【C++进阶篇】初识哈希
哈希表深度剖析:原理、冲突解决与C++容器实战
- 一. 哈希
- 1.1 哈希概念
- 1.2 哈希思想
- 1.3 常见的哈希函数
- 1.3.1 直接定址法
- 1.3.2 除留余数法
- 1.3.3 乘法散列法(了解)
- 1.3.4 平方取中法(了解)
- 1.4 哈希冲突
- 1.4.1 冲突原因
- 1.4.2 解决办法
- 二. unordered_set / unordered_map详细介绍
- 2.1 unordered_set使用
- 2.2 unordered_map使用
- 2.3 unordered_set vs set 对比
- 三. 最后
在当今数据处理的浪潮中,我们常常面临海量信息的存储与检索挑战。如何在海量数据中快速定位所需信息,成为提升效率的关键。此时,哈希技术应运而生,它如同一把神奇的钥匙,能够将复杂多样的数据通过特定算法映射为简洁的哈希值,从而实现高效的数据存储与查询。哈希技术不仅在计算机科学中占据重要地位,更广泛应用于数据库、网络安全、分布式系统等诸多领域。今天,就让我们深入探索哈希的奥秘,从它的基本概念、核心思想,到实际应用中的种种细节,一窥究竟。
一. 哈希
1.1 哈希概念
哈希(Hash),又称散列,是一种将任意长度输入数据通过特定算法映射为固定长度输出值(哈希值)的核心技术。
1.2 哈希思想
- 核心思想:
哈希的核心思想是通过哈希函数将数据转换为固定长度的哈希值,实现高效的数据处理与存储。其设计遵循以下原则:
- 确定性:相同输入必产生相同哈希值,确保结果可预测。
- 高效性:哈希函数计算速度快,适用于大规模数据处理。
- 均匀性:哈希值需均匀分布,减少不同输入映射到同一值(哈希冲突)的概率。
个人理解:哈希使用vector容器存储数据,就是将键值模上数组的大小,从而建立键值与位置的一一映射,不可避免的存在冲突,什么冲突?换句话说,难免会出现某些值通过上述的算法,会统一的映射到同一位置。
例如假设数组的大小为8,某些数据(如16,24等)进行映射,16%8=0,24%8=0,上述两个数据都映射到了0这个下标,这就是冲突的表现。所以哈希函数就需要设计的合理,一个优秀的哈希函数需要尽可能减少这种冲突。
1.3 常见的哈希函数
哈希函数的种类特别繁多,常见的哈希函数如下:
1.3.1 直接定址法
函数原型:Hashi = a * key +b
- 优点:数据较为集中,均匀
- 缺点:当数据很散乱的时候,空间利用不充分,浪费空间资源
- 适应场景:当数据较为集中时,优选使用直接地址法,例如:存储26个字母时,直接使用数组下标将键值进行一一映射,查询效率O(1)。
1.3.2 除留余数法
除留余数法也称为除法散列法思想:通过取余运算,实现键值与哈希值的映射。
函数原型:hashi = key % p(p是哈希表的大小,p必须小于哈希表的大小)
建议:p尽量不要取2的幂次方的数,建议p取不太接近2的整数次幂的⼀个质数(素数)。注意:不是不能使用,需根据特定的场景灵活使用。
- 优点:简单易用,性能平衡。
- 缺点:哈希冲突的概率高,需借助冲突探测算法解决冲突问题。
- 使用场景:范围不集中,数据分布散乱时,优先使用该方法。
1.3.3 乘法散列法(了解)
该哈希函数对哈希表的大小无要求,本质思想就是让键值乘以一个比1小的数,取出该结果后面的小数部分即为S,再让哈希表的大小M乘以S,这个结果一定小于M,实现键值与哈希值的映射。
函数原型:h(key) = floor(M × ((A × key)%1.0))
- 示例:S = A * key,M:哈希表的大小 ,这个A无明确规定,Knuth大佬认为A取黄金分割点较好。例如:假设M为1024,key为1234,A = 0.6180339887, Akey = 762.6539420558,取⼩数部分为0.6539420558, M×((A×key)%1.0) = 0.65394205581024 = 669.6366651392,那么h(1234) = 669。
- 优点:减少冲突,使用范围广,哈希表的长度灵活。
- 缺点:计算复杂,对数论要求高。
1.3.4 平方取中法(了解)
函数原型:hashi = mid(key * key)
- 适用场景:规模中等哈希,关键字分布均匀。
假设键值为 key=1234,其平方后 等于 1522756。截取中间3位227作为哈希表的键值。
补充:还有随机数法,全域散列法,折叠法等,都是尽量减少哈希冲突,前面两种最常见,也是最实用的。建议掌握它们即可。
1.4 哈希冲突
1.4.1 冲突原因
哈希值 是 键值 通过 哈希函数 计算得出的位置标识符,一个位置标识难以不被多个数据映射。
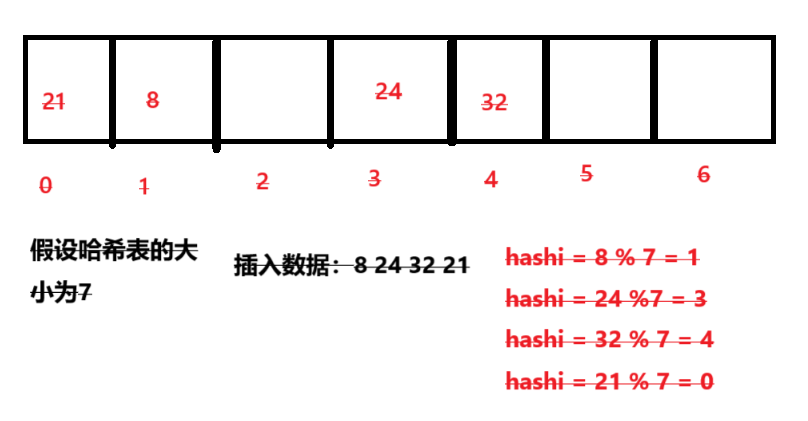
下面以示例来展示哈希冲突过程:
插入数据:8 24 32 21后的哈希表
在插入数据14后:
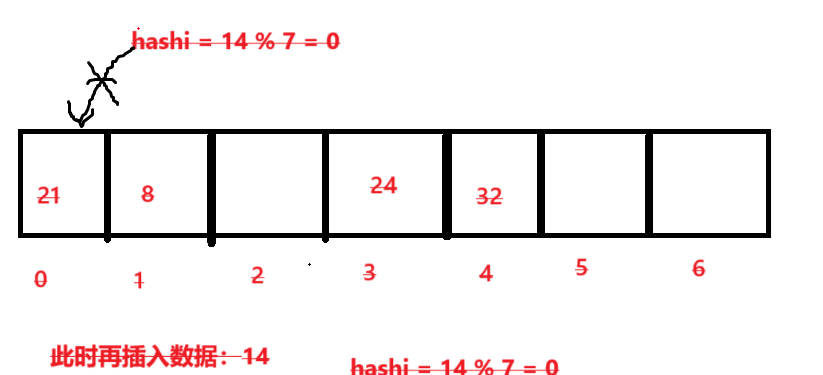
此时哈希值0位置已经有数据了,在插入就发生了哈希冲突,此时就需要解决该冲突问题。
1.4.2 解决办法
常见的解决办法:闭散列 与 开散列
开放地址法
很巧妙地思想:当哈希表中的实际存储数据量 与 哈希表的长度大小比值,超过一定范围,一般是0.7,会自动进行扩容,扩容后之前在旧的哈希表中数据需重新进行映射,可能之前冲突的数据在新表后就不冲突了,一定程度减少哈希冲突概率。所以插入数据前,哈希表的容量一定可以容纳该数据。
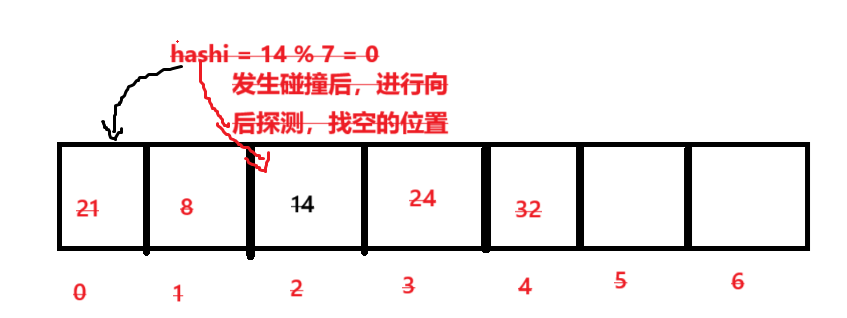
线性探测实际上可以解决哈希碰撞问题,会带来新的问题就是:踩踏。
- 何为踩踏:
简单点就是说一个数据本来就是存在该哈希值所在位置的,上面因为你发生了冲突,进行线性探测占有别人的位置,导致原来本应该在还位置的数据,也要进行线性探测,导致恶性循环,插入和查找效率大幅度下降。
**优化方案:**二次探测,发生冲突后,将键值+i的平方,再取余。碰撞的问题仍不可避免。效果不是很好。
开散列:链地址法,哈希桶
在哈希表中存储一个单链表,发生冲突后,直接往后进行头插,冲突问题就没有了,也没有踩踏问题了。
- 该方法是否需要负载因子???
不需要,因为是实际存储的是链表,当存储个数等于哈希表长度大小时,进行扩容,也需重新建立映射关系。
注意:哈希桶最坏时间复杂度O(N),平均是O(1)。
上面就是解决 哈希冲突 的常用方法,下面的文章将会用上面的理论方法模拟实现哈希表,敬请期待一下吧。
二. unordered_set / unordered_map详细介绍
哈希表的优势在于查找数据是否存在非常快。
前文已经提过set和map底层是用红黑树实现的,C++11标准使用 哈希表 重写了,造就了今天的 unordered_set 和 unordered_map。
2.1 unordered_set使用
- 示例代码:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<unordered_set>
#include<vector>
using namespace std;int main()
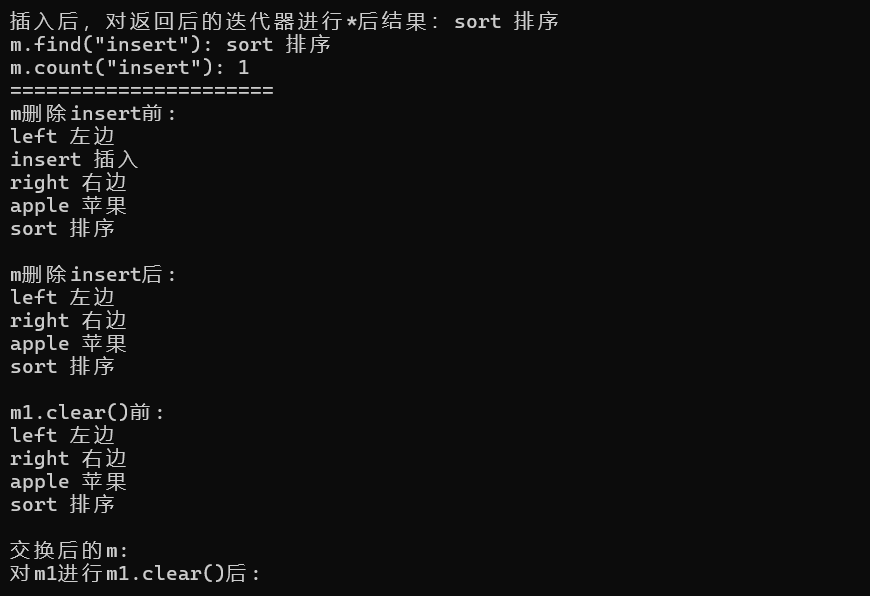
{vector<int> arr = { 2,5,7,1,1,9,8,10 };unordered_set<int> s(arr.begin(), arr.end());//迭代器遍历cout << "迭代器遍历后结果: ";unordered_set<int>::iterator it = s.begin();while (it != s.end()){cout << *it<<" ";++it;}cout << endl;//范围for遍历cout << "范围for遍历后结果: ";for (auto ch : s){cout << ch <<" ";}cout << endl;//负载因子cout << "当前s的负载因子,s.load_factor():" << s.load_factor() << endl;cout << "s最大负载因子, s.max_load_factor():" << s.max_load_factor() << endl;//判空 求大小cout << "======================" << endl;cout << "s.empty(): "s.empty() << endl;cout << "s.size(): "s.size() << endl;cout << "s.max_size(): "s.max_size() << endl;//插入元素cout << "======================" << endl;cout<<"s.insert(100): "<<endl;//pair<iterator, bool> ret = s.insert(100);error,迭代器需指定类域pair<unordered_set<int>::iterator, bool> ret = s.insert(100);cout << "插入后,对返回后的迭代器进行*后结果:";cout << *ret.first << endl;//查找,统计unordered_set<int>::iterator ret1 = s.find(1);//返回值是迭代器cout << "s.find(1): " << *ret1 << endl;cout << "s.count(1): " << s.count(1) << endl;//统计1出现的次数,默认会去重//删除cout << "======================" << endl;cout << "s删除10前: ";for (auto ch : s) cout << ch <<" ";cout << endl;s.erase(10);cout << "s删除10后: ";for (auto ch : s) cout << ch <<" ";cout << endl;//交换unordered_set<int> s1;s1.swap(s);cout << "s1.clear()前:";for (auto ch : s1) cout << ch<<" ";cout << endl;cout << "交换后的s:";//数据清空了for (auto ch : s) cout << ch;cout << endl;//清理s1.clear();//清理s1后,数据也为空了cout << "对s1进行s1.clear()后: ";for (auto ch : s1) cout << ch;return 0;
}
**注意:**迭代器需要指定类域,否则会报错。
原因:因为迭代器是容器类的内部类型,须通过类域进行限定。
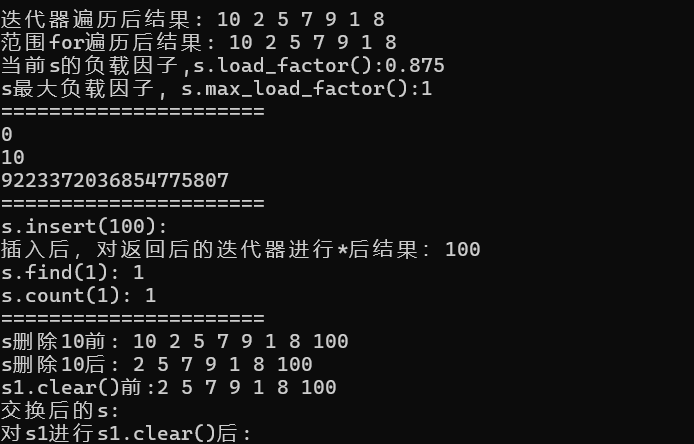
- 输出结果:
2.2 unordered_map使用
- 示例代码:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<unordered_map>
#include<vector>
#include<string>
using namespace std;int main()
{//map使用pair存储数据vector<pair<string, string>> arr{ make_pair("insert","插入"),make_pair("right","右边") ,make_pair("apple","苹果"),make_pair("left","左边") };unordered_map<string, string> m(arr.begin(), arr.end());//迭代器遍历cout << "迭代器遍历后结果: " << endl;unordered_map<string, string>::iterator it = m.begin();while (it != m.end()){cout << it->first << " " << it->second << endl;++it;}cout << endl;//范围for遍历cout << "范围for遍历后结果: " << endl;for (auto ch : m){cout << ch.first << " " << ch.second;cout << endl;}cout << endl;//负载因子cout << "当前m的负载因子,m.load_factor():" << m.load_factor() << endl;cout << "m最大负载因子, m.max_load_factor():" << m.max_load_factor() << endl;//判空 求大小cout << "======================" << endl;cout << "m.empty(): "<<m.empty() << endl;cout << "m.size(): "<<m.size() << endl;cout << "m.max_size(): " << m.max_size() << endl;//插入元素cout << "======================" << endl;//cout << "m.insert(make_pair("sort","排序")): " << endl;errorcout << "m.insert(make_pair(\"sort\",\"排序\")): " << endl;pair<unordered_map<string, string>::iterator, bool> ret = m.insert(make_pair("sort", "排序"));cout << "插入后,对返回后的迭代器进行*后结果:";cout << ret.first->first << " " << ret.first->second << endl;//查找,统计unordered_map<string,string>::iterator ret1 = m.find("insert");//返回值是迭代器cout << "m.find(\"insert\"): " << ret.first->first << " " << ret.first->second << endl;cout << "m.count(\"insert\"): " << m.count("insert") << endl;//删除cout << "======================" << endl;cout << "m删除insert前: " << endl;for (auto ch : m){cout << ch.first << " " << ch.second;cout << endl;}cout << endl;m.erase("insert");cout << "m删除insert后: " << endl;for (auto ch : m){cout << ch.first << " " << ch.second;cout << endl;}cout << endl;//交换unordered_map<string,string> m1;m1.swap(m);cout << "m1.clear()前:" << endl;for (auto ch : m1){cout << ch.first << " " << ch.second;cout << endl;}cout << endl;cout << "交换后的m:";//数据清空了for (auto ch : m){cout << ch.first << " " << ch.second;cout << endl;}cout << endl;//清理m1.clear();//清理m1后,数据也为空了cout << "对m1进行m1.clear()后: " << endl;for (auto ch : m1){cout << ch.first << " " << ch.second;cout << endl;}cout << endl;return 0;
}
注意:cout << “m.insert(make_pair(“sort”,“排序”)): " << endl; 这个是错误的

规则:要在字符串内包裹字符串必须使用双反斜杠,编译器会将这个 -> “m.insert(make_pair(”
作为字符串,后续的 -> sort”,“排序”)): " 会被当成无效字符串。最佳实践:在字符串开始前加 \ 和 字符换结束后加 \ 。可以解决该问题。
正确写法:
cout << "m.insert(make_pair(\"sort\",\"排序\")): " << endl;//true
这个问题也是小编第一次碰到,可能是小编实力还是不够,很多大佬对这问题如同技压群雄,既然碰到了,小编就将第一次记录艰难险阻过程。
- 输出结果:
2.3 unordered_set vs set 对比
相似点:
- 两者增删查的使用基本一致。
- 负载因子,交换接口一模一样。
不同点:
- key值差异:因为set的底层是红黑树实现的,所以需要key支持严格的强弱对比,需要维护有序性。unordered_set底层是哈希表实现的,插入在哪里需要严格的等于比较,因为要取余,所以key值必须是整数,不是整数需通过仿函数支持比较。
- 迭代器差异:set的 iterator 是双向迭代器,因为是树,树这个数据结构本身就支持正反向遍历。unordered_set的 iterator 是单向迭代器,因为里面是用单链表存储数据,单链表本身就不支持反向遍历。
- 性能差异:哈希表的增删查效率很快,时间复杂度为O(1),而红黑树性能没有哈希表快,时间复杂度为O(logN)。
光说无凭:下面用一段代码进行测试。
#include <iostream>
#include <iomanip>
#include <random>
#include <string>using namespace std;// 随机数生成配置
struct PerformanceData {int insert;int erase;int find;
};PerformanceData generate_random_performance() {random_device rd;mt19937 gen(rd());uniform_int_distribution<> dist(10, 200); // 生成10-200ns范围内的随机值return {dist(gen), // 插入操作dist(gen), // 删除操作dist(gen) // 查找操作};
}// 格式化输出表格
void print_table(const string& header, const string& col1, const string& col2) {cout << "\n+" << string(50, '-') << "+\n";cout << "| " << left << setw(48) << header << " |\n";cout << "+" << string(50, '-') << "+\n";cout << "| " << left << setw(24) << col1 << "| " << left << setw(24) << col2 << " |\n";cout << "+" << string(50, '-') << "+\n";
}int main() {// 生成随机性能数据PerformanceData set_perf = generate_random_performance();PerformanceData unordered_perf = generate_random_performance();// 输出对比表格print_table("对比维度", "set", "unordered_set");// 底层结构print_table("底层数据结构", "红黑树(自动排序)", "哈希表(无序存储)");// Key要求print_table("Key要求","需要严格弱序比较(默认使用<操作符)","需要哈希函数和相等比较(==操作符)");// 迭代器特性print_table("迭代器类型","双向迭代器(支持反向遍历)","单向前向迭代器");// 性能对比(带随机数)cout << "\n" << setw(50) << setfill('=') << "" << endl;cout << "| " << left << setw(22) << "操作类型" << "| " << setw(12) << "set" << "| " << setw(12) << "unordered_set" << " |\n";cout << "|" << string(48, '-') << "|\n";auto print_row = [](const string& op, int a, int b) {cout << "| " << left << setw(22) << op << "| " << setw(12) << a << "ns"<< "| " << setw(12) << b << "ns" << " |\n";};print_row("插入操作", set_perf.insert, unordered_perf.insert);print_row("删除操作", set_perf.erase, unordered_perf.erase);print_row("查找操作", set_perf.find, unordered_perf.find);cout << "+" << string(50, '-') << "+\n";// 总结输出cout << "\n对比总结:\n"<< "1. 当需要元素有序时选择set,需要快速查找时优先选unordered_set\n"<< "2. unordered_set在平均情况下性能更优,但最坏情况可能退化到O(n)\n"<< "3. 两者都要求key唯一,但实现机制不同导致性能特征差异\n";return 0;
}
输出结果:
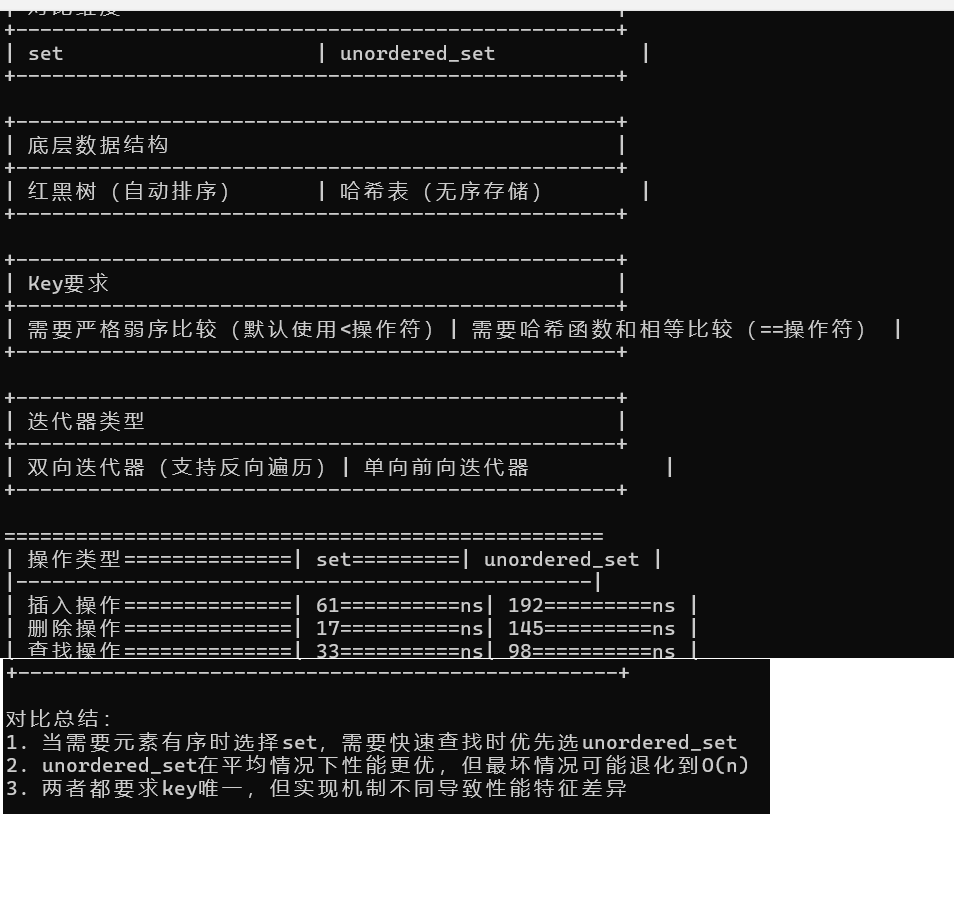
从结果可以看出哈希表在增删查都比红黑树略胜一筹。
注:unordered_map 和 map 与上述两个容器一模一样,小编不再重复说了。
说明:上述四个容器都不支持冗余,即不允许插入相同的key值,插入已经存在的值会插入失败。
如果要支持冗余下面这两个容器:unordered_multiset 和 unordered_multimap 允许插入相同的key值。其它的相似点与差异以上述描述的差异基本一致的。但该两个容器遍历的顺序不是有序的了。
- 示例代码(测试性能):
#include <iostream>
#include <unordered_set>
#include <unordered_map>
#include <ctime>
#include <cstdlib>using namespace std;const int KEY_RANGE = 1000;
const int DATA_SIZE = 10000;void simple_performance_test(const string& container_name) {// 初始化随机数srand(time(NULL));// 记录开始时间clock_t start = clock();// 创建测试容器if (container_name == "unordered_multiset") {unordered_multiset<int> container;for (int i = 0; i < DATA_SIZE; ++i) {int key = rand() % KEY_RANGE;container.insert(key);}} else if (container_name == "unordered_multimap") {unordered_multimap<int, string> container;for (int i = 0; i < DATA_SIZE; ++i) {int key = rand() % KEY_RANGE;container.insert({key, "test"});}}// 记录结束时间clock_t end = clock();double duration = double(end - start) / CLOCKS_PER_SEC * 1000;// 输出简单性能报告cout << container_name << " 插入耗时: " << duration << "ms" << endl;
}int main() {// 容器特性演示cout << "=== 容器特性演示 ===" << endl;// unordered_multiset 示例{unordered_multiset<int> ums;ums.insert(42);ums.insert(42);cout << "unordered_multiset 重复值测试: 大小=" << ums.size() << endl;}// unordered_multimap 示例{unordered_multimap<int, string> umm;umm.insert({1, "测试"});umm.insert({1, "数据"});cout << "unordered_multimap 重复key测试: 大小=" << umm.size() << endl;}// 简化性能测试cout << "\n=== 性能对比测试 ===" << endl;simple_performance_test("unordered_multiset");simple_performance_test("unordered_multimap");// 特性总结cout << "\n=== 关键特性 ===" << endl;cout << "1. 允许重复key值\n"<< "2. 平均O(1)复杂度操作\n"<< "3. 无序存储\n";return 0;
}
- 输出结果:

可以看出unordered_multiset插入时间 比 unordered_multimap 更优。
三. 最后
本文主要介绍了哈希技术及其在C++中的应用。哈希通过哈希函数将数据映射为固定长度的值,常见的哈希函数包括直接定址法、除留余数法、乘法散列法和平方取中法。哈希冲突是不可避免的,但可以通过开放地址法(如线性探测、二次探测)和开散列(链地址法)等方法解决。C++中的unordered_set和unordered_map基于哈希表实现,具有快速查找、插入和删除的特点,但不支持元素有序。与set和map相比,它们的性能在平均情况下更优,但最坏情况下可能退化。此外,unordered_multiset和unordered_multimap允许重复键值,适用于需要存储重复数据的场景。
相关文章:
【C++进阶篇】初识哈希
哈希表深度剖析:原理、冲突解决与C容器实战 一. 哈希1.1 哈希概念1.2 哈希思想1.3 常见的哈希函数1.3.1 直接定址法1.3.2 除留余数法1.3.3 乘法散列法(了解)1.3.4 平方取中法(了解) 1.4 哈希冲突1.4.1 冲突原因1.4.2 解…...

Spring Boot——自动配置
目录 1.bean加载方式 1.1XML方式声明bean 1.2 xml 注解方式声明bean 1.3通过Configuration和Bean 1.4使用Import注解 1.5使用上下文对象在容器初始化完毕后注入bean 1.6使用ImportSelector接口 1.7实现ImportBeanDefinitionRegistrar接口 1.8bean加载方式(…...

免费轻量便携截图 录屏 OCR 翻译四合一!提升办公效率
各位软件小达人们,今天来给大伙唠唠VeryCapture这款软件! 先说说它的核心功能。这软件有个超厉害的多模态屏幕捕捉系统,它就像个全能小能手,把截图、录屏、OCR文字识别、翻译这些功能全集成在一起啦!截图有6种模式&a…...
使用 Vuex 实现用户注册与登录功能
引言 在构建具有用户认证功能的应用时,Vuex 可以用来管理用户的登录状态和相关信息。以下是如何使用 Vuex 来实现用户注册与登录功能的概述。 🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端…...
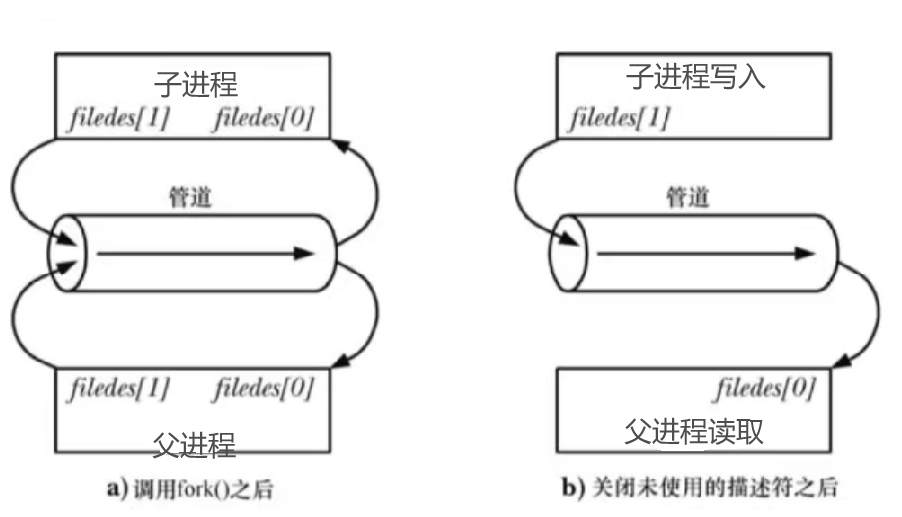
进程通信(管道,共享内存实现)
01. 进程通信简介 进程通信工具分为数据传输工具和共享内存两类。这里我们讨论进程通信工具(IPC)里面的管道、system V和共享内存。在理解阶层通信之间,我们先了解用户空间缓冲区和内核空间缓冲区两个概念。 1.1 用户空间缓冲区 存在于用户态的进程用户空间&#…...
电池预测 | 第28讲 基于CNN-GRU的锂电池剩余寿命预测
电池预测 | 第28讲 基于CNN-GRU的锂电池剩余寿命预测 目录 电池预测 | 第28讲 基于CNN-GRU的锂电池剩余寿命预测预测效果基本描述程序设计参考资料 预测效果 基本描述 电池预测 | 第28讲 基于CNN-GRU的锂电池剩余寿命预测 运行环境Matlab2023b及以上,锂电池剩余寿…...
快速上手SHELL脚本常用命令
一、设置主机名称 1.修改文件方式 重启后生效 2.命令修改 重启shell后生效 二、网卡管理nmcli 1.查看网卡 2.设置网卡 详细配置:快速上手Linux联网管理-CSDN博客 三、简单处理字符 1.打印连续数字 2.设置字体颜色 \033[颜色代号m 3.反向打印文件内容 tac&a…...

【无标题】前端如何实现分页?
前端如何实现分页? 以下是对代码的逐条总结与解释,按 HTML、JavaScript、CSS 顺序分模块列出,每条代码单独说明: 一、HTML 代码解释 1. 表格容器 html <table class"table table-bordered table-hover">作用&…...
【自然语言处理与大模型】大模型Agent四大的组件
大模型Agent是基于大型语言模型构建的智能体,它们能够模拟独立思考过程,灵活调用各类工具,逐步达成预设目标。这类智能体的设计旨在通过感知、思考与行动三者的紧密结合来完成复杂任务。下面将从大模型大脑(LLM)、规划…...
小巧高效的目录索引生成软件
软件介绍 本文介绍的软件名为Snap2html,是一款树形目录索引生成工具。 软件大小与便捷性 Snap2html这款软件已完成汉化,其体积仅170kb,小巧无比,且无需安装,可直接投入使用。 软件使用方法 该软件操作简便…...

云原生架构设计相关原则
文章目录 前言云原生架构概述云原生架构的核心原则一切皆服务原则自动化原则韧性和容错原则可观测性原则 云原生架构原则的实践意义 前言 大家好,我是沛哥儿。今天想和大家深入探讨一下云原生架构的相关原则。在如今数字化飞速发展的时代,云原生架构已经…...

android实现使用RecyclerView详细
显示页面代码:activity_category_inventory.xml代码: <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas.android.com/apk/res/android" xmlns:app"http://schemas.and…...
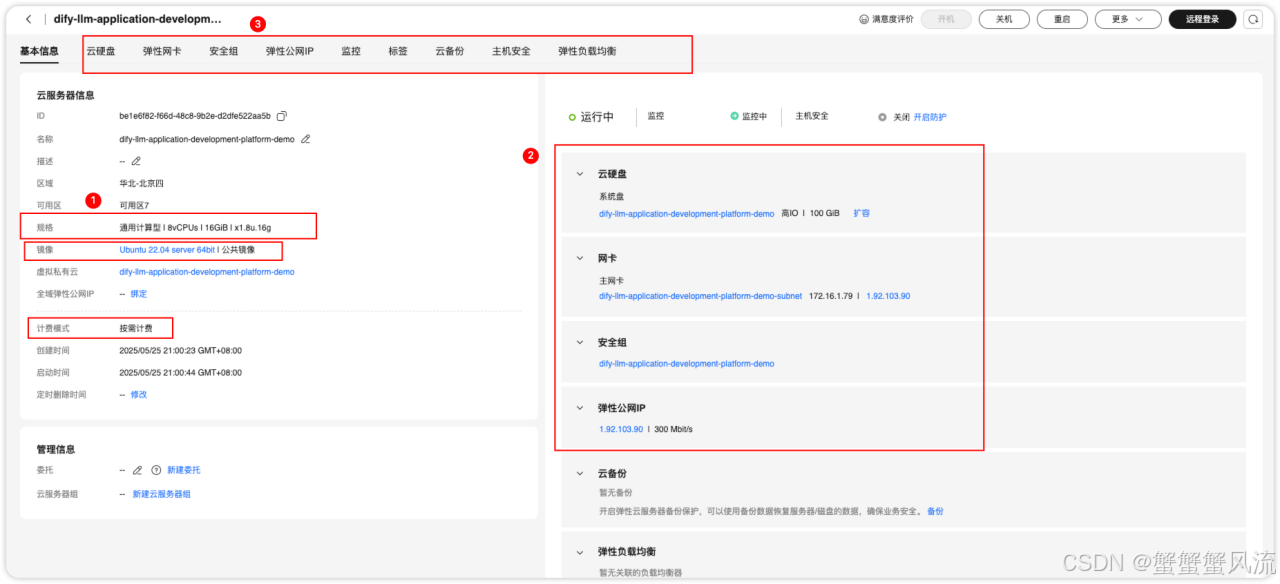
华为云Flexus+DeepSeek征文 | Flexus X实例助力 Dify-LLM 一键部署:性能跃升与成本优化的革新实践
引言 在AI大模型应用快速普及的背景下,企业对低门槛部署、高性能算力与成本可控的需求日益迫切。华为云推出的Flexus X实例,作为专为AI工作负载优化的新一代算力底座,通过1.6倍算力提升、关键业务6倍加速、综合降本30%等核心优势,…...

曼昆经济学原理第九版目录
格里高利曼昆的《经济学原理》(Principles of Economics)通常分为34章(第9版,2024年英文版),分为微观经济学(第1-18章)和宏观经济学(第19-34章)两部分 第一部…...
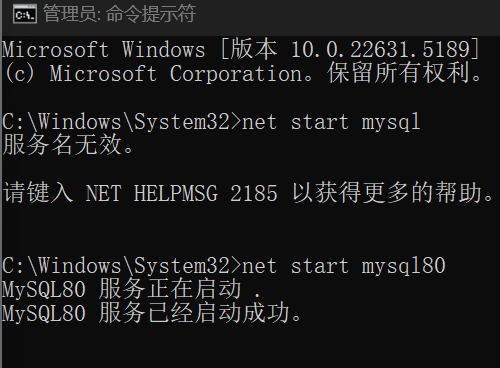
数据库blog7_MySql的下载与配置准备
🌿MySql下载 🍂1.应用版本选择 选择社区版,免费适合初学者 相关链接下载页面下载界面介绍 🍂2.OS版本选择 根据自己的OS类型(Windows/Linux(CentOS/Ubuntu …)/macOS)选择对应版本…...
YOLOv11助力地铁机场安检!!!一键识别刀具
文末有完整代码出处 随着现代社会的高速发展,交通工具和公共场所的安全管理面临着前所未有的挑战。尤其在机场、地铁、车站等公共安全检查点,如何提高安检效率、精准识别危险物品,成为了亟待解决的问题。在传统的安检过程中,X光图…...

RFID工业读写器的场景化应用选型指南
RFID工业读写器是上海岳冉RFID专为工业场景设计的高性能射频识别设备,核心功能围绕高效数据采集与可靠传输展开。其基础能力包括多协议支持(如ISO 18000-6C)与多标签防碰撞处理,可同时读取/写入EPC编码、用户数据等标签信息&#…...

java中的线程安全的集合
1.ConcurrentHashMap。 key,value结构。 jdk1.7通过分段锁保证不同段同时操作是线程安全的,但并发不足,jdk1.8通过node节点锁和CAS保证并发安全。不同node节点可以并发读写。通过它的computer,computerIfAbsent,等可以保证原子更新value。ifAbsent表示有…...

单片机如何快速实现查看实时数据
在用 Keil 做调试的时候,最让人头秃的是什么? 不是写代码的BUG,而是:这个条件变量是什么情况?为什么没进入这个判断?我代码跑到哪里了? 其实本质上都是通过变量判断代码的执行顺序有没有问题 …...
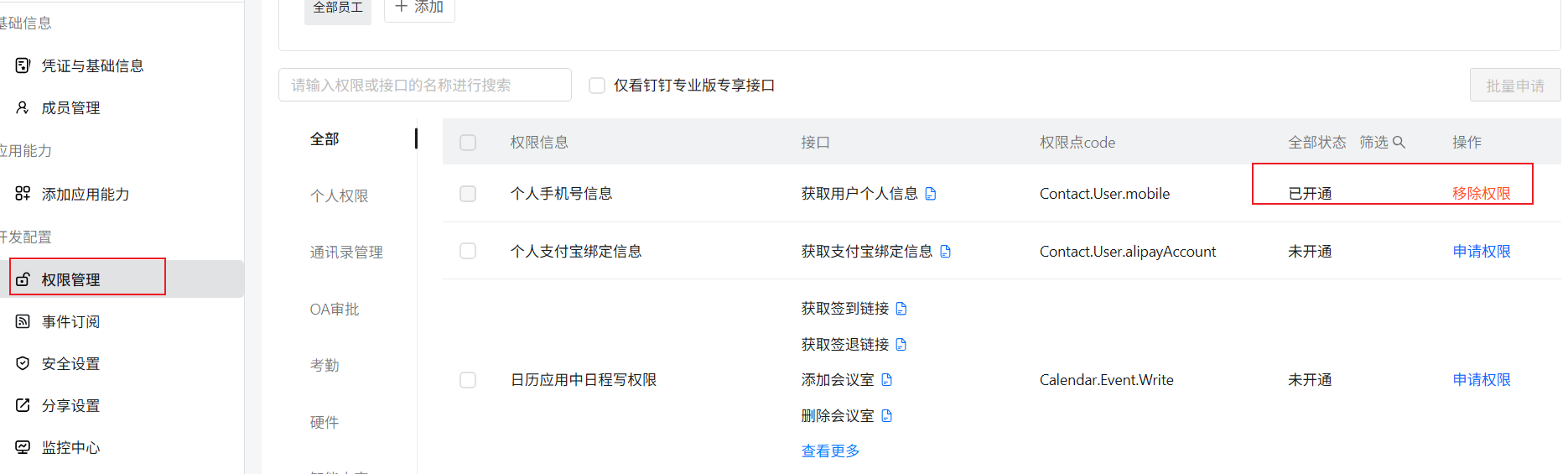
go实现钉钉三方登录
钉钉的的官方开发文档中只给出了java实现三方登录的,我们准备用go语言来实现 实现网页方式登录应用(登录第三方网站) - 钉钉开放平台 首先就是按照文档进行操作,备注好网站的信息 获得应用凭证,我们后面会用到 之后…...

YOLOv1 详解:单阶段目标检测算法的里程碑
在目标检测领域,YOLO(You Only Look Once)系列算法凭借其高效性和实用性,成为了行业内的明星算法。其中,YOLOv1 作为 YOLO 系列的开山之作,首次提出了单阶段目标检测的思想,彻底改变了目标检测算…...

5G 核心网切换机制全解析:XN、N2 与移动性注册对比
摘要 本文深入探讨了 5G 核心网中的三种关键切换方式:基于 XN 接口的切换、基于 N2 接口的切换以及移动性注册更新机制。通过对比分析它们的原理、应用场景和技术差异,帮助读者全面理解 5G 网络中用户移动性管理的核心技术。 1. 引言 随着 5G 技术的广泛应用,用户对网络连…...
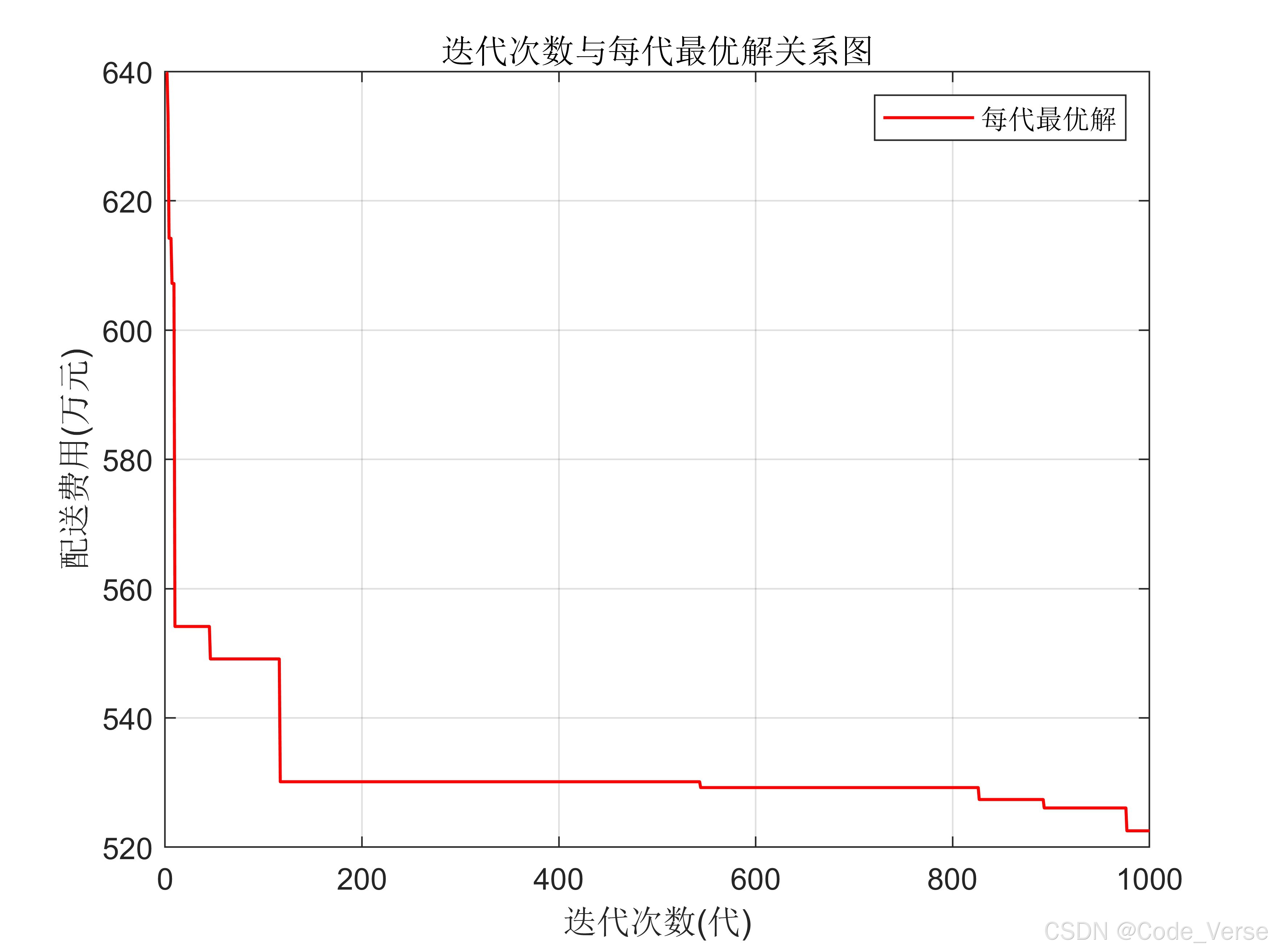
物流配送优化实战:用遗传算法破解选址难题
在电商与供应链高速发展的今天,物流配送成本优化始终是企业竞争力的核心议题之一。想象一下,当你面对 20 个分布在不同坐标的客户点、7 个可选配送中心和 1 个发件网点时,如何用最省钱的方式完成配送?今天我们就来拆解一个真实的物…...
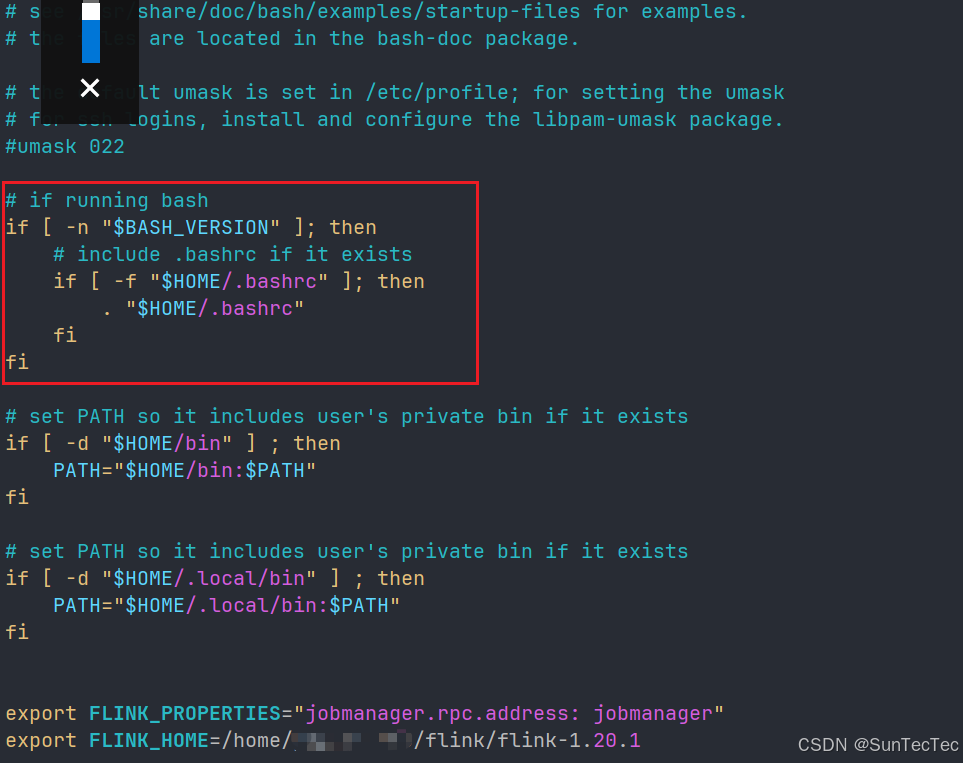
Linux 个人用户设置账号密码环境变量,四种方式
一、需要明白以下2点: 1、Linux 的环境变量是保存在变量 PATH 中,可通过 Linux shell 命令 echo $PATH 查看输出内容,或者直接输入 export 查看,或者输入 env 查看 2、Linux环境变量值之间是通过冒号进行隔开的( : ) 格式为&am…...

Three.js搭建小米SU7三维汽车实战(5)su7登场
汽车模型加载 我们在sktechfab上下载的汽车是glb的文件格式,所以使用gltfLoader进行加载。这里将小车直接加载进来看看效果; import { GLTFLoader } from "three/addons/loaders/GLTFLoader.js"; ....其余代码省略 const gltfLoader new GLT…...
过程的简要解剖)
关于 SSE(Server-Sent Events)过程的简要解剖
Js前端:发送普通请求 fetch(...) .then(()>{}) .catch(()>{})Java后端:接收请求后调用请求处理函数,函数返回一个emiiter对象 public SseEmitter handleRequest(...) {// 创建一个 SseEmitter 对象,用于发送 SSE 事件SseE…...

格恩朗管段超声波流量计:流量测量先锋
在流量测量技术不断迭代的浪潮中,格恩朗自 2019 年创立起,便以开拓者的姿态投身其中,致力于为全球用户提供先进、精准的流量测量解决方案。其旗下的管段超声波流量计,一经推出,便迅速吸引了行业的目光,成为…...

重构开发范式!飞算JavaAI革新Spring Cloud分布式系统开发
分布式系统凭借高可用性、可扩展性等核心优势,成为大型软件项目的标配架构。Spring Cloud作为Java生态最主流的分布式开发框架,虽被广泛应用于微服务架构搭建,但其传统开发模式却面临效率瓶颈——从服务注册中心配置到网关路由规则编写&#…...
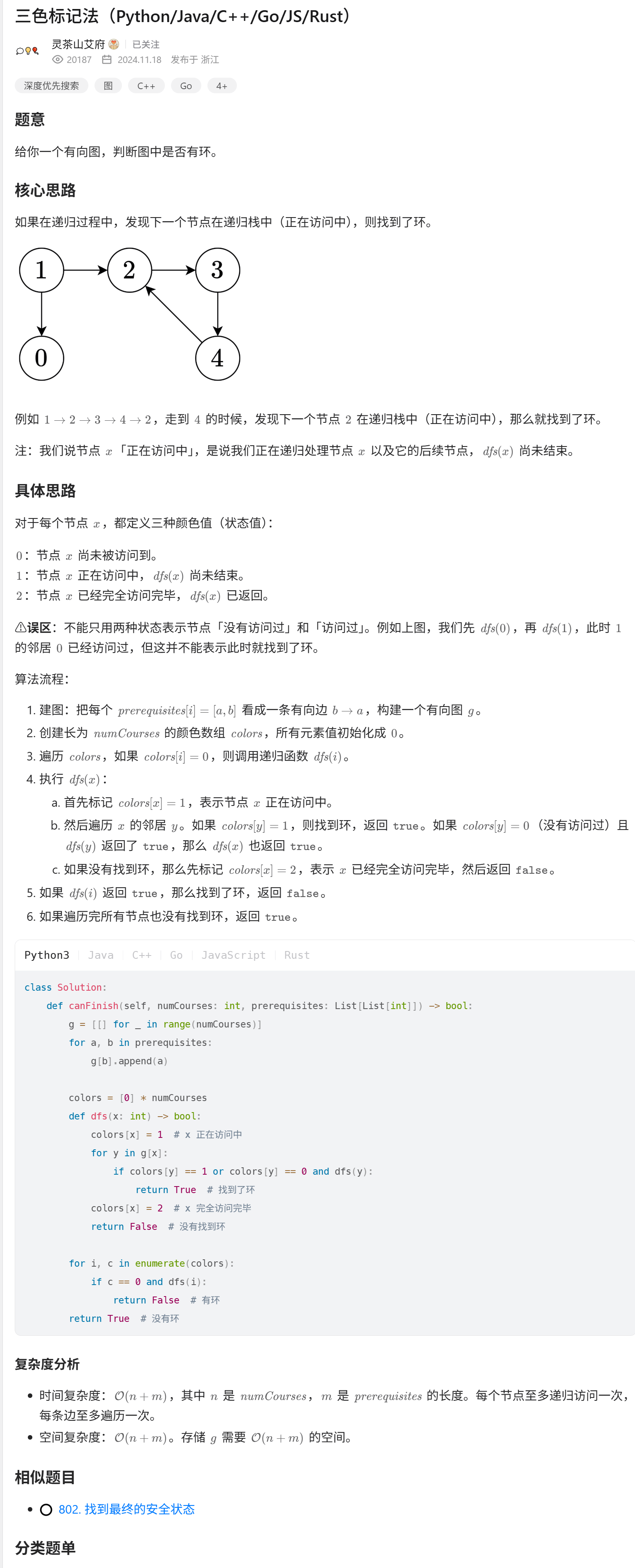
图论 判断是否有环
前言:有点忘记是怎么判断一个图中是否是有环 如果是一个无向图,其实可以直接dfs,加上一个vis数组来一起判断 如果是有向图呢, class Solution:def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool…...
Oracle性能调优、优化总结调优参考直接应用,性能提升实用案例)
(请关注)Oracle性能调优、优化总结调优参考直接应用,性能提升实用案例
Oracle性能调优涉及SQL优化、索引设计、参数配置、存储优化等多个方面。以下是一些常见的性能调优方法及示例,涵盖核心场景和最佳实践。 1. SQL优化 示例1:使用绑定变量减少硬解析 ```sql -- 错误示例(硬解析频繁) SELECT * FROM employees WHERE employee_id = 100; …...