LLM Tuning
Lora-Tuning
什么是Lora微调?
LoRA(Low-Rank Adaptation) 是一种参数高效微调方法(PEFT, Parameter-Efficient Fine-Tuning),它通过引入低秩矩阵到预训练模型的权重变换中,实现无需大规模修改原模型参数即可完成下游任务的微调。即你微调后模型的参数 = 冻结模型参数 + Lora微调参数。
什么是微调?
在早期的机器学习中,构建一个模型并对其进行训练是可行的。但到了深度学习阶段,模型的参数量大且训练的数据多,因此要从0到1训练一个模型是非常耗时和耗资源的过程。
训练,在其最简单的意义上。您将一个未经训练的模型,提供给它数据,并获得一个高性能的模型。
对于简单问题来说,这仍然是一种流行的策略,但对于更复杂的问题,将训练分为两个部分,即“预训练”和“微调”,可能会很有用。总体思路是在一个大规模数据集上进行初始训练,并在一个定制的数据集上对模型进行优化。
最基本的微调形式 是使用与预训练模型相同的过程来微调新数据上的模型。例如,您可以在大量的通用文本数据上训练模型,然后使用相同的训练策略,在更具体的数据集上微调该模型。
目前的话,在深度学习中,你所用的预训练的模型就是别人从0到1训练好给你用的,你后面的基于特定数据集所做的训练其实是基于已有模型参数的基础上去进行微调。
那在深度学习阶段,这种方式消耗GPU的程度还可以接收,那到了LLM阶段,如果想通过微调全部参数来微调上一个已预训练好的没有冻结参数模型的话,那消费的GPU就不是一个量级上的,因此Lora就是针对LLM微调消耗资源大所提出优化方案。
Lora的思想
“低秩适应”(LoRA)是一种“参数高效微调”(PEFT)的形式,它允许使用少量可学习参数对大型模型进行微调 。LoRA改善微调的几个关键点:
- 将微调视为学习参数的变化(
),而不是调整参数本身(
)。
- 通过删除重复信息,将这些变化压缩成较小的表示。
- 通过简单地将它们添加到预训练参数中来“加载”新的变化。
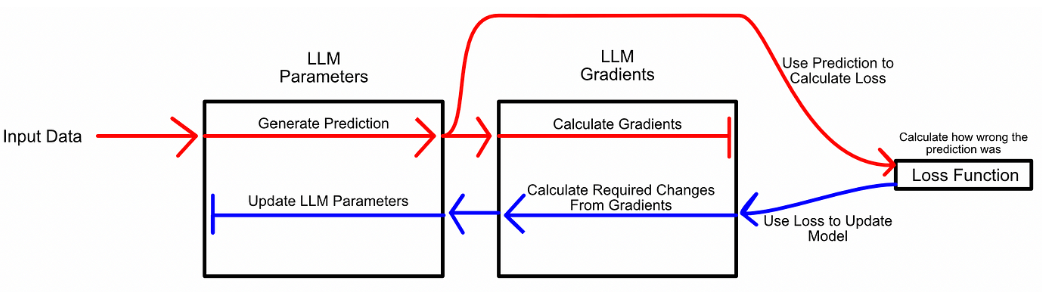
正如之前讨论的,微调的最基本方法是迭代地更新参数。就像正常的模型训练一样,你让模型进行推理,然后根据推理的错误程度更新模型的参数(反向传播)。
与其将微调视为学习更好的参数,LoRA 将微调视为学习参数变化:冻结模型参数,然后学习使模型在微调任务中表现更好所需的这些参数的变化。类似于训练,首先让模型推理,然后根据error进行更新。但是,不更新模型参数,而是更新模型参数的变化。如下面所示,蓝色箭头反向传播只是去微调模型所需要的参数变化,没有去微调模型原有的参数。
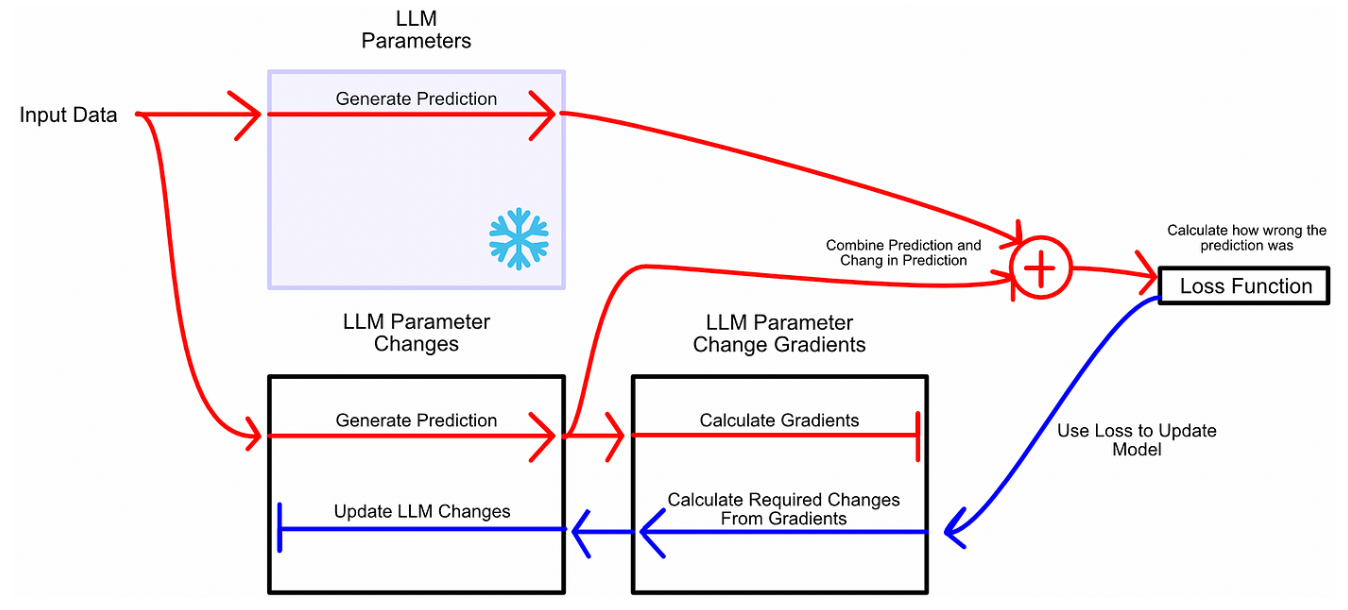
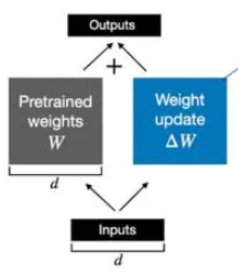
在微调的过程中可以不去微调W,去微调来捕捉
所需要进行的参数变化,那随后二者相加就得到了微调后模型的参数。
那Lora体现的降低资源在哪?如如果形状为[ 1000, 200 ] 的话,那如果我去微调原模型参数的话,那需要微调的参数有 1000 * 200 = 200,000。聪明的你可能想到了,那我去微调获得参数的变化不也是一个[ 1000, 200 ]的矩阵,不然后面矩阵怎么相加。这就是Lora的巧妙之处,它将所需微调的
矩阵分解为低秩表示,你在这个过程不需要显示计算
,只需要学习
的分解表示。比如
= [ 1000, 200 ] 可以被划分为 [1000, 1] * [1, 200],那这样的话所需要微调的参数就只有1000+200=1200,与200,000比的话,我们就可以明显看出来Lora节省计算资源的秘密了。

补充:
- 那Lora为什么是低秩?首先我们要明确矩阵的秩的概念,矩阵秩在我们学线性代数中存在的概念,其定义为:矩阵中行(或列)向量线性无关的最大数量。换句话说,换句话说,矩阵的秩表示其可以提供多少个独立的信息维度。如果秩越大,表示矩阵的行(列)越独立,它们不能被其他另外的行(列)进行线性表示获得;相反,如果秩越小,那么表示矩阵的行(列)独立程度低,那么我可以根据其中所有独立的行(列)来得到矩阵所有的行(列)。
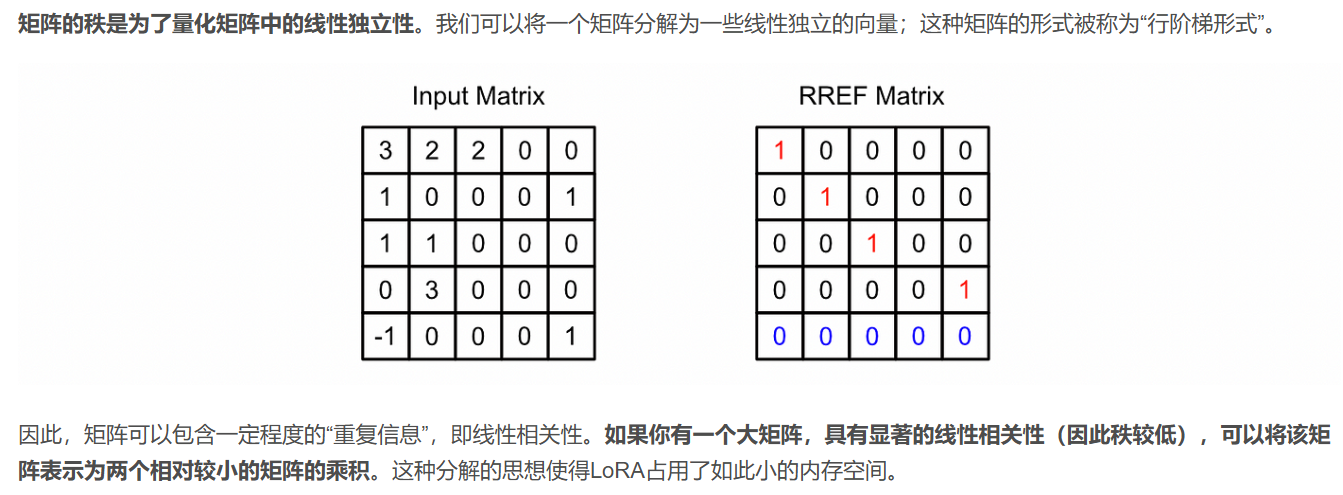
- 为什么要谈到秩?就是因为你
Lora微调的过程
- 首先冻结模型参数。使用这些参数进行推理,但不会更新它们。然后创建两个矩阵,当它们相乘时,它们的大小将与我们正在微调的模型的权重矩阵的大小相同。在一个大型模型中,有多个权重矩阵,为每个权重矩阵创建一个这样的配对。
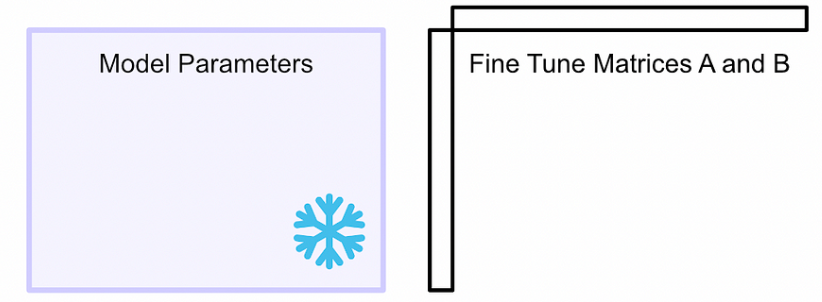
- LoRA将这些矩阵称为矩阵“A”和“B”。这些矩阵一起代表了LoRA微调过程中的可学习参数。
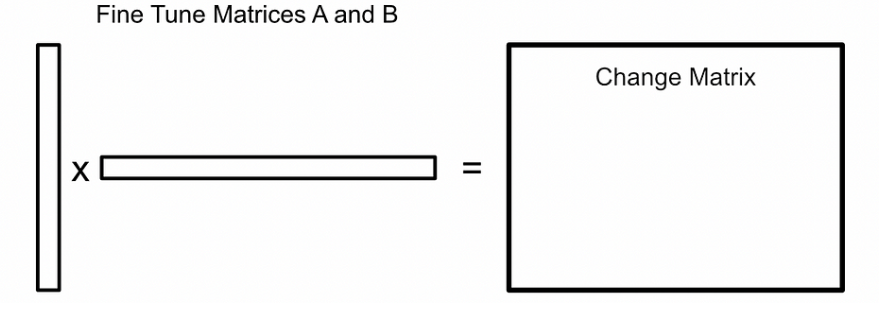
- 将输入通过冻结的权重和变化矩阵传递。
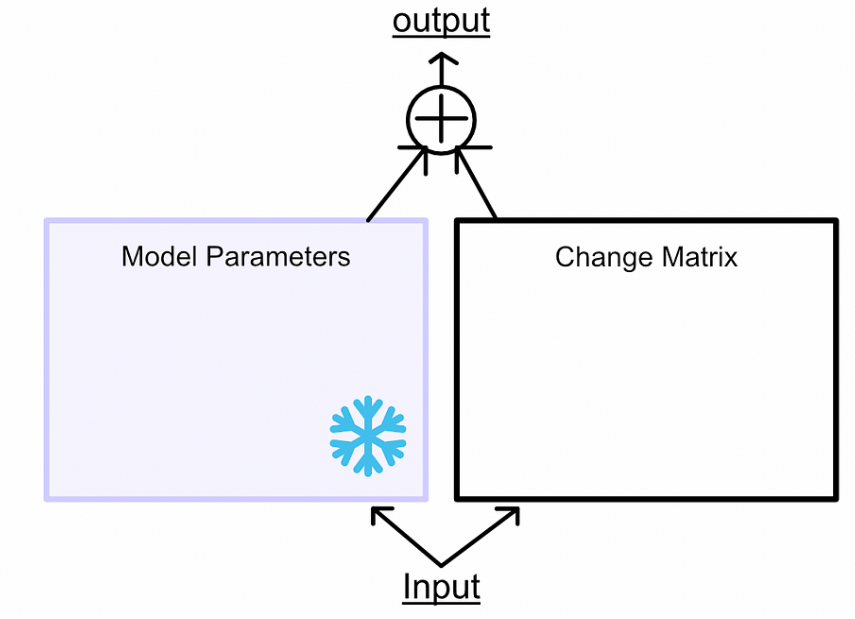
- 根据两个输出的组合计算损失,然后根据损失更新矩阵A和B。
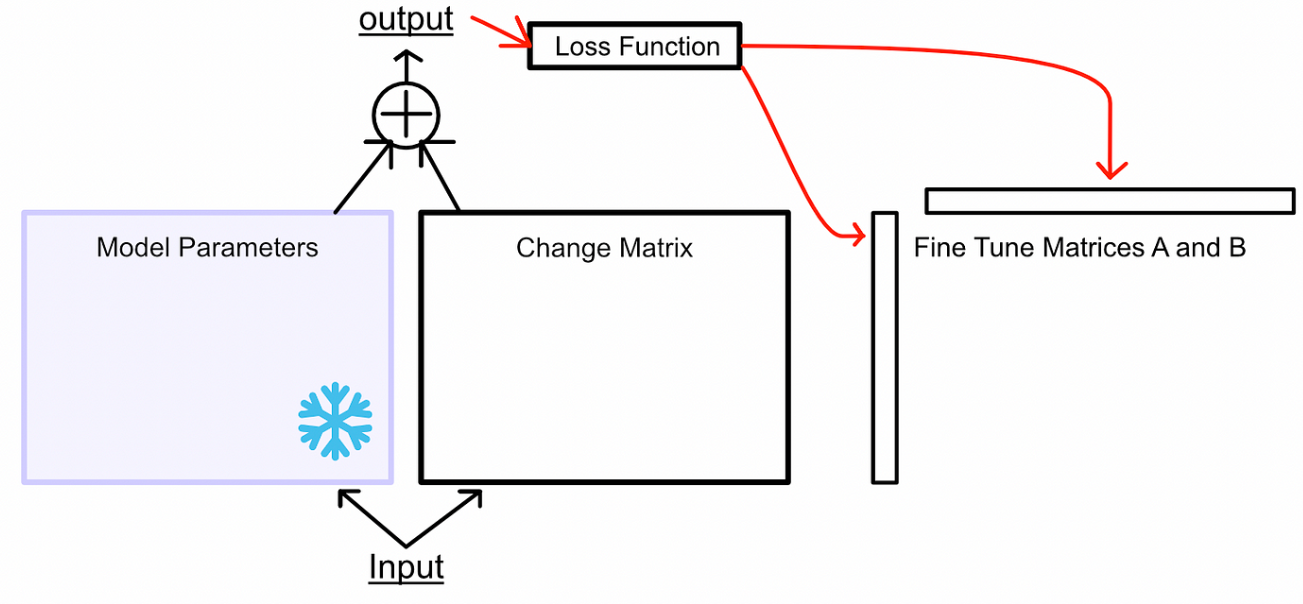
这些变化矩阵是即时计算的,从未被存储,这就是为什么LoRA的内存占用如此小的原因。实际上,在训练期间只存储模型参数、矩阵A和B以及A和B的梯度。
。
当我们最终想要使用这个微调模型进行推断时,我们只需计算变化矩阵,并将变化添加到权重中。这意味着LoRA不会改变模型的推断时间

Lora在Transformer的应用
在大模型中(如BERT、GPT-3),全参数微调需要对模型的所有参数进行更新,代价非常高,尤其是当模型规模达到数十亿甚至百亿参数时。
例如
- 通常,在Transformer的多头自注意力层中,密集网络(用于构建Q、K和V)的深度只有1。也就是说,只有一个输入层和一个由权重连接的输出层。
-
这些浅层密集网络是Transformer中大部分可学习参数,非常非常大。可能有超过100,000个输入神经元连接到100,000个输出神经元,这意味着描述其中一个网络的单个权重矩阵可能有10B个参数。因此,尽管这些网络的深度只有1,但它们非常宽,因此描述它们的权重矩阵非常大。
LoRA 认为:
神经网络中某些层的权重矩阵(如自注意力中的
,
,
,
)在特定任务微调时,其更新矩阵是低秩的。
因此,LoRA不直接更新原始大权重矩阵 W,而是将权重的变化用一个低秩矩阵来表达,从而减少需要训练的参数数量。
Lora Rank
LoRA有一个超参数,称为Rank,它描述了用于构建之前讨论的变化矩阵的深度。较高的值意味着更大的和矩阵,这意味着它们可以在变化矩阵中编码更多的线性独立信息。(联想矩阵的秩)
“r"参数可以被视为"信息瓶颈”。较小的r值意味着A和B可以用更小的内存占用编码较少的信息。较大的r值意味着A和B可以编码更多的信息,但内存占用更大。(100张1块钱,就能够表达一张100块钱,那你给我更多我钱我也愿意啊,能让我住豪宅开跑车我也愿意啊(doge))。
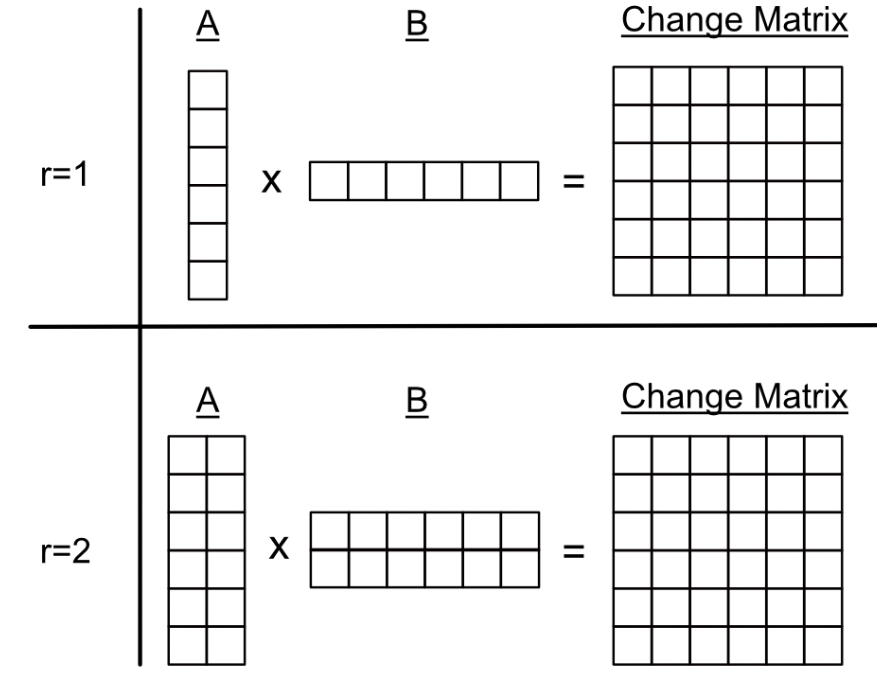
一个具有r值等于1和2的LoRA的概念图。在这两个例子中,分解的A和B矩阵导致相同大小的变化矩阵,但是r=2能够将更多线性独立的信息编码到变化矩阵中,因为A和B矩阵中包含更多信息。
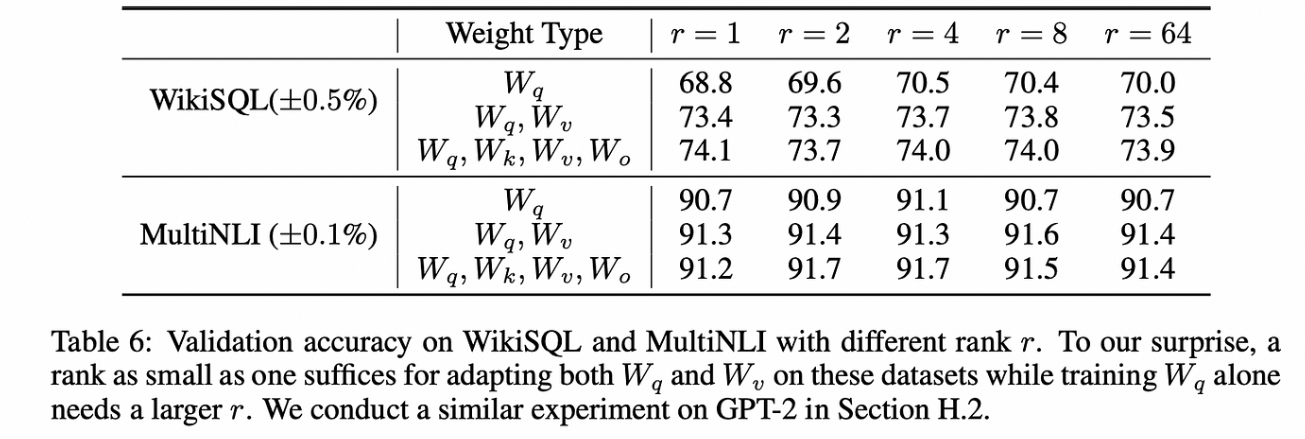
事实证明,LoRA论文所做的核心假设,即模型参数的变化具有低隐式秩(即你用较少独立的行(列)来表示一个完整的矩阵是可行的),是一个相当强的假设。微软(LoRA的出版商)的人员尝试了一些值,并发现即使是秩为一的矩阵也表现出色。
LoRA论文中建议:当数据与预训练中使用的数据相似时,较低的r值可能就足够了。当在非常新的任务上进行微调时,可能需要对模型进行重大的逻辑更改,这时可能需要较高的r值。(遇到新的问题,需要更多信息来辅助判断)
图源:【大模型微调】LoRA — 其实大模型微调也没那么难!_lora微调-CSDN博客
Prefix-Tuning
P-Tuning
Lora Tuning 是针对 encoding部分的微调,而在P-tuning中是针对embedding的微调。
什么是P-tuning?
P-Tuning,它是一种微调大语言模型(Large Language Model, LLM)的方法。与传统的全参数微调(Fine-tuning)不同,P-Tuning 只在模型输入层或中间层插入可学习的“Prompt Embeddings”(也称 Prompt Tokens/Prefix 等),从而极大减少微调参数量。其核心思想可以归纳为:
- 冻结(freeze)大部分或全部原始模型参数
- 引入少量可训练的参数(Prompt Embeddings)
- 通过梯度反向传播仅更新这部分可训练参数
即通过学习连续的、可训练的“软提示”(soft prompts)来引导预训练模型完成下游任务,而不是像传统微调那样直接修改或微调模型的全部参数。模型在训练过程中会将这些 Prompt Embeddings 拼接到原输入或模型内部隐藏层的输入里,从而让预训练模型更好地针对任务进行表征/生成。因为只训练这部分 Prompt Embeddings,而模型的主体参数并未改变,所以对硬件资源和训练数据需求更小,微调速度也更快。
两阶段对比,Prompt Tuning v.s. P Tuning
第一阶段,Prompt Tuning
冻结主模型全部参数,在训练数据前加入一小段Prompt,只训练Prompt的表示层,即一个Embedding模块。论文实验表明,只要模型规模够大,简单加入 Prompt tokens 进行微调,就能取得很好的效果。
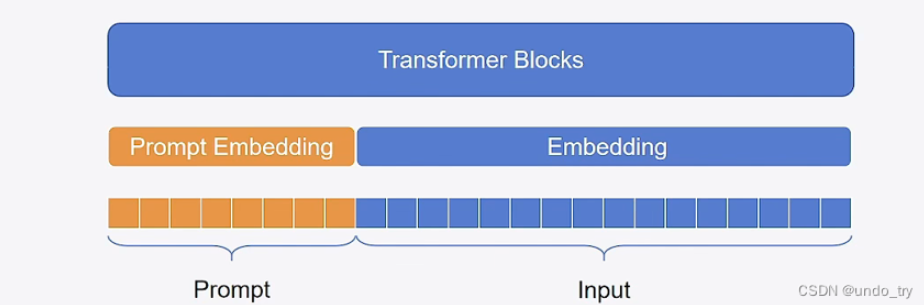
第二阶段,在Prompt Tuning的基础上,对 Prompt部分 进行进一步的encoding计算,加速收敛。具体来说,PEFT中支持两种编码方式,一种是LSTM,一种是MLP。与Prompt-Tuning不同的是,Prompt的形式只有Soft Prompt。
硬提示(Hard Prompt):离散的、人工可读的; 软提示(Soft Prompt):连续的、可训练的。
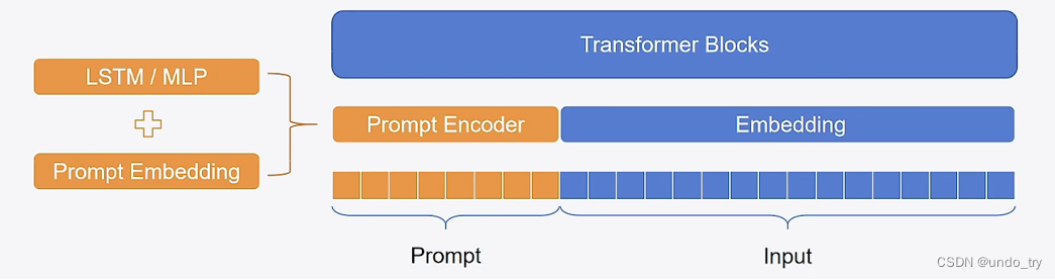
总结:P Tuning将Prompt转换为可以学习的Embedding层,并用MLP+LSTM的方式来对Prompt Embedding进行一层处理。
- 相比Prefix Tuning,P Tuning仅限于输入层,没有在每一层都加virtual token ◦
- 经过预训练的LM的词嵌入已经变得高度离散,如果随机初始化virtual token,容易优化到局部最优值,而这些virtual token理论是应该有相关关联的。因此,作者通过实验发现用一个prompt encoder来编码会收敛更快,效果更好。即用一个LSTM+MLP去编码这些virtual token以后,再输入到模型。
- 作者在实验中发现,相同参数规模,如果进行全参数微调,Bert的在NLU(自然语言理解)任务上的效果,超过GPT很多;但是在P-Tuning下,GPT可以取得超越Bert的效果。
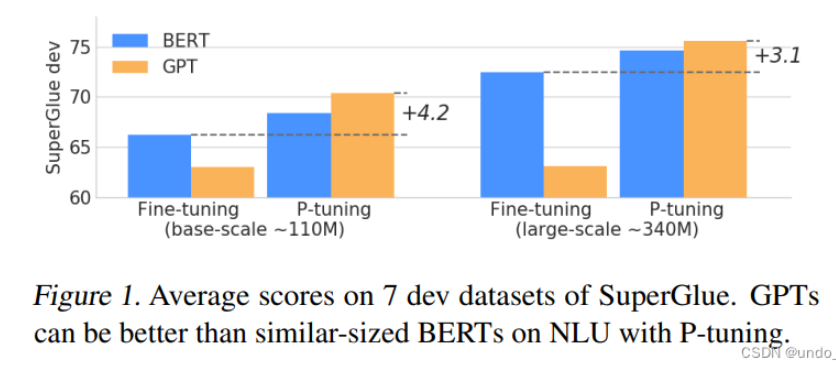
图源:参数高效微调PEFT(二)快速入门P-Tuning、P-Tuning V2-CSDN博客
P-tuning v.s. Prompt Engineering
Prompt Engineering 是人工提示工程,属于离散提示。它的做法是通过精心设计的自然语言提示(例如“请完成这个句子:...”)可以诱导模型完成任务,而无需微调。但这需要手动设计和筛选提示,效率低下且效果不稳定。
而P-tuning 则在这两者之间找到了一个平衡点。它的核心思想是:
- 不再使用离散的、人工设计的自然语言提示。
- 引入一小段可训练的连续向量(soft prompt)作为模型输入的前缀或嵌入,而不是直接修改模型的内部参数。
- 在训练过程中,只优化这部分软提示的参数,而冻结预训练模型的绝大部分参数。
P-tuning与Prompt Engineering的区别,关键就在你提示的语言是什么类型的,Prompt Engineering所使用的提示语言是人类语言,而P-tuning所使用的提示语言是我们给预训练模型“悄悄地”加上的一段“指令”,这段指令不是用人类语言写成的,而是模型自己“学出来”的最有效的连续向量,能够最大化地引导模型在特定任务上给出正确的输出。
一张图总结各种Tuning
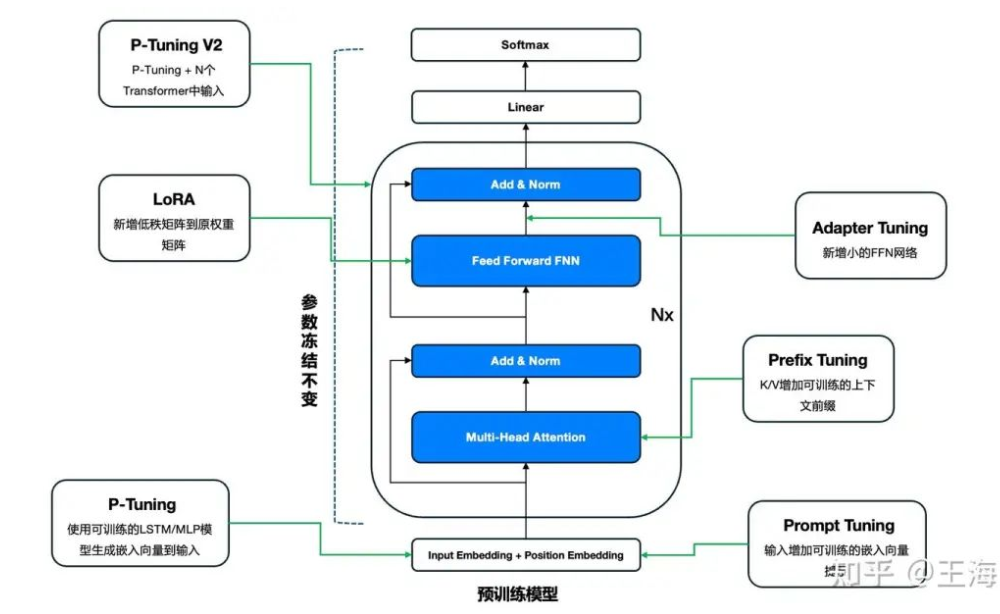
相关文章:
LLM Tuning
Lora-Tuning 什么是Lora微调? LoRA(Low-Rank Adaptation) 是一种参数高效微调方法(PEFT, Parameter-Efficient Fine-Tuning),它通过引入低秩矩阵到预训练模型的权重变换中,实现无需大规模修改…...
云计算与大数据进阶 | 28、存储系统如何突破容量天花板?可扩展架构的核心技术与实践—— 分布式、弹性扩展、高可用的底层逻辑(下)
在上篇中,我们围绕存储系统可扩展架构详细探讨了基础技术原理与典型实践。然而,在实际应用场景中,存储系统面临的挑战远不止于此。随着数据规模呈指数级增长,业务需求日益复杂多变,存储系统还需不断优化升级࿰…...
)
SQL每日一练(3)
前言: 难得看到了套好题,没考我,呜呜,今日第三更! 原始表(ai生成) 1. 销售表(sales) 用途:记录每笔销售的产品 ID 及金额。 product_id(产品 …...

Axure高级交互设计:中继器嵌套动态面板实现超强体验感台账
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢!如有帮助请订阅专栏! Axure产品经理精品视频课已登录CSDN可点击学习https://edu.csdn.net/course/detail/40420 课程主题:中继器嵌套动态面板 主要内容:中继器内部嵌套动态面板,实现可移动式台账,增强数据表现…...

水利数据采集MCU水资源的智能守护者
水利数据采集仪MCU,堪称水资源的智能守护者,其重要性不言而喻。在水利工程建设和水资源管理领域,MCU数据采集仪扮演着不可或缺的角色。它通过高精度的传感器和先进的微控制器技术,实时监测和采集水流量、水位、水质等关键数据&…...

函数式编程思想详解
函数式编程思想详解 1. 核心概念 不可变数据 (Immutable Data) 数据一旦创建,不可修改。任何操作均生成新数据,而非修改原数据。 优点:避免副作用,提升并发安全,简化调试。 Java实现:使用final字段、不可变…...

SAP全面转向AI战略,S/4HANA悄然隐身
在2025年SAP Sapphire大会上,SAP首席执行官Christian Klein提出了一个雄心勃勃的愿景:让人工智能(AI)无处不在,推动企业数字化转型。SAP的AI战略核心是将AI深度融入其业务应用生态,包括推出全新版本的AI助手…...
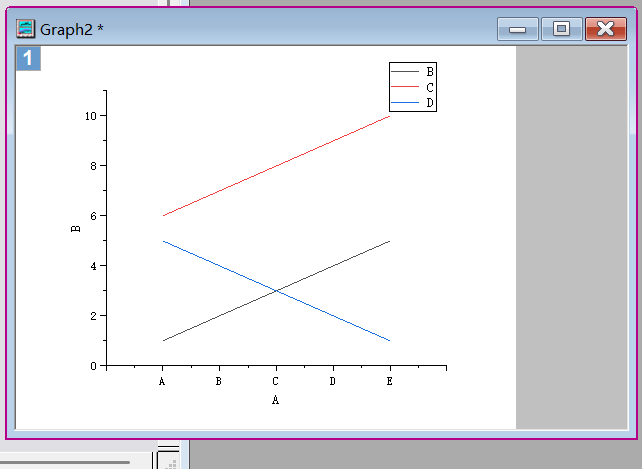
origin绘图之【如何将横坐标/x设置为文字、字母形式】
在使用 Origin 进行科研绘图或数据可视化的过程中,我们常常会遇到这样一种需求:希望将横坐标(X轴)由默认的数字形式,改为字母(如 A、B、C……)或中文文字(如 一、二、三………...

工业智能网关建立烤漆设备故障预警及远程诊断系统
一、项目背景 烤漆房是汽车、机械、家具等工业领域广泛应用的设备,主要用于产品的表面涂装。传统的烤漆房控制柜采用本地控制方式,操作人员需在现场进行参数设置和设备控制,且存在设备智能化程度低、数据孤岛、设备维护成本高以及依靠传统人…...
生成的视频无法在浏览器展)
cv2.VideoWriter_fourcc(*‘mp4v‘)生成的视频无法在浏览器展
看这个博主的博客,跟我碰到的问题的一致,都是使用AVC1写视频时报编码器不存在的异常,手动编译opencv-python或者使用conda install -c conda-forge opencv安装依赖即可。 博主博客:Python OpenCV生成视频无法浏览器播放问题说明及…...

MySQL 8.0 OCP 1Z0-908 161-170题
Q161.Examine this command, which executes successfully: cluster.addInstance ( ‘:’,{recoveryMethod: ‘clone’ 1}) Which three statements are true? (Choose three.) A)The account used to perform this recovery needs the BACKUP_ ADMIN privilege. B)A target i…...
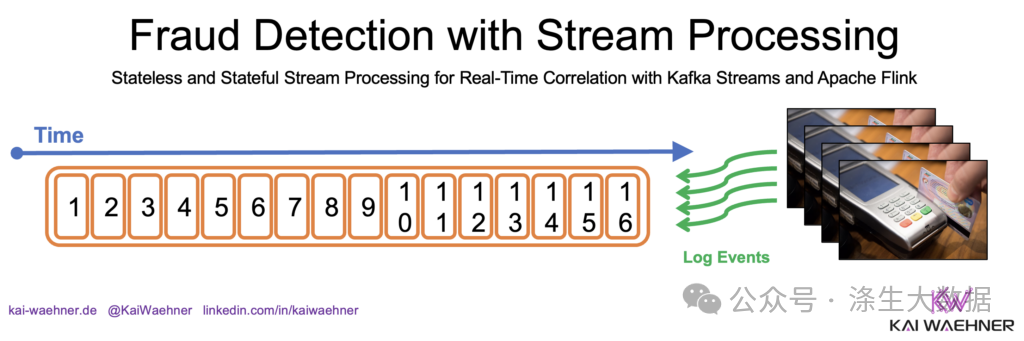
Kafka Streams 和 Apache Flink 的无状态流处理与有状态流处理
Kafka Streams 和 Apache Flink 与数据库和数据湖相比的无状态和有状态流处理的概念和优势。 在数据驱动的应用中,流处理的兴起改变了我们处理和操作数据的方式。虽然传统数据库、数据湖和数据仓库对于许多基于批处理的用例来说非常有效,但在要求低延迟…...

React从基础入门到高级实战:React 基础入门 - 简介与开发环境搭建
React 简介与开发环境搭建 引言 React 是一个强大的 JavaScript 库,用于构建用户界面(UI),尤其是在单页应用(SPA)开发中表现出色。它由 Facebook(现为 Meta)开发并于 2013 年开源&…...

LM-BFF——语言模型微调新范式
gpt3(GPT3——少样本示例推动下的通用语言模型雏形)结合提示词和少样本示例后,展示出了强大性能。但大语言模型的训练门槛太高,普通研究人员无力,LM-BFF(Making Pre-trained Language Models Better Few-shot Learners)的作者受gp…...

NVMe高速传输之摆脱XDMA设计2
NVMe IP放弃XDMA原因 选用XDMA做NVMe IP的关键传输模块,可以加速IP的设计,但是XDMA对于开发者来说,还是不方便,原因是它就象一个黑匣子,调试也非一番周折,尤其是后面PCIe4.0升级。 因此决定直接采用PCIe设…...
)
github开源版pymol安装(ubuntu22.04实战版)
1. 克隆 PyMOL 的 GitHub 仓库 首先,你需要从 GitHub 克隆 PyMOL 的源代码: git clone https://github.com/schrodinger/pymol-open-source.git cd pymol-open-source2. 安装依赖项 PyMOL 依赖一些系统库和 Python 包,确保先安装它们&…...

pycharm无需科学上网工具下载插件的解决方案
以下是两种无需科学上网即可下载 PyCharm 插件的解决思路: 方法 1:设置 PyCharm 代理 打开 PyCharm选择菜单:File → Settings → Appearance & Behavior → System Settings → HTTP Proxy在代理设置中进行如下配置: 代理地…...
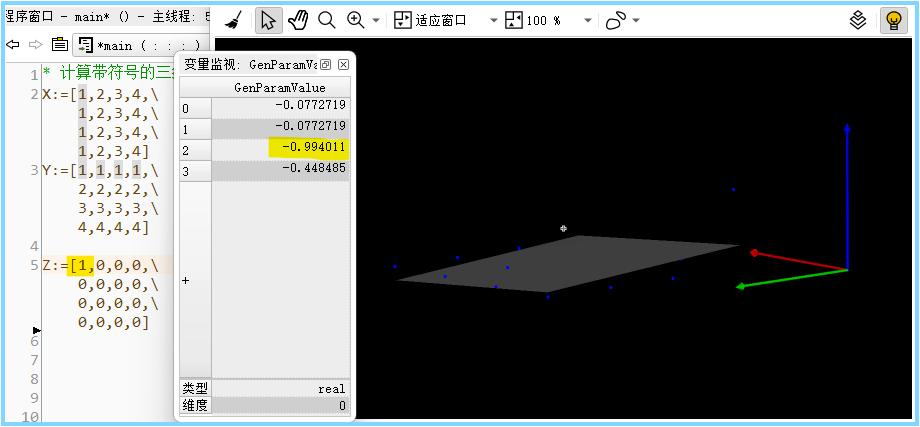
Halcon计算点到平面的距离没有那么简单
Halcon计算点到平面距离 1. 一些基本概念2. 浅谈有无符号的距离2.1 无符号距离的用武之地2.2 有符号距离的必要性 3. 无符号距离怎么算3.1 创建一个无限延展的基准平面,对距离有什么影响?Halcon代码图示 3.2 创建一个小小小的基准平面,对距离…...

基于DenseNet的医学影像辅助诊断系统开发教程
本文源码地址: https://download.csdn.net/download/shangjg03/90873921 1. 简介 本教程将使用DenseNet开发一个完整的医学影像辅助诊断系统,专注于胸部X光片的肺炎检测。我们将从环境搭建开始,逐步介绍数据处理、模型构建、训练、评估以及最终的系统部署。 2. 环境准备<…...
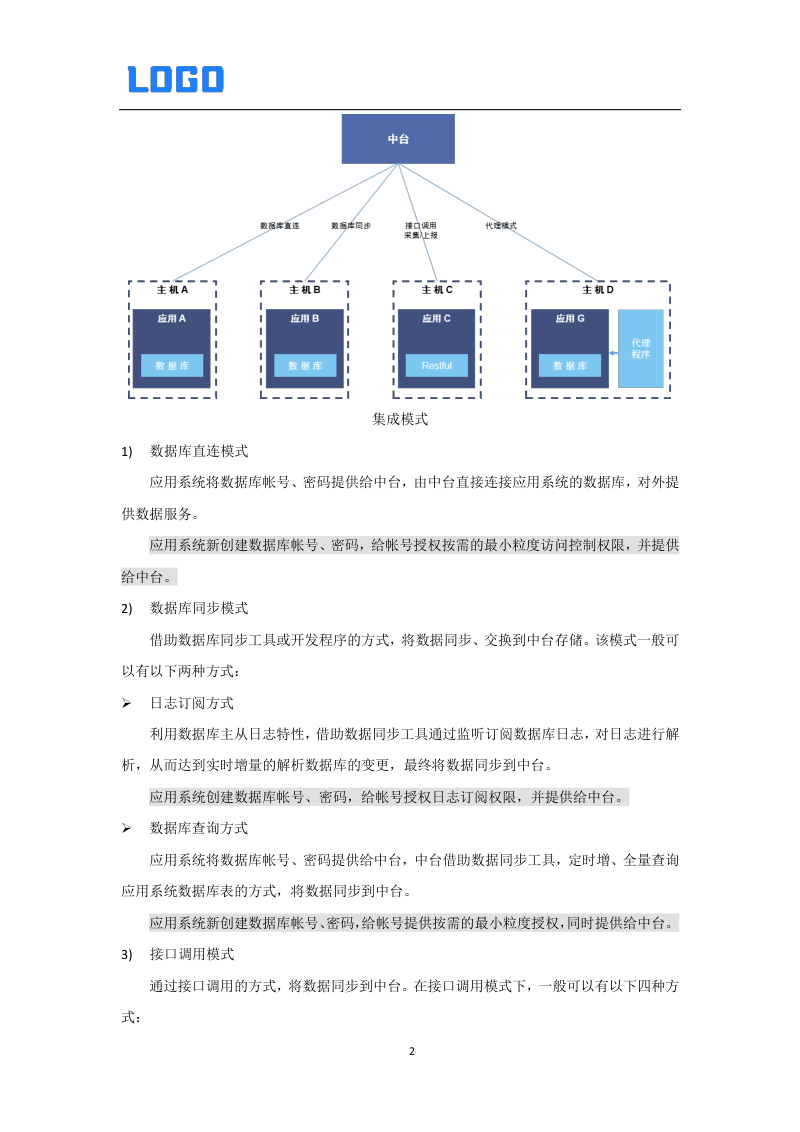
数据中台如何设计?中台开发技术方案,数据治理方案,大数据建设方案合集
中台的价值与核心理念 中台的核心在于“企业级能力复用”,其价值体现在四大维度: 能力整合:将分散的数字化能力(如营销、供应链)集中管理,形成核心竞争力; 业务创新:通过跨领域融合…...

Python爬虫设置IP代理
设置代理(Proxy) 作用: 当网站检测到某个IP的访问频率过高时,可能会封禁该IP。通过使用代理服务器,可以定期更换IP地址,避免被识别和封锁。 优势: 让网站无法追踪真实请求来源,提升…...
Adminer 连接mssql sqlserver
第一步 docker-compose.yml adminer部分: version: 3.8 services: adminer: image: adminer:latest container_name: adminer restart: unless-stopped volumes: - ./freetds/freetds.conf:/etc/freetds.conf:rw # 确保 :rw 可读写 co…...
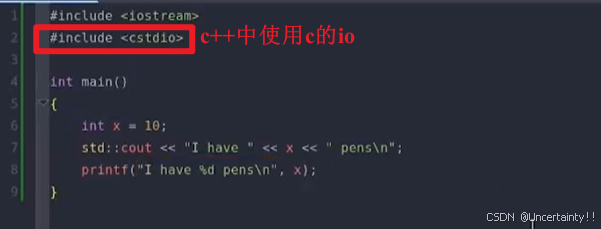
C++系统IO
C系统IO 头文件的使用 1.使用系统IO必须包含相应的头文件,通常使用#include预处理指令。 2.头文件中包含了若干变量的声明,用于实现系统IO。 3.头文件的引用方式有双引号和尖括号两种,区别在于查找路径的不同。 4.C标准库提供的头文件通常没…...

利用 Python 爬虫获取唯品会 VIP 商品详情:实战指南
在当今电商竞争激烈的环境中,VIP 商品往往是商家的核心竞争力所在。这些商品不仅代表着品牌的高端形象,更是吸引高价值客户的关键。因此,获取 VIP 商品的详细信息对于市场分析、竞品研究以及优化自身产品策略至关重要。Python 作为一种强大的…...
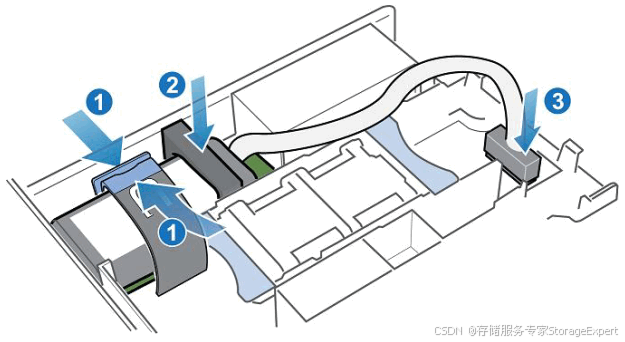
DELL EMC PowerStore BBU更换手册
写在前面 上周给客户卖了一个BBU电池,客户要写一个更换方案。顺利完成了更换,下面就把这个更换方案给大家share出来,以后客户要写,您就Ctrlc 和Ctrlv就可以了。 下面的步骤是最理想的方式,中间没有任何的问题ÿ…...

css五边形
五边形 .fu{width: 172rpx;height: 204rpx;overflow: hidden;border-radius: 10rpx;clip-path: polygon(0% 0%, 100% 0%, 100% 75%, 50% 100%, 0% 75%, 0% 25%); }六边形 clip-path: polygon(50% 0%, 100% 25%, 100% 75%, 50% 100%, 0% 75%, 0% 25%);...
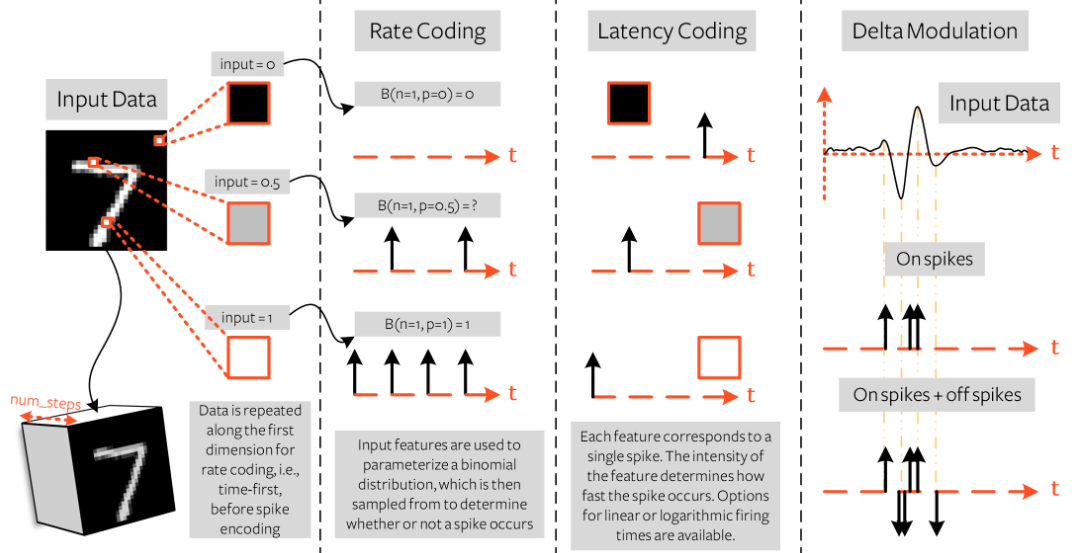
三种常见脉冲神经网络编码方式解读
速率编码(rate coding) 速率编码使用输入特征来确定尖峰频率,例如将静态输入数据(如 MNIST 图像)转换为时间上的脉冲(spike)序列。它是将神经元发放脉冲的频率与输入值(如像素强度)…...

Go语言实战:使用 excelize 实现多层复杂Excel表头导出教程
Go 实现支持多层复杂表头的 Excel 导出工具 目录 项目介绍依赖说明核心结构设计如何支持多层表头完整使用示例总结与扩展 项目介绍 在实际业务系统中,Excel 文件导出是一项常见功能,尤其是报表类需求中常见的复杂多级表头,常规表格组件往…...

STM32F103 HAL多实例通用USART驱动 - 高效DMA+RingBuffer方案,量产级工程模板
导言 《STM32F103_LL库寄存器学习笔记12.2 - 串口DMA高效收发实战2:进一步提高串口接收的效率》前阵子完成的LL库与寄存器版本的代码,有一个明显的缺点是不支持多实例化。最近,计划基于HAL库系统地梳理一遍bootloader程序开发。在bootloader程…...

HTML回顾
html全称:HyperText Markup Language(超文本标记语言) 注重标签语义,而不是默认效果 规则 块级元素包括: marquee、div等 行内元素包括: span、input等 规则1:块级元素中能写:行内元素、块级元素&…...