DeepSpeed-Ulysses:支持极长序列 Transformer 模型训练的系统优化方法
DeepSpeed-Ulysses:支持极长序列 Transformer 模型训练的系统优化方法
flyfish
名字 Ulysses
“Ulysses” 和 “奥德修斯(Odysseus)” 指的是同一人物,“Ulysses” 是 “Odysseus” 的拉丁化版本
《尤利西斯》(詹姆斯·乔伊斯著,1922年出版)
以古希腊英雄奥德修斯(拉丁名“尤利西斯”)的神话为框架,将故事置于现代(20世纪初)的都柏林,通过三位主角一天内的经历,映射奥德修斯的十年漂泊。
奥德修斯(古希腊神话核心人物)
奥德修斯是古希腊城邦伊萨卡的国王,以智慧著称(如“特洛伊木马”计策的设计者)。特洛伊战争结束后,他因触怒海神波塞冬,踏上长达十年的返乡漂泊,故事集中于《奥德赛》(荷马史诗)。
“DeepSpeed-Ulysses”的借用“奥德修斯/尤利西斯”的“长途探索与克服挑战”意象,象征长序列模型训练的技术突破。
长序列Transformer模型训练是指针对输入序列长度极长(如包含数万至百万级 tokens)的Transformer模型进行优化训练的过程,其核心挑战在于平衡计算效率、内存使用和通信开销。
一、长序列Transformer模型的定义与应用场景
1. 模型特征
Transformer模型以自注意力机制为核心,传统模型的序列长度通常限制在数千tokens(如512或2048),而长序列模型需处理远超这一范围的输入。其计算复杂度随序列长度呈二次增长(注意力计算需遍历所有token对),导致训练时内存占用和通信开销剧增。
2. 关键应用领域
- 生成式AI:
- 对话系统:处理长对话历史(需支持多轮交互的上下文)。
- 长文档处理:对书籍、学术论文等进行摘要生成(序列长度可达数万词)。
- 多模态任务:视频生成、语音识别等需处理时空维度的长序列输入。
- 科学AI:
- 基因组学:分析人类基因组的64亿碱基对序列。
- 气候预测:处理长时间序列的气象数据。
- 医疗诊断:基于患者全病程记录的预测模型。
二、长序列训练的核心挑战
1. 内存与通信效率瓶颈
- 激活值内存爆炸:Transformer的中间激活值(如注意力计算中的QKV张量)随序列长度平方增长,单GPU内存无法容纳极长序列。
- 通信开销线性增长:现有序列并行方法(如Megatron-LM)在注意力计算时需进行全聚集(all-gather)通信,通信量随序列长度线性增加,导致训练效率随序列长度下降。
2. 现有并行技术的局限性
- 数据/张量/流水线并行不适用:这些并行方式分别针对批量大小、隐藏维度、模型层数优化,但未考虑序列维度的划分,无法解决长序列特有的内存和通信问题。
- 传统序列并行方法低效:如ColAI-SP采用环形通信,Megatron-LM依赖全聚集操作,均无法在扩展序列长度时保持通信效率,且需大量代码重构。
DeepSpeed-Ulysses解决长序列Transformer模型训练难题的方案
DeepSpeed-Ulysses针对长序列Transformer训练的四大核心创新,可拆解为数据划分策略、通信原语重构、内存分层优化、注意力模块化设计四大技术模块
DeepSpeed-Ulysses通过序列分片解耦计算与存储、全对全通信重构带宽效率、ZeRO-3扩展内存边界、注意力抽象层屏蔽多样性,形成了从硬件通信到算法逻辑的端到端优化。
一、序列维度数据划分:动态分片与负载均衡
1. 分片粒度设计
- 均匀切分:将输入序列按长度均分为P份(P为GPU数),每个GPU处理
N/Ptokens(如N=1M,P=64时,单卡处理15,625 tokens),确保计算负载均衡。 - 细粒度对齐:结合注意力头数(H),将每个分片的QKV张量按头维度切分,实现“序列分片×头分片”的二维并行(如H=32,P=8时,每卡处理4个头的完整序列分片),避免头间通信冗余。
2. 分片生命周期管理
- 前向传播:分片在嵌入层后立即生成,贯穿注意力计算全流程,减少中间复制开销。
- 反向传播:梯度按分片聚合,通过通信原语自动对齐,无需显式分片重组(对比Megatron-LM需手动拼接梯度)。
二、通信原语重构:全对全替代全聚合
1. 两次全对全(All-to-All)通信
- 第一次All-to-All(QKV收集):
- 输入:各GPU持有
(N/P, b, d)的Q/K/V分片(b为微批量,d为隐藏维度)。 - 操作:通过高效的NVLink/IB网络,交换分片形成
(N, b, d/P)的全局QKV(每个GPU获取完整序列的1/P头数据)。 - 优势:通信量为
3Nh/P(h为头维度),对比Megatron-LM的全聚合(3Nh)减少P倍。
- 输入:各GPU持有
- 第二次All-to-All(结果分发):
- 输入:注意力计算后的
(N, b, d/P)输出。 - 操作:重组为
(N/P, b, d)分片,供后续MLP层处理,通信量Nh/P。 - 总通信量:
4Nh/P,复杂度O(N/P),当N与P同比增长时保持恒定(如N×2,P×2,通信量不变)。
- 输入:注意力计算后的
2. 通信拓扑优化
- 节点内NVSwitch优先:利用GPU间高速互联,将All-to-All拆分为节点内(低延迟)和节点间(高带宽)两阶段,实测减少通信时间
- 异步通信隐藏延迟:在注意力计算前预启动通信,与计算重叠(如FlashAttention的分块计算与通信流水线)。
三、内存分层优化:ZeRO-3×序列并行
1. 参数分片策略
- 跨组划分:ZeRO-3原仅在数据并行组(DP组)分片参数,Ulysses扩展至DP组×序列并行组(SP组),形成二维分片(如DP=8,SP=8时,每个参数被分为64片)。
- 动态聚合:仅在参数更新时,通过All-Gather收集分片梯度,平时仅保留本地分片,显存占用降低
DP×SP倍。
2. 激活内存压缩
- 分片激活:每个GPU仅存储
N/Ptokens的激活值,总激活内存从O(N²)降至O((N/P)²),支持N=1M时单卡激活内存仅为全序列的1/64(P=64)。 - 与激活重计算协同:结合FlashAttention的分块重计算,进一步将激活内存降至O(N/P)。
四、注意力模块化设计:统一接口与动态适配
1. 注意力计算抽象层
- 输入标准化:无论密集/稀疏,输入均为
(N, b, d/P)的分片QKV(N为全局序列长度)。 - 头级并行:每个GPU负责H/P个头的完整注意力计算,支持任意头数分片(如H=96,P=8时每卡12头)。
- 输出重组:通过第二次All-to-All自动对齐头维度,屏蔽底层注意力实现差异。
2. 稀疏注意力特化优化
- 块对角通信:针对滑动窗口等稀疏模式,仅交换相邻分片的K/V,通信量进一步降至O(N/P×W)(W为窗口大小)。
- 与Blockwise Attention协同:支持将序列划分为块,块内全连接、块间稀疏连接,通信量减少70%(对比全局密集)。
3. 兼容性验证
- FlashAttention v2集成:通过分片QKV直接输入FlashAttention内核,实测长序列(N=512K)吞吐量提升1.8倍
- 稀疏模式扩展:支持BigBird的全局+局部混合注意力,无需修改通信逻辑,仅替换注意力计算函数
五、工程实现细节:易用性与扩展性
1. 代码侵入性
- 零修改集成:仅需在模型定义中添加
@sequence_parallel装饰器,自动替换原生Attention为分布式版本 - 并行组抽象:自动管理DP/SP组的创建与销毁,用户无需显式管理通信域。
2. 故障恢复机制
- 分片检查点:仅保存本地分片参数,检查点大小减少
DP×SP倍,支持1024卡集群下30B模型的快速恢复
注意力集成
DeepSpeed-Ulysses通过优化多种注意力机制,系统性解决了长序列Transformer训练的效率瓶颈。
一、自注意力(Self-Attention)
1. 密集自注意力(Dense Self-Attention)
-
数学公式:
Attention ( Q , K , V ) = Softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=Softmax(dkQKT)V
其中:- Q ∈ R N × d Q \in \mathbb{R}^{N \times d} Q∈RN×d, K ∈ R N × d K \in \mathbb{R}^{N \times d} K∈RN×d, V ∈ R N × d V \in \mathbb{R}^{N \times d} V∈RN×d
- N N N 为序列长度, d d d 为隐藏维度
-
解决的问题:
- 传统实现瓶颈:计算复杂度 O ( N 2 ) O(N^2) O(N2) 和内存占用 O ( N 2 ) O(N^2) O(N2),难以处理超长序列(如 N > 10 k N > 10k N>10k)
- DeepSpeed-Ulysses优化:
- 通过序列并行(Sequence Parallelism)将 N N N 划分为 N / P N/P N/P( P P P 为GPU数)
- 两次All-to-All通信将计算复杂度降至 O ( N / P ) O(N/P) O(N/P)(
2. 稀疏自注意力(Sparse Self-Attention)
-
数学公式:
Attention ( Q , K , V ) = Softmax ( Q K T ⊙ M d k ) V \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T \odot M}{\sqrt{d_k}}\right)V Attention(Q,K,V)=Softmax(dkQKT⊙M)V
其中:- M M M 为稀疏掩码矩阵,仅保留部分非零连接
-
解决的问题:
- 传统密集注意力缺陷:长序列下计算和内存开销爆炸
- DeepSpeed-Ulysses优化:
- 支持滑动窗口(Sliding Window)、块对角(Block Diagonal)等稀疏模式
- 通信量降至 O ( N / P × W ) O(N/P \times W) O(N/P×W)( W W W 为窗口大小)
二、交叉注意力(Cross-Attention)
数学公式:
CrossAttention ( Q , K enc , V enc ) = Softmax ( Q K enc T d k ) V enc \text{CrossAttention}(Q, K_{\text{enc}}, V_{\text{enc}}) = \text{Softmax}\left(\frac{QK_{\text{enc}}^T}{\sqrt{d_k}}\right)V_{\text{enc}} CrossAttention(Q,Kenc,Venc)=Softmax(dkQKencT)Venc
其中:
-
Q Q Q 来自解码器, K enc , V enc K_{\text{enc}}, V_{\text{enc}} Kenc,Venc 来自编码器
-
解决的问题:
- 长序列跨模态挑战:生成式任务中,解码器需高效关注超长编码序列
- DeepSpeed-Ulysses优化:
- 通过序列分片和分布式通信,支持 N enc × N dec N_{\text{enc}} \times N_{\text{dec}} Nenc×Ndec 规模的交叉注意力
- 结合ZeRO-3减少参数内存占用,支持万亿级参数模型
三、因果注意力(Causal Attention)
数学公式:
CausalAttention ( Q , K , V ) = Softmax ( Q K T + Mask d k ) V \text{CausalAttention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T + \text{Mask}}{\sqrt{d_k}}\right)V CausalAttention(Q,K,V)=Softmax(dkQKT+Mask)V
其中:
-
Mask i , j = { 0 if i ≥ j − ∞ otherwise \text{Mask}_{i,j} = \begin{cases} 0 & \text{if } i \geq j \\ -\infty & \text{otherwise} \end{cases} Maski,j={0−∞if i≥jotherwise
-
解决的问题:
- 自回归生成的信息泄露:防止未来token影响当前预测
- DeepSpeed-Ulysses优化:
- 在分布式环境下高效应用掩码,避免跨分片的未来信息泄露
- 支持超长上下文生成
四、Blockwise Attention(分块注意力)
数学公式:
BlockwiseAttention ( Q , K , V ) = ∑ i = 1 B Softmax ( Q i K i T d k ) V i + ∑ i ≠ j Softmax ( Q i K j T d k ) V j ⋅ M i , j \text{BlockwiseAttention}(Q, K, V) = \sum_{i=1}^{B} \text{Softmax}\left(\frac{Q_i K_i^T}{\sqrt{d_k}}\right)V_i + \sum_{i \neq j} \text{Softmax}\left(\frac{Q_i K_j^T}{\sqrt{d_k}}\right)V_j \cdot M_{i,j} BlockwiseAttention(Q,K,V)=i=1∑BSoftmax(dkQiKiT)Vi+i=j∑Softmax(dkQiKjT)Vj⋅Mi,j
其中:
-
B B B 为块数, M i , j M_{i,j} Mi,j 为块间连接掩码
-
解决的问题:
- 长序列计算碎片化:将序列划分为块,块内密集计算,块间稀疏交互
- DeepSpeed-Ulysses优化:
- 块内通信量 O ( N block 2 ) O(N_{\text{block}}^2) O(Nblock2),块间通信量 O ( N block × K ) O(N_{\text{block}} \times K) O(Nblock×K)( K K K 为稀疏度)
- 实验显示通信量减少70%,支持块间全局连接(如BigBird)
五、FlashAttention优化
数学公式:
FlashAttention ( Q , K , V ) = ∑ i = 1 T Softmax ( Q i K i T d k ) V i \text{FlashAttention}(Q, K, V) = \sum_{i=1}^{T} \text{Softmax}\left(\frac{Q_i K_i^T}{\sqrt{d_k}}\right)V_i FlashAttention(Q,K,V)=i=1∑TSoftmax(dkQiKiT)Vi
其中:
-
T T T 为内存块数,通过分块计算减少峰值内存
-
解决的问题:
- 长序列内存瓶颈:传统注意力的激活值内存占用 O ( N 2 ) O(N^2) O(N2)
- DeepSpeed-Ulysses优化:
- 结合序列并行,将内存降至 O ( N / P ) O(N/P) O(N/P)
- 分块计算与通信重叠,提升计算效率
六、DeepSpeed-Ulysses的核心优化公式
1. 分布式注意力计算
Output = AllToAll ( Softmax ( AllToAll ( Q i , K i , V i ) d k ) ) \text{Output} = \text{AllToAll}\left(\text{Softmax}\left(\frac{\text{AllToAll}(Q_i, K_i, V_i)}{\sqrt{d_k}}\right)\right) Output=AllToAll(Softmax(dkAllToAll(Qi,Ki,Vi)))
其中:
-
Q i , K i , V i Q_i, K_i, V_i Qi,Ki,Vi 为第 i i i 个GPU的序列分片
-
解决的问题:
- 传统数据并行的通信瓶颈:全聚集(All-Gather)通信量 O ( N ) O(N) O(N)
- 优化后:两次All-to-All通信量降至 O ( N / P ) O(N/P) O(N/P)
2. 内存优化公式
Memory = Params + Activations + Gradients \text{Memory} = \text{Params} + \text{Activations} + \text{Gradients} Memory=Params+Activations+Gradients
其中:
-
Params = TotalParams P × S \text{Params} = \frac{\text{TotalParams}}{P \times S} Params=P×STotalParams( S S S 为ZeRO-3分片因子)
-
Activations = O ( N P ) \text{Activations} = O\left(\frac{N}{P}\right) Activations=O(PN)(通过序列分片和激活重计算)
-
解决的问题:
- 长序列训练的内存墙:传统方法无法支持 N > 100 k N > 100k N>100k 的序列
- 优化后:在7B模型上支持 N = 512 k N=512k N=512k,内存效率提升4倍
All-to-All通信
分布式计算中的All-to-All通信与DeepSpeed-Ulysses优化
DeepSpeed-Ulysses通过两次All-to-All通信,实现了长序列Transformer训练的三大突破:
将O(N)复杂度降为O(N/P),打破长序列训练的带宽瓶颈; 利用NVSwitch/IB拓扑和异步流水线,将GPU算力利用率提升至硬件峰值的54%; 支持1M token序列与万亿参数模型的联合训练,为科学AI(如基因组分析)和生成式AI(如长文本生成)提供底层支撑。
一、All-to-All通信的核心概念
1. 通信机制本质
All-to-All是分布式系统中一种数据交换模式:网络中的每个节点(如GPU)同时向其他所有节点发送自身数据分片,并接收所有节点发来的分片。例如,当有P个GPU时,每个GPU初始持有数据切片X₁, X₂, …, Xₚ,通信后每个GPU都会获得完整的[X₁, X₂, …, Xₚ],相当于每个节点都收集到全局所有数据分片,形成完整数据集。
2. 与其他通信方式的区别
- All-Gather:所有节点仅收集同一数据的不同分片(如多个GPU共同组成完整模型参数),通信量随数据规模线性增长。
- All-to-All:节点间双向交换各自分片,通信量随节点数P成反比,适合数据并行场景下的高效同步。
二、DeepSpeed-Ulysses的两次All-to-All通信设计
1. 第一次通信:QKV张量聚合(注意力计算前)
- 输入状态:每个GPU持有序列长度为N/P的Q/K/V张量(形状为(N/P, b, d),b为微批量,d为隐藏维度)。
- 通信过程:
- 每个GPU向其他P-1个GPU发送自己的Q/K/V分片;
- 每个GPU接收所有分片后,拼接成全局序列的Q/K/V张量(形状变为(N, b, d/P)),其中每个GPU负责d/P维度的注意力头计算。
- 核心作用:使每个GPU获取完整序列的部分注意力头数据,为并行计算注意力做准备。
2. 第二次通信:注意力结果重分配(计算后)
- 输入状态:注意力计算后的输出张量形状为(N, b, d/P)。
- 通信过程:
- 每个GPU将输出按序列维度重新切分为N/P长度的分片;
- 通过All-to-All将分片发送至对应GPU,最终每个GPU持有(N/P, b, d)的张量,供后续MLP层处理。
- 核心作用:将注意力计算结果按序列维度重新分配,确保后续操作的并行性。
三、通信量优化的数学逻辑
1. 传统方法(如Megatron-LM)的瓶颈
采用All-Gather+Reduce-Scatter组合:
- 每次注意力计算需2次All-Gather(收集QKV)和2次Reduce-Scatter(聚合结果),总通信量为4Nh(N为序列长度,h为隐藏维度),复杂度为O(N)。
- 问题:当N从16K增至1M时,通信量增长62.5倍,极易造成网络拥塞。
2. DeepSpeed-Ulysses的优化公式
两次All-to-All的通信量计算:
- 第一次通信(QKV收集):3Nh/P(Q、K、V三个张量);
- 第二次通信(结果分发):Nh/P;
- 总通信量:4Nh/P,复杂度降为O(N/P)。
- 关键优势:当N与P同比增长时(如N×2,P×2),通信量保持不变。例如:
- N=256K,P=64时,传统方法通信量为1024Kh,DeepSpeed仅为16Kh(减少64倍);
- N=1M,P=64时,传统方法为4000Kh,DeepSpeed为62.5Kh(仅为1.56%)。
四、硬件拓扑与效率优化
1. 现代集群的网络架构支持
- 节点内:通过NVSwitch高速互联,All-to-All分解为节点内低延迟交换(如8个GPU间的直接数据传输);
- 节点间:采用胖树IB拓扑,支持高带宽批量数据传输,避免跨节点通信瓶颈。
2. 通信-计算流水线机制
- 异步执行模式:
- GPU在发送Q/K/V分片的同时,启动部分计算任务;
- 接收完整Q/K/V后,立即开始注意力计算,将通信延迟隐藏在计算过程中。
- 效果:实测显示,该机制可使通信效率提升30%-40%,尤其适用于长序列的分块计算。
五、实验验证与实际价值
1. 性能对比数据
- 在70亿参数GPT模型上,DeepSpeed-Ulysses支持512K序列长度,而Megatron-LM仅支持128K;
- 吞吐量方面,DeepSpeed达175 TFlops/GPU,是Megatron-LM的2.5倍(硬件峰值利用率54%)。
2. 长序列训练的扩展性
- 当序列长度从64K增至1M时,DeepSpeed通过增加GPU数量(如从16增至256),保持通信量恒定,实现线性扩展;
- 内存占用方面,结合ZeRO-3优化,单GPU显存占用从O(N²)降至O((N/P)²),支持百万级token训练。
相关文章:
DeepSpeed-Ulysses:支持极长序列 Transformer 模型训练的系统优化方法
DeepSpeed-Ulysses:支持极长序列 Transformer 模型训练的系统优化方法 flyfish 名字 Ulysses “Ulysses” 和 “奥德修斯(Odysseus)” 指的是同一人物,“Ulysses” 是 “Odysseus” 的拉丁化版本 《尤利西斯》(詹姆…...
Docker 使用镜像[SpringBoot之Docker实战系列] - 第537篇
历史文章(文章累计530) 《国内最全的Spring Boot系列之一》 《国内最全的Spring Boot系列之二》 《国内最全的Spring Boot系列之三》 《国内最全的Spring Boot系列之四》 《国内最全的Spring Boot系列之五》 《国内最全的Spring Boot系列之六》 《…...

解锁MCP:AI大模型的万能工具箱
摘要:MCP(Model Context Protocol,模型上下文协议)是由Anthropic开源发布的一项技术,旨在作为AI大模型与外部数据和工具之间沟通的“通用语言”。它通过标准化协议,让大模型能够自动调用外部工具完成任务&a…...
Error in beforeDestroy hook: “Error: [ElementForm]unpected width “
使用 element 的 form 时候报错: vue.runtime.esm.js:3065 Error: [ElementForm]unpected width at VueComponent.getLabelWidthIndex (element-ui.common.js:23268:1) at VueComponent.deregisterLabelWidth (element-ui.common.js:23281:1) at Vue…...

vscode包含工程文件路径
在 VSCode 中配置 includePath 以自动识别并包含上层目录及其所有子文件夹,需结合通配符和相对/绝对路径实现。以下是具体操作步骤及原理说明: 1. 使用通配符 ** 递归包含所有子目录 在 c_cpp_properties.json 的 includePath 中,${workspac…...
私有知识库 Coco AI 实战(七):摄入本地 PDF 文件
是否有些本地文件要检索?没问题。我们先对 PDF 类的文件进行处理,其他的文件往后稍。 Coco Server Token 创建一个 token 备用。 PDF_Reader 直接写个 python 程序解析 PDF 内容,上传到 Coco Server 就行了。还记得以前都是直接写入 Coco …...

GitLab 18.0 正式发布,15.0 将不再受技术支持,须升级【二】
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 学习极狐GitLab 的相关资料: 极狐GitLab 官网极狐…...

NtfsLookupAttributeByName函数分析之和Scb->AttributeName的关系
第一部分: VOID FindFirstIndexEntry ( IN PIRP_CONTEXT IrpContext, IN PSCB Scb, IN PVOID Value, IN OUT PINDEX_CONTEXT IndexContext ) { 。。。。。。 // // Lookup the attribute record from the Scb. // if (!NtfsLookupAt…...

STM32H7系列USART驱动区别解析 stm32h7xx_hal_usart.c与stm32h7xx_ll_usart.c的区别?
在STM32H7系列中,stm32h7xx_hal_usart.c和stm32h7xx_ll_usart.c是ST提供的两种不同层次的USART驱动程序,主要区别在于设计理念、抽象层次和使用场景: 1. HAL库(Hardware Abstraction Layer) 文件:stm32h7x…...

网络原理 | TCP与UDP协议的区别以及回显服务器的实现
目录 TCP与UDP协议的区别 基于 UDP 协议实现回显服务器 UDP Socket 编程常用 Api UDP 服务器 UDP 客户端 基于 TCP 协议实现回显服务器 TCP Socket 编程常用 Api TCP 服务器 TCP 客户端 TCP 服务端常见的 bug 客户端发送数据后,没有响应 服务器仅支持…...

IP动态伪装开关
IP动态伪装开关 在OpenWrt系统中,IP动态伪装(IP Masquerading)是一种网络地址转换(NAT)技术,用于在私有网络和公共网络之间转换IP地址。它通常用于允许多个设备共享单个公共IP地址访问互联网。以下是关于O…...
【Unity3D】将自动生成的脚本包含到C#工程文件中
我们知道,在用C#开发中,通过vs编辑器新建的脚本,会自动包含到vs工程中,而通过外部创建,比如复制别的工程或代码创建的C#脚本不会包含到vs工程。 在我们的日常开发中,通常会自动创建C#脚本,特别…...

解决leetcode第3509题.最大化交错和为K的子序列乘积
3509.最大化交错和为K的子序列乘积 难度:困难 问题描述: 给你一个整数数组nums和两个整数k与limit,你的任务是找到一个非空的子序列,满足以下条件: 它的交错和等于k。 在乘积不超过limit的前提下,最大…...
【Python 深度学习】1D~3D iou计算
一维iou 二维 import numpy as npdef iou_1d(set_a, set_b):# 获得集合A和B的边界 x1, x2 set_ay1, y2 set_b# 计算交集的上下界low max(x1,y1)high - min(x2, y2)# 计算交集if high - low < 0:inter 0else:inter high - low# 计算并集union (x2 -x1) (y2 - y1) - in…...
java23
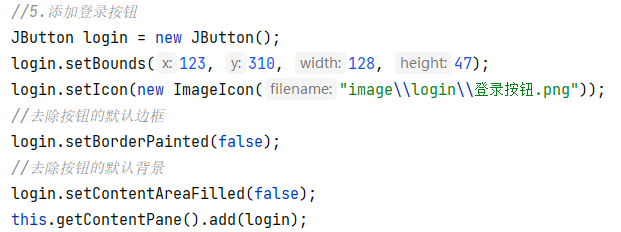
1.美化界面 添加背景图片 所以我们添加背景图片要放在后面添加 添加图片边框 绝对路径: 相对(模块)路径: 第一个是绝对路径,第二个是相对路径,但是斜杠的方向不对 总结: 2.图片移动 先实现KeyListener接口…...

嵌入式工程师常用软件
1、 Git Git 是公司常用的版本管理工具,人人都要会。在线的 git 教程可以参考菜鸟教程: https://www.runoob.com/git/git-tutorial.html 电子书教程请在搜索栏搜索: git Git 教程很多,常用的命令如下,这些命令可…...
LitCTF2025 WEB
星愿信箱 使用的是python,那么大概率是ssti注入 测试{{5*5}} 发现需要包含文字,那么添加文字 可以看到被waf过滤了,直接抓包查看参数上fenjing 可以看到这里是json格式,其实fenjing也是支持json格式的 https://github.com/Marv…...

Redisson WatchDog会一直续期吗?
取决于加锁的方式。 Lock 方法有2种形式,如果指定了leaseTime (且不为-1), 不会启用watchDog机制. 如果没有指定leaseTime, 则会启动watchDog机制,且会一直续期,除非线程宕调或者续期失败。 p…...
Linux 下VS Code 的使用
这里以创建helloworld 为例。 Step 0:准备工作: Install Visual Studio Code. Install the C extension for VS Code. You can install the C/C extension by searching for c in the Extensions view (CtrlShiftX). Step 1: 创建工作目录 helloworld࿰…...

Android开发namespace奇葩bug
Android开发namespace奇葩bug namespace "com.yibanxxx.yiban"buildFeatures {buildConfig true}namespace 对应你的module的清单下的package...

watchEffect
在处理复杂异步逻辑时,Vue 3 的 watchEffect 相比传统的 watch 具有以下优势: 1. 自动追踪依赖 watchEffect 会自动收集其回调中使用的所有响应式依赖,无需手动指定监听源: import { ref, watchEffect } from vue;const count …...
Qt 布局管理器的层级关系
1、HomeWidget.h头文件: #ifndef HOMEWIDGET_H #define HOMEWIDGET_H#include <QWidget> #include <QPushButton> #include <QVBoxLayout> #include <QHBoxLayout>class HomeWidget : public QWidget {Q_OBJECTpublic:HomeWidget(QWidget …...

Android 之 kotlin 语言学习笔记一
参考官方文档:https://developer.android.google.cn/kotlin/learn?hlzh-cn 1、变量声明 Kotlin 使用两个不同的关键字(即 val 和 var)来声明变量。 val 用于值从不更改的变量。使用 val 声明的变量无法重新赋值。var 用于值可以更改的变量…...
maven模块化开发
使用方法 将项目安装到本地仓库 mvn install 的作用 运行 mvn install 时,Maven 会执行项目的整个构建生命周期(包括 compile、test、package 等阶段),最终将构建的 artifact 安装到本地仓库(默认路径为 ~/.m2/repos…...

为什么要使用stream流
总的来说就是 它支持链式调用,方便 不会修改原始数据源,而是生成一个新的流或结果 中间操作不会立即执行,只有在终端操作触发时才会真正执行 注意事项 无状态操作:Stream 操作应该是无状态的,不要依赖外部变量的状…...

语义分割的image
假设图像的尺寸为 3x3,并且是 RGB 图像(有 3 个通道)。每个通道的像素值范围为 [0, 1],我们将构造一个 batch_size 2 的图像批次。 Image: tensor([[[[0.1347, 0.4583, 0.7102], # 第一张图像的红色通道[0.1774, 0.0328, 0.308…...
云原生安全之网络IP协议:从基础到实践指南
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 IP协议(Internet Protocol)是互联网通信的核心协议族之一,负责在设备间传递数据包。其核心特性包括&…...
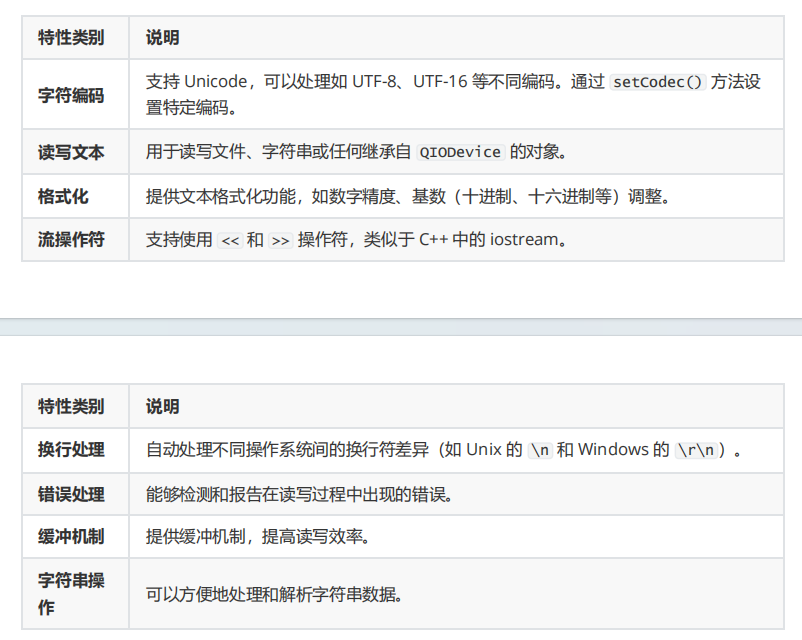
C++——QT 文件操作类
QFile 概述 QFile是Qt框架中用于文件操作的类(位于QtCore模块),继承自 QIODevice,提供文件的读写、状态查询和路径管理功能。它与 QTextStream、QDataStream 配合使用,可简化文本和二进制数据的处理,并具备…...

【排错】kylinLinx环境python读json文件报错UTF-8 BOM
kylin Linux环境python读json文件报错UTF-8 BOM 报错描述: windows环境下,python代码读取json文件正常,但是sftp到linux环境下 报错信息: json.decoder.JSONDecodeError: Unexpected UTF-8 BOM (decode using utf-8-sig): line 1 column …...
[spring] spring 框架、IOC和AOP思想
目录 传统Javaweb开发的困惑 loC、DI和AOP思想提出 Spring框架的诞生 传统Javaweb开发的困惑 问题一:层与层之间紧密耦合在了一起,接口与具体实现紧密耦合在了一起 解决思路:程序代码中不要手动new对象,第三方根据要求为程序提…...