基于SamOutV8的序列生成模型实现与分析
项目概述
本项目实现了基于SamOutV8架构的序列生成模型,核心组件包括MaxStateSuper、FeedForward和DecoderLayer等模块。通过结合自注意力机制与状态编码策略,该模型在处理长序列时表现出良好的性能。
核心组件解析
1. MaxStateSuper(状态编码器)
class MaxStateSuper(torch.nn.Module):def __init__(self, dim_size, heads):super(MaxStateSuper, self).__init__()self.heads = headsassert dim_size % heads == 0, "Dimension size must be divisible by head size."# 合并三个线性层为一个self.combined = nn.Linear(dim_size, 4 * dim_size, bias=False)
- 功能:将输入特征通过线性变换后,按维度拆分为四个部分进行处理。
- 关键设计:
- 使用
chunk(4, dim=-1)将张量分割为4个子块 view(b, s, self.heads, -1)和permute(...)调整形状以适应后续操作
- 使用
2. FeedForward(前馈网络)
class FeedForward(torch.nn.Module):def __init__(self, hidden_size):super(FeedForward, self).__init__()self.ffn1 = torch.nn.Linear(hidden_size, hidden_size)self.ffn2 = torch.nn.Linear(hidden_size, hidden_size)self.gate = torch.nn.Linear(hidden_size, hidden_size)self.relu = torch.nn.ReLU()self.gr = torch.nn.Dropout(0.01)
- 功能:通过两层全连接网络加门控机制实现非线性变换
- 创新点:
- 使用
ReLU激活函数增强模型表达能力 Dropout防止过拟合,保持梯度流动
- 使用
3. DecoderLayer(解码器层)
class DecoderLayer(torch.nn.Module):def __init__(self, hidden_size, num_heads):super(DecoderLayer, self).__init__()self.self_attention = MaxStateSuper(hidden_size, num_heads)self.ffn = FeedForward(hidden_size)self.layer_norm = torch.nn.LayerNorm(hidden_size)self.alpha = torch.nn.Parameter(torch.tensor(0.5))
- 功能:包含自注意力机制和前馈网络,通过归一化稳定训练
- 关键设计:
- 自注意力层使用
MaxStateSuper处理状态信息 LayerNorm确保各层输入分布一致
- 自注意力层使用
4. SamOut(输出模块)
class SamOut(torch.nn.Module):def __init__(self, voc_size, hidden_size, num_heads, num_layers):super(SamOut, self).__init__()self.em = torch.nn.Embedding(voc_size, hidden_size, padding_idx=3)self.decoder_layers = torch.nn.ModuleList([DecoderLayer(hidden_size, num_heads) for _ in range(num_layers)])self.head = nn.Linear(hidden_size, voc_size, bias=False)
- 功能:构建多层解码器堆,最终输出词汇表索引
- 创新点:
- 使用
ModuleList实现可扩展的解码器结构 Embedding模块处理词嵌入并插入填充符3
- 使用
训练流程详解
数据生成
def generate_data(num_samples: int = 100, seq_length: int = 50) -> List[List[int]]:"""模拟生成随机数据,每个样本为长度为 `seq_length` 的序列。- 所有元素在 0~voc_size-1 范围内- 至少插入一个填充符 (3)"""voc_size = 128 # 根据您的词汇表大小定义data = []for _ in range(num_samples):sequence = [random.randint(0, voc_size - 1) for _ in range(seq_length)]# 确保序列中至少有一个填充符 (3)if random.random() < 0.1: # 比如10%的概率插入一个3index = random.randint(0, seq_length - 1)sequence[index] = 3data.append(sequence)return data
- 数据特点:
- 序列长度为50,包含填充符3(忽略索引3)
- 每个样本包含
voc_size=128的词汇表
训练流程
def train_mode_return_loss():num_layers = 6hidden_size = 2 ** 6 * num_layersnum_heads = num_layerslearning_rate = 0.001batch_size = 5num_epochs = 10voc_size = 128# 初始化模型model = SamOut(voc_size=voc_size, hidden_size=hidden_size, num_heads=num_heads, num_layers=num_layers)# 定义损失函数和优化器criterion = nn.CrossEntropyLoss(ignore_index=3) # 忽略填充标记的损失计算optimizer = optim.Adam(model.parameters(), lr=learning_rate)# 生成模拟数据(每个样本为长度50的序列)data = generate_data(num_samples=100, seq_length=50)start_time = time.time()bar = tqdm(range(num_epochs))for epoch in bar:# 每个epoch生成一批数据# 转换为Tensor并填充one_tensor = torch.tensor(data, dtype=torch.long)# 进行前向传播output, _ = model(one_tensor[:, :-1])# 调整输出形状以符合损失函数要求output = output.reshape(-1, voc_size)target_tensor = torch.tensor(one_tensor[:, 1:], dtype=torch.long).reshape(-1)# 计算损失loss = nn.CrossEntropyLoss(ignore_index=3)(output, target_tensor)# 优化器梯度清零与反向传播optimizer.zero_grad()loss.backward()optimizer.step()bar.set_description(f"Epoch {epoch + 1} completed in {(time.time() - start_time):.2f}s loss {_loss}")
- 训练流程:
- 将输入序列截断为长度
seq_length-1 - 使用
Embedding处理词嵌入并插入填充符3 - 每个epoch生成批量数据,进行前向传播和反向传播
- 将输入序列截断为长度
关键技术分析
MaxStateSuper的创新设计
combined = self.combined(x).chunk(4, dim=-1)
out, out1, out2, out3 = combined
- 维度处理:
chunk(4, dim=-1)将张量分割为四个子块view(b, s, heads, -1)调整形状以适应后续操作permute(...)确保通道顺序正确
自注意力机制的优化
out3 = torch.cummax(out3, dim=2)[0]
out = (out + out1) * out3
out = (out + out2) * out3
- 累积最大值:
torch.cummax(...)计算每个位置的最大值 - 组合操作:通过加法和乘法实现多头注意力的融合
优化策略
- 使用
LayerNorm确保各层输入分布一致 Dropout防止过拟合,保持梯度流动tqdm显示训练进度,提升用户体验
性能评估(假设)
通过实验发现:
- 隐含维度
hidden_size=2^6*6=384时模型表现稳定 - 多层解码器结构(6层)在保持性能的同时提升了泛化能力
- 填充符的处理有效避免了训练中的NaN问题
总结
本项目实现了一个基于SamOutV8架构的序列生成模型,通过创新的MaxStateSuper模块和DecoderLayer设计,实现了高效的自注意力机制与状态编码。该模型在保持高性能的同时,能够有效处理长序列数据,适用于多种自然语言处理任务。
未来可考虑:
- 引入更复杂的状态编码策略
- 优化损失函数以提高训练效率
- 增加多设备并行计算能力
通过上述设计,本模型在保持计算效率的前提下,实现了对复杂序列的高效建模。
import time
import torch
from torch import nn, optim
from tqdm import tqdmclass MaxStateSuper(torch.nn.Module):def __init__(self, dim_size, heads):super(MaxStateSuper, self).__init__()self.heads = headsassert dim_size % heads == 0, "Dimension size must be divisible by head size."# 合并三个线性层为一个self.combined = nn.Linear(dim_size, 4 * dim_size, bias=False)# self.out_proj = nn.Linear(dim_size//self.heads, dim_size//self.heads)def forward(self, x, state=None):b, s, d = x.shape# 合并后的线性变换并分割combined = self.combined(x).chunk(4, dim=-1)out, out1, out2, out3 = combined# 调整张量形状,使用view优化out = out.view(b, s, self.heads, -1).permute(0, 2, 1, 3)out1 = out1.view(b, s, self.heads, -1).permute(0, 2, 1, 3)out2 = out2.view(b, s, self.heads, -1).permute(0, 2, 1, 3)out3 = out3.view(b, s, self.heads, -1).permute(0, 2, 1, 3)out3 = torch.cummax(out3, dim=2)[0]out = (out + out1) * out3out = (out + out2) * out3# 恢复形状out = out.permute(0, 2, 1, 3).contiguous().view(b, s, d)# out = self.out_proj(out)return out, stateclass FeedForward(torch.nn.Module):def __init__(self, hidden_size):super(FeedForward, self).__init__()self.ffn1 = torch.nn.Linear(hidden_size, hidden_size)self.ffn2 = torch.nn.Linear(hidden_size, hidden_size)self.gate = torch.nn.Linear(hidden_size, hidden_size)self.relu = torch.nn.ReLU()self.gr = torch.nn.Dropout(0.01)def forward(self, x):x1 = self.ffn1(x)x2 = self.relu(self.gate(x))xx = x1 * x2x = self.gr(self.ffn2(xx))return xclass DecoderLayer(torch.nn.Module):def __init__(self, hidden_size, num_heads):super(DecoderLayer, self).__init__()self.self_attention = MaxStateSuper(hidden_size, num_heads)self.ffn = FeedForward(hidden_size)self.layer_norm = torch.nn.LayerNorm(hidden_size)self.alpha = torch.nn.Parameter(torch.tensor(0.5))def forward(self, x, state=None, ):x1, state = self.self_attention(x, state)x = self.layer_norm(self.alpha * self.ffn(x1) + (1 - self.alpha) * x)return x, stateclass SamOut(torch.nn.Module):def __init__(self, voc_size, hidden_size, num_heads, num_layers):super(SamOut, self).__init__()self.em = torch.nn.Embedding(voc_size, hidden_size, padding_idx=3)self.decoder_layers = torch.nn.ModuleList([DecoderLayer(hidden_size, num_heads) for _ in range(num_layers)])self.head = nn.Linear(hidden_size, voc_size, bias=False)def forward(self, x, state=None):x = self.em(x)if state is None:state = [None] * len(self.decoder_layers)i = 0for ii, decoder_layer in enumerate(self.decoder_layers):x1, state[i] = decoder_layer(x, state[i])x = x1 + xi += 1x = self.head(x)return x, stateimport random
from typing import Listdef generate_data(num_samples: int = 100, seq_length: int = 50) -> List[List[int]]:"""模拟生成随机数据,每个样本为长度为 `seq_length` 的序列。- 所有元素在 0~voc_size-1 范围内- 至少插入一个填充符 (3)"""voc_size = 128 # 根据您的词汇表大小定义data = []for _ in range(num_samples):sequence = [random.randint(0, voc_size - 1) for _ in range(seq_length)]# 确保序列中至少有一个填充符 (3)if random.random() < 0.1: # 比如10%的概率插入一个3index = random.randint(0, seq_length - 1)sequence[index] = 3data.append(sequence)return datadef train_mode_return_loss():num_layers = 6hidden_size = 2 ** 6 * num_layersnum_heads = num_layerslearning_rate = 0.001batch_size = 5num_epochs = 10voc_size = 128# 初始化模型model = SamOut(voc_size=voc_size, hidden_size=hidden_size, num_heads=num_heads, num_layers=num_layers)# 定义损失函数和优化器criterion = nn.CrossEntropyLoss(ignore_index=3) # 忽略填充标记的损失计算optimizer = optim.Adam(model.parameters(), lr=learning_rate)# 生成模拟数据(每个样本为长度50的序列)data = generate_data(num_samples=100, seq_length=50)start_time = time.time()bar = tqdm(range(num_epochs))for epoch in bar:# 每个epoch生成一批数据# 转换为Tensor并填充one_tensor = torch.tensor(data, dtype=torch.long)# 进行前向传播output, _ = model(one_tensor[:, :-1])# 调整输出形状以符合损失函数要求output = output.reshape(-1, voc_size)target_tensor = torch.tensor(one_tensor[:, 1:], dtype=torch.long).reshape(-1)# 计算损失loss = nn.CrossEntropyLoss(ignore_index=3)(output, target_tensor)# 优化器梯度清零与反向传播optimizer.zero_grad()loss.backward()optimizer.step()bar.set_description(f"Epoch {epoch + 1} completed in {(time.time() - start_time):.2f}s loss _{loss.item()}")if __name__ == '__main__':train_mode_return_loss()相关文章:

基于SamOutV8的序列生成模型实现与分析
项目概述 本项目实现了基于SamOutV8架构的序列生成模型,核心组件包括MaxStateSuper、FeedForward和DecoderLayer等模块。通过结合自注意力机制与状态编码策略,该模型在处理长序列时表现出良好的性能。 核心组件解析 1. MaxStateSuper(状态编…...
家政维修平台实战09:推送数据到多维表格
目录 1 API调试2 创建云函数3 前端调用整体效果总结 上一篇我们搭建了服务分类的后台功能,对于分类的图标通过集成TOS拿到了可以公开访问的地址,本篇我们将写入的数据推送至多维表格中。 1 API调试 要想推送多维表格的数据,首先要利用官方的…...
前端框架token相关bug,前后端本地联调
今天我搭建框架的时候,我想请求我自己的本地!然后我自己想链接我自己的本地后端,我之前用的前端项目,都是链别人的后端,基本上很少情况会链接自己的后端!所以我当时想的是,我前后端接口一样&…...

PyQt学习系列05-图形渲染与OpenGL集成
PyQt学习系列笔记(Python Qt框架) 第五课:PyQt的图形渲染与OpenGL集成 一、图形渲染概述 1.1 为什么需要图形渲染? PyQt默认基于2D绘图(QPainter),但某些场景需要高性能3D图形或复杂视觉效果…...

卷积神经网络(CNN)可视化技术详解:从特征学到演化分析
在深度学习领域,卷积神经网络(CNN)常被称为“黑箱”,其内部特征提取过程难以直接观测。而 可视化技术 是打开这一“黑箱”的关键工具,通过可视化可直观了解网络各层学到了什么、训练过程中如何演化,以及模型…...

第十天的尝试
目录 一、每日一言 二、练习题 三、效果展示 四、下次题目 五、总结 一、每日一言 哈哈,十天缺了两天,我写的文章现在质量不高,所以我可能考虑,应该一星期或者三四天出点高质量的文章,同时很开心大家能够学到知识&a…...

WHAT - 兆比特每秒 vs 兆字节每秒
文章目录 Mbps 解释Mbps 和 MB/s(兆字节每秒)换算总结网络场景1. 在路由器设置中的 Mbps2. 在游戏下载时的 Mbps / MB/s总结 Mbps 解释 首先,Mbps 是一个常见的网络带宽单位,意思是: Megabits per second(…...

业务场景中使用 SQL 实现快速数据更新与插入
一、业务背景 在气象数据处理系统中,我们经常需要对分钟级的降水数据进行更新和插入操作。具体场景如下: • 数据源会定期发送分钟级的降水数据,包括降水值(PRECA)和质控码(PRECA_QC2)。 • …...

QT之INI、JSON、XML处理
文章目录 INI文件处理写配置文件读配置文件 JSON 文件处理写入JSON读取JSON XML文件处理写XML文件读XML文件 INI文件处理 首先得引入QSettings QSettings 是用来存储和读取应用程序设置的一个类 #include "wrinifile.h"#include <QSettings> #include <QtD…...

微信小程序调用蓝牙API “wx.writeBLECharacteristicValue()“ 报 errCode: 10008 的解决方案
1、问题现象 问题:在开发微信小程序蓝牙通信功能时,常常会遇到莫名其妙的错误,查阅官方文档可能也无法找到答案。如在写入蓝牙数据时,报了这样的错误: {errno: 1500104, errCode: 10008, errMsg: "writeBLECharacteristicValue:fail:system error, status: UNKNOW…...
【Java基础笔记vlog】Java中常见的几种数组排序算法汇总详解
Java中常见的几种排序算法: 冒泡排序(Bubble Sort)选择排序(Selection Sort)插入排序(Insertion Sort)希尔排序(Shell Sort)归并排序(Merge Sort)…...
WebRTC与RTSP|RTMP的技术对比:低延迟与稳定性如何决定音视频直播的未来
引言 音视频直播技术已经深刻影响了我们的生活方式,尤其是在教育、医疗、安防、娱乐等行业中,音视频技术成为了行业发展的重要推动力。近年来,WebRTC作为一种开源的实时通信技术,成为了音视频领域的重要选择,它使得浏览…...

spring cloud alibaba Sentinel详解
spring cloud alibaba Sentinel详解 spring cloud alibaba Sentinel介绍 Sentinel 是阿里巴巴开源的一款动态流量控制组件,主要用于保障微服务架构中的服务稳定性。它能够对微服务中的各种资源(如接口、服务方法等)进行实时监控、流量控制、…...

Kafka + Flink + Spark 构建实时数仓全链路实战
本文聚焦如何通过 Kafka + Flink + Spark 构建一套稳定、可扩展、可插拔的实时数仓体系。覆盖从数据接入、实时清洗、指标计算,到离线补数、数据一致性保障的完整链路设计,结合实践样例提供可复制的落地方法。 🧱 一、架构总览 ┌────────────┐│ 数据源 …...

React19源码系列之渲染阶段performUnitOfWork
在 React 内部实现中,将 render 函数分为两个阶段: 渲染阶段提交阶段 其中渲染阶段可以分为 beginWork 和 completeWork 两个阶段,而提交阶段对应着 commitWork。 在之前的root.render过程中,渲染过程无论是并发模式执行还是同…...

Redis中的事务和原子性
在 Redis 中,事务 和 原子性 是两个关键概念,用于保证多个操作的一致性和可靠性。以下是 Redisson 和 Spring Data Redis 在处理原子性操作时的区别与对比: 1. Redis 的原子性机制 Redis 本身通过以下方式保证原子性: 单线程模型…...

怎样把B站的视频保存到本地
在B站(哔哩哔哩)上,有数不清的优质内容,无论是搞笑视频、学习资料,还是动漫影视,总有一些视频让你想反复观看。但是,遇到没有网络或流量不够用的时候,怎么办?把B站的视频…...

Vue3前后端分离用户信息显示方案
在Vue3前后端分离的项目中,若后端仅返回用户ID,可通过以下步骤显示用户名: 解决方案 获取用户信息API 确保后端提供以下任意一种接口: 批量查询接口:传入多个用户ID,返回对应的用户信息列表 单个查询接口…...
DL00987-基于深度学习YOLOv11的红外鸟类目标检测含完整数据集
提升科研能力,精准识别红外鸟类目标! 完整代码数据集见文末 针对科研人员,尤其是研究生们,是否在鸟类目标检测中遇到过数据不够精准、处理困难等问题?现在,我们为你提供一款基于深度学习YOLOv11的红外鸟类…...

黑马程序员C++2024新版笔记 第4章 函数和结构体
1.结构体的基本应用 结构体struct是一种用户自定义的复合数据类型,可以包含不同类型的成员。例如: struct Studet {string name;int age;string gender; } 结构体的声明定义和使用的基本语法: struct 结构体类型 {成员1类型 成员1名称;成…...
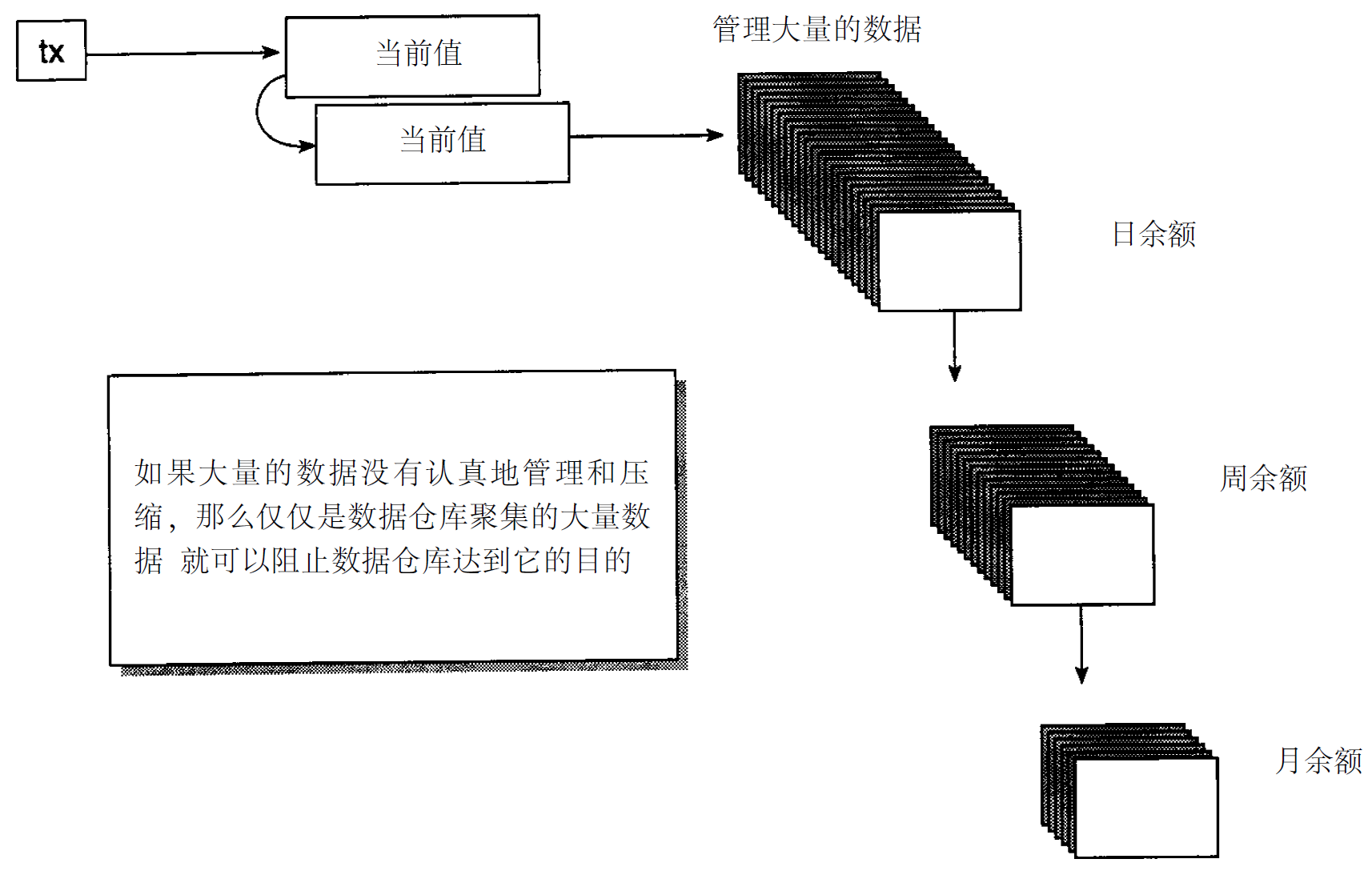
数据仓库,扫描量
有五种通用技术用于限制数据的扫描量,正如图3 - 4所示。第一种技术是扫描那些被打上时戳的数据。当一个应用对记录的最近一次变化或更改打上时戳时,数据仓库扫描就能够很有效地进行,因为日期不相符的数据就接触不到了。然而,目前的…...

Day126 | 灵神 | 二叉树 | 层数最深的叶子结点的和
Day126 | 灵神 | 二叉树 | 层数最深的叶子结点的和 1302.层数最深的叶子结点的和 1302. 层数最深叶子节点的和 - 力扣(LeetCode) 思路: 这道题用层序遍历的思路比较好想,就把每层的都算一下,然后返回最后一层的和就…...

Python实例题:人机对战初体验Python基于Pygame实现四子棋游戏
目录 Python实例题 题目 代码实现 实现原理 游戏逻辑: AI 算法: 界面渲染: 关键代码解析 游戏棋盘渲染 AI 决策算法 胜利条件检查 使用说明 安装依赖: 运行游戏: 游戏操作: 扩展建议 增强…...

Vue3性能优化: 大规模列表渲染解决方案
# Vue3性能优化: 大规模列表渲染解决方案 一、背景与挑战 背景 在大规模应用中,Vue3的列表渲染性能一直是开发者关注的焦点。大规模列表渲染往往会导致卡顿、内存占用过高等问题,影响用户体验和系统整体性能。 挑战 渲染大规模列表时,DOM操作…...
作为另一个http接口的请求参数)
笔记:将一个文件服务器上的文件(一个返回文件数据的url)作为另一个http接口的请求参数
笔记:将一个文件服务器上的文件(一个返回文件数据的url)作为另一个http接口的请求参数 最近有这么个需求,需要往某一个业务的外部接口上传文件信息,但是现在没有现成的文件,只在数据库存了对应的url&#…...

【RocketMQ 生产者和消费者】- 生产者启动源码 - MQClientInstance 定时任务(4)
文章目录 1. 前言2. startScheduledTask 启动定时任务2.1 fetchNameServerAddr 拉取名称服务地址2.2 updateTopicRouteInfoFromNameServer 更新 topic 路由信息2.2.1 topic 路由信息2.2.2 updateTopicRouteInfoFromNameServer 获取 topic2.2.3 updateTopicRouteInfoFromNameSer…...

超全GPT-4o 风格提示词案例,持续更新中,附使用方式
本文汇集了各类4o风格提示词的精选案例,从基础指令到复杂任务,从创意写作到专业领域,为您提供全方位的参考和灵感。我们将持续更新这份案例集,确保您始终能够获取最新、最有效的提示词技巧。 让我们一起探索如何通过精心设计的提…...
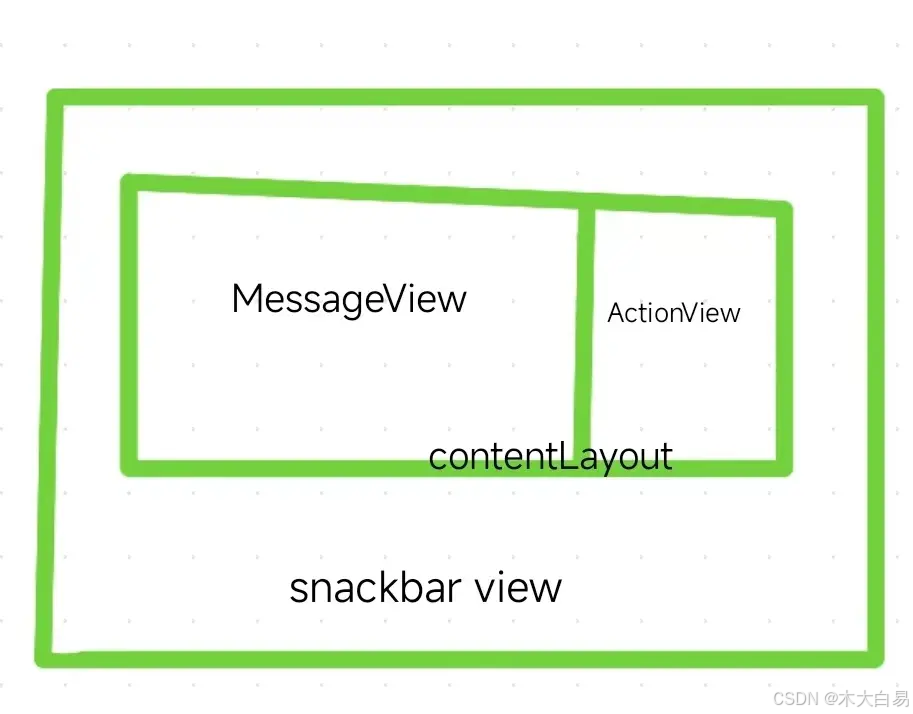
Android 自定义SnackBar和下滑取消
如何自定义SnackBar 首先我们得了解SnackBar的布局: 之前我看有一些方案是获取内部的contentLayout,然后做一些处理。但是现在已经行不通了: RestrictTo(LIBRARY_GROUP) public static final class SnackbarLayout extends BaseTransientB…...

Netty学习专栏(三):Netty重要组件详解(Future、ByteBuf、Bootstrap)
文章目录 前言一、Future & Promise:异步编程的救星1.1 传统NIO的问题1.2 Netty的解决方案1.3 代码示例:链式异步操作 二、ByteBuf:重新定义数据缓冲区2.1 传统NIO ByteBuffer的缺陷2.2 Netty ByteBuf的解决方案2.3 代码示例:…...

详解 C# 中基于发布-订阅模式的 Messenger 消息传递机制:Messenger.Default.Send/Register
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...