大模型量化原理
模型量化的原理是通过降低数值精度来减少模型大小和计算复杂度。让我详细解释其核心原理:我已经为您创建了一个全面的模型量化原理详解文档。总结几个核心要点:
量化的本质
量化的核心是精度换性能的权衡——通过降低数值精度(FP32→INT8)来获得:
- 4倍内存节省(32位→8位)
- 2-4倍推理加速(整数运算更快)
- 1-3%精度损失(在大多数情况下)
关键数学原理
最重要的量化公式:
量化值 = round((原始值 - zero_point) / scale)
其中scale和zero_point的计算直接决定了量化效果。
三种主要策略对比
| 量化类型 | 实现难度 | 性能提升 | 精度保持 | 适用场景 |
|---|---|---|---|---|
| 动态量化 | 简单 | 中等 | 好 | 快速验证 |
| 静态量化 | 中等 | 高 | 最好 | 生产部署 |
| 量化感知训练 | 复杂 | 最高 | 最好 | 精度要求极高 |
实践建议
- 从动态量化开始:简单易用,效果通常够好
- 敏感层保护:识别并保护对量化敏感的层
- 校准数据质量:静态量化的效果很大程度取决于校准数据
- 硬件适配:不同硬件对量化的支持程度不同
量化是深度学习模型优化的重要技术,特别适合在资源受限的边缘设备上部署。理解这些原理有助于您在sherpa-onnx等框架中更有效地应用量化技术。
-----------------------------------------------
模型量化原理详解
1. 量化的基本数学原理
数值表示转换
量化本质上是将高精度浮点数映射到低精度整数的过程:
原始浮点数 (FP32) → 低精度整数 (INT8/INT16)基本量化公式:
量化值 = round((原始值 - zero_point) / scale)
反量化值 = 量化值 * scale + zero_point其中:
scale:缩放因子,决定量化范围zero_point:零点偏移,用于处理非对称分布
数值精度对比
| 数据类型 | 位宽 | 数值范围 | 精度 | 内存占用 |
|---|---|---|---|---|
| FP32 | 32位 | ±3.4×10³⁸ | 7位有效数字 | 4字节 |
| FP16 | 16位 | ±6.5×10⁴ | 3-4位有效数字 | 2字节 |
| INT8 | 8位 | -128~127 | 256个离散值 | 1字节 |
| INT16 | 16位 | -32768~32767 | 65536个离散值 | 2字节 |
2. 量化类型原理
2.1 对称量化 (Symmetric Quantization)
原理特点:
- 零点偏移 zero_point = 0
- 数值分布关于零点对称
- 计算更简单,硬件友好
数学表示:
scale = max(|min_val|, |max_val|) / (2^(bits-1) - 1)
quantized = round(real_value / scale)适用场景:
- 权重量化(通常接近正态分布)
- 对称激活函数(如tanh)
2.2 非对称量化 (Asymmetric Quantization)
原理特点:
- 零点偏移 zero_point ≠ 0
- 能更好适应非对称数据分布
- 量化范围利用更充分
数学表示:
scale = (max_val - min_val) / (2^bits - 1)
zero_point = round(-min_val / scale)
quantized = round(real_value / scale + zero_point)适用场景:
- 激活值量化(通常非负,如ReLU输出)
- 不对称权重分布
3. 量化策略原理
3.1 动态量化 (Dynamic Quantization)
工作原理:
# 伪代码展示动态量化过程
def dynamic_quantization(weights, activations):# 1. 离线量化权重w_scale, w_zp = compute_scale_zeropoint(weights)quantized_weights = quantize(weights, w_scale, w_zp)# 2. 运行时量化激活值for each_inference:a_scale, a_zp = compute_scale_zeropoint(activations)quantized_activations = quantize(activations, a_scale, a_zp)# 3. 量化计算result = quantized_matmul(quantized_weights, quantized_activations)return dequantize(result)优势:
- 实现简单,无需校准数据
- 权重离线量化,激活值运行时量化
- 对不同输入自适应
劣势:
- 运行时计算scale开销
- 激活值量化精度可能不够优化
3.2 静态量化 (Static Quantization)
工作原理:
# 伪代码展示静态量化过程
def static_quantization(model, calibration_data):# 1. 校准阶段 - 收集统计信息activation_stats = {}for data in calibration_data:activations = model.forward(data)activation_stats.update(collect_stats(activations))# 2. 计算最优量化参数for layer in model.layers:scale, zero_point = optimize_quantization_params(activation_stats[layer], method='kl_divergence')layer.set_quantization_params(scale, zero_point)# 3. 量化模型quantized_model = convert_to_quantized(model)return quantized_model优势:
- 预先优化量化参数
- 推理时无额外计算开销
- 通常精度更高
劣势:
- 需要代表性校准数据
- 量化参数固定,对不同输入适应性差
4. 量化参数优化算法
4.1 最小化量化误差
目标函数:
L = ||X - dequantize(quantize(X))||²优化方法:
MinMax方法
def minmax_calibration(tensor):min_val = tensor.min()max_val = tensor.max()scale = (max_val - min_val) / (2^bits - 1)zero_point = round(-min_val / scale)return scale, zero_pointPercentile方法
def percentile_calibration(tensor, percentile=99.99):min_val = torch.quantile(tensor, (100-percentile)/100)max_val = torch.quantile(tensor, percentile/100)# 剩余计算同MinMaxKL散度方法
def kl_divergence_calibration(tensor, num_bins=2048):# 1. 构建参考直方图hist, bin_edges = np.histogram(tensor, bins=num_bins)# 2. 寻找最优截断点best_threshold = Nonemin_kl_divergence = float('inf')for threshold in candidate_thresholds:# 构建量化后分布quantized_hist = simulate_quantization(hist, threshold)kl_div = calculate_kl_divergence(hist, quantized_hist)if kl_div < min_kl_divergence:min_kl_divergence = kl_divbest_threshold = thresholdreturn compute_scale_zeropoint(best_threshold)4.2 敏感度分析
原理: 评估每一层对量化的敏感程度,优先保护敏感层
def layer_sensitivity_analysis(model, calibration_data):layer_sensitivity = {}for layer_name, layer in model.named_modules():# 1. 量化当前层quantized_layer = quantize_layer(layer)# 2. 计算精度损失original_output = model(calibration_data)model.replace_layer(layer_name, quantized_layer)quantized_output = model(calibration_data)# 3. 计算敏感度分数sensitivity = compute_accuracy_drop(original_output, quantized_output)layer_sensitivity[layer_name] = sensitivity# 4. 恢复原始层model.replace_layer(layer_name, layer)return layer_sensitivity5. 量化算法实现细节
5.1 整数运算原理
矩阵乘法量化计算:
设:A为权重矩阵,B为激活矩阵
A_real = (A_quant - A_zp) * A_scale
B_real = (B_quant - B_zp) * B_scaleC_real = A_real × B_real= [(A_quant - A_zp) * A_scale] × [(B_quant - B_zp) * B_scale]= A_scale * B_scale * [(A_quant - A_zp) × (B_quant - B_zp)]整数计算流程:
def quantized_matmul(A_quant, B_quant, A_scale, B_scale, A_zp, B_zp, C_scale, C_zp):# 1. 整数矩阵乘法C_int32 = int32_matmul(A_quant - A_zp, B_quant - B_zp)# 2. 比例缩放multiplier = (A_scale * B_scale) / C_scaleC_scaled = C_int32 * multiplier# 3. 添加零点偏移并截断C_quant = clamp(round(C_scaled) + C_zp, 0, 255) # INT8范围return C_quant5.2 激活函数量化
ReLU量化:
def quantized_relu(x_quant, x_scale, x_zp):# ReLU(x) = max(0, x)# 量化域:max(zero_point, x_quant)return np.maximum(x_zp, x_quant)Sigmoid量化(查找表法):
def build_sigmoid_lut():# 预计算查找表lut = np.zeros(256, dtype=np.uint8)for i in range(256):# 反量化到浮点x_real = (i - 128) * 0.1 # 假设scale=0.1, zp=128# 计算sigmoidsigmoid_val = 1.0 / (1.0 + np.exp(-x_real))# 重新量化lut[i] = np.round(sigmoid_val * 255)return lutdef quantized_sigmoid(x_quant, lut):return lut[x_quant]6. 量化对精度的影响分析
6.1 量化噪声模型
量化误差分析:
量化误差 ε = x_quantized - x_original误差分布特性:
- 均匀分布:ε ∈ [-scale/2, scale/2]
- 均值:E[ε] ≈ 0
- 方差:Var[ε] = scale²/12
6.2 累积误差传播
多层网络误差传播:
def error_propagation_analysis(layers, input_variance):"""分析量化误差在网络中的传播"""total_variance = input_variancefor layer in layers:# 计算当前层的量化噪声quant_noise_var = (layer.scale ** 2) / 12# 线性层误差传播if isinstance(layer, LinearLayer):# 输入误差放大 + 权重量化噪声total_variance = total_variance * layer.weight_norm_squared + quant_noise_var# 非线性层(近似线性处理)elif isinstance(layer, ActivationLayer):grad_mean = layer.average_gradient()total_variance = total_variance * (grad_mean ** 2)return total_variance7. 硬件加速原理
7.1 INT8向量化计算
SIMD指令优化:
assembly
; x86 AVX2 指令示例
; 同时处理32个INT8数据
vmovdqu ymm0, [weights] ; 加载32个INT8权重
vmovdqu ymm1, [activations] ; 加载32个INT8激活值
vpmaddubsw ymm2, ymm0, ymm1 ; 8位乘法累加到16位ARM NEON优化:
assembly
; ARM NEON指令示例
ld1 {v0.16b}, [x0] ; 加载16个INT8数据
ld1 {v1.16b}, [x1]
smull v2.8h, v0.8b, v1.8b ; 8位有符号乘法到16位7.2 专用量化硬件
TPU量化单元:
- 专用INT8矩阵乘法单元
- 硬件实现的量化参数管理
- 内置激活函数查找表
移动端NPU:
- 低功耗INT8计算单元
- 内存带宽优化
- 动态精度调整
8. 量化实践中的关键技巧
8.1 混合精度量化
策略:
def mixed_precision_strategy(model):sensitivity_scores = analyze_layer_sensitivity(model)quantization_plan = {}for layer_name, sensitivity in sensitivity_scores.items():if sensitivity > 0.1: # 高敏感度quantization_plan[layer_name] = 'FP16'elif sensitivity > 0.01: # 中等敏感度quantization_plan[layer_name] = 'INT16'else: # 低敏感度quantization_plan[layer_name] = 'INT8'return quantization_plan8.2 知识蒸馏辅助量化
原理: 使用原始FP32模型作为教师模型,指导量化模型训练
def quantization_aware_training_with_kd(student_model, teacher_model, data_loader):for batch in data_loader:# 教师模型前向传播with torch.no_grad():teacher_output = teacher_model(batch)# 学生模型(量化)前向传播student_output = student_model(batch)# 计算损失:任务损失 + 蒸馏损失task_loss = criterion(student_output, batch.labels)distill_loss = kl_divergence(student_output, teacher_output)total_loss = task_loss + alpha * distill_loss# 反向传播和优化optimizer.zero_grad()total_loss.backward()optimizer.step()通过理解这些量化原理,可以更好地选择和调优量化策略,在保持模型精度的同时获得最大的性能提升。
相关文章:

大模型量化原理
模型量化的原理是通过降低数值精度来减少模型大小和计算复杂度。让我详细解释其核心原理:我已经为您创建了一个全面的模型量化原理详解文档。总结几个核心要点: 量化的本质 量化的核心是精度换性能的权衡——通过降低数值精度(FP32→INT8&a…...

dify-api的.env配置文件
源码位置:dify\api\.env 本文使用Dify v1.3.1。配置文件中各变量的详细信息表,如下所示: 变量英文名变量中文名默认值变量功能SECRET_KEY秘密密钥XXX用于安全地签署会话cookie的应用秘密密钥。确保在部署时使用强密钥。CONSOLE_API_URL控制…...
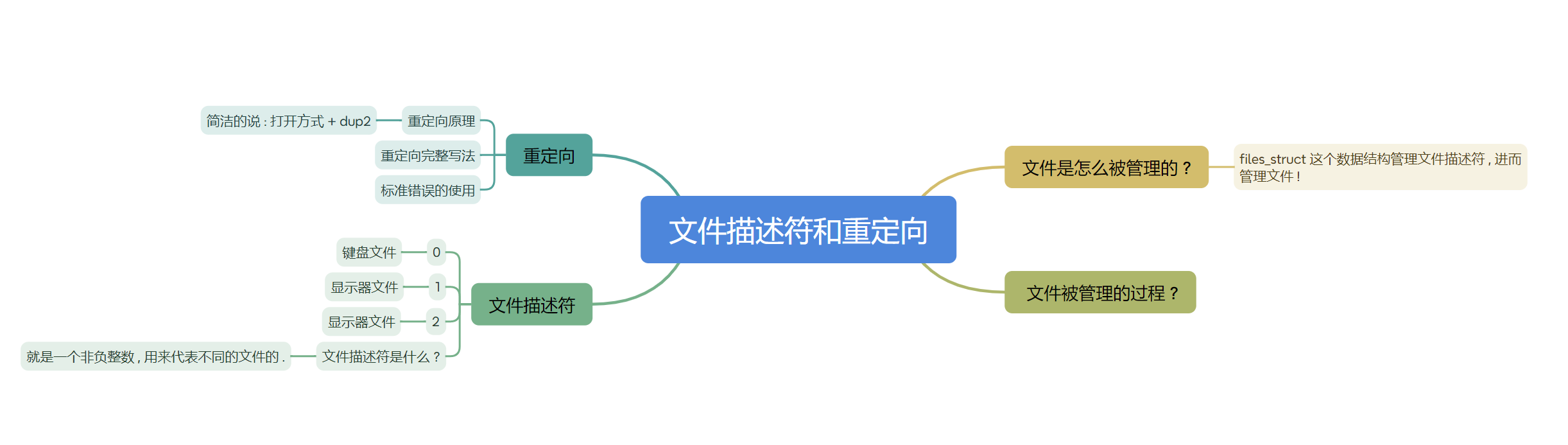
【Linux】Linux 操作系统 - 18 , 重谈文件(二) ~ 文件描述符和重定向原理 , 手把手带你彻底理解 !!!
文章目录 ● 文件描述符一 、Linux 系统对文件的管理(要知道)二 、什么是文件描述符 fd ?三 、再探文件被管理过程(重要)四 、文件描述符 0 、1、21. 文件描述符的分配原则2. 提前认识三个默认打开的文件 ● 重定向原理(重要)一 、重定向现象二 、深入剖析重定向现象(重要)1…...
第五十三节:综合项目实践-车牌识别系统
一、项目背景与意义 车牌识别系统(LPR)是智能交通领域的核心技术之一,广泛应用于停车场管理、违章抓拍、高速公路收费等场景。本文将通过Python+OpenCV实现一个完整的车牌识别系统,涵盖图像预处理→车牌定位→字符分割→字符识别四大核心环节。 二、系统架构设计 技术栈组…...
)
AI时代新词-AI伦理(AI Ethics)
一、什么是AI伦理? AI伦理(AI Ethics)是指在人工智能(AI)的设计、开发、部署和使用过程中,涉及的道德、法律和社会问题的综合考量。它关注AI技术对人类社会、文化、价值观以及个人权利的影响,并…...

湖北理元理律师事务所债务优化服务中的“四维平衡“之道
债务问题解决需要兼顾多方利益,湖北理元理律师事务所通过独特的服务模式,在法律、经济、心理、社会四个维度建立平衡点。 一、法律维度的专业把控 合规性审查: 合同效力认定 诉讼时效核查 担保责任界定 程序合法性: 所有协…...

Git Push 失败:HTTP 413 Request Entity Too Large
Git Push 失败:HTTP 413 Request Entity Too Large 问题排查 在使用 Git 推送包含较大编译产物的项目时,你是否遇到过 HTTP 413 Request Entity Too Large 错误?这通常并不是 Git 的问题,而是 Web 服务器(如 Nginx&am…...
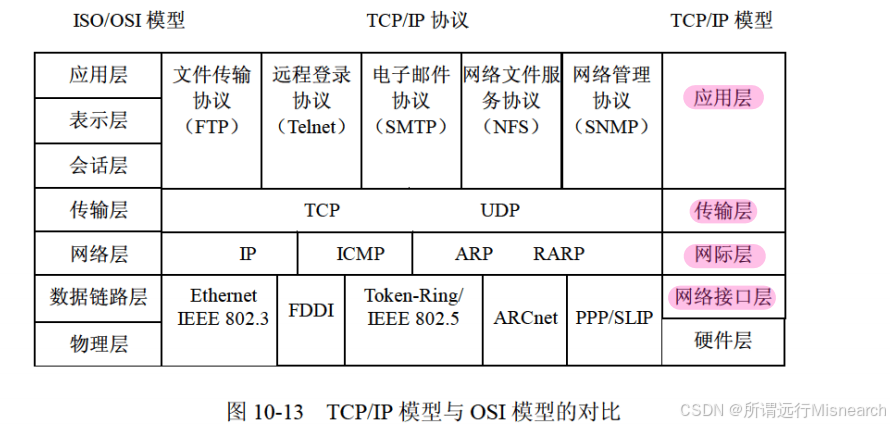
第10章 网络与信息安全基础知识
网络概述 多模光纤的特点:成本低,宽芯线,聚光好,耗散大,低效,用于低速度、短距离的通信。 单模光纤的特点:成本高,窄芯线,需要激光源,耗散小,高效…...
)
GO语言学习(九)
GO语言学习(九) 上一期我们了解了实现web的工作中极为重要的net/http抱的细节讲解,大家学会了实现web开发的一些底层基础知识,在这一期我来为大家讲解一下web工作的一个重要方法,:使用数据库,现…...

go 访问 sftp 服务 github.com/pkg/sftp 的使用踩坑,连接未关闭(含 sftp 服务测试环境搭建)
前言 最近在使用 sftp 服务时,被告知发起了海量的连接,直接把服务器搞崩,ip 被封了。 这是啥情况? golang 写的代码,我就正常的访问 sftp 服务,连接使用过后也都关闭了,咋会出现连接一直连着…...
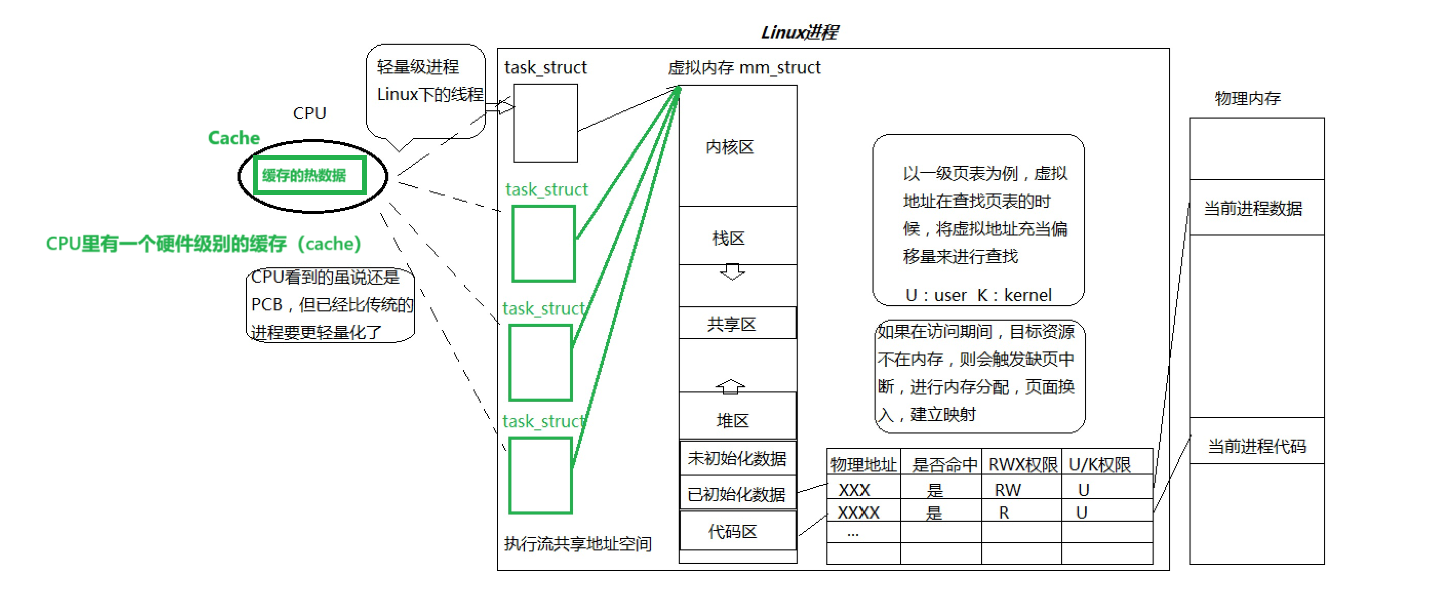
Linux多线程(二)之进程vs线程
文章目录 Linux进程VS线程进程和线程进程的多个线程共享关于进程线程的问题 重谈地址空间Linux线程周边的概念 Linux进程VS线程 进程和线程 进程是资源分配的基本单位(进程是承担分配系统资源的基本实体) 执行流也是资源!线程是进程内部的执…...

【MogDB】测试 ubuntu server 22.04 LTS 安装mogdb 5.0.11
测试 ubuntu server 22.04 LTS 安装mogdb 5.0.11 使用的操作系统镜像是 https://releases.ubuntu.com/22.04/ubuntu-22.04.5-live-server-amd64.iso 装好操作系统后,把root登录打开了,方便后续操作。 测试过程 使用官方命令在线安装ptk rootubuntu22…...
)
AI时代新词-数字孪生(Digital Twin)
一、什么是数字孪生(Digital Twin)? 数字孪生(Digital Twin)是一种通过创建物理实体的虚拟副本,并利用数据和算法来模拟、分析和优化物理实体的性能和行为的技术。数字孪生结合了物联网(IoT&am…...
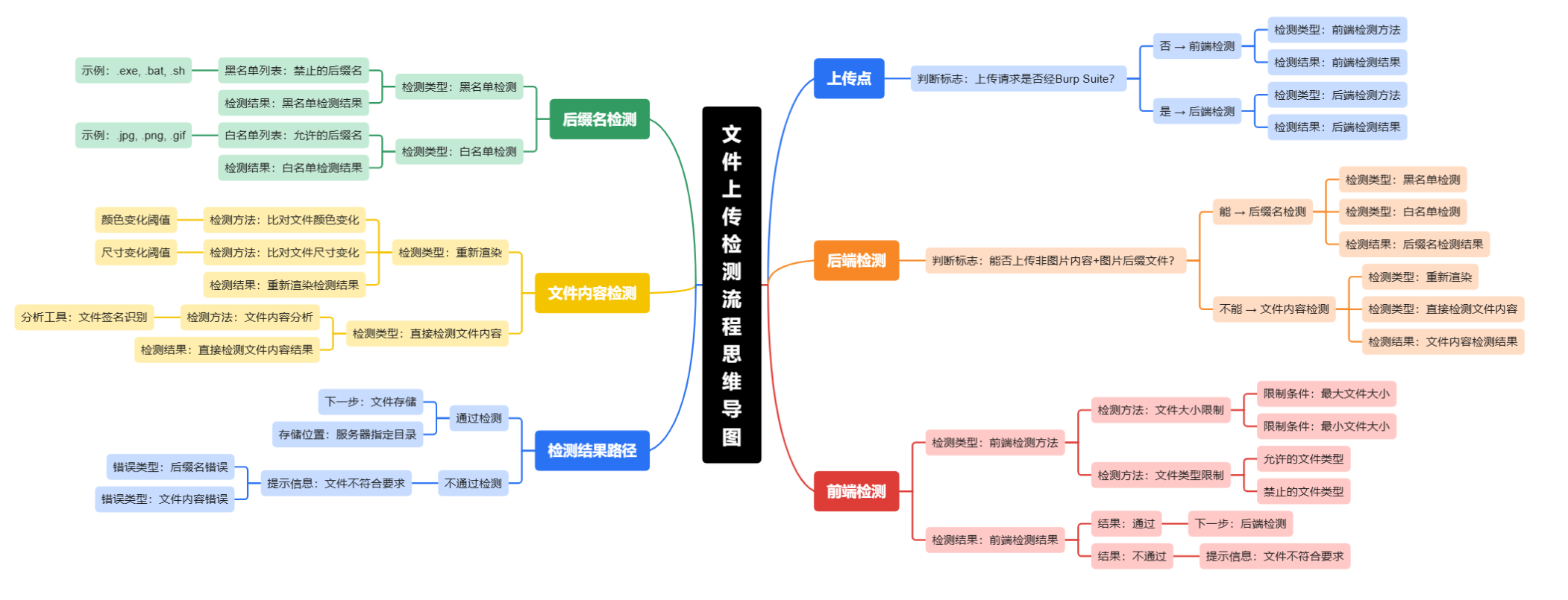
【HW系列】—web常规漏洞(文件上传漏洞)
文章目录 一、简介二、危害三、文件检测方式分类四、判断文件检测方式五、文件上传绕过技术六、漏洞防御措施 一、简介 文件上传漏洞是指Web应用程序在处理用户上传文件时,未对文件类型、内容、路径等进行严格校验和限制,导致攻击者可上传恶意文件&…...
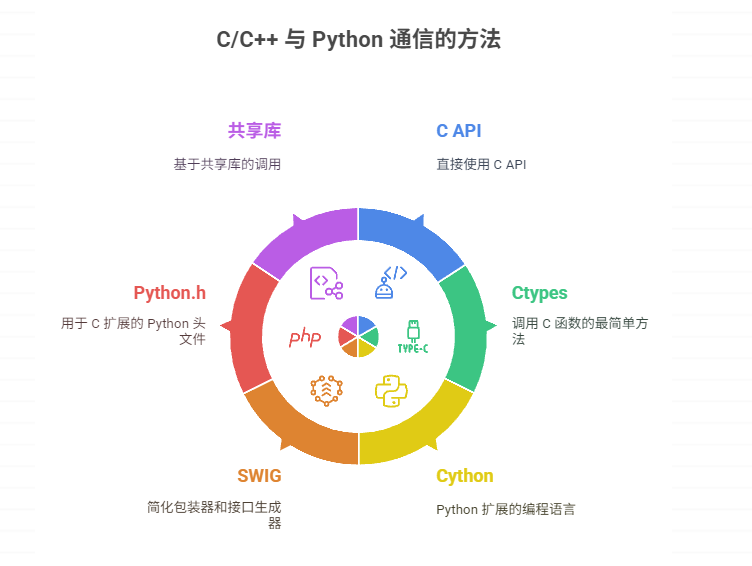
如何实现 C/C++ 与 Python 的通信
C/C 与 Python 的通信可以通过多种方式实现,如使用 C API、Ctypes、Cython、SWIG、Python.h 或基于共享库的调用等。其中,使用 Ctypes 方式最为简便,适合快速调用已有的 C 函数库。例如,通过将 C 代码编译为动态链接库(…...

python炸鱼船
import pygame, random # 加载库 from pygame.locals import * pygame.init() pygame.display.set_caption("炸渔船") canvas pygame.display.set_mode((700, 500)) bgpygame.image.load("bg.png") bgpygame.transform.scale(bg,(700,500))class Hero(py…...

使用AutoKeras2.0的AutoModel进行结构化数据回归预测
1、First of All: Read The Fucking Source Code import autokeras as ak import numpy as np from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error# 生成数据集 np.random.seed(42) x np.random.rand(1000, 10) # 生成1…...
好用但不常用的Git配置
参考文章 文章目录 tag标签分支新仓库默认分支推送 代码合并冲突处理默认diff算法 tag标签 默认是以字母顺序排序,这会导致一些问题,比如0.5.101排在0.5.1000之后。为了解决这个问题,我们可以把默认排序改为数值排序 git config --global t…...

ULVAC VWR-400M/ERH 真空蒸发器 Compact Vacuum Evaporator DEPOX (VWR-400M/ERH)
ULVAC VWR-400M/ERH 真空蒸发器 Compact Vacuum Evaporator DEPOX (VWR-400M/ERH)...

P1068 [NOIP 2009 普及组] 分数线划定
题目描述 世博会志愿者的选拔工作正在 A 市如火如荼的进行。为了选拔最合适的人才,A 市对所有报名的选手进行了笔试,笔试分数达到面试分数线的选手方可进入面试。面试分数线根据计划录取人数的 150% 划定,即如果计划录取 m 名志愿者…...

PPT连同备注页(演讲者模式)一块转为PDF
首先,进入创建PDF/XPS: 然后进入选项: 发布选项-发布内容里选备注页: 导出的原始结果是这样的: 这个时候裁剪一下,范围为所有页面: 最终结果: 如果导出不选“备注页”而是只勾选“包…...

第三十二天打卡
作业:参考pdpbox官方文档中的其他类,绘制相应的图,任选即可 1. 安装并导入库 确保安装与文档版本一致的 pdpbox(此处以 0.3.0 为例): bash 复制 下载 pip install pdpbox0.3.0 导入所需库:…...

项目三 - 任务8:实现词频统计功能
本项目旨在实现一个词频统计功能,通过读取文本文件并利用Java编程技巧处理和分析文本数据。首先,使用BufferedReader逐行读取文件内容,然后通过String.split(" ")方法将每行文本分割成单词数组。接下来,采用HashMap来存…...

MongoDB 快速整合 SpringBoot 示例
1.添加依赖<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spr…...

2025.05.22-得物春招机考真题解析-第二题
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 02. 魔法书页重排 问题描述 A先生是一位魔法师,他有一本古老的魔法书,书中有 n n n 页,每页都刻有一个魔…...

ollama list模型列表获取 接口代码
ollama list模型列表获取 接口代码 curl http://localhost:11434/v1/modelscoding package hcx.ollama;/*** ClassName DockerOllamaList* Description TODO* Author dell* Date 2025/5/26 11:31* Version 1.0**/import java.io.BufferedReader; import java.io.InputStreamR…...
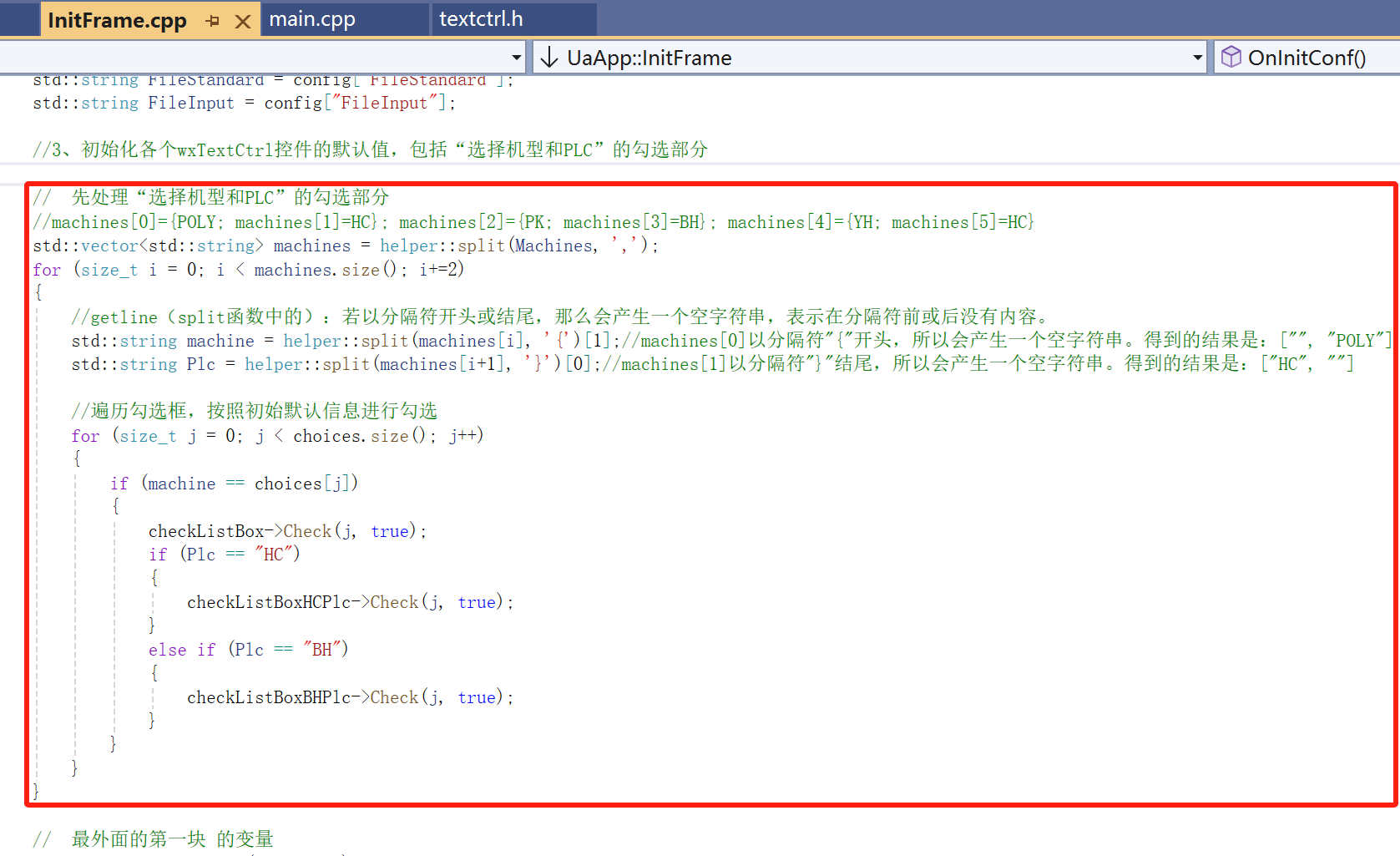
OPC Client第5讲(wxwidgets):初始界面的事件处理;按照配置文件初始化界面的内容
接上一讲,即实现下述界面的事件处理代码;并且按照配置文件初始化界面的内容(三、) 事件处理的基础知识,见下述链接五、 OPC Client第3讲(wxwidgets):wxFormBuilder;基础…...

什么是BFC,如何触发BFC,BFC有什么特性?
理解 BFC指的是块级格式化上下文,处于BFC内部的盒子与外界互不影响 触发条件 position:absolute/fixed都会产生bfcdisplay:inline-block,table,flex等float:left/right 浮动也会产生bfchtml根元素也是bfc bfc的特性 属于同一个BFC下的盒子会垂直排列属于同一个BFC下的两个…...
)
python做题日记(9)
第二十一题 第二十一题是合并两个有序链表,合并后的链表仍然需要保持有序,因为在合并之前已经是两个有序链表,因此在合并时只需要遍历比较两个链表中的下一结点数值,将其中较小的一个结点添加到新的列表中。如果有任何一个链表已经…...

Leetcode 3557. Find Maximum Number of Non Intersecting Substrings
Leetcode 3557. Find Maximum Number of Non Intersecting Substrings 1. 解题思路2. 代码实现 题目链接:3557. Find Maximum Number of Non Intersecting Substrings 1. 解题思路 这一题就是一个比较直接的动态规划的题目,我们只需要考察每一个位是否…...