Flink核心概念小结
文章目录
- 前言
- 引言
- 数据流API
- 基于POJO的数据流
- 基本源流配置示例
- 基本流接收器
- 数据管道与ETL(提取、转换、加载)
- 一对一映射构建
- 面向流映射的构建
- 键控流进行分组运算
- RichFlatMapFunction对于流的状态管理
- 连接流的使用
- 流式分析
- 水位的基本概念和示例
- 侧道输入的基本概念和示例
- Process Function
- 基本概念介绍
- 使用示例
- 参考
前言
引言
数据流API
基于POJO的数据流
一般来说flink中的源数据我们都会以简单java对象即pojo(Plain Ordinary Java Object )的形式进行传输或游走,只要满足以下条件,flink就会识别这些数据类型:
- 类中所有非静态、非transient修饰的字段,要么以public且非final修饰或者对外提供get和set方法
- 该类不存在非静态的内部类
- 提供无参构造函数
对应的我们给出日常比较常用的POJO 示例,即私有成员但是提供get、set符合上述的要求:
public class Person {private String name;private Integer age;//提供无参构造函数public Person() {}public Person(String name, Integer age) {this.name = name;this.age = age;}//......//get set方法
}
以上述POJO作为源数据,可以看到笔者通过StreamExecutionEnvironment 构建流的执行环境,并通过fromData进行关联:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//使用 fromData 关联源数据DataStreamSource<Person> source = env.fromData(new Person("Alice", 18),new Person("Bob", 28),new Person("Charlie", 32));
基于上述的源数据利用DataStream api尝试过滤出18岁以上的person数据并将过滤结果打印输出:
//基于 filter过滤出大于18岁的personSingleOutputStreamOperator<Person> filterRes = source.filter(person -> person.getAge() > 18);//输出打印filterRes.print();flink中的流操作和lambda类似需要有一个终端操作才能启动运行,所以我们再完成上述的执行环境设置之后,需确保通过 env.execute();将当前job提交到JobManager ,JobManager 切割为无数个子并行任务分发到指定的Task Managers 的slot槽中等待运行:
//执行execute后,上述任务提交到JobManager中的taskmanager某个slot中等待执行,若没提交这个则不会execute执行,这一点和java lambda的终端流操作思想一致env.execute();
需要补充的是,flink的fromData方法提供了多种的重载,上面的示例我们也可以通过List的方式将源数据传入:
List<Person> list = Arrays.asList(new Person("Alice", 18),new Person("Bob", 28),new Person("Charlie", 32));//使用 fromData 关联源数据DataStreamSource<Person> source = env.fromData(list);
基本源流配置示例
上述的示例我们基于DataStream的fromData方法来构建一些简单源流,实际上flink支持在配置直接直接指明文件流或者socket流,因为socket流相对于物理文件流更常用,所以我们给出一个采集本地9999端口的socket流示例:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> dataStream = env.socketTextStream("localhost", 9999);
因为我们本案例发送的数据格式为hello,序列化的person对象的json字符串,所以收到数据流之后需要对数据进行提取转换,所以我们还是通过map和filter完成映射转换和过滤:
dataStream.map(s -> {String jsonStr = s.substring(s.indexOf(",")+1);Person person = JSONUtil.toBean(jsonStr, Person.class);return person;}).filter(p -> p.getAge() > 18).print();env.execute();
为了方便测试,笔者这里给出个人服务端socket代码使用示例,当然读者也可以在自己的系统上使用nc示例完成:
public static void main(String[] args) {try {// 1. 创建ServerSocket,监听9999端口ServerSocket serverSocket = new ServerSocket(9999);System.out.println("服务器启动,等待客户端连接...");// 2. 接受客户端连接Socket clientSocket = serverSocket.accept();System.out.println("客户端已连接: " + clientSocket.getInetAddress());// 3. 获取输出流,用于向客户端发送数据PrintWriter out = new PrintWriter(clientSocket.getOutputStream(), true);// 4. 每隔1秒发送"hello"while (true) {Person person = new Person(RandomUtil.randomString(3), RandomUtil.randomInt(35));out.println("hello," + JSONUtil.toJsonStr(person));System.out.println("服务器发送: hello " + JSONUtil.toJsonStr(person));Thread.sleep(1000); // 暂停1秒}// 注意:这里为了简化代码,没有关闭资源,实际应用应该添加try-catch-finally} catch (Exception e) {e.printStackTrace();}}
可以看到转换和实际收到的数据流结果如下:
2> {"name":"Qex","age":27}
7> {"name":"nH7","age":25}
14> {"name":"zmN","age":34}
在实际的应用中这种配置方式常用于那些高吞吐、低延迟的数据源,例如Kafka这样的消息中间件,这一点flink也提供和上述一样方便的操作API。
基本流接收器
上文过滤出成年person的例子中我们在完成filter过滤后调用print方法进行打印输出,实际上其原理本质上就是为这个源流添加一个以打印输出的sink,这一点我们可以查看DataStream的print方法源码知晓:
@PublicEvolvingpublic DataStreamSink<T> print() {PrintSinkFunction<T> printFunction = new PrintSinkFunction<>();return addSink(printFunction).name("Print to Std. Out");}
同时我们也需要说明在输出结果前面类似于14>、7>代表当前输出是由哪个并行流线程(子任务)执行。
当然关于接收器我们也可以基于源数据类型进行自定义,例如下面这段代码,笔者指明源数据为person希望按照我们预期的方式打印,可通过创建一个SinkFunction指明person泛型重写invoke实现自定义输出逻辑:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();List<Person> list = Arrays.asList(new Person("Alice", 18),new Person("Bob", 28),new Person("Charlie", 32));//使用 fromData 关联源数据DataStreamSource<Person> source = env.fromData(list);//添加一个person的s相关文章:

Flink核心概念小结
文章目录 前言引言数据流API基于POJO的数据流基本源流配置示例基本流接收器数据管道与ETL(提取、转换、加载)一对一映射构建面向流映射的构建键控流进行分组运算RichFlatMapFunction对于流的状态管理连接流的使用流式分析水位的基本概念和示例侧道输入的基本概念和示例Process …...
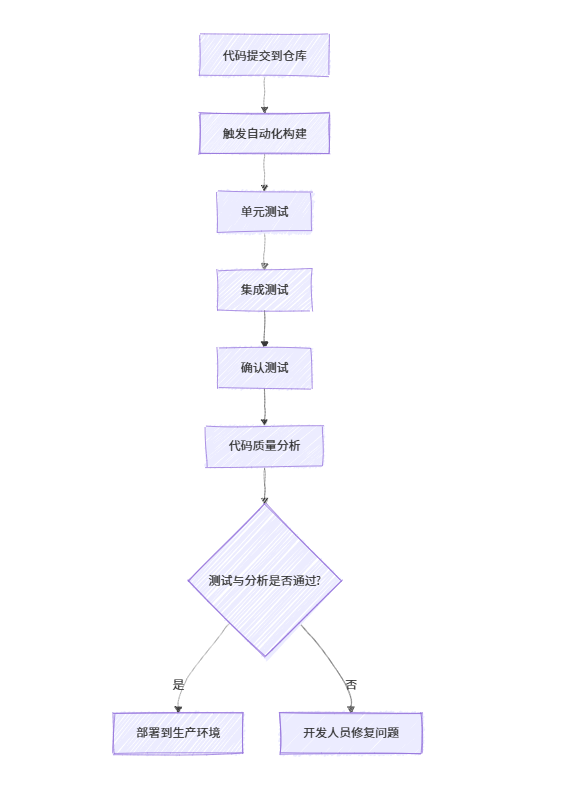
《软件工程》第 14 章 - 持续集成
在软件工程的开发流程中,持续集成是保障代码质量与开发效率的关键环节。本章将围绕持续集成的各个方面展开详细讲解,结合 Java 代码示例与可视化图表,帮助读者深入理解并实践相关知识。 14.1 持续集成概述 14.1.1 持续集成的相关概念 持续集…...

大模型 Agent 中的通用 MCP 机制详解
1. 引言 大模型(Large Language Model,LLM)技术的迅猛发展催生了一类全新的应用范式:LLM Agent(大模型 Agent)。简单来说,Agent 是基于大模型的自治智能体,它不仅能理解和生成自然语言,还能通过调用工具与环境交互,从而自主地完成复杂任务。ChatGPT 的出现让人们看到…...

Navicat 17 SQL 预览时表名异常右键表名,点击设计表->SQL预览->另存为的SQL预览时,表名都是 Untitled。
🧑💻 用户 Navicat 17 SQL 预览时表名异常右键表名,点击设计表->SQL预览->另存为的SQL预览时,表名都是 Untitled。 🧑🔧 官方技术中心 了解到您的问题,这个显示是正常的,…...
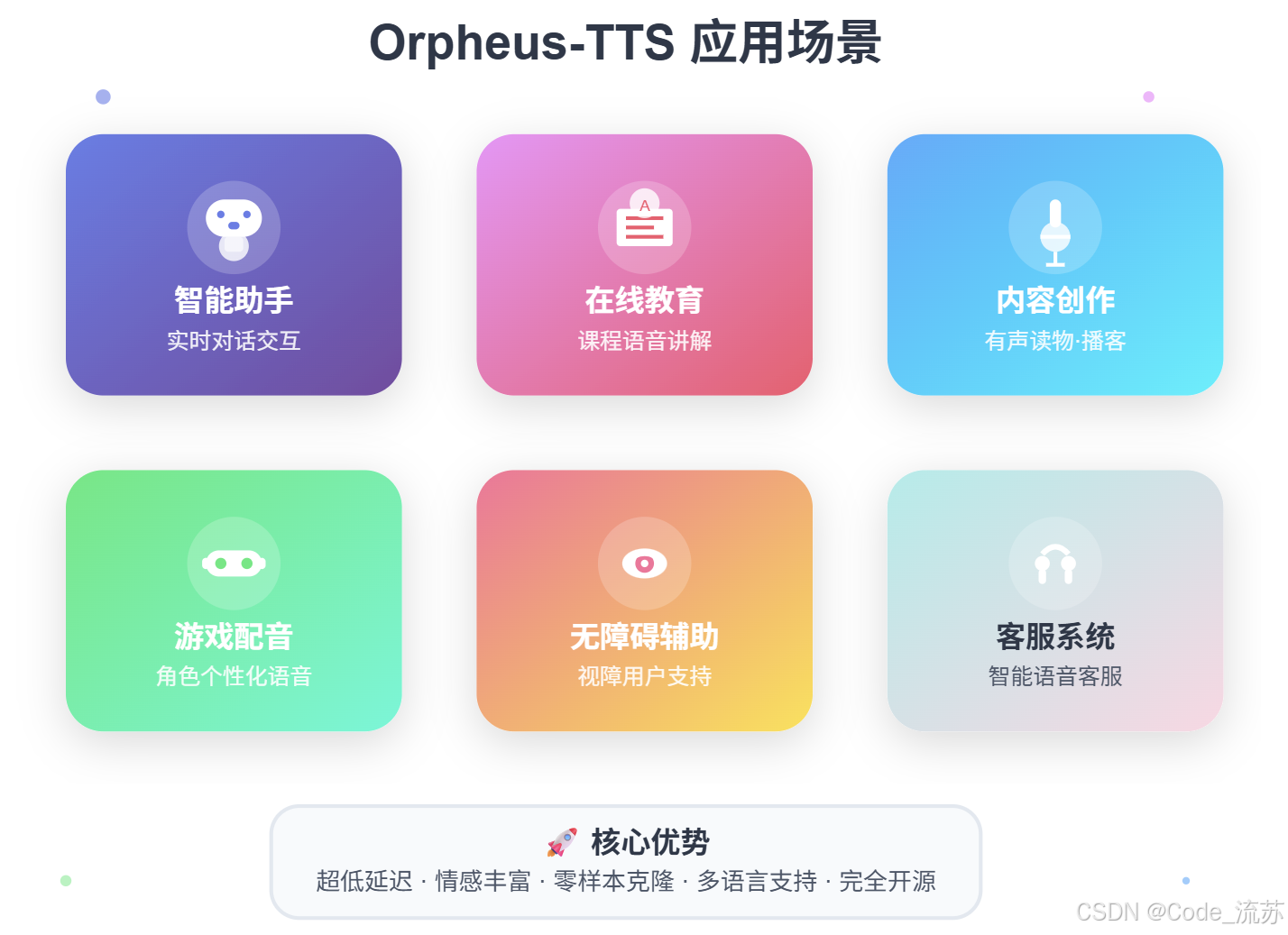
Orpheus-TTS:AI文本转语音,免费好用的TTS系统
名人说:博观而约取,厚积而薄发。——苏轼《稼说送张琥》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、Orpheus-TTS:重新定义语音合成的标准1. 什么是Orpheus-TTSÿ…...

Python爬虫实战:研究Goose框架相关技术
一、引言 随着互联网的迅速发展,网络上的信息量呈爆炸式增长。从海量的网页中提取有价值的信息成为一项重要的技术。网络爬虫作为一种自动获取网页内容的程序,在信息收集、数据挖掘、搜索引擎等领域有着广泛的应用。本文将详细介绍如何使用 Python 的 Goose 框架构建一个完整…...

webpack优化方法
以下是Webpack优化的系统性策略,涵盖构建速度、输出体积、缓存优化等多个维度,配置示例和原理分析: 一、构建速度优化 1. 缩小文件搜索范围 module.exports {resolve: {// 明确第三方模块的路径modules: [path.resolve(node_modules)],// …...
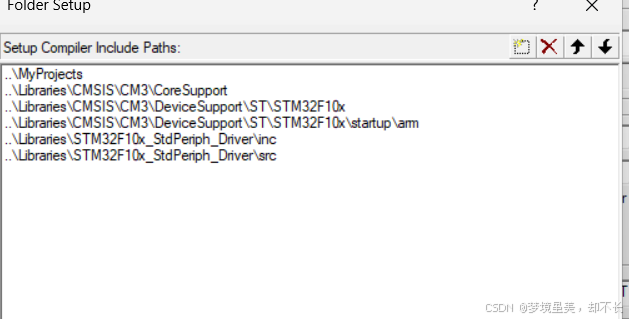
STM32 Keil工程搭建 (手动搭建)流程 2025年5月27日07:42:09
STM32 Keil工程搭建 (手动搭建)流程 觉得麻烦跳转到最底部看总配置图 1.获取官方标准外设函数库 内部结构如下: 文件夹功能分别为 图标(用不上)库函数(重点) Libraries/ ├── CMSIS/ # ARM Cortex-M Microcontroller Software Interface Standard…...

MyBatis 框架使用与 Spring 集成时的使用
MyBatis 创建项目mybatis项目,首先需要使用maven导入mybatis库 poml.xml <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema…...
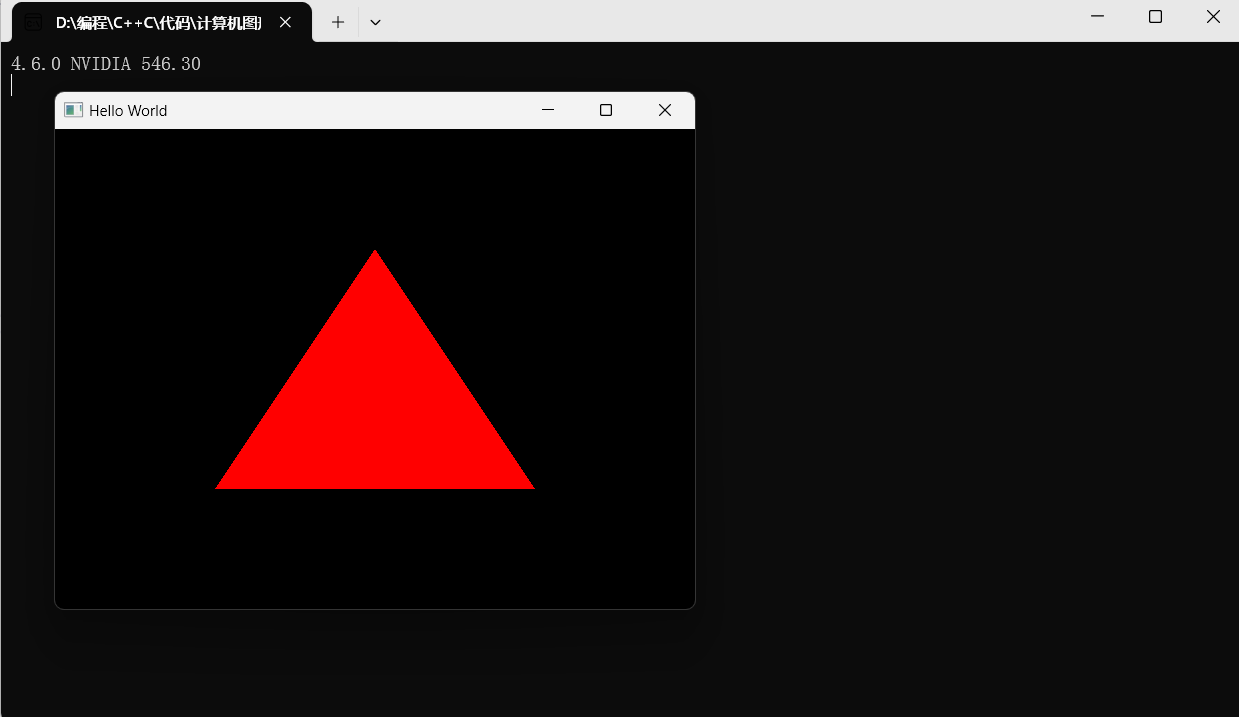
OpenGL Chan视频学习-7 Writing a Shader inOpenGL
bilibili视频链接: 【最好的OpenGL教程之一】https://www.bilibili.com/video/BV1MJ411u7Bc?p5&vd_source44b77bde056381262ee55e448b9b1973 函数网站: docs.gl 说明: 1.之后就不再整理具体函数了,网站直接翻译会更直观也会…...
顶会新方向:卡尔曼滤波+目标检测
卡尔曼虑波+目标检测创新结合,新作准确率突破100%! 一个有前景且好发论文的方向:卡尔曼滤波+目标检测! 这种创新结合,得到学术界的广泛认可,多篇成果陆续登上顶会顶刊。例如无人机竞速系统 Swift,登上nat…...

数据库相关问题
1.保留字 1.1错误案例(2025/5/27) 报错: java.sql.SQLSyntaxErrorException: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near condition, sell…...
一起学数据结构和算法(二)| 数组(线性结构)
数组(Array) 数组是最基础的数据结构,在内存中连续存储,支持随机访问。适用于需要频繁按索引访问元素的场景。 简介 数组是一种线性结构,将相同类型的元素存储在连续的内存空间中。每个元素通过其索引值(数…...
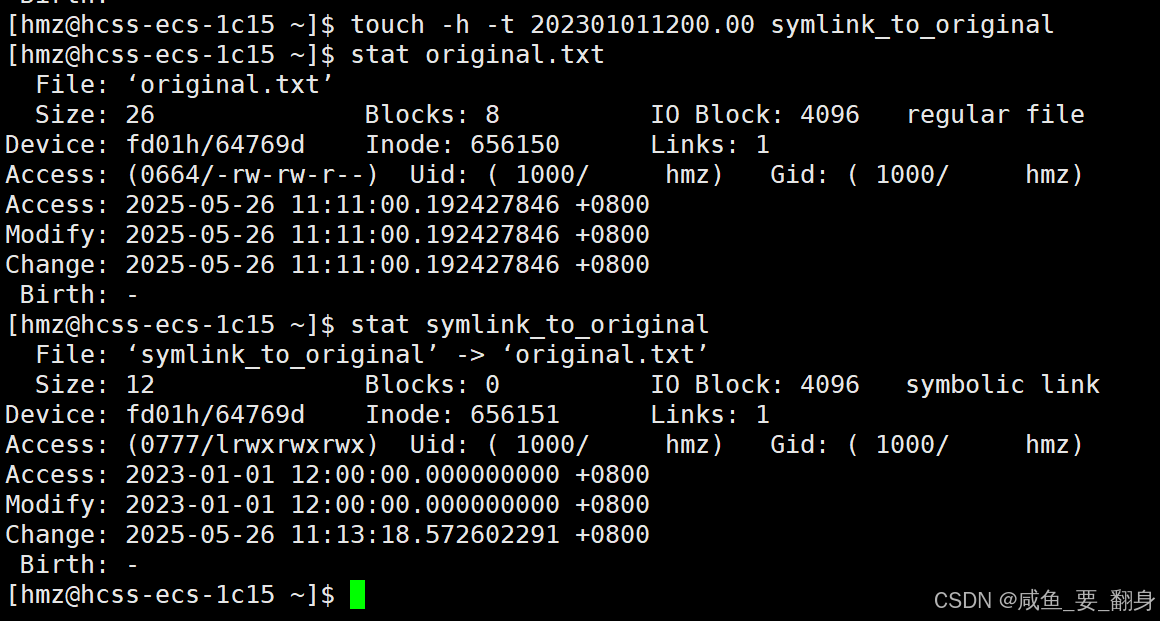
Linux基本指令篇 —— touch指令
touch是Linux和Unix系统中一个非常基础但实用的命令,主要用于操作文件的时间戳和创建空文件。下面我将详细介绍这个命令的用法和功能。 目录 一、基本功能 1. 创建空文件 2. 同时创建多个文件 3. 创建带有空格的文件名(需要使用引号) 二、…...

【后端高阶面经:消息队列篇】23、Kafka延迟消息:实现高并发场景下的延迟任务处理
一、延迟消息的核心价值与Kafka的局限性 在分布式系统中,延迟消息是实现异步延迟任务的核心能力,广泛应用于订单超时取消、库存自动释放、消息重试等场景。 然而,Apache Kafka作为高吞吐的分布式消息队列,原生并不支持延迟消息功能,需通过业务层或中间层逻辑实现。 1.1…...
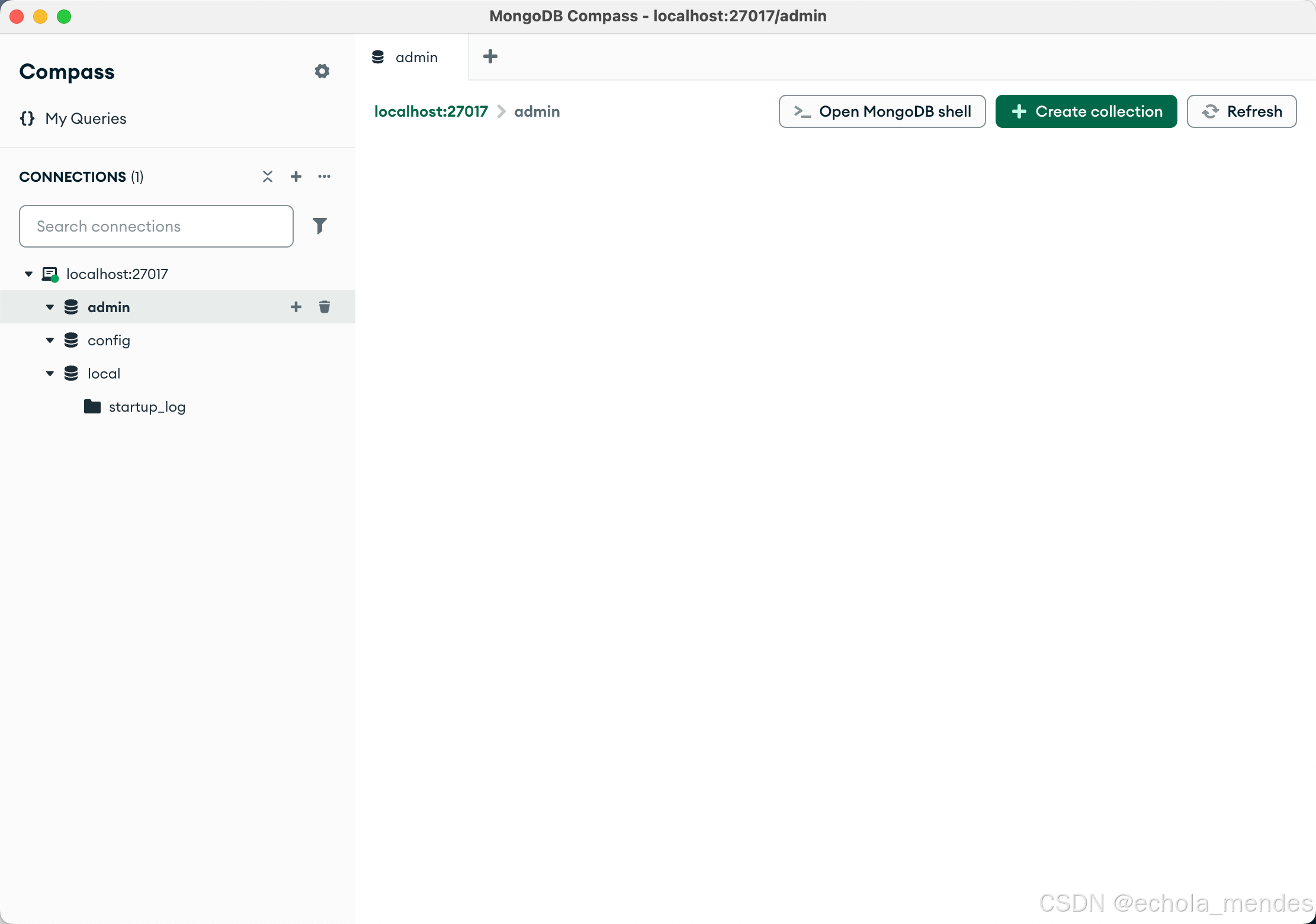
Mac安装MongoDB数据库以及MongoDB Compass可视化连接工具
目录 一、安装 MongoDB 社区版 1、下载 MongoDB 2、配置环境变量 3、配置数据和日志目录 4、启动MongoDB服务 5、使用配置文件启动 6、验证服务运行 二、MongoDB可视化工具MongoDB Compass 一、安装 MongoDB 社区版 1、下载 MongoDB 大家可以直接在官方文档下安装Mo…...
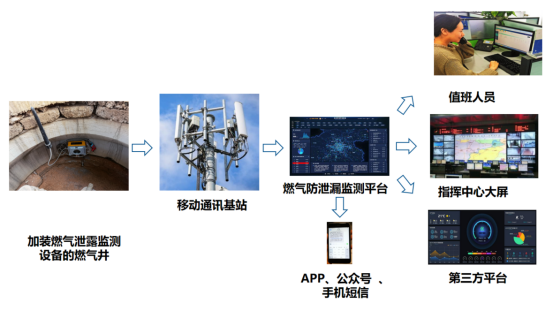
城市地下“隐形卫士”:激光甲烷传感器如何保障燃气安全?
城市“生命线”面临的安全挑战 城市地下管网如同人体的“血管”和“神经”,承载着燃气、供水、电力、通信等重要功能,一旦发生泄漏或爆炸,将严重影响城市运行和居民安全。然而,由于管线老化、违规施工、监管困难等问题࿰…...
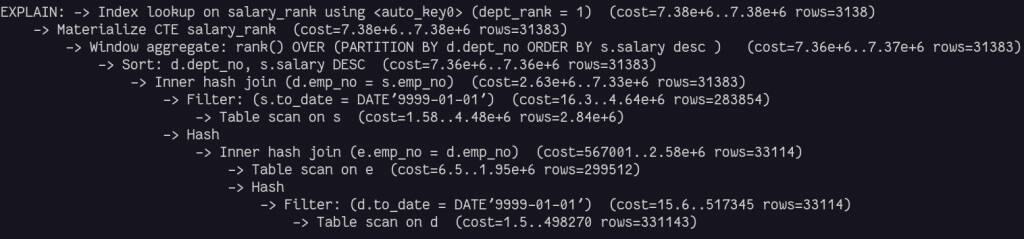
MySQL推出全新Hypergraph优化器,正式进军OLAP领域!
在刚刚过去的 MySQL Summit 2025 大会上,Oracle 发布了一个用于 MySQL 的全新 Hypergraph(超图)优化器,能够为复杂的多表查询生成更好的执行计划,从而优化查询性能。 这个功能目前只在 MySQL HeatWave 云数据库中提供&…...
飞牛fnNAS手机相册备份及AI搜图
目录 一、相册安装应用 二、手机开启自动备份 三、开始备份 四、照片检索 五、AI搜图设置 六、AI搜图测试 七、照片传递 现代的手机,已经成为我们最亲密的“伙伴”。自从手机拍照性能提升后,手机已经完全取代了简单的卡片相机,而且与入门级“单反”相机发起了挑战。在…...
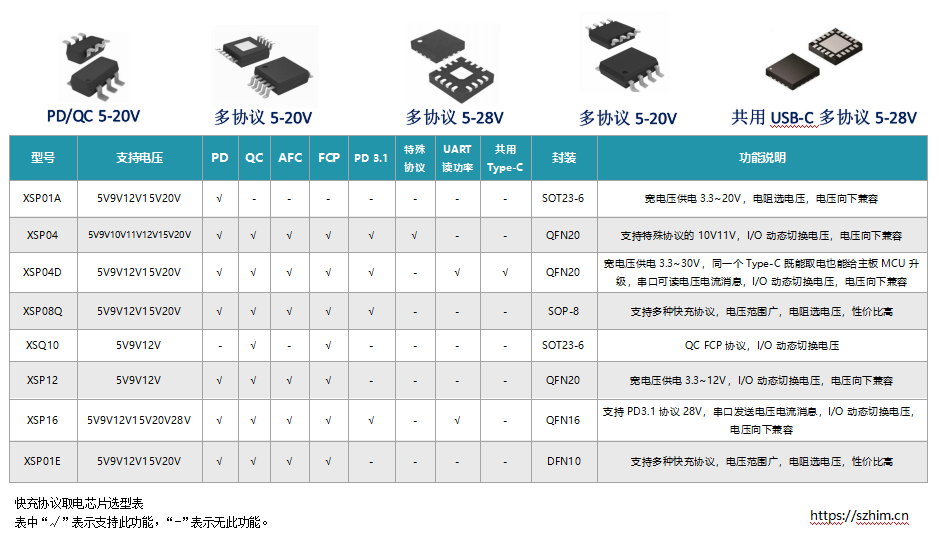
消费类,小家电产品如何做Type-C PD快充快速充电
随着快充技术的快速发展现在市场上的产品接口都在逐渐转为Type-C接口,Type-C可以支持最大20V100W的功率。未来Type-C大概会变成最通用的接口,而你的产品却还是还在用其他的接口必然会被淘汰, 而要使小家电用到PD快充,就需要使用到Type-C快充诱…...
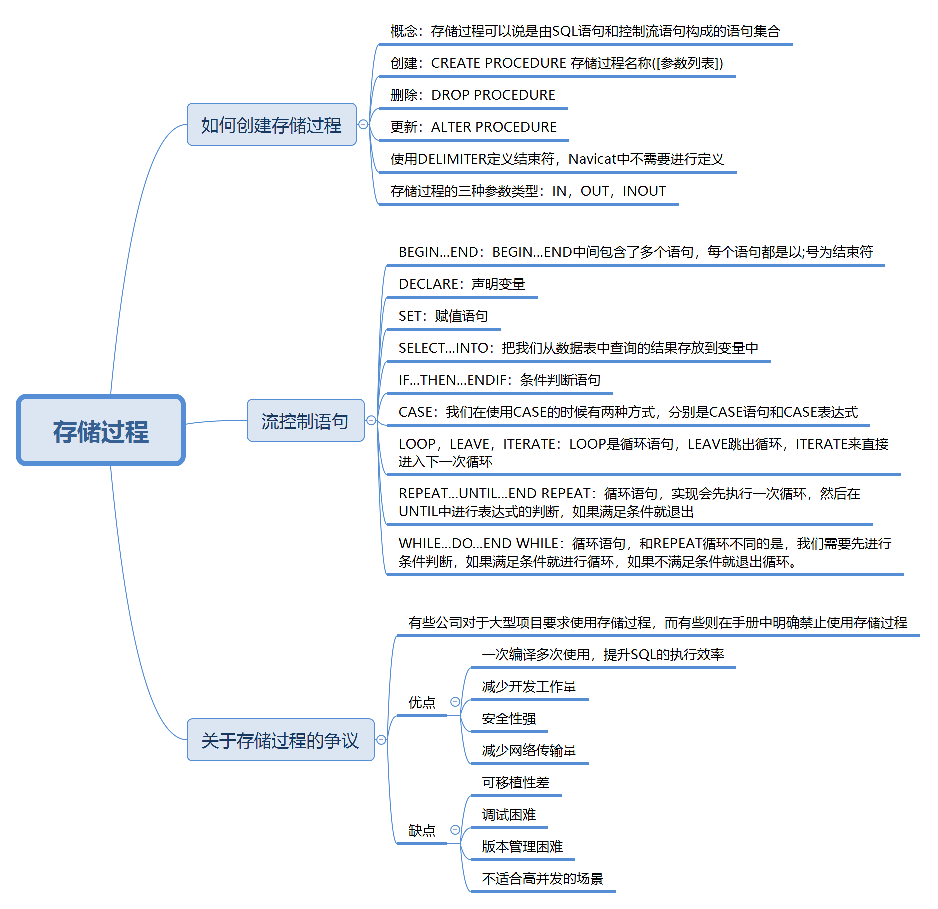
连接表、视图和存储过程
1. 视图 1.1. 视图的概念 视图(View):虚拟表,本身不存储数据,而是封装了一个 SQL 查询的结果集。 用途: 只显示部分数据,提高数据访问的安全性。简化复杂查询,提高复用性和可维护…...

人工智能赋能教育:重塑学习生态,开启智慧未来
在科技浪潮风起云涌的当下,人工智能(AI)如同一颗璀璨的新星,正以前所未有的速度和深度融入社会生活的各个领域。教育,作为塑造未来、传承文明的核心领域,自然也未能置身事外。人工智能与教育的结合…...

银河麒麟V10×R²AIN SUITE:用AI重构安全,以国产化生态定义智能未来
前言 银河麒麟是由国防科技大学研发、现由麒麟软件运营的国产操作系统,旨在打破国外技术垄断,保障国家信息安全。自2002年国家“863计划”启动以来,历经技术迭代与生态整合,现为国产操作系统领军品牌。其应用覆盖党政、国防、能源…...
JavaScript- 3.2 JavaScript实现不同显示器尺寸的响应式主题和页面
本系列可作为前端学习系列的笔记,代码的运行环境是在HBuilder中,小编会将代码复制下来,大家复制下来就可以练习了,方便大家学习。 HTML和CSS系列文章 已经收录在前端专栏,有需要的宝宝们可以点击前端专栏查看ÿ…...
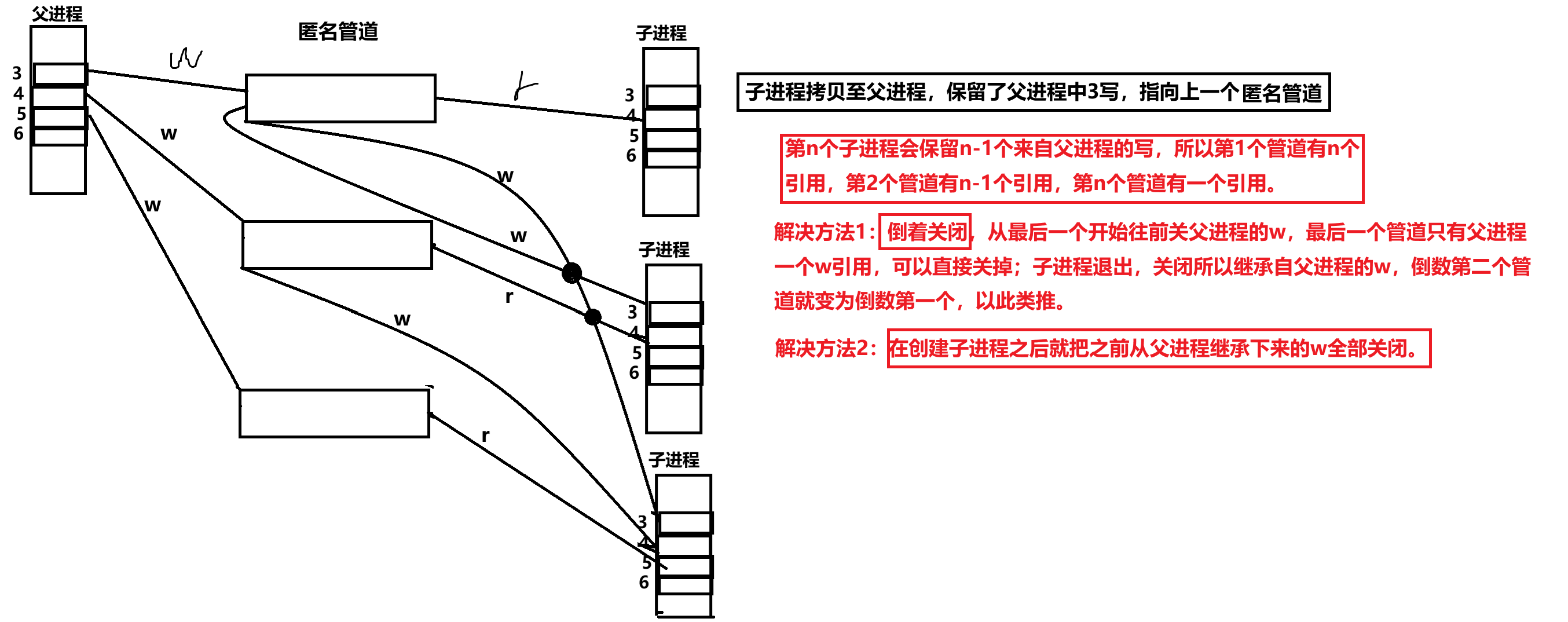
15.进程间通信(一)
一、进程间通信介绍 进程间通信目的: 数据传输:一个进程需要将它的数据发送给另⼀个进程 资源共享:多个进程之间共享同样的资源。 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们…...

AI 数据采集实战指南:基于 Bright Data 快速获取招标讯息
AI 数据采集实战指南:基于Bright Data快速获取招标讯息 在招标行业中,快速、准确地获取招标公告、项目详情、投标截止日期和其他关键招标信息,是投标企业提高竞标成功率的核心竞争力。然而,招标信息往往分散在不同的平台和网页&a…...
cursor使用mcp
问题说明 mcp就相当于给AI安装了工具包,它可以调用获取接口文档,网页,数据库等,基本上所有的mcp都是node程序,少数需要python环境 使用说明 使用mcp-mysql举例,下面是配置json "mysql": {&qu…...
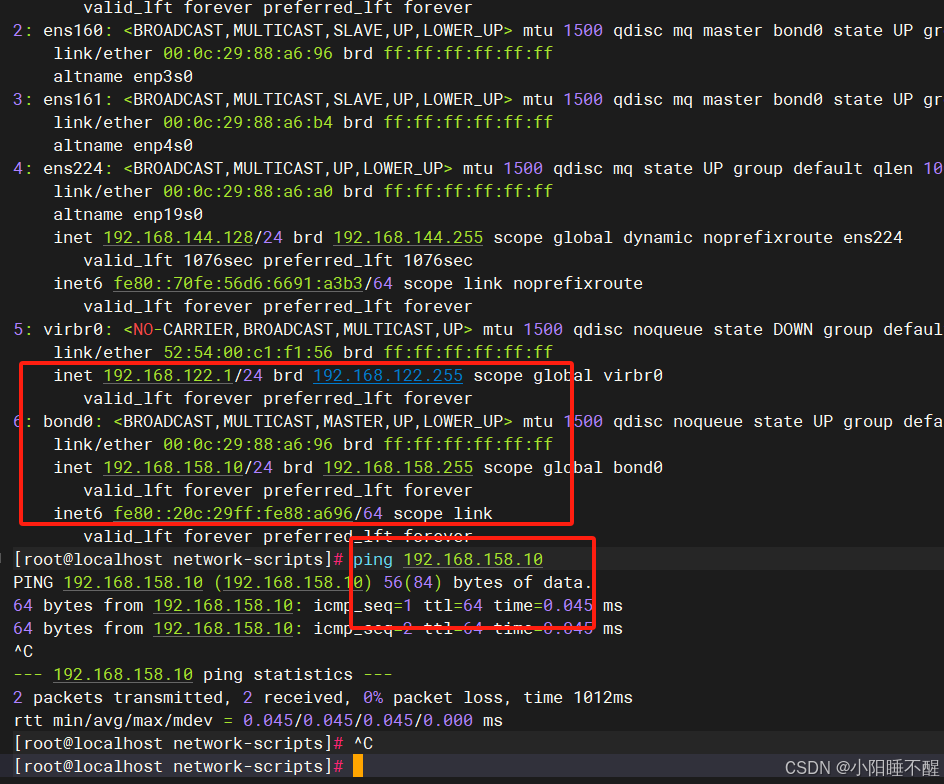
小白成长之路-计算机网络(四)
文章目录 前言一、网络连接查看1.netstat2.ss3.bond绑定3.1准备好这三个文件3.2添加bond配置文件3.3关闭网络图形化服务3.4重启 4.Linux下的抓包工具Wireshark 5、web压力测试工具6、路由追踪命令 二、[练习题](https://blog.csdn.net/m0_70730767/article/details/148262716?…...
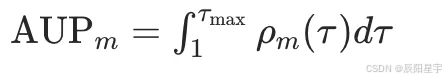
【Agent】MLGym: A New Framework and Benchmark for Advancing AI Research Agents
arxiv: https://arxiv.org/pdf/2502.14499 简介 Meta 推出的 MLGym 框架及配套基准 MLGym-Bench,为评估和开发LLM Agent在 AI 研究任务中的表现提供了全新工具。作为首个基于 Gym 的机器学习任务环境,MLGym 支持强化学习等算法对代理的训练,…...

5.27 打卡
知识点回顾: Dataset类的__getitem__和__len__方法(本质是python的特殊方法)Dataloader类minist手写数据集的了解 作业:了解下cifar数据集,尝试获取其中一张图片 import torch import torchvision from torchvision im…...