数据结构第1章编程基础 (竟成)
第 1 章 编程基础
1.1 前言
因为数据结构的代码大多采用 C 语言进行描述。而且,408 考试每年都有一道分值为 13 - 15 的编程题,要求使用 C/C++ 语言编写代码。所以,本书专门用一章来介绍 408 考试所需的 C/C++ 基础知识。有基础的考生可以快速浏览或者跳过本章。想要深入了解 C/C++ 语言的考生,可以参考其他专业书籍。
1.2 变量与数据类型
1.变量
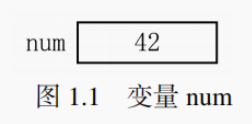
在 C 语言中,通过变量存储数据,不同类型的数据需要不同类型的变量。图 1.1 是一个整型变量的例子,方框代表存储空间,num 是变量名,42 是变量值。
在 C 语言中,所有变量必须先声明后使用。一个变量声明的同时赋初始值的实例如下:int x = 3, y = 4; int z = x + y;上述代码执行完后,int 型变量 x、y、z 的值分别为 3、4、7。相关的语法介绍如下:
(1) 可同时声明多个同类型的变量。在声明变量的同时可以进行初始化,即对其赋初始值。这里 x、y、z 都是在声明的时候就已经被赋值。
(2) C 语言变量名只能由字母、数字和下划线组成,且变量名不能以数字开头。变量名中的字母是区分大小写的。变量名不能是 C 语言关键字。2. 基本数据类型
C 语言的基本数据类型如表 1.1 所示。
其中,不同的整型类型支持的取值范围不同。通常,使用 int 表示整数类型、float 表示浮点数类型、char 表示字符类型。
在 C 语言中,可以使用 sizeof 操作符获取变量所占空间的大小,并返回变量所占的字节数。sizeof 的参数不仅可以是变量,还可以是数据类型。例如:在 64 位系统中,sizeof (x) 和 sizeof (int) 的返回值都为 4(x 为一个 int 型变量)。
除了上述基本数据类型,C++ 中还有表示真假的布尔(bool)类型。C 语言在 C99 标准之前没有 bool 类型,但可以用 0 表示假,非 0 表示真。这里的真和假可以作为判断的依据,例如:如果 if 语句的判断条件的值为 0,则不会执行对应的操作语句;如果 if 的判断条件的值非 0,则会执行对应的操作语句。如以下的代码所示:if (0) {操作语句; // 判断条件的值为0,操作语句不执行 } if (1) {操作语句; // 判断条件的值非0,执行对应的操作语句 }1.2.1 指针
1.什么是指针?
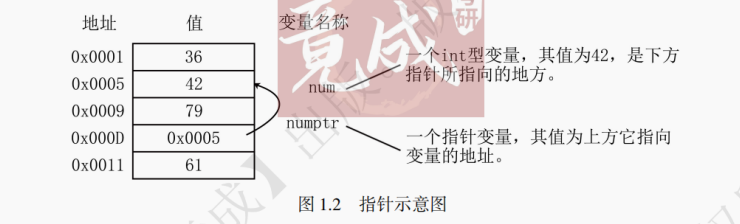
指针变量简称指针。指针变量与 int、float 等变量略有不同。指针变量存储的不是变量的值,而是变量对应的地址,即指针变量是用来存放地址的变量。如图 1.2 所示,num 是一个 int 型变量,num 变量值是 42,numptr 是一个指向 num 的指针变量,箭头代表对应指针的指向。
2.与指针相关的操作
在声明指针时,* 充当标识符,标识声明的变量是一个指针变量。在用指针访问变量时,* 表示获取指针指向地址的值。& 是取址符,&y 就是取得变量 y 的地址。此外,指针之间还可以直接进行赋值,使它们指向同一个变量。下面通过具体的例子来介绍:
//如图1.3所示: int a = 1, b = 2, c = 3; // 声明三个int型变量 int *p, *q; // 声明两个int型指针 // 指针p和指针q此时为野指针,其值在图中用××来表示//如图1.4所示: p = &a; // 将指针p指向变量a q = &b; // 将指针q指向变量b//如图1.5所示: c = *p; // 取得指针p所指向变量的值,并将其赋给变量c p = q; // 将p的指向改为q的指向,二者此时指向同一个变量 *p = 13; // 对p执行解引用操作,将p所指向的变量的值更改为13 // 此时*p等价于变量b,*q的值也应为13提示:空指针(NULL)代表空值,它指向一个不被使用的地址。可以将空指针赋值给任何指针类型变量。大多数系统都将 0 作为不被使用的地址,此时,NULL 也等价于常量 0。
1.2.2 结构体
除了基本的数据类型外,C 语言还允许用结构体实现自定义数据类型。结构体是 C 语言中一种重要的数据类型,该数据类型由一组称为成员(或称为域,或称为元素)的不同数据组成,其中每个成员可以具有不同的类型。结构体通常用来表示类型不同但是又相关的若干数据。
提示:考生有必要熟练掌握结构体的相关操作。因为在后续章节中,会经常用到结构体,在 408 考试的算法题中,有时也会要求给出特定结构体的定义。1.结构体的定义与创建
在 C 语言中,struct 关键字用于定义结构体,结构体最简单的定义方式为:
struct 结构体名 {成员列表 };提示:结构体定义必须以分号结尾,否则将无法编译通过。
例如:以下代码定义了一个用于记录学生成绩的结构体:struct stuInfo {int stuId, rank; // 学生ID、对应排名float score; // 学生分数 };以下代码定义了一个 stuInfo 型变量:
// 此句创建了一个stuInfo类型的变量,变量名为zhangSan struct stuInfo zhangSan;注意:在 C 语言中,如果采用这种结构体类型定义方式,定义一个该结构体变量时 struct 关键字不能省略。
上述两种操作也可以一步到位:在定义结构体类型的时候同时定义变量,只需要在末尾的 “}” 后面加上变量名即可。这种方式与 “int x, y, z;” 类似,定义与声明如下:struct stuInfo {int stuId, rank;float score; } zhangSan;定义结构体变量时常使用 typedef 关键字,其作用是给数据类型起一个 “别名”。例如:
typedef int stuId; // 给int取别名为stuId; // 下面两句都可以创建一个int型变量,是等价的 int zhangSan; stuId zhangSan;在 408 考试中,typedef 常用于给结构体类型取别名。这种方式在定义新的结构体变量时,可以省略 struct 关键字。例如:
typedef struct stuInfo { // 此处stuInfo也可省略int stuId, rank;float score; } stuInfo; // 给struct stuInfo {……} 取了一个stuInfo别名 stuInfo zhangSan; // 此句创建了一个stuInfo类型的变量,名为zhangSan在使用 typedef 定义结构体时,可以将结构体的定义拆分为四个部分:
(1) typedef struct 关键字:指明了这是一个结构体类型的定义,并为其取别名。
(2) typedef struct 后面的结构体名称:在已定义了结构体类型别名时这一部分可省略。
(3) 花括号内是结构体的成员列表:声明了该结构体包含的成员变量。上述代码包含了三个成员变量:stuId、rank 和 score,分别代表学生的 id、排名和分数。
(4) 结构体类型别名:即最后的 stuInfo。之后便可以把这个名称当作新的变量类型来使用。
在定义结构体类型时,当结构体成员中有指向该结构体类型变量的指针时,typedef struct 后面必须要加上该结构体的名称。以本书 5.2. 小节(第 116 页)中二叉树的结点为例:// 定义一个名为Node的结构体类型 typedef struct Node {int data; // 结点的data域struct Node *lChild, *rChild; // 结点的指针域,此句中struct不可省略 } Node;在上述代码中,分别定义了 lChild 和 rChild 两个指针。在结构体内部定义这两个指针时,需要用到结构体名 Node,因此应当在 typedef struct 的后面预先声明。只要完成了预先声明,结构体内部也可以使用它本身的类型来对变量进行定义,即实现递归定义。有如下两点需要注意:
① 在第 2 行代码 typedef struct Node 中,结构体名称 Node 不能省略,因为后面定义结构体指针变量要用;
② 在第 4 行代码 struct Node *lChild 中,结构体指针不能用别名 Node,因为别名 Node 还未定义;2. 结构体内部变量的访问
结构体变量访问其成员变量时,使用 “.” 运算符。而结构体指针访问其成员变量时,使用 “->” 运算符。如以下代码所示:
Node root, lc, rc; // 声明3个Node类型的变量 root.data = 1; root.lChild = &lc; root.rChild = &rc; // 初始化root root.lChild -> data = 2; // 通过指针对lc进行操作 root.rChild -> data = 3; // 通过指针对rc进行操作在 root.lChild -> data 这行代码中,因为 root 本身是一个 Node 类型的变量,故使用 “.” 而它的成员变量 lChild 是一个 Node 类型的指针,故使用 “->”。
1.3 数组和链表
1.3.1 数组
数组(Array)是有序排列的同类数据元素的集合。如图 1.6 所示。
提示:用于区分数组的各个元素的数字编号称为下标。
用基本数据类型来创建数组的示例如下:int arr1[10]; // int型数组,利用连续的空间存储10个int型数据 arr1[0] = 1; // 下标从0开始计数 arr1[9] = 10; // 最大下标为9 arr1[10] = 11; // 出现数组越界,会导致错误用结构体类型来创建(stuInfo 是上一节定义的结构体类型)数组的示例如下:
// stuInfo型数组,利用连续的地址空间存储50个stuInfo型数据 stuInfo students[50]; // 对students[50]数组中的第一个结构体元素的score成员变量赋值为80.0 students[0].score = 80.0;除上述两种数组创建方法外,还可用 malloc 函数或 new 关键字向内存的动态存储区申请一块连续的地址空间以创建数组。创建一个能够存放 100 个 int 型数据的数组 arr2 的代码如下:
int *arr2; // 定义一个int型指针arr2 // 用malloc函数申请大小为100个int数据的空间,并把首地址赋给arr2 arr2 = (int *)malloc(sizeof(int) * 100); // C++中可直接用new进行申请 int *arr2 = new int[100]; // 结束时要用delete []释放arr2数组空间 delete [] arr2;对于一个长度为 n 的数组,其下标从 0 开始,到 n - 1 结束。C 语言中的数组会被分配一块连续的地址空间,由于其内部元素的数据类型一致、占用存储空间的大小相等,便于通过数组的起始地址加上偏移量的方式,获得指定下标的元素地址,并访问该元素。因此,数组支持随机存取。例如,可以直接用 arr2 [10] 存取数组中下标为 10 的数组元素。
注意:C 语言数组下标从 0 开始,下标为 10 的数组元素其实是数组中第 11 个元素。
接下来介绍一下 C 语言中如何表示字符串(只推荐使用下列表示方法):// str字符数组不需要显式地指定数组大小,编译器会自动地根据字符串来判断大小数值 char str[] = "hello"; // s[0] == 'h'; 注意字符类型用单引号' '表示,字符串用双引号" "表示 // 也可以下面的形式表示字符串,此时s是指向字符串"hello"的首个字符的地址 char *s = "hello"; // 此时也可以使用s[i]来访问其第i个字符(但不可以修改)1.3.2 链表
链表是一种数据元素的逻辑地址相邻、物理地址不一定相邻的存储结构,通过链表中指针的链接次序来表示数据元素之间的逻辑顺序。由于存储空间的不连续性,当需要访问链表中的某个元素时,只能通过遍历链表的方式进行访问,故链表不支持随机存取,只能顺序存取。
与数组相比,链表的优点在于插入和删除元素比较方便,这个特征在后面的对应章节会详细介绍。链表还能够自由地扩展长度,而数组由于需要连续的空间,故在分配时就需要指定长度,当元素的数量超过数组长度时,就需要重新分配空间。
下面是一个单链表的实例,涉及了结构体的定义、指针等知识:typedef struct LinkNode { // 定义链表结点int data;struct LinkNode *next; // 指向链表下一个元素的地址 } LinkNode;LinkNode A, B, C; // 定义3个链表结点,其存储位置不一定连续 A.next = &B; // 将A的下一个元素设为B B.next = &C; // 将B的下一个元素设为C上述代码首先定义了 LinkNode 这个结构体,并声明了 3 个 LinkNode 变量,经过简单的链接操作后,得到一个如图 1.7 所示的 “A -> B -> C” 形式的链表。
1.4 程序结构
程序由一行行的代码构成,默认是顺序执行。在代码执行的过程中,常常需要根据特定的条件来选择执行相对应的代码,这种选择执行的方式对应的是分支结构。程序还可能多次执行相同的操作,直到满足特定条件,这种重复执行的方式对应的是循环结构。
1.4.1 分支结构
C 语言中的分支结构主要有两种,一是 if 语句,二是 switch 语句。if 语句更常用,这里只介绍 if 语句。if 语句的示例代码如下:
int x = 321; if (x % 3 == 0) { // C语言中用符号%取余数printf("%d能整除3", x);x = x + 1; } else if (x % 3 == 1)printf("%d除以3余1", x); else {printf("%d除以3余2", x); }if 语句有以下几个要素:
如上述代码第 2 行,if 后面接判断条件,判断条件需要用小括号包裹。如果条件为真,则执行紧接的大括号内的语句,否则跳转到 else 部分;
如上述代码第 5 行,如果上一个 if 条件不为真,else 后面还有 if(即 else if),则继续进行判断,否则直接执行 else 后面的代码块(如上述代码第 7 行);
else 后面如果有多行代码(即多个;分隔),则必须用大括号将分支对应的代码块括起来(如上述代码的第 3 到 4 行)。如果只有 1 行代码,则可以省略花括号(如上文代码的第 6 行)。
1.4.2 循环结构
循环结构有两种类型:for 循环和 while 循环,可根据实际情况选用(do - while 语句较少见,故不作介绍)。下面以遍历数组和遍历链表为例,分别介绍两种循环结构的用法。
1.for 循环 的示例代码如下:
const int N = 100; int main() {int arr[N]; //初始化一个长度为100的int型数组// ++操作符使得变量的数值+1for (int i = 0; i < N; ++i) { // 遍历数组中的每个元素if (i < 10) arr[i] = i * i; // 对前10个元素赋值else if (i < 50) continue; // 跳出当前循环,进入下一轮循环else break; // 结束循环,执行for循环之后的代码}return 0; }for 循环包括以下三个组成部分:
(1) for 关键字,指明这是一个 for 循环;
(2) 循环控制条件,即 for 之后由小括号包裹的部分。它又包括三个部分,由两个 “;” 分隔,从左到右依次是:循环初始设置,对应上述代码中的 “int i = 0”,只在首次循环时执行。它通常用来设置循环对应的下标的初始值,如设置 i 的初始值为 0,即数组的第一个下标。
进入循环的判断条件,对应上述代码中的 “i < N”。每次执行代码块之前,先求这个表达式的值,如果为 true,则进入循环,否则跳出循环。
循环代码块结束后的更新操作,对应上述代码中的 “++i”。每次执行完循环代码块后,执行更新操作,通常用来设置下一个循环的状态,例如上述代码更新了下标 i 的值。
(3) 循环代码块,每次进入循环都要执行这个代码块。它可能包含两个关键字:continue 和 break,这两个关键字的作用如下:continue 关键字:跳出本轮循环,进入下一轮循环。
break 关键字:结束循环,执行循环之后的代码。
2.while 循环 的示例代码如下:
int i = 0; while (i < 10) { // i大于或等于10时结束循环printf("%d\n", i); // 打印输出当前值的i值++i; }while 循环的功能与 for 循环相同。区别在于,while 的循环控制条件仅包含进入循环的判断条件,而循环初始设置通常在 while 语句之前,循环更新操作包含在循环代码块内部。continue 和 break 也可以用于 while 循环。
1.5 函数
1.5.1 函数定义
函数是 C 语言的基本模块,通过对函数模块的调用实现特定的功能。如果把函数比喻成一台机器,那么函数的参数就是机器所需的原材料,函数的返回值就是机器最终产出的产品。在一定程度上,函数的作用就是根据不同的参数产生不同的返回值 (对于不含返回值的函数,函数的作用就是对数据进行相应处理)。假如一个程序的很多地方需要对数组进行遍历操作,而每次执行的又都是同样的代码,可以把这段代码封装为一个函数,并在每次使用时进行调用。
提示:C 语言程序的执行总是从 main 函数开始,最后也是由 main 函数来结束整个程序。
图 1.8 以具体例子说明了函数的基本语法格式。其中 addArray 函数的功能是:对长度为 n 的数组中的各元素进行求和:
函数语法格式的要点如下:
(1) 返回值类型:函数执行结束之后的返回值的类型,可以是 void (返回值为空)、int、float 等一些基本数据类型,也可以是指针或自定义的结构体。
(2) 函数名:由用户确定,如上述函数示例中的 addArray。
(3) 参数列表:形式为 “参数类型 参数”,如 int n ,表示传入函数的参数是一个 int 型变量。传入的每一个参数都要声明参数类型,需要与变量的定义相区别,即若要传入两个 int 型变量,括号内写法应为 int a, int b 而非 int a, b 。
(4) 函数主体:函数主体包含一组定义函数执行任务的语句。
(5) 返回值:C 语言中使用 return 来返回函数需要传回的数据,且 return 后面的数据类型要与函数定义时的返回值类型保持一致。若函数返回值类型为 void,则无需返回具体值,但可以通过 return 语句来提前结束函数的执行。1.5.2 函数调用
在 C 语言中,函数调用有多种形式,例如:
// max函数返回a、b中较大的一个 int c = max(a, b); // 1.函数作为表达式中的一项 printf("%d", c); // 2.直接作为一个单独的语句使用(调用printf函数) printf("%d", max(a, b));// 3.函数的返回值作为另一个函数的实参注意:当函数作为表达式中的一项被调用,或者作为函数实参被调用时,要求函数有返回值,否则会报错。
函数还可以进行嵌套调用和递归调用,下面给出两者的定义和举例说明。
1.嵌套调用
嵌套调用是指在一个函数中调用另一个函数,调用方式与在 main 函数中调用其他函数是一致的。举例说明如下:
int max2(int a, int b) { // 返回两个整数中较大的一个return (a > b? a : b); //?:操作符含义见下面提示部分的解释 } int max4(int a, int b, int c, int d) { // 返回四个整数中最大的一个int ans;ans = max2(a, b); // 嵌套调用max2函数ans = max2(ans, c);ans = max2(ans, d);return ans; } int main() {int a, b, c, d, maxNum;// 接收来自键盘的四个值并赋给a, b, c, dscanf("%d %d %d %d", &a, &b, &c, &d);maxNum = max4(a, b, c, d);printf("%d", maxNum); // 打印输出a,b,c,d中的最大值 }上述代码中的 main 函数调用了 max4 函数,即发生了函数嵌套调用。
提示:max2 函数的定义中用到了三目运算符:“<表达式 1>? < 表达式 2>: < 表达式 3>”,它的意思是先求表达式 1 的值,如果为真,则执行表达式 2,并返回表达式 2 的结果;如果表达式 1 的值为假,则执行表达式 3,并返回表达式 3 的结果。举个例子:对于条件表达式 a? x : y,先判断条件 a 的真假,如果 a 的值为 true,那么返回表达式 x 的计算结果;否则,计算 y 的值,返回表达式 y 的计算结果。
注意:不能在函数中定义函数,即不能 “嵌套定义函数”。
分析该程序的执行过程如下:
(1) 程序执行总是从 main 函数开始,最后也是由 main 函数结束整个程序;
(2) 在 main 函数中调用 max4 函数,在执行到 “max = max4 (a, b, c, d);” 时,程序就跳转到 max4 函数执行;
(3) 在 max4 函数中又分别调用了三次 max2 函数,程序会分三次跳转到 max2 函数执行并依次将返回值赋给 ans 变量;
(4) max4 函数执行完毕,执行 “return ans;”,将 ans 的值作为返回值赋给 main 函数中的 maxNum 变量;
(5) main 函数将 maxNum 的值输出到控制台,执行完 main 函数后,程序运行结束。2. 递归调用
递归调用是指一个函数调用函数自身的行为。递归一般会有边界条件,即递归结束的条件,也称递归基。例如:斐波那契数列是满足 F (0) = 1, F (1) = 1, F (n) = F (n - 1) + F (n - 2) 的数列。以如下代码为例,F 函数调用了 F (n - 1) 和 F (n - 2),所以此函数是递归函数,“n == 0” 和 “n == 1” 就是两个递归基。
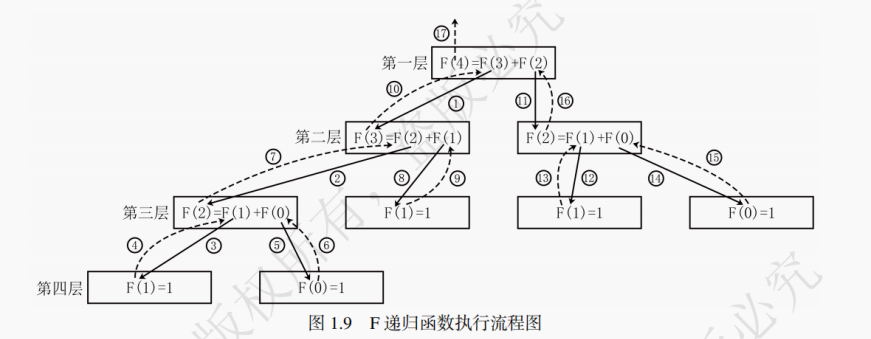
// 递归法求斐波那契数列中第n个位置上的数的值 int F(int n) {if (n == 0) { return 1; }if (n == 1) { return 1; } // 递归边界return F(n - 1) + F(n - 2); // 递归式 }以上述函数 F 为例,当 n 为 4 时,图 1.9 给出了 F 函数的具体执行流程,其中实线箭头表示 “递” 的步骤,虚线箭头表示 “归” 的过程。
如果需要求出斐波那契数列中第 n 个位置上的数,也可以采用迭代的方法,即在循环中参与运算的变量也是保存结果的变量,从某个值开始,不断地由上一步的结果计算 (或推导) 出下一步的结果。用迭代方式求解的代码如下:// 迭代法求斐波那契数列中第n个位置上的数的值 int fib(int n) {int first = 1, second = 1, cur = 0;if (n <= 1) { return 1; }for (int i = 2; i <= n; ++i) {cur = first + second;first = second;second = cur;}return cur; }对此不太熟悉的考生可以给出一个具体的 n,然后手动模拟上述程序的运行过程,以便深入理解迭代的算法思想。
关于递归和迭代的区别,有兴趣的考生可以查阅其他专业书籍,这里不再展开详述。1.5.3 C 语言函数的形参与实参
C 语言中函数的参数会出现在两个位置,在函数定义处的参数叫形参,在函数调用处的参数叫实参。下面给出两者的介绍:
形参(形式参数):在函数定义中出现,只有在该函数被调用时,才会为形参分配存储空间、接收传入函数的数据,形参才会得到具体的值。
实参(实际参数):在函数调用中出现,包含具体的数据。在发生函数调用时,实参内的值会传递给形参,从而被函数内部的代码使用。
形参和实参的示例代码如下所示:
void add(int x, int y) { // 函数定义,此处的x,y为形式参数int z = x + y;printf("%d", z); } add(3, 4); // 函数调用,此处的3,4为实际参数数据从实参向形参传递的过程叫做单向值传递。在函数内部对于形参的操作并不会影响实参的值。
注意:当数组名作为参数传入时,函数可以直接对该原数组中的元素进行操作。这是因为数组名对应的是数组的首地址,故参数传递中传递的是地址。形参数组取得该首地址之后,形参数组和实参数组便为同一数组,共享同一段内存空间。1.5.4 C/C++ 中的参数传递
在 C 语言中,参数传递的方式只有值传递。而在考试中,偶尔也会有 C++ 中的引用传递的情况,因此在这里也顺带介绍 C++ 中的引用传递。
注意:初学者在学习 C 语言时,可能会发现 C 语言有值传值和传指针的说法,这种说法也是正确的,传值和传指针的本质都是值传递。C 语言在传指针时,也只是把指针的值(即地址)传入。
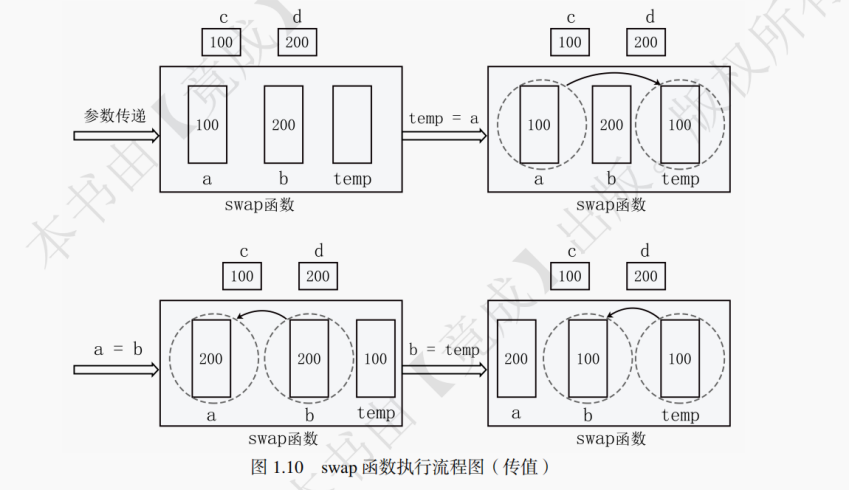
如果要设计一个 swap 函数,用于交换两个 int 型整数 c 和 d 的值,该如何设计呢?下面用 swap 函数的例子,分别介绍传值、传指针(传地址)和传引用。1.传值
初学者可能会写出这样的代码:
void swap(int a, int b) {int temp; // temp用于暂存a的值temp = a; // 暂存a的值a = b; // 把b的值赋给ab = temp; // 把temp中暂存的a的值赋给b }但不幸的是,这样的函数并不能真正完成交换两个变量的值的功能。考虑这样一种情况,初始情况下变量 c 的值为 100,变量 d 的值为 200。当在 main 函数中调用此函数来交换变量 c 和变量 d 的值时,会在函数内部重新创建两个变量 a 和 b 用于存储实参传递过来的值,这两个函数内部的变量只是外部实参的一个拷贝,而后的操作都是对这两个拷贝的操作,并不会影响到外部的实参。
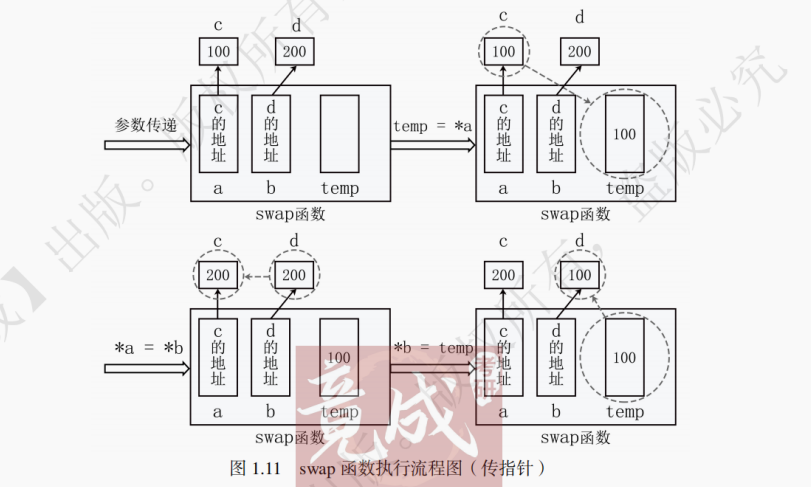
2.传指针 (传地址)
传指针(传地址)指的是在参数传递时传递的不是欲交换的数值,而是其地址。在 swap 函数中,形参为两个指针变量 a 和 b,当函数被调用时,传递给形参 a 和 b 的值为实参 c 和 d 的地址,于是,a 和 b 就变成了分别指向 c 和 d 的指针变量。通过对指针变量执行解引用操作(如 * a),就可以直接影响到指针指向变量的值,这就是在传地址方式中调用函数对实参进行操作的本质所在。
传指针的代码如下:void swap(int *a, int *b) { // 函数定义int temp;temp = *a;*a = *b;*b = temp; } swap(&c, &d); // 函数调用3.传引用
C++ 还提供了传引用这种参数传递方式,传引用能够达到和传指针同样的效果。所谓引用,是给已存在变量取一个别名,通过这个别名和原来的名称都能够找到这份数据。定义引用类型的格式类似于定义指针的格式,只是用 “&” 取代了 “”,例如:
数据类型 & 引用变量名 (对象名) = 引用实体;
注意:这里 “&” 的位置与定义指针时 “” 的位置一样,都是自由的。并且,传引用在形参定义时需添加 “&”,在函数内使用形参时,将其作为一个普通数据类型的变量进行相关操作即可。除此之外,“&” 还可以用于取地址操作以及位操作中的与运算。
在 C++ 内部,引用的本质是一个指针常量,它指向的内存地址不会发生变化,即形参的内存地址与实参的内存地址保持一致,但内存地址对应的存储单元中的值可以发生变化。故引用一经定义,就无法改变指向,但可以通过引用修改形参的数值。在定义或声明函数时,可以将函数的形参指定为引用的形式,这样在调用函数时就会将实参和形参绑定在一起,让它们都指代同一份数据。如果在函数体中修改了形参的数据,那么实参的数据也会被修改,从而拥有 “在函数内部影响函数外部数据” 的效果。因此 swap 函数也可以由以下代码实现:
void swap(int &a, int &b) { // 函数定义int temp;temp = a;a = b;b = temp; } swap(c, d); // 函数调用当函数需要传入一个结构体但函数无需对其进行修改时,建议定义 const & 的形参类型避免不必要的隐式拷贝行为(对该原理感兴趣的同学可自行查阅相关资料)。
1.6 补充
1.6.1 预处理命令
C 语言中的预处理主要是处理以 #开头的命令,例如最常见的 #include <stdio.h>。在这里简要介绍常用的 include 命令以及 define 命令。
1.include 命令
include 命令的作用是引入对应的头文件。所谓头文件,可以简单的把它看成一本 “百科全书”,里面含有各种各样的描述性内容。例如,下面是一个简单的完整 C 语言源代码实例:
#include<stdio.h> int main() {printf("Hello,World!");return 0; }这段代码包含了一个头文件 “stdio.h”,头文件默认以.h 为后缀。main 函数中调用了 printf 函数,而 printf 函数实际上是在 stdio.h 这个头文件中声明的,因此想要使用 printf 函数就必须先包含对应的头文件。一般地,函数和变量都需要先被声明与定义后才可以使用。C 语言中常用 “.h” 后缀的文件存放相关声明,而以 “.c” 为后缀的同名文件存放相关定义。例如,若要使用 sqrt 函数计算平方根,则需要先包含 “math.h” 这一头文件。
2. define 命令
宏(Macro)是预处理命令中的一种,它允许用一个标识符来表示一个字符串。在 C 语言中可以用 define 命令来实现宏定义。宏定义有很多种,这里只介绍最基础的无参宏定义:
#include<stdio.h> #define NUM 100 int main() {int sum = 2 * NUM; // 预处理后该句就变为int sum = 2 * 100;printf("%d", sum);return 0; }该 程序的输出结果为 200。例子中的 “#define NUM 100” 定义了一个宏替换,其中 NUM 是宏名,后面的内容是值。注意该句后面无需额外加分号。在进行预处理时,实际上是将代码作为一个文本,将宏定义后的所有 NUM 字符串替换为 100。
用宏来代替一个在程序中经常使用的常量,在后续需要修改该常量的值时,无需修改整个程序中每一处的值,只需修改相关的宏定义即可。但建议使用全局的 const Type 变量来代替 #define 宏替换。1.6.2 递归的进一步理解
1.递归三要素
(1) 明确递归函数
先定义递归函数,明确这个函数的功能、参数、返回值。由于递归函数在执行过程中会不断调用自身,这个函数的功能一旦确定,之后只需找到问题与子问题的递归关系即可。
(2) 寻找递推公式
所谓递推公式,其实就是问题与子问题之间的关系。问题与子问题之间通常有相同的解决思路,只是子问题的规模更小,如上文中的 F (5) = F (4) + F (3),那么 F (4) 和 F (3) 就是 F (5) 的子问题,而 F (4) = F (3) + F (2),F (3) = F (2) + F (1),即问题与它的两个子问题都有相同的解决思路,就可以同样用递归函数来解决。
(3) 确定递推边界
递归需要有递归边界,否则就会无休止地执行下去。这一步需要对传入递归函数的参数进行判断,可以使用假设法,例如考虑临界值、初始值及特殊值。可以分为两类来假设:第一是异常值,例如在斐波那契递归函数中如果 n < 0 该如何处理;第二是递归结束条件,即要寻找最终不可再分解的子问题的解,如在斐波那契递归函数中 n = 0 和 n = 1 的情况。1.6.3 分治法与减治法
分治法与减治法是两种常见的解决大规模问题的递归式算法思想。
1.分治法 (Divided And Conquer)
分治法(即分而治之)是将一个大规模问题分解成若干个相同类型的规模更小的子问题,再将子问题分解成规模更小的子问题,重复此过程,直到最后的子问题可以直接求解。最后再将子问题的解合并,从而得到原问题的解。
例如,用分治法求数组之和,参考代码如下:int sum (int A[], int low, int high) {int mid = (low + high) / 2;if (low == high) return A[low]; // 最终的子问题可以直接求解return sum(A, low, mid) + sum(A, mid + 1, high); // 子问题的解合并 }2.减治法 (Decrease And Conquer)
减治法属于一种特殊的分治法。减治法将原问题分解成若干个子问题,但只需要对其中一个子问题进行求解,通过建立原问题与子问题之间的关系,由子问题的解,得到原问题的解。
减治法应用 1:翻转数组
编写函数 void reverse (int *A, int low, int high),给定数组 A [n],将其翻转。参考代码如下:void reverse(int *A, int low, int high) {if (low < 0 || high >= n )return;if (low < high) { // 原问题减治为两端交换问题和中间翻转问题(缩减问题规模)swap(A[low], A[high]);reverse(A, low + 1, high - 1); // 问题规模缩减2} }减治法应用 2:青蛙跳台阶问题
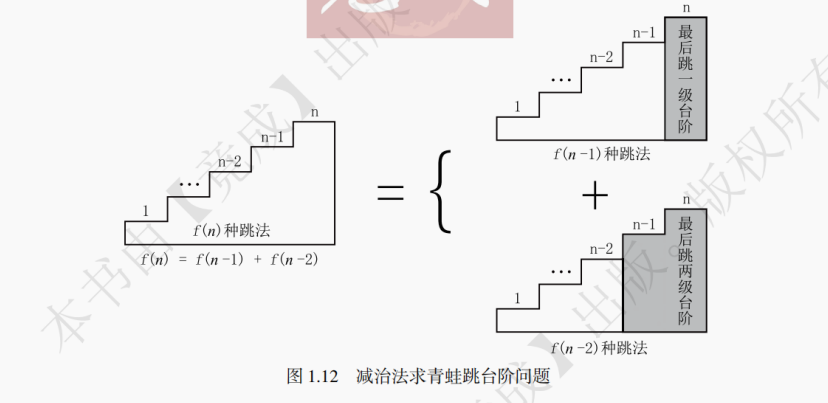
【例 1.1】一只变异小青蛙想爬上 n 级台阶,它每次在跳台阶时有 2 种选择:可以一次跳 1 级台阶,也可以一次跳 2 级台阶。求该青蛙跳上 n 级的台阶总共有多少种跳法。
解:设跳上 n 级的台阶的跳法数是 f (n),青蛙跳上第 n 级台阶,如图1.12所示,最后一次的跳法只有 2 种情况:① 从第 n - 2 级台阶起跳,跳了 2 级阶梯;② 从第 n - 1 级台阶起跳,跳了 1 级阶梯。则原问题自然分解成 f (n) = f (n - 1) + f (n - 2)(缩减问题规模)。考虑 n = 0, 1 的边界情况,f (0) = 0, f (1) = 1,递推出 f (2) = 2(跳 2 次的 1 阶台阶或跳 1 次的 2 阶台阶)。该问题的参考代码如下:int f(int n) {if (n < 2) { return 1; }return f(n-1) + f(n-2); }
1.6.4 C 语言中运算符的含义
运算符,又称操作符,是一种告诉编译器执行特定的数学或逻辑操作的符号。C 语言内置了丰富的运算符,为了让跨考生快速上手,假设 A、B、C 均为整型变量,p 为指针变量,且 A = 10,B = 3,表 1.2 给出了 C 语言中常见运算符的具体含义及相关示例。
这里有一些需要注意的地方:
(1) 关于 “/” 运算符:在 C 语言中,如果两个整型(int)变量做除法且结果出现小数,则编译器只会取整数部分,直接舍去小数点后面的数字。如以下代码会打印输出 200 而非 275:printf("%d", (2+3/4)*100);(2) 关于 “++” 和 “--”:以 “++” 为例,假设 a 是 int 型变量,则 ++a 只做了一步,a 先自增 1,再将自增后的 a 用于运算;而 a++ 做了两步:先创建一个 a 的副本保存 a 的当前值用于运算,再将 a 自增 1。故一般在 ++a 和 a++ 都适用时,使用 ++a 更加高效。
(3) 关于 “=” 和 “==”:“=” 是赋值运算符,“==” 是关系运算符,初学者常常在判断是否相等时误用 “=”,请考生留意。
1.6.5 习题精编
1.【思路】 本题考查简单的分支语句以及格式化输出,使用 if 语句进行情况判断即可。
【参考代码】#include <stdio.h>float calFunc(float x) { //实现函数f(x)的功能float y;if (x!= 0) { y = 1 / x; }else { y = 0; }return y; }int main() {double x, y;// 输入时float对应%f,double对应%lf;输出时float和double都对应%fscanf("%lf", &x);y = calFunc(x); //调用函数// 用printf函数输出浮点数时要保留n小数位数,写法为printf("%.nf", a);printf("f(%.1f) = %.1f", x, y);return 0; }2.【PAT】求奇数分之一序列前 N 项和
编写函数 double calFunc(int N),计算序列 1+1/3+1/5+⋯ 的前 N 项之和。
示例
输入:23
输出:2.5495412.【思路】 最关键的问题在于分母是递增的奇数,可以使用 for 循环进行累加,分母初始为 1,每执行一次循环体都将分母加 2。
【参考代码】#include <stdio.h> double calFunc(int N) {double sum = 0.0, t = 1.0; // sum用于暂存累加到最终结果,t作为奇数分母for (int i = 0; i < N; ++i) { // 累加sum += 1.0 / t;t += 2;}return sum; } int main() {int n; // 用于接收输入的数double sum = 0.0; // sum用于累加到最终结果,t为分母scanf("%d", &n);sum = calFunc(n);printf("%.6f", sum); // 格式化输出小数点后六位浮点数return 0; }3.【PAT】求阶乘序列前 N 项和
编写函数 int calFunc(int n),计算序列 1!+2!+3!+⋯ 的前 n(n≤12) 项之和。
示例
输入:5
输出:1533.【思路】 利用双重 for 循环,内层循环负责计算每一个阶乘,外层循环负责将这些阶乘累加起来。
【参考代码】#include <stdio.h>int calFunc(int n) {// sum用于累加得到最终结果,m用于计算阶乘int sum = 0, m = 1;for (int i = 1; i <= n; ++i) {for (int j = 1; j <= i; ++j) { m *= j; }sum += m;m = 1; //每次一个内层循环结束后将m重置为1}return sum; }int main() {int n, sum = 0;// n接收输入的数,sum用于累加得到最终结果,m用于计算阶乘scanf("%d", &n);sum = calFunc(n);printf("%d", sum);return 0; }4.【PAT】比较大小
编写函数 void sort3Num(int n1, int n2, int n3),将输入的任意 3 个整数从小到大的顺序输出。
示例
输入:4 2 8
输出:2->4->84.【思路】 分别对输入的三个数进行两两比较,利用 temp 对两两比较的值进行交换,得到有序的三个值并按要求格式输出。
【参考代码】#include<stdio.h> // 将n1,n2,n3定义为引用,才可在函数中改变实参的值 void sort3Num(int &n1, int &n2, int &n3) {int temp; // temp用于交换两个变量的值if (n1 > n2) { // 若n1比n2大,交换之temp = n1;n1 = n2;n2 = temp;}if (n1 > n3) { // 若n1比n3大,交换之temp = n1;n1 = n3;n3 = temp;}if (n2 > n3) { // 若n2比n3大,交换之temp = n2;n2 = n3;n3 = temp;} }int main() {int n1, n2, n3; // temp用于交换两个变量的值scanf("%d%d%d", &n1, &n2, &n3);sort3Num(n1,n2,n3);printf("%d->%d->%d", n1, n2, n3);return 0; }5.【PAT】求矩阵的最大值
编写函数 void findMaxWithPosition(int **arr, int m, int n),求给定的 m×n(1≤m,n≤6) 矩阵的最大值及其位置(格式是 “行下标列下标”,下标从 0 开始)。题目保证最大值惟一。输入的第一行给出两个正整数 m,n,随后 m 行每行给出 n 个整数,其间以空格分隔。
示例
输入:3 2
6 3
23 -9
6 -1
输出:
23
1 0
5.【思路】 由于矩阵元素最大值唯一,所以设置一组存储最值下标的变量即可。依次遍历数组元素,寻找更大的值并更新最大值的下标,最后输出最大值以及其位置。
【参考代码】#include<stdio.h> #include<math.h> #include<stdlib.h>// 求矩阵元素的最大值并输出 void findMaxWithPosition(int **arr, int m, int n) {int im = 0, jm = 0; // im, jm为矩阵最大元素下标for (int i = 0; i < m; ++i) {for (int j = 0; j < n; ++j) { // 利用双重for循环遍历矩阵各位置if (arr[im][jm] < arr[i][j]) { // 不断比较并更新矩阵最大元素下标im = i;jm = j;}}}printf("%d\n%d %d", arr[im][jm], im, jm); }int main() {int m, n; // m, n为矩阵的行列数scanf("%d %d", &m, &n);int** a = (int**)malloc(sizeof(int*) * m); // 二维数据初始化for (int i = 0; i < m; ++i) {a[i] = (int*)malloc(sizeof(int) * n);}for (int i = 0; i < m; i++) {for (int j = 0; j < n; j++) { // 利用双重for循环遍历矩阵各位置scanf("%d", &a[i][j]); // 接收输入的值并赋给矩阵对应元素}}findMaxWithPosition(a, m, n); // 调用函数求矩阵元素的最大值并输出return 0; }6.【PAT】猴子吃桃问题
一只猴子第一天摘下若干个桃子,当即吃了一半,还不过瘾,又多吃了一个;第二天早上又将剩下的桃子吃掉一半,又多吃了一个。以后每天早上都吃了前一天剩下的一半加一个。到第 n(1<n≤10) 天早上想再吃时,见只剩下一个桃子了。编写函数 int countPeach(int n),求第一天采摘的桃子总数。
示例
输入:3
输出:106.【思路】 考虑从反方向按题目所给的规律倒推,迭代 n−1 次即可。
【参考代码】#include<stdio.h>int countPeach(int n) {int i = 0, sum = 1;for (i = 1; i < n; ++i) { sum = (1 + sum) * 2; }return sum; }int main() {int n = 0;int i = 0, sum = 1;scanf ("%d", &n);sum = countPeach(n);printf ("%d", sum);return 0; }7.【PAT】递归实现指数函数
本题要求用递归实现计算 xn(n≥1) 的函数 double calc_pow(double x, int n)。
示例
输入:2 3
输出:87.【思路】 题目已经定义好了递归函数 calc_pow(double x, int n),它的作用是求 xn 的值,而 xn=x∗xn−1,可由此得到递推关系。再找到 x=1 的情况作为递归边界,就可以写出递归函数。
【参考代码】#include<stdio.h>double calc_pow(double x, int n) {if (n == 1) return x; // 递归边界else return x * calc_pow(x, n - 1); // 递推关系 }int main() {double x;int n;scanf ("%lf %d", &x,&n);printf ("%.0f\n", calc_pow(x,n));return 0; }8.【PAT】水仙花数
水仙花数是指一个 N(N≥3) 位正整数,它的每个位上的数字的 N 次幂之和等于它本身。例如:153=13+53+33。编写函数 void narcNum(int N),输出所有 N(3≤N≤7) 位水仙花数。
示例
输入:3
输出:153 370 371 4078.【思路】 判断一个三位数是否为 “水仙花数”,即要把给出的三位数的个位、十位、百位分别拆分,并求其立方和(设为 s),若 s 与给出的三位数相等,三位数为 “水仙花数”,反之则不是。所以可以通过遍历所有可能的数然后依次判断其是否是水仙花数来解决问题。
【参考代码】#include<stdio.h> #include<math.h>void narcNum(int N) {int min = pow(10, N - 1); // pow函数用于计算N次幂的值int max = pow(10, N) - 1; // min至max即为遍历范围/* 这里用一个整型数组s[10]存储0~9的N次幂的结果,后面在循环中要用到时直接调用,避免重复调用pow函数,节约时间 */int s[10];for (int k = 0; k <= 9; ++k) s[k] = pow(k, N);for (int i = min; i <= max; ++i) { // for循环遍历判断是否是水仙花数int sum = 0, t = i;for (int j = 1; j <= N; ++j) {sum += s[t % 10]; // 用%和/拆分各位数t /= 10;}if (sum == i) { printf("%d\n", i); }} }int main() {int N;scanf("%d", &N); // 输入NnarcNum(N);return 0 ; }





相关文章:

数据结构第1章编程基础 (竟成)
第 1 章 编程基础 1.1 前言 因为数据结构的代码大多采用 C 语言进行描述。而且,408 考试每年都有一道分值为 13 - 15 的编程题,要求使用 C/C 语言编写代码。所以,本书专门用一章来介绍 408 考试所需的 C/C 基础知识。有基础的考生可以快速浏览…...

互联网大厂Java求职面试:AI大模型与云原生架构融合中的挑战
互联网大厂Java求职面试:AI大模型与云原生架构融合中的挑战 在互联网大厂的Java求职面试中,面试官往往以技术总监的身份,针对候选人对AI、大模型应用集成、云原生和低代码等新兴技术的理解与实践能力进行考察。以下是一个典型的面试场景&…...

msql的乐观锁和幂等性问题解决方案
目录 1、介绍 2、乐观锁 2.1、核心思想 2.2、实现方式 1. 使用 version 字段(推荐) 2. 使用 timestamp 字段 2.3、如何处理冲突 2.4、乐观锁局限性 3、幂等性 3.1、什么是幂等性 3.2、乐观锁与幂等性的关系 1. 乐观锁如何辅助幂等性…...

Python 实现桶排序详解
1. 核心原理 桶排序是一种非比较型排序算法,通过将数据分配到多个“桶”中,每个桶单独排序后再合并。其核心步骤包括: 分桶:根据元素的范围或分布,将数据分配到有限数量的桶中。桶内排序:对每个非空桶内的…...
——编码器(Encoder)、解码器(Decoder))
大模型(5)——编码器(Encoder)、解码器(Decoder)
文章目录 一、编码器(Encoder)1. 核心作用2. 典型结构(以Transformer为例)3. 应用场景 二、解码器(Decoder)1. 核心作用2. 典型结构(以Transformer为例)3. 应用场景 三、编码器与解码…...

Web3怎么本地测试连接以太坊?
ETHEREUM_RPC_URLhttps://sepolia.infura.io/v3/你的_INFURA_API_KEY 如果你没有 Infura Key,注册 Infura 或 Alchemy,拿一个免费测试网节点就行: Infura:https://infura.io Alchemy:Alchemy - the web3 developme…...
)
Vue-02 (使用不同的 Vue CLI 插件)
使用不同的 Vue CLI 插件 Vue CLI 插件扩展了 Vue 项目的功能,让你可以轻松集成 TypeScript、Vuex、路由等功能。它们可以自动进行配置和设置,从而节省您的时间和精力。了解如何使用这些插件对于高效的 Vue 开发至关重要。 了解 Vue CLI 插件 Vue CLI…...

理解vue-cli 中进行构建优化
在 Vue CLI 项目中进行构建优化,是前端性能提升的重要手段。它涉及到 Webpack 配置、代码分包、懒加载、依赖优化、图片压缩等多个方面。 🧱 基础构建优化 设置生产环境变量 NODE_ENVproduction Vue CLI 会自动在 npm run build 时开启以下优化&…...

理解计算机系统_线程(九):线程安全问题
前言 以<深入理解计算机系统>(以下称“本书”)内容为基础,对程序的整个过程进行梳理。本书内容对整个计算机系统做了系统性导引,每部分内容都是单独的一门课.学习深度根据自己需要来定 引入 接续理解计算机系统_线程(八):并行-CSDN博客,内容包括12.7…...
vue3基本类型和对象类型的响应式数据
vue3中基本类型和对象类型的响应式数据 OptionsAPI与CompstitionAPI的区别 OptionsAPI Options API • 特点:基于选项(options)来组织代码,将逻辑按照生命周期、数据、方法等分类。• 结构:代码按照 data 、 methods…...

3.8.4 利用RDD实现分组排行榜
本实战任务通过Spark RDD实现学生成绩的分组排行榜。首先,准备包含学生成绩的原始数据文件,并将其上传至HDFS。接着,利用Spark的交互式环境或通过创建Maven项目的方式,读取HDFS中的成绩文件生成RDD。通过map操作将数据映射为二元组…...

python web flask专题-Flask入门指南:从安装到核心功能详解
Flask入门指南:从安装到核心功能详解 Flask作为Python最流行的轻量级Web框架之一,以其简洁灵活的特性广受开发者喜爱。本文将带你从零开始学习Flask,涵盖安装配置、项目结构、应用实例、路由系统以及请求响应处理等核心知识点。 1. Flask安…...

C语言中的“类框架”工具
C语言中的“框架”:库与轻量级工具生态解析 一、C语言的设计哲学与框架定位 C语言作为一门系统级编程语言,核心目标是提供高效、灵活的底层控制能力。与Java、Python等高级语言不同,C语言本身不内置全栈框架…...

【HW系列】—web组件漏洞(Strtus2和Apache Log4j2)
本文仅用于技术研究,禁止用于非法用途。 文章目录 Struts2Struts2 框架介绍Struts2 历史漏洞汇总(表格)Struts2-045 漏洞详解 Log4j2Log4j2 框架介绍Log4j2 漏洞原理1. JNDI 注入2. 利用过程 Log4j2 历史漏洞JNDILDAP 反弹 Shell 流程 Strut…...

第六十八篇 从“超市收银系统崩溃”看JVM性能监控与故障定位实战
目录 引言:当技术问题遇上生活场景一、JVM的“超市货架管理哲学”二、收银员工具箱:JVM监控三板斧三、典型故障诊断实录四、防患于未然的运维智慧五、结语:从故障救火到体系化防控 引言:当技术问题遇上生活场景 想象一个周末的傍…...

Debian 11 之使用hostapd与dnsmasq进行AP设置
目录 1: 安装必要的软件2: 配置dnsmasq3: 配置 hostapd4: 配置网络接口5: 启动服务总结 在Debian 11(也称为Bullseye)下设置热点,你可以使用多种方法,但最常见和简单的方法之一是使用hostapd工具配合dnsmasq。这种方法不需要额外的…...

有铜半孔的设计规范与材料创新
设计关键参数 孔径与间距限制 最小孔径需≥0.6mm,孔边距≥0.5mm,避免铜层脱落;拼版时半孔区域需预留2mm间距防止撕裂。 阻焊桥设计 必须保留阻焊桥(宽度≥0.1mm),防止焊锡流入孔内造成短路。 猎板的材料…...

机器学习知识体系:从“找规律”到“做决策”的全过程解析
你可能听说过“机器学习”,觉得它很神秘,像是让电脑自己学会做事。其实,机器学习的本质很简单:通过数据来自动建立规则,从而完成预测或决策任务。 这篇文章将用通俗的语言为你梳理机器学习的知识体系,帮助…...
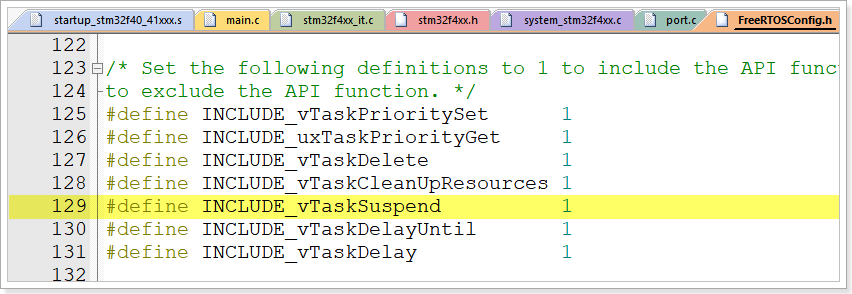
STM32之FreeRTOS移植(重点)
RTOS的基本概念 实时操作系统(Real Time Operating System)的简称就叫做RTOS,是指具有实时性、能支持实时控制系统工作的操作系统,RTOS的首要任务就是调度所有可以利用的资源来完成实时控制任务的工作,其次才是提高工…...

做好测试用例设计工作的关键是什么?
测试用例设计是软件测试的核心环节,好的测试用例能高效发现缺陷,差的测试用例则可能漏测关键问题。结合多年测试经验,我认为做好测试用例设计的关键在于以下6点: 1. 深入理解需求(核心基础) ✅ 关键点: 与产品经理/开发对齐,确保理解无偏差(避免“我以为”式测试) 拆…...

R语言科研编程-标准偏差柱状图
生成随机数据 在R中,可以使用rnorm()生成正态分布的随机数据,并模拟分组数据。以下代码生成3组(A、B、C)随机数据,每组包含10个样本: set.seed(123) # 确保可重复性 group_A <- rnorm(10, mean50, sd…...

未来教育考试答题软件4.0【自用链接备份】
未来教育考试答题软件4.0【自用链接备份】 http://www.downyi.com/downinfo/240413.html 补丁地址:https://www.wodown.com/soft/43108.html...
OpenGL Chan视频学习-11 Uniforms in OpenGL
bilibili视频链接: 【最好的OpenGL教程之一】https://www.bilibili.com/video/BV1MJ411u7Bc?p5&vd_source44b77bde056381262ee55e448b9b1973 函数网站: docs.gl 说明: 1.之后就不再单独整理网站具体函数了,网站直接翻译…...

Flink系列文章列表
把写的文章做一个汇总,会陆续更新的。 Flink流处理原理与实践:状态管理、窗口操作与容错机制-CSDN博客...

GitLab 从 17.10 到 18.0.1 的升级指南
本文分享从 GitLab 中文本 17.10.0 升级到 18.0.1 的完整过程。 升级前提 查看当前安装实例的版本。有多种方式可以查看: 方式一: /help页面 可以直接在 /help页面查看当前实例的版本。以极狐GitLab SaaS 为例,在浏览器中输入 https://ji…...
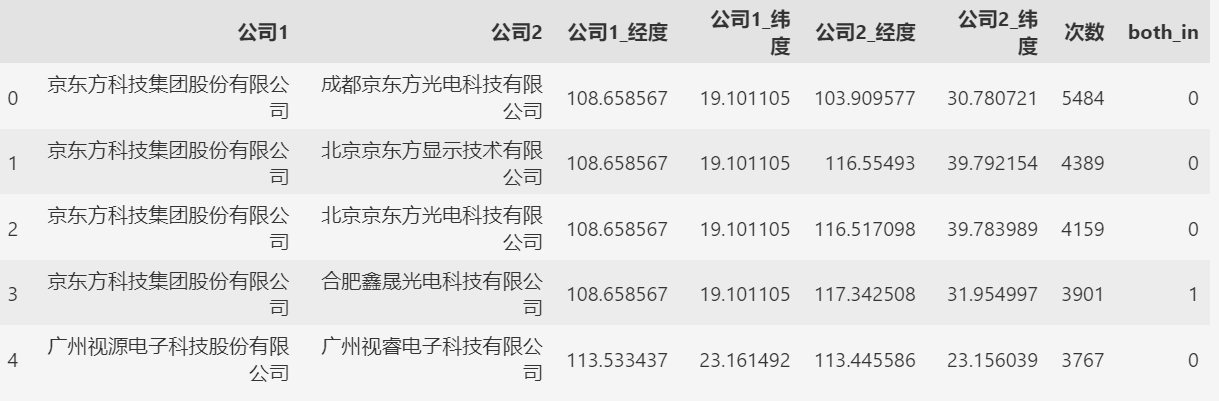
产业集群间的专利合作关系
需要准备的文件: 全国的专利表目标集群间的企业名单 根据专利的共同申请人,判断这两家企业之间存在专利合作关系。 利用1_filter_patent.py,从全国的3000多万条专利信息中,筛选出与目标集群企业相关的专利。 只要专利的申请人包…...

PyQt学习系列02-模型-视图架构与数据管理
PyQt学习系列笔记(Python Qt框架) 第二课:PyQt的模型-视图架构与数据管理 一、模型-视图架构概述 1.1 什么是模型-视图架构? 模型-视图(Model-View)是Qt框架中用于数据展示和交互的核心设计模式。它将数…...

redis主从复制架构安装与部署
redis主从复制架构安装与部署 1、Redis 一主两从架构的优势2、环境准备3、下载redis4、解压缩文件5、编辑配置文件6、创建数据目录并启动Redis7、检查主从状态8、 Redis Sentinel 模式 1、Redis 一主两从架构的优势 Redis 采用一主两从(1个主节点 2个从节点&#…...

Kotlin 中 Lambda 表达式的语法结构及简化推导
在 Kotlin 编程中,Lambda 表达式是一项非常实用且强大的功能。今天,我们就来深入探讨一下 Lambda 表达式的语法结构,以及它那些令人 “又爱又恨” 的简化写法。 一、Lambda 表达式完整语法结构 Lambda 表达式最完整的语法结构定义为{参数名…...

YOLOv2 深度解析:目标检测领域的进阶之路
在计算机视觉领域,目标检测一直是研究和应用的热点方向。YOLO(You Only Look Once)系列算法以其快速高效的特点,在目标检测领域占据了重要地位。YOLOv2 作为 YOLO 系列算法的重要迭代版本,在 YOLOv1 的基础上进行了诸多…...