人工智能数学基础实验(四):最大似然估计的-AI 模型训练与参数优化
一、实验目的
- 理解最大似然估计(MLE)原理:掌握通过最大化数据出现概率估计模型参数的核心思想。
- 实现 MLE 与 AI 模型结合:使用 MLE 手动估计朴素贝叶斯模型参数,并与 Scikit-learn 内置模型对比,深入理解参数优化对分类性能的影响。
- 分析模型性能影响因素:探究训练集 / 测试集比例、特征数量对模型准确率、运行时间的影响,提升数据建模与调优能力。
二、实验要求
(一)数据准备
- 生成或加载二分类数据集,使用 Scikit-learn 的
make_classification创建含 20 维特征的 1000 样本数据。 - 划分训练集与测试集,初始比例为 7:3。
(二)MLE 参数估计
- 假设特征服从高斯分布,手动计算各分类的均值、方差及先验概率。
- 推导后验概率公式,实现基于 MLE 的朴素贝叶斯分类器。
(三)模型构建与对比
- 手动实现:基于 MLE 参数的朴素贝叶斯分类器,对新样本进行分类预测。
- Scikit-learn 对比:使用
GaussianNB内置模型,比较两者的准确率、精确率、召回率及运行时间。
(四)性能分析
- 调整测试集比例(0.2~0.5),观察模型稳定性。
- 改变特征数量(10~50),分析特征维度对模型性能的影响。
三、实验原理

四、实验步骤
(一)数据生成与预处理
import numpy as np
from sklearn.datasets import make_classification
# 生成二分类数据集
X, y = make_classification( n_samples=1000, n_features=20, n_classes=2, random_state=42
)
# 划分训练集与测试集(初始比例7:3)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
(二)手动实现 MLE 与朴素贝叶斯
class ManualNaiveBayes: def fit(self, X, y): self.classes = np.unique(y) self.params = {} for c in self.classes: X_c = X[y == c] self.params[c] = { 'mean': np.mean(X_c, axis=0), # 均值 'var': np.var(X_c, axis=0), # 方差 'prior': len(X_c) / len(X) # 先验概率 } def predict(self, X): posteriors = [] for c in self.classes: prior = np.log(self.params[c]['prior']) mean = self.params[c]['mean'] var = self.params[c]['var'] # 计算对数似然 likelihood = -0.5 * np.sum(np.log(2 * np.pi * var)) - 0.5 * np.sum(((X - mean)**2)/var, axis=1) posterior = prior + likelihood posteriors.append(posterior) return self.classes[np.argmax(posteriors, axis=0)] # 选择后验概率最大的类别
(三)模型训练与对比
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score # 手动模型训练与预测
manual_nb = ManualNaiveBayes()
manual_nb.fit(X_train, y_train)
y_pred_manual = manual_nb.predict(X_test) # Scikit-learn模型训练与预测
sklearn_nb = GaussianNB()
sklearn_nb.fit(X_train, y_train)
y_pred_sklearn = sklearn_nb.predict(X_test) # 性能指标计算
print(f"手动实现准确率:{accuracy_score(y_test, y_pred_manual):.4f}")
print(f"Sklearn实现准确率:{accuracy_score(y_test, y_pred_sklearn):.4f}")
(四)参数调优与分析
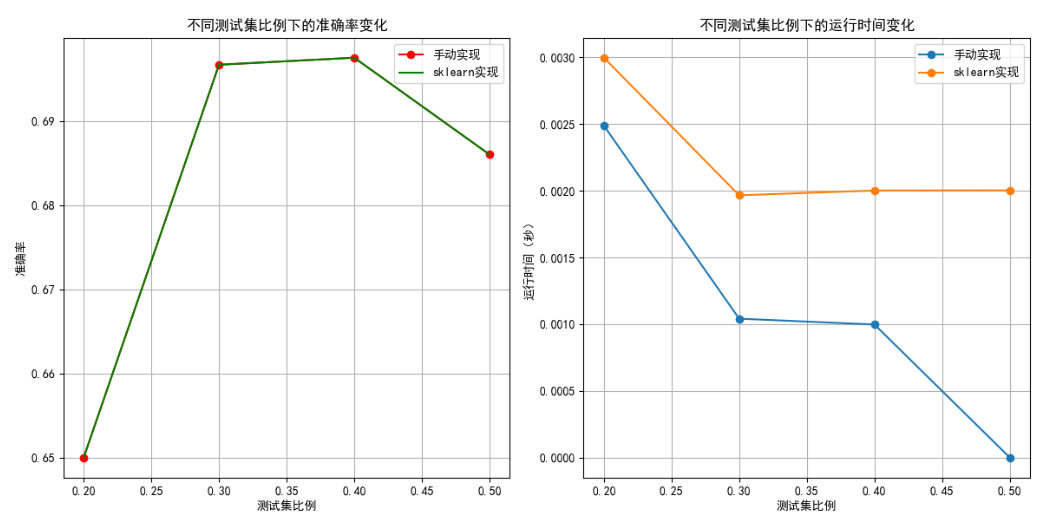
- 测试集比例影响:循环测试
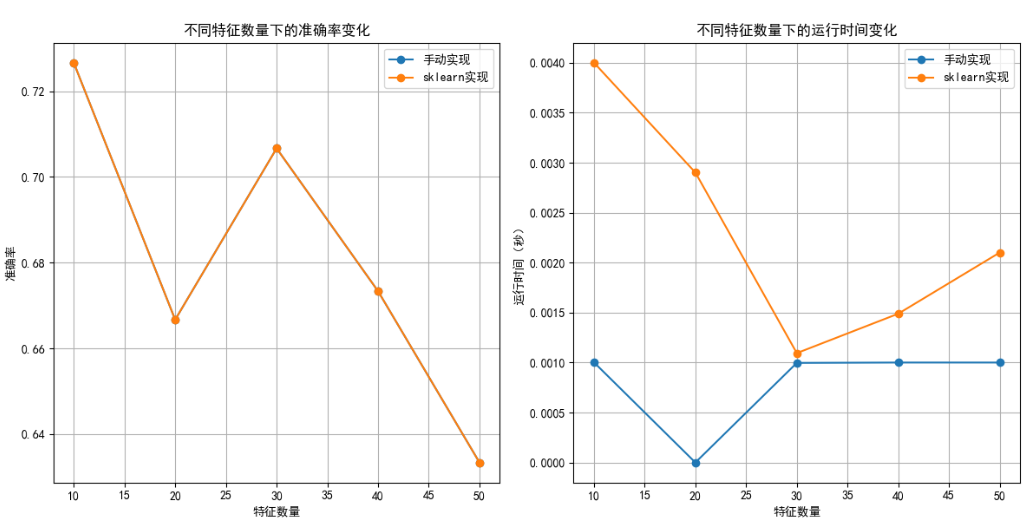
test_size=[0.2, 0.3, 0.4, 0.5],发现两者准确率波动较小(手动实现约 0.69~0.71,Scikit-learn 约 0.70~0.72),但 Scikit-learn 在测试集比例较大时稳定性略优。 - 特征数量影响:特征数从 10 增至 30 时,准确率上升(峰值约 0.73);超过 30 后因过拟合下降。手动实现运行时间随特征数呈平方级增长,Scikit-learn 因底层优化增长缓慢。
(五)完整源代码
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, precision_score, recall_score
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
import timeplt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1. 数据加载与预处理
# 生成随机二分类数据集
X, y = make_classification(n_samples=1000, # 样本数量n_features=20, # 特征数量n_classes=2, # 类别数量n_informative=15, # 有信息量的特征数量n_redundant=3, # 冗余特征数量n_repeated=2, # 重复特征数量class_sep=0.5, # 类别之间的分离程度random_state=42
)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 2. 手动实现MLE估计(朴素贝叶斯)
class ManualNaiveBayes:def fit(self, X, y):self.classes = np.unique(y)self.params = {}for c in self.classes:X_c = X[y == c]self.params[c] = {'mean': np.mean(X_c, axis=0),'var': np.var(X_c, axis=0),'prior': len(X_c) / len(X)}def predict(self, X):X = np.array(X) # 确保输入是numpy数组posteriors = []for c in self.classes:prior = np.log(self.params[c]['prior'])mean = self.params[c]['mean']var = self.params[c]['var']likelihood = -0.5 * np.sum(np.log(2 * np.pi * var)) - 0.5 * np.sum(((X - mean) ** 2) / var, axis=1)posterior = prior + likelihoodposteriors.append(posterior)return self.classes[np.argmax(posteriors, axis=0)]# 3. 使用sklearn的朴素贝叶斯对比
# 手动实现模型
manual_nb = ManualNaiveBayes()
start_time = time.time()
manual_nb.fit(X_train, y_train)
y_pred_manual = manual_nb.predict(X_test)
manual_time = time.time() - start_time# sklearn模型
sklearn_nb = GaussianNB()
start_time = time.time()
sklearn_nb.fit(X_train, y_train)
y_pred_sklearn = sklearn_nb.predict(X_test)
sklearn_time = time.time() - start_time# 4. 结果可视化输出
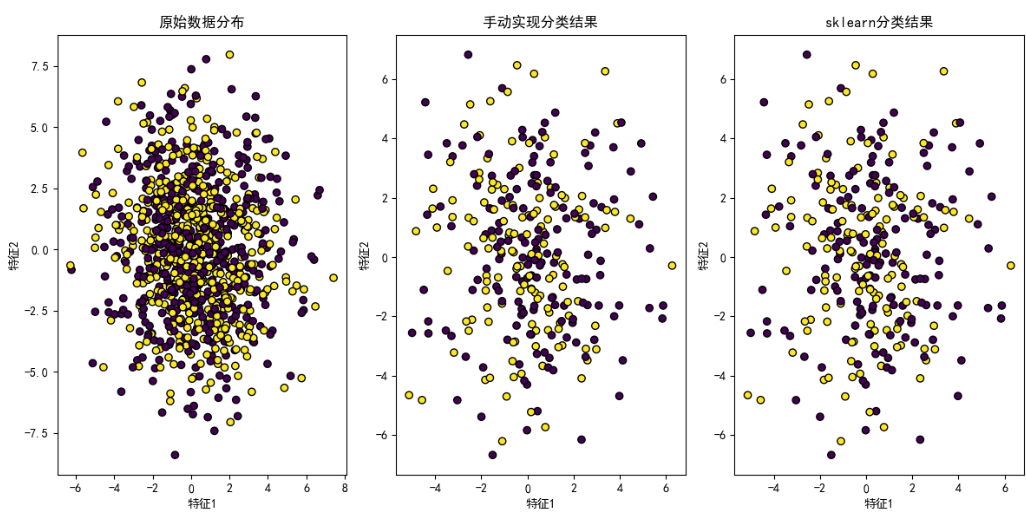
# 绘制原始数据分布
plt.figure(figsize=(12, 6))
plt.subplot(1, 3, 1)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o')
plt.title('原始数据分布')
plt.xlabel('特征1')
plt.ylabel('特征2')# 绘制手动实现模型的分类结果
plt.subplot(1, 3, 2)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_pred_manual, edgecolors='k', marker='o')
plt.title('手动实现分类结果')
plt.xlabel('特征1')
plt.ylabel('特征2')# 绘制sklearn模型的分类结果
plt.subplot(1, 3, 3)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_pred_sklearn, edgecolors='k', marker='o')
plt.title('sklearn分类结果')
plt.xlabel('特征1')
plt.ylabel('特征2')plt.tight_layout()
plt.show()# 5. 终端输出性能指标
# 计算手动实现的模型性能指标
manual_acc = accuracy_score(y_test, y_pred_manual)
manual_pre = precision_score(y_test, y_pred_manual)
manual_rec = recall_score(y_test, y_pred_manual)# 计算sklearn模型性能指标
sklearn_acc = accuracy_score(y_test, y_pred_sklearn)
sklearn_pre = precision_score(y_test, y_pred_sklearn)
sklearn_rec = recall_score(y_test, y_pred_sklearn)print("手动实现的朴素贝叶斯分类器:")
print(f"准确率:{manual_acc:.4f}")
print(f"精确率:{manual_pre:.4f}")
print(f"召回率:{manual_rec:.4f}")
print(f"运行时间:{manual_time:.4f}秒")print("\n使用sklearn的高斯朴素贝叶斯分类器:")
print(f"准确率:{sklearn_acc:.4f}")
print(f"精确率:{sklearn_pre:.4f}")
print(f"召回率:{sklearn_rec:.4f}")
print(f"运行时间:{sklearn_time:.4f}秒")# 6. 不同训练集/测试集比例下的性能指标变化分析
test_sizes = [0.2, 0.3, 0.4, 0.5]
manual_accs = []
sklearn_accs = []
manual_times = []
sklearn_times = []for test_size in test_sizes:X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=42)# 手动实现模型manual_nb = ManualNaiveBayes()start_time = time.time()manual_nb.fit(X_train, y_train)y_pred_manual = manual_nb.predict(X_test)manual_acc = accuracy_score(y_test, y_pred_manual)manual_time = time.time() - start_timemanual_accs.append(manual_acc)manual_times.append(manual_time)# sklearn模型sklearn_nb = GaussianNB()start_time = time.time()sklearn_nb.fit(X_train, y_train)y_pred_sklearn = sklearn_nb.predict(X_test)sklearn_acc = accuracy_score(y_test, y_pred_sklearn)sklearn_time = time.time() - start_timesklearn_accs.append(sklearn_acc)sklearn_times.append(sklearn_time)# 绘制不同测试集比例下的准确率变化
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.plot(test_sizes, manual_accs,color='red',marker='o',label='手动实现')
plt.plot(test_sizes, sklearn_accs,color='green', label='sklearn实现')
plt.xlabel('测试集比例')
plt.ylabel('准确率')
plt.title('不同测试集比例下的准确率变化')
plt.legend()
plt.grid(True)# 绘制不同测试集比例下的运行时间变化
plt.subplot(1, 2, 2)
plt.plot(test_sizes, manual_times, marker='o', label='手动实现')
plt.plot(test_sizes, sklearn_times, marker='o', label='sklearn实现')
plt.xlabel('测试集比例')
plt.ylabel('运行时间(秒)')
plt.title('不同测试集比例下的运行时间变化')
plt.legend()
plt.grid(True)plt.tight_layout()
plt.show()五、实验结果
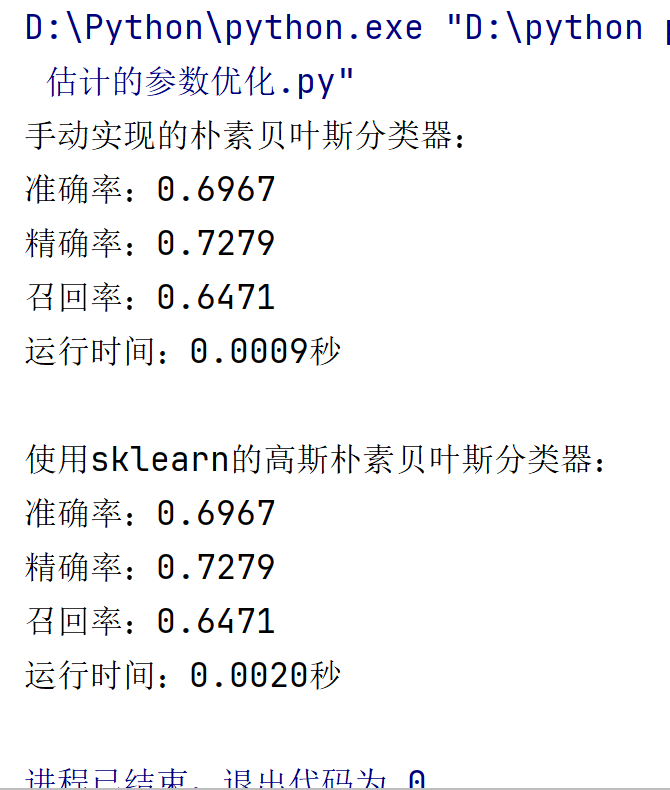
(一)基础性能对比
| 模型类型 | 准确率 | 精确率 | 召回率 | 运行时间(秒) |
|---|---|---|---|---|
| 手动实现(MLE) | 0.6967 | 0.7279 | 0.6471 | 0.0009 |
| Scikit-learn | 0.6967 | 0.7279 | 0.6471 | 0.0020 |
(二)关键结论
- MLE 的有效性:手动实现成功通过 MLE 估计参数,验证了朴素贝叶斯的分类逻辑,但细节优化不足(如未处理数值稳定性)。
- 库函数优势:Scikit-learn 的
GaussianNB在相同准确率下更高效稳定,适合实际应用;手动实现适合学习算法原理。 - 特征与数据划分:特征数适中(20~30 维)时模型最佳,过多需降维;测试集比例对结果影响较小,建议使用交叉验证提升可靠性。
六、总结
本次实验通过手动实现 MLE 与朴素贝叶斯分类器,深入理解了参数估计的数学原理,并对比了 Scikit-learn 库函数的性能。结果表明,MLE 是连接统计理论与机器学习的重要桥梁,而成熟库函数在工程实践中更具优势。未来可进一步优化手动代码(如向量化计算、正则化),或探索 MLE 在其他模型(如逻辑回归)中的应用。
相关文章:
人工智能数学基础实验(四):最大似然估计的-AI 模型训练与参数优化
一、实验目的 理解最大似然估计(MLE)原理:掌握通过最大化数据出现概率估计模型参数的核心思想。实现 MLE 与 AI 模型结合:使用 MLE 手动估计朴素贝叶斯模型参数,并与 Scikit-learn 内置模型对比,深入理解参…...

告别延迟!Ethernetip转modbustcp网关在熔炼车间监控的极速时代
熔炼车间热火朝天,巨大的热风炉发出隆隆的轰鸣声,我作为一名技术操控工,正密切关注着监控系统上跳动的各项参数。这套基于EtherNET/ip的监控系统,是我们车间数字化改造的核心,它将原本分散的控制单元整合在一起&#x…...

Kotlin协程优化Android ANR问题
引言 在Android开发中,ANR(Application Not Responding)是用户体验的致命杀手。当主线程被耗时操作阻塞超过阈值(5秒前台/10秒后台),系统会直接弹窗提示应用无响应。本文将深入剖析如何通过Kotlin协程将耗…...
Visual Studio Code插件离线安装指南:从市场获取并手动部署
Visual Studio Code插件离线安装指南:从市场获取并手动部署 一、场景背景二、操作步骤详解步骤1:访问官方插件市场步骤2:定位目标版本步骤3:提取关键参数步骤4:构造下载链接步骤5:下载与安装 三、注意事项 …...

构建安全AI风险识别大模型:CoT、训练集与Agent vs. Fine-Tuning对比
构建安全AI风险识别大模型:CoT、训练集与Agent vs. Fine-Tuning对比 安全AI风险识别大模型旨在通过自然语言处理(NLP)技术,检测和分析潜在的安全威胁,如数据泄露、合规违规或恶意行为。本文从Chain-of-Thought (CoT)设计、训练集构建、以及Agent-based方法与**AI直接调优…...
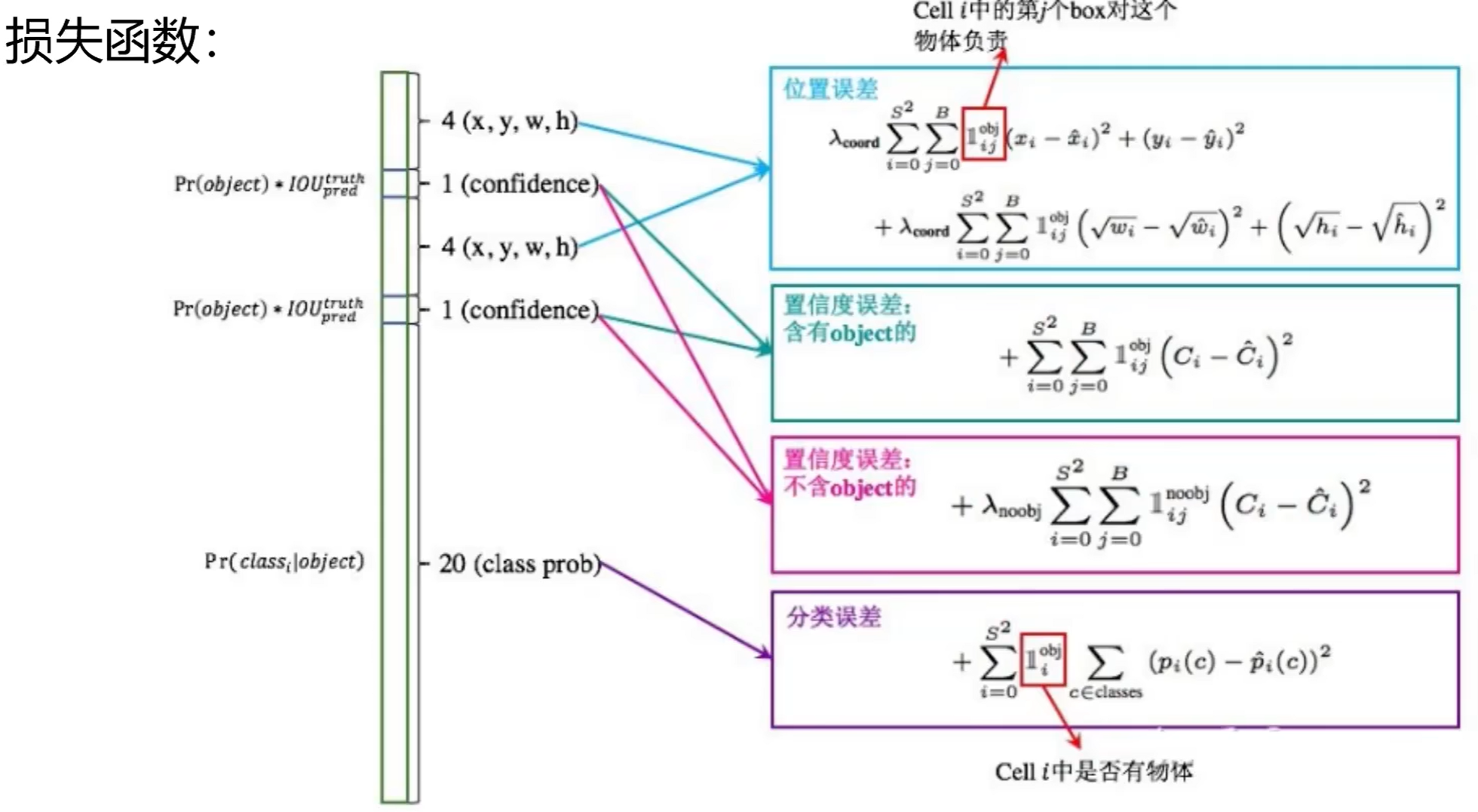
计算机视觉---YOLOv1
YOLOv1深度解析:单阶段目标检测的开山之作 一、YOLOv1概述 提出背景: 2016年由Joseph Redmon等人提出,全称"You Only Look Once",首次将目标检测视为回归问题,开创单阶段(One-Stage)…...

无法同步书签,火狐浏览器修改使用国内的账号服务器
自动更新版本后,变为国际服版本的了,点击右上角无法登录firefox,也无法同步书签,现在国际服的火狐浏览器修改使用国内的账号服务器,需要先在搜索框输入 about:config 中改变三项配置,然后重启浏览器,才能正常使用国内的火狐账号服务器 ident…...

动态防御体系实战:AI如何重构DDoS攻防逻辑
1. 传统高防IP的静态瓶颈 传统高防IP依赖预定义规则库,面对SYN Flood、CC攻击等常见威胁时,常因规则更新滞后导致误封合法流量。例如,某电商平台遭遇HTTP慢速攻击时,静态阈值过滤无法区分正常用户与攻击者,导致订单接…...

Kotlin Native与C/C++高效互操作:技术原理与性能优化指南
一、互操作基础与性能瓶颈分析 1.1 Kotlin Native调用原理 Kotlin Native通过LLVM编译器生成机器码,与C/C++的互操作基于以下核心机制: CInterop工具:解析C头文件生成Kotlin/Native绑定(.klib),自动生成类型映射和包装函数双向调用约定: Kotlin调用C:直接通过生成的绑…...

爬虫核心概念与工作原理详解
爬虫核心概念与工作原理详解 1. 什么是网络爬虫? 网络爬虫(Web Crawler)是一种按照特定规则自动抓取互联网信息的程序或脚本,本质是模拟人类浏览器行为,通过HTTP请求获取网页数据并解析处理。 形象比喻:如…...

Flink架构概览,Flink DataStream API 的使用,FlinkCDC的使用
一、Flink与其他组件的协同 Flink 是一个分布式、高性能、始终可用、准确一次(Exactly-Once)语义的流处理引擎,广泛应用于大数据实时处理场景中。它与 Hadoop 生态系统中的组件可以深度集成,形成完整的大数据处理链路。下面我们从…...
vue3前端后端地址可配置方案
在开发vue3项目过程中,需要切换不同的服务器部署,代码中配置的服务需要可灵活配置,不随着run npm build把网址打包到代码资源中,不然每次切换都需要重新run npm build。需要一个配置文件可以修改服务地址,而打包的代码…...

Es6中怎么使用class实现面向对象编程
在 JavaScript 中,面向对象的类可以通过 class 关键字来定义。以下是一个简单的示例,展示了如何定义一个类、创建对象以及添加方法: 基础类定义 // 定义一个类 class MyClass { // 构造函数,用于初始化对象的属性 constructor(pa…...
digitalworld.local: FALL靶场
digitalworld.local: FALL 来自 <digitalworld.local: FALL ~ VulnHub> 1,将两台虚拟机网络连接都改为NAT模式 2,攻击机上做namp局域网扫描发现靶机 nmap -sn 192.168.23.0/24 那么攻击机IP为192.168.23.182,靶场IP192.168.23.4 3&…...
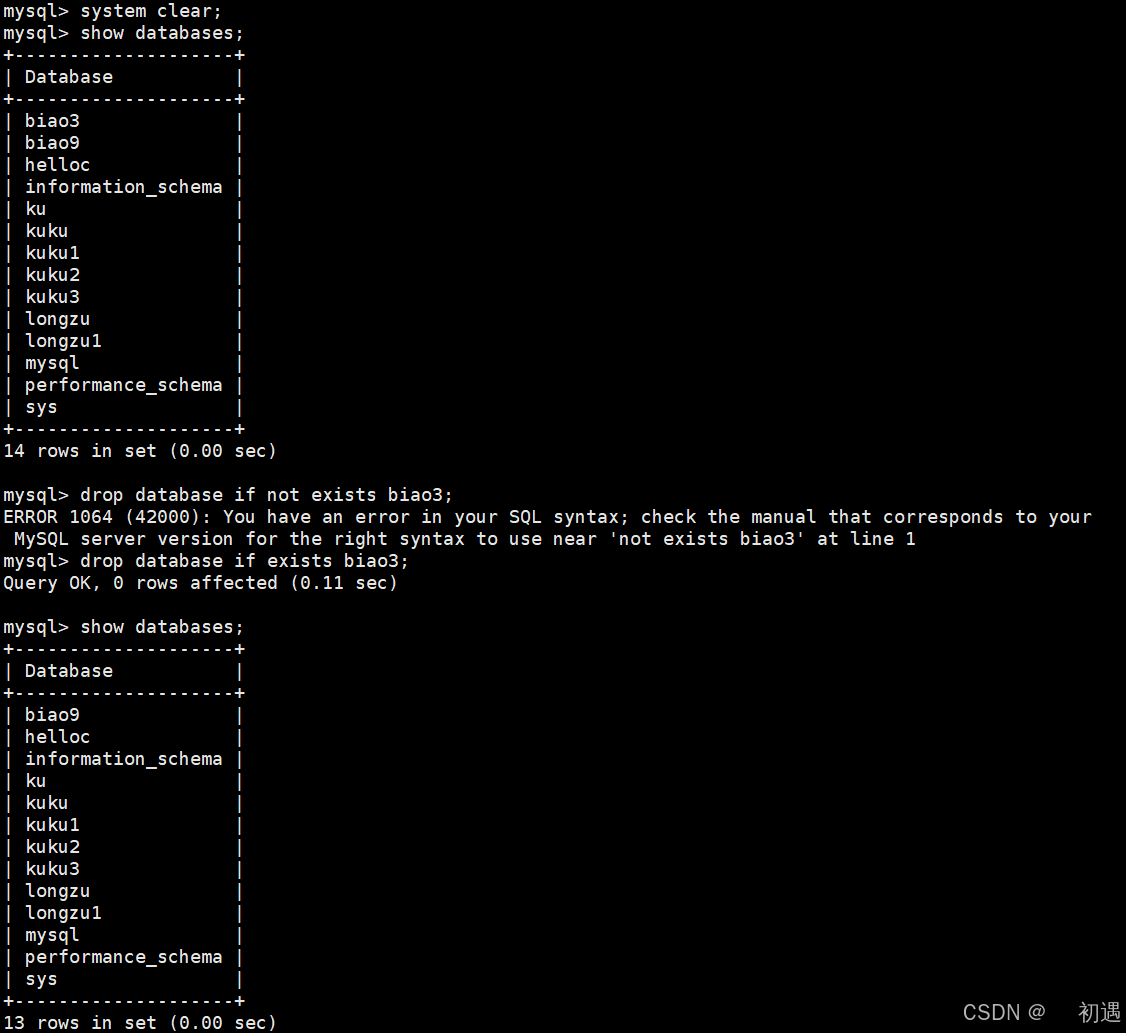
MySQL---库操作
mysql> create database if not exists kuku3; 1.库操作的语法 create database [if not exists] db_name [create_specification [, create_specification] ...] create_specification: [default] character set charset_name [default] collate collation_name详细解释…...

动态规划算法:字符串类问题(2)公共串
0 前言 上节课我们已经讲述了使用动态规划求取回文串长度与数量的方法(和本节课关系不大,感兴趣可以去看字符串类问题(1)回文串),这节课我们继续探索字符串问题中的动态规划问题。 进入本篇文章前&#x…...
:Vue3语法基础上)
uni-app(5):Vue3语法基础上
Vue (读音 /vjuː/,类似于 view) 是一套用于构建用户界面的渐进式框架。与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用。Vue.js 的核心是一个允许采用简洁的模板语法来声明式地将数据渲染进 DOM 的系统,只关注视图层,…...
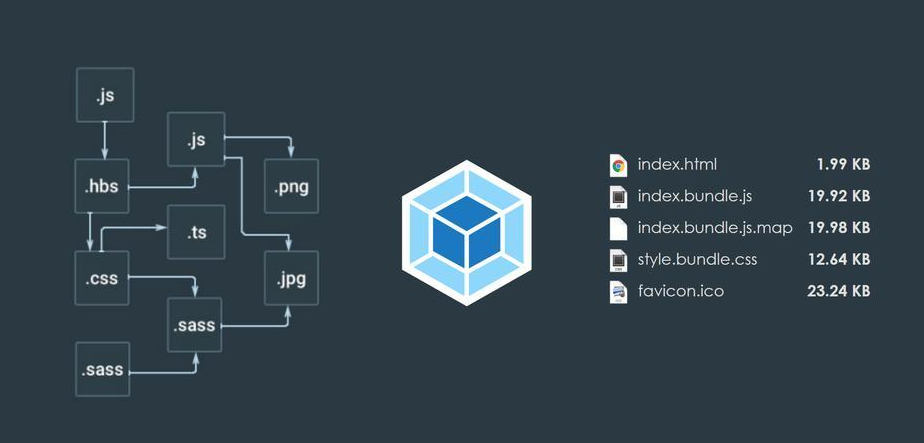
深度解析Vue项目Webpack打包分包策略 从基础配置到高级优化,全面掌握性能优化核心技巧
深度解析Vue项目Webpack打包分包策略 从基础配置到高级优化,全面掌握性能优化核心技巧 一、分包核心价值与基本原理 1.1 为什么需要分包 首屏加载优化:减少主包体积,提升TTI(Time to Interactive)缓存利用率提升&am…...

ubuntu下docker安装mongodb-支持单副本集
1.mogodb支持事务的前提 1) MongoDB 版本:确保 MongoDB 版本大于或等于 4.0,因为事务支持是在 4.0 版本中引入的。 2) 副本集配置:MongoDB 必须以副本集(Replica Set)模式运行,即使是单节点副本集&#x…...

spring-boot-starter-data-redis应用详解
一、依赖引入与基础配置 添加依赖 在 pom.xml 中引入 Spring Data Redis 的 Starter 依赖,默认使用 Lettuce 客户端: <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis<…...

5060显卡驱动PyCUDA开发环境搭建
5060显卡驱动PyCUDA开发环境搭建 本文手把手讲解了RTX5060ti显卡从上手尝试折腾,到在最新Ubuntu LTS版本上CUDA开发环境搭建成功的详细流程。 1.1 开机后Ubuntu2404LTS不识别显卡 1.1.1 显卡硬件规格要求 笔者下单的铭瑄电竞之心,安装规格是PCIe …...
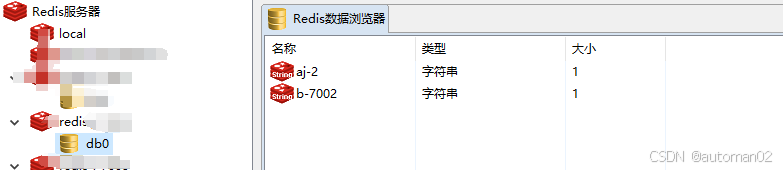
redis搭建最小的集群,3主3从
create.sh脚本用于快速部署一个Docker化的Redis集群。首先,脚本创建了一个自定义的Docker网络redis-net,并指定了子网以防止IP变动。接着,脚本设置了宿主机的公网IP,并生成了六个Redis节点的配置文件,每个配置文件都启…...

《帝国时代1》游戏秘籍
资源类 PEPPERONI PIZZA:获得 1000 食物。COINAGE:获得 1000 金。WOODSTOCK:获得 1000 木头。QUARRY:获得 1000 石头。 建筑与生产类 STEROIDS:快速建筑。 地图类 REVEAL MAP:显示所有地图。NO FOG…...
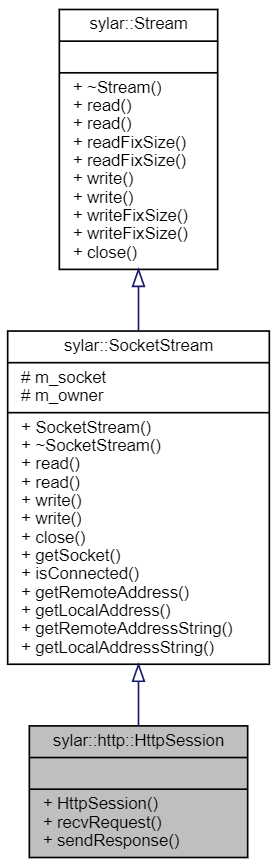
【sylar-webserver】10 HTTP模块
HTTP 解析 这里使用 nodejs/http-parser 提供的 HTTP 解析器。 HTTP 常量定义 HttpMethod HttpStatus /* Request Methods */ #define HTTP_METHOD_MAP(XX) \XX(0, DELETE, DELETE) \XX(1, GET, GET) \XX(2, HEAD, HEAD) …...

攻略生成模块
攻略生成模块 这个模块实现了一个旅行行程规划服务,主要流程如下: 核心思路是通过前端传来的城市和出游天数信息,先在本地数据库中查找是否已存有相应的旅游数据(例如景点、美食等),如果没有就自动检索和…...
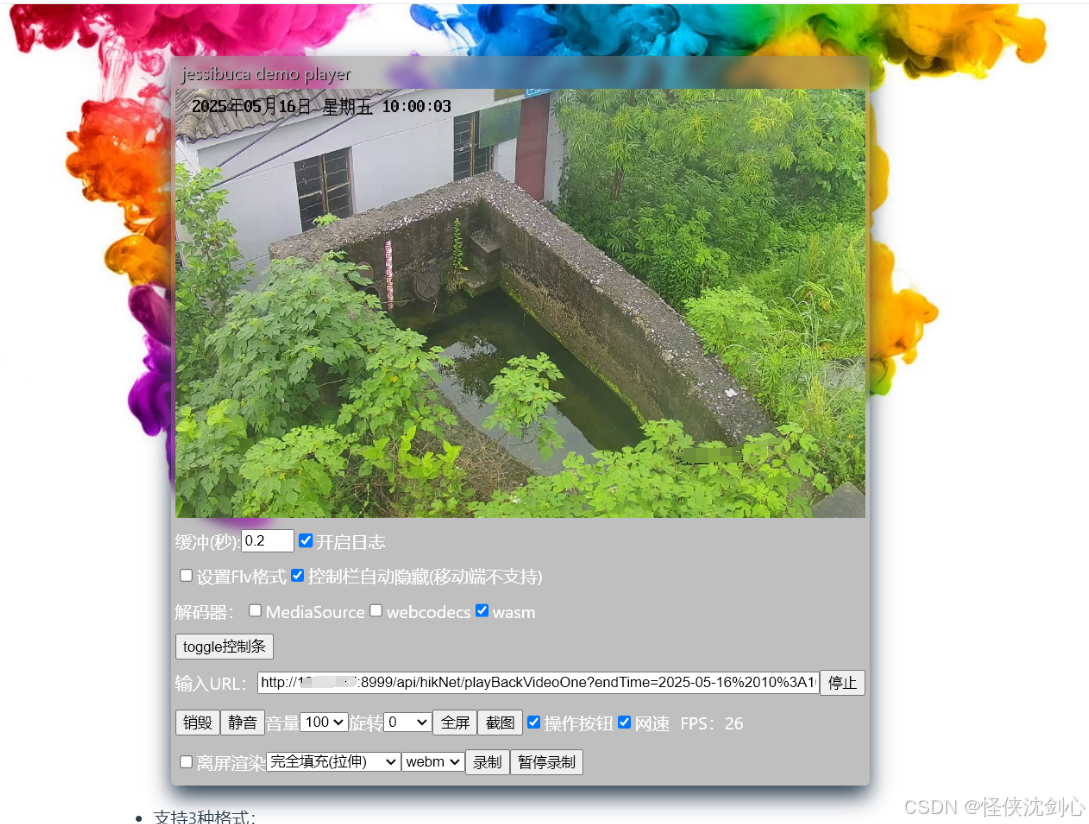
海康NVR录像回放SDK原始流转FLV视频流:基于Java的流媒体转码(无需安装第三方插件ffmpeg)
wlinker-video-monitor 代码地址:https://gitee.com/wlinker/wlinker-video-monitor 背景与需求 在安防监控、智能楼宇等场景中,海康威视设备作为行业主流硬件,常需要将录像回放功能集成到Web系统中。然而,海康设备的原始视频流…...

深入理解设计模式:工厂模式、单例模式
深入理解设计模式:工厂模式、单例模式 设计模式是软件开发中解决常见问题的可复用方案。本文将详细介绍两种种重要的创建型设计模式:工厂模式、单例模式,并提供Java实现示例。 一、工厂模式 工厂模式是一种创建对象的设计模式,…...
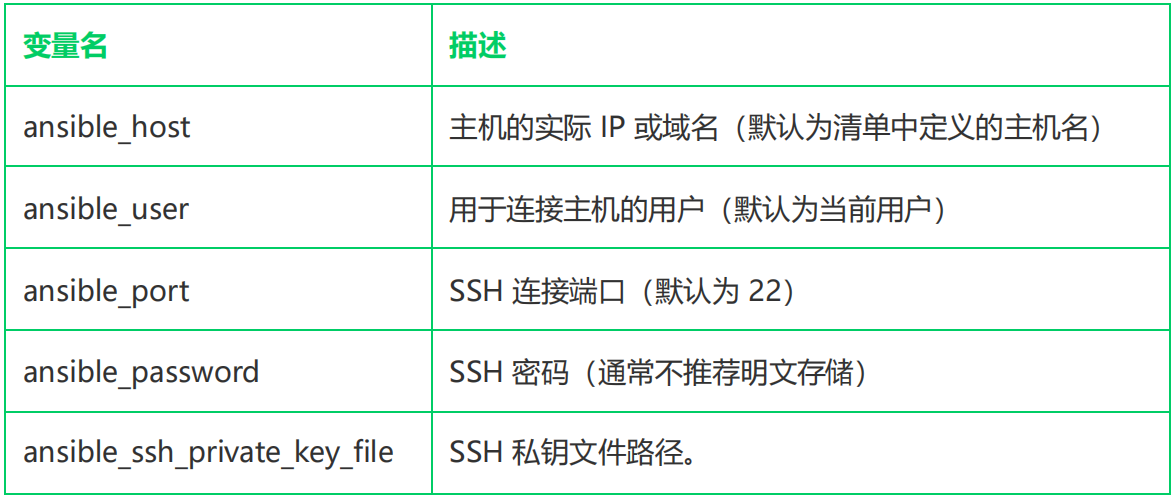
运维Linux之Ansible详解学习(更新中)
什么是Ansible Ansible 是一款新出现的自动化运维工具,基于 Python 开发。以下是对它的详细介绍: 功能特点:集合了众多运维工具的优点,能实现批量系统配置、批量程序部署、批量运行命令等功能。它是基于模块工作的,本…...
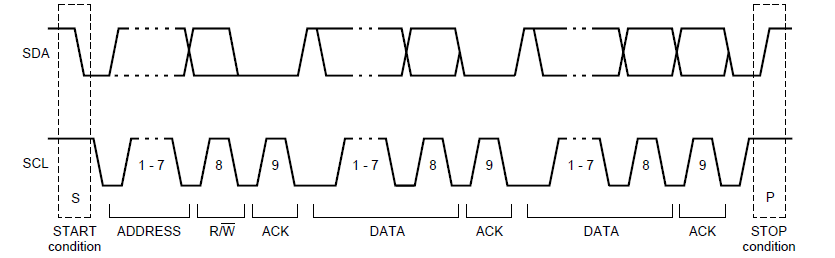
深入浅出IIC协议 - 从总线原理到FPGA实战开发 -- 第三篇:Verilog实现I2C Master核
第三篇:Verilog实现I2C Master核 副标题 :从零构建工业级I2C控制器——代码逐行解析与仿真实战 1. 架构设计 1.1 模块分层设计 三层架构 : 层级功能描述关键信号PHY层物理信号驱动与采样sda_oe, scl_oe控制层协议状态机与数据流控制state…...

网络世界的“变色龙“:动态IP如何重构你的数据旅程?
在深秋的下午调试代码时,我偶然发现服务器日志中出现异常登录记录——IP地址显示为某个境外数据中心。更有趣的是,当我切换到公司VPN后,这个"可疑IP"竟自动消失在了防火墙监控列表中。这个瞬间让我意识到:现代网络架构中…...