库,并在项目…...
记录将网站从http升级https
http与https 你知道http是什么吗,那你知道https吗?在进行升级之前我们应该都听说http不安全,要用https,那你知道这是为什么吗? 什么是http? HTTP 是超文本传输协议,也就是HyperText Transfer…...

如何利用 ORM 框架有效防范 SQL 注入攻击
如何利用 ORM 框架有效防范 SQL 注入攻击 1. 引言 在现代 Web 开发中,SQL 注入攻击始终是数据库安全的一大隐患。攻击者利用不安全的 SQL 语句执行恶意操作,可能导致数据库泄露、篡改甚至被完全控制。幸运的是,ORM(对象关系映射)框架为开发者提供了一种更安全、更高效的…...

spark-shuffle 类型及其对比
1. Hash Shuffle 原理:将数据按照分区键进行哈希计算,将相同哈希值的数据发送到同一个Reducer中。特点:实现简单,适用于数据分布均匀的场景。但在数据分布不均匀时,容易导致某些Reducer处理的数据量过大,产…...
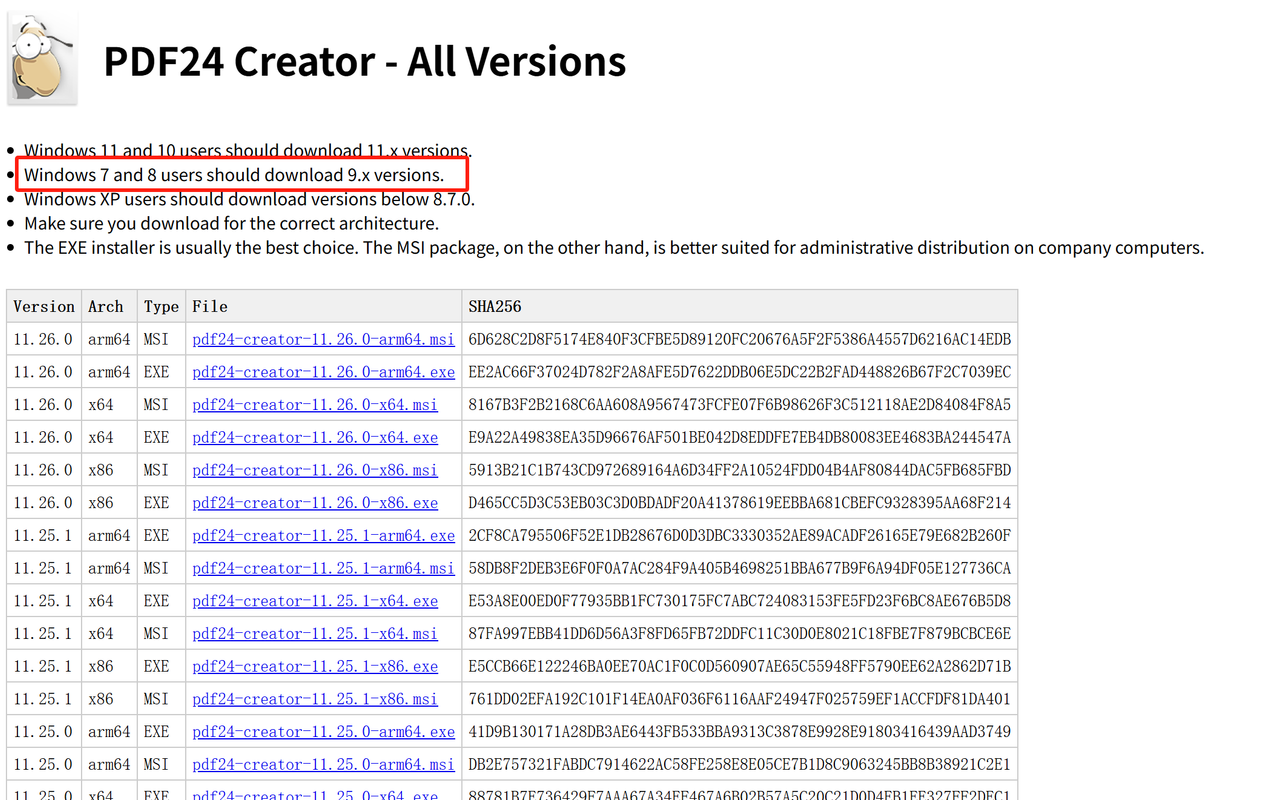
免费PDF工具-PDF24V9.16.0【win7专用版】
【百度】https://pan.baidu.com/s/1H7kvHudG5JTfxHg-eu2grA?pwd8euh 提取码: 8euh 【夸克】https://pan.quark.cn/s/92080b2e1f4c 【123】https://www.123912.com/s/0yvtTd-XAHjv https://creator.pdf24.org/listVersions.php...
:Python复刻「崩坏星穹铁道」嗷呜嗷呜事务所---源码级解析该小游戏背后的算法与设计模式【纯原创】)
游戏开发实战(二):Python复刻「崩坏星穹铁道」嗷呜嗷呜事务所---源码级解析该小游戏背后的算法与设计模式【纯原创】
文章目录 奇美拉和队列奇美拉被动技能多对多观察者关系实现自定义元类奇美拉基类 管理奇美拉的队列奇美拉队列类心得体会扩展 规则定义工作相关奇美拉相关 奇美拉属性 在本篇博文,我将介绍本项目的整体框架,以及“编码规则”,这些规则保证了本…...

人工智能发展
探秘人工智能领域的热门编程语言与关键知识 在当今科技飞速发展的时代,人工智能已渗透到生活的各个角落,从智能语音助手到精准的推荐系统,从自动驾驶汽车到医疗影像诊断,人工智能正以前所未有的速度改变着世界。而在这背后&#x…...

在Rockchip平台上利用FFmpeg实现硬件解码与缩放并导出Python接口
在Rockchip平台上利用FFmpeg实现硬件解码与缩放并导出Python接口 一、为什么需要硬件加速?二、[RK3588 Opencv-ffmpeg-rkmpp-rkrga编译与测试](https://hi20240217.blog.csdn.net/article/details/148177158)三、核心代码解释3.1 初始化硬件上下文3.2 配置解码器3.3 构建滤镜链…...

Flink集成资源管理器
Flink集成资源管理器 Apache Flink 支持多种资源管理器,主要包括以下几种: YARN ResourceManager :适用于使用 Hadoop YARN 作为资源管理器的环境。YARN ResourceManager 负责管理集群中的资源,包括 CPU、内存等,并…...
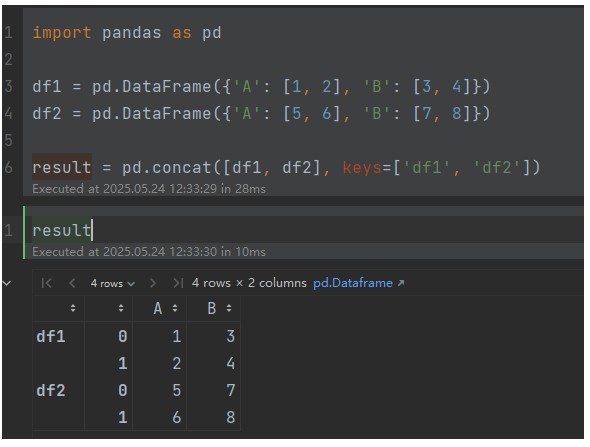
一周学会Pandas2 Python数据处理与分析-Pandas2数据合并与对比-pd.concat():轴向拼接
锋哥原创的Pandas2 Python数据处理与分析 视频教程: 2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili 在数据分析中,数据往往分散在多个来源(如不同文件、数据库表或API),需…...

安卓原生兼容服务器
安卓原生兼容服务器的定义 安卓原生兼容服务器指基于Android系统内核和服务框架构建的服务器环境,能够在不依赖第三方适配层的情况下,直接运行符合Android API规范的服务程序,并满足与其他软硬件组件的协同工作需求。其核心特征体现在以下…...

优化用户体验:拦截浏览器前进后退、刷新、关闭、路由跳转等用户行为并弹窗提示
🧑💻 写在开头 点赞 收藏 学会🤣🤣🤣 需求 首先列举一下需要拦截的行为,接下来我们逐个实现。 浏览器前进后退标签页刷新和关闭路由跳转 1、拦截浏览器前进后退 这里的实现是核心,涉及到大…...

横川机器人驱动器导入参数教程
连接端口:有分220v和380v(刷新多次无效果就重新打开软件)升级固件:区分低压版和高压版导入参数:下载参数,下载成功后必须软重启,重新连接确认电机无干涉后相序测试 (等待10s&#x…...
大学生创新创业项目管理系统设计——数据库实验九
本实验为自己设计完成,我当年数据库实验得了94分 目录 1.实验目的 2.实验内容和要求 3.实验步骤 4.实验心得 实验九 数据库设计 1.实验目的 掌握数据库设计的过程和方法。 2.实验内容和要求 (35)大学生创新创业项目管理系统设计 一…...

电磁场与电场、磁场的关系
电磁场与电场、磁场之间存在着深刻的内在联系和统一性关系。这三者共同构成了电磁相互作用的基本框架,是理解电磁现象的关键所在。 电场和磁场实际上是电磁场的两个不同表现形式,它们既相互区别又密切联系。电场主要由静止电荷产生,表现为对…...
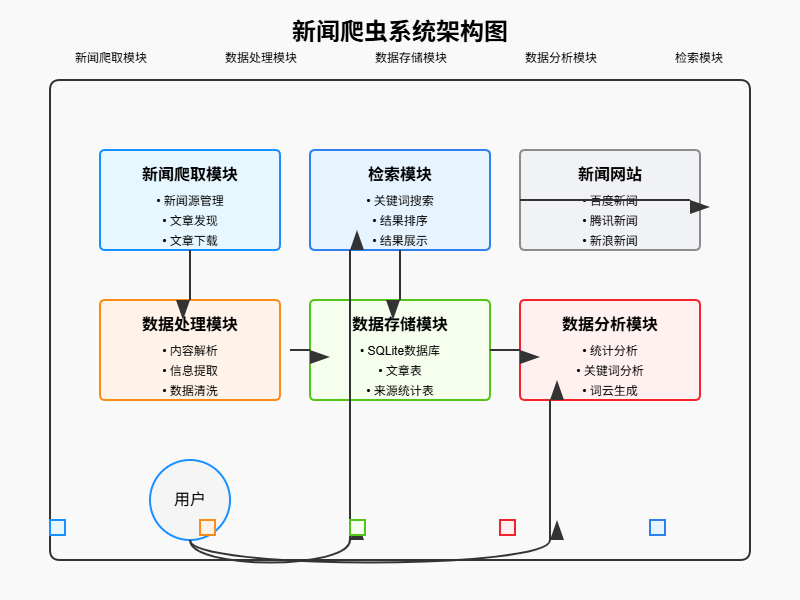
Python爬虫实战:研究Newspaper框架相关技术
1. 引言 1.1 研究背景与意义 互联网的快速发展使得新闻信息呈现爆炸式增长,如何高效地获取和分析这些新闻数据成为研究热点。新闻爬虫作为一种自动获取网页内容的技术工具,能够帮助用户从海量的互联网信息中提取有价值的新闻内容。本文基于 Python 的 …...
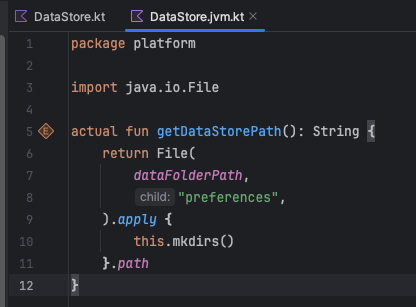
Kotlin MultiPlatform 跨平台版本的记账 App
前言 一刻记账 KMP (Kotlin MultiPlatform) 跨平台版本今天终于把 Android 和 iOS 进度拉齐了. 之前只有纯 Android 的版本. 最近大半年有空就在迁移代码到 KMP 上 中间学了 iOS 基础知识. xcode 的使用. 跨平台的架构的搭建… 感觉经历了很多很多. 一把辛酸泪 迁移的心路历…...

PIO 中的赋值魔术,MOV 指令
前言 在普通编程语言中,mov 可以理解为“赋值指令”,将一个值从一个地方拷贝到另一个地方。在 RP2040 的 PIO 汇编语言中,mov 同样是数据传递的关键指令,但它操作的是 PIO 独有的几个寄存器。 在 PIO 中,你可以用 mov …...

[docker]更新容器中镜像版本
从peccore-dev仓库拉取镜像 docker pull 10.12.135.238:8060/peccore-dev/configserver:v1.13.45如果报错,请参考docker拉取镜像失败,添加仓库地址 修改/etc/CET/Common/peccore-docker-compose.yml文件中容器的版本,为刚刚拉取的版本 # 配置中心confi…...

第十七次CCF-CSP算法(含C++源码)
第十七次CCF-CSP认证 小明种苹果AC代码 小明种苹果(续)AC代码 后面好难哈哈 小手冰凉 小明种苹果 输入输出: 题目链接 AC代码 #include<iostream> using namespace std; int n,m; int res,res3; int sum; int res21; int main(){cin …...
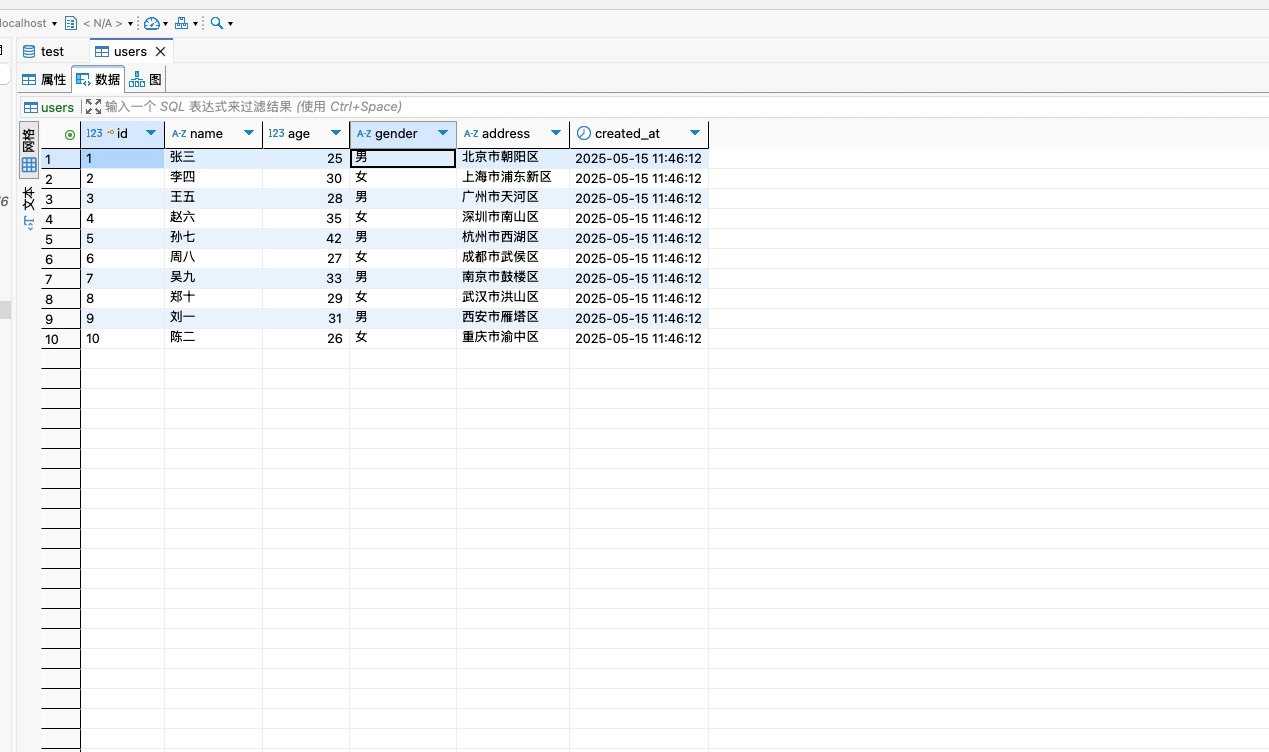
打造一个支持MySQL查询的MCP同步插件:Java实现
打造一个支持MySQL查询的MCP同步插件:Java实现 用Java实现一个MCP本地插件,直接通过JDBC操作本地MySQL,并通过STDIO与上层MCP客户端(例如Cursor)通信。插件注册一个名为mysql 的同步工具,接收连接参数及SQL…...
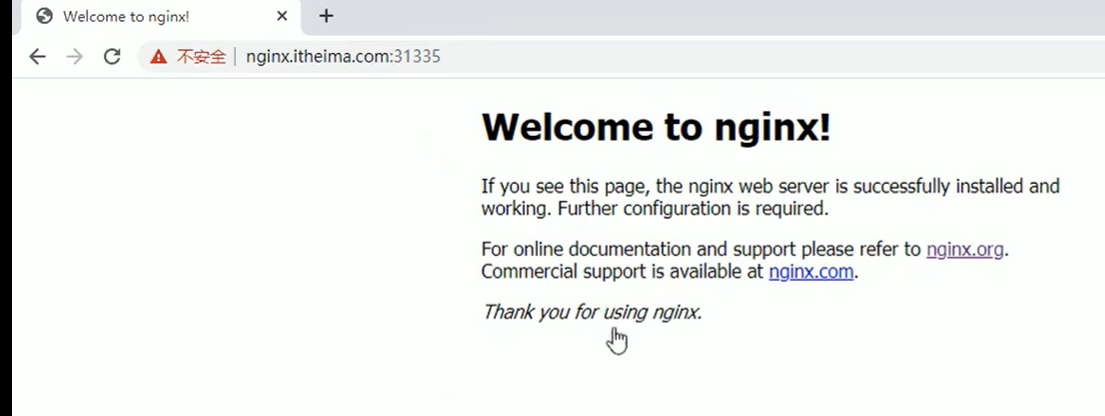
黑马k8s(十五)
1.Ingress介绍 2.Ingress使用 环境准备 Http代理 Https代理...
)
Axure项目实战:智慧运输平台后台管理端-订单管理1(多级交互)
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢!如有帮助请订阅专栏! Axure产品经理精品视频课已登录CSDN可点击学习https://edu.csdn.net/course/detail/40420 课程主题:订单管理 主要内容:条件组合、中继器筛选、表单跟随菜单拖动、审批数据互通等 应用场景…...
解决 cursor 中不能进入 conda 虚拟环境
【问题】 遇到一个小问题,我创建的conda 环境在 cmd、powershell中都可以激活,但在pycharm、cursor中却不能激活? 看图 cmd中正常: cursor中不正常: 【解决方法】 cursor 中,打开终端,输入&a…...
api的例子)
微信小程序请求扣子(coze)api的例子
1. 准备工作 在开始之前,确保已经完成了以下准备工作: 创建并发布了 Coze 智能体。获取了个人访问令牌(Personal Access Token),这是用于授权的关键凭证。确认目标智能体的 Bot ID 和其他必要参数已准备就绪。 2. 请…...
C++ 实现二叉树的后序遍历与中序遍历构建及层次遍历输出
C 实现二叉树的后序遍历与中序遍历构建及层次遍历输出 目录 C 实现二叉树的后序遍历与中序遍历构建及层次遍历输出一、实验背景与目标二、实验环境三、实验内容四、数据结构与算法数据结构算法描述1. **构建二叉树函数 buildTree**2. **层次遍历函数 LevelOrder** 关键代码与解…...

基于大模型的髋关节骨关节炎预测与治疗方案研究报告
目录 一、引言 1.1 研究背景与意义 1.2 研究目的与创新点 1.3 研究方法与技术路线 二、髋关节骨关节炎概述 2.1 疾病定义与分类 2.2 发病机制与病理过程 2.3 流行病学特征 三、大模型技术原理与应用基础 3.1 大模型的基本概念与架构 3.2 大模型在医疗领域的应用进展…...

qiankun解决的问题
qiankun 中的沙箱机制是如何实现的?解决了什么问题? 一、实现方式 qiankun 的沙箱机制主要用于隔离微应用之间的运行环境,避免相互影响。其核心实现基于两种策略: 快照沙箱(SnapshotSandbox) 适用于不支…...