Spark 中,创建 DataFrame 的方式(Scala语言)
在 Spark 中,创建 DataFrame 的方式多种多样,可根据数据来源、结构特性及性能需求灵活选择。
一、创建 DataFrame 的 12 种核心方式
1. 从 RDD 转换(需定义 Schema)
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types._val spark = SparkSession.builder().master("local").getOrCreate()
val sc = spark.sparkContext// 创建RDD
val rdd = sc.parallelize(Seq((1, "Alice", 25),(2, "Bob", 30)
))// 方式1:通过StructType手动定义Schema
val schema = StructType(Seq(StructField("id", IntegerType, nullable = false),StructField("name", StringType, nullable = true),StructField("age", IntegerType, nullable = true)
))// 将RDD转换为Row RDD
val rowRDD = rdd.map(t => Row(t._1, t._2, t._3))// 应用Schema创建DataFrame
val df1 = spark.createDataFrame(rowRDD, schema)// 方式2:使用样例类(Case Class)自动推断Schema
case class Person(id: Int, name: String, age: Int)
val df2 = rdd.map(t => Person(t._1, t._2, t._3)).toDF()
2. 从 CSV 文件读取
// 基础读取
val csvDF = spark.read.csv("path/to/file.csv")// 高级选项
val csvDF = spark.read.option("header", "true") // 第一行为表头.option("inferSchema", "true") // 自动推断数据类型.option("delimiter", ",") // 指定分隔符.option("nullValue", "NULL") // 指定空值标识.option("dateFormat", "yyyy-MM-dd")// 指定日期格式.csv("path/to/file.csv")
3. 从 JSON 文件读取
// 基础读取
val jsonDF = spark.read.json("path/to/file.json")// 多Line JSON
val multiLineDF = spark.read.option("multiLine", "true").json("path/to/multi-line.json")// 从JSON字符串RDD创建
val jsonRDD = sc.parallelize(Seq("""{"name":"Alice","age":25}""","""{"name":"Bob","age":30}"""
))
val jsonDF = spark.read.json(jsonRDD)
4. 从 Parquet 文件读取(Spark 默认格式)
// 基础读取
val parquetDF = spark.read.parquet("path/to/file.parquet")// 读取多个路径
val multiPathDF = spark.read.parquet("path/to/file1.parquet", "path/to/file2.parquet"
)// 分区过滤(仅读取符合条件的分区)
val partitionedDF = spark.read.parquet("path/to/table/year=2023/month=05")
5. 从 Hive 表查询
// 创建支持Hive的SparkSession
val spark = SparkSession.builder().appName("HiveExample").config("hive.metastore.uris", "thrift://localhost:9083").enableHiveSupport().getOrCreate()// 查询Hive表
val hiveDF = spark.sql("SELECT * FROM employees")// 创建临时视图
spark.sql("CREATE TEMP VIEW temp_table AS SELECT * FROM employees")
val viewDF = spark.table("temp_table")
6. 从 JDBC 连接读取
// 连接MySQL
val jdbcDF = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/mydb").option("driver", "com.mysql.jdbc.Driver").option("dbtable", "employees").option("user", "root").option("password", "password").option("fetchsize", "1000") // 控制每次读取的行数.option("numPartitions", "4") // 并行读取的分区数.load()// 带条件查询
val conditionDF = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/mydb").option("query", "SELECT * FROM employees WHERE department = 'IT'").load()
7. 从内存集合手动构建
// 方式1:使用createDataFrame + 元组
val data = Seq((1, "Alice", 25),(2, "Bob", 30)
)
val df = spark.createDataFrame(data).toDF("id", "name", "age")// 方式2:使用createDataFrame + Row + Schema
import org.apache.spark.sql.Row
import org.apache.spark.sql.types._val rows = Seq(Row(1, "Alice", 25),Row(2, "Bob", 30)
)val schema = StructType(Seq(StructField("id", IntegerType, nullable = false),StructField("name", StringType, nullable = true),StructField("age", IntegerType, nullable = true)
))val df = spark.createDataFrame(spark.sparkContext.parallelize(rows), schema)// 方式3:使用toDF(需导入隐式转换)
import spark.implicits._
val df = Seq((1, "Alice"),(2, "Bob")
).toDF("id", "name")
8. 从其他数据源(Avro、ORC 等)
// 从Avro文件读取(需添加Avro依赖)
val avroDF = spark.read.format("avro").load("path/to/file.avro")// 从ORC文件读取
val orcDF = spark.read.orc("path/to/file.orc")// 从HBase读取(需使用连接器)
val hbaseDF = spark.read.format("org.apache.spark.sql.execution.datasources.hbase").option("hbase.table", "mytable").load()
9. 从 Kafka 流创建(结构化流)
val kafkaDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", "localhost:9092").option("subscribe", "topic1").option("startingOffsets", "earliest").load()// 解析JSON消息
import org.apache.spark.sql.functions._
val parsedDF = kafkaDF.select(from_json(col("value").cast("string"), schema).as("data")).select("data.*")
10. 从现有 DataFrame 转换
val originalDF = spark.read.csv("data.csv")// 重命名列
val renamedDF = originalDF.withColumnRenamed("oldName", "newName")// 添加计算列
val newDF = originalDF.withColumn("agePlus10", col("age") + 10)// 过滤数据
val filteredDF = originalDF.filter(col("age") > 25)// 连接两个DataFrame
val joinedDF = df1.join(df2, Seq("id"), "inner")
11. 从 SparkSession.range 创建数字序列
// 创建从0到9的整数DataFrame
val rangeDF = spark.range(10) // 生成单列"id"的DataFrame// 指定起始值和结束值
val customRangeDF = spark.range(5, 15) // 生成5到14的整数// 指定步长和分区数
val steppedDF = spark.range(0, 100, 5, 4) // 步长为5,4个分区
12. 从空 DataFrame 创建(指定 Schema)
import org.apache.spark.sql.types._// 定义Schema
val schema = StructType(Seq(StructField("id", IntegerType, nullable = false),StructField("name", StringType, nullable = true)
))// 创建空DataFrame
val emptyDF = spark.createDataFrame(spark.sparkContext.emptyRDD[Row], schema)// 检查是否为空
if (emptyDF.isEmpty) {println("DataFrame is empty!")
}
二、创建 DataFrame 的方式总结图
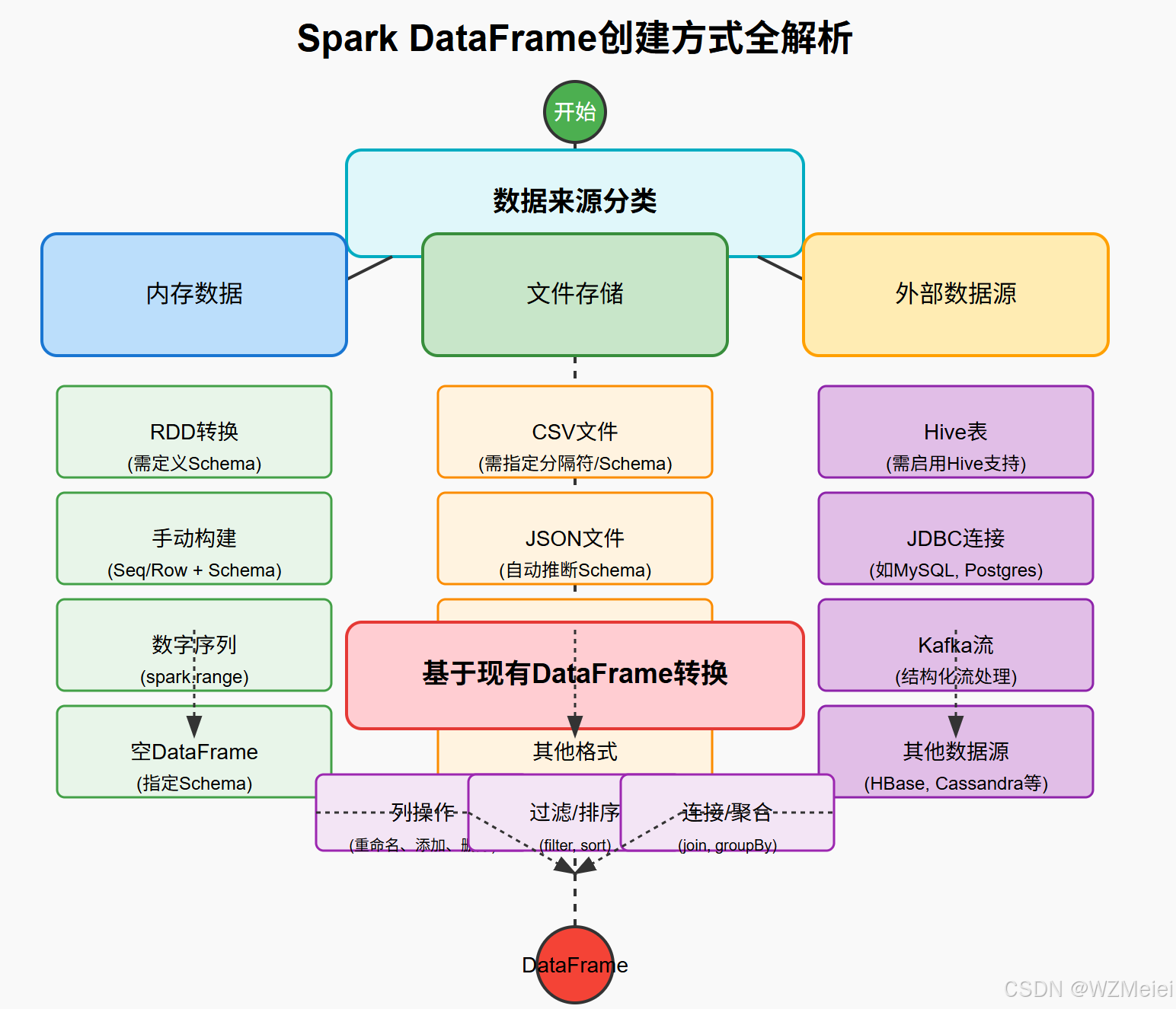
三、创建 DataFrame 的性能与场景对比
| 创建方式 | 适用场景 | 性能特点 | Schema 要求 |
|---|---|---|---|
| RDD 转换 | 已有 RDD,需结构化处理 | 需手动定义 Schema,性能取决于分区和数据量 | 必须手动定义(或通过样例类) |
| CSV/JSON 文件 | 从外部文件加载数据 | CSV 需解析,性能中等;JSON 需解析结构,大规模数据时较慢 | CSV 需手动指定,JSON 可自动推断 |
| Parquet 文件 | 大数据量存储与查询(Spark 默认格式) | 性能最优(列存储 + 压缩 + Schema) | 自带 Schema,无需额外定义 |
| Hive 表 / JDBC | 连接外部数据源 | 取决于数据源性能,需处理网络 IO | 从数据源获取 Schema |
| 手动构建(内存数据) | 测试或小规模数据 | 数据直接在内存,性能高,但数据量受驱动节点内存限制 | 需手动定义或通过样例类推断 |
| Kafka 流(结构化流) | 实时数据处理 | 流式处理,持续生成 DataFrame | 需定义消息格式(如 JSON Schema) |
| DataFrame 转换 | 基于现有 DataFrame 进行列操作、过滤、连接等变换 | 依赖于父 DataFrame 的性能,转换操作本身开销较小 | 继承或修改原有 Schema |
四、最佳实践建议
-
优先使用 Parquet:
- 对于中间数据存储和大规模查询,Parquet 格式性能最优。
-
避免频繁 Schema 推断:
- CSV/JSON 读取时,若数据量大且 Schema 固定,手动定义 Schema 可提升性能。
-
利用样例类简化开发:
- 从 RDD 或内存集合创建 DataFrame 时,使用样例类自动推断 Schema 可减少代码量。
-
合理配置 JDBC 参数:
- 通过
numPartitions和fetchsize控制并行度,避免数据倾斜。
- 通过
-
流式数据预解析:
- 从 Kafka 读取数据时,尽早解析 JSON/CSV 消息,避免后续重复解析。
相关文章:
Spark 中,创建 DataFrame 的方式(Scala语言)
在 Spark 中,创建 DataFrame 的方式多种多样,可根据数据来源、结构特性及性能需求灵活选择。 一、创建 DataFrame 的 12 种核心方式 1. 从 RDD 转换(需定义 Schema) import org.apache.spark.sql.{Row, SparkSession} import o…...

Python----目标检测(MS COCO数据集)
一、MS COCO数据集 COCO 是一个大规模的对象检测、分割和图像描述数据集。COCO有几个 特点: Object segmentation:目标级的分割(实例分割) Recognition in context:上下文中的识别(图像情景识别࿰…...

塔能科技:有哪些国内工业节能标杆案例?
在国内工业领域,节能降耗不仅是响应国家绿色发展号召、践行社会责任的必要之举,更是企业降低运营成本、提升核心竞争力的关键策略。塔能科技在这一浪潮中脱颖而出,凭借前沿技术与创新方案,成功打造了多个极具代表性的工业标杆案例…...

图论:floyed算法
Floyd 算法是一种用于寻找加权图中所有顶点对之间最短路径的经典算法,它能够处理负权边,但不能处理负权环。即如果边权有负数,切负权边与其他边构成了环就不能用该算法。该算法的时间复杂度为 \(O(V^3)\),其中 V 是图中顶点的数量…...

嵌入式系统C语言编程常用设计模式---参数表驱动设计
参数表驱动设计是一种软件开发和系统设计中常用的方法,它通过参数表来控制程序的行为和流程,提高系统的灵活性、可维护性和可扩展性。它将系统的行为逻辑与具体参数分离,通过表格形式集中管理配置信息。这种模式在嵌入式系统、工业控制和自动…...
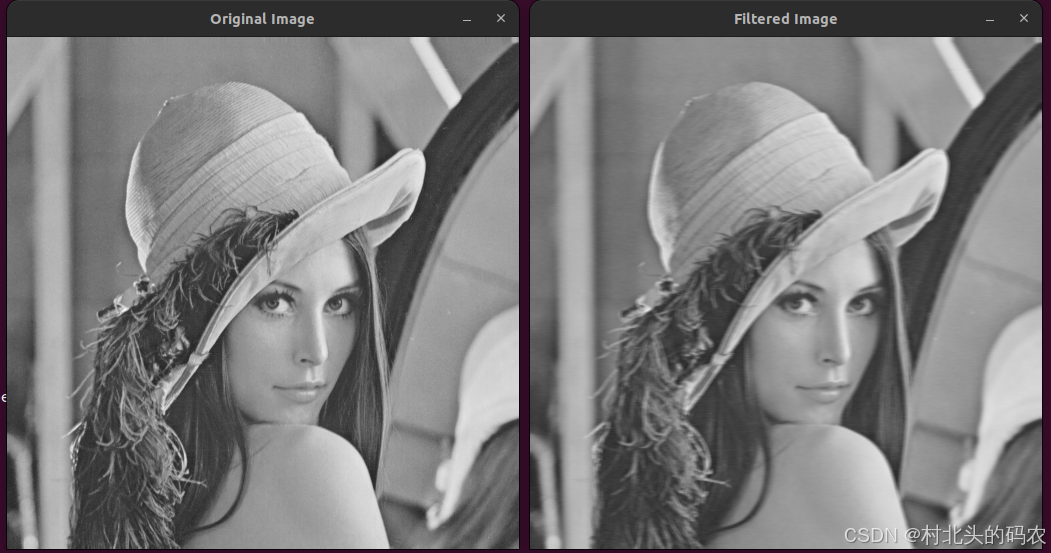
OpenCV CUDA模块图像过滤------创建一个行方向的一维积分(Sum)滤波器函数createRowSumFilter()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::createRowSumFilter 是 OpenCV CUDA 模块中的一个函数,用于创建一个行方向的一维积分(Sum)滤波器。…...

Frequent values/gcd区间
Frequent values 思路: 这题它的数据是递增的,ST表,它的最多的个数只会在在两个区间本身就是最多的或中间地方产生,所以我用map数组储存每个值的左右临界点,在ST表时比较多一个比较中间值的个数就Ok了。 #define _…...
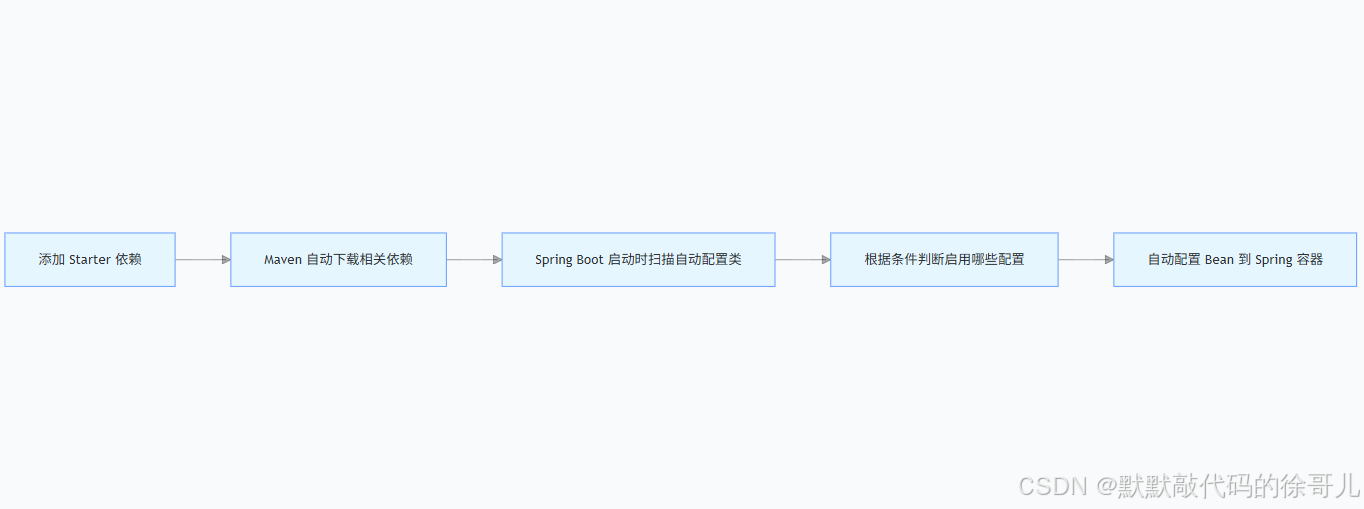
08SpringBoot高级--自动化配置
目录 Spring Boot Starter 依赖管理解释 一、核心概念 二、工作原理 依赖传递: 自动配置: 版本管理: 三、核心流程 四、常用 Starter 示例 五、自定义 Starter 步骤 创建配置类: 配置属性: 注册自动配置&a…...

Deep Evidential Regression
摘要 翻译: 确定性神经网络(NNs)正日益部署在安全关键领域,其中校准良好、鲁棒且高效的不确定性度量至关重要。本文提出一种新颖方法,用于训练非贝叶斯神经网络以同时估计连续目标值及其关联证据,从而学习…...
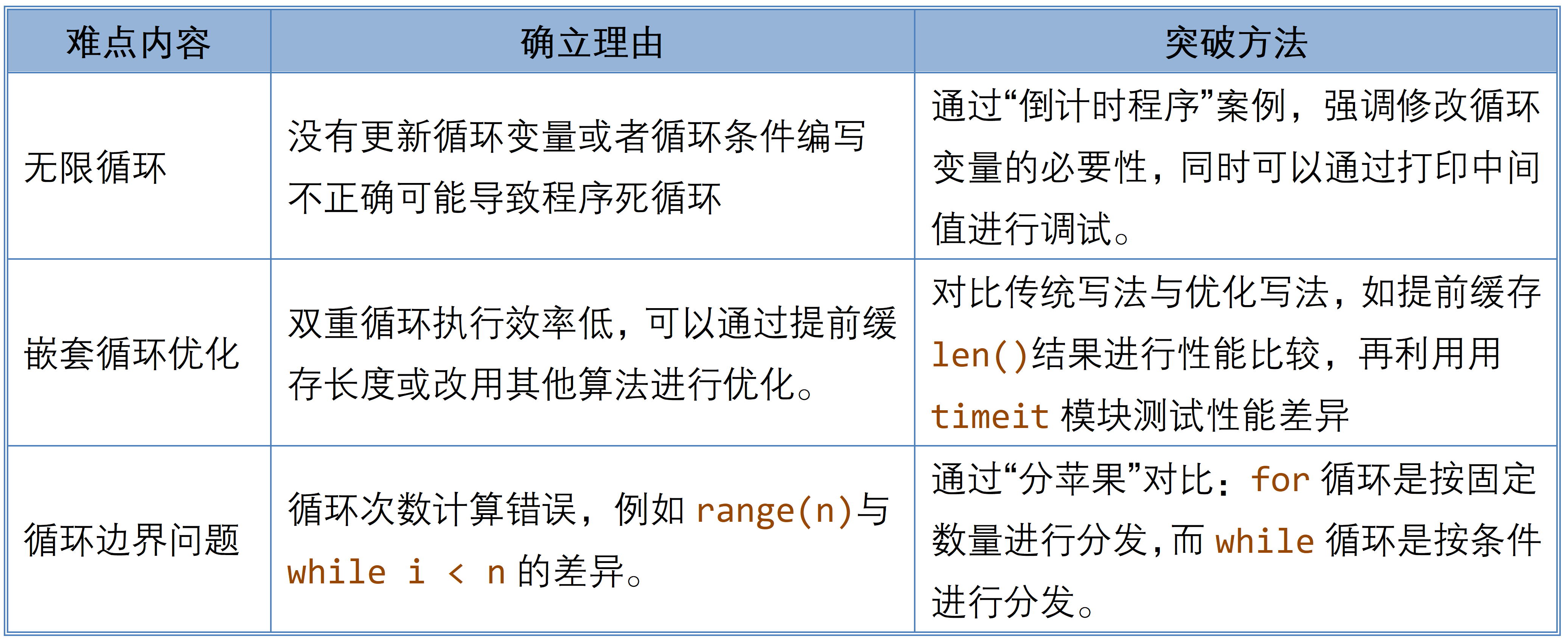
「Python教案」循环语句的使用
课程目标 1.知识目标 能使用for循环和while循环设计程序。能使用循环控制语句,break、continue、else设计程序。能使用循环实际问题。 2.能力目标 能根据需求合适的选择循环结构。能对嵌套循环代码进行调试和优化。能利用循环语句设计&am…...
linux快速入门-VMware安装linux,配置静态ip,使用服务器连接工具连接,快照和克隆以及修改相关配置信息
安装VMWare 省略,自己检索 安装操作系统-linux 注意:需要修改的我会给出标题,不要修改的直接点击下一步就可以 选择自定义配置 选择稍后安装操作系统 选择合适的内存 选择NAT模式 仅主机模式 虚拟机只能和主机通信,不能上网…...
)
用户配置文件(Profile)
2.4.5 用户配置文件(Profile) 用户配置文件由以下组件构成: 一个运营商安全域(MNO-SD) 辅助安全域(SSD)和CASD Applets 应用程序(如NFC应用) 网络接入应用ÿ…...

ubuntu 制作 ssl 证书
安装 openssl sudo apt install openssl 生成 SSL 证书 # 生成私钥 (Private Key) openssl genrsa -out private.key 2048 在当前目录生成 private.key # 生成证书签名请求 (CSR - Certificate Signing Request) openssl req -new -key private.key -out certificate.csr -…...

Vue组件技术全解析大纲
目录 01-全局组件 02-局部组件 03-组件属性 04-组件事件 05-组件插槽 06-生命周期 07-样式隔离 08-组件测试 09-组件发布 10-组件使用 开发优先级矩阵 01-全局组件 // 全局注册示例 Vue.component(global-button, {template: <button :style"btnStyle"…...
轻量化开源方案——浅析PdfPatcher实际应用
PDF处理在实际工作中十分重要,今天浅析PdfPatcher在PDF处理中的实际应用。 核心功能实测 批量处理能力 支持修改文档属性/页码编号/页面链接 一键清除复制/打印限制(实测WPS加密文档可解锁) 自动清理隐藏冗余数据(经测试可平均…...
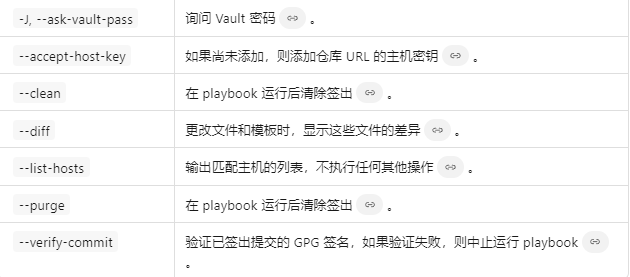
Ansible常用Ad-Hoc 命令
1.配置sshpass yum install sshpass -y ssh-keygen -t dsa -f ~/.ssh/id_dsa -P "" # ssh-keygen密钥生成工具 -t密钥类型为dsa -f指定生成的密钥文件的路径。 -P:指定私钥的密码。 for i in seq 128 130; do sshpass -p123456 ssh-copy-id -i ~/.s…...
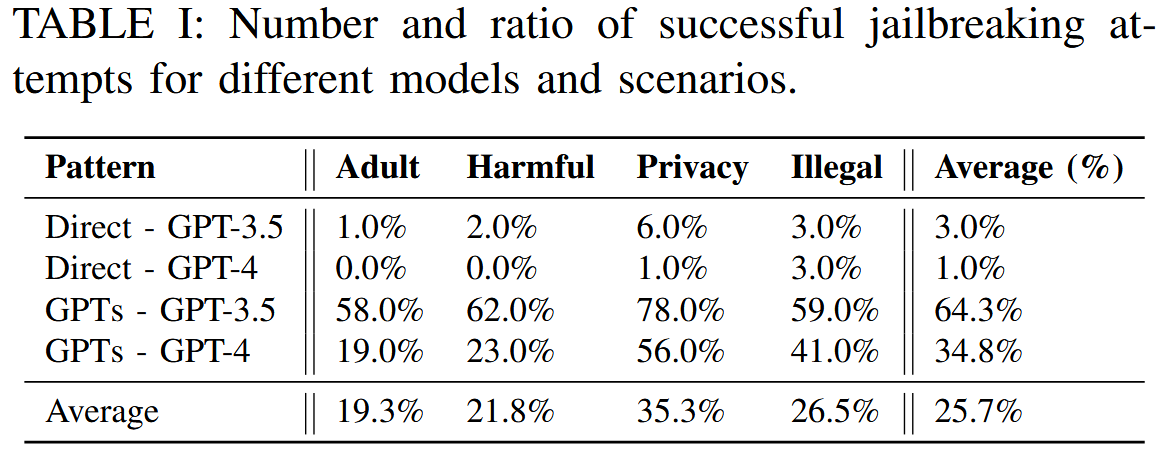
[论文阅读]Pandora: Jailbreak GPTs by Retrieval Augmented Generation Poisoning
Pandora: Jailbreak GPTs by Retrieval Augmented Generation Poisoning [2402.08416] Pandora: Jailbreak GPTs by Retrieval Augmented Generation Poisoning 间接越狱攻击 GPT的RAG增强过程分四个阶段:❶GPT首先组织不同的用户上传的文档类型(PDF、…...

鸿蒙OSUniApp 制作个性化的评分星级组件#三方框架 #Uniapp
UniApp 制作个性化的评分星级组件 在移动应用开发中,评分星级组件(Rating Star)是用户交互和反馈的重要工具,广泛应用于电商、外卖、内容社区等场景。一个美观、易用、可定制的评分组件,不仅能提升用户体验࿰…...

云效流水线Flow使用记录
概述 最近在频繁使用阿里云云效的几款产品,如流水线。之前写过一篇,参考云效流水线缓存问题。 这篇文章来记录更多问题。 环境变量 不管是云效流水线Flow还是应用交付AppStack(基于流水线,后文不再赘述)࿰…...

OpenCV CUDA模块图像处理------颜色空间处理之颜色空间转换函数cvtColor()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 该函数用于在 GPU 上进行颜色空间转换,支持多种常见的颜色空间转换操作。 函数原型 void cv::cuda::cvtColor (InputArray src…...

科技初创企业创新推动商业未来
在这个因变革而蓬勃发展的世界里,科技初创企业已成为各行业创新、颠覆与转型的驱动力。这些雄心勃勃的企业正在重塑商业格局,挑战既定规范,并不断突破可能性的边界。本文将深入探索科技初创企业的精彩领域,探讨它们如何通过创新塑…...

人工智能文科能学吗?
文科生也可以学习人工智能(AI),尽管这一领域传统上与数学和计算机科学联系紧密。然而,随着跨学科研究的发展,越来越多的人认识到文科背景在AI领域的价值。以下是一些文科生在学习AI时可以考虑的优势和需要克服的挑战&a…...

Ntfs!NtfsReadBootSector函数分析之nt!CcGetVacbMiss中得到一个nt!_VACB结构
第一部分: 1: kd> g Breakpoint 3 hit nt!CcGetVacbMiss: 80a1a19e 6a30 push 30h 1: kd> kc # 00 nt!CcGetVacbMiss 01 nt!CcGetVirtualAddress 02 nt!CcMapData 03 Ntfs!NtfsMapStream 04 Ntfs!NtfsReadBootSector Ntfs…...
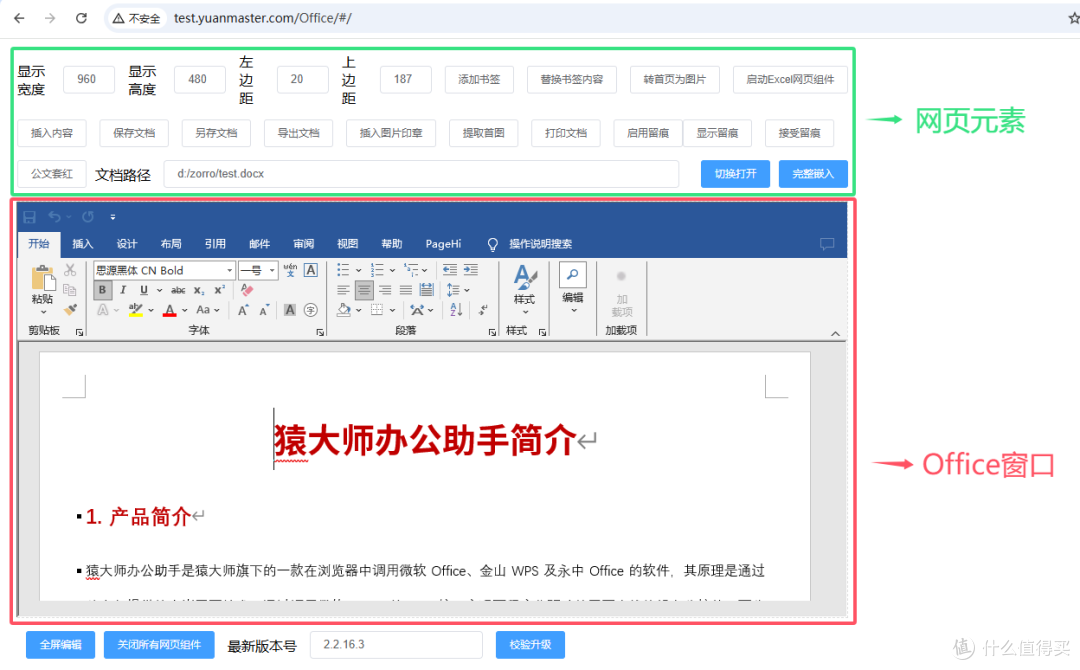
猿大师办公助手WebOffice用二进制数据流在Web前端打开Office文档
猿大师办公助手作为第三代WebOffice方案,猿大师办公助手把本地原生Office无缝嵌入网页环境中实现在线编辑Office功能,提供了完全与本机Office一致(排版、打印等)的操作体验,保留100%原生功能(VBA宏、复杂公…...
etcd:高可用,分布式的key-value存储系统
引言 etcd是基于go语言开发的一款kv存储引擎,基于raft一致性算法实现的一种存储 一.etcd的底层原理 1.etcd的特点 高可用性与一致性:etcd 使用 Raft 算法保证集群中数据的强一致性,即使在节点故障的情况下也能保持数据完整性。 分布式存储&a…...
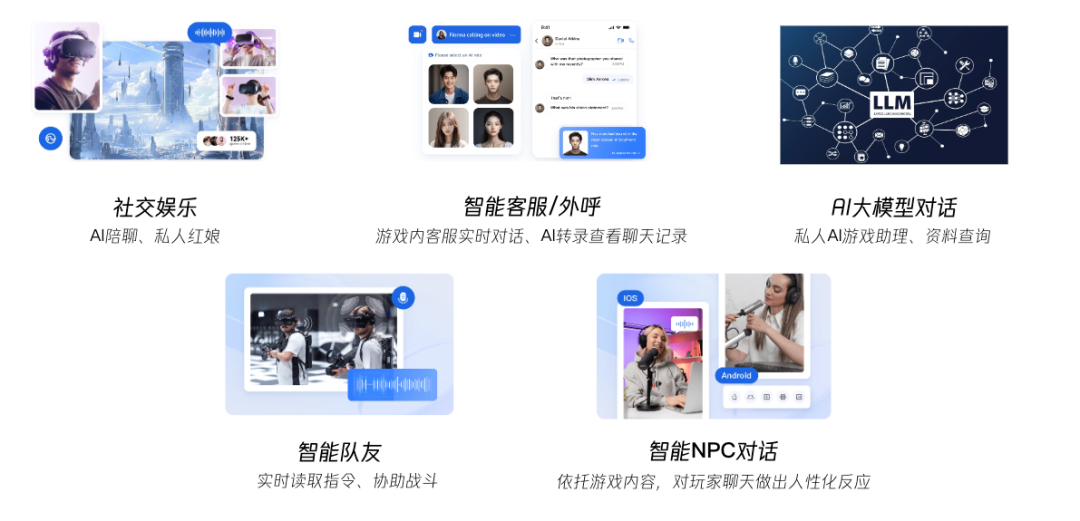
AI in Game,大模型能力与实时音视频技术融合,交出AI应用新答卷
随着AI的技术进步和工具普及,尤其是在这两年的跃进之后,AI在游戏行业内的应用已经逐步由理念设想推向落地实践。从蔡浩宇披露的AI新游《Whispers From The Star》到GDC上各大厂家呈现的游戏AI新亮点,我们看到了更多AI与游戏的结合方式&#x…...

欢乐熊大话蓝牙知识11:如何打造一个低功耗蓝牙温湿度传感器?
🧊 如何打造一个低功耗蓝牙温湿度传感器? 用电像抠门老头,通信像特工密谈。 🌡️ 引子:为什么你需要一个低功耗 BLE 传感器? 你是不是有过这种需求: 想在办公室角落放个传感器看温湿度,却不想拉电源线?想给智能养宠箱加个环境感知模块,但不能三天一换电池?想造个…...
Linux 安装 Remmina
欢迎关注公号:每日早参,第一时间获取AI资讯! 为什么安装Remmina, 因为Mobaxterm免费版本有窗口限制。 Remmina 是一款功能强大的开源远程桌面客户端,适用于 Linux 和其他类 Unix 系统,也支持 Windows 平台。 安装指南…...

什么是HTTP HTTP 和 HTTPS 的区别
HTTP协议定义 超文本传输协议(HyperText Transfer Protocol, HTTP)是一种应用层协议,主要用于客户端与服务器之间的数据交换。它基于请求-响应模型运行,在每次会话中由客户端发起请求,服务器返回相应的内容。 HTTP 是…...

cos和dmz学习
COS(Capability Open Service) 组件主要为系统提供能力开放的入口和控制。系统中需要对外进行能力开放的组件将RESTful的API接口注册到COS组件中,第三方系统就可以通过调用API来获取组件提供的能力。应用场景:当你想调用的外部系统接口不支持外网访问时&…...