【C++指南】string(四):编码
💓 博客主页:倔强的石头的CSDN主页
📝Gitee主页:倔强的石头的gitee主页
⏩ 文章专栏:《C++指南》
期待您的关注

引言
在 C++ 编程中,处理字符串是一项极为常见的任务。而理解字符串在底层是如何编码存储的,对于编写高效、健壮且可移植的代码至关重要。
本文将深入探讨 C++ 中string所涉及的多种编码规则,包括 ASCII、Unicode、UTF - 8、UTF - 16 和 UTF - 32 等,并着重讲解 UTF - 8 编码以及它在string中灵活存储字符串的机制。
常见编码规则介绍
ASCII 编码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是最古老且最基础的编码方式之一。它使用 7 位二进制数来表示 128 个字符,包括英文字母(大小写)、数字、标点符号以及一些控制字符。例如,大写字母 'A' 的 ASCII 码是 65,用二进制表示为01000001。ASCII 编码的优点是简单直观,易于理解和处理,在早期的计算机系统中被广泛应用。然而,它的局限性也很明显,只能表示英文字符和少量特殊符号,无法满足全球多语言文本处理的需求。
参考文章:
【C语言指南】ASCII码完整详细介绍_c语言ascll码-CSDN博客
Unicode 编码
Unicode 旨在为世界上所有的字符提供一个唯一的数字编号,无论其语言和平台如何。
它涵盖了几乎所有已知的字符集,包括各种语言的字母、汉字、符号、表情符号等。
Unicode 有多种编码形式,常见的有 UTF - 8、UTF - 16 和 UTF - 32。
Unicode 的编码空间非常大,使用 16 位或更多位来表示字符。例如,汉字 “你” 的 Unicode 编码是U+4F60。
Unicode 解决了全球字符统一编码的问题,但由于其编码长度不固定(对于一些基本拉丁字符也使用 16 位表示),在存储和传输时可能会造成空间浪费。
UTF - 8 编码
UTF - 8(8 - bit Unicode Transformation Format)是一种变长编码方式,它可以使用 1 到 4 个字节来表示一个字符。
UTF - 8 的设计目标是既能与 ASCII 编码兼容(对于 ASCII 字符,UTF - 8 编码与 ASCII 编码完全相同,占用 1 个字节),又能高效地表示其他 Unicode 字符。
对于大多数常用字符(如英文字母、数字、标点符号等),UTF - 8 仅用 1 个字节表示,与 ASCII 编码一致,这使得基于 ASCII 的现有软件可以无缝处理 UTF - 8 编码的文本。
对于其他非 ASCII 字符,UTF - 8 会根据字符的 Unicode 值使用 2 到 4 个字节进行编码。
例如,汉字 “你” 的 UTF - 8 编码是E4 BD A0,占用 3 个字节。
UTF - 8 编码具有良好的空间效率和兼容性,在互联网上被广泛应用,是目前最常用的编码方式之一。
UTF - 16 编码
UTF - 16 也是一种 Unicode 编码形式,它使用 16 位(2 个字节)或 32 位(4 个字节)来表示一个字符。
对于基本多文种平面(BMP)内的字符,UTF - 16 使用 16 位表示;
而对于那些在 BMP 之外的字符(如一些生僻字、表情符号等),则需要使用两个 16 位的代码单元来表示,即占用 4 个字节。
UTF - 16 在 Windows 操作系统以及一些基于 Unicode 的编程语言(如 Java)中应用较为广泛,但由于其对于非 BMP 字符的处理相对复杂,在跨平台和网络传输方面不如 UTF - 8 灵活。
UTF - 32 编码
UTF - 32 是一种定长编码方式,每个字符都固定占用 4 个字节(32 位)。
它直接将 Unicode 码点映射到 32 位的二进制数,这种编码方式简单直接,字符定位和处理非常方便,因为每个字符的长度固定。
然而,其缺点也很明显,对于大量只包含基本拉丁字符的文本,会造成大量的空间浪费。
例如,一个简单的英文字符串 “hello”,在 UTF - 32 编码下需要占用 20 个字节(每个字符 4 个字节),而在 UTF - 8 编码下只需要 5 个字节。
以下将对UTF-8这一较为广泛使用的编码规则展开详细讲解:
UTF - 8 编码详解
UTF - 8 编码规则
UTF - 8 的编码规则如下:
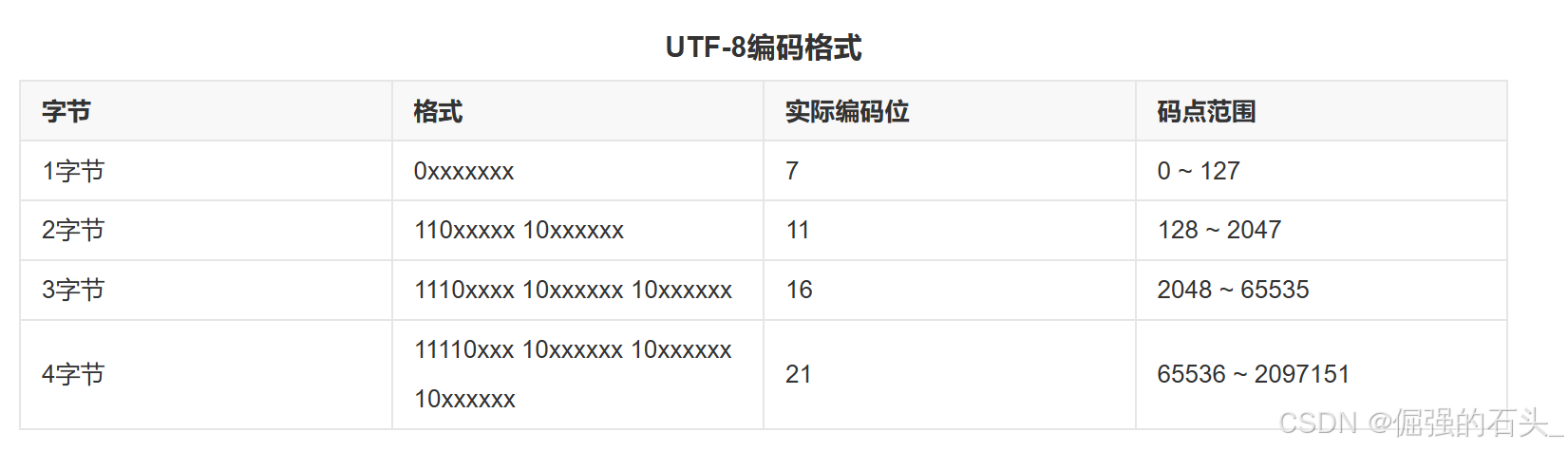
- 单字节字符(与 ASCII 兼容):对于 Unicode 码点范围在U+0000到U+007F之间的字符,UTF - 8 编码与 ASCII 编码相同,使用 1 个字节表示,且最高位为 0。例如,字符 'A' 的 Unicode 码点是U+0041,其 UTF - 8 编码为41(十六进制),二进制表示为01000001。
- 双字节字符:对于 Unicode 码点范围在U+0080到U+07FF之间的字符,UTF - 8 使用 2 个字节表示。第一个字节的前两位固定为 11,第三位到第七位是该字符 Unicode 码点的一部分;第二个字节的前两位固定为 10,其余六位是该字符 Unicode 码点的另一部分。例如,字符 'è' 的 Unicode 码点是U+00E8,转换为二进制是00000000 11101000。按照 UTF - 8 编码规则,第一个字节为11000000 | 00001110 = C0 | 0E = CE,第二个字节为10000000 | 101000 = 80 | A0 = A0,所以 'è' 的 UTF - 8 编码为CE A0。
- 三字节字符:对于 Unicode 码点范围在U+0800到U+FFFF之间的字符,UTF - 8 使用 3 个字节表示。第一个字节的前三位固定为 111,第四位到第七位是该字符 Unicode 码点的一部分;后面两个字节的前两位都固定为 10,其余六位分别是该字符 Unicode 码点的其他部分。以汉字 “中” 为例,其 Unicode 码点是U+4E2D,二进制表示为01001110 00101101。UTF - 8 编码后的第一个字节为11100000 | 01001110 = E0 | 4E = E4,第二个字节为10000000 | 00101101 = 80 | 2D = BD,第三个字节为10000000 | 00000000 = 80 | 00 = A0,所以 “中” 的 UTF - 8 编码为E4 BD A0。
- 四字节字符:对于 Unicode 码点范围在U+10000到U+10FFFF之间的字符,UTF - 8 使用 4 个字节表示。第一个字节的前四位固定为 1111,第五位到第七位是该字符 Unicode 码点的一部分;后面三个字节的前两位都固定为 10,其余六位分别是该字符 Unicode 码点的其他部分。例如,一些表情符号就属于这一类。
UTF - 8 在 C++ string 中的存储
在 C++ 中,std::string本质上是一个字符序列,默认情况下,它以字节为单位存储字符。
当使用 UTF - 8 编码时,std::string可以自然地存储 UTF - 8 编码的字符串,因为 UTF - 8 编码的每个字节都可以直接存储在std::string的字符元素中。
例如:
#include <iostream>#include <string>int main() {std::string utf8String = "你好,世界!";for (char ch : utf8String) {std::cout << std::hex << static_cast<int>(static_cast<unsigned char>(ch)) << " ";}return 0;}上述代码定义了一个包含中文字符的 UTF - 8 编码字符串utf8String,然后遍历该字符串,将每个字节以十六进制形式输出。由于 UTF - 8 编码的多字节特性,每个字符可能占用多个字节,在std::string中这些字节会依次存储。
UTF - 8 存储字符串的底层原理
在std::string内部,它维护着一块连续的内存空间,用于存放字符数据。
当存储 UTF - 8 编码的字符串时,这块内存就按照 UTF - 8 的字节序列依次填充。
比如存储 “hello” 这个字符串,每个字符都是 ASCII 字符,在 UTF - 8 中都只占 1 个字节,内存中会按顺序存放这 5 个字符对应的字节。
而当存储包含中文字符的字符串时,情况就变得复杂些。
以 “中国” 为例,“中” 的 UTF - 8 编码是E4 BD A0,“国” 的 UTF - 8 编码是E5 9B BD,在std::string的内存中,这 6 个字节会依次排列,从起始地址开始,先是 “中” 字的 3 个字节,紧接着是 “国” 字的 3 个字节。
中英文混合存储
当处理中英文混合的字符串时,UTF - 8 的变长特性就发挥了极大优势。
在std::string中,它依然是按照 UTF - 8 编码后的字节顺序依次存储。
例如字符串 “Hello,世界”,“Hello” 这 5 个英文字符,每个字符在 UTF - 8 中占用 1 个字节,共 5 个字节;英文逗号 “,” 在 UTF - 8 中占用 1 个字节;“世” 字占用 2 个字节,“界” 字占用 2 个字节'\0'占用1个字节。
所以整个字符串在std::string中存储时,从起始位置开始,先是 “H” 对应的字节,接着是 “e”“l”“l”“o”“,”“世”“界” 各自对应的字节,总共是 5 + 1 + 2 + 2 + 1 = 11 个字节。
下面通过代码来直观展示中英文混合存储的情况:
#include <iostream>#include <string>int main() {std::string mixedString = "Hello,世界";std::cout << "字符串长度(字节数): " << mixedString.size() << std::endl;for (size_t i = 0; i < mixedString.size(); ++i) {std::cout << std::hex << static_cast<int>(static_cast<unsigned char>(mixedString[i])) << " ";}return 0;} 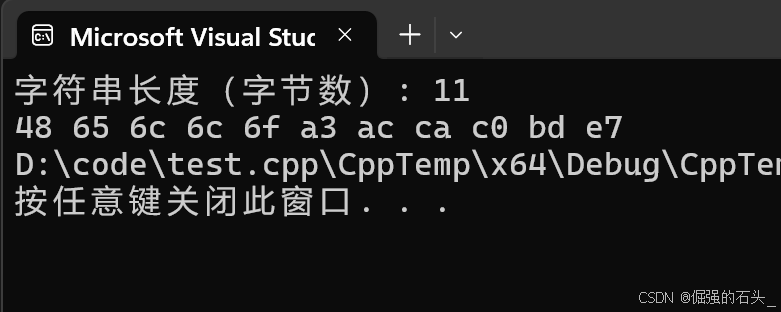
运行上述代码,输出结果中字符串长度为 11,并且能看到每个字符对应的 UTF - 8 编码字节以十六进制形式呈现。
在实际处理中英文混合字符串时,我们要特别注意std::string的操作方法。
例如,若要在字符串中查找某个字符,对于英文字符,因为其在 UTF - 8 中占 1 个字节,直接按字节查找即可;
但对于中文字符,由于它可能占用 2 个字节,不能简单地按字节遍历查找,而是要按照 UTF - 8 编码规则,每次检查 2 个字节是否构成要查找的中文字符的 UTF - 8 编码。
在进行字符串截取操作时也同理,若要截取一个中文完整字符,必须保证截取的起始和结束位置都在该中文字符 UTF - 8 编码的字节范围内,否则可能导致截取后的字符串出现乱码。
总结
不同的编码规则在 C++ string的处理中各有特点和应用场景。
ASCII 编码简单但功能有限,Unicode 提供了全球统一的字符编码方案,而 UTF - 8、UTF - 16 和 UTF - 32 则是 Unicode 的不同编码实现方式。
UTF - 8 因其良好的兼容性和空间效率,成为了目前最常用的编码方式,特别是在互联网应用和跨平台开发中。
深入理解这些编码规则以及它们在 C++ string中的存储和处理方式,对于编写高质量的 C++ 代码至关重要。
在实际开发中,应根据具体需求选择合适的编码方式,以确保程序能够正确、高效地处理各种字符集的字符串。
本文完。
相关文章:
【C++指南】string(四):编码
💓 博客主页:倔强的石头的CSDN主页 📝Gitee主页:倔强的石头的gitee主页 ⏩ 文章专栏:《C指南》 期待您的关注 引言 在 C 编程中,处理字符串是一项极为常见的任务。而理解字符串在底层是如何编码存储的&…...

深度学习之序列建模的核心技术:LSTM架构深度解析与优化策略
LSTM深度解析 一、引言 在深度学习领域,循环神经网络(RNN)在处理序列数据方面具有独特的优势,例如语音识别、自然语言处理等任务。然而,传统的 RNN 在处理长序列数据时面临着严重的梯度消失问题,这使得网…...

AI量化交易是什么?它是如何重塑金融世界的?
第一章:证券交易的进化之路 1.1 从喊价到代码:交易方式的革命性转变 在电子交易普及之前,证券交易依赖于交易所内的公开喊价系统。交易员通过手势、喊话甚至身体语言传递买卖信息,这种模式虽然直观,但效率低下且容易…...
分布式事务处理方案
1. 使用Seata框架解决 1.1 XA 事务 1.1.1 XA整体流程 第一阶段 RM1开启XA事务-> 执行业务SQL -> 上报TC执行结果RM2开启XA事务-> 执行业务SQL -> 上报TC执行结果 第二阶段 TC根据 RM上报结果通知RM一起提交/回滚XA事务 1.1.2 XA特点 XA 模式必须要有数据库的支…...

CVE-2024-36467 Zabbix权限提升
漏洞描述 在Zabbix中,具有API访问权限的已认证用户(例如具有默认用户角色的用户)可以通过调用user.update API接口,将自己添加到任何用户组(如Zabbix管理员组)。然而,用户无法添加到已被禁用或…...
Dify中的自定义模型插件开发例子:以xinference为例
本文使用Dify v1.0.0-beta.1版本。模型插件结构基本是模型供应商(模型公司,比如siliconflow、xinference)- 模型分类(模型类型,比如llm、rerank、speech2text、text_embedding、tts)- 具体模型(…...

crud方法命名示例
以下是基于表名dste_project_indicator(项目指标表)的完整命名示例,覆盖各类增删改查场景: 1. 表名与实体类映射 // 表名:dste_project_indicator // 实体类:DsteProjectIndicatorEntity public class Ds…...
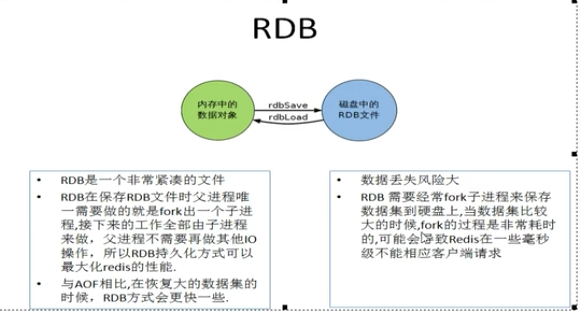
尚硅谷redis7 33-36 redis持久化之RDB优缺点及数据丢失案例
官网说明优点: RDB是Redis数据的一个非常紧凑的单文件时间点表示,RDB文件非常适合备份。例如,您可能希望在最近的24小时内每小时旧档一次RDB文件,并在30天内每天保存一个RDB快照,这使您可以在发生来难时轻松恢复不同版本的数据集。RDB非常适合灾难恢复,它是一个可以…...

No such file or directory: ‘ffprobe‘
目录 详细信息: 解决方法: No such file or directory: ffprobe 详细信息: File "/usr/local/lib/python3.10/dist-packages/framepump/framepump.py", line 168, in get_duration return float(ffmpeg.probe(video_path)[form…...

计算机网络-WebSocket/DNS/Cookie/Session/Token/Jwt/Nginx
文章目录 WebSocketDNS什么是dns域名解析底层协议 cookie/sessionToken/JWTNginx WebSocket 一种网络通信协议,允许在单个 TCP(半双工) 连接上进行全双工通信(客户端和服务器可同时双向传输数据)。 HTTP是基于请求-响…...

功能“递归模式”在 C# 7.3 中不可用,请使用 8.0 或更高的语言版本的一种兼容处理方案
原程序: internal class ControllerParameterCreator : IParameterCreator {private Controller controller;public ControllerParameterCreator(Controller controller){this.controller controller;}public Parameter CreateSystem(string name, int unused){re…...

第4章-操作系统知识
存储管理 固定分区:一种静态分区方式请求分页存储管理覆盖技术:覆盖技术是指让作业中不同时运行的程序模块共同使用同一主存区域。...
将网页带格式转化为PDF
# 一、安装插件 SingleFile | 将完整的页面保存到一个 HTML 文件中 – 下载 🦊 Firefox 扩展(zh-CN) 打开火狐浏览器,安装上面的插件 # 二、下载html单文件 打开对应的网页,点击插件下载对应的html文件 # 三、打开…...
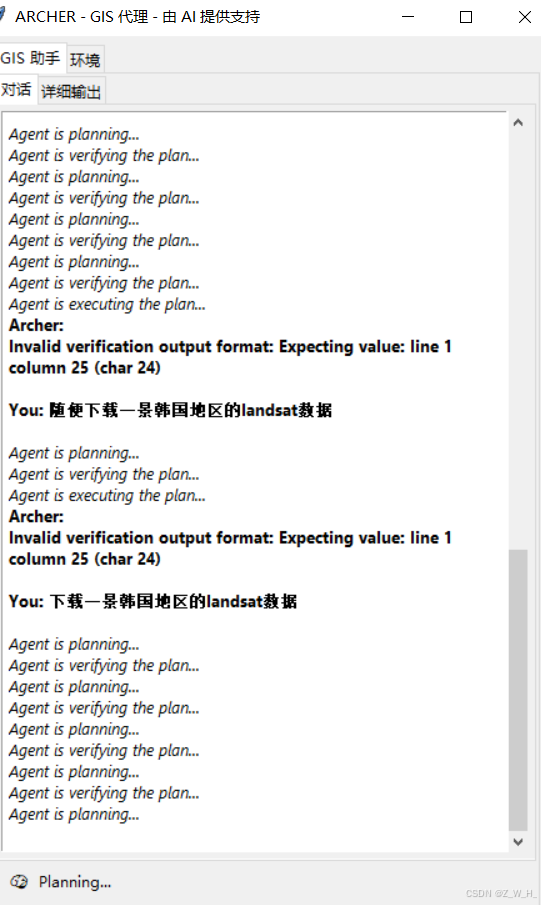
【ArcGIS】ArcGIS AI 助手----复现
github地址 korporalK/Archer-GIS-AI-Assitant:Archer 在 ArcGIS Pro 中将自然语言命令转换为自动化 GIS 工作流。它使用代理框架(计划-验证-执行)构建并由 LLM 提供支持,可简化空间分析、减少手动工作并使 GIS 更易于访问。Arch…...
)
使用 FFmpeg 将视频转换为高质量 GIF(保留原始尺寸和帧率)
在制作教程动图、产品展示、前端 UI 演示等场景中,我们经常需要将视频转换为体积合适且清晰的 GIF 动图。本文将详细介绍如何使用 FFmpeg 工具将视频转为高质量 GIF,包括: ✅ 保留原视频尺寸或自定义缩放✅ 保留原始帧率或自定义帧率✅ 使用调色板优化色彩质量✅ 降低体积同…...

《Java vs Go vs C++ vs C:四门编程语言的深度对比》
引言 从底层硬件操作到云端分布式系统,Java、Go、C 和 C 四门语言各自占据不同生态位。本文从设计哲学、语法范式、性能特性、应用场景等维度进行对比,为开发者提供技术选型参考。 一、设计哲学与历史定位…...

充电枪IEC62196/EN 62196测试内容
充电枪IEC62196/EN 62196测试内容 一、机械性能测试 插拔力测试 交流充电接口的插入/拔出力需≤100N,直流接口≤140N。若使用助力装置,操作力仍需满足上述要求。 测试方法:通过弹簧秤或专用试验机(如Sun-CB设备)测…...

有效的字母异位符--LeetCode
题目 给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的 字母异位词。 示例 1: 输入: s "anagram", t "nagaram" 输出: true示例 2: 输入: s "rat", t "car" 输出: false 思路一:排序 t 是 s …...

SAP ERP 系统拆分的七大挑战
在企业变革或管理运营风险时,剥离IT系统能带来显著效益,但SAP ERP系统的复杂性使得这项工作充满挑战。如果管理不当,可能会导致数据不一致、运营中断、合规风险和意外成本。由于SAP ERP系统深度集成于企业核心业务流程中,其拆分工…...

AcrelEMS 3.0智慧能源管理平台:构建企业微电网数智化中枢
安科瑞电气顾强 在"双碳"目标驱动下,企业能源管理正从粗放式运营向精细化、智能化转型。AcrelEMS 3.0智慧能源管理平台以微电网为核心载体,通过"感知-分析-决策-控制"的全链路数字化能力,助力工商企业、医疗机构、教育机…...

【HTML-12】HTML表格常用属性详解:从基础到高级应用
表格是HTML中最强大且常用的元素之一,它能够以结构化的方式展示数据。本文将全面介绍HTML表格的常用属性,帮助您创建美观、响应式且语义化的数据表格。 1. HTML表格基础结构 在深入了解属性之前,我们先回顾一下HTML表格的基本结构ÿ…...
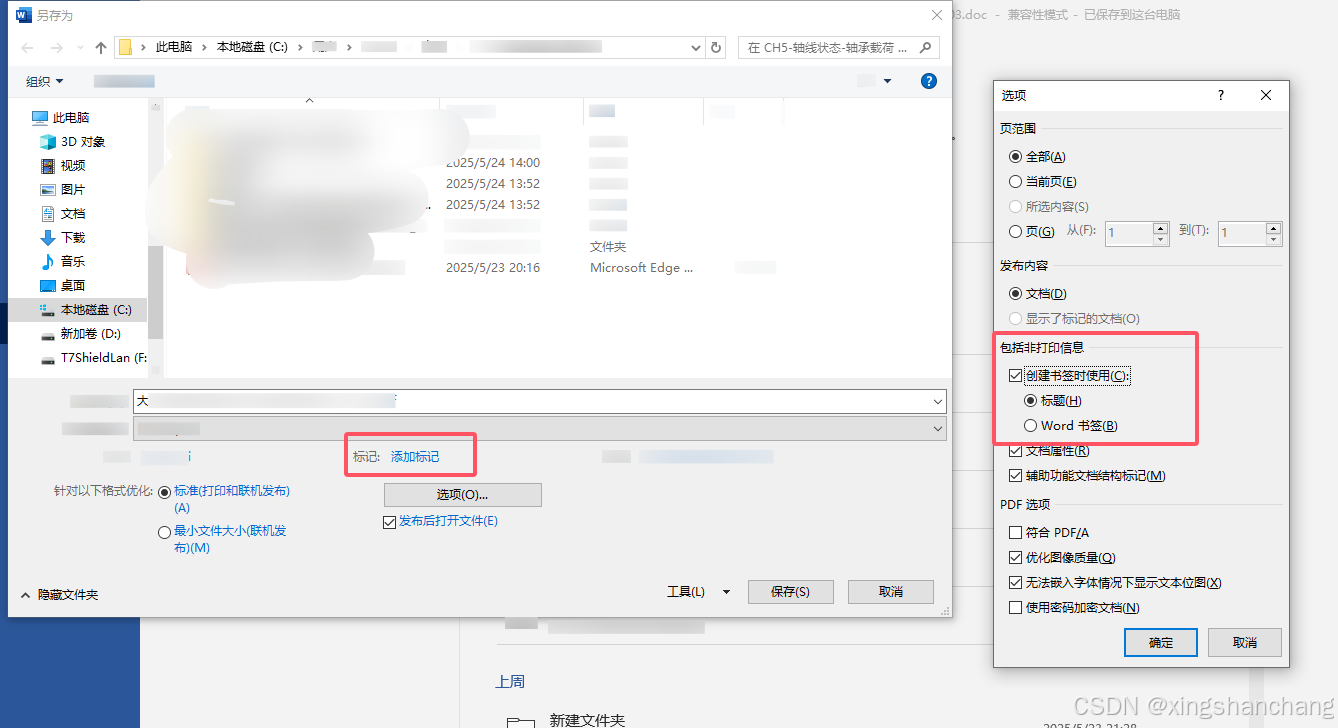
Word转PDF--自动生成目录
1-Word文档中已经包含自动生成的目录; 2-选择“文件”; 3-另存为,PDF; 4-选择“选项”按钮,在弹出的窗口中,勾选“创建书签时使用标题”。...

MySQL组合索引优化策略
优化MySQL组合索引需要综合考虑查询模式、索引结构及数据库特性。以下是关键优化策略及示例: 1. 遵循最左前缀原则 策略:确保查询条件包含组合索引最左侧列。示例:索引(a,b,c)生效场景:WHERE a1 AND b2 -- ✔️ 使用a和b W…...

Spring MVC 的的核心原理与实践指南
一、Spring MVC 概述 Spring MVC 是 Spring 框架中的一个重要模块,用于构建基于 Java 的 Web 应用程序。它遵循模型-视图-控制器(MVC)设计模式,提供了一种结构化的方式来开发灵活、松耦合的 Web 应用。 Spring MVC 的特点…...
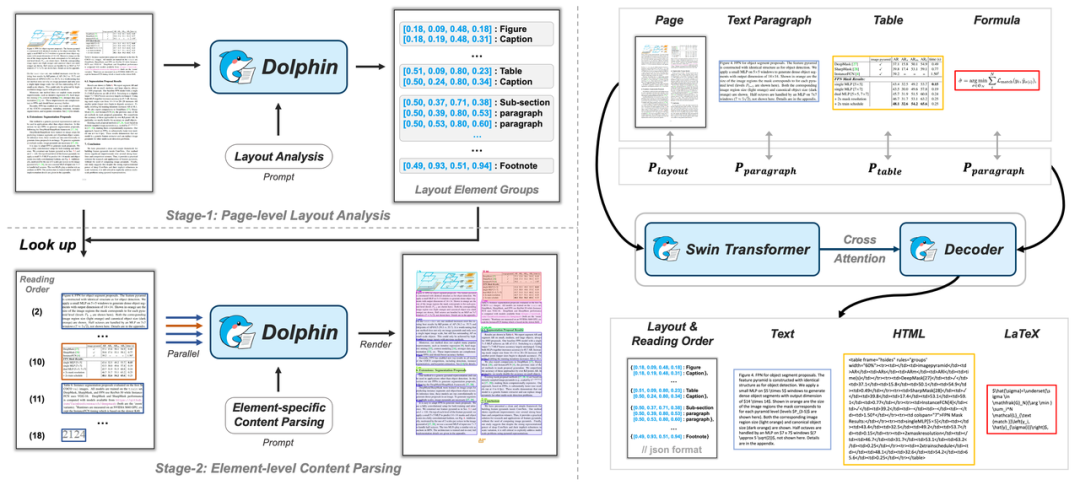
轻量级视觉语言模型 Dolphin:高效精准的文档结构化解析利器
在数字化办公和学术研究日益普及的今天,如何高效、准确地处理各类文档图像成为了一个亟需解决的问题。Dolphin 应运而生,作为一款基于异构锚点提示的多模态文档图像解析模型,它不仅打破了传统手动整理文档的繁琐流程,更以远超主流…...

如何安全配置数据库(MySQL/PostgreSQL/MongoDB)
数据库是许多应用程序的核心组成部分,因此保护数据库的安全性至关重要。无论是MySQL、PostgreSQL还是MongoDB,都需要经过适当的安全配置才能防止潜在的安全威胁。本文将介绍如何安全配置这些流行的数据库管理系统,以确保数据的保密性、完整性…...

将 Docker 镜像从服务器A迁移到服务器B的方法
在日常工作中,我们有时会需要将服务器 A上的镜像上传至服务器B上,下面给出具体操作方式,以镜像 postgres:15 为例进行讲解。 首先在服务器A上拉取 镜像 postgres:15 ,命令如下: docker pull postgres:15下面再将服务…...
git merge解冲突后,add、continue提交
git merge解冲突后,add、continue提交 git merge操作冲突后,需要手动解冲突,解完冲突后,需要: git add . 然后,进入一般的正常git代码提交流程。 git合并‘merge’其他分支的个别文件到当前branch_gitbash 合并branc…...

Lines of Thought in Large Language Models
Lines of Thought in Large Language Models 《Lines of Thought in Large Language Models》(大语言模型中的思维链)聚焦于分析大语言模型(LLMs)在生成文本时,其内部向量轨迹的统计特性。 核心目标是揭示LLMs复杂的“思维过程”(即文本生成时的隐藏状态变化)能否被简…...

八股战神-JVM知识速查
1.JVM组成 JVM由那些部分组成,运行流程是什么? JVM是Java程序的运行环境 组成部分: 类加载器:加载字节码文件到内存 运行时数据区:包括方法区,堆,栈,程序计数器,本地…...